
1. 概要
このラボでは、検索拡張生成(RAG)システムの評価パイプラインを構築する方法を学びます。Vertex AI Gen AI Evaluation Service を使用して、カスタム評価基準を作成し、質問応答タスクの評価フレームワークを構築します。
スタンフォード質問応答データセット(SQuAD 2.0)の例を使用して、評価データセットを準備し、参照なし評価と参照ベースの評価を構成して、結果を解釈します。このラボを修了すると、RAG システムの評価方法と、特定の評価アプローチが選択される理由を理解できます。
データセットの基盤
SQuAD 2.0 Question Answering Dataset にある複数のドメインにまたがる厳選された例を使用して、作業を行います。
- 神経科学: 科学的コンテキストにおける技術的な正確性のテスト
- 履歴: 過去のナラティブにおける事実の正確性を評価する
- 地理: 領土と政治に関する知識を評価する
この多様性により、さまざまな科目領域で評価アプローチがどのように一般化されるかを理解できます。
参照
- コードサンプル: このラボは、Vertex AI Evaluation のドキュメントの例に基づいています。
- データセットの基盤: SQuAD 2.0 質問応答データセット
- RAG 検索の最適化: テスト、チューニング、成功
学習内容
このラボでは、次のタスクの実行方法について学びます。
- RAG システムの評価データセットを準備します。
- グラウンディングや関連性などの指標を使用して、参照のない評価を実装します。
- 意味的類似性指標を使用して参照ベースの評価を適用します。
- 詳細なスコアリング ルーブリックを使用してカスタム評価指標を作成します。
- 評価結果を解釈して可視化し、モデルの選択に役立てます。
2. プロジェクトの設定
Google アカウント
個人の Google アカウントをお持ちでない場合は、Google アカウントを作成する必要があります。
仕事用または学校用アカウントではなく、個人アカウントを使用します。
Google Cloud コンソールにログインする
個人の Google アカウントを使用して Google Cloud コンソールにログインします。
課金を有効にする
Google Cloud クレジットを利用する(省略可)
このワークショップを実施するには、クレジットが設定された請求先アカウントが必要です。この Codelab の上部にあるバナーのクレジットを使用して、開始します。請求先アカウントにすでに接続している場合は、この手順をスキップできます。
個人用の請求先アカウントを設定する
Google Cloud クレジットを使用して課金を設定した場合は、この手順をスキップできます。
個人用の請求先アカウントを設定するには、Cloud コンソールでこちらに移動して課金を有効にします。
注意事項:
- このラボを完了するのにかかる Cloud リソースの費用は 1 米ドル未満です。
- このラボの最後の手順に沿ってリソースを削除すると、それ以上の料金は発生しません。
- 新規ユーザーは、300 米ドル分の無料トライアルをご利用いただけます。
プロジェクトの作成(省略可)
このラボで使用する現在のプロジェクトがない場合は、こちらで新しいプロジェクトを作成します。
3. 検索拡張生成(RAG)とは
RAG は、大規模言語モデル(LLM)からの回答の事実の正確性と関連性を高めるために使用される手法です。LLM を外部のナレッジベースに接続して、特定の検証可能な情報に基づいて回答を生成します。
このプロセスには次のステップが含まれます。
- ユーザーの質問を数値表現(エンベディング)に変換します。
- 類似したエンベディングを持つドキュメントをナレッジベースで検索する。
- これらの関連ドキュメントを元の質問とともに LLM にコンテキストとして提供し、回答を生成します。
RAG の詳細を確認する。
RAG の評価が複雑になるのはなぜですか?
RAG システムの評価は、従来の言語モデルの評価とは異なります。
マルチコンポーネントの課題: RAG システムは、それぞれが障害点となる可能性のある 3 つのオペレーションを組み合わせます。
- 検索の品質: システムは適切なコンテキスト ドキュメントを見つけましたか?
- コンテキストの活用: モデルは取得した情報を効果的に使用しましたか?
- 生成の品質: 最終回答は適切に記述され、有用で正確ですか?
