
1. Genel Bakış
Bu laboratuvarda, Vertex AI Gen AI Evaluation Service'i kullanarak büyük dil modellerini değerlendirmeyi öğreneceksiniz. SDK'yı değerlendirme işlerini çalıştırmak, sonuçları karşılaştırmak ve model performansı ile istem tasarımı hakkında veriye dayalı kararlar almak için kullanacaksınız.
Laboratuvarda, basit ve hesaplamaya dayalı metriklerle başlayıp daha ayrıntılı ve modele dayalı değerlendirmelere geçerek yaygın bir değerlendirme iş akışı adım adım açıklanmaktadır. Ayrıca, belirli hedeflerinize göre uyarlanmış özel metrikler oluşturmayı ve Vertex AI Experiments'ı kullanarak çalışmalarınızı izlemeyi de öğreneceksiniz.
Neler öğreneceksiniz?
Bu laboratuvarda, aşağıdaki görevleri nasıl gerçekleştireceğinizi öğreneceksiniz:
- Bir modeli hesaplamaya dayalı ve modele dayalı metriklerle değerlendirme
- Değerlendirmeyi ürün hedefleriyle uyumlu hale getirmek için özel bir metrik oluşturun.
- Farklı istem şablonlarını yan yana karşılaştırın.
- En etkili sürümü bulmak için birden fazla karaktere dayalı istemi test edin.
- Vertex AI Experiments'i kullanarak değerlendirme çalıştırmalarını izleme ve görselleştirme
Referanslar
- Kod örnekleri: Bu laboratuvar, Google Cloud Üretken Yapay Zeka deposundaki örneklerden yararlanır.
- Şunlara dayanmaktadır: Vertex AI Üretken Yapay Zeka Değerlendirme belgeleri
- Veri kümesi: Talimatları takip etme değerlendirmesi için OpenOrca veri kümesi
2. Proje ayarlama
Google Hesabı
Kişisel Google Hesabınız yoksa Google Hesabı oluşturmanız gerekir.
İş veya okul hesabı yerine kişisel hesap kullanın.
Google Cloud Console'da oturum açma
Kişisel bir Google Hesabı kullanarak Google Cloud Console'da oturum açın.
Faturalandırmayı Etkinleştir
Faturalandırmayı etkinleştirmek için iki seçeneğiniz vardır. Kişisel faturalandırma hesabınızı kullanabilir veya aşağıdaki adımları uygulayarak kredileri kullanabilirsiniz.
Google Cloud kredilerini kullanma (isteğe bağlı)
Bu atölyeyi düzenlemek için biraz kredisi olan bir faturalandırma hesabınızın olması gerekir. Başlamak için bu codelab'in üst kısmındaki banner'da yer alan kredileri kullanın. Zaten bir faturalandırma hesabına bağlıysanız bu adımı atlayabilirsiniz.
Kişisel faturalandırma hesabı oluşturma
Faturalandırmayı Google Cloud kredilerini kullanarak ayarladıysanız bu adımı atlayabilirsiniz.
Kişisel faturalandırma hesabı oluşturmak için Cloud Console'da faturalandırmayı etkinleştirmek üzere buraya gidin.
Bazı notlar:
- Bu laboratuvarı tamamlamak için 1 ABD dolarından daha az tutarda bulut kaynağı kullanmanız gerekir.
- Daha fazla ücret ödememek için bu laboratuvarın sonundaki adımları uygulayarak kaynakları silebilirsiniz.
- Yeni kullanıcılar 300 ABD doları değerinde ücretsiz deneme sürümünden yararlanabilir.
Proje oluşturma (isteğe bağlı)
Bu laboratuvarda kullanmak istediğiniz mevcut bir projeniz yoksa buradan yeni bir proje oluşturun.
3. Vertex AI Workbench ortamınızı ayarlama
Önceden yapılandırılmış not defteri ortamınıza erişip gerekli bağımlılıkları yükleyerek başlayalım.
Vertex AI Workbench'e erişme
- Google Cloud Console'da Gezinme menüsü ☰ > Vertex AI > Kontrol Paneli'ni tıklayarak Vertex AI'a gidin.
- Enable All Recommended APIs'ı (Önerilen Tüm API'leri Etkinleştir) tıklayın. Not: Lütfen bu adımın tamamlanmasını bekleyin.
- Sol taraftaki Workbench seçeneğini tıklayarak yeni bir Workbench örneği oluşturun.
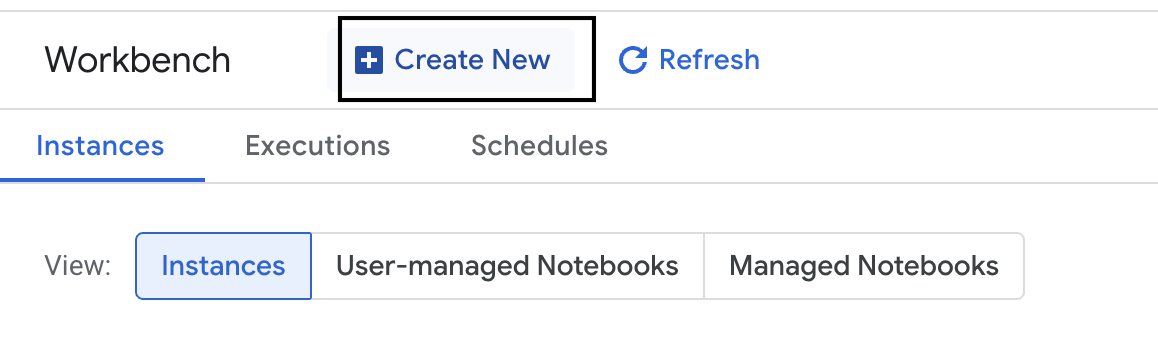
- Workbench örneğini evaluation-workbench olarak adlandırın ve Oluştur'u tıklayın.
