
1. Tổng quan
Trong phòng thí nghiệm này, bạn sẽ tìm hiểu cách đánh giá các mô hình ngôn ngữ lớn bằng Dịch vụ đánh giá AI tạo sinh của Vertex AI. Bạn sẽ sử dụng SDK để chạy các tác vụ đánh giá, so sánh kết quả và đưa ra quyết định dựa trên dữ liệu về hiệu suất mô hình và thiết kế câu lệnh.
Phòng thí nghiệm này sẽ hướng dẫn bạn quy trình đánh giá phổ biến, bắt đầu bằng các chỉ số đơn giản dựa trên tính toán và tiến đến các đánh giá tinh tế hơn dựa trên mô hình. Bạn cũng sẽ học cách tạo các chỉ số tuỳ chỉnh phù hợp với mục tiêu cụ thể của mình và theo dõi tiến trình công việc bằng Vertex AI Experiments.
Kiến thức bạn sẽ học được
Trong bài thực hành này, bạn sẽ tìm hiểu cách thực hiện các thao tác sau:
- Đánh giá một mô hình bằng các chỉ số dựa trên tính toán và dựa trên mô hình.
- Tạo chỉ số tuỳ chỉnh để điều chỉnh việc đánh giá cho phù hợp với mục tiêu của sản phẩm.
- So sánh song song các mẫu câu lệnh khác nhau.
- Thử nghiệm nhiều câu lệnh dựa trên tính cách để tìm ra phiên bản hiệu quả nhất.
- Theo dõi và trực quan hoá các lần đánh giá bằng Vertex AI Experiments.
Tài liệu tham khảo
- Mã mẫu: Lớp học này dựa trên các ví dụ trong kho lưu trữ AI tạo sinh của Google Cloud
- Dựa trên: Tài liệu Đánh giá AI tạo sinh của Vertex AI
- Tập dữ liệu: Tập dữ liệu OpenOrca để đánh giá khả năng làm theo chỉ dẫn
2. Thiết lập dự án
Tài khoản Google
Nếu chưa có Tài khoản Google cá nhân, bạn phải tạo một Tài khoản Google.
Sử dụng tài khoản cá nhân thay vì tài khoản do nơi làm việc hoặc trường học cấp.
Đăng nhập vào Google Cloud Console
Đăng nhập vào Google Cloud Console bằng Tài khoản Google cá nhân.
Bật thanh toán
Để bật tính năng thanh toán, bạn có 2 lựa chọn. Bạn có thể sử dụng tài khoản thanh toán cá nhân hoặc đổi tín dụng theo các bước sau.
Sử dụng tín dụng Google Cloud (không bắt buộc)
Để tham gia hội thảo này, bạn cần có một tài khoản thanh toán có sẵn một số tín dụng. Hãy sử dụng tín dụng trong biểu ngữ ở đầu lớp học lập trình này để bắt đầu. Nếu đã kết nối với một tài khoản thanh toán, bạn có thể bỏ qua bước này.
Thiết lập tài khoản thanh toán cá nhân
Nếu thiết lập thông tin thanh toán bằng tín dụng Google Cloud, bạn có thể bỏ qua bước này.
Để thiết lập tài khoản thanh toán cá nhân, hãy truy cập vào đây để bật tính năng thanh toán trong Cloud Console.
Một số lưu ý:
- Việc hoàn thành bài thực hành này sẽ tốn ít hơn 1 USD cho các tài nguyên trên đám mây.
- Bạn có thể làm theo các bước ở cuối bài thực hành này để xoá tài nguyên nhằm tránh bị tính thêm phí.
- Người dùng mới đủ điều kiện dùng thử miễn phí trị giá 300 USD.
Tạo dự án (không bắt buộc)
Nếu bạn không có dự án hiện tại nào muốn sử dụng cho lớp học này, hãy tạo một dự án mới tại đây.
3. Thiết lập môi trường Vertex AI Workbench
Hãy bắt đầu bằng cách truy cập vào môi trường sổ tay đã được định cấu hình trước và cài đặt các phần phụ thuộc cần thiết.
Truy cập vào Vertex AI Workbench
- Trong Google Cloud Console, hãy chuyển đến Vertex AI bằng cách nhấp vào Trình đơn điều hướng ☰ > Vertex AI > Trang tổng quan.
- Nhấp vào Bật tất cả API được đề xuất. Lưu ý: Vui lòng chờ bước này hoàn tất
- Ở phía bên trái, hãy nhấp vào Workbench để tạo một phiên bản workbench mới.
