
১. সংক্ষিপ্ত বিবরণ
এই ল্যাবে, আপনি একটি রিট্রিভাল-অগমেন্টেড জেনারেশন (RAG) সিস্টেমের জন্য কীভাবে একটি মূল্যায়ন পাইপলাইন তৈরি করতে হয় তা শিখবেন। আপনি কাস্টম মূল্যায়ন মানদণ্ড তৈরি করতে এবং একটি প্রশ্ন-উত্তর টাস্কের জন্য একটি অ্যাসেসমেন্ট ফ্রেমওয়ার্ক নির্মাণ করতে ভার্টেক্স এআই জেন এআই ইভ্যালুয়েশন সার্ভিস ব্যবহার করবেন।
আপনি স্ট্যানফোর্ড কোয়েশ্চন অ্যানসারিং ডেটাসেট (SQuAD 2.0) থেকে উদাহরণ ব্যবহার করে মূল্যায়ন ডেটাসেট প্রস্তুত করবেন, রেফারেন্স-মুক্ত ও রেফারেন্স-ভিত্তিক মূল্যায়ন কনফিগার করবেন এবং ফলাফল ব্যাখ্যা করবেন। এই ল্যাবের শেষে, আপনি বুঝতে পারবেন কীভাবে RAG সিস্টেম মূল্যায়ন করতে হয় এবং কেন নির্দিষ্ট মূল্যায়ন পদ্ধতি বেছে নেওয়া হয়।
ডেটাসেট ভিত্তি
আমরা SQuAD 2.0 প্রশ্নোত্তর ডেটাসেটে পাওয়া একাধিক ডোমেন জুড়ে যত্নসহকারে তৈরি করা উদাহরণ নিয়ে কাজ করব।
- স্নায়ুবিজ্ঞান : বৈজ্ঞানিক প্রেক্ষাপটে প্রযুক্তিগত নির্ভুলতা পরীক্ষা
- ইতিহাস : ঐতিহাসিক বর্ণনায় তথ্যের নির্ভুলতা মূল্যায়ন
- ভূগোল : আঞ্চলিক ও রাজনৈতিক জ্ঞানের মূল্যায়ন
এই বৈচিত্র্য আপনাকে বুঝতে সাহায্য করে যে, মূল্যায়ন পদ্ধতিগুলো কীভাবে বিভিন্ন বিষয় ক্ষেত্রে সাধারণীকরণ করা যায়।
তথ্যসূত্র
- কোড নমুনা: এই ল্যাবটি Vertex AI Evaluation ডকুমেন্টেশনের উদাহরণগুলোর উপর ভিত্তি করে তৈরি করা হয়েছে।
- ডেটা সেটের ভিত্তি: SQuAD 2.0 প্রশ্নোত্তর ডেটা সেট
- RAG পুনরুদ্ধার অপ্টিমাইজ করা: পরীক্ষা করুন, পরিমার্জন করুন, সফল হন
আপনি যা শিখবেন
এই ল্যাবে, আপনি নিম্নলিখিত কাজগুলো কীভাবে সম্পাদন করতে হয় তা শিখবেন:
- RAG সিস্টেমের জন্য মূল্যায়ন ডেটাসেট প্রস্তুত করুন।
- ভিত্তি ও প্রাসঙ্গিকতার মতো মেট্রিক ব্যবহার করে রেফারেন্স-মুক্ত মূল্যায়ন বাস্তবায়ন করুন।
- শব্দার্থগত সাদৃশ্য পরিমাপক ব্যবহার করে তথ্যসূত্র-ভিত্তিক মূল্যায়ন প্রয়োগ করুন।
- বিস্তারিত স্কোরিং রুব্রিকসহ নিজস্ব মূল্যায়ন মেট্রিক তৈরি করুন।
- মডেল নির্বাচনের সুবিধার্থে মূল্যায়ন ফলাফল ব্যাখ্যা করুন এবং দৃশ্যমান করুন।
২. প্রজেক্ট সেটআপ
গুগল অ্যাকাউন্ট
যদি আপনার আগে থেকে কোনো ব্যক্তিগত গুগল অ্যাকাউন্ট না থাকে, তাহলে আপনাকে অবশ্যই একটি গুগল অ্যাকাউন্ট তৈরি করতে হবে।
কর্মক্ষেত্র বা শিক্ষা প্রতিষ্ঠানের অ্যাকাউন্টের পরিবর্তে ব্যক্তিগত অ্যাকাউন্ট ব্যবহার করুন ।
গুগল ক্লাউড কনসোলে সাইন-ইন করুন
আপনার ব্যক্তিগত গুগল অ্যাকাউন্ট ব্যবহার করে গুগল ক্লাউড কনসোলে সাইন-ইন করুন।
বিলিং সক্ষম করুন
গুগল ক্লাউড ক্রেডিট রিডিম করুন (ঐচ্ছিক)
এই ওয়ার্কশপটি চালানোর জন্য আপনার কিছু ক্রেডিট সহ একটি বিলিং অ্যাকাউন্ট প্রয়োজন। শুরু করার জন্য এই কোডল্যাবের উপরের ব্যানার থেকে ক্রেডিট ব্যবহার করুন। আপনি যদি ইতিমধ্যেই একটি বিলিং অ্যাকাউন্টের সাথে সংযুক্ত থাকেন, তাহলে আপনি এই ধাপটি এড়িয়ে যেতে পারেন।
একটি ব্যক্তিগত বিলিং অ্যাকাউন্ট তৈরি করুন
আপনি যদি গুগল ক্লাউড ক্রেডিট ব্যবহার করে বিলিং সেট আপ করেন, তাহলে এই ধাপটি এড়িয়ে যেতে পারেন।
একটি ব্যক্তিগত বিলিং অ্যাকাউন্ট তৈরি করতে, ক্লাউড কনসোলে বিলিং চালু করার জন্য এখানে যান ।
কিছু নোট:
- এই ল্যাবটি সম্পন্ন করতে ক্লাউড রিসোর্সে ১ মার্কিন ডলারেরও কম খরচ হওয়া উচিত।
- পরবর্তী চার্জ এড়াতে, এই ল্যাবের শেষে দেওয়া ধাপগুলো অনুসরণ করে আপনি রিসোর্সগুলো মুছে ফেলতে পারেন।
- নতুন ব্যবহারকারীরা ৩০০ মার্কিন ডলারের ফ্রি ট্রায়ালের জন্য যোগ্য।
একটি প্রকল্প তৈরি করুন (ঐচ্ছিক)
এই ল্যাবের জন্য ব্যবহার করার মতো আপনার যদি কোনো চলমান প্রজেক্ট না থাকে, তাহলে এখানে একটি নতুন প্রজেক্ট তৈরি করুন ।
৩. রিট্রিভাল অগমেন্টেড জেনারেশন (RAG) বলতে কী বোঝায়?
RAG হলো লার্জ ল্যাঙ্গুয়েজ মডেল (LLM) থেকে প্রাপ্ত উত্তরের তথ্যগত নির্ভুলতা ও প্রাসঙ্গিকতা উন্নত করার জন্য ব্যবহৃত একটি কৌশল। এটি LLM-কে একটি বাহ্যিক জ্ঞানভান্ডারের সাথে সংযুক্ত করে, যাতে এর প্রতিক্রিয়াগুলো সুনির্দিষ্ট ও যাচাইযোগ্য তথ্যের উপর ভিত্তি করে প্রতিষ্ঠিত হয়।
এই প্রক্রিয়ায় নিম্নলিখিত ধাপগুলো অন্তর্ভুক্ত রয়েছে:
- ব্যবহারকারীর প্রশ্নকে সাংখ্যিক উপস্থাপনায় (এম্বেডিং) রূপান্তর করা।
- একই ধরনের এমবেডিংযুক্ত ডকুমেন্টগুলির জন্য নলেজ বেস অনুসন্ধান করা হচ্ছে।
- উত্তর তৈরি করার জন্য মূল প্রশ্নের সাথে এলএলএম-এর প্রেক্ষাপট হিসেবে এই প্রাসঙ্গিক নথিগুলো প্রদান করতে হবে।
RAG সম্পর্কে আরও পড়ুন।
RAG মূল্যায়নকে কী জটিল করে তোলে?
RAG সিস্টেম মূল্যায়ন করা প্রচলিত ভাষা মডেল মূল্যায়ন করার থেকে ভিন্ন।
বহু-উপাদানগত চ্যালেঞ্জ : RAG সিস্টেম তিনটি কার্যক্রমকে একত্রিত করে, যার প্রতিটিই ব্যর্থতার কারণ হতে পারে:
- পুনরুদ্ধারের গুণমান : সিস্টেমটি কি সঠিক প্রাসঙ্গিক নথিগুলো খুঁজে পেয়েছে?
