
1. 總覽
在本實驗室中,您將瞭解如何使用 Vertex AI Gen AI Evaluation Service 評估大型語言模型。您將使用 SDK 執行評估作業、比較結果,並根據資料做出有關模型成效和提示設計的決策。
本實驗室會逐步說明常見的評估工作流程,從簡單的以運算為基礎的指標開始,再進展到更細緻的模型式評估。您也會瞭解如何建立符合特定目標的自訂指標,以及如何使用 Vertex AI Experiments 追蹤工作進度。
課程內容
在本實驗室中,您將瞭解如何執行下列工作:
- 使用運算資源相關和模型式指標評估模型。
- 建立自訂指標,讓評估結果與產品目標一致。
- 並列比較不同的提示範本。
- 測試多個以角色為基礎的提示,找出最有效的版本。
- 使用 Vertex AI Experiments 追蹤及視覺化評估執行作業。
參考資料
- 程式碼範例:本實驗室以 Google Cloud 生成式 AI 存放區的範例為基礎
- 參考資料:Vertex AI Gen AI Evaluation 說明文件
- 資料集:OpenOrca 資料集,用於評估指令遵循情形
2. 專案設定
Google 帳戶
如果沒有個人 Google 帳戶,請建立 Google 帳戶。
請使用個人帳戶,而非公司或學校帳戶。
登入 Google Cloud 控制台
使用個人 Google 帳戶登入 Google Cloud 控制台。
啟用計費功能
如要啟用計費功能,有兩種方法。你可以使用個人帳單帳戶,也可以按照下列步驟兌換抵免額。
兌換 Google Cloud 抵免額 (選用)
如要參加這個研討會,您需要有具備抵免額的帳單帳戶。請使用本程式碼研究室頂端橫幅中的抵免額開始操作。如果已連結帳單帳戶,可以略過這個步驟。
設定個人帳單帳戶
如果使用 Google Cloud 抵免額設定計費,可以略過這個步驟。
如要設定個人帳單帳戶,請前往這裡在 Cloud 控制台中啟用帳單。
注意事項:
- 完成本實驗室的 Cloud 資源費用應不到 $1 美元。
- 您可以按照本實驗室結尾的步驟刪除資源,以免產生後續費用。
- 新使用者可獲得價值 $300 美元的免費試用期。
建立專案 (選用)
如果沒有要用於本實驗室的現有專案,請在這裡建立新專案。
3. 設定 Vertex AI Workbench 環境
首先,請存取預先設定的筆記本環境,並安裝必要的依附元件。
存取 Vertex AI Workbench
- 前往 Google Cloud 控制台,依序點選「導覽選單」圖示 ☰ >「Vertex AI」>「資訊主頁」,即可前往 Vertex AI 。
- 點選「啟用所有建議的 API」。注意:請等待這個步驟完成
- 點選左側的「Workbench」,建立新的 Workbench 執行個體。
- 將 Workbench 執行個體命名為 evaluation-workbench,然後按一下「Create」(建立)。
- 等待工作台設定完成。這可能需要幾分鐘的時間。

- 工作台佈建完成後,按一下「Open JupyterLab」。
- 在工作台中,建立新的 Python3 筆記本。
如要進一步瞭解這個環境的功能和特性,請參閱 Vertex AI Workbench 官方說明文件。
安裝套件並設定環境
- 在筆記本的第一個儲存格中,新增並執行下列匯入陳述式 (SHIFT+ENTER),安裝 Vertex AI SDK (含評估元件) 和其他必要套件。
%pip install -U -q google-cloud-aiplatform[evaluation] %pip install -U -q datasets anthropic[vertex] openai - 如要使用新安裝的套件,建議執行下列程式碼片段,重新啟動核心。
# Automatically restart kernel after installation so that your environment can access the new packages. import IPython app = IPython.Application.instance() app.kernel.do_shutdown(True) - 將下列內容替換為您的專案 ID 和位置,然後執行下列儲存格。預設位置設為
europe-west1,但您應使用 Vertex AI Workbench 執行個體所在的位置。# Configure your project settings PROJECT_ID = "YOUR PROJECT ID" LOCATION = "europe-west1" - 在新的儲存格中執行下列程式碼,匯入本實驗室所需的所有 Python 程式庫。
from anthropic import AnthropicVertex from google.auth import default, transport import openai import pandas as pd from vertexai.evaluation import ( EvalTask, MetricPromptTemplateExamples, PairwiseMetric, PointwiseMetric, PointwiseMetricPromptTemplate, ) from vertexai.generative_models import GenerativeModel from vertexai.preview.evaluation import notebook_utils
4. 設定評估資料集
在本教學課程中,我們會使用 OpenOrca 資料集中的 10 個樣本。這樣一來,我們就能取得足夠的資料,看出模式間的顯著差異,同時將評估時間控制在合理範圍內。
💡 專業提示:在實際製作時,您需要 100 到 500 個範例,才能獲得具有統計顯著性的結果,但 10 個樣本非常適合學習和快速原型設計!
