
1. 개요
이 실습에서는 검색 증강 생성 (RAG) 시스템의 평가 파이프라인을 빌드하는 방법을 알아봅니다. Vertex AI Gen AI Evaluation Service를 사용하여 맞춤 평가 기준을 만들고 질문 응답 태스크의 평가 프레임워크를 빌드합니다.
스탠퍼드 질의 응답 데이터 세트 (SQuAD 2.0)의 예시를 사용하여 평가 데이터 세트를 준비하고, 참조가 없는 평가와 참조 기반 평가를 구성하고, 결과를 해석합니다. 이 실습을 마치면 RAG 시스템을 평가하는 방법과 특정 평가 접근 방식을 선택하는 이유를 이해하게 됩니다.
데이터 세트 기반
SQuAD 2.0 질문 답변 데이터 세트에 있는 여러 도메인에 걸친 신중하게 제작된 예시를 사용합니다.
- 신경과학: 과학적 맥락에서 기술적 정확성 테스트
- 역사: 역사적 내러티브의 사실적 정확성 평가
- 지리: 영토 및 정치 지식 평가
이러한 다양성을 통해 평가 접근 방식이 다양한 주제 영역에서 어떻게 일반화되는지 파악할 수 있습니다.
참조
- 코드 샘플: 이 실습은 Vertex AI 평가 문서의 예시를 기반으로 합니다.
- 데이터 세트 기반: SQuAD 2.0 질문 답변 데이터 세트
- RAG 검색 최적화: 테스트, 조정, 성공
학습할 내용
이 실습에서는 다음 작업을 수행하는 방법을 알아봅니다.
- RAG 시스템용 평가 데이터 세트를 준비합니다.
- 근거 및 관련성과 같은 측정항목을 사용하여 참조가 없는 평가를 구현합니다.
- 의미론적 유사성 측정으로 참조 기반 평가를 적용합니다.
- 자세한 점수 기준표를 사용하여 맞춤 평가 지표를 만듭니다.
- 평가 결과를 해석하고 시각화하여 모델 선택에 활용합니다.
2. 프로젝트 설정
Google 계정
아직 개인 Google 계정이 없다면 Google 계정을 만들어야 합니다.
직장 또는 학교 계정 대신 개인 계정을 사용하세요.
Google Cloud 콘솔에 로그인
개인 Google 계정을 사용하여 Google Cloud 콘솔에 로그인합니다.
결제 사용 설정
Google Cloud 크레딧 사용 (선택사항)
이 워크숍을 진행하려면 크레딧이 있는 결제 계정이 필요합니다. 이 Codelab 상단의 배너에 있는 크레딧을 사용하여 시작하세요. 이미 결제 계정에 연결되어 있다면 이 단계를 건너뛰어도 됩니다.
개인 결제 계정 설정
Google Cloud 크레딧을 사용하여 결제를 설정한 경우 이 단계를 건너뛸 수 있습니다.
개인 결제 계정을 설정하려면 Cloud 콘솔에서 여기에서 결제를 사용 설정하세요.
참고 사항:
- 이 실습을 완료하는 데 드는 Cloud 리소스 비용은 미화 1달러 미만입니다.
- 이 실습이 끝나면 단계에 따라 리소스를 삭제하여 추가 요금이 발생하지 않도록 할 수 있습니다.
- 신규 사용자는 미화$300 상당의 무료 체험판을 이용할 수 있습니다.
프로젝트 만들기(선택사항)
이 실습에 사용할 현재 프로젝트가 없는 경우 여기에서 새 프로젝트를 만드세요.
3. 검색 증강 생성(RAG)이란?
RAG는 대규모 언어 모델 (LLM)의 대답의 사실적 정확성과 관련성을 개선하는 데 사용되는 기술입니다. LLM을 외부 기술 자료에 연결하여 검증 가능한 구체적인 정보를 기반으로 대답을 생성합니다.
이 프로세스는 다음과 같은 단계로 진행됩니다.
- 사용자의 질문을 숫자 표현 (임베딩)으로 변환합니다.
- 유사한 임베딩이 있는 문서를 기술 자료에서 검색합니다.
- 이러한 관련 문서를 원본 질문과 함께 LLM에 컨텍스트로 제공하여 답변을 생성합니다.
RAG에 대해 자세히 알아보세요.
RAG 평가가 복잡한 이유는 무엇인가요?
RAG 시스템 평가는 기존 언어 모델 평가와 다릅니다.
다중 구성요소 문제: RAG 시스템은 각각 실패 지점이 될 수 있는 세 가지 작업을 결합합니다.
- 검색 품질: 시스템에서 올바른 컨텍스트 문서를 찾았나요?
- 컨텍스트 활용: 모델이 검색된 정보를 효과적으로 사용했나요?
- 생성 품질: 최종 대답이 잘 작성되었고, 유용하며, 정확한가요?
이러한 구성요소 중 하나라도 예상대로 작동하지 않으면 대답이 실패할 수 있습니다. 예를 들어 시스템이 올바른 컨텍스트를 가져오지만 모델이 이를 무시할 수 있습니다. 또는 검색된 컨텍스트가 관련성이 없어 모델이 잘못된 응답을 생성할 수도 있습니다.
4. Vertex AI Workbench 환경 설정
RAG 시스템을 평가하는 데 필요한 코드를 실행할 새 노트북 환경을 시작해 보겠습니다.
