
1. סקירה כללית
בשיעור ה-Lab הזה תלמדו להעריך מודלים גדולים של שפה (LLM) באמצעות שירות ההערכה של Vertex AI ל-AI גנרטיבי. תשתמשו ב-SDK כדי להריץ משימות הערכה, להשוות תוצאות ולקבל החלטות מבוססות-נתונים לגבי ביצועי המודל ועיצוב ההנחיות.
במעבדה מוצג תהליך עבודה נפוץ להערכה, שמתחיל בהשוואות מבוססות-מחשוב פשוטות ומתקדם להערכות מורכבות יותר שמבוססות על מודלים. בנוסף, תלמדו איך ליצור מדדים מותאמים אישית שמותאמים ליעדים הספציפיים שלכם, ולעקוב אחרי העבודה באמצעות Vertex AI Experiments.
מה תלמדו
בשיעור ה-Lab הזה תלמדו איך לבצע את המשימות הבאות:
- הערכת מודל באמצעות מדדים מבוססי-חישוב ומדדים מבוססי-מודל.
- ליצור מדד מותאם אישית כדי להתאים את ההערכה ליעדי המוצר.
- להשוות בין תבניות שונות של הנחיות זו לצד זו.
- כדאי לבדוק כמה הנחיות שמבוססות על פרסונה כדי למצוא את הגרסה הכי יעילה.
- מעקב אחרי הרצות של הערכות והצגה שלהן באופן חזותי באמצעות Vertex AI Experiments.
קובצי עזר
- דוגמאות קוד: ה-Lab הזה מבוסס על דוגמאות ממאגר ה-AI הגנרטיבי של Google Cloud
- מבוסס על: Vertex AI Gen AI Evaluation documentation
- קבוצת נתונים: OpenOrca dataset להערכת ביצוע הוראות
2. הגדרת הפרויקט
חשבון Google
אם אין לכם חשבון Google אישי, אתם צריכים ליצור חשבון Google.
משתמשים בחשבון לשימוש אישי במקום בחשבון לצורכי עבודה או בחשבון בית ספרי.
כניסה למסוף Google Cloud
נכנסים למסוף Google Cloud באמצעות חשבון Google אישי.
הפעלת חיוב
יש שתי דרכים להפעיל את החיוב. אתם יכולים להשתמש בחשבון החיוב האישי שלכם או לממש את הקרדיטים באמצעות השלבים הבאים.
מימוש קרדיטים ב-Google Cloud (אופציונלי)
כדי להשתתף בסדנה הזו, צריך חשבון לחיוב עם יתרה מסוימת. כדי להתחיל, משתמשים בקרדיטים שמופיעים בבאנר בחלק העליון של ה-codelab. אם כבר קישרתם חשבון לחיוב, אתם יכולים לדלג על השלב הזה.
הגדרה של חשבון לחיוב לשימוש אישי
אם הגדרתם חיוב באמצעות קרדיטים ל-Google Cloud, אתם יכולים לדלג על השלב הזה.
כדי להגדיר חשבון לחיוב לשימוש אישי, עוברים לכאן כדי להפעיל את החיוב ב-Cloud Console.
הערות:
- העלות של השלמת ה-Lab הזה במשאבי Cloud צריכה להיות פחות מ-1$.
- כדי למחוק משאבים ולמנוע חיובים נוספים, אפשר לבצע את השלבים בסוף ה-Lab הזה.
- משתמשים חדשים זכאים לתקופת ניסיון בחינם בשווי 300$.
יצירת פרויקט (אופציונלי)
אם אין לכם פרויקט שאתם רוצים להשתמש בו בסדנה הזו, אתם יכולים ליצור פרויקט חדש כאן.
3. הגדרת הסביבה שלכם ב-Vertex AI Workbench
נתחיל בכניסה לסביבת ה-Notebook שהוגדרה מראש ובאופן אוטומטי, ובהתקנת התלויות הנדרשות.
גישה ל-Vertex AI Workbench
- במסוף Google Cloud, לוחצים על תפריט הניווט ☰ > Vertex AI > מרכז הבקרה כדי לעבור אל Vertex AI.
- לוחצים על הפעלת כל ממשקי ה-API המומלצים. הערה: צריך להמתין עד שהשלב הזה יסתיים
- בצד ימין, לוחצים על Workbench כדי ליצור מופע חדש של Workbench.
- נותנים למופע של Workbench את השם evaluation-workbench ולוחצים על Create (יצירה).
- מחכים עד שהסביבה תוגדר. הפעולה עשויה להימשך כמה דקות.

- אחרי שה-Workbench יוקצה, לוחצים על Open JupyterLab.
- בסביבת העבודה, יוצרים מחברת Python3 חדשה.
מידע נוסף על התכונות והיכולות של הסביבה הזו זמין בתיעוד הרשמי של Vertex AI Workbench.
