
1. نظرة عامة
في هذا الدرس التطبيقي، ستتعرّف على كيفية تقييم النماذج اللغوية الكبيرة باستخدام خدمة Vertex AI Gen AI Evaluation Service. ستستخدم حزمة تطوير البرامج (SDK) لتشغيل مهام التقييم ومقارنة النتائج واتخاذ قرارات مستندة إلى البيانات بشأن أداء النموذج وتصميم الطلبات.
يرشدك هذا التمرين العملي إلى سير عمل شائع للتقييم، بدءًا بمقاييس بسيطة مستندة إلى العمليات الحسابية، وصولاً إلى تقييمات أكثر دقة مستندة إلى النماذج. ستتعلّم أيضًا كيفية إنشاء مقاييس مخصّصة مصمّمة خصيصًا لأهدافك المحدّدة وتتبُّع عملك باستخدام Vertex AI Experiments.
أهداف الدورة التعليمية
في هذه الميزة الاختبارية، ستتعرّف على كيفية تنفيذ المهام التالية:
- تقييم نموذج باستخدام مقاييس مستندة إلى الحساب ومقاييس مستندة إلى النموذج
- أنشِئ مقياسًا مخصّصًا لمواءمة التقييم مع أهداف المنتج.
- مقارنة نماذج الطلبات المختلفة جنبًا إلى جنب
- اختبِر طلبات متعددة مستندة إلى شخصيات للعثور على الإصدار الأكثر فعالية.
- تتبُّع عمليات التقييم وعرضها بشكل مرئي باستخدام Vertex AI Experiments
المراجع
- نماذج الرموز البرمجية: تستند هذه التجربة العملية إلى أمثلة من مستودع الذكاء الاصطناعي التوليدي من Google Cloud
- استنادًا إلى: مستندات تقييم الذكاء الاصطناعي التوليدي في Vertex AI
- مجموعة البيانات: مجموعة بيانات OpenOrca لتقييم مدى اتّباع التعليمات
2. إعداد المشروع
حساب Google
إذا لم يكن لديك حساب Google شخصي، عليك إنشاء حساب على Google.
استخدام حساب شخصي بدلاً من حساب تابع للعمل أو تديره مؤسسة تعليمية
تسجيل الدخول إلى Google Cloud Console
سجِّل الدخول إلى Google Cloud Console باستخدام حساب Google شخصي.
تفعيل الفوترة
لتفعيل الفوترة، لديك خياران. يمكنك استخدام حساب الفوترة الشخصي أو تحصيل قيمة الرصيد باتّباع الخطوات التالية.
تحصيل قيمة أرصدة Google Cloud (اختياري)
لإجراء ورشة العمل هذه، يجب أن يكون لديك حساب فوترة يتضمّن بعض الرصيد. استخدِم الرصيد من البانر في أعلى هذا الدرس التطبيقي للبدء. إذا كنت مرتبطًا بحساب فوترة، يمكنك تخطّي هذه الخطوة.
إعداد حساب فوترة شخصي
إذا أعددت الفوترة باستخدام أرصدة Google Cloud، يمكنك تخطّي هذه الخطوة.
لإعداد حساب فوترة شخصي، يُرجى الانتقال إلى هنا لتفعيل الفوترة في Cloud Console.
ملاحظات:
- يجب أن تكلّف إكمال هذا الدرس التطبيقي أقل من دولار أمريكي واحد من موارد السحابة الإلكترونية.
- يمكنك اتّباع الخطوات في نهاية هذا المختبر لحذف الموارد وتجنُّب المزيد من الرسوم.
- يمكن للمستخدمين الجدد الاستفادة من فترة تجريبية مجانية بقيمة 300 دولار أمريكي.
إنشاء مشروع (اختياري)
إذا لم يكن لديك مشروع حالي تريد استخدامه في هذا المختبر، يمكنك إنشاء مشروع جديد هنا.
3- إعداد بيئة Vertex AI Workbench
لنبدأ بالوصول إلى بيئة دفتر الملاحظات التي تم ضبط إعداداتها مسبقًا وتثبيت التبعيات اللازمة.
الوصول إلى Vertex AI Workbench
- في Google Cloud Console، انتقِل إلى Vertex AI من خلال النقر على قائمة التنقّل ☰ > Vertex AI > لوحة البيانات.
- انقر على تفعيل جميع واجهات برمجة التطبيقات المقترَحة. ملاحظة: يُرجى الانتظار إلى أن تكتمل هذه الخطوة
- على يمين الصفحة، انقر على منصة العمل لإنشاء مثيل جديد لمنصة العمل.
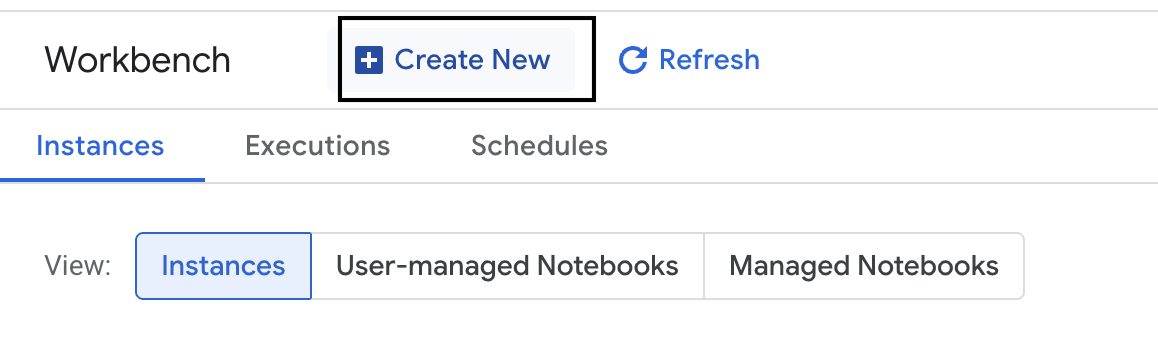
- أدخِل اسمًا لمثيل Workbench وهو evaluation-workbench وانقر على إنشاء.
