
1. Introduction
Présentation
L'objectif de cet atelier est d'apprendre à développer des applications de génération augmentée par récupération (RAG) agentiques de bout en bout dans Google Cloud. Dans cet atelier, vous allez créer un agent d'analyse financière capable de répondre à des questions en combinant des informations provenant de deux sources différentes : des documents non structurés (les documents trimestriels déposés auprès de la SEC par Alphabet, qui contiennent des états financiers et des informations opérationnelles que toutes les entreprises publiques aux États-Unis doivent soumettre à la Securities and Exchange Commission) et des données structurées (les cours boursiers historiques).
Vous allez utiliser Vertex AI Search pour créer un moteur de recherche sémantique puissant pour les rapports financiers non structurés. Pour les données structurées, vous allez créer un outil Python personnalisé. Enfin, vous utiliserez l'Agent Development Kit (ADK) pour créer un agent intelligent capable de raisonner sur la requête d'un utilisateur, de décider quel outil utiliser et de synthétiser les informations dans une réponse cohérente.
Objectifs de l'atelier
- Configurer un datastore Vertex AI Search pour la recherche sémantique dans des documents privés
- Créez une fonction Python personnalisée comme outil pour un agent.
- Utilisez Agent Development Kit (ADK) pour créer un agent multi-outils.
- Combiner la récupération à partir de sources de données non structurées et structurées pour répondre à des questions complexes.
- Testez un agent doté de capacités de raisonnement et interagissez avec lui.
Points abordés
Dans cet atelier, vous allez apprendre à :
- Concepts de base de la génération augmentée par récupération (RAG) et de la RAG agentique.
- Implémenter la recherche sémantique dans des documents à l'aide de Vertex AI Search
- Découvrez comment exposer des données structurées à un agent en créant des outils personnalisés.
- Découvrez comment créer et orchestrer un agent multi-outils avec Agent Development Kit (ADK).
- Découvrez comment les agents utilisent le raisonnement et la planification pour répondre à des questions complexes à l'aide de plusieurs sources de données.
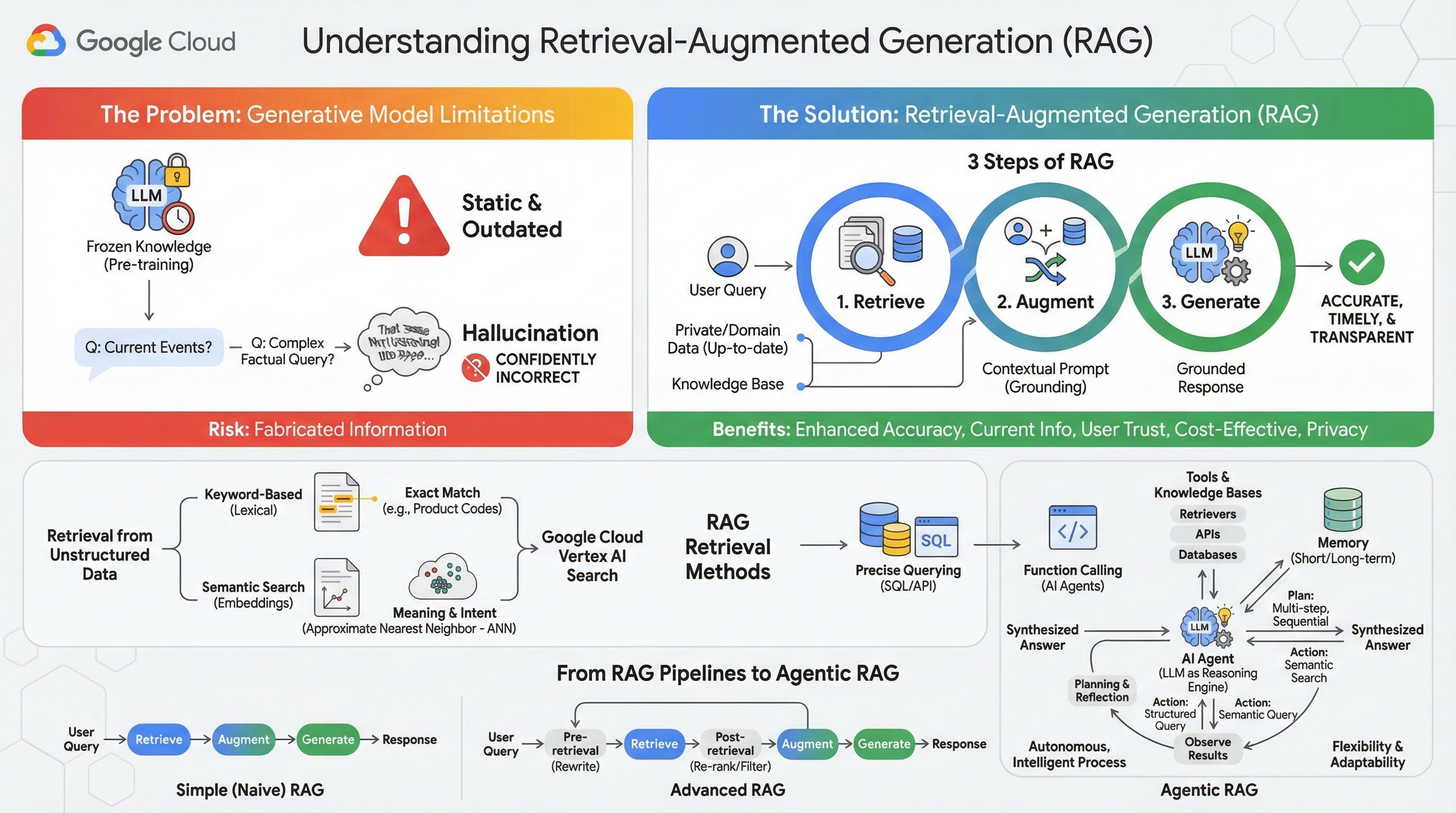
2. Comprendre la génération augmentée par récupération
Les grands modèles génératifs (grands modèles de langage ou LLM, modèles vision-langage, etc.) sont incroyablement puissants, mais ils présentent des limites inhérentes. Leurs connaissances sont figées au moment de leur pré-entraînement, ce qui les rend statiques et instantanément obsolètes. Même après le fine-tuning, les connaissances du modèle ne deviennent pas beaucoup plus récentes, car ce n'est pas l'objectif des étapes post-entraînement.
