
1. खास जानकारी
इस लैब में, Vertex AI Gen AI Evaluation Service का इस्तेमाल करके, लार्ज लैंग्वेज मॉडल का आकलन करने का तरीका जानें. एसडीके का इस्तेमाल, आकलन के टास्क चलाने, नतीजों की तुलना करने, और मॉडल की परफ़ॉर्मेंस और प्रॉम्प्ट डिज़ाइन के बारे में डेटा-ड्रिवन फ़ैसले लेने के लिए किया जाएगा.
इस लैब में, आपको आकलन के सामान्य वर्कफ़्लो के बारे में बताया जाएगा. इसकी शुरुआत, कंप्यूटेशन पर आधारित आसान मेट्रिक से होगी. इसके बाद, मॉडल पर आधारित आकलन के बारे में बताया जाएगा. आपको अपने लक्ष्यों के हिसाब से कस्टम मेट्रिक बनाने और Vertex AI Experiments का इस्तेमाल करके अपने काम को ट्रैक करने का तरीका भी सिखाया जाएगा.
आपको क्या सीखने को मिलेगा
इस लैब में, आपको ये टास्क करने का तरीका बताया जाएगा:
- कंप्यूटेशन और मॉडल पर आधारित मेट्रिक की मदद से, मॉडल का आकलन करें.
- प्रॉडक्ट के लक्ष्यों के हिसाब से आकलन करने के लिए, कस्टम मेट्रिक बनाएं.
- अलग-अलग प्रॉम्प्ट टेंप्लेट की एक-दूसरे से तुलना करें.
- सबसे असरदार वर्शन ढूंढने के लिए, पर्सोना के हिसाब से कई प्रॉम्प्ट आज़माएं.
- Vertex AI Experiments का इस्तेमाल करके, आकलन की प्रोसेस को ट्रैक और विज़ुअलाइज़ करें.
रेफ़रंस
- कोड के सैंपल: यह लैब, Google Cloud Generative AI रिपॉज़िटरी के उदाहरणों पर आधारित है
- इस पर आधारित: Vertex AI Gen AI Evaluation का दस्तावेज़
- डेटासेट: निर्देशों का पालन करने से जुड़े आकलन के लिए, OpenOrca डेटासेट
2. प्रोजेक्ट सेटअप करना
Google खाता
अगर आपके पास पहले से कोई निजी Google खाता नहीं है, तो आपको Google खाता बनाना होगा.
ऑफ़िस या स्कूल वाले खाते के बजाय, निजी खाते का इस्तेमाल करें.
Google Cloud Console में साइन इन करना
किसी निजी Google खाते का इस्तेमाल करके, Google Cloud Console में साइन इन करें.
बिलिंग चालू करें
बिलिंग चालू करने के लिए, आपके पास दो विकल्प हैं. आपके पास निजी बिलिंग खाते का इस्तेमाल करने का विकल्प होता है. इसके अलावा, यहां दिए गए तरीके से क्रेडिट रिडीम किए जा सकते हैं.
Google Cloud क्रेडिट रिडीम करना (ज़रूरी नहीं है)
इस वर्कशॉप को चलाने के लिए, आपके पास कुछ क्रेडिट वाला बिलिंग खाता होना चाहिए. शुरू करने के लिए, इस कोडलैब के सबसे ऊपर मौजूद बैनर में दिए गए क्रेडिट का इस्तेमाल करें. अगर आपका खाता पहले से ही किसी बिलिंग खाते से कनेक्ट है, तो इस चरण को छोड़ा जा सकता है.
निजी बिलिंग खाता सेट अप करना
अगर आपने Google Cloud क्रेडिट का इस्तेमाल करके बिलिंग सेट अप की है, तो इस चरण को छोड़ें.
निजी बिलिंग खाता सेट अप करने के लिए, Cloud Console में बिलिंग की सुविधा चालू करने के लिए यहां जाएं.
ध्यान दें:
- इस लैब को पूरा करने में, Cloud संसाधनों पर 1 डॉलर से कम का खर्च आना चाहिए.
- ज़्यादा शुल्क से बचने के लिए, इस लैब के आखिर में दिए गए निर्देशों का पालन करके संसाधनों को मिटाया जा सकता है.
- नए उपयोगकर्ता, 300 डॉलर के मुफ़्त में आज़माने की सुविधा का फ़ायदा पा सकते हैं.
कोई प्रोजेक्ट बनाएं (ज़रूरी नहीं)
अगर आपके पास कोई ऐसा मौजूदा प्रोजेक्ट नहीं है जिसका इस्तेमाल आपको इस लैब के लिए करना है, तो यहां नया प्रोजेक्ट बनाएं.
3. Vertex AI Workbench का एनवायरमेंट सेट अप करना
आइए, पहले से कॉन्फ़िगर किए गए नोटबुक एनवायरमेंट को ऐक्सेस करके, ज़रूरी डिपेंडेंसी इंस्टॉल करें.
Vertex AI Workbench ऐक्सेस करना
- Google Cloud Console में, नेविगेशन मेन्यू ☰ > Vertex AI > डैशबोर्ड पर क्लिक करके, Vertex AI पर जाएं.
- सुझाए गए सभी एपीआई चालू करें पर क्लिक करें. ध्यान दें: कृपया इस चरण के पूरा होने तक इंतज़ार करें
- बाईं ओर, Workbench पर क्लिक करके, नया Workbench इंस्टेंस बनाएं.
- वर्कबेंच इंस्टेंस का नाम evaluation-workbench रखें और बनाएं पर क्लिक करें.
- वर्कबेंच के सेट अप होने का इंतज़ार करें. इसमें कुछ मिनट लग सकते हैं.

- वर्कबेंच उपलब्ध हो जाने के बाद, JupyterLab खोलें पर क्लिक करें.
- वर्कबेंच में, नई Python3 नोटबुक बनाएं.
इस एनवायरमेंट की सुविधाओं और क्षमताओं के बारे में ज़्यादा जानने के लिए, Vertex AI Workbench का आधिकारिक दस्तावेज़ देखें.
