
১. ভূমিকা
সংক্ষিপ্ত বিবরণ
এই ল্যাবের উদ্দেশ্য হলো গুগল ক্লাউডে কীভাবে এন্ড-টু-এন্ড এজেন্টিক রিট্রিভাল-অগমেন্টেড জেনারেশন (RAG) অ্যাপ্লিকেশন তৈরি করতে হয় তা শেখা। এই ল্যাবে, আপনি এমন একটি ফিনান্সিয়াল অ্যানালাইসিস এজেন্ট তৈরি করবেন যা দুটি ভিন্ন উৎস থেকে তথ্য একত্রিত করে প্রশ্নের উত্তর দিতে পারে: অসংগঠিত নথি ( অ্যালফাবেটের ত্রৈমাসিক এসইসি ফাইলিং - আর্থিক বিবরণী এবং পরিচালন সংক্রান্ত বিবরণ যা মার্কিন যুক্তরাষ্ট্রের প্রতিটি পাবলিক কোম্পানি সিকিউরিটিজ অ্যান্ড এক্সচেঞ্জ কমিশনে জমা দেয়), এবং সংগঠিত ডেটা (ঐতিহাসিক স্টকের মূল্য)।
আপনি অসংগঠিত আর্থিক প্রতিবেদনগুলোর জন্য একটি শক্তিশালী সিম্যান্টিক সার্চ ইঞ্জিন তৈরি করতে ভার্টেক্স এআই সার্চ ব্যবহার করবেন। সংগঠিত ডেটার জন্য, আপনি একটি কাস্টম পাইথন টুল তৈরি করবেন। সবশেষে, আপনি এজেন্ট ডেভেলপমেন্ট কিট (ADK) ব্যবহার করে এমন একটি ইন্টেলিজেন্ট এজেন্ট তৈরি করবেন যা ব্যবহারকারীর কোয়েরি নিয়ে যুক্তি দিয়ে ভাবতে, কোন টুলটি ব্যবহার করতে হবে তা সিদ্ধান্ত নিতে এবং তথ্যগুলোকে সংশ্লেষণ করে একটি সুসংগত উত্তর দিতে সক্ষম হবে।
আপনি যা করবেন
- ব্যক্তিগত নথিপত্রের শব্দার্থিক অনুসন্ধানের জন্য একটি ভার্টেক্স এআই সার্চ ডেটা স্টোর স্থাপন করুন।
- এজেন্টের টুল হিসেবে একটি কাস্টম পাইথন ফাংশন তৈরি করুন।
- একটি মাল্টি-টুল এজেন্ট তৈরি করতে এজেন্ট ডেভেলপমেন্ট কিট (ADK) ব্যবহার করুন।
- জটিল প্রশ্নের উত্তর দেওয়ার জন্য অসংগঠিত এবং সংগঠিত ডেটা উৎস থেকে তথ্য সংগ্রহকে একত্রিত করুন।
- এমন একটি এজেন্টের সাথে পরীক্ষা ও মিথস্ক্রিয়া করুন যার যুক্তিবাদী ক্ষমতা রয়েছে।
আপনি যা শিখবেন
এই ল্যাবে আপনি শিখবেন:
- রিট্রিভাল-অগমেন্টেড জেনারেশন (RAG) এবং এজেন্টিক RAG-এর মূল ধারণাসমূহ।
- Vertex AI Search ব্যবহার করে ডকুমেন্টের উপর কীভাবে সিমান্টিক সার্চ প্রয়োগ করা যায়।
- কাস্টম টুল তৈরি করে কীভাবে এজেন্টের কাছে স্ট্রাকচার্ড ডেটা উপস্থাপন করা যায়।
- এজেন্ট ডেভেলপমেন্ট কিট (ADK) ব্যবহার করে কীভাবে একটি মাল্টি-টুল এজেন্ট তৈরি এবং পরিচালনা করা যায়।
- এজেন্টরা একাধিক ডেটা উৎস ব্যবহার করে কীভাবে যুক্তি ও পরিকল্পনার মাধ্যমে জটিল প্রশ্নের উত্তর দেয়।
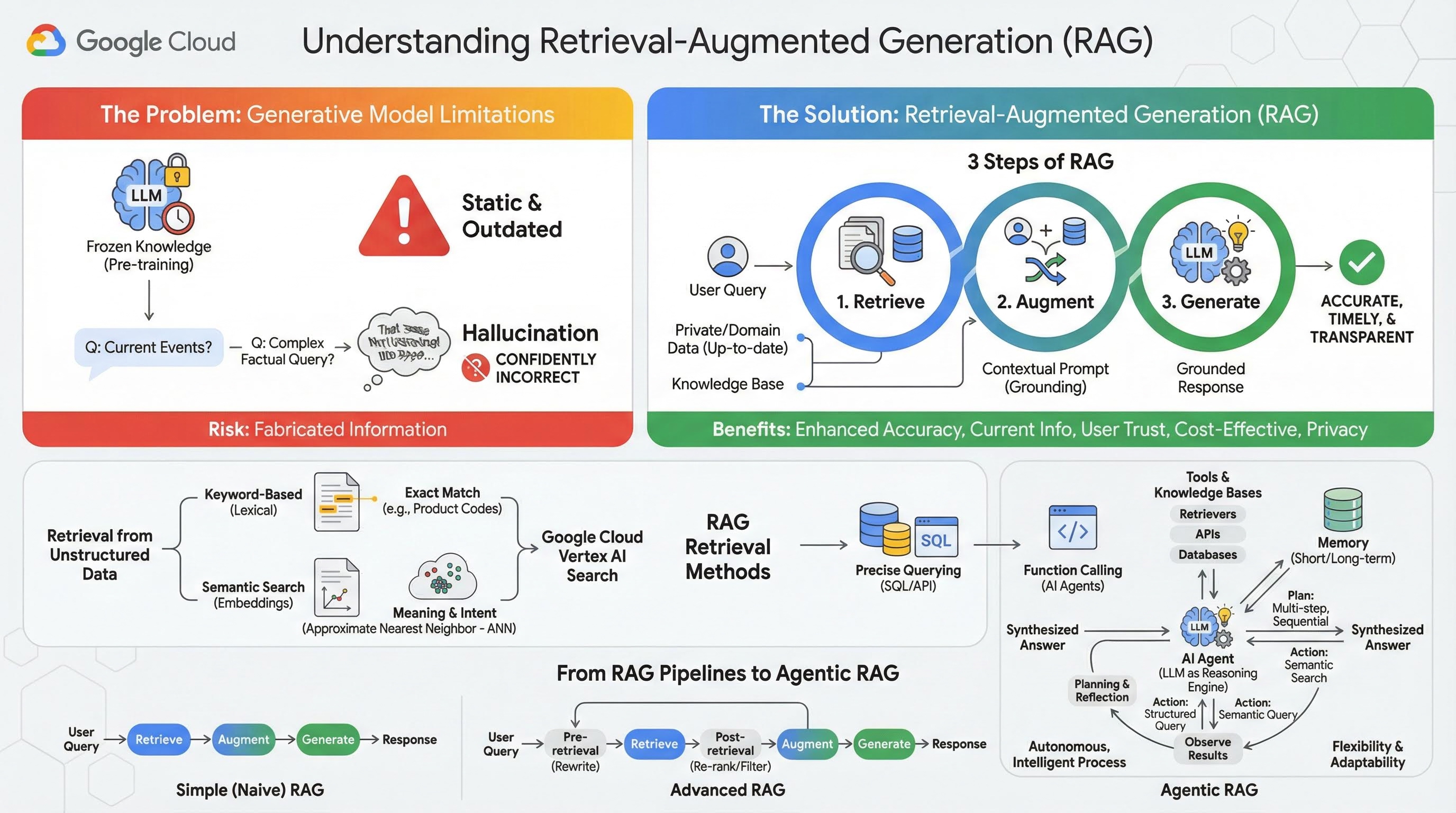
২. পুনরুদ্ধার-বর্ধিত প্রজন্ম বোঝা
বৃহৎ জেনারেটিভ মডেল (সংক্ষেপে লার্জ ল্যাঙ্গুয়েজ মডেল বা এলএলএম, ভিশন-ল্যাঙ্গুয়েজ মডেল ইত্যাদি) অত্যন্ত শক্তিশালী, কিন্তু এদের কিছু সহজাত সীমাবদ্ধতা রয়েছে। এদের জ্ঞান প্রাক-প্রশিক্ষণের সময়েই স্থির হয়ে যায়, ফলে তা অস্থিতিশীল এবং তাৎক্ষণিকভাবে সেকেলে হয়ে পড়ে। ফাইন-টিউনিং করার পরেও মডেলের জ্ঞান খুব বেশি সাম্প্রতিক হয় না, কারণ প্রশিক্ষণ-পরবর্তী পর্যায়গুলোর লক্ষ্য এটি নয়।
বৃহৎ ভাষা মডেলগুলোকে, বিশেষ করে 'চিন্তাশীল' মডেলগুলোকে, যেভাবে প্রশিক্ষণ দেওয়া হয়, তাতে কোনো একটি উত্তর দেওয়ার জন্য সেগুলোকে 'পুরস্কৃত' করা হয়, এমনকি যদি সেই উত্তরকে সমর্থন করার মতো কোনো বাস্তব তথ্য মডেলটির কাছে না-ও থাকে। এই কারণেই বলা হয় যে একটি মডেল 'বিভ্রম' করে—অর্থাৎ, আত্মবিশ্বাসের সাথে বিশ্বাসযোগ্য শোনালেও, তথ্যগতভাবে ভুল তথ্য তৈরি করে।
রিট্রিভাল-অগমেন্টেড জেনারেশন (RAG) হলো একটি শক্তিশালী আর্কিটেকচারাল প্যাটার্ন, যা ঠিক এই সমস্যাগুলো সমাধানের জন্যই ডিজাইন করা হয়েছে। এটি একটি আর্কিটেকচারাল ফ্রেমওয়ার্ক যা লার্জ ল্যাঙ্গুয়েজ মডেল (Large Language Models)-কে রিয়েল-টাইমে বাহ্যিক ও নির্ভরযোগ্য জ্ঞানের উৎসের সাথে সংযুক্ত করার মাধ্যমে তাদের সক্ষমতা বৃদ্ধি করে। একটি RAG সিস্টেমে থাকা LLM শুধুমাত্র তার স্থির ও পূর্ব-প্রশিক্ষিত জ্ঞানের উপর নির্ভর না করে, প্রথমে ব্যবহারকারীর কোয়েরি সম্পর্কিত প্রাসঙ্গিক তথ্য সংগ্রহ করে এবং তারপর সেই তথ্য ব্যবহার করে আরও নির্ভুল, সময়োপযোগী ও প্রেক্ষাপট-সচেতন প্রতিক্রিয়া তৈরি করে।
এই পদ্ধতিটি জেনারেটিভ মডেলের সবচেয়ে গুরুত্বপূর্ণ দুর্বলতাগুলোকে সরাসরি মোকাবেলা করে: তাদের জ্ঞান একটি নির্দিষ্ট সময়ে স্থির থাকে এবং এগুলো ভুল তথ্য বা 'বিভ্রম' তৈরি করতে পারে। RAG কার্যকরভাবে LLM-কে একটি 'ওপেন-বুক পরীক্ষা' প্রদান করে, যেখানে 'বই' হলো আপনার ব্যক্তিগত, বিষয়-নির্দিষ্ট এবং হালনাগাদ ডেটা। LLM-কে তথ্যগত প্রেক্ষাপট প্রদানের এই প্রক্রিয়াটি ' গ্রাউন্ডিং ' নামে পরিচিত।
RAG-এর ৩টি ধাপ
প্রমিত রিট্রিভাল-অগমেন্টেড জেনারেশন প্রক্রিয়াটিকে তিনটি সহজ ধাপে ভাগ করা যায়:
- তথ্য সংগ্রহ : যখন কোনো ব্যবহারকারী একটি কোয়েরি জমা দেন, তখন সিস্টেমটি প্রথমে কোয়েরিটির সাথে প্রাসঙ্গিক তথ্য খুঁজে বের করার জন্য একটি বাহ্যিক নলেজ বেস (যেমন ডকুমেন্ট রিপোজিটরি, ডেটাবেস বা ওয়েবসাইট) অনুসন্ধান করে।
- বর্ধন : সংগৃহীত তথ্যকে ব্যবহারকারীর মূল জিজ্ঞাসার সাথে একত্রিত করে একটি বর্ধিত প্রম্পট তৈরি করা হয়। এই কৌশলটিকে কখনও কখনও 'প্রম্পট স্টাফিং' বলা হয়, কারণ এটি বাস্তব প্রেক্ষাপট দিয়ে প্রম্পটটিকে সমৃদ্ধ করে।
- উৎপন্ন করা : এই বর্ধিত নির্দেশটি এলএলএম-এ পাঠানো হয়, যা তখন একটি প্রতিক্রিয়া তৈরি করে। যেহেতু মডেলটিকে প্রাসঙ্গিক, বাস্তব তথ্য সরবরাহ করা হয়েছে, তাই এর আউটপুটটি সুপ্রতিষ্ঠিত এবং ভুল বা সেকেলে হওয়ার সম্ভাবনা অনেক কম।
RAG এর উপকারিতা
RAG ফ্রেমওয়ার্কের প্রবর্তন বাস্তবসম্মত ও নির্ভরযোগ্য এআই অ্যাপ্লিকেশন তৈরিতে যুগান্তকারী পরিবর্তন এনেছে। এর প্রধান সুবিধাগুলো হলো:
- বর্ধিত নির্ভুলতা এবং হ্রাসকৃত বিভ্রম : যাচাইযোগ্য, বাহ্যিক তথ্যের উপর ভিত্তি করে প্রতিক্রিয়া প্রদানের মাধ্যমে, RAG নাটকীয়ভাবে LLM-এর তথ্য মনগড়া কথা বলার ঝুঁকি কমিয়ে দেয়।
- সাম্প্রতিক তথ্যে প্রবেশাধিকার : RAG সিস্টেমগুলোকে ক্রমাগত হালনাগাদ হওয়া জ্ঞানভান্ডারের সাথে সংযুক্ত করা যায়, যার ফলে তারা একেবারে সর্বশেষ তথ্যের উপর ভিত্তি করে প্রতিক্রিয়া জানাতে পারে, যা স্থিরভাবে প্রশিক্ষিত একজন LLM-এর পক্ষে অসম্ভব।
- ব্যবহারকারীর আস্থা ও স্বচ্ছতা বৃদ্ধি : যেহেতু এলএলএম-এর প্রতিক্রিয়া সংগৃহীত নথিপত্রের উপর ভিত্তি করে তৈরি হয়, তাই সিস্টেমটি এর উৎসের উদ্ধৃতি এবং লিঙ্ক প্রদান করতে পারে। এটি ব্যবহারকারীদের নিজেদের জন্য তথ্য যাচাই করার সুযোগ দেয়, যা অ্যাপ্লিকেশনটির প্রতি আস্থা তৈরি করে।
- ব্যয়-সাশ্রয়িতা : নতুন ডেটা দিয়ে একটি LLM-কে ক্রমাগত সূক্ষ্মভাবে সমন্বয় করা বা পুনরায় প্রশিক্ষণ দেওয়া গণনাগতভাবে এবং আর্থিকভাবে ব্যয়বহুল। RAG-এর সাহায্যে, মডেলের জ্ঞান আপডেট করাটা বাহ্যিক ডেটা উৎস আপডেট করার মতোই সহজ, যা অনেক বেশি কার্যকর।
- ডোমেইন স্পেশালাইজেশন এবং গোপনীয়তা : RAG ব্যক্তি ও প্রতিষ্ঠানসমূহকে তাদের ব্যক্তিগত, মালিকানাধীন ডেটা মডেলের ট্রেনিং সেটে অন্তর্ভুক্ত না করেই কোয়েরি করার সময় একটি LLM-এর কাছে উপলব্ধ করার সুযোগ দেয়। এটি ডেটার গোপনীয়তা ও নিরাপত্তা বজায় রেখে শক্তিশালী, ডোমেইন-নির্দিষ্ট অ্যাপ্লিকেশন তৈরি করতে সক্ষম করে।
পুনরুদ্ধার
যেকোনো RAG সিস্টেমের কেন্দ্রবিন্দু হলো ‘তথ্য পুনরুদ্ধার’ ধাপ। পুনরুদ্ধার করা তথ্যের গুণমান এবং প্রাসঙ্গিকতাই চূড়ান্তভাবে তৈরি হওয়া উত্তরের গুণমান এবং প্রাসঙ্গিকতাকে সরাসরি নির্ধারণ করে। একটি কার্যকর RAG অ্যাপ্লিকেশনের প্রায়শই বিভিন্ন কৌশল ব্যবহার করে নানা ধরনের ডেটা উৎস থেকে তথ্য পুনরুদ্ধার করার প্রয়োজন হয়। তথ্য পুনরুদ্ধারের প্রধান পদ্ধতিগুলোকে তিনটি শ্রেণিতে ভাগ করা যায়: কীওয়ার্ড-ভিত্তিক, শব্দার্থিক এবং কাঠামোগত।
অসংগঠিত ডেটা থেকে পুনরুদ্ধার
ঐতিহাসিকভাবে, অসংগঠিত ডেটা পুনরুদ্ধার হলো প্রচলিত সার্চেরই অপর নাম। এটি একাধিক রূপান্তরের মধ্য দিয়ে গেছে, এবং আপনি উভয় প্রধান পদ্ধতি থেকেই উপকৃত হতে পারেন।
সিমান্টিক সার্চ হলো সবচেয়ে কার্যকরী কৌশল যা আপনি গুগল ক্লাউডে অত্যাধুনিক পারফরম্যান্স এবং উচ্চ মাত্রার নিয়ন্ত্রণের সাথে বৃহৎ পরিসরে চালাতে পারেন।
- কীওয়ার্ড-ভিত্তিক (লেক্সিক্যাল) সার্চ : এটি সার্চের একটি ঐতিহ্যবাহী পদ্ধতি, যা ১৯৭০-এর দশকের প্রথম দিকের তথ্য পুনরুদ্ধার সিস্টেমগুলো থেকে প্রচলিত। লেক্সিক্যাল সার্চ কাজ করে ব্যবহারকারীর কোয়েরিতে থাকা আক্ষরিক শব্দগুলোকে (বা "টোকেন") একটি নলেজ বেসের ভেতরের ডকুমেন্টগুলোতে থাকা হুবহু একই শব্দের সাথে মিলিয়ে। এটি এমন সব কোয়েরির জন্য অত্যন্ত কার্যকর, যেখানে প্রোডাক্ট কোড, আইনি ধারা বা অনন্য নামের মতো নির্দিষ্ট টার্মের নির্ভুলতা অপরিহার্য।
