
1. مقدمة
نظرة عامة
الهدف من هذا الدرس التطبيقي هو التعرّف على كيفية تطوير تطبيقات "التوليد المعزّز بالاسترجاع" المستندة إلى الذكاء الاصطناعي الوكيل والمتكاملة في Google Cloud. في هذا المختبر، ستنشئ وكيلاً للتحليل المالي يمكنه الإجابة عن الأسئلة من خلال الجمع بين المعلومات من مصدرَين مختلفَين: المستندات غير المنظَّمة (مستندات Alphabet ربع السنوية المقدَّمة إلى هيئة الأوراق المالية والبورصة - البيانات المالية والتفاصيل التشغيلية التي تقدّمها كل شركة عامة في الولايات المتحدة إلى هيئة الأوراق المالية والبورصة) والبيانات المنظَّمة (أسعار الأسهم السابقة).
ستستخدم Vertex AI Search لإنشاء محرّك بحث دلالي قوي للتقارير المالية غير المهيكلة. بالنسبة إلى البيانات المنظَّمة، عليك إنشاء أداة Python مخصّصة. أخيرًا، ستستخدم حزمة تطوير الوكيل (ADK) لإنشاء وكيل ذكي يمكنه التفكير في طلب المستخدم وتحديد الأداة المناسبة لاستخدامها وتجميع المعلومات في إجابة متماسكة.
الإجراءات التي ستنفذّها
- إعداد مخزن بيانات Vertex AI Search للبحث الدلالي في المستندات الخاصة
- إنشاء دالة Python مخصّصة كأداة للوكيل
- استخدِم "حزمة تطوير الوكلاء" (ADK) لإنشاء وكيل متعدد الأدوات.
- الجمع بين الاسترجاع من مصادر البيانات غير المنظَّمة والمنظَّمة للإجابة عن الأسئلة المعقّدة
- اختبار وكيل يتمتّع بقدرات استدلالية والتفاعل معه
أهداف الدورة التعليمية
في هذا التمرين العملي، ستتعرّف على ما يلي:
- المفاهيم الأساسية للتوليد المعزّز بالاسترجاع (RAG) وAgentic RAG
- كيفية تنفيذ البحث الدلالي في المستندات باستخدام Vertex AI Search
- كيفية عرض البيانات المنظَّمة على وكيل من خلال إنشاء أدوات مخصّصة
- كيفية إنشاء وكيل متعدد الأدوات وتنسيقه باستخدام "حزمة تطوير الوكلاء" (ADK)
- كيف تستخدم البرامج الآلية الاستدلال والتخطيط للإجابة عن الأسئلة المعقّدة باستخدام مصادر بيانات متعددة
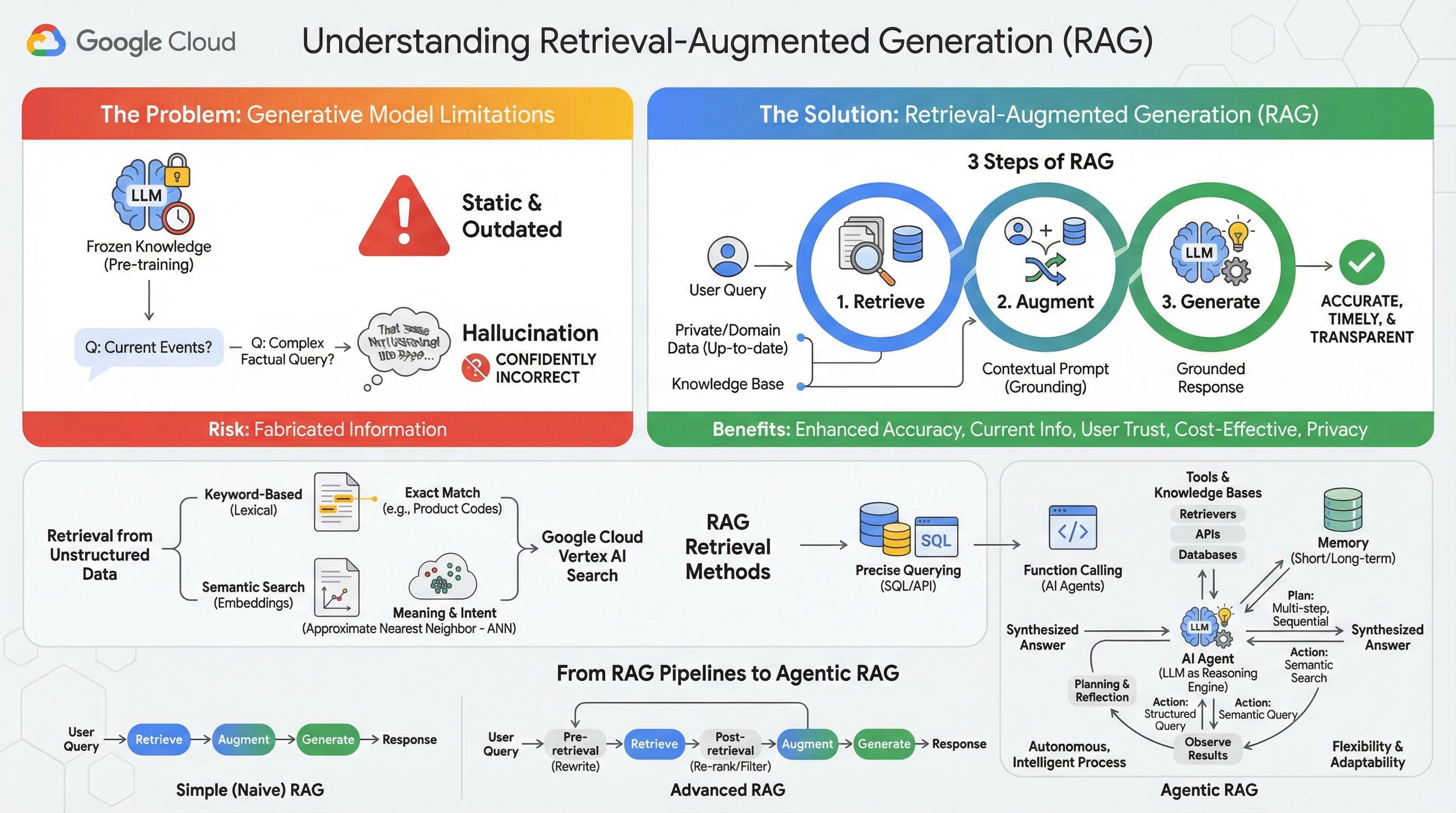
2. فهم التوليد المعزّز بالاسترجاع
تتسم النماذج التوليدية الكبيرة (النماذج اللغوية الكبيرة أو LLM باختصار، ونماذج الرؤية واللغة، وما إلى ذلك) بقدرات هائلة، ولكن لها حدود متأصلة. تتوقف معلوماتها عند وقت التدريب المُسبَق، ما يجعلها ثابتة وقديمة على الفور. حتى بعد الضبط الدقيق، لا تصبح معرفة النموذج أكثر حداثة، لأنّ هذا ليس الهدف من مراحل ما بعد التدريب.
