
1. Übersicht
In diesem Lab erfahren Sie, wie Sie Large Language Models mit dem Vertex AI Gen AI Evaluation Service bewerten. Mit dem SDK können Sie Evaluationsjobs ausführen, Ergebnisse vergleichen und datengestützte Entscheidungen zur Modellleistung und zum Prompt-Design treffen.
In diesem Lab wird ein gängiger Bewertungs-Workflow beschrieben, der mit einfachen, berechnungsbasierten Messwerten beginnt und zu differenzierteren, modellbasierten Bewertungen übergeht. Außerdem lernen Sie, wie Sie benutzerdefinierte Messwerte erstellen, die auf Ihre spezifischen Ziele zugeschnitten sind, und wie Sie Ihre Arbeit mit Vertex AI Experiments verfolgen.
Lerninhalte
Aufgaben in diesem Lab:
- Modell mit berechnungsbasierten und modellbasierten Messwerten bewerten
- Benutzerdefinierten Messwert erstellen, um die Analyse an Produktziele anzupassen
- Verschiedene Promptvorlagen nebeneinander vergleichen
- Testen Sie mehrere persona-basierte Prompts, um die effektivste Version zu finden.
- Bewertungsläufe mit Vertex AI Experiments verfolgen und visualisieren.
Verweise
- Codebeispiele: Dieses Lab basiert auf Beispielen aus dem Repository „Google Cloud Generative AI“.
- Basierend auf der Dokumentation zu Vertex AI Gen AI Evaluation
- Dataset: OpenOrca-Dataset für die Bewertung der Befolgung von Anweisungen
2. Projekt einrichten
Google-Konto
Wenn Sie noch kein privates Google-Konto haben, müssen Sie ein Google-Konto erstellen.
Verwenden Sie stattdessen ein privates Konto.
In der Google Cloud Console anmelden
Melden Sie sich mit einem privaten Google-Konto in der Google Cloud Console an.
Abrechnung aktivieren
Sie haben zwei Möglichkeiten, die Abrechnung zu aktivieren. Sie können entweder Ihr privates Abrechnungskonto verwenden oder Guthaben mit den folgenden Schritten einlösen.
Google Cloud-Guthaben einlösen (optional)
Für diesen Workshop benötigen Sie ein Rechnungskonto mit Guthaben. Verwenden Sie die Guthabenpunkte aus dem Banner oben in diesem Codelab, um loszulegen. Wenn Sie bereits mit einem Rechnungskonto verbunden sind, können Sie diesen Schritt überspringen.
Privates Rechnungskonto einrichten
Wenn Sie die Abrechnung mit Google Cloud-Guthaben eingerichtet haben, können Sie diesen Schritt überspringen.
Aktivieren Sie die Abrechnung in der Cloud Console, um ein privates Rechnungskonto einzurichten.
Hinweise:
- Die Kosten für Cloud-Ressourcen für dieses Lab sollten weniger als 1 $betragen.
- Sie können die Schritte am Ende dieses Labs ausführen, um Ressourcen zu löschen und so weitere Kosten zu vermeiden.
- Neue Nutzer haben Anspruch auf die kostenlose Testversion mit einem Guthaben von 300$.
Projekt erstellen (optional)
Wenn Sie kein aktuelles Projekt haben, das Sie für dieses Lab verwenden möchten, erstellen Sie hier ein neues Projekt.
3. Vertex AI Workbench-Umgebung einrichten
Rufen Sie zuerst Ihre vorkonfigurierte Notebook-Umgebung auf und installieren Sie die erforderlichen Abhängigkeiten.
Auf Vertex AI Workbench zugreifen
- Klicken Sie in der Google Cloud Console auf das Navigationsmenü ☰ > Vertex AI > Dashboard, um zu Vertex AI zu gelangen.
- Klicken Sie auf Alle empfohlenen APIs aktivieren. Hinweis: Warten Sie, bis dieser Schritt abgeschlossen ist.
- Klicken Sie links auf Workbench, um eine neue Workbench-Instanz zu erstellen.
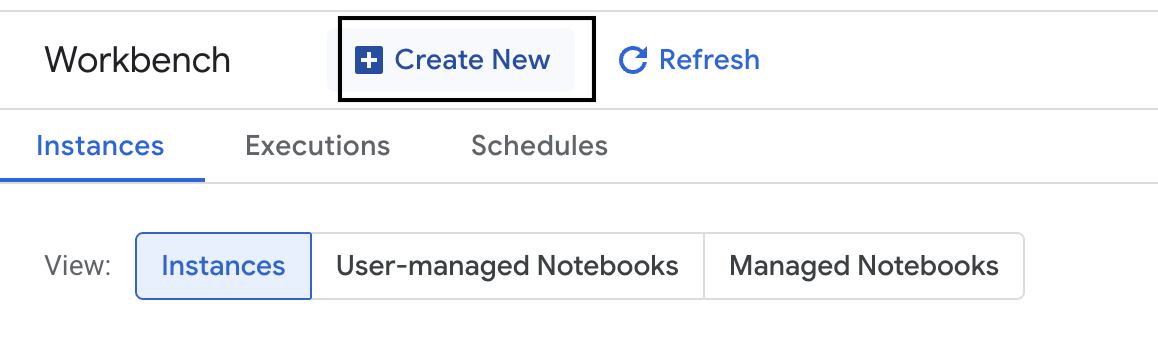
- Geben Sie der Workbench-Instanz den Namen evaluation-workbench und klicken Sie auf Erstellen.