- সিমান্টিক সার্চ : সিমান্টিক সার্চ, বা "অর্থসহ অনুসন্ধান," হলো একটি আধুনিক পদ্ধতি যার লক্ষ্য হলো শুধুমাত্র আক্ষরিক কীওয়ার্ড নয়, বরং ব্যবহারকারীর উদ্দেশ্য এবং তার অনুসন্ধানের প্রাসঙ্গিক অর্থ বোঝা। আধুনিক সিমান্টিক সার্চ এমবেডিং দ্বারা চালিত হয় – এটি একটি মেশিন লার্নিং কৌশল যা জটিল, উচ্চ-মাত্রিক ডেটাকে সংখ্যাসূচক ভেক্টরের একটি নিম্ন-মাত্রিক ভেক্টর স্পেসে রূপান্তরিত করে। এই ভেক্টরগুলো এমনভাবে ডিজাইন করা হয় যাতে একই অর্থবোধক লেখাগুলো ভেক্টর স্পেসে একে অপরের কাছাকাছি অবস্থান করে। "পরিবারের জন্য সেরা কুকুরের জাত কী কী?"-এর মতো একটি অনুসন্ধানকে একটি ভেক্টরে রূপান্তরিত করা হয়, এবং সিস্টেমটি তখন সেই স্পেসে তার "নিকটতম প্রতিবেশী" ডকুমেন্ট ভেক্টরগুলো অনুসন্ধান করে। এটি এমন ডকুমেন্ট খুঁজে পেতে সাহায্য করে যেখানে "গোল্ডেন রিট্রিভার" বা "বন্ধুত্বপূর্ণ কুকুর" সম্পর্কে আলোচনা করা হয়েছে, এমনকি যদি সেগুলোতে হুবহু "কুকুর" শব্দটি নাও থাকে। এই উচ্চ-মাত্রিক অনুসন্ধানকে অ্যাপ্রক্সিমেট নিয়ারেস্ট নেইবার (ANN) অ্যালগরিদম দ্বারা আরও কার্যকর করা হয়। প্রতিটি ডকুমেন্ট ভেক্টরের সাথে কোয়েরি ভেক্টর তুলনা করার পরিবর্তে (যা বড় ডেটাসেটের জন্য খুব ধীরগতির হবে), এএনএন অ্যালগরিদমগুলো চতুর ইনডেক্সিং কাঠামো ব্যবহার করে দ্রুত সম্ভাব্য নিকটতম ভেক্টরগুলো খুঁজে বের করে।
কাঠামোগত ডেটা থেকে পুনরুদ্ধার
সব গুরুত্বপূর্ণ জ্ঞান অসংগঠিত নথিতে সংরক্ষিত থাকে না। প্রায়শই, সবচেয়ে নির্ভুল এবং মূল্যবান তথ্য রিলেশনাল ডেটাবেস, NoSQL ডেটাবেস বা কোনো ধরনের এপিআই (যেমন আবহাওয়ার ডেটা বা শেয়ারের দামের জন্য REST API)-এর মতো সংগঠিত ফরম্যাটে থাকে।
অসংগঠিত টেক্সট অনুসন্ধানের তুলনায় সংগঠিত ডেটা থেকে তথ্য পুনরুদ্ধার সাধারণত আরও সরাসরি এবং সুনির্দিষ্ট হয়। শব্দার্থগত সাদৃশ্য খোঁজার পরিবর্তে, ল্যাঙ্গুয়েজ মডেলগুলোকে একটি সুনির্দিষ্ট কোয়েরি তৈরি ও কার্যকর করার ক্ষমতা দেওয়া যেতে পারে, যেমন একটি ডাটাবেসে SQL কোয়েরি অথবা নির্দিষ্ট স্থান ও তারিখের জন্য ওয়েদার এপিআই-তে একটি এপিআই কল।
ফাংশন-কলিং- এর মাধ্যমে বাস্তবায়িত, যা এআই এজেন্টদেরও শক্তি জোগায়, এটি ল্যাঙ্গুয়েজ মডেলগুলোকে এক্সিকিউটেবল কোড এবং বাহ্যিক সিস্টেমের সাথে একটি সুনির্দিষ্ট কাঠামোগত উপায়ে যোগাযোগ করতে সক্ষম করে।
৩. র্যাগ পাইপলাইন থেকে এজেন্টিক র্যাগ পর্যন্ত
RAG-এর ধারণাটির যেমন বিবর্তন ঘটেছে, তেমনি এটিকে বাস্তবায়নের স্থাপত্যগুলোরও বিবর্তন ঘটেছে। যা একটি সাধারণ, রৈখিক পাইপলাইন হিসেবে শুরু হয়েছিল, তা এখন AI এজেন্ট দ্বারা পরিচালিত একটি গতিশীল ও বুদ্ধিমান সিস্টেমে পরিণত হয়েছে।
- সরল (বা সাদামাটা) RAG: এটি হলো সেই মৌলিক স্থাপত্য যা নিয়ে আমরা এতক্ষণ আলোচনা করেছি: এটি পুনরুদ্ধার (retriev), পরিবর্ধন (augment), এবং উৎপাদন (generate) - এই তিন ধাপের একটি রৈখিক প্রক্রিয়া। এটি প্রতিক্রিয়াশীল (reactive); এটি প্রতিটি কোয়েরির জন্য একটি নির্দিষ্ট পথ অনুসরণ করে এবং সহজ-সরল প্রশ্নোত্তরের (Q&A) কাজের জন্য অত্যন্ত কার্যকর।
- অ্যাডভান্সড RAG: এটি এমন একটি বিবর্তন যেখানে সংগৃহীত কনটেক্সটের গুণমান উন্নত করার জন্য পাইপলাইনে অতিরিক্ত ধাপ যোগ করা হয়। এই উন্নতিগুলো সংগ্রহ ধাপের আগে বা পরে ঘটতে পারে।
- পুনরুদ্ধারের পূর্বে: কোয়েরি পুনর্লিখন বা সম্প্রসারণের মতো কৌশল ব্যবহার করা যেতে পারে। সিস্টেমটি প্রাথমিক কোয়েরিটি বিশ্লেষণ করে পুনরুদ্ধার সিস্টেমের জন্য এটিকে আরও কার্যকর করতে নতুনভাবে সাজিয়ে নিতে পারে।
- পুনরুদ্ধার-পরবর্তী: প্রাথমিকভাবে কিছু ডকুমেন্ট পুনরুদ্ধার করার পর, প্রাসঙ্গিকতার ভিত্তিতে ডকুমেন্টগুলোকে স্কোর করতে এবং সেরাগুলোকে শীর্ষে নিয়ে আসতে একটি রি-র্যাঙ্কিং মডেল প্রয়োগ করা যেতে পারে। হাইব্রিড সার্চের ক্ষেত্রে এটি বিশেষভাবে গুরুত্বপূর্ণ। পুনরুদ্ধার-পরবর্তী আরেকটি ধাপ হলো পুনরুদ্ধার করা বিষয়বস্তুকে ফিল্টার বা কম্প্রেস করা, যাতে শুধুমাত্র সবচেয়ে গুরুত্বপূর্ণ তথ্যই এলএলএম-এ পাঠানো হয়।
- এজেন্টিক র্যাগ: এটি র্যাগ আর্কিটেকচারের সর্বাধুনিক সংস্করণ, যা একটি নির্দিষ্ট কর্মপ্রবাহ থেকে একটি স্বায়ত্তশাসিত ও বুদ্ধিমান প্রক্রিয়ার দিকে যুগান্তকারী পরিবর্তন নিয়ে এসেছে। একটি এজেন্টিক র্যাগ সিস্টেমে, সম্পূর্ণ কর্মপ্রবাহ এক বা একাধিক এআই এজেন্ট দ্বারা পরিচালিত হয়, যারা যুক্তি দিয়ে চিন্তা করতে, পরিকল্পনা করতে এবং গতিশীলভাবে তাদের কার্যকলাপ বেছে নিতে পারে।
এজেন্টিক র্যাগ (Agentic RAG) বুঝতে হলে, প্রথমে বুঝতে হবে একটি এআই এজেন্ট কী। একটি এজেন্ট শুধু একটি এলএলএম (LLM) নয়। এটি এমন একটি সিস্টেম যার কয়েকটি মূল উপাদান রয়েছে:
- যুক্তি-প্রক্রিয়া ইঞ্জিন হিসেবে এলএলএম: এজেন্ট জেমিনির মতো একটি শক্তিশালী এলএলএম শুধু টেক্সট তৈরি করার জন্যই ব্যবহার করে না, বরং পরিকল্পনা, সিদ্ধান্ত গ্রহণ এবং জটিল কাজগুলোকে ছোট ছোট অংশে বিভক্ত করার জন্য এটিকে তার কেন্দ্রীয় 'মস্তিষ্ক' হিসেবে ব্যবহার করে।
