
1. Ringkasan
Dalam lab ini, Anda akan mempelajari cara mengevaluasi model bahasa besar menggunakan Layanan Evaluasi AI Generatif Vertex AI. Anda akan menggunakan SDK untuk menjalankan tugas evaluasi, membandingkan hasil, dan membuat keputusan berbasis data tentang performa model dan desain perintah.
Lab ini memandu Anda melalui alur kerja evaluasi umum, dimulai dengan metrik sederhana berbasis komputasi dan berlanjut ke evaluasi berbasis model yang lebih bernuansa. Anda juga akan mempelajari cara membuat metrik kustom yang disesuaikan dengan sasaran spesifik Anda dan melacak pekerjaan Anda menggunakan Eksperimen Vertex AI.
Yang akan Anda pelajari
Di lab ini, Anda akan mempelajari cara melakukan tugas berikut:
- Mengevaluasi model dengan metrik berbasis komputasi dan berbasis model.
- Buat metrik kustom untuk menyelaraskan evaluasi dengan sasaran produk.
- Bandingkan berbagai template perintah secara berdampingan.
- Uji beberapa perintah berbasis persona untuk menemukan versi yang paling efektif.
- Lacak dan visualisasikan operasi evaluasi menggunakan Vertex AI Experiments.
Referensi
- Contoh kode: Lab ini dibuat berdasarkan contoh dari repositori AI Generatif Google Cloud
- Berdasarkan: Dokumentasi Evaluasi AI Generatif Vertex AI
- Set data: Set data OpenOrca untuk evaluasi kepatuhan terhadap perintah
2. Penyiapan project
Akun Google
Jika belum memiliki Akun Google pribadi, Anda harus membuat Akun Google.
Gunakan akun pribadi, bukan akun kantor atau sekolah.
Login ke Konsol Google Cloud
Login ke Konsol Google Cloud menggunakan Akun Google pribadi.
Aktifkan Penagihan
Untuk mengaktifkan penagihan, Anda memiliki dua opsi. Anda dapat menggunakan akun penagihan pribadi atau menukarkan kredit dengan langkah-langkah berikut.
Menukarkan kredit Google Cloud (opsional)
Untuk menjalankan workshop ini, Anda memerlukan akun penagihan dengan sejumlah kredit. Gunakan kredit dari banner di bagian atas codelab ini untuk memulai. Jika sudah terhubung ke akun penagihan, Anda dapat melewati langkah ini.