これらのコンポーネントのいずれかが想定どおりに動作しない場合、レスポンスが失敗する可能性があります。たとえば、システムが正しいコンテキストを取得しても、モデルがそれを無視する場合があります。また、取得したコンテキストが無関係であるため、モデルが誤った回答を生成することもあります。
4. Vertex AI Workbench 環境を設定する
まず、RAG システムの評価に必要なコードを実行する新しいノートブック環境を起動します。
- Cloud Console の [API とサービス] ページに移動します。
- [Vertex AI API] の [有効にする] をクリックします。
Vertex AI Workbench にアクセスする
- Google Cloud コンソールで、ナビゲーション メニュー ☰ > [Vertex AI] > [ワークベンチ] をクリックして、[Vertex AI] に移動します。
- 新しい Workbench インスタンスを作成します。
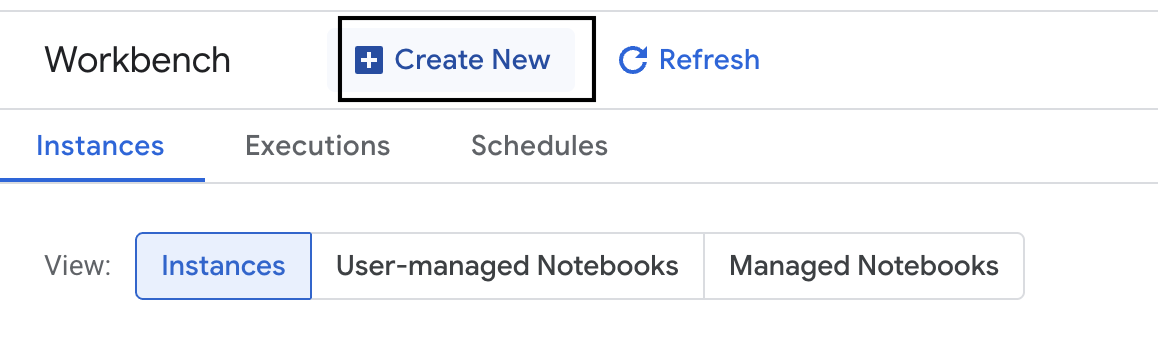
- ワークベンチ インスタンスに
evaluation-workbenchという名前を付けます。 - リージョンとゾーンがまだ設定されていない場合は、リージョンとゾーンを選択します。
- [作成] をクリックします。
- ワークベンチが設定されるまで待ちます。これには数分かかることがあります。

- ワークベンチがプロビジョニングされたら、[JupyterLab を開く] をクリックします。
- ワークベンチで、新しい Python3 ノートブックを作成します。
この環境の機能の詳細については、Vertex AI Workbench の公式ドキュメントをご覧ください。
Vertex AI 評価 SDK をインストールする
次に、RAG 評価用のツールを提供する専用の評価 SDK をインストールします。
- ノートブックの最初のセルで、次の import ステートメントを追加して実行(Shift+Enter)し、Vertex AI SDK(評価コンポーネントを含む)をインストールします。
%pip install --upgrade --user --quiet google-cloud-aiplatform[evaluation]- EvalTask: 評価を実行するためのメインクラス
- MetricPromptTemplateExamples: 事前定義された評価指標
- PointwiseMetric: カスタム指標を作成するためのフレームワーク
- notebook_utils: 結果分析用の可視化ツール
- 重要: インストール後、新しいパッケージを使用するにはカーネルを再起動する必要があります。JupyterLab ウィンドウの上部にあるメニューバーで、[Kernel] > [Restart Kernel] に移動します。
5. SDK を初期化してライブラリをインポートする
評価パイプラインを構築する前に、環境を設定する必要があります。これには、プロジェクトの詳細の構成、Google Cloud に接続するための Vertex AI SDK の初期化、評価に使用する特殊な Python ライブラリのインポートが含まれます。
- 評価ジョブの構成変数を定義します。新しいセルに次のコードを追加して実行し、この実行を整理するために
PROJECT_ID、LOCATION、EXPERIMENTの名前を設定します。import vertexai PROJECT_ID = "YOUR PROJECT ID" LOCATION = "YOUR LOCATION" # @param {type:"string"} EXPERIMENT = "rag-eval-01" # @param {type:"string"} if not PROJECT_ID or PROJECT_ID == "[your-project-id]": raise ValueError("Please set your PROJECT_ID") - Vertex AI SDK を初期化します。新しいセルに次のコードを追加して実行します。
vertexai.init(project=PROJECT_ID, location=LOCATION) - 次のセルで次のコードを実行して、評価 SDK から必要なクラスをインポートします。
import pandas as pd from vertexai.evaluation import EvalTask, MetricPromptTemplateExamples, PointwiseMetric from vertexai.preview.evaluation import notebook_utils- pandas: DataFrame でデータを作成して管理します。
- EvalTask: 評価ジョブを実行するコアクラス。
- MetricPromptTemplateExamples: Google の事前定義された評価指標へのアクセスを提供します。
- PointwiseMetric: 独自のカスタム指標を作成するためのフレームワーク。
- notebook_utils: 結果を可視化するためのツールのコレクション。
6. 評価データセットを準備する
信頼性の高い評価の基盤となるのは、適切に構造化されたデータセットです。RAG システムの場合、データセットには各例に対して次の 2 つのキーフィールドが必要です。
- プロンプト: 言語モデルに提供された合計入力です。ユーザーの質問と RAG システム(
prompt = User Question + Retrieved Context)によって取得されたコンテキストを組み合わせる必要があります。これは、評価サービスがモデルが回答の作成に使用した情報を把握するために重要です。 - response: RAG モデルによって生成された最終回答。
統計的に信頼性の高い結果を得るには、約 100 個の例を含むデータセットをおすすめします。このラボでは、プロセスを示すために小さなデータセットを使用します。
データセットを作成しましょう。質問のリストと RAG システムの retrieved_contexts から始めます。次に、2 つの回答セットを定義します。1 つはパフォーマンスが良好なモデル(generated_answers_by_rag_a)からの回答、もう 1 つはパフォーマンスが低いモデル(generated_answers_by_rag_b)からの回答です。
最後に、上記の構造に従って、これらの部分を 2 つの pandas DataFrame(eval_dataset_rag_a と eval_dataset_rag_b)に結合します。
- 新しいセルで、次のコードを追加して実行し、質問と 2 つの generated_answers のセットを定義します。