- Warten Sie, bis die Workbench eingerichtet ist. Dies kann einige Minuten dauern.

- Wenn die Workbench bereitgestellt wurde, klicken Sie auf JupyterLab öffnen.
- Erstellen Sie in der Workbench ein neues Python3-Notebook.
Weitere Informationen zu den Funktionen und Möglichkeiten dieser Umgebung finden Sie in der offiziellen Dokumentation zu Vertex AI Workbench.
Pakete installieren und Umgebung konfigurieren
- Fügen Sie in der ersten Zelle Ihres Notebooks die folgenden Importanweisungen ein und führen Sie sie aus (UMSCHALT+EINGABETASTE), um das Vertex AI SDK (mit den Bewertungskomponenten) und andere erforderliche Pakete zu installieren.
%pip install -U -q google-cloud-aiplatform[evaluation] %pip install -U -q datasets anthropic[vertex] openai - Um die neu installierten Pakete zu verwenden, empfiehlt es sich, den Kernel neu zu starten. Führen Sie dazu das folgende Code-Snippet aus.
# Automatically restart kernel after installation so that your environment can access the new packages. import IPython app = IPython.Application.instance() app.kernel.do_shutdown(True) - Ersetzen Sie die folgenden Werte durch Ihre Projekt-ID und Ihren Standort und führen Sie die folgende Zelle aus. Der Standardspeicherort ist
europe-west1. Sie sollten jedoch denselben Speicherort verwenden, an dem sich Ihre Vertex AI Workbench-Instanz befindet.# Configure your project settings PROJECT_ID = "YOUR PROJECT ID" LOCATION = "europe-west1" - Importieren Sie alle erforderlichen Python-Bibliotheken für dieses Lab, indem Sie den folgenden Code in einer neuen Zelle ausführen.
from anthropic import AnthropicVertex from google.auth import default, transport import openai import pandas as pd from vertexai.evaluation import ( EvalTask, MetricPromptTemplateExamples, PairwiseMetric, PointwiseMetric, PointwiseMetricPromptTemplate, ) from vertexai.generative_models import GenerativeModel from vertexai.preview.evaluation import notebook_utils
4. Bewertungs-Dataset einrichten
In dieser Anleitung verwenden wir 10 Beispiele aus dem OpenOrca-Dataset. So erhalten wir genügend Daten, um aussagekräftige Unterschiede zwischen den Modellen zu erkennen, und die Auswertungszeit bleibt überschaubar.
💡 Profi-Tipp:In der Produktion sind 100 bis 500 Beispiele für statistisch signifikante Ergebnisse erforderlich. Für das Lernen und schnelle Prototyping reichen jedoch 10 Beispiele aus.
Dataset vorbereiten
- Führen Sie in einer neuen Zelle die folgende Zelle aus, um die Daten zu laden, sie in einen Pandas-DataFrame zu konvertieren und die Spalte
responsezur besseren Übersicht in unseren Auswertungsaufgaben inreferenceumzubenennen. Außerdem wird eine Zufallsstichprobe von zehn Beispielen erstellt.from datasets import load_dataset ds = ( load_dataset( "Open-Orca/OpenOrca", data_files="1M-GPT4-Augmented.parquet", split="train[:100]", ) .to_pandas() .drop(columns=["id"]) .rename(columns={"response": "reference"}) ) dataset = ds.sample(n=10) - Fügen Sie nach Abschluss der Ausführung der vorherigen Zelle in der nächsten Zelle den folgenden Code ein und führen Sie ihn aus, um die ersten Zeilen Ihres Auswertungsdatasets anzuzeigen.
dataset.head()
5. Referenz mit berechnungsbasierten Messwerten festlegen
In dieser Aufgabe legen Sie einen Baseline-Wert mit einem berechnungsbasierten Messwert fest. Dieser Ansatz ist schnell und bietet einen objektiven Benchmark, an dem sich zukünftige Verbesserungen messen lassen.
Wir verwenden ROUGE (Recall-Oriented Understudy for Gisting Evaluation), einen Standardmesswert für Zusammenfassungsaufgaben. Dabei wird die Sequenz von Wörtern (n-Gramme) in der vom Modell generierten Antwort mit den Wörtern im reference-Text der Grundwahrheit verglichen.