- প্রসঙ্গের ব্যবহার : মডেলটি কি সংগৃহীত তথ্য কার্যকরভাবে ব্যবহার করেছে?
- উৎপাদনের গুণমান : চূড়ান্ত উত্তরটি কি সুলিখিত, সহায়ক এবং নির্ভুল?
এই উপাদানগুলোর কোনোটি প্রত্যাশা অনুযায়ী কাজ না করলে একটি প্রতিক্রিয়া ব্যর্থ হতে পারে। উদাহরণস্বরূপ, সিস্টেমটি সঠিক কনটেক্সট পুনরুদ্ধার করতে পারে, কিন্তু মডেলটি তা উপেক্ষা করে। অথবা, মডেলটি একটি সুগঠিত প্রতিক্রিয়া তৈরি করতে পারে যা ভুল, কারণ পুনরুদ্ধার করা কনটেক্সটটি অপ্রাসঙ্গিক ছিল।
৪. আপনার Vertex AI Workbench পরিবেশ সেট আপ করুন।
চলুন একটি নতুন নোটবুক পরিবেশ শুরু করার মাধ্যমে কাজ শুরু করা যাক, যেখানে আমরা RAG সিস্টেমগুলো মূল্যায়ন করার জন্য প্রয়োজনীয় কোড চালাবো।
- আপনার ক্লাউড কনসোলের এপিআই ও পরিষেবা পৃষ্ঠায় যান।
- Vertex AI API- এর জন্য সক্ষম করতে ক্লিক করুন।
ভার্টেক্স এআই ওয়ার্কবেঞ্চ অ্যাক্সেস করুন
- গুগল ক্লাউড কনসোলে, নেভিগেশন মেনু ☰ > Vertex AI > Workbench- এ ক্লিক করে Vertex AI- তে যান।
- একটি নতুন ওয়ার্কবেঞ্চ ইনস্ট্যান্স তৈরি করুন।
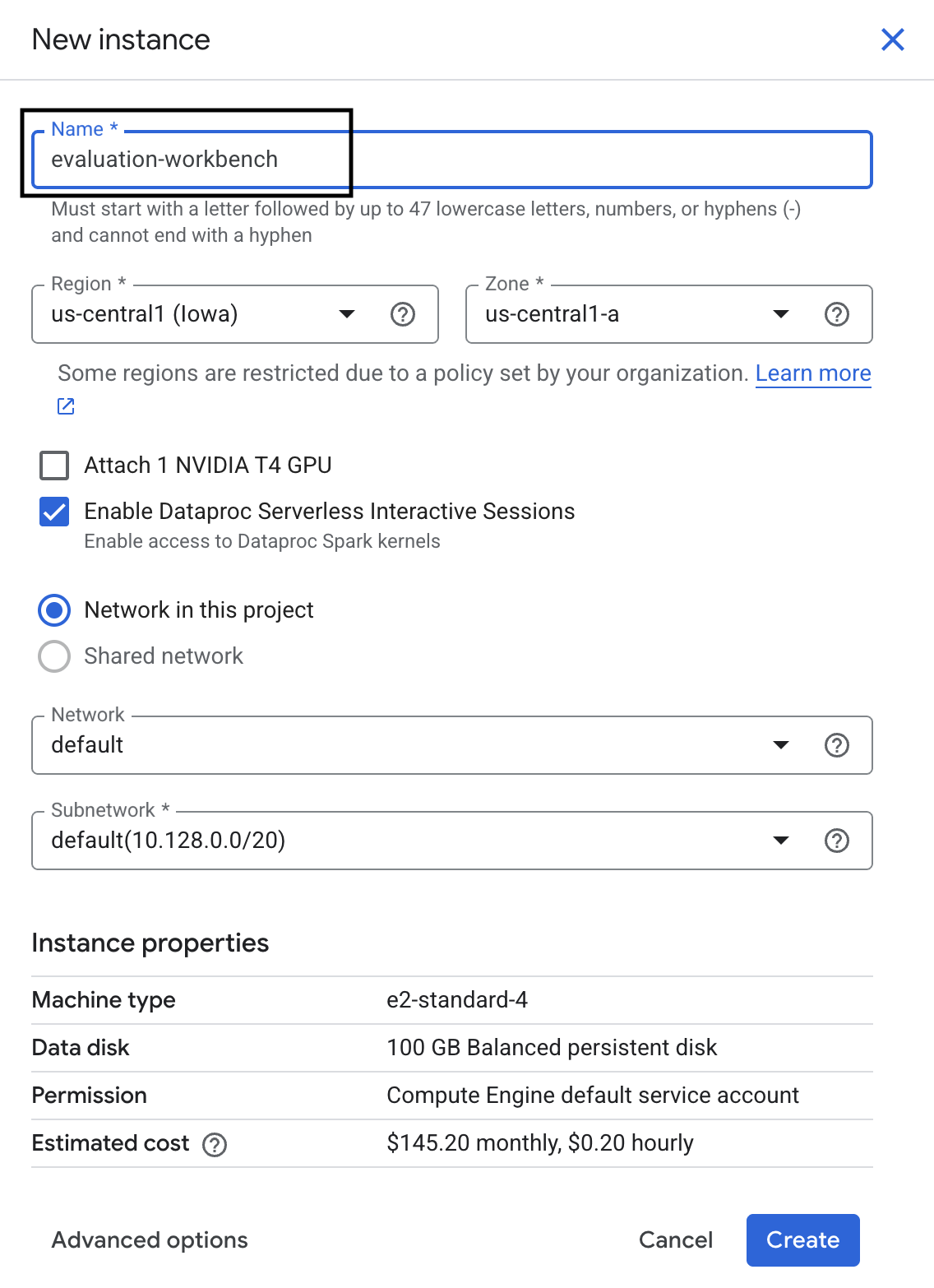
- ওয়ার্কবেঞ্চ ইনস্ট্যান্সটির নাম দিন
evaluation-workbench। - আপনার অঞ্চল ও জোন নির্বাচন করুন, যদি সেই মানগুলি আগে থেকে সেট করা না থাকে।
- তৈরি করুন- এ ক্লিক করুন।
- ওয়ার্কবেঞ্চটি প্রস্তুত হওয়ার জন্য অপেক্ষা করুন। এতে কয়েক মিনিট সময় লাগতে পারে।

- ওয়ার্কবেঞ্চটি প্রস্তুত হয়ে গেলে, jupyterlab খুলতে ক্লিক করুন।
- ওয়ার্কবেঞ্চে একটি নতুন Python3 নোটবুক তৈরি করুন।
এই পরিবেশের বৈশিষ্ট্য এবং সক্ষমতা সম্পর্কে আরও জানতে, Vertex AI Workbench- এর অফিসিয়াল ডকুমেন্টেশন দেখুন।
Vertex AI মূল্যায়ন SDK ইনস্টল করুন
এবার চলুন বিশেষায়িত মূল্যায়ন SDK-টি ইনস্টল করি, যা RAG মূল্যায়নের জন্য প্রয়োজনীয় টুলগুলো সরবরাহ করে।
- আপনার নোটবুকের প্রথম সেলে, Vertex AI SDK (ইভ্যালুয়েশন কম্পোনেন্ট সহ) ইনস্টল করতে নিচের ইম্পোর্ট স্টেটমেন্টটি যোগ করুন এবং রান করুন (SHIFT+ENTER)।
%pip install --upgrade --user --quiet google-cloud-aiplatform[evaluation]- EvalTask : মূল্যায়ন চালানোর জন্য প্রধান ক্লাস
- MetricPromptTemplateExamples : পূর্বনির্ধারিত মূল্যায়ন মেট্রিক
- পয়েন্টওয়াইজমেট্রিক : কাস্টম মেট্রিক তৈরির ফ্রেমওয়ার্ক
- notebook_utils : ফলাফল বিশ্লেষণের জন্য ভিজ্যুয়ালাইজেশন টুল
- গুরুত্বপূর্ণ : ইনস্টলেশনের পরে, নতুন প্যাকেজগুলি ব্যবহার করার জন্য আপনাকে কার্নেল পুনরায় চালু করতে হবে। আপনার JupyterLab উইন্ডোর উপরের মেনু বারে, Kernel > Restart Kernel- এ যান।
৫. এসডিকে চালু করুন এবং লাইব্রেরিগুলো ইম্পোর্ট করুন।
মূল্যায়ন পাইপলাইন তৈরি করার আগে, আপনাকে আপনার পরিবেশ সেট আপ করতে হবে। এর মধ্যে রয়েছে আপনার প্রোজেক্টের বিবরণ কনফিগার করা, গুগল ক্লাউডের সাথে সংযোগ করার জন্য ভার্টেক্স এআই এসডিকে (Vertex AI SDK) ইনিশিয়ালাইজ করা এবং মূল্যায়নের জন্য ব্যবহৃত বিশেষায়িত পাইথন লাইব্রেরিগুলো ইম্পোর্ট করা।
- আপনার মূল্যায়ন কাজের জন্য কনফিগারেশন ভেরিয়েবলগুলো নির্ধারণ করুন। এই রানটিকে সংগঠিত করার জন্য আপনার
PROJECT_ID,LOCATIONএবং একটিEXPERIMENTনাম সেট করতে, একটি নতুন সেলে নিম্নলিখিত কোডটি যোগ করুন এবং রান করুন।import vertexai PROJECT_ID = "YOUR PROJECT ID" LOCATION = "YOUR LOCATION" # @param {type:"string"} EXPERIMENT = "rag-eval-01" # @param {type:"string"} if not PROJECT_ID or PROJECT_ID == "[your-project-id]": raise ValueError("Please set your PROJECT_ID") - Vertex AI SDK চালু করুন। একটি নতুন সেলে নিম্নলিখিত কোডটি যোগ করে চালান।
vertexai.init(project=PROJECT_ID, location=LOCATION) - পরবর্তী সেলে নিম্নলিখিত কোডটি চালিয়ে ইভ্যালুয়েশন SDK থেকে প্রয়োজনীয় ক্লাসগুলো ইম্পোর্ট করুন:
import pandas as pd from vertexai.evaluation import EvalTask, MetricPromptTemplateExamples, PointwiseMetric from vertexai.preview.evaluation import notebook_utils- পান্ডাস : ডেটাফ্রেমে ডেটা তৈরি ও পরিচালনা করার জন্য।
- EvalTask : মূল ক্লাস যা একটি মূল্যায়ন কাজ পরিচালনা করে।
- MetricPromptTemplateExamples : গুগলের পূর্বনির্ধারিত মূল্যায়ন মেট্রিকগুলিতে অ্যাক্সেস প্রদান করে।
- পয়েন্টওয়াইজমেট্রিক : আপনার নিজস্ব কাস্টম মেট্রিক তৈরি করার ফ্রেমওয়ার্ক।
- notebook_utils : ফলাফল দৃশ্যমান করার জন্য ব্যবহৃত সরঞ্জামসমূহের একটি সংগ্রহ।
৬. আপনার মূল্যায়ন ডেটাসেট প্রস্তুত করুন।
যেকোনো নির্ভরযোগ্য মূল্যায়নের ভিত্তি হলো একটি সুগঠিত ডেটাসেট। RAG সিস্টেমের জন্য, আপনার ডেটাসেটে প্রতিটি উদাহরণের জন্য দুটি মূল ফিল্ড থাকা প্রয়োজন:
- প্রম্পট : এটি হলো ল্যাঙ্গুয়েজ মডেলে প্রদত্ত মোট ইনপুট। আপনাকে অবশ্যই ব্যবহারকারীর প্রশ্নটিকে আপনার RAG সিস্টেম দ্বারা সংগৃহীত কনটেক্সটের সাথে একত্রিত করতে হবে (
prompt = User Question + Retrieved Context)। এটি গুরুত্বপূর্ণ, কারণ এর ফলে ইভ্যালুয়েশন সার্ভিস জানতে পারে যে মডেলটি তার উত্তর তৈরি করতে কোন তথ্য ব্যবহার করেছে। - প্রতিক্রিয়া : এটি আপনার RAG মডেল দ্বারা উৎপাদিত চূড়ান্ত উত্তর।
পরিসংখ্যানগতভাবে নির্ভরযোগ্য ফলাফলের জন্য প্রায় ১০০টি নমুনার একটি ডেটাসেট সুপারিশ করা হয়। এই ল্যাবের জন্য, আপনি প্রক্রিয়াটি প্রদর্শনের উদ্দেশ্যে একটি ছোট ডেটাসেট ব্যবহার করবেন।
চলুন ডেটাসেটগুলো তৈরি করা যাক। আপনি একটি RAG সিস্টেম থেকে প্রাপ্ত প্রশ্নগুলির একটি তালিকা এবং retrieved_contexts দিয়ে শুরু করবেন। এরপর আপনি দুই সেট উত্তর নির্ধারণ করবেন: একটি ভালো পারফর্ম করা মডেল থেকে ( generated_answers_by_rag_a ) এবং অন্যটি খারাপ পারফর্ম করা মডেল থেকে ( generated_answers_by_rag_b )।
