
1. Visão geral
Neste laboratório, você vai aprender a avaliar modelos de linguagem grandes usando o serviço de avaliação de IA generativa da Vertex AI. Você vai usar o SDK para executar jobs de avaliação, comparar resultados e tomar decisões orientadas a dados sobre a performance do modelo e o design de comandos.
O laboratório explica um fluxo de trabalho de avaliação comum, começando com métricas baseadas em computação e progredindo para avaliações mais detalhadas baseadas em modelos. Você também vai aprender a criar métricas personalizadas adaptadas às suas metas específicas e acompanhar seu trabalho usando os experimentos da Vertex AI.
O que você vai aprender
Neste laboratório, você aprenderá a fazer o seguinte:
- Avaliar um modelo com métricas baseadas em computação e em modelos.
- Crie uma métrica personalizada para alinhar a avaliação às metas do produto.
- Compare diferentes modelos de comandos lado a lado.
- Teste vários comandos com base em personas para encontrar a versão mais eficaz.
- Rastreie e visualize execuções de avaliação usando os Experimentos da Vertex AI.
Referências
- Exemplos de código: este laboratório se baseia em exemplos do repositório de IA generativa do Google Cloud.
- Com base na documentação de avaliação da IA generativa da Vertex AI
- Conjunto de dados: OpenOrca para avaliação de obediência a instruções
2. Configurar o projeto
Conta do Google
Se você ainda não tiver uma Conta do Google pessoal, crie uma.
Use uma conta pessoal em vez de uma conta escolar ou de trabalho.
Fazer login no console do Google Cloud
Faça login no console do Google Cloud usando uma Conta do Google pessoal.
Ativar faturamento
Para ativar o faturamento, você tem duas opções. Você pode usar sua conta de faturamento pessoal ou resgatar créditos seguindo estas etapas.
Resgatar créditos do Google Cloud (opcional)
Para fazer este workshop, você precisa de uma conta de faturamento com algum crédito. Use os créditos do banner na parte de cima deste codelab para começar. Se você já estiver conectado a uma conta de faturamento, pule esta etapa.
Configurar uma conta de faturamento pessoal
Se você configurou o faturamento usando créditos do Google Cloud, pule esta etapa.
Para configurar uma conta de faturamento pessoal, acesse este link e ative o faturamento no console do Cloud.
Algumas observações:
- A conclusão deste laboratório custa menos de US $1 em recursos do Cloud.
- Siga as etapas no final deste laboratório para excluir recursos e evitar mais cobranças.
- Novos usuários podem aproveitar o teste sem custos financeiros de US$300.
Criar um projeto (opcional)
