
1. Descripción general
En este lab, aprenderás a evaluar modelos de lenguaje grandes con Gen AI Evaluation Service de Vertex AI. Usarás el SDK para ejecutar trabajos de evaluación, comparar resultados y tomar decisiones basadas en datos sobre el rendimiento del modelo y el diseño de instrucciones.
En el lab, se te guiará por un flujo de trabajo de evaluación común, que comienza con métricas simples basadas en el procesamiento y avanza hacia evaluaciones más matizadas basadas en modelos. También aprenderás a crear métricas personalizadas adaptadas a tus objetivos específicos y a hacer un seguimiento de tu trabajo con Vertex AI Experiments.
Qué aprenderás
En este lab, aprenderás a realizar las siguientes tareas:
- Evalúa un modelo con métricas basadas en el procesamiento y en el modelo.
- Crea una métrica personalizada para alinear la evaluación con los objetivos del producto.
- Comparar diferentes plantillas de instrucciones en paralelo
- Prueba varias instrucciones basadas en arquetipos para encontrar la versión más eficaz.
- Haz un seguimiento de las ejecuciones de evaluación y visualízalas con Vertex AI Experiments.
Referencias
- Muestras de código: Este lab se basa en ejemplos del repositorio de IA generativa de Google Cloud.
- Basado en la documentación de Vertex AI Gen AI Evaluation
- Conjunto de datos: Conjunto de datos de OpenOrca para la evaluación del cumplimiento de instrucciones
2. Configura el proyecto
Cuenta de Google
Si aún no tienes una Cuenta de Google personal, debes crear una.
Usa una cuenta personal en lugar de una cuenta de trabajo o institución educativa.
Accede a la consola de Google Cloud
Accede a la consola de Google Cloud con una Cuenta de Google personal.
Habilitar facturación
Para habilitar la facturación, tienes dos opciones. Puedes usar tu cuenta de facturación personal o canjear créditos siguiendo los pasos que se indican a continuación.
Canjea créditos de Google Cloud (opcional)
Para realizar este taller, necesitas una cuenta de facturación con algo de crédito. Usa los créditos del banner que se encuentra en la parte superior de este codelab para comenzar. Si ya te conectaste a una cuenta de facturación, puedes omitir este paso.