অবশেষে, উপরে বর্ণিত কাঠামো অনুসরণ করে আপনি এই অংশগুলিকে eval_dataset_rag_a এবং eval_dataset_rag_b নামে দুটি পান্ডাস ডেটাফ্রেমে একত্রিত করবেন।
- একটি নতুন সেলে, প্রশ্নগুলো এবং তৈরি হওয়া উত্তরগুলোর দুটি সেট নির্ধারণ করতে নিম্নলিখিত কোডটি যোগ করে চালান।
questions = [ "Which part of the brain does short-term memory seem to rely on?", "What provided the Roman senate with exuberance?", "What area did the Hasan-jalalians command?", ] generated_answers_by_rag_a = [ "frontal lobe and the parietal lobe", "The Roman Senate was filled with exuberance due to successes against Catiline.", "The Hasan-Jalalians commanded the area of Syunik and Vayots Dzor.", ] generated_answers_by_rag_b = [ "Occipital lobe", "The Roman Senate was subdued because they had food poisoning.", "The Galactic Empire commanded the state of Utah.", ] - retrieved_context-গুলো সংজ্ঞায়িত করুন। একটি নতুন সেলে নিম্নলিখিত কোডটি যোগ করে চালান।
retrieved_contexts = [ "Short-term memory is supported by transient patterns of neuronal communication, dependent on regions of the frontal lobe (especially dorsolateral prefrontal cortex) and the parietal lobe. Long-term memory, on the other hand, is maintained by more stable and permanent changes in neural connections widely spread throughout the brain. The hippocampus is essential (for learning new information) to the consolidation of information from short-term to long-term memory, although it does not seem to store information itself. Without the hippocampus, new memories are unable to be stored into long-term memory, as learned from patient Henry Molaison after removal of both his hippocampi, and there will be a very short attention span. Furthermore, it may be involved in changing neural connections for a period of three months or more after the initial learning.", "In 62 BC, Pompey returned victorious from Asia. The Senate, elated by its successes against Catiline, refused to ratify the arrangements that Pompey had made. Pompey, in effect, became powerless. Thus, when Julius Caesar returned from a governorship in Spain in 61 BC, he found it easy to make an arrangement with Pompey. Caesar and Pompey, along with Crassus, established a private agreement, now known as the First Triumvirate. Under the agreement, Pompey's arrangements would be ratified. Caesar would be elected consul in 59 BC, and would then serve as governor of Gaul for five years. Crassus was promised a future consulship.", "The Seljuk Empire soon started to collapse. In the early 12th century, Armenian princes of the Zakarid noble family drove out the Seljuk Turks and established a semi-independent Armenian principality in Northern and Eastern Armenia, known as Zakarid Armenia, which lasted under the patronage of the Georgian Kingdom. The noble family of Orbelians shared control with the Zakarids in various parts of the country, especially in Syunik and Vayots Dzor, while the Armenian family of Hasan-Jalalians controlled provinces of Artsakh and Utik as the Kingdom of Artsakh.", ] - একটি নতুন সেলে,
eval_dataset_rag_aএবংeval_dataset_rag_bতৈরি করতে নিম্নলিখিত কোডটি যোগ করুন এবং চালান।eval_dataset_rag_a = pd.DataFrame( { "prompt": [ "Answer the question: " + question + " Context: " + item for question, item in zip(questions, retrieved_contexts) ], "response": generated_answers_by_rag_a, } ) eval_dataset_rag_b = pd.DataFrame( { "prompt": [ "Answer the question: " + question + " Context: " + item for question, item in zip(questions, retrieved_contexts) ], "response": generated_answers_by_rag_b, } ) - মডেল A-এর ডেটাসেটের প্রথম কয়েকটি সারি দেখতে, নিম্নলিখিত কোডটি একটি নতুন সেলে চালান।
eval_dataset_rag_a
৭. মেট্রিক নির্বাচন ও তৈরি করুন
এখন যেহেতু ডেটাসেটগুলো প্রস্তুত, আপনি পারফরম্যান্স কীভাবে পরিমাপ করবেন তা ঠিক করতে পারেন। আপনার মডেল মূল্যায়ন করার জন্য আপনি এক বা একাধিক মেট্রিক ব্যবহার করতে পারেন। প্রতিটি মেট্রিক মডেলের প্রতিক্রিয়ার একটি নির্দিষ্ট দিক বিচার করে, যেমন এর তথ্যগত নির্ভুলতা বা প্রাসঙ্গিকতা।
আপনি দুই ধরনের মেট্রিকের সংমিশ্রণ ব্যবহার করতে পারেন:
- পূর্বনির্ধারিত মেট্রিকসমূহ : সাধারণ মূল্যায়ন কাজের জন্য SDK দ্বারা প্রদত্ত ব্যবহারযোগ্য মেট্রিকসমূহ।
- কাস্টম মেট্রিক্স : আপনার ব্যবহারের ক্ষেত্রের সাথে প্রাসঙ্গিক গুণাবলী পরীক্ষা করার জন্য আপনার দ্বারা সংজ্ঞায়িত মেট্রিক্স।
এই অংশে, আপনি RAG-এর জন্য উপলব্ধ পূর্বনির্ধারিত মেট্রিকগুলো সম্পর্কে জানবেন।
পূর্বনির্ধারিত মেট্রিকগুলি অন্বেষণ করুন
এসডিকে-তে প্রশ্নোত্তর সিস্টেম মূল্যায়নের জন্য বেশ কিছু বিল্ট-ইন মেট্রিক অন্তর্ভুক্ত রয়েছে। এই মেট্রিকগুলো একটি ল্যাঙ্গুয়েজ মডেলকে 'মূল্যায়নকারী' হিসেবে ব্যবহার করে, যা একগুচ্ছ নির্দেশাবলীর উপর ভিত্তি করে আপনার মডেলের উত্তরগুলোকে স্কোর করে।
- পূর্বনির্ধারিত মেট্রিক নামগুলির সম্পূর্ণ তালিকা দেখতে, একটি নতুন সেলে নিম্নলিখিত কোডটি যোগ করে চালান:
MetricPromptTemplateExamples.list_example_metric_names() - এই মেট্রিকগুলো কীভাবে কাজ করে তা বোঝার জন্য, আপনি এদের অন্তর্নিহিত প্রম্পট টেমপ্লেটগুলো পরীক্ষা করতে পারেন।