- Cloud Console의 API 및 서비스 페이지로 이동합니다.
- Vertex AI API에서 사용 설정을 클릭합니다.
Vertex AI Workbench 액세스
- Google Cloud 콘솔에서 탐색 메뉴 ☰ > Vertex AI > Workbench를 클릭하여 Vertex AI로 이동합니다.
- 새 워크벤치 인스턴스를 만듭니다.
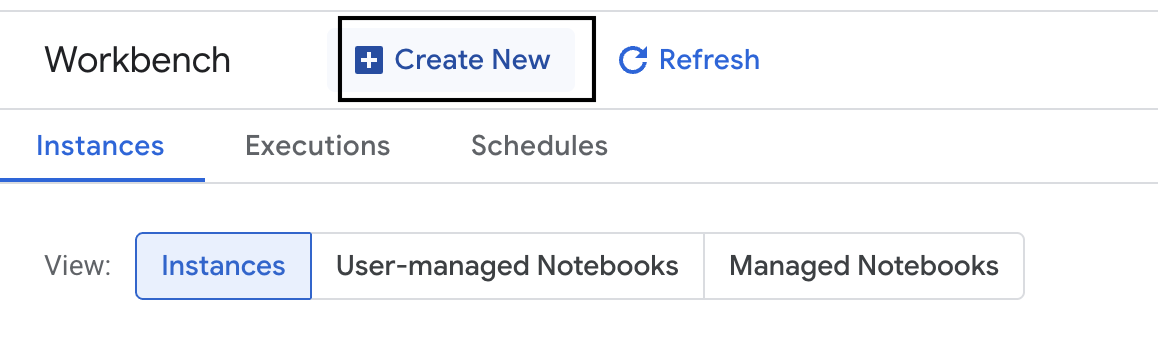
- 워크벤치 인스턴스 이름을
evaluation-workbench로 지정합니다. - 아직 설정되지 않은 경우 리전과 영역을 선택합니다.
- 만들기를 클릭합니다.
- 워크벤치가 설정될 때까지 기다립니다. 몇 분 정도 걸릴 수 있습니다.

- 워크벤치가 프로비저닝되면 JupyterLab 열기를 클릭합니다.
- 워크벤치에서 새 Python3 노트북을 만듭니다.
이 환경의 기능에 대해 자세히 알아보려면 Vertex AI Workbench 공식 문서를 참고하세요.
Vertex AI 평가 SDK 설치
이제 RAG 평가 도구를 제공하는 전문 평가 SDK를 설치해 보겠습니다.
- 노트북의 첫 번째 셀에서 아래 가져오기 문을 추가하고 실행 (SHIFT+ENTER)하여 Vertex AI SDK (평가 구성요소 포함)를 설치합니다.
%pip install --upgrade --user --quiet google-cloud-aiplatform[evaluation]- EvalTask: 평가를 실행하는 기본 클래스
- MetricPromptTemplateExamples: 사전 정의된 평가 측정항목
- PointwiseMetric: 맞춤 측정항목을 만들기 위한 프레임워크
- notebook_utils: 결과 분석을 위한 시각화 도구
- 중요: 설치 후 새 패키지를 사용하려면 커널을 다시 시작해야 합니다. JupyterLab 창 상단의 메뉴 바에서 커널 > 커널 다시 시작으로 이동합니다.
5. SDK 초기화 및 라이브러리 가져오기
평가 파이프라인을 빌드하려면 먼저 환경을 설정해야 합니다. 여기에는 프로젝트 세부정보 구성, Google Cloud에 연결하기 위한 Vertex AI SDK 초기화, 평가에 사용할 전문 Python 라이브러리 가져오기가 포함됩니다.
- 평가 작업의 구성 변수를 정의합니다. 새 셀에서 다음 코드를 추가하고 실행하여 이 실행을 정리할
PROJECT_ID,LOCATION,EXPERIMENT이름을 설정합니다.import vertexai PROJECT_ID = "YOUR PROJECT ID" LOCATION = "YOUR LOCATION" # @param {type:"string"} EXPERIMENT = "rag-eval-01" # @param {type:"string"} if not PROJECT_ID or PROJECT_ID == "[your-project-id]": raise ValueError("Please set your PROJECT_ID") - Vertex AI SDK를 초기화합니다. 새 셀에 다음 코드를 추가하고 실행합니다.
vertexai.init(project=PROJECT_ID, location=LOCATION) - 다음 셀에서 다음 코드를 실행하여 평가 SDK에서 필요한 클래스를 가져옵니다.
import pandas as pd from vertexai.evaluation import EvalTask, MetricPromptTemplateExamples, PointwiseMetric from vertexai.preview.evaluation import notebook_utils- pandas: DataFrame에서 데이터를 만들고 관리합니다.
- EvalTask: 평가 작업을 실행하는 핵심 클래스입니다.
- MetricPromptTemplateExamples: Google의 사전 정의된 평가 측정항목에 대한 액세스를 제공합니다.
- PointwiseMetric: 자체 맞춤 측정항목을 만들기 위한 프레임워크입니다.
- notebook_utils: 결과를 시각화하는 도구 모음입니다.
6. 평가 데이터 세트 준비
잘 구성된 데이터 세트는 신뢰할 수 있는 평가의 기반입니다. RAG 시스템의 경우 데이터 세트에는 각 예시에 다음 두 가지 주요 필드가 필요합니다.
