
1. Tổng quan
Trong phòng thí nghiệm này, bạn sẽ tìm hiểu cách xây dựng một quy trình đánh giá cho hệ thống Tạo sinh tăng cường truy xuất (RAG). Bạn sẽ sử dụng Dịch vụ đánh giá AI tạo sinh của Vertex AI để tạo tiêu chí đánh giá tuỳ chỉnh và xây dựng một khung đánh giá cho nhiệm vụ trả lời câu hỏi.
Bạn sẽ làm việc với các ví dụ trong Tập dữ liệu trả lời câu hỏi của Stanford (SQuAD 2.0) để chuẩn bị tập dữ liệu đánh giá, định cấu hình các hoạt động đánh giá không cần tham chiếu và dựa trên tham chiếu, đồng thời diễn giải kết quả. Khi kết thúc lớp học này, bạn sẽ hiểu cách đánh giá các hệ thống RAG và lý do bạn chọn một số phương pháp đánh giá nhất định.
Nền tảng tập dữ liệu
Chúng tôi sẽ làm việc với các ví dụ được tạo cẩn thận trên nhiều miền có trong Tập dữ liệu trả lời câu hỏi SQuAD 2.0:
- Khoa học thần kinh: Kiểm tra độ chính xác về kỹ thuật trong bối cảnh khoa học
- Lịch sử: Đánh giá độ chính xác về thực tế trong các câu chuyện lịch sử
- Địa lý: Đánh giá kiến thức về lãnh thổ và chính trị
Sự đa dạng này giúp bạn hiểu cách các phương pháp đánh giá được khái quát hoá trên nhiều lĩnh vực.
Tài liệu tham khảo
- Mã mẫu: Lớp học này dựa trên các ví dụ trong tài liệu Đánh giá Vertex AI
- Nền tảng tập dữ liệu: Tập dữ liệu trả lời câu hỏi SQuAD 2.0
- Tối ưu hoá hoạt động truy xuất RAG: Thử nghiệm, điều chỉnh, thành công
Kiến thức bạn sẽ học được
Trong bài thực hành này, bạn sẽ tìm hiểu cách thực hiện các thao tác sau:
- Chuẩn bị tập dữ liệu đánh giá cho hệ thống RAG.
- Triển khai quy trình đánh giá không cần tài liệu tham khảo bằng cách sử dụng các chỉ số như tính xác thực và mức độ liên quan.
- Áp dụng phương pháp đánh giá dựa trên tài liệu tham khảo bằng các chỉ số tương đồng về ngữ nghĩa.
- Tạo chỉ số đánh giá tuỳ chỉnh bằng các tiêu chí chấm điểm chi tiết.
- Diễn giải và trực quan hoá kết quả đánh giá để đưa ra quyết định chọn mô hình.
2. Thiết lập dự án
Tài khoản Google
Nếu chưa có Tài khoản Google cá nhân, bạn phải tạo một Tài khoản Google.
Sử dụng tài khoản cá nhân thay vì tài khoản do nơi làm việc hoặc trường học cấp.
Đăng nhập vào Google Cloud Console
Đăng nhập vào Google Cloud Console bằng Tài khoản Google cá nhân.
Bật thanh toán
Sử dụng tín dụng Google Cloud (không bắt buộc)
Để tham gia hội thảo này, bạn cần có một tài khoản thanh toán có sẵn một số tín dụng. Hãy sử dụng tín dụng trong biểu ngữ ở đầu lớp học lập trình này để bắt đầu. Nếu đã kết nối với một tài khoản thanh toán, bạn có thể bỏ qua bước này.
Thiết lập tài khoản thanh toán cá nhân
Nếu thiết lập thông tin thanh toán bằng tín dụng Google Cloud, bạn có thể bỏ qua bước này.
Để thiết lập tài khoản thanh toán cá nhân, hãy truy cập vào đây để bật tính năng thanh toán trong Cloud Console.
Một số lưu ý:
- Việc hoàn thành bài tập thực hành này sẽ tốn ít hơn 1 USD cho các tài nguyên trên Cloud.
- Bạn có thể làm theo các bước ở cuối bài thực hành này để xoá tài nguyên nhằm tránh bị tính thêm phí.
- Người dùng mới đủ điều kiện dùng thử miễn phí 300 USD.
Tạo dự án (không bắt buộc)
Nếu bạn không có dự án hiện tại muốn sử dụng cho lớp học này, hãy tạo một dự án mới tại đây.
3. Tạo sinh tăng cường truy xuất (RAG) là gì?
RAG là một kỹ thuật được dùng để cải thiện độ chính xác và mức độ phù hợp của câu trả lời do các Mô hình ngôn ngữ lớn (LLM) đưa ra. Công cụ này kết nối LLM với một cơ sở kiến thức bên ngoài để đưa ra câu trả lời dựa trên thông tin cụ thể, có thể xác minh.
Quy trình này bao gồm các bước sau:
- Chuyển đổi câu hỏi của người dùng thành một biểu diễn bằng số (một vectơ nhúng).
- Tìm kiếm trong cơ sở kiến thức những tài liệu có các vectơ nhúng tương tự.
- Cung cấp những tài liệu liên quan này làm bối cảnh cho LLM cùng với câu hỏi ban đầu để tạo câu trả lời.
Đọc thêm về RAG.
Điều gì khiến việc đánh giá RAG trở nên phức tạp?
Việc đánh giá hệ thống RAG khác với việc đánh giá các mô hình ngôn ngữ truyền thống.
Thử thách về nhiều thành phần: Hệ thống RAG kết hợp 3 thao tác, mỗi thao tác có thể là một điểm lỗi:
- Chất lượng truy xuất: Hệ thống có tìm thấy các tài liệu ngữ cảnh phù hợp không?
- Mức độ sử dụng bối cảnh: Mô hình có sử dụng thông tin đã truy xuất một cách hiệu quả không?
- Chất lượng của câu trả lời được tạo: Câu trả lời cuối cùng có được viết rõ ràng, hữu ích và chính xác không?