Configura una cuenta de facturación personal
Si configuraste la facturación con créditos de Google Cloud, puedes omitir este paso.
Para configurar una cuenta de facturación personal, ve aquí para habilitar la facturación en la consola de Cloud.
Notas:
- Completar este lab debería costar menos de USD 1 en recursos de Cloud.
- Puedes seguir los pasos al final de este lab para borrar recursos y evitar cargos adicionales.
- Los usuarios nuevos pueden acceder a la prueba gratuita de USD 300.
Crear un proyecto (opcional)
Si no tienes un proyecto actual que quieras usar para este lab, crea uno nuevo aquí.
3. Configura tu entorno de Vertex AI Workbench
Comencemos por acceder a tu entorno de notebook preconfigurado y, luego, instalar las dependencias necesarias.
Accede a Vertex AI Workbench
- En la consola de Google Cloud, navega a Vertex AI haciendo clic en el menú de navegación ☰ > Vertex AI > Panel.
- Haz clic en Habilitar todas las APIs recomendadas. Nota: Espera a que se complete este paso.
- En el lado izquierdo, haz clic en Workbench para crear una nueva instancia de Workbench.
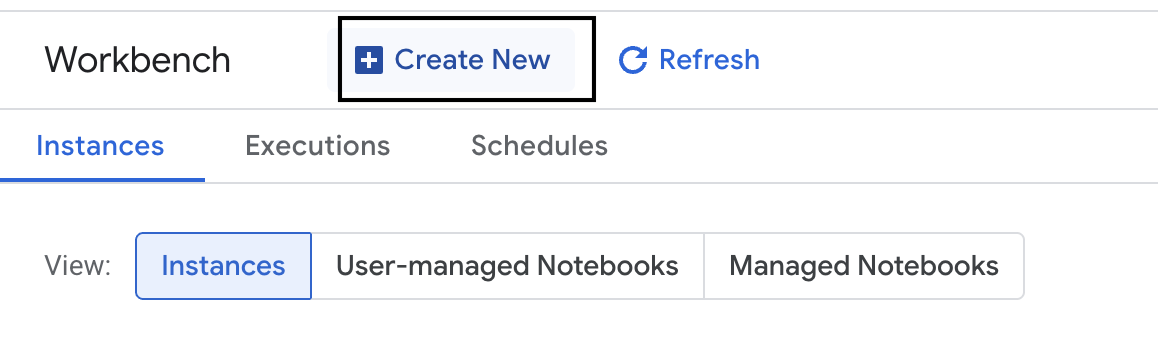
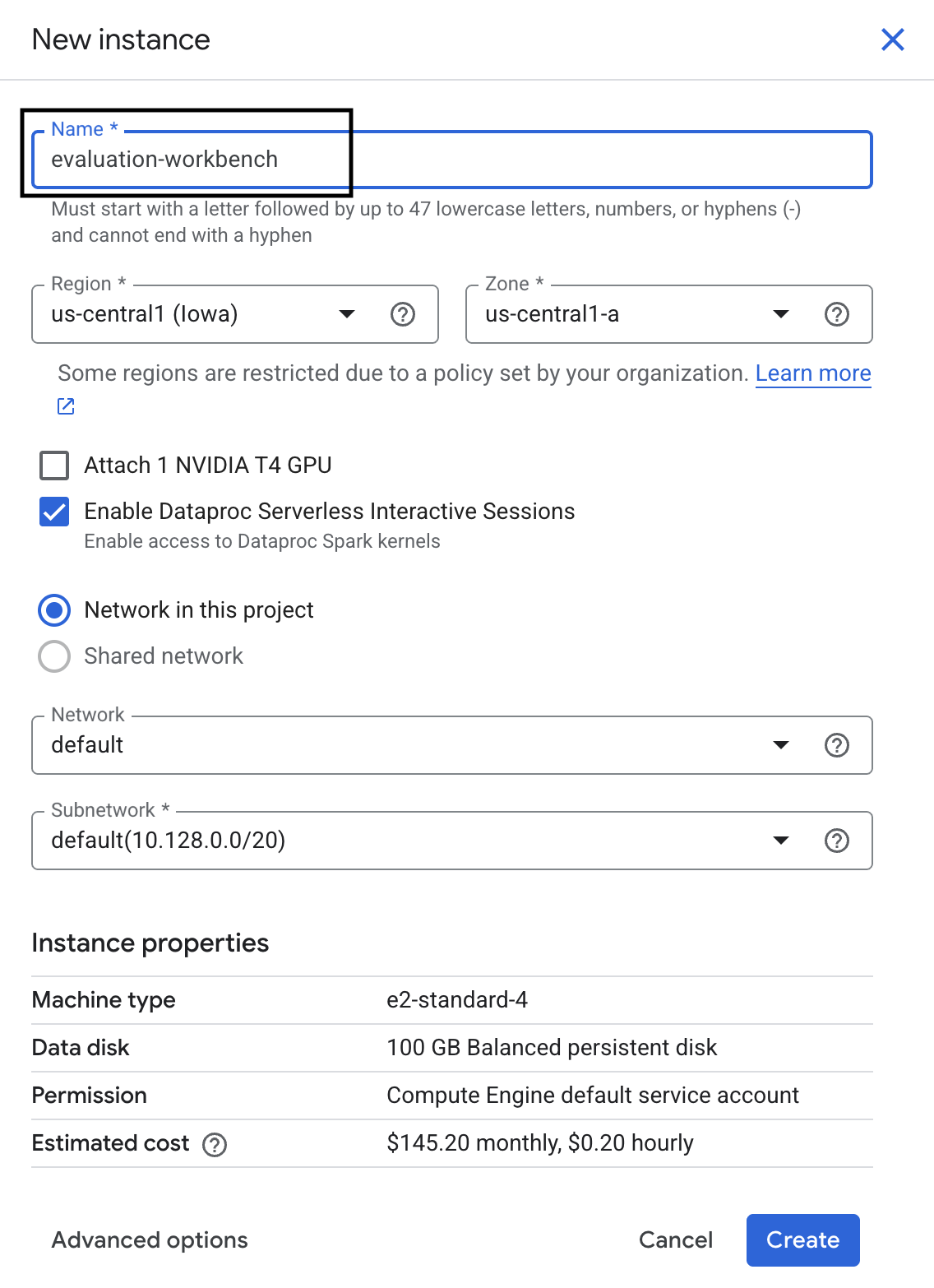
- Asigna el nombre evaluation-workbench a la instancia de Workbench y haz clic en Crear.
- Espera a que se configure el banco de trabajo. Esto puede tardar algunos minutos.

- Una vez que se aprovisione la estación de trabajo, haz clic en Abrir JupyterLab.
- En Workbench, crea un notebook nuevo de Python 3.
Para obtener más información sobre las funciones y capacidades de este entorno, consulta la documentación oficial de Vertex AI Workbench.
Instala paquetes y configura tu entorno
- En la primera celda del notebook, agrega y ejecuta las siguientes sentencias de importación (MAYÚSCULAS+INTRO) para instalar el SDK de Vertex AI (con los componentes de evaluación) y otros paquetes obligatorios.
%pip install -U -q google-cloud-aiplatform[evaluation] %pip install -U -q datasets anthropic[vertex] openai - Para usar los paquetes recién instalados, se recomienda reiniciar el kernel ejecutando el siguiente fragmento de código.
