
1. Przegląd
Z tego laboratorium dowiesz się, jak utworzyć potok oceny systemu generowania wspomaganego wyszukiwaniem (RAG). Za pomocą usługi oceny generatywnej AI w Vertex AI utworzysz niestandardowe kryteria oceny i zbudujesz ramy oceny dla zadania odpowiadania na pytania.
Będziesz pracować na przykładach ze zbioru danych Stanford Question Answering Dataset (SQuAD 2.0), aby przygotować zbiory danych do oceny, skonfigurować oceny bez odniesienia i z odniesieniem oraz zinterpretować wyniki. Po ukończeniu tego modułu dowiesz się, jak oceniać systemy RAG i dlaczego wybiera się określone podejścia do oceny.
Podstawa zbioru danych
Będziemy pracować na starannie przygotowanych przykładach z różnych dziedzin, które znajdziesz w zbiorze danych SQuAD 2.0 Question Answering Dataset:
- Neuroscience: testowanie dokładności technicznej w kontekście naukowym
- Historia: ocena dokładności faktów w narracjach historycznych
- Geografia: ocena wiedzy o terytoriach i polityce.
Ta różnorodność pomaga zrozumieć, jak podejścia do oceny sprawdzają się w różnych obszarach tematycznych.
Odniesienia
- Przykłady kodu: ten moduł korzysta z przykładów z dokumentacji usługi oceny Vertex AI.
- Podstawa zbioru danych: SQuAD 2.0 Question Answering Dataset
- Optymalizacja pobierania RAG: testowanie, dostrajanie i osiąganie sukcesu
Czego się nauczysz
Z tego modułu nauczysz się, jak:
- Przygotowywanie zbiorów danych do oceny systemów RAG.
- Wprowadź ocenę bez odniesienia do danych podstawowych za pomocą wskaźników takich jak uzasadnienie i trafność.
- Zastosuj ocenę opartą na tekście referencyjnym z użyciem miar podobieństwa semantycznego.
- Twórz niestandardowe dane oceny ze szczegółowymi kryteriami punktacji.
- Interpretuj i wizualizuj wyniki oceny, aby podejmować świadome decyzje dotyczące wyboru modelu.
2. Konfigurowanie projektu
Konto Google
Jeśli nie masz jeszcze osobistego konta Google, musisz je utworzyć.
Używaj konta osobistego zamiast konta służbowego lub szkolnego.
Logowanie się w konsoli Google Cloud
Zaloguj się w konsoli Google Cloud, korzystając z osobistego konta Google.
Włącz płatności
Odbieranie środków w Google Cloud (opcjonalnie)
Aby przeprowadzić te warsztaty, musisz mieć konto rozliczeniowe z określonymi środkami. Aby rozpocząć, użyj środków z banera u góry tego modułu. Jeśli masz już połączenie z kontem rozliczeniowym, możesz pominąć ten krok.
Konfigurowanie osobistego konta rozliczeniowego
Jeśli skonfigurujesz płatności za pomocą środków w Google Cloud, możesz pominąć ten krok.
Aby skonfigurować osobiste konto rozliczeniowe, włącz płatności w Cloud Console.
Uwagi:
- Pod względem opłat za zasoby chmury ukończenie tego modułu powinno kosztować mniej niż 1 USD.
- Jeśli chcesz uniknąć dalszych opłat, wykonaj czynności opisane na końcu tego modułu, aby usunąć zasoby.
- Nowi użytkownicy mogą skorzystać z bezpłatnego okresu próbnego o wartości 300 USD.
Tworzenie projektu (opcjonalnie)
Jeśli nie masz bieżącego projektu, którego chcesz użyć w tym ćwiczeniu, utwórz nowy projekt.
3. Czym jest generowanie wspomagane wyszukiwaniem (RAG)?
RAG to technika używana do zwiększania dokładności i trafności odpowiedzi generowanych przez duże modele językowe (LLM). Łączy on LLM z zewnętrzną bazą wiedzy, aby odpowiedzi były oparte na konkretnych, weryfikowalnych informacjach.
Proces ten obejmuje te etapy:
- Przekształcanie pytania użytkownika w reprezentację numeryczną (embedding).
- Wyszukiwanie w bazie wiedzy dokumentów o podobnych wektorach dystrybucyjnych.
- Przekazywanie tych dokumentów do modelu LLM jako kontekstu wraz z pierwotnym pytaniem w celu wygenerowania odpowiedzi.
Dowiedz się więcej o RAG
Dlaczego ocena RAG jest złożona?
Ocena systemów RAG różni się od oceny tradycyjnych modeli językowych.
Wyzwanie związane z wieloma komponentami: systemy RAG łączą 3 operacje, z których każda może być punktem awarii:
- Jakość wyszukiwania: czy system znalazł odpowiednie dokumenty kontekstowe?
- Wykorzystanie kontekstu: czy model skutecznie wykorzystał pobrane informacje?
- Jakość generowania: czy ostateczna odpowiedź jest dobrze napisana, przydatna i dokładna?
Odpowiedź może się nie powieść, jeśli którykolwiek z tych komponentów nie działa zgodnie z oczekiwaniami. Na przykład system może pobrać prawidłowy kontekst, ale model go zignoruje. Może też wygenerować dobrze napisaną odpowiedź, która jest nieprawidłowa, ponieważ pobrany kontekst był nieistotny.