- সরঞ্জামসমূহের একটি সেট: একজন এজেন্টকে এমন কিছু ফাংশনের একটি টুলকিট ব্যবহারের সুযোগ দেওয়া হয়, যা সে তার লক্ষ্য অর্জনের জন্য ব্যবহার করার সিদ্ধান্ত নিতে পারে। এই সরঞ্জামগুলো যেকোনো কিছুই হতে পারে: একটি ক্যালকুলেটর, একটি ওয়েব সার্চ এপিআই, ইমেল পাঠানোর একটি ফাংশন, অথবা এই ল্যাবের জন্য সবচেয়ে গুরুত্বপূর্ণ হলো— আমাদের বিভিন্ন নলেজ বেস থেকে তথ্য পুনরুদ্ধারকারী ফাংশন ।
- স্মৃতি: এজেন্টদের স্বল্পমেয়াদী স্মৃতি (বর্তমান কথোপকথনের প্রেক্ষাপট মনে রাখার জন্য) এবং দীর্ঘমেয়াদী স্মৃতি (অতীতের আলাপচারিতা থেকে তথ্য স্মরণ করার জন্য) উভয়ই দিয়ে ডিজাইন করা যেতে পারে, যা আরও ব্যক্তিগতকৃত এবং সুসংহত অভিজ্ঞতার সুযোগ করে দেয়।
- পরিকল্পনা ও পর্যালোচনা: সবচেয়ে উন্নত এজেন্টরা পরিশীলিত যুক্তির ধরণ প্রদর্শন করে। তারা একটি জটিল লক্ষ্য গ্রহণ করে তা অর্জনের জন্য একটি বহু-ধাপের পরিকল্পনা তৈরি করতে পারে। এরপর তারা এই পরিকল্পনাটি কার্যকর করতে পারে এবং এমনকি তাদের কাজের ফলাফলের ওপর পর্যালোচনা করতে , ভুল শনাক্ত করতে এবং চূড়ান্ত ফলাফল উন্নত করার জন্য নিজেদের কর্মপন্থা সংশোধন করতে পারে।
এজেন্টিক RAG একটি যুগান্তকারী উদ্ভাবন, কারণ এটি এমন এক স্তরের স্বায়ত্তশাসন ও বুদ্ধিমত্তা যোগ করে যা স্ট্যাটিক পাইপলাইনগুলোতে অনুপস্থিত।
- নমনীয়তা এবং অভিযোজনযোগ্যতা: একটি এজেন্ট কোনো একটি নির্দিষ্ট তথ্য সংগ্রহের পথে আবদ্ধ থাকে না। ব্যবহারকারীর কোনো জিজ্ঞাসা পেলে, এটি তথ্যের সর্বোত্তম উৎস সম্পর্কে যুক্তি দিয়ে সিদ্ধান্ত নিতে পারে। এটি প্রথমে কাঠামোগত ডেটাবেস থেকে তথ্য খোঁজার সিদ্ধান্ত নিতে পারে, তারপর অকাঠামোগত ডকুমেন্টগুলিতে শব্দার্থগত অনুসন্ধান চালাতে পারে, এবং তারপরেও উত্তর খুঁজে না পেলে, পাবলিক ওয়েবে খোঁজার জন্য গুগল সার্চ টুল ব্যবহার করতে পারে—এই সবই একটিমাত্র ব্যবহারকারীর অনুরোধের প্রেক্ষাপটেই সম্ভব।
- জটিল, বহু-ধাপবিশিষ্ট যুক্তি প্রক্রিয়া: এই আর্কিটেকচারটি এমন জটিল কোয়েরি পরিচালনায় পারদর্শী, যেগুলোর জন্য একাধিক, ধারাবাহিক পুনরুদ্ধার এবং প্রক্রিয়াকরণ ধাপের প্রয়োজন হয়।
এই কোয়েরিটি বিবেচনা করুন: "ক্রিস্টোফার নোলান পরিচালিত সেরা ৩টি সাই-ফাই মুভি খুঁজুন এবং প্রতিটির একটি সংক্ষিপ্ত কাহিনী সংক্ষেপ দিন।" একটি সাধারণ RAG পাইপলাইন এক্ষেত্রে ব্যর্থ হবে।
তবে একজন এজেন্ট এটি ভেঙে ব্যাখ্যা করতে পারেন:
- পরিকল্পনা: প্রথমে, আমাকে সিনেমাগুলো খুঁজে বের করতে হবে। তারপর, প্রতিটি সিনেমার কাহিনী খুঁজে বের করতে হবে।
- ধাপ ১: স্ট্রাকচার্ড ডেটা টুল ব্যবহার করে একটি মুভি ডেটাবেস থেকে নোলানের সাই-ফাই চলচ্চিত্রগুলো কোয়েরি করুন: সেরা ৩টি চলচ্চিত্র, রেটিং অনুসারে অবরোহী ক্রমে সাজানো।
- পর্যবেক্ষণ ১: টুলটি 'Inception,' 'Interstellar,' এবং 'Tenet' ফেরত দেয়।
- ধাপ ২: অসংগঠিত ডেটা টুল (সিমান্টিক সার্চ) ব্যবহার করে "ইনসেপশন"-এর কাহিনীসূত্রটি খুঁজুন।
- পর্যবেক্ষণ ২: প্লটটি পুনরুদ্ধার করা হয়েছে।
- ধাপ ৩: 'ইন্টারস্টেলার'-এর জন্য পুনরাবৃত্তি করুন।
- ধাপ ৪: 'Tenet'-এর জন্য পুনরাবৃত্তি করুন।
- চূড়ান্ত সংশ্লেষণ: ব্যবহারকারীর জন্য সংগৃহীত সমস্ত তথ্য একত্রিত করে একটি একক ও সুসংগত উত্তর প্রদান করা।
৪. প্রজেক্ট সেটআপ
গুগল অ্যাকাউন্ট
যদি আপনার আগে থেকে কোনো ব্যক্তিগত গুগল অ্যাকাউন্ট না থাকে, তাহলে আপনাকে অবশ্যই একটি গুগল অ্যাকাউন্ট তৈরি করতে হবে।
কর্মক্ষেত্র বা শিক্ষা প্রতিষ্ঠানের অ্যাকাউন্টের পরিবর্তে ব্যক্তিগত অ্যাকাউন্ট ব্যবহার করুন ।
গুগল ক্লাউড কনসোলে সাইন-ইন করুন
আপনার ব্যক্তিগত গুগল অ্যাকাউন্ট ব্যবহার করে গুগল ক্লাউড কনসোলে সাইন-ইন করুন।
বিলিং সক্ষম করুন
ট্রায়াল বিলিং অ্যাকাউন্ট ব্যবহার করুন (ঐচ্ছিক)
এই ওয়ার্কশপটি চালানোর জন্য আপনার কিছু ক্রেডিট সহ একটি বিলিং অ্যাকাউন্ট প্রয়োজন। শুরু করার জন্য এই কোডল্যাবের উপরের ব্যানার থেকে ক্রেডিট ব্যবহার করুন। আপনি যদি ইতিমধ্যেই একটি বিলিং অ্যাকাউন্টের সাথে সংযুক্ত থাকেন, তাহলে আপনি এই ধাপটি এড়িয়ে যেতে পারেন।
একটি ব্যক্তিগত বিলিং অ্যাকাউন্ট তৈরি করুন
আপনি যদি গুগল ক্লাউড ক্রেডিট ব্যবহার করে বিলিং সেট আপ করেন, তাহলে এই ধাপটি এড়িয়ে যেতে পারেন।
একটি ব্যক্তিগত বিলিং অ্যাকাউন্ট তৈরি করতে, ক্লাউড কনসোলে বিলিং চালু করার জন্য এখানে যান ।
কিছু নোট:
- এই ল্যাবটি সম্পন্ন করতে ক্লাউড রিসোর্সে ১ মার্কিন ডলারেরও কম খরচ হওয়া উচিত।
- পরবর্তী চার্জ এড়াতে, এই ল্যাবের শেষে দেওয়া ধাপগুলো অনুসরণ করে আপনি রিসোর্সগুলো মুছে ফেলতে পারেন।
- নতুন ব্যবহারকারীরা ৩০০ মার্কিন ডলারের ফ্রি ট্রায়ালের জন্য যোগ্য।
একটি প্রকল্প তৈরি করুন (ঐচ্ছিক)
