
1. Przegląd
W tym laboratorium nauczysz się oceniać duże modele językowe za pomocą usługi oceny generatywnej AI w Vertex AI. Za pomocą pakietu SDK będziesz uruchamiać zadania oceny, porównywać wyniki i podejmować oparte na danych decyzje dotyczące wydajności modelu i projektowania promptów.
Moduł przeprowadzi Cię przez typowy przepływ pracy oceny, zaczynając od prostych wskaźników obliczeniowych, a kończąc na bardziej złożonych ocenach opartych na modelu. Dowiesz się też, jak tworzyć dane niestandardowe dostosowane do konkretnych celów i śledzić postępy za pomocą Vertex AI Experiments.
Czego się nauczysz
Z tego modułu nauczysz się, jak:
- Oceniaj model za pomocą wskaźników obliczeniowych i opartych na modelu.
- Utwórz dane niestandardowe, aby dostosować ocenę do celów produktu.
- bezpośrednio porównywać różne szablony promptów,
- Testuj różne prompty oparte na personach, aby znaleźć najskuteczniejszą wersję.
- Śledź i wizualizuj przebiegi oceny za pomocą Vertex AI Experiments.
Odniesienia
- Przykłady kodu: ten moduł korzysta z przykładów z repozytorium dotyczącego generatywnej AI w Google Cloud.
- Na podstawie: dokumentacja oceny generatywnej AI w Vertex AI
- Zbiór danych: zbiór danych OpenOrca do oceny zgodności z instrukcjami
2. Konfigurowanie projektu
Konto Google
Jeśli nie masz jeszcze osobistego konta Google, musisz je utworzyć.
Używaj konta osobistego zamiast konta służbowego lub szkolnego.
Logowanie się w konsoli Google Cloud
Zaloguj się w konsoli Google Cloud, korzystając z osobistego konta Google.
Włącz płatności
Płatności możesz włączyć na 2 sposoby. Możesz użyć osobistego konta rozliczeniowego lub wykorzystać środki, wykonując te czynności.
Odbieranie środków w Google Cloud (opcjonalnie)
Aby przeprowadzić te warsztaty, musisz mieć konto rozliczeniowe z określonymi środkami. Aby rozpocząć, użyj środków z banera u góry tego modułu. Jeśli masz już połączenie z kontem rozliczeniowym, możesz pominąć ten krok.
Konfigurowanie osobistego konta rozliczeniowego
Jeśli skonfigurujesz płatności za pomocą środków w Google Cloud, możesz pominąć ten krok.
Aby skonfigurować osobiste konto rozliczeniowe, włącz płatności w konsoli Google Cloud.
Uwagi:
- Pod względem opłat za zasoby chmury ukończenie tego modułu powinno kosztować mniej niż 1 USD.
- Jeśli chcesz uniknąć dalszych opłat, wykonaj czynności opisane na końcu tego modułu, aby usunąć zasoby.
- Nowi użytkownicy mogą skorzystać z bezpłatnego okresu próbnego, w którym mają do dyspozycji środki w wysokości 300 USD.
Tworzenie projektu (opcjonalnie)
Jeśli nie masz bieżącego projektu, którego chcesz użyć w tym ćwiczeniu, utwórz nowy projekt.
3. Konfigurowanie środowiska Vertex AI Workbench
Zacznijmy od uzyskania dostępu do wstępnie skonfigurowanego środowiska notatnika i zainstalowania niezbędnych zależności.
Dostęp do Vertex AI Workbench
- W konsoli Google Cloud otwórz Vertex AI, klikając Menu nawigacyjne ☰ > Vertex AI > Panel.
- Kliknij Włącz wszystkie zalecane interfejsy API. Uwaga: poczekaj na zakończenie tego kroku.
- Po lewej stronie kliknij Workbench, aby utworzyć nową instancję Workbench.
