
۱. مرور کلی
در این آزمایشگاه، شما یاد میگیرید که مدلهای زبانی بزرگ را با استفاده از سرویس ارزیابی هوش مصنوعی Vertex AI Gen ارزیابی کنید. شما از SDK برای اجرای کارهای ارزیابی، مقایسه نتایج و تصمیمگیریهای مبتنی بر داده در مورد عملکرد مدل و طراحی سریع استفاده خواهید کرد.
این آزمایشگاه شما را با یک گردش کار ارزیابی رایج آشنا میکند، که با معیارهای ساده و مبتنی بر محاسبات شروع میشود و به ارزیابیهای ظریفتر و مبتنی بر مدل میرسد. همچنین یاد خواهید گرفت که معیارهای سفارشی متناسب با اهداف خاص خود ایجاد کنید و کار خود را با استفاده از Vertex AI Experiments پیگیری کنید.
آنچه یاد خواهید گرفت
در این آزمایشگاه، شما یاد میگیرید که چگونه وظایف زیر را انجام دهید:
- یک مدل را با معیارهای مبتنی بر محاسبات و مبتنی بر مدل ارزیابی کنید.
- یک معیار سفارشی برای همسو کردن ارزیابی با اهداف محصول ایجاد کنید.
- قالبهای مختلف اعلان را در کنار هم مقایسه کنید.
- چندین دستورالعمل مبتنی بر شخصیت را آزمایش کنید تا موثرترین نسخه را پیدا کنید.
- با استفاده از Vertex AI Experiments، مراحل ارزیابی را پیگیری و تجسم کنید.
منابع
- نمونههای کد: این آزمایشگاه بر اساس نمونههایی از مخزن هوش مصنوعی تولید شده توسط گوگل کلود ساخته شده است.
- بر اساس: مستندات ارزیابی هوش مصنوعی Vertex AI Gen
- مجموعه داده: مجموعه داده OpenOrca برای ارزیابی دنبال کردن دستورالعمل
۲. راهاندازی پروژه
حساب گوگل
اگر از قبل حساب گوگل شخصی ندارید، باید یک حساب گوگل ایجاد کنید .
به جای حساب کاری یا تحصیلی از حساب شخصی استفاده کنید .
ورود به کنسول ابری گوگل
با استفاده از یک حساب کاربری شخصی گوگل، وارد کنسول ابری گوگل شوید.
فعال کردن صورتحساب
برای فعال کردن پرداخت، دو گزینه دارید. میتوانید از حساب پرداخت شخصی خود استفاده کنید یا میتوانید با مراحل زیر اعتبار خود را بازخرید کنید.
استفاده از اعتبار گوگل کلود (اختیاری)
برای اجرای این کارگاه، به یک حساب صورتحساب با مقداری اعتبار نیاز دارید. برای شروع از اعتبارهای موجود در بنر بالای این codelab استفاده کنید. اگر از قبل به یک حساب صورتحساب متصل هستید، میتوانید از این مرحله صرف نظر کنید.
یک حساب پرداخت شخصی تنظیم کنید
اگر صورتحساب را با استفاده از اعتبارهای Google Cloud تنظیم کردهاید، میتوانید از این مرحله صرف نظر کنید.
برای تنظیم یک حساب پرداخت شخصی، به اینجا بروید تا پرداخت را در کنسول ابری فعال کنید .
برخی نکات:
- تکمیل این آزمایشگاه باید کمتر از ۱ دلار آمریکا از طریق منابع ابری هزینه داشته باشد.
- شما میتوانید مراحل انتهای این آزمایش را برای حذف منابع دنبال کنید تا از هزینههای بیشتر جلوگیری شود.
- کاربران جدید واجد شرایط استفاده از دوره آزمایشی رایگان ۳۰۰ دلاری هستند.
ایجاد پروژه (اختیاری)
اگر پروژه فعلی ندارید که بخواهید برای این آزمایشگاه استفاده کنید، اینجا یک پروژه جدید ایجاد کنید .
۳. محیط Vertex AI Workbench خود را تنظیم کنید
بیایید با دسترسی به محیط نوتبوک از پیش پیکربندیشده و نصب وابستگیهای لازم شروع کنیم.
به میز کار Vertex AI دسترسی پیدا کنید
- در کنسول گوگل کلود، با کلیک روی منوی ناوبری ☰ > Vertex AI > Dashboard به Vertex AI بروید.
- روی فعال کردن همه API های پیشنهادی کلیک کنید. توجه: لطفاً صبر کنید تا این مرحله تکمیل شود.
- در سمت چپ، روی Workbench کلیک کنید تا یک نمونه Workbench جدید ایجاد شود.
- نام نمونه میز کار را evaluation-workbench بگذارید و روی Create کلیک کنید.
- صبر کنید تا میز کار آماده شود. این کار ممکن است چند دقیقه طول بکشد.

- پس از آمادهسازی میز کار، روی «باز کردن JupyterLab» کلیک کنید.
- در محیط کار، یک دفترچه یادداشت پایتون ۳ جدید ایجاد کنید.
برای کسب اطلاعات بیشتر در مورد ویژگیها و قابلیتهای این محیط، به مستندات رسمی Vertex AI Workbench مراجعه کنید.
