
1. ภาพรวม
ในแล็บนี้ คุณจะได้เรียนรู้วิธีประเมินโมเดลภาษาขนาดใหญ่โดยใช้บริการ Gen AI Evaluation ของ Vertex AI คุณจะใช้ SDK เพื่อเรียกใช้การประเมินผลงาน เปรียบเทียบผลลัพธ์ และตัดสินใจโดยอิงตามข้อมูลเกี่ยวกับประสิทธิภาพของโมเดลและการออกแบบพรอมต์
แล็บจะแนะนำเวิร์กโฟลว์การประเมินทั่วไป โดยเริ่มจากเมตริกแบบง่ายที่อิงตามการคำนวณ และก้าวไปสู่การประเมินที่ซับซ้อนมากขึ้นซึ่งอิงตามโมเดล นอกจากนี้ คุณยังจะได้เรียนรู้วิธีสร้างเมตริกที่กำหนดเองซึ่งออกแบบมาให้ตรงกับเป้าหมายที่เฉพาะเจาะจง และติดตามงานโดยใช้การทดสอบ Vertex AI
สิ่งที่คุณจะได้เรียนรู้
ในแล็บนี้ คุณจะได้เรียนรู้วิธีทำงานต่อไปนี้
- ประเมินโมเดลด้วยเมตริกที่อิงตามการคำนวณและเมตริกที่อิงตามโมเดล
- สร้างเมตริกที่กำหนดเองเพื่อให้การประเมินสอดคล้องกับเป้าหมายของผลิตภัณฑ์
- เปรียบเทียบเทมเพลตพรอมต์ต่างๆ ควบคู่กัน
- ทดสอบพรอมต์ตามลักษณะตัวตนหลายรายการเพื่อค้นหาเวอร์ชันที่มีประสิทธิภาพมากที่สุด
- ติดตามและแสดงภาพการเรียกใช้การประเมินโดยใช้ Vertex AI Experiments
ข้อมูลอ้างอิง
- ตัวอย่างโค้ด: Lab นี้สร้างขึ้นจากตัวอย่างจากที่เก็บ Generative AI ของ Google Cloud
- อ้างอิงจาก: เอกสารประกอบการประเมิน Gen AI ของ Vertex AI
- ชุดข้อมูล: ชุดข้อมูล OpenOrca สำหรับการประเมินการปฏิบัติตามคำสั่ง
2. การตั้งค่าโปรเจ็กต์
บัญชี Google
หากยังไม่มีบัญชี Google ส่วนบุคคล คุณต้องสร้างบัญชี Google
ใช้บัญชีส่วนตัวแทนบัญชีของที่ทำงานหรือบัญชีโรงเรียน
ลงชื่อเข้าใช้คอนโซล Google Cloud
ลงชื่อเข้าใช้ คอนโซล Google Cloud โดยใช้บัญชี Google ส่วนบุคคล
เปิดใช้การเรียกเก็บเงิน
คุณมี 2 ตัวเลือกในการเปิดใช้การเรียกเก็บเงิน คุณจะใช้บัญชีสำหรับการเรียกเก็บเงินส่วนตัวหรือแลกสิทธิ์เครดิตได้โดยทำตามขั้นตอนต่อไปนี้
แลกรับเครดิต Google Cloud (ไม่บังคับ)
หากต้องการจัดเวิร์กช็อปนี้ คุณต้องมีบัญชีสำหรับการเรียกเก็บเงินที่มีเครดิตอยู่บ้าง ใช้เครดิตจากแบนเนอร์ที่ด้านบนของ Codelab นี้เพื่อเริ่มต้นใช้งาน หากเชื่อมต่อกับบัญชีสำหรับการเรียกเก็บเงินอยู่แล้ว ให้ข้ามขั้นตอนนี้
ตั้งค่าบัญชีสำหรับการเรียกเก็บเงินส่วนตัว
หากตั้งค่าการเรียกเก็บเงินโดยใช้เครดิต Google Cloud คุณจะข้ามขั้นตอนนี้ได้
หากต้องการตั้งค่าบัญชีสำหรับการเรียกเก็บเงินส่วนตัว ให้ไปที่นี่เพื่อเปิดใช้การเรียกเก็บเงินใน Cloud Console
ข้อควรทราบ
- การทำ Lab นี้ควรมีค่าใช้จ่ายน้อยกว่า $1 USD ในทรัพยากรระบบคลาวด์
- คุณสามารถทำตามขั้นตอนที่ส่วนท้ายของแล็บนี้เพื่อลบทรัพยากรเพื่อหลีกเลี่ยงการเรียกเก็บเงินเพิ่มเติม
- ผู้ใช้ใหม่มีสิทธิ์ใช้ช่วงทดลองใช้ฟรีมูลค่า$300 USD
สร้างโปรเจ็กต์ (ไม่บังคับ)
หากไม่มีโปรเจ็กต์ปัจจุบันที่ต้องการใช้สำหรับแล็บนี้ ให้สร้างโปรเจ็กต์ใหม่ที่นี่
3. ตั้งค่าสภาพแวดล้อม Vertex AI Workbench
มาเริ่มด้วยการเข้าถึงสภาพแวดล้อมสมุดบันทึกที่กำหนดค่าไว้ล่วงหน้าและติดตั้งการอ้างอิงที่จำเป็นกัน
เข้าถึง Vertex AI Workbench
- ในคอนโซล Google Cloud ให้ไปที่ Vertex AI โดยคลิกเมนูการนำทาง ☰ > Vertex AI > แดชบอร์ด
- คลิกเปิดใช้ API ที่แนะนำทั้งหมด หมายเหตุ: โปรดรอให้ขั้นตอนนี้เสร็จสมบูรณ์
- คลิก Workbench ทางด้านซ้ายเพื่อสร้างอินสแตนซ์ Workbench ใหม่
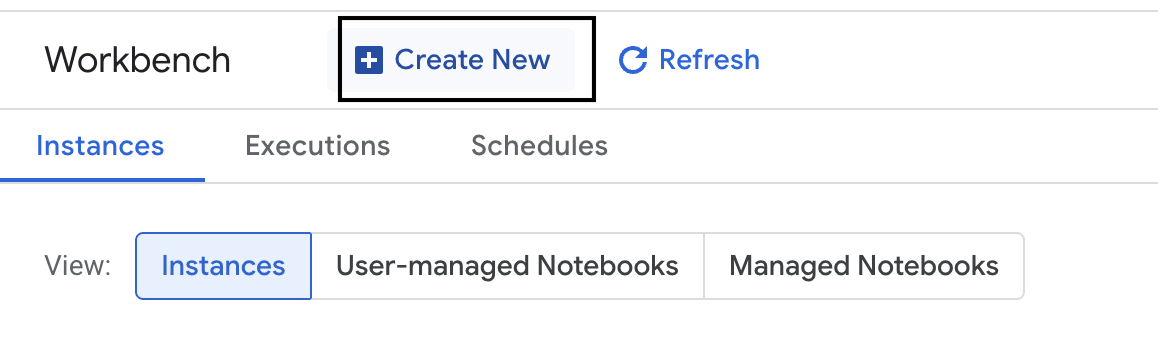
- ตั้งชื่ออินสแตนซ์ Workbench เป็น evaluation-workbench แล้วคลิกสร้าง
- รอให้เวิร์กเบนช์ตั้งค่า การดำเนินการนี้อาจใช้เวลาสักครู่

- เมื่อจัดสรรเวิร์กเบนช์แล้ว ให้คลิกเปิด JupyterLab
- สร้าง Notebook Python3 ใหม่ในเวิร์กเบนช์
ดูข้อมูลเพิ่มเติมเกี่ยวกับฟีเจอร์และความสามารถของสภาพแวดล้อมนี้ได้ในเอกสารประกอบอย่างเป็นทางการของ Vertex AI Workbench
ติดตั้งแพ็กเกจและกำหนดค่าสภาพแวดล้อม
- ในเซลล์แรกของ Notebook ให้เพิ่มและเรียกใช้คำสั่งนำเข้าด้านล่าง (SHIFT+ENTER) เพื่อติดตั้ง Vertex AI SDK (พร้อมคอมโพเนนต์การประเมิน) และแพ็กเกจอื่นๆ ที่จำเป็น
%pip install -U -q google-cloud-aiplatform[evaluation] %pip install -U -q datasets anthropic[vertex] openai - หากต้องการใช้แพ็กเกจที่ติดตั้งใหม่ เราขอแนะนำให้รีสตาร์ทเคอร์เนลโดยเรียกใช้ข้อมูลโค้ดด้านล่าง