Se você não tiver um projeto atual que gostaria de usar neste laboratório, crie um novo projeto aqui.
3. Configurar o ambiente do Vertex AI Workbench
Comece acessando o ambiente de notebook pré-configurado e instalando as dependências necessárias.
acessar o Vertex AI Workbench
- No console do Google Cloud, clique no Menu de navegação ☰ > Vertex AI > Painel.
- Selecione Ativar todas as APIs recomendadas. Observação: aguarde a conclusão desta etapa.
- À esquerda, clique em Workbench para criar uma instância.
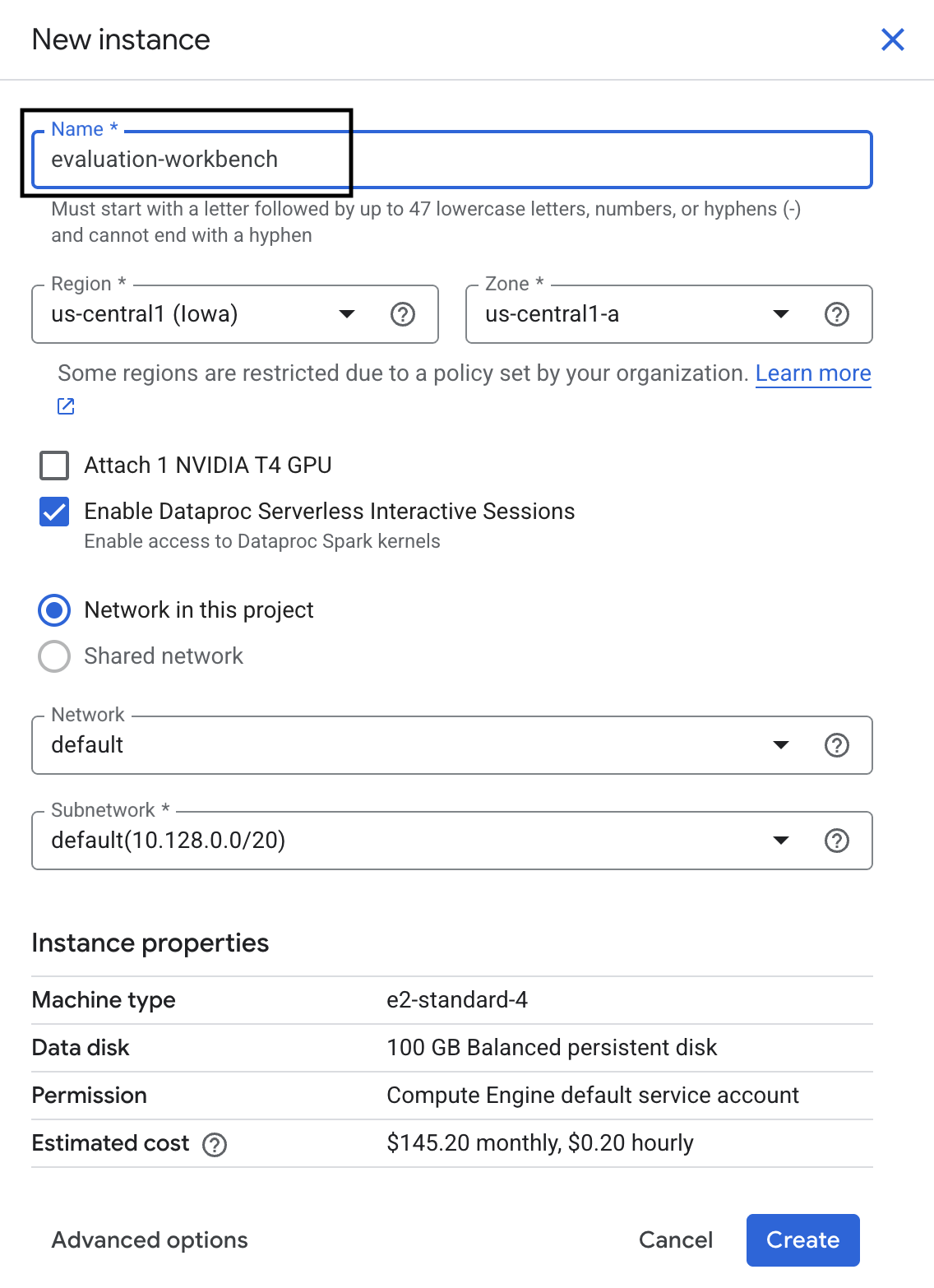
- Nomeie a instância do workbench como evaluation-workbench e clique em Criar.
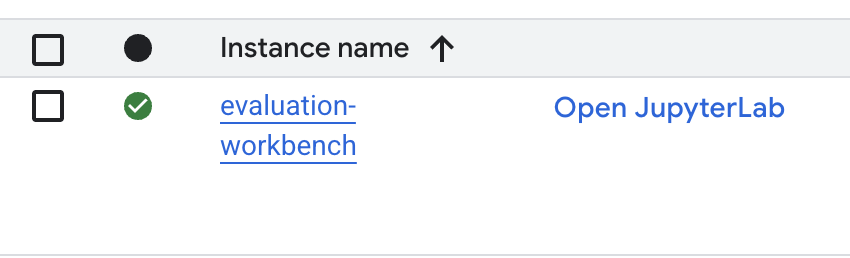
- Aguarde a configuração da estação de trabalho. Isso pode levar alguns minutos.

- Quando o workbench for provisionado, clique em Abrir JupyterLab.
- No workbench, crie um notebook Python3.
Para saber mais sobre os recursos e as funcionalidades desse ambiente, consulte a documentação oficial do Vertex AI Workbench.
Instalar pacotes e configurar o ambiente
- Na primeira célula do notebook, adicione e execute as instruções de importação abaixo (SHIFT+ENTER) para instalar o SDK da Vertex AI (com os componentes de avaliação) e outros pacotes necessários.
%pip install -U -q google-cloud-aiplatform[evaluation] %pip install -U -q datasets anthropic[vertex] openai - Para usar os pacotes recém-instalados, é recomendável reiniciar o kernel executando o snippet de código abaixo.
# Automatically restart kernel after installation so that your environment can access the new packages. import IPython app = IPython.Application.instance() app.kernel.do_shutdown(True) - Substitua o seguinte pelo ID do projeto e local e execute a célula. O local padrão é
europe-west1, mas use o mesmo local da sua instância do Vertex AI Workbench.# Configure your project settings PROJECT_ID = "YOUR PROJECT ID" LOCATION = "europe-west1" - Importe todas as bibliotecas Python necessárias para este laboratório executando o seguinte código em uma nova célula.
from anthropic import AnthropicVertex from google.auth import default, transport import openai import pandas as pd from vertexai.evaluation import ( EvalTask, MetricPromptTemplateExamples, PairwiseMetric, PointwiseMetric, PointwiseMetricPromptTemplate, ) from vertexai.generative_models import GenerativeModel from vertexai.preview.evaluation import notebook_utils
4. Configurar o conjunto de dados de avaliação
Neste tutorial, vamos usar 10 amostras do conjunto de dados OpenOrca. Isso nos dá dados suficientes para ver diferenças significativas entre os modelos, mantendo o tempo de avaliação gerenciável.