Menyiapkan akun penagihan pribadi
Jika menyiapkan penagihan menggunakan kredit Google Cloud, Anda dapat melewati langkah ini.
Untuk menyiapkan akun penagihan pribadi, buka di sini untuk mengaktifkan penagihan di Cloud Console.
Beberapa Catatan:
- Menyelesaikan lab ini akan dikenai biaya kurang dari $1 USD untuk resource Cloud.
- Anda dapat mengikuti langkah-langkah di akhir lab ini untuk menghapus resource agar tidak dikenai biaya lebih lanjut.
- Pengguna baru memenuhi syarat untuk mengikuti Uji Coba Gratis senilai$300 USD.
Membuat project (opsional)
Jika Anda tidak memiliki project saat ini yang ingin digunakan untuk lab ini, buat project baru di sini.
3. Menyiapkan lingkungan Vertex AI Workbench
Mari kita mulai dengan mengakses lingkungan notebook yang telah dikonfigurasi sebelumnya dan menginstal dependensi yang diperlukan.
Mengakses Vertex AI Workbench
- Di Konsol Google Cloud, buka Vertex AI dengan mengklik Navigation menu ☰ > Vertex AI > Dashboard.
- Klik Enable All Recommended APIs. Catatan: Harap tunggu hingga langkah ini selesai
- Di sebelah kiri, klik Workbench untuk membuat instance workbench baru.

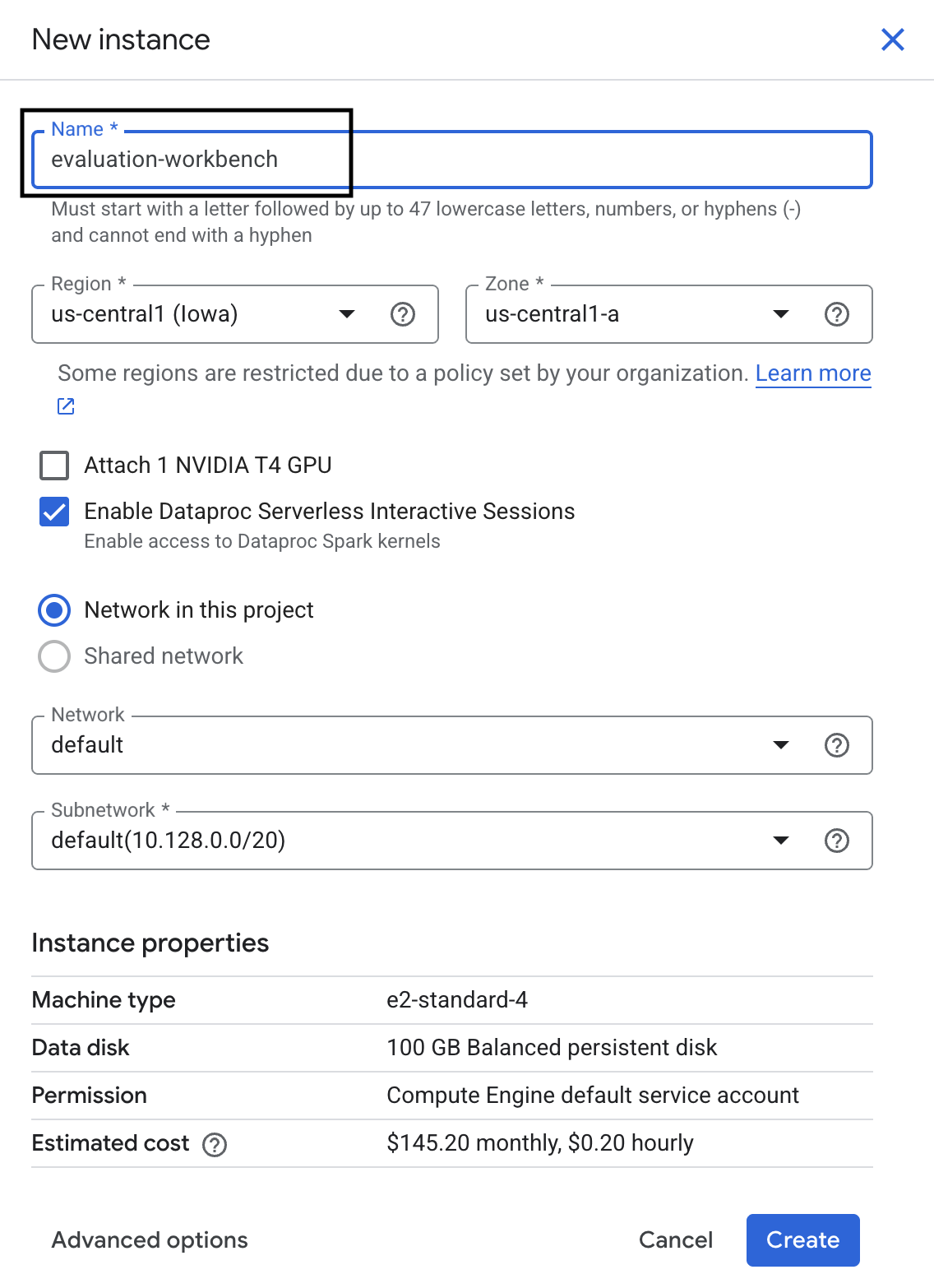
- Beri nama instance workbench evaluation-workbench, lalu klik Create.
- Tunggu hingga workbench disiapkan. Proses ini memerlukan waktu beberapa menit.

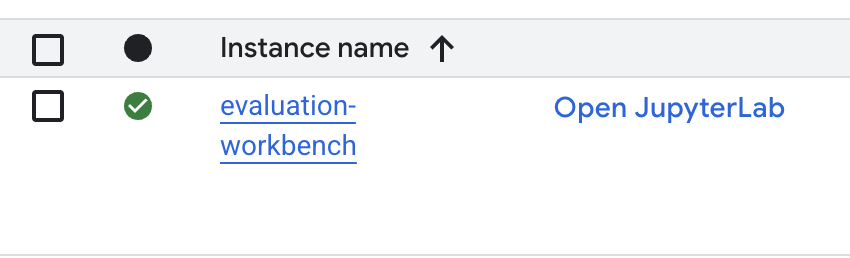
- Setelah workbench disediakan, klik Open JupyterLab.
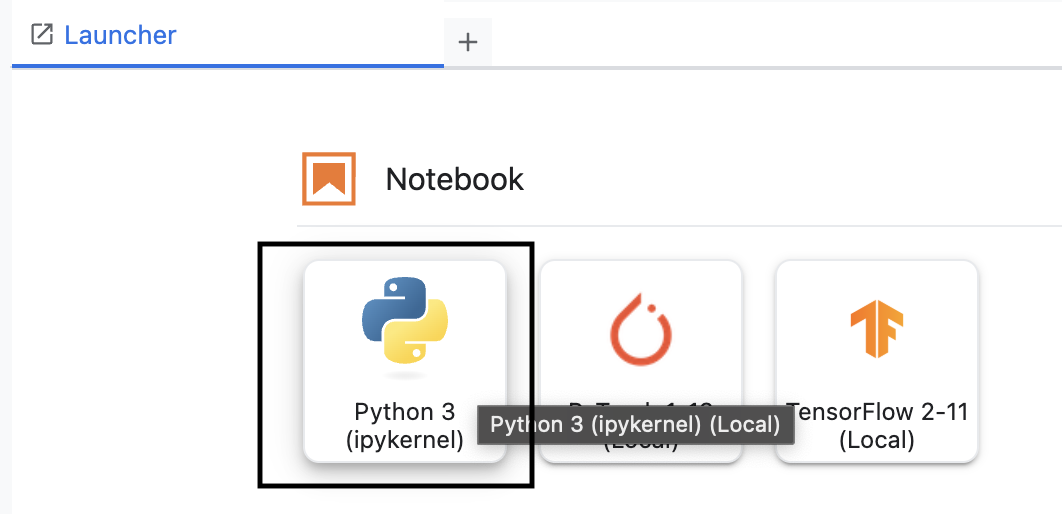
- Di workbench, buat notebook Python3 baru.
Untuk mempelajari lebih lanjut fitur dan kemampuan lingkungan ini, lihat dokumentasi resmi untuk Vertex AI Workbench.
Menginstal paket dan mengonfigurasi lingkungan Anda
- Di sel pertama notebook, tambahkan dan jalankan pernyataan impor di bawah (SHIFT+ENTER) untuk menginstal Vertex AI SDK (dengan komponen evaluasi) dan paket lain yang diperlukan.
