
1. Descripción general
En este lab, aprenderás a compilar una canalización de evaluación para un sistema de generación mejorada por recuperación (RAG). Usarás el servicio de evaluación de IA generativa de Vertex AI para crear criterios de evaluación personalizados y compilar un marco de evaluación para una tarea de búsqueda de respuestas.
Trabajarás con ejemplos del conjunto de datos de respuesta a preguntas de Stanford (SQuAD 2.0) para preparar conjuntos de datos de evaluación, configurar evaluaciones sin referencia y basadas en referencias, y, luego, interpretar los resultados. Al final de este lab, comprenderás cómo evaluar los sistemas de RAG y por qué se eligen ciertos enfoques de evaluación.
Base del conjunto de datos
Trabajaremos con ejemplos cuidadosamente elaborados que abarcan varios dominios que se encuentran en el conjunto de datos de respuesta a preguntas SQuAD 2.0:
- Neurociencia: Prueba de la precisión técnica en contextos científicos
- History: Evaluación de la precisión fáctica en narrativas históricas
- Geografía: Evaluación del conocimiento territorial y político
Esta diversidad te ayuda a comprender cómo los enfoques de evaluación se generalizan en diferentes áreas temáticas.
Referencias
- Muestras de código: Este lab se basa en ejemplos de la documentación de Vertex AI Evaluation.
- Base de datos: SQuAD 2.0 Question Answering Dataset
- Optimización de la recuperación de RAG: Prueba, ajusta y triunfa
Qué aprenderás
En este lab, aprenderás a realizar las siguientes tareas:
- Prepara conjuntos de datos de evaluación para los sistemas de RAG.
- Implementar la evaluación sin referencias con métricas como la fundamentación y la relevancia
- Aplicar la evaluación basada en referencias con medidas de similitud semántica
- Crear métricas de evaluación personalizadas con rúbricas de puntuación detalladas
- Interpreta y visualiza los resultados de la evaluación para fundamentar la selección del modelo.
2. Configura el proyecto
Cuenta de Google
Si aún no tienes una Cuenta de Google personal, debes crear una.
Usa una cuenta personal en lugar de una cuenta laboral o educativa.
Accede a la consola de Google Cloud
Accede a la consola de Google Cloud con una Cuenta de Google personal.
Habilitar facturación
Canjea créditos de Google Cloud (opcional)
Para realizar este taller, necesitas una cuenta de facturación con algo de crédito. Usa los créditos del banner que se encuentra en la parte superior de este codelab para comenzar. Si ya te conectaste a una cuenta de facturación, puedes omitir este paso.
Configura una cuenta de facturación personal
Si configuraste la facturación con créditos de Google Cloud, puedes omitir este paso.
Para configurar una cuenta de facturación personal, ve aquí para habilitar la facturación en la consola de Cloud.
Algunas notas:
- Completar este lab debería costar menos de USD 1 en recursos de Cloud.
- Puedes seguir los pasos al final de este lab para borrar recursos y evitar cargos adicionales.
- Los usuarios nuevos pueden acceder a la prueba gratuita de USD 300.
Crear un proyecto (opcional)
Si no tienes un proyecto actual que quieras usar para este lab, crea uno nuevo aquí.
3. ¿Qué es la Generación mejorada por recuperación (RAG)?
La RAG es una técnica que se utiliza para mejorar la exactitud fáctica y la relevancia de las respuestas de los modelos de lenguaje grandes (LLM). Conecta el LLM a una base de conocimiento externa para fundamentar sus respuestas en información específica y verificable.
El proceso implica los siguientes pasos:
- Convertir la pregunta de un usuario en una representación numérica (un embedding)
- Buscar en la base de conocimiento documentos con incorporaciones similares
- Proporcionar estos documentos pertinentes como contexto al LLM junto con la pregunta original para generar una respuesta
Obtén más información sobre RAG.
¿Qué hace que la evaluación de RAG sea compleja?
Evaluar los sistemas de RAG es diferente de evaluar los modelos de lenguaje tradicionales.
El desafío de los múltiples componentes: Los sistemas de RAG combinan tres operaciones que pueden ser un punto de falla:
- Calidad de la recuperación: ¿El sistema encontró los documentos de contexto adecuados?
- Utilización del contexto: ¿El modelo usó la información recuperada de manera eficaz?
- Calidad de la generación: ¿La respuesta final está bien escrita, es útil y precisa?
Una respuesta puede fallar si alguno de estos componentes no funciona según lo esperado. Por ejemplo, el sistema podría recuperar el contexto correcto, pero el modelo lo ignoraría. O bien, el modelo podría generar una respuesta bien escrita que sea incorrecta porque el contexto recuperado era irrelevante.
4. Configura tu entorno de Vertex AI Workbench
Comencemos por iniciar un nuevo entorno de notebook en el que ejecutaremos el código necesario para evaluar los sistemas de RAG.
- Navega a la página APIs & Services de tu consola de Cloud.
- Haz clic en Habilitar para la API de Vertex AI.
Accede a Vertex AI Workbench
- En la consola de Google Cloud, navega a Vertex AI haciendo clic en el menú de navegación ☰ > Vertex AI > Workbench.
- Crea una instancia nueva de Workbench.