إنّ طريقة تدريب النماذج اللغوية الكبيرة، لا سيما نماذج "التفكير"، تجعلها "تُكافأ" على تقديم بعض الإجابات حتى إذا لم يتضمّن النموذج نفسه معلومات واقعية تؤيّد هذه الإجابة. ويُطلق على ذلك اسم "الهلوسة"، أي أنّ النموذج يقدّم بثقة معلومات تبدو معقولة ولكنّها غير صحيحة.
Retrieval-Augmented Generation هو نمط معماري قوي مصمّم لحلّ هذه المشاكل تحديدًا. وهو إطار عمل هندسي يعزّز إمكانات النماذج اللغوية الكبيرة من خلال ربطها بمصادر خارجية موثوقة للمعلومات في الوقت الفعلي. بدلاً من الاعتماد فقط على المعلومات الثابتة التي تم تدريب النموذج اللغوي الكبير عليها مسبقًا، يسترجع النموذج في نظام التوليد المعزّز بالاسترجاع أولاً المعلومات ذات الصلة بطلب بحث المستخدم، ثم يستخدم هذه المعلومات لإنشاء ردّ أكثر دقة وفي الوقت المناسب ومراعيًا للسياق.
يعالج هذا الأسلوب بشكل مباشر نقاط الضعف الأكثر أهمية في النماذج التوليدية، وهي أنّ معرفتها ثابتة في وقت معيّن، وأنّها عُرضة لإنشاء معلومات غير صحيحة، أو ما يُعرف باسم "الهلوسة". يمنح التوليد المعزّز بالاسترجاع النموذج اللغوي الكبير بشكل فعّال "اختبارًا مفتوح الكتاب"، حيث يكون "الكتاب" هو بياناتك الخاصة والمحدّثة والمخصّصة لمجالك. تُعرف عملية تزويد النموذج اللغوي الكبير بسياق واقعي باسم "التأسيس".
3 خطوات في عملية التوليد المعزّز بالاسترجاع
يمكن تقسيم عملية "التوليد المعزّز بالاسترجاع" العادية إلى ثلاث خطوات بسيطة:
- الاسترجاع: عندما يرسل المستخدم طلب بحث، يبحث النظام أولاً في قاعدة معلومات خارجية (مثل مستودع مستندات أو قاعدة بيانات أو موقع إلكتروني) للعثور على معلومات ذات صلة بطلب البحث.
- التعزيز: يتم بعد ذلك دمج المعلومات المُسترجَعة مع طلب بحث المستخدم الأصلي في طلب موسّع. يُطلق على هذه التقنية أحيانًا اسم "حشو الطلب"، لأنّها تُثري الطلب بالسياق الواقعي.
- الإنشاء: يتم إدخال هذا الطلب المعزَّز إلى النموذج اللغوي الكبير، الذي ينشئ ردًا. بما أنّ النموذج مزوّد ببيانات ذات صلة وواقعية، فإنّ نتائجه تكون "مستندة إلى الواقع" وأقل عرضة لأن تكون غير دقيقة أو قديمة.
مزايا التوليد المعزّز بالاسترجاع
كان إطلاق إطار عمل "التوليد المعزّز بالاسترجاع" خطوة تحويلية في إنشاء تطبيقات ذكاء اصطناعي عملية وموثوقة. تشمل المزايا الرئيسية ما يلي:
- دقة محسّنة وتقليل الهلوسة: من خلال ربط الردود بحقائق خارجية يمكن التحقّق منها، تقلّل آلية التوليد المعزّز بالاسترجاع بشكل كبير من احتمال أن يختلق النموذج اللغوي الكبير معلومات.
- الوصول إلى المعلومات الحالية: يمكن ربط أنظمة التوليد المعزّز بالاسترجاع بقواعد معلومات يتم تعديلها باستمرار، ما يتيح لها تقديم ردود استنادًا إلى أحدث المعلومات، وهو أمر لا يمكن أن يفعله نموذج لغوي كبير تم تدريبه بشكل ثابت.
- زيادة ثقة المستخدمين والشفافية: بما أنّ رد النموذج اللغوي الكبير يستند إلى المستندات التي تم استرجاعها، يمكن للنظام تقديم اقتباسات وروابط إلى مصادره. يسمح ذلك للمستخدمين بالتحقّق من المعلومات بأنفسهم، ما يعزّز ثقتهم في التطبيق.
- فعالية التكلفة: إنّ الضبط الدقيق أو إعادة التدريب المستمر لنموذج لغوي كبير باستخدام بيانات جديدة أمر مكلف من الناحية الحسابية والمالية. باستخدام "التوليد المعزّز بالاسترجاع"، يصبح تعديل المعلومات المخزّنة في النموذج بسيطًا مثل تعديل مصدر البيانات الخارجية، ما يجعله أكثر فعالية.
- التخصّص في مجالات معيّنة والخصوصية: يتيح التوليد المعزّز بالاسترجاع للأفراد والمؤسسات إتاحة بياناتهم الخاصة والمحمية لنموذج لغوي كبير في وقت تقديم الطلب بدون الحاجة إلى تضمين هذه البيانات الحسّاسة في مجموعة التدريب الخاصة بالنموذج. يتيح ذلك تطبيقات فعّالة خاصة بمجالات معيّنة مع الحفاظ على خصوصية البيانات وأمانها.
الاسترجاع
تشكّل خطوة "الاسترجاع" جوهر أي نظام توليد معزّز بالاسترجاع. تحدّد جودة المعلومات التي يتم استرجاعها ومدى صلتها بالموضوع جودة الإجابة النهائية التي يتم إنشاؤها ومدى صلتها بالموضوع. غالبًا ما يحتاج تطبيق "التوليد المعزّز بالاسترجاع" الفعّال إلى استرداد المعلومات من أنواع مختلفة من مصادر البيانات باستخدام تقنيات متنوعة. تنقسم طرق الاسترجاع الأساسية إلى ثلاث فئات: استنادًا إلى الكلمات الرئيسية، واستنادًا إلى الدلالات، واستنادًا إلى البنية.
استرداد البيانات غير المنظَّمة
في السابق، كان استرجاع البيانات غير المنظَّمة يُعرف باسم "البحث التقليدي". وقد خضع لعمليات تحويل متعددة، ويمكنك الاستفادة من كلا النهجَين الرئيسيين.
البحث الدلالي هو الأسلوب الأكثر فعالية الذي يمكنك تنفيذه على نطاق واسع في Google Cloud بأداء متطوّر ودرجة تحكّم عالية.
- البحث المستند إلى الكلمات الرئيسية (المعجمي): هذا هو الأسلوب التقليدي للبحث، ويعود تاريخه إلى أوائل أنظمة استرجاع المعلومات في السبعينيات. يعمل البحث المعجمي من خلال مطابقة الكلمات الحرفية (أو "الرموز") في طلب بحث المستخدم مع الكلمات نفسها تمامًا في المستندات ضمن قاعدة المعلومات. وهي فعّالة للغاية في طلبات البحث التي تتطلّب دقة في ما يتعلق بعبارات معيّنة، مثل رموز المنتجات أو البنود القانونية أو الأسماء الفريدة.