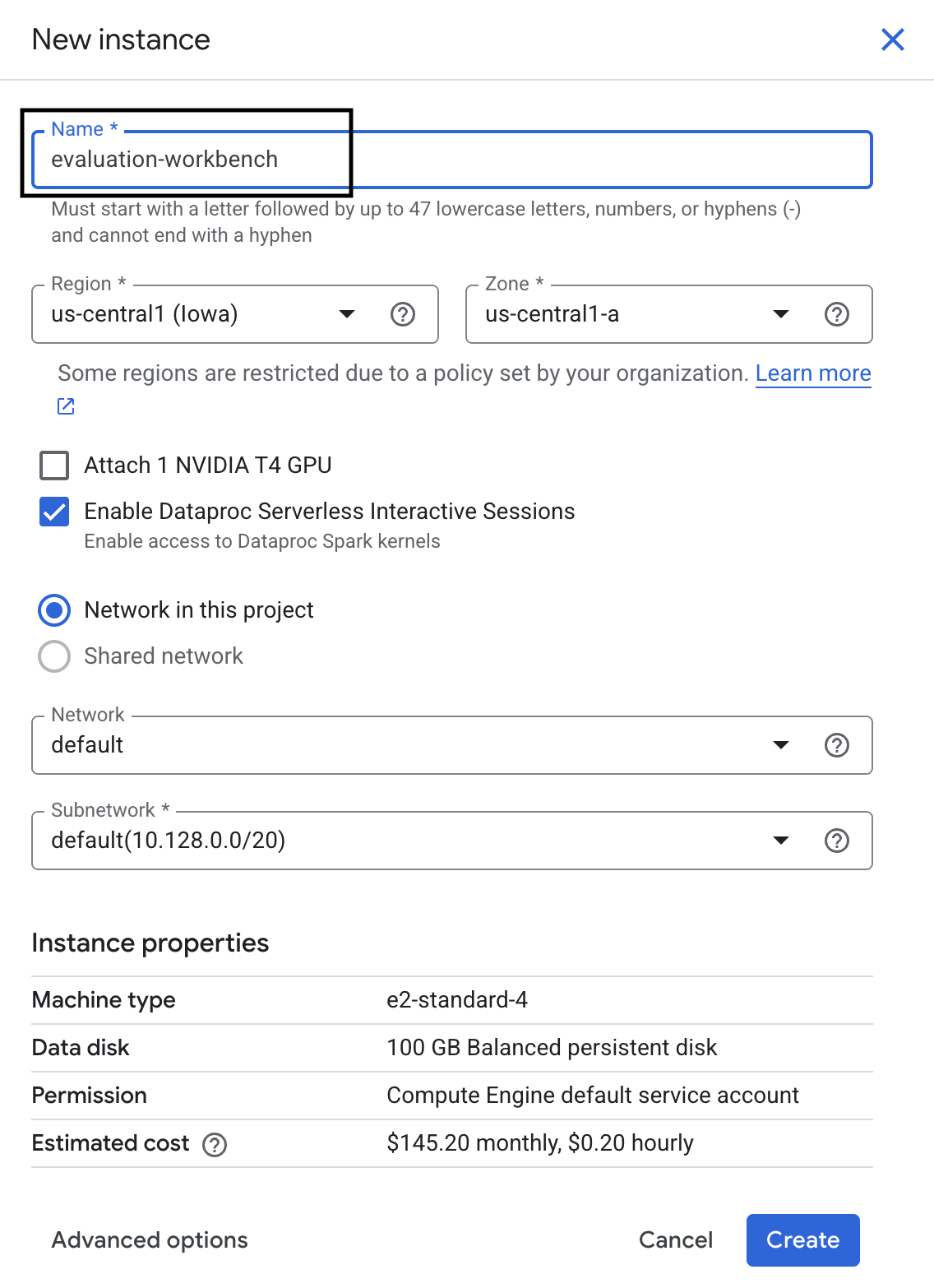
- Nazwij instancję Workbench evaluation-workbench i kliknij Utwórz.
- Poczekaj, aż platforma zostanie skonfigurowana. Może to potrwać kilka minut.

- Po udostępnieniu stacji roboczej kliknij Otwórz JupyterLab.
- W środowisku roboczym utwórz nowy notatnik w Pythonie 3.
Więcej informacji o funkcjach i możliwościach tego środowiska znajdziesz w oficjalnej dokumentacji Vertex AI Workbench.
Instalowanie pakietów i konfigurowanie środowiska
- W pierwszej komórce notatnika dodaj i uruchom poniższe instrukcje importowania (SHIFT+ENTER), aby zainstalować pakiet Vertex AI SDK (z komponentami oceny) i inne wymagane pakiety.
%pip install -U -q google-cloud-aiplatform[evaluation] %pip install -U -q datasets anthropic[vertex] openai - Aby użyć nowo zainstalowanych pakietów, zalecamy ponowne uruchomienie jądra przez uruchomienie poniższego fragmentu kodu.
# Automatically restart kernel after installation so that your environment can access the new packages. import IPython app = IPython.Application.instance() app.kernel.do_shutdown(True) - Zastąp poniższe wartości identyfikatorem projektu i lokalizacją, a następnie uruchom następną komórkę. Domyślna lokalizacja to
europe-west1, ale powinna być taka sama jak w przypadku instancji Vertex AI Workbench.# Configure your project settings PROJECT_ID = "YOUR PROJECT ID" LOCATION = "europe-west1" - Zaimportuj wszystkie biblioteki Pythona wymagane w tym module, uruchamiając ten kod w nowej komórce.
from anthropic import AnthropicVertex from google.auth import default, transport import openai import pandas as pd from vertexai.evaluation import ( EvalTask, MetricPromptTemplateExamples, PairwiseMetric, PointwiseMetric, PointwiseMetricPromptTemplate, ) from vertexai.generative_models import GenerativeModel from vertexai.preview.evaluation import notebook_utils
4. Konfigurowanie zbioru danych do oceny
W tym samouczku użyjemy 10 próbek ze zbioru danych OpenOrca. Dzięki temu mamy wystarczająco dużo danych, aby dostrzec istotne różnice między modelami, a jednocześnie czas oceny jest rozsądny.
💡 Wskazówka: w środowisku produkcyjnym warto mieć 100–500 przykładów, aby uzyskać istotne statystycznie wyniki, ale 10 próbek wystarczy do nauki i szybkiego prototypowania.