%pip install -U -q google-cloud-aiplatform[evaluation] %pip install -U -q datasets anthropic[vertex] openai - Untuk menggunakan paket yang baru diinstal, sebaiknya mulai ulang kernel dengan menjalankan cuplikan kode di bawah.
# Automatically restart kernel after installation so that your environment can access the new packages. import IPython app = IPython.Application.instance() app.kernel.do_shutdown(True) - Ganti yang berikut dengan project ID dan lokasi Anda, lalu jalankan sel berikut. Lokasi default ditetapkan sebagai
europe-west1, tetapi Anda harus menggunakan lokasi yang sama dengan instance Vertex AI Workbench Anda.# Configure your project settings PROJECT_ID = "YOUR PROJECT ID" LOCATION = "europe-west1" - Impor semua library Python yang diperlukan untuk lab ini dengan menjalankan kode berikut di sel baru.
from anthropic import AnthropicVertex from google.auth import default, transport import openai import pandas as pd from vertexai.evaluation import ( EvalTask, MetricPromptTemplateExamples, PairwiseMetric, PointwiseMetric, PointwiseMetricPromptTemplate, ) from vertexai.generative_models import GenerativeModel from vertexai.preview.evaluation import notebook_utils
4. Menyiapkan set data evaluasi
Untuk tutorial ini, kita akan menggunakan 10 sampel dari set data OpenOrca dataset. Dengan demikian, kami memiliki cukup data untuk melihat perbedaan yang signifikan antara model sekaligus menjaga waktu evaluasi tetap dapat dikelola.
💡 Tips Pro: Dalam produksi, Anda memerlukan 100-500 contoh untuk mendapatkan hasil yang signifikan secara statistik, tetapi 10 contoh sudah cukup untuk pembelajaran dan pembuatan prototipe cepat.
Menyiapkan set data
- Di sel baru, jalankan sel berikut untuk memuat data, mengonversinya menjadi DataFrame pandas, dan mengganti nama kolom
responsemenjadireferenceagar lebih jelas dalam tugas evaluasi, serta membuat sampel acak dari sepuluh contoh.from datasets import load_dataset ds = ( load_dataset( "Open-Orca/OpenOrca", data_files="1M-GPT4-Augmented.parquet", split="train[:100]", ) .to_pandas() .drop(columns=["id"]) .rename(columns={"response": "reference"}) ) dataset = ds.sample(n=10) - Setelah sel sebelumnya selesai dijalankan, di sel berikutnya, tambahkan dan jalankan kode berikut untuk menampilkan beberapa baris pertama set data evaluasi Anda.
dataset.head()
5. Menetapkan dasar pengukuran dengan metrik berbasis komputasi
Dalam tugas ini, Anda akan membuat skor dasar menggunakan metrik berbasis komputasi. Pendekatan ini cepat dan memberikan tolok ukur objektif untuk mengukur peningkatan di masa mendatang.
Kita akan menggunakan ROUGE (Recall-Oriented Understudy for Gisting Evaluation), metrik standar untuk tugas peringkasan. Cara kerjanya adalah dengan membandingkan urutan kata (n-gram) dalam respons yang dihasilkan model dengan kata-kata dalam teks reference kebenaran dasar.
Baca selengkapnya tentang metrik berbasis komputasi.
Menjalankan evaluasi dasar pengukuran
- Di sel baru, tambahkan dan jalankan sel berikut untuk menentukan model yang ingin Anda uji,
gemini-2.0-flash.generation_configmencakup parameter sepertitemperaturedanmax_output_tokensyang memengaruhi output model.# Model to be evaluated model = GenerativeModel( "gemini-2.0-flash", generation_config={"temperature": 0.6, "max_output_tokens": 256, "top_k": 1}, )GenerativeModeladalah antarmuka utama untuk berinteraksi dengan model bahasa besar di Vertex AI SDK. - Di sel berikutnya, tambahkan dan jalankan kode berikut untuk membuat dan menjalankan
EvalTask. Objek dari Vertex AI Evaluation SDK ini mengatur evaluasi. Anda mengonfigurasinya dengan set data dan metrik yang akan dihitung, yang dalam hal ini adalahrouge_l_sum.# Define an EvalTask with ROUGE-L-SUM metric rouge_eval_task = EvalTask( dataset=dataset, metrics=["rouge_l_sum"], ) rouge_result = rouge_eval_task.evaluate( model=model, prompt_template="# System_prompt\n{system_prompt} # Question\n{question}", ) - Tampilkan hasilnya dengan menjalankan kode ini di sel berikutnya.
notebook_utils.display_eval_result(rouge_result)display_eval_result()menampilkan skor rata-rata (mean) dan hasil per baris.
6. Opsional: Mengevaluasi dengan metrik pointwise berbasis model
Catatan: Bagian ini mungkin tidak berjalan dalam batas kredit gratis yang diberikan.
Meskipun berguna, ROUGE hanya mengukur tumpang-tindih leksikal (artinya, ROUGE hanya menghitung kata yang cocok, tidak memahami konteks, sinonim, atau parafrasa). Jadi, model ini bukan yang terbaik dalam menentukan apakah respons fasih atau logis. Untuk mendapatkan pemahaman yang lebih mendalam tentang performa model, Anda menggunakan metrik pointwise berbasis model.