Một phản hồi có thể không thành công nếu bất kỳ thành phần nào trong số này không hoạt động như mong đợi. Ví dụ: hệ thống có thể truy xuất đúng ngữ cảnh, nhưng mô hình lại bỏ qua ngữ cảnh đó. Hoặc mô hình có thể tạo ra một câu trả lời được viết kỹ lưỡng nhưng không chính xác vì ngữ cảnh được truy xuất không liên quan.
4. Thiết lập môi trường Vertex AI Workbench
Hãy bắt đầu bằng cách khởi động một môi trường sổ tay mới, nơi chúng ta sẽ chạy mã cần thiết để đánh giá các hệ thống RAG.
- Chuyển đến trang API và dịch vụ của Cloud Console.
- Nhấp vào Bật cho Vertex AI API.
Truy cập vào Vertex AI Workbench
- Trong Google Cloud Console, hãy chuyển đến Vertex AI bằng cách nhấp vào Trình đơn điều hướng ☰ > Vertex AI > Workbench.
- Tạo một phiên bản workbench mới.
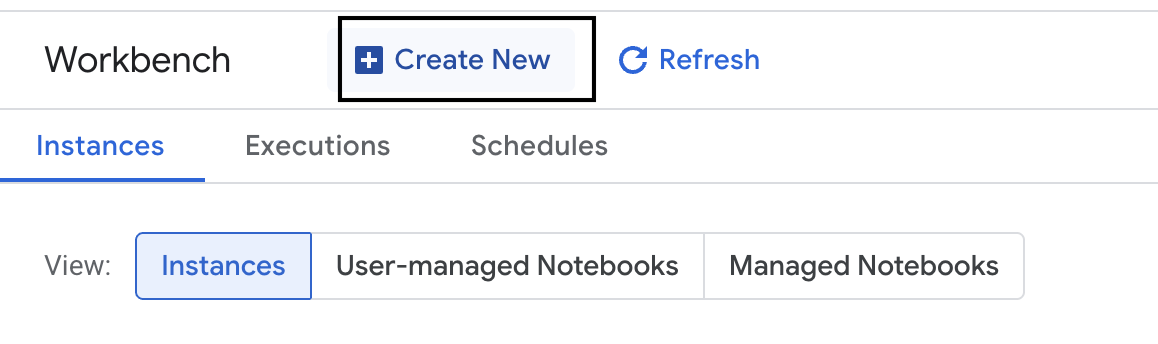
- Đặt tên cho phiên bản workbench là
evaluation-workbench. - Chọn khu vực và vùng nếu bạn chưa đặt các giá trị đó.
- Nhấp vào Tạo.
- Chờ thiết bị làm việc thiết lập xong. Quá trình này có thể mất vài phút.

- Sau khi cung cấp băng ghế dự bị, hãy nhấp vào open jupyterlab (mở jupyterlab).
- Trong môi trường làm việc, hãy tạo một sổ tay Python3 mới.
Để tìm hiểu thêm về các tính năng và chức năng của môi trường này, hãy xem tài liệu chính thức về Vertex AI Workbench.
Cài đặt SDK đánh giá Vertex AI
Bây giờ, hãy cài đặt SDK đánh giá chuyên biệt cung cấp các công cụ để đánh giá RAG.
- Trong ô đầu tiên của sổ tay, hãy thêm và chạy câu lệnh nhập bên dưới (SHIFT+ENTER) để cài đặt Vertex AI SDK (có các thành phần đánh giá).
%pip install --upgrade --user --quiet google-cloud-aiplatform[evaluation]- EvalTask: Lớp chính để chạy các quy trình đánh giá
- MetricPromptTemplateExamples: Các chỉ số đánh giá được xác định trước
- PointwiseMetric: Khung để tạo chỉ số tuỳ chỉnh
- notebook_utils: Công cụ trực quan hoá để phân tích kết quả
- Lưu ý quan trọng: Sau khi cài đặt, bạn sẽ cần khởi động lại hạt nhân để sử dụng các gói mới. Trong thanh trình đơn ở đầu cửa sổ JupyterLab, hãy chuyển đến Kernel (Nhân) > Restart Kernel (Khởi động lại nhân).
5. Khởi chạy SDK và nhập thư viện
Trước khi có thể tạo quy trình đánh giá, bạn cần thiết lập môi trường. Việc này bao gồm định cấu hình thông tin chi tiết về dự án, khởi chạy Vertex AI SDK để kết nối với Google Cloud và nhập các thư viện Python chuyên biệt mà bạn sẽ dùng để đánh giá.
- Xác định các biến cấu hình cho công việc đánh giá. Trong một ô mới, hãy thêm và chạy mã sau để đặt
PROJECT_ID,LOCATIONvà tênEXPERIMENTđể sắp xếp lần chạy này.import vertexai PROJECT_ID = "YOUR PROJECT ID" LOCATION = "YOUR LOCATION" # @param {type:"string"} EXPERIMENT = "rag-eval-01" # @param {type:"string"} if not PROJECT_ID or PROJECT_ID == "[your-project-id]": raise ValueError("Please set your PROJECT_ID") - Khởi chạy Vertex AI SDK. Trong một ô mới, hãy thêm và chạy mã sau.
vertexai.init(project=PROJECT_ID, location=LOCATION) - Nhập các lớp cần thiết từ SDK đánh giá bằng cách chạy mã sau trong ô tiếp theo:
import pandas as pd from vertexai.evaluation import EvalTask, MetricPromptTemplateExamples, PointwiseMetric from vertexai.preview.evaluation import notebook_utils- pandas: Để tạo và quản lý dữ liệu trong DataFrame.
- EvalTask: Lớp cốt lõi chạy một công việc đánh giá.
- MetricPromptTemplateExamples: Cung cấp quyền truy cập vào các chỉ số đánh giá được xác định trước của Google.
- PointwiseMetric: Khung để tạo chỉ số tuỳ chỉnh của riêng bạn.
- notebook_utils: Một tập hợp các công cụ để trực quan hoá kết quả.