# Automatically restart kernel after installation so that your environment can access the new packages. import IPython app = IPython.Application.instance() app.kernel.do_shutdown(True) - แทนที่ค่าต่อไปนี้ด้วยรหัสโปรเจ็กต์และสถานที่ตั้ง แล้วเรียกใช้เซลล์ต่อไปนี้ ตำแหน่งเริ่มต้นตั้งค่าเป็น
europe-west1แต่คุณควรใช้ตำแหน่งเดียวกับอินสแตนซ์ Vertex AI Workbench# Configure your project settings PROJECT_ID = "YOUR PROJECT ID" LOCATION = "europe-west1" - นำเข้าไลบรารี Python ที่จำเป็นทั้งหมดสำหรับ Lab นี้โดยเรียกใช้โค้ดต่อไปนี้ในเซลล์ใหม่
from anthropic import AnthropicVertex from google.auth import default, transport import openai import pandas as pd from vertexai.evaluation import ( EvalTask, MetricPromptTemplateExamples, PairwiseMetric, PointwiseMetric, PointwiseMetricPromptTemplate, ) from vertexai.generative_models import GenerativeModel from vertexai.preview.evaluation import notebook_utils
4. ตั้งค่าชุดข้อมูลการประเมิน
สำหรับบทแนะนำนี้ เราจะใช้ตัวอย่าง 10 รายการจากชุดข้อมูล OpenOrca ซึ่งจะทำให้เรามีข้อมูลเพียงพอที่จะเห็นความแตกต่างที่มีนัยสำคัญระหว่างโมเดลต่างๆ ในขณะที่ยังคงใช้เวลาในการประเมินได้
💡 เคล็ดลับสำหรับมือโปร: ในการใช้งานจริง คุณอาจต้องการตัวอย่าง 100-500 รายการเพื่อให้ได้ผลลัพธ์ที่มีนัยสำคัญทางสถิติ แต่ตัวอย่าง 10 รายการก็เพียงพอสำหรับการเรียนรู้และการสร้างต้นแบบอย่างรวดเร็วแล้ว
เตรียมชุดข้อมูล
- ในเซลล์ใหม่ ให้เรียกใช้เซลล์ต่อไปนี้เพื่อโหลดข้อมูล แปลงเป็น Pandas DataFrame และเปลี่ยนชื่อคอลัมน์
responseเป็นreferenceเพื่อความชัดเจนในงานการประเมินของเรา และสร้างตัวอย่างแบบสุ่ม 10 รายการfrom datasets import load_dataset ds = ( load_dataset( "Open-Orca/OpenOrca", data_files="1M-GPT4-Augmented.parquet", split="train[:100]", ) .to_pandas() .drop(columns=["id"]) .rename(columns={"response": "reference"}) ) dataset = ds.sample(n=10) - หลังจากเซลล์ก่อนหน้าทำงานเสร็จแล้ว ให้เพิ่มและเรียกใช้โค้ดต่อไปนี้ในเซลล์ถัดไปเพื่อแสดง 2-3 แถวแรกของชุดข้อมูลการประเมิน
dataset.head()
5. สร้างพื้นฐานด้วยเมตริกที่อิงตามการคำนวณ
ในงานนี้ คุณจะได้กำหนดคะแนนพื้นฐานโดยใช้เมตริกที่อิงตามการคำนวณ วิธีนี้รวดเร็วและมีเกณฑ์เปรียบเทียบที่เป็นกลางเพื่อวัดการปรับปรุงในอนาคต
เราจะใช้ ROUGE (Recall-Oriented Understudy for Gisting Evaluation) ซึ่งเป็นเมตริกมาตรฐานสำหรับงานสรุป โดยจะทำงานด้วยการเปรียบเทียบลำดับคำ (n-gram) ในคำตอบที่โมเดลสร้างขึ้นกับคำในข้อความ reference ของข้อมูลจากการสังเกตการณ์โดยตรง
อ่านเพิ่มเติมเกี่ยวกับเมตริกที่อิงตามการคำนวณ
การเรียกใช้การประเมินพื้นฐาน
- ในเซลล์ใหม่ ให้เพิ่มและเรียกใช้เซลล์ต่อไปนี้เพื่อกำหนดโมเดลที่ต้องการทดสอบ
gemini-2.0-flashgeneration_configประกอบด้วยพารามิเตอร์ต่างๆ เช่นtemperatureและmax_output_tokensที่มีผลต่อเอาต์พุตของโมเดล# Model to be evaluated model = GenerativeModel( "gemini-2.0-flash", generation_config={"temperature": 0.6, "max_output_tokens": 256, "top_k": 1}, )GenerativeModelเป็นอินเทอร์เฟซหลักสำหรับการโต้ตอบกับโมเดลภาษาขนาดใหญ่ใน Vertex AI SDK - ในเซลล์ถัดไป ให้เพิ่มและเรียกใช้โค้ดต่อไปนี้เพื่อสร้างและเรียกใช้
EvalTaskออบเจ็กต์นี้จาก Vertex AI Evaluation SDK จะจัดระเบียบการประเมิน คุณกําหนดค่าด้วยชุดข้อมูลและเมตริกที่จะคํานวณ ซึ่งในกรณีนี้คือrouge_l_sum# Define an EvalTask with ROUGE-L-SUM metric rouge_eval_task = EvalTask( dataset=dataset, metrics=["rouge_l_sum"], ) rouge_result = rouge_eval_task.evaluate( model=model, prompt_template="# System_prompt\n{system_prompt} # Question\n{question}", ) - แสดงผลลัพธ์โดยเรียกใช้โค้ดนี้ในเซลล์ถัดไป
notebook_utils.display_eval_result(rouge_result)display_eval_result()จะแสดงคะแนนเฉลี่ย (ค่าเฉลี่ย) และผลลัพธ์ทีละแถว
6. ไม่บังคับ: ประเมินด้วยเมตริกแบบจุดต่อจุดตามโมเดล
หมายเหตุ: ส่วนนี้อาจทำงานเกินขีดจำกัดของเครดิตฟรีที่ให้ไว้
แม้ว่า ROUGE จะมีประโยชน์ แต่ก็วัดได้เพียงการทับซ้อนของคำ (นั่นหมายความว่าระบบจะนับเฉพาะคำที่ตรงกัน ไม่เข้าใจบริบท คำพ้องความหมาย หรือการถอดความ) จึงไม่เหมาะที่จะใช้พิจารณาว่าคำตอบนั้นคล่องแคล่วหรือสมเหตุสมผลหรือไม่ หากต้องการทําความเข้าใจประสิทธิภาพของโมเดลให้ลึกซึ้งยิ่งขึ้น คุณต้องใช้เมตริกแบบจุดต่อจุดที่อิงตามโมเดล
ด้วยวิธีนี้ LLM อีกตัว ("โมเดลผู้พิพากษา") จะประเมินคำตอบแต่ละรายการเทียบกับชุดเกณฑ์ที่กำหนดไว้ล่วงหน้า เช่น ความคล่องแคล่วหรือความสอดคล้องกัน
