
۱. مقدمه
نمای کلی
هدف این آزمایشگاه یادگیری نحوه توسعه برنامههای کاربردی بازیابی عاملی-تولید افزوده (RAG) سرتاسری در گوگل کلود است. در این آزمایشگاه، شما یک عامل تحلیل مالی خواهید ساخت که میتواند با ترکیب اطلاعات از دو منبع مختلف به سوالات پاسخ دهد: اسناد بدون ساختار ( گزارشهای فصلی کمیسیون بورس و اوراق بهادار آمریکا (SEC) شرکت آلفابت - صورتهای مالی و جزئیات عملیاتی که هر شرکت سهامی عام در ایالات متحده به کمیسیون بورس و اوراق بهادار ارائه میدهد) و دادههای ساختاریافته (قیمتهای تاریخی سهام).
شما از Vertex AI Search برای ساخت یک موتور جستجوی معنایی قدرتمند برای گزارشهای مالی بدون ساختار استفاده خواهید کرد. برای دادههای ساختاریافته، یک ابزار پایتون سفارشی ایجاد خواهید کرد. در نهایت، از کیت توسعه عامل (ADK) برای ساخت یک عامل هوشمند استفاده خواهید کرد که میتواند در مورد پرسوجوی کاربر استدلال کند، تصمیم بگیرد از کدام ابزار استفاده کند و اطلاعات را به یک پاسخ منسجم تبدیل کند.
کاری که انجام خواهید داد
- یک مخزن داده Vertex AI Search برای جستجوی معنایی روی اسناد خصوصی راهاندازی کنید.
- یک تابع پایتون سفارشی به عنوان ابزاری برای یک عامل ایجاد کنید.
- از کیت توسعه عامل (ADK) برای ساخت یک عامل چند ابزاری استفاده کنید.
- بازیابی از منابع داده بدون ساختار و ساختار یافته را برای پاسخ به سوالات پیچیده ترکیب کنید.
- عاملی را که قابلیتهای استدلال را نشان میدهد، آزمایش و با آن تعامل کنید.
آنچه یاد خواهید گرفت
در این آزمایشگاه، شما یاد خواهید گرفت:
- مفاهیم اصلی تولید افزوده بازیابی (RAG) و RAG عاملی.
- نحوه پیادهسازی جستجوی معنایی روی اسناد با استفاده از Vertex AI Search.
- چگونه با ایجاد ابزارهای سفارشی، دادههای ساختاریافته را در اختیار یک عامل قرار دهیم.
- نحوه ساخت و هماهنگسازی یک عامل چند ابزاری با کیت توسعه عامل (ADK).
- چگونه عاملها از استدلال و برنامهریزی برای پاسخ به سوالات پیچیده با استفاده از منابع داده متعدد استفاده میکنند.
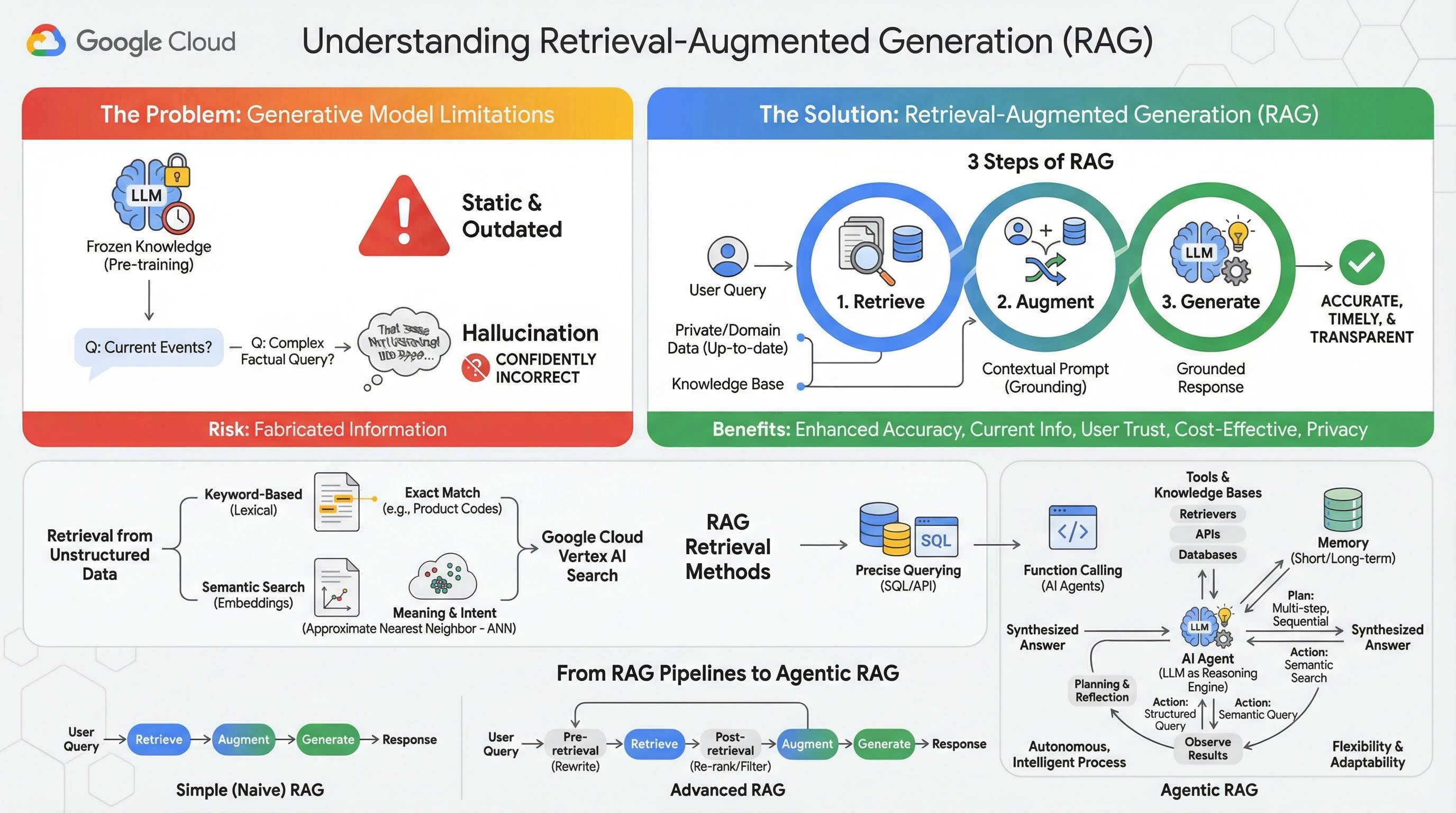
۲. درک بازیابی-تولید افزوده
مدلهای مولد بزرگ (Large Language Models یا به اختصار LLM، مدلهای زبان-بینایی و غیره) فوقالعاده قدرتمند هستند، اما محدودیتهای ذاتی دارند. دانش آنها در زمان پیشآموزش ثابت میماند و آن را ایستا و فوراً منسوخ میکند. حتی پس از تنظیم دقیق ، دانش مدل خیلی جدیدتر نمیشود، زیرا این هدف مراحل پس از آموزش نیست.
نحوه آموزش مدلهای زبان بزرگ، به ویژه مدلهای «متفکر»، به این صورت است که آنها برای ارائه پاسخی «پاداش» میگیرند، حتی اگر خود مدل اطلاعات واقعی که از چنین پاسخی پشتیبانی کند، نداشته باشد. این زمانی است که میگویند یک مدل «توهم» میکند - با اطمینان اطلاعات به ظاهر قابل قبول اما از نظر واقعی نادرست تولید میکند.