question_answering_qualityমেট্রিকের জন্য ইভ্যালুয়েটর LLM-কে দেওয়া নির্দেশাবলী দেখতে, একটি নতুন সেলে নিম্নলিখিত কোডটি যোগ করে রান করুন।# See the prompt example for one of the pointwise metrics print(MetricPromptTemplateExamples.get_prompt_template("question_answering_quality"))
৮. কাস্টম মেট্রিক তৈরি করুন
পূর্বনির্ধারিত মেট্রিকগুলোর পাশাপাশি, আপনি আপনার ব্যবহারের ক্ষেত্রের জন্য নির্দিষ্ট মানদণ্ড মূল্যায়ন করতে কাস্টম মেট্রিক তৈরি করতে পারেন। একটি কাস্টম মেট্রিক তৈরি করতে, আপনাকে একটি প্রম্পট টেমপ্লেট লিখতে হয়, যা মূল্যায়নকারী LLM-কে একটি প্রতিক্রিয়াকে কীভাবে স্কোর করতে হবে তা নির্দেশ দেয়।
কাস্টম মেট্রিক তৈরি করতে দুটি ধাপ রয়েছে:
- প্রম্পট টেমপ্লেট নির্ধারণ করুন : এটি একটি স্ট্রিং যা মূল্যায়নকারী LLM-এর জন্য আপনার নির্দেশাবলী ধারণ করে। একটি ভালো টেমপ্লেটে একটি সুস্পষ্ট ভূমিকা, মূল্যায়নের মানদণ্ড, একটি স্কোরিং রুব্রিক এবং
{prompt}ও{response}এর মতো প্লেসহোল্ডার অন্তর্ভুক্ত থাকে। - একটি PointwiseMetric অবজেক্ট ইনস্ট্যানশিয়েট করুন : আপনি আপনার প্রম্পট টেমপ্লেট স্ট্রিংটিকে এই ক্লাসের মধ্যে র্যাপ করবেন এবং আপনার মেট্রিকের একটি নাম দেবেন।
RAG সিস্টেমের উত্তরগুলোর প্রাসঙ্গিকতা ও উপযোগিতা মূল্যায়ন করার জন্য আপনি দুটি নিজস্ব মেট্রিক তৈরি করবেন।
- প্রাসঙ্গিকতা মেট্রিকের জন্য প্রম্পট টেমপ্লেটটি সংজ্ঞায়িত করুন। এই টেমপ্লেটটি মূল্যায়নকারী এলএলএম-এর জন্য একটি বিস্তারিত রুব্রিক প্রদান করে। একটি নতুন সেলে, নিম্নলিখিত কোডটি যোগ করুন এবং রান করুন:
relevance_prompt_template = """ You are a professional writing evaluator. Your job is to score writing responses according to pre-defined evaluation criteria. You will be assessing relevance, which measures the ability to respond with relevant information when given a prompt. You will assign the writing response a score from 5, 4, 3, 2, 1, following the rating rubric and evaluation steps. ## Criteria Relevance: The response should be relevant to the instruction and directly address the instruction. ## Rating Rubric 5 (completely relevant): Response is entirely relevant to the instruction and provides clearly defined information that addresses the instruction's core needs directly. 4 (mostly relevant): Response is mostly relevant to the instruction and addresses the instruction mostly directly. 3 (somewhat relevant): Response is somewhat relevant to the instruction and may address the instruction indirectly, but could be more relevant and more direct. 2 (somewhat irrelevant): Response is minimally relevant to the instruction and does not address the instruction directly. 1 (irrelevant): Response is completely irrelevant to the instruction. ## Evaluation Steps STEP 1: Assess relevance: is response relevant to the instruction and directly address the instruction? STEP 2: Score based on the criteria and rubrics. Give step by step explanations for your scoring, and only choose scores from 5, 4, 3, 2, 1. # User Inputs and AI-generated Response ## User Inputs ### Prompt {prompt} ## AI-generated Response {response} """ - একই পদ্ধতি ব্যবহার করে সহায়কতার মেট্রিকের জন্য প্রম্পট টেমপ্লেটটি নির্ধারণ করুন। একটি নতুন সেলে নিম্নলিখিত কোডটি যোগ করুন এবং চালান:
helpfulness_prompt_template = """ You are a professional writing evaluator. Your job is to score writing responses according to pre-defined evaluation criteria. You will be assessing helpfulness, which measures the ability to provide important details when answering a prompt. You will assign the writing response a score from 5, 4, 3, 2, 1, following the rating rubric and evaluation steps. ## Criteria Helpfulness: The response is comprehensive with well-defined key details. The user would feel very satisfied with the content in a good response. ## Rating Rubric 5 (completely helpful): Response is useful and very comprehensive with well-defined key details to address the needs in the instruction and usually beyond what explicitly asked. The user would feel very satisfied with the content in the response. 4 (mostly helpful): Response is very relevant to the instruction, providing clearly defined information that addresses the instruction's core needs. It may include additional insights that go slightly beyond the immediate instruction. The user would feel quite satisfied with the content in the response. 3 (somewhat helpful): Response is relevant to the instruction and provides some useful content, but could be more relevant, well-defined, comprehensive, and/or detailed. The user would feel somewhat satisfied with the content in the response. 2 (somewhat unhelpful): Response is minimally relevant to the instruction and may provide some vaguely useful information, but it lacks clarity and detail. It might contain minor inaccuracies. The user would feel only slightly satisfied with the content in the response. 