
1. Ringkasan
Di lab ini, Anda akan mempelajari cara membuat pipeline evaluasi untuk sistem Retrieval-Augmented Generation (RAG). Anda akan menggunakan Layanan Evaluasi AI Generatif Vertex AI untuk membuat kriteria evaluasi kustom dan membangun framework penilaian untuk tugas menjawab pertanyaan.
Anda akan menggunakan contoh dari Stanford Question Answering Dataset (SQuAD 2.0) untuk menyiapkan set data evaluasi, mengonfigurasi penilaian tanpa rujukan dan berbasis rujukan, serta menafsirkan hasilnya. Pada akhir lab ini, Anda akan memahami cara mengevaluasi sistem RAG dan alasan pemilihan pendekatan evaluasi tertentu.
Dasar set data
Kita akan menggunakan contoh yang dibuat dengan cermat yang mencakup beberapa domain yang ada di Set Data Jawab Pertanyaan SQuAD 2.0:
- Ilmu saraf (Neuroscience): Menguji akurasi teknis dalam konteks ilmiah
- Sejarah: Mengevaluasi presisi faktual dalam narasi historis
- Geografi: Menilai pengetahuan teritorial dan politik
Keberagaman ini membantu Anda memahami bagaimana pendekatan evaluasi digeneralisasi di berbagai bidang subjek.
Referensi
- Contoh kode: Lab ini dibuat berdasarkan contoh dari dokumentasi Evaluasi Vertex AI
- Dasar set data: Set Data Tanya Jawab SQuAD 2.0
- Mengoptimalkan pengambilan RAG: Uji, sesuaikan, berhasil
Yang akan Anda pelajari
Di lab ini, Anda akan mempelajari cara melakukan tugas berikut:
- Siapkan set data evaluasi untuk sistem RAG.
- Terapkan evaluasi bebas referensi menggunakan metrik seperti perujukan dan relevansi.
- Terapkan evaluasi berbasis referensi dengan ukuran kesamaan semantik.
- Buat metrik evaluasi kustom dengan rubrik pemberian skor yang mendetail.
- Menafsirkan dan memvisualisasikan hasil evaluasi untuk menentukan pemilihan model.
2. Penyiapan project
Akun Google
Jika belum memiliki Akun Google pribadi, Anda harus membuat Akun Google.
Gunakan akun pribadi, bukan akun kantor atau sekolah.
Login ke Konsol Google Cloud
Login ke Konsol Google Cloud menggunakan Akun Google pribadi.
Aktifkan Penagihan
Menukarkan kredit Google Cloud (opsional)
Untuk menjalankan workshop ini, Anda memerlukan akun penagihan dengan sejumlah kredit. Gunakan kredit dari banner di bagian atas codelab ini untuk memulai. Jika sudah terhubung ke akun penagihan, Anda dapat melewati langkah ini.
Menyiapkan akun penagihan pribadi
Jika menyiapkan penagihan menggunakan kredit Google Cloud, Anda dapat melewati langkah ini.
Untuk menyiapkan akun penagihan pribadi, buka di sini untuk mengaktifkan penagihan di Konsol Cloud.
Beberapa Catatan:
- Menyelesaikan lab ini akan dikenai biaya kurang dari $1 USD untuk resource Cloud.
- Anda dapat mengikuti langkah-langkah di akhir lab ini untuk menghapus resource agar tidak dikenai biaya lebih lanjut.
- Pengguna baru memenuhi syarat untuk mengikuti Uji Coba Gratis senilai$300 USD.
Membuat project (opsional)
Jika Anda tidak memiliki project saat ini yang ingin digunakan untuk lab ini, buat project baru di sini.
3. Apa itu Retrieval-Augmented Generation (RAG)?
RAG adalah teknik yang digunakan untuk meningkatkan akurasi faktual dan relevansi jawaban dari Model Bahasa Besar (LLM). Grounding menghubungkan LLM ke pusat informasi eksternal untuk mendasarkan responsnya pada informasi spesifik yang dapat diverifikasi.
Proses ini melibatkan langkah-langkah berikut:
- Mengonversi pertanyaan pengguna menjadi representasi numerik (embedding).
- Menelusuri pusat informasi untuk menemukan dokumen dengan embedding serupa.
- Memberikan dokumen yang relevan ini sebagai konteks ke LLM bersama dengan pertanyaan asli untuk menghasilkan jawaban.
Baca selengkapnya tentang RAG.
Apa yang membuat evaluasi RAG menjadi rumit?
Mengevaluasi sistem RAG berbeda dengan mengevaluasi model bahasa tradisional.
Tantangan Multi-Komponen: Sistem RAG menggabungkan tiga operasi yang masing-masing dapat menjadi titik kegagalan:
- Kualitas Pengambilan: Apakah sistem menemukan dokumen konteks yang tepat?
- Penggunaan Konteks: Apakah model menggunakan informasi yang diambil secara efektif?
- Kualitas Generasi: Apakah respons akhir ditulis dengan baik, bermanfaat, dan akurat?
Respons dapat gagal jika salah satu komponen ini tidak berfungsi seperti yang diharapkan. Misalnya, sistem mungkin mengambil konteks yang benar, tetapi model mengabaikannya. Atau, model dapat menghasilkan respons yang ditulis dengan baik tetapi salah karena konteks yang diambil tidak relevan.