💡 Dica profissional:na produção, você precisa de 100 a 500 exemplos para ter resultados estatisticamente significativos, mas 10 amostras são perfeitas para aprender e fazer prototipagem rápida.
Preparar o conjunto de dados
- Em uma nova célula, execute o seguinte para carregar os dados, convertê-los em um DataFrame do pandas, renomear a coluna
responseparareferencepara fins de esclarecimento em nossas tarefas de avaliação e criar a amostra aleatória de dez exemplos.from datasets import load_dataset ds = ( load_dataset( "Open-Orca/OpenOrca", data_files="1M-GPT4-Augmented.parquet", split="train[:100]", ) .to_pandas() .drop(columns=["id"]) .rename(columns={"response": "reference"}) ) dataset = ds.sample(n=10) - Depois que a célula anterior terminar de ser executada, adicione e execute o seguinte código na próxima célula para mostrar as primeiras linhas do conjunto de dados de avaliação.
dataset.head()
5. Estabelecer um valor de referência com métricas baseadas em computação
Nesta tarefa, você vai estabelecer uma pontuação de base usando uma métrica baseada em computação. Essa abordagem é rápida e oferece uma comparação objetiva para medir melhorias futuras.
Vamos usar o ROUGE (Recall-Oriented Understudy for Gisting Evaluation), uma métrica padrão para tarefas de resumo. Ele compara a sequência de palavras (n-gramas) na resposta gerada pelo modelo com as palavras no texto de informações empíricas reference.
Leia mais sobre as métricas baseadas em computação.
Executar a avaliação de referência
- Em uma nova célula, adicione e execute o seguinte para definir o modelo que você quer testar,
gemini-2.0-flash. Ogeneration_configinclui parâmetros comotemperatureemax_output_tokensque influenciam a saída do modelo.# Model to be evaluated model = GenerativeModel( "gemini-2.0-flash", generation_config={"temperature": 0.6, "max_output_tokens": 256, "top_k": 1}, )GenerativeModelé a principal interface para interagir com modelos de linguagem grandes no SDK da Vertex AI. - Na próxima célula, adicione e execute o código a seguir para criar e executar o
EvalTask. Esse objeto do SDK de avaliação da Vertex AI organiza a avaliação. Você o configura com o conjunto de dados e as métricas a serem calculadas, que, neste caso, érouge_l_sum.# Define an EvalTask with ROUGE-L-SUM metric rouge_eval_task = EvalTask( dataset=dataset, metrics=["rouge_l_sum"], ) rouge_result = rouge_eval_task.evaluate( model=model, prompt_template="# System_prompt\n{system_prompt} # Question\n{question}", ) - Para mostrar os resultados, execute este código na próxima célula.
notebook_utils.display_eval_result(rouge_result)display_eval_result()mostra a pontuação média e os resultados linha por linha.
6. Opcional: avaliar com métricas pontuais baseadas em modelos
Observação: talvez esta seção não seja executada dentro do limite dos créditos sem custo financeiro fornecidos.
Embora o ROUGE seja útil, ele mede apenas a sobreposição lexical. Isso significa que ele conta apenas as palavras correspondentes, sem entender o contexto, os sinônimos ou a paráfrase. Portanto, ele não é o melhor para determinar se uma resposta é fluente ou lógica. Para entender melhor a performance do modelo, use métricas pontuais baseadas em modelos.
Com esse método, outro LLM (o "modelo juiz") avalia cada resposta individualmente com base em um conjunto predefinido de critérios, como fluência ou coerência.
Leia mais sobre as métricas baseadas em modelos.
Executar a avaliação por ponto
- Execute o seguinte em uma nova célula para criar um menu suspenso interativo. Para esta execução, selecione coherence na lista.
#Select a pointwise metric to use import ipywidgets as widgets pointwise_single_turn_metrics = [ metric for metric in MetricPromptTemplateExamples.list_example_metric_names() if not metric.startswith("pairwise") and not metric.startswith("multi_turn") ] dropdown = widgets.Dropdown( options=pointwise_single_turn_metrics, description="Select a metric:", font_weight="bold", style={"description_width": "initial"}, ) def dropdown_eventhandler(change): global POINTWISE_METRIC if change["type"] == "change" and change["name"] == "value": POINTWISE_METRIC = change.new print("Selected:", change.new) POINTWISE_METRIC = dropdown.value dropdown.observe(dropdown_eventhandler, names="value") display(dropdown) - Em uma nova célula, execute o
EvalTasknovamente, desta vez usando a métrica selecionada com base em modelo. O serviço de avaliação da Vertex AI cria um comando para o modelo de avaliação, que inclui o comando original, a resposta de referência, a resposta do modelo candidato e instruções para a métrica selecionada. O modelo juiz retorna uma pontuação numérica e uma explicação para a classificação. Observação: essa etapa leva alguns minutos para ser concluída.pointwise_result = EvalTask( dataset=dataset, metrics=[POINTWISE_METRIC], ).evaluate( model=model, prompt_template="# System_prompt\n{system_prompt} # Question\n{question}", )
Mostrar os resultados
Com a avaliação concluída, a próxima etapa é analisar a saída.
