
1. Einführung
Übersicht
In diesem Lab lernen Sie, wie Sie End-to-End-Anwendungen für Agentic Retrieval-Augmented Generation (RAG) in Google Cloud entwickeln. In diesem Lab erstellen Sie einen Agenten für die Finanzanalyse, der Fragen beantworten kann, indem er Informationen aus zwei verschiedenen Quellen kombiniert: unstrukturierte Dokumente (vierteljährliche SEC-Einreichungen von Alphabet – Finanzberichte und betriebliche Details, die jedes börsennotierte Unternehmen in den USA bei der Securities and Exchange Commission einreicht) und strukturierte Daten (historische Aktienkurse).
Sie verwenden Vertex AI Search, um eine leistungsstarke semantische Suchmaschine für die unstrukturierten Finanzberichte zu erstellen. Für die strukturierten Daten erstellen Sie ein benutzerdefiniertes Python-Tool. Schließlich verwenden Sie das Agent Development Kit (ADK), um einen intelligenten Agenten zu erstellen, der die Anfrage eines Nutzers analysieren, entscheiden kann, welches Tool verwendet werden soll, und die Informationen in einer kohärenten Antwort zusammenfassen kann.
Aufgaben
- Richten Sie einen Vertex AI Search-Datenspeicher für die semantische Suche in privaten Dokumenten ein.
- Erstellen Sie eine benutzerdefinierte Python-Funktion als Tool für einen Agenten.
- Mit dem Agent Development Kit (ADK) können Sie einen Agenten mit mehreren Tools erstellen.
- Abruf aus unstrukturierten und strukturierten Datenquellen kombinieren, um komplexe Fragen zu beantworten
- Testen Sie einen Agenten, der über Begründungsfunktionen verfügt, und interagieren Sie mit ihm.
Lerninhalte
In diesem Lab lernen Sie Folgendes:
- Die Kernkonzepte von Retrieval-Augmented Generation (RAG) und Agentic RAG.
- Semantische Suche in Dokumenten mit Vertex AI Search implementieren
- So stellen Sie einem Agenten strukturierte Daten zur Verfügung, indem Sie benutzerdefinierte Tools erstellen.
- Mit dem Agent Development Kit (ADK) einen Multi-Tool-Agenten erstellen und orchestrieren
- Wie Agents logisches Schlussfolgern und Planung nutzen, um komplexe Fragen anhand mehrerer Datenquellen zu beantworten.
2. Retrieval-Augmented Generation
Große generative Modelle (Large Language Models oder kurz LLMs, Vision-Language-Modelle usw.) sind unglaublich leistungsstark, haben aber inhärente Einschränkungen. Ihr Wissen ist auf den Zeitpunkt ihres Vortrainings beschränkt, was es statisch und sofort veraltet macht. Auch nach dem Fine-Tuning wird das Wissen des Modells nicht viel aktueller, da dies nicht das Ziel der Phasen nach dem Training ist.
Bei der Art und Weise, wie Large Language Models trainiert werden, insbesondere bei „denkenden“ Modellen, werden sie dafür „belohnt“, irgendeine Antwort zu geben, auch wenn das Modell selbst keine Fakten hat, die eine solche Antwort unterstützen würden. Das ist der Fall, wenn ein Modell „halluziniert“ – es generiert selbstbewusst plausibel klingende, aber faktisch falsche Informationen.
Retrieval-Augmented Generation ist ein leistungsstarkes Architekturmuster, das genau diese Probleme lösen soll. Es handelt sich um ein Architektur-Framework, das die Fähigkeiten von Large Language Models verbessert, indem es sie in Echtzeit mit externen, autoritativen Wissensquellen verbindet. Anstatt sich nur auf sein statisches, vortrainiertes Wissen zu verlassen, ruft ein LLM in einem RAG-System zuerst relevante Informationen zu einer Nutzeranfrage ab und verwendet diese Informationen dann, um eine genauere, zeitgemäßere und kontextbezogenere Antwort zu generieren.
Dieser Ansatz geht direkt auf die größten Schwächen generativer Modelle ein: Ihr Wissen ist auf einen bestimmten Zeitpunkt festgelegt und sie neigen dazu, falsche Informationen zu generieren, sogenannte „Halluzinationen“. RAG ermöglicht dem LLM eine Art „Prüfung mit Unterlagen“, wobei die „Unterlagen“ Ihre privaten, domainspezifischen und aktuellen Daten sind. Dieser Prozess, dem LLM faktischen Kontext zur Verfügung zu stellen, wird als Fundierung bezeichnet.
