
1. Обзор
В этой лабораторной работе вы научитесь оценивать большие языковые модели с помощью сервиса оценки искусственного интеллекта Vertex AI Gen. Вы будете использовать SDK для запуска заданий оценки, сравнения результатов и принятия решений на основе данных о производительности модели и разработке подсказок.
В ходе лабораторной работы вы познакомитесь с распространенным рабочим процессом оценки, начиная с простых метрик, основанных на вычислениях, и переходя к более сложным оценкам на основе моделей. Вы также научитесь создавать пользовательские метрики, адаптированные к вашим конкретным целям, и отслеживать свою работу с помощью Vertex AI Experiments.
Что вы узнаете
В этой лабораторной работе вы научитесь выполнять следующие задачи:
- Оцените модель с помощью вычислительных и модельных метрик.
- Создайте пользовательскую метрику для согласования оценки с целями продукта.
- Сравните различные шаблоны подсказок, расположив их рядом.
- Протестируйте несколько вариантов вопросов, основанных на характеристиках пользователей, чтобы найти наиболее эффективный вариант.
- Отслеживайте и визуализируйте результаты оценочных испытаний с помощью Vertex AI Experiments.
Ссылки
- Примеры кода: В этой лабораторной работе используются примеры из репозитория генеративного искусственного интеллекта Google Cloud.
- Основано на: документации по оценке искусственного интеллекта Vertex AI Gen.
- Набор данных: набор данных OpenOrca для оценки способности следовать инструкциям.
2. Настройка проекта
Аккаунт Google
Если у вас еще нет личного аккаунта Google, вам необходимо его создать .
Используйте личный аккаунт вместо рабочего или учебного.
Войдите в консоль Google Cloud.
Войдите в консоль Google Cloud, используя личную учетную запись Google.
Включить выставление счетов
Для включения оплаты у вас есть два варианта. Вы можете использовать свой личный платежный аккаунт или обменять средства, выполнив следующие шаги.
Использовать кредиты Google Cloud (необязательно)
Для проведения этого мастер-класса вам потребуется платежный аккаунт с достаточным балансом. Используйте средства, указанные на баннере вверху этого руководства, чтобы начать. Если у вас уже есть платежный аккаунт, вы можете пропустить этот шаг.
Создайте личный платежный аккаунт.
Если вы настроили оплату с использованием кредитов Google Cloud, этот шаг можно пропустить.
Чтобы настроить личный платежный аккаунт, перейдите сюда, чтобы включить оплату в облачной консоли.
Несколько замечаний:
- Выполнение этой лабораторной работы должно обойтись менее чем в 1 доллар США в виде облачных ресурсов.
- В конце этой лабораторной работы вы можете выполнить действия по удалению ресурсов, чтобы избежать дальнейших списаний средств.
- Новые пользователи могут воспользоваться бесплатной пробной версией стоимостью 300 долларов США .
Создать проект (необязательно)
Если у вас нет текущего проекта, который вы хотели бы использовать для этой лабораторной работы, создайте новый проект здесь .
3. Настройте среду Vertex AI Workbench.
Начнём с доступа к предварительно настроенной среде блокнотов и установки необходимых зависимостей.
Доступ к Vertex AI Workbench
- В консоли Google Cloud перейдите к Vertex AI , щелкнув меню навигации ☰ > Vertex AI > Панель управления .
- Нажмите «Включить все рекомендуемые API» . Примечание: Дождитесь завершения этого шага.
- В левой части экрана нажмите «Рабочая среда» , чтобы создать новый экземпляр рабочей среды.
