
1. Visão geral
Neste laboratório, você vai aprender a criar um pipeline de avaliação para um sistema de geração aumentada por recuperação (RAG). Você vai usar o serviço de avaliação de IA generativa da Vertex AI para criar critérios de avaliação personalizados e uma estrutura de avaliação para uma tarefa de resposta a perguntas.
Você vai trabalhar com exemplos do Stanford Question Answering Dataset (SQuAD 2.0) para preparar conjuntos de dados de avaliação, configurar avaliações sem e com referência e interpretar os resultados. Ao final deste laboratório, você vai entender como avaliar sistemas de RAG e por que determinadas abordagens de avaliação são escolhidas.
Base de dados
Vamos trabalhar com exemplos cuidadosamente elaborados que abrangem vários domínios encontrados no conjunto de dados de resposta a perguntas SQuAD 2.0:
- Neurociência: teste de precisão técnica em contextos científicos
- História: avaliação da precisão factual em narrativas históricas
- Geografia: avaliação do conhecimento territorial e político
Essa diversidade ajuda você a entender como as abordagens de avaliação são generalizadas em diferentes áreas de assunto.
Referências
- Exemplos de código: este laboratório usa exemplos da documentação da avaliação da Vertex AI.
- Base do conjunto de dados: conjunto de dados de respostas a perguntas SQuAD 2.0
- Otimizar a recuperação de RAG: teste, ajuste e tenha sucesso
O que você vai aprender
Neste laboratório, você aprenderá a fazer o seguinte:
- Prepare conjuntos de dados de avaliação para sistemas de RAG.
- Implemente a avaliação sem referência usando métricas como embasamento e relevância.
- Aplicar avaliação com base em referência com medidas de similaridade semântica.
- Crie métricas de avaliação personalizadas com rubricas de pontuação detalhadas.
- Interpretar e visualizar os resultados da avaliação para informar a seleção do modelo.
2. Configurar o projeto
Conta do Google
Se você ainda não tiver uma Conta do Google pessoal, crie uma.
Use uma conta pessoal em vez de uma conta escolar ou de trabalho.
Fazer login no console do Google Cloud
Faça login no console do Google Cloud usando uma Conta do Google pessoal.
Ativar faturamento
Resgatar créditos do Google Cloud (opcional)
Para fazer este workshop, você precisa de uma conta de faturamento com algum crédito. Use os créditos do banner na parte de cima deste codelab para começar. Se você já estiver conectado a uma conta de faturamento, pule esta etapa.
Configurar uma conta de faturamento pessoal
Se você configurou o faturamento usando créditos do Google Cloud, pule esta etapa.
Para configurar uma conta de faturamento pessoal, acesse este link e ative o faturamento no console do Cloud.
Algumas observações:
- A conclusão deste laboratório custa menos de US $1 em recursos do Cloud.
- Siga as etapas no final deste laboratório para excluir recursos e evitar mais cobranças.
- Novos usuários podem aproveitar o teste sem custos financeiros de US$300.
Criar um projeto (opcional)
Se você não tiver um projeto atual que gostaria de usar neste laboratório, crie um novo aqui.
3. O que é a geração aumentada por recuperação (RAG)?
A RAG é uma técnica usada para melhorar a acurácia e a relevância das respostas dos modelos de linguagem grandes (LLMs). Ele conecta o LLM a uma base de conhecimento externa para embasar as respostas em informações específicas e verificáveis.
O processo envolve estas etapas:
- Converter a pergunta de um usuário em uma representação numérica (um embedding).
- Pesquisar na base de conhecimento documentos com embeddings semelhantes.
- Fornecer esses documentos relevantes como contexto para o LLM junto com a pergunta original para gerar uma resposta.
Saiba mais sobre o RAG.
O que torna a avaliação da RAG complexa?
A avaliação de sistemas de RAG é diferente da avaliação de modelos de linguagem tradicionais.
O desafio de vários componentes: os sistemas de RAG combinam três operações que podem ser um ponto de falha:
- Qualidade da recuperação: o sistema encontrou os documentos de contexto certos?
- Uso do contexto: o modelo usou as informações recuperadas de maneira eficaz?
- Qualidade da geração: a resposta final é bem escrita, útil e precisa?
Uma resposta pode falhar se algum desses componentes não funcionar como esperado. Por exemplo, o sistema pode recuperar o contexto correto, mas o modelo o ignora. Ou o modelo pode gerar uma resposta bem escrita, mas incorreta, porque o contexto recuperado era irrelevante.
4. Configurar o ambiente do Vertex AI Workbench
Vamos começar criando um novo ambiente de notebook em que vamos executar o código necessário para avaliar os sistemas RAG.
- Acesse a página "APIs e serviços" do Console do Cloud.