- Çalışma tezgahının kurulmasını bekleyin. Bu işlem birkaç dakika sürebilir.

- Çalışma tezgahı sağlandıktan sonra Open JupyterLab'i (JupyterLab'i aç) tıklayın.
- Workbench'te yeni bir Python3 not defteri oluşturun.
Bu ortamın özellikleri ve işlevleri hakkında daha fazla bilgi edinmek için Vertex AI Workbench'in resmi belgelerine bakın.
Paketleri yükleme ve ortamınızı yapılandırma
- Vertex AI SDK'sını (değerlendirme bileşenleriyle birlikte) ve gerekli diğer paketleri yüklemek için not defterinizin ilk hücresine aşağıdaki içe aktarma ifadelerini ekleyip çalıştırın (ÜST KARAKTER+ENTER).
%pip install -U -q google-cloud-aiplatform[evaluation] %pip install -U -q datasets anthropic[vertex] openai - Yeni yüklenen paketleri kullanmak için aşağıdaki kod snippet'ini çalıştırarak çekirdeği yeniden başlatmanız önerilir.
# Automatically restart kernel after installation so that your environment can access the new packages. import IPython app = IPython.Application.instance() app.kernel.do_shutdown(True) - Aşağıdaki yerleri proje kimliğiniz ve konumunuzla değiştirip aşağıdaki hücreyi çalıştırın. Varsayılan konum
europe-west1olarak ayarlanır ancak Vertex AI Workbench örneğinizin bulunduğu konumu kullanmanız gerekir.# Configure your project settings PROJECT_ID = "YOUR PROJECT ID" LOCATION = "europe-west1" - Yeni bir hücrede aşağıdaki kodu çalıştırarak bu laboratuvar için gereken tüm Python kitaplıklarını içe aktarın.
from anthropic import AnthropicVertex from google.auth import default, transport import openai import pandas as pd from vertexai.evaluation import ( EvalTask, MetricPromptTemplateExamples, PairwiseMetric, PointwiseMetric, PointwiseMetricPromptTemplate, ) from vertexai.generative_models import GenerativeModel from vertexai.preview.evaluation import notebook_utils
4. Değerlendirme veri kümenizi oluşturma
Bu eğitimde, OpenOrca veri kümesinden 10 örnek kullanacağız. Bu sayede, değerlendirme süresini yönetilebilir tutarken modeller arasındaki anlamlı farkları görebileceğimiz kadar veri elde ederiz.
💡 Profesyonel İpucu: Üretim aşamasında, istatistiksel olarak anlamlı sonuçlar için 100-500 örnek kullanmanız gerekir. Ancak öğrenme ve hızlı prototipleme için 10 örnek yeterlidir.
Veri kümesini hazırlama
- Yeni bir hücrede, verileri yüklemek, bunları pandas DataFrame'e dönüştürmek ve değerlendirme görevlerimizde netlik sağlamak için
responsesütununureferenceolarak yeniden adlandırmak ve on örnekten oluşan rastgele bir örnek oluşturmak için aşağıdaki hücreyi çalıştırın.from datasets import load_dataset ds = ( load_dataset( "Open-Orca/OpenOrca", data_files="1M-GPT4-Augmented.parquet", split="train[:100]", ) .to_pandas() .drop(columns=["id"]) .rename(columns={"response": "reference"}) ) dataset = ds.sample(n=10) - Önceki hücre çalışmayı tamamladıktan sonra, değerlendirme veri kümenizin ilk birkaç satırını görüntülemek için bir sonraki hücreye aşağıdaki kodu ekleyip çalıştırın.
dataset.head()
5. Hesaplamaya dayalı metriklerle bir temel oluşturma
Bu görevde, hesaplamaya dayalı bir metrik kullanarak temel bir puan oluşturacaksınız. Bu yaklaşım hızlıdır ve gelecekteki iyileştirmeleri ölçmek için objektif bir kıyaslama noktası sağlar.
Özetleme görevleri için standart bir metrik olan ROUGE (Recall-Oriented Understudy for Gisting Evaluation) kullanılacaktır. Bu özellik, model tarafından oluşturulan yanıttaki kelime dizisini (n-gram) kesin referans metnindeki kelimelerle karşılaştırarak çalışır. reference
Hesaplamaya dayalı metrikler hakkında daha fazla bilgi edinin.
