
1. Panoramica
In questo lab imparerai a creare una pipeline di valutazione per un sistema di generazione RAG (Retrieval-Augmented Generation). Utilizzerai Vertex AI Gen AI Evaluation Service per creare criteri di valutazione personalizzati e creare un framework di valutazione per un'attività di risposta alle domande.
Lavorerai con esempi del set di dati Stanford Question Answering Dataset (SQuAD 2.0) per preparare i set di dati di valutazione, configurare valutazioni senza riferimenti e basate su riferimenti e interpretare i risultati. Al termine di questo lab, avrai capito come valutare i sistemi RAG e perché vengono scelti determinati approcci di valutazione.
Nozioni di base sui set di dati
Lavoreremo con esempi accuratamente realizzati che coprono più domini trovati nel set di dati per la risposta alle domande SQuAD 2.0:
- Neuroscienze: test dell'accuratezza tecnica in contesti scientifici
- Storia: valutazione dell'accuratezza fattuale nelle narrazioni storiche
- Geografia: valutazione delle conoscenze territoriali e politiche
Questa diversità ti aiuta a capire come gli approcci di valutazione vengono generalizzati in diverse aree tematiche.
Riferimenti
- Esempi di codice: questo lab si basa sugli esempi della documentazione di Vertex AI Evaluation
- Set di dati di base: SQuAD 2.0 Question Answering Dataset
- Ottimizzazione del recupero RAG: test, ottimizzazione e successo
Obiettivi didattici
In questo lab imparerai a:
- Prepara i set di dati di valutazione per i sistemi RAG.
- Implementa la valutazione senza riferimenti utilizzando metriche come la fondatezza e la pertinenza.
- Applica la valutazione basata su riferimenti con misure di similarità semantica.
- Crea metriche di valutazione personalizzate con rubriche di valutazione dettagliate.
- Interpreta e visualizza i risultati della valutazione per prendere decisioni informate sulla selezione del modello.
2. Configurazione del progetto
Account Google
Se non hai ancora un Account Google personale, devi crearne uno.
Utilizza un account personale anziché un account di lavoro o della scuola.
Accedi alla console Google Cloud
Accedi alla console Google Cloud utilizzando un Account Google personale.
Abilita fatturazione
Riscatta i crediti Google Cloud (facoltativo)
Per partecipare a questo workshop, devi disporre di un account di fatturazione con del credito. Per iniziare, utilizza i crediti del banner nella parte superiore di questo codelab. Se hai già collegato un account di fatturazione, puoi saltare questo passaggio.
Configurare un account di fatturazione personale
Se hai configurato la fatturazione utilizzando i crediti Google Cloud, puoi saltare questo passaggio.
Per configurare un account di fatturazione personale, vai qui per abilitare la fatturazione nella console Cloud.
Alcune note:
- Il completamento di questo lab dovrebbe costare meno di 1 $in risorse cloud.
- Per evitare ulteriori addebiti, puoi seguire i passaggi alla fine di questo lab per eliminare le risorse.
- I nuovi utenti hanno diritto alla prova senza costi di 300$.
Creare un progetto (facoltativo)
Se non hai un progetto attuale che vuoi utilizzare per questo lab, creane uno nuovo qui.
3. Che cos'è la Retrieval Augmented Generation (RAG)?
La RAG è una tecnica utilizzata per migliorare l'accuratezza e la pertinenza delle risposte dei modelli linguistici di grandi dimensioni (LLM). Collega l'LLM a una knowledge base esterna per basare le sue risposte su informazioni specifiche e verificabili.
La procedura prevede i seguenti passaggi:
- Conversione della domanda di un utente in una rappresentazione numerica (un embedding).
- Ricerca nella knowledge base di documenti con incorporamenti simili.
- Fornendo questi documenti pertinenti come contesto all'LLM insieme alla domanda originale per generare una risposta.
Scopri di più su RAG.
Che cosa rende complessa la valutazione della RAG?
La valutazione dei sistemi RAG è diversa dalla valutazione dei modelli linguistici tradizionali.
La sfida multi-componente: i sistemi RAG combinano tre operazioni che possono essere ciascuna un punto di errore:
- Qualità del recupero: il sistema ha trovato i documenti di contesto giusti?
- Utilizzo del contesto: il modello ha utilizzato in modo efficace le informazioni recuperate?
- Qualità della generazione: la risposta finale è ben scritta, utile e accurata?
Una risposta può non andare a buon fine se uno di questi componenti non funziona come previsto. Ad esempio, il sistema potrebbe recuperare il contesto corretto, ma il modello lo ignora. In alternativa, il modello potrebbe generare una risposta ben scritta, ma errata perché il contesto recuperato era irrilevante.
4. Configura l'ambiente Vertex AI Workbench
Iniziamo creando un nuovo ambiente notebook in cui eseguiremo il codice necessario per valutare i sistemi RAG.
- Vai alla pagina API e servizi della console Cloud.
- Fai clic su Abilita per l'API Vertex AI.
