
1. Panoramica
In questo lab imparerai a valutare i modelli linguistici di grandi dimensioni utilizzando Vertex AI Gen AI Evaluation Service. Utilizzerai l'SDK per eseguire job di valutazione, confrontare i risultati e prendere decisioni basate sui dati sul rendimento del modello e sulla progettazione dei prompt.
Il lab ti guida attraverso un flusso di lavoro di valutazione comune, a partire da metriche basate su calcoli e passando a valutazioni più sfumate basate su modelli. Imparerai anche a creare metriche personalizzate in base ai tuoi obiettivi specifici e a monitorare il tuo lavoro utilizzando Vertex AI Experiments.
Obiettivi didattici
In questo lab imparerai a:
- Valuta un modello con metriche basate su calcolo e su modelli.
- Crea una metrica personalizzata per allineare la valutazione agli obiettivi del prodotto.
- Confronta diversi modelli di prompt affiancati.
- Prova più prompt basati su persona per trovare la versione più efficace.
- Monitora e visualizza le esecuzioni di valutazione utilizzando Vertex AI Experiments.
Riferimenti
- Esempi di codice: questo lab si basa sugli esempi del repository dell'AI generativa di Google Cloud
- In base a: documentazione di Vertex AI Gen AI Evaluation
- Set di dati: set di dati OpenOrca per la valutazione del rispetto delle istruzioni
2. Configurazione del progetto
Account Google
Se non hai ancora un Account Google personale, devi crearne uno.
Utilizza un account personale anziché un account di lavoro o della scuola.
Accedi alla console Google Cloud
Accedi a Google Cloud Console utilizzando un Account Google personale.
Abilita fatturazione
Per attivare la fatturazione, hai due opzioni. Puoi utilizzare il tuo account di fatturazione personale o riscattare i crediti seguendo questi passaggi.
Riscatta i crediti Google Cloud (facoltativo)
Per partecipare a questo workshop, devi disporre di un account di fatturazione con del credito. Per iniziare, utilizza i crediti del banner nella parte superiore di questo codelab. Se hai già collegato un account di fatturazione, puoi saltare questo passaggio.
Configurare un account di fatturazione personale
Se hai configurato la fatturazione utilizzando i crediti Google Cloud, puoi saltare questo passaggio.
Per configurare un account di fatturazione personale, vai qui per abilitare la fatturazione nella console Cloud.
Alcune note:
- Il completamento di questo lab dovrebbe costare meno di 1 $in risorse cloud.
- Per evitare ulteriori addebiti, puoi seguire i passaggi alla fine di questo lab per eliminare le risorse.
- I nuovi utenti hanno diritto alla prova senza costi di 300$.
Creare un progetto (facoltativo)
Se non hai un progetto attuale che vuoi utilizzare per questo lab, creane uno nuovo qui.
3. Configura l'ambiente Vertex AI Workbench
Iniziamo accedendo all'ambiente notebook preconfigurato e installando le dipendenze necessarie.
Accedere a Vertex AI Workbench
- Nella console Google Cloud, vai a Vertex AI facendo clic sul menu di navigazione ☰ > Vertex AI > Dashboard.
- Fai clic su Abilita tutte le API consigliate. Nota: attendi il completamento di questo passaggio
- A sinistra, fai clic su Workbench per creare una nuova istanza di workbench.
- Assegna all'istanza di workbench il nome evaluation-workbench e fai clic su Crea.
- Attendi la configurazione del workbench. L'operazione potrebbe richiedere alcuni minuti.

- Una volta eseguito il provisioning del workbench, fai clic su Apri JupyterLab.
- Nel workbench, crea un nuovo notebook Python3.
Per saperne di più sulle funzionalità e sulle capacità di questo ambiente, consulta la documentazione ufficiale di Vertex AI Workbench.
Installa i pacchetti e configura l'ambiente
- Nella prima cella del notebook, aggiungi ed esegui le istruzioni di importazione riportate di seguito (MAIUSC+INVIO) per installare l'SDK Vertex AI (con i componenti di valutazione) e altri pacchetti richiesti.
%pip install -U -q google-cloud-aiplatform[evaluation] %pip install -U -q datasets anthropic[vertex] openai - Per utilizzare i pacchetti appena installati, ti consigliamo di riavviare il kernel eseguendo lo snippet di codice riportato di seguito.