6. Chuẩn bị tập dữ liệu đánh giá
Một tập dữ liệu có cấu trúc rõ ràng là nền tảng của mọi hoạt động đánh giá đáng tin cậy. Đối với hệ thống RAG, tập dữ liệu của bạn cần có 2 trường khoá cho mỗi ví dụ:
- câu lệnh: Đây là tổng số thông tin đầu vào được cung cấp cho mô hình ngôn ngữ. Bạn phải kết hợp câu hỏi của người dùng với ngữ cảnh mà hệ thống RAG của bạn truy xuất (
prompt = User Question + Retrieved Context). Điều này rất quan trọng để dịch vụ đánh giá biết mô hình đã dùng thông tin nào để tạo câu trả lời. - response: Đây là câu trả lời cuối cùng do mô hình RAG của bạn tạo ra.
Để có kết quả đáng tin cậy về mặt thống kê, bạn nên sử dụng một tập dữ liệu gồm khoảng 100 ví dụ. Trong lớp học này, bạn sẽ sử dụng một tập dữ liệu nhỏ để minh hoạ quy trình.
Hãy tạo tập dữ liệu. Bạn sẽ bắt đầu với danh sách câu hỏi và retrieved_contexts từ hệ thống RAG. Sau đó, bạn sẽ xác định 2 nhóm câu trả lời: một nhóm từ mô hình có vẻ hoạt động hiệu quả (generated_answers_by_rag_a) và một nhóm từ mô hình hoạt động kém hiệu quả (generated_answers_by_rag_b).
Cuối cùng, bạn sẽ kết hợp các phần này thành hai DataFrame của pandas, eval_dataset_rag_a và eval_dataset_rag_b, theo cấu trúc được mô tả ở trên.
- Trong một ô mới, hãy thêm và chạy đoạn mã sau để xác định các câu hỏi và hai bộ generated_answers.
questions = [ "Which part of the brain does short-term memory seem to rely on?", "What provided the Roman senate with exuberance?", "What area did the Hasan-jalalians command?", ] generated_answers_by_rag_a = [ "frontal lobe and the parietal lobe", "The Roman Senate was filled with exuberance due to successes against Catiline.", "The Hasan-Jalalians commanded the area of Syunik and Vayots Dzor.", ] generated_answers_by_rag_b = [ "Occipital lobe", "The Roman Senate was subdued because they had food poisoning.", "The Galactic Empire commanded the state of Utah.", ] - Xác định retrieved_contexts. Thêm và chạy mã sau trong một ô mới.
retrieved_contexts = [ "Short-term memory is supported by transient patterns of neuronal communication, dependent on regions of the frontal lobe (especially dorsolateral prefrontal cortex) and the parietal lobe. Long-term memory, on the other hand, is maintained by more stable and permanent changes in neural connections widely spread throughout the brain. The hippocampus is essential (for learning new information) to the consolidation of information from short-term to long-term memory, although it does not seem to store information itself. Without the hippocampus, new memories are unable to be stored into long-term memory, as learned from patient Henry Molaison after removal of both his hippocampi, and there will be a very short attention span. Furthermore, it may be involved in changing neural connections for a period of three months or more after the initial learning.", "In 62 BC, Pompey returned victorious from Asia. The Senate, elated by its successes against Catiline, refused to ratify the arrangements that Pompey had made. Pompey, in effect, became powerless. Thus, when Julius Caesar returned from a governorship in Spain in 61 BC, he found it easy to make an arrangement with Pompey. Caesar and Pompey, along with Crassus, established a private agreement, now known as the First Triumvirate. Under the agreement, Pompey's arrangements would be ratified. Caesar would be elected consul in 59 BC, and would then serve as governor of Gaul for five years. Crassus was promised a future consulship.", "The Seljuk Empire soon started to collapse. In the early 12th century, Armenian princes of the Zakarid noble family drove out the Seljuk Turks and established a semi-independent Armenian principality in Northern and Eastern Armenia, known as Zakarid Armenia, which lasted under the patronage of the Georgian Kingdom. The noble family of Orbelians shared control with the Zakarids in various parts of the country, especially in Syunik and Vayots Dzor, while the Armenian family of Hasan-Jalalians controlled provinces of Artsakh and Utik as the Kingdom of Artsakh.", ] - Trong một ô mới, hãy thêm và chạy mã sau để tạo
eval_dataset_rag_avàeval_dataset_rag_b.eval_dataset_rag_a = pd.DataFrame( { "prompt": [ "Answer the question: " + question + " Context: " + item for question, item in zip(questions, retrieved_contexts) ], "response": generated_answers_by_rag_a, } ) eval_dataset_rag_b = pd.DataFrame( { "prompt": [ "Answer the question: " + question + " Context: " + item for question, item in zip(questions, retrieved_contexts) ], "response": generated_answers_by_rag_b, } ) - Chạy mã sau trong một ô mới để xem vài hàng đầu tiên của tập dữ liệu cho Mô hình A.
eval_dataset_rag_a
7. Chọn và tạo chỉ số
Giờ đây, khi các tập dữ liệu đã sẵn sàng, bạn có thể quyết định cách đo lường hiệu suất. Bạn có thể sử dụng một hoặc nhiều chỉ số để đánh giá mô hình của mình. Mỗi chỉ số đánh giá một khía cạnh cụ thể trong câu trả lời của mô hình, chẳng hạn như độ chính xác về mặt thực tế hoặc mức độ liên quan.
Bạn có thể sử dụng kết hợp 2 loại chỉ số:
- Chỉ số được xác định trước: Các chỉ số sẵn sàng sử dụng do SDK cung cấp cho các tác vụ đánh giá phổ biến.
- Chỉ số tuỳ chỉnh: Các chỉ số mà bạn xác định để kiểm tra những phẩm chất phù hợp với trường hợp sử dụng của bạn.
Trong phần này, bạn sẽ khám phá các chỉ số được xác định trước có sẵn cho RAG.
Khám phá các chỉ số được xác định trước
SDK này bao gồm một số chỉ số tích hợp để đánh giá các hệ thống trả lời câu hỏi. Các chỉ số này sử dụng một mô hình ngôn ngữ làm "trình đánh giá" để chấm điểm câu trả lời của mô hình dựa trên một bộ hướng dẫn.