อ่านเพิ่มเติมเกี่ยวกับเมตริกตามโมเดล
เรียกใช้การประเมินแบบจุดต่อจุด
- เรียกใช้โค้ดต่อไปนี้ในเซลล์ใหม่เพื่อสร้างเมนูแบบเลื่อนลงแบบอินเทอร์แอกทีฟ สำหรับการเรียกใช้นี้ ให้เลือก coherence จากรายการ
#Select a pointwise metric to use import ipywidgets as widgets pointwise_single_turn_metrics = [ metric for metric in MetricPromptTemplateExamples.list_example_metric_names() if not metric.startswith("pairwise") and not metric.startswith("multi_turn") ] dropdown = widgets.Dropdown( options=pointwise_single_turn_metrics, description="Select a metric:", font_weight="bold", style={"description_width": "initial"}, ) def dropdown_eventhandler(change): global POINTWISE_METRIC if change["type"] == "change" and change["name"] == "value": POINTWISE_METRIC = change.new print("Selected:", change.new) POINTWISE_METRIC = dropdown.value dropdown.observe(dropdown_eventhandler, names="value") display(dropdown) - ในเซลล์ใหม่ ให้เรียกใช้
EvalTaskอีกครั้ง โดยคราวนี้ใช้เมตริกตามโมเดลที่เลือก บริการประเมิน Vertex AI จะสร้างพรอมต์สำหรับโมเดลผู้ตัดสิน ซึ่งรวมถึงพรอมต์ต้นฉบับ คำตอบอ้างอิง คำตอบของโมเดลผู้เข้าแข่งขัน และวิธีการสำหรับเมตริกที่เลือก โมเดลผู้ตัดสินจะแสดงคะแนนที่เป็นตัวเลขและคำอธิบายสำหรับการให้คะแนน หมายเหตุ: ขั้นตอนนี้จะใช้เวลาสักครู่pointwise_result = EvalTask( dataset=dataset, metrics=[POINTWISE_METRIC], ).evaluate( model=model, prompt_template="# System_prompt\n{system_prompt} # Question\n{question}", )
แสดงผลลัพธ์
เมื่อการประเมินเสร็จสมบูรณ์แล้ว ขั้นตอนถัดไปคือการวิเคราะห์เอาต์พุต
- เรียกใช้โค้ดต่อไปนี้ในเซลล์ใหม่เพื่อดูเมตริกสรุป ซึ่งจะแสดงคะแนนเฉลี่ยของเมตริกที่คุณเลือก
notebook_utils.display_eval_result(pointwise_result) - เรียกใช้คำสั่งต่อไปนี้ในเซลล์ถัดไปเพื่อดูรายละเอียดแบบแถวต่อแถว ซึ่งรวมถึงเหตุผลที่โมเดลผู้ตัดสินเขียนไว้สำหรับคะแนน ความคิดเห็นเชิงคุณภาพนี้จะช่วยให้คุณเข้าใจสาเหตุที่คำตอบได้รับการให้คะแนนในลักษณะหนึ่งๆ
notebook_utils.display_explanations(pointwise_result, num=1, metrics=[POINTWISE_METRIC])
7. สร้างเมตริกที่กำหนดเองเพื่อรับข้อมูลเชิงลึกที่ละเอียดยิ่งขึ้น
เมตริกที่สร้างไว้ล่วงหน้า เช่น ความคล่องแคล่ว มีประโยชน์ แต่สําหรับผลิตภัณฑ์ที่เฉพาะเจาะจง คุณมักจะต้องวัดประสิทธิภาพเทียบกับเป้าหมายของคุณเอง เมตริกแบบจุดต่อจุดที่กําหนดเองช่วยให้คุณกําหนดเกณฑ์การประเมินและเกณฑ์การให้คะแนนของคุณเองได้
ในงานนี้ คุณจะสร้างเมตริกใหม่ตั้งแต่ต้นชื่อ summarization_helpfulness
กำหนดและเรียกใช้เมตริกที่กำหนดเอง
- เรียกใช้โค้ดต่อไปนี้ในเซลล์ใหม่เพื่อกําหนดเมตริกที่กําหนดเอง โดย
PointwiseMetricPromptTemplateมีองค์ประกอบพื้นฐานสําหรับเมตริก- เกณฑ์: บอกโมเดลผู้ตัดสินถึงมิติข้อมูลที่เฉพาะเจาะจงที่จะประเมิน ได้แก่ "ข้อมูลสำคัญ" "ความกระชับ" และ "ไม่มีการบิดเบือน"
- rating_rubric: ระบุมาตราส่วนการให้คะแนน 5 จุดที่กำหนดความหมายของคะแนนแต่ละคะแนน
- input_variables: ส่งคอลัมน์เพิ่มเติมจากชุดข้อมูลไปยังโมเดลผู้ตัดสินเพื่อให้มีบริบทที่จำเป็นต่อการประเมิน
# This new custom metric evaluates the actual quality and usefulness of the summary. summarization_helpfulness_metric = PointwiseMetric( metric="summarization_helpfulness", metric_prompt_template=PointwiseMetricPromptTemplate( criteria={ "Key Information": "Does the summary capture the most critical pieces of information from the original text? It should not miss the main topic or key takeaways.", "Conciseness": "Is the summary brief and to the point? It should avoid unnecessary words or repetitive information.", "No Distortion": "Does the summary introduce information or opinions that were NOT present in the original text? It must accurately reflect the source material without adding hallucinations." }, rating_rubric={ "5": "Excellent: Captures all key information, is highly concise, and has zero distortion.", "4": "Good: Captures most key information with minor omissions, is concise, and has