بستهها را نصب کنید و محیط خود را پیکربندی کنید
- در سلول اول دفترچه یادداشت خود، دستورات import زیر را اضافه و اجرا کنید (SHIFT+ENTER) تا Vertex AI SDK (به همراه اجزای ارزیابی) و سایر بستههای مورد نیاز نصب شوند.
%pip install -U -q google-cloud-aiplatform[evaluation] %pip install -U -q datasets anthropic[vertex] openai - برای استفاده از بستههای تازه نصب شده، توصیه میشود هسته را با اجرای قطعه کد زیر مجدداً راهاندازی کنید.
# Automatically restart kernel after installation so that your environment can access the new packages. import IPython app = IPython.Application.instance() app.kernel.do_shutdown(True) - موارد زیر را با شناسه و مکان پروژه خود جایگزین کنید و سلول زیر را اجرا کنید. مکان پیشفرض به صورت
europe-west1تنظیم شده است، اما شما باید از همان مکانی که نمونه میز کار Vertex AI شما در آن قرار دارد استفاده کنید.# Configure your project settings PROJECT_ID = "YOUR PROJECT ID" LOCATION = "europe-west1" - با اجرای کد زیر در یک سلول جدید، تمام کتابخانههای پایتون مورد نیاز برای این آزمایش را وارد کنید.
from anthropic import AnthropicVertex from google.auth import default, transport import openai import pandas as pd from vertexai.evaluation import ( EvalTask, MetricPromptTemplateExamples, PairwiseMetric, PointwiseMetric, PointwiseMetricPromptTemplate, ) from vertexai.generative_models import GenerativeModel from vertexai.preview.evaluation import notebook_utils
۴. مجموعه دادههای ارزیابی خود را تنظیم کنید
برای این آموزش، ما از 10 نمونه از مجموعه داده OpenOrca استفاده خواهیم کرد. این به ما دادههای کافی میدهد تا تفاوتهای معنادار بین مدلها را ببینیم و در عین حال زمان ارزیابی را نیز قابل مدیریت نگه داریم.
💡 نکته حرفهای: در محیط تولید، برای نتایج آماری معنادار به ۱۰۰ تا ۵۰۰ نمونه نیاز دارید، اما ۱۰ نمونه برای یادگیری و نمونهسازی سریع عالی است!
آمادهسازی مجموعه دادهها
- در یک سلول جدید، سلول زیر را اجرا کنید تا دادهها بارگذاری شوند، آن را به یک دیتافریم pandas تبدیل کنید و برای وضوح در وظایف ارزیابی، ستون
responseرا بهreferenceتغییر نام دهید و نمونه تصادفی ده نمونهای ایجاد کنید.from datasets import load_dataset ds = ( load_dataset( "Open-Orca/OpenOrca", data_files="1M-GPT4-Augmented.parquet", split="train[:100]", ) .to_pandas() .drop(columns=["id"]) .rename(columns={"response": "reference"}) ) dataset = ds.sample(n=10) - پس از اتمام اجرای سلول قبلی، در سلول بعدی، کد زیر را اضافه و اجرا کنید تا چند ردیف اول مجموعه دادههای ارزیابی شما نمایش داده شود.
dataset.head()
۵. یک خط مبنا با معیارهای مبتنی بر محاسبات ایجاد کنید
در این وظیفه، شما با استفاده از یک معیار مبتنی بر محاسبات، یک امتیاز پایه تعیین میکنید. این رویکرد سریع است و یک معیار عینی برای اندازهگیری پیشرفتهای آینده ارائه میدهد.
ما از ROUGE (یادآوری-محورِ جایگزین برای ارزیابی اطلاعات) استفاده خواهیم کرد، که یک معیار استاندارد برای وظایف خلاصهسازی است. این معیار با مقایسه توالی کلمات (n-grams) در پاسخ تولید شده توسط مدل با کلمات موجود در متن reference اطلاعات پایه کار میکند.
درباره معیارهای مبتنی بر محاسبات بیشتر بخوانید.
اجرای ارزیابی پایه
- در یک سلول جدید، سلول زیر را برای تعریف مدلی که میخواهید آزمایش کنید،
gemini-2.0-flashاضافه و اجرا کنید.generation_configشامل پارامترهایی مانندtemperatureوmax_output_tokensاست که بر خروجی مدل تأثیر میگذارند.# Model to be evaluated model = GenerativeModel( "gemini-2.0-flash", generation_config={"temperature": 0.6, "max_output_tokens": 256, "top_k": 1}, )GenerativeModelرابط اصلی برای تعامل با مدلهای زبانی بزرگ در Vertex AI SDK است. - در سلول بعدی، کد زیر را برای ایجاد و اجرای
EvalTaskاضافه و اجرا کنید. این شیء از Vertex AI Evaluation SDK ارزیابی را هماهنگ میکند. شما آن را با مجموعه داده و معیارهای محاسبه پیکربندی میکنید، که در این موردrouge_l_sumاست.# Define an EvalTask with ROUGE-L-SUM metric rouge_eval_task = EvalTask( dataset=dataset, metrics=["rouge_l_sum"], ) rouge_result = rouge_eval_task.evaluate( model=model, prompt_template="# System_prompt\n{system_prompt} # Question\n{question}", ) - با اجرای این کد در سلول بعدی، نتایج را نمایش دهید.
notebook_utils.display_eval_result(rouge_result)display_eval_result()میانگین (mean) نمره و نتایج ردیف به ردیف را نشان میدهد.