تولید افزوده بازیابی، یک الگوی معماری قدرتمند است که برای حل دقیق این مشکلات طراحی شده است. این یک چارچوب معماری است که قابلیتهای مدلهای زبان بزرگ را با اتصال آنها به منابع دانش خارجی و معتبر در زمان واقعی افزایش میدهد. یک LLM در یک سیستم RAG به جای تکیه صرف بر دانش ایستا و از پیش آموزش دیده خود، ابتدا اطلاعات مرتبط با پرس و جوی کاربر را بازیابی میکند و سپس از آن اطلاعات برای تولید پاسخی دقیقتر، به موقعتر و آگاه از متن استفاده میکند.
این رویکرد مستقیماً به مهمترین نقاط ضعف مدلهای مولد میپردازد: دانش آنها در یک نقطه زمانی ثابت است و مستعد تولید اطلاعات نادرست یا "توهم" هستند. RAG به طور مؤثر یک "آزمون کتاب باز" به LLM میدهد، که در آن "کتاب" دادههای خصوصی، خاص حوزه و بهروز شماست. این فرآیند ارائه زمینه واقعی به LLM به عنوان " زمینهسازی " شناخته میشود.
۳ مرحله RAG
فرآیند استاندارد تولید افزوده بازیابی را میتوان به سه مرحله ساده تقسیم کرد:
- بازیابی : وقتی کاربری درخواستی را ارسال میکند، سیستم ابتدا یک پایگاه دانش خارجی (مانند مخزن اسناد، پایگاه داده یا وبسایت) را جستجو میکند تا اطلاعات مرتبط با درخواست را پیدا کند.
- تقویت : اطلاعات بازیابی شده سپس با پرس و جوی اصلی کاربر در یک اعلان گسترش یافته ترکیب میشود. این تکنیک گاهی اوقات "پر کردن اعلان" نامیده میشود، زیرا اعلان را با زمینه واقعی غنی میکند.
- تولید : این دستور افزوده به LLM داده میشود، که سپس پاسخی تولید میکند. از آنجا که دادههای مرتبط و واقعی به مدل ارائه شده است، خروجی آن "مبتنی بر واقعیت" است و احتمال نادرست یا قدیمی بودن آن بسیار کمتر است.
مزایای RAG
معرفی چارچوب RAG برای ساخت برنامههای کاربردی و قابل اعتماد هوش مصنوعی، تحولآفرین بوده است. مزایای کلیدی آن عبارتند از:
- افزایش دقت و کاهش توهمات : با پایهگذاری پاسخها بر اساس حقایق خارجی و قابل اثبات، RAG به طور چشمگیری خطر جعل اطلاعات توسط LLM را کاهش میدهد.
- دسترسی به اطلاعات جاری : سیستمهای RAG میتوانند به پایگاههای دانش دائماً بهروز شده متصل شوند و به آنها اجازه میدهند تا بر اساس آخرین اطلاعات پاسخهایی ارائه دهند، چیزی که برای یک LLM آموزشدیده به صورت ایستا غیرممکن است.
- افزایش اعتماد و شفافیت کاربر : از آنجا که پاسخ LLM بر اساس اسناد بازیابی شده است، سیستم میتواند استنادها و پیوندهایی به منابع خود ارائه دهد. این امر به کاربران اجازه میدهد تا اطلاعات را خودشان تأیید کنند و اعتماد به برنامه را افزایش دهند.
- مقرون به صرفه بودن : تنظیم دقیق یا آموزش مجدد مداوم یک LLM با دادههای جدید از نظر محاسباتی و مالی پرهزینه است. با RAG، بهروزرسانی دانش مدل به سادگی بهروزرسانی منبع داده خارجی است که بسیار کارآمدتر است.
- تخصص دامنه و حریم خصوصی : RAG به افراد و سازمانها اجازه میدهد تا دادههای خصوصی و اختصاصی خود را در زمان پرسوجو در دسترس یک LLM قرار دهند، بدون اینکه نیازی به گنجاندن آن دادههای حساس در مجموعه آموزشی مدل باشد. این امر امکان ایجاد برنامههای قدرتمند و مختص دامنه را فراهم میکند و در عین حال حریم خصوصی و امنیت دادهها را حفظ میکند.
بازیابی
مرحله «بازیابی» قلب هر سیستم RAG است. کیفیت و مرتبط بودن اطلاعات بازیابی شده، مستقیماً کیفیت و مرتبط بودن پاسخ نهایی تولید شده را تعیین میکند. یک برنامه RAG مؤثر اغلب نیاز به بازیابی اطلاعات از انواع مختلف منابع داده با استفاده از تکنیکهای متنوع دارد. روشهای بازیابی اولیه در سه دسته قرار میگیرند: مبتنی بر کلمه کلیدی، معنایی و ساختاریافته.
بازیابی از دادههای بدون ساختار
از نظر تاریخی، بازیابی دادههای بدون ساختار نام دیگری برای جستجوی سنتی است. این روش تحولات متعددی را پشت سر گذاشته است و شما میتوانید از هر دو رویکرد اصلی بهرهمند شوید.
جستجوی معنایی کارآمدترین تکنیکی است که میتوانید در مقیاس بزرگ در Google Cloud با عملکرد پیشرفته و درجه بالایی از کنترل اجرا کنید.
- جستجوی مبتنی بر کلمات کلیدی (لغوی) : این رویکرد سنتی جستجو است که به اولین سیستمهای بازیابی اطلاعات در دهه ۱۹۷۰ برمیگردد. جستجوی لغوی با تطبیق کلمات تحتاللفظی (یا "توکنها") در عبارت جستجوی کاربر با کلمات مشابه در اسناد موجود در یک پایگاه دانش کار میکند. این روش برای عبارات جستجویی که دقت در اصطلاحات خاص، مانند کدهای محصول، بندهای قانونی یا نامهای منحصر به فرد، بسیار مهم است، بسیار مؤثر است.
- جستجوی معنایی : جستجوی معنایی یا "جستجو با معنا"، رویکردی مدرنتر است که هدف آن درک قصد کاربر و معنای زمینهای عبارت جستجو شده توسط اوست، نه فقط کلمات کلیدی تحتاللفظی. جستجوی معنایی مدرن با تعبیه کردن - یک تکنیک یادگیری ماشینی که دادههای پیچیده و با ابعاد بالا را در یک فضای برداری با ابعاد پایینتر از بردارهای عددی نگاشت میکند - پشتیبانی میشود. این بردارها به گونهای طراحی شدهاند که متون با معانی مشابه در فضای برداری نزدیک به یکدیگر قرار گیرند. جستجوی "بهترین نژادهای سگ برای خانوادهها کدامند؟" به یک بردار تبدیل میشود و سپس سیستم به دنبال بردارهای سندی میگردد که "نزدیکترین همسایههای" آن در آن فضا هستند. این به سیستم اجازه میدهد اسنادی را پیدا کند که در مورد "گلدن رتریور" یا "سگهای دوستداشتنی" صحبت میکنند، حتی اگر دقیقاً کلمه "سگ" را نداشته باشند. این جستجوی با ابعاد بالا توسط الگوریتمهای نزدیکترین همسایه تقریبی (ANN) کارآمد میشود. به جای مقایسه بردار جستجو با هر بردار سند (که برای مجموعه دادههای بزرگ بسیار کند خواهد بود)، الگوریتمهای ANN از ساختارهای نمایهسازی هوشمندانه برای یافتن سریع بردارهایی که احتمالاً نزدیکترین هستند استفاده میکنند.
بازیابی از دادههای ساختاریافته
همه دانش حیاتی در اسناد بدون ساختار ذخیره نمیشوند. اغلب، دقیقترین و ارزشمندترین اطلاعات در قالبهای ساختاریافتهای مانند پایگاههای داده رابطهای، پایگاههای داده NoSQL یا نوعی API مانند API REST برای دادههای آب و هوا یا قیمت سهام قرار دارند.
