
1. Introducción
Descripción general
El objetivo de este lab es aprender a desarrollar aplicaciones de generación mejorada por recuperación (RAG) basadas en agentes de extremo a extremo en Google Cloud. En este lab, crearás un agente de análisis financiero que puede responder preguntas combinando información de dos fuentes diferentes: documentos no estructurados (presentaciones trimestrales de Alphabet ante la SEC: estados financieros y detalles operativos que todas las empresas de capital abierto de EE.UU. envían a la Comisión de Bolsa y Valores) y datos estructurados (precios históricos de las acciones).
Usarás Vertex AI Search para compilar un potente motor de búsqueda semántica para los informes financieros no estructurados. Para los datos estructurados, crearás una herramienta personalizada de Python. Por último, usarás el Kit de desarrollo de agentes (ADK) para crear un agente inteligente que pueda razonar sobre la búsqueda de un usuario, decidir qué herramienta usar y sintetizar la información en una respuesta coherente.
Actividades
- Configura un almacén de datos de Vertex AI Search para la búsqueda semántica en documentos privados.
- Crear una función de Python personalizada como herramienta para un agente
- Usa el Kit de desarrollo de agentes (ADK) para crear un agente con varias herramientas.
- Combina la recuperación de fuentes de datos estructurados y no estructurados para responder preguntas complejas.
- Probar e interactuar con un agente que exhibe capacidades de razonamiento
Qué aprenderás
En este lab, aprenderás lo siguiente:
- Los conceptos básicos de la generación mejorada por recuperación (RAG) y la RAG basada en agentes
- Cómo implementar la búsqueda semántica en documentos con Vertex AI Search
- Cómo exponer datos estructurados a un agente creando herramientas personalizadas
- Cómo crear y organizar un agente multiherramienta con el Kit de desarrollo de agentes (ADK)
- Cómo los agentes usan el razonamiento y la planificación para responder preguntas complejas con múltiples fuentes de datos
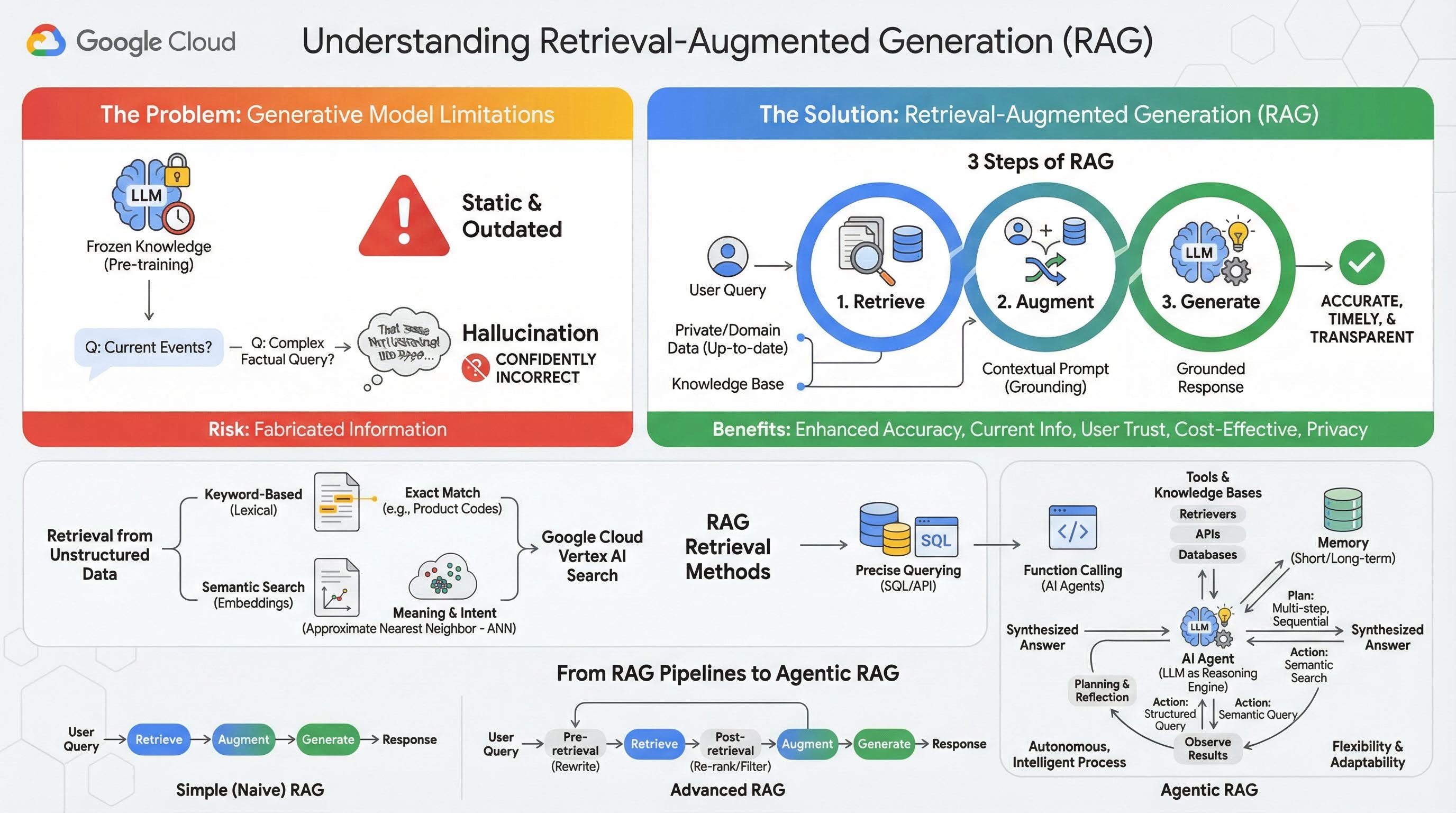
2. Información sobre la generación mejorada por recuperación
Los modelos generativos grandes (modelos de lenguaje grandes o LLM, modelos de lenguaje visual, etc.) son increíblemente potentes, pero tienen limitaciones inherentes. Su conocimiento se congela en el momento de su entrenamiento previo, lo que lo hace estático y desactualizado al instante. Incluso después del ajuste fino, el conocimiento del modelo no se vuelve mucho más reciente, ya que este no es el objetivo de las etapas posteriores al entrenamiento.