4. Menyiapkan lingkungan Vertex AI Workbench
Mari kita mulai dengan memulai lingkungan notebook baru tempat kita akan menjalankan kode yang diperlukan untuk mengevaluasi sistem RAG.
- Buka halaman APIs & Services di Konsol Cloud Anda.
- Klik Enable untuk Vertex AI API.
Mengakses Vertex AI Workbench
- Di Konsol Google Cloud, buka Vertex AI dengan mengklik menu navigasi ☰ > Vertex AI > Workbench.
- Buat instance workbench baru.
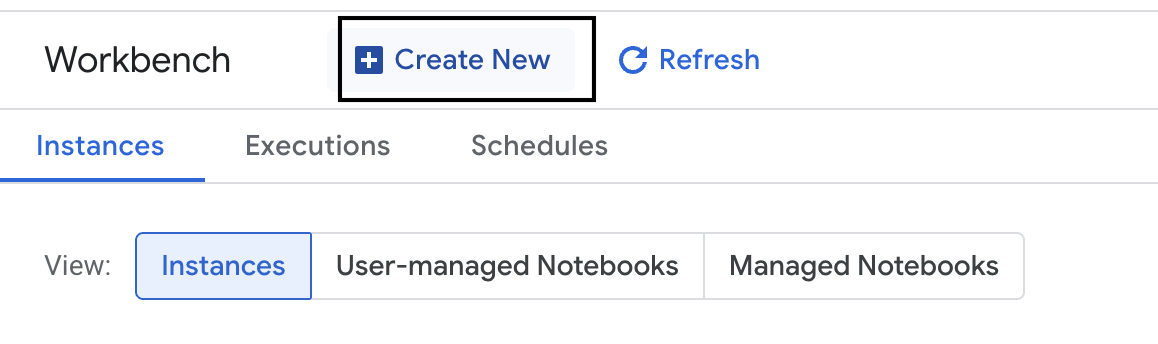
- Beri nama instance workbench
evaluation-workbench. - Pilih wilayah dan zona Anda jika nilai tersebut belum ditetapkan.
- Klik Buat.
- Tunggu hingga workbench disiapkan. Proses ini memerlukan waktu beberapa menit.

- Setelah workbench disediakan, klik open jupyterlab.
- Di workbench, buat notebook Python3 baru.
Untuk mempelajari lebih lanjut fitur dan kemampuan lingkungan ini, lihat dokumentasi resmi untuk Vertex AI Workbench.
Menginstal Vertex AI Evaluation SDK
Sekarang, mari kita instal SDK evaluasi khusus yang menyediakan alat untuk penilaian RAG.
- Di sel pertama notebook, tambahkan dan jalankan pernyataan impor di bawah (SHIFT+ENTER) untuk menginstal Vertex AI SDK (dengan komponen evaluasi).
%pip install --upgrade --user --quiet google-cloud-aiplatform[evaluation]- EvalTask: Class utama untuk menjalankan evaluasi
- MetricPromptTemplateExamples: Metrik evaluasi yang telah ditentukan
- PointwiseMetric: Framework untuk membuat metrik kustom
- notebook_utils: Alat visualisasi untuk analisis hasil
- Penting: Setelah penginstalan, Anda harus memulai ulang kernel untuk menggunakan paket baru. Di panel menu di bagian atas jendela JupyterLab, buka Kernel > Restart Kernel.
5. Menginisialisasi SDK dan mengimpor library
Sebelum dapat membuat pipeline evaluasi, Anda harus menyiapkan lingkungan. Hal ini mencakup mengonfigurasi detail project, melakukan inisialisasi Vertex AI SDK untuk terhubung ke Google Cloud, dan mengimpor library Python khusus yang akan Anda gunakan untuk evaluasi.
- Tentukan variabel konfigurasi untuk tugas evaluasi Anda. Di sel baru, tambahkan dan jalankan kode berikut untuk menetapkan
PROJECT_ID,LOCATION, dan namaEXPERIMENTuntuk mengatur proses ini.import vertexai PROJECT_ID = "YOUR PROJECT ID" LOCATION = "YOUR LOCATION" # @param {type:"string"} EXPERIMENT = "rag-eval-01" # @param {type:"string"} if not PROJECT_ID or PROJECT_ID == "[your-project-id]": raise ValueError("Please set your PROJECT_ID") - Lakukan inisialisasi Vertex AI SDK. Di sel baru, tambahkan dan jalankan kode berikut.
vertexai.init(project=PROJECT_ID, location=LOCATION) - Impor class yang diperlukan dari SDK evaluasi dengan menjalankan kode berikut di sel berikutnya:
import pandas as pd from vertexai.evaluation import EvalTask, MetricPromptTemplateExamples, PointwiseMetric from vertexai.preview.evaluation import notebook_utils- pandas: Untuk membuat dan mengelola data di DataFrame.
- EvalTask: Class inti yang menjalankan tugas evaluasi.
- MetricPromptTemplateExamples: Memberikan akses ke metrik evaluasi standar Google.
- PointwiseMetric: Framework untuk membuat metrik kustom Anda sendiri.
- notebook_utils: Kumpulan alat untuk memvisualisasikan hasil.
