
1. Genel Bakış
Bu laboratuvarda, almayla artırılmış üretim (RAG) sistemi için değerlendirme ardışık düzeni oluşturmayı öğreneceksiniz. Özel değerlendirme ölçütleri oluşturmak ve soru-cevap görevi için bir değerlendirme çerçevesi oluşturmak üzere Vertex AI Üretken Yapay Zeka Değerlendirme Hizmeti'ni kullanacaksınız.
Değerlendirme veri kümeleri hazırlamak, referanssız ve referansa dayalı değerlendirmeleri yapılandırmak ve sonuçları yorumlamak için Stanford Question Answering Dataset (SQuAD 2.0) örnekleriyle çalışacaksınız. Bu laboratuvarın sonunda, RAG sistemlerini nasıl değerlendireceğinizi ve belirli değerlendirme yaklaşımlarının neden seçildiğini anlayacaksınız.
Veri kümesi temeli
SQuAD 2.0 Soru-Cevap Veri Kümesi'nde bulunan birden fazla alanı kapsayan, dikkatle hazırlanmış örneklerle çalışacağız:
- Nörobilim: Bilimsel bağlamlarda teknik doğruluğu test etme
- Geçmiş: Geçmiş anlatılarda olgusal doğruluğu değerlendirme
- Coğrafya: Bölgesel ve siyasi bilgileri değerlendirme
Bu çeşitlilik, değerlendirme yaklaşımlarının farklı konu alanlarında nasıl genelleştirildiğini anlamanıza yardımcı olur.
Referanslar
- Kod örnekleri: Bu laboratuvar, Vertex AI Evaluation belgelerindeki örneklerden yararlanır.
- Veri kümesi temeli: SQuAD 2.0 Soru-Cevap Veri Kümesi
- RAG alımını optimize etme: Test edin, ayarlayın, başarılı olun
Neler öğreneceksiniz?
Bu laboratuvarda, aşağıdaki görevleri nasıl gerçekleştireceğinizi öğreneceksiniz:
- RAG sistemleri için değerlendirme veri kümeleri hazırlayın.
- Temellendirme ve alaka düzeyi gibi metrikleri kullanarak referanssız değerlendirme uygulayın.
- Semantik benzerlik ölçüleriyle referansa dayalı değerlendirme uygulayın.
- Ayrıntılı puanlama rubrikleri içeren özel değerlendirme metrikleri oluşturun.
- Model seçimini belirlemek için değerlendirme sonuçlarını yorumlayın ve görselleştirin.
2. Proje ayarlama
Google Hesabı
Kişisel Google Hesabınız yoksa Google Hesabı oluşturmanız gerekir.
İş veya okul hesabı yerine kişisel hesap kullanın.
Google Cloud Console'da oturum açma
Kişisel bir Google Hesabı kullanarak Google Cloud Console'da oturum açın.
Faturalandırmayı Etkinleştir
Google Cloud kredilerini kullanma (isteğe bağlı)
Bu atölyeyi düzenlemek için biraz kredisi olan bir faturalandırma hesabınızın olması gerekir. Başlamak için bu codelab'in üst kısmındaki banner'da yer alan kredileri kullanın. Zaten bir faturalandırma hesabına bağlıysanız bu adımı atlayabilirsiniz.
Kişisel faturalandırma hesabı oluşturma
Faturalandırmayı Google Cloud kredilerini kullanarak ayarladıysanız bu adımı atlayabilirsiniz.
Kişisel faturalandırma hesabı oluşturmak için Cloud Console'da faturalandırmayı etkinleştirmek üzere buraya gidin.
Bazı Notlar:
- Bu laboratuvarı tamamlamak için 1 ABD dolarından daha az tutarda bulut kaynağı kullanmanız gerekir.
- Daha fazla ücret alınmaması için bu laboratuvarın sonundaki adımları uygulayarak kaynakları silebilirsiniz.
- Yeni kullanıcılar 300 ABD doları değerinde ücretsiz deneme sürümünden yararlanabilir.
Proje oluşturma (isteğe bağlı)
Bu laboratuvarda kullanmak istediğiniz mevcut bir projeniz yoksa buradan yeni bir proje oluşturun.
3. Veriyle Artırılmış Üretim (RAG) nedir?
RAG, Büyük Dil Modelleri'nin (LLM) yanıtlarının olgusal doğruluğunu ve alaka düzeyini artırmak için kullanılan bir tekniktir. LLM'yi harici bir bilgi tabanına bağlayarak yanıtlarını belirli ve doğrulanabilir bilgilerle temellendirir.
Bu süreç aşağıdaki adımlardan oluşur:
- Kullanıcının sorusunu sayısal bir temsile (yerleştirme) dönüştürme
- Bilgi bankasında benzer yerleştirmelere sahip belgeleri arama
- Yanıt oluşturmak için bu alakalı belgeleri orijinal soruyla birlikte LLM'ye bağlam olarak sağlama.
RAG hakkında daha fazla bilgi edinin.
RAG değerlendirmesini karmaşık kılan nedir?
RAG sistemlerini değerlendirmek, geleneksel dil modellerini değerlendirmekten farklıdır.
Çok Bileşenli Zorluk: RAG sistemleri, her biri hata noktası olabilecek üç işlemi birleştirir:
- Alma Kalitesi: Sistem, doğru bağlam belgelerini buldu mu?
- Bağlam Kullanımı: Model, alınan bilgileri etkili bir şekilde kullandı mı?
- Üretim Kalitesi: Son yanıt iyi yazılmış, faydalı ve doğru mu?
Bu bileşenlerden herhangi biri beklendiği gibi çalışmazsa yanıt başarısız olabilir. Örneğin, sistem doğru bağlamı alabilir ancak model bunu yoksayabilir. Alternatif olarak, model, alınan bağlam alakasız olduğu için yanlış olan iyi yazılmış bir yanıt oluşturabilir.
