
1. Présentation
Dans cet atelier, vous allez apprendre à évaluer de grands modèles de langage à l'aide de Gen AI Evaluation Service de Vertex AI. Vous utiliserez le SDK pour exécuter des jobs d'évaluation, comparer les résultats et prendre des décisions basées sur les données concernant les performances du modèle et la conception des requêtes.
L'atelier vous guide à travers un workflow d'évaluation courant, en commençant par des métriques simples basées sur le calcul et en passant à des évaluations plus nuancées basées sur des modèles. Vous apprendrez également à créer des métriques personnalisées adaptées à vos objectifs spécifiques et à suivre votre travail à l'aide de Vertex AI Experiments.
Points abordés
Dans cet atelier, vous allez apprendre à effectuer les tâches suivantes :
- Évaluez un modèle avec des métriques basées sur le calcul et sur un modèle.
- Créez une métrique personnalisée pour aligner l'évaluation sur les objectifs du produit.
- Comparer différents modèles de requête côte à côte
- Testez plusieurs requêtes basées sur des personas pour trouver la version la plus efficace.
- Suivez et visualisez les exécutions d'évaluation à l'aide de Vertex AI Experiments.
Références
- Exemples de code : cet atelier s'appuie sur des exemples du dépôt Google Cloud pour l'IA générative.
- Basé sur la documentation sur l'évaluation de l'IA générative Vertex AI
- Ensemble de données : ensemble de données OpenOrca pour l'évaluation du respect des instructions
2. Configuration du projet
Compte Google
Si vous ne possédez pas encore de compte Google personnel, vous devez en créer un.
Utilisez un compte personnel au lieu d'un compte professionnel ou scolaire.
Se connecter à la console Google Cloud
Connectez-vous à la console Google Cloud à l'aide d'un compte Google personnel.
Activer la facturation
Pour activer la facturation, vous avez deux options. Vous pouvez utiliser votre compte de facturation personnel ou échanger des crédits en suivant les étapes ci-dessous.
Utiliser des crédits Google Cloud (facultatif)
Pour suivre cet atelier, vous avez besoin d'un compte de facturation avec un certain crédit. Utilisez les crédits de la bannière en haut de cet atelier de programmation pour commencer. Si vous êtes déjà associé à un compte de facturation, vous pouvez ignorer cette étape.
Configurer un compte de facturation personnel
Si vous avez configuré la facturation à l'aide de crédits Google Cloud, vous pouvez ignorer cette étape.
Pour configurer un compte de facturation personnel, cliquez ici pour activer la facturation dans la console Cloud.
Remarques :
- Cet atelier devrait vous coûter moins de 1 USD en ressources Cloud.
- Vous pouvez suivre les étapes à la fin de cet atelier pour supprimer les ressources et éviter ainsi des frais supplémentaires.
- Les nouveaux utilisateurs peuvent bénéficier d'un essai sans frais pour bénéficier d'un crédit de 300$.
Créer un projet (facultatif)
Si vous n'avez pas de projet que vous souhaitez utiliser pour cet atelier, créez-en un.
3. Configurer votre environnement Vertex AI Workbench
Commençons par accéder à votre environnement de notebook préconfiguré et à installer les dépendances nécessaires.
Accéder à Vertex AI Workbench
- Dans la console Google Cloud, accédez à Vertex AI en cliquant sur le menu de navigation ☰ > Vertex AI > Tableau de bord.
- Cliquez sur Activer toutes les API recommandées. Remarque : Veuillez attendre la fin de cette étape.
- Sur la gauche, cliquez sur Workbench pour créer une instance Workbench.
- Nommez l'instance Workbench evaluation-workbench, puis cliquez sur Créer.
- Attendez que l'atelier soit configuré. Cette opération peut prendre quelques minutes.

- Une fois le workbench provisionné, cliquez sur Ouvrir JupyterLab.
- Dans l'atelier, créez un notebook Python3.
Pour en savoir plus sur les fonctionnalités de cet environnement, consultez la documentation officielle de Vertex AI Workbench.
Installer des packages et configurer votre environnement
- Dans la première cellule de votre notebook, ajoutez et exécutez les instructions d'importation ci-dessous (MAJ+ENTRÉE) pour installer le SDK Vertex AI (avec les composants d'évaluation) et les autres packages requis.
%pip install -U -q google-cloud-aiplatform[evaluation] %pip install -U -q datasets anthropic[vertex] openai - Pour utiliser les packages nouvellement installés, il est recommandé de redémarrer le noyau en exécutant l'extrait de code ci-dessous.