- Execute o código a seguir em uma nova célula para conferir as métricas de resumo, que mostram a pontuação média da métrica escolhida.
notebook_utils.display_eval_result(pointwise_result) - Execute o seguinte na próxima célula para conferir o detalhamento linha por linha, que inclui a justificativa escrita do modelo de avaliação para a pontuação. Esse feedback qualitativo ajuda você a entender por que uma resposta recebeu uma determinada pontuação.
notebook_utils.display_explanations(pointwise_result, num=1, metrics=[POINTWISE_METRIC])
7. Criar uma métrica personalizada para insights mais detalhados
Métricas pré-criadas, como fluência, são úteis, mas, para um produto específico, muitas vezes é necessário medir a performance em relação às suas próprias metas. Com métricas pontuais personalizadas, é possível definir seus próprios critérios e rubricas de avaliação.
Nesta tarefa, você vai criar uma métrica do zero chamada summarization_helpfulness.
Definir e executar a métrica personalizada
- Execute o seguinte em uma nova célula para definir a métrica personalizada.O
PointwiseMetricPromptTemplatecontém os elementos básicos para a métrica:- criteria: informa ao modelo juiz as dimensões específicas a serem avaliadas: "Informações principais", "Objetividade" e "Sem distorção".
- rating_rubric: fornece uma escala de pontuação de cinco pontos que define o significado de cada pontuação.
- input_variables: transmite colunas extras do conjunto de dados para o modelo juiz, para que ele tenha o contexto necessário para realizar a avaliação.
# This new custom metric evaluates the actual quality and usefulness of the summary. summarization_helpfulness_metric = PointwiseMetric( metric="summarization_helpfulness", metric_prompt_template=PointwiseMetricPromptTemplate( criteria={ "Key Information": "Does the summary capture the most critical pieces of information from the original text? It should not miss the main topic or key takeaways.", "Conciseness": "Is the summary brief and to the point? It should avoid unnecessary words or repetitive information.", "No Distortion": "Does the summary introduce information or opinions that were NOT present in the original text? It must accurately reflect the source material without adding hallucinations." }, rating_rubric={ "5": "Excellent: Captures all key information, is highly concise, and has zero distortion.", "4": "Good: Captures most key information with minor omissions, is concise, and has no distortion.", "3": "Satisfactory: Captures the main idea but misses some key details OR is not very concise.", "2": "Unsatisfactory: Misses the main idea of the original text OR contains minor distortions/hallucinations.", "1": "Poor: Is completely irrelevant, fails to summarize the text, OR contains significant distortions.", }, input_variables=["prompt", "reference"], ), ) - Execute o código a seguir na próxima célula para executar o
EvalTaskcom sua nova métrica personalizada.# You would then update the EvalTask to use this new metric pointwise_result = EvalTask( dataset=dataset, metrics=[summarization_helpfulness_metric], ).evaluate( model=model, prompt_template="# System_prompt\n{system_prompt} # Question\n{question}", ) - Execute o seguinte em uma nova célula para mostrar os resultados.
notebook_utils.display_eval_result(pointwise_result)
8. Comparar modelos com avaliação em pares
Quando você precisa decidir qual de dois modelos tem melhor desempenho em uma tarefa específica, pode usar a avaliação em pares baseada em modelos. Esse método é uma forma de teste A/B em que um modelo juiz determina um vencedor, fornecendo uma comparação direta para a seleção de modelos baseada em dados.
Os modelos:
- Modelo candidato: a variável de modelo (que foi definida anteriormente como
gemini-2.0-flash) é transmitida ao método.evaluate(). Esse é o modelo principal que você está testando. - Modelo de referência: um segundo modelo,
gemini-2.0-flash-lite, é especificado na classe PairwiseMetric. Esse é o modelo com que você está comparando.