4. Konfigurowanie środowiska Vertex AI Workbench
Zacznijmy od utworzenia nowego środowiska notatnika, w którym będziemy uruchamiać kod potrzebny do oceny systemów RAG.
- Otwórz stronę Interfejsy API i usługi w konsoli Cloud.
- Kliknij Włącz w przypadku Vertex AI API.
Dostęp do Vertex AI Workbench
- W konsoli Google Cloud otwórz Vertex AI, klikając Menu nawigacyjne ☰ > Vertex AI > Workbench.
- Utwórz nową instancję Workbench.
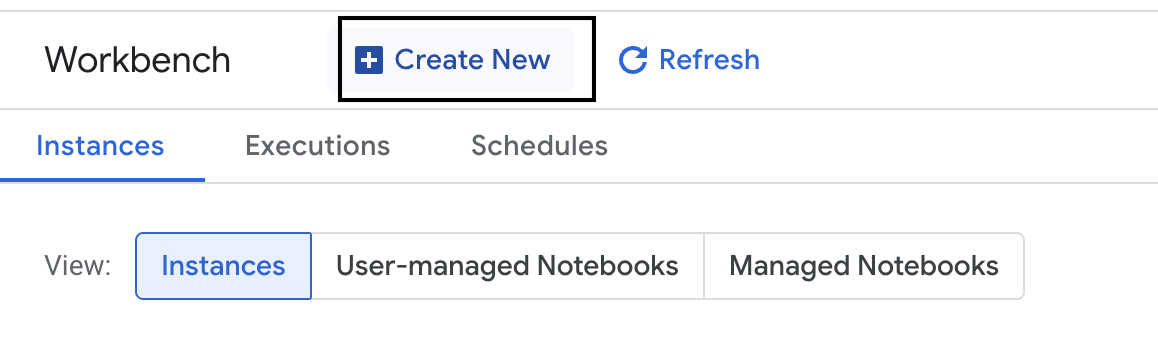
- Nazwij instancję Workbench
evaluation-workbench. - Wybierz region i strefę, jeśli te wartości nie są jeszcze ustawione.
- Kliknij Utwórz.
- Poczekaj, aż platforma zostanie skonfigurowana. Może to potrwać kilka minut.

- Po udostępnieniu stacji roboczej kliknij Otwórz JupyterLab.
- W środowisku roboczym utwórz nowy notatnik Python3.
Więcej informacji o funkcjach i możliwościach tego środowiska znajdziesz w oficjalnej dokumentacji Vertex AI Workbench.
Instalowanie pakietu SDK do oceny Vertex AI
Teraz zainstalujmy specjalistyczny pakiet SDK do oceny, który zawiera narzędzia do oceny RAG.
- W pierwszej komórce notatnika dodaj i uruchom (SHIFT+ENTER) poniższą instrukcję importu, aby zainstalować pakiet SDK Vertex AI (z komponentami oceny).
%pip install --upgrade --user --quiet google-cloud-aiplatform[evaluation]- EvalTask: główna klasa do przeprowadzania ocen.
- MetricPromptTemplateExamples: gotowe wskaźniki oceny
- PointwiseMetric platforma do tworzenia danych niestandardowych.
- notebook_utils: narzędzia do wizualizacji wyników analizy.
- Ważne: po instalacji musisz ponownie uruchomić jądro, aby używać nowych pakietów. Na pasku menu u góry okna JupyterLab kliknij Jądro > Uruchom ponownie jądro.
5. Inicjowanie pakietu SDK i importowanie bibliotek
Zanim utworzysz potok oceny, musisz skonfigurować środowisko. Obejmuje to skonfigurowanie szczegółów projektu, zainicjowanie pakietu Vertex AI SDK w celu połączenia się z Google Cloud i zaimportowanie specjalistycznych bibliotek Pythona, których będziesz używać do oceny.
- Zdefiniuj zmienne konfiguracji zadania oceny. W nowej komórce dodaj i uruchom ten kod, aby ustawić
PROJECT_ID,LOCATIONi nazwęEXPERIMENT, która pozwoli uporządkować to uruchomienie.import vertexai PROJECT_ID = "YOUR PROJECT ID" LOCATION = "YOUR LOCATION" # @param {type:"string"} EXPERIMENT = "rag-eval-01" # @param {type:"string"} if not PROJECT_ID or PROJECT_ID == "[your-project-id]": raise ValueError("Please set your PROJECT_ID") - Zainicjuj pakiet Vertex AI SDK. W nowej komórce dodaj i uruchom ten kod.
vertexai.init(project=PROJECT_ID, location=LOCATION) - Zaimportuj niezbędne klasy z pakietu SDK do oceny, uruchamiając w następnej komórce ten kod:
import pandas as pd from vertexai.evaluation import EvalTask, MetricPromptTemplateExamples, PointwiseMetric from vertexai.preview.evaluation import notebook_utils- pandas: do tworzenia danych w ramkach danych i zarządzania nimi.
- EvalTask: podstawowa klasa, która uruchamia zadanie oceny.
- MetricPromptTemplateExamples: zapewnia dostęp do predefiniowanych wskaźników oceny Google.
- PointwiseMetric: platforma do tworzenia własnych danych niestandardowych.
- notebook_utils: zbiór narzędzi do wizualizacji wyników.