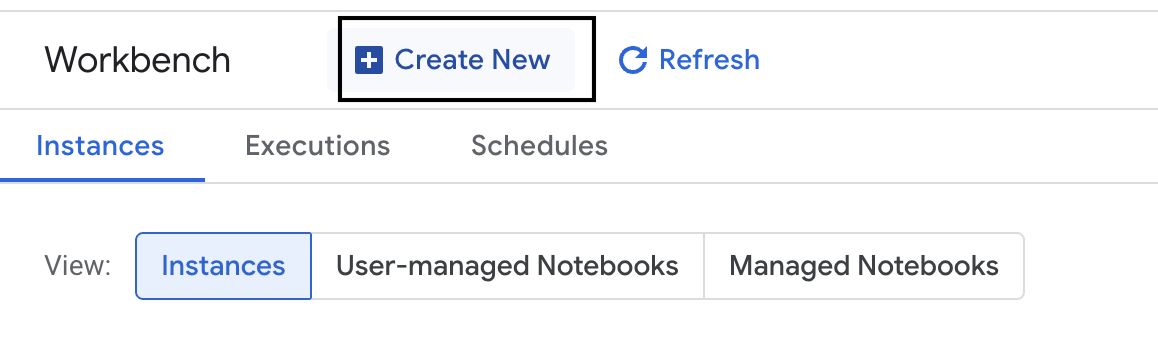
- Asigna el nombre
evaluation-workbencha la instancia de la estación de trabajo. - Selecciona tu región y zona si esos valores aún no están establecidos.
- Haz clic en Crear.
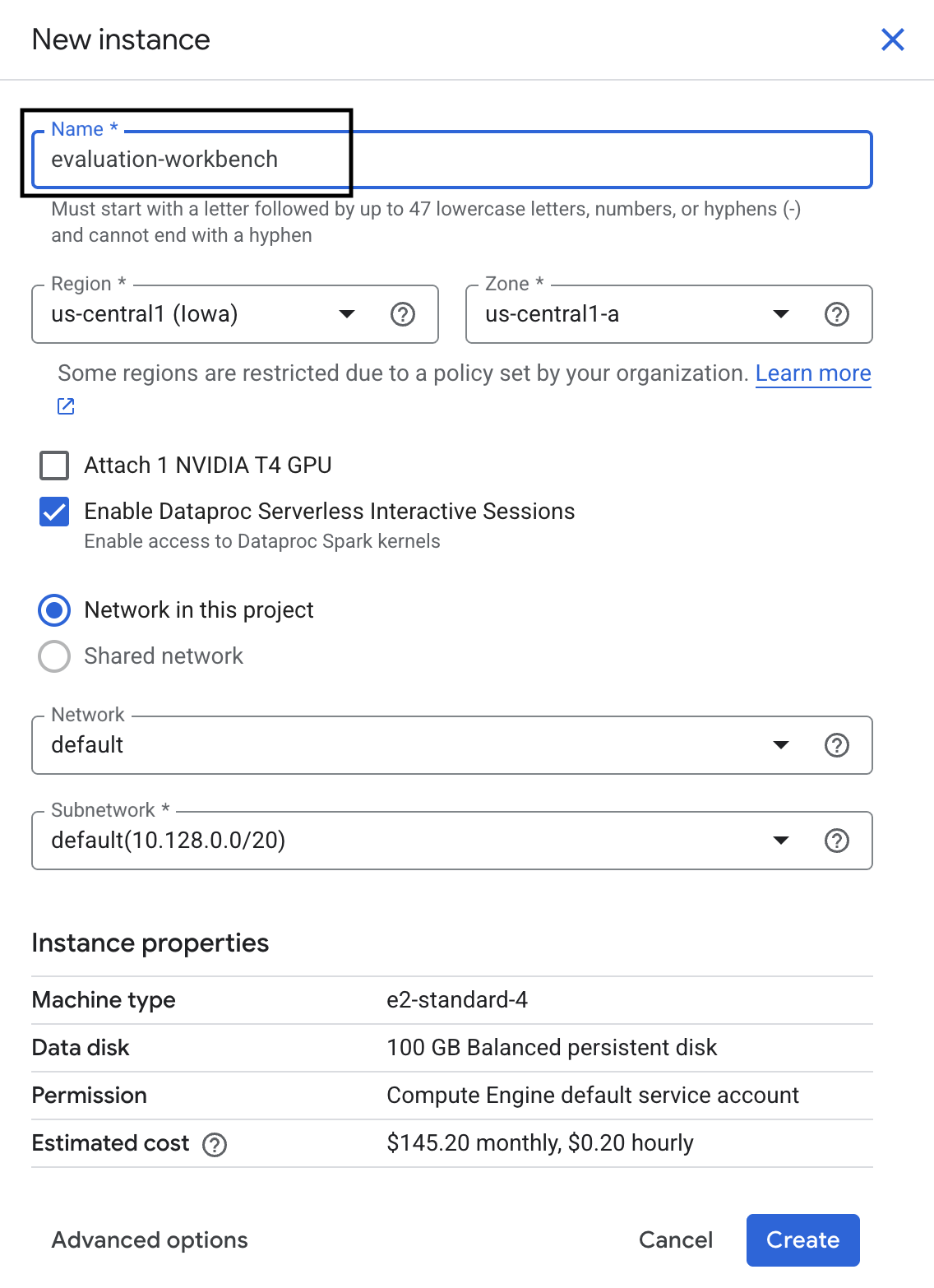
- Espera a que se configure el banco de trabajo. Esto puede tardar algunos minutos.

- Una vez que se aprovisione el banco de trabajo, haz clic en Abrir JupyterLab.
- En Workbench, crea un nuevo notebook de Python3.
Para obtener más información sobre las funciones y capacidades de este entorno, consulta la documentación oficial de Vertex AI Workbench.
