
1. ภาพรวม
ในแล็บนี้ คุณจะได้เรียนรู้วิธีสร้างไปป์ไลน์การประเมินสำหรับระบบ Retrieval-Augmented Generation (RAG) คุณจะใช้บริการประเมิน Gen AI ของ Vertex AI เพื่อสร้างเกณฑ์การประเมินที่กำหนดเองและสร้างเฟรมเวิร์กการประเมินสำหรับงานตอบคำถาม
คุณจะได้ทำงานกับตัวอย่างจากชุดข้อมูลคำถามและคำตอบของ Stanford (SQuAD 2.0) เพื่อเตรียมชุดข้อมูลการประเมิน กำหนดค่าการประเมินแบบไม่มีการอ้างอิงและแบบมีการอ้างอิง และตีความผลลัพธ์ เมื่อจบลำดับการทดลองนี้ คุณจะเข้าใจวิธีประเมินระบบ RAG และเหตุผลที่เลือกใช้แนวทางการประเมินบางอย่าง
พื้นฐานของชุดข้อมูล
เราจะทำงานร่วมกับตัวอย่างที่สร้างขึ้นอย่างพิถีพิถันซึ่งครอบคลุมหลายโดเมนที่พบในชุดข้อมูลการตอบคำถาม SQuAD 2.0
- ประสาทวิทยา: ทดสอบความถูกต้องทางเทคนิคในบริบททางวิทยาศาสตร์
- ประวัติศาสตร์: การประเมินความแม่นยำของข้อเท็จจริงในเรื่องเล่าทางประวัติศาสตร์
- ภูมิศาสตร์: การประเมินความรู้ด้านเขตแดนและการเมือง
ความหลากหลายนี้ช่วยให้คุณเข้าใจว่าแนวทางการประเมินครอบคลุมสาขาวิชาต่างๆ ได้อย่างไร
ข้อมูลอ้างอิง
- ตัวอย่างโค้ด: Lab นี้สร้างขึ้นจากตัวอย่างในเอกสารประกอบการประเมิน Vertex AI
- พื้นฐานของชุดข้อมูล: ชุดข้อมูลการตอบคำถาม SQuAD 2.0
- การเพิ่มประสิทธิภาพการดึงข้อมูล RAG: ทดสอบ ปรับแต่ง และประสบความสำเร็จ
สิ่งที่คุณจะได้เรียนรู้
ในแล็บนี้ คุณจะได้เรียนรู้วิธีทำงานต่อไปนี้
- เตรียมชุดข้อมูลการประเมินสำหรับระบบ RAG
- ใช้การประเมินแบบไม่มีการอ้างอิงโดยใช้เมตริกต่างๆ เช่น ความสมเหตุสมผลและความเกี่ยวข้อง
- ใช้การประเมินตามการอ้างอิงกับมาตรวัดความคล้ายกันเชิงความหมาย
- สร้างเมตริกการประเมินที่กำหนดเองพร้อมรูบริกการให้คะแนนโดยละเอียด
- ตีความและแสดงภาพผลการประเมินเพื่อใช้ประกอบการเลือกโมเดล
2. การตั้งค่าโปรเจ็กต์
บัญชี Google
หากยังไม่มีบัญชี Google ส่วนบุคคล คุณต้องสร้างบัญชี Google
ใช้บัญชีส่วนตัวแทนบัญชีของที่ทำงานหรือบัญชีโรงเรียน
ลงชื่อเข้าใช้คอนโซล Google Cloud
ลงชื่อเข้าใช้ คอนโซล Google Cloud โดยใช้บัญชี Google ส่วนตัว
เปิดใช้การเรียกเก็บเงิน
แลกรับเครดิต Google Cloud (ไม่บังคับ)
หากต้องการจัดเวิร์กช็อปนี้ คุณต้องมีบัญชีสำหรับการเรียกเก็บเงินที่มีเครดิตอยู่บ้าง ใช้เครดิตจากแบนเนอร์ที่ด้านบนของ Codelab นี้เพื่อเริ่มต้นใช้งาน หากเชื่อมต่อกับบัญชีสำหรับการเรียกเก็บเงินอยู่แล้ว ให้ข้ามขั้นตอนนี้
ตั้งค่าบัญชีสำหรับการเรียกเก็บเงินส่วนตัว
หากตั้งค่าการเรียกเก็บเงินโดยใช้เครดิต Google Cloud คุณจะข้ามขั้นตอนนี้ได้
หากต้องการตั้งค่าบัญชีสำหรับการเรียกเก็บเงินส่วนตัว ให้ไปที่นี่เพื่อเปิดใช้การเรียกเก็บเงินใน Cloud Console
ข้อควรทราบ
- การทำ Lab นี้ควรมีค่าใช้จ่ายน้อยกว่า $1 USD ในทรัพยากรระบบคลาวด์
- คุณสามารถทำตามขั้นตอนที่ส่วนท้ายของแล็บนี้เพื่อลบทรัพยากรเพื่อหลีกเลี่ยงการเรียกเก็บเงินเพิ่มเติม
- ผู้ใช้ใหม่มีสิทธิ์ใช้ช่วงทดลองใช้ฟรีมูลค่า$300 USD
สร้างโปรเจ็กต์ (ไม่บังคับ)
หากไม่มีโปรเจ็กต์ปัจจุบันที่ต้องการใช้สำหรับแล็บนี้ ให้สร้างโปรเจ็กต์ใหม่ที่นี่
3. Retrieval Augmented Generation (RAG) คืออะไร
RAG เป็นเทคนิคที่ใช้เพื่อปรับปรุงความถูกต้องตามข้อเท็จจริงและความเกี่ยวข้องของคำตอบจากโมเดลภาษาขนาดใหญ่ (LLM) โดยจะเชื่อมต่อ LLM กับฐานความรู้ภายนอกเพื่อให้คำตอบอิงตามข้อมูลที่เฉพาะเจาะจงและตรวจสอบได้
กระบวนการนี้มีขั้นตอนดังนี้
- แปลงคำถามของผู้ใช้ให้เป็นการแสดงตัวเลข (การฝัง)
- ค้นหาฐานความรู้เพื่อหาเอกสารที่มีการฝังที่คล้ายกัน
- การระบุเอกสารที่เกี่ยวข้องเหล่านี้เป็นบริบทให้กับ LLM พร้อมกับคำถามเดิมเพื่อสร้างคำตอบ
อ่านเพิ่มเติมเกี่ยวกับ RAG
อะไรที่ทำให้การประเมิน RAG มีความซับซ้อน
การประเมินระบบ RAG แตกต่างจากการประเมินโมเดลภาษาแบบดั้งเดิม
ความท้าทายแบบหลายองค์ประกอบ: ระบบ RAG รวมการดำเนินการ 3 อย่างที่อาจเป็นจุดที่ทำให้เกิดข้อผิดพลาดได้
- คุณภาพการดึงข้อมูล: ระบบพบเอกสารบริบทที่ถูกต้องหรือไม่
- การใช้บริบท: โมเดลใช้ข้อมูลที่ดึงมาได้อย่างมีประสิทธิภาพหรือไม่
- คุณภาพการสร้าง: คำตอบสุดท้ายเขียนได้ดี เป็นประโยชน์ และถูกต้องหรือไม่
การตอบกลับอาจล้มเหลวหากคอมโพเนนต์ใดคอมโพเนนต์หนึ่งเหล่านี้ไม่ทำงานตามที่คาดไว้ เช่น ระบบอาจดึงบริบทที่ถูกต้อง แต่โมเดลไม่สนใจ หรือโมเดลอาจสร้างคำตอบที่เขียนได้ดีแต่ไม่ถูกต้องเนื่องจากบริบทที่ดึงมาไม่เกี่ยวข้อง
4. ตั้งค่าสภาพแวดล้อม Vertex AI Workbench
มาเริ่มกันด้วยการเริ่มต้นสภาพแวดล้อม Notebook ใหม่ ซึ่งเราจะเรียกใช้โค้ดที่จำเป็นในการประเมินระบบ RAG
- ไปที่หน้า API และบริการของ Cloud Console
- คลิกเปิดใช้สำหรับ Vertex AI API
เข้าถึง Vertex AI Workbench
- ในคอนโซล Google Cloud ให้ไปที่ Vertex AI โดยคลิกเมนูการนำทาง ☰ > Vertex AI > Workbench
- สร้างอินสแตนซ์ Workbench ใหม่
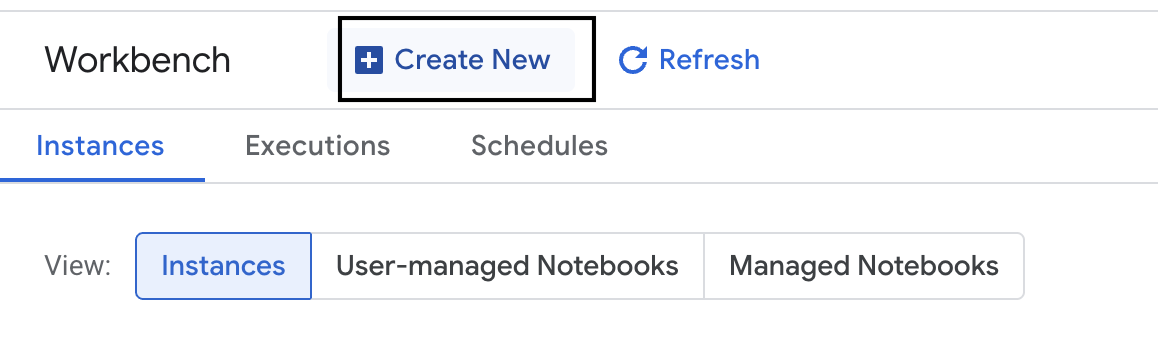
- ตั้งชื่ออินสแตนซ์ Workbench
evaluation-workbench - เลือกภูมิภาคและโซน หากยังไม่ได้ตั้งค่า
- คลิกสร้าง
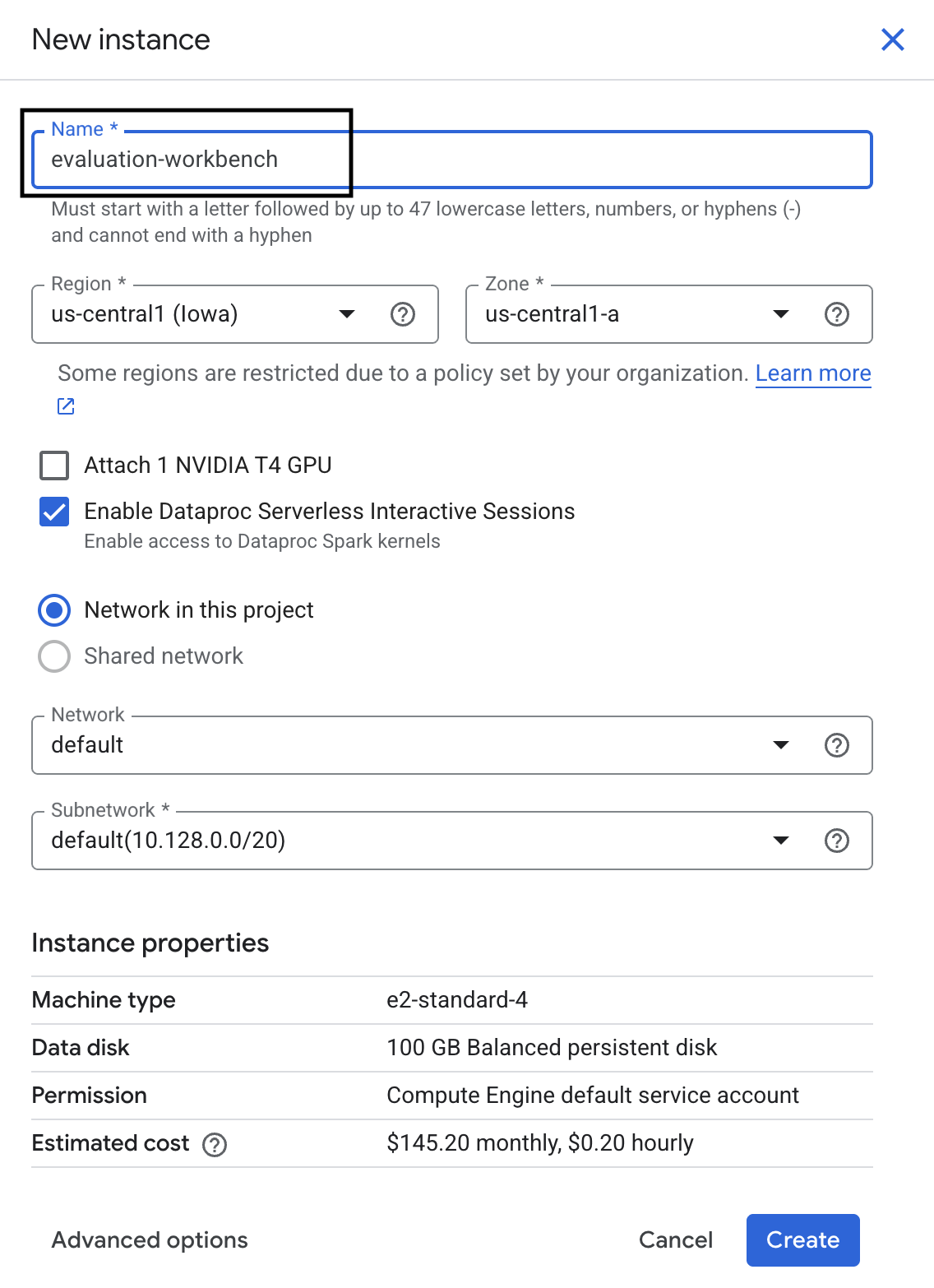