התקנת חבילות והגדרת הסביבה
- בתא הראשון של המחברת, מוסיפים ומריצים את הצהרות הייבוא שבהמשך (SHIFT+ENTER) כדי להתקין את Vertex AI SDK (עם רכיבי ההערכה) וחבילות נדרשות אחרות.
%pip install -U -q google-cloud-aiplatform[evaluation] %pip install -U -q datasets anthropic[vertex] openai - כדי להשתמש בחבילות שהותקנו לאחרונה, מומלץ להפעיל מחדש את ליבת המערכת על ידי הרצת קטע הקוד שלמטה.
# Automatically restart kernel after installation so that your environment can access the new packages. import IPython app = IPython.Application.instance() app.kernel.do_shutdown(True) - מחליפים את הערכים הבאים במזהה הפרויקט ובמיקום ומריצים את התא הבא. מיקום ברירת המחדל שהוגדר הוא
europe-west1, אבל צריך להשתמש באותו מיקום שבו נמצא מופע Vertex AI Workbench.# Configure your project settings PROJECT_ID = "YOUR PROJECT ID" LOCATION = "europe-west1" - מייבאים את כל ספריות Python הנדרשות למעבדה הזו על ידי הרצת הקוד הבא בתא חדש.
from anthropic import AnthropicVertex from google.auth import default, transport import openai import pandas as pd from vertexai.evaluation import ( EvalTask, MetricPromptTemplateExamples, PairwiseMetric, PointwiseMetric, PointwiseMetricPromptTemplate, ) from vertexai.generative_models import GenerativeModel from vertexai.preview.evaluation import notebook_utils
4. הגדרת מערך נתונים להערכה
במדריך הזה נשתמש ב-10 דוגמאות ממערך הנתונים OpenOrca dataset. כך אנחנו מקבלים מספיק נתונים כדי לראות הבדלים משמעותיים בין המודלים, ועדיין זמן ההערכה נשאר סביר.
💡 טיפ מקצועי: בסביבת ייצור, כדאי להשתמש ב-100 עד 500 דוגמאות כדי לקבל תוצאות בעלות מובהקות סטטיסטית, אבל 10 דוגמאות הן מושלמות ללמידה ולבניית אב טיפוס מהיר.
הכנת מערך הנתונים
- בתא חדש, מריצים את התא הבא כדי לטעון את הנתונים, להמיר אותם ל-pandas DataFrame ולשנות את השם של העמודה
responseל-referenceלשם הבהרה במשימות ההערכה שלנו, וליצור את המדגם האקראי של עשרה מקרים.from datasets import load_dataset ds = ( load_dataset( "Open-Orca/OpenOrca", data_files="1M-GPT4-Augmented.parquet", split="train[:100]", ) .to_pandas() .drop(columns=["id"]) .rename(columns={"response": "reference"}) ) dataset = ds.sample(n=10) - אחרי שההרצה של התא הקודם מסתיימת, מוסיפים את הקוד הבא לתא הבא ומריצים אותו כדי להציג את השורות הראשונות של מערך הנתונים של ההערכה.
dataset.head()
5. הגדרת ערך בסיסי באמצעות השוואות מבוססות-מחשוב
במשימה הזו תגדירו ציון בסיסי באמצעות מדד מבוסס-חישוב. הגישה הזו מהירה ומספקת מדד אובייקטיבי להשוואה של שיפורים עתידיים.
נשתמש ב-ROUGE (Recall-Oriented Understudy for Gisting Evaluation), מדד סטנדרטי למשימות סיכום. הוא פועל על ידי השוואה בין רצף המילים (n-grams) בתשובה שנוצרה על ידי המודל לבין המילים בטקסט reference של האמת הקרקעית.
מידע נוסף על השוואות מבוססות-מחשוב
הרצת ההערכה הראשונית
- בתא חדש, מוסיפים ומריצים את התא הבא כדי להגדיר את המודל שרוצים לבדוק,
gemini-2.0-flash. generation_configכולל פרמטרים כמוtemperatureו-max_output_tokensשמשפיעים על הפלט של המודל.# Model to be evaluated model = GenerativeModel( "gemini-2.0-flash", generation_config={"temperature": 0.6, "max_output_tokens": 256, "top_k": 1}, )GenerativeModelהן הממשק העיקרי לאינטראקציה עם מודלים גדולים של שפה ב-Vertex AI SDK. - בתא הבא, מוסיפים ומריצים את הקוד הבא כדי ליצור ולהריץ את
EvalTask. האובייקט הזה מ-Vertex AI Evaluation SDK מתזמן את ההערכה. מגדירים אותו עם מערך הנתונים והמדדים לחישוב, ובמקרה הזהrouge_l_sum.# Define an EvalTask with ROUGE-L-SUM metric rouge_eval_task = EvalTask( dataset=dataset, metrics=["rouge_l_sum"], ) rouge_result = rouge_eval_task.evaluate( model=model, prompt_template="# System_prompt\n{system_prompt} # Question\n{question}", ) - כדי להציג את התוצאות, מריצים את הקוד הזה בתא הבא.
notebook_utils.display_eval_result(rouge_result)display_eval_result()מוצג הציון הממוצע (mean) והתוצאות של כל שורה.