# Automatically restart kernel after installation so that your environment can access the new packages. import IPython app = IPython.Application.instance() app.kernel.do_shutdown(True) - Remplacez les éléments suivants par l'ID et l'emplacement de votre projet, puis exécutez la cellule suivante. L'emplacement par défaut est défini sur
europe-west1, mais vous devez utiliser le même emplacement que celui de votre instance Vertex AI Workbench.# Configure your project settings PROJECT_ID = "YOUR PROJECT ID" LOCATION = "europe-west1" - Importez toutes les bibliothèques Python requises pour cet atelier en exécutant le code suivant dans une nouvelle cellule.
from anthropic import AnthropicVertex from google.auth import default, transport import openai import pandas as pd from vertexai.evaluation import ( EvalTask, MetricPromptTemplateExamples, PairwiseMetric, PointwiseMetric, PointwiseMetricPromptTemplate, ) from vertexai.generative_models import GenerativeModel from vertexai.preview.evaluation import notebook_utils
4. Configurer votre ensemble de données d'évaluation
Pour ce tutoriel, nous allons utiliser 10 échantillons de l'ensemble de données OpenOrca. Cela nous donne suffisamment de données pour voir des différences significatives entre les modèles tout en gardant un temps d'évaluation raisonnable.
💡 Conseil de pro : En production, vous aurez besoin de 100 à 500 exemples pour obtenir des résultats statistiquement significatifs, mais 10 échantillons suffisent pour l'apprentissage et le prototypage rapide.
Préparer l'ensemble de données
- Dans une nouvelle cellule, exécutez la cellule suivante pour charger les données, les convertir en DataFrame pandas, renommer la colonne
responseenreferencepour plus de clarté dans nos tâches d'évaluation et créer l'échantillon aléatoire de dix exemples.from datasets import load_dataset ds = ( load_dataset( "Open-Orca/OpenOrca", data_files="1M-GPT4-Augmented.parquet", split="train[:100]", ) .to_pandas() .drop(columns=["id"]) .rename(columns={"response": "reference"}) ) dataset = ds.sample(n=10) - Une fois l'exécution de la cellule précédente terminée, ajoutez et exécutez le code suivant dans la cellule suivante pour afficher les premières lignes de votre ensemble de données d'évaluation.
dataset.head()
5. Établir une référence avec des métriques basées sur des calculs
Dans cette tâche, vous allez établir un score de référence à l'aide d'une métrique basée sur des calculs. Cette approche est rapide et fournit un benchmark objectif pour mesurer les améliorations futures.
Nous utiliserons ROUGE (Recall-Oriented Understudy for Gisting Evaluation), une métrique standard pour les tâches de synthèse. Pour ce faire, elle compare la séquence de mots (n-grammes) de la réponse générée par le modèle aux mots du texte de vérité terrain reference.
En savoir plus sur les métriques basées sur les calculs
Exécuter l'évaluation de référence
- Dans une nouvelle cellule, ajoutez et exécutez la cellule suivante pour définir le modèle que vous souhaitez tester,
gemini-2.0-flash.generation_configinclut des paramètres tels quetemperatureetmax_output_tokensqui influencent la sortie du modèle.# Model to be evaluated model = GenerativeModel( "gemini-2.0-flash", generation_config={"temperature": 0.6, "max_output_tokens": 256, "top_k": 1}, )GenerativeModelest l'interface principale pour interagir avec les grands modèles de langage dans le SDK Vertex AI. - Dans la cellule suivante, ajoutez et exécutez le code suivant pour créer et exécuter
EvalTask. Cet objet du SDK Vertex AI Evaluation orchestre l'évaluation. Vous le configurez avec l'ensemble de données et les métriques à calculer, qui dans ce cas sontrouge_l_sum.# Define an EvalTask with ROUGE-L-SUM metric rouge_eval_task = EvalTask( dataset=dataset, metrics=["rouge_l_sum"], ) rouge_result = rouge_eval_task.evaluate( model=model, prompt_template="# System_prompt\n{system_prompt} # Question\n{question}", ) - Affichez les résultats en exécutant ce code dans la cellule suivante.
notebook_utils.display_eval_result(rouge_result)display_eval_result()affiche le score moyen et les résultats ligne par ligne.
6. Facultatif : Évaluer avec des métriques ponctuelles basées sur un modèle
Remarque : Il est possible que cette section ne s'exécute pas dans la limite des crédits sans frais fournis.