- Clique em Ativar para a API Vertex AI.
acessar o Vertex AI Workbench
- No console do Google Cloud, clique no Menu de navegação ☰ > Vertex AI > Workbench.
- Crie uma instância do Workbench.
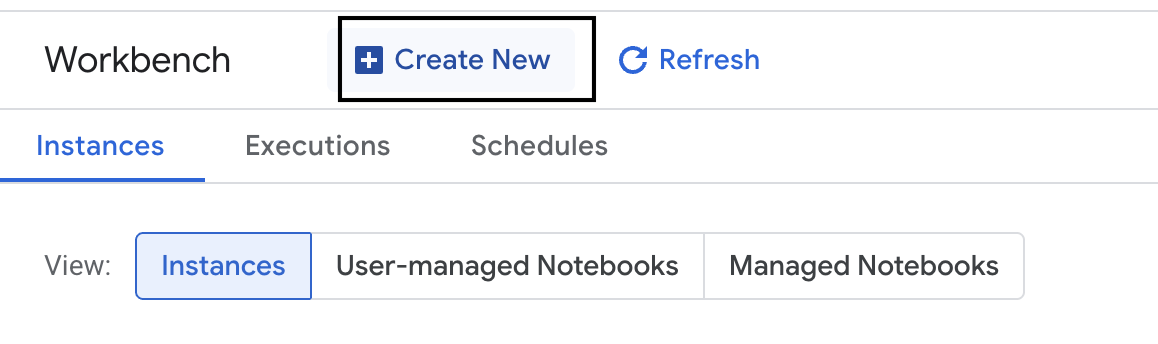
- Nomeie a instância do Workbench como
evaluation-workbench. - Selecione sua região e zona se esses valores ainda não estiverem definidos.
- Clique em Criar.
- Aguarde a configuração da estação de trabalho. Isso pode levar alguns minutos.

- Quando o workbench for provisionado, clique em abrir jupyterlab.
- No workbench, crie um notebook Python3.
Para saber mais sobre os recursos e as funcionalidades desse ambiente, consulte a documentação oficial do Vertex AI Workbench.
Instalar o SDK de avaliação da Vertex AI
Agora vamos instalar o SDK de avaliação especializada que fornece as ferramentas para avaliação de RAG.
- Na primeira célula do notebook, adicione e execute a instrução de importação abaixo (SHIFT+ENTER) para instalar o SDK da Vertex AI (com os componentes de avaliação).
%pip install --upgrade --user --quiet google-cloud-aiplatform[evaluation]- EvalTask: a classe principal para executar avaliações.
- MetricPromptTemplateExamples: métricas de avaliação predefinidas
- PointwiseMetric: framework para criar métricas personalizadas
- notebook_utils: ferramentas de visualização para análise de resultados
- Importante: depois da instalação, reinicie o kernel para usar os novos pacotes. Na barra de menus na parte de cima da janela do JupyterLab, acesse Kernel > Reiniciar kernel.
5. Inicializar o SDK e importar bibliotecas
Antes de criar o pipeline de avaliação, é preciso configurar o ambiente. Isso envolve configurar os detalhes do projeto, inicializar o SDK da Vertex AI para se conectar ao Google Cloud e importar as bibliotecas Python especializadas que você vai usar para a avaliação.
- Defina as variáveis de configuração para o job de avaliação. Em uma nova célula, adicione e execute o seguinte código para definir seu
PROJECT_ID,LOCATIONe um nomeEXPERIMENTpara organizar essa execução.import vertexai PROJECT_ID = "YOUR PROJECT ID" LOCATION = "YOUR LOCATION" # @param {type:"string"} EXPERIMENT = "rag-eval-01" # @param {type:"string"} if not PROJECT_ID or PROJECT_ID == "[your-project-id]": raise ValueError("Please set your PROJECT_ID") - Inicialize o SDK da Vertex AI. Em uma nova célula, adicione e execute o seguinte código.
vertexai.init(project=PROJECT_ID, location=LOCATION) - Importe as classes necessárias do SDK de avaliação executando o seguinte código na próxima célula:
import pandas as pd from vertexai.evaluation import EvalTask, MetricPromptTemplateExamples, PointwiseMetric from vertexai.preview.evaluation import notebook_utils- pandas: para criar e gerenciar dados em DataFrames.
- EvalTask: a classe principal que executa um job de avaliação.
- MetricPromptTemplateExamples: oferece acesso às métricas de avaliação predefinidas do Google.
- PointwiseMetric: a estrutura para criar suas próprias métricas personalizadas.
- notebook_utils: uma coleção de ferramentas para visualizar resultados.