6. אופציונלי: הערכה באמצעות מדדים נקודתיים מבוססי-מודל
הערה: יכול להיות שהחלק הזה לא יפעל במסגרת המגבלה של הזיכויים שניתנים בחינם.
המדד ROUGE שימושי, אבל הוא מודד רק חפיפה לקסיקלית (כלומר, הוא סופר רק מילים תואמות, והוא לא מבין הקשר, מילים נרדפות או ניסוח מחדש). לכן, הוא לא הכי טוב בקביעה אם התשובה רהוטה או הגיונית. כדי להבין טוב יותר את ביצועי המודל, אפשר להשתמש במדדים נקודתיים שמבוססים על המודל.
בשיטה הזו, מודל LLM אחר (המודל השופט) מעריך כל תגובה בנפרד לפי קבוצה מוגדרת מראש של קריטריונים, כמו רהיטות או קוהרנטיות.
מידע נוסף על מדדים מבוססי-מודל
הרצת ההערכה הנקודתית
- מריצים את הקוד הבא בתא חדש כדי ליצור תפריט נפתח אינטראקטיבי. בפעולה הזו, בוחרים באפשרות coherence מהרשימה.
#Select a pointwise metric to use import ipywidgets as widgets pointwise_single_turn_metrics = [ metric for metric in MetricPromptTemplateExamples.list_example_metric_names() if not metric.startswith("pairwise") and not metric.startswith("multi_turn") ] dropdown = widgets.Dropdown( options=pointwise_single_turn_metrics, description="Select a metric:", font_weight="bold", style={"description_width": "initial"}, ) def dropdown_eventhandler(change): global POINTWISE_METRIC if change["type"] == "change" and change["name"] == "value": POINTWISE_METRIC = change.new print("Selected:", change.new) POINTWISE_METRIC = dropdown.value dropdown.observe(dropdown_eventhandler, names="value") display(dropdown) - בתא חדש, מריצים שוב את הפונקציה
EvalTask, הפעם באמצעות המדד שנבחר שמבוסס על מודל. שירות ההערכה של Vertex AI יוצר הנחיה למודל השופט, שכוללת את ההנחיה המקורית, תשובת ההפניה, התשובה של המודל המועמד והוראות למדד שנבחר. מודל השופט מחזיר ציון מספרי והסבר לדירוג שלו. הערה: השלב הזה יימשך כמה דקות.pointwise_result = EvalTask( dataset=dataset, metrics=[POINTWISE_METRIC], ).evaluate( model=model, prompt_template="# System_prompt\n{system_prompt} # Question\n{question}", )
הצגת התוצאות
אחרי שההערכה מסתיימת, השלב הבא הוא לנתח את הפלט.
- מריצים את הקוד הבא בתא חדש כדי לראות את מדדי הסיכום, שכוללים את הציון הממוצע של המדד שבחרתם.
notebook_utils.display_eval_result(pointwise_result) - מריצים את הקוד הבא בתא הבא כדי לראות את הפירוט של כל שורה, כולל ההסבר הכתוב של מודל השופט לציון שניתן. המשוב האיכותי הזה עוזר להבין למה תשובה קיבלה ציון מסוים.
notebook_utils.display_explanations(pointwise_result, num=1, metrics=[POINTWISE_METRIC])
7. יצירת מדד מותאם אישית לקבלת תובנות מעמיקות יותר
מדדים מוכנים מראש כמו רמת השליטה בשפה הם שימושיים, אבל כשמדובר במוצר ספציפי, לרוב צריך למדוד את הביצועים בהשוואה ליעדים שלכם. באמצעות מדדים מותאמים אישית של נקודות, אתם יכולים להגדיר קריטריונים משלכם להערכה וקריטריון הערכה משלכם.
במשימה הזו אתם צריכים ליצור מדד חדש מאפס בשם summarization_helpfulness.
הגדרת המדד המותאם אישית והרצתו
- מריצים את הקוד הבא בתא חדש כדי להגדיר את המדד בהתאמה אישית.הקוד
PointwiseMetricPromptTemplateמכיל את אבני הבניין של המדד:- קריטריונים: מציין למודל השופט את המאפיינים הספציפיים להערכה: 'מידע מרכזי', 'תמציתיות' ו'ללא עיוות'.
- rating_rubric: מספק סולם ניקוד של 5 נקודות שמגדיר את המשמעות של כל ציון.
- input_variables: מעבירה עמודות נוספות ממערך הנתונים למודל השופט, כדי שיהיה לו ההקשר הדרוש לביצוע ההערכה.