এই ল্যাবের জন্য ব্যবহার করার মতো আপনার যদি কোনো চলমান প্রজেক্ট না থাকে, তাহলে এখানে একটি নতুন প্রজেক্ট তৈরি করুন ।
৫. ক্লাউড শেল এডিটর খুলুন
- সরাসরি ক্লাউড শেল এডিটর- এ যেতে এই লিঙ্কে ক্লিক করুন।
- আজ যেকোনো সময়ে অনুমোদনের জন্য অনুরোধ করা হলে, চালিয়ে যাওয়ার জন্য 'অনুমোদন করুন' (Authorize) বোতামে ক্লিক করুন।
- যদি স্ক্রিনের নিচে টার্মিনালটি দেখা না যায়, তাহলে এটি খুলুন:
- ভিউ ক্লিক করুন
- টার্মিনালে ক্লিক করুন
- টার্মিনালে এই কমান্ডটি দিয়ে আপনার প্রজেক্ট সেট করুন:
gcloud config set project [PROJECT_ID]- উদাহরণ:
gcloud config set project lab-project-id-example - আপনি যদি আপনার প্রজেক্ট আইডি মনে রাখতে না পারেন, তাহলে নিম্নলিখিত উপায়ে আপনার সমস্ত প্রজেক্ট আইডি তালিকাভুক্ত করতে পারেন:
gcloud projects list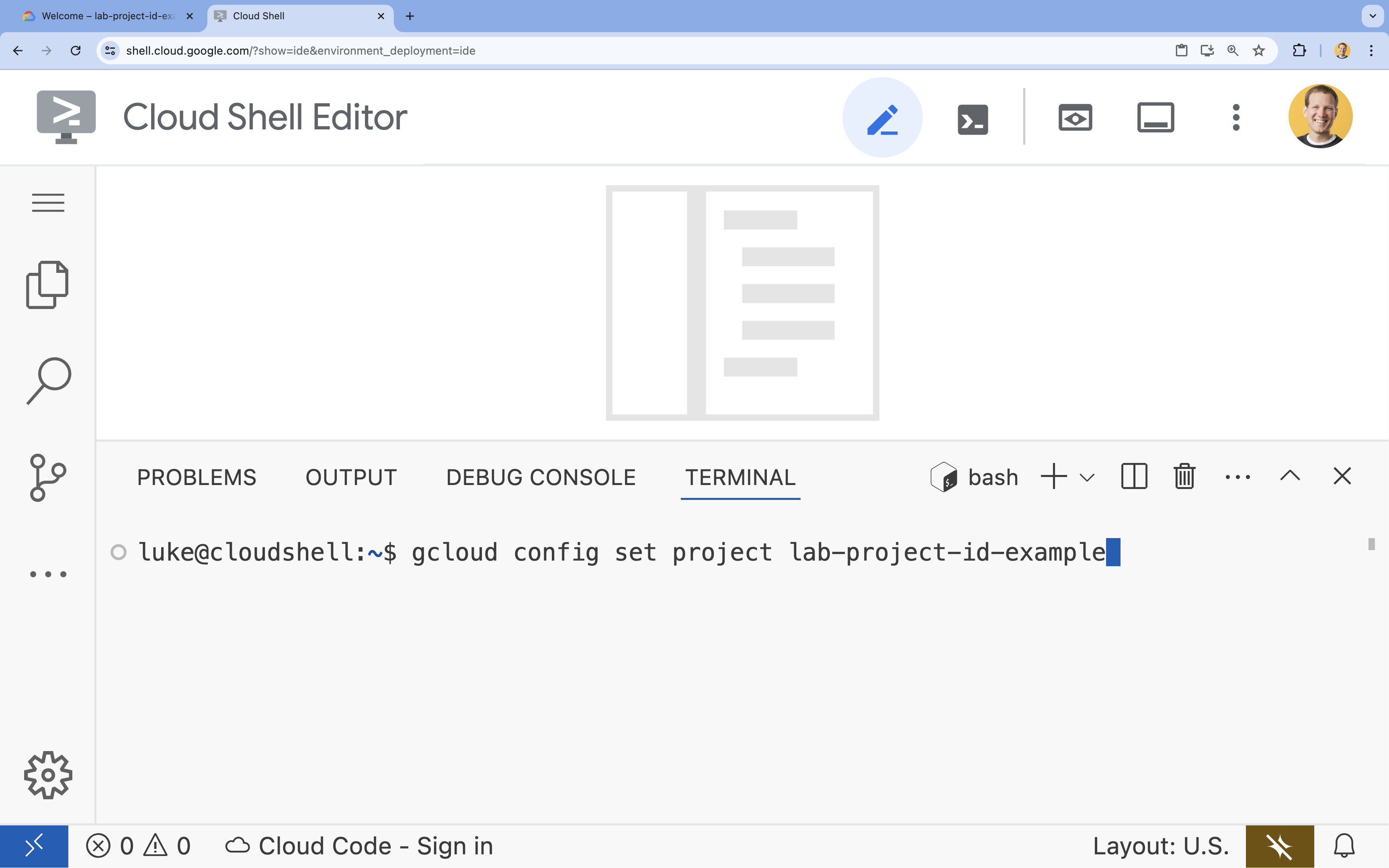
- উদাহরণ:
- আপনি এই বার্তাটি দেখতে পাবেন:
Updated property [core/project].
৬. এপিআই সক্রিয় করুন
এজেন্ট ডেভেলপমেন্ট কিট এবং ভার্টেক্স এআই সার্চ ব্যবহার করার জন্য, আপনাকে আপনার গুগল ক্লাউড প্রজেক্টে প্রয়োজনীয় এপিআইগুলো সক্রিয় করতে হবে।
- টার্মিনালে, এপিআইগুলো সক্রিয় করুন:
gcloud services enable \ aiplatform.googleapis.com \ discoveryengine.googleapis.com
এপিআইগুলো চালু করা হচ্ছে
- ভার্টেক্স এআই এপিআই (
aiplatform.googleapis.com) এজেন্টকে যুক্তি প্রদান এবং তৈরির জন্য জেমিনি মডেলের সাথে যোগাযোগ করতে সক্ষম করে। - ডিসকভারি ইঞ্জিন এপিআই (
discoveryengine.googleapis.com) ভার্টেক্স এআই সার্চকে শক্তি জোগায়, যা আপনাকে ডেটা স্টোর তৈরি করতে এবং আপনার অসংগঠিত ডকুমেন্টগুলিতে সিমান্টিক সার্চ সম্পাদন করতে সক্ষম করে।
৭. পরিবেশ প্রস্তুত করুন
এআই এজেন্ট কোডিং শুরু করার আগে, আপনাকে আপনার ডেভেলপমেন্ট এনভায়রনমেন্ট প্রস্তুত করতে হবে, প্রয়োজনীয় লাইব্রেরিগুলো ইনস্টল করতে হবে এবং প্রয়োজনীয় ডেটা ফাইলগুলো তৈরি করতে হবে।
একটি ভার্চুয়াল পরিবেশ তৈরি করুন এবং নির্ভরতাগুলি ইনস্টল করুন
- আপনার এজেন্টের জন্য একটি ডিরেক্টরি তৈরি করুন এবং সেটির ভেতরে প্রবেশ করুন। টার্মিনালে নিম্নলিখিত কোডটি চালান:
mkdir financial_agent cd financial_agent - একটি ভার্চুয়াল পরিবেশ তৈরি করুন:
uv venv --python 3.12 - ভার্চুয়াল পরিবেশ সক্রিয় করুন:
source .venv/bin/activate - এজেন্ট ডেভেলপমেন্ট কিট (ADK) এবং পান্ডাস ইনস্টল করুন।
uv pip install google-adk pandas
স্টক মূল্যের ডেটা তৈরি করুন
যেহেতু এজেন্টের কাঠামোগত সরঞ্জাম ব্যবহারের দক্ষতা প্রদর্শনের জন্য ল্যাবে নির্দিষ্ট ঐতিহাসিক স্টক ডেটার প্রয়োজন, তাই আপনাকে এই ডেটা সম্বলিত একটি CSV ফাইল তৈরি করতে হবে।
-
financial_agentডিরেক্টরিতে, টার্মিনালে নিম্নলিখিত কমান্ডটি চালিয়েgoog.csvফাইলটি তৈরি করুন:cat <<EOF > goog.csv Date,Open,High,Low,Close,Adj Close,Volume 2023-01-03,89.830002,91.550003,89.019997,89.699997,89.699997,20738500 2023-03-31,101.440002,103.889999,101.040001,103.730003,103.730003,36823200 2023-06-30,120.870003,122.029999,120.300003,120.970001,120.970001,23824700 2023-09-29,134.080002,134.550003,131.320007,131.850006,131.850006,21124200 2025-07-10,185.000000,188.000000,184.500000,186.500000,186.500000,25000000 EOF
পরিবেশ ভেরিয়েবল কনফিগার করুন
-
financial_agentডিরেক্টরিতে, আপনার এজেন্টের এনভায়রনমেন্ট ভেরিয়েবল কনফিগার করার জন্য একটি.envফাইল তৈরি করুন। এটি ADK-কে বলে দেয় কোন প্রজেক্ট, লোকেশন এবং মডেল ব্যবহার করতে হবে। টার্মিনালে নিম্নলিখিত কোডটি চালান:# Create the .env file using the captured variables cat << EOF > .env GOOGLE_GENAI_USE_VERTEXAI=TRUE GOOGLE_CLOUD_PROJECT="${GOOGLE_CLOUD_PROJECT}" GOOGLE_CLOUD_LOCATION="us-central1" EOF
দ্রষ্টব্য: ল্যাবের পরবর্তী পর্যায়ে, যদি আপনার .env ফাইলটি পরিবর্তন করার প্রয়োজন হয় কিন্তু সেটি financial_agent ডিরেক্টরিতে দেখতে না পান, তাহলে Cloud Shell Editor-এ থাকা "View / Toggle Hidden Files" মেনু আইটেমটি ব্যবহার করে লুকানো ফাইলগুলির দৃশ্যমানতা টগল করার চেষ্টা করুন।
৮. একটি ভার্টেক্স এআই সার্চ ডেটা স্টোর তৈরি করুন
অ্যালফাবেটের আর্থিক প্রতিবেদন সম্পর্কে এজেন্টকে প্রশ্নের উত্তর দিতে সক্ষম করার জন্য, আপনাকে তাদের পাবলিক এসইসি ফাইলিং সম্বলিত একটি ভার্টেক্স এআই সার্চ ডেটা স্টোর তৈরি করতে হবে।