पैकेज इंस्टॉल करना और एनवायरमेंट कॉन्फ़िगर करना
- अपनी नोटबुक की पहली सेल में, नीचे दिए गए इंपोर्ट स्टेटमेंट (SHIFT+ENTER) जोड़ें और उन्हें चलाएं. इससे, Vertex AI SDK (समीक्षा करने वाले कॉम्पोनेंट के साथ) और अन्य ज़रूरी पैकेज इंस्टॉल हो जाएंगे.
%pip install -U -q google-cloud-aiplatform[evaluation] %pip install -U -q datasets anthropic[vertex] openai - नए इंस्टॉल किए गए पैकेज का इस्तेमाल करने के लिए, हमारा सुझाव है कि आप नीचे दिए गए कोड स्निपेट को चलाकर कर्नल को रीस्टार्ट करें.
# Automatically restart kernel after installation so that your environment can access the new packages. import IPython app = IPython.Application.instance() app.kernel.do_shutdown(True) - यहां दिए गए कोड में, PROJECT_ID की जगह अपना प्रोजेक्ट आईडी और LOCATION की जगह अपनी जगह की जानकारी डालें. इसके बाद, इस सेल को चलाएं. डिफ़ॉल्ट जगह
europe-west1के तौर पर सेट की गई है. हालांकि, आपको वही जगह इस्तेमाल करनी चाहिए जहां आपका Vertex AI Workbench इंस्टेंस मौजूद है.# Configure your project settings PROJECT_ID = "YOUR PROJECT ID" LOCATION = "europe-west1" - इस लैब के लिए ज़रूरी सभी Python लाइब्रेरी इंपोर्ट करें. इसके लिए, नई सेल में यह कोड चलाएं.
from anthropic import AnthropicVertex from google.auth import default, transport import openai import pandas as pd from vertexai.evaluation import ( EvalTask, MetricPromptTemplateExamples, PairwiseMetric, PointwiseMetric, PointwiseMetricPromptTemplate, ) from vertexai.generative_models import GenerativeModel from vertexai.preview.evaluation import notebook_utils
4. आकलन के लिए डेटासेट सेट अप करना
इस ट्यूटोरियल के लिए, हम OpenOrca डेटासेट से 10 सैंपल का इस्तेमाल करेंगे. इससे हमें मॉडल के बीच के अहम अंतरों को देखने के लिए ज़रूरी डेटा मिल जाता है. साथ ही, आकलन के समय को मैनेज किया जा सकता है.
💡 अहम जानकारी: प्रोडक्शन में, आपको आंकड़ों के हिसाब से अहम नतीजे पाने के लिए, 100 से 500 उदाहरणों की ज़रूरत होगी. हालांकि, सीखने और रैपिड प्रोटोटाइपिंग के लिए 10 सैंपल काफ़ी हैं!
डेटासेट तैयार करना
- डेटा लोड करने के लिए, नई सेल में यह सेल चलाएं. साथ ही, इसे pandas DataFrame में बदलें. इसके अलावा,
responseकॉलम का नाम बदलकरreferenceकरें, ताकि हम आकलन के टास्क को आसानी से पूरा कर सकें. साथ ही, दस उदाहरणों का रैंडम सैंपल बनाएं.from datasets import load_dataset ds = ( load_dataset( "Open-Orca/OpenOrca", data_files="1M-GPT4-Augmented.parquet", split="train[:100]", ) .to_pandas() .drop(columns=["id"]) .rename(columns={"response": "reference"}) ) dataset = ds.sample(n=10) - पिछली सेल के चलने के बाद, अगली सेल में, अपने आकलन डेटासेट की शुरुआती कुछ पंक्तियों को दिखाने के लिए, यहां दिया गया कोड जोड़ें और चलाएं.
dataset.head()
5. कैलकुलेशन पर आधारित मेट्रिक की मदद से, बेसलाइन तय करना
इस टास्क में, आपको कंप्यूटेशन पर आधारित मेट्रिक का इस्तेमाल करके बेसलाइन स्कोर सेट करना है. यह तरीका तेज़ है. साथ ही, इससे आने वाले समय में होने वाले सुधारों को मेज़र करने के लिए, एक ऑब्जेक्टिव बेंचमार्क मिलता है.
हम जवाब की क्वालिटी का आकलन करने के लिए, ROUGE (रीकॉल-ओरिएंटेड अंडरस्टडी फ़ॉर गिस्टिंग इवैलुएशन) का इस्तेमाल करेंगे. यह जवाब की क्वालिटी का आकलन करने के लिए इस्तेमाल की जाने वाली एक स्टैंडर्ड मेट्रिक है. यह मॉडल, मॉडल से जनरेट किए गए जवाब में शब्दों के क्रम (n-ग्राम) की तुलना, ग्राउंड-ट्रुथ reference टेक्स्ट में मौजूद शब्दों से करता है.
कैलकुलेशन पर आधारित मेट्रिक के बारे में ज़्यादा जानें.
बेसलाइन की जांच करना
- नई सेल में, वह मॉडल जोड़ें और चलाएं जिसकी आपको जांच करनी है,
gemini-2.0-flash.generation_configमेंtemperatureऔरmax_output_tokensजैसे पैरामीटर शामिल होते हैं, जो मॉडल के आउटपुट पर असर डालते हैं.# Model to be evaluated model = GenerativeModel( "gemini-2.0-flash", generation_config={"temperature": 0.6, "max_output_tokens": 256, "top_k": 1}, )GenerativeModelक्लास, Vertex AI SDK में लार्ज लैंग्वेज मॉडल के साथ इंटरैक्ट करने के लिए मुख्य इंटरफ़ेस है. - अगले सेल में,
EvalTaskबनाने और उसे लागू करने के लिए, यह कोड जोड़ें और चलाएं. Vertex AI Evaluation SDK का यह ऑब्जेक्ट, आकलन को व्यवस्थित करता है. इसे डेटासेट और कैलकुलेट की जाने वाली मेट्रिक के साथ कॉन्फ़िगर किया जाता है. इस मामले में, यहrouge_l_sumहै.# Define an EvalTask with ROUGE-L-SUM metric rouge_eval_task = EvalTask( dataset=dataset, metrics=["rouge_l_sum"], ) rouge_result = rouge_eval_task.evaluate( model=model, prompt_template="# System_prompt\n{system_prompt} # Question\n{question}", ) - अगली सेल में इस कोड को चलाकर, नतीजे दिखाएं.
notebook_utils.display_eval_result(rouge_result)display_eval_result()यूटिलिटी, औसत (मतलब) स्कोर और हर लाइन के हिसाब से नतीजे दिखाती है.