# This new custom metric evaluates the actual quality and usefulness of the summary. summarization_helpfulness_metric = PointwiseMetric( metric="summarization_helpfulness", metric_prompt_template=PointwiseMetricPromptTemplate( criteria={ "Key Information": "Does the summary capture the most critical pieces of information from the original text? It should not miss the main topic or key takeaways.", "Conciseness": "Is the summary brief and to the point? It should avoid unnecessary words or repetitive information.", "No Distortion": "Does the summary introduce information or opinions that were NOT present in the original text? It must accurately reflect the source material without adding hallucinations." }, rating_rubric={ "5": "Excellent: Captures all key information, is highly concise, and has zero distortion.", "4": "Good: Captures most key information with minor omissions, is concise, and has no distortion.", "3": "Satisfactory: Captures the main idea but misses some key details OR is not very concise.", "2": "Unsatisfactory: Misses the main idea of the original text OR contains minor distortions/hallucinations.", "1": "Poor: Is completely irrelevant, fails to summarize the text, OR contains significant distortions.", }, input_variables=["prompt", "reference"], ), ) - מריצים את הקוד הבא בתא הבא כדי להפעיל את
EvalTaskעם המדד המותאם אישית החדש.# You would then update the EvalTask to use this new metric pointwise_result = EvalTask( dataset=dataset, metrics=[summarization_helpfulness_metric], ).evaluate( model=model, prompt_template="# System_prompt\n{system_prompt} # Question\n{question}", ) - מריצים את הקוד הבא בתא חדש כדי להציג את התוצאות.
notebook_utils.display_eval_result(pointwise_result)
8. השוואה בין מודלים באמצעות הערכה זוגית
אם אתם צריכים להחליט איזה מבין שני מודלים מניב ביצועים טובים יותר במשימה ספציפית, אתם יכולים להשתמש בהערכה מבוססת-מודל של זוגות. השיטה הזו היא סוג של בדיקת A/B שבה מודל שופט קובע את המודל המנצח, ומספק השוואה ישירה לבחירת מודל מבוסס-נתונים.
המודלים:
- מודל מועמד: משתנה המודל (שהוגדר קודם כ-
gemini-2.0-flash) מועבר אל השיטה.evaluate(). זהו המודל העיקרי שאתם בודקים. - מודל בסיסי: מודל שני,
gemini-2.0-flash-lite, מוגדר בתוך המחלקה PairwiseMetric. זהו המודל שאליו אתם משווים.
הרצת ההערכה הזוגית
- בתא חדש, מוסיפים ומריצים את הקוד הבא כדי ליצור תפריט נפתח אינטראקטיבי. כך תוכלו לבחור את המדד להשוואה בין זוגות שבו תרצו להשתמש. במקרה הזה, בוחרים באפשרות pairwise_summarization_quality.
from IPython.display import display import ipywidgets as widgets pairwise_single_turn_metrics = [ metric for metric in MetricPromptTemplateExamples.list_example_metric_names() if metric.startswith("pairwise") and "multi_turn" not in metric ] dropdown = widgets.Dropdown( options=pairwise_single_turn_metrics, description="Select a metric:", font_weight="bold", style={"description_width": "initial"}, ) def dropdown_eventhandler(change): global POINTWISE_METRIC if change["type"] == "change" and change["name"] == "value": POINTWISE_METRIC = change.new print("Selected:", change.new) def dropdown_eventhandler(change): global PAIRWISE_METRIC_NAME if change["type"] == "change" and change["name"] == "value": PAIRWISE_METRIC_NAME = change.new print("Selected:", change.new) PAIRWISE_METRIC_NAME = dropdown.value dropdown.observe(dropdown_eventhandler, names="value") display(dropdown) - בתא הבא, מוסיפים ומריצים את הקוד הבא כדי להגדיר ולהפעיל את
EvalTask. שימו לב איך נעשה שימוש במחלקהPairwiseMetricכדי להגדיר את מודל הבסיס (gemini-2.0-flash-lite), בזמן שהמודל המועמד (gemini-2.0-flash) מועבר לשיטה.evaluate().pairwise_result = EvalTask( dataset=dataset, metrics=[ PairwiseMetric( metric=PAIRWISE_METRIC_NAME, metric_prompt_template=MetricPromptTemplateExamples.get_prompt_template( PAIRWISE_METRIC_NAME ), # Define a baseline model to compare against baseline_model=GenerativeModel("gemini-2.0-flash-lite"), ) ], ).evaluate( # Specify a candidate model for pairwise comparison model=model, prompt_template="# System_prompt\n{system_prompt} # Question\n{question}", ) - בתא חדש, מוסיפים את הקוד הבא ומריצים אותו כדי להציג את התוצאות. בטבלת הסיכום יוצג 'שיעור הזכייה' של כל מודל, שיציין איזה מודל המודל השופט העדיף יותר פעמים.
notebook_utils.display_eval_result(pairwise_result)
9. אופציונלי: הערכת הנחיות שמבוססות על פרסונה
הערה: יכול להיות שהחלק הזה לא יפעל במסגרת המגבלה של הזיכויים שניתנים בחינם.