- البحث الدلالي: البحث الدلالي، أو "البحث بالمعنى"، هو أسلوب أكثر حداثة يهدف إلى فهم نية المستخدم والمعنى السياقي لطلب البحث، وليس الكلمات الرئيسية الحرفية فقط. تستند عملية البحث الدلالي الحديثة إلى التضمين، وهو أسلوب تعلُّم آلي يحوّل البيانات المعقّدة ذات الأبعاد العالية إلى مساحة متّجهة ذات أبعاد منخفضة من المتّجهات الرقمية. تم تصميم هذه المتجهات بطريقة تجعل النصوص ذات المعاني المتشابهة قريبة من بعضها البعض في مساحة المتجهات. يتم تحويل طلب البحث "ما هي أفضل سلالات الكلاب المناسبة للعائلات؟" إلى متّجه، ثم يبحث النظام عن متّجهات المستندات التي تمثّل "أقرب جيران" له في تلك المساحة. يتيح ذلك للمحرك العثور على المستندات التي تتحدث عن "كلاب الريتريفر الذهبية" أو "الكلاب الودودة"، حتى إذا لم تكن تحتوي على الكلمة "كلب" بالضبط. تصبح عملية البحث العالي الأبعاد فعّالة بفضل خوارزميات "الجار الأقرب التقريبي" (ANN). بدلاً من مقارنة متّجه طلب البحث بمتّجه كل مستند على حدة (وهو ما سيكون بطيئًا جدًا بالنسبة إلى مجموعات البيانات الكبيرة)، تستخدم خوارزميات البحث التقريبي عن أقرب جيران (ANN) هياكل فهرسة ذكية للعثور بسرعة على المتّجهات التي من المحتمل أن تكون الأقرب.
استرداد المعلومات من البيانات المنظَّمة
لا يتم تخزين كل المعلومات المهمة في مستندات غير منظَّمة. في كثير من الأحيان، تتوفّر المعلومات الأكثر دقة وقيمة بتنسيقات منظَّمة، مثل قواعد البيانات الارتباطية أو قواعد بيانات NoSQL أو نوع من واجهات برمجة التطبيقات، مثل واجهة REST API لبيانات الطقس أو أسعار الأسهم.
عادةً ما يكون استرجاع المعلومات من البيانات المنظَّمة أكثر مباشرةً ودقةً من البحث في النصوص غير المنظَّمة. بدلاً من البحث عن التشابه الدلالي، يمكن منح النماذج اللغوية القدرة على صياغة وتنفيذ طلب بيانات دقيق، مثل طلب بيانات من واجهة برمجة التطبيقات SQL في قاعدة بيانات أو طلب بيانات من واجهة برمجة التطبيقات إلى Weather API لموقع وتاريخ معيّنَين.
يتم تنفيذ هذه الميزة من خلال استدعاء الدوال، وهي التقنية نفسها التي تستند إليها "وكلاء الذكاء الاصطناعي"، وتتيح للنماذج اللغوية التفاعل مع الرموز البرمجية القابلة للتنفيذ والأنظمة الخارجية بطريقة هيكلية محددة.
3- من مسارات التوليد المعزّز بالاسترجاع إلى التوليد المعزّز بالاسترجاع المستند إلى الذكاء الاصطناعي الوكيل
وكما تطوّر مفهوم RAG نفسه، تطوّرت أيضًا البُنى الأساسية لتنفيذه. ما بدأ كمسار بسيط ومباشر تطوّر ليصبح نظامًا ديناميكيًا وذكيًا تديره برامج الذكاء الاصطناعي.
- التوليد المعزّز بالاسترجاع البسيط (أو الساذج): هذه هي البنية الأساسية التي ناقشناها حتى الآن: عملية خطية من ثلاث خطوات، وهي الاسترجاع والتعزيز والتوليد. وهي تفاعلية، إذ تتّبع مسارًا ثابتًا لكل طلب بحث، كما أنّها فعّالة للغاية في مهام الأسئلة والأجوبة المباشرة.
- الاسترجاع المتقدّم المستند إلى إنشاء المحتوى: يمثّل هذا النوع تطورًا يتم فيه إضافة خطوات إضافية إلى مسار العمل لتحسين جودة السياق الذي تم استرجاعه. يمكن أن تحدث هذه التحسينات قبل خطوة الاسترداد أو بعدها.
- الاسترجاع المُسبَق: يمكن استخدام تقنيات مثل إعادة كتابة طلب البحث أو توسيعه. قد يحلّل النظام طلب البحث الأوّلي ويعيد صياغته ليكون أكثر فعالية لنظام الاسترجاع.
- ما بعد الاسترجاع: بعد استرجاع مجموعة أولية من المستندات، يمكن تطبيق نموذج إعادة ترتيب لتقييم المستندات حسب مدى صلتها بالموضوع وعرض أفضلها في أعلى النتائج. ويُعدّ ذلك مهمًا بشكل خاص في البحث المختلط. تتمثّل خطوة أخرى بعد استرجاع المعلومات في فلترة السياق المسترجَع أو ضغطه لضمان تمرير المعلومات الأكثر أهمية فقط إلى النموذج اللغوي الكبير.
- الاسترجاع والإنشاء المستند إلى الوكيل: يمثّل هذا النوع من بنية الاسترجاع والإنشاء المستند إلى الاسترجاع أحدث التطورات في هذا المجال، وهو يمثّل تحوّلاً جذريًا من مسار ثابت إلى عملية مستقلة وذكية. في نظام RAG المستند إلى وكيل، تتم إدارة سير العمل بالكامل من خلال وكيل واحد أو أكثر من وكلاء الذكاء الاصطناعي الذين يمكنهم التفكير والتخطيط واختيار إجراءاتهم بشكل ديناميكي.
لفهم Agentic RAG، يجب أولاً فهم ما يشكّل وكيل الذكاء الاصطناعي. الوكيل هو أكثر من مجرد نموذج لغوي كبير. وهو نظام يتضمّن عدة عناصر أساسية:
- النموذج اللغوي الكبير كأداة استدلال: يستخدم الوكيل نموذجًا لغويًا كبيرًا قويًا، مثل Gemini، ليس فقط لإنشاء النصوص، بل كـ "دماغ" مركزي للتخطيط واتخاذ القرارات وتقسيم المهام المعقدة.
- مجموعة من الأدوات: يتم منح الوكيل إذن الوصول إلى مجموعة أدوات تتضمّن وظائف يمكنه استخدامها لتحقيق أهدافه. ويمكن أن تكون هذه الأدوات أي شيء، مثل آلة حاسبة أو واجهة برمجة تطبيقات للبحث على الويب أو وظيفة لإرسال رسالة إلكترونية، أو الأهم بالنسبة إلى هذا المختبر، أدوات استرجاع لقواعد المعرفة المختلفة.