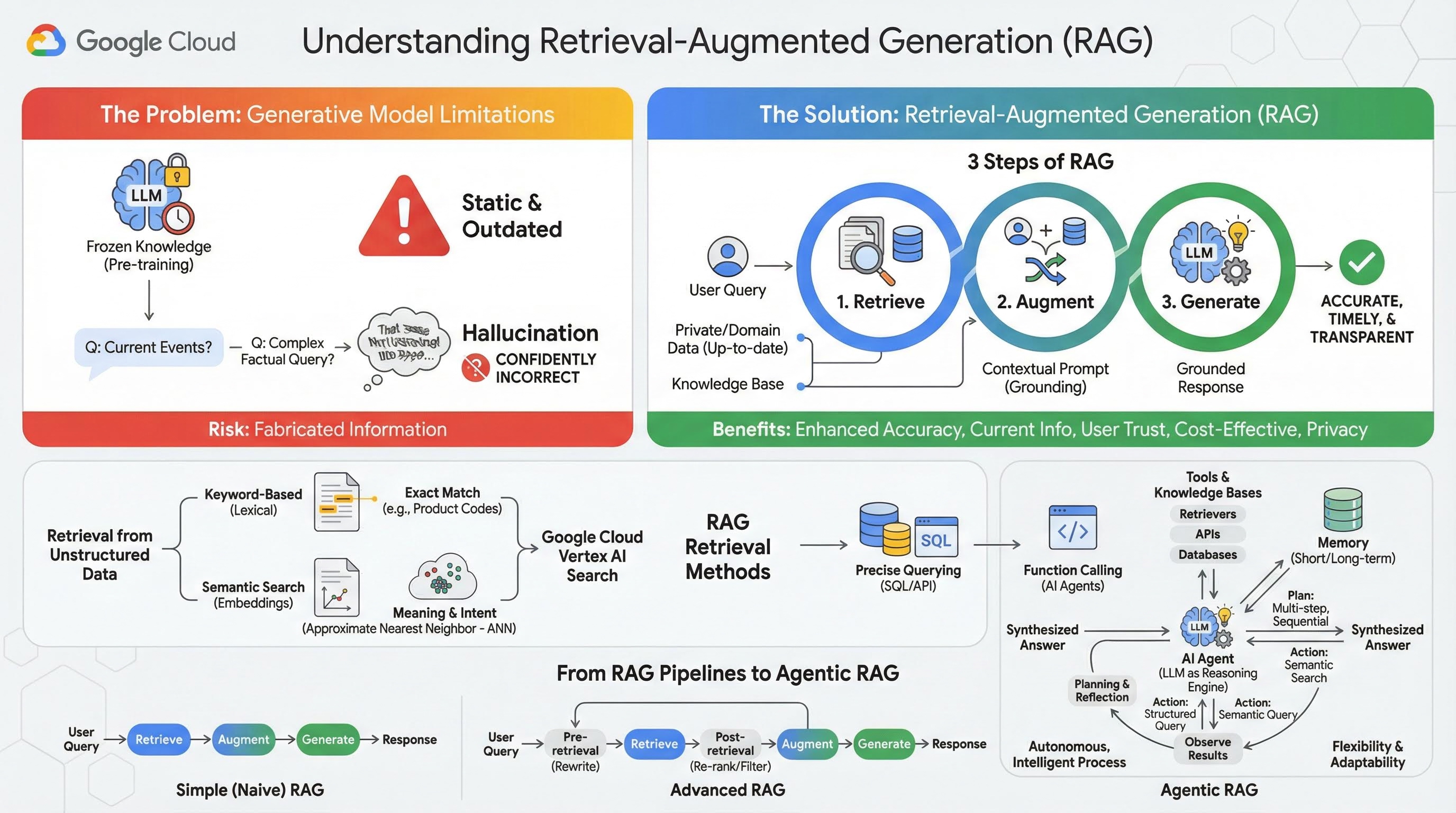
3 Schritte von RAG
Der Standardprozess der Retrieval-Augmented Generation lässt sich in drei einfache Schritte unterteilen:
- Abrufen: Wenn ein Nutzer eine Anfrage sendet, durchsucht das System zuerst eine externe Wissensdatenbank (z. B. ein Dokumentrepository, eine Datenbank oder eine Website), um Informationen zu finden, die für die Anfrage relevant sind.
- Erweitern: Die abgerufenen Informationen werden dann mit der ursprünglichen Nutzeranfrage zu einem erweiterten Prompt kombiniert. Diese Technik wird manchmal als „Prompt-Stuffing“ bezeichnet, da der Prompt mit sachlichem Kontext angereichert wird.
- Generieren: Dieser erweiterte Prompt wird an das LLM gesendet, das dann eine Antwort generiert. Da dem Modell relevante, sachliche Daten zur Verfügung gestellt wurden, ist die Ausgabe „fundiert“ und es ist viel weniger wahrscheinlich, dass sie ungenau oder veraltet ist.
Vorteile von RAG
Die Einführung des RAG-Frameworks hat die Entwicklung praktischer und vertrauenswürdiger KI-Anwendungen revolutioniert. Zu den wichtigsten Vorteilen gehören:
- Höhere Genauigkeit und weniger Halluzinationen: Da Antworten auf überprüfbaren, externen Fakten basieren, wird das Risiko, dass das LLM Informationen erfindet, durch RAG erheblich reduziert.
- Zugriff auf aktuelle Informationen: RAG-Systeme können mit ständig aktualisierten Wissensdatenbanken verbunden werden. So können sie Antworten auf Grundlage der neuesten Informationen liefern, was für ein statisch trainiertes LLM unmöglich ist.
- Höheres Nutzervertrauen und mehr Transparenz: Da die Antwort des LLM auf abgerufenen Dokumenten basiert, kann das System Zitate und Links zu den Quellen bereitstellen. So können Nutzer die Informationen selbst überprüfen und Vertrauen in die Anwendung aufbauen.
- Kosteneffizienz: Das kontinuierliche Feinabstimmen oder erneute Trainieren eines LLM mit neuen Daten ist rechen- und kostenintensiv. Bei RAG ist das Aktualisieren des Wissens des Modells so einfach wie das Aktualisieren der externen Datenquelle, was viel effizienter ist.
- Domänenspezialisierung und Datenschutz: Mit RAG können Personen und Organisationen ihre privaten, proprietären Daten zur Abfragezeit für ein LLM verfügbar machen, ohne diese sensiblen Daten in den Trainingsdatensatz des Modells aufnehmen zu müssen. So können leistungsstarke, domänenspezifische Anwendungen entwickelt werden, ohne dass Datenschutz und Datensicherheit beeinträchtigt werden.
Abruf
Der Schritt „Retrieval“ ist das Herzstück jedes RAG-Systems. Die Qualität und Relevanz der abgerufenen Informationen bestimmt direkt die Qualität und Relevanz der endgültigen generierten Antwort. Für eine effektive RAG-Anwendung müssen häufig Informationen aus verschiedenen Arten von Datenquellen mit unterschiedlichen Techniken abgerufen werden. Die primären Abrufmethoden lassen sich in drei Kategorien einteilen: stichwortbasiert, semantisch und strukturiert.
Abrufen aus unstrukturierten Daten
Das Abrufen unstrukturierter Daten ist ein anderer Name für die herkömmliche Suche. Es wurde mehrfach transformiert und Sie können von beiden wichtigen Ansätzen profitieren.
Die semantische Suche ist die effizienteste Methode, die Sie in Google Cloud mit modernster Leistung und einem hohen Maß an Kontrolle herunterskalieren können.
- Keyword-basierte (lexikalische) Suche: Dies ist der traditionelle Ansatz für die Suche, der auf die ersten Systeme zur Informationsbeschaffung aus den 1970er-Jahren zurückgeht. Bei der lexikalischen Suche werden die wörtlichen Wörter (oder „Tokens“) in der Anfrage eines Nutzers mit genau denselben Wörtern in den Dokumenten einer Wissensdatenbank abgeglichen. Es ist sehr effektiv für Anfragen, bei denen es auf die Präzision bestimmter Begriffe wie Produktcodes, rechtliche Klauseln oder eindeutige Namen ankommt.