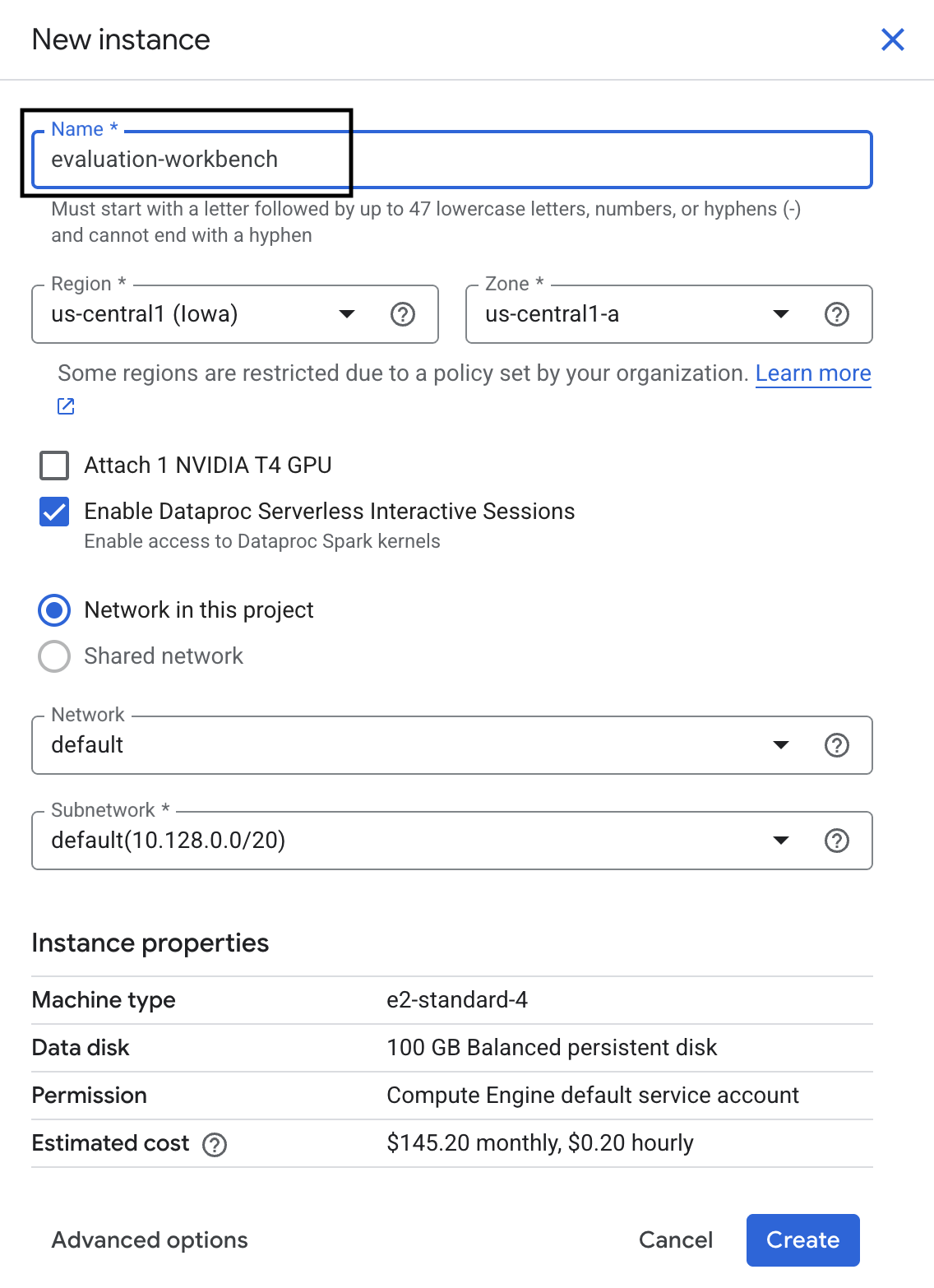
- Đặt tên cho phiên bản workbench là evaluation-workbench rồi nhấp vào Create (Tạo).
- Chờ cho đến khi băng ghế được thiết lập. Quá trình này có thể mất vài phút.

- Sau khi cung cấp băng ghế dự bị, hãy nhấp vào Mở JupyterLab.
- Trong môi trường làm việc, hãy tạo một sổ tay Python3 mới.
Để tìm hiểu thêm về các tính năng và chức năng của môi trường này, hãy xem tài liệu chính thức về Vertex AI Workbench.
Cài đặt các gói và định cấu hình môi trường
- Trong ô đầu tiên của sổ tay, hãy thêm và chạy các câu lệnh nhập bên dưới (SHIFT+ENTER) để cài đặt Vertex AI SDK (có các thành phần đánh giá) và các gói bắt buộc khác.
%pip install -U -q google-cloud-aiplatform[evaluation] %pip install -U -q datasets anthropic[vertex] openai - Để sử dụng các gói mới cài đặt, bạn nên khởi động lại nhân bằng cách chạy đoạn mã bên dưới.
# Automatically restart kernel after installation so that your environment can access the new packages. import IPython app = IPython.Application.instance() app.kernel.do_shutdown(True) - Thay thế nội dung sau bằng mã dự án và vị trí của bạn rồi chạy ô sau. Vị trí mặc định được đặt là
europe-west1nhưng bạn nên sử dụng cùng vị trí với phiên bản Workbench Vertex AI.# Configure your project settings PROJECT_ID = "YOUR PROJECT ID" LOCATION = "europe-west1" - Nhập tất cả các thư viện python cần thiết cho phòng thí nghiệm này bằng cách chạy mã sau trong một ô mới.
from anthropic import AnthropicVertex from google.auth import default, transport import openai import pandas as pd from vertexai.evaluation import ( EvalTask, MetricPromptTemplateExamples, PairwiseMetric, PointwiseMetric, PointwiseMetricPromptTemplate, ) from vertexai.generative_models import GenerativeModel from vertexai.preview.evaluation import notebook_utils
4. Thiết lập tập dữ liệu đánh giá
Trong hướng dẫn này, chúng ta sẽ sử dụng 10 mẫu từ tập dữ liệu OpenOrca. Điều này giúp chúng tôi có đủ dữ liệu để nhận thấy những điểm khác biệt có ý nghĩa giữa các mô hình trong khi vẫn duy trì được thời gian đánh giá hợp lý.
💡 Mẹo nâng cao: Trong quá trình phát hành công khai, bạn nên có từ 100 đến 500 ví dụ để có kết quả có ý nghĩa thống kê, nhưng 10 mẫu là con số lý tưởng để học tập và tạo mẫu nhanh!