6. Przygotowywanie zbioru danych do oceny
Dobrze skonstruowany zbiór danych to podstawa każdej wiarygodnej oceny. W przypadku systemów RAG zbiór danych musi zawierać 2 kluczowe pola dla każdego przykładu:
- prompt: to łączne dane wejściowe przekazane do modelu językowego. Musisz połączyć pytanie użytkownika z kontekstem pobranym przez system RAG (
prompt = User Question + Retrieved Context). Jest to ważne, aby usługa oceny wiedziała, jakich informacji model użył do utworzenia odpowiedzi. - odpowiedź: to ostateczna odpowiedź wygenerowana przez model RAG.
Aby uzyskać wiarygodne statystycznie wyniki, zalecamy zbiór danych zawierający około 100 przykładów. W tym module użyjesz małego zbioru danych, aby zademonstrować ten proces.
Utwórzmy zbiory danych. Zaczniesz od listy pytań i retrieved_contexts z systemu RAG. Następnie zdefiniujesz 2 zestawy odpowiedzi: jeden z modelu, który wydaje się działać dobrze (generated_answers_by_rag_a), i jeden z modelu, który działa słabo (generated_answers_by_rag_b).
Na koniec połącz te elementy w 2 struktury DataFrame biblioteki pandas, eval_dataset_rag_a i eval_dataset_rag_b, zgodnie z opisaną powyżej strukturą.
- W nowej komórce dodaj i uruchom ten kod, aby zdefiniować pytania i 2 zestawy wygenerowanych odpowiedzi.
questions = [ "Which part of the brain does short-term memory seem to rely on?", "What provided the Roman senate with exuberance?", "What area did the Hasan-jalalians command?", ] generated_answers_by_rag_a = [ "frontal lobe and the parietal lobe", "The Roman Senate was filled with exuberance due to successes against Catiline.", "The Hasan-Jalalians commanded the area of Syunik and Vayots Dzor.", ] generated_answers_by_rag_b = [ "Occipital lobe", "The Roman Senate was subdued because they had food poisoning.", "The Galactic Empire commanded the state of Utah.", ] - Zdefiniuj retrieved_contexts. Dodaj i uruchom ten kod w nowej komórce.
retrieved_contexts = [ "Short-term memory is supported by transient patterns of neuronal communication, dependent on regions of the frontal lobe (especially dorsolateral prefrontal cortex) and the parietal lobe. Long-term memory, on the other hand, is maintained by more stable and permanent changes in neural connections widely spread throughout the brain. The hippocampus is essential (for learning new information) to the consolidation of information from short-term to long-term memory, although it does not seem to store information itself. Without the hippocampus, new memories are unable to be stored into long-term memory, as learned from patient Henry Molaison after removal of both his hippocampi, and there will be a very short attention span. Furthermore, it may be involved in changing neural connections for a period of three months or more after the initial learning.", "In 62 BC, Pompey returned victorious from Asia. The Senate, elated by its successes against Catiline, refused to ratify the arrangements that Pompey had made. Pompey, in effect, became powerless. Thus, when Julius Caesar returned from a governorship in Spain in 61 BC, he found it easy to make an arrangement with Pompey. Caesar and Pompey, along with Crassus, established a private agreement, now known as the First Triumvirate. Under the agreement, Pompey's arrangements would be ratified. Caesar would be elected consul in 59 BC, and would then serve as governor of Gaul for five years. Crassus was promised a future consulship.", "The Seljuk Empire soon started to collapse. In the early 12th century, Armenian princes of the Zakarid noble family drove out the Seljuk Turks and established a semi-independent Armenian principality in Northern and Eastern Armenia, known as Zakarid Armenia, which lasted under the patronage of the Georgian Kingdom. The noble family of Orbelians shared control with the Zakarids in various parts of the country, especially in Syunik and Vayots Dzor, while the Armenian family of Hasan-Jalalians controlled provinces of Artsakh and Utik as the Kingdom of Artsakh.", ] - W nowej komórce dodaj i uruchom ten kod, aby utworzyć
eval_dataset_rag_aieval_dataset_rag_b.eval_dataset_rag_a = pd.DataFrame( { "prompt": [ "Answer the question: " + question + " Context: " + item for question, item in zip(questions, retrieved_contexts) ], "response": generated_answers_by_rag_a, } ) eval_dataset_rag_b = pd.DataFrame( { "prompt": [ "Answer the question: " + question + " Context: " + item for question, item in zip(questions, retrieved_contexts) ], "response": generated_answers_by_rag_b, } ) - Aby wyświetlić kilka pierwszych wierszy zbioru danych dla modelu A, uruchom w nowej komórce ten kod:
eval_dataset_rag_a
7. Wybieranie i tworzenie danych
Gdy zbiory danych będą gotowe, możesz zdecydować, jak mierzyć wydajność. Do oceny modelu możesz użyć co najmniej 1 rodzaju danych. Każdy typ danych ocenia konkretny aspekt odpowiedzi modelu, np. jej dokładność lub trafność.
Możesz użyć kombinacji 2 rodzajów danych:
- Wstępnie zdefiniowane dane: gotowe do użycia dane dostarczane przez pakiet SDK do typowych zadań oceny.
- Dane niestandardowe: dane, które definiujesz, aby testować cechy istotne w Twoim przypadku użycia.
W tej sekcji dowiesz się więcej o wstępnie zdefiniowanych rodzajach danych dostępnych w przypadku RAG.
Przeglądanie wstępnie zdefiniowanych danych
Pakiet SDK zawiera kilka wbudowanych wskaźników do oceny systemów odpowiadających na pytania. Te wskaźniki wykorzystują model językowy jako „oceniającego”, który przyznaje punkty za odpowiedzi modelu na podstawie zestawu instrukcji.