# Automatically restart kernel after installation so that your environment can access the new packages. import IPython app = IPython.Application.instance() app.kernel.do_shutdown(True) - Sostituisci i seguenti valori con l'ID progetto e la località ed esegui la seguente cella. La località predefinita è impostata su
europe-west1, ma devi utilizzare la stessa località in cui si trova l'istanza di Vertex AI Workbench.# Configure your project settings PROJECT_ID = "YOUR PROJECT ID" LOCATION = "europe-west1" - Importa tutte le librerie Python richieste per questo lab eseguendo il seguente codice in una nuova cella.
from anthropic import AnthropicVertex from google.auth import default, transport import openai import pandas as pd from vertexai.evaluation import ( EvalTask, MetricPromptTemplateExamples, PairwiseMetric, PointwiseMetric, PointwiseMetricPromptTemplate, ) from vertexai.generative_models import GenerativeModel from vertexai.preview.evaluation import notebook_utils
4. Configurare il set di dati di valutazione
Per questo tutorial, utilizzeremo 10 campioni del set di dati OpenOrca. In questo modo, abbiamo dati sufficienti per notare differenze significative tra i modelli, mantenendo al contempo un tempo di valutazione gestibile.
💡 Suggerimento professionale:in produzione, ti consigliamo di utilizzare 100-500 esempi per ottenere risultati statisticamente significativi, ma 10 campioni sono perfetti per l'apprendimento e la prototipazione rapida.
Prepara il set di dati
- In una nuova cella, esegui la seguente cella per caricare i dati, convertirli in un DataFrame Pandas, rinominare la colonna
responseinreferenceper chiarezza nelle attività di valutazione e creare il campione casuale di dieci esempi.from datasets import load_dataset ds = ( load_dataset( "Open-Orca/OpenOrca", data_files="1M-GPT4-Augmented.parquet", split="train[:100]", ) .to_pandas() .drop(columns=["id"]) .rename(columns={"response": "reference"}) ) dataset = ds.sample(n=10) - Una volta terminata l'esecuzione della cella precedente, nella cella successiva aggiungi ed esegui il seguente codice per visualizzare le prime righe del set di dati di valutazione.
dataset.head()
5. Stabilire una base di riferimento con metriche basate su calcolo
In questa attività, stabilisci un punteggio di riferimento utilizzando una metrica basata sul calcolo. Questo approccio è rapido e fornisce un benchmark oggettivo per misurare i miglioramenti futuri.
Utilizzeremo ROUGE (Recall-Oriented Understudy for Gisting Evaluation), una metrica standard per le attività di riepilogo. Funziona confrontando la sequenza di parole (n-grammi) nella risposta generata dal modello con le parole nel testo reference basato su dati di fatto.
Scopri di più sulle metriche basate su calcolo.
Esecuzione della valutazione di base
- In una nuova cella, aggiungi ed esegui la seguente cella per definire il modello che vuoi testare,
gemini-2.0-flash.generation_configinclude parametri cometemperatureemax_output_tokensche influenzano l'output del modello.# Model to be evaluated model = GenerativeModel( "gemini-2.0-flash", generation_config={"temperature": 0.6, "max_output_tokens": 256, "top_k": 1}, )GenerativeModelè l'interfaccia principale per interagire con i modelli linguistici di grandi dimensioni nell'SDK Vertex AI. - Nella cella successiva, aggiungi ed esegui il seguente codice per creare ed eseguire
EvalTask. Questo oggetto dell'SDK Vertex AI Evaluation orchestra la valutazione. Lo configuri con il set di dati e le metriche da calcolare, che in questo caso èrouge_l_sum.# Define an EvalTask with ROUGE-L-SUM metric rouge_eval_task = EvalTask( dataset=dataset, metrics=["rouge_l_sum"], ) rouge_result = rouge_eval_task.evaluate( model=model, prompt_template="# System_prompt\n{system_prompt} # Question\n{question}", ) - Visualizza i risultati eseguendo questo codice nella cella successiva.
notebook_utils.display_eval_result(rouge_result)display_eval_result()mostra il punteggio medio e i risultati riga per riga.
6. (Facoltativo) Esegui la valutazione con metriche basate su punti e modelli
Nota: questa sezione potrebbe non rientrare nel limite dei crediti senza costi forniti.
Sebbene ROUGE sia utile, misura solo la sovrapposizione lessicale (ovvero conta solo le parole corrispondenti, non comprende il contesto, i sinonimi o la parafrasi). Pertanto, non è la soluzione migliore per determinare se una risposta è fluida o logica. Per comprendere meglio le prestazioni del modello, utilizza metriche puntuali basate sul modello.