6. ज़रूरी नहीं: मॉडल पर आधारित पॉइंटवाइज़ मेट्रिक से आकलन करना
ध्यान दें: ऐसा हो सकता है कि यह सेक्शन, मुफ़्त में मिले क्रेडिट की सीमा के अंदर न चले.
ROUGE का इस्तेमाल करना फ़ायदेमंद है. हालांकि, यह सिर्फ़ लेक्सिकल ओवरलैप को मेज़र करता है. इसका मतलब है कि यह सिर्फ़ मिलते-जुलते शब्दों को गिनता है. यह कॉन्टेक्स्ट, समानार्थी शब्दों या पैराफ़्रेज़िंग को नहीं समझता. इसलिए, यह तय करने के लिए सबसे अच्छा तरीका नहीं है कि जवाब पढ़ने में आसान है या नहीं या जवाब तार्किक है या नहीं. मॉडल की परफ़ॉर्मेंस को बेहतर तरीके से समझने के लिए, मॉडल पर आधारित पॉइंटवाइज़ मेट्रिक का इस्तेमाल किया जाता है.
इस तरीके में, एक अन्य एलएलएम ("जज मॉडल") हर जवाब का आकलन, पहले से तय किए गए मानदंड के आधार पर करता है. जैसे, जवाब कितना धाराप्रवाह है या कितना सुसंगत है.
मॉडल पर आधारित मेट्रिक के बारे में ज़्यादा जानें.
पॉइंटवाइज़ इवैलुएशन को चलाएं
- इंटरैक्टिव ड्रॉपडाउन मेन्यू बनाने के लिए, नई सेल में यह कोड चलाएं. इस रन के लिए, सूची से coherence चुनें.
#Select a pointwise metric to use import ipywidgets as widgets pointwise_single_turn_metrics = [ metric for metric in MetricPromptTemplateExamples.list_example_metric_names() if not metric.startswith("pairwise") and not metric.startswith("multi_turn") ] dropdown = widgets.Dropdown( options=pointwise_single_turn_metrics, description="Select a metric:", font_weight="bold", style={"description_width": "initial"}, ) def dropdown_eventhandler(change): global POINTWISE_METRIC if change["type"] == "change" and change["name"] == "value": POINTWISE_METRIC = change.new print("Selected:", change.new) POINTWISE_METRIC = dropdown.value dropdown.observe(dropdown_eventhandler, names="value") display(dropdown) - नई सेल में,
EvalTaskको फिर से चलाएं. इस बार, मॉडल पर आधारित चुनी गई मेट्रिक का इस्तेमाल करें. Vertex AI Evaluation Service, Judge Model के लिए एक प्रॉम्प्ट बनाती है. इसमें ओरिजनल प्रॉम्प्ट, रेफ़रंस जवाब, कैंडिडेट मॉडल का जवाब, और चुनी गई मेट्रिक के लिए निर्देश शामिल होते हैं. जज मॉडल, रेटिंग के लिए एक संख्यात्मक स्कोर और वजह बताता है. ध्यान दें: इस चरण को पूरा होने में कुछ मिनट लगेंगे.pointwise_result = EvalTask( dataset=dataset, metrics=[POINTWISE_METRIC], ).evaluate( model=model, prompt_template="# System_prompt\n{system_prompt} # Question\n{question}", )
नतीजे दिखाना
समीक्षा पूरी होने के बाद, अगला चरण आउटपुट का विश्लेषण करना है.
- खास जानकारी वाली मेट्रिक देखने के लिए, नई सेल में यह कोड चलाएं. इससे चुनी गई मेट्रिक का औसत स्कोर दिखता है.
notebook_utils.display_eval_result(pointwise_result) - लाइन-दर-लाइन स्कोर देखने के लिए, अगली सेल में यह कोड चलाएं. इसमें जज मॉडल के स्कोर के लिए लिखी गई वजह भी शामिल है. इस तरह के गुणात्मक सुझाव से, आपको यह समझने में मदद मिलती है कि किसी जवाब को कोई स्कोर क्यों दिया गया.
notebook_utils.display_explanations(pointwise_result, num=1, metrics=[POINTWISE_METRIC])
7. ज़्यादा जानकारी पाने के लिए, कस्टम मेट्रिक बनाना
पहले से तैयार की गई मेट्रिक, जैसे कि फ़्लूएंसी (भाषा का सही तरीके से इस्तेमाल) काम की होती हैं. हालांकि, किसी खास प्रॉडक्ट के लिए, आपको अक्सर अपने लक्ष्यों के हिसाब से परफ़ॉर्मेंस को मेज़र करने की ज़रूरत होती है. पॉइंटवाइज़ कस्टम मेट्रिक की मदद से, आकलन के अपने मानदंड और रूब्रिक तय किए जा सकते हैं.
इस टास्क में, आपको summarization_helpfulness नाम की एक नई मेट्रिक बनानी है.
कस्टम मेट्रिक को तय करना और उसे चलाना
- कस्टम मेट्रिक तय करने के लिए, नई सेल में यह कोड चलाएं.
PointwiseMetricPromptTemplateमें मेट्रिक के मुख्य कॉम्पोनेंट शामिल हैं:- criteria: इससे जज मॉडल को उन डाइमेंशन के बारे में पता चलता है जिनका आकलन करना है: "मुख्य जानकारी," "संक्षिप्तता," और "कोई गड़बड़ी नहीं."