- Semantische Suche: Die semantische Suche oder „Suche mit Bedeutung“ ist ein modernerer Ansatz, bei dem die Absicht des Nutzers und die kontextuelle Bedeutung seiner Anfrage und nicht nur die wörtlichen Keywords berücksichtigt werden. Die moderne semantische Suche basiert auf Einbettungen, einer Technik für maschinelles Lernen, bei der komplexe, hochdimensionale Daten in einen niedrigdimensionalen Vektorraum numerischer Vektoren abgebildet werden. Diese Vektoren sind so konzipiert, dass Texte mit ähnlicher Bedeutung im Vektorraum nahe beieinander liegen. Eine Suche nach „Welche Hunderassen eignen sich am besten für Familien?“ wird in einen Vektor umgewandelt. Das System sucht dann nach Dokumentvektoren, die in diesem Raum die „nächsten Nachbarn“ sind. So können Dokumente gefunden werden, in denen es um „Golden Retriever“ oder „freundliche Hunde“ geht, auch wenn das Wort „Hund“ nicht explizit vorkommt. Diese Suche in mehreren Dimensionen wird durch ANN-Algorithmen (Approximate Nearest Neighbor) effizienter gestaltet. Anstatt den Anfragevektor mit jedem einzelnen Dokumentvektor zu vergleichen (was bei großen Datensätzen zu langsam wäre), verwenden ANN-Algorithmen clevere Indexierungsstrukturen, um schnell Vektoren zu finden, die wahrscheinlich am nächsten sind.
Abruf aus strukturierten Daten
Nicht alles wichtige Wissen ist in unstrukturierten Dokumenten gespeichert. Die präzisesten und wertvollsten Informationen sind oft in strukturierten Formaten wie relationalen Datenbanken, NoSQL-Datenbanken oder einer Art API, z. B. einer REST API für Wetterdaten oder Aktienkurse, enthalten.
Der Abruf aus strukturierten Daten ist in der Regel direkter und genauer als die Suche in unstrukturiertem Text. Anstatt nach semantischer Ähnlichkeit zu suchen, können Sprachmodelle in die Lage versetzt werden, eine präzise Anfrage zu formulieren und auszuführen, z. B. eine SQL-Anfrage an eine Datenbank oder einen API-Aufruf an eine Wetter-API für einen bestimmten Ort und ein bestimmtes Datum.
Die Funktion wird über Funktionsaufrufe implementiert, dieselbe Technik, die auch KI-Agents zugrunde liegt. Sie ermöglicht es Sprachmodellen, auf deterministische Weise strukturiert mit ausführbarem Code und externen Systemen zu interagieren.
3. Von RAG-Pipelines zu Agentic RAG
So wie sich das Konzept von RAG selbst weiterentwickelt hat, haben sich auch die Architekturen für die Implementierung weiterentwickelt. Was als einfache, lineare Pipeline begann, hat sich zu einem dynamischen, intelligenten System entwickelt, das von KI-Agenten gesteuert wird.
- Einfaches (oder naives) RAG:Dies ist die grundlegende Architektur, die wir bisher besprochen haben: ein linearer, dreistufiger Prozess aus Abrufen, Erweitern und Generieren. Sie ist reaktiv, folgt für jede Anfrage einem festen Pfad und ist sehr effektiv für einfache Frage-Antwort-Aufgaben.
- Erweitertes RAG:Hier werden der Pipeline zusätzliche Schritte hinzugefügt, um die Qualität des abgerufenen Kontexts zu verbessern. Diese Verbesserungen können vor oder nach dem Abrufvorgang erfolgen.
- Vor dem Abrufen: Es können Techniken wie das Umschreiben oder Erweitern von Anfragen verwendet werden. Das System analysiert möglicherweise die ursprüngliche Anfrage und formuliert sie so um, dass sie für das Abrufsystem effektiver ist.
- Nach dem Abrufen:Nachdem eine erste Gruppe von Dokumenten abgerufen wurde, kann ein Modell für das erneute Ranking angewendet werden, um die Dokumente nach Relevanz zu bewerten und die besten nach oben zu verschieben. Das ist besonders bei der Hybridsuche wichtig. Ein weiterer Schritt nach dem Abrufen besteht darin, den abgerufenen Kontext zu filtern oder zu komprimieren, damit nur die wichtigsten Informationen an das LLM übergeben werden.
- Agentic RAG:Dies ist die neueste RAG-Architektur, die einen Paradigmenwechsel von einer festen Pipeline zu einem autonomen, intelligenten Prozess darstellt. In einem Agentic-RAG-System wird der gesamte Workflow von einem oder mehreren KI-Agents verwaltet, die Entscheidungen treffen, planen und ihre Aktionen dynamisch auswählen können.
Um Agentic RAG zu verstehen, muss man zuerst wissen, was einen KI-Agenten ausmacht. Ein KI-Agent ist mehr als nur ein LLM. Es ist ein System mit mehreren wichtigen Komponenten:
- LLM als Reasoning Engine:Der Agent verwendet ein leistungsstarkes LLM wie Gemini nicht nur zum Generieren von Text, sondern auch als zentrales „Gehirn“ für die Planung, Entscheidungsfindung und Zerlegung komplexer Aufgaben.
- Eine Reihe von Tools:Einem Agenten wird Zugriff auf eine Reihe von Funktionen gewährt, die er verwenden kann, um seine Ziele zu erreichen. Diese Tools können alles sein: ein Taschenrechner, eine Websuch-API, eine Funktion zum Senden einer E‑Mail oder, was für dieses Lab am wichtigsten ist, Abrufer für unsere verschiedenen Wissensdatenbanken.
- Gemerkte Informationen:Agents können sowohl mit einem Kurzzeitgedächtnis (um sich an den Kontext der aktuellen Unterhaltung zu erinnern) als auch mit einem Langzeitgedächtnis (um sich an Informationen aus früheren Interaktionen zu erinnern) entwickelt werden. So können sie personalisierter und kohärenter agieren.
- Planung und Reflexion:Die fortschrittlichsten Agents weisen ausgefeilte Muster für logisches Denken auf. Sie können ein komplexes Ziel erhalten und einen mehrstufigen Plan erstellen, um es zu erreichen. Anschließend können sie diesen Plan ausführen und sogar die Ergebnisse ihrer Aktionen analysieren, Fehler erkennen und ihren Ansatz selbst korrigieren, um das Endergebnis zu verbessern.
Agentic RAG ist ein Gamechanger, da es eine Ebene der Autonomie und Intelligenz einführt, die statischen Pipelines fehlt.
- Flexibilität und Anpassungsfähigkeit:Ein Agent ist nicht an einen einzelnen Abrufpfad gebunden. Bei einer Nutzeranfrage kann es die beste Informationsquelle ermitteln. Es kann sich entscheiden, zuerst die strukturierte Datenbank abzufragen, dann eine semantische Suche in unstrukturierten Dokumenten durchzuführen und, falls es immer noch keine Antwort findet, ein Google-Suchtool zu verwenden, um im öffentlichen Web zu suchen – alles im Kontext einer einzelnen Nutzeranfrage.