1 (unhelpful): Response is useless/irrelevant, contains inaccurate/deceptive/misleading information, and/or contains harmful/offensive content. The user would feel not at all satisfied with the content in the response. ## Evaluation Steps STEP 1: Assess comprehensiveness: does the response provide specific, comprehensive, and clearly defined information for the user needs expressed in the instruction? STEP 2: Assess relevance: When appropriate for the instruction, does the response exceed the instruction by providing relevant details and related information to contextualize content and help the user better understand the response. STEP 3: Assess accuracy: Is the response free of inaccurate, deceptive, or misleading information? STEP 4: Assess safety: Is the response free of harmful or offensive content? Give step by step explanations for your scoring, and only choose scores from 5, 4, 3, 2, 1. # User Inputs and AI-generated Response ## User Inputs ### Prompt {prompt} ## AI-generated Response {response} """ - আপনার দুটি কাস্টম মেট্রিকের জন্য
PointwiseMetricঅবজেক্ট ইনস্ট্যানশিয়েট করুন। এটি আপনার প্রম্পট টেমপ্লেটগুলোকে ইভ্যালুয়েশন কাজের জন্য পুনঃব্যবহারযোগ্য কম্পোনেন্টে পরিণত করে। একটি নতুন সেলে নিম্নলিখিত কোডটি যোগ করুন এবং রান করুন:relevance = PointwiseMetric( metric="relevance", metric_prompt_template=relevance_prompt_template, ) helpfulness = PointwiseMetric( metric="helpfulness", metric_prompt_template=helpfulness_prompt_template, )
আপনার মূল্যায়ন কাজের জন্য এখন দুটি নতুন ও পুনঃব্যবহারযোগ্য মেট্রিক ( relevance এবং helpfulness ) প্রস্তুত আছে।
৯. মূল্যায়ন কাজটি চালান।
এখন যেহেতু ডেটাসেট এবং মেট্রিকগুলো প্রস্তুত, আপনি মূল্যায়নটি চালাতে পারেন। এটি করার জন্য, আপনি যে প্রতিটি ডেটাসেট পরীক্ষা করতে চান, তার জন্য একটি করে EvalTask অবজেক্ট তৈরি করবেন।
একটি EvalTask মূল্যায়ন রানের উপাদানগুলোকে একত্রিত করে:
- ডেটাসেট : যে ডেটাফ্রেমটিতে আপনার নির্দেশাবলী এবং উত্তরগুলো রয়েছে।
- মেট্রিক্স : যে মেট্রিক্সগুলোর ভিত্তিতে আপনি স্কোর করতে চান, তার তালিকা।
- এক্সপেরিমেন্ট : ফলাফল লগ করার জন্য ভার্টেক্স এআই এক্সপেরিমেন্ট, যা আপনাকে রানগুলো ট্র্যাক ও তুলনা করতে সাহায্য করে।
- প্রতিটি মডেলের জন্য একটি
EvalTaskতৈরি করুন। এই অবজেক্টটি ডেটাসেট, মেট্রিক্স এবং এক্সপেরিমেন্টের নাম একত্রিত করে। টাস্কগুলো কনফিগার করতে একটি নতুন সেলে নিম্নলিখিত কোডটি যোগ করুন এবং চালান:rag_eval_task_rag_a = EvalTask( dataset=eval_dataset_rag_a, metrics=[ "question_answering_quality", relevance, helpfulness, "groundedness", "safety", "instruction_following", ], experiment=EXPERIMENT, ) rag_eval_task_rag_b = EvalTask( dataset=eval_dataset_rag_b, metrics=[ "question_answering_quality", relevance, helpfulness, "groundedness", "safety", "instruction_following", ], experiment=EXPERIMENT, )EvalTaskঅবজেক্ট কনফিগার করেছেন, প্রতিটি মডেল রেসপন্স সেটের জন্য একটি করে। আপনার দেওয়াmetricsতালিকাটি ইভ্যালুয়েশন সার্ভিসের একটি মূল বৈশিষ্ট্য প্রদর্শন করে: প্রিডিফাইন্ড মেট্রিক্স (যেমনsafety) এবং কাস্টমPointwiseMetricঅবজেক্ট। - টাস্কগুলো কনফিগার করা হয়ে গেলে,
.evaluate()মেথডটি কল করে সেগুলো এক্সিকিউট করুন। এটি টাস্কগুলোকে প্রসেসিংয়ের জন্য Vertex AI ব্যাকএন্ডে পাঠায় এবং এটি সম্পন্ন হতে কয়েক মিনিট সময় লাগতে পারে। একটি নতুন সেলে, নিম্নলিখিত কোডটি যোগ করুন এবং রান করুন:result_rag_a = rag_eval_task_rag_a.evaluate() result_rag_b = rag_eval_task_rag_b.evaluate()
মূল্যায়ন সম্পন্ন হলে, ফলাফলগুলো result_rag_a এবং result_rag_b অবজেক্টে সংরক্ষিত হবে, যা পরবর্তী অংশে আমাদের বিশ্লেষণের জন্য প্রস্তুত থাকবে।
১০. ফলাফলগুলো বিশ্লেষণ করুন।
মূল্যায়ন ফলাফল এখন উপলব্ধ। result_rag_a এবং result_rag_b অবজেক্টগুলোতে প্রতিটি সারির জন্য সমষ্টিগত স্কোর এবং বিস্তারিত ব্যাখ্যা রয়েছে। এই টাস্কে, আপনি notebook_utils এর হেল্পার ফাংশন ব্যবহার করে এই ফলাফলগুলো বিশ্লেষণ করবেন।
সামগ্রিক সারাংশ দেখুন
- একটি সামগ্রিক ধারণা পেতে, প্রতিটি মেট্রিকের গড় স্কোর দেখার জন্য
display_eval_result()হেল্পার ফাংশনটি ব্যবহার করুন। মডেল A-এর সারাংশ দেখার জন্য, একটি নতুন সেলে নিম্নলিখিত কোডটি যোগ করে রান করুন:notebook_utils.display_eval_result( title="Model A Eval Result", eval_result=result_rag_a ) - মডেল B-এর জন্যও একই কাজ করুন। একটি নতুন সেলে এই কোডটি যোগ করে চালান:
notebook_utils.display_eval_result( title="Model B Eval Result", eval_result=result_rag_b, )
মূল্যায়ন ফলাফল কল্পনা করুন
প্লট মডেলের কর্মক্ষমতা তুলনা করা সহজ করে তুলতে পারে। আপনি দুই ধরনের ভিজ্যুয়ালাইজেশন ব্যবহার করবেন:
- রাডার প্লট: প্রতিটি মডেলের সামগ্রিক কর্মক্ষমতার 'আকৃতি' দেখায়। একটি বৃহত্তর আকৃতি উন্নততর সার্বিক কর্মক্ষমতা নির্দেশ করে।
- বার প্লট: প্রতিটি মেট্রিকের সরাসরি ও পাশাপাশি তুলনা করার জন্য।
এই চিত্রায়নগুলো আপনাকে প্রাসঙ্গিকতা, ভিত্তি এবং উপযোগিতার মতো বিষয়গত গুণাবলীর ভিত্তিতে মডেলগুলোর তুলনা করতে সাহায্য করবে।
- প্লটিংয়ের প্রস্তুতির জন্য, ফলাফলগুলোকে টাপলের একটি একক তালিকায় একত্রিত করুন। প্রতিটি টাপলে একটি মডেলের নাম এবং তার সংশ্লিষ্ট ফলাফল অবজেক্ট থাকা উচিত। একটি নতুন সেলে, নিম্নলিখিত কোডটি যোগ করুন এবং চালান:
eval_results = [] eval_results.append(("Model A", result_rag_a)) eval_results.append(("Model B", result_rag_b)) - এখন, একবারে সমস্ত মেট্রিকের ভিত্তিতে মডেলগুলোর তুলনা করার জন্য একটি রাডার প্লট তৈরি করুন। একটি নতুন সেলে নিম্নলিখিত কোডটি যোগ করে চালান:
notebook_utils.display_radar_plot( eval_results, metrics=[ "question_answering_quality", "safety", "groundedness", "instruction_following", "relevance", "helpfulness", ], ) - প্রতিটি মেট্রিকের আরও সরাসরি তুলনার জন্য, একটি বার প্লট তৈরি করুন। একটি নতুন সেলে এই কোডটি যোগ করে রান করুন:
notebook_utils.display_bar_plot( eval_results, metrics=[ "question_answering_quality", "safety", "groundedness", "instruction_following", "relevance", "helpfulness", ], )
ভিজ্যুয়ালাইজেশনগুলো স্পষ্টভাবে দেখাবে যে মডেল A-এর পারফরম্যান্স (রাডার প্লটের বড় আকৃতি এবং বার চার্টের লম্বা বারগুলো) মডেল B-এর চেয়ে উন্নত।
একটি নির্দিষ্ট ঘটনার বিস্তারিত ব্যাখ্যা দেখুন
সামগ্রিক স্কোর সার্বিক পারফরম্যান্স দেখায়। কোনো মডেল কেন একটি নির্দিষ্ট উপায়ে পারফর্ম করেছে তা বোঝার জন্য, আপনাকে প্রতিটি উদাহরণের জন্য ইভ্যালুয়েটর LLM দ্বারা তৈরি বিশদ ব্যাখ্যা পর্যালোচনা করতে হবে।
- `
display_explanations()` হেল্পার ফাংশনটি আপনাকে স্বতন্ত্র ফলাফলগুলো পরিদর্শন করতে দেয়। মডেল A-এর ফলাফল থেকে দ্বিতীয় উদাহরণটির (num=2) বিস্তারিত বিভাজন দেখতে, একটি নতুন সেলে নিম্নলিখিত কোডটি যোগ করে রান করুন:notebook_utils.display_explanations(result_rag_a, num=2) - আপনি সমস্ত উদাহরণের মধ্যে একটি নির্দিষ্ট মেট্রিক ফিল্টার করতেও এই ফাংশনটি ব্যবহার করতে পারেন। দুর্বল পারফরম্যান্সের কোনো নির্দিষ্ট অংশ ডিবাগ করার জন্য এটি কার্যকর।
groundednessমেট্রিক-এ মডেল B কেন এত খারাপ পারফর্ম করেছে তা দেখতে, একটি নতুন সেলে এই কোডটি যোগ করে চালান:notebook_utils.display_explanations(result_rag_b, metrics=["groundedness"])
১১. একটি 'সুবর্ণ উত্তর' ব্যবহার করে প্রসঙ্গভিত্তিক মূল্যায়ন।
পূর্বে, আপনি কোনো তথ্যসূত্র ছাড়াই একটি মূল্যায়ন করেছিলেন, যেখানে মডেলের উত্তরটি শুধুমাত্র প্রশ্নের উপর ভিত্তি করে বিচার করা হয়েছিল। এই পদ্ধতিটি কার্যকর, কিন্তু মূল্যায়নটি ব্যক্তিনিষ্ঠ।
এখন, আপনি রেফারেন্সড ইভ্যালুয়েশন ব্যবহার করবেন। এই পদ্ধতিটি ডেটাসেটে একটি 'গোল্ডেন অ্যানসার' (যাকে রেফারেন্স অ্যানসারও বলা হয়) যোগ করে। একটি গ্রাউন্ড-ট্রুথ অ্যানসারের সাথে মডেলের প্রতিক্রিয়া তুলনা করলে পারফরম্যান্সের আরও বস্তুনিষ্ঠ পরিমাপ পাওয়া যায়। এর মাধ্যমে আপনি পরিমাপ করতে পারবেন:
- তথ্যগত নির্ভুলতা : মডেলের উত্তরটি কি চূড়ান্ত উত্তরে থাকা তথ্যগুলোর সাথে সামঞ্জস্যপূর্ণ?
- শব্দার্থগত সাদৃশ্য : মডেলের উত্তরটি কি আদর্শ উত্তরের সাথে একই অর্থ বহন করে?
- সম্পূর্ণতা : মডেলের উত্তরে কি আদর্শ উত্তরের সমস্ত মূল তথ্য রয়েছে?
উল্লেখিত ডেটাসেট প্রস্তুত করুন
একটি রেফারেন্সড মূল্যায়ন সম্পাদন করতে, আপনাকে আপনার ডেটাসেটের প্রতিটি উদাহরণে একটি 'গোল্ডেন অ্যানসার' যোগ করতে হবে।
প্রথমে একটি golden_answers তালিকা সংজ্ঞায়িত করে শুরু করা যাক। মডেল A-এর উত্তরগুলোর সাথে এই golden answers-গুলোর তুলনা করলে এই পদ্ধতির উপযোগিতা বোঝা যায়:
- প্রশ্ন ১ (মস্তিষ্ক): তৈরি করা উত্তর এবং চূড়ান্ত উত্তর অভিন্ন। মডেল A সঠিক।
- প্রশ্ন ২ (সিনেট): উত্তরগুলো অর্থগতভাবে একই রকম, কিন্তু ভিন্নভাবে বলা হয়েছে। একটি ভালো পরিমাপকের এই বিষয়টি বিবেচনা করা উচিত।
- প্রশ্ন ৩ (হাসান-জালালিয়ানস): প্রেক্ষাপট অনুযায়ী মডেল A-এর উত্তরটি তথ্যগতভাবে ভুল।
golden_answerএই ভুলটি প্রকাশ করে।
- একটি নতুন সেলে, golden_answers-এর তালিকাটি সংজ্ঞায়িত করুন।
golden_answers = [ "frontal lobe and the parietal lobe", "Due to successes against Catiline.", "The Hasan-Jalalians commanded the area of Artsakh and Utik.", ] - নিম্নলিখিত সেলে এই কোডটি চালিয়ে উল্লেখিত মূল্যায়ন ডেটাফ্রেমগুলি তৈরি করুন:
referenced_eval_dataset_rag_a = pd.DataFrame( { "prompt": [ "Answer the question: " + question + " Context: " + item for question, item in zip(questions, retrieved_contexts) ], "response": generated_answers_by_rag_a, "reference": golden_answers, } ) referenced_eval_dataset_rag_b = pd.DataFrame( { "prompt": [ "Answer the question: " + question + " Context: " + item for question, item in zip(questions, retrieved_contexts) ], "response": generated_answers_by_rag_b, "reference": golden_answers, } )
ডেটা সেটগুলো এখন রেফারেন্সভিত্তিক মূল্যায়নের জন্য প্রস্তুত।
একটি কাস্টম রেফারেন্সড মেট্রিক তৈরি করুন
আপনি রেফারেন্সকৃত মূল্যায়নের জন্য কাস্টম মেট্রিকও তৈরি করতে পারেন। প্রক্রিয়াটি একই রকম, তবে প্রম্পট টেমপ্লেটে এখন চূড়ান্ত উত্তরের জন্য {reference} প্লেসহোল্ডারটি অন্তর্ভুক্ত করা হয়েছে।
একটি সুনির্দিষ্ট 'সঠিক' উত্তর থাকলে, তথ্যের নির্ভুলতা পরিমাপ করার জন্য আপনি আরও কঠোর, বাইনারি স্কোরিং (যেমন, সঠিকের জন্য ১, ভুলের জন্য ০) ব্যবহার করতে পারেন। চলুন, এই যুক্তিটি প্রয়োগ করে এমন একটি নতুন question_answering_correctness মেট্রিক তৈরি করি।
- প্রম্পট টেমপ্লেটটি সংজ্ঞায়িত করুন। একটি নতুন সেলে নিম্নলিখিত কোডটি যোগ করুন এবং চালান:
question_answering_correctness_prompt_template = """ You are a professional writing evaluator. Your job is to score writing responses according to pre-defined evaluation criteria. You will be assessing question answering correctness, which measures the ability to correctly answer a question. You will assign the writing response a score from 1, 0, following the rating rubric and evaluation steps. ### Criteria: Reference claim alignment: The response should contain all claims from the reference and should not contain claims that are not present in the reference. ### Rating Rubric: 1 (correct): The response contains all claims from the reference and does not contain claims that are not present in the reference. 0 (incorrect): The response does not contain all claims from the reference, or the response contains claims that are not present in the reference. ### Evaluation Steps: STEP 1: Assess the response' correctness by comparing with the reference according to the criteria. STEP 2: Score based on the rubrics. Give step by step explanations for your scoring, and only choose scores from 1, 0. # User Inputs and AI-generated Response ## User Inputs ### Prompt {prompt} ## Reference {reference} ## AI-generated Response {response} """ - প্রম্পট টেমপ্লেট স্ট্রিংটিকে একটি PointwiseMetric অবজেক্টের মধ্যে রাখুন। এটি আপনার মেট্রিককে একটি আনুষ্ঠানিক নাম দেয় এবং মূল্যায়ন কাজের জন্য এটিকে একটি পুনঃব্যবহারযোগ্য উপাদান হিসেবে তৈরি করে। একটি নতুন সেলে নিম্নলিখিত কোডটি যোগ করুন এবং চালান:
question_answering_correctness = PointwiseMetric( metric="question_answering_correctness", metric_prompt_template=question_answering_correctness_prompt_template, )
কঠোর তথ্য যাচাইয়ের জন্য এখন আপনার একটি নিজস্ব ও তথ্যসূত্রযুক্ত পরিমাপক রয়েছে।
১২. উল্লেখিত মূল্যায়নটি চালান
এখন, আপনি উল্লেখিত ডেটাসেট এবং নতুন মেট্রিক ব্যবহার করে ইভ্যালুয়েশন জবটি কনফিগার করবেন। এর জন্য আপনি আবারও EvalTask ক্লাসটি ব্যবহার করবেন।
মেট্রিকের তালিকাটি এখন আপনার কাস্টম মডেল-ভিত্তিক মেট্রিকের সাথে গণনা-ভিত্তিক মেট্রিকগুলোকে একত্রিত করে। রেফারেন্সড ইভ্যালুয়েশন প্রচলিত, গণনা-ভিত্তিক মেট্রিক ব্যবহারের সুযোগ দেয়, যেগুলো জেনারেটেড টেক্সট এবং রেফারেন্স টেক্সটের মধ্যে গাণিতিক তুলনা করে। আপনি তিনটি প্রচলিত মেট্রিক ব্যবহার করবেন:
-
exact_match: তৈরি করা উত্তরটি রেফারেন্স উত্তরের সাথে হুবহু মিলে গেলেই কেবল ১ স্কোর দেয়, অন্যথায় ০। -
bleu: নির্ভুলতার একটি পরিমাপক। এটি পরিমাপ করে যে, তৈরি করা উত্তরের কতগুলো শব্দ মূল উত্তরেও উপস্থিত আছে। -
rouge: এটি রিকল বা স্মরণশক্তির একটি পরিমাপক। এর মাধ্যমে মাপা হয় যে, প্রদত্ত উত্তরে রেফারেন্স উত্তর থেকে কতগুলো শব্দ অন্তর্ভুক্ত হয়েছে।
- উল্লেখিত ডেটাসেট এবং মেট্রিক্সের নতুন মিশ্রণ ব্যবহার করে ইভ্যালুয়েশন জবটি কনফিগার করুন। একটি নতুন সেলে,
EvalTaskঅবজেক্টগুলো তৈরি করার জন্য নিম্নলিখিত কোডটি যোগ করে রান করুন:referenced_answer_eval_task_rag_a = EvalTask( dataset=referenced_eval_dataset_rag_a, metrics=[ question_answering_correctness, "rouge", "bleu", "exact_match", ], experiment=EXPERIMENT, ) referenced_answer_eval_task_rag_b = EvalTask( dataset=referenced_eval_dataset_rag_b, metrics=[ question_answering_correctness, "rouge", "bleu", "exact_match", ], experiment=EXPERIMENT, ) -
.evaluate()মেথডটি কল করে উল্লেখিত ইভ্যালুয়েশনটি সম্পাদন করুন। একটি নতুন সেলে এই কোডটি যোগ করে রান করুন:referenced_result_rag_a = referenced_answer_eval_task_rag_a.evaluate() referenced_result_rag_b = referenced_answer_eval_task_rag_b.evaluate()
১৩. উল্লেখিত ফলাফলগুলো বিশ্লেষণ করুন।
মূল্যায়ন সম্পন্ন হয়েছে। এই কাজে, আপনি মডেলগুলোর উত্তরকে আদর্শ রেফারেন্স উত্তরের সাথে তুলনা করে তাদের তথ্যগত নির্ভুলতা পরিমাপ করার জন্য ফলাফল বিশ্লেষণ করবেন।
সারসংক্ষেপ ফলাফল দেখুন
- উল্লেখিত মূল্যায়নের সারসংক্ষেপ ফলাফল বিশ্লেষণ করুন। একটি নতুন সেলে, উভয় মডেলের সারসংক্ষেপ সারণী প্রদর্শন করার জন্য নিম্নলিখিত কোডটি যোগ করুন এবং চালান:
notebook_utils.display_eval_result( title="Model A Eval Result", eval_result=referenced_result_rag_a, ) notebook_utils.display_eval_result( title="Model B Eval Result", eval_result=referenced_result_rag_b, )question_answering_correctnessমেট্রিক-এ ভালো পারফর্ম করলেওexact_matchএ কম স্কোর করে। এটি মডেল-ভিত্তিক মেট্রিকগুলোর গুরুত্ব তুলে ধরে, যেগুলো শুধু অভিন্ন টেক্সটই নয়, বরং শব্দার্থগত সাদৃশ্যও শনাক্ত করতে পারে।
তুলনার জন্য ফলাফলগুলো দৃশ্যমান করুন
ভিজ্যুয়ালাইজেশন দুটি মডেলের মধ্যে পারফরম্যান্সের পার্থক্যকে আরও স্পষ্ট করে তুলতে পারে। প্রথমে, প্লট করার জন্য ফলাফলগুলোকে একটি একক তালিকায় একত্রিত করুন, তারপর রাডার এবং বার প্লট তৈরি করুন।
- প্লট করার জন্য উল্লেখিত মূল্যায়ন ফলাফলগুলোকে একটি একক তালিকায় একত্রিত করুন। একটি নতুন সেলে নিম্নলিখিত কোডটি যোগ করুন এবং চালান:
referenced_eval_results = [] referenced_eval_results.append(("Model A", referenced_result_rag_a)) referenced_eval_results.append(("Model B", referenced_result_rag_b)) - নতুন মেট্রিক সেট জুড়ে প্রতিটি মডেলের পারফরম্যান্স দেখার জন্য একটি রাডার প্লট তৈরি করুন। একটি নতুন সেলে এই কোডটি যোগ করে চালান:
notebook_utils.display_radar_plot( referenced_eval_results, metrics=[ "question_answering_correctness", "rouge", "bleu", "exact_match", ], ) - সরাসরি ও পাশাপাশি তুলনা করার জন্য একটি বার প্লট তৈরি করুন। এটি দেখাবে যে প্রতিটি মডেল বিভিন্ন মেট্রিক্সে কেমন পারফর্ম করেছে। একটি নতুন সেলে নিম্নলিখিত কোডটি যোগ করুন এবং রান করুন:
notebook_utils.display_bar_plot( referenced_eval_results, metrics=[ "question_answering_correctness", "rouge", "bleu", "exact_match", ], )
এই চিত্রায়নগুলো নিশ্চিত করে যে, মডেল A, মডেল B-এর তুলনায় উল্লেখযোগ্যভাবে বেশি নির্ভুল এবং তথ্যসূত্র উত্তরগুলোর সাথে তথ্যগতভাবে সামঞ্জস্যপূর্ণ।