במשימה הזו, תבדקו כמה תבניות של הנחיות שמנחות את המודל לאמץ פרסונות שונות. התהליך הזה, שנקרא לעיתים הנדסת הנחיות או עיצוב הנחיות, מאפשר לכם למצוא באופן שיטתי את ההנחיה היעילה ביותר לתרחיש שימוש ספציפי.
הכנת מערך הנתונים של הסיכום
כדי לבצע את ההערכה הזו, מערך הנתונים צריך להכיל את השדות הבאים:
-
instruction: המשימה המרכזית שאנחנו נותנים למודל. במקרה הזה, ההנחיה היא פשוטה: "תסכם את המאמר הבא:". -
context: טקסט המקור שהמודל צריך לעבוד איתו. הנה ארבעה קטעי חדשות שונים. reference: סיכום האמת או 'תקן הזהב'. הפלט שנוצר על ידי המודל יושווה לטקסט הזה כדי לחשב ציונים למדדים כמו ROUGE ואיכות הסיכום.
- בתא חדש, מוסיפים את הקוד הבא ומריצים אותו כדי ליצור
pandas.DataFrameלמשימת הסיכום.instruction = "Summarize the following article: \n" context = [ "Typhoon Phanfone has killed at least one person, a US airman on Okinawa who was washed away by high waves. Thousands of households have lost power and Japan's two largest airlines have suspended many flights. The storm also forced the suspension of the search for people missing after last week's volcanic eruption. The storm-tracking website Tropical Storm Risk forecasts that Phanfone will rapidly lose power over the next few hours as it goes further into the Pacific Ocean. Typhoon Phanfone was downgraded from an earlier status of a super typhoon, but the Japan Meteorological Agency had warned it was still a dangerous storm. Japan averages 11 typhoons a year, according to its weather agency. The typhoon made landfall on Monday morning near the central city of Hamamatsu, with winds of up to 180 km/h (112 mph). The airman was one of three US military personnel swept away by high waves whipped up by the typhoon off southern Okinawa island, where the US has a large military base. The remaining two are still missing. A police spokesman said they had been taking photographs of the sea. A university student who was surfing off the seas of Kanagawa Prefecture, south of Tokyo, was also missing, national broadcast NHK reports. It said at least 10 people had been injured and 9,500 houses were without power. The storm was expected to deposit about 100mm of rain on Tokyo over 24 hours, according to the Transport Ministry website. Many schools were closed on Monday and two car companies in Japan halted production at some plants ahead of the storm. More than 174 domestic flights were affected nationwide, NHK state broadcaster said on Sunday. On Sunday, heavy rain delayed the Japanese Formula One Grand Prix in Suzaka. French driver Jules Bianchi lost control in the wet conditions and crashed, sustaining a severe head injury.", "The blaze started at the detached building in Drivers End in Codicote, near Welwyn, during the morning. There was another fire at the building 20 years ago, after which fire-proof foil was placed under the thatch, which is protecting the main building. More than 15 fire engines and support vehicles were called to tackle the blaze. Roads in the area were closed and traffic diverted.", 'The 18-year-old fell at the New Charter Academy on Broadoak Road in Ashton-under-Lyne at about 09:10 BST, Greater Manchester Police (GMP) said. GMP said he had gone to Manchester Royal Infirmary and his condition was "serious". Principal Jenny Langley said the school would remain "fully open" while police investigated. "Our thoughts are with the family and we\'re doing everything we can to support them along with staff and pupils," she said.', 'But Belgian-born Dutchman Max Verstappen was unable to drive a car legally on his own in either country. That all changed on Wednesday when the youngster turned 18 and passed his driving test at the first attempt. Despite having competed in 14 grands prix since his debut in Australia in March, Verstappen admitted to feeling the pressure during his test. "It\'s a relief," said the Toro Rosso driver, who finished ninth in Japan on Sunday and had only started driving lessons a week ago. "I was a bit nervous to make mistakes, but the exam went well." A bonus of turning 18 is that Verstappen will now be able to drink the champagne if he ever makes it onto the podium.', ] reference = [ "A powerful typhoon has brought many parts of Japan to a standstill and briefly battered Tokyo before heading out to sea.", "A major fire has been burning in the thatched roof of a large property in Hertfordshire.", "A student has been taken to hospital after falling from a balcony at a Greater Manchester school.", "He is Formula 1's youngest ever driver and in charge of a car that can reach over 200mph.", ] response = [ "Typhoon Phanfone, while downgraded from super typhoon status, caused significant disruption and tragedy in Japan. One US airman died after being swept away by high waves, with two more missing. The storm caused power outages for thousands, flight cancellations, and the suspension of rescue efforts for missing volcano victims. Heavy rain and strong winds led to school and factory closures, transportation disruptions, and at least 10 injuries. The typhoon is expected to weaken as it moves over the Pacific Ocean.", "A large fire broke out in a detached thatched building in Codicote, near Welwyn. This is the second fire at the building in 20 years. Thankfully, fire-proof foil installed after the previous fire is protecting the main building. Over 15 fire engines and support vehicles responded, closing roads and diverting traffic in the area.", "An 18-year-old student at New Charter Academy in Ashton-under-Lyne suffered a serious fall and was hospitalized. The incident is under investigation by Greater Manchester Police, but the school remains open. The principal expressed support for the student's family and the school community.", "Max Verstappen, a Formula One driver, was finally able to get his driver's license at age 18. Despite already competing in 14 Grand Prix races, he was not of legal driving age in his native countries. He admitted to being nervous but passed the test on his first attempt. As an added bonus of turning 18, Verstappen can now enjoy champagne on the podium if he places.", ] eval_dataset = pd.DataFrame( { "instruction": instruction, "context": context, "reference": reference, } )
הפעלת משימת הערכה של הנחיה
אחרי שמכינים את מערך הנתונים של הסיכום, אפשר להריץ את הניסוי המרכזי של המשימה הזו: השוואה בין כמה תבניות של הנחיות כדי לראות איזו מהן מפיקה את הפלט האיכותי ביותר מהמודל.