- Komplexes, mehrstufiges Reasoning:Diese Architektur eignet sich hervorragend für komplexe Anfragen, die mehrere sequenzielle Abruf- und Verarbeitungsschritte erfordern.
Betrachten Sie die folgende Anfrage: „Finde die drei besten Science-Fiction-Filme unter der Regie von Christopher Nolan und gib für jeden eine kurze Zusammenfassung der Handlung an.“ Eine einfache RAG-Pipeline würde fehlschlagen.
Ein KI-Agent kann das jedoch aufschlüsseln:
- Plan:Zuerst muss ich die Filme finden. Dann muss ich für jeden Film die Handlung herausfinden.
- Aktion 1: Mit dem Tool für strukturierte Daten eine Filmdatenbank nach den drei besten Science-Fiction-Filmen von Nolan abfragen, sortiert nach absteigender Bewertung.
- Beobachtung 1:Das Tool gibt „Inception“, „Interstellar“ und „Tenet“ zurück.
- Aktion 2:Verwenden Sie das Tool für unstrukturierte Daten (semantische Suche), um die Handlung von „Inception“ zu finden.
- Beobachtung 2:Die Handlung wird abgerufen.
- Aktion 3:Wiederholen Sie den Vorgang für „Interstellar“.
- Aktion 4:Wiederhole die Schritte für „Tenet“.
- Abschließende Synthese:Fassen Sie alle abgerufenen Informationen in einer einzigen, zusammenhängenden Antwort für den Nutzer zusammen.
4. Projekt einrichten
Google-Konto
Wenn Sie noch kein privates Google-Konto haben, müssen Sie ein Google-Konto erstellen.
Verwenden Sie stattdessen ein privates Konto.
In der Google Cloud Console anmelden
Melden Sie sich mit einem privaten Google-Konto in der Google Cloud Console an.
Abrechnung aktivieren
Testabrechnungskonto verwenden (optional)
Für diesen Workshop benötigen Sie ein Rechnungskonto mit Guthaben. Verwenden Sie die Guthabenpunkte aus dem Banner oben in diesem Codelab, um loszulegen. Wenn Sie bereits mit einem Rechnungskonto verbunden sind, können Sie diesen Schritt überspringen.
Privates Rechnungskonto einrichten
Wenn Sie die Abrechnung mit Google Cloud-Guthaben eingerichtet haben, können Sie diesen Schritt überspringen.
Aktivieren Sie die Abrechnung in der Cloud Console, um ein privates Rechnungskonto einzurichten.
Hinweise:
- Die Kosten für Cloud-Ressourcen für dieses Lab sollten weniger als 1 $betragen.
- Sie können die Schritte am Ende dieses Labs ausführen, um Ressourcen zu löschen und so weitere Kosten zu vermeiden.
- Neue Nutzer haben Anspruch auf die kostenlose Testversion mit einem Guthaben von 300$.
Projekt erstellen (optional)
Wenn Sie kein aktuelles Projekt haben, das Sie für dieses Lab verwenden möchten, erstellen Sie hier ein neues Projekt.
5. Cloud Shell-Editor öffnen
- Klicken Sie auf diesen Link, um direkt zum Cloud Shell-Editor zu gelangen.
- Wenn Sie heute an irgendeinem Punkt zur Autorisierung aufgefordert werden, klicken Sie auf Autorisieren, um fortzufahren.
- Wenn das Terminal nicht unten auf dem Bildschirm angezeigt wird, öffnen Sie es:
- Klicken Sie auf Ansehen.
- Klicken Sie auf Terminal
 .
.
- Legen Sie im Terminal Ihr Projekt mit diesem Befehl fest:
gcloud config set project [PROJECT_ID]- Beispiel:
gcloud config set project lab-project-id-example - Wenn Sie sich nicht mehr an Ihre Projekt-ID erinnern, können Sie alle Ihre Projekt-IDs mit folgendem Befehl auflisten:
gcloud projects list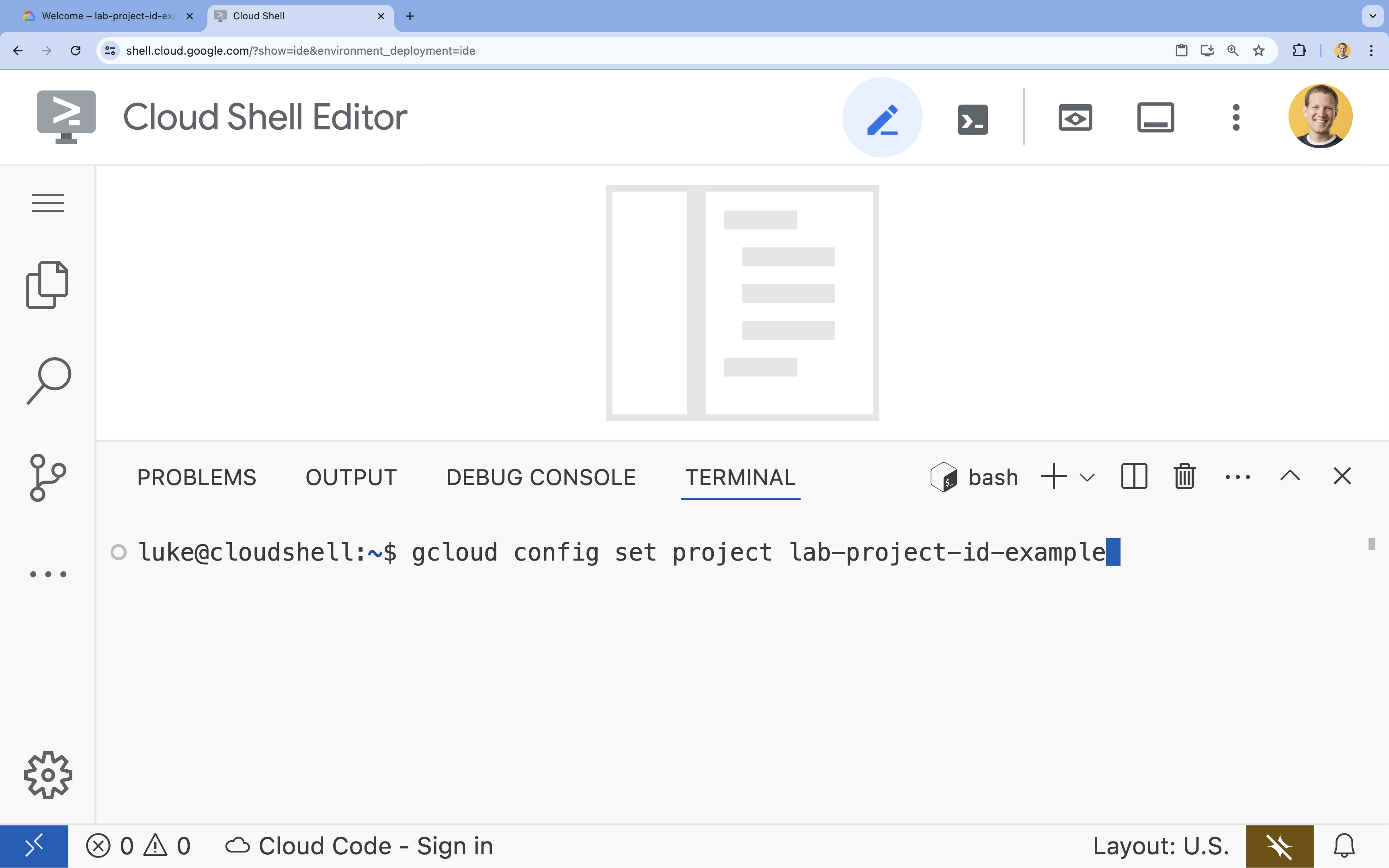
- Beispiel:
- Es sollte folgende Meldung angezeigt werden:
Updated property [core/project].