- รอให้เวิร์กเบนช์ตั้งค่า การดำเนินการนี้อาจใช้เวลาสักครู่

- เมื่อจัดสรรเวิร์กเบนช์แล้ว ให้คลิกเปิด jupyterlab
- สร้าง Notebook Python3 ใหม่ใน Workbench
ดูข้อมูลเพิ่มเติมเกี่ยวกับฟีเจอร์และความสามารถของสภาพแวดล้อมนี้ได้ในเอกสารอย่างเป็นทางการของ Vertex AI Workbench
ติดตั้ง Vertex AI Evaluation SDK
ตอนนี้มาติดตั้ง SDK การประเมินเฉพาะทางซึ่งมีเครื่องมือสำหรับการประเมิน RAG กัน
- ในเซลล์แรกของ Notebook ให้เพิ่มและเรียกใช้คำสั่งนำเข้าด้านล่าง (SHIFT+ENTER) เพื่อติดตั้ง Vertex AI SDK (พร้อมคอมโพเนนต์การประเมิน)
%pip install --upgrade --user --quiet google-cloud-aiplatform[evaluation]- EvalTask: คลาสหลักสำหรับการเรียกใช้การประเมิน
- MetricPromptTemplateExamples: เมตริกการประเมินที่กำหนดไว้ล่วงหน้า
- PointwiseMetric: เฟรมเวิร์กสําหรับสร้างเมตริกที่กําหนดเอง
- notebook_utils: เครื่องมือการแสดงภาพสำหรับการวิเคราะห์ผลลัพธ์
- สำคัญ: หลังจากติดตั้งแล้ว คุณจะต้องรีสตาร์ทเคอร์เนลเพื่อใช้แพ็กเกจใหม่ ในแถบเมนูที่ด้านบนของหน้าต่าง JupyterLab ให้ไปที่เคอร์เนล > รีสตาร์ทเคอร์เนล
5. เริ่มต้น SDK และนำเข้าไลบรารี
คุณต้องตั้งค่าสภาพแวดล้อมก่อนจึงจะสร้างไปป์ไลน์การประเมินได้ ซึ่งรวมถึงการกำหนดค่ารายละเอียดโปรเจ็กต์ การเริ่มต้น Vertex AI SDK เพื่อเชื่อมต่อกับ Google Cloud และการนำเข้าไลบรารี Python เฉพาะทางที่คุณจะใช้ในการประเมิน
- กำหนดตัวแปรการกำหนดค่าสำหรับงานการประเมิน ในเซลล์ใหม่ ให้เพิ่มและเรียกใช้โค้ดต่อไปนี้เพื่อตั้งค่า
PROJECT_ID,LOCATIONและชื่อEXPERIMENTเพื่อจัดระเบียบการเรียกใช้นี้import vertexai PROJECT_ID = "YOUR PROJECT ID" LOCATION = "YOUR LOCATION" # @param {type:"string"} EXPERIMENT = "rag-eval-01" # @param {type:"string"} if not PROJECT_ID or PROJECT_ID == "[your-project-id]": raise ValueError("Please set your PROJECT_ID") - เริ่มต้น Vertex AI SDK เพิ่มและเรียกใช้โค้ดต่อไปนี้ในเซลล์ใหม่
vertexai.init(project=PROJECT_ID, location=LOCATION) - นำเข้าคลาสที่จำเป็นจาก Evaluation SDK โดยเรียกใช้โค้ดต่อไปนี้ในเซลล์ถัดไป
import pandas as pd from vertexai.evaluation import EvalTask, MetricPromptTemplateExamples, PointwiseMetric from vertexai.preview.evaluation import notebook_utils- pandas: สำหรับสร้างและจัดการข้อมูลใน DataFrame
- EvalTask: คลาสหลักที่เรียกใช้ชื่องานการประเมิน
- MetricPromptTemplateExamples: ให้สิทธิ์เข้าถึงเมตริกการประเมินที่กำหนดไว้ล่วงหน้าของ Google
- PointwiseMetric: เฟรมเวิร์กสําหรับสร้างเมตริกที่กําหนดเอง
- notebook_utils: ชุดเครื่องมือสำหรับการแสดงผลลัพธ์ในรูปแบบภาพ
6. เตรียมชุดข้อมูลการประเมิน
ชุดข้อมูลที่มีโครงสร้างดีคือรากฐานของการประเมินที่เชื่อถือได้ สำหรับระบบ RAG ชุดข้อมูลของคุณต้องมีฟิลด์คีย์ 2 รายการสำหรับแต่ละตัวอย่าง ดังนี้
- พรอมต์: นี่คืออินพุตทั้งหมดที่ระบุให้กับโมเดลภาษา คุณต้องรวมคำถามของผู้ใช้เข้ากับบริบทที่ระบบ RAG ดึงมา (
prompt = User Question + Retrieved Context) ซึ่งเป็นสิ่งสำคัญเพื่อให้บริการประเมินทราบว่าโมเดลใช้ข้อมูลใดในการสร้างคำตอบ - คำตอบ: นี่คือคำตอบสุดท้ายที่โมเดล RAG สร้างขึ้น
ขอแนะนำให้ใช้ชุดข้อมูลที่มีตัวอย่างประมาณ 100 รายการเพื่อให้ได้ผลลัพธ์ที่เชื่อถือได้ทางสถิติ สำหรับฟีเจอร์ทดลองนี้ คุณจะใช้ชุดข้อมูลขนาดเล็กเพื่อสาธิตกระบวนการ
มาสร้างชุดข้อมูลกัน คุณจะเริ่มต้นด้วยรายการคำถามและretrieved_contextsจากระบบ RAG จากนั้นคุณจะกำหนดคำตอบ 2 ชุด ได้แก่ ชุดหนึ่งจากโมเดลที่ดูเหมือนจะทำงานได้ดี (generated_answers_by_rag_a) และอีกชุดหนึ่งจากโมเดลที่ทำงานได้ไม่ดี (generated_answers_by_rag_b)
สุดท้าย คุณจะรวมชิ้นส่วนเหล่านี้เป็น 2 pandas DataFrame ได้แก่ eval_dataset_rag_a และ eval_dataset_rag_b ตามโครงสร้างที่อธิบายไว้ข้างต้น
- ในเซลล์ใหม่ ให้เพิ่มและเรียกใช้โค้ดต่อไปนี้เพื่อกำหนดคำถามและชุดคำตอบที่สร้างขึ้น 2 ชุด
questions = [ "Which part of the brain does short-term memory seem to rely on?", "What provided the Roman senate with exuberance?", "What area did the Hasan-jalalians command?", ] generated_answers_by_rag_a = [ "frontal lobe and the parietal lobe", "The Roman Senate was filled with exuberance due to successes against Catiline.", "The Hasan-Jalalians commanded the area of Syunik and Vayots Dzor.", ] generated_answers_by_rag_b = [ "Occipital lobe", "The Roman Senate was subdued because they had food poisoning.", "The Galactic Empire commanded the state of Utah.", ] - กำหนด retrieved_contexts เพิ่มและเรียกใช้โค้ดต่อไปนี้ในเซลล์ใหม่