Con questo metodo, un altro LLM (il "modello giudice") valuta ogni risposta individualmente in base a una serie di criteri predefiniti, come la fluidità o la coerenza.
Scopri di più sulle metriche basate sul modello.
Esegui la valutazione basata su punti
- Esegui questo comando in una nuova cella per creare un menu a discesa interattivo. Per questa esecuzione, seleziona Coerenza dall'elenco.
#Select a pointwise metric to use import ipywidgets as widgets pointwise_single_turn_metrics = [ metric for metric in MetricPromptTemplateExamples.list_example_metric_names() if not metric.startswith("pairwise") and not metric.startswith("multi_turn") ] dropdown = widgets.Dropdown( options=pointwise_single_turn_metrics, description="Select a metric:", font_weight="bold", style={"description_width": "initial"}, ) def dropdown_eventhandler(change): global POINTWISE_METRIC if change["type"] == "change" and change["name"] == "value": POINTWISE_METRIC = change.new print("Selected:", change.new) POINTWISE_METRIC = dropdown.value dropdown.observe(dropdown_eventhandler, names="value") display(dropdown) - In una nuova cella, esegui di nuovo
EvalTask, questa volta utilizzando la metrica basata sul modello selezionata. Vertex AI Evaluation Service crea un prompt per il modello di valutazione, che include il prompt originale, la risposta di riferimento, la risposta del modello candidato e le istruzioni per la metrica selezionata. Il modello Judge restituisce un punteggio numerico e una spiegazione della valutazione. Nota: l'esecuzione di questo passaggio richiede alcuni minuti.pointwise_result = EvalTask( dataset=dataset, metrics=[POINTWISE_METRIC], ).evaluate( model=model, prompt_template="# System_prompt\n{system_prompt} # Question\n{question}", )
Visualizzare i risultati
Una volta completata la valutazione, il passaggio successivo consiste nell'analizzare l'output.
- Esegui il seguente codice in una nuova cella per visualizzare le metriche di riepilogo, che mostrano il punteggio medio per la metrica scelta.
notebook_utils.display_eval_result(pointwise_result) - Esegui il seguente codice nella cella successiva per visualizzare la suddivisione riga per riga, che include la motivazione scritta del modello giudice per il suo punteggio. Questo feedback qualitativo ti aiuta a capire perché una risposta ha ottenuto un determinato punteggio.
notebook_utils.display_explanations(pointwise_result, num=1, metrics=[POINTWISE_METRIC])
7. Creare una metrica personalizzata per ottenere approfondimenti più dettagliati
Le metriche predefinite come la fluidità sono utili, ma per un prodotto specifico spesso è necessario misurare il rendimento in base ai propri obiettivi. Con le metriche puntuali personalizzate, puoi definire i tuoi criteri di valutazione e la tua rubrica.
In questa attività, creerai una nuova metrica da zero denominata summarization_helpfulness.
Definisci ed esegui la metrica personalizzata
- Esegui il seguente codice in una nuova cella per definire la metrica personalizzata.
PointwiseMetricPromptTemplatecontiene i blocchi costitutivi della metrica:- Criteri: indica al modello di valutazione le dimensioni specifiche da valutare: "Informazioni chiave", "Concisezza" e "Nessuna distorsione".
- rating_rubric: fornisce una scala di punteggio a 5 punti che definisce il significato di ogni punteggio.
- input_variables: passa colonne aggiuntive dal set di dati al modello di valutazione in modo che abbia il contesto necessario per eseguire la valutazione.
# This new custom metric evaluates the actual quality and usefulness of the summary. summarization_helpfulness_metric = PointwiseMetric( metric="summarization_helpfulness", metric_prompt_template=PointwiseMetricPromptTemplate( criteria={ "Key Information": "Does the summary capture the most critical pieces of information from the original text? It should not miss the main topic or key takeaways.", "Conciseness": "Is the summary brief and to the point? It should avoid unnecessary words or repetitive information.", "No Distortion": "Does the summary introduce information or opinions that were NOT present in the original text? It must accurately reflect the source material without adding hallucinations." }, rating_rubric={ "5": "Excellent: Captures all key information, is highly concise, and has zero distortion.", "4": "Good: Captures most key information with minor omissions, is concise, and has no distortion.", "3": "Satisfactory: Captures the main idea but misses some key details OR is not very concise.", "2": "Unsatisfactory: Misses the main idea of the original text OR contains minor distortions/hallucinations.", "1": "Poor: Is completely irrelevant, fails to summarize the text, OR contains significant distortions.", }, input_variables=["prompt", "reference"], ), ) - Esegui questo codice nella cella successiva per eseguire
EvalTaskcon la nuova metrica personalizzata.# You would then update the EvalTask to use this new metric pointwise_result = EvalTask( dataset=dataset, metrics=[summarization_helpfulness_metric], ).evaluate( model=model, prompt_template="# System_prompt\n{system_prompt} # Question\n{question}", ) - Esegui il seguente codice in una nuova cella per visualizzare i risultati.