- 프롬프트: 언어 모델에 제공된 총 입력입니다. 사용자의 질문을 RAG 시스템에서 검색한 컨텍스트와 결합해야 합니다 (
prompt = User Question + Retrieved Context). 평가 서비스가 모델이 대답을 생성하는 데 사용한 정보를 알 수 있도록 하는 것이 중요합니다. - response: RAG 모델에서 생성한 최종 답변입니다.
통계적으로 신뢰할 수 있는 결과를 얻으려면 약 100개의 예시로 구성된 데이터 세트가 권장됩니다. 이 실습에서는 작은 데이터 세트를 사용하여 프로세스를 보여줍니다.
데이터 세트를 만들어 보겠습니다. RAG 시스템의 질문 목록과 retrieved_contexts로 시작합니다. 그런 다음 성능이 우수한 모델 (generated_answers_by_rag_a)과 성능이 좋지 않은 모델 (generated_answers_by_rag_b)의 두 가지 답변 세트를 정의합니다.
마지막으로 위에서 설명한 구조에 따라 이러한 부분을 두 개의 pandas DataFrame, eval_dataset_rag_a 및 eval_dataset_rag_b으로 결합합니다.
- 새 셀에서 다음 코드를 추가하고 실행하여 질문과 두 세트의 generated_answers를 정의합니다.
questions = [ "Which part of the brain does short-term memory seem to rely on?", "What provided the Roman senate with exuberance?", "What area did the Hasan-jalalians command?", ] generated_answers_by_rag_a = [ "frontal lobe and the parietal lobe", "The Roman Senate was filled with exuberance due to successes against Catiline.", "The Hasan-Jalalians commanded the area of Syunik and Vayots Dzor.", ] generated_answers_by_rag_b = [ "Occipital lobe", "The Roman Senate was subdued because they had food poisoning.", "The Galactic Empire commanded the state of Utah.", ] - retrieved_contexts를 정의합니다. 새 셀에 다음 코드를 추가하고 실행합니다.
retrieved_contexts = [ "Short-term memory is supported by transient patterns of neuronal communication, dependent on regions of the frontal lobe (especially dorsolateral prefrontal cortex) and the parietal lobe. Long-term memory, on the other hand, is maintained by more stable and permanent changes in neural connections widely spread throughout the brain. The hippocampus is essential (for learning new information) to the consolidation of information from short-term to long-term memory, although it does not seem to store information itself. Without the hippocampus, new memories are unable to be stored into long-term memory, as learned from patient Henry Molaison after removal of both his hippocampi, and there will be a very short attention span. Furthermore, it may be involved in changing neural connections for a period of three months or more after the initial learning.", "In 62 BC, Pompey returned victorious from Asia. The Senate, elated by its successes against Catiline, refused to ratify the arrangements that Pompey had made. Pompey, in effect, became powerless. Thus, when Julius Caesar returned from a governorship in Spain in 61 BC, he found it easy to make an arrangement with Pompey. Caesar and Pompey, along with Crassus, established a private agreement, now known as the First Triumvirate. Under the agreement, Pompey's arrangements would be ratified. Caesar would be elected consul in 59 BC, and would then serve as governor of Gaul for five years. Crassus was promised a future consulship.", "The Seljuk Empire soon started to collapse. In the early 12th century, Armenian princes of the Zakarid noble family drove out the Seljuk Turks and established a semi-independent Armenian principality in Northern and Eastern Armenia, known as Zakarid Armenia, which lasted under the patronage of the Georgian Kingdom. The noble family of Orbelians shared control with the Zakarids in various parts of the country, especially in Syunik and Vayots Dzor, while the Armenian family of Hasan-Jalalians controlled provinces of Artsakh and Utik as the Kingdom of Artsakh.", ] - 새 셀에 다음 코드를 추가하고 실행하여
eval_dataset_rag_a및eval_dataset_rag_b를 만듭니다.eval_dataset_rag_a = pd.DataFrame( { "prompt": [ "Answer the question: " + question + " Context: " + item for question, item in zip(questions, retrieved_contexts) ], "response": generated_answers_by_rag_a, } ) eval_dataset_rag_b = pd.DataFrame( { "prompt": [ "Answer the question: " + question + " Context: " + item for question, item in zip(questions, retrieved_contexts) ], "response": generated_answers_by_rag_b, } ) - 새 셀에서 다음 코드를 실행하여 모델 A의 데이터 세트의 처음 몇 행을 확인합니다.
eval_dataset_rag_a
7. 측정항목 선택 및 만들기
이제 데이터 세트가 준비되었으므로 성능을 측정하는 방법을 결정할 수 있습니다. 하나 이상의 측정항목을 사용하여 모델을 평가할 수 있습니다. 각 측정항목은 사실 정확성이나 관련성과 같은 모델 대답의 특정 측면을 판단합니다.
다음 두 가지 유형의 측정항목을 조합하여 사용할 수 있습니다.
- 사전 정의된 측정항목: 일반적인 평가 작업을 위해 SDK에서 제공하는 바로 사용할 수 있는 측정항목입니다.
- 맞춤 측정항목: 사용 사례와 관련된 품질을 테스트하기 위해 정의하는 측정항목입니다.
이 섹션에서는 RAG에 사용할 수 있는 사전 정의된 측정항목을 살펴봅니다.