- انتظِر إلى أن يتم إعداد مساحة العمل. قد تستغرق هذه العملية بضع دقائق.

- بعد توفير مساحة العمل، انقر على فتح JupyterLab.
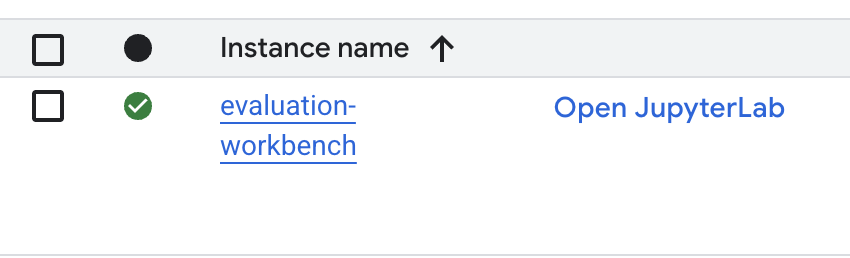
- في مساحة العمل، أنشئ دفتر ملاحظات جديدًا في Python3.
لمزيد من المعلومات حول ميزات هذه البيئة وإمكاناتها، يُرجى الاطّلاع على المستندات الرسمية الخاصة بـ Vertex AI Workbench.
تثبيت الحِزم وضبط البيئة
- في الخلية الأولى من دفتر الملاحظات، أضِف عبارات الاستيراد أدناه وشغِّلها (SHIFT+ENTER) لتثبيت حزمة تطوير البرامج (SDK) الخاصة بمنصة Vertex AI (مع مكوّنات التقييم) والحِزم الأخرى المطلوبة.
%pip install -U -q google-cloud-aiplatform[evaluation] %pip install -U -q datasets anthropic[vertex] openai - لاستخدام الحِزم المثبَّتة حديثًا، يُنصح بإعادة تشغيل النواة من خلال تشغيل مقتطف الرمز البرمجي أدناه.
# Automatically restart kernel after installation so that your environment can access the new packages. import IPython app = IPython.Application.instance() app.kernel.do_shutdown(True) - استبدِل القيم التالية برقم تعريف مشروعك وموقعه الجغرافي، ثم نفِّذ الخلية التالية. تم ضبط الموقع الجغرافي التلقائي على
europe-west1، ولكن عليك استخدام الموقع الجغرافي نفسه الذي توجد فيه آلة Vertex AI Workbench الافتراضية.# Configure your project settings PROJECT_ID = "YOUR PROJECT ID" LOCATION = "europe-west1" - استورِد جميع مكتبات Python المطلوبة لهذا المختبر من خلال تشغيل الرمز التالي في خلية جديدة.
from anthropic import AnthropicVertex from google.auth import default, transport import openai import pandas as pd from vertexai.evaluation import ( EvalTask, MetricPromptTemplateExamples, PairwiseMetric, PointwiseMetric, PointwiseMetricPromptTemplate, ) from vertexai.generative_models import GenerativeModel from vertexai.preview.evaluation import notebook_utils
4. إعداد مجموعة بيانات التقييم
في هذا البرنامج التعليمي، سنستخدم 10 عيّنات من مجموعة بيانات OpenOrca. يمنحنا ذلك بيانات كافية لرصد اختلافات مهمة بين النماذج مع الحفاظ على وقت التقييم قابلاً للإدارة.
💡 ملاحظة احترافية: في مرحلة الإنتاج، ستحتاج إلى 100 إلى 500 مثال للحصول على نتائج ذات دلالة إحصائية، ولكن 10 أمثلة تكفي للتعلم وإنشاء نماذج أولية بسرعة.
إعداد مجموعة البيانات
- في خلية جديدة، شغِّل الخلية التالية لتحميل البيانات وتحويلها إلى pandas DataFrame وإعادة تسمية العمود
responseإلىreferenceلتوضيح مهام التقييم وإنشاء عيّنة عشوائية من عشرة أمثلة.from datasets import load_dataset ds = ( load_dataset( "Open-Orca/OpenOrca", data_files="1M-GPT4-Augmented.parquet", split="train[:100]", ) .to_pandas() .drop(columns=["id"]) .rename(columns={"response": "reference"}) ) dataset = ds.sample(n=10) - بعد انتهاء تشغيل الخلية السابقة، أضِف الرمز التالي وشغِّله في الخلية التالية لعرض الصفوف القليلة الأولى من مجموعة بيانات التقييم.
dataset.head()
5- تحديد خط أساس باستخدام مقاييس مستندة إلى العمليات الحسابية
في هذه المهمة، عليك تحديد نتيجة أساسية باستخدام مقياس مستند إلى العمليات الحسابية. هذا النهج سريع ويوفّر مقياسًا موضوعيًا يمكن الاستناد إليه لقياس التحسينات المستقبلية.