۶. اختیاری: ارزیابی با معیارهای نقطهای مبتنی بر مدل
توجه: این بخش ممکن است در محدوده اعتبار رایگان ارائه شده نباشد.
اگرچه ROUGE مفید است، اما فقط همپوشانی واژگانی را اندازهگیری میکند (یعنی فقط کلمات منطبق را میشمارد، متن، مترادفها یا بازنویسی را درک نمیکند). بنابراین در تعیین اینکه آیا یک پاسخ روان یا منطقی است، بهترین گزینه نیست. برای درک عمیقتر عملکرد مدل، از معیارهای نقطهای مبتنی بر مدل استفاده میکنید.
با این روش، یک LLM دیگر ("مدل قاضی") هر پاسخ را به صورت جداگانه در برابر مجموعهای از معیارهای از پیش تعریف شده، مانند روان بودن یا انسجام، ارزیابی میکند.
درباره معیارهای مبتنی بر مدل بیشتر بخوانید.
ارزیابی نقطهای را اجرا کنید
- برای ایجاد یک منوی کشویی تعاملی، دستور زیر را در یک سلول جدید اجرا کنید. برای این اجرا، coherence را از لیست انتخاب کنید.
#Select a pointwise metric to use import ipywidgets as widgets pointwise_single_turn_metrics = [ metric for metric in MetricPromptTemplateExamples.list_example_metric_names() if not metric.startswith("pairwise") and not metric.startswith("multi_turn") ] dropdown = widgets.Dropdown( options=pointwise_single_turn_metrics, description="Select a metric:", font_weight="bold", style={"description_width": "initial"}, ) def dropdown_eventhandler(change): global POINTWISE_METRIC if change["type"] == "change" and change["name"] == "value": POINTWISE_METRIC = change.new print("Selected:", change.new) POINTWISE_METRIC = dropdown.value dropdown.observe(dropdown_eventhandler, names="value") display(dropdown) - در یک سلول جدید، دوباره
EvalTaskاجرا کنید، این بار با استفاده از معیار مبتنی بر مدل انتخاب شده. سرویس ارزیابی هوش مصنوعی Vertex یک اعلان برای مدل قاضی ایجاد میکند که شامل اعلان اصلی، پاسخ مرجع، پاسخ مدل کاندید و دستورالعملهایی برای معیار انتخاب شده است. مدل قاضی یک امتیاز عددی و توضیحی برای رتبهبندی آن برمیگرداند. توجه: اجرای این مرحله چند دقیقه طول میکشد.pointwise_result = EvalTask( dataset=dataset, metrics=[POINTWISE_METRIC], ).evaluate( model=model, prompt_template="# System_prompt\n{system_prompt} # Question\n{question}", )
نمایش نتایج
با تکمیل ارزیابی، مرحله بعدی تجزیه و تحلیل خروجی است.
- کد زیر را در یک سلول جدید اجرا کنید تا خلاصه معیارها را مشاهده کنید، که میانگین امتیاز برای معیار انتخابی شما را نشان میدهد.
notebook_utils.display_eval_result(pointwise_result) - برای مشاهدهی تفکیک ردیف به ردیف، که شامل منطق کتبی مدل قاضی برای نمرهدهی آن است، دستور زیر را در سلول بعدی اجرا کنید. این بازخورد کیفی به شما کمک میکند تا بفهمید که چرا یک پاسخ به روش خاصی نمره داده شده است.
notebook_utils.display_explanations(pointwise_result, num=1, metrics=[POINTWISE_METRIC])
۷. برای بینشهای عمیقتر، یک معیار سفارشی بسازید
معیارهای از پیش تعیینشده مانند روان بودن زبان مفید هستند، اما برای یک محصول خاص، اغلب باید عملکرد را در مقایسه با اهداف خودتان بسنجید. با معیارهای نقطهای سفارشی، میتوانید معیارها و سرفصلهای ارزیابی خودتان را تعریف کنید.
در این کار، شما یک معیار جدید از ابتدا به نام summarization_helpfulness ایجاد میکنید.
تعریف و اجرای معیار سفارشی
- برای تعریف معیار سفارشی، کد زیر را در یک سلول جدید اجرا کنید.
PointwiseMetricPromptTemplateشامل بلوکهای سازنده برای این معیار است:- معیارها : ابعاد خاصی را که باید ارزیابی شوند به مدل قاضی میگوید: «اطلاعات کلیدی»، «مختصر بودن» و «عدم تحریف».
- rating_rubric : یک مقیاس امتیازدهی ۵ امتیازی ارائه میدهد که معنی هر امتیاز را تعریف میکند.
- input_variables : ستونهای اضافی را از مجموعه دادهها به مدل Judge ارسال میکند تا زمینه لازم برای انجام ارزیابی را داشته باشد.