6. APIs aktivieren
Wenn Sie das Agent Development Kit und Vertex AI Search verwenden möchten, müssen Sie die erforderlichen APIs in Ihrem Google Cloud-Projekt aktivieren.
- Aktivieren Sie die APIs im Terminal:
gcloud services enable \ aiplatform.googleapis.com \ discoveryengine.googleapis.com
Einführung der APIs
- Über die Vertex AI API (
aiplatform.googleapis.com) kann der Agent mit Gemini-Modellen kommunizieren, um Schlussfolgerungen zu ziehen und Inhalte zu generieren. - Die Discovery Engine API (
discoveryengine.googleapis.com) ist die Grundlage von Vertex AI Search. Damit können Sie Datenspeicher erstellen und semantische Suchvorgänge für Ihre unstrukturierten Dokumente ausführen.
7. Umgebung einrichten
Bevor Sie mit dem Programmieren des KI-Agents beginnen, müssen Sie Ihre Entwicklungsumgebung vorbereiten, die erforderlichen Bibliotheken installieren und die erforderlichen Datendateien erstellen.
Virtuelle Umgebung erstellen und Abhängigkeiten installieren
- Erstellen Sie ein Verzeichnis für Ihren Agenten und wechseln Sie in dieses Verzeichnis. Führen Sie im Terminal den folgenden Code aus:
mkdir financial_agent cd financial_agent - Virtuelle Umgebung erstellen:
uv venv --python 3.12 - Aktivieren Sie die virtuelle Umgebung:
source .venv/bin/activate - Installieren Sie das Agent Development Kit (ADK) und pandas.
uv pip install google-adk pandas
Aktienkursdaten erstellen
Da für das Lab bestimmte historische Aktiendaten erforderlich sind, um die Fähigkeit des Agents zu demonstrieren, strukturierte Tools zu verwenden, erstellen Sie eine CSV-Datei mit diesen Daten.
- Erstellen Sie im Verzeichnis
financial_agentdie Dateigoog.csv, indem Sie den folgenden Befehl im Terminal ausführen:cat <<EOF > goog.csv Date,Open,High,Low,Close,Adj Close,Volume 2023-01-03,89.830002,91.550003,89.019997,89.699997,89.699997,20738500 2023-03-31,101.440002,103.889999,101.040001,103.730003,103.730003,36823200 2023-06-30,120.870003,122.029999,120.300003,120.970001,120.970001,23824700 2023-09-29,134.080002,134.550003,131.320007,131.850006,131.850006,21124200 2025-07-10,185.000000,188.000000,184.500000,186.500000,186.500000,25000000 EOF
Umgebungsvariablen konfigurieren
- Erstellen Sie im Verzeichnis
financial_agenteine.env-Datei, um die Umgebungsvariablen Ihres Agents zu konfigurieren. Damit wird dem ADK mitgeteilt, welches Projekt, welcher Standort und welches Modell verwendet werden sollen. Führen Sie im Terminal den folgenden Code aus:# Create the .env file using the captured variables cat << EOF > .env GOOGLE_GENAI_USE_VERTEXAI=TRUE GOOGLE_CLOUD_PROJECT="${GOOGLE_CLOUD_PROJECT}" GOOGLE_CLOUD_LOCATION="us-central1" EOF
Hinweis:Wenn Sie die Datei .env später im Lab ändern müssen, sie aber nicht im Verzeichnis financial_agent sehen, versuchen Sie, die Sichtbarkeit versteckter Dateien im Cloud Shell-Editor über das Menüelement „Ansicht / Versteckte Dateien einblenden“ zu aktivieren.
8. Vertex AI Search-Datenspeicher erstellen
Damit der Agent Fragen zu den Finanzberichten von Alphabet beantworten kann, erstellen Sie einen Vertex AI Search-Datenspeicher mit den öffentlichen SEC-Einreichungen des Unternehmens.
- Öffnen Sie auf einem neuen Browsertab die Cloud Console (console.cloud.google.com) und rufen Sie über die Suchleiste oben AI Applications auf.
- Klicken Sie das Kästchen für die Nutzungsbedingungen an, wenn Sie dazu aufgefordert werden, und klicken Sie auf Fortfahren und die API aktivieren.
- Wählen Sie im Navigationsmenü auf der linken Seite die Option Datenspeicher aus.
- Klicken Sie auf + Datenspeicher erstellen.
- Suchen Sie die Karte Cloud Storage und klicken Sie auf Auswählen.
- Wählen Sie als Datenquelle Unstrukturierte Dokumente aus.

- Geben Sie für die Importquelle (Ordner oder Datei auswählen, die importiert werden soll) den Google Cloud Storage-Pfad
cloud-samples-data/gen-app-builder/search/alphabet-sec-filingsein. - Klicken Sie auf Weiter.
- Lassen Sie den Standort auf global festgelegt.
- Geben Sie als Name des Datenspeichers Folgendes ein:
alphabet-sec-filings - Maximieren Sie den Bereich Dokumentverarbeitungsoptionen.

- Wählen Sie in der Drop-down-Liste Standard-Dokumentparser die Option Layout Parser (Layout-Parser) aus.