سنستخدم ROUGE (Recall-Oriented Understudy for Gisting Evaluation)، وهو مقياس معياري لمهام التلخيص. ويتم ذلك من خلال مقارنة تسلسل الكلمات (n-grams) في الرد الذي أنشأه النموذج بالكلمات في النص reference الصحيح.
مزيد من المعلومات عن المقاييس المستندة إلى العمليات الحسابية
إجراء التقييم الأساسي
- في خلية جديدة، أضِف الخلية التالية وشغِّلها لتحديد النموذج الذي تريد اختباره،
gemini-2.0-flash. يتضمّنgeneration_configمَعلمات مثلtemperatureوmax_output_tokensالتي تؤثّر في الردّ الذي يقدّمه النموذج.# Model to be evaluated model = GenerativeModel( "gemini-2.0-flash", generation_config={"temperature": 0.6, "max_output_tokens": 256, "top_k": 1}, )GenerativeModelالواجهة الأساسية للتفاعل مع النماذج اللغوية الكبيرة في حزمة تطوير البرامج (SDK) الخاصة بمنصة Vertex AI. - في الخلية التالية، أضِف الرمز التالي وشغِّله لإنشاء
EvalTaskوتنفيذه. يتولّى هذا العنصر من حزمة Vertex AI Evaluation SDK تنظيم عملية التقييم. يمكنك ضبطها باستخدام مجموعة البيانات والمقاييس المطلوب احتسابها، وهي في هذه الحالةrouge_l_sum.# Define an EvalTask with ROUGE-L-SUM metric rouge_eval_task = EvalTask( dataset=dataset, metrics=["rouge_l_sum"], ) rouge_result = rouge_eval_task.evaluate( model=model, prompt_template="# System_prompt\n{system_prompt} # Question\n{question}", ) - اعرض النتائج من خلال تنفيذ هذا الرمز في الخلية التالية.
notebook_utils.display_eval_result(rouge_result)display_eval_result()متوسط النتيجة (المتوسط الحسابي) والنتائج صفًا بصف.
6. اختياري: التقييم باستخدام مقاييس نقطية مستندة إلى النموذج
ملاحظة: قد لا يتم تشغيل هذا القسم في حدود الرصيد المجاني المقدَّم.
على الرغم من أنّ مقياس ROUGE مفيد، إلا أنّه يقيس فقط التداخل المعجمي (أي أنّه يحسب فقط الكلمات المتطابقة، ولا يفهم السياق أو المرادفات أو إعادة الصياغة). لذلك، لا يمكن الاعتماد عليه في تحديد ما إذا كان الردّ بليغًا أو منطقيًا. للحصول على فهم أعمق لأداء النموذج، يمكنك استخدام مقاييس نقطية مستندة إلى النموذج.
باستخدام هذه الطريقة، يقيّم نموذج لغوي كبير آخر ("نموذج التقييم") كل رد على حدة استنادًا إلى مجموعة محدّدة مسبقًا من المعايير، مثل الطلاقة أو التماسك.
مزيد من المعلومات عن المقاييس المستندة إلى نماذج
تنفيذ التقييم النقطي
- نفِّذ ما يلي في خلية جديدة لإنشاء قائمة منسدلة تفاعلية. بالنسبة إلى عملية التشغيل هذه، اختَر coherence من القائمة.
#Select a pointwise metric to use import ipywidgets as widgets pointwise_single_turn_metrics = [ metric for metric in MetricPromptTemplateExamples.list_example_metric_names() if not metric.startswith("pairwise") and not metric.startswith("multi_turn") ] dropdown = widgets.Dropdown( options=pointwise_single_turn_metrics, description="Select a metric:", font_weight="bold", style={"description_width": "initial"}, ) def dropdown_eventhandler(change): global POINTWISE_METRIC if change["type"] == "change" and change["name"] == "value": POINTWISE_METRIC = change.new print("Selected:", change.new) POINTWISE_METRIC = dropdown.value dropdown.observe(dropdown_eventhandler, names="value") display(dropdown) - في خلية جديدة، شغِّل
EvalTaskمرة أخرى، ولكن هذه المرة باستخدام المقياس المستند إلى النموذج الذي تم اختياره. تنشئ خدمة التقييم في Vertex AI طلبًا لنموذج التقييم، ويتضمّن الطلب الأصلي والإجابة المرجعية وردّ النموذج المرشّح وتعليمات المقياس المحدّد. يعرض Judge Model نتيجة رقمية وتفسيرًا للتقييم. ملاحظة: سيستغرق تنفيذ هذه الخطوة بضع دقائق.pointwise_result = EvalTask( dataset=dataset, metrics=[POINTWISE_METRIC], ).evaluate( model=model, prompt_template="# System_prompt\n{system_prompt} # Question\n{question}", )
عرض النتائج
بعد اكتمال التقييم، تتمثل الخطوة التالية في تحليل النتائج.
- نفِّذ الرمز التالي في خلية جديدة لعرض مقاييس الملخّص التي تعرض متوسط النتيجة للمقياس الذي اخترته.
notebook_utils.display_eval_result(pointwise_result) - نفِّذ ما يلي في الخلية التالية للاطّلاع على التفاصيل حسب الصف، والتي تتضمّن الأساس المنطقي المكتوب الذي استند إليه "نموذج التقييم" في تحديد النتيجة. تساعدك هذه الملاحظات النوعية في فهم سبب حصول ردّ على درجة معيّنة.
notebook_utils.display_explanations(pointwise_result, num=1, metrics=[POINTWISE_METRIC])
7. إنشاء مقياس مخصّص للحصول على إحصاءات أكثر تفصيلاً
تكون المقاييس المُعدّة مسبقًا، مثل الطلاقة، مفيدة، ولكن بالنسبة إلى منتج معيّن، غالبًا ما تحتاج إلى قياس الأداء مقارنةً بأهدافك. باستخدام المقاييس المخصّصة على مستوى النقطة، يمكنك تحديد معايير التقييم وقواعد التقييم الخاصة بك.