# Automatically restart kernel after installation so that your environment can access the new packages. import IPython app = IPython.Application.instance() app.kernel.do_shutdown(True) - Reemplaza lo siguiente por el ID y la ubicación de tu proyecto, y ejecuta la siguiente celda. La ubicación predeterminada se establece como
europe-west1, pero debes usar la misma ubicación en la que se encuentra tu instancia de Vertex AI Workbench.# Configure your project settings PROJECT_ID = "YOUR PROJECT ID" LOCATION = "europe-west1" - Ejecuta el siguiente código en una celda nueva para importar todas las bibliotecas de Python necesarias para este lab.
from anthropic import AnthropicVertex from google.auth import default, transport import openai import pandas as pd from vertexai.evaluation import ( EvalTask, MetricPromptTemplateExamples, PairwiseMetric, PointwiseMetric, PointwiseMetricPromptTemplate, ) from vertexai.generative_models import GenerativeModel from vertexai.preview.evaluation import notebook_utils
4. Configura tu conjunto de datos de evaluación
Para este instructivo, usaremos 10 muestras del conjunto de datos OpenOrca. Esto nos proporciona suficientes datos para observar diferencias significativas entre los modelos y, al mismo tiempo, mantener un tiempo de evaluación razonable.
💡 Sugerencia profesional: En producción, te convendría tener entre 100 y 500 ejemplos para obtener resultados estadísticamente significativos, pero 10 muestras son perfectas para el aprendizaje y la creación rápida de prototipos.
Prepara el conjunto de datos
- En una celda nueva, ejecuta la siguiente celda para cargar los datos, convertirlos en un DataFrame de Pandas, cambiar el nombre de la columna
responseareferencepara mayor claridad en nuestras tareas de evaluación y crear la muestra aleatoria de diez ejemplos.from datasets import load_dataset ds = ( load_dataset( "Open-Orca/OpenOrca", data_files="1M-GPT4-Augmented.parquet", split="train[:100]", ) .to_pandas() .drop(columns=["id"]) .rename(columns={"response": "reference"}) ) dataset = ds.sample(n=10) - Después de que se ejecute la celda anterior, en la siguiente, agrega y ejecuta el siguiente código para mostrar las primeras filas de tu conjunto de datos de evaluación.
dataset.head()
5. Establece un valor de referencia con métricas basadas en el procesamiento
En esta tarea, establecerás una puntuación de referencia con una métrica basada en el cálculo. Este enfoque es rápido y proporciona una referencia objetiva para medir las mejoras futuras.
Usaremos ROUGE (Recall-Oriented Understudy for Gisting Evaluation), una métrica estándar para las tareas de resumen. Funciona comparando la secuencia de palabras (n-gramas) en la respuesta generada por el modelo con las palabras del texto de reference de verdad fundamental.
Obtén más información sobre las métricas basadas en el procesamiento.
Ejecuta la evaluación del modelo de referencia
- En una celda nueva, agrega y ejecuta la siguiente celda para definir el modelo que deseas probar,
gemini-2.0-flash. Elgeneration_configincluye parámetros comotemperatureymax_output_tokensque influyen en la salida del modelo.# Model to be evaluated model = GenerativeModel( "gemini-2.0-flash", generation_config={"temperature": 0.6, "max_output_tokens": 256, "top_k": 1}, )GenerativeModeles la interfaz principal para interactuar con modelos de lenguaje grandes en el SDK de Vertex AI. - En la siguiente celda, agrega y ejecuta el siguiente código para crear y ejecutar el
EvalTask. Este objeto del SDK de Vertex AI Evaluation coordina la evaluación. Lo configuras con el conjunto de datos y las métricas que se deben calcular, que en este caso esrouge_l_sum.# Define an EvalTask with ROUGE-L-SUM metric rouge_eval_task = EvalTask( dataset=dataset, metrics=["rouge_l_sum"], ) rouge_result = rouge_eval_task.evaluate( model=model, prompt_template="# System_prompt\n{system_prompt} # Question\n{question}", ) - Para mostrar los resultados, ejecuta este código en la siguiente celda.
notebook_utils.display_eval_result(rouge_result)display_eval_result()muestra la puntuación promedio (media) y los resultados fila por fila.
6. Opcional: Evalúa con métricas basadas en modelos por puntos
Nota: Es posible que esta sección no se ejecute dentro del límite de los créditos gratuitos proporcionados.
Si bien ROUGE es útil, solo mide la superposición léxica (es decir, solo cuenta las palabras coincidentes, no comprende el contexto, los sinónimos ni las paráfrasis). Por lo tanto, no es la mejor opción para determinar si una respuesta es fluida o lógica. Para comprender mejor el rendimiento del modelo, usa métricas puntuales basadas en el modelo.
Con este método, otro LLM (el "modelo juez") evalúa cada respuesta de forma individual en función de un conjunto predefinido de criterios, como la fluidez o la coherencia.
Obtén más información sobre las métricas basadas en modelos.
Ejecuta la evaluación por puntos
- Ejecuta lo siguiente en una celda nueva para crear un menú desplegable interactivo. Para esta ejecución, selecciona coherence en la lista.