- rating_rubric: इसमें पांच पॉइंट वाला स्कोरिंग स्केल दिया जाता है. इससे यह पता चलता है कि हर स्कोर का क्या मतलब है.
- input_variables: यह पैरामीटर, डेटासेट से अतिरिक्त कॉलम को जज मॉडल को पास करता है, ताकि उसके पास आकलन करने के लिए ज़रूरी कॉन्टेक्स्ट हो.
# This new custom metric evaluates the actual quality and usefulness of the summary. summarization_helpfulness_metric = PointwiseMetric( metric="summarization_helpfulness", metric_prompt_template=PointwiseMetricPromptTemplate( criteria={ "Key Information": "Does the summary capture the most critical pieces of information from the original text? It should not miss the main topic or key takeaways.", "Conciseness": "Is the summary brief and to the point? It should avoid unnecessary words or repetitive information.", "No Distortion": "Does the summary introduce information or opinions that were NOT present in the original text? It must accurately reflect the source material without adding hallucinations." }, rating_rubric={ "5": "Excellent: Captures all key information, is highly concise, and has zero distortion.", "4": "Good: Captures most key information with minor omissions, is concise, and has no distortion.", "3": "Satisfactory: Captures the main idea but misses some key details OR is not very concise.", "2": "Unsatisfactory: Misses the main idea of the original text OR contains minor distortions/hallucinations.", "1": "Poor: Is completely irrelevant, fails to summarize the text, OR contains significant distortions.", }, input_variables=["prompt", "reference"], ), ) - अपनी नई कस्टम मेट्रिक के साथ
EvalTaskको लागू करने के लिए, अगली सेल में यह कोड चलाएं.# You would then update the EvalTask to use this new metric pointwise_result = EvalTask( dataset=dataset, metrics=[summarization_helpfulness_metric], ).evaluate( model=model, prompt_template="# System_prompt\n{system_prompt} # Question\n{question}", ) - नतीजे देखने के लिए, नई सेल में यह कोड चलाएं.
notebook_utils.display_eval_result(pointwise_result)
8. जोड़े के हिसाब से तुलना करके मॉडल का आकलन करना
जब आपको यह तय करना हो कि किसी टास्क के लिए, दो मॉडल में से कौनसा मॉडल बेहतर परफ़ॉर्म करता है, तब मॉडल के आधार पर पेयरवाइज़ आकलन का इस्तेमाल किया जा सकता है. यह तरीका, A/B टेस्टिंग का एक रूप है. इसमें जज मॉडल, विजेता का फ़ैसला करता है. साथ ही, डेटा-ड्रिवन मॉडल चुनने के लिए सीधे तौर पर तुलना करता है.
मॉडल:
- कैंडिडेट मॉडल: मॉडल वैरिएबल (जिसे पहले
gemini-2.0-flashके तौर पर तय किया गया था) को.evaluate()तरीके में पास किया जाता है. यह वह मुख्य मॉडल है जिसकी टेस्टिंग की जा रही है. - बेसलाइन मॉडल: दूसरा मॉडल,
gemini-2.0-flash-lite, को PairwiseMetric क्लास में तय किया गया है. यह वह मॉडल है जिससे तुलना की जा रही है.
पेयरवाइज़ आकलन करना
- इंटरैक्टिव ड्रॉपडाउन मेन्यू बनाने के लिए, नई सेल में यह कोड जोड़ें और चलाएं. इससे, आपके पास यह चुनने का विकल्प होगा कि तुलना के लिए, आपको कौनसी पेयरवाइज़ मेट्रिक का इस्तेमाल करना है. इस रन के लिए, pairwise_summarization_quality को चुनें.
from IPython.display import display import ipywidgets as widgets pairwise_single_turn_metrics = [ metric for metric in MetricPromptTemplateExamples.list_example_metric_names() if metric.startswith("pairwise") and "multi_turn" not in metric ] dropdown = widgets.Dropdown( options=pairwise_single_turn_metrics, description="Select a metric:", font_weight="bold", style={"description_width": "initial"}, ) def dropdown_eventhandler(change): global POINTWISE_METRIC if change["type"] == "change" and change["name"] == "value": POINTWISE_METRIC = change.new print("Selected:", change.new) def dropdown_eventhandler(change): global PAIRWISE_METRIC_NAME if change["type"] == "change" and change["name"] == "value": PAIRWISE_METRIC_NAME = change.new print("Selected:", change.new) PAIRWISE_METRIC_NAME = dropdown.value dropdown.observe(dropdown_eventhandler, names="value") display(dropdown) - अगली सेल में,
EvalTaskको कॉन्फ़िगर और लागू करने के लिए, यहां दिया गया कोड जोड़ें और चलाएं. ध्यान दें किPairwiseMetricक्लास का इस्तेमाल, बेसलाइन मॉडल (gemini-2.0-flash-lite) को तय करने के लिए किया जाता है. वहीं, कैंडिडेट मॉडल (gemini-2.0-flash) को.evaluate()तरीके में पास किया जाता है.pairwise_result = EvalTask( dataset=dataset, metrics=[ PairwiseMetric( metric=PAIRWISE_METRIC_NAME, metric_prompt_template=MetricPromptTemplateExamples.get_prompt_template( PAIRWISE_METRIC_NAME ), # Define a baseline model to compare against baseline_model=GenerativeModel("gemini-2.0-flash-lite"), ) ], ).evaluate( # Specify a candidate model for pairwise comparison model=model, prompt_template="# System_prompt\n{system_prompt} # Question\n{question}", ) - नतीजे दिखाने के लिए, नई सेल में यह कोड जोड़ें और चलाएं. खास जानकारी वाली टेबल में, हर मॉडल के लिए "जीतने की दर" दिखेगी. इससे पता चलेगा कि जज मॉडल ने किस मॉडल को ज़्यादा बार चुना.
notebook_utils.display_eval_result(pairwise_result)
9. ज़रूरी नहीं: पर्सोना के हिसाब से बनाए गए प्रॉम्प्ट का आकलन करना
ध्यान दें: ऐसा हो सकता है कि यह सेक्शन, मुफ़्त में मिले क्रेडिट की सीमा के अंदर न चले.