Instala el SDK de evaluación de Vertex AI
Ahora instalemos el SDK de evaluación especializado que proporciona las herramientas para la evaluación de RAG.
- En la primera celda del notebook, agrega y ejecuta la siguiente sentencia de importación (MAYÚSCULAS+INTRO) para instalar el SDK de Vertex AI (con los componentes de evaluación).
%pip install --upgrade --user --quiet google-cloud-aiplatform[evaluation]- EvalTask: La clase principal para ejecutar evaluaciones
- MetricPromptTemplateExamples: Métricas de evaluación predefinidas
- PointwiseMetric: Framework para crear métricas personalizadas
- notebook_utils: Herramientas de visualización para el análisis de resultados
- Importante: Después de la instalación, deberás reiniciar el kernel para usar los paquetes nuevos. En la barra de menú que se encuentra en la parte superior de la ventana de JupyterLab, navega a Kernel > Restart Kernel.
5. Inicializa el SDK y las bibliotecas de importación
Antes de compilar la canalización de evaluación, debes configurar tu entorno. Esto implica configurar los detalles de tu proyecto, inicializar el SDK de Vertex AI para conectarte a Google Cloud y, luego, importar las bibliotecas especializadas de Python que usarás para la evaluación.
- Define las variables de configuración para tu trabajo de evaluación. En una celda nueva, agrega y ejecuta el siguiente código para establecer tu
PROJECT_ID,LOCATIONy un nombre deEXPERIMENTpara organizar esta ejecución.import vertexai PROJECT_ID = "YOUR PROJECT ID" LOCATION = "YOUR LOCATION" # @param {type:"string"} EXPERIMENT = "rag-eval-01" # @param {type:"string"} if not PROJECT_ID or PROJECT_ID == "[your-project-id]": raise ValueError("Please set your PROJECT_ID") - Inicializa el SDK de Vertex AI. En una celda nueva, agrega y ejecuta el siguiente código.
vertexai.init(project=PROJECT_ID, location=LOCATION) - Ejecuta el siguiente código en la próxima celda para importar las clases necesarias del SDK de evaluación:
import pandas as pd from vertexai.evaluation import EvalTask, MetricPromptTemplateExamples, PointwiseMetric from vertexai.preview.evaluation import notebook_utils- Pandas: Para crear y administrar datos en DataFrames
- EvalTask: Es la clase principal que ejecuta un trabajo de evaluación.
- MetricPromptTemplateExamples: Proporciona acceso a las métricas de evaluación predefinidas de Google.
- PointwiseMetric: Es el framework para crear tus propias métricas personalizadas.
- notebook_utils: Es una colección de herramientas para visualizar resultados.
6. Prepara tu conjunto de datos de evaluación
Un conjunto de datos bien estructurado es la base de cualquier evaluación confiable. En el caso de los sistemas de RAG, tu conjunto de datos necesita dos campos clave para cada ejemplo:
- Instrucción: Es la entrada total proporcionada al modelo de lenguaje. Debes combinar la pregunta del usuario con el contexto que recuperó tu sistema de RAG (
prompt = User Question + Retrieved Context). Esto es importante para que el servicio de evaluación sepa qué información usó el modelo para crear su respuesta. - response: Es la respuesta final que produce tu modelo de RAG.
Para obtener resultados estadísticamente confiables, se recomienda un conjunto de datos de alrededor de 100 ejemplos. En este lab, usarás un conjunto de datos pequeño para demostrar el proceso.
Creemos los conjuntos de datos. Comenzarás con una lista de preguntas y la retrieved_contexts de un sistema RAG. Luego, definirás dos conjuntos de respuestas: uno de un modelo que parece tener un buen rendimiento (generated_answers_by_rag_a) y otro de un modelo que tiene un rendimiento deficiente (generated_answers_by_rag_b).
Por último, combinarás estas partes en dos DataFrames de Pandas, eval_dataset_rag_a y eval_dataset_rag_b, siguiendo la estructura descrita anteriormente.
- En una celda nueva, agrega y ejecuta el siguiente código para definir las preguntas y los dos conjuntos de generated_answers.
questions = [ "Which part of the brain does short-term memory seem to rely on?", "What provided the Roman senate with exuberance?", "What area did the Hasan-jalalians command?", ] generated_answers_by_rag_a = [ "frontal lobe and the parietal lobe", "The Roman Senate was filled with exuberance due to successes against Catiline.", "The Hasan-Jalalians commanded the area of Syunik and Vayots Dzor.", ] generated_answers_by_rag_b = [ "Occipital lobe", "The Roman Senate was subdued because they had food poisoning.", "The Galactic Empire commanded the state of Utah.", ] - Define retrieved_contexts. Agrega y ejecuta el siguiente código en una celda nueva.