Temel değerlendirmeyi çalıştırma
- Yeni bir hücrede, test etmek istediğiniz modeli (
gemini-2.0-flash) tanımlamak için aşağıdaki hücreyi ekleyip çalıştırın.generation_config, modelin çıkışını etkileyentemperaturevemax_output_tokensgibi parametreleri içerir.# Model to be evaluated model = GenerativeModel( "gemini-2.0-flash", generation_config={"temperature": 0.6, "max_output_tokens": 256, "top_k": 1}, )GenerativeModelsınıfı, Vertex AI SDK'da büyük dil modelleriyle etkileşim kurmak için kullanılan birincil arayüzdür. - Sonraki hücreye aşağıdaki kodu ekleyip çalıştırarak
EvalTaskoluşturun ve yürütün. Vertex AI Evaluation SDK'sındaki bu nesne, değerlendirmeyi düzenler. Bu işlevi, veri kümesi ve hesaplanacak metriklerle (bu örnekterouge_l_sum) yapılandırırsınız.# Define an EvalTask with ROUGE-L-SUM metric rouge_eval_task = EvalTask( dataset=dataset, metrics=["rouge_l_sum"], ) rouge_result = rouge_eval_task.evaluate( model=model, prompt_template="# System_prompt\n{system_prompt} # Question\n{question}", ) - Sonraki hücrede bu kodu çalıştırarak sonuçları görüntüleyin.
notebook_utils.display_eval_result(rouge_result)display_eval_result()yardımcı programı, ortalama puanı ve satır satır sonuçları gösterir.
6. İsteğe bağlı: Modele dayalı nokta metrikleriyle değerlendirme
Not: Bu bölüm, sağlanan ücretsiz kredilerin sınırı içinde çalışmayabilir.
ROUGE kullanışlı olsa da yalnızca sözcüksel örtüşmeyi ölçer (yani yalnızca eşleşen kelimeleri sayar, bağlamı, eş anlamlıları veya yeniden ifadeyi anlamaz). Bu nedenle, bir yanıtın akıcı veya mantıklı olup olmadığını belirlemede en iyi seçenek değildir. Modelin performansını daha iyi anlamak için modele dayalı nokta metriklerini kullanırsınız.
Bu yöntemde, başka bir LLM ("Yargıç Modeli") her yanıtı akıcılık veya tutarlılık gibi önceden tanımlanmış bir dizi ölçüte göre ayrı ayrı değerlendirir.
Modele dayalı metrikler hakkında daha fazla bilgi edinin.
Noktasal değerlendirmeyi çalıştırma
- Etkileşimli bir açılır menü oluşturmak için yeni bir hücrede aşağıdakileri çalıştırın. Bu çalıştırma için listeden tutarlılık'ı seçin.
#Select a pointwise metric to use import ipywidgets as widgets pointwise_single_turn_metrics = [ metric for metric in MetricPromptTemplateExamples.list_example_metric_names() if not metric.startswith("pairwise") and not metric.startswith("multi_turn") ] dropdown = widgets.Dropdown( options=pointwise_single_turn_metrics, description="Select a metric:", font_weight="bold", style={"description_width": "initial"}, ) def dropdown_eventhandler(change): global POINTWISE_METRIC if change["type"] == "change" and change["name"] == "value": POINTWISE_METRIC = change.new print("Selected:", change.new) POINTWISE_METRIC = dropdown.value dropdown.observe(dropdown_eventhandler, names="value") display(dropdown) - Yeni bir hücrede
EvalTaskkomutunu tekrar çalıştırın. Bu kez seçilen modele dayalı metriği kullanın. Vertex AI Evaluation Service, Judge Model için bir istem oluşturur. Bu istemde orijinal istem, referans yanıt, aday modelin yanıtı ve seçilen metrikle ilgili talimatlar yer alır. Hakim modeli, sayısal bir puan ve derecelendirmesiyle ilgili bir açıklama döndürür. Not: Bu adımın tamamlanması birkaç dakika sürer.pointwise_result = EvalTask( dataset=dataset, metrics=[POINTWISE_METRIC], ).evaluate( model=model, prompt_template="# System_prompt\n{system_prompt} # Question\n{question}", )
Sonuçları görüntüleme
Değerlendirme tamamlandıktan sonraki adım, çıkışı analiz etmektir.
- Seçtiğiniz metriğin ortalama puanını gösteren özet metrikleri görüntülemek için yeni bir hücrede aşağıdaki kodu çalıştırın.
notebook_utils.display_eval_result(pointwise_result) - Puanla ilgili Yargıç Model'in yazılı gerekçesini de içeren satır satır dökümü görmek için sonraki hücrede aşağıdakileri çalıştırın. Bu niteliksel geri bildirim, bir yanıtın neden belirli bir şekilde puanlandığını anlamanıza yardımcı olur.
notebook_utils.display_explanations(pointwise_result, num=1, metrics=[POINTWISE_METRIC])
7. Daha ayrıntılı analizler için özel metrik oluşturma
Akıcılık gibi önceden oluşturulmuş metrikler faydalı olsa da belirli bir ürün için genellikle performansı kendi hedeflerinize göre ölçmeniz gerekir. Özel puan bazlı metriklerle kendi değerlendirme ölçütlerinizi ve puan anahtarınızı tanımlayabilirsiniz.
Bu görevde, summarization_helpfulness adlı yeni bir metriği sıfırdan oluşturmanız gerekiyor.