بازیابی از دادههای ساختاریافته معمولاً مستقیمتر و دقیقتر از جستجوی متن بدون ساختار است. به جای جستجوی شباهت معنایی، میتوان به مدلهای زبانی این امکان را داد که یک پرسوجوی دقیق، مانند یک پرسوجوی SQL در یک پایگاه داده یا یک فراخوانی API به یک API آب و هوا برای مکان و تاریخ خاص، را فرموله و اجرا کنند.
این روش که از طریق فراخوانی تابع ، همان تکنیکی که عاملهای هوش مصنوعی را قدرتمند میکند، پیادهسازی شده است، مدلهای زبانی را قادر میسازد تا با کد اجرایی و سیستمهای خارجی به روشی ساختاری قطعی تعامل داشته باشند.
۳. از خطوط لوله RAG تا Agentic RAG
همانطور که مفهوم RAG تکامل یافته است، معماریهای پیادهسازی آن نیز تکامل یافتهاند. آنچه که به عنوان یک خط لوله ساده و خطی آغاز شد، به یک سیستم پویا و هوشمند تبدیل شده است که توسط عوامل هوش مصنوعی هماهنگ شده است.
- RAG ساده (یا ساده): این معماری بنیادی است که تاکنون در مورد آن بحث کردهایم: یک فرآیند خطی و سه مرحلهای بازیابی، افزایش و تولید. این معماری واکنشی است؛ برای هر پرسوجو از یک مسیر ثابت پیروی میکند و برای وظایف پرسش و پاسخ ساده بسیار مؤثر است.
- RAG پیشرفته: این نشان دهنده تکاملی است که در آن مراحل اضافی به خط لوله اضافه میشود تا کیفیت متن بازیابی شده را بهبود بخشد. این پیشرفتها میتوانند قبل یا بعد از مرحله بازیابی رخ دهند.
- پیش بازیابی: میتوان از تکنیکهایی مانند بازنویسی یا بسط پرسوجو استفاده کرد. سیستم ممکن است پرسوجوی اولیه را تجزیه و تحلیل کرده و آن را به گونهای بازنویسی کند که برای سیستم بازیابی مؤثرتر باشد.
- پس از بازیابی: پس از بازیابی مجموعه اولیه اسناد، میتوان از یک مدل رتبهبندی مجدد برای امتیازدهی به اسناد از نظر مرتبط بودن و قرار دادن بهترینها در صدر استفاده کرد. این امر به ویژه در جستجوی ترکیبی اهمیت دارد. یکی دیگر از مراحل پس از بازیابی، فیلتر کردن یا فشردهسازی متن بازیابی شده است تا اطمینان حاصل شود که فقط برجستهترین اطلاعات به LLM منتقل میشود.
- Agentic RAG: این لبه تیز معماری RAG است که نشاندهنده تغییر الگو از یک خط لوله ثابت به یک فرآیند هوشمند و مستقل است. در یک سیستم Agentic RAG، کل گردش کار توسط یک یا چند عامل هوش مصنوعی مدیریت میشود که میتوانند استدلال کنند، برنامهریزی کنند و به صورت پویا اقدامات خود را انتخاب کنند.
برای درک Agentic RAG، ابتدا باید فهمید که یک عامل هوش مصنوعی چیست. یک عامل چیزی بیش از یک LLM است. این سیستمی با چندین مؤلفه کلیدی است:
- یک LLM به عنوان موتور استدلال: عامل از یک LLM قدرتمند مانند Gemini نه تنها برای تولید متن، بلکه به عنوان "مغز" مرکزی خود برای برنامهریزی، تصمیمگیری و تجزیه وظایف پیچیده استفاده میکند.
- مجموعهای از ابزارها: به یک عامل، دسترسی به مجموعهای از توابع داده میشود که میتواند برای دستیابی به اهداف خود از آنها استفاده کند. این ابزارها میتوانند هر چیزی باشند: یک ماشین حساب، یک API جستجوی وب، تابعی برای ارسال ایمیل یا از همه مهمتر برای این آزمایشگاه - بازیابیکنندههایی برای پایگاههای دانش مختلف ما .
- حافظه: عاملها را میتوان با حافظه کوتاهمدت (برای به خاطر سپردن زمینه مکالمه فعلی) و حافظه بلندمدت (برای یادآوری اطلاعات از تعاملات گذشته) طراحی کرد که امکان تجربیات شخصیتر و منسجمتری را فراهم میکند.
- برنامهریزی و تأمل: پیشرفتهترین عاملها الگوهای استدلال پیچیدهای را از خود نشان میدهند. آنها میتوانند یک هدف پیچیده را دریافت کنند و یک برنامه چند مرحلهای برای دستیابی به آن ایجاد کنند. سپس میتوانند این برنامه را اجرا کنند و حتی در مورد نتایج اقدامات خود تأمل کنند ، خطاها را شناسایی کنند و رویکرد خود را برای بهبود نتیجه نهایی اصلاح کنند.
Agentic RAG یک تغییر دهندهی بازی است زیرا لایهای از استقلال و هوشمندی را معرفی میکند که خطوط لولهی ایستا فاقد آن هستند.
- انعطافپذیری و سازگاری: یک عامل به یک مسیر بازیابی واحد محدود نمیشود. با دریافت یک پرسوجوی کاربر، میتواند در مورد بهترین منبع اطلاعات استدلال کند. ممکن است ابتدا تصمیم بگیرد که پایگاه داده ساختاریافته را پرسوجو کند، سپس یک جستجوی معنایی روی اسناد بدون ساختار انجام دهد و اگر هنوز نمیتواند پاسخی پیدا کند، از یک ابزار جستجوی گوگل برای جستجو در وب عمومی استفاده کند، همه اینها در چارچوب یک درخواست کاربر واحد.
- استدلال پیچیده و چند مرحلهای: این معماری در مدیریت پرسوجوهای پیچیدهای که نیاز به مراحل بازیابی و پردازش چندگانه و متوالی دارند، عالی عمل میکند.
این عبارت را در نظر بگیرید: «۳ فیلم علمی تخیلی برتر به کارگردانی کریستوفر نولان را پیدا کنید و برای هر کدام، خلاصهای مختصر از طرح داستان ارائه دهید.» یک خط لوله ساده RAG با شکست مواجه میشود.
با این حال، یک نماینده میتواند این را به صورت زیر تجزیه و تحلیل کند:
- نقشه: اول، باید فیلمها را پیدا کنم. سپس، برای هر فیلم، باید طرح داستان آن را پیدا کنم.
- اقدام ۱: از ابزار دادههای ساختاریافته برای جستجوی یک پایگاه داده فیلم برای فیلمهای علمی تخیلی نولان استفاده کنید: ۳ فیلم برتر، مرتب شده بر اساس رتبهبندی نزولی.
- مشاهده ۱: این ابزار فیلمهای «آغاز»، «میانستارهای» و «تنت» را برمیگرداند.
- اقدام ۲: از ابزار دادههای بدون ساختار (جستجوی معنایی) برای یافتن طرح داستان «آغاز» استفاده کنید.
- مشاهده ۲: نمودار بازیابی میشود.
- اقدام ۳: برای «میانستارهای» تکرار کنید.
- اقدام ۴: برای «تنت» تکرار کنید.
- ترکیب نهایی: تمام اطلاعات بازیابی شده را در یک پاسخ واحد و منسجم برای کاربر ترکیب کنید.
۴. راهاندازی پروژه
حساب گوگل
اگر از قبل حساب گوگل شخصی ندارید، باید یک حساب گوگل ایجاد کنید .
به جای حساب کاری یا تحصیلی از حساب شخصی استفاده کنید .
ورود به کنسول ابری گوگل
با استفاده از یک حساب کاربری شخصی گوگل، وارد کنسول ابری گوگل شوید.