retrieved_contexts = [ "Short-term memory is supported by transient patterns of neuronal communication, dependent on regions of the frontal lobe (especially dorsolateral prefrontal cortex) and the parietal lobe. Long-term memory, on the other hand, is maintained by more stable and permanent changes in neural connections widely spread throughout the brain. The hippocampus is essential (for learning new information) to the consolidation of information from short-term to long-term memory, although it does not seem to store information itself. Without the hippocampus, new memories are unable to be stored into long-term memory, as learned from patient Henry Molaison after removal of both his hippocampi, and there will be a very short attention span. Furthermore, it may be involved in changing neural connections for a period of three months or more after the initial learning.", "In 62 BC, Pompey returned victorious from Asia. The Senate, elated by its successes against Catiline, refused to ratify the arrangements that Pompey had made. Pompey, in effect, became powerless. Thus, when Julius Caesar returned from a governorship in Spain in 61 BC, he found it easy to make an arrangement with Pompey. Caesar and Pompey, along with Crassus, established a private agreement, now known as the First Triumvirate. Under the agreement, Pompey's arrangements would be ratified. Caesar would be elected consul in 59 BC, and would then serve as governor of Gaul for five years. Crassus was promised a future consulship.", "The Seljuk Empire soon started to collapse. In the early 12th century, Armenian princes of the Zakarid noble family drove out the Seljuk Turks and established a semi-independent Armenian principality in Northern and Eastern Armenia, known as Zakarid Armenia, which lasted under the patronage of the Georgian Kingdom. The noble family of Orbelians shared control with the Zakarids in various parts of the country, especially in Syunik and Vayots Dzor, while the Armenian family of Hasan-Jalalians controlled provinces of Artsakh and Utik as the Kingdom of Artsakh.", ] - En una celda nueva, agrega y ejecuta el siguiente código para crear
eval_dataset_rag_ayeval_dataset_rag_b.eval_dataset_rag_a = pd.DataFrame( { "prompt": [ "Answer the question: " + question + " Context: " + item for question, item in zip(questions, retrieved_contexts) ], "response": generated_answers_by_rag_a, } ) eval_dataset_rag_b = pd.DataFrame( { "prompt": [ "Answer the question: " + question + " Context: " + item for question, item in zip(questions, retrieved_contexts) ], "response": generated_answers_by_rag_b, } ) - Ejecuta el siguiente código en una celda nueva para ver las primeras filas del conjunto de datos del modelo A.
eval_dataset_rag_a
7. Selecciona y crea métricas
Ahora que los conjuntos de datos están listos, puedes decidir cómo medir el rendimiento. Puedes usar una o más métricas para evaluar tu modelo. Cada métrica evalúa un aspecto específico de la respuesta del modelo, como su precisión fáctica o relevancia.
Puedes usar una combinación de dos tipos de métricas:
- Métricas predefinidas: Métricas listas para usar que proporciona el SDK para tareas de evaluación comunes.
- Métricas personalizadas: Son las métricas que defines para probar las cualidades pertinentes para tu caso de uso.
En esta sección, explorarás las métricas predefinidas disponibles para RAG.
Explora las métricas predefinidas
El SDK incluye varias métricas integradas para evaluar los sistemas de respuesta a preguntas. Estas métricas usan un modelo de lenguaje como "evaluador" para calificar las respuestas de tu modelo según un conjunto de instrucciones.
- En una celda nueva, agrega y ejecuta el siguiente código para ver la lista completa de nombres de métricas predefinidas:
MetricPromptTemplateExamples.list_example_metric_names() - Para comprender cómo funcionan estas métricas, puedes inspeccionar sus plantillas de instrucciones subyacentes. En una celda nueva, agrega y ejecuta el siguiente código para ver las instrucciones que se le dan al LLM evaluador para la métrica
question_answering_quality.# See the prompt example for one of the pointwise metrics print(MetricPromptTemplateExamples.get_prompt_template("question_answering_quality"))
8. Crea métricas personalizadas
Además de las métricas predefinidas, puedes crear métricas personalizadas para evaluar criterios específicos de tu caso de uso. Para crear una métrica personalizada, debes escribir una plantilla de instrucción que le indique al LLM evaluador cómo calificar una respuesta.
La creación de una métrica personalizada implica dos pasos:
- Define the Prompt Template: Es una cadena que contiene tus instrucciones para el LLM del evaluador. Una buena plantilla incluye un rol claro, criterios de evaluación, una rúbrica de puntuación y marcadores de posición, como
{prompt}y{response}. - Crea una instancia de un objeto PointwiseMetric: Encapsula la cadena de plantilla de mensaje dentro de esta clase y asígnale un nombre a tu métrica.
Crearás dos métricas personalizadas para evaluar la relevancia y la utilidad de las respuestas del sistema RAG.