no distortion.", "3": "Satisfactory: Captures the main idea but misses some key details OR is not very concise.", "2": "Unsatisfactory: Misses the main idea of the original text OR contains minor distortions/hallucinations.", "1": "Poor: Is completely irrelevant, fails to summarize the text, OR contains significant distortions.", }, input_variables=["prompt", "reference"], ), ) - เรียกใช้โค้ดต่อไปนี้ในเซลล์ถัดไปเพื่อเรียกใช้
EvalTaskด้วยเมตริกที่กำหนดเองใหม่# You would then update the EvalTask to use this new metric pointwise_result = EvalTask( dataset=dataset, metrics=[summarization_helpfulness_metric], ).evaluate( model=model, prompt_template="# System_prompt\n{system_prompt} # Question\n{question}", ) - เรียกใช้คำสั่งต่อไปนี้ในเซลล์ใหม่เพื่อแสดงผลลัพธ์
notebook_utils.display_eval_result(pointwise_result)
8. การเปรียบเทียบโมเดลด้วยการประเมินแบบคู่
เมื่อต้องการตัดสินใจว่าโมเดลใด 2 โมเดลมีประสิทธิภาพดีกว่าในงานที่เฉพาะเจาะจง คุณสามารถใช้การประเมินตามโมเดลแบบเป็นคู่ได้ วิธีนี้เป็นการทดสอบ A/B รูปแบบหนึ่งที่โมเดลผู้ตัดสินจะกำหนดผู้ชนะ ซึ่งช่วยให้เปรียบเทียบโดยตรงสำหรับการเลือกโมเดลที่อิงตามข้อมูล
โมเดล
- โมเดลผู้สมัคร: ระบบจะส่งตัวแปรโมเดล (ซึ่งก่อนหน้านี้กำหนดเป็น
gemini-2.0-flash) ไปยังเมธอด.evaluate()นี่คือโมเดลหลักที่คุณกำลังทดสอบ - โมเดลพื้นฐาน: โมเดลที่ 2
gemini-2.0-flash-liteจะระบุไว้ในคลาส PairwiseMetric นี่คือโมเดลที่คุณกำลังเปรียบเทียบ
เรียกใช้การประเมินแบบเป็นคู่
- ในเซลล์ใหม่ ให้เพิ่มและเรียกใช้โค้ดต่อไปนี้เพื่อสร้างเมนูแบบเลื่อนลงแบบอินเทอร์แอกทีฟ ซึ่งจะช่วยให้คุณเลือกเมตริกคู่ที่ต้องการใช้ในการเปรียบเทียบได้ สำหรับการเรียกใช้นี้ ให้เลือก pairwise_summarization_quality
from IPython.display import display import ipywidgets as widgets pairwise_single_turn_metrics = [ metric for metric in MetricPromptTemplateExamples.list_example_metric_names() if metric.startswith("pairwise") and "multi_turn" not in metric ] dropdown = widgets.Dropdown( options=pairwise_single_turn_metrics, description="Select a metric:", font_weight="bold", style={"description_width": "initial"}, ) def dropdown_eventhandler(change): global POINTWISE_METRIC if change["type"] == "change" and change["name"] == "value": POINTWISE_METRIC = change.new print("Selected:", change.new) def dropdown_eventhandler(change): global PAIRWISE_METRIC_NAME if change["type"] == "change" and change["name"] == "value": PAIRWISE_METRIC_NAME = change.new print("Selected:", change.new) PAIRWISE_METRIC_NAME = dropdown.value dropdown.observe(dropdown_eventhandler, names="value") display(dropdown) - ในเซลล์ถัดไป ให้เพิ่มและเรียกใช้โค้ดต่อไปนี้เพื่อกำหนดค่าและเรียกใช้
EvalTaskโปรดสังเกตวิธีใช้คลาสPairwiseMetricเพื่อกำหนดโมเดลพื้นฐาน (gemini-2.0-flash-lite) ขณะที่ส่งโมเดลผู้สมัคร (gemini-2.0-flash) ไปยังเมธอด.evaluate()pairwise_result = EvalTask( dataset=dataset, metrics=[ PairwiseMetric( metric=PAIRWISE_METRIC_NAME, metric_prompt_template=MetricPromptTemplateExamples.get_prompt_template( PAIRWISE_METRIC_NAME ), # Define a baseline model to compare against baseline_model=GenerativeModel("gemini-2.0-flash-lite"), ) ], ).evaluate( # Specify a candidate model for pairwise comparison model=model, prompt_template="# System_prompt\n{system_prompt} # Question\n{question}", ) - ในเซลล์ใหม่ ให้เพิ่มและเรียกใช้โค้ดต่อไปนี้เพื่อแสดงผลลัพธ์ ตารางสรุปจะแสดง "อัตราการชนะ" ของแต่ละโมเดล ซึ่งบ่งบอกว่าโมเดลผู้พิพากษาชอบโมเดลใดมากกว่า
notebook_utils.display_eval_result(pairwise_result)
9. ไม่บังคับ: ประเมินพรอมต์ที่อิงตามเพอร์โซนา
หมายเหตุ: ส่วนนี้อาจทำงานเกินขีดจำกัดของเครดิตฟรีที่ให้ไว้
ในงานนี้ คุณจะได้ทดสอบเทมเพลตพรอมต์หลายรายการที่สั่งให้โมเดลใช้บุคลิกต่างๆ กระบวนการนี้มักเรียกว่าวิศวกรรมพรอมต์ (Prompt Engineering) หรือการออกแบบพรอมต์ ซึ่งช่วยให้คุณค้นหาพรอมต์ที่มีประสิทธิภาพมากที่สุดสำหรับกรณีการใช้งานที่เฉพาะเจาะจงได้อย่างเป็นระบบ