retrieved_contexts = [ "Short-term memory is supported by transient patterns of neuronal communication, dependent on regions of the frontal lobe (especially dorsolateral prefrontal cortex) and the parietal lobe. Long-term memory, on the other hand, is maintained by more stable and permanent changes in neural connections widely spread throughout the brain. The hippocampus is essential (for learning new information) to the consolidation of information from short-term to long-term memory, although it does not seem to store information itself. Without the hippocampus, new memories are unable to be stored into long-term memory, as learned from patient Henry Molaison after removal of both his hippocampi, and there will be a very short attention span. Furthermore, it may be involved in changing neural connections for a period of three months or more after the initial learning.", "In 62 BC, Pompey returned victorious from Asia. The Senate, elated by its successes against Catiline, refused to ratify the arrangements that Pompey had made. Pompey, in effect, became powerless. Thus, when Julius Caesar returned from a governorship in Spain in 61 BC, he found it easy to make an arrangement with Pompey. Caesar and Pompey, along with Crassus, established a private agreement, now known as the First Triumvirate. Under the agreement, Pompey's arrangements would be ratified. Caesar would be elected consul in 59 BC, and would then serve as governor of Gaul for five years. Crassus was promised a future consulship.", "The Seljuk Empire soon started to collapse. In the early 12th century, Armenian princes of the Zakarid noble family drove out the Seljuk Turks and established a semi-independent Armenian principality in Northern and Eastern Armenia, known as Zakarid Armenia, which lasted under the patronage of the Georgian Kingdom. The noble family of Orbelians shared control with the Zakarids in various parts of the country, especially in Syunik and Vayots Dzor, while the Armenian family of Hasan-Jalalians controlled provinces of Artsakh and Utik as the Kingdom of Artsakh.", ] - ในเซลล์ใหม่ ให้เพิ่มและเรียกใช้โค้ดต่อไปนี้เพื่อสร้าง
eval_dataset_rag_aและeval_dataset_rag_beval_dataset_rag_a = pd.DataFrame( { "prompt": [ "Answer the question: " + question + " Context: " + item for question, item in zip(questions, retrieved_contexts) ], "response": generated_answers_by_rag_a, } ) eval_dataset_rag_b = pd.DataFrame( { "prompt": [ "Answer the question: " + question + " Context: " + item for question, item in zip(questions, retrieved_contexts) ], "response": generated_answers_by_rag_b, } ) - เรียกใช้โค้ดต่อไปนี้ในเซลล์ใหม่เพื่อดู 2-3 แถวแรกของชุดข้อมูลสำหรับโมเดล A
eval_dataset_rag_a
7. เลือกและสร้างเมตริก
เมื่อชุดข้อมูลพร้อมแล้ว คุณก็สามารถตัดสินใจได้ว่าจะวัดประสิทธิภาพอย่างไร คุณใช้เมตริกอย่างน้อย 1 รายการเพื่อประเมินโมเดลได้ เมตริกแต่ละรายการจะประเมินลักษณะเฉพาะของการตอบกลับของโมเดล เช่น ความถูกต้องตามข้อเท็จจริงหรือความเกี่ยวข้อง
คุณใช้เมตริก 2 ประเภทต่อไปนี้ร่วมกันได้
- เมตริกที่กำหนดไว้ล่วงหน้า: เมตริกที่พร้อมใช้งานซึ่ง SDK จัดไว้ให้สำหรับงานประเมินทั่วไป
- เมตริกที่กำหนดเอง: เมตริกที่คุณกำหนดเพื่อทดสอบคุณภาพที่เกี่ยวข้องกับกรณีการใช้งานของคุณ
ในส่วนนี้ คุณจะได้สำรวจเมตริกที่กำหนดไว้ล่วงหน้าซึ่งใช้ได้กับ RAG
สํารวจเมตริกที่กําหนดไว้ล่วงหน้า
SDK มีเมตริกในตัวหลายรายการสําหรับการประเมินระบบตอบคําถาม เมตริกเหล่านี้ใช้โมเดลภาษาเป็น "ผู้ประเมิน" เพื่อให้คะแนนคำตอบของโมเดลตามชุดคำสั่ง
- ในเซลล์ใหม่ ให้เพิ่มและเรียกใช้โค้ดต่อไปนี้เพื่อดูรายการชื่อเมตริกที่กำหนดไว้ล่วงหน้าทั้งหมด
MetricPromptTemplateExamples.list_example_metric_names() - หากต้องการทำความเข้าใจวิธีการทำงานของเมตริกเหล่านี้ คุณสามารถตรวจสอบเทมเพลตพรอมต์พื้นฐานได้ ในเซลล์ใหม่ ให้เพิ่มและเรียกใช้โค้ดต่อไปนี้เพื่อดูวิธีการที่ LLM สำหรับการประเมินได้รับสำหรับเมตริก
question_answering_quality# See the prompt example for one of the pointwise metrics print(MetricPromptTemplateExamples.get_prompt_template("question_answering_quality"))
8. สร้างเมตริกที่กำหนดเอง
นอกเหนือจากเมตริกที่กําหนดไว้ล่วงหน้าแล้ว คุณยังสร้างเมตริกที่กําหนดเองเพื่อประเมินเกณฑ์ที่เฉพาะเจาะจงสําหรับกรณีการใช้งานของคุณได้ด้วย หากต้องการสร้างเมตริกที่กำหนดเอง คุณต้องเขียนเทมเพลตพรอมต์ที่สั่งให้ LLM สำหรับการประเมินให้คะแนนคำตอบ
การสร้างเมตริกที่กําหนดเองมี 2 ขั้นตอนดังนี้
- กําหนดเทมเพลตพรอมต์: สตริงที่มีวิธีการสําหรับ LLM ของผู้ประเมิน เทมเพลตที่ดีควรมีบทบาทที่ชัดเจน เกณฑ์การประเมิน เกณฑ์การให้คะแนน และตัวยึดตำแหน่ง เช่น
{prompt}และ{response} - สร้างออบเจ็กต์ PointwiseMetric: คุณจะห่อสตริงเทมเพลตพรอมต์ไว้ในคลาสนี้และตั้งชื่อเมตริก