Executar a avaliação por pares
- Em uma nova célula, adicione e execute o código a seguir para criar um menu suspenso interativo. Assim, você pode selecionar qual métrica entre pares quer usar para a comparação. Para esta execução, selecione pairwise_summarization_quality.
from IPython.display import display import ipywidgets as widgets pairwise_single_turn_metrics = [ metric for metric in MetricPromptTemplateExamples.list_example_metric_names() if metric.startswith("pairwise") and "multi_turn" not in metric ] dropdown = widgets.Dropdown( options=pairwise_single_turn_metrics, description="Select a metric:", font_weight="bold", style={"description_width": "initial"}, ) def dropdown_eventhandler(change): global POINTWISE_METRIC if change["type"] == "change" and change["name"] == "value": POINTWISE_METRIC = change.new print("Selected:", change.new) def dropdown_eventhandler(change): global PAIRWISE_METRIC_NAME if change["type"] == "change" and change["name"] == "value": PAIRWISE_METRIC_NAME = change.new print("Selected:", change.new) PAIRWISE_METRIC_NAME = dropdown.value dropdown.observe(dropdown_eventhandler, names="value") display(dropdown) - Na próxima célula, adicione e execute o código a seguir para configurar e executar o
EvalTask. Observe como a classePairwiseMetricé usada para definir o modelo de referência (gemini-2.0-flash-lite), enquanto o modelo candidato (gemini-2.0-flash) é transmitido para o método.evaluate().pairwise_result = EvalTask( dataset=dataset, metrics=[ PairwiseMetric( metric=PAIRWISE_METRIC_NAME, metric_prompt_template=MetricPromptTemplateExamples.get_prompt_template( PAIRWISE_METRIC_NAME ), # Define a baseline model to compare against baseline_model=GenerativeModel("gemini-2.0-flash-lite"), ) ], ).evaluate( # Specify a candidate model for pairwise comparison model=model, prompt_template="# System_prompt\n{system_prompt} # Question\n{question}", ) - Em uma nova célula, adicione e execute o código a seguir para mostrar os resultados. A tabela de resumo mostra a "taxa de vitória" de cada modelo, indicando qual deles o modelo de avaliação preferiu com mais frequência.
notebook_utils.display_eval_result(pairwise_result)
9. Opcional: avaliar comandos com base em personas
Observação: talvez esta seção não seja executada dentro do limite dos créditos sem custo financeiro fornecidos.
Nesta tarefa, você vai testar vários modelos de comandos que instruem o modelo a adotar diferentes personas. Esse processo, geralmente chamado de engenharia de comando ou design de comando, permite encontrar sistematicamente o comando mais eficaz para um caso de uso específico.
Preparar o conjunto de dados de resumo
Para realizar essa avaliação, o conjunto de dados precisa conter os seguintes campos:
instruction: A tarefa principal que estamos atribuindo ao modelo. Nesse caso, é um simples "Resuma o artigo a seguir".context: o texto de origem com que o modelo precisa trabalhar. Aqui, fornecemos quatro trechos de notícias diferentes.reference: o resumo de verdade ou "padrão ouro". A saída gerada pelo modelo será comparada a esse texto para calcular pontuações de métricas como ROUGE e qualidade do resumo.
- Em uma nova célula, adicione e execute o código a seguir para criar um
pandas.DataFramepara a tarefa de resumo.instruction = "Summarize the following article: \n" context = [ "Typhoon Phanfone has killed at least one person, a US airman on Okinawa who was washed away by high waves. Thousands of households have lost power and Japan's two largest airlines have suspended many flights. The storm also forced the suspension of the search for people missing after last week's volcanic eruption. The storm-tracking website Tropical Storm Risk forecasts that Phanfone will rapidly lose power over the next few hours as it goes further into the Pacific Ocean. Typhoon Phanfone was downgraded from an earlier status of a super typhoon, but the Japan Meteorological Agency had warned it was still a dangerous storm. Japan averages 11 typhoons a year, according to its weather agency. The typhoon made landfall on Monday morning near the central city of Hamamatsu, with winds of up to 180 km/h (112 mph). The airman was one of three US military personnel swept away by high waves whipped up by the typhoon off southern Okinawa island, where the US has a large military base. The remaining two are still missing. A police spokesman said they had been taking photographs of the sea. A university student who was surfing off the seas of Kanagawa Prefecture, south of Tokyo, was also missing, national broadcast NHK reports. It said at least 10 people had been injured and 9,500 houses were without power. The storm was expected to deposit about 100mm of rain on Tokyo over 24 hours, according to the Transport Ministry website. Many schools were closed on Monday and two car companies in Japan halted production at some plants ahead of the storm. More than 174 domestic flights were affected nationwide, NHK state broadcaster said on Sunday. On Sunday, heavy rain delayed the Japanese Formula One Grand Prix in Suzaka. French driver Jules Bianchi lost control in the wet conditions and crashed, sustaining a severe head injury.", "The blaze started at the detached building in Drivers End in Codicote, near Welwyn, during the morning. There was another fire at the building 20 years ago, after which fire-proof foil was placed under the thatch, which is protecting