فعال کردن صورتحساب
استفاده از حساب پرداخت آزمایشی (اختیاری)
برای اجرای این کارگاه، به یک حساب صورتحساب با مقداری اعتبار نیاز دارید. برای شروع از اعتبارهای موجود در بنر بالای این codelab استفاده کنید. اگر از قبل به یک حساب صورتحساب متصل هستید، میتوانید از این مرحله صرف نظر کنید.
یک حساب پرداخت شخصی تنظیم کنید
اگر صورتحساب را با استفاده از اعتبارهای Google Cloud تنظیم کردهاید، میتوانید از این مرحله صرف نظر کنید.
برای تنظیم یک حساب پرداخت شخصی، به اینجا بروید تا پرداخت را در کنسول ابری فعال کنید .
برخی نکات:
- تکمیل این آزمایشگاه باید کمتر از ۱ دلار آمریکا از طریق منابع ابری هزینه داشته باشد.
- شما میتوانید مراحل انتهای این آزمایش را برای حذف منابع دنبال کنید تا از هزینههای بیشتر جلوگیری شود.
- کاربران جدید واجد شرایط استفاده از دوره آزمایشی رایگان ۳۰۰ دلاری هستند.
ایجاد پروژه (اختیاری)
اگر پروژه فعلی ندارید که بخواهید برای این آزمایشگاه استفاده کنید، اینجا یک پروژه جدید ایجاد کنید .
۵. ویرایشگر Cloud Shell را باز کنید
- برای دسترسی مستقیم به ویرایشگر Cloud Shell ، روی این لینک کلیک کنید.
- اگر امروز در هر مرحلهای از شما خواسته شد که مجوز دهید، برای ادامه روی تأیید کلیک کنید.
- اگر ترمینال در پایین صفحه نمایش داده نشد، آن را باز کنید:
- روی مشاهده کلیک کنید
- روی ترمینال کلیک کنید
- در ترمینال، پروژه خود را با این دستور تنظیم کنید:
gcloud config set project [PROJECT_ID]- مثال:
gcloud config set project lab-project-id-example - اگر نمیتوانید شناسه پروژه خود را به خاطر بیاورید، میتوانید تمام شناسههای پروژه خود را با استفاده از دستور زیر فهرست کنید:
gcloud projects list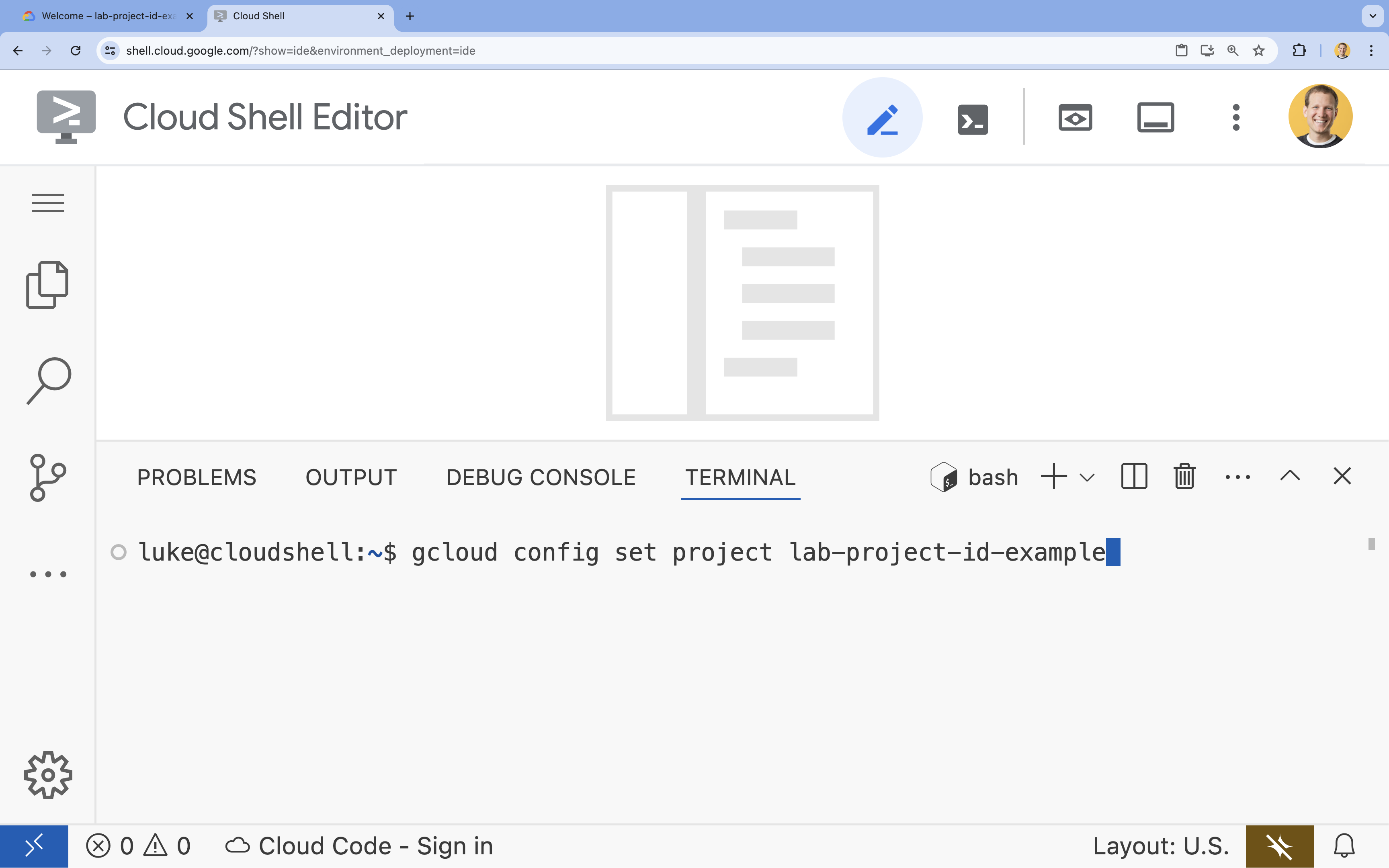
- مثال:
- شما باید این پیام را ببینید:
Updated property [core/project].
۶. فعال کردن APIها
برای استفاده از کیت توسعه عامل و جستجوی هوش مصنوعی Vertex، باید APIهای لازم را در پروژه Google Cloud خود فعال کنید.
- در ترمینال، APIها را فعال کنید:
gcloud services enable \ aiplatform.googleapis.com \ discoveryengine.googleapis.com
معرفی API ها
- رابط برنامهنویسی کاربردی هوش مصنوعی ورتکس (
aiplatform.googleapis.com) به عامل این امکان را میدهد که برای استدلال و تولید، با مدلهای Gemini ارتباط برقرار کند. - رابط برنامهنویسی کاربردی موتور اکتشاف (
discoveryengine.googleapis.com) به Vertex AI Search قدرت میدهد و به شما امکان میدهد انبارهای داده ایجاد کنید و جستجوهای معنایی را روی اسناد بدون ساختار خود انجام دهید.
۷. محیط را آماده کنید
قبل از شروع کدنویسی عامل هوش مصنوعی، باید محیط توسعه خود را آماده کنید، کتابخانههای لازم را نصب کنید و فایلهای داده مورد نیاز را ایجاد کنید.
ایجاد یک محیط مجازی و نصب وابستگیها
- یک دایرکتوری برای عامل خود ایجاد کنید و به آن بروید. کد زیر را در ترمینال اجرا کنید:
mkdir financial_agent cd financial_agent - ایجاد یک محیط مجازی:
uv venv --python 3.12 - فعال کردن محیط مجازی:
source .venv/bin/activate - کیت توسعه عامل (ADK) و پانداها را نصب کنید.
uv pip install google-adk pandas
دادههای قیمت سهام را ایجاد کنید
از آنجایی که این آزمایشگاه به دادههای تاریخی خاصی برای نشان دادن توانایی عامل در استفاده از ابزارهای ساختاریافته نیاز دارد، شما یک فایل CSV حاوی این دادهها ایجاد خواهید کرد.