# This new custom metric evaluates the actual quality and usefulness of the summary. summarization_helpfulness_metric = PointwiseMetric( metric="summarization_helpfulness", metric_prompt_template=PointwiseMetricPromptTemplate( criteria={ "Key Information": "Does the summary capture the most critical pieces of information from the original text? It should not miss the main topic or key takeaways.", "Conciseness": "Is the summary brief and to the point? It should avoid unnecessary words or repetitive information.", "No Distortion": "Does the summary introduce information or opinions that were NOT present in the original text? It must accurately reflect the source material without adding hallucinations." }, rating_rubric={ "5": "Excellent: Captures all key information, is highly concise, and has zero distortion.", "4": "Good: Captures most key information with minor omissions, is concise, and has no distortion.", "3": "Satisfactory: Captures the main idea but misses some key details OR is not very concise.", "2": "Unsatisfactory: Misses the main idea of the original text OR contains minor distortions/hallucinations.", "1": "Poor: Is completely irrelevant, fails to summarize the text, OR contains significant distortions.", }, input_variables=["prompt", "reference"], ), ) - کد زیر را در سلول بعدی اجرا کنید تا
EvalTaskبا معیار سفارشی جدید شما اجرا شود.# You would then update the EvalTask to use this new metric pointwise_result = EvalTask( dataset=dataset, metrics=[summarization_helpfulness_metric], ).evaluate( model=model, prompt_template="# System_prompt\n{system_prompt} # Question\n{question}", ) - برای نمایش نتایج، کد زیر را در یک سلول جدید اجرا کنید.
notebook_utils.display_eval_result(pointwise_result)
۸. مقایسه مدلها با ارزیابی جفتی
وقتی نیاز دارید تصمیم بگیرید کدام یک از دو مدل در یک کار خاص عملکرد بهتری دارند، میتوانید از ارزیابی مبتنی بر مدل جفتی استفاده کنید. این روش نوعی تست A/B است که در آن یک مدل قضاوتی، مدل برنده را تعیین میکند و مقایسه مستقیمی را برای انتخاب مدل مبتنی بر داده فراهم میکند.
مدلها:
- مدل کاندید : متغیر مدل (که قبلاً به صورت
gemini-2.0-flashتعریف شده بود) به متد.evaluate()ارسال میشود. این مدل اصلی است که شما در حال آزمایش آن هستید. - مدل پایه : مدل دوم،
gemini-2.0-flash-lite، درون کلاس PairwiseMetric مشخص شده است. این مدلی است که شما با آن مقایسه میکنید.
ارزیابی دو به دو را اجرا کنید
- در یک سلول جدید، کد زیر را اضافه و اجرا کنید تا یک منوی کشویی تعاملی ایجاد شود. این به شما امکان میدهد معیار مقایسه دو به دوی مورد نظر خود را انتخاب کنید. برای این اجرا، pairwise_summarization_quality را انتخاب کنید.
from IPython.display import display import ipywidgets as widgets pairwise_single_turn_metrics = [ metric for metric in MetricPromptTemplateExamples.list_example_metric_names() if metric.startswith("pairwise") and "multi_turn" not in metric ] dropdown = widgets.Dropdown( options=pairwise_single_turn_metrics, description="Select a metric:", font_weight="bold", style={"description_width": "initial"}, ) def dropdown_eventhandler(change): global POINTWISE_METRIC if change["type"] == "change" and change["name"] == "value": POINTWISE_METRIC = change.new print("Selected:", change.new) def dropdown_eventhandler(change): global PAIRWISE_METRIC_NAME if change["type"] == "change" and change["name"] == "value": PAIRWISE_METRIC_NAME = change.new print("Selected:", change.new) PAIRWISE_METRIC_NAME = dropdown.value dropdown.observe(dropdown_eventhandler, names="value") display(dropdown) - در سلول بعدی، کد زیر را برای پیکربندی و اجرای
EvalTaskاضافه و اجرا کنید. توجه کنید که چگونه از کلاسPairwiseMetricبرای تعریف مدل پایه (gemini-2.0-flash-lite) استفاده شده است، در حالی که مدل کاندید (gemini-2.0-flash) به متد.evaluate()ارسال شده است.pairwise_result = EvalTask( dataset=dataset, metrics=[ PairwiseMetric( metric=PAIRWISE_METRIC_NAME, metric_prompt_template=MetricPromptTemplateExamples.get_prompt_template( PAIRWISE_METRIC_NAME ), # Define a baseline model to compare against baseline_model=GenerativeModel("gemini-2.0-flash-lite"), ) ], ).evaluate( # Specify a candidate model for pairwise comparison model=model, prompt_template="# System_prompt\n{system_prompt} # Question\n{question}", ) - در یک سلول جدید، کد زیر را اضافه و اجرا کنید تا نتایج نمایش داده شود. جدول خلاصه، "نرخ برد" را برای هر مدل نشان میدهد که نشان میدهد مدل قاضی کدام مدل را بیشتر ترجیح میدهد.
notebook_utils.display_eval_result(pairwise_result)
۹. اختیاری: ارزیابی درخواستهای مبتنی بر شخصیت
توجه: این بخش ممکن است در محدوده اعتبار رایگان ارائه شده نباشد.