La forma en que se entrenan los modelos de lenguaje grandes, en especial los modelos de "pensamiento", hace que se los "recompense" por dar alguna respuesta, incluso si el modelo en sí no tiene información fáctica que respalde esa respuesta. Esto sucede cuando se dice que un modelo "alucina", es decir, genera con confianza información que suena plausible, pero que es incorrecta.
La generación aumentada por recuperación es un patrón arquitectónico potente diseñado para resolver estos problemas exactos. Es un framework arquitectónico que mejora las capacidades de los modelos de lenguaje grandes conectándolos con fuentes de conocimiento externas y autorizadas en tiempo real. En lugar de depender únicamente de su conocimiento estático previamente entrenado, un LLM en un sistema de RAG primero recupera información pertinente relacionada con la consulta de un usuario y, luego, usa esa información para generar una respuesta más precisa, oportuna y consciente del contexto.
Este enfoque aborda directamente las debilidades más significativas de los modelos generativos: su conocimiento se fija en un momento determinado y son propensos a generar información incorrecta, o "alucinaciones". El RAG le proporciona al LLM un "examen de libro abierto" eficaz, en el que el "libro" son tus datos privados, específicos del dominio y actualizados. Este proceso de proporcionar contexto fáctico al LLM se conoce como "fundamentación".
3 pasos de RAG
El proceso estándar de generación mejorada por recuperación se puede dividir en tres pasos simples:
- Recuperación: Cuando un usuario envía una búsqueda, el sistema primero busca en una base de conocimiento externa (como un repositorio de documentos, una base de datos o un sitio web) para encontrar información pertinente para la búsqueda.
- Mejora: Luego, la información recuperada se combina con la consulta original del usuario en una instrucción expandida. A veces, esta técnica se denomina "relleno de instrucciones", ya que enriquece la instrucción con contexto fáctico.
- Generar: Esta instrucción aumentada se envía al LLM, que luego genera una respuesta. Dado que se le proporcionaron datos pertinentes y fácticos al modelo, su resultado está "fundamentado" y es mucho menos probable que sea impreciso o esté desactualizado.
Beneficios de la RAG
La introducción del framework de RAG ha sido transformadora para crear aplicaciones de IA prácticas y confiables. Estos son algunos de sus beneficios clave:
- Mayor exactitud y menos alucinaciones: Al fundamentar las respuestas en hechos externos verificables, la RAG reduce drásticamente el riesgo de que el LLM invente información.
- Acceso a información actual: Los sistemas de RAG se pueden conectar a bases de conocimiento que se actualizan constantemente, lo que les permite proporcionar respuestas basadas en la información más reciente, algo imposible para un LLM entrenado de forma estática.
- Mayor confianza y transparencia para el usuario: Como la respuesta del LLM se basa en los documentos recuperados, el sistema puede proporcionar citas y vínculos a sus fuentes. Esto permite que los usuarios verifiquen la información por sí mismos, lo que genera confianza en la aplicación.
- Rentabilidad: Ajustar o volver a entrenar un LLM de forma continua con datos nuevos es costoso desde el punto de vista computacional y financiero. Con la RAG, actualizar el conocimiento del modelo es tan simple como actualizar la fuente de datos externa, lo que es mucho más eficiente.
- Especialización y privacidad del dominio: La técnica de RAG permite que las personas y las organizaciones pongan sus datos privados y propios a disposición de un LLM en el momento de la consulta sin necesidad de incluir esos datos sensibles en el conjunto de entrenamiento del modelo. Esto permite crear aplicaciones potentes y específicas para cada dominio, a la vez que se mantiene la privacidad y la seguridad de los datos.
Recuperación
El paso de "Recuperación" es el núcleo de cualquier sistema de RAG. La calidad y la relevancia de la información recuperada determinan directamente la calidad y la relevancia de la respuesta final generada. Una aplicación de RAG eficaz a menudo necesita recuperar información de diferentes tipos de fuentes de datos con diversas técnicas. Los métodos de recuperación principales se dividen en tres categorías: basados en palabras clave, semánticos y estructurados.
Recuperación de datos no estructurados
Históricamente, la recuperación de datos no estructurados es otro nombre para la Búsqueda tradicional. Pasó por varias transformaciones, y puedes aprovechar ambos enfoques principales.
La búsqueda semántica es la técnica más eficiente que puedes ejecutar a gran escala en Google Cloud con un rendimiento de vanguardia y un alto grado de control.