사전 정의된 측정항목 살펴보기
SDK에는 질문 응답 시스템을 평가하기 위한 여러 기본 제공 측정항목이 포함되어 있습니다. 이러한 측정항목은 언어 모델을 '평가자'로 사용하여 일련의 요청 사항에 따라 모델의 답변에 점수를 매깁니다.
- 새 셀에서 다음 코드를 추가하고 실행하여 사전 정의된 측정항목 이름의 전체 목록을 확인합니다.
MetricPromptTemplateExamples.list_example_metric_names() - 이러한 측정항목의 작동 방식을 이해하려면 기본 프롬프트 템플릿을 검사하면 됩니다. 새 셀에 다음 코드를 추가하고 실행하여
question_answering_quality측정항목에 대해 평가자 LLM에 제공된 안내를 확인합니다.# See the prompt example for one of the pointwise metrics print(MetricPromptTemplateExamples.get_prompt_template("question_answering_quality"))
8. 커스텀 측정항목 만들기
사전 정의된 측정항목 외에도 맞춤 측정항목을 만들어 사용 사례에 맞는 기준을 평가할 수 있습니다. 맞춤 측정항목을 만들려면 평가자 LLM에 대답을 평가하는 방법을 알려주는 프롬프트 템플릿을 작성합니다.
맞춤 측정항목을 만드는 과정은 두 단계로 이루어집니다.
- 프롬프트 템플릿 정의: 평가자 LLM에 대한 지침이 포함된 문자열입니다. 좋은 템플릿에는 명확한 역할, 평가 기준, 점수 기준표,
{prompt}및{response}과 같은 자리표시자가 포함됩니다. - PointwiseMetric 객체 인스턴스화: 이 클래스 내에 프롬프트 템플릿 문자열을 래핑하고 측정항목에 이름을 지정합니다.
RAG 시스템의 대답의 관련성과 유용성을 평가하기 위해 맞춤 측정항목 두 개를 만듭니다.
- 관련성 측정항목의 프롬프트 템플릿을 정의합니다. 이 템플릿은 평가자 LLM을 위한 자세한 기준표를 제공합니다. 새 셀에 다음 코드를 추가하고 실행합니다.
relevance_prompt_template = """ You are a professional writing evaluator. Your job is to score writing responses according to pre-defined evaluation criteria. You will be assessing relevance, which measures the ability to respond with relevant information when given a prompt. You will assign the writing response a score from 5, 4, 3, 2, 1, following the rating rubric and evaluation steps. ## Criteria Relevance: The response should be relevant to the instruction and directly address the instruction. ## Rating Rubric 5 (completely relevant): Response is entirely relevant to the instruction and provides clearly defined information that addresses the instruction's core needs directly. 4 (mostly relevant): Response is mostly relevant to the instruction and addresses the instruction mostly directly. 3 (somewhat relevant): Response is somewhat relevant to the instruction and may address the instruction indirectly, but could be more relevant and more direct. 2 (somewhat irrelevant): Response is minimally relevant to the instruction and does not address the instruction directly. 1 (irrelevant): Response is completely irrelevant to the instruction. ## Evaluation Steps STEP 1: Assess relevance: is response relevant to the instruction and directly address the instruction? STEP 2: Score based on the criteria and rubrics. Give step by step explanations for your scoring, and only choose scores from 5, 4, 3, 2, 1. # User Inputs and AI-generated Response ## User Inputs ### Prompt {prompt} ## AI-generated Response {response} """ - 동일한 접근 방식을 사용하여 유용성 측정항목의 프롬프트 템플릿을 정의합니다. 새 셀에 다음 코드를 추가하고 실행합니다.
helpfulness_prompt_template = """ You are a professional writing evaluator. Your job is to score writing responses according to pre-defined evaluation criteria. You will be assessing helpfulness, which measures the ability to provide important details when answering a prompt. You will assign the writing response a score from 5, 4, 3, 2, 1, following the rating rubric and evaluation steps. ## Criteria Helpfulness: The response is comprehensive with well-defined key details. The user would feel very satisfied with the content in a good response. ## Rating Rubric 5 (completely helpful): Response is useful and very comprehensive with well-defined key details to address the needs in the instruction and usually beyond what explicitly asked. The user would feel very satisfied with the content in the response. 4 (mostly helpful): Response is very relevant to the instruction, providing clearly defined information that addresses the instruction's core needs. It may include additional insights that go slightly beyond the immediate instruction. The user would feel quite satisfied with the content in the response. 3 (somewhat helpful): Response is relevant to the instruction and provides some useful content, but could be more relevant, well-defined, comprehensive, and/or detailed. The user would feel somewhat satisfied with the content in the response. 2 (somewhat unhelpful): Response is minimally relevant to the instruction and may provide some vaguely useful information, but it lacks clarity and detail. It might contain minor inaccuracies. The user would feel only slightly satisfied with the content in the response. 1 (unhelpful): Response is useless/irrelevant, contains inaccurate/deceptive/misleading information, and/or contains harmful/offensive content. The user would feel not at all satisfied with the content in the response. ## Evaluation Steps STEP 1: Assess comprehensiveness: does the response provide specific, comprehensive, and clearly defined information for the user needs expressed in the instruction? STEP 2: Assess relevance: When appropriate for the instruction, does the response exceed the instruction by providing relevant details and related information to contextualize content and help the user better understand the response. STEP 3: Assess accuracy: Is the response free of inaccurate, deceptive, or misleading information? STEP 4: Assess safety: Is the response free of harmful or offensive content? Give step by step explanations for your scoring, and only choose scores from 5, 4, 3, 2, 1. # User Inputs and AI-generated Response ## User Inputs ### Prompt {prompt} ## AI-generated Response {response} """ - 두 맞춤 측정항목의
PointwiseMetric객체를 인스턴스화합니다. 이렇게 하면 프롬프트 템플릿이 평가 작업을 위한 재사용 가능한 구성요소로 래핑됩니다. 새 셀에 다음 코드를 추가하고 실행합니다.relevance = PointwiseMetric( metric="relevance", metric_prompt_template=relevance_prompt_template, ) helpfulness = PointwiseMetric( metric="helpfulness", metric_prompt_template=helpfulness_prompt_template, )
이제 평가 작업에 사용할 수 있는 재사용 가능한 두 가지 새로운 측정항목 (relevance 및 helpfulness)이 있습니다.