Weitere Informationen zu berechnungsbasierten Messwerten
Baseline-Bewertung ausführen
- Fügen Sie in einer neuen Zelle die folgende Zelle hinzu und führen Sie sie aus, um das zu testende Modell
gemini-2.0-flashzu definieren. Diegeneration_configenthält Parameter wietemperatureundmax_output_tokens, die die Ausgabe des Modells beeinflussen.# Model to be evaluated model = GenerativeModel( "gemini-2.0-flash", generation_config={"temperature": 0.6, "max_output_tokens": 256, "top_k": 1}, )GenerativeModelist die primäre Schnittstelle für die Interaktion mit Large Language Models im Vertex AI SDK. - Fügen Sie in der nächsten Zelle den folgenden Code hinzu und führen Sie ihn aus, um die
EvalTaskzu erstellen und auszuführen. Dieses Objekt aus dem Vertex AI Evaluation SDK orchestriert die Bewertung. Sie konfigurieren sie mit dem Datensatz und den zu berechnenden Messwerten, in diesem Fallrouge_l_sum.# Define an EvalTask with ROUGE-L-SUM metric rouge_eval_task = EvalTask( dataset=dataset, metrics=["rouge_l_sum"], ) rouge_result = rouge_eval_task.evaluate( model=model, prompt_template="# System_prompt\n{system_prompt} # Question\n{question}", ) - Führen Sie den folgenden Code in der nächsten Zelle aus, um die Ergebnisse anzuzeigen.
notebook_utils.display_eval_result(rouge_result)display_eval_result()-Tool zeigt die durchschnittliche Punktzahl und die Ergebnisse für jede Zeile an.
6. Optional: Mit modellbasierten punktweisen Messwerten bewerten
Hinweis: Dieser Abschnitt kann das Limit der bereitgestellten kostenlosen Guthaben überschreiten.
ROUGE ist zwar nützlich, misst aber nur die lexikalische Überschneidung. Das bedeutet, dass nur übereinstimmende Wörter gezählt werden und Kontext, Synonyme oder Paraphrasierungen nicht berücksichtigt werden. Daher ist es nicht die beste Methode, um zu ermitteln, ob eine Antwort flüssig oder logisch ist. Um die Leistung des Modells besser zu verstehen, verwenden Sie modellbasierte punktweise Messwerte.
Bei dieser Methode bewertet ein anderes LLM (das „Judge Model“) jede Antwort einzeln anhand einer vordefinierten Reihe von Kriterien wie Flüssigkeit oder Kohärenz.
Weitere Informationen zu modellbasierten Messwerten
Punktweise Bewertung ausführen
- Führen Sie den folgenden Code in einer neuen Zelle aus, um ein interaktives Drop-down-Menü zu erstellen. Wählen Sie für diesen Lauf Kohärenz aus der Liste aus.
#Select a pointwise metric to use import ipywidgets as widgets pointwise_single_turn_metrics = [ metric for metric in MetricPromptTemplateExamples.list_example_metric_names() if not metric.startswith("pairwise") and not metric.startswith("multi_turn") ] dropdown = widgets.Dropdown( options=pointwise_single_turn_metrics, description="Select a metric:", font_weight="bold", style={"description_width": "initial"}, ) def dropdown_eventhandler(change): global POINTWISE_METRIC if change["type"] == "change" and change["name"] == "value": POINTWISE_METRIC = change.new print("Selected:", change.new) POINTWISE_METRIC = dropdown.value dropdown.observe(dropdown_eventhandler, names="value") display(dropdown) - Führen Sie
EvalTasknoch einmal in einer neuen Zelle aus, diesmal mit dem ausgewählten modellbasierten Messwert. Der Vertex AI Evaluation Service erstellt einen Prompt für das Judge-Modell, der den ursprünglichen Prompt, die Referenzantwort, die Antwort des Kandidatenmodells und Anleitungen für den ausgewählten Messwert enthält. Das Bewertungsmodell gibt eine numerische Punktzahl und eine Erklärung für die Bewertung zurück. Hinweis: Die Ausführung dieses Schritts dauert einige Minuten.pointwise_result = EvalTask( dataset=dataset, metrics=[POINTWISE_METRIC], ).evaluate( model=model, prompt_template="# System_prompt\n{system_prompt} # Question\n{question}", )
Ergebnisse anzeigen
Nach Abschluss der Auswertung besteht der nächste Schritt darin, die Ausgabe zu analysieren.
- Führen Sie den folgenden Code in einer neuen Zelle aus, um die Zusammenfassungsmesswerte aufzurufen. Sie zeigen den Durchschnittswert für den ausgewählten Messwert.
notebook_utils.display_eval_result(pointwise_result) - Führen Sie den folgenden Code in der nächsten Zelle aus, um die Aufschlüsselung nach Zeilen zu sehen, die auch die schriftliche Begründung des Judge-Modells für seine Bewertung enthält. Dieses qualitative Feedback hilft Ihnen zu verstehen, warum eine Antwort auf eine bestimmte Weise bewertet wurde.
notebook_utils.display_explanations(pointwise_result, num=1, metrics=[POINTWISE_METRIC])
7. Benutzerdefinierten Messwert erstellen, um detailliertere Statistiken zu erhalten
Vorgefertigte Messwerte wie die Flüssigkeit sind zwar nützlich, aber für ein bestimmtes Produkt müssen Sie die Leistung oft anhand Ihrer eigenen Ziele messen. Mit benutzerdefinierten punktweisen Messwerten können Sie Ihre eigenen Bewertungskriterien und ‑schemata definieren.
In dieser Aufgabe erstellen Sie einen neuen Messwert mit dem Namen summarization_helpfulness.
Benutzerdefinierten Messwert definieren und ausführen
- Führen Sie den folgenden Code in einer neuen Zelle aus, um den benutzerdefinierten Messwert zu definieren.