6. Preparar o conjunto de dados de avaliação
Um conjunto de dados bem estruturado é a base de qualquer avaliação confiável. Para sistemas RAG, seu conjunto de dados precisa de dois campos principais para cada exemplo:
- comando: é a entrada total fornecida ao modelo de linguagem. Você precisa combinar a pergunta do usuário com o contexto recuperado pelo sistema de RAG (
prompt = User Question + Retrieved Context). Isso é importante para que o serviço de avaliação saiba quais informações o modelo usou para criar a resposta. - response: é a resposta final produzida pelo seu modelo RAG.
Para resultados estatisticamente confiáveis, recomendamos um conjunto de dados com cerca de 100 exemplos. Neste laboratório, você vai usar um pequeno conjunto de dados para demonstrar o processo.
Vamos criar os conjuntos de dados. Você vai começar com uma lista de perguntas e o retrieved_contexts de um sistema RAG. Em seguida, defina dois conjuntos de respostas: um de um modelo que parece ter um bom desempenho (generated_answers_by_rag_a) e outro de um modelo com desempenho ruim (generated_answers_by_rag_b).
Por fim, você vai combinar essas partes em dois DataFrames do pandas, eval_dataset_rag_a e eval_dataset_rag_b, seguindo a estrutura descrita acima.
- Em uma nova célula, adicione e execute o código a seguir para definir as perguntas e os dois conjuntos de generated_answers.
questions = [ "Which part of the brain does short-term memory seem to rely on?", "What provided the Roman senate with exuberance?", "What area did the Hasan-jalalians command?", ] generated_answers_by_rag_a = [ "frontal lobe and the parietal lobe", "The Roman Senate was filled with exuberance due to successes against Catiline.", "The Hasan-Jalalians commanded the area of Syunik and Vayots Dzor.", ] generated_answers_by_rag_b = [ "Occipital lobe", "The Roman Senate was subdued because they had food poisoning.", "The Galactic Empire commanded the state of Utah.", ] - Defina os retrieved_contexts. Adicione e execute o seguinte código em uma nova célula.
retrieved_contexts = [ "Short-term memory is supported by transient patterns of neuronal communication, dependent on regions of the frontal lobe (especially dorsolateral prefrontal cortex) and the parietal lobe. Long-term memory, on the other hand, is maintained by more stable and permanent changes in neural connections widely spread throughout the brain. The hippocampus is essential (for learning new information) to the consolidation of information from short-term to long-term memory, although it does not seem to store information itself. Without the hippocampus, new memories are unable to be stored into long-term memory, as learned from patient Henry Molaison after removal of both his hippocampi, and there will be a very short attention span. Furthermore, it may be involved in changing neural connections for a period of three months or more after the initial learning.", "In 62 BC, Pompey returned victorious from Asia. The Senate, elated by its successes against Catiline, refused to ratify the arrangements that Pompey had made. Pompey, in effect, became powerless. Thus, when Julius Caesar returned from a governorship in Spain in 61 BC, he found it easy to make an arrangement with Pompey. Caesar and Pompey, along with Crassus, established a private agreement, now known as the First Triumvirate. Under the agreement, Pompey's arrangements would be ratified. Caesar would be elected consul in 59 BC, and would then serve as governor of Gaul for five years. Crassus was promised a future consulship.", "The Seljuk Empire soon started to collapse. In the early 12th century, Armenian princes of the Zakarid noble family drove out the Seljuk Turks and established a semi-independent Armenian principality in Northern and Eastern Armenia, known as Zakarid Armenia, which lasted under the patronage of the Georgian Kingdom. The noble family of Orbelians shared control with the Zakarids in various parts of the country, especially in Syunik and Vayots Dzor, while the Armenian family of Hasan-Jalalians controlled provinces of Artsakh and Utik as the Kingdom of Artsakh.", ] - Em uma nova célula, adicione e execute o seguinte código para criar
eval_dataset_rag_aeeval_dataset_rag_b.eval_dataset_rag_a = pd.DataFrame( { "prompt": [ "Answer the question: " + question + " Context: " + item for question, item in zip(questions, retrieved_contexts) ], "response": generated_answers_by_rag_a, } ) eval_dataset_rag_b = pd.DataFrame( { "prompt": [ "Answer the question: " + question + " Context: " + item for question, item in zip(questions, retrieved_contexts) ], "response": generated_answers_by_rag_b, } ) - Execute o código a seguir em uma nova célula para conferir as primeiras linhas do conjunto de dados do Modelo A.
eval_dataset_rag_a
7. Selecionar e criar métricas
Agora que os conjuntos de dados estão prontos, você pode decidir como medir a performance. Você pode usar uma ou mais métricas para avaliar seu modelo. Cada métrica avalia um aspecto específico da resposta do modelo, como acurácia factual ou relevância.
É possível usar uma combinação de dois tipos de métricas:
- Métricas predefinidas: métricas prontas para uso fornecidas pelo SDK para tarefas de avaliação comuns.
- Métricas personalizadas: métricas definidas para testar qualidades relevantes para seu caso de uso.