Accedere a Vertex AI Workbench
- Nella console Google Cloud, vai a Vertex AI facendo clic sul menu di navigazione ☰ > Vertex AI > Workbench.
- Crea una nuova istanza di workbench.
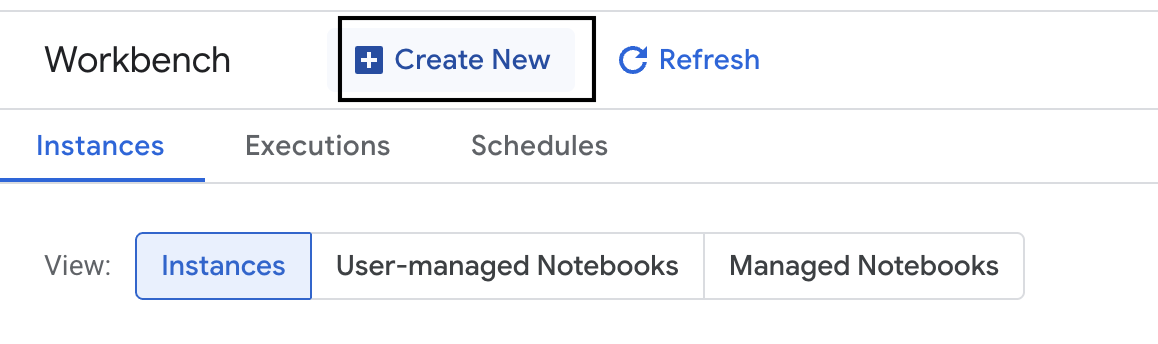
- Assegna all'istanza del workbench il nome
evaluation-workbench. - Seleziona la regione e la zona se questi valori non sono già impostati.
- Fai clic su Crea.
- Attendi la configurazione del workbench. L'operazione potrebbe richiedere alcuni minuti.

- Una volta eseguito il provisioning del workbench, fai clic su Apri JupyterLab.
- In Workbench, crea un nuovo notebook Python3.
Per saperne di più sulle funzionalità e sulle capacità di questo ambiente, consulta la documentazione ufficiale di Vertex AI Workbench.
Installa l'SDK Vertex AI Evaluation
Ora installiamo l'SDK di valutazione specializzato che fornisce gli strumenti per la valutazione RAG.
- Nella prima cella del notebook, aggiungi ed esegui l'istruzione di importazione riportata di seguito (MAIUSC+INVIO) per installare l'SDK Vertex AI (con i componenti di valutazione).
%pip install --upgrade --user --quiet google-cloud-aiplatform[evaluation]- EvalTask: la classe principale per l'esecuzione delle valutazioni
- MetricPromptTemplateExamples: metriche di valutazione predefinite
- PointwiseMetric: framework per la creazione di metriche personalizzate
- notebook_utils: strumenti di visualizzazione per l'analisi dei risultati
- Importante: dopo l'installazione, devi riavviare il kernel per utilizzare i nuovi pacchetti. Nella barra dei menu nella parte superiore della finestra di JupyterLab, vai a Kernel > Riavvia kernel.
5. Inizializza l'SDK e importa le librerie
Prima di poter creare la pipeline di valutazione, devi configurare l'ambiente. Ciò comporta la configurazione dei dettagli del progetto, l'inizializzazione dell'SDK Vertex AI per connettersi a Google Cloud e l'importazione delle librerie Python specializzate che utilizzerai per la valutazione.
- Definisci le variabili di configurazione per il job di valutazione. In una nuova cella, aggiungi ed esegui il seguente codice per impostare
PROJECT_ID,LOCATIONe un nomeEXPERIMENTper organizzare questa esecuzione.import vertexai PROJECT_ID = "YOUR PROJECT ID" LOCATION = "YOUR LOCATION" # @param {type:"string"} EXPERIMENT = "rag-eval-01" # @param {type:"string"} if not PROJECT_ID or PROJECT_ID == "[your-project-id]": raise ValueError("Please set your PROJECT_ID") - Inizializza l'SDK Vertex AI. In una nuova cella, aggiungi ed esegui il seguente codice.
vertexai.init(project=PROJECT_ID, location=LOCATION) - Importa le classi necessarie dall'SDK di valutazione eseguendo il seguente codice nella cella successiva:
import pandas as pd from vertexai.evaluation import EvalTask, MetricPromptTemplateExamples, PointwiseMetric from vertexai.preview.evaluation import notebook_utils- pandas: per creare e gestire i dati nei DataFrame.
- EvalTask: la classe principale che esegue un job di valutazione.
- MetricPromptTemplateExamples: fornisce l'accesso alle metriche di valutazione predefinite di Google.
- PointwiseMetric: il framework per creare metriche personalizzate.
- notebook_utils: una raccolta di strumenti per visualizzare i risultati.