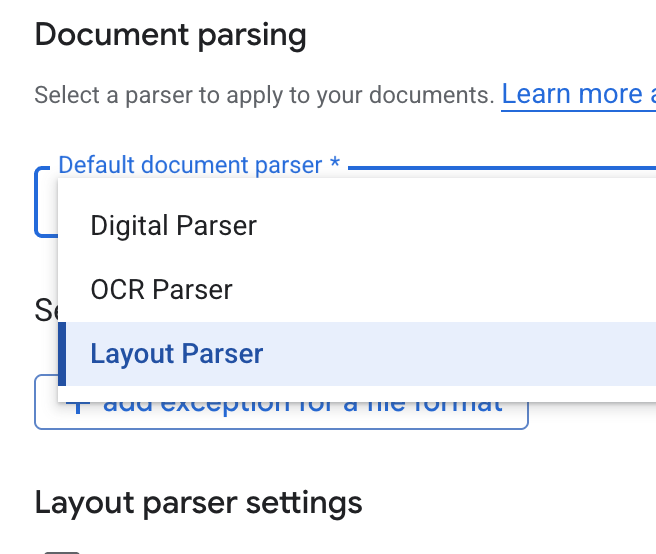
- Wählen Sie in den Optionen für Layout-Parser-Einstellungen die Optionen Tabellenanmerkungen aktivieren und Bildanmerkungen aktivieren aus.
- Klicken Sie auf Weiter.
- Wählen Sie Allgemeine Preise als Preismodell aus (ein Pay as you go, verbrauchsabhängiges Modell) und klicken Sie auf Erstellen.
- Die Dokumente werden in Ihren Datenspeicher importiert.
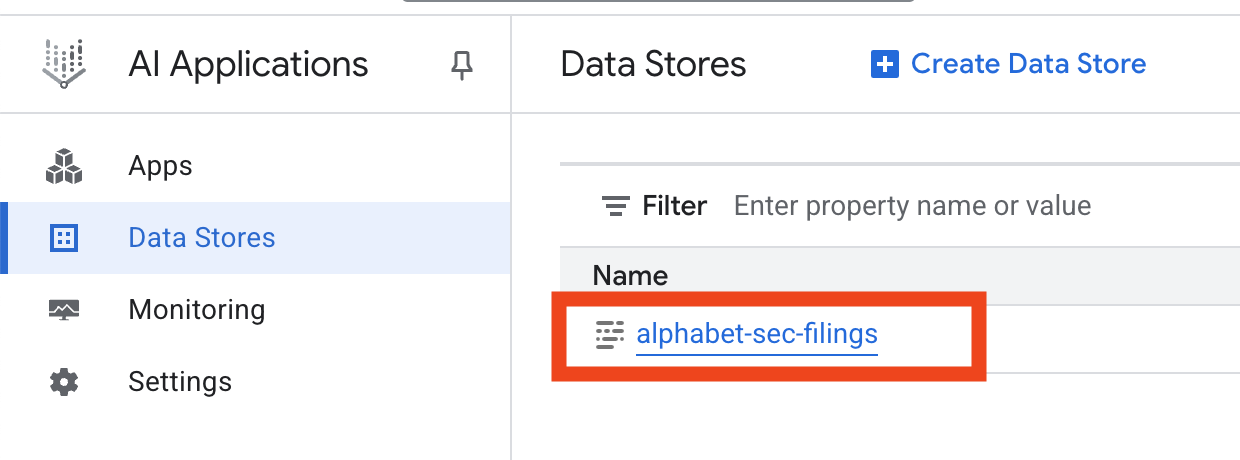
- Klicken Sie auf den Namen des Datenspeichers und kopieren Sie seine ID aus der Tabelle „Datenspeicher“. Sie benötigen sie im nächsten Schritt.
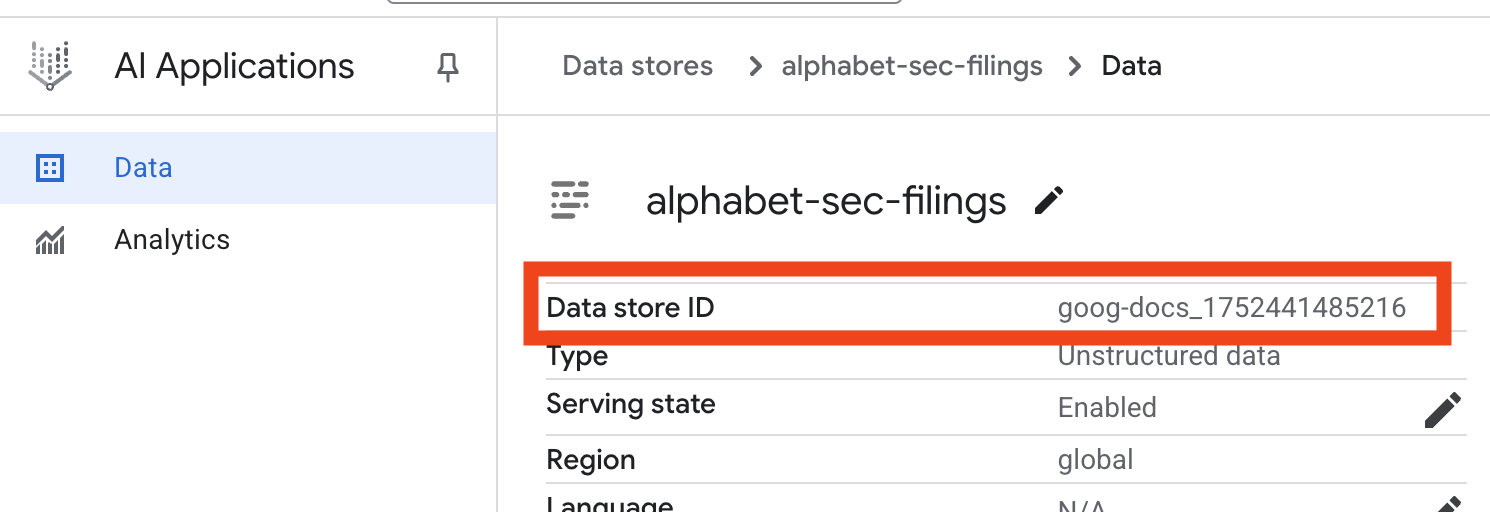
- Öffnen Sie die Datei
.envim Cloud Shell-Editor und hängen Sie die Datenspeicher-ID alsDATA_STORE_ID="YOUR_DATA_STORE_ID"an. Ersetzen SieYOUR_DATA_STORE_IDdurch die tatsächliche ID aus dem vorherigen Schritt. Hinweis:Das Importieren, Parsen und Indexieren von Daten im Datenspeicher dauert einige Minuten. Wenn Sie den Prozess prüfen möchten, klicken Sie auf den Namen des Datenspeichers, um seine Eigenschaften zu öffnen, und dann auf den Tab Aktivität. Warten Sie, bis der Status „Import abgeschlossen“ lautet.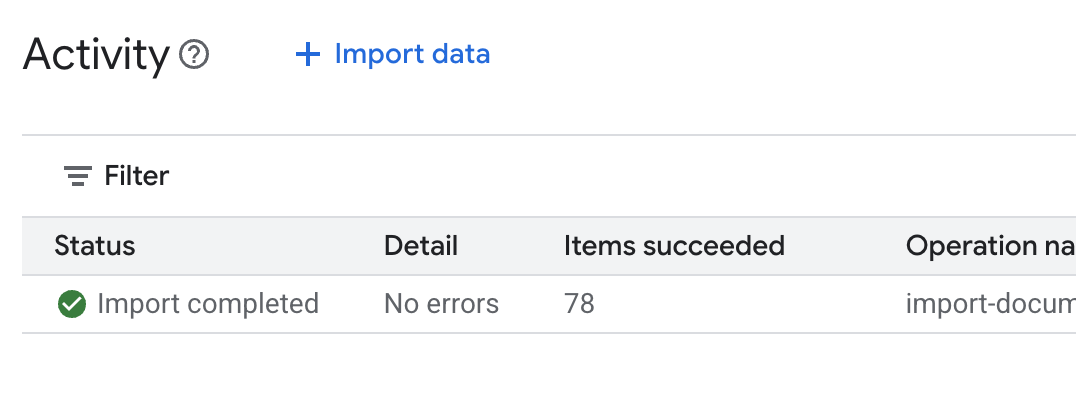
9. Benutzerdefiniertes Tool für strukturierte Daten erstellen
Als Nächstes erstellen Sie eine Python-Funktion, die als Tool für den KI-Agenten dient. Mit diesem Tool wird die Datei goog.csv gelesen, um historische Aktienkurse für ein bestimmtes Datum abzurufen.