Nesta seção, você vai conhecer as métricas predefinidas disponíveis para RAG.
Conhecer as métricas predefinidas
O SDK inclui várias métricas integradas para avaliar sistemas de resposta a perguntas. Essas métricas usam um modelo de linguagem como "avaliador" para pontuar as respostas do seu modelo com base em um conjunto de instruções.
- Em uma nova célula, adicione e execute o seguinte código para conferir a lista completa de nomes de métricas predefinidas:
MetricPromptTemplateExamples.list_example_metric_names() - Para entender como essas métricas funcionam, inspecione os modelos de solicitação subjacentes. Em uma nova célula, adicione e execute o código a seguir para conferir as instruções dadas ao LLM avaliador para a métrica
question_answering_quality.# See the prompt example for one of the pointwise metrics print(MetricPromptTemplateExamples.get_prompt_template("question_answering_quality"))
8. Criar métricas personalizadas
Além das métricas predefinidas, é possível criar métricas personalizadas para avaliar critérios específicos do seu caso de uso. Para criar uma métrica personalizada, escreva um modelo de comando que instrua o LLM avaliador a pontuar uma resposta.
A criação de uma métrica personalizada envolve duas etapas:
- Defina o modelo de solicitação: uma string que contém suas instruções para o LLM avaliador. Um bom modelo inclui uma função clara, critérios de avaliação, uma rubrica de pontuação e marcadores de posição como
{prompt}e{response}. - Instancie um objeto PointwiseMetric: encapsule a string do modelo de comando nessa classe e dê um nome à métrica.
Você vai criar duas métricas personalizadas para avaliar a relevância e a utilidade das respostas do sistema RAG.
- Defina o modelo de comando para a métrica de relevância. Esse modelo fornece uma rubrica detalhada para o LLM avaliador. Em uma nova célula, adicione e execute o seguinte código:
relevance_prompt_template = """ You are a professional writing evaluator. Your job is to score writing responses according to pre-defined evaluation criteria. You will be assessing relevance, which measures the ability to respond with relevant information when given a prompt. You will assign the writing response a score from 5, 4, 3, 2, 1, following the rating rubric and evaluation steps. ## Criteria Relevance: The response should be relevant to the instruction and directly address the instruction. ## Rating Rubric 5 (completely relevant): Response is entirely relevant to the instruction and provides clearly defined information that addresses the instruction's core needs directly. 4 (mostly relevant): Response is mostly relevant to the instruction and addresses the instruction mostly directly. 3 (somewhat relevant): Response is somewhat relevant to the instruction and may address the instruction indirectly, but could be more relevant and more direct. 2 (somewhat irrelevant): Response is minimally relevant to the instruction and does not address the instruction directly. 1 (irrelevant): Response is completely irrelevant to the instruction. ## Evaluation Steps STEP 1: Assess relevance: is response relevant to the instruction and directly address the instruction? STEP 2: Score based on the criteria and rubrics. Give step by step explanations for your scoring, and only choose scores from 5, 4, 3, 2, 1. # User Inputs and AI-generated Response ## User Inputs ### Prompt {prompt} ## AI-generated Response {response} """ - Defina o modelo de comando para a métrica de utilidade usando a mesma abordagem. Adicione e execute o seguinte código em uma nova célula:
helpfulness_prompt_template = """ You are a professional writing evaluator. Your job is to score writing responses according to pre-defined evaluation criteria. You will be assessing helpfulness, which measures the ability to provide important details when answering a prompt. You will assign the writing response a score from 5, 4, 3, 2, 1, following the rating rubric and evaluation steps. ## Criteria Helpfulness: The response is comprehensive with well-defined key details. The user would feel very satisfied with the content in a good response. ## Rating Rubric 5 (completely helpful): Response is useful and very comprehensive with well-defined key details to address the needs in the instruction and usually beyond what explicitly asked. The user would feel very satisfied with the content in the response. 4 (mostly helpful): Response is very relevant to the instruction, providing clearly defined information that addresses the instruction's core needs. It may include additional insights that go slightly beyond the immediate instruction. The user would feel quite satisfied with the content in the response. 3 (somewhat helpful): Response is relevant to the instruction and provides some useful content, but could be more relevant, well-defined, comprehensive, and/or detailed. The user would feel somewhat satisfied with the content in the response. 2 (somewhat unhelpful): Response is minimally relevant to the instruction and may provide some vaguely useful information, but it lacks clarity and detail. It might contain minor inaccuracies. The user would feel only slightly satisfied with the content in the response. 1 (unhelpful): Response is useless/irrelevant, contains inaccurate/deceptive/misleading information, and/or contains harmful/offensive content. The user would feel not at all satisfied with the content in the response. ## Evaluation Steps STEP 1: Assess comprehensiveness: does the response provide specific, comprehensive, and clearly defined information for the user needs expressed in the instruction? STEP 2: Assess relevance: When appropriate for the instruction, does the response exceed the instruction by providing relevant details and related information to contextualize content and help the user better understand the response. STEP 3: Assess accuracy: Is the response free of inaccurate, deceptive, or misleading information? STEP 4: Assess safety: Is the response free of harmful or offensive content? Give step by step explanations for your scoring, and only choose scores from 5, 4, 3, 2, 1. # User Inputs and AI-generated Response ## User Inputs ### Prompt {prompt} ## AI-generated Response {response} """ - Instancie objetos
PointwiseMetricpara suas duas métricas personalizadas. Isso encapsula seus modelos de solicitação em componentes reutilizáveis para o job de avaliação. Adicione e execute o seguinte código em uma nova célula:relevance = PointwiseMetric( metric="relevance", metric_prompt_template=relevance_prompt_template, ) helpfulness = PointwiseMetric( metric="helpfulness", metric_prompt_template=helpfulness_prompt_template, )
Agora você tem duas novas métricas reutilizáveis (relevance e helpfulness) prontas para seu job de avaliação.