the main building. More than 15 fire engines and support vehicles were called to tackle the blaze. Roads in the area were closed and traffic diverted.", 'The 18-year-old fell at the New Charter Academy on Broadoak Road in Ashton-under-Lyne at about 09:10 BST, Greater Manchester Police (GMP) said. GMP said he had gone to Manchester Royal Infirmary and his condition was "serious". Principal Jenny Langley said the school would remain "fully open" while police investigated. "Our thoughts are with the family and we\'re doing everything we can to support them along with staff and pupils," she said.', 'But Belgian-born Dutchman Max Verstappen was unable to drive a car legally on his own in either country. That all changed on Wednesday when the youngster turned 18 and passed his driving test at the first attempt. Despite having competed in 14 grands prix since his debut in Australia in March, Verstappen admitted to feeling the pressure during his test. "It\'s a relief," said the Toro Rosso driver, who finished ninth in Japan on Sunday and had only started driving lessons a week ago. "I was a bit nervous to make mistakes, but the exam went well." A bonus of turning 18 is that Verstappen will now be able to drink the champagne if he ever makes it onto the podium.', ] reference = [ "A powerful typhoon has brought many parts of Japan to a standstill and briefly battered Tokyo before heading out to sea.", "A major fire has been burning in the thatched roof of a large property in Hertfordshire.", "A student has been taken to hospital after falling from a balcony at a Greater Manchester school.", "He is Formula 1's youngest ever driver and in charge of a car that can reach over 200mph.", ] response = [ "Typhoon Phanfone, while downgraded from super typhoon status, caused significant disruption and tragedy in Japan. One US airman died after being swept away by high waves, with two more missing. The storm caused power outages for thousands, flight cancellations, and the suspension of rescue efforts for missing volcano victims. Heavy rain and strong winds led to school and factory closures, transportation disruptions, and at least 10 injuries. The typhoon is expected to weaken as it moves over the Pacific Ocean.", "A large fire broke out in a detached thatched building in Codicote, near Welwyn. This is the second fire at the building in 20 years. Thankfully, fire-proof foil installed after the previous fire is protecting the main building. Over 15 fire engines and support vehicles responded, closing roads and diverting traffic in the area.", "An 18-year-old student at New Charter Academy in Ashton-under-Lyne suffered a serious fall and was hospitalized. The incident is under investigation by Greater Manchester Police, but the school remains open. The principal expressed support for the student's family and the school community.", "Max Verstappen, a Formula One driver, was finally able to get his driver's license at age 18. Despite already competing in 14 Grand Prix races, he was not of legal driving age in his native countries. He admitted to being nervous but passed the test on his first attempt. As an added bonus of turning 18, Verstappen can now enjoy champagne on the podium if he places.", ] eval_dataset = pd.DataFrame( { "instruction": instruction, "context": context, "reference": reference, } )
Executar a tarefa de avaliação de comandos
Com o conjunto de dados de resumo preparado, você pode executar o experimento principal desta tarefa: comparar vários modelos de comandos para ver qual deles produz a saída de maior qualidade do modelo.
- Na próxima célula, crie um único
EvalTaskque será reutilizado em cada experimento de solicitação. Ao definir o parâmetroexperiment, todas as execuções de avaliação dessa tarefa são registradas e agrupadas automaticamente nos Experimentos da Vertex AI.EXPERIMENT_NAME = "eval-sdk-prompt-engineering" # @param {type:"string"} summarization_eval_task = EvalTask( dataset=eval_dataset, metrics=[ "rouge_l_sum", "bleu", "fluency", "coherence", "safety", "groundedness", "summarization_quality", "verbosity", "instruction_following", "text_quality", ], experiment=EXPERIMENT_NAME, )rouge_l_sumebleuaté uma ampla variedade de métricas baseadas em modelos (fluency,coherence,summarization_quality,instruction_followingetc.). Isso nos dá uma visão holística de 360 graus de como cada comando afeta a qualidade da saída do modelo. - Em uma nova célula, adicione e execute o código a seguir para definir e avaliar quatro estratégias de solicitação orientadas por personas. O loop itera por cada modelo e executa uma avaliação. Cada modelo é projetado para gerar um estilo diferente de resumo, atribuindo ao modelo uma persona ou objetivo específico:
- Personagem nº 1 (padrão): um pedido de resumo neutro e direto.
- Persona nº 2 (executivo): pede um resumo em tópicos, com foco em resultados e impacto, como um executivo ocupado preferiria.
- Personagem nº 3 (aluno do 5º ano): instrui o modelo a usar uma linguagem simples, testando a capacidade de ajustar a complexidade da resposta.
- Persona 4 (analista técnico): exige um resumo altamente factual em que as principais estatísticas e entidades são preservadas, testando a precisão do modelo. Observe que os marcadores de posição nesses novos modelos, como
{context}e{instruction}, correspondem aos novos nomes de coluna noeval_datasetque você criou para esta tarefa.