準備資料集
- 在新的儲存格中執行下列儲存格,載入資料、轉換為 pandas DataFrame,並將
response欄重新命名為reference,為求明確,方便評估工作,然後建立十個範例的隨機樣本。from datasets import load_dataset ds = ( load_dataset( "Open-Orca/OpenOrca", data_files="1M-GPT4-Augmented.parquet", split="train[:100]", ) .to_pandas() .drop(columns=["id"]) .rename(columns={"response": "reference"}) ) dataset = ds.sample(n=10) - 上一個儲存格執行完畢後,請在下一個儲存格中新增並執行下列程式碼,顯示評估資料集的前幾列。
dataset.head()
5. 以運算為基礎的指標建立基準
在這項工作中,您將使用以運算為基礎的指標建立基準分數。這種做法速度快,且能提供客觀的基準,用來評估日後的改善成效。
我們會使用 ROUGE (喚回度導向的摘要評估研究),這是摘要製作工作的標準指標。這項指標會比較模型生成的回應中字詞的順序 (n 元語法) 與基準真相reference文字中的字詞。
進一步瞭解以運算為基礎的指標。
執行基準評估
- 在新的儲存格中,新增並執行下列儲存格,定義要測試的模型
gemini-2.0-flash。generation_config包含temperature和max_output_tokens等參數,可影響模型的輸出內容。# Model to be evaluated model = GenerativeModel( "gemini-2.0-flash", generation_config={"temperature": 0.6, "max_output_tokens": 256, "top_k": 1}, )GenerativeModel類別是 Vertex AI SDK 中與大型語言模型互動的主要介面。 - 在下一個儲存格中,新增並執行下列程式碼,建立及執行
EvalTask。這個 Vertex AI Evaluation SDK 物件會協調評估作業。您可以使用資料集和要計算的指標 (在本例中為rouge_l_sum) 進行設定。# Define an EvalTask with ROUGE-L-SUM metric rouge_eval_task = EvalTask( dataset=dataset, metrics=["rouge_l_sum"], ) rouge_result = rouge_eval_task.evaluate( model=model, prompt_template="# System_prompt\n{system_prompt} # Question\n{question}", ) - 在下一個儲存格中執行這段程式碼,即可顯示結果。
notebook_utils.display_eval_result(rouge_result)display_eval_result()公用程式會顯示平均 (平均值) 分數和逐列結果。
6. 選用:使用以模型為基準的逐點指標評估
注意:這個部分可能超出免費抵免額的限制。
ROUGE 雖然實用,但只能測量詞彙重疊程度 (也就是只會計算相符的字詞,不會理解脈絡、同義詞或改述)。因此無法準確判斷回覆是否流暢或合乎邏輯。如要深入瞭解模型效能,請使用以模型為準的逐點指標。
採用這種方法時,另一個 LLM (即「評估模型」) 會根據預先定義的一組標準 (例如流暢度或連貫性),個別評估每個回覆。
進一步瞭解以模型為準的指標。
執行逐點評估
- 在新的儲存格中執行下列程式碼,建立互動式下拉式選單。針對這次執行,請從清單中選取「coherence」。
#Select a pointwise metric to use import ipywidgets as widgets pointwise_single_turn_metrics = [ metric for metric in MetricPromptTemplateExamples.list_example_metric_names() if not metric.startswith("pairwise") and not metric.startswith("multi_turn") ] dropdown = widgets.Dropdown( options=pointwise_single_turn_metrics, description="Select a metric:", font_weight="bold", style={"description_width": "initial"}, ) def dropdown_eventhandler(change): global POINTWISE_METRIC if change["type"] == "change" and change["name"] == "value": POINTWISE_METRIC = change.new print("Selected:", change.new) POINTWISE_METRIC = dropdown.value dropdown.observe(dropdown_eventhandler, names="value") display(dropdown) - 在新的儲存格中再次執行
EvalTask,這次請使用所選模型指標。Vertex AI 評估服務會為評估模型建構提示,其中包含原始提示、參考答案、候選模型的回應,以及所選指標的指示。評估模型會傳回數值分數和評分說明。注意:這個步驟需要幾分鐘才能完成。pointwise_result = EvalTask( dataset=dataset, metrics=[POINTWISE_METRIC], ).evaluate( model=model, prompt_template="# System_prompt\n{system_prompt} # Question\n{question}", )