في هذه المهمة، ستنشئ مقياسًا جديدًا من البداية باسم summarization_helpfulness.
تحديد المقياس المخصّص وتشغيله
- نفِّذ ما يلي في خلية جديدة لتحديد المقياس المخصّص.يحتوي
PointwiseMetricPromptTemplateعلى الوحدات الأساسية للمقياس:- المعايير: تحدّد هذه السمة للنموذج الحاكم السمات المحدّدة التي يجب تقييمها، وهي "المعلومات الأساسية" و"الإيجاز" و "عدم التشويه".
- rating_rubric: تقدّم مقياسًا للنتائج من 5 نقاط يحدّد معنى كل نتيجة.
- input_variables: تمرِّر هذه السمة أعمدة إضافية من مجموعة البيانات إلى "نموذج التقييم" ليتوفّر له السياق اللازم لإجراء التقييم.
# This new custom metric evaluates the actual quality and usefulness of the summary. summarization_helpfulness_metric = PointwiseMetric( metric="summarization_helpfulness", metric_prompt_template=PointwiseMetricPromptTemplate( criteria={ "Key Information": "Does the summary capture the most critical pieces of information from the original text? It should not miss the main topic or key takeaways.", "Conciseness": "Is the summary brief and to the point? It should avoid unnecessary words or repetitive information.", "No Distortion": "Does the summary introduce information or opinions that were NOT present in the original text? It must accurately reflect the source material without adding hallucinations." }, rating_rubric={ "5": "Excellent: Captures all key information, is highly concise, and has zero distortion.", "4": "Good: Captures most key information with minor omissions, is concise, and has no distortion.", "3": "Satisfactory: Captures the main idea but misses some key details OR is not very concise.", "2": "Unsatisfactory: Misses the main idea of the original text OR contains minor distortions/hallucinations.", "1": "Poor: Is completely irrelevant, fails to summarize the text, OR contains significant distortions.", }, input_variables=["prompt", "reference"], ), ) - نفِّذ الرمز التالي في الخلية التالية لتنفيذ
EvalTaskباستخدام المقياس المخصّص الجديد.# You would then update the EvalTask to use this new metric pointwise_result = EvalTask( dataset=dataset, metrics=[summarization_helpfulness_metric], ).evaluate( model=model, prompt_template="# System_prompt\n{system_prompt} # Question\n{question}", ) - نفِّذ ما يلي في خلية جديدة لعرض النتائج.
notebook_utils.display_eval_result(pointwise_result)
8. مقارنة النماذج باستخدام التقييم الثنائي
عندما تحتاج إلى تحديد أيّ من النموذجين يحقّق أداءً أفضل في مهمة معيّنة، يمكنك استخدام التقييم المستند إلى النموذج والمقارنة بين كل نموذجين. هذه الطريقة هي شكل من أشكال اختبار A/B حيث يحدّد "نموذج التقييم" الفائز، ما يوفّر مقارنة مباشرة لاختيار النموذج المستند إلى البيانات.
الطُرز:
- نموذج مرشّح: يتم تمرير متغيّر النموذج (الذي تم تعريفه سابقًا على أنّه
gemini-2.0-flash) إلى الطريقة.evaluate(). هذا هو النموذج الرئيسي الذي تختبره. - النموذج الأساسي: يتم تحديد نموذج ثانٍ،
gemini-2.0-flash-lite، داخل فئة PairwiseMetric. هذا هو النموذج الذي تتم المقارنة به.
إجراء التقييم الثنائي
- في خلية جديدة، أضِف الرمز التالي وشغِّله لإنشاء قائمة منسدلة تفاعلية. سيسمح لك ذلك باختيار المقياس الزوجي الذي تريد استخدامه للمقارنة. بالنسبة إلى عملية التشغيل هذه، اختَر pairwise_summarization_quality.
from IPython.display import display import ipywidgets as widgets pairwise_single_turn_metrics = [ metric for metric in MetricPromptTemplateExamples.list_example_metric_names() if metric.startswith("pairwise") and "multi_turn" not in metric ] dropdown = widgets.Dropdown( options=pairwise_single_turn_metrics, description="Select a metric:", font_weight="bold", style={"description_width": "initial"}, ) def dropdown_eventhandler(change): global POINTWISE_METRIC if change["type"] == "change" and change["name"] == "value": POINTWISE_METRIC = change.new print("Selected:", change.new) def dropdown_eventhandler(change): global PAIRWISE_METRIC_NAME if change["type"] == "change" and change["name"] == "value": PAIRWISE_METRIC_NAME = change.new print("Selected:", change.new) PAIRWISE_METRIC_NAME = dropdown.value dropdown.observe(dropdown_eventhandler, names="value") display(dropdown) - في الخلية التالية، أضِف الرمز التالي وشغِّله لضبط
EvalTaskوتنفيذه. لاحظ كيف يتم استخدام الفئةPairwiseMetricلتحديد النموذج الأساسي (gemini-2.0-flash-lite)، بينما يتم تمرير النموذج المرشّح (gemini-2.0-flash) إلى الطريقة.evaluate().pairwise_result = EvalTask( dataset=dataset, metrics=[ PairwiseMetric( metric=PAIRWISE_METRIC_NAME, metric_prompt_template=MetricPromptTemplateExamples.get_prompt_template( PAIRWISE_METRIC_NAME ), # Define a baseline model to compare against baseline_model=GenerativeModel("gemini-2.0-flash-lite"), ) ], ).evaluate( # Specify a candidate model for pairwise comparison model=model, prompt_template="# System_prompt\n{system_prompt} # Question\n{question}", ) - في خلية جديدة، أضِف الرمز التالي وشغِّله لعرض النتائج. سيعرض جدول الملخّص "معدّل الفوز" لكل نموذج، ما يشير إلى النموذج الذي فضّله "نموذج التقييم" في أغلب الأحيان.