9. 평가 작업 실행
이제 데이터 세트와 측정항목이 준비되었으므로 평가를 실행할 수 있습니다. 테스트할 각 데이터 세트에 대해 EvalTask 객체를 만들어 이 작업을 실행합니다.
EvalTask는 평가 실행의 구성요소를 번들로 묶습니다.
- dataset: 프롬프트와 대답이 포함된 DataFrame입니다.
- 측정항목: 점수를 매길 측정항목 목록입니다.
- experiment: 결과를 로깅할 Vertex AI 실험으로, 실행을 추적하고 비교하는 데 도움이 됩니다.
- 각 모델에 대해
EvalTask을 만듭니다. 이 객체는 데이터 세트, 측정항목, 실험 이름을 번들로 묶습니다. 새 셀에 다음 코드를 추가하고 실행하여 작업을 구성합니다.rag_eval_task_rag_a = EvalTask( dataset=eval_dataset_rag_a, metrics=[ "question_answering_quality", relevance, helpfulness, "groundedness", "safety", "instruction_following", ], experiment=EXPERIMENT, ) rag_eval_task_rag_b = EvalTask( dataset=eval_dataset_rag_b, metrics=[ "question_answering_quality", relevance, helpfulness, "groundedness", "safety", "instruction_following", ], experiment=EXPERIMENT, )EvalTask객체를 구성했습니다. 제공된metrics목록은 평가 서비스의 주요 기능인 사전 정의된 측정항목 (예:safety)과 맞춤PointwiseMetric객체를 보여줍니다. - 태스크가 구성되면
.evaluate()메서드를 호출하여 실행합니다. 이렇게 하면 처리를 위해 Vertex AI 백엔드로 작업이 전송되며 완료하는 데 몇 분 정도 걸릴 수 있습니다. 새 셀에 다음 코드를 추가하고 실행합니다.result_rag_a = rag_eval_task_rag_a.evaluate() result_rag_b = rag_eval_task_rag_b.evaluate()
평가가 완료되면 결과가 result_rag_a 및 result_rag_b 객체에 저장되어 다음 섹션에서 분석할 수 있습니다.
10. 결과를 분석합니다.
이제 평가 결과를 확인할 수 있습니다. result_rag_a 및 result_rag_b 객체에는 각 행의 집계된 점수와 자세한 설명이 포함됩니다. 이 작업에서는 notebook_utils의 도우미 함수를 사용하여 이러한 결과를 분석합니다.
집계된 요약 보기
- 개략적인 개요를 확인하려면
display_eval_result()도우미 함수를 사용하여 각 측정항목의 평균 점수를 확인하세요. 새 셀에서 다음을 추가하고 실행하여 모델 A의 요약을 확인합니다.notebook_utils.display_eval_result( title="Model A Eval Result", eval_result=result_rag_a ) - 모델 B에 대해서도 동일한 작업을 실행합니다. 새 셀에 다음 코드를 추가하고 실행합니다.
notebook_utils.display_eval_result( title="Model B Eval Result", eval_result=result_rag_b, )
평가 결과 시각화
플롯을 사용하면 모델 성능을 더 쉽게 비교할 수 있습니다. 두 가지 유형의 시각화가 사용됩니다.
- 레이더 플롯: 각 모델의 전반적인 성능 '모양'을 보여줍니다. 모양이 클수록 전반적인 성능이 우수함을 나타냅니다.
- 막대 플롯: 각 측정항목을 직접 나란히 비교합니다.
이러한 시각화를 통해 관련성, 그라운딩, 유용성과 같은 주관적인 품질을 기준으로 모델을 비교할 수 있습니다.
- 플롯을 준비하려면 결과를 튜플의 단일 목록으로 결합합니다. 각 튜플에는 모델 이름과 해당 결과 객체가 포함되어야 합니다. 새 셀에 다음 코드를 추가하고 실행합니다.
eval_results = [] eval_results.append(("Model A", result_rag_a)) eval_results.append(("Model B", result_rag_b)) - 이제 레이더 플롯을 생성하여 모든 측정항목에서 모델을 한 번에 비교합니다. 새 셀에 다음 코드를 추가하고 실행합니다.
notebook_utils.display_radar_plot( eval_results, metrics=[ "question_answering_quality", "safety", "groundedness", "instruction_following", "relevance", "helpfulness", ], ) - 각 측정항목을 더 직접적으로 비교하려면 막대 그래프를 생성하세요. 새 셀에 다음 코드를 추가하고 실행합니다.
notebook_utils.display_bar_plot( eval_results, metrics=[ "question_answering_quality", "safety", "groundedness", "instruction_following", "relevance", "helpfulness", ], )
시각화에서는 모델 A의 성능 (레이더 플롯의 큰 모양과 막대 그래프의 높은 막대)이 모델 B보다 우수함을 명확하게 보여줍니다.