- الذاكرة: يمكن تصميم الوكلاء باستخدام ذاكرة قصيرة المدى (لتذكُّر سياق المحادثة الحالية) وذاكرة طويلة المدى (لاسترجاع المعلومات من التفاعلات السابقة)، ما يتيح تجارب أكثر تخصيصًا وتماسكًا.
- التخطيط والتفكير: تعرض البرامج الأكثر تقدّمًا أنماطًا معقّدة من الاستدلال. يمكنها تلقّي هدف معقّد ووضع خطة متعدّدة الخطوات لتحقيقه. يمكنهم بعد ذلك تنفيذ هذه الخطة، بل والتفكير في نتائج أفعالهم، وتحديد الأخطاء، وتصحيح نهجهم ذاتيًا لتحسين النتيجة النهائية.
تُعدّ طريقة RAG المستندة إلى الوكيل من التقنيات الثورية لأنّها تقدّم مستوى من الاستقلالية والذكاء لا توفّره قنوات المعالجة الثابتة.
- المرونة والقدرة على التكيّف: لا يقتصر عمل الوكيل على مسار استرجاع واحد. وبالنظر إلى طلب بحث من مستخدم، يمكنه تحديد أفضل مصدر للمعلومات. قد يقرّر أولاً البحث في قاعدة البيانات المنظَّمة، ثم إجراء بحث دلالي في المستندات غير المنظَّمة، وإذا لم يتمكّن من العثور على إجابة، سيستخدم أداة "بحث Google" للبحث على الويب العام، وكل ذلك في سياق طلب واحد من المستخدم.
- الاستدلال المعقّد والمتعدد الخطوات: يتفوّق هذا التصميم في التعامل مع الاستعلامات المعقّدة التي تتطلّب عدّة خطوات متسلسلة لاسترجاع البيانات ومعالجتها.
لنفترض أنّ طلب البحث هو: "أريد العثور على أفضل 3 أفلام خيال علمي من إخراج كريستوفر نولان، مع ملخّص موجز لكل فيلم". سيفشل مسار RAG بسيط.
مع ذلك، يمكن للوكيل تقسيمها على النحو التالي:
- الخطة: أولاً، يجب أن أعثر على الأفلام. بعد ذلك، عليّ البحث عن حبكة كل فيلم.
- الإجراء 1: استخدِم أداة البيانات المنظَّمة للاستعلام عن قاعدة بيانات أفلام بحثًا عن أفلام الخيال العلمي التي أخرجها "نولان": أفضل 3 أفلام، مرتّبة حسب التقييم من الأعلى إلى الأدنى.
- الملاحظة 1: تعرض الأداة "بداية" و"بين النجوم" و "عقيدة".
- الخطوة 2: استخدِم أداة البيانات غير المنظَّمة (البحث الدلالي) للعثور على حبكة فيلم "بداية".
- الملاحظة 2: يتم استرداد الرسم البياني.
- الخطوة 3: كرِّر الخطوات نفسها لفيلم "بين النجوم".
- الخطوة 4: كرِّر الخطوات نفسها لفيلم "تينيت".
- الخلاصة النهائية: ادمِج كل المعلومات التي تم استرجاعها في إجابة واحدة متماسكة للمستخدم.
4. إعداد المشروع
حساب Google
إذا لم يكن لديك حساب Google شخصي، عليك إنشاء حساب على Google.
استخدام حساب شخصي بدلاً من حساب تابع للعمل أو تديره مؤسسة تعليمية
تسجيل الدخول إلى Google Cloud Console
سجِّل الدخول إلى Google Cloud Console باستخدام حساب Google شخصي.
تفعيل الفوترة
استخدام حساب فوترة تجريبي (اختياري)
لإجراء ورشة العمل هذه، يجب أن يكون لديك حساب فوترة يتضمّن بعض الرصيد. استخدِم الرصيد من البانر في أعلى هذا الدرس التطبيقي للبدء. إذا كنت مرتبطًا بحساب فوترة، يمكنك تخطّي هذه الخطوة.
إعداد حساب فوترة شخصي
إذا أعددت الفوترة باستخدام أرصدة Google Cloud، يمكنك تخطّي هذه الخطوة.
لإعداد حساب فوترة شخصي، يُرجى الانتقال إلى هنا لتفعيل الفوترة في Cloud Console.
ملاحظات:
- يجب أن تكلّف إكمال هذا الدرس التطبيقي أقل من دولار أمريكي واحد من موارد السحابة الإلكترونية.
- يمكنك اتّباع الخطوات في نهاية هذا المختبر لحذف الموارد وتجنُّب المزيد من الرسوم.
- يمكن للمستخدمين الجدد الاستفادة من فترة تجريبية مجانية بقيمة 300 دولار أمريكي.
إنشاء مشروع (اختياري)
إذا لم يكن لديك مشروع حالي تريد استخدامه في هذا المختبر، يمكنك إنشاء مشروع جديد هنا.
5- فتح "محرّر Cloud Shell"
- انقر على هذا الرابط للانتقال مباشرةً إلى محرّر Cloud Shell
- إذا طُلب منك منح الإذن في أي وقت اليوم، انقر على منح الإذن للمتابعة.
- إذا لم تظهر المحطة الطرفية في أسفل الشاشة، افتحها باتّباع الخطوات التالية:
- انقر على عرض.