- Búsqueda basada en palabras clave (léxica): Este es el enfoque tradicional de la búsqueda, que se remonta a los primeros sistemas de recuperación de información de la década de 1970. La búsqueda léxica funciona haciendo coincidir las palabras literales (o "tokens") de la búsqueda de un usuario con las mismas palabras exactas en los documentos de una base de conocimiento. Es muy eficaz para las búsquedas en las que la precisión en términos específicos, como códigos de productos, cláusulas legales o nombres únicos, es fundamental.
- Búsqueda semántica: La búsqueda semántica, o "búsqueda con significado", es un enfoque más moderno que tiene como objetivo comprender la intención del usuario y el significado contextual de su búsqueda, no solo las palabras clave literales. La búsqueda semántica moderna se basa en el embedding, una técnica de aprendizaje automático que asigna datos complejos y de alta dimensión a un espacio vectorial de menor dimensión de vectores numéricos. Estos vectores están diseñados de tal manera que los textos con significados similares se ubiquen cerca unos de otros en el espacio vectorial. Una búsqueda de "¿Cuáles son las mejores razas de perros para familias?" se convierte en un vector, y el sistema busca vectores de documentos que sean sus "vecinos más cercanos" en ese espacio. Esto le permite encontrar documentos que hablan de "golden retrievers" o "caninos amigables", incluso si no contienen la palabra exacta "perro". Los algoritmos de vecino más cercano aproximado (ANN) hacen que esta búsqueda de alta dimensión sea eficiente. En lugar de comparar el vector de búsqueda con cada vector de documento (lo que sería demasiado lento para conjuntos de datos grandes), los algoritmos de ANN usan estructuras de indexación inteligentes para encontrar rápidamente los vectores que probablemente sean los más cercanos.
Recuperación de datos estructurados
No todo el conocimiento crítico se almacena en documentos no estructurados. A menudo, la información más precisa y valiosa se encuentra en formatos estructurados, como bases de datos relacionales, bases de datos NoSQL o algún tipo de API, como una API de REST para datos meteorológicos o precios de acciones.
La recuperación de datos estructurados suele ser más directa y exacta que la búsqueda de texto no estructurado. En lugar de buscar similitud semántica, se les puede dar a los modelos de lenguaje la capacidad de formular y ejecutar una consulta precisa, como una consulta en SQL en una base de datos o una llamada a la API del clima para una ubicación y una fecha determinadas.
Implementada a través de la llamada a funciones, la misma técnica que impulsa a los agentes de IA, permite que los modelos de lenguaje interactúen con código ejecutable y sistemas externos de una manera estructural determinística.
3. De las canalizaciones de RAG al RAG basado en agentes
Así como evolucionó el concepto de RAG, también lo hicieron las arquitecturas para implementarlo. Lo que comenzó como una canalización lineal simple maduró hasta convertirse en un sistema dinámico e inteligente orquestado por agentes de IA.
- RAG simple (o ingenuo): Esta es la arquitectura fundamental que analizamos hasta ahora: un proceso lineal de tres pasos para recuperar, aumentar y generar. Es reactivo, sigue una ruta fija para cada búsqueda y es muy eficaz para las tareas de preguntas y respuestas sencillas.
- RAG avanzado: Representa una evolución en la que se agregan pasos adicionales a la canalización para mejorar la calidad del contexto recuperado. Estas mejoras pueden ocurrir antes o después del paso de recuperación.
- Previa a la recuperación: Se pueden usar técnicas como la expansión o la reescritura de consultas. Es posible que el sistema analice la búsqueda inicial y la reformule para que sea más eficaz para el sistema de recuperación.
- Posterior a la recuperación: Después de recuperar un conjunto inicial de documentos, se puede aplicar un modelo de reclasificación para calificar los documentos según su relevancia y colocar los mejores en la parte superior. Esto es especialmente importante en la búsqueda híbrida. Otro paso posterior a la recuperación es filtrar o comprimir el contexto recuperado para garantizar que solo se pase la información más destacada al LLM.
- RAG con agentes: Esta es la vanguardia de la arquitectura de RAG, que representa un cambio de paradigma de una canalización fija a un proceso autónomo e inteligente. En un sistema RAG agente, todo el flujo de trabajo se administra con uno o más agentes de IA que pueden razonar, planificar y elegir sus acciones de forma dinámica.
Para comprender el RAG agentivo, primero se debe entender qué constituye un agente de IA. Un agente es más que un LLM. Es un sistema con varios componentes clave:
- Un LLM como motor de razonamiento: El agente usa un LLM potente, como Gemini, no solo para generar texto, sino también como su "cerebro" central para planificar, tomar decisiones y desglosar tareas complejas.
- Un conjunto de herramientas: Se le otorga a un agente acceso a un kit de herramientas de funciones que puede decidir usar para lograr sus objetivos. Estas herramientas pueden ser cualquier cosa: una calculadora, una API de búsqueda web, una función para enviar un correo electrónico o, lo que es más importante para este lab, recuperadores para nuestras diversas bases de conocimiento.
- Memoria: Los agentes se pueden diseñar con memoria a corto plazo (para recordar el contexto de la conversación actual) y memoria a largo plazo (para recordar información de interacciones pasadas), lo que permite experiencias más personalizadas y coherentes.