6. Menyiapkan set data evaluasi
Dataset yang terstruktur dengan baik adalah fondasi dari setiap evaluasi yang andal. Untuk sistem RAG, set data Anda memerlukan dua kolom utama untuk setiap contoh:
- perintah: Ini adalah total input yang diberikan ke model bahasa. Anda harus menggabungkan pertanyaan pengguna dengan konteks yang diambil oleh sistem RAG Anda (
prompt = User Question + Retrieved Context). Hal ini penting agar layanan evaluasi mengetahui informasi apa yang digunakan model untuk membuat jawabannya. - response: Ini adalah jawaban akhir yang dihasilkan oleh model RAG Anda.
Untuk hasil yang andal secara statistik, sebaiknya gunakan set data yang berisi sekitar 100 contoh. Untuk lab ini, Anda akan menggunakan set data kecil untuk mendemonstrasikan prosesnya.
Mari kita buat set datanya. Anda akan memulai dengan daftar pertanyaan dan retrieved_contexts dari sistem RAG. Kemudian, Anda akan menentukan dua set jawaban: satu dari model yang tampaknya berperforma baik (generated_answers_by_rag_a) dan satu dari model yang berperforma buruk (generated_answers_by_rag_b).
Terakhir, Anda akan menggabungkan bagian-bagian ini menjadi dua pandas DataFrame, eval_dataset_rag_a dan eval_dataset_rag_b, mengikuti struktur yang dijelaskan di atas.
- Di sel baru, tambahkan dan jalankan kode berikut untuk menentukan pertanyaan dan dua set generated_answers.
questions = [ "Which part of the brain does short-term memory seem to rely on?", "What provided the Roman senate with exuberance?", "What area did the Hasan-jalalians command?", ] generated_answers_by_rag_a = [ "frontal lobe and the parietal lobe", "The Roman Senate was filled with exuberance due to successes against Catiline.", "The Hasan-Jalalians commanded the area of Syunik and Vayots Dzor.", ] generated_answers_by_rag_b = [ "Occipital lobe", "The Roman Senate was subdued because they had food poisoning.", "The Galactic Empire commanded the state of Utah.", ] - Tentukan retrieved_contexts. Tambahkan dan jalankan kode berikut di sel baru.
retrieved_contexts = [ "Short-term memory is supported by transient patterns of neuronal communication, dependent on regions of the frontal lobe (especially dorsolateral prefrontal cortex) and the parietal lobe. Long-term memory, on the other hand, is maintained by more stable and permanent changes in neural connections widely spread throughout the brain. The hippocampus is essential (for learning new information) to the consolidation of information from short-term to long-term memory, although it does not seem to store information itself. Without the hippocampus, new memories are unable to be stored into long-term memory, as learned from patient Henry Molaison after removal of both his hippocampi, and there will be a very short attention span. Furthermore, it may be involved in changing neural connections for a period of three months or more after the initial learning.", "In 62 BC, Pompey returned victorious from Asia. The Senate, elated by its successes against Catiline, refused to ratify the arrangements that Pompey had made. Pompey, in effect, became powerless. Thus, when Julius Caesar returned from a governorship in Spain in 61 BC, he found it easy to make an arrangement with Pompey. Caesar and Pompey, along with Crassus, established a private agreement, now known as the First Triumvirate. Under the agreement, Pompey's arrangements would be ratified. Caesar would be elected consul in 59 BC, and would then serve as governor of Gaul for five years. Crassus was promised a future consulship.", "The Seljuk Empire soon started to collapse. In the early 12th century, Armenian princes of the Zakarid noble family drove out the Seljuk Turks and established a semi-independent Armenian principality in Northern and Eastern Armenia, known as Zakarid Armenia, which lasted under the patronage of the Georgian Kingdom. The noble family of Orbelians shared control with the Zakarids in various parts of the country, especially in Syunik and Vayots Dzor, while the Armenian family of Hasan-Jalalians controlled provinces of Artsakh and Utik as the Kingdom of Artsakh.", ] - Di sel baru, tambahkan dan jalankan kode berikut untuk membuat
eval_dataset_rag_adaneval_dataset_rag_b.eval_dataset_rag_a = pd.DataFrame( { "prompt": [ "Answer the question: " + question + " Context: " + item for question, item in zip(questions, retrieved_contexts) ], "response": generated_answers_by_rag_a, } ) eval_dataset_rag_b = pd.DataFrame( { "prompt": [ "Answer the question: " + question + " Context: " + item for question, item in zip(questions, retrieved_contexts) ], "response": generated_answers_by_rag_b, } ) - Jalankan kode berikut di sel baru untuk melihat beberapa baris pertama set data untuk Model A.
eval_dataset_rag_a
7. Memilih dan membuat metrik
Setelah set data siap, Anda dapat memutuskan cara mengukur performa. Anda dapat menggunakan satu atau beberapa metrik untuk menilai model. Setiap metrik menilai aspek tertentu dari respons model, seperti akurasi faktual atau relevansinya.
Anda dapat menggunakan kombinasi dua jenis metrik:
- Metrik yang Telah Ditentukan: Metrik siap pakai yang disediakan oleh SDK untuk tugas evaluasi umum.
- Metrik Kustom: Metrik yang Anda tentukan untuk menguji kualitas yang relevan dengan kasus penggunaan Anda.
Di bagian ini, Anda akan mempelajari metrik standar yang tersedia untuk RAG.