questions = [ "Which part of the brain does short-term memory seem to rely on?", "What provided the Roman senate with exuberance?", "What area did the Hasan-jalalians command?", ] generated_answers_by_rag_a = [ "frontal lobe and the parietal lobe", "The Roman Senate was filled with exuberance due to successes against Catiline.", "The Hasan-Jalalians commanded the area of Syunik and Vayots Dzor.", ] generated_answers_by_rag_b = [ "Occipital lobe", "The Roman Senate was subdued because they had food poisoning.", "The Galactic Empire commanded the state of Utah.", ] - retrieved_contexts を定義します。新しいセルに次のコードを追加して実行します。
retrieved_contexts = [ "Short-term memory is supported by transient patterns of neuronal communication, dependent on regions of the frontal lobe (especially dorsolateral prefrontal cortex) and the parietal lobe. Long-term memory, on the other hand, is maintained by more stable and permanent changes in neural connections widely spread throughout the brain. The hippocampus is essential (for learning new information) to the consolidation of information from short-term to long-term memory, although it does not seem to store information itself. Without the hippocampus, new memories are unable to be stored into long-term memory, as learned from patient Henry Molaison after removal of both his hippocampi, and there will be a very short attention span. Furthermore, it may be involved in changing neural connections for a period of three months or more after the initial learning.", "In 62 BC, Pompey returned victorious from Asia. The Senate, elated by its successes against Catiline, refused to ratify the arrangements that Pompey had made. Pompey, in effect, became powerless. Thus, when Julius Caesar returned from a governorship in Spain in 61 BC, he found it easy to make an arrangement with Pompey. Caesar and Pompey, along with Crassus, established a private agreement, now known as the First Triumvirate. Under the agreement, Pompey's arrangements would be ratified. Caesar would be elected consul in 59 BC, and would then serve as governor of Gaul for five years. Crassus was promised a future consulship.", "The Seljuk Empire soon started to collapse. In the early 12th century, Armenian princes of the Zakarid noble family drove out the Seljuk Turks and established a semi-independent Armenian principality in Northern and Eastern Armenia, known as Zakarid Armenia, which lasted under the patronage of the Georgian Kingdom. The noble family of Orbelians shared control with the Zakarids in various parts of the country, especially in Syunik and Vayots Dzor, while the Armenian family of Hasan-Jalalians controlled provinces of Artsakh and Utik as the Kingdom of Artsakh.", ] - 新しいセルに次のコードを追加して実行し、
eval_dataset_rag_aとeval_dataset_rag_bを作成します。eval_dataset_rag_a = pd.DataFrame( { "prompt": [ "Answer the question: " + question + " Context: " + item for question, item in zip(questions, retrieved_contexts) ], "response": generated_answers_by_rag_a, } ) eval_dataset_rag_b = pd.DataFrame( { "prompt": [ "Answer the question: " + question + " Context: " + item for question, item in zip(questions, retrieved_contexts) ], "response": generated_answers_by_rag_b, } ) - 新しいセルで次のコードを実行して、モデル A のデータセットの最初の数行を表示します。
eval_dataset_rag_a
7. 指標を選択して作成する
データセットの準備ができたので、パフォーマンスの測定方法を決定できます。1 つ以上の指標を使用してモデルを評価できます。各指標は、事実の正確性や関連性など、モデルのレスポンスの特定の側面を評価します。
次の 2 種類の指標を組み合わせて使用できます。
- 事前定義された指標: 一般的な評価タスク用に SDK によって提供される、すぐに使用できる指標。
- カスタム指標: ユースケースに関連する品質をテストするために定義する指標。
このセクションでは、RAG で使用できる事前定義された指標について説明します。
事前定義された指標を確認する