คุณจะสร้างเมตริกที่กําหนดเอง 2 รายการเพื่อประเมินความเกี่ยวข้องและประโยชน์ของคําตอบของระบบ RAG
- กำหนดเทมเพลตพรอมต์สำหรับเมตริกความเกี่ยวข้อง เทมเพลตนี้มีเกณฑ์การให้คะแนนโดยละเอียดสำหรับ LLM ของผู้ประเมิน เพิ่มและเรียกใช้โค้ดต่อไปนี้ในเซลล์ใหม่
relevance_prompt_template = """ You are a professional writing evaluator. Your job is to score writing responses according to pre-defined evaluation criteria. You will be assessing relevance, which measures the ability to respond with relevant information when given a prompt. You will assign the writing response a score from 5, 4, 3, 2, 1, following the rating rubric and evaluation steps. ## Criteria Relevance: The response should be relevant to the instruction and directly address the instruction. ## Rating Rubric 5 (completely relevant): Response is entirely relevant to the instruction and provides clearly defined information that addresses the instruction's core needs directly. 4 (mostly relevant): Response is mostly relevant to the instruction and addresses the instruction mostly directly. 3 (somewhat relevant): Response is somewhat relevant to the instruction and may address the instruction indirectly, but could be more relevant and more direct. 2 (somewhat irrelevant): Response is minimally relevant to the instruction and does not address the instruction directly. 1 (irrelevant): Response is completely irrelevant to the instruction. ## Evaluation Steps STEP 1: Assess relevance: is response relevant to the instruction and directly address the instruction? STEP 2: Score based on the criteria and rubrics. Give step by step explanations for your scoring, and only choose scores from 5, 4, 3, 2, 1. # User Inputs and AI-generated Response ## User Inputs ### Prompt {prompt} ## AI-generated Response {response} """ - กำหนดเทมเพลตพรอมต์สำหรับเมตริกความมีประโยชน์โดยใช้วิธีเดียวกัน เพิ่มและเรียกใช้โค้ดต่อไปนี้ในเซลล์ใหม่
helpfulness_prompt_template = """ You are a professional writing evaluator. Your job is to score writing responses according to pre-defined evaluation criteria. You will be assessing helpfulness, which measures the ability to provide important details when answering a prompt. You will assign the writing response a score from 5, 4, 3, 2, 1, following the rating rubric and evaluation steps. ## Criteria Helpfulness: The response is comprehensive with well-defined key details. The user would feel very satisfied with the content in a good response. ## Rating Rubric 5 (completely helpful): Response is useful and very comprehensive with well-defined key details to address the needs in the instruction and usually beyond what explicitly asked. The user would feel very satisfied with the content in the response. 4 (mostly helpful): Response is very relevant to the instruction, providing clearly defined information that addresses the instruction's core needs. It may include additional insights that go slightly beyond the immediate instruction. The user would feel quite satisfied with the content in the response. 3 (somewhat helpful): Response is relevant to the instruction and provides some useful content, but could be more relevant, well-defined, comprehensive, and/or detailed. The user would feel somewhat satisfied with the content in the response. 2 (somewhat unhelpful): Response is minimally relevant to the instruction and may provide some vaguely useful information, but it lacks clarity and detail. It might contain minor inaccuracies. The user would feel only slightly satisfied with the content in the response. 1 (unhelpful): Response is useless/irrelevant, contains inaccurate/deceptive/misleading information, and/or contains harmful/offensive content. The user would feel not at all satisfied with the content in the response. ## Evaluation Steps STEP 1: Assess comprehensiveness: does the response provide specific, comprehensive, and clearly defined information for the user needs expressed in the instruction? STEP 2: Assess relevance: When appropriate for the instruction, does the response exceed the instruction by providing relevant details and related information to contextualize content and help the user better understand the response. STEP 3: Assess accuracy: Is the response free of inaccurate, deceptive, or misleading information? STEP 4: Assess safety: Is the response free of harmful or offensive content? Give step by step explanations for your scoring, and only choose scores from 5, 4, 3, 2, 1. # User Inputs and AI-generated Response ## User Inputs ### Prompt {prompt} ## AI-generated Response {response} """ - สร้างอินสแตนซ์ออบเจ็กต์