Bien que ROUGE soit utile, il ne mesure que le chevauchement lexical (c'est-à-dire qu'il ne compte que les mots correspondants, sans tenir compte du contexte, des synonymes ni des paraphrases). Ce n'est donc pas la meilleure solution pour déterminer si une réponse est fluide ou logique. Pour mieux comprendre les performances du modèle, vous utilisez des métriques ponctuelles basées sur le modèle.
Avec cette méthode, un autre LLM (le "modèle juge") évalue chaque réponse individuellement en fonction d'un ensemble de critères prédéfinis, comme la fluidité ou la cohérence.
En savoir plus sur les métriques basées sur des modèles
Exécuter l'évaluation par point
- Exécutez le code suivant dans une nouvelle cellule pour créer un menu déroulant interactif. Pour cette exécution, sélectionnez coherence dans la liste.
#Select a pointwise metric to use import ipywidgets as widgets pointwise_single_turn_metrics = [ metric for metric in MetricPromptTemplateExamples.list_example_metric_names() if not metric.startswith("pairwise") and not metric.startswith("multi_turn") ] dropdown = widgets.Dropdown( options=pointwise_single_turn_metrics, description="Select a metric:", font_weight="bold", style={"description_width": "initial"}, ) def dropdown_eventhandler(change): global POINTWISE_METRIC if change["type"] == "change" and change["name"] == "value": POINTWISE_METRIC = change.new print("Selected:", change.new) POINTWISE_METRIC = dropdown.value dropdown.observe(dropdown_eventhandler, names="value") display(dropdown) - Dans une nouvelle cellule, exécutez de nouveau
EvalTask, cette fois en utilisant la métrique basée sur le modèle sélectionné. Vertex AI Evaluation Service crée une requête pour le modèle d'évaluation, qui inclut la requête d'origine, la réponse de référence, la réponse du modèle candidat et les instructions pour la métrique sélectionnée. Le modèle d'évaluation renvoie un score numérique et une explication pour sa note. Remarque : L'exécution de cette étape prendra quelques minutes.pointwise_result = EvalTask( dataset=dataset, metrics=[POINTWISE_METRIC], ).evaluate( model=model, prompt_template="# System_prompt\n{system_prompt} # Question\n{question}", )
Afficher les résultats
Une fois l'évaluation terminée, l'étape suivante consiste à analyser le résultat.
- Exécutez le code suivant dans une nouvelle cellule pour afficher les métriques récapitulatives, qui indiquent le score moyen de la métrique choisie.
notebook_utils.display_eval_result(pointwise_result) - Exécutez le code suivant dans la cellule suivante pour afficher la répartition ligne par ligne, qui inclut la justification écrite du modèle Judge pour son score. Ces commentaires qualitatifs vous aident à comprendre pourquoi une réponse a été notée d'une certaine manière.
notebook_utils.display_explanations(pointwise_result, num=1, metrics=[POINTWISE_METRIC])
7. Créer une métrique personnalisée pour obtenir des insights plus approfondis
Les métriques prédéfinies telles que la fluidité sont utiles, mais pour un produit spécifique, vous devez souvent mesurer les performances par rapport à vos propres objectifs. Les métriques ponctuelles personnalisées vous permettent de définir vos propres critères et rubriques d'évaluation.
Dans cette tâche, vous allez créer une métrique de toutes pièces appelée summarization_helpfulness.
Définir et exécuter la métrique personnalisée
- Exécutez le code suivant dans une nouvelle cellule pour définir la métrique personnalisée.
PointwiseMetricPromptTemplatecontient les blocs de construction de la métrique :- criteria : indique au modèle d'évaluation les dimensions spécifiques à évaluer : "Informations clés", "Concision" et "Absence de distorsion".
- rating_rubric : fournit une échelle de notation à cinq points qui définit la signification de chaque score.
- input_variables : transmet des colonnes supplémentaires de l'ensemble de données au modèle d'évaluation afin qu'il dispose du contexte nécessaire pour effectuer l'évaluation.