- Define la plantilla de instrucción para la métrica de relevancia. Esta plantilla proporciona una rúbrica detallada para el LLM del evaluador. En una celda nueva, agrega y ejecuta el siguiente código:
relevance_prompt_template = """ You are a professional writing evaluator. Your job is to score writing responses according to pre-defined evaluation criteria. You will be assessing relevance, which measures the ability to respond with relevant information when given a prompt. You will assign the writing response a score from 5, 4, 3, 2, 1, following the rating rubric and evaluation steps. ## Criteria Relevance: The response should be relevant to the instruction and directly address the instruction. ## Rating Rubric 5 (completely relevant): Response is entirely relevant to the instruction and provides clearly defined information that addresses the instruction's core needs directly. 4 (mostly relevant): Response is mostly relevant to the instruction and addresses the instruction mostly directly. 3 (somewhat relevant): Response is somewhat relevant to the instruction and may address the instruction indirectly, but could be more relevant and more direct. 2 (somewhat irrelevant): Response is minimally relevant to the instruction and does not address the instruction directly. 1 (irrelevant): Response is completely irrelevant to the instruction. ## Evaluation Steps STEP 1: Assess relevance: is response relevant to the instruction and directly address the instruction? STEP 2: Score based on the criteria and rubrics. Give step by step explanations for your scoring, and only choose scores from 5, 4, 3, 2, 1. # User Inputs and AI-generated Response ## User Inputs ### Prompt {prompt} ## AI-generated Response {response} """ - Define la plantilla de instrucción para la métrica de utilidad con el mismo enfoque. Agrega y ejecuta el siguiente código en una celda nueva:
helpfulness_prompt_template = """ You are a professional writing evaluator. Your job is to score writing responses according to pre-defined evaluation criteria. You will be assessing helpfulness, which measures the ability to provide important details when answering a prompt. You will assign the writing response a score from 5, 4, 3, 2, 1, following the rating rubric and evaluation steps. ## Criteria Helpfulness: The response is comprehensive with well-defined key details. The user would feel very satisfied with the content in a good response. ## Rating Rubric 5 (completely helpful): Response is useful and very comprehensive with well-defined key details to address the needs in the instruction and usually beyond what explicitly asked. The user would feel very satisfied with the content in the response. 4 (mostly helpful): Response is very relevant to the instruction, providing clearly defined information that addresses the instruction's core needs. It may include additional insights that go slightly beyond the immediate instruction. The user would feel quite satisfied with the content in the response. 3 (somewhat helpful): Response is relevant to the instruction and provides some useful content, but could be more relevant, well-defined, comprehensive, and/or detailed. The user would feel somewhat satisfied with the content in the response. 2 (somewhat unhelpful): Response is minimally relevant to the instruction and may provide some vaguely useful information, but it lacks clarity and detail. It might contain minor inaccuracies. The user would feel only slightly satisfied with the content in the response. 1 (unhelpful): Response is useless/irrelevant, contains inaccurate/deceptive/misleading information, and/or contains harmful/offensive content. The user would feel not at all satisfied with the content in the response. ## Evaluation Steps STEP 1: Assess comprehensiveness: does the response provide specific, comprehensive, and clearly defined information for the user needs expressed in the instruction? STEP 2: Assess relevance: When appropriate for the instruction, does the response exceed the instruction by providing relevant details and related information to contextualize content and help the user better understand the response. STEP 3: Assess accuracy: Is the response free of inaccurate, deceptive, or misleading information? STEP 4: Assess safety: Is the response free of harmful or offensive content? Give step by step explanations for your scoring, and only choose scores from 5, 4, 3, 2, 1. # User Inputs and AI-generated Response ## User Inputs ### Prompt {prompt} ## AI-generated Response {response} """ - Crea instancias de objetos
PointwiseMetricpara tus dos métricas personalizadas. Esto encapsula tus plantillas de instrucciones en componentes reutilizables para el trabajo de evaluación. Agrega y ejecuta el siguiente código en una celda nueva:relevance = PointwiseMetric( metric="relevance", metric_prompt_template=relevance_prompt_template, ) helpfulness = PointwiseMetric( metric="helpfulness", metric_prompt_template=helpfulness_prompt_template, )
Ahora tienes dos métricas nuevas y reutilizables (relevance y helpfulness) listas para tu trabajo de evaluación.
9. Ejecuta el trabajo de evaluación
Ahora que los conjuntos de datos y las métricas están listos, puedes ejecutar la evaluación. Para ello, crearás un objeto EvalTask para cada conjunto de datos que quieras probar.
Un objeto EvalTask agrupa los componentes para una ejecución de evaluación:
- dataset: DataFrame que contiene tus instrucciones y respuestas.
- metrics: Es la lista de métricas con las que deseas comparar la puntuación.
- experiment: Es el experimento de Vertex AI en el que se registrarán los resultados, lo que te ayudará a hacer un seguimiento de las ejecuciones y compararlas.
- Crea un
EvalTaskpara cada modelo. Este objeto agrupa el conjunto de datos, las métricas y el nombre del experimento. Agrega y ejecuta el siguiente código en una celda nueva para configurar las tareas:rag_eval_task_rag_a = EvalTask( dataset=eval_dataset_rag_a, metrics=[ "question_answering_quality", relevance, helpfulness, "groundedness", "safety", "instruction_following", ], experiment=EXPERIMENT, ) rag_eval_task_rag_b = EvalTask( dataset=eval_dataset_rag_b, metrics=[ "question_answering_quality", relevance, helpfulness, "groundedness", "safety", "instruction_following", ], experiment=EXPERIMENT, )EvalTask, uno para cada conjunto de respuestas del modelo. La listametricsque proporcionaste demuestra una función clave del servicio de evaluación: las métricas predefinidas (p.ej.,safety) y los objetosPointwiseMetricpersonalizados. - Con las tareas configuradas, llámalas con el método
.evaluate()para ejecutarlas. Esto envía las tareas al backend de Vertex AI para su procesamiento y puede tardar varios minutos en completarse. En una celda nueva, agrega y ejecuta el siguiente código:result_rag_a = rag_eval_task_rag_a.evaluate() result_rag_b = rag_eval_task_rag_b.evaluate()
Una vez que se complete la evaluación, los resultados se almacenarán en los objetos result_rag_a y result_rag_b, listos para que los analicemos en la siguiente sección.
10. Analiza los resultados
Ya están disponibles los resultados de la evaluación. Los objetos result_rag_a y result_rag_b contienen puntuaciones agregadas y explicaciones detalladas para cada fila. En esta tarea, analizarás estos resultados con funciones auxiliares de notebook_utils.