顯示結果
評估完成後,下一步是分析輸出內容。
- 在新儲存格中執行下列程式碼,即可查看摘要指標,其中會顯示所選指標的平均分數。
notebook_utils.display_eval_result(pointwise_result) - 在下一個儲存格中執行下列程式碼,即可查看逐列細目,包括評估模型為分數撰寫的理由。這類意見回饋有助於瞭解特定回覆獲得某種分數的原因。
notebook_utils.display_explanations(pointwise_result, num=1, metrics=[POINTWISE_METRIC])
7. 建立自訂指標,取得更深入的洞察資料
流暢度等預先建立的指標很有用,但針對特定產品,您通常需要根據自己的目標評估成效。透過自訂逐點指標,您可以定義自己的評估條件和評分標準。
在這項工作中,您將從頭開始建立名為 summarization_helpfulness 的新指標。
定義及執行自訂指標
- 在新儲存格中執行下列程式碼,定義自訂指標。
PointwiseMetricPromptTemplate包含指標的建構區塊:- criteria:告知評估模型要評估的特定維度:「重要資訊」、「簡潔」和「無扭曲」。
- rating_rubric:提供 5 分制評分量表,說明各個分數的意義。
- input_variables:將資料集中的其他資料欄傳遞至評估模型,讓模型取得評估所需的背景資訊。
# This new custom metric evaluates the actual quality and usefulness of the summary. summarization_helpfulness_metric = PointwiseMetric( metric="summarization_helpfulness", metric_prompt_template=PointwiseMetricPromptTemplate( criteria={ "Key Information": "Does the summary capture the most critical pieces of information from the original text? It should not miss the main topic or key takeaways.", "Conciseness": "Is the summary brief and to the point? It should avoid unnecessary words or repetitive information.", "No Distortion": "Does the summary introduce information or opinions that were NOT present in the original text? It must accurately reflect the source material without adding hallucinations." }, rating_rubric={ "5": "Excellent: Captures all key information, is highly concise, and has zero distortion.", "4": "Good: Captures most key information with minor omissions, is concise, and has no distortion.", "3": "Satisfactory: Captures the main idea but misses some key details OR is not very concise.", "2": "Unsatisfactory: Misses the main idea of the original text OR contains minor distortions/hallucinations.", "1": "Poor: Is completely irrelevant, fails to summarize the text, OR contains significant distortions.", }, input_variables=["prompt", "reference"], ), ) - 在下一個儲存格中執行下列程式碼,使用新的自訂指標執行
EvalTask。# You would then update the EvalTask to use this new metric pointwise_result = EvalTask( dataset=dataset, metrics=[summarization_helpfulness_metric], ).evaluate( model=model, prompt_template="# System_prompt\n{system_prompt} # Question\n{question}", ) - 在新儲存格中執行下列程式碼,即可顯示結果。
notebook_utils.display_eval_result(pointwise_result)
8. 透過逐對評估比較模型
如要判斷哪一個模型在特定工作上的表現較佳,可以使用逐對模型評估。這項方法屬於 A/B 測試,由評估模型決定勝出者,直接比較結果,以利根據資料選取模型。
模型:
- 候選模型:模型變數 (先前定義為
gemini-2.0-flash) 會傳遞至.evaluate()方法。這是您要測試的主要模型。 - 基準模型:第二個模型
gemini-2.0-flash-lite是在 PairwiseMetric 類別中指定。這是您要比較的模型。