4. Vertex AI Workbench ortamınızı ayarlama
RAG sistemlerini değerlendirmek için gereken kodumuzu çalıştıracağımız yeni bir not defteri ortamı başlatarak başlayalım.
- Cloud Console'unuzun API'ler ve Hizmetler sayfasına gidin.
- Vertex AI API için Etkinleştir'i tıklayın.
Vertex AI Workbench'e erişme
- Google Cloud Console'da Gezinme menüsü ☰ > Vertex AI > Workbench'i tıklayarak Vertex AI'a gidin.
- Yeni bir Workbench örneği oluşturun.
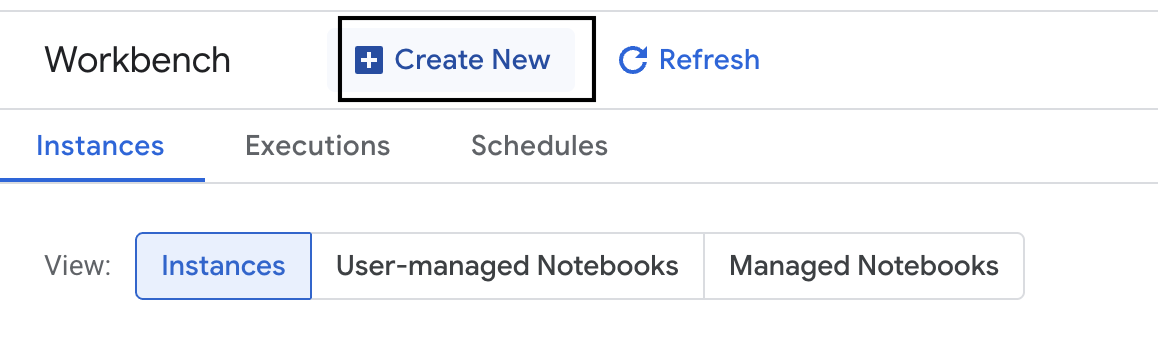
- Workbench örneğini
evaluation-workbencholarak adlandırın. - Bu değerler henüz ayarlanmamışsa bölgenizi ve alt bölgenizi seçin.
- Oluştur'u tıklayın.
- Çalışma tezgahının kurulmasını bekleyin. Bu işlem birkaç dakika sürebilir.

- Çalışma alanı sağlandıktan sonra open jupyterlab'i (JupyterLab'i aç) tıklayın.
- Workbench'te yeni bir Python3 not defteri oluşturun.
Bu ortamın özellikleri ve işlevleri hakkında daha fazla bilgi edinmek için Vertex AI Workbench'in resmi belgelerine bakın.
Vertex AI değerlendirme SDK'sını yükleme
Şimdi RAG değerlendirmesi için araçlar sağlayan özel değerlendirme SDK'sını yükleyelim.
- Vertex AI SDK'sını (değerlendirme bileşenleriyle birlikte) yüklemek için not defterinizin ilk hücresine aşağıdaki içe aktarma ifadesini ekleyin ve çalıştırın (Üst Karakter+Enter).
%pip install --upgrade --user --quiet google-cloud-aiplatform[evaluation]- EvalTask: Değerlendirmeleri çalıştırmak için kullanılan ana sınıf
- MetricPromptTemplateExamples: Önceden tanımlanmış değerlendirme metrikleri
- PointwiseMetric: Özel metrikler oluşturmaya yönelik çerçeve
- notebook_utils: Sonuç analizi için görselleştirme araçları
- Önemli: Yeni paketleri kullanmak için yükleme işleminden sonra çekirdeği yeniden başlatmanız gerekir. JupyterLab pencerenizin üst kısmındaki menü çubuğunda Kernel > Restart Kernel'a (Çekirdeği Yeniden Başlat) gidin.
5. SDK'yı başlatma ve kitaplıkları içe aktarma
Değerlendirme ardışık düzenini oluşturmadan önce ortamınızı ayarlamanız gerekir. Bu işlemde proje ayrıntılarınızı yapılandırma, Google Cloud'a bağlanmak için Vertex AI SDK'sını başlatma ve değerlendirme için kullanacağınız özel Python kitaplıklarını içe aktarma yer alır.
- Değerlendirme işiniz için yapılandırma değişkenlerini tanımlayın. Yeni bir hücrede, bu çalıştırmayı düzenlemek için
PROJECT_ID,LOCATIONveEXPERIMENTadınızı ayarlamak üzere aşağıdaki kodu ekleyip çalıştırın.import vertexai PROJECT_ID = "YOUR PROJECT ID" LOCATION = "YOUR LOCATION" # @param {type:"string"} EXPERIMENT = "rag-eval-01" # @param {type:"string"} if not PROJECT_ID or PROJECT_ID == "[your-project-id]": raise ValueError("Please set your PROJECT_ID") - Vertex AI SDK'yı başlatın. Yeni bir hücreye aşağıdaki kodu ekleyip çalıştırın.
vertexai.init(project=PROJECT_ID, location=LOCATION) - Gerekli sınıfları değerlendirme SDK'sından içe aktarmak için sonraki hücrede aşağıdaki kodu çalıştırın:
import pandas as pd from vertexai.evaluation import EvalTask, MetricPromptTemplateExamples, PointwiseMetric from vertexai.preview.evaluation import notebook_utils- pandas: DataFrame'lerde veri oluşturmak ve yönetmek için kullanılır.
- EvalTask: Değerlendirme işini çalıştıran temel sınıf.
- MetricPromptTemplateExamples: Google'ın önceden tanımlanmış değerlendirme metriklerine erişim sağlar.