در این کار، شما چندین الگوی اعلان را آزمایش خواهید کرد که به مدل دستور میدهند شخصیتهای مختلف را اتخاذ کند. این فرآیند که اغلب مهندسی اعلان یا طراحی اعلان نامیده میشود، به شما امکان میدهد تا به طور سیستماتیک موثرترین اعلان را برای یک مورد استفاده خاص پیدا کنید.
آمادهسازی مجموعه دادههای خلاصهسازی
برای انجام این ارزیابی، مجموعه دادهها باید شامل فیلدهای زیر باشد:
-
instruction: وظیفه اصلی که به مدل میدهیم. در این مورد، این یک دستور ساده است: «خلاصه کردن مقاله زیر:». -
context: متن منبعی که مدل باید با آن کار کند. در اینجا، ما چهار قطعه خبر مختلف ارائه دادهایم. -
reference: خلاصهی حقیقت پایه یا «استاندارد طلایی». خروجی تولید شده توسط مدل با این متن مقایسه میشود تا امتیازهایی برای معیارهایی مانند ROUGE و کیفیت خلاصهسازی محاسبه شود.
- در یک سلول جدید، کد زیر را اضافه و اجرا کنید تا یک
pandas.DataFrameبرای وظیفه خلاصهسازی ایجاد شود.instruction = "Summarize the following article: \n" context = [ "Typhoon Phanfone has killed at least one person, a US airman on Okinawa who was washed away by high waves. Thousands of households have lost power and Japan's two largest airlines have suspended many flights. The storm also forced the suspension of the search for people missing after last week's volcanic eruption. The storm-tracking website Tropical Storm Risk forecasts that Phanfone will rapidly lose power over the next few hours as it goes further into the Pacific Ocean. Typhoon Phanfone was downgraded from an earlier status of a super typhoon, but the Japan Meteorological Agency had warned it was still a dangerous storm. Japan averages 11 typhoons a year, according to its weather agency. The typhoon made landfall on Monday morning near the central city of Hamamatsu, with winds of up to 180 km/h (112 mph). The airman was one of three US military personnel swept away by high waves whipped up by the typhoon off southern Okinawa island, where the US has a large military base. The remaining two are still missing. A police spokesman said they had been taking photographs of the sea. A university student who was surfing off the seas of Kanagawa Prefecture, south of Tokyo, was also missing, national broadcast NHK reports. It said at least 10 people had been injured and 9,500 houses were without power. The storm was expected to deposit about 100mm of rain on Tokyo over 24 hours, according to the Transport Ministry website. Many schools were closed on Monday and two car companies in Japan halted production at some plants ahead of the storm. More than 174 domestic flights were affected nationwide, NHK state broadcaster said on Sunday. On Sunday, heavy rain delayed the Japanese Formula One Grand Prix in Suzaka. French driver Jules Bianchi lost control in the wet conditions and crashed, sustaining a severe head injury.", "The blaze started at the detached building in Drivers End in Codicote, near Welwyn, during the morning. There was another fire at the building 20 years ago, after which fire-proof foil was placed under the thatch, which is protecting the main building. More than 15 fire engines and support vehicles were called to tackle the blaze. Roads in the area were closed and traffic diverted.", 'The 18-year-old fell at the New Charter Academy on Broadoak Road in Ashton-under-Lyne at about 09:10 BST, Greater Manchester Police (GMP) said. GMP said he had gone to Manchester Royal Infirmary and his condition was "serious". Principal Jenny Langley said the school would remain "fully open" while police investigated. "Our thoughts are with the family and we\'re doing everything we can to support them along with staff and pupils," she said.', 'But Belgian-born Dutchman Max Verstappen was unable to drive a car legally on his own in either country. That all changed on Wednesday when the youngster turned 18 and passed his driving test at the first attempt. Despite having competed in 14 grands prix since his debut in Australia in March, Verstappen admitted to feeling the pressure during his test. "It\'s a relief," said the Toro Rosso driver, who finished ninth in Japan on Sunday and had only started driving lessons a week ago. "I was a bit nervous to make mistakes, but the exam went well." A bonus of turning 18 is that Verstappen will now be able to drink the champagne if he ever makes it onto the podium.', ] reference = [ "A powerful typhoon has brought many parts of Japan to a standstill and briefly battered Tokyo before heading out to sea.", "A major fire has been burning in the thatched roof of a large property in Hertfordshire.", "A student has been taken to hospital after falling from a balcony at a Greater Manchester school.", "He is Formula 1's youngest ever driver and in charge of a car that can reach over 200mph.", ] response = [ "Typhoon Phanfone, while downgraded from super typhoon status, caused significant disruption and tragedy in Japan. One US airman died after being swept away by high waves, with two more missing. The storm caused power outages for thousands, flight cancellations, and the suspension of rescue efforts for missing volcano victims. Heavy rain and strong winds led to school and factory closures, transportation disruptions, and at least 10 injuries. The typhoon is expected to weaken as it moves over the Pacific Ocean.", "A large fire broke out in a detached thatched building in Codicote, near Welwyn. This is the second fire at the building in 20 years. Thankfully, fire-proof foil installed after the previous fire is protecting the main building. Over 15 fire engines and support vehicles responded, closing roads and diverting traffic in the area.", "An 18-year-old student at New Charter Academy in Ashton-under-Lyne suffered a serious fall and was hospitalized. The incident is under investigation by Greater Manchester Police, but the school remains open. The principal expressed support for the student's family and the school community.", "Max Verstappen, a Formula One driver, was finally able to get his driver's license at age 18. Despite already competing in 14 Grand Prix races, he was not of legal driving age in his native countries. He admitted to being nervous but passed the test on his first attempt. As an added bonus of turning 18, Verstappen can now enjoy champagne on the podium if he places.", ] eval_dataset = pd.DataFrame( { "instruction": instruction, "context": context, "reference": reference, } )
اجرای وظیفه ارزیابی سریع
با آماده شدن مجموعه دادههای خلاصهسازی، شما آماده اجرای آزمایش اصلی این کار هستید: مقایسه چندین قالب اعلان برای دیدن اینکه کدام یک خروجی با بالاترین کیفیت را از مدل تولید میکند.