เตรียมชุดข้อมูลสรุป
หากต้องการทำการประเมินนี้ ชุดข้อมูลต้องมีฟิลด์ต่อไปนี้
instruction: งานหลักที่เรามอบหมายให้โมเดล ในกรณีนี้จะเป็น "สรุปบทความต่อไปนี้"context: ข้อความต้นฉบับที่โมเดลต้องใช้ในการทำงาน เราได้แสดงตัวอย่างข่าว 4 รายการที่แตกต่างกันไว้ที่นี่reference: สรุปความจริงพื้นฐานหรือ "มาตรฐานทองคำ" ระบบจะเปรียบเทียบเอาต์พุตที่โมเดลสร้างขึ้นกับข้อความนี้เพื่อคำนวณคะแนนสำหรับเมตริก เช่น ROUGE และคุณภาพการสรุป
- ในเซลล์ใหม่ ให้เพิ่มและเรียกใช้โค้ดต่อไปนี้เพื่อสร้าง
pandas.DataFrameสำหรับงานสรุปinstruction = "Summarize the following article: \n" context = [ "Typhoon Phanfone has killed at least one person, a US airman on Okinawa who was washed away by high waves. Thousands of households have lost power and Japan's two largest airlines have suspended many flights. The storm also forced the suspension of the search for people missing after last week's volcanic eruption. The storm-tracking website Tropical Storm Risk forecasts that Phanfone will rapidly lose power over the next few hours as it goes further into the Pacific Ocean. Typhoon Phanfone was downgraded from an earlier status of a super typhoon, but the Japan Meteorological Agency had warned it was still a dangerous storm. Japan averages 11 typhoons a year, according to its weather agency. The typhoon made landfall on Monday morning near the central city of Hamamatsu, with winds of up to 180 km/h (112 mph). The airman was one of three US military personnel swept away by high waves whipped up by the typhoon off southern Okinawa island, where the US has a large military base. The remaining two are still missing. A police spokesman said they had been taking photographs of the sea. A university student who was surfing off the seas of Kanagawa Prefecture, south of Tokyo, was also missing, national broadcast NHK reports. It said at least 10 people had been injured and 9,500 houses were without power. The storm was expected to deposit about 100mm of rain on Tokyo over 24 hours, according to the Transport Ministry website. Many schools were closed on Monday and two car companies in Japan halted production at some plants ahead of the storm. More than 174 domestic flights were affected nationwide, NHK state broadcaster said on Sunday. On Sunday, heavy rain delayed the Japanese Formula One Grand Prix in Suzaka. French driver Jules Bianchi lost control in the wet conditions and crashed, sustaining a severe head injury.", "The blaze started at the detached building in Drivers End in Codicote, near Welwyn, during the morning. There was another fire at the building 20 years ago, after which fire-proof foil was placed under the thatch, which is protecting the main building. More than 15 fire engines and support vehicles were called to tackle the blaze. Roads in the area were closed and traffic diverted.", 'The 18-year-old fell at the New Charter Academy on Broadoak Road in Ashton-under-Lyne at about 09:10 BST, Greater Manchester Police (GMP) said. GMP said he had gone to Manchester Royal Infirmary and his condition was "serious". Principal Jenny Langley said the school would remain "fully open" while police investigated. "Our thoughts are with the family and we\'re doing everything we can to support them along with staff and pupils," she said.', 'But Belgian-born Dutchman Max Verstappen was unable to drive a car legally on his own in either country. That all changed on Wednesday when the youngster turned 18 and passed his driving test at the first attempt. Despite having competed in 14 grands prix since his debut in Australia in March, Verstappen admitted to feeling the pressure during his test. "It\'s a relief," said the Toro Rosso driver, who finished ninth in Japan on Sunday and had only started driving lessons a week ago. "I was a bit