6. Prepara il set di dati di valutazione
Un set di dati ben strutturato è la base di qualsiasi valutazione affidabile. Per i sistemi RAG, il set di dati deve contenere due campi chiave per ogni esempio:
- Prompt: l'input totale fornito al modello linguistico. Devi combinare la domanda dell'utente con il contesto recuperato dal sistema RAG (
prompt = User Question + Retrieved Context). Questo è importante per consentire al servizio di valutazione di sapere quali informazioni ha utilizzato il modello per creare la risposta. - Risposta: questa è la risposta finale prodotta dal modello RAG.
Per ottenere risultati statisticamente affidabili, è consigliabile un set di dati di circa 100 esempi. Per questo lab, utilizzerai un piccolo set di dati per dimostrare la procedura.
Creiamo i set di dati. Inizierai con un elenco di domande e il retrieved_contexts di un sistema RAG. Definisci quindi due set di risposte: uno da un modello che sembra funzionare bene (generated_answers_by_rag_a) e uno da un modello che funziona male (generated_answers_by_rag_b).
Infine, combinerai questi elementi in due DataFrame pandas, eval_dataset_rag_a e eval_dataset_rag_b, seguendo la struttura descritta sopra.
- In una nuova cella, aggiungi ed esegui il codice seguente per definire le domande e i due set di generated_answers.
questions = [ "Which part of the brain does short-term memory seem to rely on?", "What provided the Roman senate with exuberance?", "What area did the Hasan-jalalians command?", ] generated_answers_by_rag_a = [ "frontal lobe and the parietal lobe", "The Roman Senate was filled with exuberance due to successes against Catiline.", "The Hasan-Jalalians commanded the area of Syunik and Vayots Dzor.", ] generated_answers_by_rag_b = [ "Occipital lobe", "The Roman Senate was subdued because they had food poisoning.", "The Galactic Empire commanded the state of Utah.", ] - Definisci retrieved_contexts. Aggiungi ed esegui il seguente codice in una nuova cella.
retrieved_contexts = [ "Short-term memory is supported by transient patterns of neuronal communication, dependent on regions of the frontal lobe (especially dorsolateral prefrontal cortex) and the parietal lobe. Long-term memory, on the other hand, is maintained by more stable and permanent changes in neural connections widely spread throughout the brain. The hippocampus is essential (for learning new information) to the consolidation of information from short-term to long-term memory, although it does not seem to store information itself. Without the hippocampus, new memories are unable to be stored into long-term memory, as learned from patient Henry Molaison after removal of both his hippocampi, and there will be a very short attention span. Furthermore, it may be involved in changing neural connections for a period of three months or more after the initial learning.", "In 62 BC, Pompey returned victorious from Asia. The Senate, elated by its successes against Catiline, refused to ratify the arrangements that Pompey had made. Pompey, in effect, became powerless. Thus, when Julius Caesar returned from a governorship in Spain in 61 BC, he found it easy to make an arrangement with Pompey. Caesar and Pompey, along with Crassus, established a private agreement, now known as the First Triumvirate. Under the agreement, Pompey's arrangements would be ratified. Caesar would be elected consul in 59 BC, and would then serve as governor of Gaul for five years. Crassus was promised a future consulship.", "The Seljuk Empire soon started to collapse. In the early 12th century, Armenian princes of the Zakarid noble family drove out the Seljuk Turks and established a semi-independent Armenian principality in Northern and Eastern Armenia, known as Zakarid Armenia, which lasted under the patronage of the Georgian Kingdom. The noble family of Orbelians shared control with the Zakarids in various parts of the country, especially in Syunik and Vayots Dzor, while the Armenian family of Hasan-Jalalians controlled provinces of Artsakh and Utik as the Kingdom of Artsakh.", ] - In una nuova cella, aggiungi ed esegui il seguente codice per creare
eval_dataset_rag_aeeval_dataset_rag_b.eval_dataset_rag_a = pd.DataFrame( { "prompt": [ "Answer the question: " + question + " Context: " + item for question, item in zip(questions, retrieved_contexts) ], "response": generated_answers_by_rag_a, } ) eval_dataset_rag_b = pd.DataFrame( { "prompt": [ "Answer the question: " + question + " Context: " + item for question, item in zip(questions, retrieved_contexts) ], "response": generated_answers_by_rag_b, } ) - Esegui il seguente codice in una nuova cella per visualizzare le prime righe del set di dati per il modello A.
eval_dataset_rag_a
7. Selezionare e creare metriche
Ora che i set di dati sono pronti, puoi decidere come misurare il rendimento. Puoi utilizzare una o più metriche per valutare il modello. Ogni metrica valuta un aspetto specifico della risposta del modello, ad esempio la sua accuratezza o pertinenza.
Puoi utilizzare una combinazione di due tipi di metriche:
- Metriche predefinite: metriche pronte all'uso fornite dall'SDK per le attività di valutazione comuni.
- Metriche personalizzate: metriche che definisci per testare le qualità pertinenti al tuo caso d'uso.
In questa sezione, esplorerai le metriche predefinite disponibili per RAG.
Esplorare le metriche predefinite
L'SDK include diverse metriche integrate per valutare i sistemi di domande e risposte. Queste metriche utilizzano un modello linguistico come "valutatore" per assegnare un punteggio alle risposte del modello in base a una serie di istruzioni.