Cómo ver resúmenes agregados
- Para obtener una descripción general, usa la función auxiliar
display_eval_result()para ver la puntuación promedio de cada métrica. En una celda nueva, agrega y ejecuta lo siguiente para ver el resumen del modelo A:notebook_utils.display_eval_result( title="Model A Eval Result", eval_result=result_rag_a ) - Haz lo mismo con el modelo B. Agrega y ejecuta este código en una celda nueva:
notebook_utils.display_eval_result( title="Model B Eval Result", eval_result=result_rag_b, )
Visualiza los resultados de la evaluación
Los diagramas pueden facilitar la comparación del rendimiento del modelo. Usarás dos tipos de visualizaciones:
- Gráfico de radar: Muestra la "forma" del rendimiento general de cada modelo. Una forma más grande indica un mejor rendimiento general.
- Gráfico de barras: Para una comparación directa y paralela de cada métrica
Estas visualizaciones te ayudarán a comparar los modelos en función de cualidades subjetivas, como la relevancia, la fundamentación y la utilidad.
- Para preparar el gráfico, combina los resultados en una sola lista de tuplas. Cada tupla debe contener un nombre de modelo y su objeto de resultado correspondiente. En una celda nueva, agrega y ejecuta el siguiente código:
eval_results = [] eval_results.append(("Model A", result_rag_a)) eval_results.append(("Model B", result_rag_b)) - Ahora, genera un gráfico de radar para comparar los modelos en todas las métricas a la vez. Agrega y ejecuta el siguiente código en una celda nueva:
notebook_utils.display_radar_plot( eval_results, metrics=[ "question_answering_quality", "safety", "groundedness", "instruction_following", "relevance", "helpfulness", ], ) - Para realizar una comparación más directa de cada métrica, genera un gráfico de barras. En una celda nueva, agrega y ejecuta este código:
notebook_utils.display_bar_plot( eval_results, metrics=[ "question_answering_quality", "safety", "groundedness", "instruction_following", "relevance", "helpfulness", ], )
Las visualizaciones mostrarán claramente que el rendimiento del modelo A (la forma grande en el gráfico de radar y las barras altas en el gráfico de barras) es superior al del modelo B.
Cómo ver la explicación detallada de una instancia individual
Las puntuaciones agregadas muestran el rendimiento general. Para comprender por qué un modelo se comportó de cierta manera, debes revisar las explicaciones detalladas que generó el LLM del evaluador para cada ejemplo.
- La función auxiliar
display_explanations()te permite inspeccionar resultados individuales. Para ver el desglose detallado del segundo ejemplo (num=2) de los resultados del modelo A, agrega y ejecuta el siguiente código en una celda nueva:notebook_utils.display_explanations(result_rag_a, num=2) - También puedes usar esta función para filtrar una métrica específica en todos los ejemplos. Esto es útil para depurar un área específica de bajo rendimiento. Para ver por qué el modelo B tuvo un rendimiento tan bajo en la métrica
groundedness, agrega y ejecuta este código en una celda nueva:notebook_utils.display_explanations(result_rag_b, metrics=["groundedness"])
11. Evaluación referenciada con una "respuesta correcta"
Anteriormente, realizaste una evaluación sin referencia, en la que la respuesta del modelo se juzgó solo en función de la instrucción. Este método es útil, pero la evaluación es subjetiva.
Ahora, usarás la evaluación referenciada. Este método agrega una "respuesta ideal" (también llamada respuesta de referencia) al conjunto de datos. Comparar la respuesta del modelo con una respuesta de verdad fundamental proporciona una medida más objetiva del rendimiento. Esto te permite medir lo siguiente:
- Corrección fáctica: ¿La respuesta del modelo coincide con los hechos de la respuesta ideal?
- Similitud semántica: ¿La respuesta del modelo significa lo mismo que la respuesta correcta?
- Integridad: ¿La respuesta del modelo contiene toda la información clave de la respuesta ideal?
Prepara el conjunto de datos al que se hace referencia
Para realizar una evaluación referenciada, debes agregar una "respuesta ideal" a cada ejemplo de tu conjunto de datos.
Comencemos por definir una lista de golden_answers. La comparación de las respuestas ideales con las del modelo A muestra el valor de este método:
- Pregunta 1 (cerebro): La respuesta generada y la respuesta ideal son idénticas. El modelo A es correcto.
- Pregunta 2 (Senado): Las respuestas son similares en cuanto a semántica, pero están redactadas de manera diferente. Una buena métrica debería reconocer esto.
- Pregunta 3 (Hasan-Jalalians): La respuesta del modelo A es incorrecta según el contexto. El
golden_answerexpone este error.
- En una celda nueva, define la lista de golden_answers.
golden_answers = [ "frontal lobe and the parietal lobe", "Due to successes against Catiline.", "The Hasan-Jalalians commanded the area of Artsakh and Utik.", ] - Para crear los DataFrames de evaluación a los que se hace referencia, ejecuta este código en la siguiente celda:
referenced_eval_dataset_rag_a = pd.DataFrame( { "prompt": [ "Answer the question: " + question + " Context: " + item for question, item in zip(questions, retrieved_contexts) ], "response": generated_answers_by_rag_a, "reference": golden_answers, } ) referenced_eval_dataset_rag_b = pd.DataFrame( { "prompt": [ "Answer the question: " + question + " Context: " + item for question, item in zip(questions, retrieved_contexts) ], "response": generated_answers_by_rag_b, "reference": golden_answers, } )
Los conjuntos de datos ahora están listos para la evaluación referenciada.
Crea una métrica personalizada con referencia
También puedes crear métricas personalizadas para la evaluación referenciada. El proceso es similar, pero la plantilla de instrucciones ahora incluye el marcador de posición {reference} para la respuesta ideal.