- انقر على Terminal
- في الوحدة الطرفية، اضبط مشروعك باستخدام الأمر التالي:
gcloud config set project [PROJECT_ID]- مثال:
gcloud config set project lab-project-id-example - إذا تعذّر عليك تذكُّر رقم تعريف مشروعك، يمكنك إدراج جميع أرقام تعريف المشاريع باستخدام:
gcloud projects list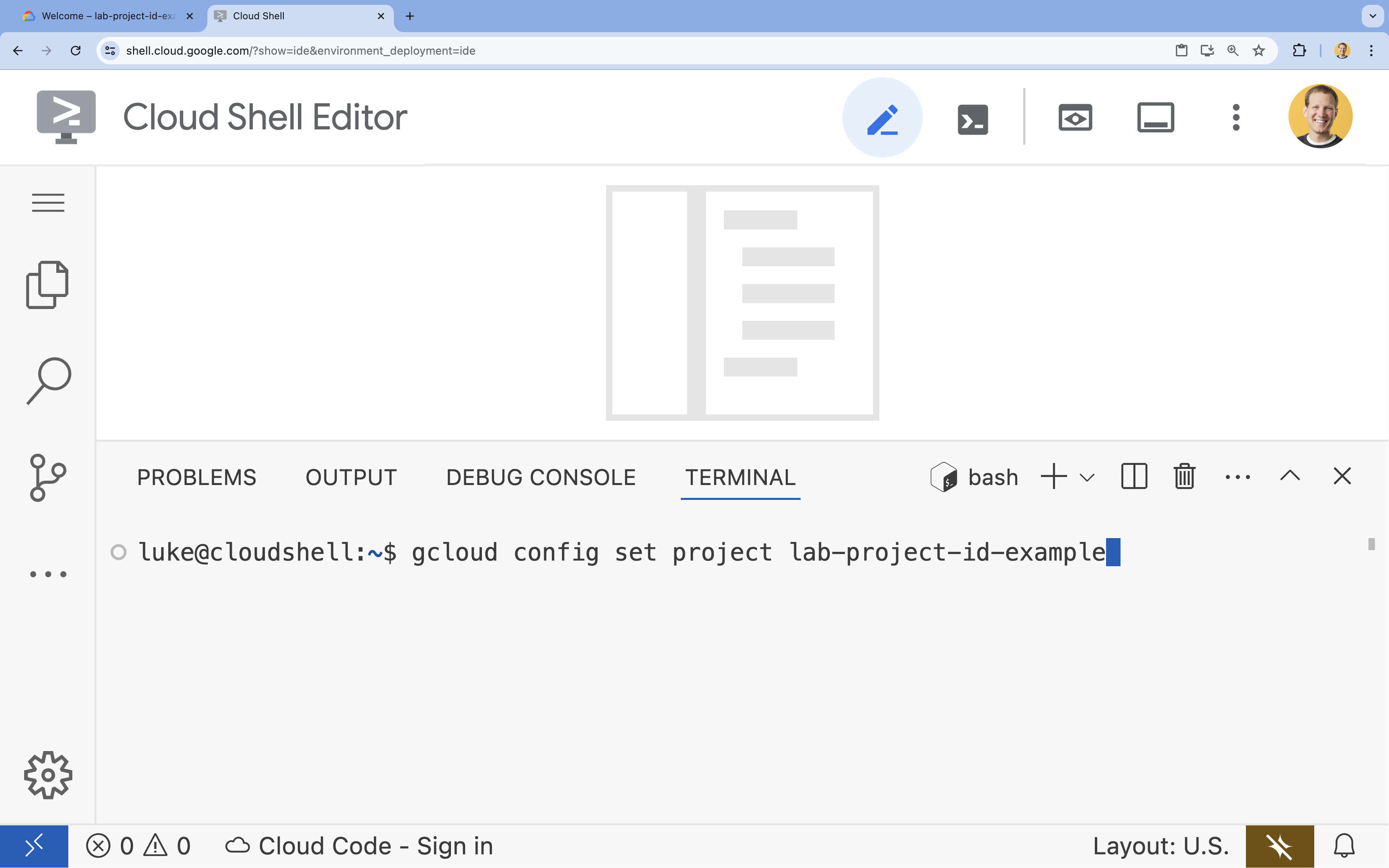
- مثال:
- من المفترض أن تظهر لك هذه الرسالة:
Updated property [core/project].
6. تفعيل واجهات برمجة التطبيقات
لاستخدام مجموعة أدوات تطوير الوكيل وVertex AI Search، عليك تفعيل واجهات برمجة التطبيقات اللازمة في مشروعك على السحابة الإلكترونية على Google.
- في الوحدة الطرفية، فعِّل واجهات برمجة التطبيقات:
gcloud services enable \ aiplatform.googleapis.com \ discoveryengine.googleapis.com
لمحة عن واجهات برمجة التطبيقات
- تتيح واجهة برمجة التطبيقات Vertex AI API (
aiplatform.googleapis.com) للوكيل التواصل مع نماذج Gemini لإجراء عمليات الاستنتاج والإنشاء. - تتيح Discovery Engine API (
discoveryengine.googleapis.com) التي تشغّل Vertex AI Search إنشاء مستودعات بيانات وإجراء عمليات بحث دلالية في مستنداتك غير المنظَّمة.
7. إعداد البيئة
قبل البدء في ترميز "وكيل الذكاء الاصطناعي"، عليك إعداد بيئة التطوير وتثبيت المكتبات اللازمة وإنشاء ملفات البيانات المطلوبة.
إنشاء بيئة افتراضية وتثبيت التبعيات
- أنشئ دليلاً للوكيل وانتقِل إليه. نفِّذ الرمز التالي في الوحدة الطرفية:
mkdir financial_agent cd financial_agent - إنشاء بيئة افتراضية:
uv venv --python 3.12 - فعِّل البيئة الافتراضية:
source .venv/bin/activate - ثبِّت "حزمة تطوير الوكلاء" (ADK) وpandas.
uv pip install google-adk pandas
إنشاء بيانات أسعار الأسهم
بما أنّ المختبر يتطلّب بيانات أسهم سابقة محدّدة لإثبات قدرة الوكيل على استخدام أدوات منظَّمة، عليك إنشاء ملف CSV يحتوي على هذه البيانات.
- في دليل
financial_agent، أنشئ الملفgoog.csvمن خلال تنفيذ الأمر التالي في الوحدة الطرفية:cat <<EOF > goog.csv Date,Open,High,Low,Close,Adj Close,Volume 2023-01-03,89.830002,91.550003,89.019997,89.699997,89.699997,20738500 2023-03-31,101.440002,103.889999,101.040001,103.730003,103.730003,36823200 2023-06-30,120.870003,122.029999,120.300003,120.970001,120.970001,23824700 2023-09-29,134.080002,134.550003,131.320007,131.850006,131.850006,21124200 2025-07-10,185.000000,188.000000,184.500000,186.500000,186.500000,25000000 EOF
ضبط متغيرات البيئة
- في الدليل
financial_agent، أنشئ ملف.envلضبط متغيّرات بيئة البرنامج. يُعلم هذا المعرّف حزمة تطوير التطبيقات (ADK) بالمشروع والموقع الجغرافي والنموذج المطلوب استخدامها. نفِّذ الرمز التالي في الوحدة الطرفية:# Create the .env file using the captured variables cat << EOF > .env GOOGLE_GENAI_USE_VERTEXAI=TRUE GOOGLE_CLOUD_PROJECT="${GOOGLE_CLOUD_PROJECT}" GOOGLE_CLOUD_LOCATION="us-central1" EOF
ملاحظة: في وقت لاحق من هذا الدرس التطبيقي، إذا كنت بحاجة إلى تعديل الملف .env ولكن لم يظهر لك في الدليل financial_agent، جرِّب تبديل رؤية الملفات المخفية في Cloud Shell Editor باستخدام عنصر القائمة "عرض / تبديل الملفات المخفية".
8. إنشاء مخزن بيانات Vertex AI Search
لتمكين الوكيل من الإجابة عن أسئلة حول التقارير المالية لشركة Alphabet، عليك إنشاء مستودع بيانات في Vertex AI Search يحتوي على مستندات الإفصاح العلني التي تم إيداعها لدى هيئة الأوراق المالية والبورصة.
- في علامة تبويب متصفّح جديدة، افتح وحدة تحكّم Cloud (console.cloud.google.com)، وانتقِل إلى تطبيقات الذكاء الاصطناعي باستخدام شريط البحث في أعلى الصفحة.
- إذا طُلب منك ذلك، ضَع علامة في مربّع الاختيار الخاص بالبنود والشروط، ثم انقر على متابعة وتفعيل واجهة برمجة التطبيقات.
- من قائمة التنقّل اليمنى، اختَر مخازن البيانات.
- انقر على + إنشاء مستودع بيانات.
- ابحث عن بطاقة Cloud Storage وانقر على اختيار.
- بالنسبة إلى مصدر البيانات، اختَر المستندات غير المنظَّمة.