# This new custom metric evaluates the actual quality and usefulness of the summary. summarization_helpfulness_metric = PointwiseMetric( metric="summarization_helpfulness", metric_prompt_template=PointwiseMetricPromptTemplate( criteria={ "Key Information": "Does the summary capture the most critical pieces of information from the original text? It should not miss the main topic or key takeaways.", "Conciseness": "Is the summary brief and to the point? It should avoid unnecessary words or repetitive information.", "No Distortion": "Does the summary introduce information or opinions that were NOT present in the original text? It must accurately reflect the source material without adding hallucinations." }, rating_rubric={ "5": "Excellent: Captures all key information, is highly concise, and has zero distortion.", "4": "Good: Captures most key information with minor omissions, is concise, and has no distortion.", "3": "Satisfactory: Captures the main idea but misses some key details OR is not very concise.", "2": "Unsatisfactory: Misses the main idea of the original text OR contains minor distortions/hallucinations.", "1": "Poor: Is completely irrelevant, fails to summarize the text, OR contains significant distortions.", }, input_variables=["prompt", "reference"], ), ) - Exécutez le code suivant dans la cellule suivante pour exécuter
EvalTaskavec votre nouvelle métrique personnalisée.# You would then update the EvalTask to use this new metric pointwise_result = EvalTask( dataset=dataset, metrics=[summarization_helpfulness_metric], ).evaluate( model=model, prompt_template="# System_prompt\n{system_prompt} # Question\n{question}", ) - Exécutez le code suivant dans une nouvelle cellule pour afficher les résultats.
notebook_utils.display_eval_result(pointwise_result)
8. Comparer des modèles avec l'évaluation par paire
Lorsque vous devez déterminer lequel de deux modèles est le plus performant pour une tâche spécifique, vous pouvez utiliser l'évaluation par paire basée sur un modèle. Cette méthode est une forme de test A/B dans laquelle un modèle de juge détermine un gagnant, ce qui permet une comparaison directe pour la sélection de modèles basée sur les données.
Les modèles :
- Modèle candidat : la variable de modèle (qui était précédemment définie comme
gemini-2.0-flash) est transmise à la méthode.evaluate(). Il s'agit du modèle principal que vous testez. - Modèle de référence : un deuxième modèle,
gemini-2.0-flash-lite, est spécifié dans la classe PairwiseMetric. Il s'agit du modèle que vous comparez.
Exécuter l'évaluation par paire
- Dans une nouvelle cellule, ajoutez et exécutez le code suivant pour créer un menu déroulant interactif. Vous pourrez ainsi sélectionner la métrique par paire que vous souhaitez utiliser pour la comparaison. Pour cette exécution, sélectionnez pairwise_summarization_quality.
from IPython.display import display import ipywidgets as widgets pairwise_single_turn_metrics = [ metric for metric in MetricPromptTemplateExamples.list_example_metric_names() if metric.startswith("pairwise") and "multi_turn" not in metric ] dropdown = widgets.Dropdown( options=pairwise_single_turn_metrics, description="Select a metric:", font_weight="bold", style={"description_width": "initial"}, ) def dropdown_eventhandler(change): global POINTWISE_METRIC if change["type"] == "change" and change["name"] == "value": POINTWISE_METRIC = change.new print("Selected:", change.new) def dropdown_eventhandler(change): global PAIRWISE_METRIC_NAME if change["type"] == "change" and change["name"] == "value": PAIRWISE_METRIC_NAME = change.new print("Selected:", change.new) PAIRWISE_METRIC_NAME = dropdown.value dropdown.observe(dropdown_eventhandler, names="value") display(dropdown) - Dans la cellule suivante, ajoutez et exécutez le code suivant pour configurer et exécuter
EvalTask. Notez que la classePairwiseMetricest utilisée pour définir le modèle de référence (gemini-2.0-flash-lite), tandis que le modèle candidat (gemini-2.0-flash) est transmis à la méthode.evaluate().pairwise_result = EvalTask( dataset=dataset, metrics=[ PairwiseMetric( metric=PAIRWISE_METRIC_NAME, metric_prompt_template=MetricPromptTemplateExamples.get_prompt_template( PAIRWISE_METRIC_NAME ), # Define a baseline model to compare against baseline_model=GenerativeModel("gemini-2.0-flash-lite"), ) ], ).evaluate( # Specify a candidate model for pairwise comparison model=model, prompt_template="# System_prompt\n{system_prompt} # Question\n{question}", ) - Dans une nouvelle cellule, ajoutez et exécutez le code suivant pour afficher les résultats. Le tableau récapitulatif affichera le "taux de victoire" de chaque modèle, indiquant celui que le modèle Judge a préféré le plus souvent.
notebook_utils.display_eval_result(pairwise_result)
9. Facultatif : Évaluer les requêtes axées sur les personas
Remarque : Il est possible que cette section ne s'exécute pas dans la limite des crédits sans frais fournis.
Dans cette tâche, vous allez tester plusieurs modèles d'invite qui demandent au modèle d'adopter différentes personnalités. Ce processus, souvent appelé ingénierie des requêtes ou conception des requêtes, vous permet de trouver systématiquement la requête la plus efficace pour un cas d'utilisation spécifique.