PointwiseMetricPromptTemplateenthält die Bausteine für den Messwert:- Kriterien: Hier werden dem Judge-Modell die spezifischen Dimensionen mitgeteilt, die bewertet werden sollen: „Wichtige Informationen“, „Prägnanz“ und „Keine Verzerrung“.
- rating_rubric: Stellt eine 5-Punkte-Bewertungsskala bereit, die definiert, was die einzelnen Punktzahlen bedeuten.
- input_variables: Übergibt zusätzliche Spalten aus dem Datensatz an das Judge-Modell, damit es den Kontext hat, der für die Bewertung erforderlich ist.
# This new custom metric evaluates the actual quality and usefulness of the summary. summarization_helpfulness_metric = PointwiseMetric( metric="summarization_helpfulness", metric_prompt_template=PointwiseMetricPromptTemplate( criteria={ "Key Information": "Does the summary capture the most critical pieces of information from the original text? It should not miss the main topic or key takeaways.", "Conciseness": "Is the summary brief and to the point? It should avoid unnecessary words or repetitive information.", "No Distortion": "Does the summary introduce information or opinions that were NOT present in the original text? It must accurately reflect the source material without adding hallucinations." }, rating_rubric={ "5": "Excellent: Captures all key information, is highly concise, and has zero distortion.", "4": "Good: Captures most key information with minor omissions, is concise, and has no distortion.", "3": "Satisfactory: Captures the main idea but misses some key details OR is not very concise.", "2": "Unsatisfactory: Misses the main idea of the original text OR contains minor distortions/hallucinations.", "1": "Poor: Is completely irrelevant, fails to summarize the text, OR contains significant distortions.", }, input_variables=["prompt", "reference"], ), ) - Führen Sie den folgenden Code in der nächsten Zelle aus, um
EvalTaskmit Ihrem neuen benutzerdefinierten Messwert auszuführen.# You would then update the EvalTask to use this new metric pointwise_result = EvalTask( dataset=dataset, metrics=[summarization_helpfulness_metric], ).evaluate( model=model, prompt_template="# System_prompt\n{system_prompt} # Question\n{question}", ) - Führen Sie den folgenden Code in einer neuen Zelle aus, um die Ergebnisse anzuzeigen.
notebook_utils.display_eval_result(pointwise_result)
8. Modelle mit paarweiser Bewertung vergleichen
Wenn Sie entscheiden müssen, welches von zwei Modellen bei einer bestimmten Aufgabe besser abschneidet, können Sie die paarweise modellbasierte Bewertung verwenden. Diese Methode ist eine Form des A/B-Tests, bei dem ein Judge-Modell einen Gewinner ermittelt. So ist ein direkter Vergleich für die datengestützte Modellauswahl möglich.
Die Modelle:
- Kandidatenmodell: Die Modellvariable (die zuvor als
gemini-2.0-flashdefiniert wurde) wird an die Methode.evaluate()übergeben. Dies ist das Hauptmodell, das Sie testen. - Basismodell: Ein zweites Modell,
gemini-2.0-flash-lite, wird in der PairwiseMetric-Klasse angegeben. Dies ist das Modell, mit dem Sie das andere Modell vergleichen.
Paarweise Bewertung ausführen
- Fügen Sie in einer neuen Zelle den folgenden Code hinzu und führen Sie ihn aus, um ein interaktives Drop-down-Menü zu erstellen. So können Sie auswählen, welchen paarweisen Messwert Sie für den Vergleich verwenden möchten. Wählen Sie für diesen Lauf pairwise_summarization_quality aus.
from IPython.display import display import ipywidgets as widgets pairwise_single_turn_metrics = [ metric for metric in MetricPromptTemplateExamples.list_example_metric_names() if metric.startswith("pairwise") and "multi_turn" not in metric ] dropdown = widgets.Dropdown( options=pairwise_single_turn_metrics, description="Select a metric:", font_weight="bold", style={"description_width": "initial"}, ) def dropdown_eventhandler(change): global POINTWISE_METRIC if change["type"] == "change" and change["name"] == "value": POINTWISE_METRIC = change.new print("Selected:", change.new) def dropdown_eventhandler(change): global PAIRWISE_METRIC_NAME if change["type"] == "change" and change["name"] == "value": PAIRWISE_METRIC_NAME = change.new print("Selected:", change.new) PAIRWISE_METRIC_NAME = dropdown.value dropdown.observe(dropdown_eventhandler, names="value") display(dropdown) - Fügen Sie in der nächsten Zelle den folgenden Code hinzu und führen Sie ihn aus, um die
EvalTaskzu konfigurieren und auszuführen. Beachten Sie, wie die KlassePairwiseMetricverwendet wird, um das Basismodell (gemini-2.0-flash-lite) zu definieren, während das Kandidatenmodell (gemini-2.0-flash) an die Methode.evaluate()übergeben wird.pairwise_result = EvalTask( dataset=dataset, metrics=[ PairwiseMetric( metric=PAIRWISE_METRIC_NAME, metric_prompt_template=MetricPromptTemplateExamples.get_prompt_template( PAIRWISE_METRIC_NAME ), # Define a baseline model to compare against baseline_model=GenerativeModel("gemini-2.0-flash-lite"), ) ], ).evaluate( # Specify a candidate model for pairwise comparison model=model, prompt_template="# System_prompt\n{system_prompt} # Question\n{question}", ) - Fügen Sie in einer neuen Zelle den folgenden Code hinzu und führen Sie ihn aus, um die Ergebnisse anzuzeigen. In der Zusammenfassungstabelle wird die „Gewinnrate“ für jedes Modell angezeigt. So sehen Sie, welches Modell vom Judge-Modell häufiger bevorzugt wurde.
notebook_utils.display_eval_result(pairwise_result)
9. Optional: Persona-basierte Prompts bewerten
Hinweis: Dieser Abschnitt kann das Limit der bereitgestellten kostenlosen Guthaben überschreiten.