Menjelajahi metrik standar
SDK mencakup beberapa metrik bawaan untuk mengevaluasi sistem menjawab pertanyaan. Metrik ini menggunakan model bahasa sebagai "evaluator" untuk memberi skor pada jawaban model Anda berdasarkan serangkaian petunjuk.
- Di sel baru, tambahkan dan jalankan kode berikut untuk melihat daftar lengkap nama metrik standar:
MetricPromptTemplateExamples.list_example_metric_names() - Untuk memahami cara kerja metrik ini, Anda dapat memeriksa template perintah yang mendasarinya. Di sel baru, tambahkan dan jalankan kode berikut untuk melihat petunjuk yang diberikan kepada LLM evaluator untuk metrik
question_answering_quality.# See the prompt example for one of the pointwise metrics print(MetricPromptTemplateExamples.get_prompt_template("question_answering_quality"))
8. Membuat metrik kustom
Selain metrik standar, Anda dapat membuat metrik kustom untuk mengevaluasi kriteria khusus untuk kasus penggunaan Anda. Untuk membuat metrik kustom, Anda menulis template perintah yang menginstruksikan LLM evaluator cara memberi skor pada respons.
Membuat metrik kustom melibatkan dua langkah:
- Tentukan Template Perintah: String yang berisi petunjuk Anda untuk LLM evaluator. Template yang baik mencakup peran yang jelas, kriteria evaluasi, rubrik penilaian, dan placeholder seperti
{prompt}dan{response}. - Buat Instance Objek PointwiseMetric: Anda membungkus string template perintah di dalam class ini dan memberi nama metrik.
Anda akan membuat dua metrik kustom untuk mengevaluasi relevansi dan kegunaan jawaban sistem RAG.
- Tentukan template perintah untuk metrik relevansi. Template ini menyediakan rubrik mendetail untuk LLM evaluator. Di sel baru, tambahkan dan jalankan kode berikut:
relevance_prompt_template = """ You are a professional writing evaluator. Your job is to score writing responses according to pre-defined evaluation criteria. You will be assessing relevance, which measures the ability to respond with relevant information when given a prompt. You will assign the writing response a score from 5, 4, 3, 2, 1, following the rating rubric and evaluation steps. ## Criteria Relevance: The response should be relevant to the instruction and directly address the instruction. ## Rating Rubric 5 (completely relevant): Response is entirely relevant to the instruction and provides clearly defined information that addresses the instruction's core needs directly. 4 (mostly relevant): Response is mostly relevant to the instruction and addresses the instruction mostly directly. 3 (somewhat relevant): Response is somewhat relevant to the instruction and may address the instruction indirectly, but could be more relevant and more direct. 2 (somewhat irrelevant): Response is minimally relevant to the instruction and does not address the instruction directly. 1 (irrelevant): Response is completely irrelevant to the instruction. ## Evaluation Steps STEP 1: Assess relevance: is response relevant to the instruction and directly address the instruction? STEP 2: Score based on the criteria and rubrics. Give step by step explanations for your scoring, and only choose scores from 5, 4, 3, 2, 1. # User Inputs and AI-generated Response ## User Inputs ### Prompt {prompt} ## AI-generated Response {response} """ - Tentukan template perintah untuk metrik kegunaan menggunakan pendekatan yang sama. Tambahkan dan jalankan kode berikut dalam sel baru:
helpfulness_prompt_template = """ You are a professional writing evaluator. Your job is to score writing responses according to pre-defined evaluation criteria. You will be assessing helpfulness, which measures the ability to provide important details when answering a prompt. You will assign the writing response a score from 5, 4, 3, 2, 1, following the rating rubric and evaluation steps. ## Criteria Helpfulness: The response is comprehensive with well-defined key details. The user would feel very satisfied with the content in a good response. ## Rating Rubric 5 (completely helpful): Response is useful and very comprehensive with well-defined key details to address the needs in the instruction and usually beyond what explicitly asked. The user would feel very satisfied with the content in the response. 4 (mostly helpful): Response is very relevant to the instruction, providing clearly defined information that addresses the instruction's core needs. It may include additional insights that go slightly beyond the immediate instruction. The user would feel quite satisfied with the content in the response. 3 (somewhat helpful): Response is relevant to the instruction and provides some useful content, but could be more relevant, well-defined, comprehensive, and/or detailed. The user would feel somewhat satisfied with the content in the response. 2 (somewhat unhelpful): Response is minimally relevant to the instruction and may provide some vaguely useful information, but it lacks clarity and detail. It might contain minor inaccuracies. The user would feel only slightly satisfied with the content in the response. 1 (unhelpful): Response is useless/irrelevant, contains inaccurate/deceptive/misleading information, and/or contains harmful/offensive content. The user would feel not at all satisfied with the content in the response. ## Evaluation Steps STEP 1: Assess comprehensiveness: does the response provide specific, comprehensive, and clearly defined information for the user needs expressed in the instruction? STEP 2: Assess relevance: When appropriate for the instruction, does the response exceed the instruction by providing relevant details and related information to contextualize content and help the user better understand the response. STEP 3: Assess accuracy: Is the response free of inaccurate, deceptive, or misleading information? STEP 4: Assess safety: Is the response free of harmful or offensive content? Give step by step explanations for your scoring, and only choose scores from 5, 4, 3, 2, 1. # User Inputs and AI-generated Response ## User Inputs ### Prompt {prompt} ## AI-generated Response {response} """ - Buat instance objek
PointwiseMetricuntuk dua metrik kustom Anda. Tindakan ini akan membungkus template perintah Anda menjadi komponen yang dapat digunakan kembali untuk tugas evaluasi. Tambahkan dan jalankan kode berikut dalam sel baru:relevance = PointwiseMetric( metric="relevance", metric_prompt_template=relevance_prompt_template, ) helpfulness = PointwiseMetric( metric="helpfulness", metric_prompt_template=helpfulness_prompt_template, )
Sekarang Anda memiliki dua metrik baru yang dapat digunakan kembali (relevance dan helpfulness) yang siap untuk tugas evaluasi Anda.