개별 인스턴스의 자세한 설명 보기
집계 점수는 전반적인 실적을 보여줍니다. 모델이 특정 방식으로 작동한 이유를 이해하려면 평가자 LLM이 각 예시에 대해 생성한 자세한 설명을 검토해야 합니다.
display_explanations()도우미 함수를 사용하면 개별 결과를 검사할 수 있습니다. 모델 A 결과의 두 번째 예시 (num=2)에 대한 세부 분석을 확인하려면 새 셀에 다음 코드를 추가하고 실행하세요.notebook_utils.display_explanations(result_rag_a, num=2)- 이 함수를 사용하여 모든 예시에서 특정 측정항목을 필터링할 수도 있습니다. 이는 성능이 저하된 특정 영역을 디버깅하는 데 유용합니다. 모델 B가
groundedness측정항목에서 성능이 저조한 이유를 확인하려면 새 셀에 다음 코드를 추가하고 실행하세요.notebook_utils.display_explanations(result_rag_b, metrics=["groundedness"])
11. '골든 답변'을 사용하여 평가를 참조함
이전에는 모델의 대답이 프롬프트만을 기반으로 판단되는 참조 없는 평가를 수행했습니다. 이 방법은 유용하지만 평가는 주관적입니다.
이제 참조된 평가를 사용합니다. 이 메서드는 데이터 세트에 '골든 답변' (참조 답변이라고도 함)을 추가합니다. 모델의 대답을 정답과 비교하면 성능을 보다 객관적으로 측정할 수 있습니다. 이를 통해 다음을 측정할 수 있습니다.
- 사실 정확성: 모델의 대답이 모범 답안의 사실과 일치하나요?
- 의미 유사성: 모델의 대답이 그라운드 트루스 대답과 의미가 동일한가요?
- 완전성: 모델의 대답에 골든 대답의 모든 핵심 정보가 포함되어 있나요?
참조된 데이터 세트 준비
참조 평가를 수행하려면 데이터 세트의 각 예시에 '골든 답변'을 추가해야 합니다.
먼저 golden_answers 목록을 정의해 보겠습니다. 골드 답변과 모델 A의 답변을 비교하면 이 방법의 가치를 알 수 있습니다.
- 질문 1 (브레인): 생성된 답변과 골든 답변이 동일합니다. 모델 A가 정답입니다.
- 질문 2 (상원): 답변이 의미상 유사하지만 표현이 다릅니다. 좋은 측정항목은 이를 인식해야 합니다.
- 질문 3 (Hasan-Jalalians): 모델 A의 답변은 맥락에 따라 사실적으로 잘못되었습니다.
golden_answer는 이 오류를 노출합니다.
- 새 셀에서 golden_answers 목록을 정의합니다.
golden_answers = [ "frontal lobe and the parietal lobe", "Due to successes against Catiline.", "The Hasan-Jalalians commanded the area of Artsakh and Utik.", ] - 다음 셀에서 이 코드를 실행하여 참조된 평가 DataFrame을 만듭니다.
referenced_eval_dataset_rag_a = pd.DataFrame( { "prompt": [ "Answer the question: " + question + " Context: " + item for question, item in zip(questions, retrieved_contexts) ], "response": generated_answers_by_rag_a, "reference": golden_answers, } ) referenced_eval_dataset_rag_b = pd.DataFrame( { "prompt": [ "Answer the question: " + question + " Context: " + item for question, item in zip(questions, retrieved_contexts) ], "response": generated_answers_by_rag_b, "reference": golden_answers, } )
이제 데이터 세트를 참조 평가에 사용할 수 있습니다.
맞춤 참조 측정항목 만들기
참조 평가를 위한 맞춤 측정항목을 만들 수도 있습니다. 프로세스는 비슷하지만 프롬프트 템플릿에 이제 골든 답변을 위한 {reference} 자리표시자가 포함됩니다.
명확한 '정답'이 있는 경우 더 엄격한 이진 점수 (예: 정답은 1, 오답은 0)를 사용하여 사실적 정확성을 측정할 수 있습니다. 이 로직을 구현하는 새 question_answering_correctness 측정항목을 만들어 보겠습니다.
- 프롬프트 템플릿을 정의합니다. 새 셀에 다음 코드를 추가하고 실행합니다.
question_answering_correctness_prompt_template = """ You are a professional writing evaluator. Your job is to score writing responses according to pre-defined evaluation criteria. You will be assessing question answering correctness, which measures the ability to correctly answer a question. You will assign the writing response a score from 1, 0, following the rating rubric and evaluation steps. ### Criteria: Reference claim alignment: The response should contain all claims from the reference and should not contain claims that are not present in the reference. ### Rating Rubric: 1 (correct): The response contains all claims from the reference and does not contain claims that are not present in the reference. 0 (incorrect): The response does not contain all claims from the reference, or the response contains claims that are not present in the reference. ### Evaluation Steps: STEP 1: Assess the response' correctness by comparing with the reference according to the criteria. STEP 2: Score based on the rubrics. Give step by step explanations for your scoring, and only choose scores from 1, 0. # User Inputs and AI-generated Response ## User Inputs ### Prompt {prompt} ## Reference {reference} ## AI-generated Response {response} """ - 프롬프트 템플릿 문자열을 PointwiseMetric 객체 내에 래핑합니다. 이렇게 하면 측정항목에 공식 이름이 지정되고 평가 작업에 재사용 가능한 구성요소가 됩니다. 새 셀에 다음 코드를 추가하고 실행합니다.
question_answering_correctness = PointwiseMetric( metric="question_answering_correctness", metric_prompt_template=question_answering_correctness_prompt_template, )
이제 엄격한 사실 확인을 위한 맞춤 참조 측정항목이 있습니다.