In dieser Aufgabe testen Sie mehrere Prompt-Vorlagen, mit denen das Modell angewiesen wird, verschiedene Personas anzunehmen. Mit diesem Prozess, der oft als Prompt Engineering oder Prompt-Design bezeichnet wird, können Sie systematisch den effektivsten Prompt für einen bestimmten Anwendungsfall finden.
Zusammenfassungs-Dataset vorbereiten
Für diese Analyse muss das Dataset die folgenden Felder enthalten:
instruction: Die Kernaufgabe, die wir dem Modell geben. In diesem Fall ist es einfach „Fasse den folgenden Artikel zusammen:“context: Der Quelltext, mit dem das Modell arbeiten muss. Hier haben wir vier verschiedene Nachrichtenausschnitte bereitgestellt.reference: Die Zusammenfassung mit dem „Goldstandard“. Die vom Modell generierte Ausgabe wird mit diesem Text verglichen, um Werte für Messwerte wie ROUGE und die Qualität der Zusammenfassung zu berechnen.
- Fügen Sie in einer neuen Zelle den folgenden Code hinzu und führen Sie ihn aus, um ein
pandas.DataFramefür die Zusammenfassungsaufgabe zu erstellen.instruction = "Summarize the following article: \n" context = [ "Typhoon Phanfone has killed at least one person, a US airman on Okinawa who was washed away by high waves. Thousands of households have lost power and Japan's two largest airlines have suspended many flights. The storm also forced the suspension of the search for people missing after last week's volcanic eruption. The storm-tracking website Tropical Storm Risk forecasts that Phanfone will rapidly lose power over the next few hours as it goes further into the Pacific Ocean. Typhoon Phanfone was downgraded from an earlier status of a super typhoon, but the Japan Meteorological Agency had warned it was still a dangerous storm. Japan averages 11 typhoons a year, according to its weather agency. The typhoon made landfall on Monday morning near the central city of Hamamatsu, with winds of up to 180 km/h (112 mph). The airman was one of three US military personnel swept away by high waves whipped up by the typhoon off southern Okinawa island, where the US has a large military base. The remaining two are still missing. A police spokesman said they had been taking photographs of the sea. A university student who was surfing off the seas of Kanagawa Prefecture, south of Tokyo, was also missing, national broadcast NHK reports. It said at least 10 people had been injured and 9,500 houses were without power. The storm was expected to deposit about 100mm of rain on Tokyo over 24 hours, according to the Transport Ministry website. Many schools were closed on Monday and two car companies in Japan halted production at some plants ahead of the storm. More than 174 domestic flights were affected nationwide, NHK state broadcaster said on Sunday. On Sunday, heavy rain delayed the Japanese Formula One Grand Prix in Suzaka. French driver Jules Bianchi lost control in the wet conditions and crashed, sustaining a severe head injury.", "The blaze started at the detached building in Drivers End in Codicote, near Welwyn, during the morning. There was another fire at the building 20 years ago, after which fire-proof foil was placed under the thatch, which is protecting the main building. More than 15 fire engines and support vehicles were called to tackle the blaze. Roads in the area were closed and traffic diverted.", 'The 18-year-old fell at the New Charter Academy on Broadoak Road in Ashton-under-Lyne at about 09:10 BST, Greater Manchester Police (GMP) said. GMP said he had gone to Manchester Royal Infirmary and his condition was "serious". Principal Jenny Langley said the school would remain "fully open" while police investigated. "Our thoughts are with the family and we\'re doing everything we can to support them along with staff and pupils," she said.', 'But Belgian-born Dutchman Max Verstappen was unable to drive a car legally on his own in either country. That all changed on Wednesday when the youngster turned 18 and passed his driving test at the first attempt. Despite having competed in 14 grands prix since his debut in Australia in March, Verstappen admitted to feeling the pressure during his test. "It\'s a relief," said the Toro Rosso driver, who finished ninth in Japan on Sunday and had only started driving lessons a week ago. "I was a bit nervous to make mistakes, but the exam went well." A bonus of turning 18 is that Verstappen will now be able to drink the champagne if he ever makes it onto the podium.', ] reference = [ "A powerful typhoon has brought many parts of Japan to a standstill and briefly battered Tokyo before heading out to sea.", "A major fire has been burning in the thatched roof of a large property in Hertfordshire.", "A student has been taken to hospital after falling from a balcony at a Greater Manchester school.", "He is Formula 1's youngest ever driver and in charge of a car that can reach over 200mph.", ] response = [ "Typhoon Phanfone, while downgraded from super typhoon status, caused significant disruption and tragedy in Japan. One US airman died after being swept away by high waves, with two more missing. The storm caused power outages for thousands, flight cancellations, and the suspension of rescue efforts for missing volcano victims. Heavy rain and strong winds led to school and factory closures, transportation disruptions, and at least 10 injuries. The typhoon is expected to weaken as it moves over the Pacific Ocean.", "A large fire broke out in a detached thatched building in Codicote, near Welwyn. This is the second fire at the building in 20 years. Thankfully, fire-proof foil installed after the previous fire is protecting the main building. Over 15 fire engines and support vehicles responded, closing roads and diverting traffic in the area.", "An 18-year-old student at New Charter Academy in Ashton-under-Lyne suffered a serious fall and was hospitalized. The incident is under investigation by Greater Manchester Police, but the school remains open. The principal expressed support for the student's family and the school community.", "Max Verstappen, a Formula One driver, was finally able to get his driver's license at age 18. Despite already competing in 14 Grand Prix races, he was not of legal driving age in his native countries. He admitted to being nervous but passed the test on his first attempt. As an added bonus of turning 18, Verstappen can now enjoy champagne on the podium if he places.", ] eval_dataset = pd.DataFrame( { "instruction": instruction, "context": context, "reference": reference, } )
Prompt-Bewertungsaufgabe ausführen
Nachdem Sie das Dataset für die Zusammenfassung vorbereitet haben, können Sie das Kernexperiment dieser Aufgabe durchführen: Sie vergleichen mehrere Prompt-Vorlagen, um herauszufinden, welche die hochwertigste Ausgabe des Modells erzeugt.