この SDK には、質問応答システムを評価するための組み込み指標がいくつか含まれています。これらの指標は、言語モデルを「評価者」として使用し、一連の指示に基づいてモデルの回答にスコアを付けます。
- 新しいセルに次のコードを追加して実行し、事前定義された指標名の完全なリストを表示します。
MetricPromptTemplateExamples.list_example_metric_names() - これらの指標の仕組みを理解するには、基盤となるプロンプト テンプレートを調べます。新しいセルに次のコードを追加して実行し、
question_answering_quality指標の評価用 LLM に与えられた指示を確認します。# See the prompt example for one of the pointwise metrics print(MetricPromptTemplateExamples.get_prompt_template("question_answering_quality"))
8. カスタム指標を作成する
事前定義された指標に加えて、ユースケースに固有の基準を評価するカスタム指標を作成できます。カスタム指標を作成するには、回答をスコア付けする方法を評価用 LLM に指示するプロンプト テンプレートを作成します。
カスタム指標を作成する手順は次のとおりです。
- プロンプト テンプレートを定義する: 評価用 LLM の手順を含む文字列。優れたテンプレートには、明確な役割、評価基準、採点ルーブリック、
{prompt}や{response}などのプレースホルダが含まれています。 - PointwiseMetric オブジェクトをインスタンス化する: このクラス内でプロンプト テンプレート文字列をラップし、指標に名前を付けます。
RAG システムの回答の関連性と有用性を評価する 2 つのカスタム指標を作成します。
- 関連性指標のプロンプト テンプレートを定義します。このテンプレートは、評価者 LLM の詳細なルーブリックを提供します。新しいセルに次のコードを追加して実行します。
relevance_prompt_template = """ You are a professional writing evaluator. Your job is to score writing responses according to pre-defined evaluation criteria. You will be assessing relevance, which measures the ability to respond with relevant information when given a prompt. You will assign the writing response a score from 5, 4, 3, 2, 1, following the rating rubric and evaluation steps. ## Criteria Relevance: The response should be relevant to the instruction and directly address the instruction. ## Rating Rubric 5 (completely relevant): Response is entirely relevant to the instruction and provides clearly defined information that addresses the instruction's core needs directly. 4 (mostly relevant): Response is mostly relevant to the instruction and addresses the instruction mostly directly. 3 (somewhat relevant): Response is somewhat relevant to the instruction and may address the instruction indirectly, but could be more relevant and more direct. 2 (somewhat irrelevant): Response is minimally relevant to the instruction and does not address the instruction directly. 1 (irrelevant): Response is completely irrelevant to the instruction. ## Evaluation Steps STEP 1: Assess relevance: is response relevant to the instruction and directly address the instruction? STEP 2: Score based on the criteria and rubrics. Give step by step explanations for your scoring, and only choose scores from 5, 4, 3, 2, 1. # User Inputs and AI-generated Response ## User Inputs ### Prompt {prompt} ## AI-generated Response {response} """ - 同じアプローチを使用して、有用性指標のプロンプト テンプレートを定義します。新しいセルに次のコードを追加して実行します。
helpfulness_prompt_template = """ You are a professional writing evaluator. Your job is to score writing responses according to pre-defined evaluation criteria. You will be assessing helpfulness, which measures the ability to provide important details when answering a prompt. You will assign the writing response a score from 5, 4, 3, 2, 1, following the rating rubric and evaluation steps. ## Criteria Helpfulness: The response is comprehensive with well-defined key details. The user would feel very satisfied with the content in a good response. ## Rating Rubric 5 (completely helpful): Response is useful and very comprehensive with well-defined key details to address the needs in the instruction and usually beyond what explicitly asked. The user would feel very satisfied with the content in the response. 