執行逐對評估
- 在新的儲存格中,新增並執行下列程式碼,建立互動式下拉式選單。這樣一來,您就能選取要用於比較的成對指標。這次執行時,請選取 pairwise_summarization_quality。
from IPython.display import display import ipywidgets as widgets pairwise_single_turn_metrics = [ metric for metric in MetricPromptTemplateExamples.list_example_metric_names() if metric.startswith("pairwise") and "multi_turn" not in metric ] dropdown = widgets.Dropdown( options=pairwise_single_turn_metrics, description="Select a metric:", font_weight="bold", style={"description_width": "initial"}, ) def dropdown_eventhandler(change): global POINTWISE_METRIC if change["type"] == "change" and change["name"] == "value": POINTWISE_METRIC = change.new print("Selected:", change.new) def dropdown_eventhandler(change): global PAIRWISE_METRIC_NAME if change["type"] == "change" and change["name"] == "value": PAIRWISE_METRIC_NAME = change.new print("Selected:", change.new) PAIRWISE_METRIC_NAME = dropdown.value dropdown.observe(dropdown_eventhandler, names="value") display(dropdown) - 在下一個儲存格中,新增並執行下列程式碼,設定及執行
EvalTask。請注意,PairwiseMetric類別用於定義基準模型 (gemini-2.0-flash-lite),而候選模型 (gemini-2.0-flash) 則會傳遞至.evaluate()方法。pairwise_result = EvalTask( dataset=dataset, metrics=[ PairwiseMetric( metric=PAIRWISE_METRIC_NAME, metric_prompt_template=MetricPromptTemplateExamples.get_prompt_template( PAIRWISE_METRIC_NAME ), # Define a baseline model to compare against baseline_model=GenerativeModel("gemini-2.0-flash-lite"), ) ], ).evaluate( # Specify a candidate model for pairwise comparison model=model, prompt_template="# System_prompt\n{system_prompt} # Question\n{question}", ) - 在新的儲存格中新增並執行下列程式碼,即可顯示結果。摘要表格會顯示每個模型的「勝率」,指出 Judge Model 較常偏好哪個模型。
notebook_utils.display_eval_result(pairwise_result)
9. 選用:評估以角色為導向的提示
注意:這個部分可能超出免費抵免額的限制。
在這項工作中,您將測試多個提示範本,指示模型採用不同的人物角色。這個程序通常稱為「提示工程」或「提示設計」,可協助您有系統地找出最適合特定用途的提示。
準備摘要資料集
如要執行這項評估,資料集必須包含下列欄位:
instruction:我們提供給模型的核心工作。在本例中,提示很簡單:「請總結下列文章:」。context:模型需要處理的來源文字。我們提供四則不同的新聞片段。reference:真實或「黃金標準」摘要。系統會比較模型生成的輸出內容與這段文字,計算 ROUGE 和摘要品質等指標的分數。
- 在新的儲存格中,新增並執行下列程式碼,為摘要工作建立
pandas.DataFrame。instruction = "Summarize the following article: \n" context = [ "Typhoon Phanfone has killed at least one person, a US airman on Okinawa who was washed away by high waves. Thousands of households have lost power and Japan's two largest airlines have suspended many flights. The storm also forced the suspension of the search for people missing after last week's volcanic eruption. The storm-tracking website Tropical Storm Risk forecasts that Phanfone will rapidly lose power over the next few hours as it goes further into the Pacific Ocean. Typhoon Phanfone