- Erstellen Sie in der nächsten Zelle einen einzelnen
EvalTask, der für jedes Prompt-Experiment wiederverwendet wird. Wenn Sie den Parameterexperimentfestlegen, werden alle Testläufe dieser Aufgabe automatisch protokolliert und in Vertex AI Experiments gruppiert.EXPERIMENT_NAME = "eval-sdk-prompt-engineering" # @param {type:"string"} summarization_eval_task = EvalTask( dataset=eval_dataset, metrics=[ "rouge_l_sum", "bleu", "fluency", "coherence", "safety", "groundedness", "summarization_quality", "verbosity", "instruction_following", "text_quality", ], experiment=EXPERIMENT_NAME, )rouge_l_sumundbleubis hin zu einer Vielzahl von modellbasierten Messwerten (fluency,coherence,summarization_quality,instruction_followingusw.). So erhalten wir einen ganzheitlichen Überblick darüber, wie sich die einzelnen Prompts auf die Ausgabequalität des Modells auswirken. - Fügen Sie in einer neuen Zelle den folgenden Code hinzu und führen Sie ihn aus, um vier persona-basierte Prompt-Strategien zu definieren und zu bewerten. Die
for-Schleife durchläuft jede Vorlage und führt eine Auswertung durch.Jede Vorlage ist darauf ausgelegt, durch die Angabe einer bestimmten Rolle oder eines bestimmten Ziels eine Zusammenfassung in einem anderen Stil zu erhalten:- Persona 1 (Standard): Eine neutrale, direkte Zusammenfassungsanfrage.
- Persona 2 (Führungskraft): Bittet um eine Zusammenfassung in Form von Aufzählungspunkten, die sich auf Ergebnisse und Auswirkungen konzentriert, da Führungskräfte in der Regel wenig Zeit haben.
- Persona 3 (Fünftklässler): Das Modell wird angewiesen, eine einfache Sprache zu verwenden, um seine Fähigkeit zu testen, die Komplexität seiner Ausgabe anzupassen.
- Persona 4 (Technischer Analyst): Erfordert eine sehr sachliche Zusammenfassung, in der wichtige Statistiken und Einheiten beibehalten werden. So wird die Präzision des Modells getestet. Die Platzhalter in diesen neuen Vorlagen, z. B.
{context}und{instruction}, entsprechen den neuen Spaltennamen in dereval_dataset, die Sie für diese Aufgabe erstellt haben.
# Define prompt templates that target different user personas prompt_templates = [ # Persona 1: Standard, neutral summary "Article: {context}. Task: {instruction}. Summary:", # Persona 2: For a busy executive (bullet points) "Instruction: {instruction} into three key bullet points for a busy executive. Focus on the main outcome and impact. Article: {context}. Summary:", # Persona 3: For a 5th grader (simple language) "Instruction: {instruction} such that you're explaining it to a 10-year-old. Use simple words. Article: {context}. Summary:", # Persona 4: For a technical analyst (fact-focused) "Instruction: Provide a detailed, factual summary of the following text, ensuring all key statistics, names, and locations are preserved. Article: {context}. Summary:", ] eval_results = [] for i, prompt_template in enumerate(prompt_templates): eval_result = summarization_eval_task.evaluate( prompt_template=prompt_template, model=GenerativeModel( "gemini-2.0-flash", generation_config={ "temperature": 0.3, "max_output_tokens": 256, "top_k": 1, }, ), evaluation_service_qps=5, ) eval_results.append((f"Prompt Persona #{i+1}", eval_result))
Ergebnisse analysieren und visualisieren
Das Durchführen von Tests ist der erste Schritt. Der eigentliche Wert liegt in der Analyse der Ergebnisse, um eine datengestützte Entscheidung zu treffen. In dieser Aufgabe verwenden Sie die Visualisierungstools des SDK, um die Ergebnisse des Persona-Tests für Prompts zu interpretieren.