La façon dont les grands modèles de langage sont entraînés, en particulier les modèles de "réflexion", les "récompense" pour avoir donné une réponse, même si le modèle lui-même ne dispose pas d'informations factuelles qui pourraient étayer cette réponse. C'est ce qu'on appelle une "hallucination" : le modèle génère avec assurance des informations qui semblent plausibles, mais qui sont factuellement incorrectes.
La génération augmentée par récupération est un modèle architectural puissant conçu pour résoudre précisément ces problèmes. Il s'agit d'un framework architectural qui améliore les capacités des grands modèles de langage en les connectant à des sources de connaissances externes et fiables en temps réel. Au lieu de s'appuyer uniquement sur ses connaissances statiques pré-entraînées, un LLM dans un système RAG récupère d'abord les informations pertinentes liées à la requête d'un utilisateur, puis les utilise pour générer une réponse plus précise, plus rapide et plus adaptée au contexte.
Cette approche s'attaque directement aux faiblesses les plus importantes des modèles génératifs : leurs connaissances sont figées à un moment donné et ils sont susceptibles de générer des informations incorrectes, ou "hallucinations". Le RAG donne efficacement au LLM un "examen à livre ouvert", où le "livre" est constitué de vos données privées, spécifiques à un domaine et à jour. Ce processus, qui consiste à fournir un contexte factuel au LLM, est appelé ancrage.
Trois étapes du RAG
Le processus standard de génération augmentée par récupération peut être décomposé en trois étapes simples :
- Récupérer : lorsqu'un utilisateur envoie une requête, le système recherche d'abord dans une base de connaissances externe (comme un dépôt de documents, une base de données ou un site Web) des informations pertinentes pour la requête.
- Augmenter : les informations récupérées sont ensuite combinées à la requête d'origine de l'utilisateur pour créer une requête étendue. Cette technique est parfois appelée "bourrage de prompt", car elle enrichit la requête avec un contexte factuel.
- Générer : ce prompt augmenté est transmis au LLM, qui génère ensuite une réponse. Comme le modèle a reçu des données factuelles et pertinentes, sa sortie est "ancrée" et beaucoup moins susceptible d'être inexacte ou obsolète.