- بالنسبة إلى مصدر الاستيراد (اختَر مجلدًا أو ملفًا تريد استيراده)، أدخِل مسار Google Cloud Storage
cloud-samples-data/gen-app-builder/search/alphabet-sec-filings. - انقر على متابعة.
- اترك الموقع الجغرافي مضبوطًا على global.
- بالنسبة إلى اسم مستودع البيانات، أدخِل
alphabet-sec-filings - وسِّع قسم خيارات معالجة المستندات.

- في القائمة المنسدلة محلّل المستندات التلقائي، اختَر محلّل التنسيق.
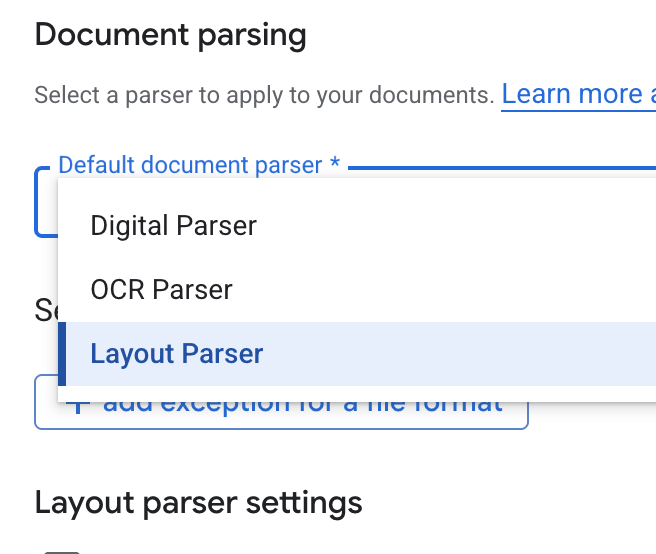
- في خيارات إعدادات محلّل التنسيق، اختَر تفعيل التعليق التوضيحي للجدول وتفعيل التعليق التوضيحي للصورة.
- انقر على متابعة.
- اختَر الأسعار العامة كنموذج الأسعار (نموذج الدفع حسب الاستخدام)، ثم انقر على إنشاء.
- سيبدأ مستودع البيانات في استيراد المستندات.
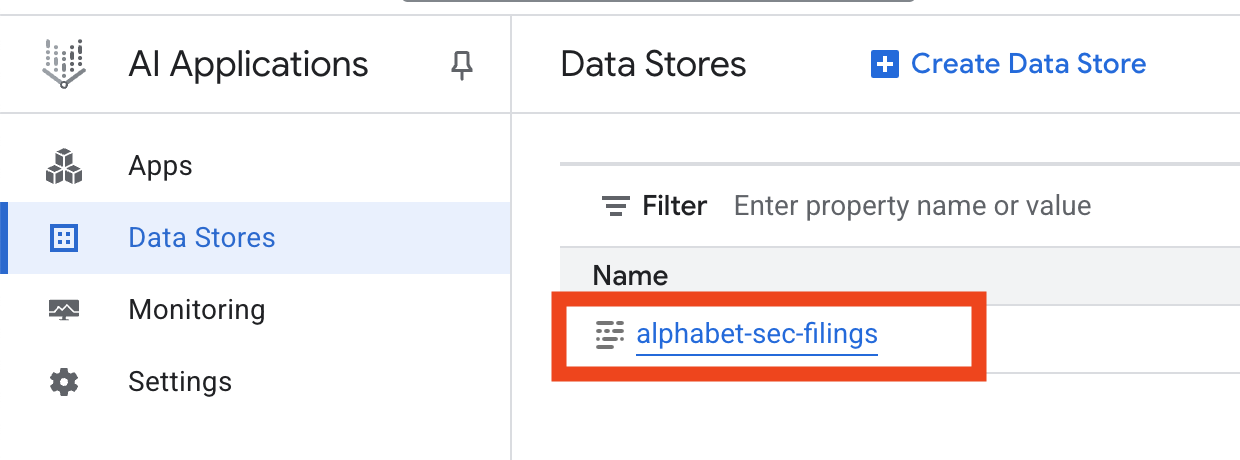
- انقر على اسم مستودع البيانات، ثم انسخ معرّفه من جدول "مستودعات البيانات". ستحتاج إليه في الخطوة التالية.
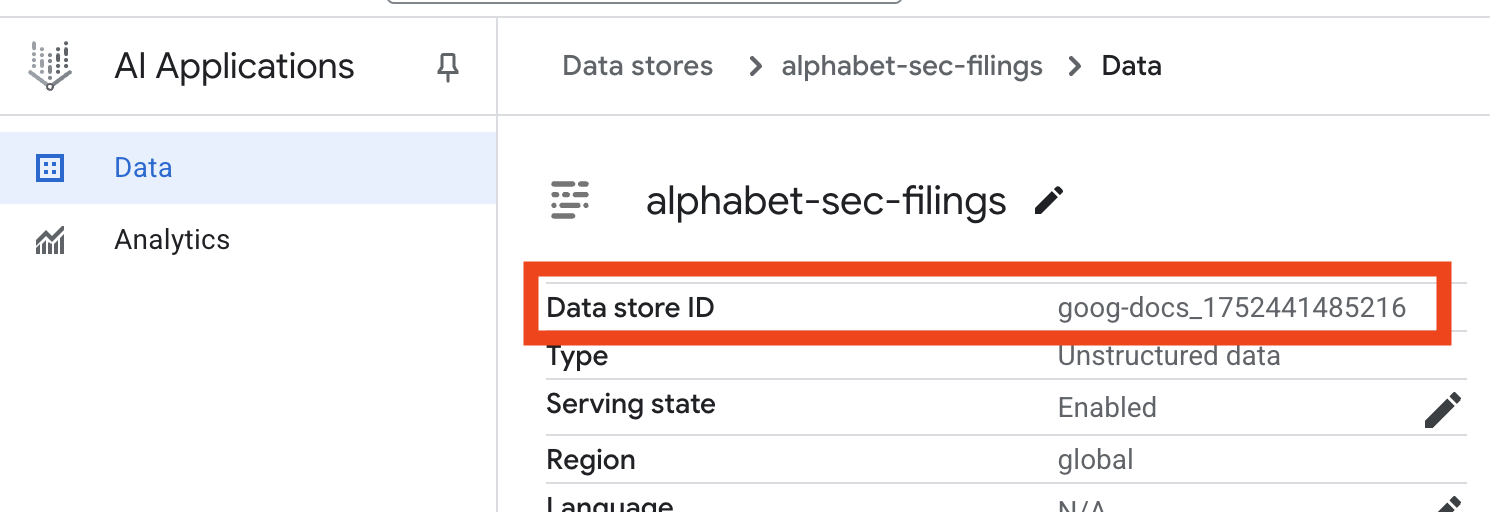
- افتح الملف
.envفي Cloud Shell Editor وأضِف معرّف مخزن البيانات كـDATA_STORE_ID="YOUR_DATA_STORE_ID"(استبدِلYOUR_DATA_STORE_IDبالمعرّف الفعلي من الخطوة السابقة.ملاحظة: ستستغرق عملية استيراد البيانات وتحليلها وفهرستها في مخزن البيانات بضع دقائق. للاطّلاع على العملية، انقر على اسم مستودع البيانات لفتح خصائصه، ثم افتح علامة التبويب النشاط. انتظِر إلى أن تصبح الحالة "اكتملت عملية الاستيراد".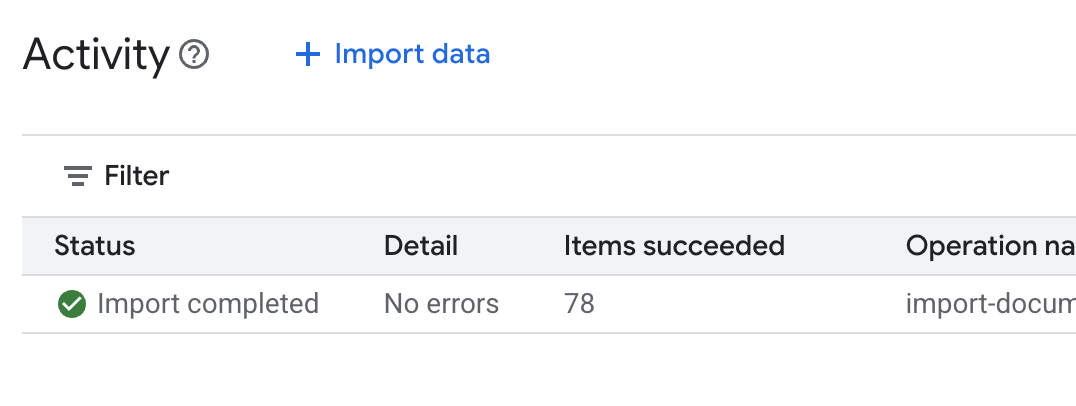
9- إنشاء أداة مخصّصة للبيانات المنظَّمة
بعد ذلك، ستنشئ دالة Python تعمل كأداة للوكيل. ستقرأ هذه الأداة الملف goog.csv لاسترداد أسعار الأسهم السابقة لتاريخ معيّن.
- في الدليل
financial_agent، أنشئ ملفًا جديدًا باسمagent.py. نفِّذ الأمر التالي في الوحدة الطرفية:cloudshell edit agent.py - أضِف رمز Python التالي إلى
agent.py. يستورد هذا الرمز التبعيات ويحدّد الدالةget_stock_price.from datetime import datetime import os import logging import google.cloud.logging from google.adk.tools import VertexAiSearchTool from google.adk.tools.agent_tool import AgentTool from google.adk.agents import LlmAgent import pandas as pd def get_stock_price(date: str) -> dict: """Gets the closing stock price for a given date. Args: date: The date to get the stock price for, in YYYY-MM-DD format. Returns: A dictionary containing the closing price, or an error message if the date is not found or the format is incorrect. """ try: # Load the CSV file df = pd.read_csv('goog.csv') # Convert the 'Date' column to datetime objects df['Date'] = pd.to_datetime(df['Date']) # Convert the input string to a datetime object query_date = datetime.strptime(date, '%Y-%m-%d') # Find the row for the given date row = df[df['Date'] == query_date] if not row.empty: # Get the closing price close_price = row['Close'].iloc[0] return {"status": "success", "date": date, "closing_price": close_price} else: return {"status": "error", "message": f"No data found for date: {date}"} except FileNotFoundError: return {"status": "error", "message": "Stock data file (goog.csv) not found."} except Exception as e: return {"status": "error", "message": f"An error occurred: {str(e)}"}