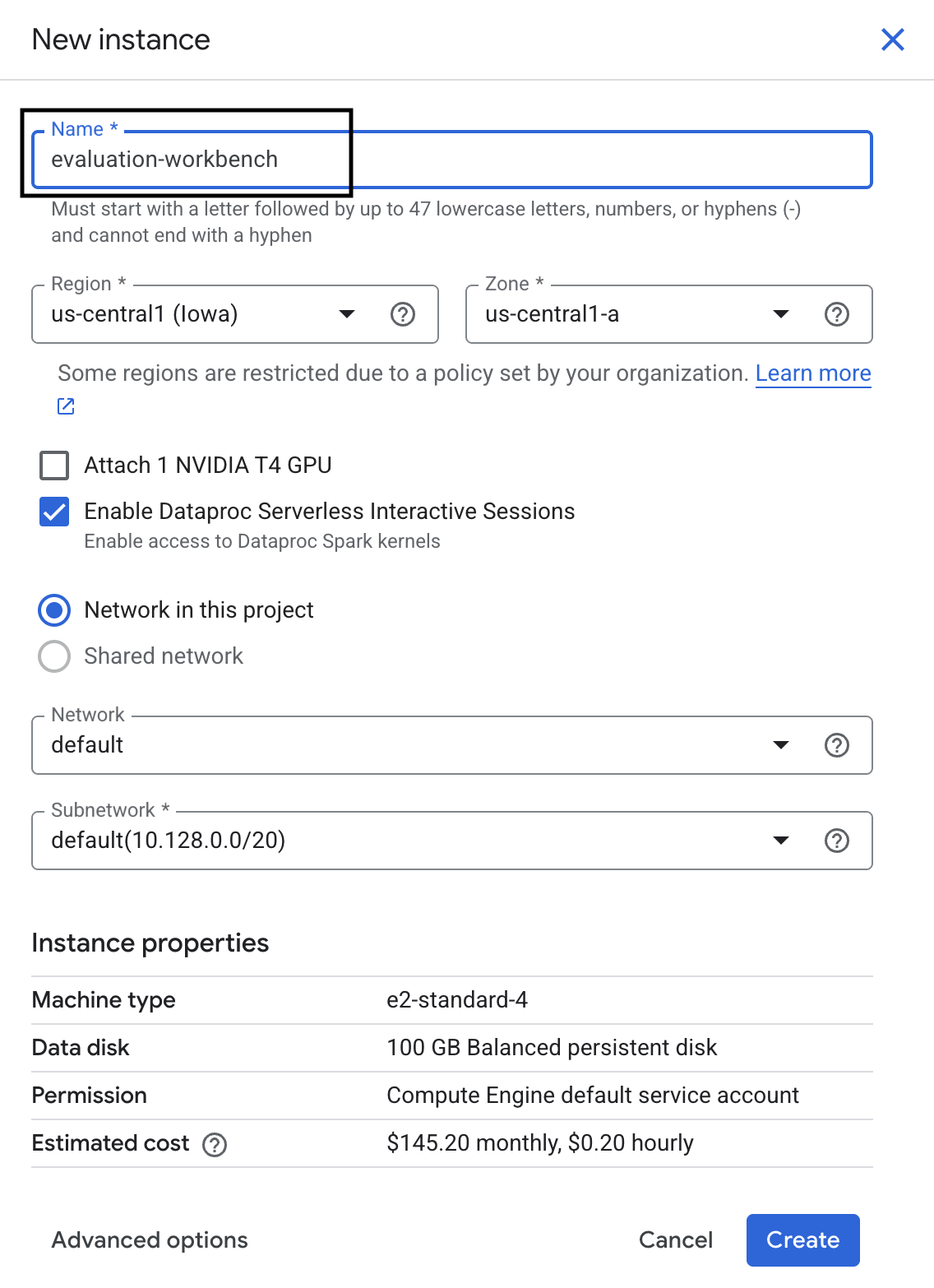
- Назовите экземпляр рабочей среды evaluation-workbench и нажмите «Создать» .
- Подождите, пока верстак подготовится. Это может занять несколько минут.

- После того, как рабочая среда будет подготовлена, нажмите «Открыть JupyterLab» .
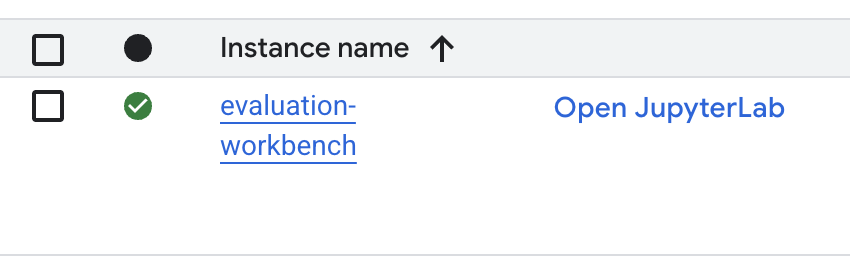
- В рабочей среде создайте новый блокнот Python3.
Чтобы узнать больше о возможностях и функциях этой среды, ознакомьтесь с официальной документацией Vertex AI Workbench .
Установите пакеты и настройте свою среду.
- В первой ячейке вашего блокнота добавьте и выполните следующие операторы импорта (SHIFT+ENTER), чтобы установить Vertex AI SDK (с компонентами для ознакомительной версии) и другие необходимые пакеты.
%pip install -U -q google-cloud-aiplatform[evaluation] %pip install -U -q datasets anthropic[vertex] openai - Для использования недавно установленных пакетов рекомендуется перезапустить ядро, выполнив приведенный ниже фрагмент кода.
# Automatically restart kernel after installation so that your environment can access the new packages. import IPython app = IPython.Application.instance() app.kernel.do_shutdown(True) - Замените следующие значения на идентификатор вашего проекта и его местоположение и запустите следующую ячейку. Местоположение по умолчанию установлено как
europe-west1но вам следует использовать то же местоположение, где находится ваш экземпляр рабочей среды Vertex AI.# Configure your project settings PROJECT_ID = "YOUR PROJECT ID" LOCATION = "europe-west1" - Для выполнения этой лабораторной работы импортируйте все необходимые библиотеки Python, запустив следующий код в новой ячейке.
from anthropic import AnthropicVertex from google.auth import default, transport import openai import pandas as pd from vertexai.evaluation import ( EvalTask, MetricPromptTemplateExamples, PairwiseMetric, PointwiseMetric, PointwiseMetricPromptTemplate, ) from vertexai.generative_models import GenerativeModel from vertexai.preview.evaluation import notebook_utils
4. Подготовьте набор данных для оценки.