Dengan metode ini, LLM lain ("Model Penilai") mengevaluasi setiap respons satu per satu berdasarkan serangkaian kriteria yang telah ditentukan, seperti kelancaran atau koherensi.
Baca selengkapnya tentang metrik berbasis model.
Menjalankan evaluasi pointwise
- Jalankan kode berikut di sel baru untuk membuat menu dropdown interaktif. Untuk proses ini, pilih koherensi dari daftar.
#Select a pointwise metric to use import ipywidgets as widgets pointwise_single_turn_metrics = [ metric for metric in MetricPromptTemplateExamples.list_example_metric_names() if not metric.startswith("pairwise") and not metric.startswith("multi_turn") ] dropdown = widgets.Dropdown( options=pointwise_single_turn_metrics, description="Select a metric:", font_weight="bold", style={"description_width": "initial"}, ) def dropdown_eventhandler(change): global POINTWISE_METRIC if change["type"] == "change" and change["name"] == "value": POINTWISE_METRIC = change.new print("Selected:", change.new) POINTWISE_METRIC = dropdown.value dropdown.observe(dropdown_eventhandler, names="value") display(dropdown) - Di sel baru, jalankan
EvalTasklagi, kali ini menggunakan metrik berbasis model yang dipilih. Vertex AI Evaluation Service membuat perintah untuk Model Penilaian, yang mencakup perintah asli, jawaban referensi, respons model kandidat, dan petunjuk untuk metrik yang dipilih. Model Penilaian menampilkan skor numerik dan penjelasan untuk ratingnya. Catatan: Langkah ini akan memerlukan waktu beberapa menit untuk dijalankan.pointwise_result = EvalTask( dataset=dataset, metrics=[POINTWISE_METRIC], ).evaluate( model=model, prompt_template="# System_prompt\n{system_prompt} # Question\n{question}", )
Menampilkan hasil
Setelah evaluasi selesai, langkah berikutnya adalah menganalisis output.
- Jalankan kode berikut di sel baru untuk melihat metrik ringkasan, yang menunjukkan skor rata-rata untuk metrik yang Anda pilih.
notebook_utils.display_eval_result(pointwise_result) - Jalankan kode berikut di sel berikutnya untuk melihat perincian baris demi baris, yang mencakup alasan tertulis Model Penilaian untuk skornya. Masukan kualitatif ini membantu Anda memahami alasan respons diberi skor tertentu.
notebook_utils.display_explanations(pointwise_result, num=1, metrics=[POINTWISE_METRIC])
7. Membuat metrik kustom untuk mendapatkan insight yang lebih mendalam
Metrik bawaan seperti kelancaran berguna, tetapi untuk produk tertentu, Anda sering kali perlu mengukur performa berdasarkan sasaran Anda sendiri. Dengan metrik pointwise kustom, Anda dapat menentukan kriteria dan rubrik evaluasi Anda sendiri.
Dalam tugas ini, Anda akan membuat metrik baru dari awal yang disebut summarization_helpfulness.
Menentukan dan menjalankan metrik kustom
- Jalankan kode berikut di sel baru untuk menentukan metrik kustom.
PointwiseMetricPromptTemplateberisi blok penyusun untuk metrik:- kriteria: Memberi tahu Model Hakim dimensi spesifik yang akan dievaluasi: "Informasi Penting", "Keringkasan", dan "Tidak Ada Distorsi".
- rating_rubric: Menyediakan skala penilaian 5 poin yang menentukan arti setiap skor.
- input_variables: Meneruskan kolom tambahan dari set data ke Model Penilaian sehingga memiliki konteks yang diperlukan untuk melakukan evaluasi.
# This new custom metric evaluates the actual quality and usefulness of the summary. summarization_helpfulness_metric = PointwiseMetric( metric="summarization_helpfulness", metric_prompt_template=PointwiseMetricPromptTemplate( criteria={ "Key Information": "Does the summary capture the most critical pieces of information from the original text? It should not miss the main topic or key takeaways.", "Conciseness": "Is the summary brief and to the point? It should avoid unnecessary words or repetitive information.", "No Distortion": "Does the summary introduce information or opinions that were NOT present in the original text? It must accurately reflect the source material without adding hallucinations." }, rating_rubric={ "5": "Excellent: Captures all key information, is highly concise, and has zero distortion.", "4": "Good: Captures most key information with minor omissions, is concise, and has no distortion.", "3": "Satisfactory: Captures the main idea but misses some key details OR is not very concise.", "2": "Unsatisfactory: Misses the main idea of the original text OR contains minor distortions/hallucinations.", "1": "Poor: Is completely irrelevant, fails to summarize the text, OR contains significant distortions.", }, input_variables=["prompt", "reference"], ), ) - Jalankan kode berikut di sel berikutnya untuk mengeksekusi
EvalTaskdengan metrik kustom baru Anda.# You would then update the EvalTask to use this new metric pointwise_result = EvalTask( dataset=dataset, metrics=[summarization_helpfulness_metric], ).evaluate( model=model, prompt_template="# System_prompt\n{system_prompt} # Question\n{question}", ) - Jalankan kode berikut di sel baru untuk menampilkan hasilnya.
notebook_utils.display_eval_result(pointwise_result)
8. Membandingkan model dengan evaluasi berpasangan
Saat Anda perlu memutuskan mana dari dua model yang berperforma lebih baik pada tugas tertentu, Anda dapat menggunakan evaluasi berbasis model berpasangan. Metode ini adalah bentuk pengujian A/B di mana Model Penilaian menentukan pemenang, sehingga memberikan perbandingan langsung untuk pemilihan model berbasis data.