Préparer l'ensemble de données de synthèse
Pour effectuer cette évaluation, l'ensemble de données doit contenir les champs suivants :
instruction: tâche principale que nous confions au modèle. Dans ce cas, il s'agit d'une simple requête "Résume l'article suivant :".context: texte source avec lequel le modèle doit travailler. Nous avons fourni ici quatre extraits d'actualités différents.reference: résumé de référence ou "gold standard". La sortie générée par le modèle sera comparée à ce texte pour calculer les scores de métriques telles que ROUGE et la qualité de la synthèse.
- Dans une nouvelle cellule, ajoutez et exécutez le code suivant pour créer un
pandas.DataFramepour la tâche de synthèse.instruction = "Summarize the following article: \n" context = [ "Typhoon Phanfone has killed at least one person, a US airman on Okinawa who was washed away by high waves. Thousands of households have lost power and Japan's two largest airlines have suspended many flights. The storm also forced the suspension of the search for people missing after last week's volcanic eruption. The storm-tracking website Tropical Storm Risk forecasts that Phanfone will rapidly lose power over the next few hours as it goes further into the Pacific Ocean. Typhoon Phanfone was downgraded from an earlier status of a super typhoon, but the Japan Meteorological Agency had warned it was still a dangerous storm. Japan averages 11 typhoons a year, according to its weather agency. The typhoon made landfall on Monday morning near the central city of Hamamatsu, with winds of up to 180 km/h (112 mph). The airman was one of three US military personnel swept away by high waves whipped up by the typhoon off southern Okinawa island, where the US has a large military base. The remaining two are still missing. A police spokesman said they had been taking photographs of the sea. A university student who was surfing off the seas of Kanagawa Prefecture, south of Tokyo, was also missing, national broadcast NHK reports. It said at least 10 people had been injured and 9,500 houses were without power. The storm was expected to deposit about 100mm of rain on Tokyo over 24 hours, according to the Transport Ministry website. Many schools were closed on Monday and two car companies in Japan halted production at some plants ahead of the storm. More than 174 domestic flights were affected nationwide, NHK state broadcaster said on Sunday. On Sunday, heavy rain delayed the Japanese Formula One Grand Prix in Suzaka. French driver Jules Bianchi lost control in the wet conditions and crashed, sustaining a severe head injury.", "The blaze started at the detached building in Drivers End in Codicote, near Welwyn, during the morning. There was another fire at the building 20 years ago, after which fire-proof foil was placed under the thatch, which is protecting the main building. More than 15 fire engines and support vehicles were called to tackle the blaze. Roads in the area were closed and traffic diverted.", 'The 18-year-old fell at the New Charter Academy on Broadoak Road in Ashton-under-Lyne at about 09:10 BST, Greater Manchester Police (GMP) said. GMP said he had gone to Manchester Royal Infirmary and his condition was "serious". Principal Jenny Langley said the school would remain "fully open" while police investigated. "Our thoughts are with the family and we\'re doing everything we can to support them along with staff and pupils," she said.', 'But Belgian-born Dutchman Max Verstappen was unable to drive a car legally on his own in either country. That all changed on Wednesday when the youngster turned 18 and passed his driving test at the first attempt. Despite having competed in 14 grands prix since his debut in Australia in March, Verstappen admitted to feeling the pressure during his test. "It\'s a relief," said the Toro Rosso driver, who finished ninth in Japan on Sunday and had only started driving lessons a week ago. "I was a bit nervous to make mistakes, but the exam went well." A bonus of turning 18 is that Verstappen will now be able to drink the champagne if he ever makes it onto the podium.', ] reference = [ "A powerful typhoon has brought many parts of Japan to a standstill and briefly battered Tokyo before heading out to sea.", "A major fire has been burning in the thatched roof of a large property in Hertfordshire.", "A student has been taken to hospital after falling from a balcony at a Greater Manchester school.", "He is Formula 1's youngest ever driver and in charge of a car that can reach over 200mph.", ] response = [ "Typhoon Phanfone, while downgraded from super typhoon status, caused significant disruption and tragedy in Japan. One US airman died after being swept away by high waves, with two more missing. The storm caused power outages for thousands, flight cancellations, and the suspension of rescue efforts for missing volcano victims. Heavy rain and strong winds led to school and factory closures, transportation disruptions, and at least 10 injuries. The typhoon is expected to weaken as it moves over the Pacific Ocean.", "A large fire broke out in a detached thatched building in Codicote, near Welwyn. This is the second fire at the building in 20 years. Thankfully, fire-proof foil installed after the previous fire is protecting the main building. Over 15 fire engines and support vehicles responded, closing roads and diverting traffic in the area.", "An 18-year-old student at New Charter Academy in Ashton-under-Lyne suffered a serious fall and was hospitalized. The incident is under investigation by Greater Manchester Police, but the school remains open. The principal expressed support for the student's family and the school community.", "Max Verstappen, a Formula One driver, was finally able to get his driver's license at age 18. Despite already competing in 14 Grand Prix races, he was not of legal driving age in his native countries. He admitted to being nervous but passed the test on his first attempt. As an added bonus of turning 18, Verstappen can now enjoy champagne on the podium if he places.", ] eval_dataset = pd.DataFrame( { "instruction": instruction, "context": context, "reference": reference, } )
Exécuter la tâche d'évaluation des prompts
Une fois l'ensemble de données de synthèse préparé, vous êtes prêt à exécuter l'expérience principale de cette tâche : comparer plusieurs modèles de requête pour déterminer celui qui produit la sortie de la plus haute qualité à partir du modèle.