इस टास्क में, आपको अलग-अलग प्रॉम्प्ट टेंप्लेट की जांच करनी होगी. इन टेंप्लेट में, मॉडल को अलग-अलग पर्सोना अपनाने के निर्देश दिए गए हैं. इस प्रोसेस को अक्सर प्रॉम्प्ट इंजीनियरिंग या प्रॉम्प्ट डिज़ाइन कहा जाता है. इससे आपको किसी खास इस्तेमाल के उदाहरण के लिए, सबसे असरदार प्रॉम्प्ट को व्यवस्थित तरीके से ढूंढने में मदद मिलती है.
जवाब तैयार करने के लिए डेटासेट तैयार करना
इस आकलन को करने के लिए, डेटासेट में ये फ़ील्ड होने चाहिए:
instruction: यह वह मुख्य टास्क है जो हम मॉडल को दे रहे हैं. इस मामले में, यह एक सामान्य प्रॉम्प्ट है: "इस लेख के बारे में खास जानकारी दो:".context: यह वह सोर्स टेक्स्ट है जिस पर मॉडल को काम करना है. यहां हमने चार अलग-अलग समाचार स्निपेट दिए हैं.reference: ग्राउंड-ट्रुथ या "गोल्ड स्टैंडर्ड" जवाब. मॉडल के जनरेट किए गए आउटपुट की तुलना इस टेक्स्ट से की जाएगी. इससे ROUGE और जवाब की क्वालिटी जैसी मेट्रिक के लिए स्कोर का हिसाब लगाया जा सकेगा.
pandas.DataFrameबनाने के लिए, नई सेल में यह कोड जोड़ें और चलाएं.instruction = "Summarize the following article: \n" context = [ "Typhoon Phanfone has killed at least one person, a US airman on Okinawa who was washed away by high waves. Thousands of households have lost power and Japan's two largest airlines have suspended many flights. The storm also forced the suspension of the search for people missing after last week's volcanic eruption. The storm-tracking website Tropical Storm Risk forecasts that Phanfone will rapidly lose power over the next few hours as it goes further into the Pacific Ocean. Typhoon Phanfone was downgraded from an earlier status of a super typhoon, but the Japan Meteorological Agency had warned it was still a dangerous storm. Japan averages 11 typhoons a year, according to its weather agency. The typhoon made landfall on Monday morning near the central city of Hamamatsu, with winds of up to 180 km/h (112 mph). The airman was one of three US military personnel swept away by high waves whipped up by the typhoon off southern Okinawa island, where the US has a large military base. The remaining two are still missing. A police spokesman said they had been taking photographs of the sea. A university student who was surfing off the seas of Kanagawa Prefecture, south of Tokyo, was also missing, national broadcast NHK reports. It said at least 10 people had been injured and 9,500 houses were without power. The storm was expected to deposit about 100mm of rain on Tokyo over 24 hours, according to the Transport Ministry website. Many schools were closed on Monday and two car companies in Japan halted production at some plants ahead of the storm. More than 174 domestic flights were affected nationwide, NHK state broadcaster said on Sunday. On Sunday, heavy rain delayed the Japanese Formula One Grand Prix in Suzaka. French driver Jules Bianchi lost control in the wet conditions and crashed, sustaining a severe head injury.", "The blaze started at the detached building in Drivers End in Codicote, near Welwyn, during the morning. There was another fire at the building 20 years ago, after which fire-proof foil was placed under the thatch, which is protecting the main building. More than 15 fire engines and support vehicles were called to tackle the blaze. Roads in the area were closed and traffic diverted.", 'The 18-year-old fell at the New Charter Academy on Broadoak Road in Ashton-under-Lyne at about 09:10 BST, Greater Manchester Police (GMP) said. GMP said he had gone to Manchester Royal Infirmary and his condition was "serious". Principal Jenny Langley said the school would remain "fully open" while police investigated. "Our thoughts are with the family and we\'re doing everything we can to support them along with staff and pupils," she said.', 'But Belgian-born Dutchman Max Verstappen was unable to drive a car legally on his own in either country. That all changed on Wednesday when the youngster turned 18 and passed his driving test at the first attempt. Despite having competed in 14 grands prix since his debut in Australia in March, Verstappen admitted to feeling the pressure during his test. "It\'s a relief," said the Toro Rosso driver, who finished ninth in Japan on Sunday and had only started driving lessons a week ago. "I was a bit nervous to make mistakes, but the exam went well." A bonus of turning 18 is that Verstappen will now be able to drink the champagne if he ever makes it onto the podium.', ] reference = [ "A powerful typhoon has brought many parts of Japan to a standstill and briefly battered Tokyo before heading out to sea.", "A major fire has been burning in the thatched roof of a large property in Hertfordshire.", "A student has been taken to hospital after falling from a balcony at a Greater Manchester school.", "He is Formula 1's youngest ever driver and in charge of a car that can reach over 200mph.", ] response = [ "Typhoon Phanfone, while downgraded from super typhoon status, caused significant disruption and tragedy in Japan. One US airman died after being swept away by high waves, with two more missing. The storm caused power outages for thousands, flight cancellations, and the suspension of rescue efforts for missing volcano victims. Heavy rain and strong winds led to school and factory closures, transportation disruptions, and at least 10 injuries. The typhoon is expected to weaken as it moves over the Pacific Ocean.", "A large fire broke out in a detached thatched building in Codicote, near Welwyn. This is the second fire at the building in 20 years. Thankfully, fire-proof foil installed after the previous fire is protecting the main building. Over 15 fire engines and support vehicles responded, closing roads and diverting traffic in the area.", "An 18-year-old student at New Charter Academy in Ashton-under-Lyne suffered a serious fall and was hospitalized. The incident is under investigation by Greater Manchester Police, but the school remains open. The principal expressed support for the student's family and the school community.", "Max Verstappen, a Formula One driver, was finally able to get his driver's license at age 18. Despite already competing in 14 Grand Prix races, he was not of legal driving age in his native countries. He admitted to being nervous but passed the test on his first attempt. As an added bonus of turning 18, Verstappen can now enjoy champagne on the podium if he places.", ] eval_dataset = pd.DataFrame( { "instruction": instruction, "context": context, "reference": reference, } )
प्रॉम्प्ट के आकलन का टास्क चलाना
खास जानकारी तैयार करने से जुड़ा डेटासेट तैयार हो जाने के बाद, इस टास्क का मुख्य एक्सपेरिमेंट चलाया जा सकता है. इसमें, अलग-अलग प्रॉम्प्ट टेंप्लेट की तुलना करके यह देखा जाता है कि मॉडल से सबसे अच्छी क्वालिटी का आउटपुट किस टेंप्लेट से मिलता है.