Özel metriği tanımlama ve çalıştırma
- Özel metriği tanımlamak için yeni bir hücrede aşağıdakileri çalıştırın.
PointwiseMetricPromptTemplate, metriğin yapı taşlarını içerir:- criteria: Yargıç modeline değerlendirilecek boyutları ("Temel Bilgiler", "Kısa ve Öz Olma" ve "Boşluk Yok") bildirir.
- rating_rubric: Her puanın ne anlama geldiğini tanımlayan 5 puanlık bir puanlama ölçeği sağlar.
- input_variables: Veri kümesindeki ek sütunları, değerlendirmeyi gerçekleştirmek için gereken bağlama sahip olması amacıyla Judge Model'e iletir.
# This new custom metric evaluates the actual quality and usefulness of the summary. summarization_helpfulness_metric = PointwiseMetric( metric="summarization_helpfulness", metric_prompt_template=PointwiseMetricPromptTemplate( criteria={ "Key Information": "Does the summary capture the most critical pieces of information from the original text? It should not miss the main topic or key takeaways.", "Conciseness": "Is the summary brief and to the point? It should avoid unnecessary words or repetitive information.", "No Distortion": "Does the summary introduce information or opinions that were NOT present in the original text? It must accurately reflect the source material without adding hallucinations." }, rating_rubric={ "5": "Excellent: Captures all key information, is highly concise, and has zero distortion.", "4": "Good: Captures most key information with minor omissions, is concise, and has no distortion.", "3": "Satisfactory: Captures the main idea but misses some key details OR is not very concise.", "2": "Unsatisfactory: Misses the main idea of the original text OR contains minor distortions/hallucinations.", "1": "Poor: Is completely irrelevant, fails to summarize the text, OR contains significant distortions.", }, input_variables=["prompt", "reference"], ), ) - Yeni özel metriğinizle
EvalTaskişlevini yürütmek için sonraki hücrede aşağıdaki kodu çalıştırın.# You would then update the EvalTask to use this new metric pointwise_result = EvalTask( dataset=dataset, metrics=[summarization_helpfulness_metric], ).evaluate( model=model, prompt_template="# System_prompt\n{system_prompt} # Question\n{question}", ) - Sonuçları görüntülemek için yeni bir hücrede aşağıdakileri çalıştırın.
notebook_utils.display_eval_result(pointwise_result)
8. Çiftler halinde değerlendirme ile modelleri karşılaştırma
Belirli bir görevde iki modelden hangisinin daha iyi performans gösterdiğine karar vermeniz gerektiğinde ikili karşılaştırmaya dayalı model değerlendirmesini kullanabilirsiniz. Bu yöntem, bir Yargıç Modeli'nin kazananı belirlediği bir A/B testi biçimidir ve veriye dayalı model seçimi için doğrudan karşılaştırma sağlar.
Modeller:
- Aday modeli: Model değişkeni (daha önce
gemini-2.0-flasholarak tanımlanmıştı).evaluate()yöntemine aktarılır. Bu, test ettiğiniz ana modeldir. - Temel model: PairwiseMetric sınıfında ikinci bir model,
gemini-2.0-flash-lite, belirtilir. Bu, karşılaştırma yaptığınız modeldir.
Çiftler halinde değerlendirmeyi çalıştırma
- Yeni bir hücrede, etkileşimli bir açılır menü oluşturmak için aşağıdaki kodu ekleyip çalıştırın. Bu sayede, karşılaştırma için hangi ikili metriği kullanmak istediğinizi seçebilirsiniz. Bu çalıştırma için pairwise_summarization_quality'yi seçin.
from IPython.display import display import ipywidgets as widgets pairwise_single_turn_metrics = [ metric for metric in MetricPromptTemplateExamples.list_example_metric_names() if metric.startswith("pairwise") and "multi_turn" not in metric ] dropdown = widgets.Dropdown( options=pairwise_single_turn_metrics, description="Select a metric:", font_weight="bold", style={"description_width": "initial"}, ) def dropdown_eventhandler(change): global POINTWISE_METRIC if change["type"] == "change" and change["name"] == "value": POINTWISE_METRIC = change.new print("Selected:", change.new) def dropdown_eventhandler(change): global PAIRWISE_METRIC_NAME if change["type"] == "change" and change["name"] == "value": PAIRWISE_METRIC_NAME = change.new print("Selected:", change.new) PAIRWISE_METRIC_NAME = dropdown.value dropdown.observe(dropdown_eventhandler, names="value") display(dropdown) - Bir sonraki hücrede,
EvalTask'yı yapılandırmak ve yürütmek için aşağıdaki kodu ekleyip çalıştırın.PairwiseMetricsınıfının temel modeli (gemini-2.0-flash-lite) tanımlamak için nasıl kullanıldığına, aday modelin (gemini-2.0-flash) ise.evaluate()yöntemine nasıl aktarıldığına dikkat edin.pairwise_result = EvalTask( dataset=dataset, metrics=[ PairwiseMetric( metric=PAIRWISE_METRIC_NAME, metric_prompt_template=MetricPromptTemplateExamples.get_prompt_template( PAIRWISE_METRIC_NAME ), # Define a baseline model to compare against baseline_model=GenerativeModel("gemini-2.0-flash-lite"), ) ], ).evaluate( # Specify a candidate model for pairwise comparison model=model, prompt_template="# System_prompt\n{system_prompt} # Question\n{question}", ) - Sonuçları görüntülemek için yeni bir hücreye aşağıdaki kodu ekleyip çalıştırın. Özet tablosunda her modelin "kazanma oranı" gösterilir. Bu oran, Yargıç Modelin hangi modeli daha sık tercih ettiğini belirtir.