- In una nuova cella, aggiungi ed esegui il seguente codice per visualizzare l'elenco completo dei nomi delle metriche predefinite:
MetricPromptTemplateExamples.list_example_metric_names() - Per capire come funzionano queste metriche, puoi esaminare i modelli di prompt sottostanti. In una nuova cella, aggiungi ed esegui il seguente codice per visualizzare le istruzioni fornite all'LLM di valutazione per la metrica
question_answering_quality.# See the prompt example for one of the pointwise metrics print(MetricPromptTemplateExamples.get_prompt_template("question_answering_quality"))
8. Crea metriche personalizzate
Oltre alle metriche predefinite, puoi creare metriche personalizzate per valutare i criteri specifici del tuo caso d'uso. Per creare una metrica personalizzata, scrivi un template di prompt che indica all'LLM di valutazione come assegnare un punteggio a una risposta.
La creazione di una metrica personalizzata prevede due passaggi:
- Definisci il modello di prompt: una stringa che contiene le istruzioni per l'LLM di valutazione. Un buon modello include un ruolo chiaro, criteri di valutazione, una griglia di valutazione e segnaposto come
{prompt}e{response}. - Istanzia un oggetto PointwiseMetric: racchiudi la stringa del modello di prompt all'interno di questa classe e assegna un nome alla metrica.
Creerai due metriche personalizzate per valutare la pertinenza e l'utilità delle risposte del sistema RAG.
- Definisci il template di prompt per la metrica di pertinenza. Questo modello fornisce una rubrica dettagliata per l'LLM di valutazione. In una nuova cella, aggiungi ed esegui il seguente codice:
relevance_prompt_template = """ You are a professional writing evaluator. Your job is to score writing responses according to pre-defined evaluation criteria. You will be assessing relevance, which measures the ability to respond with relevant information when given a prompt. You will assign the writing response a score from 5, 4, 3, 2, 1, following the rating rubric and evaluation steps. ## Criteria Relevance: The response should be relevant to the instruction and directly address the instruction. ## Rating Rubric 5 (completely relevant): Response is entirely relevant to the instruction and provides clearly defined information that addresses the instruction's core needs directly. 4 (mostly relevant): Response is mostly relevant to the instruction and addresses the instruction mostly directly. 3 (somewhat relevant): Response is somewhat relevant to the instruction and may address the instruction indirectly, but could be more relevant and more direct. 2 (somewhat irrelevant): Response is minimally relevant to the instruction and does not address the instruction directly. 1 (irrelevant): Response is completely irrelevant to the instruction. ## Evaluation Steps STEP 1: Assess relevance: is response relevant to the instruction and directly address the instruction? STEP 2: Score based on the criteria and rubrics. Give step by step explanations for your scoring, and only choose scores from 5, 4, 3, 2, 1. # User Inputs and AI-generated Response ## User Inputs ### Prompt {prompt} ## AI-generated Response {response} """ - Definisci il template di prompt per la metrica di utilità utilizzando lo stesso approccio. Aggiungi ed esegui il seguente codice in una nuova cella:
helpfulness_prompt_template = """ You are a professional writing evaluator. Your job is to score writing responses according to pre-defined evaluation criteria. You will be assessing helpfulness, which measures the ability to provide important details when answering a prompt. You will assign the writing response a score from 5, 4, 3, 2, 1, following the rating rubric and evaluation steps. ## Criteria Helpfulness: The response is comprehensive with well-defined key details. The user would feel very satisfied with the content in a good response. ## Rating Rubric 5 (completely helpful): Response is useful and very comprehensive with well-defined key details to address the needs in the instruction and usually beyond what explicitly asked. The user would feel very satisfied with the content in the response. 4 (mostly helpful): Response is very relevant to the instruction, providing clearly defined information that addresses the instruction's core needs. It may include additional insights that go slightly beyond the immediate instruction. The user would feel quite satisfied with the content in the response. 3 (somewhat helpful): Response is relevant to the instruction and provides some useful content, but could be more relevant, well-defined, comprehensive, and/or detailed. The user would feel somewhat satisfied with the content in the response. 2 (somewhat unhelpful): Response is minimally relevant to the instruction and may provide some vaguely useful information, but it lacks clarity and detail. It might contain minor inaccuracies. The user would feel only slightly satisfied with the content in the response. 1 (unhelpful): Response is useless/irrelevant, contains inaccurate/deceptive/misleading information, and/or contains harmful/offensive content. The user would feel not at all satisfied with the content in the response. ## Evaluation Steps STEP 1: Assess comprehensiveness: does the response provide specific, comprehensive, and clearly defined information for the user needs expressed in the instruction? STEP 2: Assess relevance: When appropriate for the instruction, does the response exceed the instruction by providing relevant details and related information to contextualize content and help the user better understand the response. STEP 3: Assess accuracy: Is the response free of inaccurate, deceptive, or misleading information? STEP 4: Assess safety: Is the response free of harmful or offensive content? Give step by step explanations for your scoring, and only choose scores from 5, 4, 3, 2, 1. # User Inputs and AI-generated Response ## User Inputs ### Prompt {prompt} ## AI-generated Response {response} """ - Crea istanze di oggetti
PointwiseMetricper le due metriche personalizzate. In questo modo, i modelli di prompt vengono inseriti in componenti riutilizzabili per il job di valutazione. Aggiungi ed esegui il seguente codice in una nuova cella:relevance = PointwiseMetric( metric="relevance", metric_prompt_template=relevance_prompt_template, ) helpfulness = PointwiseMetric( metric="helpfulness", metric_prompt_template=helpfulness_prompt_template, )
Ora hai a disposizione due nuove metriche riutilizzabili (relevance e helpfulness) pronte per il tuo job di valutazione.