- Erstellen Sie in Ihrem
financial_agent-Verzeichnis eine neue Datei mit dem Namenagent.py. Führen Sie im Terminal den folgenden Befehl aus:cloudshell edit agent.py - Fügen Sie den folgenden Python-Code zu
agent.pyhinzu. Mit diesem Code werden Abhängigkeiten importiert und die Funktionget_stock_pricedefiniert.from datetime import datetime import os import logging import google.cloud.logging from google.adk.tools import VertexAiSearchTool from google.adk.tools.agent_tool import AgentTool from google.adk.agents import LlmAgent import pandas as pd def get_stock_price(date: str) -> dict: """Gets the closing stock price for a given date. Args: date: The date to get the stock price for, in YYYY-MM-DD format. Returns: A dictionary containing the closing price, or an error message if the date is not found or the format is incorrect. """ try: # Load the CSV file df = pd.read_csv('goog.csv') # Convert the 'Date' column to datetime objects df['Date'] = pd.to_datetime(df['Date']) # Convert the input string to a datetime object query_date = datetime.strptime(date, '%Y-%m-%d') # Find the row for the given date row = df[df['Date'] == query_date] if not row.empty: # Get the closing price close_price = row['Close'].iloc[0] return {"status": "success", "date": date, "closing_price": close_price} else: return {"status": "error", "message": f"No data found for date: {date}"} except FileNotFoundError: return {"status": "error", "message": "Stock data file (goog.csv) not found."} except Exception as e: return {"status": "error", "message": f"An error occurred: {str(e)}"}
Beachten Sie den ausführlichen Docstring der Funktion. Darin wird beschrieben, was die Funktion tut, welche Parameter sie hat (Args) und was sie zurückgibt (Returns). Das ADK verwendet diesen Docstring, um dem Agenten beizubringen, wie und wann er dieses Tool verwenden soll.
10. RAG-Agent erstellen und ausführen
Jetzt ist es an der Zeit, den Agenten zusammenzustellen. Sie kombinieren das Vertex AI Search-Tool für unstrukturierte Daten mit Ihrem benutzerdefinierten get_stock_price-Tool für strukturierte Daten.
- Hängen Sie den folgenden Code an Ihre
agent.py-Datei an. Mit diesem Code werden die erforderlichen ADK-Klassen importiert, Instanzen der Tools erstellt und der Agent definiert.logging.basicConfig(level=logging.INFO) cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() # 1. Create the Vertex AI Search tool full_datastore_id = f"projects/{os.environ['GOOGLE_CLOUD_PROJECT']}/locations/global/collections/default_collection/dataStores/{os.environ['DATA_STORE_ID']}" vertex_ai_search_tool = VertexAiSearchTool( data_store_id=full_datastore_id ) # 2. Define the Search+Q&A agent # Since we cannot combine tools with other tools in a single agent, # we create a separate Search+Q&A agent which will be used as a tool by the main root agent. doc_qa_agent = LlmAgent( name="search_and_qna_agent", model="gemini-2.5-flash", tools=[vertex_ai_search_tool], instruction="""You are a helpful assistant that answers questions based on information found in the document store. Use the search tool to find relevant information before answering. If the answer isn't in the documents, say that you couldn't find the information. """, description="Answers questions using a specific Vertex AI Search datastore.", ) # 3. Define the root agent with 2 tools. root_agent = LlmAgent( name="financial_agent", model="gemini-2.5-flash", tools=[ AgentTool(doc_qa_agent), get_stock_price, ], instruction="""You are an Financial Analytics Agent that answers question about Alphabet stock prices (using get_stock_price tool) and historical performance based on the data in Vertex AI Search datastore (using doc_qa_agent tool).""" ) - Starten Sie im Terminal im Verzeichnis
financial_agentdie ADK-Weboberfläche, um mit Ihrem Agenten zu interagieren:adk web ~ - Klicken Sie auf den Link, der in der Terminalausgabe angegeben ist (normalerweise
http://127.0.0.1:8000), um die ADK-Entwicklungsoberfläche in Ihrem Browser zu öffnen.
11. KI-Agenten testen
Sie können jetzt testen, wie gut Ihr Agent komplexe Fragen beantworten und seine Tools dafür einsetzen kann.
- Achten Sie darauf, dass in der ADK-Entwicklungsoberfläche Ihr
financial_agentim Drop-down-Menü ausgewählt ist. - Stellen Sie eine Frage, für die Informationen aus den SEC-Einreichungen (unstrukturierte Daten) erforderlich sind. Geben Sie die folgende Abfrage in den Chat ein:
What were the total revenues for the quarter ending on March 31, 2023?search_and_qna_agentaufrufen, um mitVertexAiSearchTooldie Antwort in den Finanzdokumenten zu finden. - Stellen Sie als Nächstes eine Frage, für die Ihr benutzerdefiniertes Tool (strukturierte Daten) verwendet werden muss. Das Datumsformat im Prompt muss nicht genau dem Format entsprechen, das für die Funktion erforderlich ist. Das LLM ist intelligent genug, um es neu zu formatieren.