- در سلول بعدی، یک
EvalTaskواحد ایجاد کنید که برای هر آزمایش سریع مورد استفاده مجدد قرار خواهد گرفت. با تنظیم پارامترexperiment، تمام ارزیابیهای انجام شده از این وظیفه به طور خودکار ثبت شده و در Vertex AI Experiments گروهبندی میشوند.EXPERIMENT_NAME = "eval-sdk-prompt-engineering" # @param {type:"string"} summarization_eval_task = EvalTask( dataset=eval_dataset, metrics=[ "rouge_l_sum", "bleu", "fluency", "coherence", "safety", "groundedness", "summarization_quality", "verbosity", "instruction_following", "text_quality", ], experiment=EXPERIMENT_NAME, )rouge_l_sumوbleuگرفته تا طیف گستردهای از معیارهای مبتنی بر مدل (fluency،coherence،summarization_quality،instruction_followingو غیره) محاسبه کند. این به ما یک دید جامع و ۳۶۰ درجه از چگونگی تأثیر هر اعلان بر کیفیت خروجی مدل میدهد. - در یک سلول جدید، کد زیر را برای تعریف و ارزیابی چهار استراتژی اعلان مبتنی بر شخصیت اضافه و اجرا کنید. حلقه
forروی هر الگو تکرار میشود و یک ارزیابی اجرا میکند. هر الگو به گونهای طراحی شده است که با دادن یک شخصیت یا هدف خاص به مدل، سبک متفاوتی از خلاصه را استخراج کند:- پرسونا شماره ۱ (استاندارد) : یک درخواست خلاصهسازی بیطرفانه و سرراست.
- پرسونا شماره ۲ (مدیر اجرایی) : همانطور که یک مدیر اجرایی پرمشغله ترجیح میدهد، خلاصهای از مطالب را به صورت فهرستوار میخواهد و بر نتایج و تأثیر آن تمرکز دارد.
- پرسونا شماره ۳ (کلاس پنجم) : به مدل دستور میدهد که از زبان ساده استفاده کند و توانایی آن را در تنظیم پیچیدگی خروجیاش آزمایش میکند.
- پرسونا شماره ۴ (تحلیلگر فنی) : خلاصهای کاملاً واقعی را میطلبد که در آن آمارها و موجودیتهای کلیدی حفظ شده و دقت مدل آزمایش شود. توجه داشته باشید که متغیرهای موجود در این قالبهای جدید، مانند
{context}و{instruction}، با نام ستونهای جدید در مجموعهeval_datasetکه برای این کار ایجاد کردهاید، مطابقت دارند.
# Define prompt templates that target different user personas prompt_templates = [ # Persona 1: Standard, neutral summary "Article: {context}. Task: {instruction}. Summary:", # Persona 2: For a busy executive (bullet points) "Instruction: {instruction} into three key bullet points for a busy executive. Focus on the main outcome and impact. Article: {context}. Summary:", # Persona 3: For a 5th grader (simple language) "Instruction: {instruction} such that you're explaining it to a 10-year-old. Use simple words. Article: {context}. Summary:", # Persona 4: For a technical analyst (fact-focused) "Instruction: Provide a detailed, factual summary of the following text, ensuring all key statistics, names, and locations are preserved. Article: {context}. Summary:", ] eval_results = [] for i, prompt_template in enumerate(prompt_templates): eval_result = summarization_eval_task.evaluate( prompt_template=prompt_template, model=GenerativeModel( "gemini-2.0-flash", generation_config={ "temperature": 0.3, "max_output_tokens": 256, "top_k": 1, }, ), evaluation_service_qps=5, ) eval_results.append((f"Prompt Persona #{i+1}", eval_result))
تجزیه و تحلیل و تجسم نتایج
اجرای آزمایشها اولین قدم است. ارزش واقعی از تجزیه و تحلیل نتایج برای تصمیمگیری مبتنی بر داده حاصل میشود. در این کار، شما از ابزارهای تجسم SDK برای تفسیر خروجیهای آزمایش شخصیت سریع استفاده خواهید کرد.