- در پوشه
financial_agent، با اجرای دستور زیر در ترمینال ، فایلgoog.csvرا ایجاد کنید:cat <<EOF > goog.csv Date,Open,High,Low,Close,Adj Close,Volume 2023-01-03,89.830002,91.550003,89.019997,89.699997,89.699997,20738500 2023-03-31,101.440002,103.889999,101.040001,103.730003,103.730003,36823200 2023-06-30,120.870003,122.029999,120.300003,120.970001,120.970001,23824700 2023-09-29,134.080002,134.550003,131.320007,131.850006,131.850006,21124200 2025-07-10,185.000000,188.000000,184.500000,186.500000,186.500000,25000000 EOF
پیکربندی متغیرهای محیطی
- در پوشه
financial_agent، یک فایل.envبرای پیکربندی متغیرهای محیطی عامل خود ایجاد کنید. این به ADK میگوید که از کدام پروژه، مکان و مدل استفاده کند. کد زیر را در ترمینال اجرا کنید:# Create the .env file using the captured variables cat << EOF > .env GOOGLE_GENAI_USE_VERTEXAI=TRUE GOOGLE_CLOUD_PROJECT="${GOOGLE_CLOUD_PROJECT}" GOOGLE_CLOUD_LOCATION="us-central1" EOF
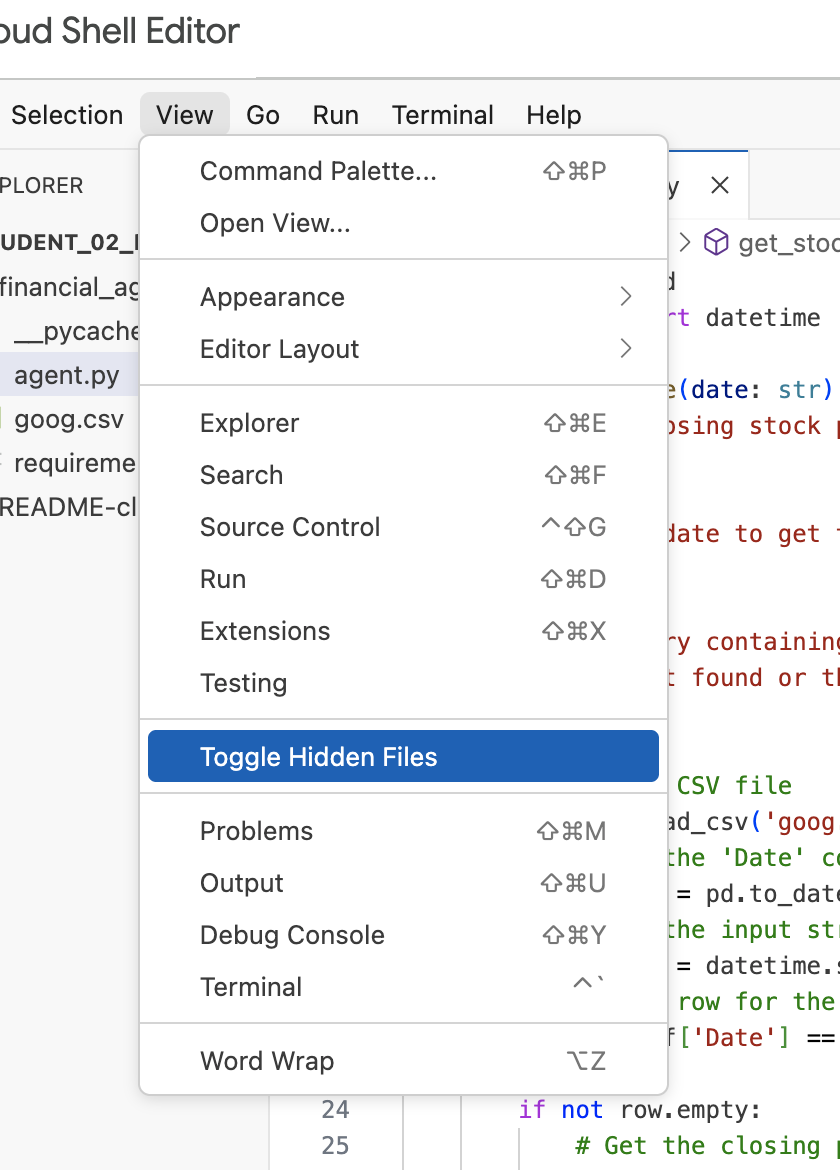
توجه: اگر بعداً در ادامهی تمرین، نیاز به تغییر فایل .env داشتید اما آن را در دایرکتوری financial_agent ندیدید، سعی کنید قابلیت مشاهدهی فایلهای مخفی را در ویرایشگر Cloud Shell با استفاده از گزینهی منوی «مشاهده / تغییر فایلهای مخفی» فعال یا غیرفعال کنید.
۸. یک مخزن داده جستجوی هوش مصنوعی Vertex ایجاد کنید
برای اینکه نماینده بتواند به سوالات مربوط به گزارشهای مالی آلفابت پاسخ دهد، شما یک مخزن داده Vertex AI Search ایجاد خواهید کرد که شامل پروندههای عمومی SEC آنها باشد.
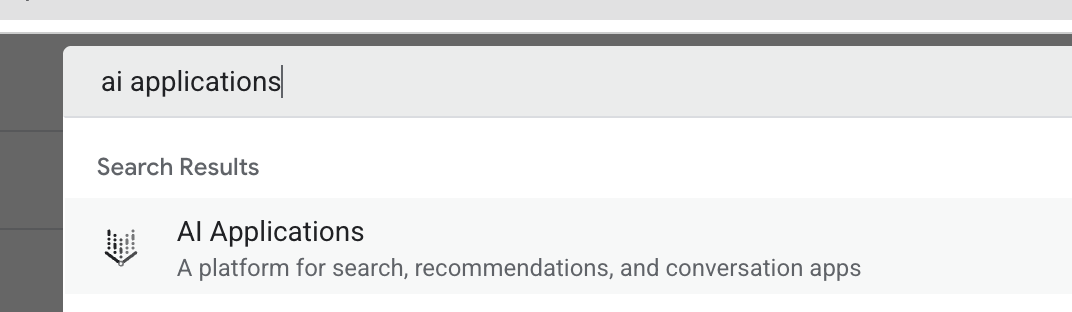
- در یک تب جدید مرورگر، کنسول ابری (console.cloud.google.com) را باز کنید، با استفاده از نوار جستجو در بالا، به برنامههای هوش مصنوعی بروید.
- در صورت درخواست، کادر انتخاب شرایط و ضوابط را انتخاب کنید و روی ادامه و فعال کردن API کلیک کنید.
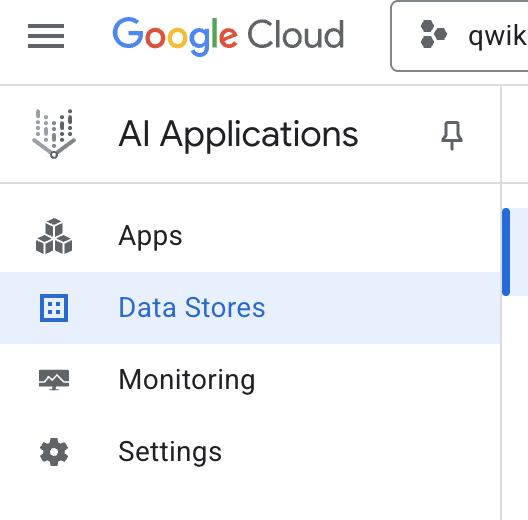
- از منوی ناوبری سمت چپ، گزینه «ذخیره دادهها» را انتخاب کنید.
- Click + Create Data Store .