Przygotowywanie zbioru danych
- W nowej komórce uruchom następującą komórkę, aby wczytać dane, przekształcić je w strukturę DataFrame biblioteki pandas i zmienić nazwę kolumny
responsenareference, w celu uniknięcia wątpliwości w naszych zadaniach związanych z oceną. Utwórz też losową próbę 10 przykładów.from datasets import load_dataset ds = ( load_dataset( "Open-Orca/OpenOrca", data_files="1M-GPT4-Augmented.parquet", split="train[:100]", ) .to_pandas() .drop(columns=["id"]) .rename(columns={"response": "reference"}) ) dataset = ds.sample(n=10) - Gdy poprzednia komórka zakończy działanie, w następnej komórce dodaj i uruchom ten kod, aby wyświetlić kilka pierwszych wierszy zbioru danych do oceny.
dataset.head()
5. Ustalanie poziomu odniesienia za pomocą wskaźników obliczeniowych
W tym zadaniu ustalisz wynik podstawowy za pomocą wskaźnika opartego na obliczeniach. Jest to szybkie podejście, które zapewnia obiektywne dane porównawcze do pomiaru przyszłych ulepszeń.
Użyjemy ROUGE (Recall-Oriented Understudy for Gisting Evaluation), standardowego wskaźnika do zadań podsumowania. Działa on poprzez porównanie sekwencji słów (n-gramów) w odpowiedzi wygenerowanej przez model ze słowami w tekście reference.
Dowiedz się więcej o wskaźnikach obliczeniowych.
Przeprowadzanie oceny podstawowej
- W nowej komórce dodaj i uruchom następującą komórkę, aby zdefiniować model, który chcesz przetestować,
gemini-2.0-flash.generation_configobejmuje parametry takie jaktemperatureimax_output_tokens, które wpływają na wyniki modelu.# Model to be evaluated model = GenerativeModel( "gemini-2.0-flash", generation_config={"temperature": 0.6, "max_output_tokens": 256, "top_k": 1}, )GenerativeModelto główny interfejs do interakcji z dużymi modelami językowymi w pakiecie Vertex AI SDK. - W następnej komórce dodaj i uruchom ten kod, aby utworzyć i wykonać
EvalTask. Ten obiekt z pakietu Vertex AI Evaluation SDK koordynuje ocenę. Konfigurujesz go za pomocą zbioru danych i wskaźników do obliczenia, w tym przypadkurouge_l_sum.# Define an EvalTask with ROUGE-L-SUM metric rouge_eval_task = EvalTask( dataset=dataset, metrics=["rouge_l_sum"], ) rouge_result = rouge_eval_task.evaluate( model=model, prompt_template="# System_prompt\n{system_prompt} # Question\n{question}", ) - Wyświetl wyniki, uruchamiając ten kod w następnej komórce.
notebook_utils.display_eval_result(rouge_result)display_eval_result()pokazuje średni wynik i wyniki wiersz po wierszu.
6. Opcjonalnie: ocena za pomocą wskaźników punktowych opartych na modelu
Uwaga: ta sekcja może nie mieścić się w limicie bezpłatnych środków.
ROUGE jest przydatny, ale mierzy tylko pokrywanie się słownictwa (czyli zlicza tylko pasujące słowa, nie rozumie kontekstu, synonimów ani parafraz). Nie jest więc najlepszy w określaniu, czy odpowiedź jest płynna i logiczna. Aby lepiej poznać wydajność modelu, użyj wskaźników punktowych opartych na modelu.
W tej metodzie inny LLM („model oceniający”) ocenia każdą odpowiedź indywidualnie na podstawie wstępnie zdefiniowanego zestawu kryteriów, takich jak płynność czy spójność.
Dowiedz się więcej o wskaźnikach opartych na modelach.
Przeprowadź ocenę punktową
- Aby utworzyć interaktywne menu, w nowej komórce uruchom to polecenie. W przypadku tego uruchomienia wybierz z listy coherence.
#Select a pointwise metric to use import ipywidgets as widgets pointwise_single_turn_metrics = [ metric for metric in MetricPromptTemplateExamples.list_example_metric_names() if not metric.startswith("pairwise") and not metric.startswith("multi_turn") ] dropdown = widgets.Dropdown( options=pointwise_single_turn_metrics, description="Select a metric:", font_weight="bold", style={"description_width": "initial"}, ) def dropdown_eventhandler(change): global POINTWISE_METRIC if change["type"] == "change" and change["name"] == "value": POINTWISE_METRIC = change.new print("Selected:", change.new) POINTWISE_METRIC = dropdown.value dropdown.observe(dropdown_eventhandler, names="value") display(dropdown) - W nowej komórce ponownie uruchom
EvalTask, tym razem używając wybranego wskaźnika opartego na modelu. Usługa oceny Vertex AI tworzy prompt dla modelu oceniającego, który zawiera oryginalny prompt, odpowiedź referencyjną, odpowiedź modelu kandydata i instrukcje dotyczące wybranej wartości. Model oceniający zwraca wynik liczbowy i wyjaśnienie oceny. Uwaga: wykonanie tego kroku zajmie kilka minut.pointwise_result = EvalTask( dataset=dataset, metrics=[POINTWISE_METRIC], ).evaluate( model=model, prompt_template="# System_prompt\n{system_prompt} # Question\n{question}", )
Wyświetlanie wyników
Po zakończeniu oceny należy przeanalizować wyniki.