Avantages du RAG
L'introduction du framework RAG a transformé la création d'applications d'IA pratiques et fiables. Voici ses principaux avantages :
- Précision améliorée et hallucinations réduites : en ancrant les réponses dans des faits externes vérifiables, le RAG réduit considérablement le risque que le LLM fabrique des informations.
- Accès aux informations actuelles : les systèmes RAG peuvent être connectés à des bases de connaissances constamment mises à jour, ce qui leur permet de fournir des réponses basées sur les informations les plus récentes, ce qui est impossible pour un LLM entraîné de manière statique.
- Transparence et confiance des utilisateurs accrues : comme la réponse du LLM est basée sur des documents récupérés, le système peut fournir des citations et des liens vers ses sources. Cela permet aux utilisateurs de vérifier eux-mêmes les informations, ce qui renforce leur confiance dans l'application.
- Rentabilité : l'affinage ou le réentraînement continu d'un LLM avec de nouvelles données sont coûteux en termes de calcul et de finances. Avec le RAG, il suffit de mettre à jour la source de données externe pour actualiser les connaissances du modèle, ce qui est beaucoup plus efficace.
- Spécialisation du domaine et confidentialité : la technique RAG permet aux personnes et aux organisations de mettre leurs données privées et propriétaires à la disposition d'un LLM au moment de la requête, sans avoir à inclure ces données sensibles dans l'ensemble d'entraînement du modèle. Cela permet de créer des applications puissantes et spécifiques à un domaine tout en préservant la confidentialité et la sécurité des données.
Récupération
L'étape de récupération est au cœur de tout système RAG. La qualité et la pertinence des informations récupérées déterminent directement la qualité et la pertinence de la réponse finale générée. Une application RAG efficace doit souvent récupérer des informations à partir de différents types de sources de données à l'aide de diverses techniques. Les principales méthodes de récupération se répartissent en trois catégories : par mots clés, sémantiques et structurées.
Récupération de données non structurées
Historiquement, la récupération de données non structurées est un autre nom pour la recherche traditionnelle. Il a subi de nombreuses transformations, et vous pouvez bénéficier des deux approches principales.
La recherche sémantique est la technique la plus efficace que vous pouvez exécuter à grande échelle dans Google Cloud avec des performances de pointe et un degré de contrôle élevé.
- Recherche par mots clés (lexicale) : il s'agit de l'approche traditionnelle de la recherche, qui remonte aux premiers systèmes de récupération d'informations des années 1970. La recherche lexicale fonctionne en faisant correspondre les mots littéraux (ou "jetons") de la requête d'un utilisateur aux mots exacts des documents d'une base de connaissances. Elle est très efficace pour les requêtes où la précision sur des termes spécifiques, comme les codes produit, les clauses juridiques ou les noms uniques, est essentielle.
- Recherche sémantique : la recherche sémantique, ou "recherche avec signification", est une approche plus moderne qui vise à comprendre l'intention de l'utilisateur et la signification contextuelle de sa requête, et pas seulement les mots clés littéraux. La recherche sémantique moderne repose sur l'embedding, une technique de machine learning qui mappe des données complexes de grande dimension dans un espace vectoriel de dimension inférieure. Ces vecteurs sont conçus de sorte que les textes ayant des significations similaires soient situés à proximité les uns des autres dans l'espace vectoriel. Une recherche "Quelles sont les meilleures races de chiens pour les familles ?" est convertie en vecteur, puis le système recherche les vecteurs de documents qui sont ses "plus proches voisins" dans cet espace. Il peut ainsi trouver des documents qui parlent de "golden retrievers" ou de "canidés amicaux", même s'ils ne contiennent pas le mot exact "chien". Cette recherche de grande dimension est rendue efficace par les algorithmes ANN (Approximate Nearest Neighbor, recherche approximative du voisin le plus proche). Au lieu de comparer le vecteur de requête à chaque vecteur de document (ce qui serait trop lent pour les grands ensembles de données), les algorithmes ANN utilisent des structures d'indexation intelligentes pour trouver rapidement les vecteurs les plus proches.