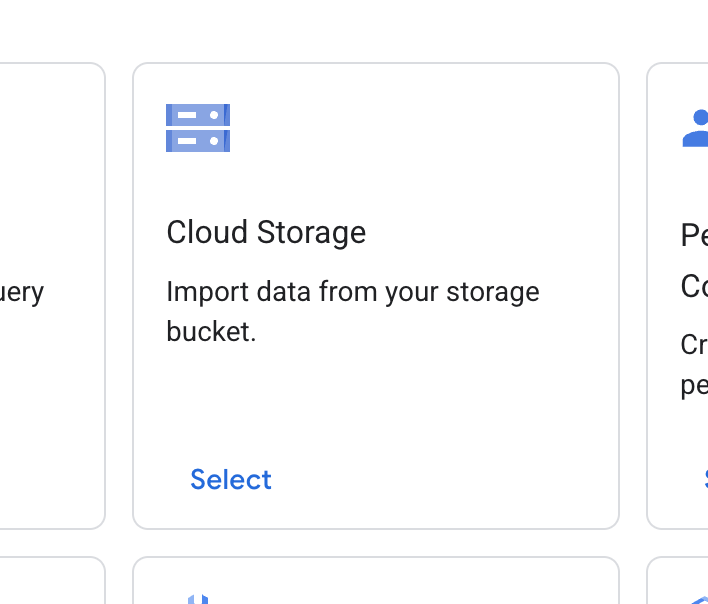
- کارت فضای ذخیرهسازی ابری را پیدا کنید و روی «انتخاب» کلیک کنید.
- برای منبع داده، اسناد بدون ساختار (Unstructured documents) را انتخاب کنید.

- برای منبع واردات (یک پوشه یا فایلی را که میخواهید وارد کنید انتخاب کنید)، مسیر ذخیرهسازی ابری گوگل را وارد کنید
cloud-samples-data/gen-app-builder/search/alphabet-sec-filings. - روی ادامه کلیک کنید.
- موقعیت مکانی را روی حالت جهانی (global) نگه دارید.
- برای نام فروشگاه داده ، وارد کنید
alphabet-sec-filings - بخش گزینههای پردازش سند را گسترش دهید.

- در لیست کشویی «تجزیهکنندهی پیشفرض سند» ، «تجزیهکنندهی طرحبندی» را انتخاب کنید.
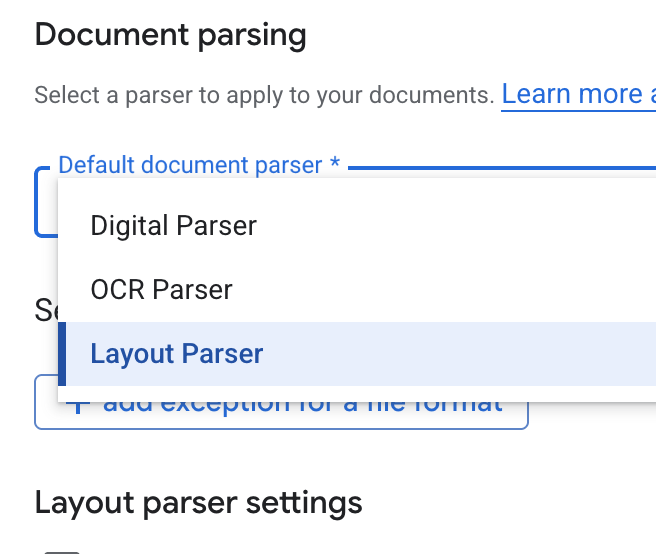
- در گزینههای تنظیمات تجزیهگر طرحبندی ، گزینههای «فعال کردن حاشیهنویسی جدول» و «فعال کردن حاشیهنویسی تصویر» را انتخاب کنید.
- روی ادامه کلیک کنید.
- قیمتگذاری عمومی را به عنوان مدل قیمتگذاری (یک مدل پرداخت به ازای استفاده و مبتنی بر مصرف) انتخاب کنید و روی ایجاد کلیک کنید.
- فروشگاه داده شما شروع به وارد کردن اسناد خواهد کرد.
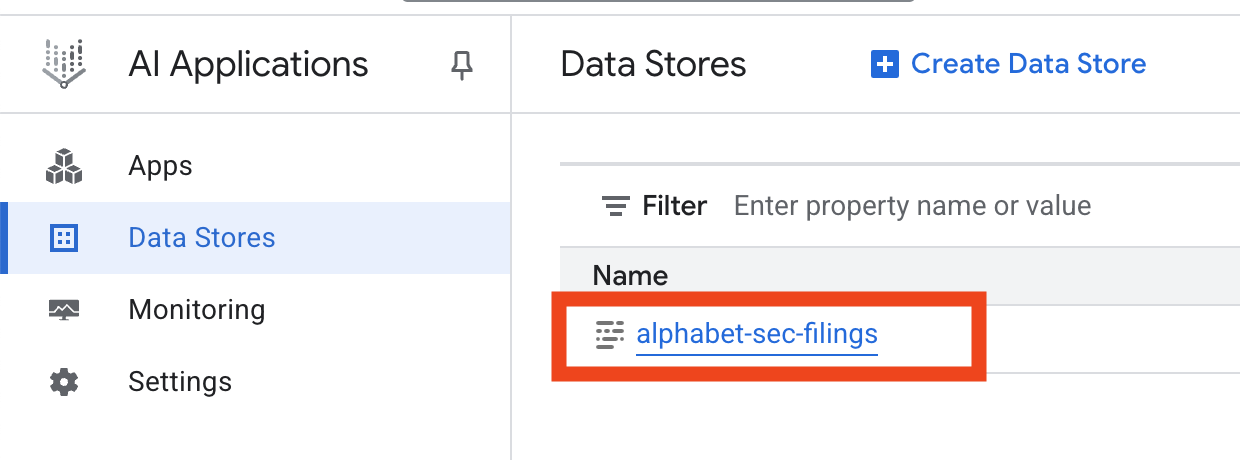
- روی نام فروشگاه داده کلیک کنید و شناسه (ID) آن را از جدول فروشگاههای داده کپی کنید . در مرحله بعدی به آن نیاز خواهید داشت.