- একটি নতুন ব্রাউজার ট্যাবে ক্লাউড কনসোল (console.cloud.google.com) খুলুন এবং উপরের সার্চ বারটি ব্যবহার করে এআই অ্যাপ্লিকেশনস (AI Applications) -এ যান।
- অনুরোধ করা হলে, শর্তাবলীর চেকবক্সটি নির্বাচন করুন এবং 'চালিয়ে যান ও এপিআই সক্রিয় করুন'-এ ক্লিক করুন।
- বাম দিকের নেভিগেশন মেনু থেকে ডেটা স্টোর নির্বাচন করুন।
- ডেটা স্টোর তৈরি করতে ক্লিক করুন।
- ক্লাউড স্টোরেজ কার্ডটি খুঁজুন এবং সিলেক্ট-এ ক্লিক করুন।
- ডেটা উৎস হিসেবে, ‘Unstructured documents’ নির্বাচন করুন।

- ইম্পোর্ট সোর্সের জন্য (আপনি যে ফোল্ডার বা ফাইলটি ইম্পোর্ট করতে চান তা নির্বাচন করুন), Google Cloud Storage পাথ
cloud-samples-data/gen-app-builder/search/alphabet-sec-filingsলিখুন। - চালিয়ে যান-এ ক্লিক করুন।
- অবস্থানটি গ্লোবাল- এ সেট করে রাখুন।
- ডেটা স্টোরের নামের জন্য, লিখুন
alphabet-sec-filings - ডকুমেন্ট প্রসেসিং অপশন সেকশনটি প্রসারিত করুন।

- ডিফল্ট ডকুমেন্ট পার্সার ড্রপডাউন তালিকা থেকে লেআউট পার্সার নির্বাচন করুন।
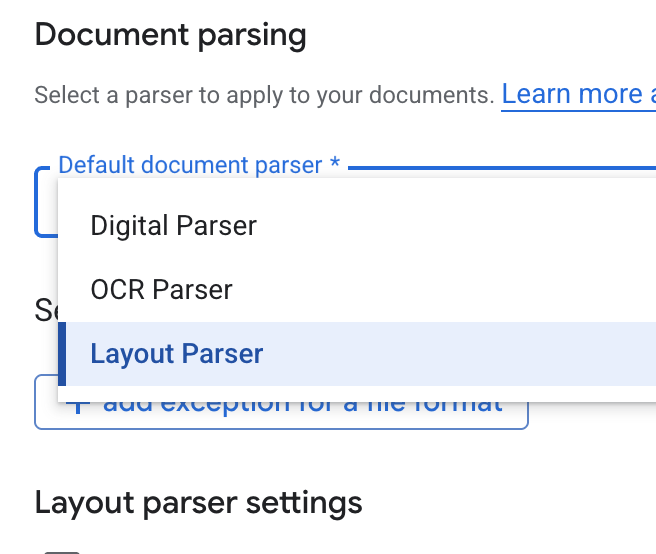
- লেআউট পার্সার সেটিংস অপশনগুলিতে, ‘টেবিল অ্যানোটেশন সক্ষম করুন ’ এবং ‘ইমেজ অ্যানোটেশন সক্ষম করুন’ নির্বাচন করুন।
- চালিয়ে যান-এ ক্লিক করুন।
- মূল্য নির্ধারণ মডেল হিসেবে জেনারেল প্রাইসিং (ব্যবহার অনুযায়ী অর্থ প্রদানের মডেল) নির্বাচন করুন এবং ক্রিয়েট-এ ক্লিক করুন।
- আপনার ডেটা স্টোর নথিগুলো আমদানি করা শুরু করবে।
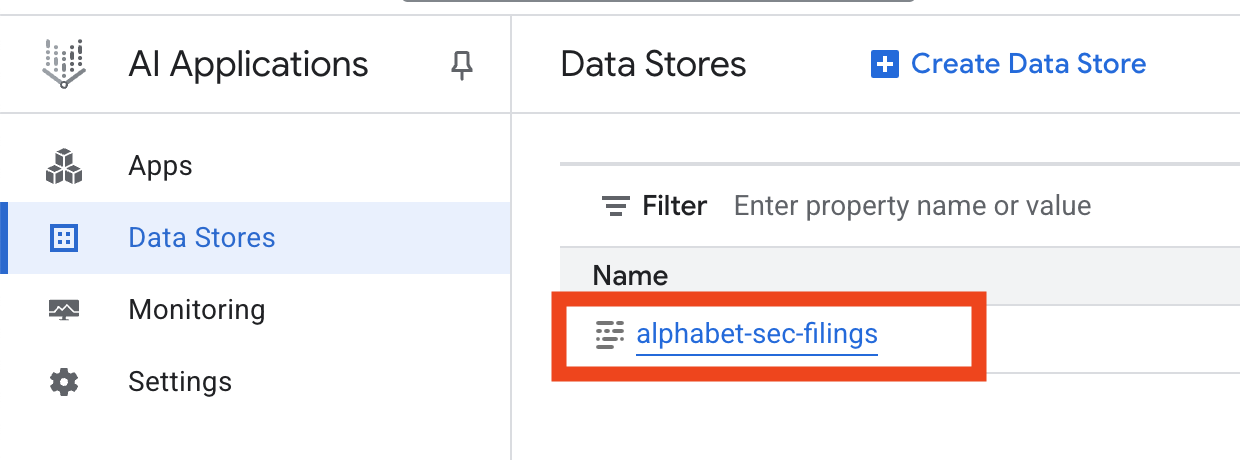
- ডেটা স্টোরের নামে ক্লিক করুন এবং ডেটা স্টোরস টেবিল থেকে এর আইডিটি কপি করুন । পরবর্তী ধাপে আপনার এটি প্রয়োজন হবে।
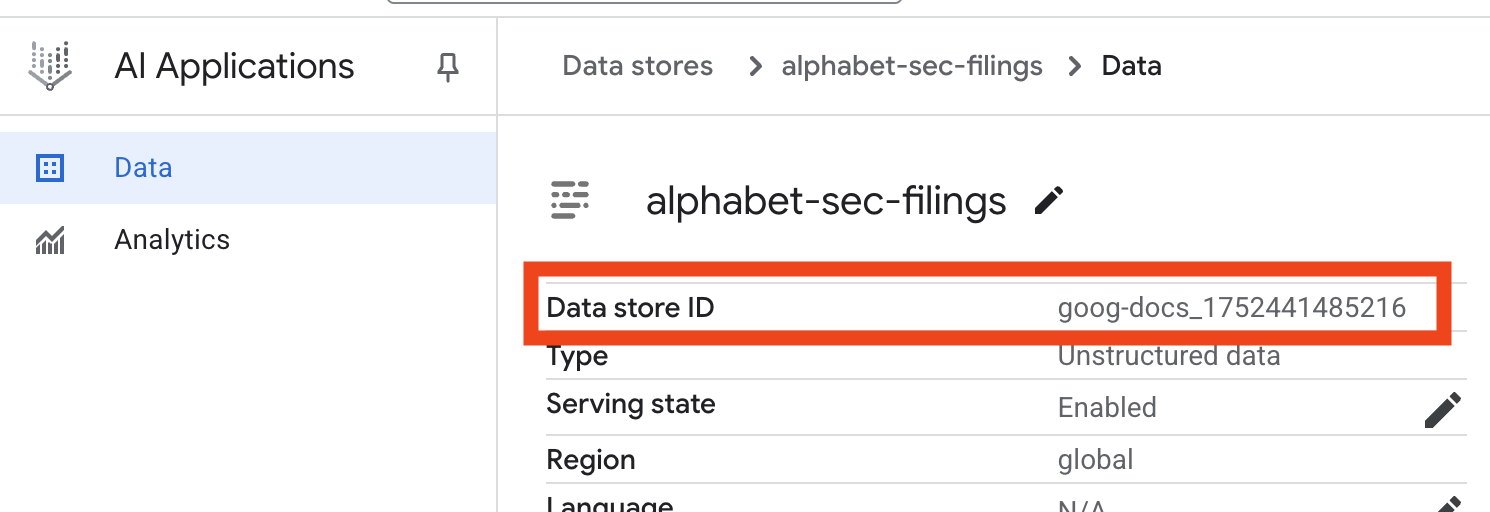
- Cloud Shell Editor-এ
.envফাইলটি খুলুন এবং ডেটা স্টোর আইডিটিDATA_STORE_ID="YOUR_DATA_STORE_ID"হিসাবে যুক্ত করুন (এখানেYOUR_DATA_STORE_IDএর জায়গায় আগের ধাপের আসল আইডিটি বসান)। দ্রষ্টব্য: ডেটা স্টোরে ডেটা ইম্পোর্ট, পার্সিং এবং ইনডেক্সিং করতে কয়েক মিনিট সময় লাগবে। প্রক্রিয়াটি পরীক্ষা করতে, ডেটা স্টোরের নামের উপর ক্লিক করে এর প্রোপার্টিজ খুলুন, তারপর অ্যাক্টিভিটি ট্যাবটি খুলুন। স্ট্যাটাস "Import completed" হওয়া পর্যন্ত অপেক্ষা করুন।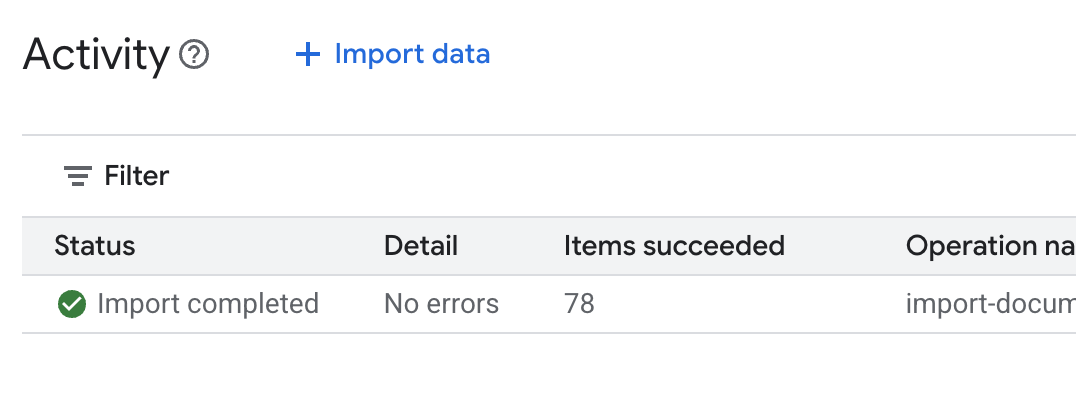
৯. কাঠামোগত ডেটার জন্য একটি কাস্টম টুল তৈরি করুন
এরপরে, আপনি একটি পাইথন ফাংশন তৈরি করবেন যা এজেন্টের টুল হিসেবে কাজ করবে। এই টুলটি একটি নির্দিষ্ট তারিখের ঐতিহাসিক স্টক মূল্য সংগ্রহ করার জন্য goog.csv ফাইলটি পড়বে।
- আপনার
financial_agentডিরেক্টরিতেagent.pyনামে একটি নতুন ফাইল তৈরি করুন। টার্মিনালে নিম্নলিখিত কমান্ডটি চালান:cloudshell edit agent.py -
agent.pyফাইলে নিম্নলিখিত পাইথন কোডটি যোগ করুন। এই কোডটি ডিপেন্ডেন্সি ইম্পোর্ট করে এবংget_stock_priceফাংশনটি সংজ্ঞায়িত করে।from datetime import datetime import os import logging import google.cloud.logging from google.adk.tools import VertexAiSearchTool from google.adk.tools.agent_tool import AgentTool from google.adk.agents import LlmAgent import pandas as pd def get_stock_price(date: str) -> dict: """Gets the closing stock price for a given date. Args: date: The date to get the stock price for, in YYYY-MM-DD format. Returns: A dictionary containing the closing price, or an error message if the date is not found or the format is incorrect. """ try: # Load the CSV file df = pd.read_csv('goog.csv') # Convert the 'Date' column to datetime objects df['Date'] = pd.to_datetime(df['Date']) # Convert the input string to a datetime object query_date = datetime.strptime(date, '%Y-%m-%d') # Find the row for the given date row = df[df['Date'] == query_date] if not row.empty: # Get the closing price close_price = row['Close'].iloc[0] return {"status": "success", "date": date, "closing_price": close_price} else: return {"status": "error", "message": f"No data found for date: {date}"} except FileNotFoundError: return {"status": "error", "message": "Stock data file (goog.csv) not found."} except Exception as e: return {"status": "error", "message": f"An error occurred: {str(e)}"}