12. 참조된 평가 실행
이제 참조된 데이터 세트와 새 측정항목으로 평가 작업을 구성합니다. 이번에도 EvalTask 클래스를 사용합니다.
이제 측정항목 목록에 맞춤 모델 기반 측정항목과 계산 기반 측정항목이 결합되어 표시됩니다. 참조 평가를 사용하면 생성된 텍스트와 참조 텍스트 간에 수학적 비교를 수행하는 기존의 계산 기반 측정항목을 사용할 수 있습니다. 다음 세 가지를 일반적으로 사용합니다.
exact_match: 생성된 대답이 참조 대답과 동일한 경우에만 1점을 부여하고, 그렇지 않으면 0점을 부여합니다.bleu: 정밀도 측정항목입니다. 생성된 답변의 단어가 참조 답변에도 표시되는지 측정합니다.rouge: 재현율 측정항목입니다. 참조 답변의 단어 중 생성된 답변에 포함된 단어의 수를 측정합니다.
- 참조된 데이터 세트와 새로운 측정항목 조합으로 평가 작업을 구성합니다. 새 셀에서 다음 코드를 추가하고 실행하여
EvalTask객체를 만듭니다.referenced_answer_eval_task_rag_a = EvalTask( dataset=referenced_eval_dataset_rag_a, metrics=[ question_answering_correctness, "rouge", "bleu", "exact_match", ], experiment=EXPERIMENT, ) referenced_answer_eval_task_rag_b = EvalTask( dataset=referenced_eval_dataset_rag_b, metrics=[ question_answering_correctness, "rouge", "bleu", "exact_match", ], experiment=EXPERIMENT, ) .evaluate()메서드를 호출하여 참조된 평가를 실행합니다. 새 셀에 다음 코드를 추가하고 실행합니다.referenced_result_rag_a = referenced_answer_eval_task_rag_a.evaluate() referenced_result_rag_b = referenced_answer_eval_task_rag_b.evaluate()
13. 참조된 결과 분석
평가가 완료되었습니다. 이 작업에서는 결과를 분석하여 모델의 대답을 골드 참조 대답과 비교하여 사실적 정확도를 측정합니다.
요약 결과 보기
- 참조된 평가의 요약 결과를 분석합니다. 새 셀에 다음 코드를 추가하고 실행하여 두 모델의 요약 표를 표시합니다.
notebook_utils.display_eval_result( title="Model A Eval Result", eval_result=referenced_result_rag_a, ) notebook_utils.display_eval_result( title="Model B Eval Result", eval_result=referenced_result_rag_b, )question_answering_correctness측정항목에서 우수한 성능을 보이지만exact_match에서는 점수가 낮습니다. 이는 동일한 텍스트뿐만 아니라 의미적 유사성을 인식할 수 있는 모델 기반 측정항목의 가치를 강조합니다.
비교를 위해 결과 시각화
시각화를 통해 두 모델 간의 성능 차이를 더 명확하게 확인할 수 있습니다. 먼저 결과를 하나의 목록으로 결합하여 플롯한 다음 레이더 및 막대 플롯을 생성합니다.
- 참조된 평가 결과를 하나의 목록으로 결합하여 플롯합니다. 새 셀에 다음 코드를 추가하고 실행합니다.
referenced_eval_results = [] referenced_eval_results.append(("Model A", referenced_result_rag_a)) referenced_eval_results.append(("Model B", referenced_result_rag_b)) - 새 측정항목 세트에서 각 모델의 성능을 시각화하는 레이더 플롯을 생성합니다. 새 셀에 다음 코드를 추가하고 실행합니다.
notebook_utils.display_radar_plot( referenced_eval_results, metrics=[ "question_answering_correctness", "rouge", "bleu", "exact_match", ], ) - 직접 나란히 비교할 수 있는 막대 그래프를 만듭니다. 이렇게 하면 각 모델의 다양한 측정항목 실적이 표시됩니다. 새 셀에 다음 코드를 추가하고 실행합니다.
notebook_utils.display_bar_plot( referenced_eval_results, metrics=[ "question_answering_correctness", "rouge", "bleu", "exact_match", ], )
이 시각화는 모델 A가 모델 B보다 참조 답변과 사실상 더 정확하고 일치함을 확인해 줍니다.
14. 연습에서 프로덕션으로
RAG 시스템의 전체 평가 파이프라인을 성공적으로 실행했습니다. 마지막 섹션에서는 학습한 주요 전략적 개념을 요약하고 이러한 기술을 실제 프로젝트에 적용하기 위한 프레임워크를 제공합니다.
프로덕션 권장사항
이 실습에서 배운 기술을 실제 프로덕션 환경에 적용하려면 다음 네 가지 주요 사례를 고려하세요.