- PointwiseMetric: Kendi özel metriklerinizi oluşturma çerçevesi.
- notebook_utils: Sonuçları görselleştirmeye yönelik bir araç koleksiyonu.
6. Değerlendirme veri kümenizi hazırlama
İyi yapılandırılmış bir veri kümesi, güvenilir değerlendirmelerin temelini oluşturur. RAG sistemlerinde, veri kümenizde her örnek için iki temel alan bulunmalıdır:
- istem: Bu, dil modeline sağlanan toplam giriştir. Kullanıcının sorusunu, RAG sisteminiz tarafından alınan bağlamla birleştirmeniz gerekir (
prompt = User Question + Retrieved Context). Bu, değerlendirme hizmetinin modelin yanıtını oluşturmak için hangi bilgileri kullandığını bilmesi açısından önemlidir. - response (yanıt): Bu, RAG modeliniz tarafından üretilen nihai yanıttır.
İstatistiksel olarak güvenilir sonuçlar için yaklaşık 100 örnekten oluşan bir veri kümesi önerilir. Bu laboratuvarda, süreci göstermek için küçük bir veri kümesi kullanacaksınız.
Veri kümelerini oluşturalım. Bir soru listesi ve RAG sisteminden gelen retrieved_contexts ile başlarsınız. Ardından iki yanıt grubu tanımlarsınız: Biri iyi performans gösteren bir modelden (generated_answers_by_rag_a), diğeri ise kötü performans gösteren bir modelden (generated_answers_by_rag_b) alınır.
Son olarak, yukarıda açıklanan yapıyı izleyerek bu parçaları iki pandas DataFrame'e (eval_dataset_rag_a ve eval_dataset_rag_b) birleştireceksiniz.
- Soruları ve generated_answers adlı iki grubu tanımlamak için yeni bir hücreye aşağıdaki kodu ekleyip çalıştırın.
questions = [ "Which part of the brain does short-term memory seem to rely on?", "What provided the Roman senate with exuberance?", "What area did the Hasan-jalalians command?", ] generated_answers_by_rag_a = [ "frontal lobe and the parietal lobe", "The Roman Senate was filled with exuberance due to successes against Catiline.", "The Hasan-Jalalians commanded the area of Syunik and Vayots Dzor.", ] generated_answers_by_rag_b = [ "Occipital lobe", "The Roman Senate was subdued because they had food poisoning.", "The Galactic Empire commanded the state of Utah.", ] - retrieved_contexts öğesini tanımlayın. Yeni bir hücreye aşağıdaki kodu ekleyip çalıştırın.
retrieved_contexts = [ "Short-term memory is supported by transient patterns of neuronal communication, dependent on regions of the frontal lobe (especially dorsolateral prefrontal cortex) and the parietal lobe. Long-term memory, on the other hand, is maintained by more stable and permanent changes in neural connections widely spread throughout the brain. The hippocampus is essential (for learning new information) to the consolidation of information from short-term to long-term memory, although it does not seem to store information itself. Without the hippocampus, new memories are unable to be stored into long-term memory, as learned from patient Henry Molaison after removal of both his hippocampi, and there will be a very short attention span. Furthermore, it may be involved in changing neural connections for a period of three months or more after the initial learning.", "In 62 BC, Pompey returned victorious from Asia. The Senate, elated by its successes against Catiline, refused to ratify the arrangements that Pompey had made. Pompey, in effect, became powerless. Thus, when Julius Caesar returned from a governorship in Spain in 61 BC, he found it easy to make an arrangement with Pompey. Caesar and Pompey, along with Crassus, established a private agreement, now known as the First Triumvirate. Under the agreement, Pompey's arrangements would be ratified. Caesar would be elected consul in 59 BC, and would then serve as governor of Gaul for five years. Crassus was promised a future consulship.", "The Seljuk Empire soon started to collapse. In the early 12th century, Armenian princes of the Zakarid noble family drove out the Seljuk Turks and established a semi-independent Armenian principality in Northern and Eastern Armenia, known as Zakarid Armenia, which lasted under the patronage of the Georgian Kingdom. The noble family of Orbelians shared control with the Zakarids in various parts of the country, especially in Syunik and Vayots Dzor, while the Armenian family of Hasan-Jalalians controlled provinces of Artsakh and Utik as the Kingdom of Artsakh.", ] - Yeni bir hücrede,
eval_dataset_rag_aveeval_dataset_rag_boluşturmak için aşağıdaki kodu ekleyip çalıştırın.eval_dataset_rag_a = pd.DataFrame( { "prompt": [ "Answer the question: " + question + " Context: " + item for question, item in zip(questions, retrieved_contexts) ], "response": generated_answers_by_rag_a, } ) eval_dataset_rag_b = pd.DataFrame( { "prompt": [ "Answer the question: " + question + " Context: " + item for question, item in zip(questions, retrieved_contexts) ], "response": generated_answers_by_rag_b, } ) - A modeline ait veri kümesinin ilk birkaç satırını görüntülemek için yeni bir hücrede aşağıdaki kodu çalıştırın.
eval_dataset_rag_a
7. Metrik seçme ve oluşturma
Veri kümeleri hazır olduğuna göre artık performansı nasıl ölçeceğinize karar verebilirsiniz. Modelinizi değerlendirmek için bir veya daha fazla metrik kullanabilirsiniz. Her metrik, modelin yanıtının belirli bir yönünü (ör. olgusal doğruluğu veya alaka düzeyi) değerlendirir.
İki tür metriğin kombinasyonunu kullanabilirsiniz:
- Önceden tanımlanmış metrikler: SDK tarafından yaygın değerlendirme görevleri için sağlanan, kullanıma hazır metrikler.