- Planificación y reflexión: Los agentes más avanzados exhiben patrones de razonamiento sofisticados. Pueden recibir un objetivo complejo y crear un plan de varios pasos para lograrlo. Luego, pueden ejecutar este plan y hasta reflexionar sobre los resultados de sus acciones, identificar errores y corregir su enfoque por sí mismos para mejorar el resultado final.
El RAG basado en agentes es un cambio radical porque introduce una capa de autonomía e inteligencia de la que carecen las canalizaciones estáticas.
- Flexibilidad y adaptabilidad: Un agente no está limitado a una sola ruta de recuperación. Dada una búsqueda del usuario, puede razonar sobre la mejor fuente de información. Puede decidir primero consultar la base de datos estructurada, luego realizar una búsqueda semántica en documentos no estructurados y, si aún no puede encontrar una respuesta, usar una herramienta de la Búsqueda de Google para buscar en la Web pública, todo dentro del contexto de una sola solicitud del usuario.
- Razonamiento complejo de varios pasos: Esta arquitectura se destaca por manejar consultas complejas que requieren varios pasos de recuperación y procesamiento secuenciales.
Considera la siguiente búsqueda: "Encuentra las 3 mejores películas de ciencia ficción dirigidas por Christopher Nolan y, para cada una, proporciona un breve resumen de la trama". Una canalización de RAG simple fallaría.
Sin embargo, un agente puede desglosarlo de la siguiente manera:
- Plan: Primero, debo encontrar las películas. Luego, para cada película, debo encontrar su trama.
- Acción 1: Usa la herramienta de datos estructurados para consultar una base de datos de películas sobre las películas de ciencia ficción de Nolan: las 3 mejores películas, ordenadas de forma descendente por calificación.
- Observación 1: La herramienta devuelve "El origen", "Interestelar" y "Tenet".
- Acción 2: Usa la herramienta de datos no estructurados (búsqueda semántica) para encontrar la trama de "El origen".
- Observación 2: Se recupera el argumento.
- Acción 3: Repite el proceso para "Interstellar".
- Acción 4: Repite el proceso para "Tenet".
- Síntesis final: Combina toda la información recuperada en una sola respuesta coherente para el usuario.
4. Configura el proyecto
Cuenta de Google
Si aún no tienes una Cuenta de Google personal, debes crear una.
Usa una cuenta personal en lugar de una cuenta de trabajo o institución educativa.
Accede a la consola de Google Cloud
Accede a la consola de Google Cloud con una Cuenta de Google personal.
Habilitar facturación
Usar la cuenta de facturación de prueba (opcional)
Para realizar este taller, necesitas una cuenta de facturación con algo de crédito. Usa los créditos del banner que se encuentra en la parte superior de este codelab para comenzar. Si ya te conectaste a una cuenta de facturación, puedes omitir este paso.
Configura una cuenta de facturación personal
Si configuraste la facturación con créditos de Google Cloud, puedes omitir este paso.
Para configurar una cuenta de facturación personal, ve aquí para habilitar la facturación en la consola de Cloud.
Notas:
- Completar este lab debería costar menos de USD 1 en recursos de Cloud.
- Puedes seguir los pasos al final de este lab para borrar recursos y evitar cargos adicionales.
- Los usuarios nuevos pueden acceder a la prueba gratuita de USD 300.
Crear un proyecto (opcional)
Si no tienes un proyecto actual que quieras usar para este lab, crea uno nuevo aquí.
5. Abre el editor de Cloud Shell
- Haz clic en este vínculo para navegar directamente al editor de Cloud Shell.
- Si se te solicita autorización en algún momento, haz clic en Autorizar para continuar.
- Si la terminal no aparece en la parte inferior de la pantalla, ábrela:
- Haz clic en Ver.
- Haz clic en Terminal.
- En la terminal, configura tu proyecto con este comando:
gcloud config set project [PROJECT_ID]- Ejemplo:
gcloud config set project lab-project-id-example - Si no recuerdas el ID de tu proyecto, puedes enumerar todos tus IDs de proyecto con el siguiente comando:
gcloud projects list
- Ejemplo:
- Deberías ver el siguiente mensaje:
Updated property [core/project].
6. Habilita las APIs
Para usar el Kit de desarrollo de agentes y Vertex AI Search, debes habilitar las APIs necesarias en tu proyecto de Google Cloud.
- En la terminal, habilita las APIs:
gcloud services enable \ aiplatform.googleapis.com \ discoveryengine.googleapis.com
Presentamos las APIs
- La API de Vertex AI (
aiplatform.googleapis.com) permite que el agente se comunique con los modelos de Gemini para el razonamiento y la generación. - La API de Discovery Engine (
discoveryengine.googleapis.com) potencia Vertex AI Search, lo que te permite crear almacenes de datos y realizar búsquedas semánticas en tus documentos no estructurados.
7. Configura el entorno
Antes de comenzar a codificar el agente de IA, debes preparar tu entorno de desarrollo, instalar las bibliotecas necesarias y crear los archivos de datos requeridos.
Crea un entorno virtual y, luego, instala las dependencias
- Crea un directorio para tu agente y navega hasta él. Ejecuta el siguiente código en la terminal:
mkdir financial_agent cd financial_agent - Crea un entorno virtual:
uv venv --python 3.12 - Activa el entorno virtual:
source .venv/bin/activate - Instala el Kit de desarrollo de agentes (ADK) y pandas.
uv pip install google-adk pandas
Crea los datos del precio de las acciones
Dado que el lab requiere datos históricos específicos de acciones para demostrar la capacidad del agente de usar herramientas estructuradas, crearás un archivo CSV que contenga estos datos.