- Dans la cellule suivante, créez un seul
EvalTaskqui sera réutilisé pour chaque test d'invite. En définissant le paramètreexperiment, toutes les exécutions d'évaluation de cette tâche sont automatiquement enregistrées et regroupées dans Vertex AI Experiments.EXPERIMENT_NAME = "eval-sdk-prompt-engineering" # @param {type:"string"} summarization_eval_task = EvalTask( dataset=eval_dataset, metrics=[ "rouge_l_sum", "bleu", "fluency", "coherence", "safety", "groundedness", "summarization_quality", "verbosity", "instruction_following", "text_quality", ], experiment=EXPERIMENT_NAME, )rouge_l_sumetbleuà un large éventail de métriques basées sur des modèles (fluency,coherence,summarization_quality,instruction_following, etc.). Nous obtenons ainsi une vue globale à 360 degrés de l'impact de chaque requête sur la qualité des résultats du modèle. - Dans une nouvelle cellule, ajoutez et exécutez le code suivant pour définir et évaluer quatre stratégies de requête axées sur les personas. La boucle
foritère sur chaque modèle et exécute une évaluation.Chaque modèle est conçu pour susciter un style de résumé différent en donnant au modèle un persona ou un objectif spécifique :- Personnalité 1 (standard) : demande de synthèse neutre et simple.
- Personnalité 2 (cadre) : demande un résumé sous forme de points à puces, en se concentrant sur les résultats et l'impact, comme le ferait un cadre très occupé.
- Persona 3 (élève de CM2) : demande au modèle d'utiliser un langage simple, ce qui permet de tester sa capacité à ajuster la complexité de son résultat.
- Persona 4 (analyste technique) : exige un résumé très factuel où les statistiques et les entités clés sont conservées, ce qui permet de tester la précision du modèle. Notez que les espaces réservés de ces nouveaux modèles, tels que
{context}et{instruction}, correspondent aux nouveaux noms de colonnes dueval_datasetque vous avez créé pour cette tâche.
# Define prompt templates that target different user personas prompt_templates = [ # Persona 1: Standard, neutral summary "Article: {context}. Task: {instruction}. Summary:", # Persona 2: For a busy executive (bullet points) "Instruction: {instruction} into three key bullet points for a busy executive. Focus on the main outcome and impact. Article: {context}. Summary:", # Persona 3: For a 5th grader (simple language) "Instruction: {instruction} such that you're explaining it to a 10-year-old. Use simple words. Article: {context}. Summary:", # Persona 4: For a technical analyst (fact-focused) "Instruction: Provide a detailed, factual summary of the following text, ensuring all key statistics, names, and locations are preserved. Article: {context}. Summary:", ] eval_results = [] for i, prompt_template in enumerate(prompt_templates): eval_result = summarization_eval_task.evaluate( prompt_template=prompt_template, model=GenerativeModel( "gemini-2.0-flash", generation_config={ "temperature": 0.3, "max_output_tokens": 256, "top_k": 1, }, ), evaluation_service_qps=5, ) eval_results.append((f"Prompt Persona #{i+1}", eval_result))
Analyser et visualiser les résultats
La première étape consiste à effectuer des tests. La véritable valeur réside dans l'analyse des résultats pour prendre une décision basée sur les données. Dans cette tâche, vous allez utiliser les outils de visualisation du SDK pour interpréter les résultats de l'expérience sur les personas de requête.