was downgraded from an earlier status of a super typhoon, but the Japan Meteorological Agency had warned it was still a dangerous storm. Japan averages 11 typhoons a year, according to its weather agency. The typhoon made landfall on Monday morning near the central city of Hamamatsu, with winds of up to 180 km/h (112 mph). The airman was one of three US military personnel swept away by high waves whipped up by the typhoon off southern Okinawa island, where the US has a large military base. The remaining two are still missing. A police spokesman said they had been taking photographs of the sea. A university student who was surfing off the seas of Kanagawa Prefecture, south of Tokyo, was also missing, national broadcast NHK reports. It said at least 10 people had been injured and 9,500 houses were without power. The storm was expected to deposit about 100mm of rain on Tokyo over 24 hours, according to the Transport Ministry website. Many schools were closed on Monday and two car companies in Japan halted production at some plants ahead of the storm. More than 174 domestic flights were affected nationwide, NHK state broadcaster said on Sunday. On Sunday, heavy rain delayed the Japanese Formula One Grand Prix in Suzaka. French driver Jules Bianchi lost control in the wet conditions and crashed, sustaining a severe head injury.", "The blaze started at the detached building in Drivers End in Codicote, near Welwyn, during the morning. There was another fire at the building 20 years ago, after which fire-proof foil was placed under the thatch, which is protecting the main building. More than 15 fire engines and support vehicles were called to tackle the blaze. Roads in the area were closed and traffic diverted.", 'The 18-year-old fell at the New Charter Academy on Broadoak Road in Ashton-under-Lyne at about 09:10 BST, Greater Manchester Police (GMP) said. GMP said he had gone to Manchester Royal Infirmary and his condition was "serious". Principal Jenny Langley said the school would remain "fully open" while police investigated. "Our thoughts are with the family and we\'re doing everything we can to support them along with staff and pupils," she said.', 'But Belgian-born Dutchman Max Verstappen was unable to drive a car legally on his own in either country. That all changed on Wednesday when the youngster turned 18 and passed his driving test at the first attempt. Despite having competed in 14 grands prix since his debut in Australia in March, Verstappen admitted to feeling the pressure during his test. "It\'s a relief," said the Toro Rosso driver, who