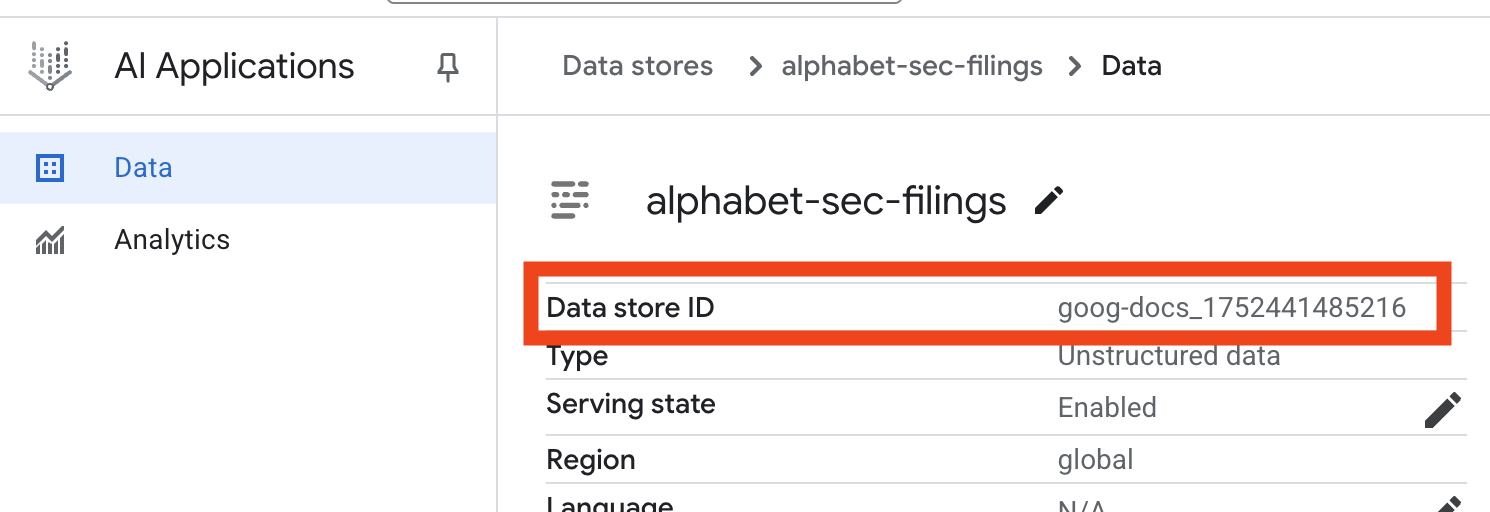
- فایل
.envرا در ویرایشگر Cloud Shell باز کنید و شناسهی انبار داده را به صورتDATA_STORE_ID="YOUR_DATA_STORE_ID"اضافه کنید (به جایYOUR_DATA_STORE_ID، شناسهی واقعی مرحلهی قبل را وارد کنید). توجه: وارد کردن، تجزیه و نمایهسازی دادهها در انبار داده چند دقیقه طول میکشد. برای بررسی فرآیند، روی نام انبار داده کلیک کنید تا ویژگیهای آن باز شود، سپس برگهی فعالیت را باز کنید. صبر کنید تا وضعیت به "وارد کردن تکمیل شد" تغییر کند.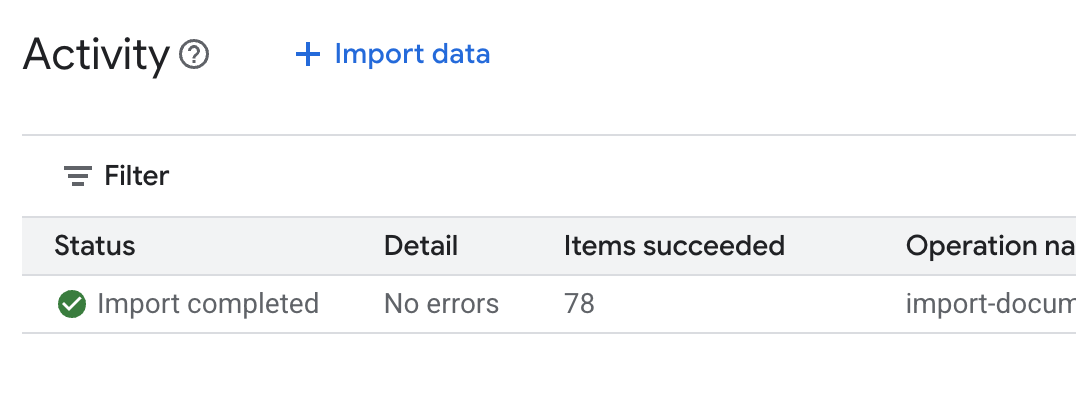
۹. یک ابزار سفارشی برای دادههای ساختاریافته ایجاد کنید
در مرحله بعد، یک تابع پایتون ایجاد خواهید کرد که به عنوان ابزاری برای عامل عمل میکند. این ابزار فایل goog.csv را میخواند تا قیمتهای تاریخی سهام را برای یک تاریخ معین بازیابی کند.
- در پوشه
financial_agentخود، یک فایل جدید با نامagent.pyایجاد کنید. دستور زیر را در ترمینال اجرا کنید:cloudshell edit agent.py - کد پایتون زیر را به
agent.pyاضافه کنید. این کد وابستگیها را وارد میکند و تابعget_stock_priceرا تعریف میکند.from datetime import datetime import os import logging import google.cloud.logging from google.adk.tools import VertexAiSearchTool from google.adk.tools.agent_tool import AgentTool from google.adk.agents import LlmAgent import pandas as pd def get_stock_price(date: str) -> dict: """Gets the closing stock price for a given date. Args: date: The date to get the stock price for, in YYYY-MM-DD format. Returns: A dictionary containing the closing price, or an error message if the date is not found or the format is incorrect. """ try: # Load the CSV file df = pd.read_csv('goog.csv') # Convert the 'Date' column to datetime objects df['Date'] = pd.to_datetime(df['Date']) # Convert the input string to a datetime object query_date = datetime.strptime(date, '%Y-%m-%d') # Find the row for the given date row = df[df['Date'] == query_date] if not row.empty: # Get the closing price close_price = row['Close'].iloc[0] return {"status": "success", "date": date, "closing_price": close_price} else: return {"status": "error", "message": f"No data found for date: {date}"} except FileNotFoundError: return {"status": "error", "message": "Stock data file (goog.csv) not found."} except Exception as e: return {"status": "error", "message": f"An error occurred: {str(e)}"}
به رشتهی مستندات دقیق تابع توجه کنید. این رشته توضیح میدهد که تابع چه کاری انجام میدهد، پارامترهای آن ( Args ) چیست و چه چیزی را برمیگرداند ( Returns ). ADK از این رشتهی مستندات برای آموزش نحوه و زمان استفاده از این ابزار به عامل استفاده میکند.
۱۰. عامل RAG را بسازید و اجرا کنید
حالا وقت آن رسیده که عامل را سرهم کنید. شما ابزار Vertex AI Search را برای دادههای بدون ساختار با ابزار سفارشی get_stock_price خود برای دادههای ساختاریافته ترکیب خواهید کرد.
- کد زیر را به فایل
agent.pyخود اضافه کنید. این کد کلاسهای ADK لازم را وارد میکند، نمونههایی از ابزارها ایجاد میکند و عامل را تعریف میکند.logging.basicConfig(level=logging.INFO) cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() # 1. Create the Vertex AI Search tool full_datastore_id = f"projects/{os.environ['GOOGLE_CLOUD_PROJECT']}/locations/global/collections/default_collection/dataStores/{os.environ['DATA_STORE_ID']}" vertex_ai_search_tool = VertexAiSearchTool( data_store_id=full_datastore_id ) # 2. Define the Search+Q&A agent # Since we cannot combine tools with other tools in a single agent, # we create a separate Search+Q&A agent which will be used as a tool by the main root agent. doc_qa_agent = LlmAgent( name="search_and_qna_agent", model="gemini-2.5-flash", tools=[vertex_ai_search_tool], instruction="""You are a helpful assistant that answers questions based on information found in the document store. Use the search tool to find relevant information before answering. If the answer isn't in the documents, say that you couldn't find the information. """, description="Answers questions using a specific Vertex AI Search datastore.", ) # 3. Define the root agent with 2 tools. root_agent = LlmAgent( name="financial_agent", model="gemini-2.5-flash", tools=[ AgentTool(doc_qa_agent), get_stock_price, ], instruction="""You are an Financial Analytics Agent that answers question about Alphabet stock prices (using get_stock_price tool) and historical performance based on the data in Vertex AI Search datastore (using doc_qa_agent tool).""" ) - از ترمینال خود، داخل دایرکتوری
financial_agent، رابط وب ADK را برای تعامل با نماینده خود اجرا کنید:adk web ~ - روی لینک ارائه شده در خروجی ترمینال (معمولاً
http://127.0.0.1:8000) کلیک کنید تا رابط کاربری ADK Dev در مرورگر شما باز شود.
۱۱. عامل را آزمایش کنید
اکنون میتوانید توانایی استدلال عامل خود را آزمایش کنید و از ابزارهای آن برای پاسخ به سوالات پیچیده استفاده کنید.