- Aby wyświetlić dane podsumowujące, które pokazują średni wynik dla wybranych danych, uruchom ten kod w nowej komórce.
notebook_utils.display_eval_result(pointwise_result) - W następnej komórce uruchom poniższy kod, aby wyświetlić szczegółowe informacje o poszczególnych wierszach, w tym pisemne uzasadnienie oceny modelu Judge. Te jakościowe opinie pomagają zrozumieć, dlaczego odpowiedź została oceniona w określony sposób.
notebook_utils.display_explanations(pointwise_result, num=1, metrics=[POINTWISE_METRIC])
7. Tworzenie danych niestandardowych na potrzeby bardziej szczegółowych statystyk
Gotowe wskaźniki, takie jak płynność, są przydatne, ale w przypadku konkretnego produktu często trzeba mierzyć skuteczność na podstawie własnych celów. Dzięki niestandardowym wskaźnikom punktowym możesz zdefiniować własne kryteria oceny i ocenę cząstkową.
W tym zadaniu utworzysz od zera nowe dane o nazwie summarization_helpfulness.
Definiowanie i uruchamianie danych niestandardowych
- Aby zdefiniować dane niestandardowe, w nowej komórce uruchom to polecenie.Symbol
PointwiseMetricPromptTemplatezawiera elementy składowe danych:- criteria: podaje modelowi oceniającemu konkretne wymiary do oceny: „Kluczowe informacje”, „Zwięzłość” i „Brak zniekształceń”.
- rating_rubric: zawiera 5-punktową skalę ocen, która określa znaczenie każdej oceny.
- input_variables: przekazuje dodatkowe kolumny ze zbioru danych do modelu oceniającego, aby zapewnić mu kontekst potrzebny do przeprowadzenia oceny.
# This new custom metric evaluates the actual quality and usefulness of the summary. summarization_helpfulness_metric = PointwiseMetric( metric="summarization_helpfulness", metric_prompt_template=PointwiseMetricPromptTemplate( criteria={ "Key Information": "Does the summary capture the most critical pieces of information from the original text? It should not miss the main topic or key takeaways.", "Conciseness": "Is the summary brief and to the point? It should avoid unnecessary words or repetitive information.", "No Distortion": "Does the summary introduce information or opinions that were NOT present in the original text? It must accurately reflect the source material without adding hallucinations." }, rating_rubric={ "5": "Excellent: Captures all key information, is highly concise, and has zero distortion.", "4": "Good: Captures most key information with minor omissions, is concise, and has no distortion.", "3": "Satisfactory: Captures the main idea but misses some key details OR is not very concise.", "2": "Unsatisfactory: Misses the main idea of the original text OR contains minor distortions/hallucinations.", "1": "Poor: Is completely irrelevant, fails to summarize the text, OR contains significant distortions.", }, input_variables=["prompt", "reference"], ), ) - Uruchom w następnej komórce ten kod, aby wykonać
EvalTaskz nową niestandardową wartością.# You would then update the EvalTask to use this new metric pointwise_result = EvalTask( dataset=dataset, metrics=[summarization_helpfulness_metric], ).evaluate( model=model, prompt_template="# System_prompt\n{system_prompt} # Question\n{question}", ) - Aby wyświetlić wyniki, uruchom w nowej komórce to polecenie.
notebook_utils.display_eval_result(pointwise_result)
8. Porównywanie modeli za pomocą oceny parami
Jeśli chcesz sprawdzić, który z 2 modeli lepiej radzi sobie z określonym zadaniem, możesz użyć oceny parami opartej na modelu. Ta metoda jest formą testu A/B, w którym model oceniający wyłania zwycięzcę, co umożliwia bezpośrednie porównanie na potrzeby wyboru modelu opartego na danych.
Modele:
- Model kandydujący: zmienna modelu (zdefiniowana wcześniej jako
gemini-2.0-flash) jest przekazywana do metody.evaluate(). To główny model, który testujesz. - Model bazowy: drugi model,
gemini-2.0-flash-lite, jest określony w klasie PairwiseMetric. Jest to model, z którym porównujesz.
Przeprowadzanie oceny parami
- W nowej komórce dodaj i uruchom ten kod, aby utworzyć interaktywne menu. Umożliwi to wybranie danych do porównania. W tym przypadku wybierz pairwise_summarization_quality.