notebook_utils.display_eval_result(pairwise_result)
9. İsteğe bağlı: Karakter odaklı istemleri değerlendirme
Not: Bu bölüm, sağlanan ücretsiz kredilerin sınırı içinde çalışmayabilir.
Bu görevde, modele farklı karakterler benimsemesini söyleyen birden fazla istem şablonunu test edeceksiniz. Genellikle istem mühendisliği veya istem tasarımı olarak adlandırılan bu süreç, belirli bir kullanım alanı için en etkili istemi sistematik olarak bulmanıza olanak tanır.
Özetleme veri kümesini hazırlama
Bu değerlendirmeyi gerçekleştirmek için veri kümesi aşağıdaki alanları içermelidir:
instruction: Modele verdiğimiz temel görev. Bu durumda, "Aşağıdaki makaleyi özetle:" şeklinde basit bir istem kullanılıyor.context: Modelin çalışması gereken kaynak metin. Burada dört farklı haber snippet'i verilmiştir.reference: Gerçek veya "altın standart" özet. Modelin oluşturduğu çıkış, ROUGE ve özetleme kalitesi gibi metriklerin puanlarını hesaplamak için bu metinle karşılaştırılır.
- Yeni bir hücrede, özetleme görevi için
pandas.DataFrameoluşturmak üzere aşağıdaki kodu ekleyip çalıştırın.instruction = "Summarize the following article: \n" context = [ "Typhoon Phanfone has killed at least one person, a US airman on Okinawa who was washed away by high waves. Thousands of households have lost power and Japan's two largest airlines have suspended many flights. The storm also forced the suspension of the search for people missing after last week's volcanic eruption. The storm-tracking website Tropical Storm Risk forecasts that Phanfone will rapidly lose power over the next few hours as it goes further into the Pacific Ocean. Typhoon Phanfone was downgraded from an earlier status of a super typhoon, but the Japan Meteorological Agency had warned it was still a dangerous storm. Japan averages 11 typhoons a year, according to its weather agency. The typhoon made landfall on Monday morning near the central city of Hamamatsu, with winds of up to 180 km/h (112 mph). The airman was one of three US military personnel swept away by high waves whipped up by the typhoon off southern Okinawa island, where the US has a large military base. The remaining two are still missing. A police spokesman said they had been taking photographs of the sea. A university student who was surfing off the seas of Kanagawa Prefecture, south of Tokyo, was also missing, national broadcast NHK reports. It said at least 10 people had been injured and 9,500 houses were without power. The storm was expected to deposit about 100mm of rain on Tokyo over 24 hours, according to the Transport Ministry website. Many schools were closed on Monday and two car companies in Japan halted production at some plants ahead of the storm. More than 174 domestic flights were affected nationwide, NHK state broadcaster said on Sunday. On Sunday, heavy rain delayed the Japanese Formula One Grand Prix in Suzaka. French driver Jules Bianchi lost control in the wet conditions and crashed, sustaining a severe head injury.", "The blaze started at the detached building in Drivers End in Codicote, near Welwyn, during the morning. There was another fire at the building 20 years ago, after which fire-proof foil was placed under the thatch, which is protecting the main building. More than 15 fire engines and support vehicles were called to tackle the blaze. Roads in the area were closed and traffic diverted.", 'The 18-year-old fell at the New Charter Academy on Broadoak Road in Ashton-under-Lyne at about 09:10 BST, Greater Manchester Police (GMP) said. GMP said he had gone to Manchester Royal Infirmary and his condition was "serious". Principal Jenny Langley said the school would remain "fully open" while police investigated. "Our thoughts are with the family and we\'re doing everything we can to support them along with staff and pupils," she said.', 'But Belgian-born Dutchman Max Verstappen was unable to drive a car legally on his own in either country. That all changed on Wednesday when the youngster turned 18 and passed his driving test at the first attempt. Despite having competed in 14 grands prix since his debut in Australia in March, Verstappen admitted to feeling the pressure during his test. "It\'s a relief," said the Toro Rosso driver, who finished ninth in Japan on Sunday and had only started driving lessons a week ago. "I was a bit nervous to make mistakes, but the exam went well." A bonus of turning 18 is that Verstappen will now be able to drink the champagne if he ever makes it onto the podium.', ] reference = [ "A powerful typhoon has brought many parts of Japan to a standstill and briefly battered Tokyo before heading out to sea.", "A major fire has been burning in the thatched roof of a large property in Hertfordshire.", "A student has been taken to hospital after falling from a balcony at a Greater Manchester school.", "He is Formula 1's youngest ever driver and in charge of a car that can reach over 200mph.", ] response = [ "Typhoon Phanfone, while downgraded from super typhoon status, caused significant