#Select a pointwise metric to use import ipywidgets as widgets pointwise_single_turn_metrics = [ metric for metric in MetricPromptTemplateExamples.list_example_metric_names() if not metric.startswith("pairwise") and not metric.startswith("multi_turn") ] dropdown = widgets.Dropdown( options=pointwise_single_turn_metrics, description="Select a metric:", font_weight="bold", style={"description_width": "initial"}, ) def dropdown_eventhandler(change): global POINTWISE_METRIC if change["type"] == "change" and change["name"] == "value": POINTWISE_METRIC = change.new print("Selected:", change.new) POINTWISE_METRIC = dropdown.value dropdown.observe(dropdown_eventhandler, names="value") display(dropdown) - En una celda nueva, vuelve a ejecutar
EvalTask, esta vez con la métrica basada en el modelo seleccionada. El servicio de evaluación de Vertex AI crea una instrucción para el modelo de juez, que incluye la instrucción original, la respuesta de referencia, la respuesta del modelo candidato y las instrucciones para la métrica seleccionada. El modelo del juez devuelve una puntuación numérica y una explicación de su calificación. Nota: Este paso tardará unos minutos en ejecutarse.pointwise_result = EvalTask( dataset=dataset, metrics=[POINTWISE_METRIC], ).evaluate( model=model, prompt_template="# System_prompt\n{system_prompt} # Question\n{question}", )
Cómo mostrar los resultados
Una vez que se completa la evaluación, el siguiente paso es analizar el resultado.
- Ejecuta el siguiente código en una celda nueva para ver las métricas de resumen, que muestran la puntuación promedio de la métrica que elegiste.
notebook_utils.display_eval_result(pointwise_result) - Ejecuta lo siguiente en la siguiente celda para ver el desglose fila por fila, que incluye la explicación escrita del modelo de juez para su puntuación. Estos comentarios cualitativos te ayudan a comprender por qué se calificó una respuesta de una manera determinada.
notebook_utils.display_explanations(pointwise_result, num=1, metrics=[POINTWISE_METRIC])
7. Crea una métrica personalizada para obtener estadísticas más detalladas
Las métricas prediseñadas, como la fluidez, son útiles, pero, para un producto específico, a menudo necesitas medir el rendimiento en función de tus propios objetivos. Con las métricas personalizadas de punto a punto, puedes definir tus propios criterios y rúbricas de evaluación.
En esta tarea, crearás una métrica nueva desde cero llamada summarization_helpfulness.
Define y ejecuta la métrica personalizada
- Ejecuta lo siguiente en una celda nueva para definir la métrica personalizada.El objeto
PointwiseMetricPromptTemplatecontiene los componentes básicos de la métrica:- criterios: Le indica al modelo de Judge las dimensiones específicas que debe evaluar: "Información clave", "Concisión" y "Sin distorsión".
- rating_rubric: Proporciona una escala de puntuación de 5 puntos que define el significado de cada puntuación.
- input_variables: Pasa columnas adicionales del conjunto de datos al modelo de juez para que tenga el contexto necesario para realizar la evaluación.
# This new custom metric evaluates the actual quality and usefulness of the summary. summarization_helpfulness_metric = PointwiseMetric( metric="summarization_helpfulness", metric_prompt_template=PointwiseMetricPromptTemplate( criteria={ "Key Information": "Does the summary capture the most critical pieces of information from the original text? It should not miss the main topic or key takeaways.", "Conciseness": "Is the summary brief and to the point? It should avoid unnecessary words or repetitive information.", "No Distortion": "Does the summary introduce information or opinions that were NOT present in the original text? It must accurately reflect the source material without adding hallucinations." }, rating_rubric={ "5": "Excellent: Captures all key information, is highly concise, and has zero distortion.", "4": "Good: Captures most key information with minor omissions, is concise, and has no distortion.", "3": "Satisfactory: Captures the main idea but misses some key details OR is not very concise.", "2": "Unsatisfactory: Misses the main idea of the original text OR contains minor distortions/hallucinations.", "1": "Poor: Is completely irrelevant, fails to summarize the text, OR contains significant distortions.", }, input_variables=["prompt", "reference"], ), ) - Ejecuta el siguiente código en la celda siguiente para ejecutar
EvalTaskcon tu nueva métrica personalizada.# You would then update the EvalTask to use this new metric pointwise_result = EvalTask( dataset=dataset, metrics=[summarization_helpfulness_metric], ).evaluate( model=model, prompt_template="# System_prompt\n{system_prompt} # Question\n{question}", ) - Ejecuta lo siguiente en una celda nueva para mostrar los resultados.
notebook_utils.display_eval_result(pointwise_result)
8. Cómo comparar modelos con la evaluación por pares
Cuando necesites decidir cuál de dos modelos se desempeña mejor en una tarea específica, puedes usar la evaluación por pares basada en modelos. Este método es una forma de prueba A/B en la que un modelo de juez determina un ganador, lo que proporciona una comparación directa para la selección de modelos basada en datos.
Los modelos:
- Modelo candidato: La variable del modelo (que se definió anteriormente como
gemini-2.0-flash) se pasa al método.evaluate(). Este es el modelo principal que estás probando. - Modelo de referencia: Se especifica un segundo modelo,
gemini-2.0-flash-lite, dentro de la clase PairwiseMetric. Este es el modelo con el que realizas la comparación.