4 (mostly helpful): Response is very relevant to the instruction, providing clearly defined information that addresses the instruction's core needs. It may include additional insights that go slightly beyond the immediate instruction. The user would feel quite satisfied with the content in the response. 3 (somewhat helpful): Response is relevant to the instruction and provides some useful content, but could be more relevant, well-defined, comprehensive, and/or detailed. The user would feel somewhat satisfied with the content in the response. 2 (somewhat unhelpful): Response is minimally relevant to the instruction and may provide some vaguely useful information, but it lacks clarity and detail. It might contain minor inaccuracies. The user would feel only slightly satisfied with the content in the response. 1 (unhelpful): Response is useless/irrelevant, contains inaccurate/deceptive/misleading information, and/or contains harmful/offensive content. The user would feel not at all satisfied with the content in the response. ## Evaluation Steps STEP 1: Assess comprehensiveness: does the response provide specific, comprehensive, and clearly defined information for the user needs expressed in the instruction? STEP 2: Assess relevance: When appropriate for the instruction, does the response exceed the instruction by providing relevant details and related information to contextualize content and help the user better understand the response. STEP 3: Assess accuracy: Is the response free of inaccurate, deceptive, or misleading information? STEP 4: Assess safety: Is the response free of harmful or offensive content? Give step by step explanations for your scoring, and only choose scores from 5, 4, 3, 2, 1. # User Inputs and AI-generated Response ## User Inputs ### Prompt {prompt} ## AI-generated Response {response} """ - 2 つのカスタム指標の
PointwiseMetricオブジェクトをインスタンス化します。これにより、プロンプト テンプレートが評価ジョブの再利用可能なコンポーネントにラップされます。新しいセルに次のコードを追加して実行します。relevance = PointwiseMetric( metric="relevance", metric_prompt_template=relevance_prompt_template, ) helpfulness = PointwiseMetric( metric="helpfulness", metric_prompt_template=helpfulness_prompt_template, )
これで、評価ジョブで使用できる再利用可能な新しい指標(relevance と helpfulness)が 2 つ用意されました。
9. 評価ジョブを実行する
データセットと指標の準備が整ったので、評価を実行できます。これを行うには、テストするデータセットごとに EvalTask オブジェクトを作成します。
EvalTask は、評価実行のコンポーネントをバンドルします。
- dataset: プロンプトとレスポンスを含む DataFrame。
- metrics: スコアを比較する指標のリスト。
- experiment: 結果をロギングする Vertex AI Experiment。実行の追跡と比較に役立ちます。
- モデルごとに
EvalTaskを作成します。このオブジェクトは、データセット、指標、テスト名をバンドルします。新しいセルに次のコードを追加して実行し、タスクを構成します。rag_eval_task_rag_a = EvalTask( dataset=eval_dataset_rag_a, metrics=[ "question_answering_quality", relevance, helpfulness, "groundedness", "safety", "instruction_following", ], experiment=EXPERIMENT, ) rag_eval_task_rag_b = EvalTask( dataset=eval_dataset_rag_b, metrics=[ "question_answering_quality", relevance, helpfulness, "groundedness", "safety", "instruction_following", ], experiment=EXPERIMENT, )EvalTaskオブジェクトが構成されました。提供されたmetricsリストは、評価サービスの重要な機能(事前定義された指標(safetyなど)とカスタムPointwiseMetricオブジェクト)を示しています。 - タスクを設定したら、
.evaluate()メソッドを呼び出して実行します。これにより、タスクが処理のために Vertex AI バックエンドに送信されます。完了までに数分かかることがあります。新しいセルに次のコードを追加して実行します。result_rag_a = rag_eval_task_rag_a.evaluate() result_rag_b = rag_eval_task_rag_b.evaluate()