from IPython.display import display import ipywidgets as widgets pairwise_single_turn_metrics = [ metric for metric in MetricPromptTemplateExamples.list_example_metric_names() if metric.startswith("pairwise") and "multi_turn" not in metric ] dropdown = widgets.Dropdown( options=pairwise_single_turn_metrics, description="Select a metric:", font_weight="bold", style={"description_width": "initial"}, ) def dropdown_eventhandler(change): global POINTWISE_METRIC if change["type"] == "change" and change["name"] == "value": POINTWISE_METRIC = change.new print("Selected:", change.new) def dropdown_eventhandler(change): global PAIRWISE_METRIC_NAME if change["type"] == "change" and change["name"] == "value": PAIRWISE_METRIC_NAME = change.new print("Selected:", change.new) PAIRWISE_METRIC_NAME = dropdown.value dropdown.observe(dropdown_eventhandler, names="value") display(dropdown) - W następnej komórce dodaj i uruchom ten kod, aby skonfigurować i wykonać
EvalTask. Zwróć uwagę, jak klasaPairwiseMetricsłuży do definiowania modelu bazowego (gemini-2.0-flash-lite), a model kandydujący (gemini-2.0-flash) jest przekazywany do metody.evaluate().pairwise_result = EvalTask( dataset=dataset, metrics=[ PairwiseMetric( metric=PAIRWISE_METRIC_NAME, metric_prompt_template=MetricPromptTemplateExamples.get_prompt_template( PAIRWISE_METRIC_NAME ), # Define a baseline model to compare against baseline_model=GenerativeModel("gemini-2.0-flash-lite"), ) ], ).evaluate( # Specify a candidate model for pairwise comparison model=model, prompt_template="# System_prompt\n{system_prompt} # Question\n{question}", ) - W nowej komórce dodaj i uruchom ten kod, aby wyświetlić wyniki. W tabeli podsumowującej zobaczysz „odsetek wygranych” każdego modelu, co wskazuje, który z nich był częściej preferowany przez model oceniający.
notebook_utils.display_eval_result(pairwise_result)
9. Opcjonalnie: ocena promptów opartych na personach
Uwaga: ta sekcja może nie mieścić się w limicie bezpłatnych środków.
W tym zadaniu przetestujesz kilka szablonów promptów, które instruują model, aby przyjął różne role. Ten proces, często nazywany tworzeniem promptów, pozwala systematycznie znajdować najskuteczniejsze prompty w określonych przypadkach użycia.
Przygotowywanie zbioru danych do podsumowywania
Aby przeprowadzić tę ocenę, zbiór danych musi zawierać te pola:
instruction: główne zadanie, które przekazujemy modelowi. W tym przypadku jest to proste polecenie „Podsumuj ten artykuł:”.context: tekst źródłowy, z którym model musi pracować. Poniżej znajdziesz 4 różne fragmenty wiadomości.reference: podsumowanie referencyjne lub „złoty standard”. Wygenerowane dane wyjściowe modelu zostaną porównane z tym tekstem w celu obliczenia wyników wskaźników takich jak ROUGE i jakość podsumowania.
- W nowej komórce dodaj i uruchom ten kod, aby utworzyć
pandas.DataFramena potrzeby zadania podsumowania.instruction = "Summarize the following article: \n" context = [ "Typhoon Phanfone has killed at least one person, a US airman on Okinawa who was washed away by high waves. Thousands of households have lost power and Japan's two largest airlines have suspended many flights. The storm also forced the suspension of the search for people missing after last week's volcanic eruption. The storm-tracking website Tropical Storm Risk forecasts that Phanfone will rapidly lose power over the next few hours as it goes further into the Pacific Ocean. Typhoon Phanfone was downgraded from an earlier status of a super typhoon, but the Japan Meteorological Agency had warned it was still a dangerous storm. Japan averages 11 typhoons a year, according to its weather agency. The typhoon made landfall on Monday morning near the central city of Hamamatsu, with winds of up to 180 km/h (112 mph). The airman was one of three US military personnel swept away by high waves whipped up by the typhoon off southern Okinawa island, where the US has a large military base. The remaining two are still missing. A police spokesman said they had been taking photographs of the sea. A university student who was surfing off the seas of Kanagawa Prefecture, south of Tokyo, was also missing, national broadcast NHK reports. It said at least 10 people had been injured and 9,500 houses were without power. The storm was expected to deposit about 100mm of rain on Tokyo over 24 hours, according to the Transport Ministry website. Many schools were closed on Monday and two car companies in Japan halted production at some plants ahead of the storm. More than 174 domestic flights were affected nationwide, NHK state broadcaster said on Sunday. On Sunday, heavy rain delayed the Japanese Formula One Grand Prix in Suzaka. French driver Jules Bianchi lost control in the wet conditions and crashed, sustaining a severe head injury.", "The blaze started at the detached building in Drivers End in Codicote, near Welwyn, during the morning. There was another fire at the building 20 years ago, after which fire-proof foil was placed under the thatch, which is protecting the main building. More than 15 fire engines and support vehicles were called to tackle the blaze. Roads in the area were closed and traffic diverted.", 'The 18-year-old fell at the New Charter