9. Esegui il job di valutazione
Ora che i set di dati e le metriche sono pronti, puoi eseguire la valutazione. Per farlo, crea un oggetto EvalTask per ogni set di dati che vuoi testare.
Un EvalTask raggruppa i componenti per un'esecuzione di valutazione:
- dataset: il DataFrame contenente i prompt e le risposte.
- metriche: l'elenco delle metriche rispetto alle quali vuoi calcolare il punteggio.
- experiment: l'esperimento Vertex AI in cui registrare i risultati, per aiutarti a monitorare e confrontare le esecuzioni.
- Crea un
EvalTaskper ogni modello. Questo oggetto raggruppa il set di dati, le metriche e il nome dell'esperimento. Aggiungi ed esegui il seguente codice in una nuova cella per configurare le attività:rag_eval_task_rag_a = EvalTask( dataset=eval_dataset_rag_a, metrics=[ "question_answering_quality", relevance, helpfulness, "groundedness", "safety", "instruction_following", ], experiment=EXPERIMENT, ) rag_eval_task_rag_b = EvalTask( dataset=eval_dataset_rag_b, metrics=[ "question_answering_quality", relevance, helpfulness, "groundedness", "safety", "instruction_following", ], experiment=EXPERIMENT, )EvalTask, uno per ogni insieme di risposte del modello. L'elencometricsche hai fornito dimostra una funzionalità chiave del servizio di valutazione: metriche predefinite (ad es.safety) e oggettiPointwiseMetricpersonalizzati. - Con le attività configurate, eseguile chiamando il metodo
.evaluate(). Le attività vengono inviate al backend di Vertex AI per l'elaborazione e il completamento potrebbe richiedere diversi minuti. In una nuova cella, aggiungi ed esegui il seguente codice:result_rag_a = rag_eval_task_rag_a.evaluate() result_rag_b = rag_eval_task_rag_b.evaluate()
Una volta completata la valutazione, i risultati verranno archiviati negli oggetti result_rag_a e result_rag_b, pronti per essere analizzati nella sezione successiva.
10. Analizzare i risultati
I risultati della valutazione sono ora disponibili. Gli oggetti result_rag_a e result_rag_b contengono i punteggi aggregati e spiegazioni dettagliate per ogni riga. In questa attività, analizzerai questi risultati utilizzando le funzioni helper di notebook_utils.
Visualizzare i riepiloghi aggregati
- Per una panoramica di alto livello, utilizza la funzione helper
display_eval_result()per visualizzare il punteggio medio per ogni metrica. In una nuova cella, aggiungi ed esegui il seguente codice per visualizzare il riepilogo del modello A:notebook_utils.display_eval_result( title="Model A Eval Result", eval_result=result_rag_a ) - Fai lo stesso per il modello B. Aggiungi ed esegui questo codice in una nuova cella:
notebook_utils.display_eval_result( title="Model B Eval Result", eval_result=result_rag_b, )
Visualizzare i risultati della valutazione
I grafici possono semplificare il confronto delle prestazioni del modello. Utilizzerai due tipi di visualizzazioni:
- Grafico radar: mostra la "forma" complessiva del rendimento di ogni modello. Una forma più grande indica prestazioni complessive migliori.
- Grafico a barre: per un confronto diretto e fianco a fianco di ogni metrica.
Queste visualizzazioni ti aiuteranno a confrontare i modelli in base a qualità soggettive come pertinenza, grounding e utilità.
- Per prepararti al tracciamento, combina i risultati in un unico elenco di tuple. Ogni tupla deve contenere il nome di un modello e l'oggetto risultato corrispondente. In una nuova cella, aggiungi ed esegui il seguente codice:
eval_results = [] eval_results.append(("Model A", result_rag_a)) eval_results.append(("Model B", result_rag_b)) - Ora genera un grafico radar per confrontare i modelli in base a tutte le metriche contemporaneamente. Aggiungi ed esegui il seguente codice in una nuova cella:
notebook_utils.display_radar_plot( eval_results, metrics=[ "question_answering_quality", "safety", "groundedness", "instruction_following", "relevance", "helpfulness", ], ) - Per un confronto più diretto su ogni metrica, genera un grafico a barre. In una nuova cella, aggiungi ed esegui questo codice:
notebook_utils.display_bar_plot( eval_results, metrics=[ "question_answering_quality", "safety", "groundedness", "instruction_following", "relevance", "helpfulness", ], )
Le visualizzazioni mostreranno chiaramente che il rendimento del modello A (la forma grande nel grafico radar e le barre alte nel grafico a barre) è superiore a quello del modello B.