notebook_utils.display_eval_result(pairwise_result)
9- اختياري: تقييم الطلبات المستندة إلى شخصيات
ملاحظة: قد لا يتم تشغيل هذا القسم في حدود الرصيد المجاني المقدَّم.
في هذه المهمة، ستختبر نماذج طلبات متعددة توجّه النموذج إلى اتّباع شخصيات مختلفة. تتيح لك هذه العملية، التي يُطلق عليها غالبًا هندسة الطلبات أو تصميم الطلبات، العثور بشكل منهجي على الطلب الأكثر فعالية لحالة استخدام معيّنة.
إعداد مجموعة بيانات التلخيص
لإجراء هذا التقييم، يجب أن تحتوي مجموعة البيانات على الحقول التالية:
instruction: المهمة الأساسية التي نكلّف النموذج بها في هذه الحالة، يكون الطلب بسيطًا: "لخِّص المقالة التالية:".context: النص المصدر الذي يحتاج النموذج إلى استخدامه. في ما يلي أربعة مقتطفات إخبارية مختلفة.reference: الملخّص الصحيح أو "المعيار الذهبي". ستتم مقارنة الناتج الذي أنشأه النموذج بهذا النص لاحتساب نتائج مقاييس مثل ROUGE وجودة التلخيص.
- في خلية جديدة، أضِف التعليمة البرمجية التالية وشغِّلها لإنشاء
pandas.DataFrameلمهمة التلخيص.instruction = "Summarize the following article: \n" context = [ "Typhoon Phanfone has killed at least one person, a US airman on Okinawa who was washed away by high waves. Thousands of households have lost power and Japan's two largest airlines have suspended many flights. The storm also forced the suspension of the search for people missing after last week's volcanic eruption. The storm-tracking website Tropical Storm Risk forecasts that Phanfone will rapidly lose power over the next few hours as it goes further into the Pacific Ocean. Typhoon Phanfone was downgraded from an earlier status of a super typhoon, but the Japan Meteorological Agency had warned it was still a dangerous storm. Japan averages 11 typhoons a year, according to its weather agency. The typhoon made landfall on Monday morning near the central city of Hamamatsu, with winds of up to 180 km/h (112 mph). The airman was one of three US military personnel swept away by high waves whipped up by the typhoon off southern Okinawa island, where the US has a large military base. The remaining two are still missing. A police spokesman said they had been taking photographs of the sea. A university student who was surfing off the seas of Kanagawa Prefecture, south of Tokyo, was also missing, national broadcast NHK reports. It said at least 10 people had been injured and 9,500 houses were without power. The storm was expected to deposit about 100mm of rain on Tokyo over 24 hours, according to the Transport Ministry website. Many schools were closed on Monday and two car companies in Japan halted production at some plants ahead of the storm. More than 174 domestic flights were affected nationwide, NHK state broadcaster said on Sunday. On Sunday, heavy rain delayed the Japanese Formula One Grand Prix in Suzaka. French driver Jules Bianchi lost control in the wet conditions and crashed, sustaining a severe head injury.", "The blaze started at the detached building in Drivers End in Codicote, near Welwyn, during the morning. There was another fire at the building 20 years ago, after which fire-proof foil was placed under the thatch, which is protecting the main building. More than 15 fire engines and support vehicles were called to tackle the blaze. Roads in the area were closed and traffic diverted.", 'The 18-year-old fell at the New Charter Academy on Broadoak Road in Ashton-under-Lyne at about 09:10 BST, Greater Manchester Police (GMP) said. GMP said he had gone to Manchester Royal Infirmary and his condition was "serious". Principal Jenny Langley said the school would remain "fully open" while police investigated. "Our thoughts are with the family and we\'re doing everything we can to support them along with staff and pupils," she said.', 'But Belgian-born Dutchman Max Verstappen was unable to drive a car legally on his own in either country. That all changed on Wednesday when the youngster turned 18 and passed his driving test at the first attempt. Despite having competed in 14 grands prix since his debut in Australia in March, Verstappen admitted to feeling the pressure during his test. "It\'s a relief," said the Toro Rosso driver, who finished ninth in Japan on Sunday and had only started driving lessons a week ago. "I was a bit nervous to make mistakes, but the exam went well." A bonus of turning 18 is that Verstappen will now be able to drink the champagne if he ever makes it onto the podium.', ] reference = [ "A powerful typhoon has brought many parts of Japan to a standstill and briefly battered Tokyo before heading out to sea.", "A major fire has been burning in the thatched roof of a large property in Hertfordshire.", "A student has been taken to hospital after falling from a balcony at a Greater Manchester school.", "He is Formula 1's youngest ever driver and in charge of a car that can reach over 200mph.", ] response = [ "Typhoon Phanfone, while downgraded from super typhoon status, caused significant disruption and tragedy in Japan. One US airman died after being swept away by high waves, with two more missing. The storm caused power outages for thousands, flight cancellations, and the suspension of rescue efforts for missing volcano victims. Heavy rain and strong winds led to school and factory closures, transportation disruptions, and at least 10 injuries. The typhoon is expected to weaken as it moves over the Pacific Ocean.", "A large fire broke out in a detached thatched building in Codicote, near Welwyn. This is the second fire at the building in 20 years. Thankfully, fire-proof foil installed after the previous fire is protecting the main building. Over 15 fire engines and support vehicles responded, closing roads and diverting traffic in the area.", "An 18-year-old student at New Charter Academy in Ashton-under-Lyne suffered a serious fall and was hospitalized. The incident is under investigation by Greater Manchester Police, but the school remains open. The principal expressed support for the student's family and the school community.", "Max Verstappen, a Formula One driver, was finally able to get his driver's license at age 18. Despite already competing in 14 Grand Prix races, he was not of legal driving age in his native countries. He admitted to being nervous but passed the test on his first attempt. As an added bonus of turning 18, Verstappen can now enjoy champagne on the podium if he places.", ] eval_dataset = pd.DataFrame( { "instruction": instruction, "context": context, "reference": reference, } )
تنفيذ مهمة تقييم الطلب
بعد إعداد مجموعة بيانات التلخيص، أنت جاهز لتنفيذ التجربة الأساسية لهذه المهمة: مقارنة نماذج طلبات متعدّدة لمعرفة النموذج الذي ينتج أعلى جودة من المخرجات.
- في الخلية التالية، أنشئ
EvalTaskواحدًا سيتم إعادة استخدامه لكل تجربة طلب. من خلال ضبط المَعلمةexperiment، يتم تلقائيًا تسجيل جميع عمليات التقييم من هذه المهمة وتجميعها في Vertex AI Experiments.EXPERIMENT_NAME = "eval-sdk-prompt-engineering" # @param {type:"string"} summarization_eval_task = EvalTask( dataset=eval_dataset, metrics=[ "rouge_l_sum", "bleu", "fluency", "coherence", "safety", "groundedness", "summarization_quality", "verbosity", "instruction_following", "text_quality", ], experiment=EXPERIMENT_NAME, )rouge_l_sumوbleuوصولاً إلى مجموعة كبيرة من المقاييس المستندة إلى النماذج (fluencyوcoherenceوsummarization_qualityوinstruction_followingوما إلى ذلك). يمنحنا ذلك نظرة شاملة بزاوية 360 درجة حول كيفية تأثير كل طلب على جودة النتائج التي يقدّمها النموذج. - في خلية جديدة، أضِف التعليمات البرمجية التالية وشغِّلها لتحديد وتقييم أربع استراتيجيات موجّهة حسب الشخصية. تكرّر حلقة
forكل نموذج وتجري تقييمًا له.تم تصميم كل نموذج لاستخلاص نمط مختلف من الملخّص من خلال منح النموذج شخصية أو هدفًا محدّدًا:- الشخصية رقم 1 (عادية): طلب تلخيص محايد ومباشر
- الشخصية رقم 2 (تنفيذية): تطلب ملخّصًا على شكل نقاط، مع التركيز على النتائج والتأثير، كما يفضّل المسؤول التنفيذي المشغول.
- الشخصية رقم 3 (طالب في الصف الخامس): توجّه النموذج إلى استخدام لغة بسيطة، ما يختبر قدرته على تعديل مستوى تعقيد الناتج.
- الشخصية رقم 4 (المحلّل الفني): تتطلّب هذه الشخصية ملخّصًا قائمًا على الحقائق مع الحفاظ على الإحصاءات والكيانات الرئيسية، ما يختبر دقة النموذج. لاحظ أنّ العناصر النائبة في هذه النماذج الجديدة، مثل
{context}و{instruction}، تتطابق مع أسماء الأعمدة الجديدة فيeval_datasetالتي أنشأتها لهذه المهمة.
# Define prompt templates that target different user personas prompt_templates = [ # Persona 1: Standard, neutral summary "Article: {context}. Task: {instruction}. Summary:", # Persona 2: For a busy executive (bullet points) "Instruction: {instruction} into three key bullet points for a busy executive. Focus on the main outcome and impact. Article: {context}. Summary:", # Persona 3: For a 5th grader (simple language) "Instruction: {instruction} such that you're explaining it to a 10-year-old. Use simple words. Article: {context}. Summary:", # Persona 4: For a technical analyst (fact-focused) "Instruction: Provide a detailed, factual summary of the following text, ensuring all key statistics, names, and locations are preserved. Article: {context}. Summary:", ] eval_results = [] for i, prompt_template in enumerate(prompt_templates): eval_result = summarization_eval_task.evaluate( prompt_template=prompt_template, model=GenerativeModel( "gemini-2.0-flash", generation_config={ "temperature": 0.3, "max_output_tokens": 256, "top_k": 1, }, ), evaluation_service_qps=5, ) eval_results.append((f"Prompt Persona #{i+1}", eval_result))
تحليل النتائج وعرضها بشكل مرئي
إجراء التجارب هو الخطوة الأولى. تكمن القيمة الحقيقية في تحليل النتائج لاتخاذ قرار يستند إلى البيانات. في هذه المهمة، ستستخدم أدوات العرض المرئي في حزمة SDK لتفسير النتائج من تجربة شخصية الطلب.