Academy on Broadoak Road in Ashton-under-Lyne at about 09:10 BST, Greater Manchester Police (GMP) said. GMP said he had gone to Manchester Royal Infirmary and his condition was "serious". Principal Jenny Langley said the school would remain "fully open" while police investigated. "Our thoughts are with the family and we\'re doing everything we can to support them along with staff and pupils," she said.', 'But Belgian-born Dutchman Max Verstappen was unable to drive a car legally on his own in either country. That all changed on Wednesday when the youngster turned 18 and passed his driving test at the first attempt. Despite having competed in 14 grands prix since his debut in Australia in March, Verstappen admitted to feeling the pressure during his test. "It\'s a relief," said the Toro Rosso driver, who finished ninth in Japan on Sunday and had only started driving lessons a week ago. "I was a bit nervous to make mistakes, but the exam went well." A bonus of turning 18 is that Verstappen will now be able to drink the champagne if he ever makes it onto the podium.', ] reference = [ "A powerful typhoon has brought many parts of Japan to a standstill and briefly battered Tokyo before heading out to sea.", "A major fire has been burning in the thatched roof of a large property in Hertfordshire.", "A student has been taken to hospital after falling from a balcony at a Greater Manchester school.", "He is Formula 1's youngest ever driver and in charge of a car that can reach over 200mph.", ] response = [ "Typhoon Phanfone, while downgraded from super typhoon status, caused significant disruption and tragedy in Japan. One US airman died after being swept away by high waves, with two more missing. The storm caused power outages for thousands, flight cancellations, and the suspension of rescue efforts for missing volcano victims. Heavy rain and strong winds led to school and factory closures, transportation disruptions, and at least 10 injuries. The typhoon is expected to weaken as it moves over the Pacific Ocean.", "A large fire broke out in a detached thatched building in Codicote, near Welwyn. This is the second fire at the building in 20 years. Thankfully, fire-proof foil installed after the previous fire is protecting the main building. Over 15 fire engines and support vehicles responded, closing roads and diverting traffic in the area.", "An 18-year-old student at New Charter Academy in Ashton-under-Lyne suffered a serious fall and was hospitalized. The incident is under investigation by Greater Manchester Police, but the school remains open. The principal expressed support for the student's family and the school community.", "Max Verstappen, a Formula One driver, was finally able to get his driver's license at age 18. Despite already competing in 14 Grand Prix races, he was not of legal driving age in his native countries. He admitted to being nervous but passed the test on his first attempt. As an added bonus of turning 18, Verstappen can now enjoy champagne on the podium if he places.", ] eval_dataset = pd.DataFrame( { "instruction": instruction, "context": context, "reference": reference, } )
Uruchamianie zadania oceny prompta
Po przygotowaniu zbioru danych do podsumowywania możesz przeprowadzić główny eksperyment w tym zadaniu: porównać kilka szablonów promptów, aby sprawdzić, który z nich generuje najwyższej jakości dane wyjściowe z modelu.
- W następnej komórce utwórz pojedynczy znak
EvalTask, który będzie używany w każdym eksperymencie z promptem. Ustawiając parametrexperiment, wszystkie przebiegi oceny z tego zadania są automatycznie rejestrowane i grupowane w Vertex AI Experiments.EXPERIMENT_NAME = "eval-sdk-prompt-engineering" # @param {type:"string"} summarization_eval_task = EvalTask( dataset=eval_dataset, metrics=[ "rouge_l_sum", "bleu", "fluency", "coherence", "safety", "groundedness", "summarization_quality", "verbosity", "instruction_following", "text_quality", ], experiment=EXPERIMENT_NAME, )rouge_l_sumibleu, po szeroki zakres wskaźników opartych na modelach (fluency,coherence,summarization_quality,instruction_followingitp.). Dzięki temu uzyskujemy całościowy, 360-stopniowy obraz tego, jak każdy prompt wpływa na jakość danych wyjściowych modelu. - W nowej komórce dodaj i uruchom ten kod, aby zdefiniować i ocenić 4 strategie promptów oparte na personach. Pętla
foriteruje po każdym szablonie i przeprowadza ocenę.Każdy szablon ma na celu uzyskanie innego stylu podsumowania poprzez przypisanie modelowi określonej osobowości lub celu:- Persona 1 (standardowa): neutralna, prosta prośba o streszczenie.
- Persona 2 (dyrektor): prosi o podsumowanie w punktach, skupiając się na wynikach i wpływie, tak jak zrobiłby to zapracowany dyrektor.
- Profil 3 (uczeń 5 klasy): prosi model o używanie prostego języka, testując jego zdolność do dostosowywania złożoności odpowiedzi.
- Persona 4 (analityk techniczny): wymaga bardzo rzeczowego podsumowania, w którym zachowane są kluczowe statystyki i podmioty, co pozwala sprawdzić precyzję modelu. Zwróć uwagę, że symbole zastępcze w tych nowych szablonach, np.
{context}i{instruction}, są zgodne z nazwami nowych kolumn w arkuszueval_datasetutworzonym na potrzeby tego zadania.