Récupération à partir de données structurées
Toutes les connaissances critiques ne sont pas stockées dans des documents non structurés. Souvent, les informations les plus précises et les plus utiles se trouvent dans des formats structurés tels que les bases de données relationnelles, les bases de données NoSQL ou certains types d'API, comme une API REST pour les données météorologiques ou les cours de la bourse.
La récupération de données structurées est généralement plus directe et exacte que la recherche de texte non structuré. Au lieu de rechercher une similarité sémantique, les modèles de langage peuvent être en mesure de formuler et d'exécuter une requête précise, telle qu'une requête SQL sur une base de données ou un appel d'API à une API météo pour un lieu et une date spécifiques.
Implémentée via l'appel de fonction, la même technique que celle utilisée par les agents IA, elle permet aux modèles de langage d'interagir avec du code exécutable et des systèmes externes de manière déterministe et structurée.
3. Des pipelines RAG au RAG agentique
Tout comme le concept de RAG lui-même a évolué, les architectures pour l'implémenter ont également changé. Ce qui a commencé comme un simple pipeline linéaire est devenu un système dynamique et intelligent orchestré par des agents d'IA.
- RAG simple (ou naïf) : il s'agit de l'architecture de base que nous avons abordée jusqu'à présent. Il s'agit d'un processus linéaire en trois étapes : récupération, augmentation et génération. Il est réactif, suit un chemin fixe pour chaque requête et est très efficace pour les tâches simples de questions/réponses.
- RAG avancé : il s'agit d'une évolution où des étapes supplémentaires sont ajoutées au pipeline pour améliorer la qualité du contexte récupéré. Ces améliorations peuvent se produire avant ou après l'étape de récupération.
- Avant la récupération : des techniques telles que la réécriture ou l'expansion des requêtes peuvent être utilisées. Le système peut analyser la requête initiale et la reformuler pour qu'elle soit plus efficace pour le système de récupération.
- Post-récupération : après avoir récupéré un ensemble initial de documents, un modèle de reclassification peut être appliqué pour évaluer la pertinence des documents et placer les meilleurs en haut de la liste. C'est particulièrement important dans la recherche hybride. Une autre étape post-récupération consiste à filtrer ou à compresser le contexte récupéré pour s'assurer que seules les informations les plus importantes sont transmises au LLM.
- RAG agentique : il s'agit de l'architecture RAG la plus avancée, qui représente un changement de paradigme, passant d'un pipeline fixe à un processus autonome et intelligent. Dans un système RAG agentique, l'ensemble du workflow est géré par un ou plusieurs agents d'IA capables de raisonner, de planifier et de choisir dynamiquement leurs actions.
Pour comprendre le RAG agentique, il faut d'abord comprendre ce qui constitue un agent d'IA. Un agent est bien plus qu'un LLM. Il s'agit d'un système comportant plusieurs composants clés :
- Un LLM comme moteur de raisonnement : l'agent utilise un LLM puissant comme Gemini, non seulement pour générer du texte, mais aussi comme "cerveau" central pour planifier, prendre des décisions et décomposer des tâches complexes.
- Ensemble d'outils : un agent a accès à un ensemble de fonctions qu'il peut décider d'utiliser pour atteindre ses objectifs. Ces outils peuvent être n'importe quoi : une calculatrice, une API de recherche sur le Web, une fonction d'envoi d'e-mails ou, plus important encore pour cet atelier, des extracteurs pour nos différentes bases de connaissances.
- Mémoire : les agents peuvent être conçus avec une mémoire à court terme (pour se souvenir du contexte de la conversation en cours) et une mémoire à long terme (pour se souvenir des informations des interactions passées), ce qui permet d'offrir des expériences plus personnalisées et cohérentes.
- Planification et réflexion : les agents les plus avancés présentent des schémas de raisonnement sophistiqués. Ils peuvent recevoir un objectif complexe et créer un plan en plusieurs étapes pour l'atteindre. Ils peuvent ensuite exécuter ce plan et même réfléchir aux résultats de leurs actions, identifier les erreurs et corriger leur approche pour améliorer le résultat final.
Le RAG agentique change la donne, car il introduit une couche d'autonomie et d'intelligence qui manque aux pipelines statiques.