9. Executar o job de avaliação
Agora que os conjuntos de dados e as métricas estão prontos, você pode executar a avaliação. Para isso, crie um objeto EvalTask para cada conjunto de dados que você quer testar.
Um EvalTask agrupa os componentes de uma execução de avaliação:
- dataset: o DataFrame que contém seus comandos e respostas.
- metrics: a lista de métricas que você quer comparar.
- experiment: o experimento da Vertex AI para registrar os resultados, ajudando você a monitorar e comparar execuções.
- Crie um
EvalTaskpara cada modelo. Esse objeto agrupa o conjunto de dados, as métricas e o nome do experimento. Adicione e execute o seguinte código em uma nova célula para configurar as tarefas:rag_eval_task_rag_a = EvalTask( dataset=eval_dataset_rag_a, metrics=[ "question_answering_quality", relevance, helpfulness, "groundedness", "safety", "instruction_following", ], experiment=EXPERIMENT, ) rag_eval_task_rag_b = EvalTask( dataset=eval_dataset_rag_b, metrics=[ "question_answering_quality", relevance, helpfulness, "groundedness", "safety", "instruction_following", ], experiment=EXPERIMENT, )EvalTask, um para cada conjunto de respostas do modelo. A listametricsque você forneceu demonstra um recurso principal do serviço de avaliação: métricas predefinidas (por exemplo,safety) e os objetosPointwiseMetricpersonalizados. - Com as tarefas configuradas, execute-as chamando o método
.evaluate(). Isso envia as tarefas para o back-end da Vertex AI para processamento e pode levar vários minutos para ser concluído. Em uma nova célula, adicione e execute o seguinte código:result_rag_a = rag_eval_task_rag_a.evaluate() result_rag_b = rag_eval_task_rag_b.evaluate()
Depois que a avaliação for concluída, os resultados serão armazenados nos objetos result_rag_a e result_rag_b, prontos para serem analisados na próxima seção.
10. Analisar os resultados
Os resultados da avaliação já estão disponíveis. Os objetos result_rag_a e result_rag_b contêm pontuações agregadas e explicações detalhadas para cada linha. Nesta tarefa, você vai analisar esses resultados usando funções auxiliares de notebook_utils.
Ver resumos agregados
- Para ter uma visão geral, use a função auxiliar
display_eval_result()e confira a pontuação média de cada métrica. Em uma nova célula, adicione e execute o seguinte para ver o resumo do modelo A:notebook_utils.display_eval_result( title="Model A Eval Result", eval_result=result_rag_a ) - Faça o mesmo para o modelo B. Adicione e execute este código em uma nova célula:
notebook_utils.display_eval_result( title="Model B Eval Result", eval_result=result_rag_b, )
Exibir os resultados da avaliação
Os gráficos facilitam a comparação da performance do modelo. Você vai usar dois tipos de visualizações:
- Gráfico de radar: mostra o "formato" geral de desempenho de cada modelo. Uma forma maior indica uma performance geral melhor.
- Gráfico de barras: para uma comparação direta lado a lado de cada métrica.
Essas visualizações ajudam você a comparar os modelos em qualidades subjetivas, como relevância, embasamento e utilidade.