- Affichez les résultats récapitulatifs pour chacune des quatre personas de requête que vous avez testées en exécutant le code suivant dans une nouvelle cellule. Vous obtenez ainsi une vue quantitative globale des performances.
for title, eval_result in eval_results: notebook_utils.display_eval_result(title=title, eval_result=eval_result) - Dans une nouvelle cellule, ajoutez et exécutez le code suivant pour afficher la justification de la métrique
summarization_qualitypour chaque persona.for title, eval_result in eval_results: notebook_utils.display_explanations( eval_result, metrics=["summarization_quality"], num=2 ) - Générez un graphique radar pour visualiser les compromis entre différentes métriques de qualité pour chaque requête. Dans une nouvelle cellule, ajoutez et exécutez le code suivant.
notebook_utils.display_radar_plot( eval_results, metrics=["instruction_following", "fluency", "coherence", "text_quality"], ) - Pour une comparaison côte à côte plus directe, créez un graphique à barres. Dans une nouvelle cellule, ajoutez et exécutez le code suivant.
notebook_utils.display_bar_plot( eval_results, metrics=["instruction_following", "fluency", "coherence", "text_quality"], )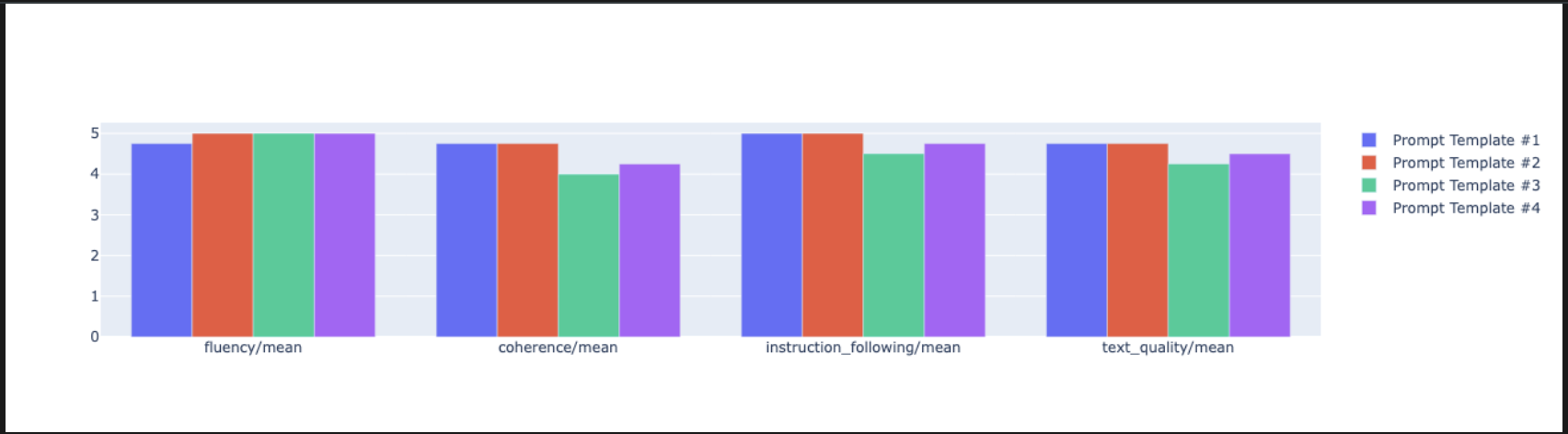
- Vous pouvez désormais afficher un récapitulatif de toutes les exécutions enregistrées dans votre test Vertex AI pour cette tâche. Cela vous permet de suivre votre travail au fil du temps. Dans une nouvelle cellule, ajoutez et exécutez le code suivant :
summarization_eval_task.display_runs()
10. Nettoyer le test
Pour que votre projet reste organisé et éviter des frais inutiles, nous vous recommandons de nettoyer les ressources que vous avez créées. Tout au long de cet atelier, chaque exécution d'évaluation a été consignée dans un test Vertex AI. Le code suivant supprime ce test parent, ce qui supprime également toutes les exécutions associées et leurs données sous-jacentes.
- Exécutez ce code dans une nouvelle cellule pour supprimer le test Vertex AI et les exécutions associées.
delete_experiment = True # Please set your LOCATION to the same one used during Vertex AI SDK initialization. LOCATION = "YOUR LOCATION" # @param {type:"string"} if delete_experiment: from google.cloud import aiplatform aiplatform.init(project=PROJECT_ID, location=LOCATION) experiment = aiplatform.Experiment(EXPERIMENT_NAME) experiment.delete()
11. De la pratique à la production
Les compétences que vous avez acquises dans cet atelier sont les éléments de base pour créer des applications d'IA fiables. Toutefois, le passage d'un notebook exécuté manuellement à un système d'évaluation de qualité production nécessite une infrastructure supplémentaire et une approche plus systématique. Cette section décrit les pratiques clés et les frameworks stratégiques à prendre en compte lorsque vous évoluez.