notebook_utils.display_eval_result(pointwise_result)
8. Confrontare i modelli con la valutazione basata su coppie
Quando devi decidere quale dei due modelli ha un rendimento migliore in un'attività specifica, puoi utilizzare la valutazione basata su coppie di modelli. Questo metodo è una forma di test A/B in cui un modello di valutazione determina un vincitore, fornendo un confronto diretto per la selezione del modello basata sui dati.
I modelli:
- Modello candidato: la variabile del modello (precedentemente definita come
gemini-2.0-flash) viene passata al metodo.evaluate(). Questo è il modello principale che stai testando. - Modello di base: un secondo modello,
gemini-2.0-flash-lite, è specificato all'interno della classe PairwiseMetric. Questo è il modello con cui stai effettuando il confronto.
Esegui la valutazione basata su coppie
- In una nuova cella, aggiungi ed esegui il seguente codice per creare un menu a discesa interattivo. In questo modo potrai selezionare la metrica a coppie da utilizzare per il confronto. Per questa esecuzione, seleziona pairwise_summarization_quality.
from IPython.display import display import ipywidgets as widgets pairwise_single_turn_metrics = [ metric for metric in MetricPromptTemplateExamples.list_example_metric_names() if metric.startswith("pairwise") and "multi_turn" not in metric ] dropdown = widgets.Dropdown( options=pairwise_single_turn_metrics, description="Select a metric:", font_weight="bold", style={"description_width": "initial"}, ) def dropdown_eventhandler(change): global POINTWISE_METRIC if change["type"] == "change" and change["name"] == "value": POINTWISE_METRIC = change.new print("Selected:", change.new) def dropdown_eventhandler(change): global PAIRWISE_METRIC_NAME if change["type"] == "change" and change["name"] == "value": PAIRWISE_METRIC_NAME = change.new print("Selected:", change.new) PAIRWISE_METRIC_NAME = dropdown.value dropdown.observe(dropdown_eventhandler, names="value") display(dropdown) - Nella cella successiva, aggiungi ed esegui il seguente codice per configurare ed eseguire
EvalTask. Nota come la classePairwiseMetricviene utilizzata per definire il modello di base (gemini-2.0-flash-lite), mentre il modello candidato (gemini-2.0-flash) viene passato al metodo.evaluate().pairwise_result = EvalTask( dataset=dataset, metrics=[ PairwiseMetric( metric=PAIRWISE_METRIC_NAME, metric_prompt_template=MetricPromptTemplateExamples.get_prompt_template( PAIRWISE_METRIC_NAME ), # Define a baseline model to compare against baseline_model=GenerativeModel("gemini-2.0-flash-lite"), ) ], ).evaluate( # Specify a candidate model for pairwise comparison model=model, prompt_template="# System_prompt\n{system_prompt} # Question\n{question}", ) - In una nuova cella, aggiungi ed esegui il seguente codice per visualizzare i risultati. La tabella riepilogativa mostrerà la "percentuale di vincite" per ogni modello, indicando quello che il modello giudice ha preferito più spesso.
notebook_utils.display_eval_result(pairwise_result)
9. (Facoltativo) Valuta i prompt basati sulle buyer persona
Nota: questa sezione potrebbe non essere eseguita entro il limite dei crediti senza costi forniti.
In questa attività, testerai più modelli di prompt che istruiscono il modello ad adottare personalità diverse. Questo processo, spesso chiamato prompt engineering o progettazione dei prompt, ti consente di trovare sistematicamente il prompt più efficace per un caso d'uso specifico.