- Trong một ô mới, hãy thêm và chạy đoạn mã sau để xem danh sách đầy đủ các tên chỉ số được xác định trước:
MetricPromptTemplateExamples.list_example_metric_names() - Để hiểu cách hoạt động của các chỉ số này, bạn có thể kiểm tra các mẫu câu lệnh cơ bản của chúng. Trong một ô mới, hãy thêm và chạy mã sau để xem hướng dẫn được đưa ra cho LLM của trình đánh giá cho chỉ số
question_answering_quality.# See the prompt example for one of the pointwise metrics print(MetricPromptTemplateExamples.get_prompt_template("question_answering_quality"))
8. Tạo chỉ số tùy chỉnh
Ngoài các chỉ số được xác định trước, bạn có thể tạo chỉ số tuỳ chỉnh để đánh giá các tiêu chí cụ thể cho trường hợp sử dụng của mình. Để tạo chỉ số tuỳ chỉnh, bạn viết một mẫu câu lệnh hướng dẫn LLM đánh giá cách tính điểm cho một câu trả lời.
Để tạo chỉ số tuỳ chỉnh, bạn cần thực hiện hai bước:
- Xác định Mẫu câu lệnh: Một chuỗi chứa hướng dẫn của bạn cho LLM đánh giá. Một mẫu tốt bao gồm vai trò rõ ràng, tiêu chí đánh giá, tiêu chí chấm điểm và các phần giữ chỗ như
{prompt}và{response}. - Tạo thực thể cho Đối tượng PointwiseMetric: Bạn gói chuỗi mẫu lời nhắc bên trong lớp này và đặt tên cho chỉ số.
Bạn sẽ tạo 2 chỉ số tuỳ chỉnh để đánh giá mức độ phù hợp và hữu ích của câu trả lời do hệ thống RAG đưa ra.
- Xác định mẫu câu lệnh cho chỉ số mức độ liên quan. Mẫu này cung cấp một thang điểm chi tiết cho LLM đánh giá. Trong một ô mới, hãy thêm và chạy mã sau:
relevance_prompt_template = """ You are a professional writing evaluator. Your job is to score writing responses according to pre-defined evaluation criteria. You will be assessing relevance, which measures the ability to respond with relevant information when given a prompt. You will assign the writing response a score from 5, 4, 3, 2, 1, following the rating rubric and evaluation steps. ## Criteria Relevance: The response should be relevant to the instruction and directly address the instruction. ## Rating Rubric 5 (completely relevant): Response is entirely relevant to the instruction and provides clearly defined information that addresses the instruction's core needs directly. 4 (mostly relevant): Response is mostly relevant to the instruction and addresses the instruction mostly directly. 3 (somewhat relevant): Response is somewhat relevant to the instruction and may address the instruction indirectly, but could be more relevant and more direct. 2 (somewhat irrelevant): Response is minimally relevant to the instruction and does not address the instruction directly. 1 (irrelevant): Response is completely irrelevant to the instruction. ## Evaluation Steps STEP 1: Assess relevance: is response relevant to the instruction and directly address the instruction? STEP 2: Score based on the criteria and rubrics. Give step by step explanations for your scoring, and only choose scores from 5, 4, 3, 2, 1. # User Inputs and AI-generated Response ## User Inputs ### Prompt {prompt} ## AI-generated Response {response} """ - Xác định mẫu câu lệnh cho chỉ số hữu ích bằng cách sử dụng cùng một phương pháp. Thêm và chạy mã sau trong một ô mới:
helpfulness_prompt_template = """ You are a professional writing evaluator. Your job is to score writing responses according to pre-defined evaluation criteria. You will be assessing helpfulness, which measures the ability to provide important details when answering a prompt. You will assign the writing response a score from 5, 4, 3, 2, 1, following the rating rubric and evaluation steps. ## Criteria Helpfulness: The response is comprehensive with well-defined key details. The user would feel very satisfied with the content in a good response. ## Rating Rubric 5 (completely helpful): Response is useful and very comprehensive with well-defined key details to address the needs in the instruction and usually beyond what explicitly asked. The user would feel very satisfied with the content in the response. 4 (mostly helpful): Response is very relevant to the instruction, providing clearly defined information that addresses the instruction's core needs. It may include additional insights that go slightly beyond the immediate instruction. The user would feel quite satisfied with the content in the response. 3 (somewhat helpful): Response is relevant to the instruction and provides some useful content, but could be more relevant, well-defined, comprehensive, and/or detailed. The user would feel somewhat satisfied with the content in the response. 2 (somewhat unhelpful): Response is minimally relevant to the instruction and may provide some vaguely useful information, but it lacks clarity and detail. It might contain minor inaccuracies. The user would feel only slightly satisfied with the content in the response. 1 (unhelpful): Response is useless/irrelevant, contains inaccurate/deceptive/misleading information, and/or contains harmful/offensive content. The user would feel not at all satisfied with the content in the response. ## Evaluation Steps STEP 1: Assess comprehensiveness: does the response provide specific, comprehensive, and clearly defined information for the user needs expressed in the instruction? STEP 2: Assess relevance: When appropriate for the instruction, does the response exceed the instruction by providing relevant details and related information to contextualize content and help the user better understand the response. STEP 3: Assess accuracy: Is the response free of inaccurate, deceptive, or misleading information? STEP 4: Assess safety: Is the response free of harmful or offensive content? Give step by step explanations for your scoring, and only choose scores from 5, 4, 3, 2, 1. # User Inputs and AI-generated Response ## User Inputs ### Prompt {prompt} ## AI-generated Response {response} """ - Tạo thực thể cho các đối tượng
PointwiseMetriccho hai chỉ số tuỳ chỉnh của bạn. Thao tác này sẽ gói các mẫu câu lệnh của bạn thành các thành phần có thể dùng lại cho công việc đánh giá. Thêm và chạy mã sau trong một ô mới:relevance = PointwiseMetric( metric="relevance", metric_prompt_template=relevance_prompt_template, ) helpfulness = PointwiseMetric( metric="helpfulness", metric_prompt_template=helpfulness_prompt_template, )
Giờ đây, bạn có 2 chỉ số mới có thể sử dụng lại (relevance và helpfulness) cho công việc đánh giá của mình.