PointwiseMetricสำหรับเมตริกที่กำหนดเอง 2 รายการ ซึ่งจะรวมเทมเพลตพรอมต์ของคุณไว้ในคอมโพเนนต์ที่นำกลับมาใช้ใหม่ได้สำหรับงานประเมิน เพิ่มและเรียกใช้โค้ดต่อไปนี้ในเซลล์ใหม่relevance = PointwiseMetric( metric="relevance", metric_prompt_template=relevance_prompt_template, ) helpfulness = PointwiseMetric( metric="helpfulness", metric_prompt_template=helpfulness_prompt_template, )
ตอนนี้คุณมีเมตริกใหม่ 2 รายการที่นำกลับมาใช้ซ้ำได้ (relevance และ helpfulness) ซึ่งพร้อมใช้งานในงานการประเมินแล้ว
9. เรียกใช้งานการประเมิน
เมื่อชุดข้อมูลและเมตริกพร้อมแล้ว คุณก็เรียกใช้การประเมินได้ คุณจะทำเช่นนี้ได้โดยการสร้างออบเจ็กต์ EvalTask สำหรับชุดข้อมูลแต่ละชุดที่ต้องการทดสอบ
EvalTask จะรวมคอมโพเนนต์สำหรับการเรียกใช้การประเมิน
- dataset: DataFrame ที่มีพรอมต์และการตอบกลับ
- เมตริก: รายการเมตริกที่คุณต้องการให้คะแนนเทียบกับ
- การทดลอง: การทดลอง Vertex AI เพื่อบันทึกผลลัพธ์ ซึ่งจะช่วยให้คุณติดตามและเปรียบเทียบการเรียกใช้ได้
- สร้าง
EvalTaskสำหรับแต่ละโมเดล ออบเจ็กต์นี้รวมชุดข้อมูล เมตริก และชื่อการทดสอบ เพิ่มและเรียกใช้โค้ดต่อไปนี้ในเซลล์ใหม่เพื่อกำหนดค่างานrag_eval_task_rag_a = EvalTask( dataset=eval_dataset_rag_a, metrics=[ "question_answering_quality", relevance, helpfulness, "groundedness", "safety", "instruction_following", ], experiment=EXPERIMENT, ) rag_eval_task_rag_b = EvalTask( dataset=eval_dataset_rag_b, metrics=[ "question_answering_quality", relevance, helpfulness, "groundedness", "safety", "instruction_following", ], experiment=EXPERIMENT, )EvalTaskจำนวน 2 รายการแล้ว โดยแต่ละรายการจะใช้สำหรับคำตอบของโมเดลแต่ละชุดmetricsรายการที่คุณระบุแสดงให้เห็นฟีเจอร์หลักของบริการประเมิน นั่นคือ เมตริกที่กำหนดไว้ล่วงหน้า (เช่นsafety) และออบเจ็กต์PointwiseMetricที่กำหนดเอง - เมื่อกำหนดค่างานแล้ว ให้เรียกใช้โดยเรียกใช้เมธอด
.evaluate()ซึ่งจะส่งงานไปยังแบ็กเอนด์ของ Vertex AI เพื่อประมวลผล และอาจใช้เวลาหลายนาทีจึงจะเสร็จสมบูรณ์ เพิ่มและเรียกใช้โค้ดต่อไปนี้ในเซลล์ใหม่result_rag_a = rag_eval_task_rag_a.evaluate() result_rag_b = rag_eval_task_rag_b.evaluate()
เมื่อการประเมินเสร็จสมบูรณ์แล้ว ระบบจะจัดเก็บผลลัพธ์ไว้ในออบเจ็กต์ result_rag_a และ result_rag_b เพื่อให้เราวิเคราะห์ในส่วนถัดไป
10. วิเคราะห์ผลลัพธ์
ตอนนี้ผลการประเมินพร้อมใช้งานแล้ว ออบเจ็กต์ result_rag_a และ result_rag_b มีคะแนนรวมและคำอธิบายโดยละเอียดสำหรับแต่ละแถว ในงานนี้ คุณจะได้วิเคราะห์ผลลัพธ์เหล่านี้โดยใช้ฟังก์ชันช่วยจาก notebook_utils
ดูข้อมูลสรุปรวม
- หากต้องการดูภาพรวมระดับสูง ให้ใช้ฟังก์ชันตัวช่วย
display_eval_result()เพื่อดูคะแนนเฉลี่ยของแต่ละเมตริก ในเซลล์ใหม่ ให้เพิ่มและเรียกใช้โค้ดต่อไปนี้เพื่อดูข้อมูลสรุปของโมเดล Anotebook_utils.display_eval_result( title="Model A Eval Result", eval_result=result_rag_a ) - ให้ทำแบบเดียวกันกับโมเดล B เพิ่มและเรียกใช้โค้ดนี้ในเซลล์ใหม่
notebook_utils.display_eval_result( title="Model B Eval Result", eval_result=result_rag_b, )
แสดงผลการประเมินด้วยภาพ
พล็อตช่วยให้เปรียบเทียบประสิทธิภาพของโมเดลได้ง่ายขึ้น คุณจะใช้การแสดงภาพ 2 ประเภท ได้แก่
- แผนภูมิเรดาร์: แสดง "รูปร่าง" ประสิทธิภาพโดยรวมของแต่ละโมเดล รูปร่างที่ใหญ่ขึ้นแสดงถึงประสิทธิภาพโดยรวมที่ดีขึ้น
- แผนภูมิแท่ง: สำหรับการเปรียบเทียบข้อมูลคู่กันโดยตรงในแต่ละเมตริก
การแสดงภาพเหล่านี้จะช่วยให้คุณเปรียบเทียบโมเดลในด้านคุณภาพเชิงอัตวิสัย เช่น ความเกี่ยวข้อง ความสมเหตุสมผล และความเป็นประโยชน์
- หากต้องการเตรียมพร้อมสำหรับการพล็อต ให้รวมผลลัพธ์เป็นรายการทูเพิลเดียว แต่ละทูเพิลควรมีชื่อโมเดลและออบเจ็กต์ผลลัพธ์ที่เกี่ยวข้อง เพิ่มและเรียกใช้โค้ดต่อไปนี้ในเซลล์ใหม่
eval_results = [] eval_results.append(("Model A", result_rag_a)) eval_results.append(("Model B", result_rag_b)) - ตอนนี้ให้สร้างแผนภูมิเรดาร์เพื่อเปรียบเทียบโมเดลในเมตริกทั้งหมดพร้อมกัน เพิ่มและเรียกใช้โค้ดต่อไปนี้ในเซลล์ใหม่
notebook_utils.display_radar_plot( eval_results, metrics=[ "question_answering_quality", "safety", "groundedness", "instruction_following", "relevance", "helpfulness", ], ) - หากต้องการเปรียบเทียบเมตริกแต่ละรายการโดยตรงมากขึ้น ให้สร้างแผนภูมิแท่ง ในเซลล์ใหม่ ให้เพิ่มและเรียกใช้โค้ดนี้
notebook_utils.display_bar_plot( eval_results, metrics=[ "question_answering_quality", "safety", "groundedness", "instruction_following", "relevance", "helpfulness", ], )