Prepara il set di dati di riepilogo
Per eseguire questa valutazione, il set di dati deve contenere i seguenti campi:
instruction: l'attività principale che stiamo assegnando al modello. In questo caso, è un semplice "Riassumi il seguente articolo:".context: il testo di origine con cui deve lavorare il modello. Qui abbiamo fornito quattro snippet di notizie diversi.reference: Il riepilogo di riferimento o "gold standard". L'output generato del modello verrà confrontato con questo testo per calcolare i punteggi per metriche come ROUGE e la qualità del riepilogo.
- In una nuova cella, aggiungi ed esegui il seguente codice per creare un
pandas.DataFrameper l'attività di riepilogo.instruction = "Summarize the following article: \n" context = [ "Typhoon Phanfone has killed at least one person, a US airman on Okinawa who was washed away by high waves. Thousands of households have lost power and Japan's two largest airlines have suspended many flights. The storm also forced the suspension of the search for people missing after last week's volcanic eruption. The storm-tracking website Tropical Storm Risk forecasts that Phanfone will rapidly lose power over the next few hours as it goes further into the Pacific Ocean. Typhoon Phanfone was downgraded from an earlier status of a super typhoon, but the Japan Meteorological Agency had warned it was still a dangerous storm. Japan averages 11 typhoons a year, according to its weather agency. The typhoon made landfall on Monday morning near the central city of Hamamatsu, with winds of up to 180 km/h (112 mph). The airman was one of three US military personnel swept away by high waves whipped up by the typhoon off southern Okinawa island, where the US has a large military base. The remaining two are still missing. A police spokesman said they had been taking photographs of the sea. A university student who was surfing off the seas of Kanagawa Prefecture, south of Tokyo, was also missing, national broadcast NHK reports. It said at least 10 people had been injured and 9,500 houses were without power. The storm was expected to deposit about 100mm of rain on Tokyo over 24 hours, according to the Transport Ministry website. Many schools were closed on Monday and two car companies in Japan halted production at some plants ahead of the storm. More than 174 domestic flights were affected nationwide, NHK state broadcaster said on Sunday. On Sunday, heavy rain delayed the Japanese Formula One Grand Prix in Suzaka. French driver Jules Bianchi lost control in the wet conditions and crashed, sustaining a severe head injury.", "The blaze started at the detached building in Drivers End in Codicote, near Welwyn, during the morning. There was another fire at the building 20 years ago, after which fire-proof foil was placed under the thatch, which is protecting the main building. More than 15 fire engines and support vehicles were called to tackle the blaze. Roads in the area were closed and traffic diverted.", 'The 18-year-old fell at the New Charter Academy on Broadoak Road in Ashton-under-Lyne at about 09:10 BST, Greater Manchester Police (GMP) said. GMP said he had gone to Manchester Royal Infirmary and his condition was "serious". Principal Jenny Langley said the school would remain "fully open" while police investigated. "Our thoughts are with the family and we\'re doing everything we can to support them along with staff and pupils," she said.', 'But Belgian-born Dutchman Max Verstappen was unable to drive a car legally on his own in either country. That all changed on Wednesday when the youngster turned 18 and passed his driving test at the first attempt. Despite having competed in 14 grands prix since his debut in Australia in March, Verstappen admitted to feeling the pressure during his test. "It\'s a relief," said the Toro Rosso driver, who finished ninth in Japan on Sunday and had only started driving lessons a week ago. "I was a bit nervous to make mistakes, but the exam went well." A bonus of turning 18 is that Verstappen will now be able to drink the champagne if he ever makes it onto the podium.', ] reference = [ "A powerful typhoon has brought many parts of Japan to a standstill and briefly battered Tokyo before heading out to sea.", "A major fire has been burning in the thatched roof of a large property in Hertfordshire.", "A student has been taken to hospital after falling from a balcony at a Greater Manchester school.", "He is Formula 1's youngest ever driver and in charge of a car that can reach over 200mph.", ] response = [ "Typhoon Phanfone, while downgraded from super typhoon status, caused significant disruption and tragedy in Japan. One US airman died after being swept away by high waves, with two more missing. The storm caused power outages for thousands, flight cancellations, and the suspension of rescue efforts for missing volcano victims. Heavy rain and strong winds led to school and factory closures, transportation disruptions, and at least 10 injuries. The typhoon is expected to weaken as it moves over the Pacific Ocean.", "A large fire broke out in a detached thatched building in Codicote, near Welwyn. This is the second fire at the building in 20 years. Thankfully, fire-proof foil installed after the previous fire is protecting the main building. Over 15 fire engines and support vehicles responded, closing roads and diverting traffic in the area.", "An 18-year-old student at New Charter Academy in Ashton-under-Lyne suffered a serious fall and was hospitalized. The incident is under investigation by Greater Manchester Police, but the school remains open. The principal expressed support for the student's family and the school community.", "Max Verstappen, a Formula One driver, was finally able to get his driver's license at age 18. Despite already competing in 14 Grand Prix races, he was not of legal driving age in his native countries. He admitted to being nervous but passed the test on his first attempt. As an added bonus of turning 18, Verstappen can now enjoy champagne on the podium if he places.", ] eval_dataset = pd.DataFrame( { "instruction": instruction, "context": context, "reference": reference, } )
Esegui l'attività di valutazione del prompt
Con il set di dati di riepilogo preparato, puoi eseguire l'esperimento principale di questa attività: confrontare più modelli di prompt per vedere quale produce l'output di qualità migliore dal modello.