- Özel Metrikler: Kullanım alanınızla ilgili nitelikleri test etmek için tanımladığınız metrikler.
Bu bölümde, RAG için kullanılabilen önceden tanımlanmış metrikleri inceleyeceksiniz.
Önceden tanımlanmış metrikleri inceleme
SDK, soru-cevap sistemlerini değerlendirmek için çeşitli yerleşik metrikler içerir. Bu metrikler, modelinizin yanıtlarını bir dizi talimata göre puanlamak için bir dil modelini "değerlendirici" olarak kullanır.
- Önceden tanımlanmış metrik adlarının tam listesini görmek için yeni bir hücreye aşağıdaki kodu ekleyip çalıştırın:
MetricPromptTemplateExamples.list_example_metric_names() - Bu metriklerin nasıl çalıştığını anlamak için temel istem şablonlarını inceleyebilirsiniz. Yeni bir hücrede,
question_answering_qualitymetriği için değerlendirici LLM'ye verilen talimatları görmek üzere aşağıdaki kodu ekleyip çalıştırın.# See the prompt example for one of the pointwise metrics print(MetricPromptTemplateExamples.get_prompt_template("question_answering_quality"))
8. Özel metrik oluşturun
Önceden tanımlanmış metriklerin yanı sıra, kullanım alanınıza özel ölçütleri değerlendirmek için özel metrikler de oluşturabilirsiniz. Özel metrik oluşturmak için değerlendirici LLM'ye yanıtı nasıl puanlayacağını bildiren bir istem şablonu yazarsınız.
Özel metrik oluşturma iki adımdan oluşur:
- İstem Şablonunu Tanımlayın: Değerlendirici LLM'ye yönelik talimatlarınızı içeren bir dize. İyi bir şablon; net bir rol, değerlendirme ölçütleri, puanlama anahtarı ve
{prompt}ile{response}gibi yer tutucular içerir. - PointwiseMetric Nesnesi Oluşturma: İstem şablonu dizesini bu sınıfın içine sarar ve metriğinize bir ad verirsiniz.
RAG sisteminin yanıtlarının alaka düzeyini ve fayda düzeyini değerlendirmek için iki özel metrik oluşturacaksınız.
- Alaka düzeyi metriği için istem şablonunu tanımlayın. Bu şablon, değerlendirici LLM için ayrıntılı bir değerlendirme ölçeği sağlar. Yeni bir hücreye aşağıdaki kodu ekleyip çalıştırın:
relevance_prompt_template = """ You are a professional writing evaluator. Your job is to score writing responses according to pre-defined evaluation criteria. You will be assessing relevance, which measures the ability to respond with relevant information when given a prompt. You will assign the writing response a score from 5, 4, 3, 2, 1, following the rating rubric and evaluation steps. ## Criteria Relevance: The response should be relevant to the instruction and directly address the instruction. ## Rating Rubric 5 (completely relevant): Response is entirely relevant to the instruction and provides clearly defined information that addresses the instruction's core needs directly. 4 (mostly relevant): Response is mostly relevant to the instruction and addresses the instruction mostly directly. 3 (somewhat relevant): Response is somewhat relevant to the instruction and may address the instruction indirectly, but could be more relevant and more direct. 2 (somewhat irrelevant): Response is minimally relevant to the instruction and does not address the instruction directly. 1 (irrelevant): Response is completely irrelevant to the instruction. ## Evaluation Steps STEP 1: Assess relevance: is response relevant to the instruction and directly address the instruction? STEP 2: Score based on the criteria and rubrics. Give step by step explanations for your scoring, and only choose scores from 5, 4, 3, 2, 1. # User Inputs and AI-generated Response ## User Inputs ### Prompt {prompt} ## AI-generated Response {response} """ - Aynı yaklaşımı kullanarak fayda düzeyi metriği için istem şablonunu tanımlayın. Yeni bir hücreye aşağıdaki kodu ekleyip çalıştırın:
helpfulness_prompt_template = """ You are a professional writing evaluator. Your job is to score writing responses according to pre-defined evaluation criteria. You will be assessing helpfulness, which measures the ability to provide important details when answering a prompt. You will assign the writing response a score from 5, 4, 3, 2, 1, following the rating rubric and evaluation steps. ## Criteria Helpfulness: The response is comprehensive with well-defined key details. The user would feel very satisfied with the content in a good response. ## Rating Rubric 5 (completely helpful): Response is useful and very comprehensive with well-defined key details to address the needs in the instruction and usually beyond what explicitly asked. The user would feel very satisfied with the content in the response. 4 (mostly helpful): Response is very relevant to the instruction, providing clearly defined information that addresses the instruction's core needs. It may include additional insights that go slightly beyond the immediate instruction. The user would feel quite satisfied with the content in the response. 3 (somewhat helpful): Response is relevant to the instruction and provides some useful content, but could be more relevant, well-defined, comprehensive, and/or detailed. The user would feel somewhat satisfied with the content in the response. 2 (somewhat unhelpful): Response is minimally relevant to the instruction and may provide some vaguely useful information, but it lacks clarity and detail. It might contain minor inaccuracies. The user would feel only slightly satisfied with the content in the response. 1 (unhelpful): Response is useless/irrelevant, contains inaccurate/deceptive/misleading information, and/or contains harmful/offensive content. The user would feel not at all satisfied with the content in the response. ## Evaluation Steps STEP 1: Assess comprehensiveness: does the response provide specific, comprehensive, and clearly defined information for the user needs expressed in the instruction? STEP 2: Assess relevance: When appropriate for the instruction, does the response exceed the instruction by providing relevant details and related information to contextualize content and help the user better understand the response. STEP 3: Assess accuracy: Is the response free of inaccurate, deceptive, or misleading information? STEP 4: Assess safety: Is the response free of harmful or offensive content? Give step by step explanations for your scoring, and only choose scores from 5, 4, 3, 2, 1. # User Inputs and AI-generated Response ## User Inputs ### Prompt {prompt} ## AI-generated Response {response} """ - İki özel metriğiniz için
PointwiseMetricnesneleri oluşturun. Bu, istem şablonlarınızı değerlendirme işi için yeniden kullanılabilir bileşenlere sarar. Yeni bir hücreye aşağıdaki kodu ekleyip çalıştırın:relevance = PointwiseMetric( metric="relevance", metric_prompt_template=relevance_prompt_template, ) helpfulness = PointwiseMetric( metric="helpfulness", metric_prompt_template=helpfulness_prompt_template, )
Artık değerlendirme göreviniz için iki yeni, yeniden kullanılabilir metriğiniz (relevance ve helpfulness) var.