- En el directorio
financial_agent, ejecuta el siguiente comando en la terminal para crear el archivogoog.csv:cat <<EOF > goog.csv Date,Open,High,Low,Close,Adj Close,Volume 2023-01-03,89.830002,91.550003,89.019997,89.699997,89.699997,20738500 2023-03-31,101.440002,103.889999,101.040001,103.730003,103.730003,36823200 2023-06-30,120.870003,122.029999,120.300003,120.970001,120.970001,23824700 2023-09-29,134.080002,134.550003,131.320007,131.850006,131.850006,21124200 2025-07-10,185.000000,188.000000,184.500000,186.500000,186.500000,25000000 EOF
Configure las variables de entorno
- En el directorio
financial_agent, crea un archivo.envpara configurar las variables de entorno de tu agente. Esto le indica al ADK qué proyecto, ubicación y modelo usar. Ejecuta el siguiente código en la terminal:# Create the .env file using the captured variables cat << EOF > .env GOOGLE_GENAI_USE_VERTEXAI=TRUE GOOGLE_CLOUD_PROJECT="${GOOGLE_CLOUD_PROJECT}" GOOGLE_CLOUD_LOCATION="us-central1" EOF
Nota: Más adelante en el lab, si necesitas modificar el archivo .env, pero no lo ves en el directorio financial_agent, intenta alternar la visibilidad de los archivos ocultos en el editor de Cloud Shell con el elemento de menú "Ver / Alternar archivos ocultos".
8. Crea un almacén de datos de Vertex AI Search
Para permitir que el agente responda preguntas sobre los informes financieros de Alphabet, crearás un almacén de datos de Vertex AI Search que contenga sus presentaciones públicas ante la SEC.
- En una nueva pestaña del navegador, abre la consola de Cloud (console.cloud.google.com) y navega a AI Applications con la barra de búsqueda en la parte superior.
- Si se te solicita, selecciona la casilla de verificación de los términos y condiciones y haz clic en Continuar y activar la API.
- En el menú de navegación de la izquierda, selecciona Almacenes de datos.
- Haz clic en + Crear almacén de datos.
- Busca la tarjeta Cloud Storage y haz clic en Seleccionar.
- En la fuente de datos, selecciona Documentos no estructurados.

- En la fuente de importación (Selecciona una carpeta o un archivo que desees importar), ingresa la ruta de Google Cloud Storage
cloud-samples-data/gen-app-builder/search/alphabet-sec-filings. - Haz clic en Continuar.
- Mantén la ubicación establecida en global.
- En el nombre del almacén de datos, ingresa
alphabet-sec-filings - Expande la sección Opciones de procesamiento de documentos.

- En la lista desplegable Default document parser, selecciona Layout Parser.
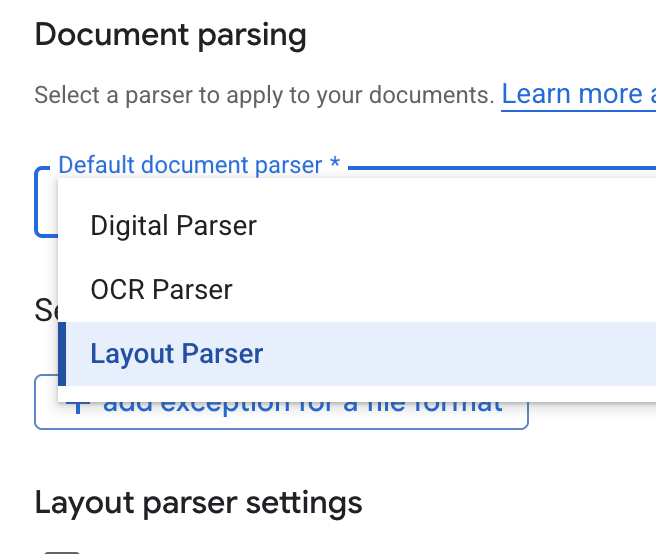
- En las opciones de Configuración del analizador de diseño, selecciona Habilitar anotación de tablas y Habilitar anotación de imágenes.
- Haz clic en Continuar.
- Selecciona Precios generales como el modelo de precios (un modelo de pago por uso basado en el consumo) y haz clic en Crear.
- Tu almacén de datos comenzará a importar los documentos.