- اعرض نتائج الملخّص لكل شخصية من الشخصيات الأربع التي اختبرتها من خلال تشغيل الرمز التالي في خلية جديدة. يمنحك ذلك نظرة عامة كمّية على الأداء.
for title, eval_result in eval_results: notebook_utils.display_eval_result(title=title, eval_result=eval_result) - في خلية جديدة، أضِف الرمز التالي وشغِّله للاطّلاع على الأساس المنطقي لمقياس
summarization_qualityلكل شخصية.for title, eval_result in eval_results: notebook_utils.display_explanations( eval_result, metrics=["summarization_quality"], num=2 ) - أنشئ رسمًا بيانيًا راداريًا لتصوّر المفاضلات بين مقاييس الجودة المختلفة لكل طلب. في خلية جديدة، أضِف الرمز التالي وشغِّله.
notebook_utils.display_radar_plot( eval_results, metrics=["instruction_following", "fluency", "coherence", "text_quality"], ) - لإجراء مقارنة مباشرة جنبًا إلى جنب، أنشئ مخططًا شريطيًا. في خلية جديدة، أضِف الرمز التالي وشغِّله.
notebook_utils.display_bar_plot( eval_results, metrics=["instruction_following", "fluency", "coherence", "text_quality"], )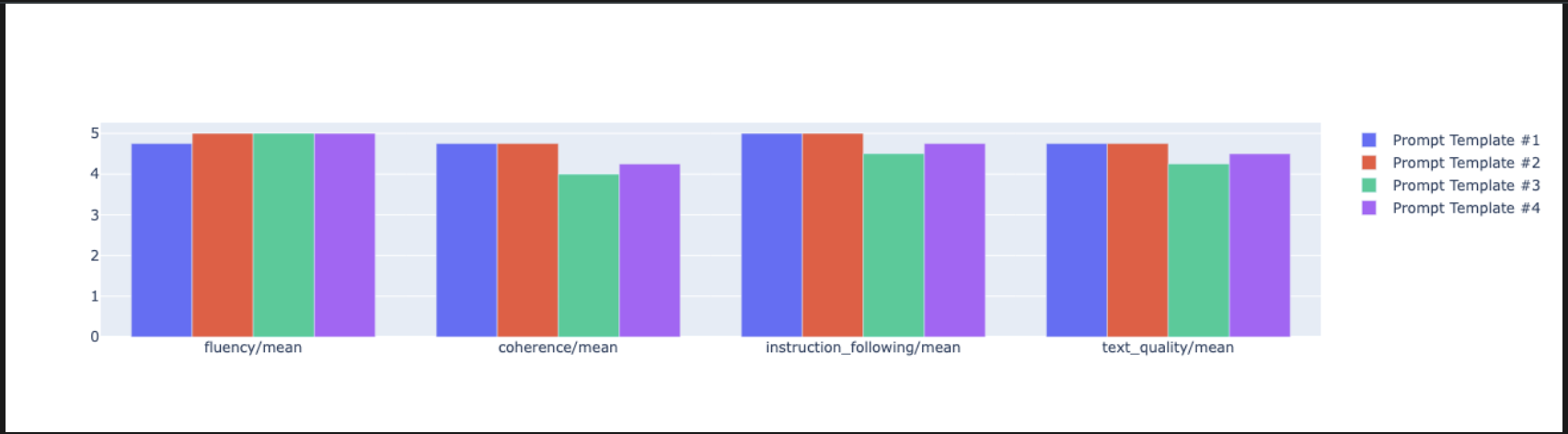
- يمكنك الآن الاطّلاع على ملخّص لجميع عمليات التشغيل التي تم تسجيلها في Vertex AI Experiment لهذه المهمة. ويكون ذلك مفيدًا لتتبُّع عملك بمرور الوقت. في خلية جديدة، أضِف الرمز التالي وشغِّله:
summarization_eval_task.display_runs()
10. تنظيف التجربة
للحفاظ على تنظيم مشروعك وتجنُّب تكبُّد رسوم غير ضرورية، من أفضل الممارسات تنظيف الموارد التي أنشأتها. خلال هذا المختبر، تم تسجيل كل عملية تقييم في إحدى تجارب Vertex AI. يحذف الرمز التالي التجربة الرئيسية، ما يؤدي أيضًا إلى إزالة جميع عمليات التشغيل المرتبطة بها والبيانات الأساسية الخاصة بها.
- نفِّذ هذا الرمز في خلية جديدة لحذف تجربة Vertex AI وعمليات التشغيل المرتبطة بها.
delete_experiment = True # Please set your LOCATION to the same one used during Vertex AI SDK initialization. LOCATION = "YOUR LOCATION" # @param {type:"string"} if delete_experiment: from google.cloud import aiplatform aiplatform.init(project=PROJECT_ID, location=LOCATION) experiment = aiplatform.Experiment(EXPERIMENT_NAME) experiment.delete()
11. من التدريب إلى الإنتاج
إنّ المهارات التي تعلّمتها في هذا التمرين العملي هي اللبنات الأساسية لإنشاء تطبيقات ذكاء اصطناعي موثوقة. ومع ذلك، يتطلّب الانتقال من دفتر ملاحظات يتم تشغيله يدويًا إلى نظام تقييم مناسب للإنتاج بنية أساسية إضافية ونهجًا أكثر منهجية. يقدّم هذا القسم الممارسات الأساسية والأُطر الاستراتيجية التي يجب مراعاتها أثناء التوسّع.