finished ninth in Japan on Sunday and had only started driving lessons a week ago. "I was a bit nervous to make mistakes, but the exam went well." A bonus of turning 18 is that Verstappen will now be able to drink the champagne if he ever makes it onto the podium.', ] reference = [ "A powerful typhoon has brought many parts of Japan to a standstill and briefly battered Tokyo before heading out to sea.", "A major fire has been burning in the thatched roof of a large property in Hertfordshire.", "A student has been taken to hospital after falling from a balcony at a Greater Manchester school.", "He is Formula 1's youngest ever driver and in charge of a car that can reach over 200mph.", ] response = [ "Typhoon Phanfone, while downgraded from super typhoon status, caused significant disruption and tragedy in Japan. One US airman died after being swept away by high waves, with two more missing. The storm caused power outages for thousands, flight cancellations, and the suspension of rescue efforts for missing volcano victims. Heavy rain and strong winds led to school and factory closures, transportation disruptions, and at least 10 injuries. The typhoon is expected to weaken as it moves over the Pacific Ocean.", "A large fire broke out in a detached thatched building in Codicote, near Welwyn. This is the second fire at the building in 20 years. Thankfully, fire-proof foil installed after the previous fire is protecting the main building. Over 15 fire engines and support vehicles responded, closing roads and diverting traffic in the area.", "An 18-year-old student at New Charter Academy in Ashton-under-Lyne suffered a serious fall and was hospitalized. The incident is under investigation by Greater Manchester Police, but the school remains open. The principal expressed support for the student's family and the school community.", "Max Verstappen, a Formula One driver, was finally able to get his driver's license at age 18. Despite already competing in 14 Grand Prix races, he was not of legal driving age in his native countries. He admitted to being nervous but passed the test on his first attempt. As an added bonus of turning 18, Verstappen can now enjoy champagne on the podium if he places.", ] eval_dataset = pd.DataFrame( { "instruction": instruction, "context": context, "reference": reference, } )
執行提示評估工作
準備好摘要資料集後,即可執行這項工作的核心實驗:比較多個提示範本,找出能讓模型產生最高品質輸出的範本。
- 在下一個儲存格中,建立單一