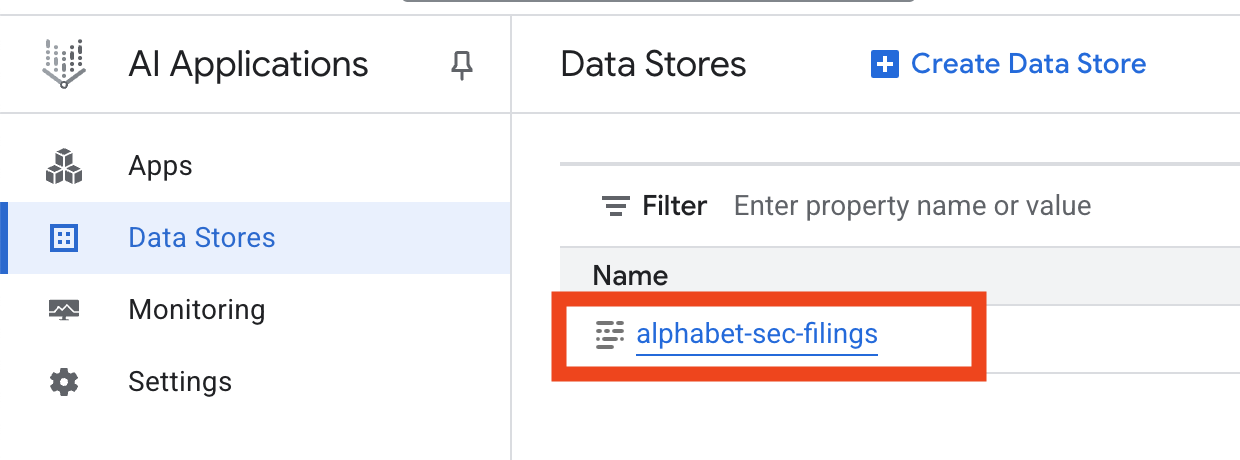
- Haz clic en el nombre del almacén de datos y copia su ID de la tabla Almacenes de datos. La necesitarás en el próximo paso.
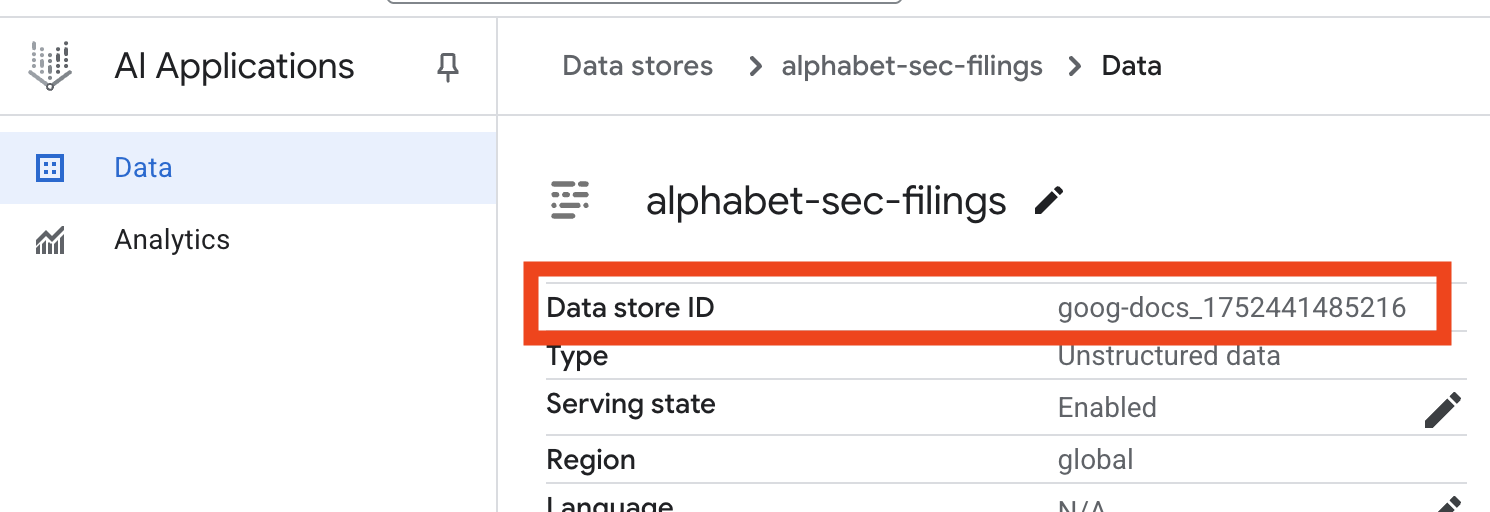
- Abre el archivo
.enven el editor de Cloud Shell y agrega el ID del almacén de datos comoDATA_STORE_ID="YOUR_DATA_STORE_ID"(reemplazaYOUR_DATA_STORE_IDpor el ID real del paso anterior). Nota: La importación, el análisis y la indexación de los datos en el almacén de datos tardarán unos minutos. Para verificar el proceso, haz clic en el nombre del almacén de datos para abrir sus propiedades y, luego, abre la pestaña Actividad. Espera a que el estado cambie a "La importación se completó".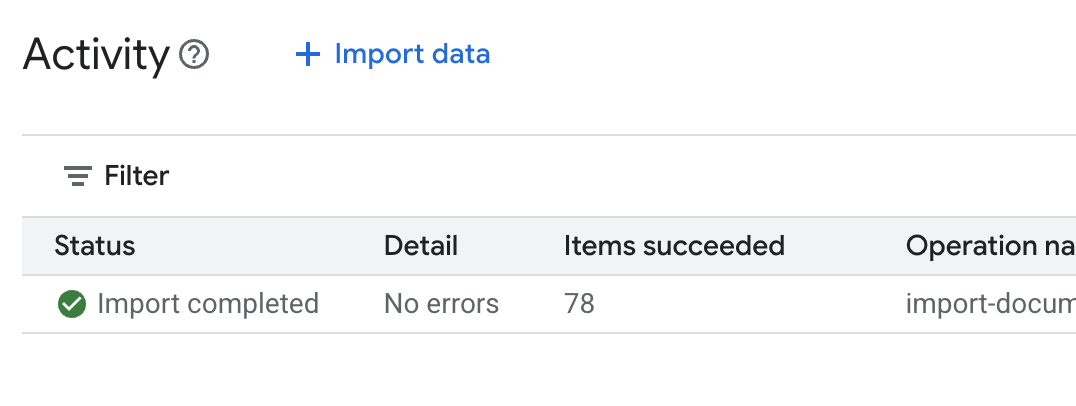
9. Crea una herramienta personalizada para datos estructurados
A continuación, crearás una función de Python que actuará como herramienta para el agente. Esta herramienta leerá el archivo goog.csv para recuperar los precios históricos de las acciones para una fecha determinada.