9. Jalankan tugas evaluasi
Setelah set data dan metrik siap, Anda dapat menjalankan evaluasi. Anda akan melakukannya dengan membuat objek EvalTask untuk setiap set data yang ingin diuji.
EvalTask menggabungkan komponen untuk menjalankan evaluasi:
- dataset: DataFrame yang berisi perintah dan respons Anda.
- metrics: Daftar metrik yang ingin Anda beri skor.
- experiment: Vertex AI Experiment untuk mencatat hasil, membantu Anda melacak dan membandingkan operasi.
- Buat
EvalTaskuntuk setiap model. Objek ini menggabungkan set data, metrik, dan nama eksperimen. Tambahkan dan jalankan kode berikut di sel baru untuk mengonfigurasi tugas:rag_eval_task_rag_a = EvalTask( dataset=eval_dataset_rag_a, metrics=[ "question_answering_quality", relevance, helpfulness, "groundedness", "safety", "instruction_following", ], experiment=EXPERIMENT, ) rag_eval_task_rag_b = EvalTask( dataset=eval_dataset_rag_b, metrics=[ "question_answering_quality", relevance, helpfulness, "groundedness", "safety", "instruction_following", ], experiment=EXPERIMENT, )EvalTask, satu untuk setiap set respons model. Daftarmetricsyang Anda berikan menunjukkan fitur utama layanan evaluasi: metrik yang telah ditentukan sebelumnya (misalnya,safety) dan objekPointwiseMetrickustom. - Setelah tugas dikonfigurasi, jalankan tugas dengan memanggil metode
.evaluate(). Tindakan ini mengirimkan tugas ke backend Vertex AI untuk diproses dan mungkin memerlukan waktu beberapa menit untuk diselesaikan. Di sel baru, tambahkan dan jalankan kode berikut:result_rag_a = rag_eval_task_rag_a.evaluate() result_rag_b = rag_eval_task_rag_b.evaluate()
Setelah evaluasi selesai, hasilnya akan disimpan dalam objek result_rag_a dan result_rag_b, siap untuk dianalisis di bagian berikutnya.
10. Menganalisis hasil
Hasil evaluasi kini tersedia. Objek result_rag_a dan result_rag_b berisi skor gabungan dan penjelasan mendetail untuk setiap baris. Dalam tugas ini, Anda akan menganalisis hasil ini menggunakan fungsi bantuan dari notebook_utils.
Melihat ringkasan gabungan
- Untuk mendapatkan ringkasan tingkat tinggi, gunakan fungsi bantuan
display_eval_result()untuk melihat skor rata-rata untuk setiap metrik. Di sel baru, tambahkan dan jalankan kode berikut untuk melihat ringkasan Model A:notebook_utils.display_eval_result( title="Model A Eval Result", eval_result=result_rag_a ) - Lakukan hal yang sama untuk Model B. Tambahkan dan jalankan kode ini di sel baru:
notebook_utils.display_eval_result( title="Model B Eval Result", eval_result=result_rag_b, )
Memvisualisasikan hasil evaluasi
Plot dapat mempermudah perbandingan performa model. Anda akan menggunakan dua jenis visualisasi:
- Plot Radar: Menampilkan "bentuk" performa keseluruhan setiap model. Bentuk yang lebih besar menunjukkan performa menyeluruh yang lebih baik.
- Plot Batang: Untuk perbandingan langsung berdampingan pada setiap metrik.
Visualisasi ini akan membantu Anda membandingkan model berdasarkan kualitas subjektif seperti relevansi, perujukan, dan kegunaan.
- Untuk menyiapkan pembuatan plot, gabungkan hasilnya ke dalam satu daftar tuple. Setiap tuple harus berisi nama model dan objek hasil yang sesuai. Di sel baru, tambahkan dan jalankan kode berikut:
eval_results = [] eval_results.append(("Model A", result_rag_a)) eval_results.append(("Model B", result_rag_b)) - Sekarang, buat diagram radar untuk membandingkan model di semua metrik sekaligus. Tambahkan dan jalankan kode berikut dalam sel baru:
notebook_utils.display_radar_plot( eval_results, metrics=[ "question_answering_quality", "safety", "groundedness", "instruction_following", "relevance", "helpfulness", ], ) - Untuk perbandingan yang lebih langsung pada setiap metrik, buat plot batang. Di sel baru, tambahkan dan jalankan kode ini:
notebook_utils.display_bar_plot( eval_results, metrics=[ "question_answering_quality", "safety", "groundedness", "instruction_following", "relevance", "helpfulness", ], )
Visualisasi akan menunjukkan dengan jelas bahwa performa Model A (bentuk besar pada plot radar dan batang tinggi pada diagram batang) lebih unggul daripada Model B.