Ejecuta la evaluación por pares
- En una celda nueva, agrega y ejecuta el siguiente código para crear un menú desplegable interactivo. Esto te permitirá seleccionar qué métrica por pares deseas usar para la comparación. Para esta ejecución, selecciona pairwise_summarization_quality.
from IPython.display import display import ipywidgets as widgets pairwise_single_turn_metrics = [ metric for metric in MetricPromptTemplateExamples.list_example_metric_names() if metric.startswith("pairwise") and "multi_turn" not in metric ] dropdown = widgets.Dropdown( options=pairwise_single_turn_metrics, description="Select a metric:", font_weight="bold", style={"description_width": "initial"}, ) def dropdown_eventhandler(change): global POINTWISE_METRIC if change["type"] == "change" and change["name"] == "value": POINTWISE_METRIC = change.new print("Selected:", change.new) def dropdown_eventhandler(change): global PAIRWISE_METRIC_NAME if change["type"] == "change" and change["name"] == "value": PAIRWISE_METRIC_NAME = change.new print("Selected:", change.new) PAIRWISE_METRIC_NAME = dropdown.value dropdown.observe(dropdown_eventhandler, names="value") display(dropdown) - En la siguiente celda, agrega y ejecuta el siguiente código para configurar y ejecutar
EvalTask. Ten en cuenta cómo se usa la clasePairwiseMetricpara definir el modelo de referencia (gemini-2.0-flash-lite), mientras que el modelo candidato (gemini-2.0-flash) se pasa al método.evaluate().pairwise_result = EvalTask( dataset=dataset, metrics=[ PairwiseMetric( metric=PAIRWISE_METRIC_NAME, metric_prompt_template=MetricPromptTemplateExamples.get_prompt_template( PAIRWISE_METRIC_NAME ), # Define a baseline model to compare against baseline_model=GenerativeModel("gemini-2.0-flash-lite"), ) ], ).evaluate( # Specify a candidate model for pairwise comparison model=model, prompt_template="# System_prompt\n{system_prompt} # Question\n{question}", ) - En una celda nueva, agrega y ejecuta el siguiente código para mostrar los resultados. En la tabla de resumen, se mostrará el "índice de victorias" de cada modelo, lo que indica cuál prefirió el Modelo de juez con mayor frecuencia.
notebook_utils.display_eval_result(pairwise_result)
9. Opcional: Evalúa las instrucciones basadas en arquetipos
Nota: Es posible que esta sección no se ejecute dentro del límite de los créditos gratuitos proporcionados.
En esta tarea, probarás varias plantillas de instrucciones que le indican al modelo que adopte diferentes arquetipos. Este proceso, que a menudo se denomina ingeniería de instrucciones o diseño de instrucciones, te permite encontrar de forma sistemática la instrucción más eficaz para un caso de uso específico.
Prepara el conjunto de datos de resumen
Para realizar esta evaluación, el conjunto de datos debe contener los siguientes campos:
instruction: Es la tarea principal que le asignamos al modelo. En este caso, es un simple "Resume el siguiente artículo:".context: Es el texto fuente con el que debe trabajar el modelo. Aquí proporcionamos cuatro fragmentos de noticias diferentes.reference: Es el resumen de referencia o "estándar de oro". El texto generado por el modelo se comparará con este texto para calcular las puntuaciones de métricas como ROUGE y la calidad de la síntesis.
- En una celda nueva, agrega y ejecuta el siguiente código para crear un
pandas.DataFramepara la tarea de resumen.instruction = "Summarize the following article: \n" context = [ "Typhoon Phanfone has killed at least one person, a US airman on Okinawa who was washed away by high waves. Thousands of households have lost power and Japan's two largest airlines have suspended many flights. The storm also forced the suspension of the search for people missing after last week's volcanic eruption. The storm-tracking website Tropical Storm Risk forecasts that Phanfone will rapidly lose power over the next few hours as it goes further into the Pacific Ocean. Typhoon Phanfone was downgraded from an earlier status of a super typhoon, but the Japan Meteorological Agency had warned it was still a dangerous storm. Japan averages 11 typhoons a year, according to its weather agency. The typhoon made landfall on Monday morning near the central city of Hamamatsu, with winds of up to 180 km/h (112 mph). The airman was one of three US military personnel swept away by high waves whipped up by the typhoon off southern Okinawa island, where the US has a large military base. The remaining two are still missing. A police spokesman said they had been taking photographs of the sea. A university student who was surfing off the seas of Kanagawa Prefecture, south of Tokyo, was also missing, national broadcast NHK reports. It said at least 10 people had been injured and 9,500 houses were without power. The storm was expected to deposit about 100mm of rain on Tokyo over 24 hours, according to the Transport Ministry website. Many schools were closed on Monday and two car companies in Japan halted production at some plants ahead of the storm. More than 174 domestic flights were affected nationwide, NHK state broadcaster said on Sunday. On Sunday, heavy rain delayed the Japanese Formula One Grand Prix in Suzaka. French driver Jules Bianchi lost control in the wet conditions and crashed, sustaining a severe head injury.", "The blaze started at the detached building in Drivers End in Codicote, near Welwyn, during the morning. There was another fire at the building 20 years ago, after which fire-proof foil was placed under the thatch, which is protecting the main building. More