EvalTask,供每個提示實驗重複使用。設定experiment參數後,這項工作的所有評估執行作業都會自動記錄在 Vertex AI Experiments 中,並歸入同一群組。EXPERIMENT_NAME = "eval-sdk-prompt-engineering" # @param {type:"string"} summarization_eval_task = EvalTask( dataset=eval_dataset, metrics=[ "rouge_l_sum", "bleu", "fluency", "coherence", "safety", "groundedness", "summarization_quality", "verbosity", "instruction_following", "text_quality", ], experiment=EXPERIMENT_NAME, )rouge_l_sum和bleu等運算指標,以及各種模型指標 (fluency、coherence、summarization_quality、instruction_following等)。這有助於我們全面瞭解各項提示對模型輸出內容品質的影響。 - 在新的儲存格中,新增並執行下列程式碼,定義及評估四種以角色為導向的提示策略。
for迴圈會逐一疊代每個範本,並執行評估。每個範本都會為模型提供特定角色或目標,藉此引導模型生成不同風格的摘要:- 角色 #1 (標準):中性、直接的摘要要求。
- 角色 #2 (主管):要求以條列式重點總結內容,並著重於結果和影響,因為忙碌的主管會偏好這種方式。
- 角色 #3 (五年級學生):指示模型使用簡單的語言,測試模型調整輸出內容複雜度的能力。
- 角色 #4 (技術分析師):要求提供高度事實性的摘要,其中保留重要統計資料和實體,測試模型的準確度。請注意,這些新範本中的預留位置 (例如
{context}和{instruction}) 與您為這項工作建立的eval_dataset中的新資料欄名稱相符。
# Define prompt templates that target different user personas prompt_templates = [ # Persona 1: Standard, neutral summary "Article: {context}. Task: {instruction}. Summary:", # Persona 2: For a busy executive (bullet points) "Instruction: {instruction} into three key bullet points for a busy executive. Focus on the main outcome and impact. Article: {context}. Summary:", # Persona 3: For a 5th grader (simple language) "Instruction: {instruction} such that you're explaining it to a 10-year-old. Use simple words. Article: {context}. Summary:", # Persona 4: For a technical analyst (fact-focused) "Instruction: Provide a detailed, factual summary of the following text, ensuring all key statistics, names, and locations are preserved. Article: {context}. Summary:", ] eval_results = [] for i, prompt_template in enumerate(prompt_templates): eval_result = summarization_eval_task.evaluate( prompt_template=prompt_template, model=GenerativeModel( "gemini-2.0-flash", generation_config={ "temperature": 0.3, "max_output_tokens": 256, "top_k": 1, }, ), evaluation_service_qps=5, ) eval_results.append((f"Prompt Persona #{i+1}", eval_result))
分析結果並以圖表呈現
執行實驗是第一步。分析結果並根據資料做出決策,才是這項功能的真正價值。在這項工作中,您將使用 SDK 的視覺化工具,解讀提示角色實驗的輸出內容。
- 在新儲存格中執行下列程式碼,顯示您測試的四個提示角色各自的摘要結果。讓你從量化角度掌握成效。
for title, eval_result in eval_results: notebook_utils.display_eval_result(title=title, eval_result=eval_result) - 在新的儲存格中新增並執行下列程式碼,即可查看每個人物角色的
summarization_quality指標理由。for title, eval_result in eval_results: notebook_utils.display_explanations( eval_result, metrics=["summarization_quality"], num=2 ) - 產生雷達圖,顯示每個提示不同品質指標之間的取捨。在新的儲存格中新增並執行下列程式碼。
notebook_utils.display_radar_plot( eval_results, metrics=["instruction_following", "fluency", "coherence", "text_quality"], ) - 如要進行更直接的並排比較,請建立長條圖。在新的儲存格中新增並執行下列程式碼。
notebook_utils.display_bar_plot( eval_results, metrics=["instruction_following", "fluency", "coherence", "text_quality"], )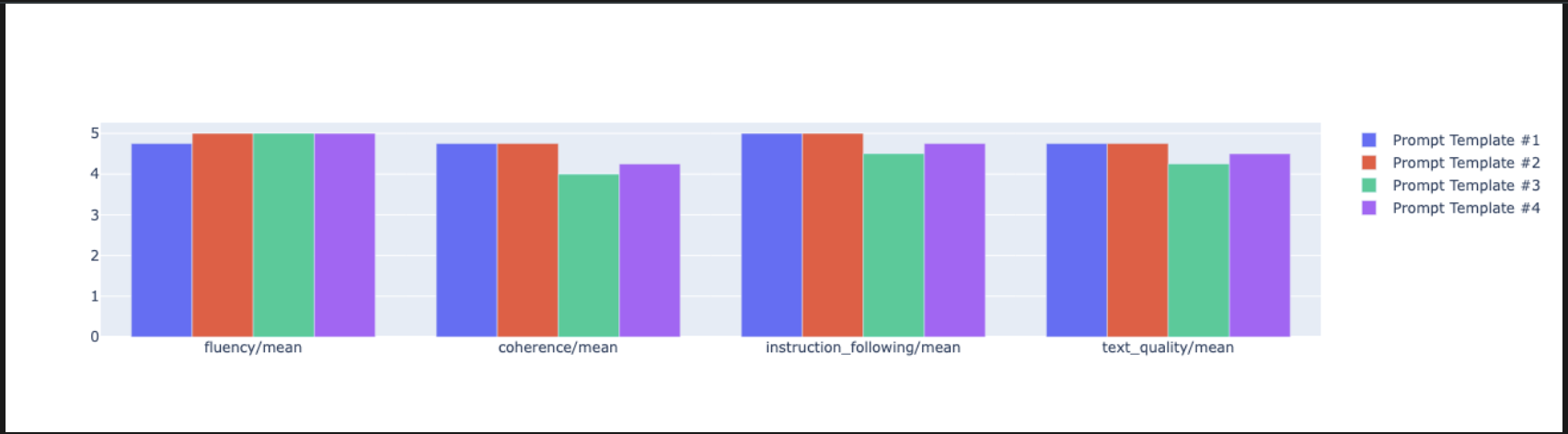