Model:
- Model kandidat: Variabel model (yang sebelumnya ditentukan sebagai
gemini-2.0-flash) diteruskan ke metode.evaluate(). Ini adalah model utama yang Anda uji. - Model dasar: Model kedua,
gemini-2.0-flash-lite, ditentukan di dalam class PairwiseMetric. Ini adalah model yang Anda bandingkan.
Menjalankan evaluasi berpasangan
- Di sel baru, tambahkan dan jalankan kode berikut untuk membuat menu dropdown interaktif. Dengan begitu, Anda dapat memilih metrik berpasangan yang ingin digunakan untuk perbandingan. Untuk proses ini, pilih pairwise_summarization_quality.
from IPython.display import display import ipywidgets as widgets pairwise_single_turn_metrics = [ metric for metric in MetricPromptTemplateExamples.list_example_metric_names() if metric.startswith("pairwise") and "multi_turn" not in metric ] dropdown = widgets.Dropdown( options=pairwise_single_turn_metrics, description="Select a metric:", font_weight="bold", style={"description_width": "initial"}, ) def dropdown_eventhandler(change): global POINTWISE_METRIC if change["type"] == "change" and change["name"] == "value": POINTWISE_METRIC = change.new print("Selected:", change.new) def dropdown_eventhandler(change): global PAIRWISE_METRIC_NAME if change["type"] == "change" and change["name"] == "value": PAIRWISE_METRIC_NAME = change.new print("Selected:", change.new) PAIRWISE_METRIC_NAME = dropdown.value dropdown.observe(dropdown_eventhandler, names="value") display(dropdown) - Di sel berikutnya, tambahkan dan jalankan kode berikut untuk mengonfigurasi dan menjalankan
EvalTask. Perhatikan cara classPairwiseMetricdigunakan untuk menentukan model dasar (gemini-2.0-flash-lite), sementara model kandidat (gemini-2.0-flash) diteruskan ke metode.evaluate().pairwise_result = EvalTask( dataset=dataset, metrics=[ PairwiseMetric( metric=PAIRWISE_METRIC_NAME, metric_prompt_template=MetricPromptTemplateExamples.get_prompt_template( PAIRWISE_METRIC_NAME ), # Define a baseline model to compare against baseline_model=GenerativeModel("gemini-2.0-flash-lite"), ) ], ).evaluate( # Specify a candidate model for pairwise comparison model=model, prompt_template="# System_prompt\n{system_prompt} # Question\n{question}", ) - Di sel baru, tambahkan dan jalankan kode berikut untuk menampilkan hasilnya. Tabel ringkasan akan menampilkan "rasio kemenangan" untuk setiap model, yang menunjukkan model mana yang lebih sering disukai Model Penilaian.
notebook_utils.display_eval_result(pairwise_result)
9. Opsional: Mengevaluasi perintah berbasis persona
Catatan: Bagian ini mungkin tidak berjalan dalam batas kredit gratis yang diberikan.
Dalam tugas ini, Anda akan menguji beberapa template perintah yang menginstruksikan model untuk mengadopsi persona yang berbeda. Proses ini, yang sering disebut rekayasa perintah atau desain perintah, memungkinkan Anda menemukan perintah yang paling efektif secara sistematis untuk kasus penggunaan tertentu.
Menyiapkan set data peringkasan
Untuk melakukan evaluasi ini, set data harus berisi kolom berikut:
instruction: Tugas inti yang kita berikan kepada model. Dalam hal ini, perintahnya adalah "Ringkas artikel berikut:".context: Teks sumber yang perlu diproses model. Di sini, kami telah memberikan empat cuplikan berita yang berbeda.reference: Ringkasan kebenaran atau "standar emas". Output yang dihasilkan model akan dibandingkan dengan teks ini untuk menghitung skor metrik seperti ROUGE dan kualitas peringkasan.