than 15 fire engines and support vehicles were called to tackle the blaze. Roads in the area were closed and traffic diverted.", 'The 18-year-old fell at the New Charter Academy on Broadoak Road in Ashton-under-Lyne at about 09:10 BST, Greater Manchester Police (GMP) said. GMP said he had gone to Manchester Royal Infirmary and his condition was "serious". Principal Jenny Langley said the school would remain "fully open" while police investigated. "Our thoughts are with the family and we\'re doing everything we can to support them along with staff and pupils," she said.', 'But Belgian-born Dutchman Max Verstappen was unable to drive a car legally on his own in either country. That all changed on Wednesday when the youngster turned 18 and passed his driving test at the first attempt. Despite having competed in 14 grands prix since his debut in Australia in March, Verstappen admitted to feeling the pressure during his test. "It\'s a relief," said the Toro Rosso driver, who finished ninth in Japan on Sunday and had only started driving lessons a week ago. "I was a bit nervous to make mistakes, but the exam went well." A bonus of turning 18 is that Verstappen will now be able to drink the champagne if he ever makes it onto the podium.', ] reference = [ "A powerful typhoon has brought many parts of Japan to a standstill and briefly battered Tokyo before heading out to sea.", "A major fire has been burning in the thatched roof of a large property in Hertfordshire.", "A student has been taken to hospital after falling from a balcony at a Greater Manchester school.", "He is Formula 1's youngest ever driver and in charge of a car that can reach over 200mph.", ] response = [ "Typhoon Phanfone, while downgraded from super typhoon status, caused significant disruption and tragedy in Japan. One US airman died after being swept away by high waves, with two more missing. The storm caused power outages for thousands, flight cancellations, and the suspension of rescue efforts for missing volcano victims. Heavy rain and strong winds led to school and factory closures, transportation disruptions, and at least 10 injuries. The typhoon is expected to weaken as it moves over the Pacific Ocean.", "A large fire broke out in a detached thatched building in Codicote, near Welwyn. This is the second fire at the building in 20 years. Thankfully, fire-proof foil installed after the previous fire is protecting the main building. Over 15 fire engines and support vehicles responded, closing roads and diverting traffic in the area.", "An 18-year-old student at New Charter Academy in Ashton-under-Lyne suffered a serious fall and was hospitalized. The incident is under investigation by Greater Manchester Police, but the school remains open. The principal expressed support for the student's family and the school community.", "Max Verstappen, a Formula One driver, was finally able to get his driver's license at age 18. Despite already competing in 14 Grand Prix races, he was not of legal driving age in his native countries. He admitted to being nervous but passed the test on his first attempt. As an added bonus of turning 18, Verstappen can now enjoy champagne on the podium if he places.", ] eval_dataset = pd.DataFrame( { "instruction": instruction, "context": context, "reference": reference, } )
Ejecuta la tarea de evaluación de instrucciones
Con el conjunto de datos de resumen preparado, puedes ejecutar el experimento principal de esta tarea: comparar varias plantillas de instrucciones para ver cuál produce el resultado de mayor calidad del modelo.
- En la siguiente celda, crea un solo
EvalTaskque se reutilizará para cada experimento de instrucciones. Si configuras el parámetroexperiment, todas las ejecuciones de evaluación de esta tarea se registran y agrupan automáticamente en Vertex AI Experiments.EXPERIMENT_NAME = "eval-sdk-prompt-engineering" # @param {type:"string"} summarization_eval_task = EvalTask( dataset=eval_dataset, metrics=[ "rouge_l_sum", "bleu", "fluency", "coherence", "safety", "groundedness", "summarization_quality", "verbosity", "instruction_following", "text_quality", ], experiment=EXPERIMENT_NAME, )rouge_l_sumybleuhasta una amplia variedad de métricas basadas en modelos (fluency,coherence,summarization_quality,instruction_following, etcétera). Esto nos brinda una visión integral de 360 grados sobre cómo cada instrucción afecta la calidad del resultado del modelo. - En una celda nueva, agrega y ejecuta el siguiente código para definir y evaluar cuatro estrategias de instrucciones basadas en arquetipos. El bucle
foritera a través de cada plantilla y ejecuta una evaluación.Cada plantilla está diseñada para obtener un estilo diferente de resumen, ya que le otorga al modelo un objetivo o un arquetipo específico:- Arquetipo 1 (estándar): Una solicitud de resumen neutral y directa.
- Arquetipo núm. 2 (ejecutivo): Solicita un resumen con viñetas, centrándose en los resultados y el impacto, como lo preferiría un ejecutivo ocupado.
- Arquetipo núm. 3 (estudiante de 5º grado): Le indica al modelo que use un lenguaje sencillo, lo que pone a prueba su capacidad para ajustar la complejidad de su resultado.
- Arquetipo núm. 4 (analista técnico): Exige un resumen muy fáctico en el que se conserven las estadísticas y las entidades clave, lo que pone a prueba la precisión del modelo. Observa que los marcadores de posición en estas plantillas nuevas, como
{context}y{instruction}, coinciden con los nombres de las columnas nuevas en eleval_datasetque creaste para esta tarea.