disruption and tragedy in Japan. One US airman died after being swept away by high waves, with two more missing. The storm caused power outages for thousands, flight cancellations, and the suspension of rescue efforts for missing volcano victims. Heavy rain and strong winds led to school and factory closures, transportation disruptions, and at least 10 injuries. The typhoon is expected to weaken as it moves over the Pacific Ocean.", "A large fire broke out in a detached thatched building in Codicote, near Welwyn. This is the second fire at the building in 20 years. Thankfully, fire-proof foil installed after the previous fire is protecting the main building. Over 15 fire engines and support vehicles responded, closing roads and diverting traffic in the area.", "An 18-year-old student at New Charter Academy in Ashton-under-Lyne suffered a serious fall and was hospitalized. The incident is under investigation by Greater Manchester Police, but the school remains open. The principal expressed support for the student's family and the school community.", "Max Verstappen, a Formula One driver, was finally able to get his driver's license at age 18. Despite already competing in 14 Grand Prix races, he was not of legal driving age in his native countries. He admitted to being nervous but passed the test on his first attempt. As an added bonus of turning 18, Verstappen can now enjoy champagne on the podium if he places.", ] eval_dataset = pd.DataFrame( { "instruction": instruction, "context": context, "reference": reference, } )
İstem değerlendirme görevini çalıştırma
Özetleme veri kümesi hazır olduğunda bu görevin temel denemesini çalıştırmaya hazırsınız: Hangi istem şablonunun modelden en yüksek kaliteli çıktıyı ürettiğini görmek için birden fazla istem şablonunu karşılaştırma.
- Sonraki hücrede, her istem denemesinde yeniden kullanılacak tek bir
EvalTaskoluşturun.experimentparametresi ayarlandığında bu görevdeki tüm değerlendirme çalıştırmaları otomatik olarak Vertex AI Experiments'e kaydedilir ve gruplandırılır.EXPERIMENT_NAME = "eval-sdk-prompt-engineering" # @param {type:"string"} summarization_eval_task = EvalTask( dataset=eval_dataset, metrics=[ "rouge_l_sum", "bleu", "fluency", "coherence", "safety", "groundedness", "summarization_quality", "verbosity", "instruction_following", "text_quality", ], experiment=EXPERIMENT_NAME, )rouge_l_sumvebleugibi hesaplama metriklerinden model tabanlı çok çeşitli metriklere (fluency,coherence,summarization_quality,instruction_followingvb.) kadar her şeyi hesaplaması talimatı veriyoruz. Bu sayede, her istemin modelin çıkış kalitesi üzerindeki etkisine dair bütünsel ve 360 derecelik bir görünüm elde ederiz. - Yeni bir hücrede, dört karakter odaklı istem stratejisini tanımlamak ve değerlendirmek için aşağıdaki kodu ekleyip çalıştırın.
fordöngüsü her şablonu yineler ve bir değerlendirme çalıştırır.Her şablon, modele belirli bir karakter veya hedef vererek farklı bir özet stili elde etmek için tasarlanmıştır:- Karakter #1 (Standart): Nötr ve basit bir özetleme isteği.
- 2. Karakter (Yönetici): Yoğun bir yönetici gibi, sonuçlara ve etkiye odaklanarak madde işaretli bir özet istiyor.
- 3. Kişi (5. sınıf öğrencisi): Modelin basit bir dil kullanmasını isteyerek çıktısının karmaşıklığını ayarlama becerisini test eder.
- 4. Karakter (Teknik Analist): Anahtar istatistiklerin ve öğelerin korunduğu, modelin doğruluğunu test eden son derece olgusal bir özet ister. Bu yeni şablonlardaki
{context}ve{instruction}gibi yer tutucuların, bu görev için oluşturduğunuzeval_dataset'daki yeni sütun adlarıyla eşleştiğini unutmayın.
# Define prompt templates that target different user personas prompt_templates = [ # Persona 1: Standard, neutral summary "Article: {context}. Task: {instruction}. Summary:", # Persona 2: For a busy executive (bullet points) "Instruction: {instruction} into three key bullet points for a busy executive. Focus on the main outcome and impact. Article: {context}. Summary:", # Persona 3: For a 5th grader (simple language) "Instruction: {instruction} such that you're explaining it to a 10-year-old. Use simple words. Article: {context}. Summary:", # Persona 4: For a technical analyst (fact-focused) "Instruction: Provide a detailed, factual summary of the following text, ensuring all key statistics, names, and locations are preserved. Article: {context}. Summary:", ] eval_results = [] for i, prompt_template in enumerate(prompt_templates): eval_result = summarization_eval_task.evaluate( prompt_template=prompt_template, model=GenerativeModel( "gemini-2.0-flash", generation_config={ "temperature": 0.3, "max_output_tokens": 256, "top_k": 1, }, ), evaluation_service_qps=5, ) eval_results.append((f"Prompt Persona #{i+1}", eval_result))
Sonuçları analiz etme ve görselleştirme
İlk adım, denemeler yapmaktır. Gerçek değer, veriye dayalı bir karar vermek için sonuçları analiz etmekten gelir. Bu görevde, istem karakteri denemesinin çıktılarının yorumlanması için SDK'nın görselleştirme araçlarını kullanacaksınız.