評価が完了すると、結果は result_rag_a オブジェクトと result_rag_b オブジェクトに保存され、次のセクションで分析できるようになります。
10. 結果を分析する
評価結果は、以下のとおりです。result_rag_a オブジェクトと result_rag_b オブジェクトには、各行の集計スコアと詳細な説明が含まれています。このタスクでは、notebook_utils のヘルパー関数を使用してこれらの結果を分析します。
集計された概要を表示する
- 概要を把握するには、
display_eval_result()ヘルパー関数を使用して、各指標の平均スコアを確認します。新しいセルに次のコードを追加して実行し、モデル A の概要を表示します。notebook_utils.display_eval_result( title="Model A Eval Result", eval_result=result_rag_a ) - モデル B についても同様に操作します。新しいセルに次のコードを追加して実行します。
notebook_utils.display_eval_result( title="Model B Eval Result", eval_result=result_rag_b, )
評価結果を可視化する
プロットを使用すると、モデルのパフォーマンスを簡単に比較できます。次の 2 種類の可視化を使用します。
- レーダー プロット: 各モデルの全体的なパフォーマンスの「形状」を示します。図形が大きいほど、総合的なパフォーマンスが高いことを示します。
- 棒グラフ: 各指標を直接比較する場合に使用します。
これらの可視化により、関連性、根拠、有用性などの主観的な品質でモデルを比較できます。
- プロットの準備として、結果をタプルの単一リストに結合します。各タプルには、モデル名と対応する結果オブジェクトが含まれている必要があります。新しいセルに次のコードを追加して実行します。
eval_results = [] eval_results.append(("Model A", result_rag_a)) eval_results.append(("Model B", result_rag_b)) - 次に、レーダーチャートを生成して、すべての指標でモデルを一度に比較します。新しいセルに次のコードを追加して実行します。
notebook_utils.display_radar_plot( eval_results, metrics=[ "question_answering_quality", "safety", "groundedness", "instruction_following", "relevance", "helpfulness", ], ) - 各指標をより直接的に比較するには、棒グラフを生成します。新しいセルに次のコードを追加して実行します。
notebook_utils.display_bar_plot( eval_results, metrics=[ "question_answering_quality", "safety", "groundedness", "instruction_following", "relevance", "helpfulness", ], )
可視化により、モデル A のパフォーマンス(レーダーチャートの大きな図形と棒グラフの長い棒)がモデル B よりも優れていることが明確に示されます。
個々のインスタンスの詳細な説明を表示する
総合スコアは全体的なパフォーマンスを示します。モデルが特定の動作をした理由を理解するには、評価用 LLM が各例に対して生成した詳細な説明を確認する必要があります。
display_explanations()ヘルパー関数を使用すると、個々の結果を検査できます。モデル A の結果から 2 つ目の例(num=2)の詳細な内訳を確認するには、新しいセルに次のコードを追加して実行します。notebook_utils.display_explanations(result_rag_a, num=2)- この関数を使用して、すべての例で特定の指標をフィルタすることもできます。これは、パフォーマンスの低い特定の領域をデバッグするのに役立ちます。モデル B の
groundedness指標のパフォーマンスが非常に低い理由を確認するには、新しいセルに次のコードを追加して実行します。notebook_utils.display_explanations(result_rag_b, metrics=["groundedness"])
11. 「ゴールデン アンサー」を使用した参照評価
以前は、モデルの回答がプロンプトのみに基づいて判断される参照なし評価を行っていました。この方法は便利ですが、評価は主観的です。
次に、参照評価を使用します。このメソッドは、データセットに「正解」(参照回答とも呼ばれます)を追加します。モデルの回答をグラウンド トゥルースの回答と比較すると、パフォーマンスをより客観的に測定できます。これにより、次の指標を測定できます。
- 事実の正確性: モデルの回答はゴールデン アンサーの事実と一致しているか?
- 意味的類似性: モデルの回答は正解と同じ意味ですか?
- 完全性: モデルの回答に、正解の重要な情報がすべて含まれているか?
参照されるデータセットを準備する
参照評価を行うには、データセット内の各例に「正解」を追加する必要があります。
まず、golden_answers リストを定義します。正解とモデル A の回答を比較すると、この方法の価値がわかります。
- 質問 1(Brain): 生成された回答と正解が同一です。モデル A が正解です。
- 質問 2(上院): 回答は意味的に類似していますが、表現が異なります。優れた指標はこれを認識している必要があります。
- 質問 3(Hasan-Jalalians): モデル A の回答は、コンテキストによると事実と異なります。
golden_answerはこのエラーを公開します。
- 新しいセルで、golden_answers のリストを定義します。
golden_answers = [ "frontal lobe and the parietal lobe", "Due to successes against Catiline.", "The Hasan-Jalalians commanded the area of Artsakh and Utik.", ] - 次のセルでこのコードを実行して、参照される評価 DataFrame を作成します。
referenced_eval_dataset_rag_a = pd.DataFrame( { "prompt": [ "Answer the question: " + question + " Context: " + item for question, item in zip(questions, retrieved_contexts) ], "response": generated_answers_by_rag_a, "reference": golden_answers, } ) referenced_eval_dataset_rag_b = pd.DataFrame( { "prompt": [ "Answer the question: " + question + " Context: " + item for question, item in zip(questions, retrieved_contexts) ], "response": generated_answers_by_rag_b, "reference": golden_answers, } )