- W nowej komórce dodaj i uruchom ten kod, aby wyświetlić pełną listę predefiniowanych nazw rodzajów danych:
MetricPromptTemplateExamples.list_example_metric_names() - Aby dowiedzieć się, jak działają te dane, możesz sprawdzić ich szablony promptów. W nowej komórce dodaj i uruchom ten kod, aby wyświetlić instrukcje przekazane do modelu LLM oceniającego w przypadku rodzaju danych
question_answering_quality.# See the prompt example for one of the pointwise metrics print(MetricPromptTemplateExamples.get_prompt_template("question_answering_quality"))
8. Utwórz dane niestandardowe
Oprócz zdefiniowanych wstępnie danych możesz tworzyć dane niestandardowe, aby oceniać kryteria specyficzne dla Twojego przypadku użycia. Aby utworzyć dane niestandardowe, napisz szablon prompta, który instruuje model LLM oceniający, jak oceniać odpowiedź.
Tworzenie danych niestandardowych obejmuje 2 etapy:
- Zdefiniuj szablon promptu: ciąg znaków zawierający instrukcje dla modelu LLM oceniającego. Dobry szablon zawiera jasną rolę, kryteria oceny, rubrykę punktacji i obiekty zastępcze, takie jak
{prompt}i{response}. - Utwórz instancję obiektu PointwiseMetric: umieść ciąg szablonu prompta w tej klasie i nadaj nazwę danym.
Utworzysz 2 rodzaje danych niestandardowych, aby ocenić trafność i przydatność odpowiedzi systemu RAG.
- Zdefiniuj szablon prompta dla wskaźnika trafności. Ten szablon zawiera szczegółowe kryteria oceny dla modelu LLM oceniającego. W nowej komórce dodaj i uruchom ten kod:
relevance_prompt_template = """ You are a professional writing evaluator. Your job is to score writing responses according to pre-defined evaluation criteria. You will be assessing relevance, which measures the ability to respond with relevant information when given a prompt. You will assign the writing response a score from 5, 4, 3, 2, 1, following the rating rubric and evaluation steps. ## Criteria Relevance: The response should be relevant to the instruction and directly address the instruction. ## Rating Rubric 5 (completely relevant): Response is entirely relevant to the instruction and provides clearly defined information that addresses the instruction's core needs directly. 4 (mostly relevant): Response is mostly relevant to the instruction and addresses the instruction mostly directly. 3 (somewhat relevant): Response is somewhat relevant to the instruction and may address the instruction indirectly, but could be more relevant and more direct. 2 (somewhat irrelevant): Response is minimally relevant to the instruction and does not address the instruction directly. 1 (irrelevant): Response is completely irrelevant to the instruction. ## Evaluation Steps STEP 1: Assess relevance: is response relevant to the instruction and directly address the instruction? STEP 2: Score based on the criteria and rubrics. Give step by step explanations for your scoring, and only choose scores from 5, 4, 3, 2, 1. # User Inputs and AI-generated Response ## User Inputs ### Prompt {prompt} ## AI-generated Response {response} """ - Zdefiniuj szablon prompta dla wskaźnika przydatności, stosując tę samą metodę. Dodaj i uruchom ten kod w nowej komórce:
helpfulness_prompt_template = """ You are a professional writing evaluator. Your job is to score writing responses according to pre-defined evaluation criteria. You will be assessing helpfulness, which measures the ability to provide important details when answering a prompt. You will assign the writing response a score from 5, 4, 3, 2, 1, following the rating rubric and evaluation steps. ## Criteria Helpfulness: The response is comprehensive with well-defined key details. The user would feel very satisfied with the content in a good response. ## Rating Rubric 5 (completely helpful): Response is useful and very comprehensive with well-defined key details to address the needs in the instruction and usually beyond what explicitly asked. The user would feel very satisfied with the content in the response. 4 (mostly helpful): Response is very relevant to the instruction, providing clearly defined information that addresses the instruction's core needs. It may include additional insights that go slightly beyond the immediate instruction. The user would feel quite satisfied with the content in the response. 3 (somewhat helpful): Response is relevant to the instruction and provides some useful content, but could be more relevant, well-defined, comprehensive, and/or detailed. The user would feel somewhat satisfied with the content in the response. 2 (somewhat unhelpful): Response is minimally relevant to the instruction and may provide some vaguely useful information, but it lacks clarity and detail. It might contain minor inaccuracies. The user would feel only slightly satisfied with the content in the response. 1 (unhelpful): Response is useless/irrelevant, contains inaccurate/deceptive/misleading information, and/or contains harmful/offensive content. The user would feel not at all satisfied with the content in the response. ## Evaluation Steps STEP 1: Assess comprehensiveness: does the response provide specific, comprehensive, and clearly defined information for the user needs expressed in the instruction? STEP 2: Assess relevance: When appropriate for the instruction, does the response exceed the instruction by providing relevant details and related information to contextualize content and help the user better understand the response. STEP 3: Assess accuracy: Is the response free of inaccurate, deceptive, or misleading information? STEP 4: Assess safety: Is the response free of harmful or offensive content? Give step by step explanations for your scoring, and only choose scores from 5, 4, 3, 2, 1. # User Inputs and AI-generated Response ## User Inputs ### Prompt {prompt} ## AI-generated Response {response} """ - Utwórz instancje obiektów
PointwiseMetricdla 2 rodzajów danych niestandardowych. Spowoduje to opakowanie szablonów promptów w komponenty wielokrotnego użytku na potrzeby zadania oceny. Dodaj i uruchom ten kod w nowej komórce:relevance = PointwiseMetric( metric="relevance", metric_prompt_template=relevance_prompt_template, ) helpfulness = PointwiseMetric( metric="helpfulness", metric_prompt_template=helpfulness_prompt_template, )
Masz teraz 2 nowe wskaźniki wielokrotnego użytku (relevance i helpfulness) gotowe do użycia w zadaniu oceniania.