- Nella cella successiva, crea un singolo
EvalTaskche verrà riutilizzato per ogni esperimento con i prompt. Se imposti il parametroexperiment, tutte le esecuzioni di valutazione di questa attività vengono registrate e raggruppate automaticamente in Vertex AI Experiments.EXPERIMENT_NAME = "eval-sdk-prompt-engineering" # @param {type:"string"} summarization_eval_task = EvalTask( dataset=eval_dataset, metrics=[ "rouge_l_sum", "bleu", "fluency", "coherence", "safety", "groundedness", "summarization_quality", "verbosity", "instruction_following", "text_quality", ], experiment=EXPERIMENT_NAME, )rouge_l_sumebleua un'ampia gamma di metriche basate su modelli (fluency,coherence,summarization_quality,instruction_followinge così via). In questo modo, otteniamo una visione olistica a 360 gradi di come ogni prompt influisce sulla qualità dell'output del modello. - In una nuova cella, aggiungi ed esegui il seguente codice per definire e valutare quattro strategie di prompt basate sulle buyer persona. Il ciclo
forscorre ogni modello ed esegue una valutazione.Ogni modello è progettato per ottenere uno stile di riepilogo diverso assegnando al modello un obiettivo o una persona specifica:- Persona n. 1 (standard): una richiesta di riepilogo neutra e semplice.
- Persona n. 2 (dirigente): chiede un riepilogo puntato, concentrandosi sui risultati e sull'impatto, come preferirebbe un dirigente impegnato.
- Utente tipo n. 3 (alunno di quinta elementare): chiede al modello di utilizzare un linguaggio semplice, testando la sua capacità di regolare la complessità dell'output.
- Persona n. 4 (analista tecnico): richiede un riepilogo altamente oggettivo in cui vengono conservate le statistiche e le entità chiave, mettendo alla prova la precisione del modello. Nota che i segnaposto in questi nuovi modelli, come
{context}e{instruction}, corrispondono ai nuovi nomi delle colonne neleval_datasetche hai creato per questa attività.
# Define prompt templates that target different user personas prompt_templates = [ # Persona 1: Standard, neutral summary "Article: {context}. Task: {instruction}. Summary:", # Persona 2: For a busy executive (bullet points) "Instruction: {instruction} into three key bullet points for a busy executive. Focus on the main outcome and impact. Article: {context}. Summary:", # Persona 3: For a 5th grader (simple language) "Instruction: {instruction} such that you're explaining it to a 10-year-old. Use simple words. Article: {context}. Summary:", # Persona 4: For a technical analyst (fact-focused) "Instruction: Provide a detailed, factual summary of the following text, ensuring all key statistics, names, and locations are preserved. Article: {context}. Summary:", ] eval_results = [] for i, prompt_template in enumerate(prompt_templates): eval_result = summarization_eval_task.evaluate( prompt_template=prompt_template, model=GenerativeModel( "gemini-2.0-flash", generation_config={ "temperature": 0.3, "max_output_tokens": 256, "top_k": 1, }, ), evaluation_service_qps=5, ) eval_results.append((f"Prompt Persona #{i+1}", eval_result))
Analizzare e visualizzare i risultati
L'esecuzione di esperimenti è il primo passo. Il vero valore deriva dall'analisi dei risultati per prendere una decisione basata sui dati. In questa attività utilizzerai gli strumenti di visualizzazione dell'SDK per interpretare gli output dell'esperimento con le persona del prompt.