В этом уроке мы будем использовать 10 примеров из набора данных OpenOrca . Этого количества данных достаточно, чтобы увидеть значимые различия между моделями, при этом время оценки останется приемлемым.
💡 Полезный совет: В процессе производства для получения статистически значимых результатов вам понадобится 100-500 примеров, но 10 примеров идеально подойдут для обучения и быстрого прототипирования!
Подготовьте набор данных
- В новой ячейке выполните следующую команду, чтобы загрузить данные, преобразовать их в DataFrame pandas, переименовать столбец
responseвreferenceдля большей ясности в задачах оценки и создать случайную выборку из десяти примеров.from datasets import load_dataset ds = ( load_dataset( "Open-Orca/OpenOrca", data_files="1M-GPT4-Augmented.parquet", split="train[:100]", ) .to_pandas() .drop(columns=["id"]) .rename(columns={"response": "reference"}) ) dataset = ds.sample(n=10) - После завершения обработки предыдущей ячейки в следующей ячейке добавьте и выполните следующий код, чтобы отобразить первые несколько строк вашего оценочного набора данных.
dataset.head()
5. Установите базовый уровень с помощью вычислительных метрик.
В этом задании вам нужно установить базовый показатель, используя вычислительную метрику. Такой подход быстр и обеспечивает объективный ориентир для оценки будущих улучшений.
Мы будем использовать ROUGE (Recall-Oriented Understudy for Gisting Evaluation), стандартную метрику для задач суммаризации. Она работает путем сравнения последовательности слов (n-грамм) в ответе, сгенерированном моделью, со словами в reference тексте.
Подробнее о метриках, основанных на вычислениях .
Проведение базовой оценки
- В новой ячейке добавьте и запустите следующую ячейку, чтобы определить модель, которую вы хотите протестировать:
gemini-2.0-flash. Параметрgeneration_configвключает такие параметры, какtemperatureиmax_output_tokens, которые влияют на выходные данные модели.# Model to be evaluated model = GenerativeModel( "gemini-2.0-flash", generation_config={"temperature": 0.6, "max_output_tokens": 256, "top_k": 1}, )GenerativeModelявляется основным интерфейсом для взаимодействия с большими языковыми моделями в SDK Vertex AI. - В следующей ячейке добавьте и выполните следующий код для создания и выполнения задачи
EvalTask. Этот объект из SDK Vertex AI Evaluation управляет процессом оценки. Вы настраиваете его, указывая набор данных и метрики для вычисления, в данном случае этоrouge_l_sum.# Define an EvalTask with ROUGE-L-SUM metric rouge_eval_task = EvalTask( dataset=dataset, metrics=["rouge_l_sum"], ) rouge_result = rouge_eval_task.evaluate( model=model, prompt_template="# System_prompt\n{system_prompt} # Question\n{question}", ) - Чтобы отобразить результаты, выполните следующий код в следующей ячейке.
notebook_utils.display_eval_result(rouge_result)display_eval_result()отображает средний балл и результаты по каждой строке.
6. Необязательно: Оценка с использованием точечных метрик на основе модели.
Примечание: Работа этого раздела может быть ограничена предоставленным лимитом бесплатных кредитов.
Хотя ROUGE полезен, он измеряет только лексическое совпадение (это означает, что он подсчитывает только совпадающие слова, не учитывая контекст, синонимы или перефразирование). Поэтому он не лучший инструмент для определения того, является ли ответ беглым или логичным. Для более глубокого понимания производительности модели используются точечные метрики, основанные на самой модели.
При использовании этого метода другая модель LLM («модель оценки») оценивает каждый ответ индивидуально по заранее определенному набору критериев, таких как беглость или связность.
Подробнее о метриках, основанных на моделях .
Выполните поточечную оценку
- Чтобы создать интерактивное выпадающее меню, выполните следующий код в новой ячейке. Для этого выберите пункт «Согласованность» из списка.
#Select a pointwise metric to use import ipywidgets as widgets pointwise_single_turn_metrics = [ metric for metric in MetricPromptTemplateExamples.list_example_metric_names() if not metric.startswith("pairwise") and not metric.startswith("multi_turn") ] dropdown = widgets.Dropdown( options=pointwise_single_turn_metrics, description="Select a metric:", font_weight="bold", style={"description_width": "initial"}, ) def dropdown_eventhandler(change): global POINTWISE_METRIC if change["type"] == "change" and change["name"] == "value": POINTWISE_METRIC = change.new print("Selected:", change.new) POINTWISE_METRIC = dropdown.value dropdown.observe(dropdown_eventhandler, names="value") display(dropdown) - В новой ячейке снова запустите задачу
EvalTask, на этот раз используя выбранную метрику на основе модели. Служба оценки Vertex AI создаст запрос для модели-судьи, который будет включать исходный запрос, эталонный ответ, ответ модели-кандидата и инструкции для выбранной метрики. Модель-судья вернет числовой балл и объяснение своей оценки. Примечание: выполнение этого шага займет несколько минут.pointwise_result = EvalTask( dataset=dataset, metrics=[POINTWISE_METRIC], ).evaluate( model=model, prompt_template="# System_prompt\n{system_prompt} # Question\n{question}", )
Отобразить результаты
После завершения оценки следующим шагом является анализ полученных результатов.