# Define prompt templates that target different user personas prompt_templates = [ # Persona 1: Standard, neutral summary "Article: {context}. Task: {instruction}. Summary:", # Persona 2: For a busy executive (bullet points) "Instruction: {instruction} into three key bullet points for a busy executive. Focus on the main outcome and impact. Article: {context}. Summary:", # Persona 3: For a 5th grader (simple language) "Instruction: {instruction} such that you're explaining it to a 10-year-old. Use simple words. Article: {context}. Summary:", # Persona 4: For a technical analyst (fact-focused) "Instruction: Provide a detailed, factual summary of the following text, ensuring all key statistics, names, and locations are preserved. Article: {context}. Summary:", ] eval_results = [] for i, prompt_template in enumerate(prompt_templates): eval_result = summarization_eval_task.evaluate( prompt_template=prompt_template, model=GenerativeModel( "gemini-2.0-flash", generation_config={ "temperature": 0.3, "max_output_tokens": 256, "top_k": 1, }, ), evaluation_service_qps=5, ) eval_results.append((f"Prompt Persona #{i+1}", eval_result))
Analiza y visualiza los resultados
Ejecutar experimentos es el primer paso. El valor real proviene del análisis de los resultados para tomar una decisión basada en datos. En esta tarea, usarás las herramientas de visualización del SDK para interpretar los resultados del experimento de arquetipo de instrucción.
- Ejecuta el siguiente código en una celda nueva para mostrar los resultados del resumen de cada uno de los cuatro arquetipos de instrucciones que probaste. Esto te brinda una vista cuantitativa general del rendimiento.
for title, eval_result in eval_results: notebook_utils.display_eval_result(title=title, eval_result=eval_result) - En una celda nueva, agrega y ejecuta el siguiente código para ver la justificación de la métrica
summarization_qualitypara cada arquetipo.for title, eval_result in eval_results: notebook_utils.display_explanations( eval_result, metrics=["summarization_quality"], num=2 ) - Genera un gráfico de radar para visualizar las compensaciones entre diferentes métricas de calidad para cada instrucción. En una celda nueva, agrega y ejecuta el siguiente código.
notebook_utils.display_radar_plot( eval_results, metrics=["instruction_following", "fluency", "coherence", "text_quality"], ) - Para una comparación más directa y paralela, crea un gráfico de barras. En una celda nueva, agrega y ejecuta el siguiente código.
notebook_utils.display_bar_plot( eval_results, metrics=["instruction_following", "fluency", "coherence", "text_quality"], )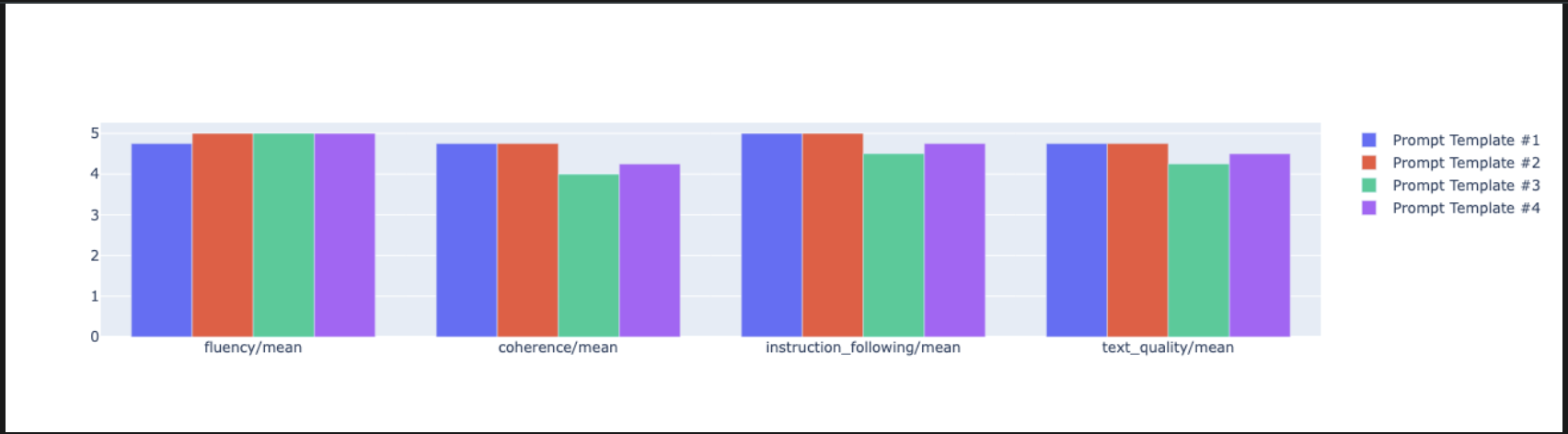
- Ahora puedes ver un resumen de todas las ejecuciones que se registraron en tu experimento de Vertex AI para esta tarea. Esto es útil para hacer un seguimiento de tu trabajo a lo largo del tiempo. En una celda nueva, agrega y ejecuta el siguiente código:
summarization_eval_task.display_runs()
10. Limpia el experimento
Para mantener tu proyecto organizado y evitar cargos innecesarios, es una práctica recomendada limpiar los recursos que creaste. A lo largo de este lab, cada ejecución de evaluación se registró en un experimento de Vertex AI. El siguiente código borra este experimento principal, lo que también quita todas las ejecuciones asociadas y sus datos subyacentes.