Visualizzare la spiegazione dettagliata di una singola istanza
I punteggi aggregati mostrano il rendimento complessivo. Per capire perché un modello ha funzionato in un determinato modo, devi esaminare le spiegazioni dettagliate generate dall'LLM di valutazione per ogni esempio.
- La funzione helper
display_explanations()consente di esaminare i singoli risultati. Per visualizzare la suddivisione dettagliata del secondo esempio (num=2) dai risultati del modello A, aggiungi ed esegui il seguente codice in una nuova cella:notebook_utils.display_explanations(result_rag_a, num=2) - Puoi anche utilizzare questa funzione per filtrare una metrica specifica in tutti gli esempi. Ciò è utile per eseguire il debug di un'area specifica con prestazioni scarse. Per capire perché il modello B ha ottenuto risultati così scarsi nella metrica
groundedness, aggiungi ed esegui questo codice in una nuova cella:notebook_utils.display_explanations(result_rag_b, metrics=["groundedness"])
11. Valutazione di riferimento utilizzando una "risposta corretta"
In precedenza, eseguivi una valutazione senza riferimenti, in cui la risposta del modello veniva giudicata solo in base al prompt. Questo metodo è utile, ma la valutazione è soggettiva.
Ora utilizzerai la valutazione con riferimento. Questo metodo aggiunge una "risposta ideale" (chiamata anche risposta di riferimento) al set di dati. Il confronto della risposta del modello con una risposta basata su dati empirici reali fornisce una misurazione più oggettiva delle prestazioni. In questo modo, puoi misurare:
- Correttezza fattuale: la risposta del modello è in linea con i fatti della risposta di riferimento?
- Similarità semantica: la risposta del modello ha lo stesso significato della risposta di riferimento?
- Completezza: la risposta del modello contiene tutte le informazioni chiave della risposta di riferimento?
Prepara il set di dati a cui viene fatto riferimento
Per eseguire una valutazione con riferimento, devi aggiungere una "risposta corretta" a ogni esempio nel set di dati.
Iniziamo definendo un elenco golden_answers. Il confronto tra le risposte di riferimento e quelle del modello A mostra il valore di questo metodo:
- Domanda 1 (cervello): la risposta generata e la risposta corretta sono identiche. Il modello A è corretto.
- Domanda 2 (Senato): le risposte sono semanticamente simili, ma formulate in modo diverso. Una buona metrica dovrebbe riconoscerlo.
- Domanda 3 (Hasan-Jalalians): la risposta del modello A è oggettivamente errata in base al contesto.
golden_answerespone questo errore.
- In una nuova cella, definisci l'elenco di golden_answers
golden_answers = [ "frontal lobe and the parietal lobe", "Due to successes against Catiline.", "The Hasan-Jalalians commanded the area of Artsakh and Utik.", ] - Crea i DataFrame di valutazione a cui viene fatto riferimento eseguendo questo codice nella cella seguente:
referenced_eval_dataset_rag_a = pd.DataFrame( { "prompt": [ "Answer the question: " + question + " Context: " + item for question, item in zip(questions, retrieved_contexts) ], "response": generated_answers_by_rag_a, "reference": golden_answers, } ) referenced_eval_dataset_rag_b = pd.DataFrame( { "prompt": [ "Answer the question: " + question + " Context: " + item for question, item in zip(questions, retrieved_contexts) ], "response": generated_answers_by_rag_b, "reference": golden_answers, } )
I set di dati sono ora pronti per la valutazione di riferimento.
Creare una metrica personalizzata di riferimento
Puoi anche creare metriche personalizzate per la valutazione con riferimento a un criterio. Il processo è simile, ma il template di prompt ora include il segnaposto {reference} per la risposta corretta.
Con una risposta "corretta" definitiva, puoi utilizzare un punteggio binario più rigoroso (ad es. 1 per la risposta corretta, 0 per quella errata) per misurare l'accuratezza fattuale. Creiamo una nuova metrica question_answering_correctness che implementi questa logica.
- Definisci il template di prompt. In una nuova cella, aggiungi ed esegui il seguente codice:
question_answering_correctness_prompt_template = """ You are a professional writing evaluator. Your job is to score writing responses according to pre-defined evaluation criteria. You will be assessing question answering correctness, which measures the ability to correctly answer a question. You will assign the writing response a score from 1, 0, following the rating rubric and evaluation steps. ### Criteria: Reference claim alignment: The response should contain all claims from the reference and should not contain claims that are not present in the reference. ### Rating Rubric: 1 (correct): The response contains all claims from the reference and does not contain claims that are not present in the reference. 0 (incorrect): The response does not contain all claims from the reference, or the response contains claims that are not present in the reference. ### Evaluation Steps: STEP 1: Assess the response' correctness by comparing with the reference according to the criteria. STEP 2: Score based on the rubrics. Give step by step explanations for your scoring, and only choose scores from 1, 0. # User Inputs and AI-generated Response ## User Inputs ### Prompt {prompt} ## Reference {reference} ## AI-generated Response {response} """ - Racchiudi la stringa del modello di prompt all'interno di un oggetto PointwiseMetric. In questo modo, la metrica ha un nome formale e diventa un componente riutilizzabile per il job di valutazione. Aggiungi ed esegui il seguente codice in una nuova cella:
question_answering_correctness = PointwiseMetric( metric="question_answering_correctness", metric_prompt_template=question_answering_correctness_prompt_template, )
Ora hai una metrica personalizzata con riferimenti per un controllo rigoroso dei fatti.