- Чтобы просмотреть сводные показатели, отображающие средний балл по выбранному вами показателю, выполните следующий код в новой ячейке.
notebook_utils.display_eval_result(pointwise_result) - В следующей ячейке выполните следующий запрос, чтобы увидеть построчный анализ, включая письменное обоснование оценки, предоставленное судьей. Эта качественная обратная связь поможет вам понять, почему ответ был оценен определенным образом.
notebook_utils.display_explanations(pointwise_result, num=1, metrics=[POINTWISE_METRIC])
7. Создайте собственную метрику для получения более глубокого анализа.
Встроенные метрики, такие как беглость речи, полезны, но для конкретного продукта часто необходимо измерять производительность в соответствии с собственными целями. С помощью пользовательских точечных метрик вы можете определить собственные критерии оценки и рубрику.
В этом задании вам нужно создать с нуля новую метрику под названием summarization_helpfulness .
Определите и запустите пользовательскую метрику.
- Выполните следующий код в новой ячейке, чтобы определить пользовательскую метрику.
PointwiseMetricPromptTemplateсодержит основные компоненты для метрики:- Критерии : указывают модели оценки конкретные параметры, которые необходимо оценить: «Ключевая информация», «Краткость» и «Отсутствие искажений».
- rating_rubric : Предоставляет 5-балльную шкалу оценок, которая определяет значение каждой оценки.
- input_variables : Передает дополнительные столбцы из набора данных в модель оценки, чтобы она имела необходимый контекст для выполнения оценки.
# This new custom metric evaluates the actual quality and usefulness of the summary. summarization_helpfulness_metric = PointwiseMetric( metric="summarization_helpfulness", metric_prompt_template=PointwiseMetricPromptTemplate( criteria={ "Key Information": "Does the summary capture the most critical pieces of information from the original text? It should not miss the main topic or key takeaways.", "Conciseness": "Is the summary brief and to the point? It should avoid unnecessary words or repetitive information.", "No Distortion": "Does the summary introduce information or opinions that were NOT present in the original text? It must accurately reflect the source material without adding hallucinations." }, rating_rubric={ "5": "Excellent: Captures all key information, is highly concise, and has zero distortion.", "4": "Good: Captures most key information with minor omissions, is concise, and has no distortion.", "3": "Satisfactory: Captures the main idea but misses some key details OR is not very concise.", "2": "Unsatisfactory: Misses the main idea of the original text OR contains minor distortions/hallucinations.", "1": "Poor: Is completely irrelevant, fails to summarize the text, OR contains significant distortions.", }, input_variables=["prompt", "reference"], ), ) - В следующей ячейке выполните следующий код, чтобы запустить задачу
EvalTaskс вашей новой пользовательской метрикой.# You would then update the EvalTask to use this new metric pointwise_result = EvalTask( dataset=dataset, metrics=[summarization_helpfulness_metric], ).evaluate( model=model, prompt_template="# System_prompt\n{system_prompt} # Question\n{question}", ) - Чтобы отобразить результаты, выполните следующую команду в новой ячейке.
notebook_utils.display_eval_result(pointwise_result)
8. Сравнение моделей с помощью попарной оценки.
Когда необходимо определить, какая из двух моделей лучше справляется с конкретной задачей, можно использовать попарную оценку моделей. Этот метод представляет собой разновидность A/B-тестирования, где модель-судья определяет победителя, обеспечивая прямое сравнение для выбора модели на основе данных.
Модели:
- Модель-кандидат : переменная модели (которая ранее была определена как
gemini-2.0-flash) передается в метод.evaluate(). Это основная модель, которую вы тестируете. - Базовая модель : Вторая модель,
gemini-2.0-flash-lite, указана в классе PairwiseMetric. Именно с этой моделью вы будете сравнивать данные.