# Define prompt templates that target different user personas prompt_templates = [ # Persona 1: Standard, neutral summary "Article: {context}. Task: {instruction}. Summary:", # Persona 2: For a busy executive (bullet points) "Instruction: {instruction} into three key bullet points for a busy executive. Focus on the main outcome and impact. Article: {context}. Summary:", # Persona 3: For a 5th grader (simple language) "Instruction: {instruction} such that you're explaining it to a 10-year-old. Use simple words. Article: {context}. Summary:", # Persona 4: For a technical analyst (fact-focused) "Instruction: Provide a detailed, factual summary of the following text, ensuring all key statistics, names, and locations are preserved. Article: {context}. Summary:", ] eval_results = [] for i, prompt_template in enumerate(prompt_templates): eval_result = summarization_eval_task.evaluate( prompt_template=prompt_template, model=GenerativeModel( "gemini-2.0-flash", generation_config={ "temperature": 0.3, "max_output_tokens": 256, "top_k": 1, }, ), evaluation_service_qps=5, ) eval_results.append((f"Prompt Persona #{i+1}", eval_result))
Analizowanie i wizualizowanie wyników
Przeprowadzanie eksperymentów to pierwszy krok. Prawdziwa wartość pochodzi z analizy wyników, która umożliwia podejmowanie decyzji na podstawie danych. W tym zadaniu użyjesz narzędzi do wizualizacji z pakietu SDK, aby zinterpretować wyniki eksperymentu dotyczącego persony prompta.
- Wyświetl wyniki podsumowania dla każdej z 4 osób, które testujesz, uruchamiając w nowej komórce ten kod: Dzięki temu uzyskasz ogólny obraz skuteczności w postaci danych liczbowych.
for title, eval_result in eval_results: notebook_utils.display_eval_result(title=title, eval_result=eval_result) - W nowej komórce dodaj i uruchom ten kod, aby zobaczyć uzasadnienie wartości
summarization_qualitydla każdej persony.for title, eval_result in eval_results: notebook_utils.display_explanations( eval_result, metrics=["summarization_quality"], num=2 ) - Wygeneruj wykres radarowy, aby wizualizować kompromisy między różnymi wskaźnikami jakości dla każdego promptu. W nowej komórce dodaj i uruchom ten kod.
notebook_utils.display_radar_plot( eval_results, metrics=["instruction_following", "fluency", "coherence", "text_quality"], ) - Aby uzyskać bardziej bezpośrednie porównanie obok siebie, utwórz wykres słupkowy. W nowej komórce dodaj i uruchom ten kod.
notebook_utils.display_bar_plot( eval_results, metrics=["instruction_following", "fluency", "coherence", "text_quality"], )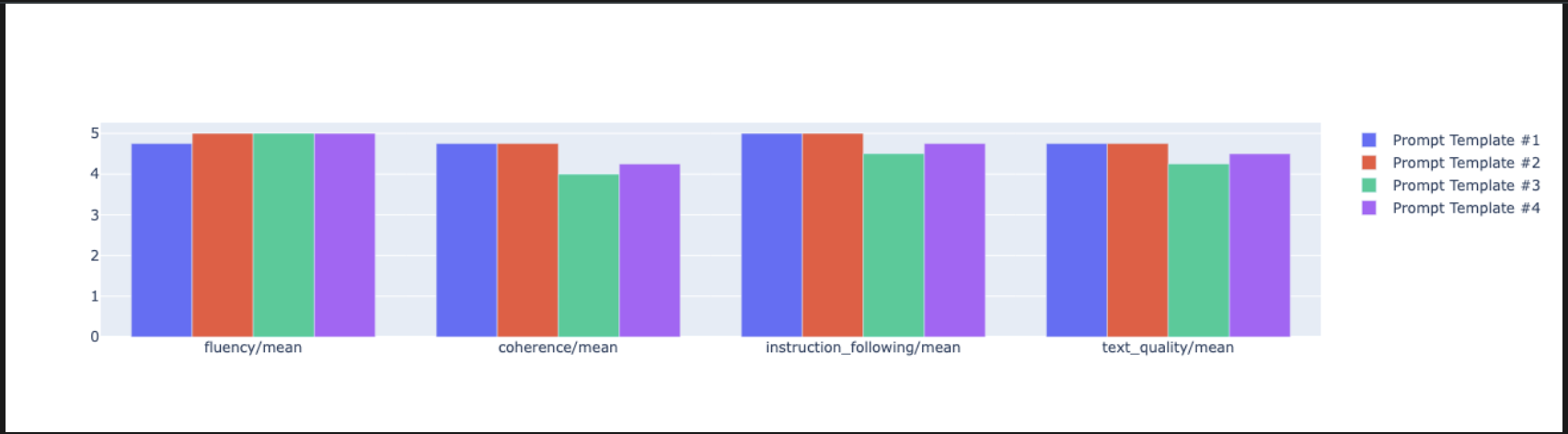
- Możesz teraz wyświetlić podsumowanie wszystkich uruchomień zarejestrowanych w eksperymencie Vertex AI dla tego zadania. Jest to przydatne do śledzenia pracy w czasie. W nowej komórce dodaj i uruchom ten kod:
summarization_eval_task.display_runs()
10. Zwalnianie miejsca eksperymentu
Aby zachować porządek w projekcie i uniknąć niepotrzebnych opłat, warto zwolnić miejsce, usuwając utworzone zasoby. W tym module każdy przebieg oceny był rejestrowany w eksperymencie Vertex AI. Poniższy kod usuwa ten eksperyment nadrzędny, co powoduje też usunięcie wszystkich powiązanych z nim uruchomień i ich danych bazowych.