- En el directorio
financial_agent, crea un archivo nuevo llamadoagent.py. Ejecuta el siguiente comando en la terminal:cloudshell edit agent.py - Agrega el siguiente código de Python a
agent.py. Este código importa dependencias y define la funciónget_stock_price.from datetime import datetime import os import logging import google.cloud.logging from google.adk.tools import VertexAiSearchTool from google.adk.tools.agent_tool import AgentTool from google.adk.agents import LlmAgent import pandas as pd def get_stock_price(date: str) -> dict: """Gets the closing stock price for a given date. Args: date: The date to get the stock price for, in YYYY-MM-DD format. Returns: A dictionary containing the closing price, or an error message if the date is not found or the format is incorrect. """ try: # Load the CSV file df = pd.read_csv('goog.csv') # Convert the 'Date' column to datetime objects df['Date'] = pd.to_datetime(df['Date']) # Convert the input string to a datetime object query_date = datetime.strptime(date, '%Y-%m-%d') # Find the row for the given date row = df[df['Date'] == query_date] if not row.empty: # Get the closing price close_price = row['Close'].iloc[0] return {"status": "success", "date": date, "closing_price": close_price} else: return {"status": "error", "message": f"No data found for date: {date}"} except FileNotFoundError: return {"status": "error", "message": "Stock data file (goog.csv) not found."} except Exception as e: return {"status": "error", "message": f"An error occurred: {str(e)}"}
Observa la cadena de documentación detallada de la función. Explica qué hace la función, sus parámetros (Args) y qué devuelve (Returns). El ADK usa esta cadena de documentación para enseñarle al agente cómo y cuándo usar esta herramienta.
10. Compila y ejecuta el agente de RAG
Ahora es el momento de ensamblar el agente. Combinarás la herramienta de Vertex AI Search para datos no estructurados con tu herramienta personalizada get_stock_price para datos estructurados.
- Agrega el siguiente código a tu archivo
agent.py. Este código importa las clases necesarias del ADK, crea instancias de las herramientas y define el agente.logging.basicConfig(level=logging.INFO) cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() # 1. Create the Vertex AI Search tool full_datastore_id = f"projects/{os.environ['GOOGLE_CLOUD_PROJECT']}/locations/global/collections/default_collection/dataStores/{os.environ['DATA_STORE_ID']}" vertex_ai_search_tool = VertexAiSearchTool( data_store_id=full_datastore_id ) # 2. Define the Search+Q&A agent # Since we cannot combine tools with other tools in a single agent, # we create a separate Search+Q&A agent which will be used as a tool by the main root agent. doc_qa_agent = LlmAgent( name="search_and_qna_agent", model="gemini-2.5-flash", tools=[vertex_ai_search_tool], instruction="""You are a helpful assistant that answers questions based on information found in the document store. Use the search tool to find relevant information before answering. If the answer isn't in the documents, say that you couldn't find the information. """, description="Answers questions using a specific Vertex AI Search datastore.", ) # 3. Define the root agent with 2 tools. root_agent = LlmAgent( name="financial_agent", model="gemini-2.5-flash", tools=[ AgentTool(doc_qa_agent), get_stock_price, ], instruction="""You are an Financial Analytics Agent that answers question about Alphabet stock prices (using get_stock_price tool) and historical performance based on the data in Vertex AI Search datastore (using doc_qa_agent tool).""" ) - Desde tu terminal, dentro del directorio
financial_agent, inicia la interfaz web del ADK para interactuar con tu agente:adk web ~ - Haz clic en el vínculo que se proporciona en el resultado de la terminal (por lo general,
http://127.0.0.1:8000) para abrir la IU de desarrollo del ADK en tu navegador.
11. Prueba el agente
Ahora puedes probar la capacidad de razonamiento de tu agente y su capacidad para usar herramientas para responder preguntas complejas.
- En la IU de desarrollo del ADK, asegúrate de que tu
financial_agentesté seleccionado en el menú desplegable. - Intenta hacer una pregunta que requiera información de las presentaciones ante la SEC (datos no estructurados). Ingresa la siguiente consulta en el chat:
What were the total revenues for the quarter ending on March 31, 2023?search_and_qna_agent, que usaVertexAiSearchToolpara encontrar la respuesta en los documentos financieros. - A continuación, haz una pregunta que requiera el uso de tu herramienta personalizada (datos estructurados). Ten en cuenta que el formato de fecha en la instrucción no tiene que coincidir exactamente con el formato que requiere la función. El LLM es lo suficientemente inteligente como para reformatearlo.
What was the closing stock price for Alphabet on July 10, 2025?get_stock_price. Puedes hacer clic en el ícono de herramientas en el chat para inspeccionar la llamada a función y su resultado. - Por último, haz una pregunta compleja que requiera que el agente use ambas herramientas y sintetice los resultados.