لاحظ سلسلة التوثيق التفصيلية للدالة. توضّح هذه السلسلة ما تفعله الدالة، ومَعلماتها (Args)، وما تعرضه (Returns). يستخدم ADK هذه السلسلة لتعليم الوكيل كيفية استخدام هذه الأداة ومتى يجب استخدامها.
10. إنشاء وكيل RAG وتشغيله
حان الوقت الآن لتجميع الوكيل. ستجمع بين أداة Vertex AI Search للبيانات غير المنظَّمة وأداة get_stock_price المخصّصة للبيانات المنظَّمة.
- أضِف الرمز التالي إلى ملف
agent.py. تستورد هذه التعليمات البرمجية فئات ADK اللازمة، وتنشئ مثيلات للأدوات، وتعرّف الوكيل.logging.basicConfig(level=logging.INFO) cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() # 1. Create the Vertex AI Search tool full_datastore_id = f"projects/{os.environ['GOOGLE_CLOUD_PROJECT']}/locations/global/collections/default_collection/dataStores/{os.environ['DATA_STORE_ID']}" vertex_ai_search_tool = VertexAiSearchTool( data_store_id=full_datastore_id ) # 2. Define the Search+Q&A agent # Since we cannot combine tools with other tools in a single agent, # we create a separate Search+Q&A agent which will be used as a tool by the main root agent. doc_qa_agent = LlmAgent( name="search_and_qna_agent", model="gemini-2.5-flash", tools=[vertex_ai_search_tool], instruction="""You are a helpful assistant that answers questions based on information found in the document store. Use the search tool to find relevant information before answering. If the answer isn't in the documents, say that you couldn't find the information. """, description="Answers questions using a specific Vertex AI Search datastore.", ) # 3. Define the root agent with 2 tools. root_agent = LlmAgent( name="financial_agent", model="gemini-2.5-flash", tools=[ AgentTool(doc_qa_agent), get_stock_price, ], instruction="""You are an Financial Analytics Agent that answers question about Alphabet stock prices (using get_stock_price tool) and historical performance based on the data in Vertex AI Search datastore (using doc_qa_agent tool).""" ) - من نافذة الجهاز، داخل الدليل
financial_agent، شغِّل واجهة الويب الخاصة بـ "حزمة تطوير التطبيقات" للتفاعل مع الوكيل:adk web ~ - انقر على الرابط المقدَّم في ناتج الوحدة الطرفية (عادةً
http://127.0.0.1:8000) لفتح واجهة مستخدم ADK Dev في المتصفّح.
11. اختبار الوكيل
يمكنك الآن اختبار قدرة الوكيل على التفكير واستخدام أدواته للإجابة عن الأسئلة المعقّدة.
- في واجهة مستخدم مطوّر ADK، تأكَّد من اختيار
financial_agentمن القائمة المنسدلة. - جرِّب طرح سؤال يتطلّب معلومات من مستندات هيئة الأوراق المالية والبورصة (بيانات غير منظَّمة). أدخِل طلب البحث التالي في المحادثة:
What were the total revenues for the quarter ending on March 31, 2023?search_and_qna_agent، الذي يستخدمVertexAiSearchToolللعثور على الإجابة في المستندات المالية. - بعد ذلك، اطرح سؤالاً يتطلّب استخدام أداتك المخصّصة (البيانات المنظَّمة). يُرجى العِلم أنّه ليس من الضروري أن يتطابق تنسيق التاريخ في الطلب مع التنسيق المطلوب من الدالة، فالنموذج اللغوي الكبير ذكي بما يكفي لإعادة تنسيقه.