- Flexibilité et adaptabilité : un agent n'est pas limité à un seul chemin de récupération. À partir d'une requête utilisateur, il peut déterminer la meilleure source d'informations. Il peut décider d'interroger d'abord la base de données structurée, puis d'effectuer une recherche sémantique sur des documents non structurés et, s'il ne trouve toujours pas de réponse, d'utiliser un outil de recherche Google pour effectuer une recherche sur le Web public, le tout dans le contexte d'une seule demande utilisateur.
- Raisonnement complexe en plusieurs étapes : cette architecture excelle dans le traitement des requêtes complexes qui nécessitent plusieurs étapes de récupération et de traitement séquentielles.
Prenons l'exemple de la requête "Trouve les trois meilleurs films de science-fiction réalisés par Christopher Nolan et, pour chacun d'eux, donne un bref résumé de l'intrigue". Un pipeline RAG simple échouerait.
Un agent peut toutefois décomposer cette requête :
- Plan : Je dois d'abord trouver les films. Ensuite, pour chaque film, je dois trouver son intrigue.
- Action 1 : Utilisez l'outil de données structurées pour interroger une base de données de films et obtenir les trois meilleurs films de science-fiction de Nolan, classés par note décroissante.
- Observation 1 : l'outil renvoie "Inception", "Interstellar" et "Tenet".
- Action 2 : Utilisez l'outil de données non structurées (recherche sémantique) pour trouver l'intrigue du film "Inception".
- Observation 2 : L'intrigue est récupérée.
- Action 3 : Répétez l'opération pour "Interstellar".
- Étape 4 : Répétez l'opération pour "Tenet".
- Synthèse finale : combinez toutes les informations récupérées en une seule réponse cohérente pour l'utilisateur.
4. Configuration du projet
Compte Google
Si vous ne possédez pas encore de compte Google personnel, vous devez en créer un.
Utilisez un compte personnel au lieu d'un compte professionnel ou scolaire.
Se connecter à la console Google Cloud
Connectez-vous à la console Google Cloud à l'aide d'un compte Google personnel.
Activer la facturation
Utiliser un compte de facturation test (facultatif)
Pour suivre cet atelier, vous avez besoin d'un compte de facturation avec un certain crédit. Utilisez les crédits de la bannière en haut de cet atelier de programmation pour commencer. Si vous êtes déjà associé à un compte de facturation, vous pouvez ignorer cette étape.
Configurer un compte de facturation personnel
Si vous avez configuré la facturation à l'aide de crédits Google Cloud, vous pouvez ignorer cette étape.
Pour configurer un compte de facturation personnel, cliquez ici pour activer la facturation dans la console Cloud.
Remarques :
- Cet atelier devrait vous coûter moins de 1 USD en ressources Cloud.
- Vous pouvez suivre les étapes à la fin de cet atelier pour supprimer les ressources et éviter ainsi des frais supplémentaires.
- Les nouveaux utilisateurs peuvent bénéficier d'un essai sans frais pour bénéficier d'un crédit de 300$.
Créer un projet (facultatif)
Si vous n'avez pas de projet que vous souhaitez utiliser pour cet atelier, créez-en un.
5. Ouvrir l'éditeur Cloud Shell
- Cliquez sur ce lien pour accéder directement à l'éditeur Cloud Shell.
- Si vous êtes invité à autoriser l'accès à un moment donné aujourd'hui, cliquez sur Autoriser pour continuer.
- Si le terminal ne s'affiche pas en bas de l'écran, ouvrez-le :
- Cliquez sur Afficher.
- Cliquez sur Terminal
 .
.