Выполните попарную оценку
- В новой ячейке добавьте и запустите следующий код, чтобы создать интерактивное выпадающее меню. Это позволит вам выбрать, какую попарную метрику вы хотите использовать для сравнения. Для этого запуска выберите pairwise_summarization_quality .
from IPython.display import display import ipywidgets as widgets pairwise_single_turn_metrics = [ metric for metric in MetricPromptTemplateExamples.list_example_metric_names() if metric.startswith("pairwise") and "multi_turn" not in metric ] dropdown = widgets.Dropdown( options=pairwise_single_turn_metrics, description="Select a metric:", font_weight="bold", style={"description_width": "initial"}, ) def dropdown_eventhandler(change): global POINTWISE_METRIC if change["type"] == "change" and change["name"] == "value": POINTWISE_METRIC = change.new print("Selected:", change.new) def dropdown_eventhandler(change): global PAIRWISE_METRIC_NAME if change["type"] == "change" and change["name"] == "value": PAIRWISE_METRIC_NAME = change.new print("Selected:", change.new) PAIRWISE_METRIC_NAME = dropdown.value dropdown.observe(dropdown_eventhandler, names="value") display(dropdown) - В следующей ячейке добавьте и выполните следующий код для настройки и выполнения задачи
EvalTask. Обратите внимание, как классPairwiseMetricиспользуется для определения базовой модели (gemini-2.0-flash-lite), а модель-кандидат (gemini-2.0-flash) передается в метод.evaluate().pairwise_result = EvalTask( dataset=dataset, metrics=[ PairwiseMetric( metric=PAIRWISE_METRIC_NAME, metric_prompt_template=MetricPromptTemplateExamples.get_prompt_template( PAIRWISE_METRIC_NAME ), # Define a baseline model to compare against baseline_model=GenerativeModel("gemini-2.0-flash-lite"), ) ], ).evaluate( # Specify a candidate model for pairwise comparison model=model, prompt_template="# System_prompt\n{system_prompt} # Question\n{question}", ) - В новой ячейке добавьте и выполните следующий код для отображения результатов. В сводной таблице будет показана «процент выигрышей» для каждой модели, указывающая, какую из них модель судьи предпочитала чаще.
notebook_utils.display_eval_result(pairwise_result)
9. Дополнительно: Оцените подсказки, основанные на портретах целевой аудитории.
Примечание: Работа этого раздела может быть ограничена предоставленным лимитом бесплатных кредитов.
В этом задании вы протестируете несколько шаблонов подсказок, которые указывают модели, как адаптироваться к различным персонажам. Этот процесс, часто называемый разработкой подсказок или проектированием подсказок , позволяет систематически находить наиболее эффективные подсказки для конкретного случая использования.
Подготовьте набор данных для суммирования.
Для проведения этой оценки набор данных должен содержать следующие поля:
-
instruction: Основная задача, которую мы ставим перед моделью. В данном случае это простая задача: «Кратко изложите содержание следующей статьи:». -
context: Исходный текст, с которым должна работать модель. Здесь мы предоставили четыре разных фрагмента новостей. -
reference: Эталонное или «золотое» резюме. Сгенерированные моделью выходные данные будут сравниваться с этим текстом для расчета оценок по таким метрикам, как ROUGE и качество суммирования.
- В новой ячейке добавьте и выполните следующий код для создания объекта
pandas.DataFrameдля задачи суммирования.instruction = "Summarize the following article: \n" context = [ "Typhoon Phanfone has killed at least one person, a US airman on Okinawa who was washed away by high waves. Thousands of households have lost power and Japan's two largest airlines have suspended many flights. The storm also forced the suspension of the search for people missing after last week's volcanic eruption. The storm-tracking website Tropical Storm Risk forecasts that Phanfone will rapidly lose power over the next few hours as it goes further into the Pacific Ocean. Typhoon Phanfone was downgraded from an earlier status of a super typhoon, but the Japan Meteorological Agency had warned it was still a dangerous storm. Japan averages 11 typhoons a year, according to its weather agency. The typhoon made landfall on Monday morning near the central city of Hamamatsu, with winds of up to 180 km/h (112 mph). The airman was one of three US military personnel swept away by high waves whipped up by the typhoon off southern Okinawa island, where the US has a large military base. The remaining two are still missing. A police spokesman said they had been taking photographs of the sea. A university student who was surfing off the seas of Kanagawa Prefecture, south of Tokyo, was also missing, national broadcast NHK reports. It said at least 10 people had been injured and 9,500 houses were without power. The storm was expected to deposit about 100mm of rain on Tokyo over 24 hours, according to the Transport Ministry website. Many schools were closed on Monday and two car companies in Japan halted production at some plants ahead of the storm. More than 174 domestic flights were affected nationwide, NHK state broadcaster said on Sunday. On Sunday, heavy rain delayed the Japanese Formula One Grand Prix in Suzaka. French driver Jules Bianchi lost control in the wet conditions and crashed, sustaining a severe head injury.", "The blaze started at the detached building in Drivers End in Codicote, near Welwyn, during the morning. There was another fire at the building 20 years ago, after which fire-proof foil was placed under the thatch, which is protecting