- 您現在可以查看已記錄至這項工作 Vertex AI 實驗的所有執行作業摘要。這項功能有助於追蹤一段時間內的工作進度。在新的儲存格中,新增並執行下列程式碼:
summarization_eval_task.display_runs()
10. 清理實驗
為確保專案井然有序,並避免產生不必要的費用,建議您清理所建立的資源。在本實驗室中,每次評估執行作業都會記錄到 Vertex AI 實驗。下列程式碼會刪除這個父項實驗,並一併移除所有相關聯的執行作業和基礎資料。
- 在新儲存格中執行這段程式碼,即可刪除 Vertex AI 實驗和相關執行作業。
delete_experiment = True # Please set your LOCATION to the same one used during Vertex AI SDK initialization. LOCATION = "YOUR LOCATION" # @param {type:"string"} if delete_experiment: from google.cloud import aiplatform aiplatform.init(project=PROJECT_ID, location=LOCATION) experiment = aiplatform.Experiment(EXPERIMENT_NAME) experiment.delete()
11. 從練習到正式版
您在本實驗室中學到的技能,是建構可靠 AI 應用程式的基礎。不過,從手動執行的筆記本轉移至正式環境等級的評估系統,需要額外的基礎架構和更系統化的做法。本節將說明擴大規模時應考量的主要做法和策略架構。
制定正式環境評估策略
如要在正式環境中運用本實驗室的技能,建議將這些技能歸納為可重複執行的策略。以下架構列出常見情境的重要考量,例如模型選取、提示最佳化和持續監控。
如要選取模型,請按照下列步驟操作:
# Evaluation strategy for choosing models
evaluation_strategy = {
"dataset_size": "100+ examples for statistical significance",
"metrics": ["task-specific", "general quality", "efficiency"],
"comparison_type": "pairwise with statistical testing",
"baseline": "established_model_or_human_benchmark"
}
提示最佳化
# Systematic prompt improvement workflow
prompt_optimization = {
"hypothesis": "Clear statement of what you're testing",
"variants": "3-5 different prompt strategies",
"evaluation": "Same metrics across all variants",
"analysis": "Statistical significance + qualitative review"
}
持續監控
# Production evaluation pipeline
production_eval = {
"frequency": "Every model update + weekly monitoring",
"automation": "CI/CD integration with quality gates",
"metrics": "Speed + quality + cost tracking",
"alerting": "Performance degradation detection"
}
成本效益考量
以模型為基準的評估可能需要大量資源。高效率的製作策略會針對不同目的採用不同方法。下表列出不同評估類型在速度、成本和用途之間的取捨:
評估類型 | 時間 | 單一樣本費用 | 適用情境 |
ROUGE/BLEU | 秒 | 約$0.001 美元 | 大量篩選 |
以模型為基礎的逐點 | 約 1 到 2 秒 | 約$0.01 美元 | 品質評估 |
成對比較 | 約 2 到 3 秒 | 約$0.02 美元 | 多種模型供您選擇 |
人工評估 | 分鐘 | $1 美元至 $10 美元 | 黃金標準驗證 |
透過 CI/CD 和監控功能自動化作業
手動執行筆記本無法擴充。在持續整合/持續部署 (CI/CD) 管道中自動進行評估。
- 建立品質閘道:將評估工作整合至 CI/CD 管道 (例如 Cloud Build)。自動對新提示或模型執行評估,並在主要品質分數低於您定義的門檻時,封鎖部署作業。
- 監控趨勢:將評估作業的摘要指標匯出至 Google Cloud Monitoring 等服務。建立資訊主頁來追蹤一段時間內的品質,並設定自動快訊,在效能大幅降低時通知團隊。
12. 結語
您已完成實驗室。您已學會評估生成式 AI 模型的基本技能。
這個實驗室屬於「Google Cloud 學習路徑:打造可用於正式環境的 AI」。
- 探索完整課程,從設計原型開始,一步步把專案投入正式環境。
- 使用主題標記
ProductionReadyAI分享你的進度。
重點回顧
在本實驗室中,您已學會如何執行下列工作:
- 運用
EvalTask架構,套用評估最佳做法。 - 使用不同類型的指標,從以運算為基礎的指標到以模型為基礎的評估者。
- 測試不同版本的提示,找出最佳提示。
- 建立可重現的工作流程,並追蹤實驗。
持續學習的資源
您在本實驗室中學到的系統性評估方法,將成為建構可靠優質 AI 應用程式的基礎。請記住,良好的評估是實驗性 AI 與正式環境成功之間的橋樑。