- Visualizza i risultati riepilogativi per ciascuna delle quattro persona del prompt che hai testato eseguendo il seguente codice in una nuova cella. In questo modo, avrai una visione quantitativa generale del rendimento.
for title, eval_result in eval_results: notebook_utils.display_eval_result(title=title, eval_result=eval_result) - In una nuova cella, aggiungi ed esegui il seguente codice per visualizzare la logica della metrica
summarization_qualityper ogni persona.for title, eval_result in eval_results: notebook_utils.display_explanations( eval_result, metrics=["summarization_quality"], num=2 ) - Genera un grafico radar per visualizzare i compromessi tra le diverse metriche di qualità per ogni prompt. In una nuova cella, aggiungi ed esegui il seguente codice.
notebook_utils.display_radar_plot( eval_results, metrics=["instruction_following", "fluency", "coherence", "text_quality"], ) - Per un confronto più diretto e fianco a fianco, crea un grafico a barre. In una nuova cella, aggiungi ed esegui il seguente codice.
notebook_utils.display_bar_plot( eval_results, metrics=["instruction_following", "fluency", "coherence", "text_quality"], )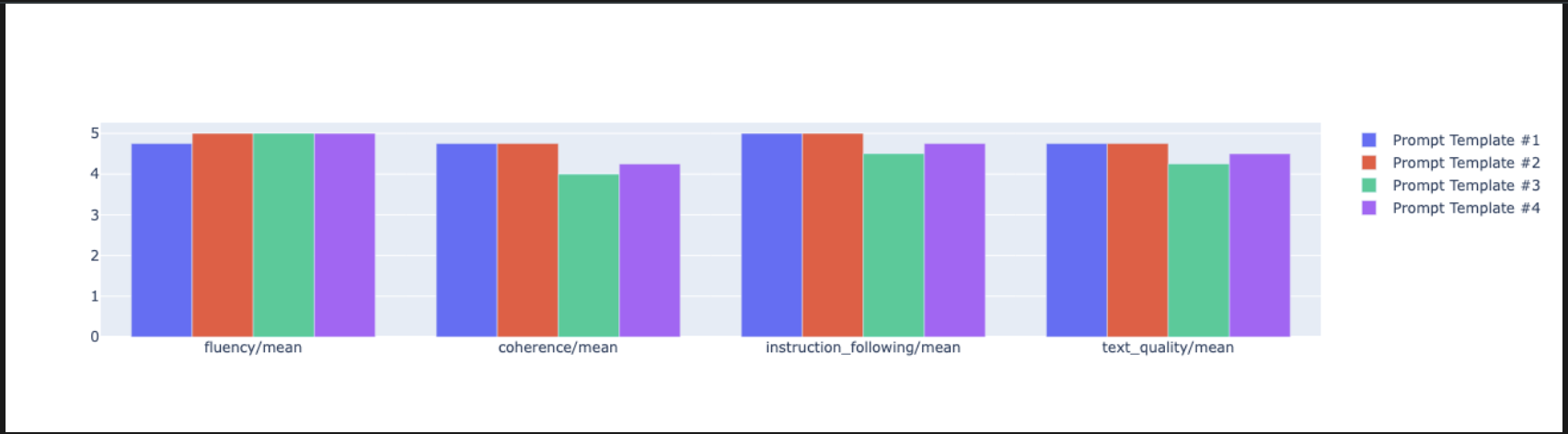
- Ora puoi visualizzare un riepilogo di tutte le esecuzioni registrate in Vertex AI Experiment per questa attività. Questa opzione è utile per monitorare il tuo lavoro nel tempo. In una nuova cella, aggiungi ed esegui il seguente codice:
summarization_eval_task.display_runs()
10. Liberare spazio nell'esperimento
Per mantenere il progetto organizzato ed evitare addebiti non necessari, ti consigliamo di pulire le risorse che hai creato. Durante questo lab, ogni esecuzione della valutazione è stata registrata in un esperimento Vertex AI. Il seguente codice elimina questo esperimento principale, rimuovendo anche tutte le esecuzioni associate e i relativi dati sottostanti.
- Esegui questo codice in una nuova cella per eliminare l'esperimento Vertex AI e le relative esecuzioni.
delete_experiment = True # Please set your LOCATION to the same one used during Vertex AI SDK initialization. LOCATION = "YOUR LOCATION" # @param {type:"string"} if delete_experiment: from google.cloud import aiplatform aiplatform.init(project=PROJECT_ID, location=LOCATION) experiment = aiplatform.Experiment(EXPERIMENT_NAME) experiment.delete()
11. Dalla pratica alla produzione
Le competenze che hai acquisito in questo lab sono i componenti di base per la creazione di applicazioni AI affidabili. Tuttavia, il passaggio da un notebook eseguito manualmente a un sistema di valutazione di livello di produzione richiede un'infrastruttura aggiuntiva e un approccio più sistematico. Questa sezione illustra le pratiche chiave e i framework strategici da prendere in considerazione durante lo scale up.