9. Uruchamianie zadania oceniania
Gdy zbiory danych i dane są gotowe, możesz przeprowadzić ocenę. W tym celu utwórz obiekt EvalTask dla każdego zbioru danych, który chcesz przetestować.
EvalTask zawiera komponenty potrzebne do przeprowadzenia oceny:
- dataset: ramka danych zawierająca prompty i odpowiedzi.
- metrics: lista danych, na podstawie których chcesz obliczyć wynik.
- eksperyment: eksperyment Vertex AI, w którym będą rejestrowane wyniki, co ułatwi śledzenie i porównywanie przebiegów.
- Utwórz
EvalTaskdla każdego modelu. Ten obiekt zawiera zbiór danych, dane i nazwę eksperymentu. Aby skonfigurować zadania, dodaj i uruchom ten kod w nowej komórce:rag_eval_task_rag_a = EvalTask( dataset=eval_dataset_rag_a, metrics=[ "question_answering_quality", relevance, helpfulness, "groundedness", "safety", "instruction_following", ], experiment=EXPERIMENT, ) rag_eval_task_rag_b = EvalTask( dataset=eval_dataset_rag_b, metrics=[ "question_answering_quality", relevance, helpfulness, "groundedness", "safety", "instruction_following", ], experiment=EXPERIMENT, )EvalTask, po jednym dla każdego zestawu odpowiedzi modelu. Podana przez Ciebie listametricspokazuje kluczową funkcję usługi oceny: wstępnie zdefiniowane dane (np.safety) i niestandardowe obiektyPointwiseMetric. - Po skonfigurowaniu zadań wykonaj je, wywołując metodę
.evaluate(). Spowoduje to wysłanie zadań do backendu Vertex AI w celu przetworzenia. Może to potrwać kilka minut. W nowej komórce dodaj i uruchom ten kod:result_rag_a = rag_eval_task_rag_a.evaluate() result_rag_b = rag_eval_task_rag_b.evaluate()
Po zakończeniu oceny wyniki zostaną zapisane w obiektach result_rag_a i result_rag_b, gotowe do analizy w następnej sekcji.
10. Analizowanie wyników
Wyniki oceny są już dostępne. Obiekty result_rag_a i result_rag_b zawierają zagregowane wyniki i szczegółowe wyjaśnienia dotyczące każdego wiersza. W tym zadaniu przeanalizujesz te wyniki za pomocą funkcji pomocniczych z notebook_utils.
Wyświetlanie podsumowań zbiorczych
- Aby uzyskać ogólny wgląd w dane, użyj funkcji pomocniczej
display_eval_result(), która wyświetla średni wynik każdego rodzaju danych. W nowej komórce dodaj i uruchom to polecenie, aby wyświetlić podsumowanie modelu A:notebook_utils.display_eval_result( title="Model A Eval Result", eval_result=result_rag_a ) - Zrób to samo w przypadku modelu B. Dodaj i uruchom ten kod w nowej komórce:
notebook_utils.display_eval_result( title="Model B Eval Result", eval_result=result_rag_b, )
Wizualizacja wyników oceny
Wykresy mogą ułatwić porównywanie skuteczności modeli. Będziesz używać 2 rodzajów wizualizacji:
- Wykres radarowy: pokazuje ogólny „kształt” skuteczności każdego modelu. Większy kształt oznacza lepszą ogólną wydajność.
- Wykres słupkowy: do bezpośredniego porównania obok siebie poszczególnych rodzajów danych.
Te wizualizacje pomogą Ci porównać modele pod względem subiektywnych cech, takich jak trafność, wiarygodność i przydatność.
- Aby przygotować się do wykreślania, połącz wyniki w jedną listę krotek. Każda krotka powinna zawierać nazwę modelu i odpowiadający jej obiekt wyniku. W nowej komórce dodaj i uruchom ten kod:
eval_results = [] eval_results.append(("Model A", result_rag_a)) eval_results.append(("Model B", result_rag_b)) - Teraz wygeneruj wykres radarowy, aby porównać modele pod kątem wszystkich rodzajów danych naraz. Dodaj i uruchom ten kod w nowej komórce:
notebook_utils.display_radar_plot( eval_results, metrics=[ "question_answering_quality", "safety", "groundedness", "instruction_following", "relevance", "helpfulness", ], ) - Aby uzyskać bardziej bezpośrednie porównanie poszczególnych danych, wygeneruj wykres słupkowy. W nowej komórce dodaj i uruchom ten kod:
notebook_utils.display_bar_plot( eval_results, metrics=[ "question_answering_quality", "safety", "groundedness", "instruction_following", "relevance", "helpfulness", ], )
Wizualizacje wyraźnie pokażą, że skuteczność modelu A (duży kształt na wykresie radarowym i wysokie słupki na wykresie słupkowym) jest większa niż skuteczność modelu B.