Chuẩn bị tập dữ liệu
- Trong một ô mới, hãy chạy ô sau để tải dữ liệu, chuyển đổi dữ liệu đó thành một pandas DataFrame và đổi tên cột
responsethànhreferenceđể cho rõ ràng trong các tác vụ đánh giá của chúng ta, đồng thời tạo mẫu ngẫu nhiên gồm 10 ví dụ.from datasets import load_dataset ds = ( load_dataset( "Open-Orca/OpenOrca", data_files="1M-GPT4-Augmented.parquet", split="train[:100]", ) .to_pandas() .drop(columns=["id"]) .rename(columns={"response": "reference"}) ) dataset = ds.sample(n=10) - Sau khi ô trước đó chạy xong, trong ô tiếp theo, hãy thêm và chạy mã sau để hiển thị một vài hàng đầu tiên của tập dữ liệu đánh giá.
dataset.head()
5. Thiết lập đường cơ sở bằng các chỉ số dựa trên tính toán
Trong nhiệm vụ này, bạn sẽ thiết lập điểm cơ sở bằng cách sử dụng chỉ số dựa trên tính toán. Phương pháp này nhanh chóng và cung cấp một điểm chuẩn khách quan để đo lường những điểm cải thiện trong tương lai.
Chúng tôi sẽ sử dụng ROUGE (Recall-Oriented Understudy for Gisting Evaluation – Nghiên cứu phụ trợ định hướng thu hồi để đánh giá tóm tắt), một chỉ số tiêu chuẩn cho các tác vụ tóm tắt. Phương pháp này hoạt động bằng cách so sánh chuỗi từ (n-gram) trong câu trả lời do mô hình tạo với các từ trong văn bản reference thông tin thực tế.
Đọc thêm về các chỉ số dựa trên phép tính.
Chạy quy trình đánh giá cơ sở
- Trong một ô mới, hãy thêm và chạy ô sau để xác định mô hình mà bạn muốn kiểm thử,
gemini-2.0-flash.generation_configbao gồm các tham số nhưtemperaturevàmax_output_tokensảnh hưởng đến đầu ra của mô hình.# Model to be evaluated model = GenerativeModel( "gemini-2.0-flash", generation_config={"temperature": 0.6, "max_output_tokens": 256, "top_k": 1}, )GenerativeModellà giao diện chính để tương tác với các mô hình ngôn ngữ lớn trong Vertex AI SDK. - Trong ô tiếp theo, hãy thêm và chạy mã sau để tạo và thực thi
EvalTask. Đối tượng này trong Vertex AI Evaluation SDK điều phối quá trình đánh giá. Bạn định cấu hình chỉ số này bằng tập dữ liệu và các chỉ số cần tính toán, trong trường hợp này làrouge_l_sum.# Define an EvalTask with ROUGE-L-SUM metric rouge_eval_task = EvalTask( dataset=dataset, metrics=["rouge_l_sum"], ) rouge_result = rouge_eval_task.evaluate( model=model, prompt_template="# System_prompt\n{system_prompt} # Question\n{question}", ) - Hiển thị kết quả bằng cách chạy mã này trong ô tiếp theo.
notebook_utils.display_eval_result(rouge_result)display_eval_result()cho biết điểm trung bình và kết quả theo từng hàng.
6. Không bắt buộc: Đánh giá bằng các chỉ số theo điểm dựa trên mô hình
Lưu ý: Phần này có thể không chạy trong giới hạn của tín dụng miễn phí được cung cấp.
Mặc dù ROUGE rất hữu ích, nhưng chỉ đo lường mức độ trùng lặp từ vựng (tức là chỉ đếm các từ trùng khớp, không hiểu ngữ cảnh, từ đồng nghĩa hoặc cách diễn đạt lại). Vì vậy, mô hình này không phải là lựa chọn tốt nhất để xác định xem một câu trả lời có trôi chảy hay hợp lý hay không. Để hiểu rõ hơn về hiệu suất của mô hình, bạn có thể sử dụng các chỉ số theo từng điểm dựa trên mô hình.
Với phương pháp này, một LLM khác ("Mô hình đánh giá") sẽ đánh giá từng câu trả lời riêng lẻ dựa trên một bộ tiêu chí được xác định trước, chẳng hạn như mức độ trôi chảy hoặc mạch lạc.
Đọc thêm về các chỉ số dựa trên mô hình.
Chạy quy trình đánh giá từng điểm
- Chạy đoạn mã sau trong một ô mới để tạo một trình đơn thả xuống có tính tương tác. Đối với lần chạy này, hãy chọn coherence trong danh sách.
#Select a pointwise metric to use import ipywidgets as widgets pointwise_single_turn_metrics = [ metric for metric in MetricPromptTemplateExamples.list_example_metric_names() if not metric.startswith("pairwise") and not metric.startswith("multi_turn") ] dropdown = widgets.Dropdown( options=pointwise_single_turn_metrics, description="Select a metric:", font_weight="bold", style={"description_width": "initial"}, ) def dropdown_eventhandler(change): global POINTWISE_METRIC if change["type"] == "change" and change["name"] == "value": POINTWISE_METRIC = change.new print("Selected:", change.new) POINTWISE_METRIC = dropdown.value dropdown.observe(dropdown_eventhandler, names="value") display(dropdown) - Trong một ô mới, hãy chạy lại
EvalTask, lần này sử dụng chỉ số dựa trên mô hình đã chọn. Vertex AI Evaluation Service tạo một câu lệnh cho Judge Model, bao gồm câu lệnh ban đầu, câu trả lời tham chiếu, câu trả lời của mô hình đề xuất và hướng dẫn cho chỉ số đã chọn. Mô hình đánh giá trả về điểm số bằng số và giải thích cho điểm xếp hạng của mô hình đó. Lưu ý: Bước này sẽ mất vài phút để chạy.pointwise_result = EvalTask( dataset=dataset, metrics=[POINTWISE_METRIC], ).evaluate( model=model, prompt_template="# System_prompt\n{system_prompt} # Question\n{question}", )
Hiện kết quả
Sau khi hoàn tất quy trình đánh giá, bước tiếp theo là phân tích kết quả.