- در رابط کاربری ADK Dev، مطمئن شوید که گزینه
financial_agentاز منوی کشویی انتخاب شده است. - سعی کنید سوالی بپرسید که به اطلاعات موجود در پروندههای کمیسیون بورس و اوراق بهادار آمریکا (دادههای بدون ساختار) نیاز داشته باشد. عبارت زیر را در چت وارد کنید:
What were the total revenues for the quarter ending on March 31, 2023?search_and_qna_agentفراخوانی کند که ازVertexAiSearchToolبرای یافتن پاسخ در اسناد مالی استفاده میکند. - در مرحله بعد، سوالی بپرسید که نیاز به استفاده از ابزار سفارشی شما (دادههای ساختاریافته) داشته باشد. توجه داشته باشید که قالب تاریخ در اعلان لازم نیست دقیقاً با قالب مورد نیاز تابع مطابقت داشته باشد؛ LLM به اندازه کافی هوشمند است که آن را دوباره قالببندی کند.
What was the closing stock price for Alphabet on July 10, 2025?get_stock_priceشما را فراخوانی کند. میتوانید روی نماد ابزار در چت کلیک کنید تا فراخوانی تابع و نتیجه آن را بررسی کنید. - در نهایت، یک سوال پیچیده بپرسید که مستلزم استفاده از هر دو ابزار توسط عامل و ترکیب نتایج باشد.
According to the 10-Q filing for the period ending March 31, 2023, what were the company's net cash provided by operating activities, and what was the stock's closing price on that date?- ابتدا، از ابزار
VertexAiSearchToolبرای یافتن اطلاعات جریان نقدی در پروندههای کمیسیون بورس و اوراق بهادار آمریکا (SEC) استفاده خواهد کرد. - سپس، نیاز به قیمت سهام را تشخیص داده و تابع
get_stock_priceرا با تاریخ2023-03-31فراخوانی میکند. - در نهایت، هر دو بخش اطلاعات را در یک پاسخ واحد و جامع ترکیب میکند.
- ابتدا، از ابزار
- وقتی کارتان تمام شد، میتوانید تب مرورگر را ببندید و در ترمینال
CTRL+Cرا فشار دهید تا سرور ADK متوقف شود.
۱۲. انتخاب یک سرویس برای کار خود
جستجوی هوش مصنوعی ورتکس تنها سرویس جستجوی برداری نیست که میتوانید از آن استفاده کنید. همچنین میتوانید از یک سرویس مدیریتشده که کل جریان تولید افزوده بازیابی را خودکار میکند استفاده کنید: موتور RAG هوش مصنوعی ورتکس .
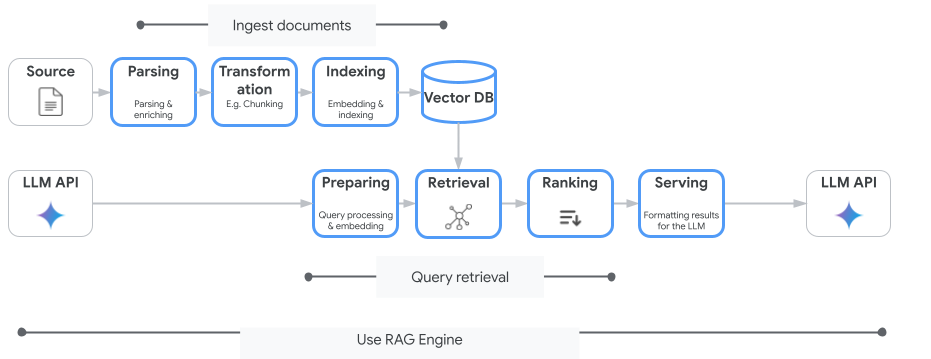
این موتور همه چیز را از دریافت سند گرفته تا بازیابی و رتبهبندی مجدد، مدیریت میکند. موتور RAG از چندین مخزن برداری از جمله Pinecone و Weaviate پشتیبانی میکند.
شما همچنین میتوانید بسیاری از پایگاههای داده برداری تخصصی را به صورت خود-میزبانی (self-host) کنید یا از قابلیتهای شاخص برداری در موتورهای پایگاه داده، مانند pgvector در سرویس PostgreSQL (مانند AlloyDB یا BigQuery Vector Search ) استفاده کنید.
چند سرویس دیگر که از جستجوی برداری پشتیبانی میکنند عبارتند از:
راهنمای کلی برای انتخاب یک سرویس خاص در گوگل کلود به شرح زیر است:
- اگر از قبل زیرساخت Vector Search Do-It-Yourself را دارید که به خوبی کار میکند و مقیاسبندی خوبی دارد، آن را روی Google Kubernetes Engine مانند Weaviate یا DIY PostgreSQL مستقر کنید.
- اگر دادههای شما در BigQuery، AlloyDB، Firestore یا هر پایگاه داده دیگری است، در صورتی که جستجوی معنایی بتواند در مقیاس بزرگ به عنوان بخشی از یک پرسوجوی بزرگتر در آن پایگاه داده انجام شود، استفاده از قابلیتهای Vector Search آن را در نظر بگیرید. به عنوان مثال، اگر توضیحات محصول و/یا تصاویر را در یک جدول BigQuery دارید، اضافه کردن یک ستون جاسازی متن و/یا تصویر، امکان استفاده از جستجوی شباهت را در مقیاس بزرگ فراهم میکند. شاخصهای برداری با جستجوی ScanANN از میلیاردها مورد در شاخص پشتیبانی میکنند.
- اگر نیاز دارید که با حداقل تلاش و روی یک پلتفرم مدیریتشده، به سرعت شروع به کار کنید، Vertex AI Search را انتخاب کنید - یک موتور جستجو و رابط برنامهنویسی کاربردی بازیابی کاملاً مدیریتشده که برای موارد استفاده پیچیده سازمانی که نیاز به کیفیت بالا، مقیاسپذیری و کنترلهای دسترسی دقیق و از پیش تعیینشده دارند، ایدهآل است. این ابزار اتصال به منابع داده متنوع سازمانی را ساده میکند و امکان جستجو در منابع متعدد را فراهم میسازد.
- اگر به دنبال یک نقطهی مطلوب برای توسعهدهندگانی هستید که به دنبال تعادل بین سهولت استفاده و سفارشیسازی هستند، از Vertex AI RAG Engine استفاده کنید. این موتور، نمونهسازی و توسعه سریع را بدون از دست دادن انعطافپذیری امکانپذیر میکند.
- معماریهای مرجع برای تولید افزودهشده با بازیابی را بررسی کنید.
۱۳. نتیجهگیری
تبریک! شما با موفقیت یک عامل هوش مصنوعی با نسل بازیابی-تقویتشده ساختید و آزمایش کردید. شما یاد گرفتید که چگونه:
- با استفاده از قابلیتهای قدرتمند جستجوی معنایی Vertex AI Search، یک پایگاه دانش برای اسناد بدون ساختار ایجاد کنید.
- یک تابع پایتون سفارشی توسعه دهید تا به عنوان ابزاری برای بازیابی دادههای ساختاریافته عمل کند.
- از کیت توسعه عامل (ADK) برای ایجاد یک عامل چند ابزاری با پشتیبانی Gemini استفاده کنید.
- عاملی بسازید که قادر به استدلال پیچیده و چند مرحلهای برای پاسخ به پرسشهایی باشد که نیاز به ترکیب اطلاعات از منابع متعدد دارند.
این آزمایشگاه اصول اصلی Agentic RAG، یک معماری قدرتمند برای ساخت برنامههای هوش مصنوعی هوشمند، دقیق و آگاه از متن در Google Cloud، را نشان میدهد.
از نمونه اولیه تا تولید
این آزمایشگاه بخشی از پروژه «هوش مصنوعی آماده تولید با مسیر یادگیری ابری گوگل» است.
- برای پر کردن شکاف بین نمونه اولیه و تولید، برنامه درسی کامل را بررسی کنید .
- پیشرفت خود را با هشتگ #ProductionReadyAI به اشتراک بگذارید .