# Define prompt templates that target different user personas
prompt_templates = [
# Persona 1: Standard, neutral summary
"Article: {context}. Task: {instruction}. Summary:",
# Persona 2: For a busy executive (bullet points)
"Instruction: {instruction} into three key bullet points for a busy executive. Focus on the main outcome and impact. Article: {context}. Summary:",
# Persona 3: For a 5th grader (simple language)
"Instruction: {instruction} such that you're explaining it to a 10-year-old. Use simple words. Article: {context}. Summary:",
# Persona 4: For a technical analyst (fact-focused)
"Instruction: Provide a detailed, factual summary of the following text, ensuring all key statistics, names, and locations are preserved. Article: {context}. Summary:",
]
eval_results = []
for i, prompt_template in enumerate(prompt_templates):
eval_result = summarization_eval_task.evaluate(
prompt_template=prompt_template,
model=GenerativeModel(
"gemini-2.0-flash",
generation_config={
"temperature": 0.3,
"max_output_tokens": 256,
"top_k": 1,
},
),
evaluation_service_qps=5,
)
eval_results.append((f"Prompt Persona #{i+1}", eval_result))
Analisar e visualizar resultados
A primeira etapa é executar experimentos. O valor real vem da análise dos resultados para tomar uma decisão baseada em dados. Nesta tarefa, você vai usar as ferramentas de visualização do SDK para interpretar as saídas do experimento de persona de comando.
- Execute o código a seguir em uma nova célula para mostrar os resultados do resumo de cada uma das quatro personas de comando que você testou. Isso oferece uma visão quantitativa de alto nível da performance.
for title, eval_result in eval_results: notebook_utils.display_eval_result(title=title, eval_result=eval_result) - Em uma nova célula, adicione e execute o código a seguir para conferir a justificativa da métrica
summarization_qualitypara cada perfil.for title, eval_result in eval_results: notebook_utils.display_explanations( eval_result, metrics=["summarization_quality"], num=2 ) - Gere um gráfico radar para visualizar os trade-offs entre diferentes métricas de qualidade para cada comando. Em uma nova célula, adicione e execute o seguinte código.
notebook_utils.display_radar_plot( eval_results, metrics=["instruction_following", "fluency", "coherence", "text_quality"], ) - Para uma comparação mais direta, lado a lado, crie um gráfico de barras. Em uma nova célula, adicione e execute o seguinte código.
notebook_utils.display_bar_plot( eval_results, metrics=["instruction_following", "fluency", "coherence", "text_quality"], )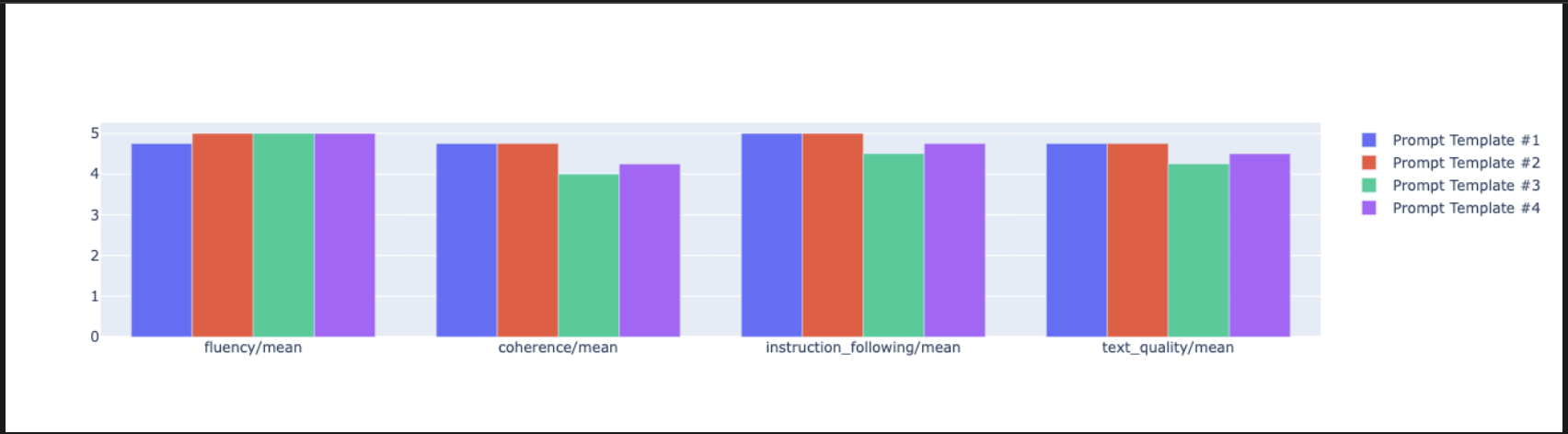
- Agora é possível conferir um resumo de todas as execuções registradas no seu experimento da Vertex AI para essa tarefa. Isso é útil para acompanhar seu trabalho ao longo do tempo. Em uma nova célula, adicione e execute o seguinte código:
summarization_eval_task.display_runs()
10. Limpar o experimento
Para manter seu projeto organizado e evitar cobranças desnecessárias, é recomendável limpar os recursos criados. Ao longo deste laboratório, cada execução de avaliação foi registrada em um experimento da Vertex AI. O código a seguir exclui esse experimento principal, o que também remove todas as execuções associadas e os dados subjacentes.