- Chạy mã sau đây trong một ô mới để xem các chỉ số tóm tắt, cho biết điểm trung bình cho chỉ số bạn đã chọn.
notebook_utils.display_eval_result(pointwise_result) - Chạy nội dung sau trong ô tiếp theo để xem thông tin chi tiết theo từng hàng, bao gồm cả lý do bằng văn bản của Mô hình đánh giá cho điểm số của mô hình đó. Ý kiến phản hồi định tính này giúp bạn hiểu lý do một câu trả lời được chấm điểm theo một cách nhất định.
notebook_utils.display_explanations(pointwise_result, num=1, metrics=[POINTWISE_METRIC])
7. Tạo chỉ số tuỳ chỉnh để có thông tin chi tiết chuyên sâu hơn
Các chỉ số được tạo sẵn như độ lưu loát rất hữu ích, nhưng đối với một sản phẩm cụ thể, bạn thường cần đo lường hiệu suất dựa trên mục tiêu của riêng mình. Với các chỉ số tuỳ chỉnh theo điểm, bạn có thể xác định tiêu chí và thang điểm đánh giá của riêng mình.
Trong nhiệm vụ này, bạn sẽ tạo một chỉ số mới từ đầu có tên là summarization_helpfulness.
Xác định và chạy chỉ số tuỳ chỉnh
- Chạy đoạn mã sau trong một ô mới để xác định chỉ số tuỳ chỉnh.
PointwiseMetricPromptTemplatechứa các khối dựng cho chỉ số:- tiêu chí: Cho Mô hình đánh giá biết các phương diện cụ thể cần đánh giá: "Thông tin chính", "Tính súc tích" và "Không xuyên tạc".
- rating_rubric: Cung cấp thang điểm 5 điểm để xác định ý nghĩa của từng điểm số.
- input_variables: Truyền các cột bổ sung từ tập dữ liệu đến Mô hình đánh giá để mô hình này có ngữ cảnh cần thiết để thực hiện việc đánh giá.
# This new custom metric evaluates the actual quality and usefulness of the summary. summarization_helpfulness_metric = PointwiseMetric( metric="summarization_helpfulness", metric_prompt_template=PointwiseMetricPromptTemplate( criteria={ "Key Information": "Does the summary capture the most critical pieces of information from the original text? It should not miss the main topic or key takeaways.", "Conciseness": "Is the summary brief and to the point? It should avoid unnecessary words or repetitive information.", "No Distortion": "Does the summary introduce information or opinions that were NOT present in the original text? It must accurately reflect the source material without adding hallucinations." }, rating_rubric={ "5": "Excellent: Captures all key information, is highly concise, and has zero distortion.", "4": "Good: Captures most key information with minor omissions, is concise, and has no distortion.", "3": "Satisfactory: Captures the main idea but misses some key details OR is not very concise.", "2": "Unsatisfactory: Misses the main idea of the original text OR contains minor distortions/hallucinations.", "1": "Poor: Is completely irrelevant, fails to summarize the text, OR contains significant distortions.", }, input_variables=["prompt", "reference"], ), ) - Chạy mã sau trong ô tiếp theo để thực thi
EvalTaskbằng chỉ số tùy chỉnh mới của bạn.# You would then update the EvalTask to use this new metric pointwise_result = EvalTask( dataset=dataset, metrics=[summarization_helpfulness_metric], ).evaluate( model=model, prompt_template="# System_prompt\n{system_prompt} # Question\n{question}", ) - Chạy đoạn mã sau trong một ô mới để hiển thị kết quả.
notebook_utils.display_eval_result(pointwise_result)
8. So sánh các mô hình bằng cách đánh giá theo cặp
Khi cần quyết định xem mô hình nào trong số hai mô hình hoạt động hiệu quả hơn trong một tác vụ cụ thể, bạn có thể sử dụng phương pháp đánh giá dựa trên mô hình theo cặp. Phương pháp này là một dạng thử nghiệm A/B, trong đó Mô hình đánh giá sẽ xác định mô hình hiệu quả nhất, giúp so sánh trực tiếp để chọn mô hình dựa trên dữ liệu.
Các mô hình:
- Mô hình đề xuất: Biến mô hình (trước đây được xác định là
gemini-2.0-flash) được truyền vào phương thức.evaluate(). Đây là mô hình chính mà bạn đang kiểm thử. - Mô hình cơ sở: Mô hình thứ hai,
gemini-2.0-flash-lite, được chỉ định trong lớp PairwiseMetric. Đây là mô hình mà bạn đang so sánh.