การแสดงภาพจะแสดงอย่างชัดเจนว่าประสิทธิภาพของโมเดล A (รูปร่างขนาดใหญ่ในแผนภูมิเรดาร์และแท่งสูงในแผนภูมิแท่ง) เหนือกว่าโมเดล B
ดูคำอธิบายโดยละเอียดสำหรับอินสแตนซ์แต่ละรายการ
คะแนนรวมจะแสดงประสิทธิภาพโดยรวม หากต้องการทราบสาเหตุที่โมเดลทำงานในลักษณะหนึ่งๆ คุณต้องตรวจสอบคำอธิบายโดยละเอียดที่ LLM สำหรับการประเมินสร้างขึ้นสำหรับแต่ละตัวอย่าง
display_explanations()ฟังก์ชันตัวช่วยช่วยให้คุณตรวจสอบผลลัพธ์แต่ละรายการได้ หากต้องการดูรายละเอียดการแบ่งย่อยของตัวอย่างที่ 2 (num=2) จากผลลัพธ์ของโมเดล A ให้เพิ่มและเรียกใช้โค้ดต่อไปนี้ในเซลล์ใหม่notebook_utils.display_explanations(result_rag_a, num=2)- นอกจากนี้ คุณยังใช้ฟังก์ชันนี้เพื่อกรองเมตริกที่เฉพาะเจาะจงในตัวอย่างทั้งหมดได้ด้วย ซึ่งมีประโยชน์สำหรับการแก้ไขข้อบกพร่องในพื้นที่ที่เฉพาะเจาะจงซึ่งมีประสิทธิภาพไม่ดี หากต้องการดูว่าเหตุใดโมเดล B จึงมีประสิทธิภาพต่ำในเมตริก
groundednessให้เพิ่มและเรียกใช้โค้ดนี้ในเซลล์ใหม่notebook_utils.display_explanations(result_rag_b, metrics=["groundedness"])
11. การประเมินโดยอิงตาม "คำตอบที่ถูกต้อง"
ก่อนหน้านี้ คุณได้ทำการประเมินแบบไม่มีข้อมูลอ้างอิง ซึ่งคำตอบของโมเดลได้รับการตัดสินโดยอิงตามพรอมต์เท่านั้น วิธีนี้มีประโยชน์ แต่การประเมินขึ้นอยู่กับความคิดเห็นส่วนบุคคล
ตอนนี้คุณจะใช้การประเมินแบบอิงเกณฑ์ วิธีนี้จะเพิ่ม "คำตอบที่ถูกต้อง" (หรือที่เรียกว่าคำตอบอ้างอิง) ลงในชุดข้อมูล การเปรียบเทียบคำตอบของโมเดลกับคำตอบสำหรับข้อมูลจากการสังเกตการณ์โดยตรงจะช่วยให้วัดประสิทธิภาพได้อย่างเป็นกลางมากขึ้น ซึ่งจะช่วยให้คุณวัดผลสิ่งต่อไปนี้ได้
- ความถูกต้องตามข้อเท็จจริง: คำตอบของโมเดลสอดคล้องกับข้อเท็จจริงในคำตอบที่ถูกต้องหรือไม่
- ความคล้ายคลึงกันของความหมาย: คำตอบของโมเดลมีความหมายเหมือนกับคำตอบที่ถูกต้องหรือไม่
- ความครบถ้วนสมบูรณ์: คำตอบของโมเดลมีข้อมูลสำคัญทั้งหมดจากคำตอบที่ถูกต้องหรือไม่
เตรียมชุดข้อมูลที่อ้างอิง
หากต้องการทำการประเมินที่อ้างอิง คุณต้องเพิ่ม "คำตอบที่ถูกต้อง" ให้กับแต่ละตัวอย่างในชุดข้อมูล
มาเริ่มด้วยการกำหนดgolden_answersรายการกัน การเปรียบเทียบคำตอบที่ถูกต้องกับคำตอบจากโมเดล A แสดงให้เห็นถึงคุณค่าของวิธีนี้
- คำถามที่ 1 (สมอง): คำตอบที่สร้างขึ้นและคำตอบที่ถูกต้องเหมือนกัน โมเดล ก ถูกต้อง
- คำถามที่ 2 (วุฒิสภา): คำตอบมีความหมายคล้ายกันแต่ใช้คำต่างกัน เมตริกที่ดีควรรับรู้ถึงเรื่องนี้
- คำถามที่ 3 (Hasan-Jalalians): คำตอบของโมเดล A ไม่ถูกต้องตามข้อเท็จจริงตามบริบท
golden_answerจะแสดงข้อผิดพลาดนี้
- กำหนดรายการ golden_answers ในเซลล์ใหม่
golden_answers = [ "frontal lobe and the parietal lobe", "Due to successes against Catiline.", "The Hasan-Jalalians commanded the area of Artsakh and Utik.", ] - สร้าง DataFrame การประเมินที่อ้างอิงโดยเรียกใช้โค้ดนี้ในเซลล์ต่อไปนี้
referenced_eval_dataset_rag_a = pd.DataFrame( { "prompt": [ "Answer the question: " + question + " Context: " + item for question, item in zip(questions, retrieved_contexts) ], "response": generated_answers_by_rag_a, "reference": golden_answers, } ) referenced_eval_dataset_rag_b = pd.DataFrame( { "prompt": [ "Answer the question: " + question + " Context: " + item for question, item in zip(questions, retrieved_contexts) ], "response": generated_answers_by_rag_b, "reference": golden_answers, } )
ตอนนี้ชุดข้อมูลพร้อมสำหรับการประเมินโดยอิงตามการอ้างอิงแล้ว
สร้างเมตริกที่อ้างอิงที่กำหนดเอง
นอกจากนี้ คุณยังสร้างเมตริกที่กำหนดเองสำหรับการประเมินที่อ้างอิงได้ด้วย กระบวนการนี้คล้ายกัน แต่ตอนนี้เทมเพลตพรอมต์มีตัวยึดตำแหน่ง {reference} สำหรับคำตอบที่ดีที่สุดแล้ว
เมื่อมีคำตอบที่ "ถูกต้อง" อย่างชัดเจน คุณจะใช้การให้คะแนนแบบไบนารีที่เข้มงวดมากขึ้น (เช่น 1 สำหรับคำตอบที่ถูกต้อง 0 สำหรับคำตอบที่ไม่ถูกต้อง) เพื่อวัดความถูกต้องตามข้อเท็จจริงได้ มาสร้างquestion_answering_correctnessเมตริกใหม่ที่ใช้ตรรกะนี้กัน
- กำหนดเทมเพลตพรอมต์ เพิ่มและเรียกใช้โค้ดต่อไปนี้ในเซลล์ใหม่
question_answering_correctness_prompt_template = """ You are a professional writing evaluator. Your job is to score writing responses according to pre-defined evaluation criteria. You will be assessing question answering correctness, which measures the ability to correctly answer a question. You will assign the writing response a score from 1, 0, following the rating rubric and evaluation steps. ### Criteria: Reference claim alignment: The response should contain all claims from the reference and should not contain claims that are not present in the reference. ### Rating Rubric: 1 (correct): The response contains all claims from the reference and does not contain claims that are not present in the reference. 