the main building. More than 15 fire engines and support vehicles were called to tackle the blaze. Roads in the area were closed and traffic diverted.", 'The 18-year-old fell at the New Charter Academy on Broadoak Road in Ashton-under-Lyne at about 09:10 BST, Greater Manchester Police (GMP) said. GMP said he had gone to Manchester Royal Infirmary and his condition was "serious". Principal Jenny Langley said the school would remain "fully open" while police investigated. "Our thoughts are with the family and we\'re doing everything we can to support them along with staff and pupils," she said.', 'But Belgian-born Dutchman Max Verstappen was unable to drive a car legally on his own in either country. That all changed on Wednesday when the youngster turned 18 and passed his driving test at the first attempt. Despite having competed in 14 grands prix since his debut in Australia in March, Verstappen admitted to feeling the pressure during his test. "It\'s a relief," said the Toro Rosso driver, who finished ninth in Japan on Sunday and had only started driving lessons a week ago. "I was a bit nervous to make mistakes, but the exam went well." A bonus of turning 18 is that Verstappen will now be able to drink the champagne if he ever makes it onto the podium.', ] reference = [ "A powerful typhoon has brought many parts of Japan to a standstill and briefly battered Tokyo before heading out to sea.", "A major fire has been burning in the thatched roof of a large property in Hertfordshire.", "A student has been taken to hospital after falling from a balcony at a Greater Manchester school.", "He is Formula 1's youngest ever driver and in charge of a car that can reach over 200mph.", ] response = [ "Typhoon Phanfone, while downgraded from super typhoon status, caused significant disruption and tragedy in Japan. One US airman died after being swept away by high waves, with two more missing. The storm caused power outages for thousands, flight cancellations, and the suspension of rescue efforts for missing volcano victims. Heavy rain and strong winds led to school and factory closures, transportation disruptions, and at least 10 injuries. The typhoon is expected to weaken as it moves over the Pacific Ocean.", "A large fire broke out in a detached thatched building in Codicote, near Welwyn. This is the second fire at the building in 20 years. Thankfully, fire-proof foil installed after the previous fire is protecting the main building. Over 15 fire engines and support vehicles responded, closing roads and diverting traffic in the area.", "An 18-year-old student at New Charter Academy in Ashton-under-Lyne suffered a serious fall and was hospitalized. The incident is under investigation by Greater Manchester Police, but the school remains open. The principal expressed support for the student's family and the school community.", "Max Verstappen, a Formula One driver, was finally able to get his driver's license at age 18. Despite already competing in 14 Grand Prix races, he was not of legal driving age in his native countries. He admitted to being nervous but passed the test on his first attempt. As an added bonus of turning 18, Verstappen can now enjoy champagne on the podium if he places.", ] eval_dataset = pd.DataFrame( { "instruction": instruction, "context": context, "reference": reference, } )
Запустите задачу оценки подсказки.
Подготовив набор данных для суммирования, вы готовы провести основной эксперимент этой задачи: сравнить несколько шаблонов подсказок, чтобы определить, какой из них обеспечивает наилучшее качество выходных данных от модели.
- В следующей ячейке создайте одну
EvalTask, которая будет использоваться повторно для каждого эксперимента. Установив параметрexperiment, все запуски оценки из этой задачи будут автоматически регистрироваться и группироваться в Vertex AI Experiments.EXPERIMENT_NAME = "eval-sdk-prompt-engineering" # @param {type:"string"} summarization_eval_task = EvalTask( dataset=eval_dataset, metrics=[ "rouge_l_sum", "bleu", "fluency", "coherence", "safety", "groundedness", "summarization_quality", "verbosity", "instruction_following", "text_quality", ], experiment=EXPERIMENT_NAME, )rouge_l_sumиbleuи заканчивая широким спектром метрик, основанных на модели (fluency,coherence,summarization_quality,instruction_followingи т. д.). Это дает нам целостное, всестороннее представление о том, как каждый запрос влияет на качество выходных данных модели. - В новой ячейке добавьте и запустите следующий код для определения и оценки четырех стратегий подсказок, основанных на персонах. Цикл
forпроходит по каждому шаблону и выполняет оценку. Каждый шаблон предназначен для получения различных стилей резюме путем присвоения модели конкретной персоны или цели:- Персона №1 (стандартный) : Нейтральный, прямой запрос на составление краткого изложения.
- Персона №2 (руководитель) : Просит краткое изложение в виде пунктов, с упором на результаты и влияние, как и предпочел бы занятый руководитель.
- Персонаж №3 (ученик 5-го класса) : Дает модели указание использовать простой язык, проверяя ее способность регулировать сложность своего вывода.
- Персона №4 (Технический аналитик) : Требует максимально точного резюме с сохранением ключевых статистических данных и сущностей, проверяющего точность модели. Обратите внимание, что заполнители в этих новых шаблонах, такие как
{context}и{instruction}, соответствуют новым именам столбцов в набореeval_dataset, созданном вами для этой задачи.