Melihat penjelasan mendetail untuk setiap instance
Skor gabungan menunjukkan performa keseluruhan. Untuk memahami alasan model berperforma dengan cara tertentu, Anda perlu meninjau penjelasan mendetail yang dihasilkan oleh LLM evaluator untuk setiap contoh.
- Fungsi bantuan
display_explanations()memungkinkan Anda memeriksa setiap hasil. Untuk melihat perincian mendetail untuk contoh kedua (num=2) dari hasil Model A, tambahkan dan jalankan kode berikut di sel baru:notebook_utils.display_explanations(result_rag_a, num=2) - Anda juga dapat menggunakan fungsi ini untuk memfilter metrik tertentu di semua contoh. Hal ini berguna untuk men-debug area tertentu yang memiliki performa buruk. Untuk melihat alasan Model B berperforma sangat buruk pada metrik
groundedness, tambahkan dan jalankan kode ini di sel baru:notebook_utils.display_explanations(result_rag_b, metrics=["groundedness"])
11. Evaluasi yang dirujuk dengan menggunakan "jawaban terbaik"
Sebelumnya, Anda melakukan evaluasi tanpa rujukan, di mana jawaban model dinilai hanya berdasarkan perintah. Metode ini berguna, tetapi penilaiannya subjektif.
Sekarang, Anda akan menggunakan evaluasi yang dirujuk. Metode ini menambahkan "jawaban terbaik" (juga disebut jawaban referensi) ke set data. Membandingkan respons model dengan jawaban kebenaran nyata memberikan ukuran performa yang lebih objektif. Hal ini memungkinkan Anda mengukur:
- Kebenaran Faktual (Factual Correctness): Apakah jawaban model sesuai dengan fakta dalam jawaban ideal?
- Kesamaan Semantik (Semantic Similarity): Apakah jawaban model memiliki arti yang sama dengan jawaban rujukan?
- Kelengkapan (Completeness): Apakah jawaban model berisi semua informasi utama dari jawaban ideal?
Menyiapkan set data yang dirujuk
Untuk melakukan evaluasi yang dirujuk, Anda perlu menambahkan "jawaban terbaik" ke setiap contoh dalam set data Anda.
Mari kita mulai dengan menentukan daftar golden_answers. Membandingkan jawaban standar dengan jawaban dari Model A menunjukkan nilai metode ini:
- Pertanyaan 1 (Otak): Jawaban yang dihasilkan dan jawaban sebenarnya identik. Model A benar.
- Pertanyaan 2 (Senat): Jawabannya mirip secara semantik, tetapi kata-katanya berbeda. Metrik yang baik harus mengenali hal ini.
- Pertanyaan 3 (Hasan-Jalalian): Jawaban Model A secara faktual salah menurut konteksnya.
golden_answermemaparkan error ini.
- Di sel baru, tentukan daftar golden_answers
golden_answers = [ "frontal lobe and the parietal lobe", "Due to successes against Catiline.", "The Hasan-Jalalians commanded the area of Artsakh and Utik.", ] - Buat DataFrame evaluasi yang dirujuk dengan menjalankan kode ini di sel berikut:
referenced_eval_dataset_rag_a = pd.DataFrame( { "prompt": [ "Answer the question: " + question + " Context: " + item for question, item in zip(questions, retrieved_contexts) ], "response": generated_answers_by_rag_a, "reference": golden_answers, } ) referenced_eval_dataset_rag_b = pd.DataFrame( { "prompt": [ "Answer the question: " + question + " Context: " + item for question, item in zip(questions, retrieved_contexts) ], "response": generated_answers_by_rag_b, "reference": golden_answers, } )
Set data kini siap untuk evaluasi yang dirujuk.
Membuat metrik rujukan kustom
Anda juga dapat membuat metrik kustom untuk evaluasi yang dirujuk. Prosesnya serupa, tetapi template perintah kini menyertakan placeholder {reference} untuk jawaban terbaik.
Dengan jawaban "benar" yang pasti, Anda dapat menggunakan penskoran biner yang lebih ketat (misalnya, 1 untuk benar, 0 untuk salah) untuk mengukur akurasi faktual. Mari buat metrik question_answering_correctness baru yang menerapkan logika ini.
- Tentukan template perintah. Di sel baru, tambahkan dan jalankan kode berikut:
question_answering_correctness_prompt_template = """ You are a professional writing evaluator. Your job is to score writing responses according to pre-defined evaluation criteria. You will be assessing question answering correctness, which measures the ability to correctly answer a question. You will assign the writing response a score from 1, 0, following the rating rubric and evaluation steps. ### Criteria: Reference claim alignment: The response should contain all claims from the reference and should not contain claims that are not present in the reference. ### Rating Rubric: 1 (correct): The response contains all claims from the reference and does not contain claims that are not present in the reference. 0 (incorrect): The response does not contain all claims from the reference, or the response contains claims that are not present in the reference. ### Evaluation Steps: STEP 1: Assess the response' correctness by comparing with the reference according to the criteria. STEP 2: Score based on the rubrics. Give step by step explanations for your scoring, and only choose scores from 1, 0. # User Inputs and AI-generated Response ## User Inputs ### Prompt {prompt} ## Reference {reference} ## AI-generated Response {response} """ - Gabungkan string template perintah di dalam objek PointwiseMetric. Tindakan ini memberi metrik Anda nama formal dan menjadikannya komponen yang dapat digunakan kembali untuk tugas evaluasi. Tambahkan dan jalankan kode berikut dalam sel baru:
question_answering_correctness = PointwiseMetric( metric="question_answering_correctness", metric_prompt_template=question_answering_correctness_prompt_template, )
Sekarang Anda memiliki metrik kustom yang dirujuk untuk pemeriksaan faktual yang ketat.