9. Chạy quy trình đánh giá
Giờ đây, khi đã chuẩn bị xong các tập dữ liệu và chỉ số, bạn có thể chạy quy trình đánh giá. Bạn sẽ thực hiện việc này bằng cách tạo một đối tượng EvalTask cho từng tập dữ liệu mà bạn muốn kiểm thử.
EvalTask sẽ liên kết các thành phần cho một lần chạy đánh giá:
- dataset: DataFrame chứa câu lệnh và câu trả lời của bạn.
- metrics: Danh sách các chỉ số mà bạn muốn tính điểm.
- experiment: Thử nghiệm Vertex AI để ghi lại kết quả, giúp bạn theo dõi và so sánh các lượt chạy.
- Tạo một
EvalTaskcho mỗi mô hình. Đối tượng này kết hợp tập dữ liệu, chỉ số và tên thử nghiệm. Thêm và chạy mã sau trong một ô mới để định cấu hình các tác vụ:rag_eval_task_rag_a = EvalTask( dataset=eval_dataset_rag_a, metrics=[ "question_answering_quality", relevance, helpfulness, "groundedness", "safety", "instruction_following", ], experiment=EXPERIMENT, ) rag_eval_task_rag_b = EvalTask( dataset=eval_dataset_rag_b, metrics=[ "question_answering_quality", relevance, helpfulness, "groundedness", "safety", "instruction_following", ], experiment=EXPERIMENT, )EvalTask, mỗi đối tượng cho một nhóm phản hồi của mô hình. Danh sáchmetricsmà bạn cung cấp minh hoạ một tính năng chính của dịch vụ đánh giá: các chỉ số được xác định trước (ví dụ:safety) và các đối tượngPointwiseMetrictuỳ chỉnh. - Sau khi định cấu hình các tác vụ, hãy thực thi các tác vụ đó bằng cách gọi phương thức
.evaluate(). Thao tác này sẽ gửi các tác vụ đến phần phụ trợ Vertex AI để xử lý và có thể mất vài phút để hoàn tất. Trong một ô mới, hãy thêm và chạy mã sau:result_rag_a = rag_eval_task_rag_a.evaluate() result_rag_b = rag_eval_task_rag_b.evaluate()
Sau khi quá trình đánh giá hoàn tất, kết quả sẽ được lưu trữ trong các đối tượng result_rag_a và result_rag_b, sẵn sàng để chúng ta phân tích trong phần tiếp theo.
10. Phân tích kết quả
Kết quả đánh giá hiện đã có. Các đối tượng result_rag_a và result_rag_b chứa điểm số tổng hợp và giải thích chi tiết cho từng hàng. Trong nhiệm vụ này, bạn sẽ phân tích các kết quả này bằng cách sử dụng các hàm trợ giúp từ notebook_utils.
Xem bản tóm tắt tổng hợp
- Để xem thông tin tổng quan cấp cao, hãy sử dụng hàm trợ giúp
display_eval_result()để xem điểm trung bình cho từng chỉ số. Trong một ô mới, hãy thêm và chạy nội dung sau để xem thông tin tóm tắt cho Mô hình A:notebook_utils.display_eval_result( title="Model A Eval Result", eval_result=result_rag_a ) - Làm tương tự cho Mô hình B. Thêm và chạy mã này trong một ô mới:
notebook_utils.display_eval_result( title="Model B Eval Result", eval_result=result_rag_b, )
Trực quan hoá kết quả đánh giá
Biểu đồ có thể giúp bạn dễ dàng so sánh hiệu suất của mô hình. Bạn sẽ sử dụng 2 loại hình ảnh hoá:
- Biểu đồ radar: Cho biết "hình dạng" hiệu suất tổng thể của từng mô hình. Hình dạng càng lớn thì hiệu suất tổng thể càng cao.
- Biểu đồ thanh: Để so sánh trực tiếp, song song trên từng chỉ số.
Những hình ảnh trực quan này sẽ giúp bạn so sánh các mô hình dựa trên những đặc điểm chủ quan như mức độ liên quan, tính xác thực và mức độ hữu ích.
- Để chuẩn bị cho việc vẽ biểu đồ, hãy kết hợp các kết quả thành một danh sách bộ dữ liệu duy nhất. Mỗi bộ giá trị phải chứa tên mô hình và đối tượng kết quả tương ứng. Trong một ô mới, hãy thêm và chạy mã sau:
eval_results = [] eval_results.append(("Model A", result_rag_a)) eval_results.append(("Model B", result_rag_b)) - Bây giờ, hãy tạo một biểu đồ radar để so sánh các mô hình trên tất cả các chỉ số cùng một lúc. Thêm và chạy mã sau trong một ô mới:
notebook_utils.display_radar_plot( eval_results, metrics=[ "question_answering_quality", "safety", "groundedness", "instruction_following", "relevance", "helpfulness", ], ) - Để so sánh trực tiếp hơn về từng chỉ số, hãy tạo một biểu đồ thanh. Trong một ô mới, hãy thêm và chạy mã sau:
notebook_utils.display_bar_plot( eval_results, metrics=[ "question_answering_quality", "safety", "groundedness", "instruction_following", "relevance", "helpfulness", ], )
Hình ảnh trực quan sẽ cho thấy rõ rằng hiệu suất của Mô hình A (hình dạng lớn trên biểu đồ radar và các thanh cao trên biểu đồ thanh) vượt trội hơn so với Mô hình B.
Xem nội dung giải thích chi tiết cho từng phiên bản
Điểm số tổng hợp cho biết hiệu suất tổng thể. Để hiểu lý do một mô hình hoạt động theo một cách nào đó, bạn cần xem xét những lời giải thích chi tiết do LLM đánh giá tạo ra cho từng ví dụ.