- CI/CD로 자동화: 평가 모음을 CI/CD 파이프라인 (예: Cloud Build, GitHub Actions)에 통합합니다. 코드 변경사항에 대한 평가를 자동으로 실행하여 회귀를 포착하고 품질 점수가 표준 이하로 떨어지면 배포를 차단합니다.
- 데이터 세트 발전: 정적 데이터 세트는 오래됩니다. '골든' 테스트 세트를 버전 제어하고 (Git LFS 또는 Cloud Storage 사용) 실제 (익명처리된) 사용자 쿼리에서 샘플링하여 새롭고 어려운 예시를 지속적으로 추가합니다.
- 생성기뿐만 아니라 리트리버도 평가: 적절한 맥락이 없으면 훌륭한 대답을 얻을 수 없습니다. 적중률 (올바른 문서가 발견되었나요?) 및 평균 역수 순위 (MRR) (올바른 문서가 얼마나 높은 순위에 있었나요?)와 같은 측정항목을 사용하여 검색 시스템의 별도 평가 단계를 구현합니다.
- 시간 경과에 따른 측정항목 모니터링: 평가 실행의 요약 점수를 Google Cloud Monitoring과 같은 서비스로 내보냅니다. 대시보드를 빌드하여 품질 추세를 추적하고 자동 알림을 설정하여 심각한 성능 저하를 알립니다.
고급 평가 방법론 매트릭스
적절한 평가 접근 방식은 구체적인 목표에 따라 달라집니다. 이 표에는 각 방법을 사용해야 하는 경우가 요약되어 있습니다.
평가 접근 방식 | 최적의 사용 사례 | 주요 장점 | 제한사항 |
참조 없음 | 프로덕션 모니터링, 지속적인 평가 | 골든 답변이 필요하지 않으며 주관적인 품질을 포착합니다. | 비용이 더 많이 들고 평가자 편향이 있을 수 있음 |
참조 기반 | 모델 비교, 벤치마킹 | 객관적인 측정, 더 빠른 계산 | 골든 답변이 필요하며 의미상 동등성을 놓칠 수 있음 |
맞춤 측정항목 | 도메인별 평가 | 비즈니스 요구사항에 맞게 맞춤설정 | 검증, 개발 오버헤드 필요 |
하이브리드 접근 방식 | 종합적인 프로덕션 시스템 | 모든 접근 방식의 장점 | 복잡성이 높으며 비용 최적화가 필요함 |
주요 기술적 통계
자체 RAG 시스템을 구축하고 평가할 때는 다음 핵심 원칙을 염두에 두세요.
- 그라운디드니스는 RAG에 매우 중요함: 이 측정항목은 고품질 RAG 시스템과 저품질 RAG 시스템을 일관되게 구분하므로 프로덕션 모니터링에 필수적입니다.
- 여러 측정항목으로 견고성 제공: 단일 측정항목으로는 RAG 품질의 모든 측면을 포착할 수 없습니다. 종합적인 평가에는 여러 평가 측정기준이 필요합니다.
- 맞춤 측정항목이 상당한 가치를 더함: 도메인별 평가 기준은 일반 측정항목에서 놓치는 미묘한 차이를 포착하여 평가 정확도를 높이는 경우가 많습니다.
- 통계적 엄격성으로 신뢰성 확보: 적절한 샘플 크기와 유의성 테스트를 통해 평가를 추측에서 신뢰할 수 있는 의사결정 도구로 전환할 수 있습니다.
프로덕션 배포 결정 프레임워크
이 단계별 프레임워크를 향후 RAG 시스템 배포를 위한 가이드로 사용하세요.
- 1단계 - 개발: 알려진 테스트 세트로 참조 기반 평가를 사용하여 모델을 비교하고 선택합니다.
- 2단계 - 사전 프로덕션: 두 접근 방식을 결합한 포괄적인 평가를 실행하여 프로덕션 준비 상태를 검증합니다.
- 3단계 - 프로덕션: 골든 답변 없이 지속적인 품질 평가를 위해 참조가 없는 모니터링을 구현합니다.
- 4단계 - 최적화: 평가 통계를 사용하여 모델 개선 및 검색 시스템 향상을 안내합니다.
15. 결론
수고하셨습니다 실습을 완료했습니다.
이 실습은 Google Cloud를 사용한 프로덕션 레디 AI 학습 과정의 일부입니다.
- 전체 교육과정을 살펴보고 프로토타입에서 프로덕션으로 전환하세요.
ProductionReadyAI해시태그를 사용하여 진행 상황을 공유하세요.
요약
지금까지 학습한 내용은 다음과 같습니다.
- 검색된 컨텍스트를 기반으로 답변의 품질을 평가하기 위해 참조가 필요 없는 평가를 수행합니다.
- 사실적 정확성을 측정하기 위해 '골든 답변'을 추가하여 참조 평가를 실행합니다.
- 두 접근 방식 모두에 사전 정의된 측정항목과 맞춤 측정항목을 함께 사용합니다.
- 모델 기반 측정항목 (예:
question_answering_quality)과 계산 기반 측정항목 (rouge,bleu,exact_match)을 모두 사용합니다. - 결과를 분석하고 시각화하여 모델의 장단점을 파악합니다.
이 평가 접근 방식을 사용하면 더 안정적이고 정확한 생성형 AI 애플리케이션을 빌드할 수 있습니다.