Chạy quy trình đánh giá theo cặp
- Trong một ô mới, hãy thêm và chạy mã sau để tạo một trình đơn thả xuống có tính tương tác. Thao tác này sẽ cho phép bạn chọn chỉ số theo cặp mà bạn muốn dùng để so sánh. Đối với lần chạy này, hãy chọn pairwise_summarization_quality.
from IPython.display import display import ipywidgets as widgets pairwise_single_turn_metrics = [ metric for metric in MetricPromptTemplateExamples.list_example_metric_names() if metric.startswith("pairwise") and "multi_turn" not in metric ] dropdown = widgets.Dropdown( options=pairwise_single_turn_metrics, description="Select a metric:", font_weight="bold", style={"description_width": "initial"}, ) def dropdown_eventhandler(change): global POINTWISE_METRIC if change["type"] == "change" and change["name"] == "value": POINTWISE_METRIC = change.new print("Selected:", change.new) def dropdown_eventhandler(change): global PAIRWISE_METRIC_NAME if change["type"] == "change" and change["name"] == "value": PAIRWISE_METRIC_NAME = change.new print("Selected:", change.new) PAIRWISE_METRIC_NAME = dropdown.value dropdown.observe(dropdown_eventhandler, names="value") display(dropdown) - Trong ô tiếp theo, hãy thêm và chạy mã sau để định cấu hình và thực thi
EvalTask. Hãy lưu ý cách lớpPairwiseMetricđược dùng để xác định mô hình cơ sở (gemini-2.0-flash-lite), trong khi mô hình đề xuất (gemini-2.0-flash) được truyền vào phương thức.evaluate().pairwise_result = EvalTask( dataset=dataset, metrics=[ PairwiseMetric( metric=PAIRWISE_METRIC_NAME, metric_prompt_template=MetricPromptTemplateExamples.get_prompt_template( PAIRWISE_METRIC_NAME ), # Define a baseline model to compare against baseline_model=GenerativeModel("gemini-2.0-flash-lite"), ) ], ).evaluate( # Specify a candidate model for pairwise comparison model=model, prompt_template="# System_prompt\n{system_prompt} # Question\n{question}", ) - Trong một ô mới, hãy thêm và chạy đoạn mã sau để hiển thị kết quả. Bảng tóm tắt sẽ cho biết "tỷ lệ chiến thắng" của từng mô hình, cho biết Mô hình đánh giá thích mô hình nào hơn.
notebook_utils.display_eval_result(pairwise_result)
9. Không bắt buộc: Đánh giá câu lệnh dựa trên tính cách
Lưu ý: Phần này có thể không chạy trong giới hạn của tín dụng miễn phí được cung cấp.
Trong tác vụ này, bạn sẽ kiểm thử nhiều mẫu câu lệnh hướng dẫn mô hình áp dụng các vai trò khác nhau. Quy trình này (thường được gọi là kỹ thuật đặt câu lệnh hoặc thiết kế câu lệnh) cho phép bạn tìm ra câu lệnh hiệu quả nhất cho một trường hợp sử dụng cụ thể một cách có hệ thống.
Chuẩn bị tập dữ liệu tóm tắt
Để thực hiện quy trình đánh giá này, tập dữ liệu cần chứa các trường sau:
instruction: Tác vụ cốt lõi mà chúng ta giao cho mô hình. Trong trường hợp này, đó là một câu lệnh đơn giản "Tóm tắt bài viết sau:".context: Văn bản nguồn mà mô hình cần xử lý. Ở đây, chúng tôi đã cung cấp 4 đoạn tin tức khác nhau.reference: Bản tóm tắt thực tế hoặc "tiêu chuẩn vàng". Đầu ra do mô hình tạo sẽ được so sánh với văn bản này để tính điểm cho các chỉ số như ROUGE và chất lượng tóm tắt.
- Trong một ô mới, hãy thêm và chạy mã sau để tạo
pandas.DataFramecho tác vụ tóm tắt.instruction = "Summarize the following article: \n" context = [ "Typhoon Phanfone has killed at least one person, a US airman on Okinawa who was washed away by high waves. Thousands of households have lost power and Japan's two largest airlines have suspended many flights. The storm also forced the suspension of the search for people missing after last week's volcanic eruption. The storm-tracking website Tropical Storm Risk forecasts that Phanfone will rapidly lose power over the next few hours as it goes further into the Pacific Ocean. Typhoon Phanfone was downgraded from an earlier status of a super typhoon, but the Japan Meteorological Agency had warned it was still a dangerous storm. Japan averages 11 typhoons a year, according to its weather agency. The typhoon made landfall on Monday morning near the central city of Hamamatsu, with winds of up to 180 km/h (112 mph). The airman was one of three US military personnel swept away by high waves whipped up by the typhoon off southern Okinawa island, where the US has a large military base. The remaining two are still missing. A police spokesman said they had been taking photographs of the sea. A university student who was surfing off the seas of Kanagawa Prefecture, south of Tokyo, was also missing, national broadcast NHK reports. It said at least 10 people had been injured and 9,500 houses were without power. The storm was expected to deposit about 100mm of rain on Tokyo over 24 hours, according to the Transport Ministry website. Many schools were closed on Monday and two car companies in Japan halted production at some plants ahead of the storm. More than 174 domestic flights were affected nationwide, NHK state broadcaster said on Sunday. On Sunday, heavy rain delayed the Japanese Formula One Grand Prix in Suzaka. French driver Jules Bianchi lost control in the wet conditions and crashed, sustaining a severe head injury.", "The blaze started at the detached building in Drivers End in Codicote, near Welwyn, during the morning. There was another fire at the building 20 years ago, after which fire-proof foil was placed under the thatch, which is protecting the main building. More than 15 fire engines and support vehicles were