- Para se preparar para a criação de gráficos, combine os resultados em uma única lista de tuplas. Cada tupla precisa conter um nome de modelo e o objeto de resultado correspondente. Em uma nova célula, adicione e execute o seguinte código:
eval_results = [] eval_results.append(("Model A", result_rag_a)) eval_results.append(("Model B", result_rag_b)) - Agora, gere um gráfico radar para comparar os modelos em todas as métricas de uma só vez. Adicione e execute o seguinte código em uma nova célula:
notebook_utils.display_radar_plot( eval_results, metrics=[ "question_answering_quality", "safety", "groundedness", "instruction_following", "relevance", "helpfulness", ], ) - Para uma comparação mais direta de cada métrica, gere um gráfico de barras. Em uma nova célula, adicione e execute este código:
notebook_utils.display_bar_plot( eval_results, metrics=[ "question_answering_quality", "safety", "groundedness", "instruction_following", "relevance", "helpfulness", ], )
As visualizações mostram claramente que a performance do Modelo A (a forma grande no gráfico de radar e as barras altas no gráfico de barras) é superior à do Modelo B.
Ver uma explicação detalhada de uma instância específica
As pontuações agregadas mostram a performance geral. Para entender por que um modelo teve um determinado desempenho, revise as explicações detalhadas geradas pelo LLM avaliador para cada exemplo.
- A função auxiliar
display_explanations()permite inspecionar resultados individuais. Para conferir o detalhamento do segundo exemplo (num=2) dos resultados do Modelo A, adicione e execute o seguinte código em uma nova célula:notebook_utils.display_explanations(result_rag_a, num=2) - Você também pode usar essa função para filtrar uma métrica específica em todos os exemplos. Isso é útil para depurar uma área específica de baixa performance. Para entender por que o modelo B teve uma performance tão ruim na métrica
groundedness, adicione e execute este código em uma nova célula:notebook_utils.display_explanations(result_rag_b, metrics=["groundedness"])
11. Avaliação referenciada usando uma "resposta de referência"
Antes, você fazia uma avaliação sem referência, em que a resposta do modelo era julgada apenas com base no comando. Esse método é útil, mas a avaliação é subjetiva.
Agora, você vai usar a avaliação referenciada. Esse método adiciona uma "resposta ideal" (também chamada de resposta de referência) ao conjunto de dados. Comparar a resposta do modelo com uma resposta baseada em informações empíricas oferece uma medida mais objetiva de performance. Isso permite medir:
- Correção factual: a resposta do modelo está alinhada aos fatos na resposta ideal?
- Semelhança semântica: a resposta do modelo tem o mesmo significado da resposta ideal?
- Completude: a resposta do modelo contém todas as informações principais da resposta de referência?
Preparar o conjunto de dados referenciado
Para fazer uma avaliação referenciada, adicione uma "resposta ideal" a cada exemplo no conjunto de dados.
Vamos começar definindo uma lista golden_answers. Comparar as respostas de ouro com as do Modelo A mostra o valor desse método:
- Pergunta 1 (cérebro): a resposta gerada e a resposta correta são idênticas. O modelo A está correto.
- Pergunta 2 (Senado): as respostas são semanticamente semelhantes, mas formuladas de maneira diferente. Uma boa métrica reconhece isso.
- Pergunta 3 (Hasan-Jalalians): a resposta do modelo A está factualmente incorreta de acordo com o contexto. O
golden_answerexpõe esse erro.
- Em uma nova célula, defina a lista de golden_answers
golden_answers = [ "frontal lobe and the parietal lobe", "Due to successes against Catiline.", "The Hasan-Jalalians commanded the area of Artsakh and Utik.", ] - Crie os DataFrames de avaliação referenciados executando este código na célula a seguir:
referenced_eval_dataset_rag_a = pd.DataFrame( { "prompt": [ "Answer the question: " + question + " Context: " + item for question, item in zip(questions, retrieved_contexts) ], "response": generated_answers_by_rag_a, "reference": golden_answers, } ) referenced_eval_dataset_rag_b = pd.DataFrame( { "prompt": [ "Answer the question: " + question + " Context: " + item for question, item in zip(questions, retrieved_contexts) ], "response": generated_answers_by_rag_b, "reference": golden_answers, } )
Os conjuntos de dados estão prontos para avaliação referenciada.
Criar uma métrica de referência personalizada
Também é possível criar métricas personalizadas para avaliação referenciada. O processo é semelhante, mas o modelo de comando agora inclui o marcador de posição {reference} para a resposta ideal.
Com uma resposta "correta" definitiva, você pode usar uma pontuação binária mais rigorosa (por exemplo, 1 para correto, 0 para incorreto) para medir a acurácia factual. Vamos criar uma métrica question_answering_correctness que implementa essa lógica.