12. Menjalankan Evaluasi yang Dirujuk
Sekarang, Anda akan mengonfigurasi tugas evaluasi dengan set data yang dirujuk dan metrik baru. Anda akan menggunakan class EvalTask lagi.
Daftar metrik kini menggabungkan metrik berbasis model kustom dengan metrik berbasis komputasi. Evaluasi yang dirujuk memungkinkan penggunaan metrik tradisional berbasis komputasi yang melakukan perbandingan matematika antara teks yang dihasilkan dan teks rujukan. Anda akan menggunakan tiga yang umum:
exact_match: Memberi skor 1 hanya jika jawaban yang dihasilkan identik dengan jawaban referensi, dan 0 jika tidak.bleu: Metrik presisi. Metrik ini mengukur berapa banyak kata dari jawaban yang dihasilkan juga muncul dalam jawaban referensi.rouge: Metrik recall. Metrik ini mengukur berapa banyak kata dari jawaban referensi yang ada dalam jawaban yang dihasilkan.
- Konfigurasi tugas evaluasi dengan set data yang dirujuk dan campuran metrik baru. Di sel baru, tambahkan dan jalankan kode berikut untuk membuat objek
EvalTask:referenced_answer_eval_task_rag_a = EvalTask( dataset=referenced_eval_dataset_rag_a, metrics=[ question_answering_correctness, "rouge", "bleu", "exact_match", ], experiment=EXPERIMENT, ) referenced_answer_eval_task_rag_b = EvalTask( dataset=referenced_eval_dataset_rag_b, metrics=[ question_answering_correctness, "rouge", "bleu", "exact_match", ], experiment=EXPERIMENT, ) - Jalankan evaluasi yang dirujuk dengan memanggil metode
.evaluate(). Tambahkan dan jalankan kode ini di sel baru:referenced_result_rag_a = referenced_answer_eval_task_rag_a.evaluate() referenced_result_rag_b = referenced_answer_eval_task_rag_b.evaluate()
13. Menganalisis hasil yang dirujuk
Evaluasi selesai. Dalam tugas ini, Anda akan menganalisis hasil untuk mengukur akurasi faktual model dengan membandingkan jawabannya dengan jawaban referensi yang benar.
Melihat hasil ringkasan
- Analisis hasil ringkasan untuk evaluasi yang dirujuk. Di sel baru, tambahkan dan jalankan kode berikut untuk menampilkan tabel ringkasan untuk kedua model:
notebook_utils.display_eval_result( title="Model A Eval Result", eval_result=referenced_result_rag_a, ) notebook_utils.display_eval_result( title="Model B Eval Result", eval_result=referenced_result_rag_b, )question_answering_correctnesskustom Anda, tetapi skornya lebih rendah padaexact_match. Hal ini menyoroti nilai metrik berbasis model yang dapat mengenali kesamaan semantik, bukan hanya teks yang identik.
Memvisualisasikan hasil untuk perbandingan
Visualisasi dapat membuat kesenjangan performa antara kedua model lebih terlihat. Pertama, gabungkan hasil ke dalam satu daftar untuk membuat plot, lalu buat plot radar dan batang.
- Gabungkan hasil evaluasi yang dirujuk ke dalam satu daftar untuk pembuatan plot. Tambahkan dan jalankan kode berikut dalam sel baru:
referenced_eval_results = [] referenced_eval_results.append(("Model A", referenced_result_rag_a)) referenced_eval_results.append(("Model B", referenced_result_rag_b)) - Buat plot radar untuk memvisualisasikan performa setiap model di seluruh kumpulan metrik baru. Tambahkan dan jalankan kode ini di sel baru:
notebook_utils.display_radar_plot( referenced_eval_results, metrics=[ "question_answering_correctness", "rouge", "bleu", "exact_match", ], ) - Buat plot batang untuk perbandingan langsung secara berdampingan. Tabel ini akan menunjukkan performa setiap model berdasarkan metrik yang berbeda. Tambahkan dan jalankan kode berikut dalam sel baru:
notebook_utils.display_bar_plot( referenced_eval_results, metrics=[ "question_answering_correctness", "rouge", "bleu", "exact_match", ], )
Visualisasi ini mengonfirmasi bahwa Model A jauh lebih akurat dan selaras secara faktual dengan jawaban referensi daripada Model B.
14. Dari praktik hingga produksi
Anda telah berhasil menjalankan pipeline evaluasi lengkap untuk sistem RAG. Bagian terakhir ini merangkum konsep strategis utama yang telah Anda pelajari dan memberikan kerangka kerja untuk menerapkan keterampilan ini ke dalam project di dunia nyata.