- בתא הבא, יוצרים
EvalTaskיחיד שיוכל לשמש שוב לכל ניסוי של הנחיה. אם מגדירים את הפרמטרexperiment, כל ההרצות של ההערכה מהמשימה הזו נרשמות ומקובצות באופן אוטומטי ב-Vertex AI Experiments.EXPERIMENT_NAME = "eval-sdk-prompt-engineering" # @param {type:"string"} summarization_eval_task = EvalTask( dataset=eval_dataset, metrics=[ "rouge_l_sum", "bleu", "fluency", "coherence", "safety", "groundedness", "summarization_quality", "verbosity", "instruction_following", "text_quality", ], experiment=EXPERIMENT_NAME, )rouge_l_sumו-bleuועד למגוון רחב של מדדים מבוססי-מודל (fluency, coherence, summarization_quality, instruction_followingוכו'). כך אנחנו מקבלים תמונה הוליסטית של 360 מעלות לגבי ההשפעה של כל הנחיה על איכות הפלט של המודל. - בתא חדש, מוסיפים ומריצים את הקוד הבא כדי להגדיר ולהעריך ארבע אסטרטגיות הנחיות שמבוססות על פרסונות. הלולאה
forחוזרת על עצמה עבור כל תבנית ומריצה הערכה.כל תבנית מיועדת ליצור סגנון שונה של סיכום על ידי הקצאת פרסונה או יעד ספציפיים למודל:- פרסונה מספר 1 (רגילה): בקשה ניטרלית ופשוטה לסיכום.
- פרסונה מספר 2 (מנהל/ת): מבקש/ת סיכום בנקודות, עם דגש על התוצאות וההשפעה, כמו שמנהל/ת עסוק/ה יעדיפו.
- פרסונה מספר 3 (תלמיד בכיתה ה'): הנחיה למודל להשתמש בשפה פשוטה, כדי לבדוק את היכולת שלו להתאים את מורכבות הפלט.
- פרסונה מספר 4 (אנליסט טכני): דורשת סיכום עובדתי מאוד שבו נשמרים נתונים סטטיסטיים וישויות מרכזיים, כדי לבדוק את הדיוק של המודל. שימו לב שה-placeholder בתבניות החדשות האלה, כמו
{context}ו-{instruction}, תואמים לשמות העמודות החדשים ב-eval_datasetשיצרתם למשימה הזו.
# Define prompt templates that target different user personas prompt_templates = [ # Persona 1: Standard, neutral summary "Article: {context}. Task: {instruction}. Summary:", # Persona 2: For a busy executive (bullet points) "Instruction: {instruction} into three key bullet points for a busy executive. Focus on the main outcome and impact. Article: {context}. Summary:", # Persona 3: For a 5th grader (simple language) "Instruction: {instruction} such that you're explaining it to a 10-year-old. Use simple words. Article: {context}. Summary:", # Persona 4: For a technical analyst (fact-focused) "Instruction: Provide a detailed, factual summary of the following text, ensuring all key statistics, names, and locations are preserved. Article: {context}. Summary:", ] eval_results = [] for i, prompt_template in enumerate(prompt_templates): eval_result = summarization_eval_task.evaluate( prompt_template=prompt_template, model=GenerativeModel( "gemini-2.0-flash", generation_config={ "temperature": 0.3, "max_output_tokens": 256, "top_k": 1, }, ), evaluation_service_qps=5, ) eval_results.append((f"Prompt Persona #{i+1}", eval_result))
ניתוח התוצאות והצגתן בתרשים
השלב הראשון הוא הפעלת ניסויים. הערך האמיתי הוא בניתוח התוצאות כדי לקבל החלטה מבוססת-נתונים. במשימה הזו תשתמשו בכלי ההדמיה של ה-SDK כדי לפרש את הפלט של הניסוי בנושא פרסונות של הנחיות.