Creazione di strategie di valutazione della produzione
Per applicare le competenze acquisite in questo lab in un ambiente di produzione, è utile formalizzarle in strategie ripetibili. I seguenti framework delineano considerazioni chiave per scenari comuni come la selezione del modello, l'ottimizzazione dei prompt e il monitoraggio continuo.
Per la selezione del modello:
# Evaluation strategy for choosing models
evaluation_strategy = {
"dataset_size": "100+ examples for statistical significance",
"metrics": ["task-specific", "general quality", "efficiency"],
"comparison_type": "pairwise with statistical testing",
"baseline": "established_model_or_human_benchmark"
}
Per l'ottimizzazione dei prompt
# Systematic prompt improvement workflow
prompt_optimization = {
"hypothesis": "Clear statement of what you're testing",
"variants": "3-5 different prompt strategies",
"evaluation": "Same metrics across all variants",
"analysis": "Statistical significance + qualitative review"
}
Per il monitoraggio continuo
# Production evaluation pipeline
production_eval = {
"frequency": "Every model update + weekly monitoring",
"automation": "CI/CD integration with quality gates",
"metrics": "Speed + quality + cost tracking",
"alerting": "Performance degradation detection"
}
Considerazioni sull'efficacia in termini di costi
La valutazione basata su modelli può essere costosa su larga scala. Una strategia di produzione economicamente vantaggiosa utilizza metodi diversi per scopi diversi. Questa tabella riepiloga i compromessi tra velocità, costo e caso d'uso per i diversi tipi di valutazione:
Tipo di valutazione | Ora | Costo per campione | I migliori per |
ROUGE/BLEU | Secondi | ~0,001 $ | Screening ad alto volume |
Pointwise basato sul modello | Circa 1-2 secondi | ~0,01 $ | Valutazione della qualità |
Confronto a coppie | Circa 2-3 secondi | ~0,02 $ | Selezione del modello |
Valutazione umana | Minuti | 1-10 $ | Convalida gold standard |
Automatizza con CI/CD e monitoraggio
Le esecuzioni manuali dei notebook non sono scalabili. Automatizza la valutazione in una pipeline di integrazione continua/deployment continuo (CI/CD).
- Crea gate di qualità: integra l'attività di valutazione in una pipeline CI/CD (ad es. Cloud Build). Esegui automaticamente valutazioni su nuovi prompt o modelli e blocca le implementazioni se i punteggi di qualità chiave scendono al di sotto delle soglie definite.
- Monitoraggio delle tendenze: esporta le metriche di riepilogo delle esecuzioni di valutazione in un servizio come Google Cloud Monitoring. Crea dashboard per monitorare la qualità nel tempo e configura avvisi automatici per informare il tuo team di eventuali cali significativi delle prestazioni.
12. Conclusione
Hai completato il lab. Hai acquisito le competenze essenziali per valutare i modelli di AI generativa.
Questo lab fa parte del percorso di apprendimento AI pronta per la produzione con Google Cloud.
- Esplora il curriculum completo per colmare il divario tra prototipo e produzione.
- Condividi i tuoi progressi con l'hashtag
ProductionReadyAI.
Riepilogo
In questo lab hai imparato a:
- Applica le best practice di valutazione utilizzando il framework
EvalTask. - Utilizza diversi tipi di metriche, dai giudici basati su calcoli a quelli basati su modelli.
- Ottimizza i prompt testando versioni diverse.
- Crea un workflow riproducibile con il monitoraggio degli esperimenti.
Risorse per l'apprendimento continuo
- Documentazione sulla valutazione dell'AI generativa di Vertex AI
- Notebook su tecniche di valutazione avanzate
- Riferimento all'SDK Gen AI Evaluation
- Model-Based Metrics Research
- Best practice per l'ingegneria dei prompt
Gli approcci di valutazione sistematica che hai appreso in questo lab ti serviranno da base per creare applicazioni di AI affidabili e di alta qualità. Ricorda: una buona valutazione è il ponte tra l'AI sperimentale e il successo della produzione.