- با اجرای کد زیر در یک سلول جدید، خلاصه نتایج هر یک از چهار پرسونا (شخصیت) مورد آزمایش را نمایش دهید. این به شما یک نمای کمی سطح بالا از عملکرد میدهد.
for title, eval_result in eval_results: notebook_utils.display_eval_result(title=title, eval_result=eval_result) - در یک سلول جدید، کد زیر را اضافه و اجرا کنید تا منطق معیار
summarization_qualityرا برای هر پرسونا مشاهده کنید.for title, eval_result in eval_results: notebook_utils.display_explanations( eval_result, metrics=["summarization_quality"], num=2 ) - یک نمودار رادار ایجاد کنید تا بده بستانهای بین معیارهای کیفی مختلف را برای هر درخواست به تصویر بکشید. در یک سلول جدید، کد زیر را اضافه و اجرا کنید.
notebook_utils.display_radar_plot( eval_results, metrics=["instruction_following", "fluency", "coherence", "text_quality"], ) - برای مقایسهی مستقیمتر و پهلو به پهلو، یک نمودار میلهای ایجاد کنید. در یک سلول جدید، کد زیر را اضافه و اجرا کنید.
notebook_utils.display_bar_plot( eval_results, metrics=["instruction_following", "fluency", "coherence", "text_quality"], )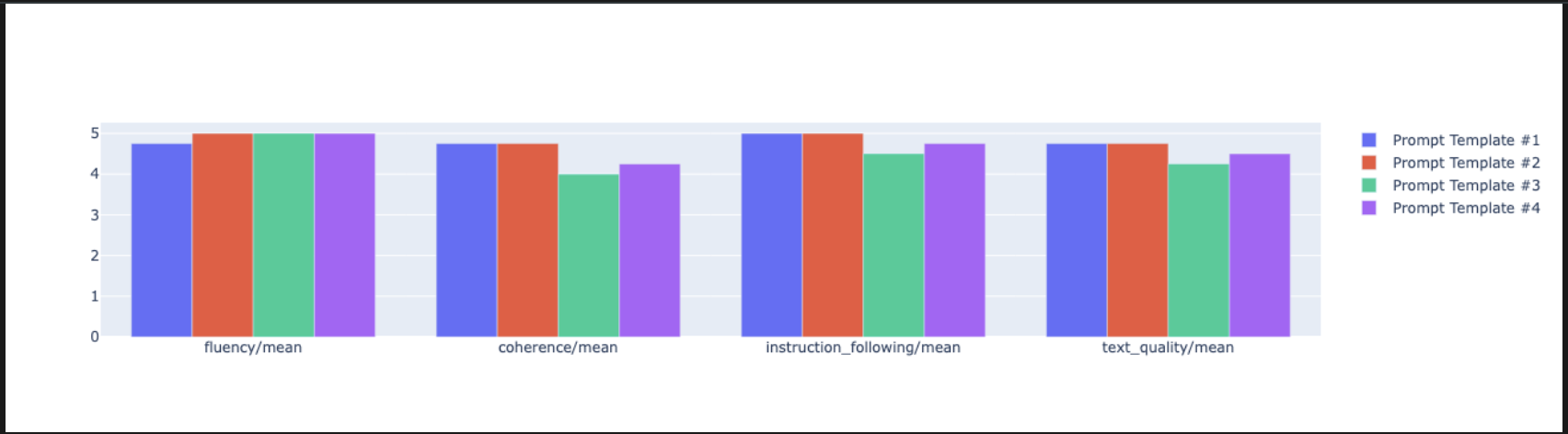
- اکنون میتوانید خلاصهای از تمام اجراهایی که برای این کار در Vertex AI Experiment ثبت شدهاند را مشاهده کنید. این برای پیگیری کار شما در طول زمان مفید است. در یک سلول جدید، کد زیر را اضافه و اجرا کنید:
summarization_eval_task.display_runs()
۱۰. آزمایش را تمیز کنید
برای سازماندهی پروژه و جلوگیری از هزینههای غیرضروری، بهترین روش پاکسازی منابعی است که ایجاد کردهاید. در طول این آزمایش، هر اجرای ارزیابی در یک آزمایش هوش مصنوعی Vertex ثبت شد. کد زیر این آزمایش والد را حذف میکند که این امر باعث حذف تمام اجراهای مرتبط و دادههای زیربنایی آنها نیز میشود.
- این کد را در یک سلول جدید اجرا کنید تا آزمایش هوش مصنوعی و اجراهای مرتبط با آن حذف شوند.
delete_experiment = True # Please set your LOCATION to the same one used during Vertex AI SDK initialization. LOCATION = "YOUR LOCATION" # @param {type:"string"} if delete_experiment: from google.cloud import aiplatform aiplatform.init(project=PROJECT_ID, location=LOCATION) experiment = aiplatform.Experiment(EXPERIMENT_NAME) experiment.delete()
۱۱. از تمرین تا تولید
مهارتهایی که در این آزمایشگاه آموختهاید، بلوکهای سازنده برای ایجاد برنامههای کاربردی هوش مصنوعی قابل اعتماد هستند. با این حال، حرکت از یک دفترچه یادداشت دستی به یک سیستم ارزیابی در سطح تولید، نیاز به زیرساختهای اضافی و رویکردی سیستماتیکتر دارد. این بخش، شیوههای کلیدی و چارچوبهای استراتژیک را که باید هنگام افزایش مقیاس در نظر بگیرید، تشریح میکند.