- Hàm trợ giúp
display_explanations()cho phép bạn kiểm tra từng kết quả. Để xem thông tin chi tiết về ví dụ thứ hai (num=2) trong kết quả của Mô hình A, hãy thêm và chạy mã sau trong một ô mới:notebook_utils.display_explanations(result_rag_a, num=2) - Bạn cũng có thể dùng chức năng này để lọc một chỉ số cụ thể trong tất cả các ví dụ. Điều này hữu ích khi bạn cần gỡ lỗi một khu vực cụ thể có hiệu suất kém. Để xem lý do khiến Mô hình B hoạt động kém hiệu quả trên chỉ số
groundedness, hãy thêm và chạy mã này trong một ô mới:notebook_utils.display_explanations(result_rag_b, metrics=["groundedness"])
11. Đánh giá có tham chiếu bằng cách sử dụng "câu trả lời mẫu"
Trước đây, bạn đã thực hiện một quy trình đánh giá không cần thông tin tham khảo, trong đó câu trả lời của mô hình chỉ được đánh giá dựa trên câu lệnh. Phương pháp này hữu ích nhưng việc đánh giá mang tính chủ quan.
Giờ đây, bạn sẽ sử dụng phương pháp đánh giá dựa trên tiêu chí. Phương thức này thêm "câu trả lời chính xác" (còn gọi là câu trả lời tham khảo) vào tập dữ liệu. Việc so sánh câu trả lời của mô hình với câu trả lời thực tế giúp đo lường hiệu suất một cách khách quan hơn. Nhờ đó, bạn có thể đo lường:
- Tính chính xác về thông tin: Câu trả lời của mô hình có phù hợp với thông tin trong câu trả lời mẫu không?
- Độ tương đồng về ngữ nghĩa: Câu trả lời của mô hình có cùng nghĩa với câu trả lời mẫu không?
- Tính đầy đủ: Câu trả lời của mô hình có chứa tất cả thông tin chính trong câu trả lời mẫu không?
Chuẩn bị tập dữ liệu được tham chiếu
Để thực hiện đánh giá có tham chiếu, bạn cần thêm "câu trả lời chính xác" vào từng ví dụ trong tập dữ liệu.
Hãy bắt đầu bằng cách xác định danh sách golden_answers. Việc so sánh câu trả lời chính xác với câu trả lời của Mô hình A cho thấy giá trị của phương pháp này:
- Câu hỏi 1 (Kiến thức): Câu trả lời được tạo và câu trả lời chính xác giống hệt nhau. Mô hình A là mô hình chính xác.
- Câu hỏi 2 (Thượng viện): Các câu trả lời tương đồng về mặt ngữ nghĩa nhưng được diễn đạt khác nhau. Một chỉ số tốt sẽ nhận ra điều này.
- Câu hỏi 3 (Hasan-Jalalians): Câu trả lời của Mô hình A không chính xác theo ngữ cảnh.
golden_answercho thấy lỗi này.
- Trong một ô mới, hãy xác định danh sách golden_answers
golden_answers = [ "frontal lobe and the parietal lobe", "Due to successes against Catiline.", "The Hasan-Jalalians commanded the area of Artsakh and Utik.", ] - Tạo DataFrame đánh giá được tham chiếu bằng cách chạy mã này trong ô sau:
referenced_eval_dataset_rag_a = pd.DataFrame( { "prompt": [ "Answer the question: " + question + " Context: " + item for question, item in zip(questions, retrieved_contexts) ], "response": generated_answers_by_rag_a, "reference": golden_answers, } ) referenced_eval_dataset_rag_b = pd.DataFrame( { "prompt": [ "Answer the question: " + question + " Context: " + item for question, item in zip(questions, retrieved_contexts) ], "response": generated_answers_by_rag_b, "reference": golden_answers, } )
Các tập dữ liệu hiện đã sẵn sàng để đánh giá có tham chiếu.
Tạo chỉ số tuỳ chỉnh được tham chiếu
Bạn cũng có thể tạo chỉ số tuỳ chỉnh cho hoạt động đánh giá được tham chiếu. Quy trình này tương tự, nhưng mẫu câu lệnh hiện có phần giữ chỗ {reference} cho câu trả lời hoàn hảo.
Với câu trả lời "chính xác" rõ ràng, bạn có thể sử dụng phương pháp chấm điểm nhị phân nghiêm ngặt hơn (ví dụ: 1 cho câu trả lời chính xác, 0 cho câu trả lời không chính xác) để đo lường độ chính xác về mặt thực tế. Hãy tạo một chỉ số question_answering_correctness mới triển khai logic này.
- Xác định mẫu câu lệnh. Trong một ô mới, hãy thêm và chạy mã sau:
question_answering_correctness_prompt_template = """ You are a professional writing evaluator. Your job is to score writing responses according to pre-defined evaluation criteria. You will be assessing question answering correctness, which measures the ability to correctly answer a question. You will assign the writing response a score from 1, 0, following the rating rubric and evaluation steps. ### Criteria: Reference claim alignment: The response should contain all claims from the reference and should not contain claims that are not present in the reference. ### Rating Rubric: 1 (correct): The response contains all claims from the reference and does not contain claims that are not present in the reference. 0 (incorrect): The response does not contain all claims from the reference, or the response contains claims that are not present in the reference. ### Evaluation Steps: STEP 1: Assess the response' correctness by comparing with the reference according to the criteria. STEP 2: Score based on the rubrics. Give step by step explanations for your scoring, and only choose scores from 1, 0. # User Inputs and AI-generated Response ## User Inputs ### Prompt {prompt} ## Reference {reference} ## AI-generated Response {response} """ - Bao bọc chuỗi mẫu câu lệnh bên trong một đối tượng PointwiseMetric. Điều này giúp chỉ số của bạn có tên chính thức và trở thành một thành phần có thể dùng lại cho công việc đánh giá. Thêm và chạy mã sau trong một ô mới:
question_answering_correctness = PointwiseMetric( metric="question_answering_correctness", metric_prompt_template=question_answering_correctness_prompt_template, )
Giờ đây, bạn đã có một chỉ số tuỳ chỉnh được tham chiếu để kiểm tra tính chính xác nghiêm ngặt.