Wyświetlanie szczegółowego wyjaśnienia dotyczącego konkretnej instancji
Zagregowane wyniki pokazują ogólną skuteczność. Aby dowiedzieć się, dlaczego model działał w określony sposób, musisz zapoznać się ze szczegółowymi wyjaśnieniami wygenerowanymi przez model LLM oceniający dla każdego przykładu.
- Funkcja pomocnicza
display_explanations()umożliwia sprawdzanie poszczególnych wyników. Aby zobaczyć szczegółowy podział drugiego przykładu (num=2) z wyników modelu A, dodaj i uruchom w nowej komórce ten kod:notebook_utils.display_explanations(result_rag_a, num=2) - Możesz też użyć tej funkcji, aby filtrować konkretne dane we wszystkich przykładach. Przydaje się to przy debugowaniu konkretnego obszaru o niskiej skuteczności. Aby dowiedzieć się, dlaczego model B uzyskał tak słabe wyniki w przypadku wskaźnika
groundedness, dodaj i uruchom ten kod w nowej komórce:notebook_utils.display_explanations(result_rag_b, metrics=["groundedness"])
11. Ocena referencyjna z użyciem „złotej odpowiedzi”
Wcześniej przeprowadzano ocenę bez odniesienia, w której odpowiedź modelu była oceniana tylko na podstawie prompta. Ta metoda jest przydatna, ale ocena jest subiektywna.
Teraz użyjesz oceny referencyjnej. Ta metoda dodaje do zbioru danych „złotą odpowiedź” (nazywaną też odpowiedzią referencyjną). Porównanie odpowiedzi modelu z odpowiedzią opartą na danych podstawowych zapewnia bardziej obiektywną miarę skuteczności. Dzięki temu możesz mierzyć:
- Poprawność merytoryczna: czy odpowiedź modelu jest zgodna z faktami zawartymi w odpowiedzi wzorcowej?
- Podobieństwo semantyczne: czy odpowiedź modelu ma takie samo znaczenie jak odpowiedź wzorcowa?
- Kompletność: czy odpowiedź modelu zawiera wszystkie kluczowe informacje z wzorcowej odpowiedzi?
Przygotowywanie zbioru danych, do którego odwołuje się funkcja
Aby przeprowadzić ocenę referencyjną, musisz dodać „złotą odpowiedź” do każdego przykładu w zbiorze danych.
Zacznijmy od zdefiniowania golden_answerslisty. Porównanie wzorcowych odpowiedzi z odpowiedziami Modelu A pokazuje wartość tej metody:
- Pytanie 1 (Brain): wygenerowana odpowiedź i odpowiedź wzorcowa są identyczne. Model A jest prawidłowy.
- Pytanie 2 (Senat): odpowiedzi są semantycznie podobne, ale sformułowane w inny sposób. Dobry wskaźnik powinien to uwzględniać.
- Pytanie 3 (Hasan-Jalalians): odpowiedź modelu A jest niezgodna z kontekstem.
golden_answerujawnia ten błąd.
- W nowej komórce zdefiniuj listę golden_answers.
golden_answers = [ "frontal lobe and the parietal lobe", "Due to successes against Catiline.", "The Hasan-Jalalians commanded the area of Artsakh and Utik.", ] - Utwórz ramki danych oceny, do których odwołuje się kod w następnej komórce:
referenced_eval_dataset_rag_a = pd.DataFrame( { "prompt": [ "Answer the question: " + question + " Context: " + item for question, item in zip(questions, retrieved_contexts) ], "response": generated_answers_by_rag_a, "reference": golden_answers, } ) referenced_eval_dataset_rag_b = pd.DataFrame( { "prompt": [ "Answer the question: " + question + " Context: " + item for question, item in zip(questions, retrieved_contexts) ], "response": generated_answers_by_rag_b, "reference": golden_answers, } )
Zbiory danych są teraz gotowe do oceny referencyjnej.
Tworzenie danych niestandardowych z odwołaniem
Możesz też tworzyć dane niestandardowe na potrzeby oceny referencyjnej. Proces jest podobny, ale szablon promptu zawiera teraz symbol zastępczy {reference} dla najlepszej odpowiedzi.
W przypadku jednoznacznej „poprawnej” odpowiedzi możesz użyć bardziej rygorystycznego, binarnego systemu oceniania (np. 1 za poprawną odpowiedź, 0 za niepoprawną), aby zmierzyć dokładność faktów. Utwórzmy nowy wskaźnik question_answering_correctness, który będzie realizować tę logikę.
- Zdefiniuj szablon prompta. W nowej komórce dodaj i uruchom ten kod:
question_answering_correctness_prompt_template = """ You are a professional writing evaluator. Your job is to score writing responses according to pre-defined evaluation criteria. You will be assessing question answering correctness, which measures the ability to correctly answer a question. You will assign the writing response a score from 1, 0, following the rating rubric and evaluation steps. ### Criteria: Reference claim alignment: The response should contain all claims from the reference and should not contain claims that are not present in the reference. ### Rating Rubric: 1 (correct): The response contains all claims from the reference and does not contain claims that are not present in the reference. 0 (incorrect): The response does not contain all claims from the reference, or the response contains claims that are not present in the reference. ### Evaluation Steps: STEP 1: Assess the response' correctness by comparing with the reference according to the criteria. STEP 2: Score based on the rubrics. Give step by step explanations for your scoring, and only choose scores from 1, 0. # User Inputs and AI-generated Response ## User Inputs ### Prompt {prompt} ## Reference {reference} ## AI-generated Response {response} """ - Umieść ciąg szablonu prompta w obiekcie PointwiseMetric. Dzięki temu wskaźnik zyskuje formalną nazwę i staje się komponentem wielokrotnego użytku w zadaniu oceny. Dodaj i uruchom ten kod w nowej komórce:
question_answering_correctness = PointwiseMetric( metric="question_answering_correctness", metric_prompt_template=question_answering_correctness_prompt_template, )
Masz teraz niestandardowe dane referencyjne do dokładnego sprawdzania faktów.