- כדי להציג את תוצאות הסיכום של כל אחת מארבעת ההנחיות שבדקתם, מריצים את הקוד הבא בתא חדש. כך אפשר לקבל תמונה כמותית ברמה גבוהה של הביצועים.
for title, eval_result in eval_results: notebook_utils.display_eval_result(title=title, eval_result=eval_result) - בתא חדש, מוסיפים את הקוד הבא ומריצים אותו כדי לראות את ההסבר למדד
summarization_qualityלכל פרסונה.for title, eval_result in eval_results: notebook_utils.display_explanations( eval_result, metrics=["summarization_quality"], num=2 ) - ליצור תרשים מכ"ם כדי להמחיש את נקודות האיזון בין מדדי איכות שונים לכל הנחיה. בתא חדש, מוסיפים את הקוד הבא ומריצים אותו.
notebook_utils.display_radar_plot( eval_results, metrics=["instruction_following", "fluency", "coherence", "text_quality"], ) - כדי ליצור השוואה ישירה יותר, זה לצד זה, יוצרים תרשים עמודות. בתא חדש, מוסיפים את הקוד הבא ומריצים אותו.
notebook_utils.display_bar_plot( eval_results, metrics=["instruction_following", "fluency", "coherence", "text_quality"], )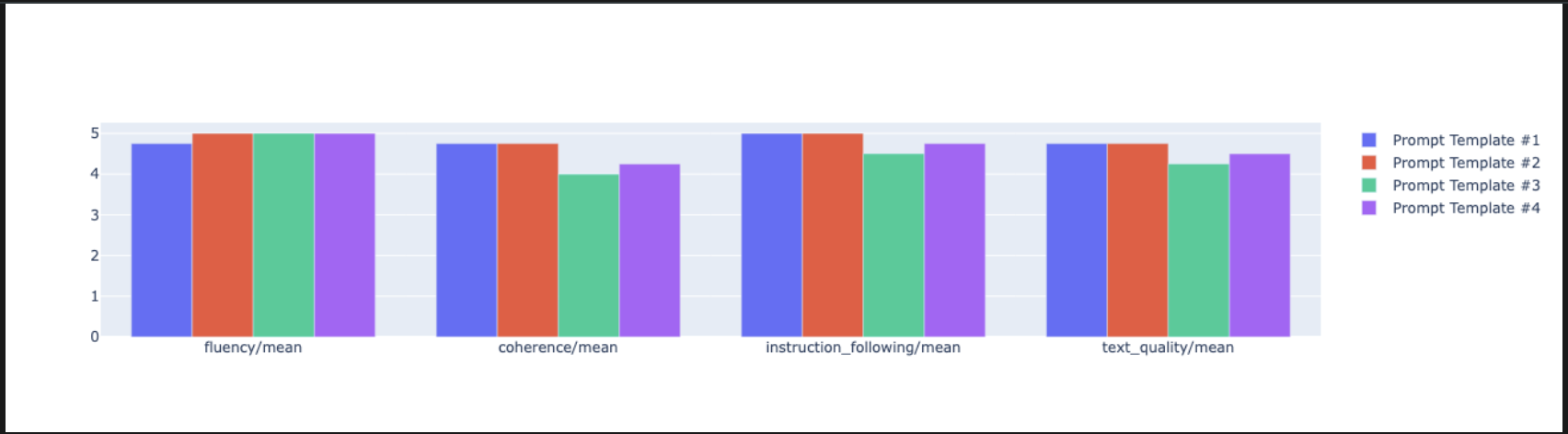
- עכשיו אפשר לראות סיכום של כל ההרצות שנרשמו ב-Vertex AI Experiment למשימה הזו. האפשרות הזו שימושית למעקב אחרי העבודה לאורך זמן. בתא חדש, מוסיפים את הקוד הבא ומריצים אותו:
summarization_eval_task.display_runs()
10. ניקוי הניסוי
כדי לשמור על הסדר בפרויקט ולהימנע מחיובים מיותרים, מומלץ לנקות את המשאבים שיצרתם. במהלך שיעור ה-Lab הזה, כל הפעלת הערכה נרשמה ב-Vertex AI Experiment. הקוד הבא מוחק את ניסוי האב הזה, וגם מסיר את כל ההרצות המשויכות ואת הנתונים הבסיסיים שלהן.
- מריצים את הקוד הזה בתא חדש כדי למחוק את הניסוי ב-Vertex AI ואת הריצות שמשויכות אליו.
delete_experiment = True # Please set your LOCATION to the same one used during Vertex AI SDK initialization. LOCATION = "YOUR LOCATION" # @param {type:"string"} if delete_experiment: from google.cloud import aiplatform aiplatform.init(project=PROJECT_ID, location=LOCATION) experiment = aiplatform.Experiment(EXPERIMENT_NAME) experiment.delete()
11. מתרגול לייצור
הכישורים שלמדתם בשיעור ה-Lab הזה הם אבני הבניין ליצירת אפליקציות AI אמינות. עם זאת, כדי לעבור ממחברת שמופעלת באופן ידני למערכת הערכה ברמת ייצור, נדרשת תשתית נוספת וגישה שיטתית יותר. בקטע הזה מפורטות שיטות עבודה מומלצות ומסגרות אסטרטגיות שכדאי להביא בחשבון כשמגדילים את היקף הפעילות.