ফাংশনটির বিস্তারিত ডকস্ট্রিংটি লক্ষ্য করুন। এটি ব্যাখ্যা করে যে ফাংশনটি কী কাজ করে, এর প্যারামিটারগুলো ( Args ) কী এবং এটি কী রিটার্ন করে ( Returns )। ADK এই ডকস্ট্রিংটি ব্যবহার করে এজেন্টকে শেখায় যে এই টুলটি কীভাবে এবং কখন ব্যবহার করতে হবে।
১০. RAG এজেন্ট তৈরি ও চালনা করুন
এখন এজেন্টটি তৈরি করার সময়। আপনি অসংগঠিত ডেটার জন্য ভার্টেক্স এআই সার্চ টুলের সাথে সংগঠিত ডেটার জন্য আপনার নিজস্ব get_stock_price টুলকে একত্রিত করবেন।
- আপনার
agent.pyফাইলে নিম্নলিখিত কোডটি যুক্ত করুন। এই কোডটি প্রয়োজনীয় ADK ক্লাসগুলো ইম্পোর্ট করে, টুলগুলোর ইনস্ট্যান্স তৈরি করে এবং এজেন্টকে সংজ্ঞায়িত করে।logging.basicConfig(level=logging.INFO) cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() # 1. Create the Vertex AI Search tool full_datastore_id = f"projects/{os.environ['GOOGLE_CLOUD_PROJECT']}/locations/global/collections/default_collection/dataStores/{os.environ['DATA_STORE_ID']}" vertex_ai_search_tool = VertexAiSearchTool( data_store_id=full_datastore_id ) # 2. Define the Search+Q&A agent # Since we cannot combine tools with other tools in a single agent, # we create a separate Search+Q&A agent which will be used as a tool by the main root agent. doc_qa_agent = LlmAgent( name="search_and_qna_agent", model="gemini-2.5-flash", tools=[vertex_ai_search_tool], instruction="""You are a helpful assistant that answers questions based on information found in the document store. Use the search tool to find relevant information before answering. If the answer isn't in the documents, say that you couldn't find the information. """, description="Answers questions using a specific Vertex AI Search datastore.", ) # 3. Define the root agent with 2 tools. root_agent = LlmAgent( name="financial_agent", model="gemini-2.5-flash", tools=[ AgentTool(doc_qa_agent), get_stock_price, ], instruction="""You are an Financial Analytics Agent that answers question about Alphabet stock prices (using get_stock_price tool) and historical performance based on the data in Vertex AI Search datastore (using doc_qa_agent tool).""" ) - আপনার টার্মিনাল থেকে,
financial_agentডিরেক্টরির ভিতরে, আপনার এজেন্টের সাথে যোগাযোগ করার জন্য ADK ওয়েব ইন্টারফেসটি চালু করুন:adk web ~ - আপনার ব্রাউজারে ADK Dev UI খোলার জন্য টার্মিনাল আউটপুটে দেওয়া লিঙ্কে (সাধারণত
http://127.0.0.1:8000) ক্লিক করুন।
১১. এজেন্টকে পরীক্ষা করুন
এখন আপনি আপনার এজেন্টের যুক্তিবোধ এবং জটিল প্রশ্নের উত্তর দেওয়ার জন্য এর সরঞ্জামগুলো ব্যবহারের ক্ষমতা পরীক্ষা করতে পারেন।
- ADK Dev UI-তে, ড্রপডাউন মেনু থেকে আপনার
financial_agentনির্বাচিত আছে কিনা তা নিশ্চিত করুন। - এমন একটি প্রশ্ন করার চেষ্টা করুন যার জন্য SEC ফাইলিং (আনস্ট্রাকচার্ড ডেটা) থেকে তথ্যের প্রয়োজন। চ্যাটে নিম্নলিখিত কোয়েরিটি লিখুন:
What were the total revenues for the quarter ending on March 31, 2023?search_and_qna_agentকল করতে হবে, যা আর্থিক নথিগুলো থেকে উত্তর খুঁজে বের করার জন্যVertexAiSearchToolব্যবহার করে। - এরপর, এমন একটি প্রশ্ন করুন যার জন্য আপনার নিজস্ব টুল (স্ট্রাকচার্ড ডেটা) ব্যবহার করতে হবে। মনে রাখবেন, প্রম্পটে থাকা তারিখের ফরম্যাটটি ফাংশনের প্রয়োজনীয় ফরম্যাটের সাথে হুবহু মিলতে হবে এমন কোনো বাধ্যবাধকতা নেই; এলএলএম (LLM) এটিকে পুনরায় ফরম্যাট করার জন্য যথেষ্ট স্মার্ট।
What was the closing stock price for Alphabet on July 10, 2025?get_stock_priceটুলটি কল করবে। ফাংশন কল এবং এর ফলাফল খতিয়ে দেখতে আপনি চ্যাটে থাকা টুল আইকনটিতে ক্লিক করতে পারেন। - অবশেষে, এমন একটি জটিল প্রশ্ন করুন যার জন্য এজেন্টকে উভয় সরঞ্জাম ব্যবহার করতে এবং ফলাফলগুলো সংশ্লেষণ করতে হবে।
According to the 10-Q filing for the period ending March 31, 2023, what were the company's net cash provided by operating activities, and what was the stock's closing price on that date?- প্রথমে, এটি SEC ফাইলিং থেকে নগদ প্রবাহের তথ্য খুঁজে বের করার জন্য
VertexAiSearchToolব্যবহার করবে। - তারপর, এটি শেয়ারের দামের প্রয়োজনীয়তা শনাক্ত করবে এবং
2023-03-31তারিখটি দিয়েget_stock_priceফাংশনটিকে কল করবে। - অবশেষে, এটি উভয় তথ্যকে একত্রিত করে একটি একক ও পূর্ণাঙ্গ উত্তর প্রদান করবে।