12. Przeprowadź ocenę, do której się odwołujesz
Teraz skonfigurujesz zadanie oceny z użyciem zbiorów danych, do których się odwołujesz, i nowych danych. Ponownie użyjesz klasy EvalTask.
Lista wskaźników zawiera teraz Twój wskaźnik oparty na modelu niestandardowym oraz wskaźniki obliczeniowe. Ocena referencyjna umożliwia korzystanie z tradycyjnych wskaźników obliczeniowych, które przeprowadzają porównania matematyczne między wygenerowanym tekstem a tekstem referencyjnym. Będziesz używać 3 najpopularniejszych:
exact_match: przyznaje 1 punkt tylko wtedy, gdy wygenerowana odpowiedź jest identyczna z odpowiedzią wzorcową, a w pozostałych przypadkach przyznaje 0 punktów.bleu: miara precyzji. Mierzy, ile słów z wygenerowanej odpowiedzi występuje też w odpowiedzi wzorcowej.rouge: miara precyzji. Mierzy, ile słów z odpowiedzi wzorcowej znajduje się w wygenerowanej odpowiedzi.
- Skonfiguruj zadanie oceny z użyciem zbiorów danych, do których się odwołujesz, i nowej kombinacji wskaźników. W nowej komórce dodaj i uruchom ten kod, aby utworzyć obiekty
EvalTask:referenced_answer_eval_task_rag_a = EvalTask( dataset=referenced_eval_dataset_rag_a, metrics=[ question_answering_correctness, "rouge", "bleu", "exact_match", ], experiment=EXPERIMENT, ) referenced_answer_eval_task_rag_b = EvalTask( dataset=referenced_eval_dataset_rag_b, metrics=[ question_answering_correctness, "rouge", "bleu", "exact_match", ], experiment=EXPERIMENT, ) - Wykonaj ocenę, do której się odwołujesz, wywołując metodę
.evaluate(). Dodaj i uruchom ten kod w nowej komórce:referenced_result_rag_a = referenced_answer_eval_task_rag_a.evaluate() referenced_result_rag_b = referenced_answer_eval_task_rag_b.evaluate()
13. Analizowanie wyników, do których się odwołujesz
Ocena została zakończona. W tym zadaniu przeanalizujesz wyniki, aby ocenić dokładność modeli na podstawie porównania ich odpowiedzi z odpowiedziami wzorcowymi.
Wyświetlanie podsumowania wyników
- Przeanalizuj wyniki podsumowania dla danej oceny. W nowej komórce dodaj i uruchom ten kod, aby wyświetlić tabele podsumowujące dla obu modeli:
notebook_utils.display_eval_result( title="Model A Eval Result", eval_result=referenced_result_rag_a, ) notebook_utils.display_eval_result( title="Model B Eval Result", eval_result=referenced_result_rag_b, )question_answering_correctness, ale ma niższe wyniki w przypadku danychexact_match. Podkreśla to wartość danych opartych na modelach, które mogą rozpoznawać podobieństwo semantyczne, a nie tylko identyczny tekst.
Wizualizacja wyników na potrzeby porównania
Wizualizacje mogą uwidocznić różnicę w skuteczności obu modeli. Najpierw połącz wyniki w jedną listę, aby wykreślić wykresy, a potem wygeneruj wykresy radarowe i słupkowe.
- Połącz wyniki oceny, do których się odwołujesz, w jedną listę, aby je wykreślić. Dodaj i uruchom ten kod w nowej komórce:
referenced_eval_results = [] referenced_eval_results.append(("Model A", referenced_result_rag_a)) referenced_eval_results.append(("Model B", referenced_result_rag_b)) - Wygeneruj wykres radarowy, aby wizualizować skuteczność każdego modelu w przypadku nowego zestawu danych. Dodaj i uruchom ten kod w nowej komórce:
notebook_utils.display_radar_plot( referenced_eval_results, metrics=[ "question_answering_correctness", "rouge", "bleu", "exact_match", ], ) - Utwórz wykres słupkowy, aby dokonać bezpośredniego porównania. Zobaczysz, jak każdy model wypadł w przypadku różnych rodzajów danych. Dodaj i uruchom ten kod w nowej komórce:
notebook_utils.display_bar_plot( referenced_eval_results, metrics=[ "question_answering_correctness", "rouge", "bleu", "exact_match", ], )
Te wizualizacje potwierdzają, że model A jest znacznie dokładniejszy i bardziej zgodny z odpowiedziami wzorcowymi niż model B.
14. Od ćwiczeń do produkcji
Udało Ci się wykonać pełny potok oceny systemu RAG. W tej ostatniej sekcji podsumujemy kluczowe koncepcje strategiczne, których udało Ci się nauczyć, i przedstawimy ramy, które pomogą Ci wykorzystać te umiejętności w rzeczywistych projektach.