- Di sel baru, tambahkan dan jalankan kode berikut untuk membuat
pandas.DataFrameuntuk tugas peringkasan.instruction = "Summarize the following article: \n" context = [ "Typhoon Phanfone has killed at least one person, a US airman on Okinawa who was washed away by high waves. Thousands of households have lost power and Japan's two largest airlines have suspended many flights. The storm also forced the suspension of the search for people missing after last week's volcanic eruption. The storm-tracking website Tropical Storm Risk forecasts that Phanfone will rapidly lose power over the next few hours as it goes further into the Pacific Ocean. Typhoon Phanfone was downgraded from an earlier status of a super typhoon, but the Japan Meteorological Agency had warned it was still a dangerous storm. Japan averages 11 typhoons a year, according to its weather agency. The typhoon made landfall on Monday morning near the central city of Hamamatsu, with winds of up to 180 km/h (112 mph). The airman was one of three US military personnel swept away by high waves whipped up by the typhoon off southern Okinawa island, where the US has a large military base. The remaining two are still missing. A police spokesman said they had been taking photographs of the sea. A university student who was surfing off the seas of Kanagawa Prefecture, south of Tokyo, was also missing, national broadcast NHK reports. It said at least 10 people had been injured and 9,500 houses were without power. The storm was expected to deposit about 100mm of rain on Tokyo over 24 hours, according to the Transport Ministry website. Many schools were closed on Monday and two car companies in Japan halted production at some plants ahead of the storm. More than 174 domestic flights were affected nationwide, NHK state broadcaster said on Sunday. On Sunday, heavy rain delayed the Japanese Formula One Grand Prix in Suzaka. French driver Jules Bianchi lost control in the wet conditions and crashed, sustaining a severe head injury.", "The blaze started at the detached building in Drivers End in Codicote, near Welwyn, during the morning. There was another fire at the building 20 years ago, after which fire-proof foil was placed under the thatch, which is protecting the main building. More than 15 fire engines and support vehicles were called to tackle the blaze. Roads in the area were closed and traffic diverted.", 'The 18-year-old fell at the New Charter Academy on Broadoak Road in Ashton-under-Lyne at about 09:10 BST, Greater Manchester Police (GMP) said. GMP said he had gone to Manchester Royal Infirmary and his condition was "serious". Principal Jenny Langley said the school would remain "fully open" while police investigated. "Our thoughts are with the family and we\'re doing everything we can to support them along with staff and pupils," she said.', 'But Belgian-born Dutchman Max Verstappen was unable to drive a car legally on his own in either country. That all changed on Wednesday when the youngster turned 18 and passed his driving test at the first attempt. Despite having competed in 14 grands prix since his debut in Australia in March, Verstappen admitted to feeling the pressure during his test. "It\'s a relief," said the Toro Rosso driver, who finished ninth in Japan on Sunday and had only started driving lessons a week ago. "I was a bit nervous to make mistakes, but the exam went well." A bonus of turning 18 is that Verstappen will now be able to drink the champagne if he ever makes it onto the podium.', ] reference = [ "A powerful typhoon has brought many parts of Japan to a standstill and briefly battered Tokyo before heading out to sea.", "A major fire has been burning in the thatched roof of a large property in Hertfordshire.", "A student has been taken to hospital after falling from a balcony at a Greater Manchester school.", "He is Formula 1's youngest ever driver and in charge of a car that can reach over 200mph.", ] response = [ "Typhoon Phanfone, while downgraded from super typhoon status, caused significant disruption and tragedy in Japan. One US airman died after being swept away by high waves, with two more missing. The storm caused power outages for thousands, flight cancellations, and the suspension of rescue efforts for missing volcano victims. Heavy rain and strong winds led to school and factory closures, transportation disruptions, and at least 10 injuries. The typhoon is expected to weaken as it moves over the Pacific Ocean.", "A large fire broke out in a detached thatched building in Codicote, near Welwyn. This is the second fire at the building in 20 years. Thankfully, fire-proof foil installed after the previous fire is protecting the main building. Over 15 fire engines and support vehicles responded, closing roads and diverting traffic in the area.", "An 18-year-old student at New Charter Academy in Ashton-under-Lyne suffered a serious fall and was hospitalized. The incident is under investigation by Greater Manchester Police, but the school remains open. The principal expressed support for the student's family and the school community.", "Max Verstappen, a Formula One driver, was finally able to get his driver's license at age 18. Despite already competing in 14 Grand Prix races, he was not of legal driving age in his native countries. He admitted to being nervous but passed the test on his first attempt. As an added bonus of turning 18, Verstappen can now enjoy champagne on the podium if he places.", ] eval_dataset = pd.DataFrame( { "instruction": instruction, "context": context, "reference": reference, } )
Menjalankan tugas evaluasi perintah
Setelah set data ringkasan disiapkan, Anda siap menjalankan eksperimen inti tugas ini: membandingkan beberapa template perintah untuk melihat mana yang menghasilkan output berkualitas tertinggi dari model.
- Di sel berikutnya, buat satu
EvalTaskyang akan digunakan kembali untuk setiap eksperimen perintah. Dengan menetapkan parameterexperiment, semua operasi evaluasi dari tugas ini akan otomatis dicatat dan dikelompokkan di Vertex AI Experiments.EXPERIMENT_NAME = "eval-sdk-prompt-engineering" # @param {type:"string"} summarization_eval_task = EvalTask( dataset=eval_dataset, metrics=[ "rouge_l_sum", "bleu", "fluency", "coherence", "safety", "groundedness", "summarization_quality", "verbosity", "instruction_following", "text_quality", ], experiment=EXPERIMENT_NAME, )rouge_l_sumdanbleuhingga berbagai metrik berbasis model (fluency,coherence,summarization_quality,instruction_following, dll.). Hal ini memberi kita gambaran menyeluruh 360 derajat tentang bagaimana setiap perintah memengaruhi kualitas output model. - Di sel baru, tambahkan dan jalankan kode berikut untuk menentukan dan mengevaluasi empat strategi perintah berbasis persona. Loop
formelakukan iterasi melalui setiap template dan menjalankan evaluasi.Setiap template dirancang untuk menghasilkan gaya ringkasan yang berbeda dengan memberikan persona atau tujuan tertentu kepada model:- Persona #1 (Standar): Permintaan ringkasan yang netral dan langsung.
- Persona #2 (Eksekutif): Meminta ringkasan dalam poin-poin, yang berfokus pada hasil dan dampak, seperti yang diinginkan oleh seorang eksekutif yang sibuk.
- Persona #3 (Siswa Kelas 5): Memerintahkan model untuk menggunakan bahasa sederhana, menguji kemampuannya untuk menyesuaikan kompleksitas outputnya.
- Persona #4 (Analis Teknis): Membutuhkan ringkasan yang sangat faktual dengan statistik dan entity utama yang dipertahankan, untuk menguji presisi model. Perhatikan bahwa placeholder dalam template baru ini, seperti
{context}dan{instruction}, cocok dengan nama kolom baru dieval_datasetyang Anda buat untuk tugas ini.