According to the 10-Q filing for the period ending March 31, 2023, what were the company's net cash provided by operating activities, and what was the stock's closing price on that date?- Primero, usará
VertexAiSearchToolpara encontrar la información del flujo de efectivo en las presentaciones ante la SEC. - Luego, reconocerá la necesidad del precio de las acciones y llamará a la función
get_stock_pricecon la fecha2023-03-31. - Por último, combinará ambas partes de la información en una sola respuesta integral.
- Primero, usará
- Cuando termines, puedes cerrar la pestaña del navegador y presionar
CTRL+Cen la terminal para detener el servidor del ADK.
12. Cómo elegir un servicio para tu tarea
Vertex AI Search no es el único servicio de búsqueda de vectores que puedes usar. También puedes usar un servicio administrado que automatice todo el flujo de la generación mejorada por recuperación: Vertex AI RAG Engine.
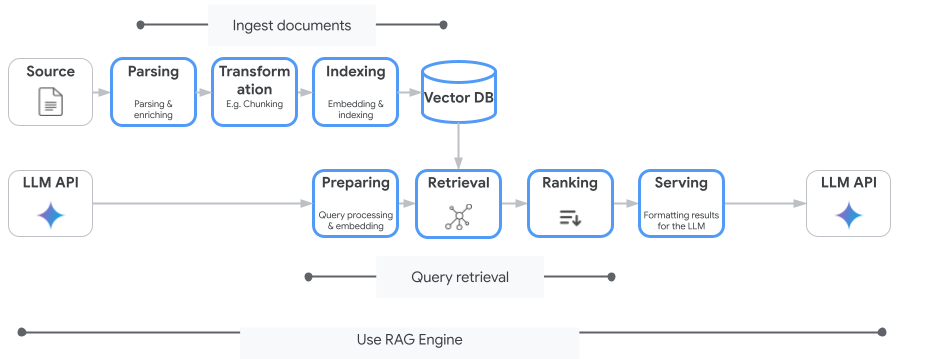
Maneja todo, desde la transferencia de documentos hasta la recuperación y la nueva clasificación. El motor de RAG admite varios almacenes de vectores, incluidos Pinecone y Weaviate.
También puedes alojar por tu cuenta muchas bases de datos vectoriales especializadas o aprovechar las capacidades de indexación de vectores en motores de bases de datos, como pgvector en el servicio de PostgreSQL (como AlloyDB o la Búsqueda de vectores de BigQuery).
Estos son algunos otros servicios que admiten la búsqueda de vectores:
- Cloud SQL para PostgreSQL
- Cloud SQL para MySQL
- Cloud Spanner
- Memorystore para Redis
- Firestore
- Bigtable
La orientación general para elegir un servicio en particular en Google Cloud es la siguiente:
- Si ya tienes una infraestructura de búsqueda vectorial autogestionada que funciona y está bien escalada, impleméntala en Google Kubernetes Engine, como Weaviate o PostgreSQL autogestionado.
- Si tus datos están en BigQuery, AlloyDB, Firestore o cualquier otra base de datos, considera usar sus capacidades de búsqueda de vectores si la búsqueda semántica se puede realizar a gran escala como parte de una consulta más grande en esa base de datos. Por ejemplo, si tienes descripciones o imágenes de productos en una tabla de BigQuery, agregar una columna de embedding de texto o imagen te permitirá usar la búsqueda de similitud a gran escala. Los índices de vectores con búsqueda de ScaNN admiten miles de millones de elementos en el índice.
- Si necesitas comenzar rápidamente con el mínimo esfuerzo y en una plataforma administrada, elige Vertex AI Search, una API de motor de búsqueda y recuperación completamente administrada, ideal para casos de uso empresariales complejos que requieren alta calidad lista para usar, escalabilidad y controles de acceso detallados. Simplifica la conexión a diversas fuentes de datos empresariales y permite realizar búsquedas en varias fuentes.
- Usa Vertex AI RAG Engine si buscas un punto óptimo para los desarrolladores que desean un equilibrio entre la facilidad de uso y la personalización. Permite crear prototipos y desarrollar rápidamente sin sacrificar la flexibilidad.
- Explora las arquitecturas de referencia para la generación mejorada por recuperación.
13. Conclusión
¡Felicitaciones! Creaste y probaste correctamente un agente de IA con Generación mejorada por recuperación. Aprendiste todo esto:
- Crea una base de conocimiento para documentos no estructurados con las potentes capacidades de búsqueda semántica de Vertex AI Search.
- Desarrolla una función de Python personalizada para que actúe como herramienta de recuperación de datos estructurados.
- Usa el Kit de desarrollo de agentes (ADK) para crear un agente con múltiples herramientas potenciado por Gemini.
- Crea un agente capaz de realizar razonamientos complejos de varios pasos para responder preguntas que requieren sintetizar información de múltiples fuentes.
En este lab, se demuestran los principios básicos de RAG con agentes, una arquitectura potente para crear aplicaciones basadas en IA inteligentes, precisas y con reconocimiento del contexto en Google Cloud.
Del prototipo a la producción
Este lab forma parte de la ruta de aprendizaje de IA lista para producción con Google Cloud.
- Explora el plan de estudios completo para cerrar la brecha entre el prototipo y la producción.
- Comparte tu progreso con el hashtag #ProductionReadyAI.