- Lassen Sie sich die Zusammenfassung der Ergebnisse für jede der vier getesteten Prompt-Personas anzeigen, indem Sie den folgenden Code in einer neuen Zelle ausführen. So erhalten Sie einen quantitativen Überblick über die Leistung.
for title, eval_result in eval_results: notebook_utils.display_eval_result(title=title, eval_result=eval_result) - Fügen Sie in einer neuen Zelle den folgenden Code hinzu und führen Sie ihn aus, um die Begründung für den
summarization_quality-Messwert für jede Persona zu sehen.for title, eval_result in eval_results: notebook_utils.display_explanations( eval_result, metrics=["summarization_quality"], num=2 ) - Erstellen Sie ein Radardiagramm, um die Kompromisse zwischen verschiedenen Qualitätsmesswerten für jeden Prompt zu visualisieren. Fügen Sie in einer neuen Zelle den folgenden Code hinzu und führen Sie ihn aus.
notebook_utils.display_radar_plot( eval_results, metrics=["instruction_following", "fluency", "coherence", "text_quality"], ) - Für einen direkteren, nebeneinanderliegenden Vergleich können Sie ein Balkendiagramm erstellen. Fügen Sie in einer neuen Zelle den folgenden Code hinzu und führen Sie ihn aus.
notebook_utils.display_bar_plot( eval_results, metrics=["instruction_following", "fluency", "coherence", "text_quality"], )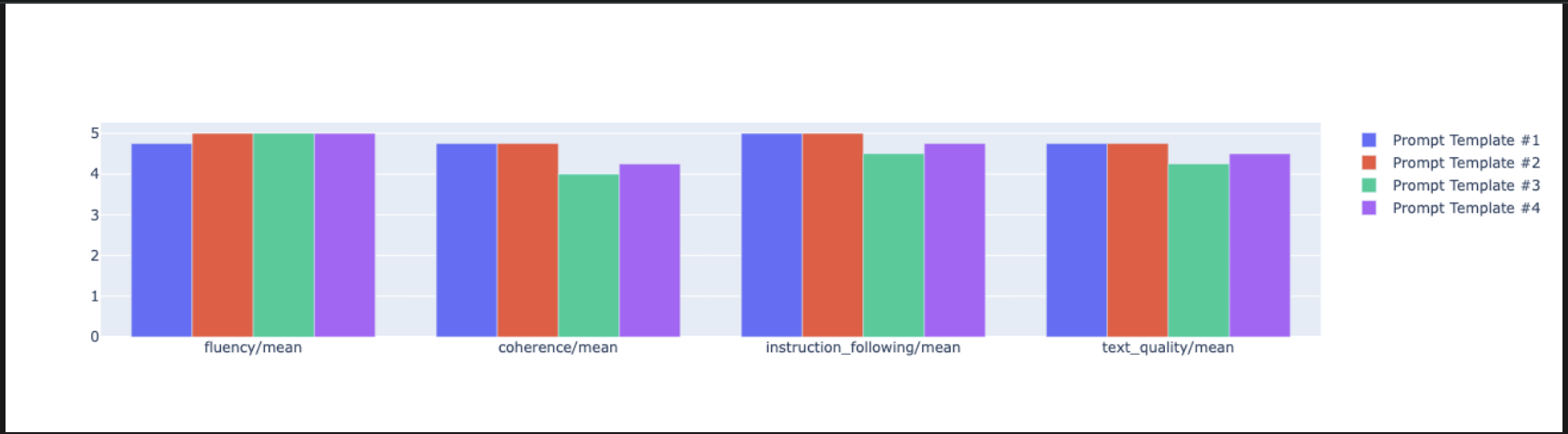
- Sie können jetzt eine Zusammenfassung aller Ausführungen aufrufen, die für diese Aufgabe in Ihrem Vertex AI-Test protokolliert wurden. Das ist nützlich, um Ihre Arbeit im Zeitverlauf zu verfolgen. Fügen Sie in einer neuen Zelle den folgenden Code hinzu und führen Sie ihn aus:
summarization_eval_task.display_runs()
10. Test bereinigen
Damit Ihr Projekt übersichtlich bleibt und Sie unnötige Kosten vermeiden, sollten Sie die von Ihnen erstellten Ressourcen bereinigen. In diesem Lab wurde jede Ausführung der Bewertung in einem Vertex AI-Test protokolliert. Mit dem folgenden Code wird dieser übergeordnete Test gelöscht. Dadurch werden auch alle zugehörigen Ausführungen und die zugrunde liegenden Daten entfernt.