وضع استراتيجيات لتقييم الإنتاج
لتطبيق المهارات المكتسبة من هذا الدرس التطبيقي في بيئة إنتاج، من المفيد وضعها في إطار استراتيجيات قابلة للتكرار. توضّح أُطر العمل التالية الاعتبارات الأساسية للحالات الشائعة، مثل اختيار النموذج وتحسين الطلبات والمراقبة المستمرة.
بالنسبة إلى اختيار النموذج:
# Evaluation strategy for choosing models
evaluation_strategy = {
"dataset_size": "100+ examples for statistical significance",
"metrics": ["task-specific", "general quality", "efficiency"],
"comparison_type": "pairwise with statistical testing",
"baseline": "established_model_or_human_benchmark"
}
لتحسين الطلب
# Systematic prompt improvement workflow
prompt_optimization = {
"hypothesis": "Clear statement of what you're testing",
"variants": "3-5 different prompt strategies",
"evaluation": "Same metrics across all variants",
"analysis": "Statistical significance + qualitative review"
}
للتتبُّع المستمر
# Production evaluation pipeline
production_eval = {
"frequency": "Every model update + weekly monitoring",
"automation": "CI/CD integration with quality gates",
"metrics": "Speed + quality + cost tracking",
"alerting": "Performance degradation detection"
}
اعتبارات الفعالية من حيث التكلفة
يمكن أن يكون التقييم المستند إلى النموذج مكلفًا على نطاق واسع. تستخدم استراتيجية الإنتاج الفعّالة من حيث التكلفة طرقًا مختلفة لأغراض مختلفة. يلخّص هذا الجدول المفاضلة بين السرعة والتكلفة وحالة الاستخدام لأنواع التقييم المختلفة:
نوع التقييم | الوقت | التكلفة لكل عيّنة | متوافق مع: |
ROUGE/BLEU | الثواني | ~$0.001 | الفحص بكميات كبيرة |
Pointwise المستند إلى النموذج | من ثانية واحدة إلى ثانيتين تقريبًا | ~0.01 دولار أمريكي | تقييم الجودة |
المقارنة الثنائية | من ثانيتين إلى 3 ثوانٍ تقريبًا | ~$0.02 | اختيار النموذج |
التقييم البشري | دقائق | من 1 إلى 10 دولار أمريكي | التحقّق من صحة قاعدة الذهب |
التنفيذ الآلي باستخدام التكامل المستمر/التسليم المستمر والمراقبة
لا يمكن توسيع نطاق عمليات تشغيل دفاتر الملاحظات اليدوية. أتمِت عملية التقييم في مسارَي التعلّم "الدمج المستمر" (CI) أو "النشر المستمر" (CD).
- إنشاء بوابات الجودة: يمكنك دمج مهمة التقييم في مسار CI/CD (مثل Cloud Build). إجراء تقييمات تلقائية بشأن الطلبات أو النماذج الجديدة وحظر عمليات النشر إذا انخفضت نقاط الجودة الرئيسية إلى ما دون الحدود المحدّدة
- مراقبة المؤشّرات: يمكنك تصدير مقاييس الملخّص من عمليات التقييم إلى خدمة مثل Google Cloud Monitoring. يمكنك إنشاء لوحات بيانات لتتبُّع الجودة بمرور الوقت وإعداد تنبيهات تلقائية لإعلام فريقك بأي انخفاض كبير في الأداء.
12. الخاتمة
لقد أكملت الدرس التطبيقي. لقد تعلّمت المهارات الأساسية لتقييم نماذج الذكاء الاصطناعي التوليدي.
هذا المختبر هو جزء من مسار "الذكاء الاصطناعي الجاهز للإنتاج" التعليمي على Google Cloud.
- استكشاف المنهج الدراسي الكامل لسدّ الفجوة بين النموذج الأوّلي والإنتاج
- شارِك مستوى تقدّمك باستخدام الهاشتاغ
ProductionReadyAI.
ملخّص
في هذا التمرين المعملي، تعلّمت كيفية:
- تطبيق أفضل ممارسات التقييم باستخدام إطار عمل
EvalTask - استخدِم أنواعًا مختلفة من المقاييس، بدءًا من المقاييس المستندة إلى الحسابات إلى المقاييس المستندة إلى النماذج.
- حسِّن الطلبات من خلال اختبار إصدارات مختلفة.
- إنشاء سير عمل قابل للتكرار مع تتبُّع التجارب
مراجع لمواصلة التعلّم
- مستندات تقييم الذكاء الاصطناعي التوليدي في Vertex AI
- دفاتر ملاحظات حول تقنيات التقييم المتقدّمة
- مرجع حزمة تطوير البرامج (SDK) لتقييم الذكاء الاصطناعي التوليدي
- البحث في المقاييس المستندة إلى النماذج
- أفضل الممارسات المتعلّقة بهندسة الطلبات
ستشكّل أساليب التقييم المنهجية التي تعلّمتها في هذا الدرس التطبيقي أساسًا لإنشاء تطبيقات ذكاء اصطناعي موثوقة وعالية الجودة. تذكَّر أنّ التقييم الجيد هو الجسر بين الذكاء الاصطناعي التجريبي والنجاح في الإنتاج.