- Uruchom ten kod w nowej komórce, aby usunąć eksperyment Vertex AI i powiązane z nim uruchomienia.
delete_experiment = True # Please set your LOCATION to the same one used during Vertex AI SDK initialization. LOCATION = "YOUR LOCATION" # @param {type:"string"} if delete_experiment: from google.cloud import aiplatform aiplatform.init(project=PROJECT_ID, location=LOCATION) experiment = aiplatform.Experiment(EXPERIMENT_NAME) experiment.delete()
11. Od ćwiczeń do produkcji
Umiejętności zdobyte w tym module są podstawą do tworzenia niezawodnych aplikacji AI. Przejście od ręcznie uruchamianego notatnika do systemu oceny klasy produkcyjnej wymaga jednak dodatkowej infrastruktury i bardziej systematycznego podejścia. W tej sekcji znajdziesz najważniejsze praktyki i ramy strategiczne, które warto wziąć pod uwagę podczas skalowania w górę.
Tworzenie strategii oceny w środowisku produkcyjnym
Aby zastosować umiejętności zdobyte w tym module w środowisku produkcyjnym, warto sformalizować je w powtarzalne strategie. Poniższe ramy określają kluczowe kwestie w przypadku typowych scenariuszy, takich jak wybór modelu, optymalizacja promptów i ciągłe monitorowanie.
Wybór modelu:
# Evaluation strategy for choosing models
evaluation_strategy = {
"dataset_size": "100+ examples for statistical significance",
"metrics": ["task-specific", "general quality", "efficiency"],
"comparison_type": "pairwise with statistical testing",
"baseline": "established_model_or_human_benchmark"
}
Optymalizacja promptów
# Systematic prompt improvement workflow
prompt_optimization = {
"hypothesis": "Clear statement of what you're testing",
"variants": "3-5 different prompt strategies",
"evaluation": "Same metrics across all variants",
"analysis": "Statistical significance + qualitative review"
}
Ciągłe monitorowanie
# Production evaluation pipeline
production_eval = {
"frequency": "Every model update + weekly monitoring",
"automation": "CI/CD integration with quality gates",
"metrics": "Speed + quality + cost tracking",
"alerting": "Performance degradation detection"
}
Kwestie związane z opłacalnością
Ocena na podstawie modelu może być kosztowna na dużą skalę. Opłacalna strategia produkcji wykorzystuje różne metody do różnych celów. W tej tabeli znajdziesz podsumowanie kompromisów między szybkością, kosztem i przypadkiem użycia w przypadku różnych typów oceny:
Rodzaj oceny | Godzina | Koszt próbki | Najlepsze na |
ROUGE/BLEU | Sekundy | ~0,001 USD | Filtrowanie dużej liczby połączeń |
Model-based Pointwise | około 1–2 sekund. | ~0,01 USD | Ocena jakości |
Porównanie parami | ~2–3 sekundy | ~0,02 USD | Wybór modelu |
Ocena przez człowieka | Minuty | 1–10 USD | Weryfikacja za pomocą złotego standardu |
Automatyzacja za pomocą CI/CD i monitorowania
Ręczne uruchamianie notatników nie jest skalowalne. Zautomatyzuj ocenę w potoku ciągłej integracji/ciągłego wdrażania (CI/CD).
- Tworzenie bramek jakości: zintegruj zadanie oceny z potokiem CI/CD (np. Cloud Build). Automatycznie przeprowadzaj oceny nowych promptów lub modeli i blokuj wdrożenia, jeśli kluczowe wyniki jakości spadną poniżej określonych progów.
- Obserwowanie trendów: eksportuj wskaźniki podsumowujące z uruchomień oceny do usługi takiej jak Google Cloud Monitoring. Twórz panele, aby śledzić jakość w czasie, i konfiguruj automatyczne alerty, które będą powiadamiać Twój zespół o każdym znaczącym pogorszeniu skuteczności.
12. Podsumowanie
Udało Ci się ukończyć moduł. Poznałeś(-aś) podstawowe umiejętności potrzebne do oceny modeli generatywnej AI.
Ten moduł jest częścią ścieżki szkoleniowej Wdrożenie AI w Google Cloud.
- Poznaj pełny program nauczania, aby przejść od prototypu do produkcji.
- Podziel się swoimi postępami, używając hashtagu
ProductionReadyAI.
Podsumowanie
Z tego laboratorium dowiesz się, jak:
- Stosuj sprawdzone metody oceny, korzystając z
EvalTask. - Używaj różnych typów wskaźników, od sędziów opartych na obliczeniach po sędziów opartych na modelach.
- Optymalizuj prompty, testując różne wersje.
- Tworzenie powtarzalnego przepływu pracy ze śledzeniem eksperymentów.
Materiały do dalszej nauki
- Dokumentacja oceny generatywnej AI w Vertex AI
- Notatniki z zaawansowanymi technikami oceny
- Dokumentacja pakietu Gen AI Evaluation SDK
- Badania nad wskaźnikami opartymi na modelach
- Sprawdzone metody tworzenia promptów
Systematyczne podejścia do oceny, których nauczysz się w tym laboratorium, będą stanowić podstawę do tworzenia niezawodnych aplikacji AI o wysokiej jakości. Pamiętaj: dobra ocena to pomost między eksperymentalną AI a sukcesem w produkcji.