- अगली सेल में, एक
EvalTaskबनाएं. इसका इस्तेमाल हर प्रॉम्प्ट एक्सपेरिमेंट के लिए किया जाएगा.experimentपैरामीटर सेट करने पर, इस टास्क से जुड़े सभी आकलन अपने-आप लॉग हो जाते हैं. साथ ही, इन्हें Vertex AI Experiments में ग्रुप कर दिया जाता है.EXPERIMENT_NAME = "eval-sdk-prompt-engineering" # @param {type:"string"} summarization_eval_task = EvalTask( dataset=eval_dataset, metrics=[ "rouge_l_sum", "bleu", "fluency", "coherence", "safety", "groundedness", "summarization_quality", "verbosity", "instruction_following", "text_quality", ], experiment=EXPERIMENT_NAME, )rouge_l_sumऔरbleuसे लेकर मॉडल पर आधारित मेट्रिक (fluency,coherence,summarization_quality,instruction_followingवगैरह) तक की सभी चीज़ों का हिसाब लगाने के लिए कह रहे हैं. इससे हमें यह समझने में मदद मिलती है कि हर प्रॉम्प्ट, मॉडल के आउटपुट की क्वालिटी पर किस तरह से असर डालता है. - नई सेल में, यहां दिया गया कोड जोड़ें और चलाएं. इससे, पर्सोना के हिसाब से प्रॉम्प्ट बनाने की चार रणनीतियों को तय किया जा सकेगा और उनका आकलन किया जा सकेगा.
forलूप, हर टेंप्लेट के हिसाब से काम करता है और उसका आकलन करता है.हर टेंप्लेट को इस तरह से डिज़ाइन किया गया है कि वह मॉडल को कोई खास पर्सोना या लक्ष्य देकर, अलग-अलग स्टाइल में जवाब जनरेट कर सके:- पर्सोना #1 (स्टैंडर्ड): इसमें, जवाब को छोटा करने के लिए सामान्य अनुरोध किया गया है.
- पर्सोना #2 (कार्यकारी): बुलेट पॉइंट में खास जानकारी देने के लिए कहता है. साथ ही, नतीजों और असर पर फ़ोकस करने के लिए कहता है, क्योंकि एक व्यस्त कार्यकारी ऐसा ही चाहेगा.
- पर्सोना #3 (पांचवीं क्लास का छात्र): मॉडल को आसान भाषा का इस्तेमाल करने का निर्देश देता है. इससे यह जांच की जाती है कि मॉडल, अपने आउटपुट की जटिलता को अडजस्ट कर सकता है या नहीं.
- पर्सोना #4 (टेक्निकल विश्लेषक): इसे तथ्यों के आधार पर तैयार की गई ऐसी खास जानकारी चाहिए जिसमें मुख्य आंकड़े और इकाइयां शामिल हों. इससे मॉडल की सटीकता की जांच की जा सकेगी. ध्यान दें कि इन नए टेंप्लेट में मौजूद प्लेसहोल्डर, जैसे कि
{context}और{instruction}, इस टास्क के लिए बनाए गएeval_datasetमें मौजूद नए कॉलम के नामों से मेल खाते हैं.
# Define prompt templates that target different user personas prompt_templates = [ # Persona 1: Standard, neutral summary "Article: {context}. Task: {instruction}. Summary:", # Persona 2: For a busy executive (bullet points) "Instruction: {instruction} into three key bullet points for a busy executive. Focus on the main outcome and impact. Article: {context}. Summary:", # Persona 3: For a 5th grader (simple language) "Instruction: {instruction} such that you're explaining it to a 10-year-old. Use simple words. Article: {context}. Summary:", # Persona 4: For a technical analyst (fact-focused) "Instruction: Provide a detailed, factual summary of the following text, ensuring all key statistics, names, and locations are preserved. Article: {context}. Summary:", ] eval_results = [] for i, prompt_template in enumerate(prompt_templates): eval_result = summarization_eval_task.evaluate( prompt_template=prompt_template, model=GenerativeModel( "gemini-2.0-flash", generation_config={ "temperature": 0.3, "max_output_tokens": 256, "top_k": 1, }, ), evaluation_service_qps=5, ) eval_results.append((f"Prompt Persona #{i+1}", eval_result))
नतीजों का विश्लेषण करना और उन्हें विज़ुअलाइज़ करना
एक्सपेरिमेंट करना पहला चरण है. डेटा के आधार पर फ़ैसला लेने के लिए, नतीजों का विश्लेषण करना ज़रूरी है. इस टास्क में, आपको एसडीके के विज़ुअलाइज़ेशन टूल का इस्तेमाल करके, प्रॉम्प्ट पर्सोना एक्सपेरिमेंट के आउटपुट को समझना होगा.