استراتژیهای ارزیابی تولید ساختمان
برای بهکارگیری مهارتهای این آزمایشگاه در یک محیط عملیاتی، فرموله کردن آنها در استراتژیهای تکرارپذیر مفید است. چارچوبهای زیر ملاحظات کلیدی برای سناریوهای رایج مانند انتخاب مدل، بهینهسازی سریع و نظارت مستمر را تشریح میکنند.
برای انتخاب مدل:
# Evaluation strategy for choosing models
evaluation_strategy = {
"dataset_size": "100+ examples for statistical significance",
"metrics": ["task-specific", "general quality", "efficiency"],
"comparison_type": "pairwise with statistical testing",
"baseline": "established_model_or_human_benchmark"
}
برای بهینه سازی سریع
# Systematic prompt improvement workflow
prompt_optimization = {
"hypothesis": "Clear statement of what you're testing",
"variants": "3-5 different prompt strategies",
"evaluation": "Same metrics across all variants",
"analysis": "Statistical significance + qualitative review"
}
برای نظارت مداوم
# Production evaluation pipeline
production_eval = {
"frequency": "Every model update + weekly monitoring",
"automation": "CI/CD integration with quality gates",
"metrics": "Speed + quality + cost tracking",
"alerting": "Performance degradation detection"
}
ملاحظات مقرون به صرفه بودن
ارزیابی مبتنی بر مدل میتواند در مقیاس بزرگ گران باشد. یک استراتژی تولید مقرون به صرفه از روشهای مختلفی برای اهداف مختلف استفاده میکند. این جدول خلاصهای از بده بستانهای بین سرعت، هزینه و مورد استفاده برای انواع مختلف ارزیابی را نشان میدهد:
نوع ارزیابی | زمان | هزینه هر نمونه | بهترین برای |
سرخ/آبی | ثانیهها | ~0.001 دلار | غربالگری با حجم بالا |
مدل مبتنی بر نقطه | حدود ۱-۲ ثانیه | ~0.01 دلار | ارزیابی کیفیت |
مقایسه دو به دو | حدود ۲-۳ ثانیه | ~0.02 دلار | انتخاب مدل |
ارزیابی انسانی | دقیقه | ۱ تا ۱۰ دلار | اعتبارسنجی استاندارد طلایی |
خودکارسازی با CI/CD و نظارت
اجرای دستی نوتبوکها مقیاسپذیر نیست. ارزیابی خود را در یک خط لوله ادغام مداوم/استقرار مداوم (CI/CD) خودکار کنید.
- ایجاد دروازههای کیفیت : وظیفه ارزیابی خود را در یک خط لوله CI/CD (مثلاً Cloud Build) ادغام کنید. ارزیابیها را به طور خودکار روی پیشنهادات یا مدلهای جدید اجرا کنید و در صورت کاهش نمرات کیفیت کلیدی به زیر آستانههای تعریف شده، استقرارها را مسدود کنید.
- روندها را رصد کنید : خلاصهای از معیارهای ارزیابی خود را به سرویسی مانند Google Cloud Monitoring منتقل کنید. داشبوردهایی برای ردیابی کیفیت در طول زمان بسازید و هشدارهای خودکار تنظیم کنید تا تیم خود را از هرگونه افت عملکرد قابل توجه مطلع کنید.
۱۲. نتیجهگیری
شما آزمایشگاه را به پایان رساندهاید. مهارتهای ضروری برای ارزیابی مدلهای هوش مصنوعی مولد را آموختهاید.
این آزمایشگاه بخشی از پروژه «هوش مصنوعی آماده تولید با مسیر یادگیری ابری گوگل» است.
- برای پر کردن شکاف بین نمونه اولیه و تولید، برنامه درسی کامل را بررسی کنید .
- پیشرفت خود را با هشتگ
ProductionReadyAIبه اشتراک بگذارید.
خلاصه
در این آزمایشگاه، شما یاد گرفتید که چگونه:
- با استفاده از چارچوب
EvalTaskبهترین شیوههای ارزیابی را به کار بگیرید. - از انواع مختلف معیارها، از معیارهای مبتنی بر محاسبات گرفته تا معیارهای مبتنی بر مدل، استفاده کنید.
- با آزمایش نسخههای مختلف، دستورالعملها را بهینه کنید.
- با ردیابی آزمایش، یک گردش کار تکرارپذیر بسازید.
منابع برای یادگیری مداوم
- مستندات ارزیابی هوش مصنوعی Vertex AI Gen
- دفترچههای راهنمای تکنیکهای ارزیابی پیشرفته
- مرجع SDK ارزیابی هوش مصنوعی عمومی
- تحقیقات معیارهای مبتنی بر مدل
- بهترین شیوههای مهندسی سریع
رویکردهای ارزیابی سیستماتیکی که در این آزمایشگاه آموختهاید، به عنوان پایهای برای ساخت برنامههای کاربردی هوش مصنوعی قابل اعتماد و با کیفیت بالا عمل خواهند کرد. به یاد داشته باشید: ارزیابی خوب، پلی بین هوش مصنوعی تجربی و موفقیت در تولید است.