これで、データセットを参照評価に使用できるようになりました。
カスタム参照指標を作成する
参照評価用のカスタム指標を作成することもできます。プロセスは同様ですが、プロンプト テンプレートに正解の {reference} プレースホルダが含まれるようになりました。
明確な「正解」がある場合は、より厳密なバイナリ スコアリング(正解の場合は 1、不正解の場合は 0 など)を使用して、事実の正確性を測定できます。このロジックを実装する新しい question_answering_correctness 指標を作成しましょう。
- プロンプト テンプレートを定義します。新しいセルに次のコードを追加して実行します。
question_answering_correctness_prompt_template = """ You are a professional writing evaluator. Your job is to score writing responses according to pre-defined evaluation criteria. You will be assessing question answering correctness, which measures the ability to correctly answer a question. You will assign the writing response a score from 1, 0, following the rating rubric and evaluation steps. ### Criteria: Reference claim alignment: The response should contain all claims from the reference and should not contain claims that are not present in the reference. ### Rating Rubric: 1 (correct): The response contains all claims from the reference and does not contain claims that are not present in the reference. 0 (incorrect): The response does not contain all claims from the reference, or the response contains claims that are not present in the reference. ### Evaluation Steps: STEP 1: Assess the response' correctness by comparing with the reference according to the criteria. STEP 2: Score based on the rubrics. Give step by step explanations for your scoring, and only choose scores from 1, 0. # User Inputs and AI-generated Response ## User Inputs ### Prompt {prompt} ## Reference {reference} ## AI-generated Response {response} """ - プロンプト テンプレート文字列を PointwiseMetric オブジェクトでラップします。これにより、指標に正式な名前が付けられ、評価ジョブで再利用可能なコンポーネントになります。新しいセルに次のコードを追加して実行します。
question_answering_correctness = PointwiseMetric( metric="question_answering_correctness", metric_prompt_template=question_answering_correctness_prompt_template, )
これで、厳密な事実確認のためのカスタムの参照指標が作成されました。
12. 参照評価を実行します。
次に、参照データセットと新しい指標を使用して評価ジョブを構成します。ここでも EvalTask クラスを使用します。
指標のリストに、カスタム モデルベースの指標と計算ベースの指標が組み合わされて表示されます。参照評価では、生成されたテキストと参照テキストの数学的比較を行う従来の計算ベースの指標を使用できます。ここでは、一般的な 3 つの関数を使用します。
exact_match: 生成された回答が参照の回答と同一の場合にのみ 1 を返し、それ以外の場合は 0 を返します。bleu: 適合率の指標。生成された回答の単語が参照回答にも含まれているかどうかを測定します。rouge: 再現率の指標。生成された回答に参照回答の単語がどの程度含まれているかを測定します。
- 参照データセットと新しい指標の組み合わせを使用して、評価ジョブを構成します。新しいセルに次のコードを追加して実行し、
EvalTaskオブジェクトを作成します。referenced_answer_eval_task_rag_a = EvalTask( dataset=referenced_eval_dataset_rag_a, metrics=[ question_answering_correctness, "rouge", "bleu", "exact_match", ], experiment=EXPERIMENT, ) referenced_answer_eval_task_rag_b = EvalTask( dataset=referenced_eval_dataset_rag_b, metrics=[ question_answering_correctness, "rouge", "bleu", "exact_match", ], experiment=EXPERIMENT, ) .evaluate()メソッドを呼び出して、参照された評価を実行します。新しいセルに次のコードを追加して実行します。referenced_result_rag_a = referenced_answer_eval_task_rag_a.evaluate() referenced_result_rag_b = referenced_answer_eval_task_rag_b.evaluate()
13. 参照された結果を分析する
評価が完了しました。このタスクでは、結果を分析して、モデルの回答をゴールデン リファレンス回答と比較することで、モデルの事実の正確性を測定します。
結果の概要を表示する
- 参照された評価の概要結果を分析します。新しいセルに次のコードを追加して実行し、両方のモデルの概要テーブルを表示します。