# Define prompt templates that target different user personas prompt_templates = [ # Persona 1: Standard, neutral summary "Article: {context}. Task: {instruction}. Summary:", # Persona 2: For a busy executive (bullet points) "Instruction: {instruction} into three key bullet points for a busy executive. Focus on the main outcome and impact. Article: {context}. Summary:", # Persona 3: For a 5th grader (simple language) "Instruction: {instruction} such that you're explaining it to a 10-year-old. Use simple words. Article: {context}. Summary:", # Persona 4: For a technical analyst (fact-focused) "Instruction: Provide a detailed, factual summary of the following text, ensuring all key statistics, names, and locations are preserved. Article: {context}. Summary:", ] eval_results = [] for i, prompt_template in enumerate(prompt_templates): eval_result = summarization_eval_task.evaluate( prompt_template=prompt_template, model=GenerativeModel( "gemini-2.0-flash", generation_config={ "temperature": 0.3, "max_output_tokens": 256, "top_k": 1, }, ), evaluation_service_qps=5, ) eval_results.append((f"Prompt Persona #{i+1}", eval_result))
Menganalisis dan memvisualisasikan hasil
Menjalankan eksperimen adalah langkah pertama. Nilai sebenarnya berasal dari analisis hasil untuk membuat keputusan berdasarkan data. Dalam tugas ini, Anda akan menggunakan alat visualisasi SDK untuk menafsirkan output dari eksperimen persona perintah.
- Tampilkan hasil ringkasan untuk setiap persona perintah yang Anda uji dengan menjalankan kode berikut di sel baru. Dengan demikian, Anda bisa mendapatkan gambaran kuantitatif tingkat tinggi tentang performa.
for title, eval_result in eval_results: notebook_utils.display_eval_result(title=title, eval_result=eval_result) - Di sel baru, tambahkan dan jalankan kode berikut untuk melihat alasan metrik
summarization_qualityuntuk setiap persona.for title, eval_result in eval_results: notebook_utils.display_explanations( eval_result, metrics=["summarization_quality"], num=2 ) - Buat plot radar untuk memvisualisasikan pertukaran antara metrik kualitas yang berbeda untuk setiap perintah. Di sel baru, tambahkan dan jalankan kode berikut.
notebook_utils.display_radar_plot( eval_results, metrics=["instruction_following", "fluency", "coherence", "text_quality"], ) - Untuk perbandingan berdampingan yang lebih langsung, buat plot batang. Di sel baru, tambahkan dan jalankan kode berikut.
notebook_utils.display_bar_plot( eval_results, metrics=["instruction_following", "fluency", "coherence", "text_quality"], )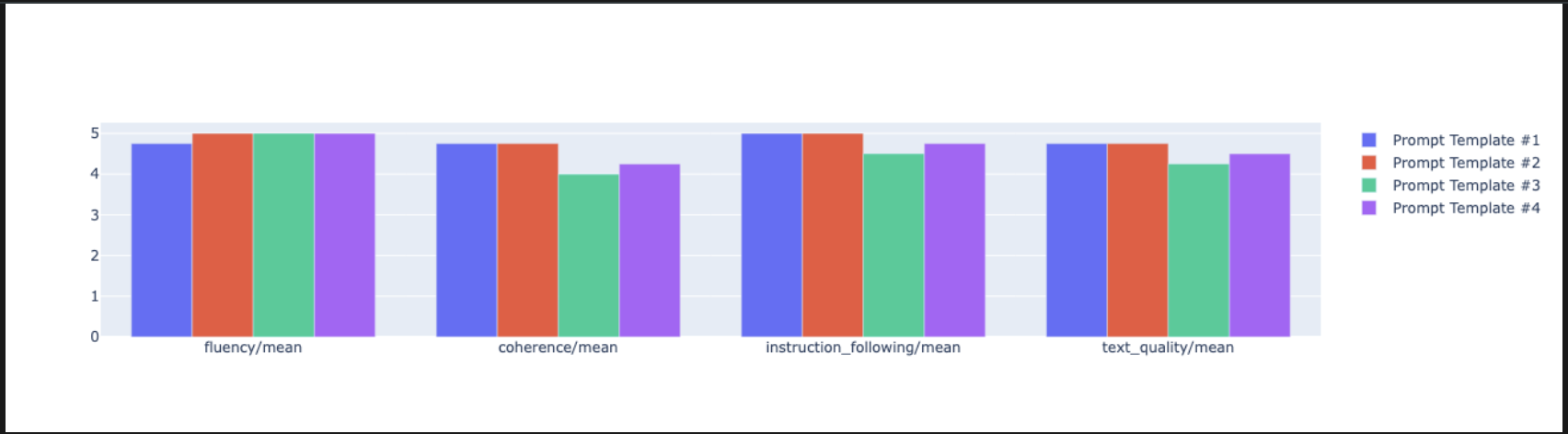
- Anda kini dapat melihat ringkasan semua proses yang telah dicatat ke Vertex AI Experiment untuk tugas ini. Hal ini berguna untuk melacak pekerjaan Anda dari waktu ke waktu. Di sel baru, tambahkan dan jalankan kode berikut:
summarization_eval_task.display_runs()
10. Membersihkan eksperimen
Untuk menjaga project Anda tetap teratur dan menghindari timbulnya biaya yang tidak perlu, sebaiknya bersihkan resource yang Anda buat. Selama lab ini, setiap evaluasi yang dijalankan dicatat ke Vertex AI Experiment. Kode berikut menghapus eksperimen induk ini, yang juga menghapus semua proses terkait dan data dasarnya.