12. Esegui la valutazione con riferimenti
Ora configurerai il job di valutazione con i set di dati a cui viene fatto riferimento e la nuova metrica. Utilizzerai di nuovo il corso EvalTask.
L'elenco delle metriche ora combina la metrica personalizzata basata sul modello con le metriche basate sul calcolo. La valutazione con riferimento consente l'utilizzo di metriche basate sul calcolo tradizionali che eseguono confronti matematici tra il testo generato e il testo di riferimento. Ne utilizzerai tre comuni:
exact_match: assegna 1 solo se la risposta generata è identica alla risposta di riferimento, altrimenti 0.bleu: Una metrica di precisione. Misura il numero di parole della risposta generata che compaiono anche nella risposta di riferimento.rouge: una metrica del richiamo. Misura il numero di parole della risposta di riferimento che vengono acquisite nella risposta generata.
- Configura il job di valutazione con i set di dati a cui viene fatto riferimento e la nuova combinazione di metriche. In una nuova cella, aggiungi ed esegui il seguente codice per creare gli oggetti
EvalTask:referenced_answer_eval_task_rag_a = EvalTask( dataset=referenced_eval_dataset_rag_a, metrics=[ question_answering_correctness, "rouge", "bleu", "exact_match", ], experiment=EXPERIMENT, ) referenced_answer_eval_task_rag_b = EvalTask( dataset=referenced_eval_dataset_rag_b, metrics=[ question_answering_correctness, "rouge", "bleu", "exact_match", ], experiment=EXPERIMENT, ) - Esegui la valutazione a cui viene fatto riferimento chiamando il metodo
.evaluate(). Aggiungi ed esegui questo codice in una nuova cella:referenced_result_rag_a = referenced_answer_eval_task_rag_a.evaluate() referenced_result_rag_b = referenced_answer_eval_task_rag_b.evaluate()
13. Analizza i risultati a cui viene fatto riferimento
La valutazione è stata completata. In questa attività, analizzerai i risultati per misurare l'accuratezza fattuale dei modelli confrontando le loro risposte con le risposte di riferimento.
Visualizza i risultati del riepilogo
- Analizza i risultati del riepilogo per la valutazione a cui viene fatto riferimento. In una nuova cella, aggiungi ed esegui il seguente codice per visualizzare le tabelle riepilogative per entrambi i modelli:
notebook_utils.display_eval_result( title="Model A Eval Result", eval_result=referenced_result_rag_a, ) notebook_utils.display_eval_result( title="Model B Eval Result", eval_result=referenced_result_rag_b, )question_answering_correctness, ma un punteggio inferiore inexact_match. Ciò evidenzia il valore delle metriche basate su modelli che possono riconoscere la somiglianza semantica, non solo il testo identico.
Visualizzare i risultati per il confronto
Le visualizzazioni possono rendere più evidente il divario di rendimento tra i due modelli. Per prima cosa, combina i risultati in un unico elenco per il tracciamento, poi genera i grafici radar e a barre.
- Combina i risultati della valutazione a cui viene fatto riferimento in un unico elenco per il tracciamento. Aggiungi ed esegui il seguente codice in una nuova cella:
referenced_eval_results = [] referenced_eval_results.append(("Model A", referenced_result_rag_a)) referenced_eval_results.append(("Model B", referenced_result_rag_b)) - Genera un grafico radar per visualizzare il rendimento di ogni modello nel nuovo insieme di metriche. Aggiungi ed esegui questo codice in una nuova cella:
notebook_utils.display_radar_plot( referenced_eval_results, metrics=[ "question_answering_correctness", "rouge", "bleu", "exact_match", ], ) - Crea un grafico a barre per un confronto diretto e affiancato. In questo modo, vedrai il rendimento di ogni modello nelle diverse metriche. Aggiungi ed esegui il seguente codice in una nuova cella:
notebook_utils.display_bar_plot( referenced_eval_results, metrics=[ "question_answering_correctness", "rouge", "bleu", "exact_match", ], )
Queste visualizzazioni confermano che il modello A è significativamente più accurato e in linea con le risposte di riferimento rispetto al modello B.
14. Dalla pratica alla produzione
Hai eseguito correttamente una pipeline di valutazione completa per un sistema RAG. Questa sezione finale riassume i concetti strategici chiave che hai appreso e fornisce un framework per applicare queste competenze a progetti reali.