9. Değerlendirme işini çalıştırma
Veri kümeleri ve metrikler hazır olduğuna göre değerlendirmeyi çalıştırabilirsiniz. Bunu, test etmek istediğiniz her veri kümesi için bir EvalTask nesnesi oluşturarak yaparsınız.
EvalTask, bir değerlendirme çalıştırması için bileşenleri paketler:
- dataset: İstemlerinizi ve yanıtlarınızı içeren DataFrame.
- metrics: Karşılaştırmak istediğiniz metriklerin listesi.
- experiment: Sonuçların kaydedileceği Vertex AI denemesi. Bu sayede çalıştırmaları izleyip karşılaştırabilirsiniz.
- Her model için bir
EvalTaskoluşturun. Bu nesne, veri kümesini, metrikleri ve deneme adını paketler. Görevleri yapılandırmak için yeni bir hücreye aşağıdaki kodu ekleyip çalıştırın:rag_eval_task_rag_a = EvalTask( dataset=eval_dataset_rag_a, metrics=[ "question_answering_quality", relevance, helpfulness, "groundedness", "safety", "instruction_following", ], experiment=EXPERIMENT, ) rag_eval_task_rag_b = EvalTask( dataset=eval_dataset_rag_b, metrics=[ "question_answering_quality", relevance, helpfulness, "groundedness", "safety", "instruction_following", ], experiment=EXPERIMENT, )EvalTasknesnesi yapılandırdınız. Sağladığınızmetricslistesi, değerlendirme hizmetinin temel bir özelliğini gösteriyor: önceden tanımlanmış metrikler (ör.safety) ve özelPointwiseMetricnesneleri. - Yapılandırılan görevleri
.evaluate()yöntemini çağırarak yürütün. Bu işlem, görevleri işlenmek üzere Vertex AI arka ucuna gönderir ve tamamlanması birkaç dakika sürebilir. Yeni bir hücreye aşağıdaki kodu ekleyip çalıştırın:result_rag_a = rag_eval_task_rag_a.evaluate() result_rag_b = rag_eval_task_rag_b.evaluate()
Değerlendirme tamamlandıktan sonra sonuçlar result_rag_a ve result_rag_b nesnelerinde saklanır ve bir sonraki bölümde analiz edilmeye hazır hâle gelir.
10. Sonuçları analiz etme
Değerlendirme sonuçları artık kullanılabilir. result_rag_a ve result_rag_b nesneleri, her satır için toplu puanlar ve ayrıntılı açıklamalar içerir. Bu görevde, notebook_utils yardımcı işlevlerini kullanarak bu sonuçları analiz edeceksiniz.
Toplu özetleri görüntüleme
- Genel bir bakış için
display_eval_result()yardımcı işlevini kullanarak her metriğin ortalama puanını görebilirsiniz. A modelinin özetini görüntülemek için yeni bir hücreye aşağıdakileri ekleyip çalıştırın:notebook_utils.display_eval_result( title="Model A Eval Result", eval_result=result_rag_a ) - Aynı işlemi B modeli için de yapın. Yeni bir hücreye aşağıdaki kodu ekleyip çalıştırın:
notebook_utils.display_eval_result( title="Model B Eval Result", eval_result=result_rag_b, )
Değerlendirme sonuçlarını görselleştirme
Grafikler, model performansını karşılaştırmayı kolaylaştırabilir. İki tür görselleştirme kullanacaksınız:
- Radar grafiği: Her modelin genel performans "şeklini" gösterir. Daha büyük bir şekil, genel olarak daha iyi performansı gösterir.
- Çubuk grafiği: Her metrikte doğrudan, yan yana karşılaştırma için.
Bu görselleştirmeler, modelleri alaka düzeyi, temellendirme ve fayda düzeyi gibi öznel nitelikler açısından karşılaştırmanıza yardımcı olur.
- Çizim yapmaya hazırlanmak için sonuçları tek bir demet listesinde birleştirin. Her demet bir model adı ve karşılık gelen sonuç nesnesini içermelidir. Yeni bir hücreye aşağıdaki kodu ekleyip çalıştırın:
eval_results = [] eval_results.append(("Model A", result_rag_a)) eval_results.append(("Model B", result_rag_b)) - Artık modelleri tüm metrikler genelinde aynı anda karşılaştırmak için radar grafiği oluşturabilirsiniz. Yeni bir hücreye aşağıdaki kodu ekleyip çalıştırın:
notebook_utils.display_radar_plot( eval_results, metrics=[ "question_answering_quality", "safety", "groundedness", "instruction_following", "relevance", "helpfulness", ], ) - Her metrikle ilgili daha doğrudan bir karşılaştırma için çubuk grafik oluşturun. Yeni bir hücreye şu kodu ekleyip çalıştırın:
notebook_utils.display_bar_plot( eval_results, metrics=[ "question_answering_quality", "safety", "groundedness", "instruction_following", "relevance", "helpfulness", ], )
Görselleştirmeler, A modelinin performansının (radar grafiğindeki büyük şekil ve çubuk grafikteki uzun çubuklar) B modelinden daha iyi olduğunu net bir şekilde gösterir.