- Führen Sie diesen Code in einer neuen Zelle aus, um den Vertex AI-Test und die zugehörigen Ausführungen zu löschen.
delete_experiment = True # Please set your LOCATION to the same one used during Vertex AI SDK initialization. LOCATION = "YOUR LOCATION" # @param {type:"string"} if delete_experiment: from google.cloud import aiplatform aiplatform.init(project=PROJECT_ID, location=LOCATION) experiment = aiplatform.Experiment(EXPERIMENT_NAME) experiment.delete()
11. Von der Übung zur Produktion
Die in diesem Lab erworbenen Kenntnisse sind die Grundlage für die Entwicklung zuverlässiger KI-Anwendungen. Der Übergang von einem manuell ausgeführten Notebook zu einem Evaluationssystem für die Produktion erfordert jedoch zusätzliche Infrastruktur und einen systematischeren Ansatz. In diesem Abschnitt werden wichtige Praktiken und strategische Frameworks beschrieben, die Sie bei der Skalierung berücksichtigen sollten.
Strategien zur Produktionsbewertung entwickeln
Wenn Sie die in diesem Lab erworbenen Kenntnisse in einer Produktionsumgebung anwenden möchten, ist es hilfreich, sie in wiederholbare Strategien zu formalisieren. In den folgenden Frameworks werden wichtige Überlegungen für gängige Szenarien wie die Modellauswahl, die Prompt-Optimierung und das kontinuierliche Monitoring beschrieben.
Für die Modellauswahl:
# Evaluation strategy for choosing models
evaluation_strategy = {
"dataset_size": "100+ examples for statistical significance",
"metrics": ["task-specific", "general quality", "efficiency"],
"comparison_type": "pairwise with statistical testing",
"baseline": "established_model_or_human_benchmark"
}
Zur Prompt-Optimierung
# Systematic prompt improvement workflow
prompt_optimization = {
"hypothesis": "Clear statement of what you're testing",
"variants": "3-5 different prompt strategies",
"evaluation": "Same metrics across all variants",
"analysis": "Statistical significance + qualitative review"
}
Für kontinuierliches Monitoring
# Production evaluation pipeline
production_eval = {
"frequency": "Every model update + weekly monitoring",
"automation": "CI/CD integration with quality gates",
"metrics": "Speed + quality + cost tracking",
"alerting": "Performance degradation detection"
}
Überlegungen zur Kosteneffektivität
Die modellbasierte Bewertung kann in großem Maßstab teuer sein. Bei einer kosteneffizienten Produktionsstrategie werden für unterschiedliche Zwecke unterschiedliche Methoden verwendet. In dieser Tabelle sind die Kompromisse zwischen Geschwindigkeit, Kosten und Anwendungsfall für die verschiedenen Arten der Auswertung zusammengefasst:
Bewertungstyp | Zeit | Kosten pro Probe | Optimal für |
ROUGE/BLEU | Sekunden | ≈0,001 $ | Screening mit hohem Volumen |
Modellbasiert – punktweise | ~1–2 Sekunden | ≈0,01 $ | Qualitätsbewertung |
Paarweiser Vergleich | ~2–3 Sekunden | ~0,02 $ | Modellauswahl |
Manuelle Bewertung | Minuten | 1–10 $ | Goldstandard-Validierung |
Automatisieren mit CI/CD und Monitoring
Manuelle Notebook-Ausführungen sind nicht skalierbar. Automatisieren Sie die Auswertung in einer CI/CD-Pipeline (Continuous Integration/Continuous Deployment).
- Qualitätssicherungen erstellen: Binden Sie Ihre Bewertungsaufgabe in eine CI/CD-Pipeline ein (z.B. Cloud Build). Bewertungen für neue Prompts oder Modelle werden automatisch ausgeführt und Bereitstellungen werden blockiert, wenn wichtige Qualitätspunkte unter die von Ihnen festgelegten Grenzwerte fallen.
- Trends beobachten: Exportieren Sie Zusammenfassungsmesswerte aus Ihren Auswertungen in einen Dienst wie Google Cloud Monitoring. Erstellen Sie Dashboards, um die Qualität im Zeitverlauf zu verfolgen, und richten Sie automatische Benachrichtigungen ein, um Ihr Team über erhebliche Leistungseinbußen zu informieren.
12. Fazit
Sie haben das Lab abgeschlossen. Sie haben die grundlegenden Fähigkeiten zur Bewertung von Modellen erworben, die auf generativer KI basieren.
Dieses Lab ist Teil des Lernpfads „Produktionsreife KI mit Google Cloud“.
- Gesamten Lehrplan ansehen
- Teile deinen Fortschritt mit dem Hashtag
ProductionReadyAI.
Zusammenfassung
In diesem Lab haben Sie Folgendes gelernt:
- Wenden Sie die Best Practices für die Bewertung mit dem
EvalTask-Framework an. - Verwenden Sie verschiedene Messwerttypen, von berechnungsbasierten bis hin zu modellbasierten Schätzungen.
- Optimieren Sie Prompts, indem Sie verschiedene Versionen testen.
- Reproduzierbaren Workflow mit Test-Tracking erstellen
Ressourcen für die Weiterbildung
- Dokumentation zur Bewertung von generativer KI in Vertex AI
- Notebooks mit erweiterten Auswertungstechniken
- Referenz zum Gen AI Evaluation SDK
- Forschung zu modellbasierten Messwerten
- Best Practices für Prompt Engineering
Die systematischen Bewertungsansätze, die Sie in diesem Lab kennengelernt haben, bilden die Grundlage für die Entwicklung zuverlässiger, hochwertiger KI-Anwendungen. Eine gute Evaluierung ist die Brücke zwischen experimenteller KI und Produktionserfolg.