- Aşağıdaki kodu yeni bir hücrede çalıştırarak test ettiğiniz dört istem karakterinin her birine ait özet sonuçları görüntüleyin. Bu sayede, performansla ilgili üst düzey bir nicel görünüm elde edersiniz.
for title, eval_result in eval_results: notebook_utils.display_eval_result(title=title, eval_result=eval_result) - Yeni bir hücrede, her karakter için
summarization_qualitymetriğinin gerekçesini görmek üzere aşağıdaki kodu ekleyip çalıştırın.for title, eval_result in eval_results: notebook_utils.display_explanations( eval_result, metrics=["summarization_quality"], num=2 ) - Her istem için farklı kalite metrikleri arasındaki dengeyi görselleştirmek üzere bir radar grafiği oluşturun. Yeni bir hücreye aşağıdaki kodu ekleyip çalıştırın.
notebook_utils.display_radar_plot( eval_results, metrics=["instruction_following", "fluency", "coherence", "text_quality"], ) - Daha doğrudan, yan yana bir karşılaştırma için çubuk grafiği oluşturun. Yeni bir hücreye aşağıdaki kodu ekleyip çalıştırın.
notebook_utils.display_bar_plot( eval_results, metrics=["instruction_following", "fluency", "coherence", "text_quality"], )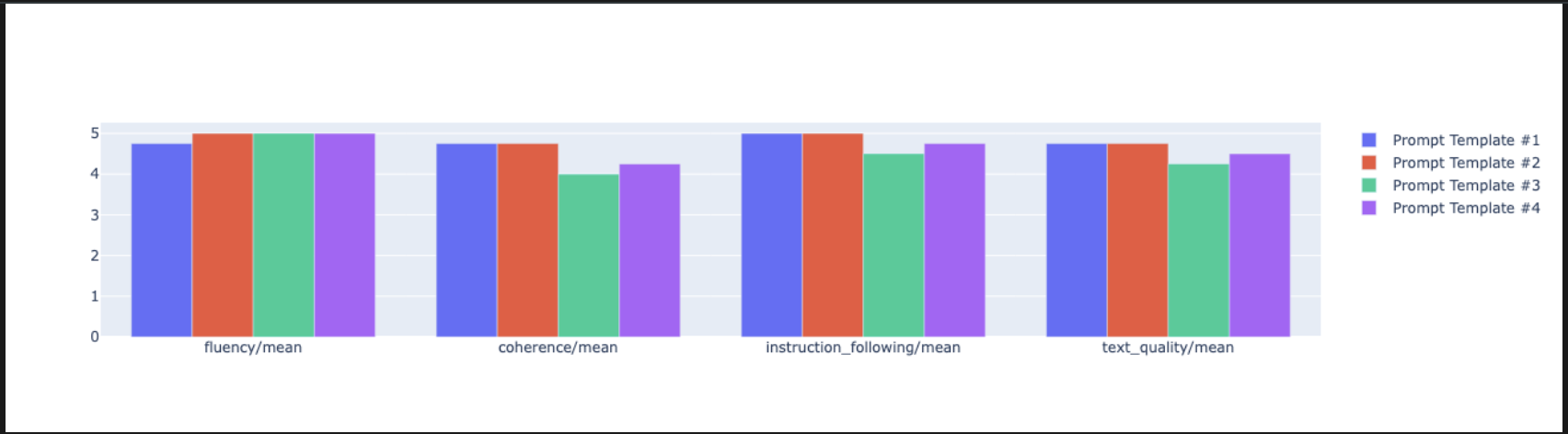
- Artık bu görev için Vertex AI Experiment'inize kaydedilen tüm çalıştırmaların özetini görüntüleyebilirsiniz. Bu, zaman içindeki çalışmalarınızı izlemek için yararlıdır. Yeni bir hücreye aşağıdaki kodu ekleyip çalıştırın:
summarization_eval_task.display_runs()
10. Denemeyi temizleme
Projenizi düzenli tutmak ve gereksiz ücretlerden kaçınmak için oluşturduğunuz kaynakları temizlemeniz önerilir. Bu laboratuvar boyunca her değerlendirme çalıştırması bir Vertex AI denemesine kaydedildi. Aşağıdaki kod, bu üst deneyi siler. Bu işlem, ilişkili tüm çalıştırmaları ve temel verilerini de kaldırır.
- Vertex AI denemesini ve ilişkili çalıştırmalarını silmek için bu kodu yeni bir hücrede çalıştırın.
delete_experiment = True # Please set your LOCATION to the same one used during Vertex AI SDK initialization. LOCATION = "YOUR LOCATION" # @param {type:"string"} if delete_experiment: from google.cloud import aiplatform aiplatform.init(project=PROJECT_ID, location=LOCATION) experiment = aiplatform.Experiment(EXPERIMENT_NAME) experiment.delete()
11. Pratikteki kullanımdan üretime
Bu laboratuvarda öğrendiğiniz beceriler, güvenilir yapay zeka uygulamaları oluşturmanın temelini oluşturur. Ancak manuel olarak çalıştırılan bir not defterinden üretime hazır bir değerlendirme sistemine geçmek için ek altyapı ve daha sistematik bir yaklaşım gerekir. Bu bölümde, ölçeği artırırken göz önünde bulundurmanız gereken temel uygulamalar ve stratejik çerçeveler özetlenmektedir.