- Execute este código em uma nova célula para excluir o experimento da Vertex AI e as execuções associadas.
delete_experiment = True # Please set your LOCATION to the same one used during Vertex AI SDK initialization. LOCATION = "YOUR LOCATION" # @param {type:"string"} if delete_experiment: from google.cloud import aiplatform aiplatform.init(project=PROJECT_ID, location=LOCATION) experiment = aiplatform.Experiment(EXPERIMENT_NAME) experiment.delete()
11. Da prática à produção
As habilidades que você aprendeu neste laboratório são os blocos de construção para criar aplicativos de IA confiáveis. No entanto, migrar de um notebook executado manualmente para um sistema de avaliação de nível de produção exige infraestrutura adicional e uma abordagem mais sistemática. Esta seção descreve as principais práticas e frameworks estratégicos a serem considerados ao escalonar verticalmente.
Como criar estratégias de avaliação de produção
Para aplicar as habilidades deste laboratório em um ambiente de produção, é útil formalizá-las em estratégias repetíveis. Os frameworks a seguir descrevem considerações importantes para cenários comuns, como seleção de modelos, otimização de comandos e monitoramento contínuo.
Para seleção de modelo:
# Evaluation strategy for choosing models
evaluation_strategy = {
"dataset_size": "100+ examples for statistical significance",
"metrics": ["task-specific", "general quality", "efficiency"],
"comparison_type": "pairwise with statistical testing",
"baseline": "established_model_or_human_benchmark"
}
Para otimização de comandos
# Systematic prompt improvement workflow
prompt_optimization = {
"hypothesis": "Clear statement of what you're testing",
"variants": "3-5 different prompt strategies",
"evaluation": "Same metrics across all variants",
"analysis": "Statistical significance + qualitative review"
}
Para monitoramento contínuo
# Production evaluation pipeline
production_eval = {
"frequency": "Every model update + weekly monitoring",
"automation": "CI/CD integration with quality gates",
"metrics": "Speed + quality + cost tracking",
"alerting": "Performance degradation detection"
}
Considerações sobre custo-benefício
A avaliação baseada em modelo pode ser cara em grande escala. Uma estratégia de produção econômica usa métodos diferentes para fins diferentes. Esta tabela resume as compensações entre velocidade, custo e caso de uso para diferentes tipos de avaliação:
Tipo de avaliação | Tempo | Custo por amostra | Ideal para |
ROUGE/BLEU | Segundos | ~US$0,001 | Triagem de alto volume |
Pointwise com base em modelo | 1 a 2 segundos | ~$0,01 | Avaliação de qualidade |
Comparação aos pares | 2 a 3 segundos | ~$0,02 | Seleção de modelos |
Avaliação humana | Minutos | US$ 1 a US$ 10 | Validação padrão ouro |
Automatizar com CI/CD e monitoramento
As execuções manuais de notebooks não são escalonáveis. Automatize sua avaliação em um pipeline de integração contínua/implantação contínua (CI/CD).
- Criar gates de qualidade: integre sua tarefa de avaliação a um pipeline de CI/CD (por exemplo, o Cloud Build). Execute avaliações automaticamente em novos comandos ou modelos e bloqueie implantações se as principais pontuações de qualidade ficarem abaixo dos limites definidos.
- Monitore tendências: exporte métricas de resumo das execuções de avaliação para um serviço como o Google Cloud Monitoring. Crie painéis para acompanhar a qualidade ao longo do tempo e configure alertas automáticos para notificar sua equipe sobre qualquer degradação significativa de desempenho.
12. Conclusão
Você concluiu o laboratório. Você aprendeu as habilidades essenciais para avaliar modelos de IA generativa.
Este laboratório faz parte do programa de aprendizado "IA pronta para produção com o Google Cloud".
- Confira o currículo completo para ir do protótipo à produção.
- Compartilhe seu progresso com a hashtag
ProductionReadyAI.
Recapitulação
Neste laboratório, você aprendeu a executar as seguintes tarefas:
- Aplique as práticas recomendadas de avaliação usando a estrutura
EvalTask. - Use diferentes tipos de métricas, desde juízes baseados em computação até aqueles baseados em modelos.
- Otimize os comandos testando diferentes versões.
- Crie um fluxo de trabalho reproduzível com o acompanhamento de experimentos.
Recursos para aprendizado contínuo
- Documentação da avaliação de IA generativa da Vertex AI
- Notebooks de técnicas avançadas de avaliação
- Referência do SDK de avaliação de IA generativa
- Pesquisa sobre métricas baseadas em modelos
- Práticas recomendadas de engenharia de comando
As abordagens de avaliação sistemática que você aprendeu neste laboratório vão servir como base para criar aplicativos de IA confiáveis e de alta qualidade. Lembre-se: uma boa avaliação é a ponte entre a IA experimental e o sucesso da produção.