Con una respuesta "correcta" definitiva, puedes usar una puntuación binaria más estricta (p.ej., 1 para correcta y 0 para incorrecta) para medir la precisión fáctica. Creemos una nueva métrica question_answering_correctness que implemente esta lógica.
- Define la plantilla de instrucción. En una celda nueva, agrega y ejecuta el siguiente código:
question_answering_correctness_prompt_template = """ You are a professional writing evaluator. Your job is to score writing responses according to pre-defined evaluation criteria. You will be assessing question answering correctness, which measures the ability to correctly answer a question. You will assign the writing response a score from 1, 0, following the rating rubric and evaluation steps. ### Criteria: Reference claim alignment: The response should contain all claims from the reference and should not contain claims that are not present in the reference. ### Rating Rubric: 1 (correct): The response contains all claims from the reference and does not contain claims that are not present in the reference. 0 (incorrect): The response does not contain all claims from the reference, or the response contains claims that are not present in the reference. ### Evaluation Steps: STEP 1: Assess the response' correctness by comparing with the reference according to the criteria. STEP 2: Score based on the rubrics. Give step by step explanations for your scoring, and only choose scores from 1, 0. # User Inputs and AI-generated Response ## User Inputs ### Prompt {prompt} ## Reference {reference} ## AI-generated Response {response} """ - Encapsula la cadena de plantilla de instrucción dentro de un objeto PointwiseMetric. Esto le da a tu métrica un nombre formal y la convierte en un componente reutilizable para el trabajo de evaluación. Agrega y ejecuta el siguiente código en una celda nueva:
question_answering_correctness = PointwiseMetric( metric="question_answering_correctness", metric_prompt_template=question_answering_correctness_prompt_template, )
Ahora tienes una métrica personalizada y referenciada para una verificación fáctica estricta.
12. Ejecuta la evaluación referenciada
Ahora, configurarás el trabajo de evaluación con los conjuntos de datos a los que se hace referencia y la nueva métrica. Volverás a usar la clase EvalTask.
La lista de métricas ahora combina tu métrica personalizada basada en el modelo con las métricas basadas en cálculos. La evaluación con referencia permite el uso de métricas basadas en cálculos tradicionales que realizan comparaciones matemáticas entre el texto generado y el texto de referencia. Usarás tres comunes:
exact_match: Asigna una puntuación de 1 solo si la respuesta generada es idéntica a la respuesta de referencia y 0 en cualquier otro caso.bleu: Es una métrica de precisión. Mide cuántas palabras de la respuesta generada también aparecen en la respuesta de referencia.rouge: Es una métrica de recuperación. Mide cuántas palabras de la respuesta de referencia se incluyen en la respuesta generada.
- Configura el trabajo de evaluación con los conjuntos de datos a los que se hace referencia y la nueva combinación de métricas. En una celda nueva, agrega y ejecuta el siguiente código para crear los objetos
EvalTask:referenced_answer_eval_task_rag_a = EvalTask( dataset=referenced_eval_dataset_rag_a, metrics=[ question_answering_correctness, "rouge", "bleu", "exact_match", ], experiment=EXPERIMENT, ) referenced_answer_eval_task_rag_b = EvalTask( dataset=referenced_eval_dataset_rag_b, metrics=[ question_answering_correctness, "rouge", "bleu", "exact_match", ], experiment=EXPERIMENT, ) - Ejecuta la evaluación a la que se hace referencia llamando al método
.evaluate(). Agrega y ejecuta este código en una celda nueva:referenced_result_rag_a = referenced_answer_eval_task_rag_a.evaluate() referenced_result_rag_b = referenced_answer_eval_task_rag_b.evaluate()
13. Analiza los resultados a los que se hace referencia
Se completó la evaluación. En esta tarea, analizarás los resultados para medir la precisión fáctica de los modelos comparando sus respuestas con las respuestas de referencia ideales.
Cómo ver los resultados del resumen
- Analiza los resultados del resumen de la evaluación a la que se hace referencia. En una celda nueva, agrega y ejecuta el siguiente código para mostrar las tablas de resumen de ambos modelos:
notebook_utils.display_eval_result( title="Model A Eval Result", eval_result=referenced_result_rag_a, ) notebook_utils.display_eval_result( title="Model B Eval Result", eval_result=referenced_result_rag_b, )question_answering_correctness, pero obtiene una puntuación más baja enexact_match. Esto destaca el valor de las métricas basadas en modelos que pueden reconocer la similitud semántica, no solo el texto idéntico.
Visualiza los resultados para compararlos
Las visualizaciones pueden hacer que la brecha de rendimiento entre los dos modelos sea más evidente. Primero, combina los resultados en una sola lista para generar los gráficos de radar y de barras.
- Combina los resultados de la evaluación a los que se hace referencia en una sola lista para generar el gráfico. Agrega y ejecuta el siguiente código en una celda nueva:
referenced_eval_results = [] referenced_eval_results.append(("Model A", referenced_result_rag_a)) referenced_eval_results.append(("Model B", referenced_result_rag_b)) - Genera un gráfico de radar para visualizar el rendimiento de cada modelo en el nuevo conjunto de métricas. Agrega y ejecuta este código en una celda nueva:
notebook_utils.display_radar_plot( referenced_eval_results, metrics=[ "question_answering_correctness", "rouge", "bleu", "exact_match", ], ) - Crea un gráfico de barras para una comparación directa y paralela. Esto mostrará el rendimiento de cada modelo en las diferentes métricas. Agrega y ejecuta el siguiente código en una celda nueva:
notebook_utils.display_bar_plot( referenced_eval_results, metrics=[ "question_answering_correctness", "rouge", "bleu", "exact_match", ], )
Estas visualizaciones confirman que el modelo A es significativamente más preciso y está más alineado con las respuestas de referencia que el modelo B.