nervous to make mistakes, but the exam went well." A bonus of turning 18 is that Verstappen will now be able to drink the champagne if he ever makes it onto the podium.', ] reference = [ "A powerful typhoon has brought many parts of Japan to a standstill and briefly battered Tokyo before heading out to sea.", "A major fire has been burning in the thatched roof of a large property in Hertfordshire.", "A student has been taken to hospital after falling from a balcony at a Greater Manchester school.", "He is Formula 1's youngest ever driver and in charge of a car that can reach over 200mph.", ] response = [ "Typhoon Phanfone, while downgraded from super typhoon status, caused significant disruption and tragedy in Japan. One US airman died after being swept away by high waves, with two more missing. The storm caused power outages for thousands, flight cancellations, and the suspension of rescue efforts for missing volcano victims. Heavy rain and strong winds led to school and factory closures, transportation disruptions, and at least 10 injuries. The typhoon is expected to weaken as it moves over the Pacific Ocean.", "A large fire broke out in a detached thatched building in Codicote, near Welwyn. This is the second fire at the building in 20 years. Thankfully, fire-proof foil installed after the previous fire is protecting the main building. Over 15 fire engines and support vehicles responded, closing roads and diverting traffic in the area.", "An 18-year-old student at New Charter Academy in Ashton-under-Lyne suffered a serious fall and was hospitalized. The incident is under investigation by Greater Manchester Police, but the school remains open. The principal expressed support for the student's family and the school community.", "Max Verstappen, a Formula One driver, was finally able to get his driver's license at age 18. Despite already competing in 14 Grand Prix races, he was not of legal driving age in his native countries. He admitted to being nervous but passed the test on his first attempt. As an added bonus of turning 18, Verstappen can now enjoy champagne on the podium if he places.", ] eval_dataset = pd.DataFrame( { "instruction": instruction, "context": context, "reference": reference, } )
เรียกใช้งานการประเมินพรอมต์
เมื่อเตรียมชุดข้อมูลสรุปแล้ว คุณก็พร้อมที่จะทำการทดสอบหลักของงานนี้ นั่นคือการเปรียบเทียบเทมเพลตพรอมต์หลายรายการเพื่อดูว่าเทมเพลตใดสร้างเอาต์พุตคุณภาพสูงสุดจากโมเดล
- ในเซลล์ถัดไป ให้สร้าง
EvalTaskเดียวที่จะนำกลับมาใช้ซ้ำสำหรับการทดสอบพรอมต์แต่ละรายการ การตั้งค่าพารามิเตอร์experimentจะทำให้ระบบบันทึกและจัดกลุ่มการประเมินทั้งหมดจากงานนี้โดยอัตโนมัติใน Vertex AI ExperimentsEXPERIMENT_NAME = "eval-sdk-prompt-engineering" # @param {type:"string"} summarization_eval_task = EvalTask( dataset=eval_dataset, metrics=[ "rouge_l_sum", "bleu", "fluency", "coherence", "safety", "groundedness", "summarization_quality", "verbosity", "instruction_following", "text_quality", ], experiment=EXPERIMENT_NAME, )rouge_l_sumและbleuไปจนถึงเมตริกที่อิงตามโมเดลต่างๆ (fluency,coherence,summarization_quality,instruction_followingฯลฯ) ซึ่งจะช่วยให้เราเห็นภาพรวมแบบ 360 องศาว่าแต่ละพรอมต์ส่งผลต่อคุณภาพเอาต์พุตของโมเดลอย่างไร - ในเซลล์ใหม่ ให้เพิ่มและเรียกใช้โค้ดต่อไปนี้เพื่อกำหนดและประเมินกลยุทธ์พรอมต์ 4 แบบที่อิงตามเพอร์โซนา ลูป
forจะวนซ้ำผ่านแต่ละเทมเพลตและเรียกใช้การประเมิน เทมเพลตแต่ละรายการได้รับการออกแบบมาเพื่อดึงข้อมูลสรุปในรูปแบบต่างๆ โดยการกำหนดลักษณะตัวตนหรือเป้าหมายที่เฉพาะเจาะจงให้กับโมเดล- ลักษณะตัวตน #1 (มาตรฐาน): คำขอสรุปที่เป็นกลางและตรงไปตรงมา
- ลักษณะตัวตน #2 (ผู้บริหาร): ขอสรุปในรูปแบบหัวข้อย่อย โดยเน้นที่ผลลัพธ์และผลกระทบ เนื่องจากผู้บริหารที่ยุ่งมักจะชอบรูปแบบนี้
- ลักษณะตัวตน #3 (นักเรียนชั้นประถมศึกษาปีที่ 5): สั่งให้โมเดลใช้ภาษาที่เรียบง่ายเพื่อทดสอบความสามารถในการปรับความซับซ้อนของเอาต์พุต