called to tackle the blaze. Roads in the area were closed and traffic diverted.", 'The 18-year-old fell at the New Charter Academy on Broadoak Road in Ashton-under-Lyne at about 09:10 BST, Greater Manchester Police (GMP) said. GMP said he had gone to Manchester Royal Infirmary and his condition was "serious". Principal Jenny Langley said the school would remain "fully open" while police investigated. "Our thoughts are with the family and we\'re doing everything we can to support them along with staff and pupils," she said.', 'But Belgian-born Dutchman Max Verstappen was unable to drive a car legally on his own in either country. That all changed on Wednesday when the youngster turned 18 and passed his driving test at the first attempt. Despite having competed in 14 grands prix since his debut in Australia in March, Verstappen admitted to feeling the pressure during his test. "It\'s a relief," said the Toro Rosso driver, who finished ninth in Japan on Sunday and had only started driving lessons a week ago. "I was a bit nervous to make mistakes, but the exam went well." A bonus of turning 18 is that Verstappen will now be able to drink the champagne if he ever makes it onto the podium.', ] reference = [ "A powerful typhoon has brought many parts of Japan to a standstill and briefly battered Tokyo before heading out to sea.", "A major fire has been burning in the thatched roof of a large property in Hertfordshire.", "A student has been taken to hospital after falling from a balcony at a Greater Manchester school.", "He is Formula 1's youngest ever driver and in charge of a car that can reach over 200mph.", ] response = [ "Typhoon Phanfone, while downgraded from super typhoon status, caused significant disruption and tragedy in Japan. One US airman died after being swept away by high waves, with two more missing. The storm caused power outages for thousands, flight cancellations, and the suspension of rescue efforts for missing volcano victims. Heavy rain and strong winds led to school and factory closures, transportation disruptions, and at least 10 injuries. The typhoon is expected to weaken as it moves over the Pacific Ocean.", "A large fire broke out in a detached thatched building in Codicote, near Welwyn. This is the second fire at the building in 20 years. Thankfully, fire-proof foil installed after the previous fire is protecting the main building. Over 15 fire engines and support vehicles responded, closing roads and diverting traffic in the area.", "An 18-year-old student at New Charter Academy in Ashton-under-Lyne suffered a serious fall and was hospitalized. The incident is under investigation by Greater Manchester Police, but the school remains open. The principal expressed support for the student's family and the school community.", "Max Verstappen, a Formula One driver, was finally able to get his driver's license at age 18. Despite already competing in 14 Grand Prix races, he was not of legal driving age in his native countries. He admitted to being nervous but passed the test on his first attempt. As an added bonus of turning 18, Verstappen can now enjoy champagne on the podium if he places.", ] eval_dataset = pd.DataFrame( { "instruction": instruction, "context": context, "reference": reference, } )
Chạy tác vụ đánh giá câu lệnh
Sau khi chuẩn bị tập dữ liệu tóm tắt, bạn đã sẵn sàng chạy thử nghiệm cốt lõi của nhiệm vụ này: so sánh nhiều mẫu câu lệnh để xem mẫu nào tạo ra kết quả có chất lượng cao nhất từ mô hình.
- Trong ô tiếp theo, hãy tạo một
EvalTaskduy nhất sẽ được dùng lại cho mỗi thử nghiệm về câu lệnh. Bằng cách đặt tham sốexperiment, tất cả các lần chạy đánh giá từ tác vụ này sẽ được tự động ghi nhật ký và nhóm trong Vertex AI Experiments.EXPERIMENT_NAME = "eval-sdk-prompt-engineering" # @param {type:"string"} summarization_eval_task = EvalTask( dataset=eval_dataset, metrics=[ "rouge_l_sum", "bleu", "fluency", "coherence", "safety", "groundedness", "summarization_quality", "verbosity", "instruction_following", "text_quality", ], experiment=EXPERIMENT_NAME, )rouge_l_sumvàbleucho đến nhiều chỉ số dựa trên mô hình (fluency,coherence,summarization_quality,instruction_following, v.v.). Điều này giúp chúng tôi có được cái nhìn toàn diện, 360 độ về mức độ ảnh hưởng của từng câu lệnh đến chất lượng đầu ra của mô hình. - Trong một ô mới, hãy thêm và chạy mã sau đây để xác định và đánh giá 4 chiến lược câu lệnh dựa trên tính cách. Vòng lặp
forlặp lại qua từng mẫu và chạy một quy trình đánh giá.Mỗi mẫu được thiết kế để tạo ra một kiểu tóm tắt khác nhau bằng cách cung cấp cho mô hình một tính cách hoặc mục tiêu cụ thể:- Nhân vật #1 (Tiêu chuẩn): Yêu cầu tóm tắt trung lập và đơn giản.
- Nhân vật mẫu số 2 (Nhà quản lý): Yêu cầu tóm tắt bằng dấu đầu dòng, tập trung vào kết quả và mức độ tác động, vì một nhà quản lý bận rộn sẽ thích điều này.
- Nhân vật mẫu số 3 (học sinh lớp 5): Hướng dẫn mô hình sử dụng ngôn ngữ đơn giản, kiểm tra khả năng điều chỉnh độ phức tạp của đầu ra.
- Nhân vật #4 (Nhà phân tích kỹ thuật): Yêu cầu bản tóm tắt có độ chính xác cao, trong đó các số liệu thống kê và thực thể chính được giữ nguyên, nhằm kiểm tra độ chính xác của mô hình. Lưu ý rằng các phần giữ chỗ trong những mẫu mới này, chẳng hạn như
{context}và{instruction}, khớp với tên cột mới trongeval_datasetmà bạn đã tạo cho nhiệm vụ này.