Tek bir örnekle ilgili ayrıntılı açıklamayı görüntüleme
Toplam puanlar genel performansı gösterir. Bir modelin neden belirli bir şekilde performans gösterdiğini anlamak için değerlendirici LLM tarafından her örnek için oluşturulan ayrıntılı açıklamaları incelemeniz gerekir.
display_explanations()yardımcı işlevi, sonuçları tek tek incelemenize olanak tanır. A modelinin sonuçlarındaki ikinci örneğin (num=2) ayrıntılı dökümünü görmek için yeni bir hücreye aşağıdaki kodu ekleyip çalıştırın:notebook_utils.display_explanations(result_rag_a, num=2)- Bu işlevi, tüm örneklerde belirli bir metriği filtrelemek için de kullanabilirsiniz. Bu, düşük performansın belirli bir alanında hata ayıklamak için kullanışlıdır. B modelinin
groundednessmetriğinde neden bu kadar kötü performans gösterdiğini görmek için yeni bir hücreye aşağıdaki kodu ekleyip çalıştırın:notebook_utils.display_explanations(result_rag_b, metrics=["groundedness"])
11. "Altın yanıt" kullanarak referanslı değerlendirme
Daha önce, modelin yanıtının yalnızca isteme göre değerlendirildiği referanssız bir değerlendirme gerçekleştirmiştiniz. Bu yöntem faydalı olsa da değerlendirme özneldir.
Artık referanslı değerlendirme kullanacaksınız. Bu yöntem, veri kümesine "altın yanıt" (referans yanıt olarak da adlandırılır) ekler. Modelin yanıtını kesin referans yanıtıyla karşılaştırmak, performansı daha nesnel bir şekilde ölçmenizi sağlar. Bu sayede şunları ölçebilirsiniz:
- Olgusal Doğruluk: Modelin yanıtı, doğru yanıttaki olgularla uyumlu mu?
- Semantik Benzerlik: Modelin yanıtı, referans yanıtla aynı anlama mı geliyor?
- Eksiksizlik (Completeness): Modelin yanıtı, referans yanıttaki tüm önemli bilgileri içeriyor mu?
Referans verilen veri kümesini hazırlama
Referanslı değerlendirme yapmak için veri kümenizdeki her örneğe "altın yanıt" eklemeniz gerekir.
Öncelikle golden_answers listesini tanımlayarak başlayalım. Doğru cevapları A modelinin cevaplarıyla karşılaştırdığımızda bu yöntemin değeri ortaya çıkıyor:
- 1. Soru (Beyin): Üretilen yanıt ve doğru yanıt aynı. A modeli doğrudur.
- 2. soru (Senato): Yanıtlar anlam olarak benzer ancak farklı şekilde ifade edilmiş. İyi bir metrik bunu dikkate almalıdır.
- 3. soru (Hasan-Jalalians): A modelinin yanıtı, bağlama göre yanlış.
golden_answerbu hatayı gösterir.
- Yeni bir hücrede golden_answers listesini tanımlayın.
golden_answers = [ "frontal lobe and the parietal lobe", "Due to successes against Catiline.", "The Hasan-Jalalians commanded the area of Artsakh and Utik.", ] - Aşağıdaki hücrede bu kodu çalıştırarak referans verilen değerlendirme DataFrames'lerini oluşturun:
referenced_eval_dataset_rag_a = pd.DataFrame( { "prompt": [ "Answer the question: " + question + " Context: " + item for question, item in zip(questions, retrieved_contexts) ], "response": generated_answers_by_rag_a, "reference": golden_answers, } ) referenced_eval_dataset_rag_b = pd.DataFrame( { "prompt": [ "Answer the question: " + question + " Context: " + item for question, item in zip(questions, retrieved_contexts) ], "response": generated_answers_by_rag_b, "reference": golden_answers, } )
Veri kümeleri artık referanslı değerlendirmeye hazır.
Özel referanslı metrik oluşturma
Referanslı değerlendirme için özel metrikler de oluşturabilirsiniz. Süreç benzerdir ancak istem şablonu artık altın yanıt için {reference} yer tutucusunu içerir.
Kesin bir "doğru" yanıt olduğunda, doğruluk açısından doğruluğu ölçmek için daha katı, ikili puanlama (ör. doğru için 1, yanlış için 0) kullanabilirsiniz. Bu mantığı uygulayan yeni bir question_answering_correctness metriği oluşturalım.
- İstem şablonunu tanımlayın. Yeni bir hücreye aşağıdaki kodu ekleyip çalıştırın:
question_answering_correctness_prompt_template = """ You are a professional writing evaluator. Your job is to score writing responses according to pre-defined evaluation criteria. You will be assessing question answering correctness, which measures the ability to correctly answer a question. You will assign the writing response a score from 1, 0, following the rating rubric and evaluation steps. ### Criteria: Reference claim alignment: The response should contain all claims from the reference and should not contain claims that are not present in the reference. ### Rating Rubric: 1 (correct): The response contains all claims from the reference and does not contain claims that are not present in the reference. 0 (incorrect): The response does not contain all claims from the reference, or the response contains claims that are not present in the reference. ### Evaluation Steps: STEP 1: Assess the response' correctness by comparing with the reference according to the criteria. STEP 2: Score based on the rubrics. Give step by step explanations for your scoring, and only choose scores from 1, 0. # User Inputs and AI-generated Response ## User Inputs ### Prompt {prompt} ## Reference {reference} ## AI-generated Response {response} """ - İstem şablonu dizesini PointwiseMetric nesnesinin içine yerleştirin. Bu işlem, metriğinize resmi bir ad verir ve değerlendirme işi için yeniden kullanılabilir bir bileşen haline getirir. Yeni bir hücreye aşağıdaki kodu ekleyip çalıştırın:
question_answering_correctness = PointwiseMetric( metric="question_answering_correctness", metric_prompt_template=question_answering_correctness_prompt_template, )
Artık katı bir doğruluk kontrolü için özel, referanslı bir metriğiniz var.