12. Chạy quy trình Đánh giá có tham chiếu
Bây giờ, bạn sẽ định cấu hình công việc đánh giá bằng các tập dữ liệu được tham chiếu và chỉ số mới. Bạn sẽ sử dụng lại lớp EvalTask.
Danh sách chỉ số hiện kết hợp chỉ số tuỳ chỉnh dựa trên mô hình với chỉ số dựa trên tính toán. Đánh giá có tham chiếu cho phép sử dụng các chỉ số truyền thống dựa trên tính toán để thực hiện so sánh toán học giữa văn bản được tạo và văn bản tham chiếu. Bạn sẽ sử dụng 3 loại phổ biến:
exact_match: Chỉ tính 1 điểm nếu câu trả lời được tạo giống hệt câu trả lời tham khảo, nếu không thì tính 0 điểm.bleu: Một chỉ số về độ chính xác. Chỉ số này đo lường số lượng từ trong câu trả lời được tạo cũng xuất hiện trong câu trả lời tham khảo.rouge: Một chỉ số về khả năng nhớ lại. Chỉ số này đo lường số lượng từ trong câu trả lời tham khảo được đưa vào câu trả lời được tạo.
- Định cấu hình quy trình đánh giá bằng các tập dữ liệu được tham chiếu và tổ hợp chỉ số mới. Trong một ô mới, hãy thêm và chạy mã sau để tạo các đối tượng
EvalTask:referenced_answer_eval_task_rag_a = EvalTask( dataset=referenced_eval_dataset_rag_a, metrics=[ question_answering_correctness, "rouge", "bleu", "exact_match", ], experiment=EXPERIMENT, ) referenced_answer_eval_task_rag_b = EvalTask( dataset=referenced_eval_dataset_rag_b, metrics=[ question_answering_correctness, "rouge", "bleu", "exact_match", ], experiment=EXPERIMENT, ) - Thực thi quá trình đánh giá được tham chiếu bằng cách gọi phương thức
.evaluate(). Thêm và chạy mã này trong một ô mới:referenced_result_rag_a = referenced_answer_eval_task_rag_a.evaluate() referenced_result_rag_b = referenced_answer_eval_task_rag_b.evaluate()
13. Phân tích kết quả được tham chiếu
Quá trình đánh giá đã hoàn tất. Trong nhiệm vụ này, bạn sẽ phân tích kết quả để đo lường độ chính xác thực tế của các mô hình bằng cách so sánh câu trả lời của chúng với câu trả lời tham chiếu chính xác.
Xem kết quả tóm tắt
- Phân tích kết quả tóm tắt cho hoạt động đánh giá được tham chiếu. Trong một ô mới, hãy thêm và chạy mã sau đây để hiển thị các bảng tóm tắt cho cả hai mô hình:
notebook_utils.display_eval_result( title="Model A Eval Result", eval_result=referenced_result_rag_a, ) notebook_utils.display_eval_result( title="Model B Eval Result", eval_result=referenced_result_rag_b, )question_answering_correctnesstuỳ chỉnh nhưng lại có điểm số thấp hơn đối vớiexact_match. Điều này làm nổi bật giá trị của các chỉ số dựa trên mô hình có thể nhận ra sự tương đồng về ngữ nghĩa, chứ không chỉ văn bản giống hệt nhau.
Trực quan hoá kết quả để so sánh
Hình ảnh trực quan có thể giúp bạn thấy rõ hơn khoảng cách về hiệu suất giữa hai mô hình. Trước tiên, hãy kết hợp các kết quả thành một danh sách duy nhất để vẽ biểu đồ, sau đó tạo biểu đồ radar và biểu đồ thanh.
- Kết hợp các kết quả đánh giá được tham chiếu thành một danh sách duy nhất để vẽ biểu đồ. Thêm và chạy mã sau trong một ô mới:
referenced_eval_results = [] referenced_eval_results.append(("Model A", referenced_result_rag_a)) referenced_eval_results.append(("Model B", referenced_result_rag_b)) - Tạo biểu đồ radar để trực quan hoá hiệu quả của từng mô hình trên bộ chỉ số mới. Thêm và chạy mã này trong một ô mới:
notebook_utils.display_radar_plot( referenced_eval_results, metrics=[ "question_answering_correctness", "rouge", "bleu", "exact_match", ], ) - Tạo biểu đồ thanh để so sánh trực tiếp, song song. Thao tác này sẽ cho biết hiệu suất của từng mô hình trên các chỉ số khác nhau. Thêm và chạy mã sau trong một ô mới:
notebook_utils.display_bar_plot( referenced_eval_results, metrics=[ "question_answering_correctness", "rouge", "bleu", "exact_match", ], )
Những hình ảnh trực quan này xác nhận rằng Mô hình A chính xác hơn đáng kể và phù hợp với câu trả lời tham khảo hơn Mô hình B.
14. Từ thực hành đến phát hành công khai
Bạn đã thực hiện thành công một quy trình đánh giá hoàn chỉnh cho hệ thống RAG. Phần cuối cùng này tóm tắt các khái niệm chiến lược chính mà bạn đã học và cung cấp một khung sườn để áp dụng những kỹ năng này vào các dự án thực tế.
Các phương pháp hay nhất về sản xuất
Để áp dụng các kỹ năng trong phòng thí nghiệm này vào môi trường sản xuất thực tế, hãy cân nhắc 4 phương pháp chính sau:
- Tự động hoá bằng CI/CD: Tích hợp bộ đánh giá vào quy trình CI/CD (ví dụ: Cloud Build, GitHub Actions). Tự động chạy quy trình đánh giá khi có thay đổi về mã để phát hiện các lỗi hồi quy và chặn việc triển khai nếu điểm chất lượng giảm xuống dưới tiêu chuẩn của bạn.