- Ejecuta este código en una celda nueva para borrar el experimento de Vertex AI y sus ejecuciones asociadas.
delete_experiment = True # Please set your LOCATION to the same one used during Vertex AI SDK initialization. LOCATION = "YOUR LOCATION" # @param {type:"string"} if delete_experiment: from google.cloud import aiplatform aiplatform.init(project=PROJECT_ID, location=LOCATION) experiment = aiplatform.Experiment(EXPERIMENT_NAME) experiment.delete()
11. De la práctica a la producción
Las habilidades que aprendiste en este lab son los componentes básicos para crear aplicaciones de IA confiables. Sin embargo, pasar de un notebook ejecutado manualmente a un sistema de evaluación de nivel de producción requiere infraestructura adicional y un enfoque más sistemático. En esta sección, se describen las prácticas clave y los marcos estratégicos que debes tener en cuenta a medida que expandes tu negocio.
Cómo crear estrategias de evaluación de la producción
Para aplicar las habilidades de este lab en un entorno de producción, es útil formalizarlas en estrategias repetibles. Los siguientes marcos de trabajo describen consideraciones clave para situaciones comunes, como la selección de modelos, la optimización de instrucciones y la supervisión continua.
Para la selección del modelo, haz lo siguiente:
# Evaluation strategy for choosing models
evaluation_strategy = {
"dataset_size": "100+ examples for statistical significance",
"metrics": ["task-specific", "general quality", "efficiency"],
"comparison_type": "pairwise with statistical testing",
"baseline": "established_model_or_human_benchmark"
}
Para la optimización de instrucciones
# Systematic prompt improvement workflow
prompt_optimization = {
"hypothesis": "Clear statement of what you're testing",
"variants": "3-5 different prompt strategies",
"evaluation": "Same metrics across all variants",
"analysis": "Statistical significance + qualitative review"
}
Para la supervisión continua
# Production evaluation pipeline
production_eval = {
"frequency": "Every model update + weekly monitoring",
"automation": "CI/CD integration with quality gates",
"metrics": "Speed + quality + cost tracking",
"alerting": "Performance degradation detection"
}
Consideraciones sobre la rentabilidad
La evaluación basada en modelos puede ser costosa a gran escala. Una estrategia de producción rentable utiliza diferentes métodos para diferentes propósitos. En esta tabla, se resumen las compensaciones entre la velocidad, el costo y el caso de uso para los diferentes tipos de evaluación:
Tipo de evaluación | Hora | Costo por muestra | Ideal para |
ROUGE/BLEU | Segundos | Aprox. USD 0.001 | Filtro de alto volumen |
Model-based Pointwise | Entre 1 y 2 segundos | Aprox. USD 0.01 | Evaluación de calidad |
Comparación por pares | Entre 2 y 3 segundos | ~$0.02 | Selección del modelo |
Evaluación humana | Minutos | De USD 1 a USD 10 | Validación de referencia |
Automatiza con CI/CD y supervisión
Las ejecuciones manuales de notebooks no son escalables. Automatiza tu evaluación en una canalización de integración continua y desarrollo continuo (CI/CD).
- Crea puertas de calidad: Integra tu tarea de evaluación en una canalización de CI/CD (p.ej., Cloud Build). Ejecuta automáticamente evaluaciones en modelos o instrucciones nuevos y bloquea las implementaciones si las puntuaciones de calidad clave caen por debajo de los umbrales definidos.
- Supervisa las tendencias: Exporta las métricas de resumen de tus ejecuciones de evaluación a un servicio como Google Cloud Monitoring. Crea paneles para hacer un seguimiento de la calidad a lo largo del tiempo y configura alertas automáticas para notificar a tu equipo sobre cualquier disminución significativa del rendimiento.
12. Conclusión
Completaste el lab. Aprendiste las habilidades esenciales para evaluar modelos de IA generativa.
Este lab forma parte de la ruta de aprendizaje de IA lista para producción con Google Cloud.
- Explora el plan de estudios completo para cerrar la brecha entre el prototipo y la producción.
- Comparte tu progreso con el hashtag
ProductionReadyAI.
Resumen
En este lab, aprendiste a realizar las siguientes tareas:
- Aplica las prácticas recomendadas de evaluación con el marco de trabajo de
EvalTask. - Usar diferentes tipos de métricas, desde jueces basados en el procesamiento hasta jueces basados en modelos
- Optimiza las instrucciones probando diferentes versiones.
- Crea un flujo de trabajo reproducible con seguimiento de experimentos.
Recursos para seguir aprendiendo
- Documentación de la evaluación de IA generativa de Vertex AI
- Notebooks de técnicas de evaluación avanzadas
- Referencia del SDK de Gen AI Evaluation
- Investigación de métricas basadas en modelos
- Prácticas recomendadas para la ingeniería de instrucciones
Los enfoques de evaluación sistemática que aprendiste en este lab te servirán como base para crear aplicaciones de IA confiables y de alta calidad. Recuerda que una buena evaluación es el puente entre la IA experimental y el éxito en la producción.