- Defina o modelo de comando. Em uma nova célula, adicione e execute o seguinte código:
question_answering_correctness_prompt_template = """ You are a professional writing evaluator. Your job is to score writing responses according to pre-defined evaluation criteria. You will be assessing question answering correctness, which measures the ability to correctly answer a question. You will assign the writing response a score from 1, 0, following the rating rubric and evaluation steps. ### Criteria: Reference claim alignment: The response should contain all claims from the reference and should not contain claims that are not present in the reference. ### Rating Rubric: 1 (correct): The response contains all claims from the reference and does not contain claims that are not present in the reference. 0 (incorrect): The response does not contain all claims from the reference, or the response contains claims that are not present in the reference. ### Evaluation Steps: STEP 1: Assess the response' correctness by comparing with the reference according to the criteria. STEP 2: Score based on the rubrics. Give step by step explanations for your scoring, and only choose scores from 1, 0. # User Inputs and AI-generated Response ## User Inputs ### Prompt {prompt} ## Reference {reference} ## AI-generated Response {response} """ - Encapsule a string do modelo de solicitação em um objeto PointwiseMetric. Isso dá à sua métrica um nome formal e a torna um componente reutilizável para o job de avaliação. Adicione e execute o seguinte código em uma nova célula:
question_answering_correctness = PointwiseMetric( metric="question_answering_correctness", metric_prompt_template=question_answering_correctness_prompt_template, )
Agora você tem uma métrica personalizada e referenciada para uma verificação estrita de fatos.
12. Executar a avaliação referenciada
Agora, você vai configurar o job de avaliação com os conjuntos de dados referenciados e a nova métrica. Você vai usar a classe EvalTask novamente.
A lista de métricas agora combina sua métrica personalizada baseada em modelo com métricas baseadas em computação. A avaliação referenciada permite o uso de métricas tradicionais baseadas em computação que fazem comparações matemáticas entre o texto gerado e o texto de referência. Você vai usar três comuns:
exact_match: atribui 1 somente se a resposta gerada for idêntica à resposta de referência e 0 caso contrário.bleu: uma métrica de precisão. Ela mede quantas palavras da resposta gerada também aparecem na resposta de referência.rouge: uma métrica de recall. Ela mede quantas palavras da resposta de referência são capturadas na resposta gerada.
- Configure o job de avaliação com os conjuntos de dados referenciados e a nova combinação de métricas. Em uma nova célula, adicione e execute o seguinte código para criar os objetos
EvalTask:referenced_answer_eval_task_rag_a = EvalTask( dataset=referenced_eval_dataset_rag_a, metrics=[ question_answering_correctness, "rouge", "bleu", "exact_match", ], experiment=EXPERIMENT, ) referenced_answer_eval_task_rag_b = EvalTask( dataset=referenced_eval_dataset_rag_b, metrics=[ question_answering_correctness, "rouge", "bleu", "exact_match", ], experiment=EXPERIMENT, ) - Execute a avaliação referenciada chamando o método
.evaluate(). Adicione e execute este código em uma nova célula:referenced_result_rag_a = referenced_answer_eval_task_rag_a.evaluate() referenced_result_rag_b = referenced_answer_eval_task_rag_b.evaluate()
13. Analisar os resultados referenciados
A avaliação foi concluída. Nesta tarefa, você vai analisar os resultados para medir a acurácia factual dos modelos comparando as respostas deles com as respostas de referência.
Ver os resultados do resumo
- Analise os resultados do resumo da avaliação referenciada. Em uma nova célula, adicione e execute o código a seguir para mostrar as tabelas de resumo dos dois modelos:
notebook_utils.display_eval_result( title="Model A Eval Result", eval_result=referenced_result_rag_a, ) notebook_utils.display_eval_result( title="Model B Eval Result", eval_result=referenced_result_rag_b, )question_answering_correctness, mas uma pontuação menor emexact_match. Isso destaca o valor das métricas baseadas em modelos que podem reconhecer a similaridade semântica, não apenas o texto idêntico.
Visualizar resultados para comparação
As visualizações podem tornar mais evidente a diferença de performance entre os dois modelos. Primeiro, combine os resultados em uma única lista para gerar os gráficos de radar e de barras.
- Combine os resultados da avaliação referenciada em uma única lista para geração de gráficos. Adicione e execute o seguinte código em uma nova célula:
referenced_eval_results = [] referenced_eval_results.append(("Model A", referenced_result_rag_a)) referenced_eval_results.append(("Model B", referenced_result_rag_b)) - Gere um gráfico radar para visualizar a performance de cada modelo no novo conjunto de métricas. Adicione e execute este código em uma nova célula:
notebook_utils.display_radar_plot( referenced_eval_results, metrics=[ "question_answering_correctness", "rouge", "bleu", "exact_match", ], ) - Crie um gráfico de barras para uma comparação direta lado a lado. Isso vai mostrar a performance de cada modelo nas diferentes métricas. Adicione e execute o seguinte código em uma nova célula:
notebook_utils.display_bar_plot( referenced_eval_results, metrics=[ "question_answering_correctness", "rouge", "bleu", "exact_match", ], )
Essas visualizações confirmam que o Modelo A é significativamente mais preciso e alinhado aos fatos com as respostas de referência do que o Modelo B.