- आपने जिन चार प्रॉम्प्ट पर्सोना का इस्तेमाल करके टेस्ट किया है उनके लिए, खास जानकारी वाले नतीजे दिखाएं. इसके लिए, नई सेल में यह कोड चलाएं. इससे आपको परफ़ॉर्मेंस के बारे में खास जानकारी मिलती है.
for title, eval_result in eval_results: notebook_utils.display_eval_result(title=title, eval_result=eval_result) - नई सेल में, हर पर्सोना के लिए
summarization_qualityमेट्रिक की वजह जानने के लिए, यह कोड जोड़ें और चलाएं.for title, eval_result in eval_results: notebook_utils.display_explanations( eval_result, metrics=["summarization_quality"], num=2 ) - हर प्रॉम्प्ट के लिए, अलग-अलग क्वालिटी मेट्रिक के बीच ट्रेड-ऑफ़ को विज़ुअलाइज़ करने के लिए, रडार प्लॉट जनरेट करें. नई सेल में, यह कोड जोड़ें और चलाएं.
notebook_utils.display_radar_plot( eval_results, metrics=["instruction_following", "fluency", "coherence", "text_quality"], ) - आसानी से तुलना करने के लिए, बार प्लैट बनाएं. नई सेल में, यह कोड जोड़ें और चलाएं.
notebook_utils.display_bar_plot( eval_results, metrics=["instruction_following", "fluency", "coherence", "text_quality"], )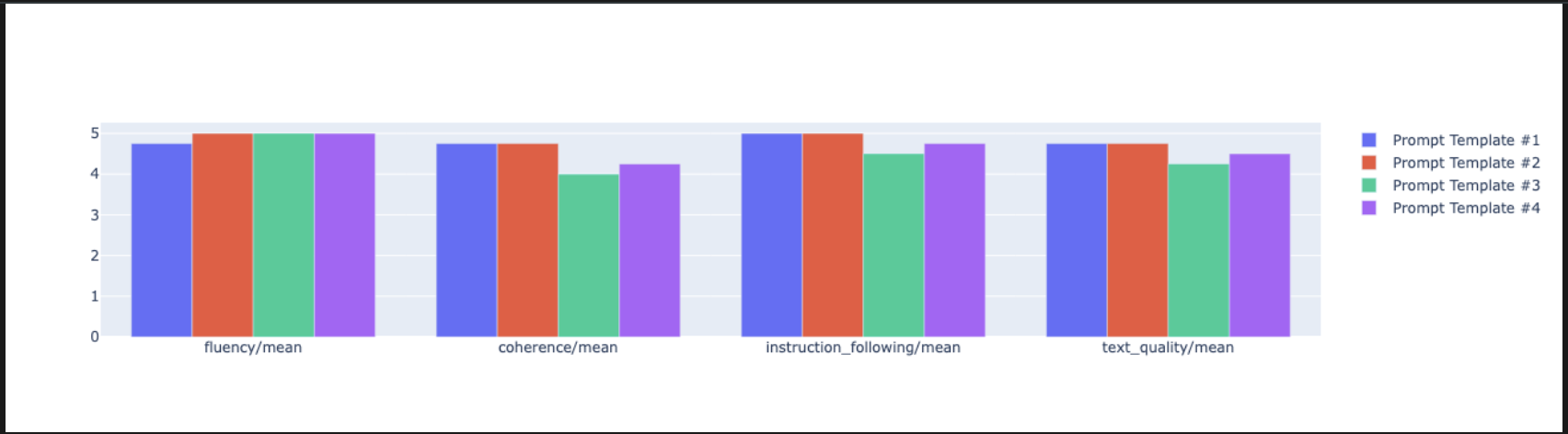
- अब इस टास्क के लिए, Vertex AI Experiment में लॉग किए गए सभी रन की खास जानकारी देखी जा सकती है. इससे समय के साथ-साथ अपने काम को ट्रैक करने में मदद मिलती है. नई सेल में, यह कोड जोड़ें और चलाएं:
summarization_eval_task.display_runs()
10. एक्सपेरिमेंट को क्लीन अप करना
अपने प्रोजेक्ट को व्यवस्थित रखने और गैर-ज़रूरी शुल्क से बचने के लिए, बनाए गए संसाधनों को मिटा देना सबसे सही तरीका है. इस लैब में, हर आकलन को Vertex AI Experiment में लॉग किया गया था. नीचे दिए गए कोड से, इस पैरंट एक्सपेरिमेंट को मिटाया जाता है. इससे इससे जुड़े सभी रन और उनका डेटा भी मिट जाता है.
- Vertex AI Experiment और उससे जुड़ी रन को मिटाने के लिए, इस कोड को नई सेल में चलाएं.
delete_experiment = True # Please set your LOCATION to the same one used during Vertex AI SDK initialization. LOCATION = "YOUR LOCATION" # @param {type:"string"} if delete_experiment: from google.cloud import aiplatform aiplatform.init(project=PROJECT_ID, location=LOCATION) experiment = aiplatform.Experiment(EXPERIMENT_NAME) experiment.delete()
11. प्रैक्टिस से लेकर प्रोडक्शन तक
इस लैब में सीखी गई स्किल, भरोसेमंद एआई ऐप्लिकेशन बनाने के लिए ज़रूरी हैं. हालांकि, मैन्युअल तरीके से चलाई जाने वाली नोटबुक से प्रोडक्शन-ग्रेड के आकलन सिस्टम पर माइग्रेट करने के लिए, अतिरिक्त बुनियादी ढांचे और ज़्यादा व्यवस्थित तरीके की ज़रूरत होती है. इस सेक्शन में, कारोबार को बड़ा करने के लिए ज़रूरी तरीकों और रणनीतिक फ़्रेमवर्क के बारे में बताया गया है.
प्रोडक्शन इवैलुएशन की रणनीतियां बनाना
इस लैब में सीखी गई बातों को प्रोडक्शन एनवायरमेंट में लागू करने के लिए, उन्हें दोहराई जा सकने वाली रणनीतियों में शामिल करना फ़ायदेमंद होता है. यहां दिए गए फ़्रेमवर्क में, सामान्य स्थितियों के लिए कुछ अहम बातों के बारे में बताया गया है. जैसे, मॉडल चुनना, प्रॉम्प्ट को ऑप्टिमाइज़ करना, और लगातार निगरानी करना.