# Define prompt templates that target different user personas prompt_templates = [ # Persona 1: Standard, neutral summary "Article: {context}. Task: {instruction}. Summary:", # Persona 2: For a busy executive (bullet points) "Instruction: {instruction} into three key bullet points for a busy executive. Focus on the main outcome and impact. Article: {context}. Summary:", # Persona 3: For a 5th grader (simple language) "Instruction: {instruction} such that you're explaining it to a 10-year-old. Use simple words. Article: {context}. Summary:", # Persona 4: For a technical analyst (fact-focused) "Instruction: Provide a detailed, factual summary of the following text, ensuring all key statistics, names, and locations are preserved. Article: {context}. Summary:", ] eval_results = [] for i, prompt_template in enumerate(prompt_templates): eval_result = summarization_eval_task.evaluate( prompt_template=prompt_template, model=GenerativeModel( "gemini-2.0-flash", generation_config={ "temperature": 0.3, "max_output_tokens": 256, "top_k": 1, }, ), evaluation_service_qps=5, ) eval_results.append((f"Prompt Persona #{i+1}", eval_result))
Анализ и визуализация результатов
Проведение экспериментов — это первый шаг. Настоящая ценность заключается в анализе результатов для принятия решений на основе данных. В этом задании вы будете использовать инструменты визуализации SDK для интерпретации результатов эксперимента с созданием портрета целевой аудитории.
- Чтобы отобразить сводные результаты для каждого из четырех протестированных вами вариантов ответов, выполните следующий код в новой ячейке. Это позволит получить общее количественное представление о производительности.
for title, eval_result in eval_results: notebook_utils.display_eval_result(title=title, eval_result=eval_result) - В новой ячейке добавьте и запустите следующий код, чтобы увидеть обоснование метрики
summarization_qualityдля каждого персонажа.for title, eval_result in eval_results: notebook_utils.display_explanations( eval_result, metrics=["summarization_quality"], num=2 ) - Создайте радарную диаграмму для визуализации компромиссов между различными показателями качества для каждого запроса. В новой ячейке добавьте и выполните следующий код.
notebook_utils.display_radar_plot( eval_results, metrics=["instruction_following", "fluency", "coherence", "text_quality"], ) - Для более наглядного сравнения, постройте столбчатую диаграмму. В новой ячейке добавьте и выполните следующий код.
notebook_utils.display_bar_plot( eval_results, metrics=["instruction_following", "fluency", "coherence", "text_quality"], )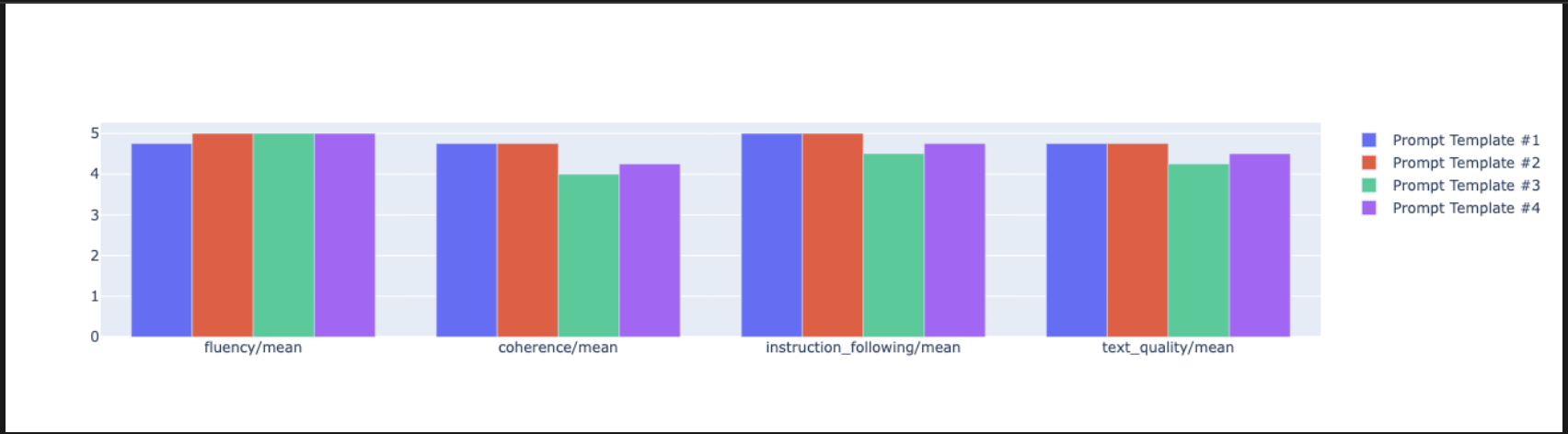
- Теперь вы можете просмотреть сводку всех запусков, зарегистрированных в вашем эксперименте Vertex AI для этой задачи. Это полезно для отслеживания вашей работы во времени. В новой ячейке добавьте и запустите следующий код:
summarization_eval_task.display_runs()
10. Завершите эксперимент.
Чтобы поддерживать порядок в проекте и избежать ненужных расходов, рекомендуется очищать созданные ресурсы. В ходе этой лабораторной работы каждый запуск оценки регистрировался в эксперименте Vertex AI. Следующий код удаляет этот родительский эксперимент, а также все связанные с ним запуски и их базовые данные.