פיתוח אסטרטגיות להערכה של סביבת הייצור
כדי ליישם את הכישורים שנרכשו בסדנה הזו בסביבת ייצור, כדאי להפוך אותם לשיטות שניתן לחזור עליהן. במסגרות הבאות מפורטים שיקולים חשובים לתרחישים נפוצים כמו בחירת מודל, אופטימיזציה של הנחיות ומעקב רציף.
לגבי בחירת מודל:
# Evaluation strategy for choosing models
evaluation_strategy = {
"dataset_size": "100+ examples for statistical significance",
"metrics": ["task-specific", "general quality", "efficiency"],
"comparison_type": "pairwise with statistical testing",
"baseline": "established_model_or_human_benchmark"
}
לאופטימיזציה של הנחיות
# Systematic prompt improvement workflow
prompt_optimization = {
"hypothesis": "Clear statement of what you're testing",
"variants": "3-5 different prompt strategies",
"evaluation": "Same metrics across all variants",
"analysis": "Statistical significance + qualitative review"
}
למעקב רציף
# Production evaluation pipeline
production_eval = {
"frequency": "Every model update + weekly monitoring",
"automation": "CI/CD integration with quality gates",
"metrics": "Speed + quality + cost tracking",
"alerting": "Performance degradation detection"
}
שיקולים לגבי עלות-תועלת
הערכה מבוססת-מודל יכולה להיות יקרה בהיקף גדול. אסטרטגיית הפקה חסכונית משתמשת בשיטות שונות למטרות שונות. בטבלה הזו מפורטים היתרונות והחסרונות של סוגי ההערכות השונים מבחינת מהירות, עלות ותרחישי שימוש:
סוג ההערכה | שעה | עלות לכל דגימה | מתאים במיוחד עבור |
ROUGE/BLEU | שניות | ~0.001$ | סינון של נפח גדול של שיחות |
Pointwise מבוסס-מודל | ~1-2 שניות | ~$0.01 | הערכת איכות |
השוואה בין זוגות | ~2-3 שניות | ~$0.02 | בחירת מודל |
Human Evaluation | דקות | 1-10$ | אימות לפי מדד הזהב |
אוטומציה באמצעות CI/CD ומעקב
אי אפשר להרחיב את ההרצה הידנית של מחברות. אוטומציה של ההערכה בצינור עיבוד נתונים של אינטגרציה רציפה (CI) או פריסה רציפה (CD).
- יצירת שערים לאיכות: שילוב משימת ההערכה בצינור עיבוד נתונים של CI/CD (למשל Cloud Build). הפעלת הערכות אוטומטית של הנחיות או מודלים חדשים וחסימת פריסות אם ציוני האיכות העיקריים יורדים מתחת לסף שהגדרתם.
- מעקב אחרי מגמות: מייצאים מדדי סיכום מהרצות ההערכה לשירות כמו Google Cloud Monitoring. כדאי לבנות מרכזי בקרה כדי לעקוב אחרי האיכות לאורך זמן ולהגדיר התראות אוטומטיות כדי להודיע לצוות על ירידה משמעותית בביצועים.
12. סיכום
השלמתם את ה-Lab. למדתם את המיומנויות החיוניות להערכת מודלים של AI גנרטיבי.
שיעור ה-Lab הזה הוא חלק מתוכנית הלימודים Production-Ready AI with Google Cloud (שימוש ב-AI מוכן לייצור עם Google Cloud).
- כאן אפשר לעיין בתוכנית הלימודים המלאה כדי לגשר על הפער בין אב טיפוס לבין ייצור.
- שתפו את ההתקדמות שלכם באמצעות ההאשטאג
ProductionReadyAI.
Recap
בשיעור ה-Lab הזה למדתם איך:
- אפשר ליישם שיטות מומלצות להערכה באמצעות מסגרת
EvalTask. - שימוש בסוגים שונים של מדדים, החל משופטים מבוססי-חישוב ועד שופטים מבוססי-מודל.
- אפשר לבצע אופטימיזציה להנחיות על ידי בדיקת גרסאות שונות.
- ליצור תהליך עבודה שניתן לשחזור באמצעות מעקב אחר ניסויים.
מקורות מידע להמשך הלמידה
- מסמכי הערכה של AI גנרטיבי ב-Vertex AI
- Advanced Evaluation Techniques Notebooks
- הפניה ל-Gen AI Evaluation SDK
- מחקר מדדים מבוסס-מודל
- שיטות מומלצות ליצירת הנחיות
הגישות השיטתיות להערכה שלמדתם בשיעור ה-Lab הזה ישמשו אתכם כבסיס לבניית אפליקציות AI מהימנות ואיכותיות. חשוב לזכור: הערכה טובה היא הגשר בין AI ניסיוני לבין הצלחה בייצור.