- Phát triển tập dữ liệu: Tập dữ liệu tĩnh sẽ trở nên lỗi thời. Quản lý phiên bản các bộ thử nghiệm "vàng" (bằng Git LFS hoặc Cloud Storage) và liên tục thêm các ví dụ mới, đầy thách thức bằng cách lấy mẫu từ các cụm từ tìm kiếm thực tế (đã ẩn danh) của người dùng.
- Đánh giá trình truy xuất, chứ không chỉ trình tạo: Không thể có câu trả lời hay nếu không có ngữ cảnh phù hợp. Triển khai một bước đánh giá riêng cho hệ thống truy xuất bằng cách sử dụng các chỉ số như Tỷ lệ trùng khớp (có tìm thấy tài liệu phù hợp không?) và Thứ hạng tương hỗ trung bình (MRR) (tài liệu phù hợp được xếp hạng ở vị trí nào?).
- Theo dõi các chỉ số theo thời gian: Xuất điểm số tóm tắt từ các lần đánh giá sang một dịch vụ như Google Cloud Monitoring. Tạo trang tổng quan để theo dõi xu hướng chất lượng và thiết lập thông báo tự động để thông báo cho bạn về những trường hợp hiệu suất giảm đáng kể.
Ma trận phương pháp đánh giá nâng cao
Việc chọn phương pháp đánh giá phù hợp phụ thuộc vào mục tiêu cụ thể của bạn. Ma trận này tóm tắt thời điểm nên sử dụng từng phương pháp.
Phương pháp đánh giá | Các trường hợp sử dụng phù hợp nhất | Ưu điểm chính | Giới hạn |
Không cần tham chiếu | Giám sát quá trình sản xuất, đánh giá liên tục | Không cần câu trả lời hoàn hảo, chỉ cần ghi lại chất lượng chủ quan | Tốn kém hơn, người đánh giá có thể thiên vị |
Dựa trên tệp đối chiếu | So sánh mô hình, đo điểm chuẩn | Đo lường khách quan, tính toán nhanh hơn | Cần có câu trả lời chính xác, có thể bỏ lỡ sự tương đương về ngữ nghĩa |
Chỉ số tuỳ chỉnh | Bài đánh giá theo miền cụ thể | Phù hợp với nhu cầu kinh doanh | Yêu cầu xác thực, chi phí phát triển |
Phương pháp kết hợp | Hệ thống sản xuất toàn diện | Cách tiếp cận hiệu quả nhất | Độ phức tạp cao hơn, cần tối ưu hoá chi phí |
Thông tin chi tiết chính về kỹ thuật
Hãy ghi nhớ những nguyên tắc cốt lõi này khi bạn xây dựng và đánh giá các hệ thống RAG của riêng mình:
- Tính xác thực là yếu tố quan trọng đối với RAG: Chỉ số này luôn phân biệt giữa các hệ thống RAG chất lượng cao và chất lượng thấp, vì vậy, đây là chỉ số cần thiết để giám sát quá trình sản xuất.
- Nhiều chỉ số mang lại độ tin cậy: Không có chỉ số nào nắm bắt được mọi khía cạnh về chất lượng của RAG. Việc đánh giá toàn diện đòi hỏi nhiều phương diện đánh giá.
- Chỉ số tuỳ chỉnh mang lại giá trị đáng kể: Tiêu chí đánh giá theo miền thường nắm bắt được những sắc thái mà các chỉ số chung bỏ lỡ, giúp cải thiện độ chính xác của việc đánh giá.
- Tính chặt chẽ về mặt thống kê giúp bạn tự tin: Cỡ mẫu phù hợp và kiểm định ý nghĩa thống kê sẽ biến hoạt động đánh giá từ phỏng đoán thành công cụ đưa ra quyết định đáng tin cậy.
Khung quyết định triển khai phiên bản phát hành công khai
Hãy sử dụng khung từng giai đoạn này làm hướng dẫn cho việc triển khai hệ thống RAG trong tương lai:
- Giai đoạn 1 – Phát triển: Sử dụng quy trình đánh giá dựa trên thông tin tham khảo với các bộ thử nghiệm đã biết để so sánh và chọn mô hình.
- Giai đoạn 2 – Trước khi phát hành công khai: Chạy quy trình đánh giá toàn diện kết hợp cả hai phương pháp để xác thực mức độ sẵn sàng phát hành công khai.
- Giai đoạn 3 – Sản xuất: Triển khai tính năng giám sát không cần câu trả lời mẫu để liên tục đánh giá chất lượng mà không cần câu trả lời mẫu.
- Giai đoạn 4 – Tối ưu hoá: Sử dụng thông tin chi tiết về việc đánh giá để hướng dẫn việc cải thiện mô hình và nâng cao hệ thống truy xuất.
15. Kết luận
Xin chúc mừng! Bạn đã hoàn thành bài thực hành.
Phòng thí nghiệm này thuộc Lộ trình học tập về AI sẵn sàng cho hoạt động sản xuất trên Google Cloud.
- Khám phá toàn bộ chương trình học để thu hẹp khoảng cách từ nguyên mẫu đến phát hành công khai.
- Chia sẻ tiến trình của bạn bằng thẻ bắt đầu bằng #
ProductionReadyAI.
Tóm tắt
Bạn đã tìm hiểu cách:
- Thực hiện đánh giá không cần thông tin tham khảo để đánh giá chất lượng của câu trả lời dựa trên ngữ cảnh đã truy xuất.
- Thực hiện đánh giá có tham chiếu bằng cách thêm "câu trả lời mẫu" để đo lường độ chính xác về mặt thực tế.
- Sử dụng kết hợp các chỉ số được xác định trước và chỉ số tuỳ chỉnh cho cả hai phương pháp.
- Sử dụng cả chỉ số dựa trên mô hình (chẳng hạn như
question_answering_quality) và chỉ số dựa trên tính toán (rouge,bleu,exact_match). - Phân tích và trực quan hoá kết quả để hiểu rõ điểm mạnh và điểm yếu của một mô hình.
Phương pháp đánh giá này giúp bạn xây dựng các ứng dụng AI tạo sinh đáng tin cậy và chính xác hơn.