- ลักษณะตัวตน #4 (นักวิเคราะห์ด้านเทคนิค): ต้องการข้อมูลสรุปที่อิงตามข้อเท็จจริงอย่างมาก โดยจะเก็บสถิติและเอนทิตีที่สำคัญไว้เพื่อทดสอบความแม่นยำของโมเดล โปรดสังเกตว่าตัวยึดตำแหน่งในเทมเพลตใหม่เหล่านี้ เช่น
{context}และ{instruction}จะตรงกับชื่อคอลัมน์ใหม่ในeval_datasetที่คุณสร้างขึ้นสำหรับงานนี้
# Define prompt templates that target different user personas prompt_templates = [ # Persona 1: Standard, neutral summary "Article: {context}. Task: {instruction}. Summary:", # Persona 2: For a busy executive (bullet points) "Instruction: {instruction} into three key bullet points for a busy executive. Focus on the main outcome and impact. Article: {context}. Summary:", # Persona 3: For a 5th grader (simple language) "Instruction: {instruction} such that you're explaining it to a 10-year-old. Use simple words. Article: {context}. Summary:", # Persona 4: For a technical analyst (fact-focused) "Instruction: Provide a detailed, factual summary of the following text, ensuring all key statistics, names, and locations are preserved. Article: {context}. Summary:", ] eval_results = [] for i, prompt_template in enumerate(prompt_templates): eval_result = summarization_eval_task.evaluate( prompt_template=prompt_template, model=GenerativeModel( "gemini-2.0-flash", generation_config={ "temperature": 0.3, "max_output_tokens": 256, "top_k": 1, }, ), evaluation_service_qps=5, ) eval_results.append((f"Prompt Persona #{i+1}", eval_result))
วิเคราะห์และแสดงผลลัพธ์ด้วยภาพ
การทำการทดสอบเป็นขั้นตอนแรก คุณค่าที่แท้จริงมาจากการวิเคราะห์ผลลัพธ์เพื่อทำการตัดสินใจโดยอิงตามข้อมูล ในงานนี้ คุณจะได้ใช้เครื่องมือแสดงภาพของ SDK เพื่อตีความเอาต์พุตจากการทดสอบลักษณะตัวตนของพรอมต์
- แสดงผลลัพธ์สรุปสำหรับพรอมต์แต่ละตัวตนทั้ง 4 รายการที่คุณทดสอบโดยเรียกใช้โค้ดต่อไปนี้ในเซลล์ใหม่ ซึ่งจะช่วยให้คุณเห็นภาพรวมเชิงปริมาณของประสิทธิภาพ
for title, eval_result in eval_results: notebook_utils.display_eval_result(title=title, eval_result=eval_result) - ในเซลล์ใหม่ ให้เพิ่มและเรียกใช้โค้ดต่อไปนี้เพื่อดูเหตุผลสำหรับเมตริก
summarization_qualityของผู้ใช้แต่ละประเภทfor title, eval_result in eval_results: notebook_utils.display_explanations( eval_result, metrics=["summarization_quality"], num=2 ) - สร้างแผนภูมิเรดาร์เพื่อแสดงภาพการแลกเปลี่ยนระหว่างเมตริกคุณภาพต่างๆ สำหรับแต่ละพรอมต์ เพิ่มและเรียกใช้โค้ดต่อไปนี้ในเซลล์ใหม่
notebook_utils.display_radar_plot( eval_results, metrics=["instruction_following", "fluency", "coherence", "text_quality"], ) - หากต้องการเปรียบเทียบข้อมูลคู่กันที่ตรงกว่า ให้สร้างแผนภูมิแท่ง เพิ่มและเรียกใช้โค้ดต่อไปนี้ในเซลล์ใหม่
notebook_utils.display_bar_plot( eval_results, metrics=["instruction_following", "fluency", "coherence", "text_quality"], )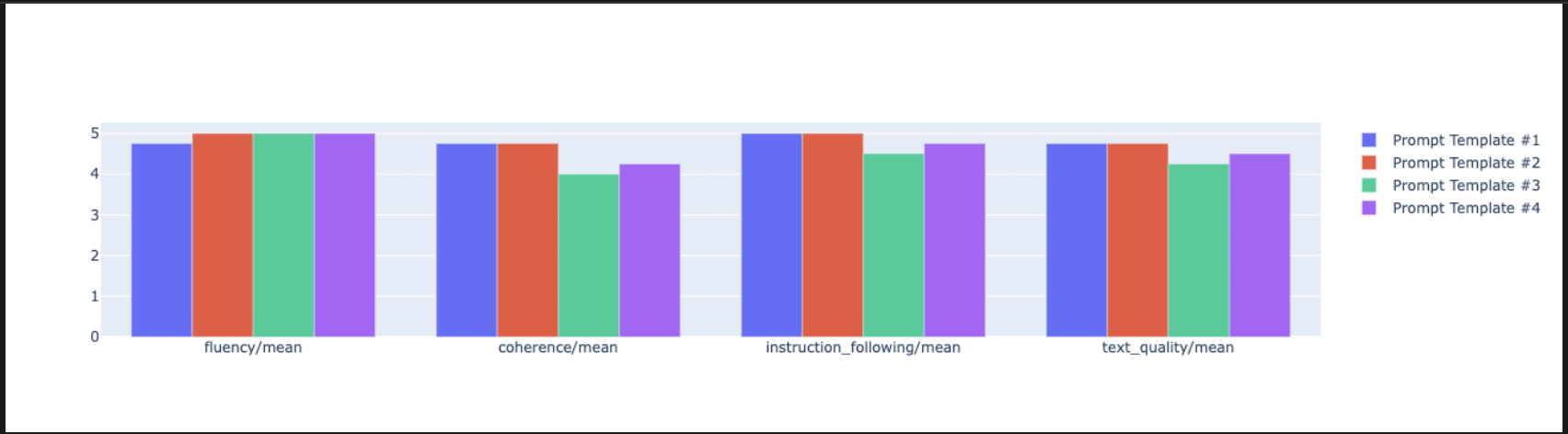
- ตอนนี้คุณสามารถดูสรุปการเรียกใช้ทั้งหมดที่บันทึกไว้ใน Vertex AI Experiment สำหรับงานนี้ได้แล้ว ซึ่งจะเป็นประโยชน์ในการติดตามงานของคุณเมื่อเวลาผ่านไป เพิ่มและเรียกใช้โค้ดต่อไปนี้ในเซลล์ใหม่
summarization_eval_task.display_runs()
10. ล้างข้อมูลการทดสอบ
แนวทางปฏิบัติแนะนำคือการล้างข้อมูลทรัพยากรที่คุณสร้างขึ้น เพื่อให้โปรเจ็กต์เป็นระเบียบและหลีกเลี่ยงการเรียกเก็บเงินที่ไม่จำเป็น ตลอดแล็บนี้ ระบบจะบันทึกการเรียกใช้การประเมินทุกครั้งไปยังการทดลอง Vertex AI โค้ดต่อไปนี้จะลบการทดสอบหลักนี้ ซึ่งจะนำการเรียกใช้ที่เกี่ยวข้องทั้งหมดและข้อมูลพื้นฐานออกด้วย
- เรียกใช้โค้ดนี้ในเซลล์ใหม่เพื่อลบการทดลอง Vertex AI และการเรียกใช้ที่เกี่ยวข้อง
delete_experiment = True # Please set your LOCATION to the same one used during Vertex AI SDK initialization. LOCATION = "YOUR LOCATION" # @param {type:"string"} if delete_experiment: from google.cloud import aiplatform aiplatform.init(project=PROJECT_ID, location=LOCATION) experiment = aiplatform.Experiment(EXPERIMENT_NAME) experiment.delete()
11. จากเวอร์ชันทดลองสู่เวอร์ชันที่ใช้งานจริง