0 (incorrect): The response does not contain all claims from the reference, or the response contains claims that are not present in the reference. ### Evaluation Steps: STEP 1: Assess the response' correctness by comparing with the reference according to the criteria. STEP 2: Score based on the rubrics. Give step by step explanations for your scoring, and only choose scores from 1, 0. # User Inputs and AI-generated Response ## User Inputs ### Prompt {prompt} ## Reference {reference} ## AI-generated Response {response} """ - ห่อสตริงเทมเพลตพรอมต์ภายในออบเจ็กต์ PointwiseMetric ซึ่งจะช่วยให้เมตริกมีชื่ออย่างเป็นทางการและทำให้เป็นคอมโพเนนต์ที่นำกลับมาใช้ใหม่ได้สำหรับงานประเมิน เพิ่มและเรียกใช้โค้ดต่อไปนี้ในเซลล์ใหม่
question_answering_correctness = PointwiseMetric( metric="question_answering_correctness", metric_prompt_template=question_answering_correctness_prompt_template, )
ตอนนี้คุณมีเมตริกที่อ้างอิงที่กำหนดเองสำหรับการตรวจสอบข้อเท็จจริงอย่างเข้มงวดแล้ว
12. เรียกใช้การประเมินที่อ้างอิง
ตอนนี้คุณจะกำหนดค่างานการประเมินด้วยชุดข้อมูลที่อ้างอิงและเมตริกใหม่ คุณจะใช้ชั้นเรียน EvalTask อีกครั้ง
ตอนนี้รายการเมตริกจะรวมเมตริกที่อิงตามโมเดลที่กําหนดเองเข้ากับเมตริกที่อิงตามการคํานวณ การประเมินที่อ้างอิงช่วยให้ใช้เมตริกแบบดั้งเดิมที่อิงตามการคำนวณซึ่งทำการเปรียบเทียบทางคณิตศาสตร์ระหว่างข้อความที่สร้างขึ้นกับข้อความอ้างอิงได้ คุณจะใช้ 3 รายการที่พบบ่อย ได้แก่
exact_match: ให้คะแนน 1 เฉพาะในกรณีที่คำตอบที่สร้างขึ้นเหมือนกับคำตอบอ้างอิง และให้คะแนน 0 ในกรณีอื่นๆbleu: เมตริกความแม่นยำ โดยจะวัดจำนวนคำจากคำตอบที่สร้างขึ้นซึ่งปรากฏในคำตอบอ้างอิงด้วยrouge: เมตริกของการเรียกคืน โดยจะวัดจำนวนคำจากคำตอบอ้างอิงที่อยู่ในคำตอบที่สร้างขึ้น
- กำหนดค่างานประเมินด้วยชุดข้อมูลที่อ้างอิงและชุดเมตริกใหม่ ในเซลล์ใหม่ ให้เพิ่มและเรียกใช้โค้ดต่อไปนี้เพื่อสร้างออบเจ็กต์
EvalTaskreferenced_answer_eval_task_rag_a = EvalTask( dataset=referenced_eval_dataset_rag_a, metrics=[ question_answering_correctness, "rouge", "bleu", "exact_match", ], experiment=EXPERIMENT, ) referenced_answer_eval_task_rag_b = EvalTask( dataset=referenced_eval_dataset_rag_b, metrics=[ question_answering_correctness, "rouge", "bleu", "exact_match", ], experiment=EXPERIMENT, ) - เรียกใช้การประเมินที่อ้างอิงโดยเรียกใช้เมธอด
.evaluate()เพิ่มและเรียกใช้โค้ดนี้ในเซลล์ใหม่referenced_result_rag_a = referenced_answer_eval_task_rag_a.evaluate() referenced_result_rag_b = referenced_answer_eval_task_rag_b.evaluate()
13. วิเคราะห์ผลลัพธ์ที่อ้างอิง
การประเมินเสร็จสมบูรณ์แล้ว ในงานนี้ คุณจะต้องวิเคราะห์ผลลัพธ์เพื่อวัดความถูกต้องตามข้อเท็จจริงของโมเดลโดยเปรียบเทียบคำตอบของโมเดลกับคำตอบอ้างอิงที่ถูกต้อง
ดูผลลัพธ์สรุป
- วิเคราะห์ผลลัพธ์สรุปสำหรับการประเมินที่อ้างอิง ในเซลล์ใหม่ ให้เพิ่มและเรียกใช้โค้ดต่อไปนี้เพื่อแสดงตารางสรุปสําหรับทั้ง 2 โมเดล
notebook_utils.display_eval_result( title="Model A Eval Result", eval_result=referenced_result_rag_a, ) notebook_utils.display_eval_result( title="Model B Eval Result", eval_result=referenced_result_rag_b, )question_answering_correctnessที่กำหนดเอง แต่ได้คะแนนต่ำกว่าในexact_matchซึ่งแสดงให้เห็นถึงคุณค่าของเมตริกที่อิงตามโมเดลซึ่งสามารถจดจำความคล้ายคลึงกันทางความหมายได้ ไม่ใช่แค่ข้อความที่เหมือนกัน
แสดงภาพผลลัพธ์เพื่อเปรียบเทียบ
การแสดงภาพจะช่วยให้เห็นความแตกต่างด้านประสิทธิภาพระหว่าง 2 โมเดลได้ชัดเจนยิ่งขึ้น ก่อนอื่นให้รวมผลลัพธ์ไว้ในรายการเดียวเพื่อพล็อต จากนั้นสร้างแผนภูมิเรดาร์และแผนภูมิแท่ง
- รวมผลการประเมินที่อ้างอิงไว้เป็นรายการเดียวเพื่อสร้างแผนภูมิ เพิ่มและเรียกใช้โค้ดต่อไปนี้ในเซลล์ใหม่
referenced_eval_results = [] referenced_eval_results.append(("Model A", referenced_result_rag_a)) referenced_eval_results.append(("Model B", referenced_result_rag_b)) - สร้างแผนภูมิเรดาร์เพื่อแสดงภาพประสิทธิภาพของแต่ละโมเดลในชุดเมตริกใหม่ เพิ่มและเรียกใช้โค้ดนี้ในเซลล์ใหม่
notebook_utils.display_radar_plot( referenced_eval_results, metrics=[ "question_answering_correctness", "rouge", "bleu", "exact_match", ], ) - สร้างแผนภูมิแท่งเพื่อการเปรียบเทียบข้อมูลคู่กันโดยตรง ซึ่งจะแสดงประสิทธิภาพของแต่ละโมเดลในเมตริกต่างๆ เพิ่มและเรียกใช้โค้ดต่อไปนี้ในเซลล์ใหม่
notebook_utils.display_bar_plot( referenced_eval_results, metrics=[ "question_answering_correctness", "rouge", "bleu", "exact_match", ], )
ภาพข้อมูลเหล่านี้ยืนยันว่าโมเดล ก. มีความแม่นยำมากกว่าและสอดคล้องกับคำตอบอ้างอิงมากกว่าโมเดล ข. อย่างมีนัยสำคัญ
14. จากเวอร์ชันทดลองสู่เวอร์ชันที่ใช้งานจริง