14. Da prática à produção
Você executou um pipeline de avaliação completo para um sistema RAG. Esta seção final resume os principais conceitos estratégicos que você aprendeu e oferece uma estrutura para aplicar essas habilidades a projetos do mundo real.
Práticas recomendadas de produção
Para levar as habilidades deste laboratório a um ambiente de produção real, considere estas quatro práticas principais:
- Automatize com CI/CD:integre seu conjunto de avaliação a um pipeline de CI/CD (por exemplo, Cloud Build, GitHub Actions). Execute avaliações automaticamente em mudanças de código para detectar regressões e bloquear implantações se as pontuações de qualidade ficarem abaixo dos seus padrões.
- Evolua seus conjuntos de dados:um conjunto de dados estático fica desatualizado. Faça o controle de versão dos seus conjuntos de teste "ouro" (usando o Git LFS ou o Cloud Storage) e adicione continuamente exemplos novos e desafiadores, fazendo amostragem de consultas de usuários reais (anônimas).
- Avalie o extrator, não apenas o gerador:uma ótima resposta é impossível sem o contexto certo. Implemente uma etapa de avaliação separada para seu sistema de recuperação usando métricas como taxa de acerto (o documento certo foi encontrado?) e classificação recíproca média (MRR) (qual foi a posição do documento certo?).
- Monitore as métricas ao longo do tempo:exporte as pontuações de resumo das execuções de avaliação para um serviço como o Google Cloud Monitoring. Crie painéis para acompanhar as tendências de qualidade e configure alertas automatizados para notificar você sobre quedas significativas de desempenho.
Matriz de metodologia de avaliação avançada
A escolha da abordagem de avaliação certa depende das suas metas específicas. Esta matriz resume quando usar cada método.
Abordagem de avaliação | Melhores casos de uso | Principais vantagens | Limitações |
Sem referência | Monitoramento da produção, avaliação contínua | Não precisa de respostas perfeitas, captura a qualidade subjetiva | Mais caro, possível viés do avaliador |
Baseado em referência | Comparação e comparativo de mercado de modelos | Medição objetiva, computação mais rápida | Exige respostas perfeitas, pode perder a equivalência semântica |
Métricas personalizadas | Avaliação específica do domínio | Adaptado às necessidades da empresa | Requer validação e overhead de desenvolvimento |
Abordagem híbrida | Sistemas de produção abrangentes | O melhor de todas as abordagens | Maior complexidade, otimização de custos necessária |
Principais insights técnicos
Lembre-se destes princípios fundamentais ao criar e avaliar seus próprios sistemas RAG:
- A fundamentação é essencial para a RAG: essa métrica diferencia consistentemente sistemas de RAG de alta e baixa qualidade, o que a torna essencial para o monitoramento da produção.
- Várias métricas oferecem robustez: nenhuma métrica captura todos os aspectos da qualidade da RAG. A avaliação abrangente exige várias dimensões de avaliação.
- As métricas personalizadas agregam valor significativo: os critérios de avaliação específicos do domínio geralmente capturam nuances que as métricas genéricas não percebem, melhorando a precisão da avaliação.
- O rigor estatístico aumenta a confiança: tamanhos de amostra adequados e testes de significância transformam a avaliação de palpites em ferramentas confiáveis de tomada de decisão.
Framework de decisão de implantação de produção
Use essa estrutura gradual como um guia para futuras implantações do sistema RAG:
- Fase 1: desenvolvimento: use a avaliação baseada em referência com conjuntos de teste conhecidos para comparação e seleção de modelos.
- Fase 2: pré-produção: faça uma avaliação abrangente combinando as duas abordagens para validar a prontidão da produção.
- Fase 3: produção: implemente o monitoramento sem referência para avaliação contínua da qualidade sem respostas de referência.
- Fase 4: otimização: use insights de avaliação para orientar melhorias no modelo e aprimoramentos no sistema de recuperação.
15. Conclusão
Parabéns! Você concluiu o laboratório.
Este laboratório faz parte do programa de aprendizado "IA pronta para produção com o Google Cloud".
- Confira o currículo completo para diminuir a distância entre o protótipo e a produção.
- Compartilhe seu progresso com a hashtag
ProductionReadyAI.
Recapitulação
Você aprendeu a:
- Realize uma avaliação sem referência para analisar a qualidade de uma resposta com base no contexto recuperado.
- Faça uma avaliação referenciada adicionando uma "resposta de referência" para medir a correção factual.
- Use uma combinação de métricas predefinidas e personalizadas para as duas abordagens.
- Use métricas baseadas em modelos (como
question_answering_quality) e métricas baseadas em computação (rouge,bleu,exact_match). - Analise e visualize os resultados para entender os pontos fortes e fracos de um modelo.
Essa abordagem ajuda você a criar aplicativos de IA generativa mais confiáveis e precisos.