मॉडल चुनने के लिए:
# Evaluation strategy for choosing models
evaluation_strategy = {
"dataset_size": "100+ examples for statistical significance",
"metrics": ["task-specific", "general quality", "efficiency"],
"comparison_type": "pairwise with statistical testing",
"baseline": "established_model_or_human_benchmark"
}
प्रॉम्प्ट को ऑप्टिमाइज़ करने के लिए
# Systematic prompt improvement workflow
prompt_optimization = {
"hypothesis": "Clear statement of what you're testing",
"variants": "3-5 different prompt strategies",
"evaluation": "Same metrics across all variants",
"analysis": "Statistical significance + qualitative review"
}
लगातार मॉनिटर करने के लिए
# Production evaluation pipeline
production_eval = {
"frequency": "Every model update + weekly monitoring",
"automation": "CI/CD integration with quality gates",
"metrics": "Speed + quality + cost tracking",
"alerting": "Performance degradation detection"
}
लागत के हिसाब से ज़्यादा असरदार होने से जुड़ी बातें
बड़े पैमाने पर मॉडल के आधार पर आकलन करना महंगा हो सकता है. कम लागत में प्रोडक्शन करने की रणनीति में, अलग-अलग कामों के लिए अलग-अलग तरीकों का इस्तेमाल किया जाता है. इस टेबल में, अलग-अलग तरह के आकलन के लिए, स्पीड, लागत, और इस्तेमाल के उदाहरणों के बीच के फ़र्क़ के बारे में खास जानकारी दी गई है:
इवैलुएशन टाइप | समय | हर सैंपल की लागत | इनके लिए सर्वश्रेष्ठ: |
ROUGE/BLEU | सेकंड | ~0.001 डॉलर | ज़्यादा कॉल की स्क्रीनिंग करना |
मॉडल पर आधारित पॉइंटवाइज़ | ~1-2 सेकंड | ~0.01 डॉलर | क्वालिटी का आकलन |
जोड़े के हिसाब से तुलना करना | ~2 से 3 सेकंड | ~2 रुपये | मॉडल चुनना |
इंसानों से आकलन कराना | मिनट | $1-10 | गोल्ड स्टैंडर्ड की पुष्टि करना |
सीआई/सीडी और मॉनिटरिंग की मदद से ऑटोमेट करना
मैन्युअल तरीके से नोटबुक रन को बढ़ाया नहीं जा सकता. लगातार इंटिग्रेशन/लगातार डिप्लॉयमेंट (सीआई/सीडी) पाइपलाइन में, अपने आकलन को ऑटोमेट करें.
- क्वालिटी गेट बनाना: अपने आकलन के टास्क को सीआई/सीडी पाइपलाइन (जैसे, Cloud Build) में इंटिग्रेट करें. नए प्रॉम्प्ट या मॉडल पर अपने-आप आकलन चलाएं. साथ ही, अगर क्वालिटी के मुख्य स्कोर, तय की गई थ्रेशोल्ड से नीचे गिरते हैं, तो डिप्लॉयमेंट को ब्लॉक करें.
- रुझानों पर नज़र रखना: अपनी जांच के नतीजों से जुड़ी खास मेट्रिक को Google Cloud Monitoring जैसी सेवा में एक्सपोर्ट करें. समय के साथ क्वालिटी को ट्रैक करने के लिए डैशबोर्ड बनाएं. साथ ही, परफ़ॉर्मेंस में गिरावट आने पर अपनी टीम को सूचना देने के लिए, अपने-आप सूचनाएं मिलने की सुविधा सेट अप करें.
12. नतीजा
आपने लैब पूरी कर ली है. आपने जनरेटिव एआई मॉडल का आकलन करने के लिए ज़रूरी स्किल सीख ली हैं.
यह लैब, 'Google Cloud के साथ प्रोडक्शन-रेडी एआई' लर्निंग पाथ का हिस्सा है.
- प्रोटोटाइप से प्रोडक्शन तक के अंतर को कम करने के लिए, पूरा पाठ्यक्रम देखें.
- अपनी प्रोग्रेस को
ProductionReadyAIहैशटैग के साथ शेयर करें.
रीकैप
इस लैब में, आपने ये सीखा:
EvalTaskफ़्रेमवर्क का इस्तेमाल करके, आकलन करने के सबसे सही तरीके लागू करें.- मेट्रिक के अलग-अलग टाइप का इस्तेमाल करें. जैसे, कंप्यूटेशन पर आधारित मेट्रिक से लेकर मॉडल पर आधारित मेट्रिक तक.
- अलग-अलग वर्शन आज़माकर, प्रॉम्प्ट को ऑप्टिमाइज़ करें.
- एक्सपेरिमेंट ट्रैकिंग की मदद से, दोहराए जा सकने वाला वर्कफ़्लो बनाएं.
सीखते रहने के लिए संसाधन
- Vertex AI Gen AI के आकलन से जुड़ा दस्तावेज़
- बेहतर तरीके से आकलन करने की तकनीकों के बारे में जानकारी देने वाली नोटबुक
- Gen AI Evaluation SDK का रेफ़रंस
- मॉडल पर आधारित मेट्रिक की रिसर्च
- प्रॉम्प्ट इंजीनियरिंग के सबसे सही तरीके
इस लैब में आपने सिस्टमैटिक तरीके से आकलन करने के जो तरीके सीखे हैं वे भरोसेमंद और अच्छी क्वालिटी वाले एआई ऐप्लिकेशन बनाने के लिए, एक मज़बूत आधार के तौर पर काम करेंगे. याद रखें: अच्छी तरह से आकलन करना, एक्सपेरिमेंट के तौर पर उपलब्ध एआई और प्रोडक्शन की सफलता के बीच का पुल है.