12. Referanslı Değerlendirmeyi Çalıştırma
Şimdi, değerlendirme işini referans verilen veri kümeleri ve yeni metrikle yapılandıracaksınız. EvalTask sınıfını tekrar kullanırsınız.
Metrikler listesi artık özel modele dayalı metriğinizi hesaplamaya dayalı metriklerle birleştiriyor. Referanslı değerlendirme, oluşturulan metin ile referans metin arasında matematiksel karşılaştırmalar yapan geleneksel, hesaplamaya dayalı metriklerin kullanılmasına olanak tanır. Üç yaygın tür kullanacaksınız:
exact_match: Yalnızca oluşturulan yanıt referans yanıtla aynıysa 1, aksi takdirde 0 puan alır.bleu: Kesinlik metriği. Oluşturulan yanıttaki kaç kelimenin referans yanıtta da yer aldığını ölçer.rouge: Geri çağırma metriği. Referans yanıttaki kaç kelimenin oluşturulan yanıtta yer aldığını ölçer.
- Değerlendirme işini, referans verilen veri kümeleri ve yeni metrik karışımıyla yapılandırın.
EvalTasknesnelerini oluşturmak için yeni bir hücreye aşağıdaki kodu ekleyip çalıştırın:referenced_answer_eval_task_rag_a = EvalTask( dataset=referenced_eval_dataset_rag_a, metrics=[ question_answering_correctness, "rouge", "bleu", "exact_match", ], experiment=EXPERIMENT, ) referenced_answer_eval_task_rag_b = EvalTask( dataset=referenced_eval_dataset_rag_b, metrics=[ question_answering_correctness, "rouge", "bleu", "exact_match", ], experiment=EXPERIMENT, ) .evaluate()yöntemini çağırarak referans verilen değerlendirmeyi yürütün. Yeni bir hücreye aşağıdaki kodu ekleyip çalıştırın:referenced_result_rag_a = referenced_answer_eval_task_rag_a.evaluate() referenced_result_rag_b = referenced_answer_eval_task_rag_b.evaluate()
13. Referans verilen sonuçları analiz etme
Değerlendirme tamamlandı. Bu görevde, modellerin yanıtlarını altın referans yanıtlarla karşılaştırarak modellerin olgusal doğruluğunu ölçmek için sonuçları analiz edeceksiniz.
Özet sonuçları görüntüleme
- Referans verilen değerlendirmenin özet sonuçlarını analiz edin. Her iki modelin özet tablolarını göstermek için yeni bir hücreye aşağıdaki kodu ekleyip çalıştırın:
notebook_utils.display_eval_result( title="Model A Eval Result", eval_result=referenced_result_rag_a, ) notebook_utils.display_eval_result( title="Model B Eval Result", eval_result=referenced_result_rag_b, )question_answering_correctnessmetriğinizde iyi performans gösterdiğini ancakexact_matchmetriğinde daha düşük puan aldığını fark edeceksiniz. Bu durum, yalnızca aynı metni değil, semantik benzerliği de tanıyabilen modele dayalı metriklerin değerini vurgular.
Karşılaştırma için sonuçları görselleştirme
Görselleştirmeler, iki model arasındaki performans farkını daha belirgin hale getirebilir. Öncelikle sonuçları tek bir listede birleştirerek grafiğini çizin, ardından radar ve çubuk grafiklerini oluşturun.
- Grafik oluşturmak için referans verilen değerlendirme sonuçlarını tek bir listede birleştirin. Yeni bir hücreye aşağıdaki kodu ekleyip çalıştırın:
referenced_eval_results = [] referenced_eval_results.append(("Model A", referenced_result_rag_a)) referenced_eval_results.append(("Model B", referenced_result_rag_b)) - Her modelin yeni metrik grubundaki performansını görselleştirmek için radar grafiği oluşturun. Yeni bir hücreye aşağıdaki kodu ekleyip çalıştırın:
notebook_utils.display_radar_plot( referenced_eval_results, metrics=[ "question_answering_correctness", "rouge", "bleu", "exact_match", ], ) - Doğrudan yan yana karşılaştırma için çubuk grafiği oluşturun. Bu işlem, her modelin farklı metriklerde nasıl performans gösterdiğini gösterir. Yeni bir hücreye aşağıdaki kodu ekleyip çalıştırın:
notebook_utils.display_bar_plot( referenced_eval_results, metrics=[ "question_answering_correctness", "rouge", "bleu", "exact_match", ], )
Bu görselleştirmeler, A modelinin referans yanıtlara kıyasla B modelinden çok daha doğru ve olgusal olarak uyumlu olduğunu doğruluyor.
14. Pratikte üretime
Bir RAG sistemi için tam bir değerlendirme ardışık düzenini başarıyla yürüttünüz. Bu son bölümde, öğrendiğiniz temel stratejik kavramlar özetlenir ve bu becerileri gerçek dünya projelerinde uygulayabileceğiniz bir çerçeve sunulur.
Üretimle ilgili en iyi uygulamalar
Bu laboratuvarda öğrendiğiniz becerileri gerçek hayattaki bir üretim ortamına aktarmak için şu dört temel uygulamayı göz önünde bulundurun:
- CI/CD ile otomasyon: Değerlendirme paketinizi bir CI/CD ardışık düzenine (ör. Cloud Build, GitHub Actions) entegre edin. Regresyonları yakalamak ve kalite puanları standartlarınızın altına düşerse dağıtımları engellemek için kod değişikliklerinde otomatik olarak değerlendirme yapın.