What was the closing stock price for Alphabet on July 10, 2025?get_stock_price-Tool aufrufen. Sie können im Chat auf das Werkzeugsymbol klicken, um den Funktionsaufruf und das Ergebnis zu prüfen. - Stellen Sie zum Schluss eine komplexe Frage, für die der KI-Agent beide Tools verwenden und die Ergebnisse zusammenfassen muss.
According to the 10-Q filing for the period ending March 31, 2023, what were the company's net cash provided by operating activities, and what was the stock's closing price on that date?- Zuerst wird
VertexAiSearchToolverwendet, um die Cashflow-Informationen in den SEC-Einreichungen zu finden. - Anschließend wird erkannt, dass der Aktienkurs benötigt wird, und die Funktion
get_stock_pricewird mit dem Datum2023-03-31aufgerufen. - Schließlich werden beide Informationen in einer einzigen, umfassenden Antwort zusammengefasst.
- Zuerst wird
- Wenn Sie fertig sind, können Sie den Browsertab schließen und im Terminal
CTRL+Cdrücken, um den ADK-Server zu beenden.
12. Dienst für Ihre Aufgabe auswählen
Vertex AI Search ist nicht der einzige Vektorsuchdienst, den Sie verwenden können. Sie können auch einen verwalteten Dienst verwenden, der den gesamten Ablauf von Retrieval-Augmented Generation automatisiert: die Vertex AI RAG Engine.
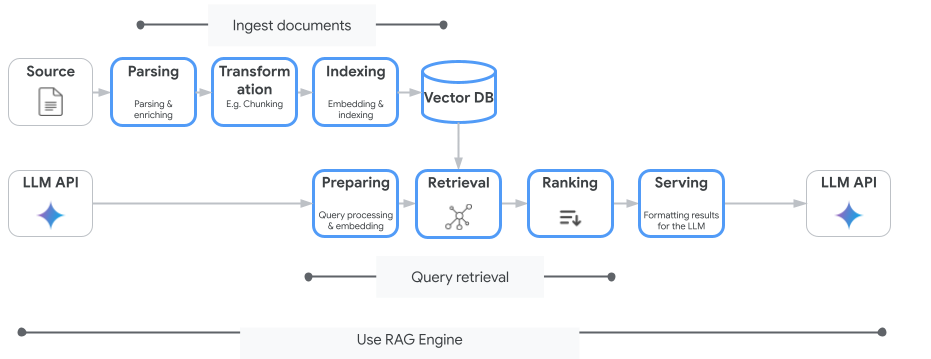
Es kümmert sich um alles, von der Aufnahme von Dokumenten bis zum Abrufen und Neusortieren. Die RAG Engine unterstützt mehrere Vektorspeicher, darunter Pinecone und Weaviate.
Sie können auch viele spezialisierte Vektordatenbanken selbst hosten oder Vektorindexfunktionen in Datenbank-Engines wie pgvector im PostgreSQL-Dienst (z. B. AlloyDB oder BigQuery Vector Search) nutzen.
Einige andere Dienste, die die Vektorsuche unterstützen, sind:
Die allgemeine Anleitung zur Auswahl eines bestimmten Dienstes in Google Cloud lautet so:
- Wenn Sie bereits eine funktionierende und gut skalierte Do-it-yourself-Infrastruktur für die Vektorsuche haben, stellen Sie sie in Google Kubernetes Engine bereit, z. B. Weaviate oder DIY PostgreSQL.
- Wenn sich Ihre Daten in BigQuery, AlloyDB, Firestore oder einer anderen Datenbank befinden, sollten Sie die Vektorsuchfunktionen der Datenbank verwenden, wenn die semantische Suche im Rahmen einer größeren Abfrage in dieser Datenbank skaliert werden kann. Wenn Sie beispielsweise Produktbeschreibungen und/oder ‑bilder in einer BigQuery-Tabelle haben, können Sie durch Hinzufügen einer Spalte für Text- und/oder Bildeinbettungen die Ähnlichkeitssuche im großen Maßstab nutzen. Vektorindexe mit ScANN-Suchunterstützung können Milliarden von Elementen im Index unterstützen.
- Wenn Sie schnell und mit minimalem Aufwand auf einer verwalteten Plattform loslegen möchten, wählen Sie Vertex AI Search aus. Das ist eine vollständig verwaltete Suchmaschinen- und Retriever-API, die sich ideal für komplexe Unternehmensanwendungsfälle eignet, die eine hohe Out-of-the-box-Qualität, Skalierbarkeit und detaillierte Zugriffssteuerung erfordern. Sie vereinfacht die Verbindung zu verschiedenen Unternehmensdatenquellen und ermöglicht die Suche in mehreren Quellen.
- Verwenden Sie die Vertex AI RAG Engine, wenn Sie eine Lösung für Entwickler suchen, die ein Gleichgewicht zwischen Benutzerfreundlichkeit und Anpassungsmöglichkeiten wünschen. Es ermöglicht schnelles Prototyping und schnelle Entwicklung, ohne die Flexibilität zu beeinträchtigen.
- Referenzarchitekturen für Retrieval-Augmented Generation
13. Fazit
Glückwunsch! Sie haben einen KI-Agenten mit Retrieval-Augmented Generation erstellt und getestet. Sie haben Folgendes gelernt:
- Mit den leistungsstarken semantischen Suchfunktionen von Vertex AI Search eine Wissensdatenbank für unstrukturierte Dokumente erstellen
- Entwickeln Sie eine benutzerdefinierte Python-Funktion, die als Tool zum Abrufen strukturierter Daten dient.
- Mit dem Agent Development Kit (ADK) können Sie einen Multi-Tool-Agenten auf Basis von Gemini erstellen.
- Entwicklung eines Agenten, der in der Lage ist, komplexe, mehrstufige Problemlösung zu betreiben, um Anfragen zu beantworten, die die Zusammenführung von Informationen aus mehreren Quellen erfordern.
In diesem Lab werden die wichtigsten Prinzipien von Agentic RAG vorgestellt, einer leistungsstarken Architektur zum Erstellen intelligenter, genauer und kontextbezogener KI-Anwendungen in Google Cloud.
Vom Prototyp zur Produktion
Dieses Lab ist Teil des Lernpfads „Produktionsreife KI mit Google Cloud“.
- Gesamten Lehrplan ansehen
- Teilen Sie Ihre Fortschritte mit dem Hashtag #ProductionReadyAI.