notebook_utils.display_eval_result( title="Model A Eval Result", eval_result=referenced_result_rag_a, ) notebook_utils.display_eval_result( title="Model B Eval Result", eval_result=referenced_result_rag_b, )question_answering_correctness指標では高いパフォーマンスを示しますが、exact_matchでは低いスコアになります。これは、同一のテキストだけでなく、セマンティックな類似性を認識できるモデルベースの指標の価値を示しています。
比較用に結果を可視化する
可視化により、2 つのモデル間のパフォーマンスの差がより明確になります。まず、結果を 1 つのリストに結合してプロットし、レーダーチャートと棒グラフを生成します。
- 参照された評価結果を 1 つのリストに結合してプロットします。新しいセルに次のコードを追加して実行します。
referenced_eval_results = [] referenced_eval_results.append(("Model A", referenced_result_rag_a)) referenced_eval_results.append(("Model B", referenced_result_rag_b)) - レーダーチャートを生成して、新しい一連の指標における各モデルのパフォーマンスを可視化します。新しいセルに次のコードを追加して実行します。
notebook_utils.display_radar_plot( referenced_eval_results, metrics=[ "question_answering_correctness", "rouge", "bleu", "exact_match", ], ) - 直接的な比較を行うための棒グラフを作成します。これにより、各モデルがさまざまな指標でどのように機能したかを確認できます。新しいセルに次のコードを追加して実行します。
notebook_utils.display_bar_plot( referenced_eval_results, metrics=[ "question_answering_correctness", "rouge", "bleu", "exact_match", ], )
これらの可視化により、モデル A はモデル B よりも大幅に精度が高く、基準となる回答と事実に基づいて整合していることが確認できます。
14. 実践から本番環境へ
RAG システムの完全な評価パイプラインが正常に実行されました。最後のセクションでは、学んだ重要な戦略コンセプトをまとめ、これらのスキルを実際のプロジェクトに適用するためのフレームワークを提供します。
本番環境のベスト プラクティス
このラボで学んだスキルを実際の運用環境に適用するには、次の 4 つの重要なプラクティスを検討してください。
- CI/CD で自動化する: 評価スイートを CI/CD パイプライン(Cloud Build、GitHub Actions など)に統合します。コード変更に対して評価を自動的に実行し、品質スコアが標準を下回った場合に機能低下を検出してデプロイをブロックします。
- データセットを進化させる: 静的データセットは古くなります。「ゴールデン」テストセットをバージョン管理し(Git LFS または Cloud Storage を使用)、実際の(匿名化された)ユーザークエリからサンプリングして、新しい難しい例を継続的に追加します。
- 生成ツールだけでなく、検索ツールも評価する: 適切なコンテキストがなければ、優れた回答は得られません。ヒット率(適切なドキュメントが見つかったか)や平均逆順位(MRR)(適切なドキュメントはどの程度の順位だったか)などの指標を使用して、検索システム用の個別の評価ステップを実装します。
- 指標を時間の経過とともにモニタリングする: 評価実行の要約スコアを Google Cloud Monitoring などのサービスにエクスポートします。ダッシュボードを作成して品質の傾向を追跡し、パフォーマンスの著しい低下を通知する自動アラートを設定します。
高度な評価方法のマトリックス
適切な評価アプローチの選択は、具体的な目標によって異なります。次の表は、各方法を使用するタイミングをまとめたものです。
評価アプローチ | ベスト ユースケース | 主なメリット | 制限事項 |
リファレンス フリー | 本番環境のモニタリング、継続的な評価 | 正解は必要なく、主観的な品質を捉える | 費用が高く、評価者のバイアスが生じる可能性がある |
リファレンス ベース | モデル比較、ベンチマーク | 客観的な測定、高速な計算 | 正解が必要。意味的同等性を逃す可能性がある |
カスタム指標 | ドメイン固有の評価 | ビジネスニーズに合わせてカスタマイズ | 検証と開発のオーバーヘッドが必要 |
ハイブリッド アプローチ | 包括的な本番環境システム | すべてのアプローチのベスト | 複雑性が増し、費用の最適化が必要になる |
主な技術的分析情報
独自の RAG システムを構築して評価する際は、次の基本原則に留意してください。
- RAG にとっての根拠の重要性: この指標は、高品質の RAG システムと低品質の RAG システムを常に区別するため、本番環境のモニタリングに不可欠です。
- 複数の指標で堅牢性を確保する: 単一の指標では RAG の品質のすべての側面を捉えられません。包括的な評価には、複数の評価ディメンションが必要です。
- カスタム指標は大きな価値をもたらす: ドメイン固有の評価基準は、一般的な指標では見逃されるニュアンスを捉え、評価の精度を高めます。
- 統計的厳密性により信頼性が向上: 適切なサンプルサイズと有意性テストにより、評価が推測から信頼性の高い意思決定ツールに変わります。
本番環境へのデプロイの決定フレームワーク
このフェーズ別フレームワークを、今後の RAG システムのデプロイのガイドとして使用します。
- フェーズ 1 - 開発: 既知のテストセットで参照ベースの評価を使用して、モデルの比較と選択を行います。
- フェーズ 2 - 本番前: 両方のアプローチを組み合わせた包括的な評価を実行して、本番環境の準備状況を検証します。
- フェーズ 3 - 本番環境: ゴールデン アンサーなしで、継続的な品質評価のための参照なしモニタリングを実装します。
- フェーズ 4 - 最適化: 評価分析情報を使用して、モデルの改善と検索システムの強化を行います。
15. まとめ
おめでとうございます!これでラボは完了です。
このラボは、「Google Cloud でのプロダクション レディな AI の開発」学習プログラムの一部です。
- カリキュラム全体で、プロトタイプから本番環境への移行についてご確認ください。
- ハッシュタグ
ProductionReadyAIで進捗状況を共有しましょう。
内容のまとめ
ここでは次の内容を学習しました。
- 参照なしの評価を実行して、取得したコンテキストに基づいて回答の品質を評価します。
- 「ゴールデン アンサー」を追加して事実の正しさを測定し、参照評価を行います。
- どちらのアプローチでも、事前定義された指標とカスタム指標を組み合わせて使用します。
- モデルベースの指標(
question_answering_qualityなど)と計算ベースの指標(rouge、bleu、exact_match)の両方を使用します。 - 結果を分析して可視化し、モデルの長所と短所を把握します。
この評価アプローチは、より信頼性が高く正確な生成 AI アプリケーションの構築に役立ちます。