- Veri kümelerinizi geliştirin: Statik bir veri kümesi eskimeye başlar. "Altın" test kümelerinizin sürüm denetimini yapın (Git LFS veya Cloud Storage kullanarak) ve gerçek (anonimleştirilmiş) kullanıcı sorgularından örnekler alarak sürekli olarak yeni ve zorlu örnekler ekleyin.
- Yalnızca oluşturma aracını değil, alıcıyı da değerlendirin: Doğru bağlam olmadan mükemmel bir yanıt almak mümkün değildir. İsabet oranı (Doğru belge bulundu mu?) ve Ortalama Karşılıklı Sıra (MRR) (Doğru belge ne kadar üst sıralarda yer aldı?) gibi metrikleri kullanarak alma sisteminiz için ayrı bir değerlendirme adımı uygulayın.
- Metrikleri zaman içinde izleme: Değerlendirme çalıştırmalarınızdaki özet puanları Google Cloud Monitoring gibi bir hizmete aktarın. Kalite trendlerini izlemek için kontrol panelleri oluşturun ve önemli performans düşüşleri hakkında sizi bilgilendirecek otomatik uyarılar ayarlayın.
Gelişmiş değerlendirme metodolojisi matrisi
Doğru değerlendirme yaklaşımını seçmek, hedeflerinize bağlıdır. Bu matris, her yöntemin ne zaman kullanılacağını özetlemektedir.
Değerlendirme Yaklaşımı | En İyi Kullanım Alanları | Temel Avantajlar | Sınırlamalar |
Referanssız (Reference-Free) | Üretim izleme, sürekli değerlendirme | Doğru cevaplar gerekmez, öznel kaliteyi yakalar | Daha pahalı, değerlendirici önyargısı olasılığı |
Referansa Dayalı (Reference-Based) | Model karşılaştırması, karşılaştırmalı değerlendirme | Daha hızlı hesaplama, objektif ölçüm | Doğru yanıtlar gerektirir, anlamsal eşdeğerlik eksik olabilir. |
Özel Metrikler | Alana özgü değerlendirme | İşletme ihtiyaçlarına göre uyarlanır | Doğrulama ve geliştirme ek yükü gerektirir. |
Karma Yaklaşım | Kapsamlı üretim sistemleri | Tüm yaklaşımların en iyisi | Daha yüksek karmaşıklık, maliyet optimizasyonu gerekir |
Önemli teknik analizler
Kendi RAG sistemlerinizi oluşturup değerlendirirken aşağıdaki temel ilkeleri göz önünde bulundurun:
- Temellendirme, RAG için kritik öneme sahiptir: Bu metrik, yüksek ve düşük kaliteli RAG sistemleri arasında tutarlı bir şekilde ayrım yapar. Bu nedenle, üretim izleme için gereklidir.
- Birden fazla metrik, sağlamlık sağlar: Tek bir metrik, RAG kalitesinin tüm yönlerini yakalamaz. Kapsamlı değerlendirme için birden fazla değerlendirme boyutu gerekir.
- Özel Metrikler Önemli Değer Katar: Alana özgü değerlendirme ölçütleri, genellikle genel metriklerin kaçırdığı nüansları yakalayarak değerlendirme doğruluğunu artırır.
- İstatistiksel titizlik, güven sağlar: Uygun örneklem boyutları ve önem testi, değerlendirmeyi tahminden güvenilir karar alma araçlarına dönüştürür.
Üretim dağıtımı karar çerçevesi
Gelecekteki RAG sistemi dağıtımlarında rehber olarak bu aşamalı çerçeveyi kullanın:
- 1. Aşama: Geliştirme: Model karşılaştırması ve seçimi için bilinen test kümeleriyle referansa dayalı değerlendirme kullanın.
- 2. Aşama: Üretim Öncesi: Üretime hazırlık durumunu doğrulamak için her iki yaklaşımı birleştiren kapsamlı bir değerlendirme yapın.
- 3. Aşama: Üretim: Referanssız izlemeyi uygulayarak altın cevaplar olmadan sürekli kalite değerlendirmesi yapın.
- 4. Aşama: Optimizasyon: Model iyileştirmelerine ve alma sistemi geliştirmelerine yön vermek için değerlendirme analizlerinden yararlanın.
15. Sonuç
Tebrikler! Laboratuvarı tamamladınız.
Bu laboratuvar, Google Cloud ile Üretime Hazır Yapay Zeka Öğrenme Rotası'nın bir parçasıdır.
- Prototip aşamasından üretim aşamasına geçiş yapmak için tüm müfredatı inceleyin.
- İlerleme durumunuzu
ProductionReadyAIhashtag'iyle paylaşın.
Özet
Aşağıdaki işlemleri yapmayı öğrendiniz:
- Alınan bağlama göre bir yanıtın kalitesini değerlendirmek için referanssız değerlendirme yapın.
- Doğruluğu ölçmek için "altın cevap" ekleyerek referanslı değerlendirme yapın.
- Her iki yaklaşım için de önceden tanımlanmış ve özel metriklerin bir karışımını kullanın.
- Hem modele dayalı metrikleri (ör.
question_answering_quality) hem de hesaplamaya dayalı metrikleri (rouge,bleu,exact_match) kullanın. - Modelin güçlü ve zayıf yönlerini anlamak için sonuçları analiz edin ve görselleştirin.
Bu değerlendirme yaklaşımı, daha güvenilir ve doğru üretken yapay zeka uygulamaları geliştirmenize yardımcı olur.