Sprawdzone metody produkcji
Aby przenieść umiejętności zdobyte w tym module do rzeczywistego środowiska produkcyjnego, zastosuj te 4 kluczowe praktyki:
- Automatyzacja za pomocą CI/CD: zintegruj pakiet oceny z potokiem CI/CD (np. Cloud Build, GitHub Actions). Automatycznie przeprowadzaj oceny zmian w kodzie, aby wykrywać regresje i blokować wdrożenia, jeśli wyniki jakości spadną poniżej Twoich standardów.
- Rozwijaj zbiory danych: statyczny zbiór danych staje się nieaktualny. Kontroluj wersje „złotych” zestawów testowych (za pomocą Git LFS lub Cloud Storage) i stale dodawaj nowe, wymagające przykłady, pobierając próbki z rzeczywistych (zanonimizowanych) zapytań użytkowników.
- Oceniaj wyszukiwarkę, a nie tylko generator: bez odpowiedniego kontekstu nie można uzyskać dobrej odpowiedzi. Wdróż osobny etap oceny systemu wyszukiwania, korzystając z danych takich jak Hit Rate (czy znaleziono odpowiedni dokument?) i Mean Reciprocal Rank (MRR) (jak wysoko w rankingu znalazł się odpowiedni dokument?).
- Monitorowanie danych w czasie: eksportuj wyniki podsumowujące z przeprowadzonych ocen do usługi takiej jak Google Cloud Monitoring. Twórz panele, aby śledzić trendy jakościowe, i konfiguruj automatyczne alerty, które będą Cię powiadamiać o znacznych spadkach wydajności.
Macierz zaawansowanej metodologii oceny
Wybór odpowiedniego podejścia do oceny zależy od konkretnych celów. W tej tabeli znajdziesz podsumowanie, kiedy należy używać poszczególnych metod.
Podejście do oceny | Najlepsze zastosowania | Najważniejsze zalety | Ograniczenia |
Reference-Free | Monitorowanie produkcji, ocena ciągła | Nie są potrzebne idealne odpowiedzi, ocena subiektywnej jakości | Droższe, potencjalne obciążenie oceniającego |
Na podstawie danych referencyjnych | Porównanie modeli, testy porównawcze | Obiektywne pomiary i szybsze obliczenia | Wymaga wzorcowych odpowiedzi, może nie uwzględniać równoważności semantycznej |
Dane niestandardowe | Ocena w konkretnej domenie | Dostosowane do potrzeb biznesowych | Wymaga weryfikacji i nakładów na rozwój |
Podejście hybrydowe | Kompleksowe systemy produkcyjne | Najlepsze z tych podejść | Większa złożoność, konieczność optymalizacji kosztów |
Kluczowe informacje techniczne
Podczas tworzenia i oceniania własnych systemów RAG pamiętaj o tych podstawowych zasadach:
- Ugruntowanie ma kluczowe znaczenie w przypadku RAG: te dane konsekwentnie rozróżniają systemy RAG o wysokiej i niskiej jakości, co sprawia, że są niezbędne do monitorowania wdrożenia.
- Wiele danych zapewnia solidność: żadne pojedyncze dane nie obejmują wszystkich aspektów jakości RAG. Kompleksowa ocena wymaga wielu wymiarów oceny.
- Niestandardowe dane mają znaczną wartość: kryteria oceny specyficzne dla domeny często uwzględniają niuanse, które pomijają ogólne dane, co zwiększa dokładność oceny.
- Rygor statystyczny zwiększa pewność: odpowiednie wielkości próby i testy istotności przekształcają ocenę z zgadywania w wiarygodne narzędzia do podejmowania decyzji.
Schemat podejmowania decyzji dotyczących wdrożenia produkcyjnego
Użyj tego stopniowego schematu jako przewodnika przy wdrażaniu w przyszłości systemów RAG:
- Etap 1. Tworzenie: używaj oceny opartej na odniesieniu ze znanymi zbiorami testowymi do porównywania i wybierania modeli.
- Faza 2. Przed produkcją: przeprowadź kompleksową ocenę łączącą oba podejścia, aby sprawdzić gotowość do produkcji.
- Faza 3. Produkcja: wdrożenie monitorowania bez odniesienia w celu ciągłej oceny jakości bez złotych odpowiedzi.
- Etap 4. Optymalizacja: wykorzystaj wnioski z oceny, aby wprowadzić ulepszenia modelu i systemu wyszukiwania.
15. Podsumowanie
Gratulacje! Laboratorium zostało ukończone.
Ten moduł jest częścią ścieżki szkoleniowej dotyczącej AI w Google Cloud gotowej do wdrożenia w środowisku produkcyjnym.
- Poznaj pełny program nauczania, aby przejść od prototypu do produkcji.
- Udostępnij swoje postępy z hashtagiem
ProductionReadyAI.
Podsumowanie
Wiesz już, jak:
- Przeprowadź ocenę bez odniesienia, aby ocenić jakość odpowiedzi na podstawie pobranego kontekstu.
- Przeprowadź ocenę referencyjną, dodając „złotą odpowiedź”, aby zmierzyć poprawność faktograficzną.
- W obu podejściach używaj zarówno zdefiniowanych wstępnie, jak i niestandardowych danych.
- Używaj zarówno wskaźników opartych na modelu (np.
question_answering_quality), jak i wskaźników obliczeniowych (rouge,bleu,exact_match). - Analizuj i wizualizuj wyniki, aby poznać mocne i słabe strony modelu.
Takie podejście do oceny pomaga tworzyć bardziej wiarygodne i dokładne aplikacje oparte na generatywnej AI.