- Jalankan kode ini di sel baru untuk menghapus Eksperimen Vertex AI dan operasi terkaitnya.
delete_experiment = True # Please set your LOCATION to the same one used during Vertex AI SDK initialization. LOCATION = "YOUR LOCATION" # @param {type:"string"} if delete_experiment: from google.cloud import aiplatform aiplatform.init(project=PROJECT_ID, location=LOCATION) experiment = aiplatform.Experiment(EXPERIMENT_NAME) experiment.delete()
11. Dari latihan hingga produksi
Keterampilan yang telah Anda pelajari di lab ini adalah dasar untuk membuat aplikasi AI yang andal. Namun, beralih dari notebook yang dijalankan secara manual ke sistem evaluasi tingkat produksi memerlukan infrastruktur tambahan dan pendekatan yang lebih sistematis. Bagian ini menguraikan praktik utama dan framework strategis yang perlu dipertimbangkan saat Anda melakukan penskalaan.
Membangun strategi evaluasi produksi
Untuk menerapkan keterampilan dari lab ini di lingkungan produksi, sebaiknya formalisasikan keterampilan tersebut menjadi strategi yang dapat diulang. Framework berikut menguraikan pertimbangan utama untuk skenario umum seperti pemilihan model, pengoptimalan perintah, dan pemantauan berkelanjutan.
Untuk pemilihan model:
# Evaluation strategy for choosing models
evaluation_strategy = {
"dataset_size": "100+ examples for statistical significance",
"metrics": ["task-specific", "general quality", "efficiency"],
"comparison_type": "pairwise with statistical testing",
"baseline": "established_model_or_human_benchmark"
}
Untuk pengoptimalan perintah
# Systematic prompt improvement workflow
prompt_optimization = {
"hypothesis": "Clear statement of what you're testing",
"variants": "3-5 different prompt strategies",
"evaluation": "Same metrics across all variants",
"analysis": "Statistical significance + qualitative review"
}
Untuk pemantauan berkelanjutan
# Production evaluation pipeline
production_eval = {
"frequency": "Every model update + weekly monitoring",
"automation": "CI/CD integration with quality gates",
"metrics": "Speed + quality + cost tracking",
"alerting": "Performance degradation detection"
}
Pertimbangan efektivitas biaya
Evaluasi berbasis model bisa mahal dalam skala besar. Strategi produksi yang hemat biaya menggunakan metode yang berbeda untuk tujuan yang berbeda. Tabel ini merangkum kompromi antara kecepatan, biaya, dan kasus penggunaan untuk berbagai jenis evaluasi:
Jenis Evaluasi | Waktu | Biaya per Sampel | Paling Cocok Untuk |
ROUGE/BLEU | Detik | ~$0,001 | Penyaringan bervolume tinggi |
Pointwise Berbasis Model | ~1-2 detik | ~$0,01 | Penilaian kualitas |
Perbandingan Berpasangan | ~2-3 detik | ~$0,02 | Pemilihan model |
Evaluasi oleh Manusia | Menit | $1-10 | Validasi standar emas |
Mengotomatiskan dengan CI/CD dan pemantauan
Eksekusi notebook manual tidak dapat diskalakan. Otomatiskan evaluasi Anda dalam pipeline Continuous Integration/Continuous Deployment (CI/CD).
- Buat gerbang kualitas: Integrasikan tugas evaluasi Anda ke dalam pipeline CI/CD (misalnya, Cloud Build). Jalankan evaluasi secara otomatis pada perintah atau model baru dan blokir deployment jika skor kualitas utama turun di bawah nilai minimum yang Anda tetapkan.
- Pantau tren: Ekspor metrik ringkasan dari proses evaluasi Anda ke layanan seperti Google Cloud Monitoring. Buat dasbor untuk melacak kualitas dari waktu ke waktu dan siapkan notifikasi otomatis untuk memberi tahu tim Anda jika ada penurunan performa yang signifikan.
12. Kesimpulan
Anda telah menyelesaikan lab ini. Anda telah mempelajari keterampilan penting untuk mengevaluasi model AI generatif.
Lab ini merupakan bagian dari Alur Pembelajaran AI Siap Produksi dengan Google Cloud.
- Jelajahi kurikulum lengkap untuk menjembatani kesenjangan dari prototipe hingga produksi.
- Bagikan progres Anda dengan hashtag
ProductionReadyAI.
Rangkuman
Di lab ini, Anda telah mempelajari cara:
- Terapkan praktik terbaik evaluasi menggunakan framework
EvalTask. - Gunakan berbagai jenis metrik, mulai dari juri berbasis komputasi hingga juri berbasis model.
- Optimalkan perintah dengan menguji berbagai versi.
- Buat alur kerja yang dapat direproduksi dengan pelacakan eksperimen.
Referensi untuk melanjutkan pembelajaran
- Dokumentasi Evaluasi AI Generatif Vertex AI
- Notebook Teknik Evaluasi Lanjutan
- Referensi SDK Evaluasi AI Generatif
- Riset Metrik Berbasis Model
- Praktik Terbaik Rekayasa Perintah
Pendekatan evaluasi sistematis yang telah Anda pelajari di lab ini akan berfungsi sebagai dasar untuk membangun aplikasi AI yang andal dan berkualitas tinggi. Ingat: evaluasi yang baik adalah jembatan antara AI eksperimental dan kesuksesan produksi.