# Define prompt templates that target different user personas prompt_templates = [ # Persona 1: Standard, neutral summary "Article: {context}. Task: {instruction}. Summary:", # Persona 2: For a busy executive (bullet points) "Instruction: {instruction} into three key bullet points for a busy executive. Focus on the main outcome and impact. Article: {context}. Summary:", # Persona 3: For a 5th grader (simple language) "Instruction: {instruction} such that you're explaining it to a 10-year-old. Use simple words. Article: {context}. Summary:", # Persona 4: For a technical analyst (fact-focused) "Instruction: Provide a detailed, factual summary of the following text, ensuring all key statistics, names, and locations are preserved. Article: {context}. Summary:", ] eval_results = [] for i, prompt_template in enumerate(prompt_templates): eval_result = summarization_eval_task.evaluate( prompt_template=prompt_template, model=GenerativeModel( "gemini-2.0-flash", generation_config={ "temperature": 0.3, "max_output_tokens": 256, "top_k": 1, }, ), evaluation_service_qps=5, ) eval_results.append((f"Prompt Persona #{i+1}", eval_result))
Phân tích và trực quan hoá kết quả
Chạy thử nghiệm là bước đầu tiên. Giá trị thực sự đến từ việc phân tích kết quả để đưa ra quyết định dựa trên dữ liệu. Trong nhiệm vụ này, bạn sẽ sử dụng các công cụ trực quan hoá của SDK để diễn giải kết quả từ thử nghiệm về vai trò của câu lệnh.
- Hiển thị kết quả tóm tắt cho từng nhân cách của bốn câu lệnh mà bạn đã thử nghiệm bằng cách chạy mã sau trong một ô mới. Nhờ đó, bạn sẽ có được thông tin tổng quan định lượng về hiệu suất.
for title, eval_result in eval_results: notebook_utils.display_eval_result(title=title, eval_result=eval_result) - Trong một ô mới, hãy thêm và chạy mã sau để xem lý do cho chỉ số
summarization_qualitycủa từng nhân vật.for title, eval_result in eval_results: notebook_utils.display_explanations( eval_result, metrics=["summarization_quality"], num=2 ) - Tạo biểu đồ radar để hình dung sự đánh đổi giữa các chỉ số chất lượng khác nhau cho từng câu lệnh. Trong một ô mới, hãy thêm và chạy mã sau.
notebook_utils.display_radar_plot( eval_results, metrics=["instruction_following", "fluency", "coherence", "text_quality"], ) - Để so sánh song song trực tiếp hơn, hãy tạo một biểu đồ thanh. Trong một ô mới, hãy thêm và chạy mã sau.
notebook_utils.display_bar_plot( eval_results, metrics=["instruction_following", "fluency", "coherence", "text_quality"], )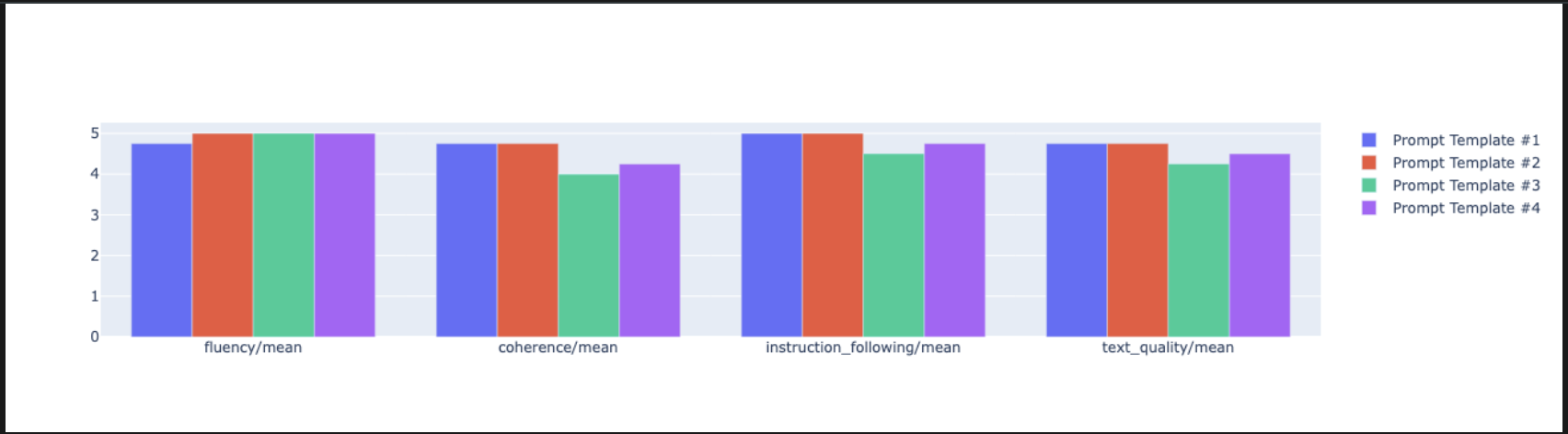
- Giờ đây, bạn có thể xem bản tóm tắt về tất cả các lần chạy đã được ghi vào Vertex AI Experiment cho tác vụ này. Điều này hữu ích khi bạn theo dõi công việc của mình theo thời gian. Trong một ô mới, hãy thêm và chạy mã sau:
summarization_eval_task.display_runs()
10. Dọn dẹp thử nghiệm
Để dự án của bạn được sắp xếp gọn gàng và tránh phát sinh các khoản phí không cần thiết, bạn nên dọn dẹp các tài nguyên mà bạn đã tạo. Trong suốt phòng thí nghiệm này, mọi lần đánh giá đều được ghi lại vào một Thử nghiệm Vertex AI. Đoạn mã sau đây sẽ xoá thử nghiệm mẹ này, đồng thời xoá tất cả các lần chạy liên quan và dữ liệu cơ bản của các lần chạy đó.