คุณได้ดำเนินการไปป์ไลน์การประเมินที่สมบูรณ์สำหรับระบบ RAG เรียบร้อยแล้ว ส่วนสุดท้ายนี้จะสรุปแนวคิดเชิงกลยุทธ์ที่สำคัญที่คุณได้เรียนรู้ และให้กรอบการทำงานสำหรับการนำทักษะเหล่านี้ไปใช้กับโปรเจ็กต์ในโลกแห่งความเป็นจริง
แนวทางปฏิบัติแนะนำในการผลิต
หากต้องการนำทักษะจากแล็บนี้ไปใช้ในสภาพแวดล้อมฮาร์ดแวร์และซอฟต์แวร์จริง ให้พิจารณาแนวทางปฏิบัติที่สำคัญ 4 ประการต่อไปนี้
- ทำให้เป็นอัตโนมัติด้วย CI/CD: ผสานรวมชุดการประเมินเข้ากับไปป์ไลน์ CI/CD (เช่น Cloud Build, GitHub Actions) เรียกใช้การประเมินโดยอัตโนมัติเมื่อมีการเปลี่ยนแปลงโค้ดเพื่อตรวจหาการถดถอยและบล็อกการติดตั้งใช้งานหากคะแนนคุณภาพต่ำกว่ามาตรฐาน
- พัฒนาชุดข้อมูล: ชุดข้อมูลแบบคงที่จะล้าสมัย ควบคุมเวอร์ชันชุดทดสอบ "ทองคำ" (โดยใช้ Git LFS หรือ Cloud Storage) และเพิ่มตัวอย่างใหม่ๆ ที่ท้าทายอย่างต่อเนื่องโดยการสุ่มตัวอย่างจากคำค้นหาของผู้ใช้จริง (ที่ลบข้อมูลระบุตัวบุคคลแล้ว)
- ประเมินตัวดึงข้อมูล ไม่ใช่แค่ตัวสร้าง: คำตอบที่ยอดเยี่ยมจะเกิดขึ้นไม่ได้หากไม่มีบริบทที่เหมาะสม ใช้ขั้นตอนการประเมินแยกต่างหากสำหรับระบบการดึงข้อมูลโดยใช้เมตริก เช่น อัตราการเข้าชม (พบเอกสารที่ถูกต้องหรือไม่) และอันดับซึ่งกันและกันเฉลี่ย (MRR) (เอกสารที่ถูกต้องได้รับการจัดอันดับสูงเพียงใด)
- ตรวจสอบเมตริกเมื่อเวลาผ่านไป: ส่งออกคะแนนสรุปจากการเรียกใช้การประเมินไปยังบริการ เช่น Google Cloud Monitoring สร้างแดชบอร์ดเพื่อติดตามแนวโน้มคุณภาพและตั้งค่าการแจ้งเตือนอัตโนมัติเพื่อแจ้งให้คุณทราบถึงประสิทธิภาพที่ลดลงอย่างมาก
เมทริกซ์วิธีการประเมินขั้นสูง
การเลือกแนวทางการประเมินที่เหมาะสมขึ้นอยู่กับเป้าหมายที่เฉพาะเจาะจงของคุณ เมทริกซ์นี้สรุปเวลาที่ควรใช้วิธีการแต่ละอย่าง
แนวทางการประเมิน | Use Case ที่ดีที่สุด | ข้อดีหลัก | ข้อจำกัด |
ไม่ต้องอ้างอิง | การตรวจสอบเวอร์ชันที่ใช้งานจริง การประเมินอย่างต่อเนื่อง | ไม่จำเป็นต้องมีคำตอบที่ถูกต้อง แต่ต้องจับคุณภาพเชิงอัตวิสัย | มีราคาแพงกว่า อาจเกิดอคติของผู้ประเมิน |
อิงตามการอ้างอิง | การเปรียบเทียบรูปแบบการระบุแหล่งที่มา การเปรียบเทียบ | การวัดผลตามวัตถุประสงค์ การคำนวณที่เร็วขึ้น | ต้องมีคำตอบที่ถูกต้องที่สุด อาจพลาดความหมายที่เทียบเท่า |
เมตริกที่กำหนดเอง | การประเมินเฉพาะโดเมน | ปรับให้เหมาะกับความต้องการทางธุรกิจ | ต้องมีการตรวจสอบความถูกต้อง ค่าใช้จ่ายในการพัฒนา |
แนวทางแบบผสมผสาน | ระบบการผลิตที่ครอบคลุม | แนวทางที่ดีที่สุด | ความซับซ้อนสูงขึ้น ต้องเพิ่มประสิทธิภาพต้นทุน |
ข้อมูลเชิงลึกทางเทคนิคที่สำคัญ
โปรดคำนึงถึงหลักการสำคัญเหล่านี้ขณะสร้างและประเมินระบบ RAG ของคุณเอง
- ความถูกต้องเป็นสิ่งสำคัญสำหรับ RAG: เมตริกนี้แยกความแตกต่างระหว่างระบบ RAG คุณภาพสูงและต่ำได้อย่างสม่ำเสมอ จึงเป็นสิ่งจำเป็นสำหรับการตรวจสอบการใช้งานจริง
- เมตริกหลายรายการช่วยให้มีความแข็งแกร่ง: ไม่มีเมตริกใดเมตริกเดียวที่ครอบคลุมทุกด้านของคุณภาพ RAG การประเมินที่ครอบคลุมต้องใช้มิติการประเมินหลายมิติ
- เมตริกที่กำหนดเองช่วยเพิ่มคุณค่าอย่างมาก: เกณฑ์การประเมินเฉพาะโดเมนมักจะจับรายละเอียดที่เมตริกทั่วไปพลาดไป ซึ่งช่วยปรับปรุงความแม่นยำในการประเมิน
- ความเข้มงวดทางสถิติช่วยให้มั่นใจได้: ขนาดกลุ่มตัวอย่างที่เหมาะสมและการทดสอบนัยสำคัญจะเปลี่ยนการประเมินจากการคาดเดาให้เป็นเครื่องมือการตัดสินใจที่เชื่อถือได้
กรอบการตัดสินใจในการติดตั้งใช้งานเวอร์ชันที่ใช้งานจริง
ใช้เฟรมเวิร์กแบบเป็นระยะนี้เป็นแนวทางสำหรับการติดตั้งใช้งานระบบ RAG ในอนาคต
- ระยะที่ 1 - การพัฒนา: ใช้การประเมินตามการอ้างอิงกับชุดทดสอบที่ทราบเพื่อเปรียบเทียบและเลือกรุ่น
- ระยะที่ 2 - ก่อนการผลิต: ดำเนินการประเมินอย่างครอบคลุมโดยใช้ทั้ง 2 แนวทางร่วมกันเพื่อตรวจสอบความพร้อมของเวอร์ชันที่ใช้งานจริง
- ระยะที่ 3 - การผลิต: ใช้การตรวจสอบแบบไม่มีการอ้างอิงสำหรับการประเมินคุณภาพอย่างต่อเนื่องโดยไม่ต้องมีคำตอบที่ถูกต้อง
- ระยะที่ 4 - การเพิ่มประสิทธิภาพ: ใช้ข้อมูลเชิงลึกจากการประเมินเพื่อเป็นแนวทางในการปรับปรุงโมเดลและการเพิ่มประสิทธิภาพระบบการดึงข้อมูล
15. บทสรุป
ยินดีด้วย คุณทำแล็บเสร็จแล้ว
Lab นี้เป็นส่วนหนึ่งของเส้นทางการเรียนรู้ AI พร้อมใช้งานจริงด้วย Google Cloud
- สำรวจหลักสูตรทั้งหมดเพื่อเชื่อมช่องว่างจากต้นแบบไปสู่การผลิต
- แชร์ความคืบหน้าของคุณด้วยแฮชแท็ก
ProductionReadyAI
สรุป
คุณได้เรียนรู้วิธีต่อไปนี้
- ทำการประเมินแบบไม่มีการอ้างอิงเพื่อประเมินคุณภาพของคำตอบตามบริบทที่ดึงข้อมูลมา
- ทำการประเมินที่อ้างอิงโดยเพิ่ม "คำตอบที่ถูกต้อง" เพื่อวัดความถูกต้องตามข้อเท็จจริง
- ใช้เมตริกที่กำหนดไว้ล่วงหน้าและเมตริกที่กำหนดเองผสมกันสำหรับทั้ง 2 วิธี
- ใช้ทั้งเมตริกตามโมเดล (เช่น
question_answering_quality) และเมตริกตามการคำนวณ (rouge,bleu,exact_match) - วิเคราะห์และแสดงผลลัพธ์ผ่านภาพเพื่อทำความเข้าใจจุดแข็งและจุดอ่อนของโมเดล
แนวทางการประเมินนี้จะช่วยให้คุณสร้างแอปพลิเคชัน Generative AI ที่เชื่อถือได้และแม่นยำมากขึ้น