What was the closing stock price for Alphabet on July 10, 2025?get_stock_price. يمكنك النقر على رمز الأداة في المحادثة لفحص استدعاء الدالة ونتيجته. - أخيرًا، اطرح سؤالاً معقّدًا يتطلّب من الوكيل استخدام كلتا الأداتين وتجميع النتائج.
According to the 10-Q filing for the period ending March 31, 2023, what were the company's net cash provided by operating activities, and what was the stock's closing price on that date?- أولاً، سيستخدم
VertexAiSearchToolللعثور على معلومات التدفق النقدي في مستندات هيئة الأوراق المالية والبورصة. - بعد ذلك، ستدرك الحاجة إلى سعر السهم وتستدعي الدالة
get_stock_priceمع التاريخ2023-03-31. - أخيرًا، سيجمع بين هاتين المعلومتين في إجابة واحدة شاملة.
- أولاً، سيستخدم
- عند الانتهاء، يمكنك إغلاق علامة تبويب المتصفّح والضغط على
CTRL+Cفي الوحدة الطرفية لإيقاف خادم ADK.
12. اختيار خدمة لمهمتك
Vertex AI Search ليس خدمة البحث عن المتّجهات الوحيدة التي يمكنك استخدامها. يمكنك أيضًا استخدام خدمة مُدارة تعمل على أتمتة عملية التوليد المعزّز بالاسترجاع بأكملها: Vertex AI RAG Engine.
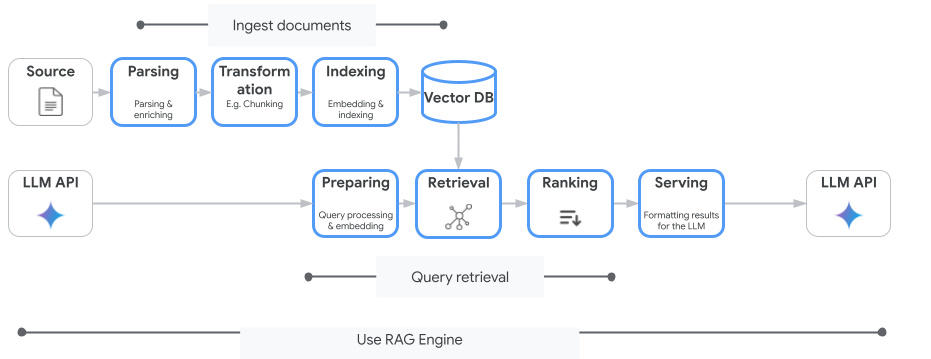
وهي تتعامل مع كل شيء بدءًا من استيعاب المستندات إلى استرجاعها وإعادة ترتيبها. يتوافق محرّك RAG مع العديد من مستودعات المتجهات، بما في ذلك Pinecone وWeaviate.
يمكنك أيضًا استضافة العديد من قواعد بيانات المتجهات المتخصّصة أو الاستفادة من إمكانات فهرسة المتجهات في محركات قواعد البيانات، مثل pgvector في خدمة PostgreSQL (مثل AlloyDB أو البحث المتّجه في BigQuery).
في ما يلي بعض الخدمات الأخرى التي تتيح استخدام ميزة "البحث المتّجه":
- Cloud SQL for PostgreSQL
- Cloud SQL for MySQL
- Cloud Spanner
- Memorystore for Redis
- Firestore
- Bigtable
في ما يلي الإرشادات العامة بشأن اختيار خدمة معيّنة على Google Cloud:
- إذا كانت لديك بنية أساسية تعمل بشكل جيد وقابلة للتوسّع في Vector Search Do-It-Yourself، يمكنك نشرها على Google Kubernetes Engine، مثل Weaviate أو DIY PostgreSQL.
- إذا كانت بياناتك في BigQuery أو AlloyDB أو Firestore أو أي قاعدة بيانات أخرى، ننصحك باستخدام إمكانات "البحث المتّجه" إذا كان بإمكانك إجراء البحث الدلالي على نطاق واسع كجزء من طلب بحث أكبر في قاعدة البيانات هذه. على سبيل المثال، إذا كانت لديك أوصاف و/أو صور منتجات في جدول BigQuery، ستتيح إضافة عمود تضمين نص و/أو صورة استخدام البحث عن التشابه على نطاق واسع. تتيح فهارس المتجهات التي تتوافق مع بحث ScANN تخزين مليارات العناصر في الفهرس.
- إذا كنت بحاجة إلى البدء بسرعة وبأقل جهد ممكن وعلى منصة مُدارة، اختَر Vertex AI Search، وهو محرّك بحث مُدار بالكامل وواجهة برمجة تطبيقات لاسترجاع البيانات، ويُعدّ مثاليًا لحالات الاستخدام المعقّدة في المؤسسات التي تتطلّب جودة عالية وقابلية للتوسيع وعناصر تحكّم دقيقة في إمكانية الوصول. فهو يسهّل الربط بمصادر بيانات المؤسسة المتنوّعة ويتيح البحث في مصادر متعددة.
- استخدِم Vertex AI RAG Engine إذا كنت تبحث عن حلّ مناسب للمطوّرين الذين يريدون تحقيق التوازن بين سهولة الاستخدام والتخصيص. فهي تتيح إنشاء نماذج أولية وتطويرها بسرعة بدون التضحية بالمرونة.
- استكشِف البُنى المرجعية للتوليد المعزّز بالاسترجاع.
13. الخاتمة
تهانينا! لقد نجحت في إنشاء وكيل ذكاء اصطناعي واختباره باستخدام التوليد المعزّز بالاسترجاع. لقد تعلّمت كيفية:
- يمكنك إنشاء قاعدة معلومات للمستندات غير المنظَّمة باستخدام إمكانات البحث الدلالي الفعّالة في Vertex AI Search.
- طوِّر دالة Python مخصّصة تعمل كأداة لاسترداد البيانات المنظَّمة.
- استخدِم "حزمة تطوير الوكلاء" (ADK) لإنشاء وكيل متعدد الأدوات يستند إلى Gemini.
- إنشاء وكيل قادر على إجراء عمليات الاستدلال المتعدّد الخطوات المعقّدة للإجابة عن طلبات البحث التي تتطلّب تجميع المعلومات من مصادر متعددة
يوضّح هذا التمرين المعملي المبادئ الأساسية لـ "التوليد المعزّز بالاسترجاع" (RAG) المستند إلى الوكلاء، وهي بنية قوية لإنشاء تطبيقات ذكاء اصطناعي ذكية ودقيقة ومراعية للسياق على Google Cloud.
من النموذج الأوّلي إلى مرحلة الإصدار
يشكّل هذا المختبر جزءًا من المسار التعليمي "الذكاء الاصطناعي الجاهز للإنتاج" من Google Cloud.
- استكشاف المنهج الدراسي الكامل لسدّ الفجوة بين النموذج الأوّلي والإنتاج
- شارِك مستوى تقدّمك باستخدام الهاشتاغ #ProductionReadyAI.