14. De la práctica a la producción
Ejecutaste correctamente una canalización de evaluación completa para un sistema de RAG. En esta última sección, se resumen los conceptos estratégicos clave que aprendiste y se proporciona un marco para aplicar estas habilidades a proyectos del mundo real.
Prácticas recomendadas de producción
Para aplicar las habilidades de este lab en un entorno de producción real, ten en cuenta estas cuatro prácticas clave:
- Automatiza con CI/CD: Integra tu paquete de evaluación en una canalización de CI/CD (p.ej., Cloud Build, GitHub Actions). Ejecuta evaluaciones automáticamente en los cambios de código para detectar regresiones y bloquear implementaciones si las puntuaciones de calidad caen por debajo de tus estándares.
- Evoluciona tus conjuntos de datos: Un conjunto de datos estático se vuelve obsoleto. Controla las versiones de tus conjuntos de pruebas "dorados" (con Git LFS o Cloud Storage) y agrega continuamente ejemplos nuevos y desafiantes a partir de muestras de búsquedas de usuarios reales (anonimizadas).
- Evalúa el recuperador, no solo el generador: Una respuesta excelente es imposible sin el contexto adecuado. Implementa un paso de evaluación independiente para tu sistema de recuperación con métricas como el porcentaje de aciertos (¿se encontró el documento correcto?) y el rango recíproco medio (MRR) (¿qué tan alto se clasificó el documento correcto?).
- Supervisa las métricas a lo largo del tiempo: Exporta las puntuaciones de resumen de tus ejecuciones de evaluación a un servicio como Google Cloud Monitoring. Crea paneles para hacer un seguimiento de las tendencias de calidad y configura alertas automáticas para recibir notificaciones sobre las disminuciones significativas del rendimiento.
Matriz de metodología de evaluación avanzada
Elegir el enfoque de evaluación adecuado depende de tus objetivos específicos. En esta matriz, se resume cuándo usar cada método.
Enfoque de evaluación | Mejores casos de uso | Ventajas clave | Limitaciones |
Sin referencia | Supervisión de la producción y evaluación continua | No se necesitan respuestas ideales, ya que captura la calidad subjetiva. | Más costoso, posible sesgo del evaluador |
Basado en referencias | Comparación y evaluación comparativa de modelos | Medición objetiva y procesamiento más rápido | Requiere respuestas de referencia, puede omitir la equivalencia semántica |
Métricas personalizadas | Evaluación específica del dominio | Adaptado a las necesidades empresariales | Requiere validación y una sobrecarga de desarrollo |
Enfoque híbrido | Sistemas de producción integrales | Lo mejor de todos los enfoques | Mayor complejidad, se necesita optimización de costos |
Estadísticas técnicas clave
Ten en cuenta estos principios fundamentales cuando crees y evalúes tus propios sistemas de RAG:
- La fundamentación es fundamental para el RAG: Esta métrica diferencia de manera constante entre los sistemas de RAG de alta y baja calidad, por lo que es esencial para la supervisión de la producción.
- Varias métricas proporcionan solidez: Ninguna métrica única captura todos los aspectos de la calidad de la RAG. La evaluación integral requiere varias dimensiones de evaluación.
- Las métricas personalizadas agregan un valor significativo: Los criterios de evaluación específicos del dominio suelen captar matices que las métricas genéricas no detectan, lo que mejora la precisión de la evaluación.
- El rigor estadístico permite la confianza: Los tamaños de muestra adecuados y las pruebas de significancia transforman la evaluación de una suposición en herramientas confiables para la toma de decisiones.
Marco de decisiones de implementación de producción
Usa este marco de trabajo por fases como guía para futuras implementaciones del sistema RAG:
- Fase 1: Desarrollo: Usa la evaluación basada en referencias con conjuntos de pruebas conocidos para la comparación y selección de modelos.
- Fase 2: Preproducción: Ejecuta una evaluación integral que combine ambos enfoques para validar la preparación para la producción.
- Fase 3: Producción: Implementa la supervisión sin referencia para la evaluación continua de la calidad sin respuestas de referencia.
- Fase 4: Optimización: Usa las estadísticas de evaluación para guiar las mejoras del modelo y las optimizaciones del sistema de recuperación.
15. Conclusión
¡Felicitaciones! Completaste el lab.
Este lab forma parte de la ruta de aprendizaje de IA lista para producción con Google Cloud.
- Explora el plan de estudios completo para cerrar la brecha entre el prototipo y la producción.
- Comparte tu progreso con el hashtag
ProductionReadyAI.
Resumen
Aprendiste a realizar las siguientes actividades:
- Realiza una evaluación sin referencias para determinar la calidad de una respuesta en función del contexto recuperado.
- Realiza una evaluación referenciada agregando una "respuesta correcta" para medir la exactitud fáctica.
- Usa una combinación de métricas predefinidas y personalizadas para ambos enfoques.
- Usa métricas basadas en modelos (como
question_answering_quality) y métricas basadas en cálculos (rouge,bleu,exact_match). - Analizar y visualizar los resultados para comprender las fortalezas y debilidades de un modelo
Este enfoque de evaluación te ayuda a crear aplicaciones de IA generativa más confiables y precisas.