ทักษะที่คุณได้เรียนรู้ในแล็บนี้เป็นองค์ประกอบพื้นฐานในการสร้างแอปพลิเคชัน AI ที่เชื่อถือได้ อย่างไรก็ตาม การเปลี่ยนจาก Notebook ที่เรียกใช้ด้วยตนเองไปเป็นระบบการประเมินระดับโปรดักชันต้องใช้โครงสร้างพื้นฐานเพิ่มเติมและแนวทางที่เป็นระบบมากขึ้น ส่วนนี้จะอธิบายแนวทางปฏิบัติที่สำคัญและกรอบการทำงานเชิงกลยุทธ์ที่ควรพิจารณาเมื่อคุณเพิ่มทรัพยากร
การสร้างกลยุทธ์การประเมินการผลิต
หากต้องการนำทักษะจาก Lab นี้ไปใช้ในสภาพแวดล้อมที่ใช้งานจริง คุณควรจัดรูปแบบทักษะเหล่านั้นให้เป็นกลยุทธ์ที่ทำซ้ำได้ เฟรมเวิร์กต่อไปนี้จะอธิบายข้อควรพิจารณาที่สำคัญสำหรับสถานการณ์ทั่วไป เช่น การเลือกโมเดล การเพิ่มประสิทธิภาพพรอมต์ และการตรวจสอบอย่างต่อเนื่อง
สำหรับการเลือกรุ่น
# Evaluation strategy for choosing models
evaluation_strategy = {
"dataset_size": "100+ examples for statistical significance",
"metrics": ["task-specific", "general quality", "efficiency"],
"comparison_type": "pairwise with statistical testing",
"baseline": "established_model_or_human_benchmark"
}
สำหรับการเพิ่มประสิทธิภาพพรอมต์
# Systematic prompt improvement workflow
prompt_optimization = {
"hypothesis": "Clear statement of what you're testing",
"variants": "3-5 different prompt strategies",
"evaluation": "Same metrics across all variants",
"analysis": "Statistical significance + qualitative review"
}
สำหรับการตรวจสอบอย่างต่อเนื่อง
# Production evaluation pipeline
production_eval = {
"frequency": "Every model update + weekly monitoring",
"automation": "CI/CD integration with quality gates",
"metrics": "Speed + quality + cost tracking",
"alerting": "Performance degradation detection"
}
ข้อควรพิจารณาด้านความคุ้มค่า
การประเมินตามโมเดลอาจมีค่าใช้จ่ายสูงเมื่อขยายขนาด กลยุทธ์การผลิตที่คุ้มค่าใช้หลายวิธีเพื่อวัตถุประสงค์ที่แตกต่างกัน ตารางนี้สรุปข้อแลกเปลี่ยนระหว่างความเร็ว ต้นทุน และกรณีการใช้งานสำหรับการประเมินประเภทต่างๆ
ประเภทการประเมิน | เวลา | ต้นทุนต่อตัวอย่าง | เหมาะสำหรับ |
ROUGE/BLEU | วินาที | ~$0.001 | การคัดกรองปริมาณมาก |
Pointwise ตามโมเดล | ~1-2 วินาที | ~$0.01 | การประเมินคุณภาพ |
การเปรียบเทียบแบบเป็นคู่ | ~2-3 วินาที | ~$0.02 | การเลือกโมเดล |
การประเมินโดยมนุษย์ | นาที | $1-10 | การตรวจสอบมาตรฐานระดับสูงสุด |
ทำงานอัตโนมัติด้วย CI/CD และการตรวจสอบ
การเรียกใช้ Notebook ด้วยตนเองไม่รองรับการปรับขนาด ทำให้การประเมินเป็นแบบอัตโนมัติในไปป์ไลน์การรวมอย่างต่อเนื่อง/การติดตั้งใช้งานอย่างต่อเนื่อง (CI/CD)
- สร้างเกณฑ์คุณภาพ: ผสานรวมงานการประเมินเข้ากับไปป์ไลน์ CI/CD (เช่น Cloud Build) เรียกใช้การประเมินพรอมต์หรือโมเดลใหม่โดยอัตโนมัติ และบล็อกการติดตั้งใช้งานหากคะแนนคุณภาพหลักต่ำกว่าเกณฑ์ที่กำหนด
- ตรวจสอบแนวโน้ม: ส่งออกเมตริกสรุปจากการเรียกใช้การประเมินไปยังบริการ เช่น Google Cloud Monitoring สร้างแดชบอร์ดเพื่อติดตามคุณภาพเมื่อเวลาผ่านไป และตั้งค่าการแจ้งเตือนอัตโนมัติเพื่อแจ้งให้ทีมทราบถึงประสิทธิภาพที่ลดลงอย่างมาก
12. บทสรุป
คุณทำแล็บเสร็จแล้ว คุณได้เรียนรู้ทักษะที่จำเป็นสำหรับการประเมินโมเดล Generative AI แล้ว
แล็บนี้เป็นส่วนหนึ่งของเส้นทางการเรียนรู้ AI พร้อมใช้งานจริงด้วย Google Cloud
- สำรวจหลักสูตรทั้งหมดเพื่อเชื่อมช่องว่างจากต้นแบบไปสู่การผลิต
- แชร์ความคืบหน้าของคุณด้วยแฮชแท็ก
ProductionReadyAI
สรุป
ในแล็บนี้ คุณได้เรียนรู้วิธีทำสิ่งต่อไปนี้
- ใช้แนวทางปฏิบัติแนะนำในการประเมินโดยใช้กรอบ
EvalTask - ใช้เมตริกประเภทต่างๆ ตั้งแต่กรรมการที่พิจารณาตามการคำนวณไปจนถึงกรรมการที่พิจารณาตามโมเดล
- เพิ่มประสิทธิภาพพรอมต์โดยทดสอบเวอร์ชันต่างๆ
- สร้างเวิร์กโฟลว์ที่ทำซ้ำได้ด้วยการติดตามการทดสอบ
แหล่งข้อมูลสำหรับการเรียนรู้อย่างต่อเนื่อง
- เอกสารประกอบการประเมิน Gen AI ของ Vertex AI
- Notebook เทคนิคการประเมินขั้นสูง
- เอกสารอ้างอิง SDK สำหรับการประเมิน Gen AI
- การวิจัยเมตริกตามโมเดล
- แนวทางปฏิบัติแนะนำในการสร้างพรอมต์
แนวทางการประเมินอย่างเป็นระบบที่คุณได้เรียนรู้ในแล็บนี้จะเป็นรากฐานในการสร้างแอปพลิเคชัน AI ที่เชื่อถือได้และมีคุณภาพสูง โปรดทราบว่าการประเมินที่ดีคือสะพานเชื่อมระหว่าง AI ที่อยู่ในขั้นทดลองกับความสำเร็จในการใช้งานจริง