- Chạy mã này trong một ô mới để xoá Thử nghiệm Vertex AI và các lần chạy được liên kết.
delete_experiment = True # Please set your LOCATION to the same one used during Vertex AI SDK initialization. LOCATION = "YOUR LOCATION" # @param {type:"string"} if delete_experiment: from google.cloud import aiplatform aiplatform.init(project=PROJECT_ID, location=LOCATION) experiment = aiplatform.Experiment(EXPERIMENT_NAME) experiment.delete()
11. Từ thực hành đến phát hành công khai
Những kỹ năng bạn đã học được trong phòng thí nghiệm này là nền tảng để tạo ra các ứng dụng AI đáng tin cậy. Tuy nhiên, việc chuyển từ một sổ tay chạy theo cách thủ công sang một hệ thống đánh giá cấp sản xuất đòi hỏi thêm cơ sở hạ tầng và một phương pháp có hệ thống hơn. Phần này trình bày những phương pháp chính và khung chiến lược cần cân nhắc khi bạn mở rộng quy mô.
Xây dựng chiến lược đánh giá hiệu suất
Để áp dụng các kỹ năng trong phòng thí nghiệm này vào môi trường sản xuất, bạn nên chính thức hoá các kỹ năng đó thành những chiến lược có thể lặp lại. Các khung sau đây trình bày những điểm chính cần cân nhắc cho các trường hợp phổ biến như lựa chọn mô hình, tối ưu hoá câu lệnh và giám sát liên tục.
Đối với lựa chọn mô hình:
# Evaluation strategy for choosing models
evaluation_strategy = {
"dataset_size": "100+ examples for statistical significance",
"metrics": ["task-specific", "general quality", "efficiency"],
"comparison_type": "pairwise with statistical testing",
"baseline": "established_model_or_human_benchmark"
}
Để tối ưu hoá câu lệnh
# Systematic prompt improvement workflow
prompt_optimization = {
"hypothesis": "Clear statement of what you're testing",
"variants": "3-5 different prompt strategies",
"evaluation": "Same metrics across all variants",
"analysis": "Statistical significance + qualitative review"
}
Để giám sát liên tục
# Production evaluation pipeline
production_eval = {
"frequency": "Every model update + weekly monitoring",
"automation": "CI/CD integration with quality gates",
"metrics": "Speed + quality + cost tracking",
"alerting": "Performance degradation detection"
}
Những điều cần cân nhắc về hiệu quả chi phí
Việc đánh giá dựa trên mô hình có thể tốn kém khi mở rộng quy mô. Chiến lược sản xuất tiết kiệm chi phí sử dụng nhiều phương pháp cho nhiều mục đích. Bảng này tóm tắt sự đánh đổi giữa tốc độ, chi phí và trường hợp sử dụng cho các loại đánh giá khác nhau:
Loại đánh giá | Thời gian | Chi phí cho mỗi mẫu | Tốt nhất cho |
ROUGE/BLEU | Giây | ~0,001 USD | Sàng lọc số lượng lớn |
Model-based Pointwise | Khoảng 1-2 giây | ~0,01 USD | Đánh giá chất lượng |
So sánh theo cặp | Khoảng 2-3 giây | ~0,02 USD | Lựa chọn mô hình |
Đánh giá của con người | Số phút | $1-10 | Xác thực theo tiêu chuẩn vàng |
Tự động hoá bằng CI/CD và giám sát
Không thể mở rộng các lần chạy sổ tay theo cách thủ công. Tự động hoá quy trình đánh giá trong quy trình Tích hợp liên tục/Triển khai liên tục (CI/CD).
- Tạo các tiêu chuẩn về chất lượng: Tích hợp tác vụ đánh giá vào quy trình CI/CD (ví dụ: Cloud Build). Tự động chạy quy trình đánh giá trên các câu lệnh hoặc mô hình mới và chặn việc triển khai nếu điểm chất lượng chính giảm xuống dưới ngưỡng mà bạn xác định.
- Theo dõi xu hướng: Xuất các chỉ số tóm tắt từ các lần đánh giá sang một dịch vụ như Google Cloud Monitoring. Tạo trang tổng quan để theo dõi chất lượng theo thời gian và thiết lập cảnh báo tự động để thông báo cho nhóm của bạn về mọi trường hợp hiệu suất giảm đáng kể.
12. Kết luận
Bạn đã hoàn thành bài thực hành. Bạn đã học được các kỹ năng cần thiết để đánh giá mô hình AI tạo sinh.
Phòng thí nghiệm này thuộc Lộ trình học tập về AI sẵn sàng cho sản xuất trên Google Cloud.
- Khám phá toàn bộ chương trình học để thu hẹp khoảng cách từ nguyên mẫu đến phát hành công khai.
- Chia sẻ tiến trình của bạn bằng thẻ bắt đầu bằng #
ProductionReadyAI.
Tóm tắt
Trong phòng thí nghiệm này, bạn đã tìm hiểu cách:
- Áp dụng các phương pháp hay nhất để đánh giá bằng cách sử dụng khung
EvalTask. - Sử dụng nhiều loại chỉ số, từ chỉ số dựa trên tính toán đến chỉ số dựa trên mô hình.
- Tối ưu hoá câu lệnh bằng cách thử nghiệm các phiên bản khác nhau.
- Xây dựng quy trình có thể tái tạo bằng tính năng theo dõi thử nghiệm.
Tài nguyên để tiếp tục học tập
- Tài liệu đánh giá AI tạo sinh của Vertex AI
- Sổ tay về các kỹ thuật đánh giá nâng cao
- Tài liệu tham khảo về SDK đánh giá AI tạo sinh
- Nghiên cứu chỉ số dựa trên mô hình
- Các phương pháp hay nhất về thiết kế câu lệnh
Các phương pháp đánh giá có hệ thống mà bạn đã học được trong lớp học lập trình này sẽ là nền tảng để xây dựng các ứng dụng AI đáng tin cậy và chất lượng cao. Lưu ý: đánh giá hiệu quả là cầu nối giữa AI thử nghiệm và thành công trong thực tế.