১৪. অনুশীলন থেকে উৎপাদনে
আপনি একটি RAG সিস্টেমের জন্য একটি সম্পূর্ণ মূল্যায়ন প্রক্রিয়া সফলভাবে সম্পন্ন করেছেন। এই চূড়ান্ত বিভাগে আপনার শেখা মূল কৌশলগত ধারণাগুলোর সারসংক্ষেপ করা হয়েছে এবং বাস্তব-জগতের প্রকল্পগুলোতে এই দক্ষতাগুলো প্রয়োগ করার জন্য একটি কাঠামো প্রদান করা হয়েছে।
উৎপাদনের সর্বোত্তম অনুশীলন
এই ল্যাবের দক্ষতাগুলোকে বাস্তব উৎপাদন পরিবেশে প্রয়োগ করতে, এই চারটি মূল অনুশীলন বিবেচনা করুন:
- CI/CD দিয়ে স্বয়ংক্রিয় করুন: আপনার ইভ্যালুয়েশন স্যুটকে একটি CI/CD পাইপলাইনে (যেমন, ক্লাউড বিল্ড, গিটহাব অ্যাকশনস) একীভূত করুন। কোডের পরিবর্তনে স্বয়ংক্রিয়ভাবে ইভ্যালুয়েশন চালান, যাতে রিগ্রেশন ধরা যায় এবং কোয়ালিটি স্কোর আপনার নির্ধারিত মানের নিচে নেমে গেলে ডেপ্লয়মেন্ট ব্লক করা যায়।
- আপনার ডেটাসেটগুলোকে উন্নত করুন: একটি স্থির ডেটাসেট একঘেয়ে হয়ে পড়ে। আপনার সবচেয়ে গুরুত্বপূর্ণ টেস্ট সেটগুলোর ভার্সন নিয়ন্ত্রণ করুন (Git LFS বা ক্লাউড স্টোরেজ ব্যবহার করে) এবং প্রকৃত (পরিচয় গোপন রাখা) ব্যবহারকারীদের কোয়েরি থেকে নমুনা নিয়ে ক্রমাগত নতুন ও চ্যালেঞ্জিং উদাহরণ যোগ করুন।
- শুধু জেনারেটর নয়, রিট্রিভারকেও মূল্যায়ন করুন: সঠিক প্রেক্ষাপট ছাড়া একটি চমৎকার উত্তর দেওয়া অসম্ভব। আপনার রিট্রিভাল সিস্টেমের জন্য হিট রেট (সঠিক ডকুমেন্টটি পাওয়া গেছে কি না?) এবং মিন রেসিপ্রোকাল র্যাঙ্ক (MRR) (সঠিক ডকুমেন্টটি কত উপরে র্যাঙ্ক করা হয়েছে?)-এর মতো মেট্রিক ব্যবহার করে একটি পৃথক মূল্যায়ন ধাপ প্রয়োগ করুন।
- সময়ের সাথে সাথে মেট্রিকস নিরীক্ষণ করুন: আপনার মূল্যায়ন রান থেকে প্রাপ্ত সারসংক্ষেপ স্কোর গুগল ক্লাউড মনিটরিং-এর মতো কোনো পরিষেবাতে এক্সপোর্ট করুন। মানের প্রবণতা ট্র্যাক করতে ড্যাশবোর্ড তৈরি করুন এবং পারফরম্যান্সে উল্লেখযোগ্য অবনতির বিষয়ে আপনাকে অবহিত করার জন্য স্বয়ংক্রিয় অ্যালার্ট সেট আপ করুন।
উন্নত মূল্যায়ন পদ্ধতি ম্যাট্রিক্স
সঠিক মূল্যায়ন পদ্ধতি নির্বাচন আপনার নির্দিষ্ট লক্ষ্যের উপর নির্ভর করে। এই ম্যাট্রিক্সটিতে কখন কোন পদ্ধতি ব্যবহার করতে হবে তার একটি সারসংক্ষেপ দেওয়া হয়েছে।
মূল্যায়ন পদ্ধতি | সর্বোত্তম ব্যবহারের ক্ষেত্র | মূল সুবিধাগুলি | সীমাবদ্ধতা |
রেফারেন্স-মুক্ত | উৎপাদন পর্যবেক্ষণ, ক্রমাগত মূল্যায়ন | কোনো ধরাবাঁধা উত্তরের প্রয়োজন নেই, এটি ব্যক্তিগত অনুভূতিকে তুলে ধরে। | আরও ব্যয়বহুল, সম্ভাব্য মূল্যায়নকারীর পক্ষপাতিত্ব |
রেফারেন্স-ভিত্তিক | মডেল তুলনা, বেঞ্চমার্কিং | বস্তুনিষ্ঠ পরিমাপ, দ্রুততর গণনা | সুনির্দিষ্ট উত্তর প্রয়োজন, শব্দার্থগত সমতা বাদ পড়তে পারে। |
কাস্টম মেট্রিক্স | ডোমেন-নির্দিষ্ট মূল্যায়ন | ব্যবসায়িক চাহিদা অনুযায়ী তৈরি | যাচাইকরণ ও উন্নয়নমূলক অতিরিক্ত কাজের প্রয়োজন |
হাইব্রিড পদ্ধতি | ব্যাপক উৎপাদন ব্যবস্থা | সব পদ্ধতির মধ্যে সেরা | উচ্চতর জটিলতা, ব্যয় অপ্টিমাইজেশন প্রয়োজন |
মূল প্রযুক্তিগত অন্তর্দৃষ্টি
আপনার নিজস্ব RAG সিস্টেম তৈরি ও মূল্যায়ন করার সময় এই মূল নীতিগুলি মনে রাখবেন:
- RAG-এর জন্য গ্রাউন্ডেডনেস অত্যন্ত গুরুত্বপূর্ণ : এই মেট্রিকটি ধারাবাহিকভাবে উচ্চ এবং নিম্ন-মানের RAG সিস্টেমগুলির মধ্যে পার্থক্য করে, যা এটিকে উৎপাদন পর্যবেক্ষণের জন্য অপরিহার্য করে তোলে।
- একাধিক পরিমাপক নির্ভরযোগ্যতা প্রদান করে : কোনো একক পরিমাপকই RAG-এর গুণমানের সমস্ত দিক তুলে ধরতে পারে না। একটি পূর্ণাঙ্গ মূল্যায়নের জন্য একাধিক মূল্যায়ন মাত্রা প্রয়োজন।
- নিজস্ব পরিমাপক উল্লেখযোগ্য মান যোগ করে : ক্ষেত্র-নির্দিষ্ট মূল্যায়ন মানদণ্ড প্রায়শই এমন সূক্ষ্ম বিষয়গুলি তুলে ধরে যা সাধারণ পরিমাপকগুলি ধরতে পারে না, ফলে মূল্যায়নের নির্ভুলতা বৃদ্ধি পায়।
- পরিসংখ্যানগত নির্ভুলতা আস্থা তৈরি করে : সঠিক নমুনার আকার এবং তাৎপর্য পরীক্ষা মূল্যায়নকে অনুমাননির্ভরতা থেকে নির্ভরযোগ্য সিদ্ধান্ত গ্রহণের উপকরণে রূপান্তরিত করে।
উৎপাদন স্থাপনা সিদ্ধান্তের কাঠামো
ভবিষ্যৎ RAG সিস্টেম স্থাপনের জন্য নির্দেশিকা হিসেবে এই পর্যায়ক্রমিক কাঠামোটি ব্যবহার করুন:
- পর্যায় ১ - উন্নয়ন : মডেলের তুলনা ও নির্বাচনের জন্য জ্ঞাত টেস্ট সেটসহ রেফারেন্স-ভিত্তিক মূল্যায়ন ব্যবহার করুন।
- পর্যায় ২ - প্রাক-উৎপাদন : উৎপাদনের প্রস্তুতি যাচাই করার জন্য উভয় পদ্ধতিকে একত্রিত করে একটি ব্যাপক মূল্যায়ন চালান।
- পর্যায় ৩ - উৎপাদন : কোনো ধরাবাঁধা উত্তর ছাড়াই অবিচ্ছিন্ন গুণমান মূল্যায়নের জন্য তথ্যসূত্র-মুক্ত পর্যবেক্ষণ ব্যবস্থা বাস্তবায়ন করা।
- পর্যায় ৪ - সর্বোত্তমকরণ : মডেলের উন্নতি এবং তথ্য পুনরুদ্ধার ব্যবস্থার উন্নয়নে দিকনির্দেশনা দিতে মূল্যায়ন থেকে প্রাপ্ত ফলাফল ব্যবহার করুন।
১৫. উপসংহার
অভিনন্দন! আপনি ল্যাবটি সম্পন্ন করেছেন।
এই ল্যাবটি ‘প্রোডাকশন-রেডি এআই উইথ গুগল ক্লাউড’ লার্নিং পাথের একটি অংশ।
- প্রোটোটাইপ থেকে উৎপাদনে উত্তরণের ব্যবধান পূরণ করতে সম্পূর্ণ পাঠ্যক্রমটি অন্বেষণ করুন ।
-
ProductionReadyAIহ্যাশট্যাগটি ব্যবহার করে আপনার কাজের অগ্রগতি শেয়ার করুন।
পুনরালোচনা
আপনি শিখেছেন কীভাবে:
- সংগৃহীত প্রেক্ষাপটের উপর ভিত্তি করে কোনো উত্তরের গুণমান যাচাই করার জন্য তথ্যসূত্র-মুক্ত মূল্যায়ন করুন।
- তথ্যগত নির্ভুলতা পরিমাপ করার জন্য একটি 'গোল্ডেন অ্যানসার' যোগ করে উল্লিখিত মূল্যায়ন সম্পাদন করুন।
- উভয় পদ্ধতির জন্যই পূর্বনির্ধারিত ও নিজস্ব মেট্রিকের মিশ্রণ ব্যবহার করুন।
- মডেল-ভিত্তিক মেট্রিক (যেমন
question_answering_quality) এবং গণনা-ভিত্তিক মেট্রিক (যেমনrouge,bleu,exact_match) উভয়ই ব্যবহার করুন। - একটি মডেলের সবলতা ও দুর্বলতা বোঝার জন্য ফলাফল বিশ্লেষণ ও দৃশ্যায়ন করুন।
মূল্যায়নের এই পদ্ধতি আপনাকে আরও নির্ভরযোগ্য ও নির্ভুল জেনারেটিভ এআই অ্যাপ্লিকেশন তৈরি করতে সাহায্য করে।