- Запустите этот код в новой ячейке, чтобы удалить эксперимент Vertex AI и связанные с ним запуски.
delete_experiment = True # Please set your LOCATION to the same one used during Vertex AI SDK initialization. LOCATION = "YOUR LOCATION" # @param {type:"string"} if delete_experiment: from google.cloud import aiplatform aiplatform.init(project=PROJECT_ID, location=LOCATION) experiment = aiplatform.Experiment(EXPERIMENT_NAME) experiment.delete()
11. От практики к производству
Навыки, полученные в этой лабораторной работе, являются основой для создания надежных приложений искусственного интеллекта. Однако переход от ноутбука, запускаемого вручную, к системе оценки производственного уровня требует дополнительной инфраструктуры и более систематического подхода. В этом разделе описаны ключевые методы и стратегические концепции, которые следует учитывать по мере масштабирования.
Разработка стратегий оценки производства
Для применения навыков, полученных в этой лаборатории, в производственной среде полезно формализовать их в повторяемые стратегии. Следующие модели описывают ключевые аспекты типичных сценариев, таких как выбор модели, оптимизация оперативного реагирования и непрерывный мониторинг.
Для выбора модели:
# Evaluation strategy for choosing models
evaluation_strategy = {
"dataset_size": "100+ examples for statistical significance",
"metrics": ["task-specific", "general quality", "efficiency"],
"comparison_type": "pairwise with statistical testing",
"baseline": "established_model_or_human_benchmark"
}
Для оперативной оптимизации
# Systematic prompt improvement workflow
prompt_optimization = {
"hypothesis": "Clear statement of what you're testing",
"variants": "3-5 different prompt strategies",
"evaluation": "Same metrics across all variants",
"analysis": "Statistical significance + qualitative review"
}
Для непрерывного мониторинга
# Production evaluation pipeline
production_eval = {
"frequency": "Every model update + weekly monitoring",
"automation": "CI/CD integration with quality gates",
"metrics": "Speed + quality + cost tracking",
"alerting": "Performance degradation detection"
}
соображения экономической эффективности
Оценка на основе моделей может быть дорогостоящей в больших масштабах. Экономически эффективная стратегия производства предполагает использование различных методов для разных целей. В таблице приведено краткое описание компромиссов между скоростью, стоимостью и вариантами применения для различных типов оценки:
Тип оценки | Время | Стоимость за образец | Лучше всего подходит для |
КРАСНЫЙ/СИНИЙ | Секунды | ~0,001 долл. | Массовый скрининг |
Модель на основе точечного подхода | ~1-2 секунды | ~0,01 долл. | Оценка качества |
Попарное сравнение | ~2-3 секунды | ~0,02 долл. | Выбор модели |
Оценка человеком | Протокол | 1-10 долларов | Золотой стандарт валидации |
Автоматизируйте процессы с помощью CI/CD и мониторинга.
Ручное выполнение блокнотов не масштабируемо. Автоматизируйте оценку в конвейере непрерывной интеграции/непрерывного развертывания (CI/CD).
- Создайте контрольные точки качества : интегрируйте задачу оценки в конвейер CI/CD (например, Cloud Build). Автоматически запускайте оценку новых запросов или моделей и блокируйте развертывания, если ключевые показатели качества падают ниже заданных вами пороговых значений.
- Отслеживайте тенденции : экспортируйте сводные метрики из ваших оценочных запусков в такой сервис, как Google Cloud Monitoring. Создавайте панели мониторинга для отслеживания качества во времени и настраивайте автоматические оповещения, чтобы уведомлять вашу команду о любом значительном снижении производительности.
12. Заключение
Вы завершили лабораторную работу. Вы освоили основные навыки оценки моделей генеративного искусственного интеллекта.
Данная лабораторная работа является частью учебного курса "Готовый к внедрению ИИ в производство с использованием Google Cloud".
- Изучите полный учебный план , чтобы преодолеть разрыв между прототипом и серийным производством.
- Делитесь своими успехами, используя хэштег
ProductionReadyAI.
Краткий обзор
В этой лабораторной работе вы научились:
- Применяйте лучшие практики оценки, используя структуру
EvalTask. - Используйте различные типы метрик, от вычислительных до модельных.
- Оптимизируйте подсказки, протестировав различные версии.
- Создайте воспроизводимый рабочий процесс с отслеживанием экспериментов.
Ресурсы для непрерывного обучения
- Документация по оценке искусственного интеллекта Vertex AI Gen
- Тетради по передовым методам оценки
- Справочник по SDK для оценки искусственного интеллекта Gen AI
- Исследование метрик на основе моделей
- Передовые методы оперативного проектирования
Освоенные в этой лабораторной работе систематические подходы к оценке послужат основой для создания надежных и высококачественных приложений искусственного интеллекта. Помните: качественная оценка — это мост между экспериментальным ИИ и успехом в производстве.