Üretim değerlendirme stratejileri oluşturma
Bu laboratuvarda öğrendiğiniz becerileri üretim ortamında uygulamak için bunları tekrarlanabilir stratejiler haline getirmeniz faydalı olur. Aşağıdaki çerçeveler, model seçimi, istem optimizasyonu ve sürekli izleme gibi yaygın senaryolarda dikkate alınması gereken temel noktaları özetlemektedir.
Model seçimi için:
# Evaluation strategy for choosing models
evaluation_strategy = {
"dataset_size": "100+ examples for statistical significance",
"metrics": ["task-specific", "general quality", "efficiency"],
"comparison_type": "pairwise with statistical testing",
"baseline": "established_model_or_human_benchmark"
}
İstem optimizasyonu için
# Systematic prompt improvement workflow
prompt_optimization = {
"hypothesis": "Clear statement of what you're testing",
"variants": "3-5 different prompt strategies",
"evaluation": "Same metrics across all variants",
"analysis": "Statistical significance + qualitative review"
}
Sürekli izleme için
# Production evaluation pipeline
production_eval = {
"frequency": "Every model update + weekly monitoring",
"automation": "CI/CD integration with quality gates",
"metrics": "Speed + quality + cost tracking",
"alerting": "Performance degradation detection"
}
Maliyet etkinliğiyle ilgili dikkat edilmesi gereken noktalar
Modele dayalı değerlendirme, büyük ölçekte pahalı olabilir. Uygun maliyetli bir üretim stratejisinde, farklı amaçlar için farklı yöntemler kullanılır. Bu tabloda, farklı değerlendirme türleri için hız, maliyet ve kullanım alanı arasındaki denge özetlenmektedir:
Değerlendirme Türü | Saat | Örnek başına maliyet | Desteklendiği Cihazlar |
ROUGE/BLEU | Saniye | Yaklaşık 0,001 ABD doları | Yüksek hacimli süzme |
Model tabanlı nokta nokta | ~1-2 saniye | Yaklaşık 0,01 ABD doları | Kalite değerlendirmesi |
İkili Karşılaştırma | ~2-3 saniye | Yaklaşık 0,02 ABD doları | Model seçimi |
İnsan Değerlendirmesi | Dakika | 1-10 ABD doları | Altın standart doğrulama |
CI/CD ve izleme ile otomasyon
Manuel not defteri çalıştırmaları ölçeklenebilir değildir. Sürekli entegrasyon/sürekli dağıtım (CI/CD) ardışık düzeninde değerlendirmenizi otomatikleştirin.
- Kalite kapıları oluşturma: Değerlendirme görevinizi bir CI/CD ardışık düzenine (ör. Cloud Build) entegre edin. Yeni istemler veya modeller üzerinde otomatik olarak değerlendirmeler yapın ve temel kalite puanları tanımladığınız eşiklerin altına düşerse dağıtımları engelleyin.
- Trendleri izleme: Değerlendirme çalıştırmalarınızdaki özet metrikleri Google Cloud Monitoring gibi bir hizmete aktarın. Zaman içindeki kaliteyi izlemek için kontrol panelleri oluşturun ve ekibinizi önemli performans düşüşleri konusunda bilgilendirmek için otomatik uyarılar ayarlayın.
12. Sonuç
Laboratuvarı tamamladınız. Üretken yapay zeka modellerini değerlendirmek için gereken temel becerileri öğrendiniz.
Bu laboratuvar, Google Cloud ile Üretime Hazır Yapay Zeka öğrenme rotasının bir parçasıdır.
- Prototip aşamasından üretim aşamasına geçiş yapmak için tüm müfredatı inceleyin.
- İlerleme durumunuzu
ProductionReadyAIhashtag'iyle paylaşın.
Özet
Bu laboratuvarda şunları öğrendiniz:
EvalTaskçerçevesini kullanarak değerlendirmeyle ilgili en iyi uygulamaları uygulayın.- Hesaplamaya dayalı olanlardan modele dayalı olanlara kadar farklı metrik türleri kullanın.
- Farklı versiyonları test ederek istemleri optimize edin.
- Deneme izleme ile tekrarlanabilir bir iş akışı oluşturun.
Sürekli öğrenme kaynakları
- Vertex AI Üretken Yapay Zeka Değerlendirme Belgeleri
- Gelişmiş Değerlendirme Teknikleri Not Defterleri
- Gen AI Evaluation SDK Reference (Gen AI Evaluation SDK Referansı)
- Model Tabanlı Metrikler Araştırması
- İstem Mühendisliği ile İlgili En İyi Uygulamalar
Bu laboratuvarda öğrendiğiniz sistematik değerlendirme yaklaşımları, güvenilir ve yüksek kaliteli yapay zeka uygulamaları oluşturmak için temel oluşturacaktır. Unutmayın: İyi bir değerlendirme, deneysel yapay zeka ile üretim başarısı arasındaki köprüdür.