Best practice per la produzione
Per applicare le competenze acquisite in questo lab in un ambiente di produzione reale, prendi in considerazione queste quattro pratiche chiave:
- Automatizza con CI/CD: integra la tua suite di valutazione in una pipeline CI/CD (ad es. Cloud Build, GitHub Actions). Esegui valutazioni automatiche sulle modifiche al codice per rilevare le regressioni e bloccare i deployment se i punteggi di qualità scendono al di sotto dei tuoi standard.
- Evolvi i tuoi set di dati:un set di dati statico diventa obsoleto. Controlla la versione dei tuoi set di test "golden" (utilizzando Git LFS o Cloud Storage) e aggiungi continuamente nuovi esempi difficili campionando query utente reali (anonimizzate).
- Valuta il recuperatore, non solo il generatore: una risposta valida è impossibile senza il contesto giusto. Implementa un passaggio di valutazione separato per il sistema di recupero utilizzando metriche come Hit Rate (è stato trovato il documento giusto?) e Mean Reciprocal Rank (MRR) (a quale posizione è stato classificato il documento giusto?).
- Monitora le metriche nel tempo:esporta i punteggi riepilogativi delle esecuzioni di valutazione in un servizio come Google Cloud Monitoring. Crea dashboard per monitorare le tendenze della qualità e configura avvisi automatici per ricevere notifiche in caso di cali significativi delle prestazioni.
Matrice della metodologia di valutazione avanzata
La scelta dell'approccio di valutazione corretto dipende dai tuoi obiettivi specifici. Questa matrice riassume quando utilizzare ciascun metodo.
Approccio di valutazione | Best Use Cases | Vantaggi principali | Limitazioni |
Senza riferimenti | Monitoraggio della produzione, valutazione continua | Non sono necessarie risposte perfette, acquisisce la qualità soggettiva | Più costoso, potenziale bias del valutatore |
Basato sul riferimento | Confronto modelli, benchmarking | Misurazione oggettiva, calcolo più rapido | Richiede risposte perfette, potrebbe non rilevare l'equivalenza semantica |
Metriche personalizzate | Valutazione specifica del dominio | Personalizzato in base alle esigenze aziendali | Richiede convalida, overhead di sviluppo |
Approccio ibrido | Sistemi di produzione completi | Il meglio di tutti gli approcci | Maggiore complessità, è necessaria l'ottimizzazione dei costi |
Approfondimenti tecnici chiave
Tieni a mente questi principi fondamentali quando crei e valuti i tuoi sistemi RAG:
- L'accuratezza è fondamentale per RAG: questa metrica distingue in modo coerente i sistemi RAG di alta e bassa qualità, rendendola essenziale per il monitoraggio della produzione.
- Più metriche forniscono robustezza: nessuna singola metrica acquisisce tutti gli aspetti della qualità RAG. La valutazione completa richiede più dimensioni di valutazione.
- Le metriche personalizzate aggiungono un valore significativo: i criteri di valutazione specifici per il dominio spesso acquisiscono sfumature che le metriche generiche non rilevano, migliorando l'accuratezza della valutazione.
- Il rigore statistico aumenta l'affidabilità: dimensioni del campione e test di significatività adeguati trasformano la valutazione da congettura in strumenti affidabili per il processo decisionale.
Framework decisionale per il deployment di produzione
Utilizza questo framework in più fasi come guida per i futuri deployment del sistema RAG:
- Fase 1 - Sviluppo: utilizza la valutazione basata su riferimenti con set di test noti per il confronto e la selezione dei modelli.
- Fase 2 - Pre-produzione: esegui una valutazione completa combinando entrambi gli approcci per convalidare la preparazione alla produzione.
- Fase 3 - Produzione: implementa il monitoraggio senza riferimenti per la valutazione continua della qualità senza risposte di riferimento.
- Fase 4: ottimizzazione. Utilizza gli approfondimenti della valutazione per guidare i miglioramenti del modello e del sistema di recupero.
15. Conclusione
Complimenti! Hai completato il lab.
Questo lab fa parte del percorso di apprendimento per l'AI pronta per la produzione con Google Cloud.
- Esplora il curriculum completo per colmare il divario tra prototipo e produzione.
- Condividi i tuoi progressi con l'hashtag
ProductionReadyAI.
Riepilogo
Hai imparato a:
- Esegui una valutazione senza riferimenti per valutare la qualità di una risposta in base al contesto recuperato.
- Esegui una valutazione con riferimenti aggiungendo una "risposta corretta" per misurare l'accuratezza dei fatti.
- Utilizza un mix di metriche predefinite e personalizzate per entrambi gli approcci.
- Utilizza sia metriche basate su modelli (come
question_answering_quality) sia metriche basate su calcoli (rouge,bleu,exact_match). - Analizza e visualizza i risultati per comprendere i punti di forza e di debolezza di un modello.
Questo approccio alla valutazione ti aiuta a creare applicazioni di AI generativa più affidabili e accurate.