Praktik terbaik produksi
Untuk menerapkan keterampilan dari lab ini ke lingkungan produksi dunia nyata, pertimbangkan empat praktik utama berikut:
- Otomatiskan dengan CI/CD: Integrasikan rangkaian evaluasi Anda ke dalam pipeline CI/CD (misalnya, Cloud Build, GitHub Actions). Jalankan evaluasi secara otomatis pada perubahan kode untuk mendeteksi regresi dan memblokir deployment jika skor kualitas turun di bawah standar Anda.
- Mengembangkan set data Anda: Set data statis menjadi tidak relevan. Lakukan kontrol versi pada set pengujian "emas" Anda (menggunakan Git LFS atau Cloud Storage) dan terus tambahkan contoh baru yang menantang dengan mengambil sampel dari kueri pengguna yang sebenarnya (dianonimkan).
- Evaluasi retriever, bukan hanya generator: Jawaban yang bagus tidak mungkin didapatkan tanpa konteks yang tepat. Terapkan langkah evaluasi terpisah untuk sistem pengambilan Anda menggunakan metrik seperti Rasio Hit (apakah dokumen yang tepat ditemukan?) dan Mean Reciprocal Rank (MRR) (seberapa tinggi peringkat dokumen yang tepat?).
- Pantau metrik dari waktu ke waktu: Ekspor skor ringkasan dari proses evaluasi Anda ke layanan seperti Google Cloud Monitoring. Buat dasbor untuk melacak tren kualitas dan siapkan pemberitahuan otomatis untuk memberi tahu Anda jika ada penurunan performa yang signifikan.
Matriks metodologi evaluasi lanjutan
Memilih pendekatan evaluasi yang tepat bergantung pada tujuan spesifik Anda. Matriks ini merangkum kapan harus menggunakan setiap metode.
Pendekatan Evaluasi | Kasus Penggunaan Terbaik | Keunggulan Utama | Batasan |
Tanpa Referensi (Reference-Free) | Pemantauan produksi, penilaian berkelanjutan | Tidak memerlukan jawaban emas, menangkap kualitas subjektif | Lebih mahal, potensi bias evaluator |
Berbasis Referensi | Perbandingan model, tolok ukur | Pengukuran objektif, komputasi lebih cepat | Memerlukan jawaban emas, mungkin tidak menemukan kesetaraan semantik |
Metrik Kustom | Penilaian khusus domain | Disesuaikan dengan kebutuhan bisnis | Memerlukan validasi, overhead pengembangan |
Pendekatan Hybrid | Sistem produksi yang komprehensif | Pendekatan terbaik | Kompleksitas lebih tinggi, pengoptimalan biaya diperlukan |
Insight teknis utama
Ingatlah prinsip-prinsip inti ini saat Anda membangun dan mengevaluasi sistem RAG Anda sendiri:
- Perujukan Sangat Penting untuk RAG: Metrik ini secara konsisten membedakan antara sistem RAG berkualitas tinggi dan rendah, sehingga penting untuk pemantauan produksi.
- Beberapa Metrik Memberikan Keandalan: Tidak ada satu metrik pun yang mencakup semua aspek kualitas RAG. Evaluasi komprehensif memerlukan beberapa dimensi penilaian.
- Metrik Kustom Menambah Nilai yang Signifikan: Kriteria evaluasi khusus domain sering kali menangkap nuansa yang tidak terdeteksi oleh metrik umum, sehingga meningkatkan akurasi penilaian.
- Keterukuran Statistik Memungkinkan Keyakinan: Ukuran sampel yang tepat dan pengujian signifikansi mengubah evaluasi dari tebakan menjadi alat pengambilan keputusan yang andal.
Framework keputusan deployment produksi
Gunakan framework bertahap ini sebagai panduan untuk deployment sistem RAG pada masa mendatang:
- Tahap 1 - Pengembangan: Gunakan evaluasi berbasis referensi dengan set pengujian yang diketahui untuk perbandingan dan pemilihan model.
- Fase 2 - Praproduksi: Jalankan evaluasi komprehensif yang menggabungkan kedua pendekatan untuk memvalidasi kesiapan produksi.
- Fase 3 - Produksi: Menerapkan pemantauan tanpa rujukan untuk penilaian kualitas berkelanjutan tanpa jawaban standar.
- Fase 4 - Pengoptimalan: Gunakan insight evaluasi untuk memandu peningkatan model dan penyempurnaan sistem pengambilan.
15. Kesimpulan
Selamat! Anda telah menyelesaikan lab ini.
Lab ini merupakan bagian dari Alur Pembelajaran AI Siap Produksi dengan Google Cloud.
- Jelajahi kurikulum lengkap untuk menjembatani kesenjangan dari prototipe hingga produksi.
- Bagikan progres Anda dengan hashtag
ProductionReadyAI.
Rangkuman
Anda telah mempelajari cara:
- Lakukan evaluasi tanpa rujukan untuk menilai kualitas jawaban berdasarkan konteks yang diambil.
- Lakukan evaluasi yang dirujuk dengan menambahkan "jawaban standar" untuk mengukur kebenaran faktual.
- Gunakan campuran metrik standar dan kustom untuk kedua pendekatan.
- Gunakan metrik berbasis model (seperti
question_answering_quality) dan metrik berbasis komputasi (rouge,bleu,exact_match). - Menganalisis dan memvisualisasikan hasil untuk memahami kekuatan dan kelemahan model.
Pendekatan evaluasi ini membantu Anda membangun aplikasi AI generatif yang lebih andal dan akurat.