- প্রথমে, এটি SEC ফাইলিং থেকে নগদ প্রবাহের তথ্য খুঁজে বের করার জন্য
- আপনার কাজ শেষ হলে, আপনি ব্রাউজার ট্যাবটি বন্ধ করে দিতে পারেন এবং ADK সার্ভারটি বন্ধ করতে টার্মিনালে
CTRL+Cচাপতে পারেন।
১২. আপনার কাজের জন্য পরিষেবা নির্বাচন করা
ভার্টেক্স এআই সার্চই একমাত্র ভেক্টর সার্চ সার্ভিস নয় যা আপনি ব্যবহার করতে পারেন। আপনি এমন একটি ম্যানেজড সার্ভিসও ব্যবহার করতে পারেন যা রিট্রিভাল-অগমেন্টেড জেনারেশনের সম্পূর্ণ প্রক্রিয়াটিকে স্বয়ংক্রিয় করে তোলে: ভার্টেক্স এআই র্যাগ ইঞ্জিন ।
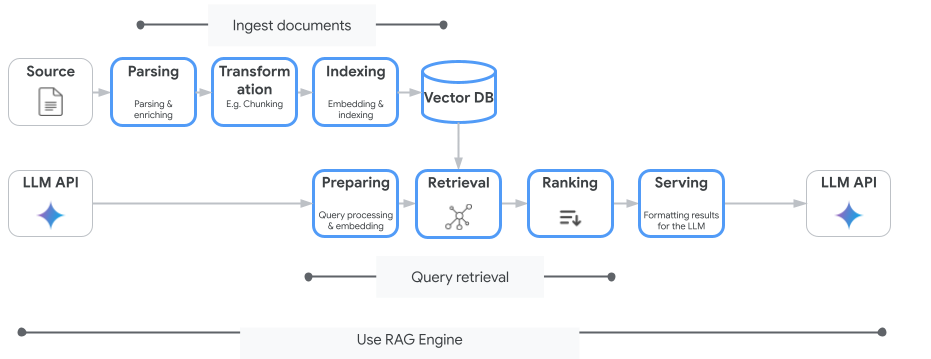
এটি ডকুমেন্ট গ্রহণ থেকে শুরু করে পুনরুদ্ধার এবং পুনর্বিন্যাস পর্যন্ত সবকিছু পরিচালনা করে। RAG Engine, Pinecone এবং Weaviate সহ একাধিক ভেক্টর স্টোর সমর্থন করে।
এছাড়াও আপনি অনেক বিশেষায়িত ভেক্টর ডেটাবেস নিজে হোস্ট করতে পারেন অথবা ডেটাবেস ইঞ্জিনগুলিতে থাকা ভেক্টর ইনডেক্স সক্ষমতা কাজে লাগাতে পারেন, যেমন PostgreSQL পরিষেবার pgvector (উদাহরণস্বরূপ AlloyDB বা BigQuery Vector Search )।
ভেক্টর সার্চ সমর্থন করে এমন আরও কয়েকটি পরিষেবা হলো:
- পোস্টগ্রেসকিউএল-এর জন্য ক্লাউড এসকিউএল
- ক্লাউড এসকিউএল ফর মাইএসকিউএল
- ক্লাউড স্প্যানার
- রেডিসের জন্য মেমোরিস্টোর
- ফায়ারস্টোর
- বিগটেবিল
গুগল ক্লাউডে কোনো নির্দিষ্ট পরিষেবা বেছে নেওয়ার সাধারণ নির্দেশিকাটি নিম্নরূপ:
- আপনার যদি আগে থেকেই কার্যকর এবং ভালোভাবে স্কেল করা ভেক্টর সার্চ ডু-ইট-ইয়োরসেলফ পরিকাঠামো থাকে, তবে তা গুগল কুবারনেটিস ইঞ্জিনে ডেপ্লয় করুন, যেমন উইভিয়েট বা ডিআইওয়াই পোস্টগ্রেসকিউএল ।
- আপনার ডেটা যদি BigQuery, AlloyDB, Firestore বা অন্য কোনো ডেটাবেসে থাকে, তবে সেটির ভেক্টর সার্চ (Vector Search) সক্ষমতা ব্যবহার করার কথা বিবেচনা করুন , যদি সেই ডেটাবেসে একটি বৃহত্তর কোয়েরির অংশ হিসেবে বৃহৎ পরিসরে সিমান্টিক সার্চ (semantic search) করা সম্ভব হয় । উদাহরণস্বরূপ, যদি আপনার BigQuery টেবিলে পণ্যের বিবরণ এবং/অথবা ছবি থাকে, তবে একটি টেক্সট এবং/অথবা ইমেজ এমবেডিং কলাম যোগ করলে বৃহৎ পরিসরে সিমিলারিটি সার্চ (similarity search) ব্যবহার করা সম্ভব হবে। ScANN সার্চ সহ ভেক্টর ইনডেক্সগুলো ইনডেক্সে থাকা বিলিয়ন বিলিয়ন আইটেম সমর্থন করে।
- যদি আপনি ন্যূনতম পরিশ্রমে এবং একটি পরিচালিত প্ল্যাটফর্মে দ্রুত কাজ শুরু করতে চান, তবে ভার্টেক্স এআই সার্চ (Vertex AI Search) বেছে নিন – এটি একটি সম্পূর্ণ পরিচালিত সার্চ ইঞ্জিন এবং রিট্রিভার এপিআই, যা জটিল এন্টারপ্রাইজ ব্যবহারের জন্য আদর্শ, যেখানে উচ্চমানের আউট-অফ-দ্য-বক্স কোয়ালিটি, স্কেলেবিলিটি এবং সূক্ষ্ম অ্যাক্সেস কন্ট্রোলের প্রয়োজন হয়। এটি বিভিন্ন এন্টারপ্রাইজ ডেটা সোর্সের সাথে সংযোগ স্থাপনকে সহজ করে এবং একাধিক সোর্স জুড়ে সার্চ করার সুবিধা দেয়।
- যেসব ডেভেলপাররা ব্যবহারের সহজতা এবং কাস্টমাইজেশনের মধ্যে ভারসাম্য খুঁজছেন, তাদের জন্য Vertex AI RAG Engine ব্যবহার করুন। এটি নমনীয়তার সাথে আপোস না করেই দ্রুত প্রোটোটাইপিং এবং ডেভেলপমেন্টকে শক্তিশালী করে।
- রিট্রিভাল-অগমেন্টেড জেনারেশনের জন্য রেফারেন্স আর্কিটেকচারগুলো অন্বেষণ করুন।
১৩. উপসংহার
অভিনন্দন! আপনি রিট্রিভাল-অগমেন্টেড জেনারেশন ব্যবহার করে সফলভাবে একটি এআই এজেন্ট তৈরি ও পরীক্ষা করেছেন। আপনি শিখেছেন কীভাবে:
- Vertex AI Search-এর শক্তিশালী সিমান্টিক সার্চ ক্ষমতা ব্যবহার করে অসংগঠিত ডকুমেন্টের জন্য একটি নলেজ বেস তৈরি করুন।
- স্ট্রাকচার্ড ডেটা পুনরুদ্ধারের একটি টুল হিসেবে কাজ করার জন্য একটি কাস্টম পাইথন ফাংশন তৈরি করুন।
- জেমিনি দ্বারা চালিত একটি মাল্টি-টুল এজেন্ট তৈরি করতে এজেন্ট ডেভেলপমেন্ট কিট (ADK) ব্যবহার করুন।
- এমন একটি এজেন্ট তৈরি করুন যা একাধিক উৎস থেকে তথ্য সংশ্লেষণ করে প্রশ্নের উত্তর দেওয়ার জন্য জটিল ও বহু-ধাপের যুক্তি প্রক্রিয়ায় সক্ষম।
এই ল্যাবটি এজেন্টিক র্যাগ (Agentic RAG)-এর মূল নীতিগুলি প্রদর্শন করে, যা গুগল ক্লাউডে বুদ্ধিমান, নির্ভুল এবং পরিস্থিতি-সচেতন এআই অ্যাপ্লিকেশন তৈরির জন্য একটি শক্তিশালী আর্কিটেকচার।
প্রোটোটাইপ থেকে উৎপাদন পর্যন্ত
এই ল্যাবটি ‘প্রোডাকশন-রেডি এআই উইথ গুগল ক্লাউড’ লার্নিং পাথ- এর একটি অংশ।
- প্রোটোটাইপ থেকে উৎপাদনে উত্তরণের ব্যবধান পূরণ করতে সম্পূর্ণ পাঠ্যক্রমটি অন্বেষণ করুন ।
- #ProductionReadyAI হ্যাশট্যাগটি ব্যবহার করে আপনার কাজের অগ্রগতি শেয়ার করুন ।