Élaborer des stratégies d'évaluation de la production
Pour appliquer les compétences acquises dans cet atelier dans un environnement de production, il est utile de les formaliser en stratégies reproductibles. Les frameworks suivants décrivent les principaux points à prendre en compte pour les scénarios courants, comme la sélection de modèles, l'optimisation des requêtes et la surveillance continue.
Pour la sélection de modèles :
# Evaluation strategy for choosing models
evaluation_strategy = {
"dataset_size": "100+ examples for statistical significance",
"metrics": ["task-specific", "general quality", "efficiency"],
"comparison_type": "pairwise with statistical testing",
"baseline": "established_model_or_human_benchmark"
}
Pour l'optimisation des requêtes
# Systematic prompt improvement workflow
prompt_optimization = {
"hypothesis": "Clear statement of what you're testing",
"variants": "3-5 different prompt strategies",
"evaluation": "Same metrics across all variants",
"analysis": "Statistical significance + qualitative review"
}
Pour la surveillance continue
# Production evaluation pipeline
production_eval = {
"frequency": "Every model update + weekly monitoring",
"automation": "CI/CD integration with quality gates",
"metrics": "Speed + quality + cost tracking",
"alerting": "Performance degradation detection"
}
Considérations sur la rentabilité
L'évaluation basée sur un modèle peut être coûteuse à grande échelle. Une stratégie de production économique utilise différentes méthodes à des fins différentes. Ce tableau récapitule les compromis entre la vitesse, le coût et le cas d'utilisation pour différents types d'évaluation :
Type d'évaluation | Temps | Coût par échantillon | Application idéale |
ROUGE/BLEU | Secondes | Environ 0,001 $ | Sélection à fort volume |
Pointwise basé sur un modèle | ~1 à 2 secondes | Environ 0,01 $ | Évaluation de la qualité |
Comparaison par paires | ~2-3 secondes | ~0,02 $ | Sélection du modèle |
Évaluation humaine | Minutes | 1 $ à 10 $ | Validation de référence |
Automatiser avec la CI/CD et la surveillance
Les exécutions manuelles de notebooks ne sont pas évolutives. Automatisez votre évaluation dans un pipeline d'intégration et de déploiement continus (CI/CD).
- Créez des portes de qualité : intégrez votre tâche d'évaluation dans un pipeline CI/CD (par exemple, Cloud Build). Exécutez automatiquement des évaluations sur de nouveaux modèles ou requêtes, et bloquez les déploiements si les scores de qualité clés descendent en dessous des seuils que vous avez définis.
- Surveiller les tendances : exportez les métriques récapitulatives de vos exécutions d'évaluation vers un service tel que Google Cloud Monitoring. Créez des tableaux de bord pour suivre la qualité au fil du temps et configurez des alertes automatiques pour avertir votre équipe en cas de dégradation significative des performances.
12. Conclusion
Vous avez terminé l'atelier. Vous avez acquis les compétences essentielles pour évaluer les modèles d'IA générative.
Cet atelier fait partie du parcours de formation "L'IA prête pour la production avec Google Cloud".
- Découvrez le programme complet pour passer du prototype à la production.
- Partagez votre progression avec le hashtag
ProductionReadyAI.
Récapitulatif
Dans cet atelier, vous avez appris à effectuer les tâches suivantes :
- Appliquez les bonnes pratiques d'évaluation à l'aide du framework
EvalTask. - Utilisez différents types de métriques, allant des juges basés sur le calcul à ceux basés sur des modèles.
- Optimisez les requêtes en testant différentes versions.
- Créez un workflow reproductible avec le suivi des tests.
Ressources pour poursuivre votre apprentissage
- Documentation sur l'évaluation de l'IA générative Vertex AI
- Notebooks sur les techniques d'évaluation avancées
- Documentation de référence du SDK Gen AI Evaluation
- Recherche sur les métriques basées sur des modèles
- Bonnes pratiques en matière de prompt engineering
Les approches d'évaluation systématiques que vous avez apprises dans cet atelier vous serviront de base pour créer des applications d'IA fiables et de haute qualité. N'oubliez pas : une bonne évaluation est le lien entre l'IA expérimentale et le succès en production.