- Dans le terminal, définissez votre projet à l'aide de la commande suivante :
gcloud config set project [PROJECT_ID]- Exemple :
gcloud config set project lab-project-id-example - Si vous ne vous souvenez pas de l'ID de votre projet, vous pouvez lister tous vos ID de projet avec la commande suivante :
gcloud projects list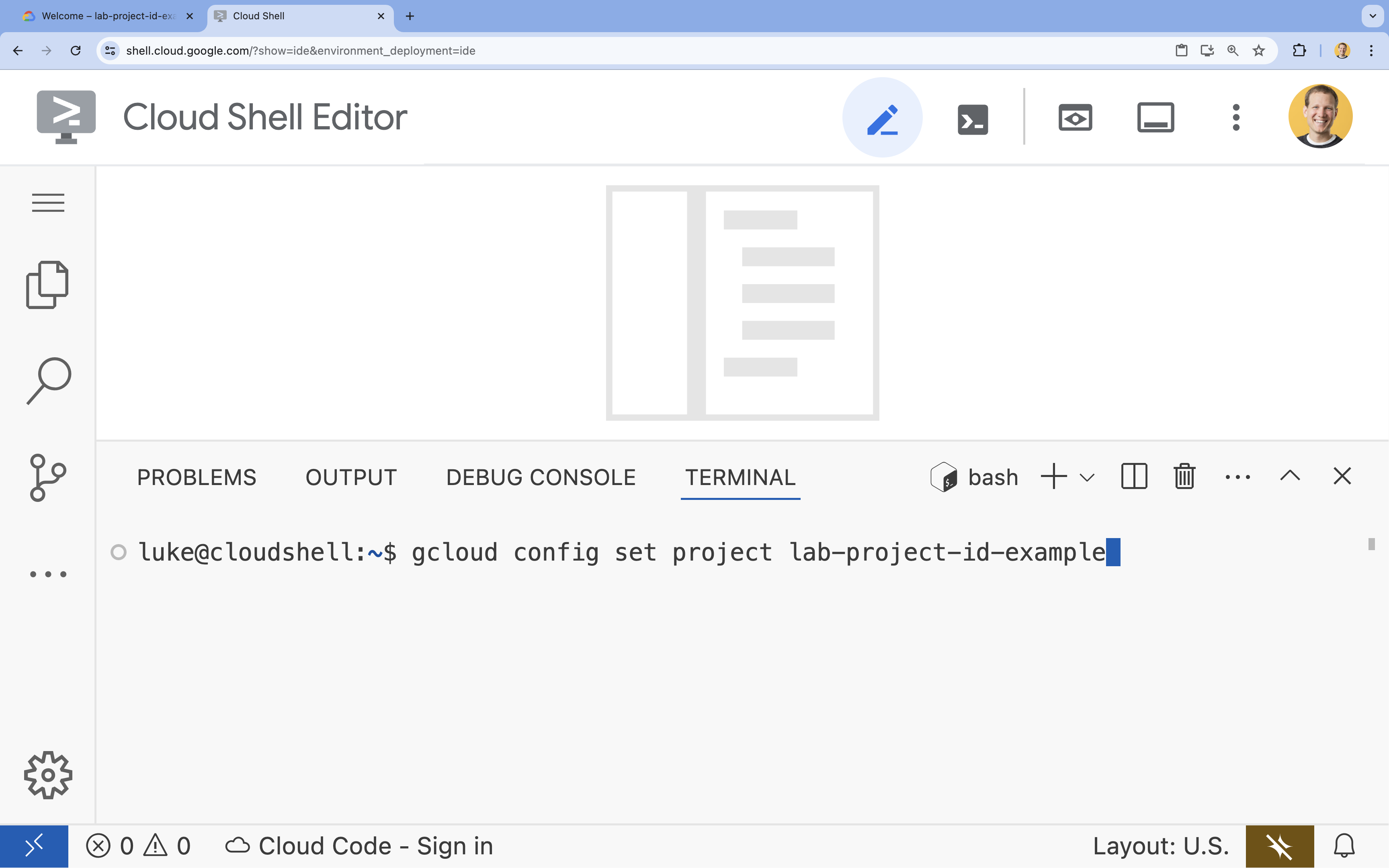
- Exemple :
- Le message suivant doit s'afficher :
Updated property [core/project].
6. Activer les API
Pour utiliser le kit de développement d'agents et Vertex AI Search, vous devez activer les API nécessaires dans votre projet Google Cloud.
- Dans le terminal, activez les API :
gcloud services enable \ aiplatform.googleapis.com \ discoveryengine.googleapis.com
Présentation des API
- L'API Vertex AI (
aiplatform.googleapis.com) permet à l'agent de communiquer avec les modèles Gemini pour le raisonnement et la génération. - L'API Discovery Engine (
discoveryengine.googleapis.com) alimente Vertex AI Search, ce qui vous permet de créer des magasins de données et d'effectuer des recherches sémantiques sur vos documents non structurés.
7. Configurer l'environnement
Avant de commencer à coder l'agent d'IA, vous devez préparer votre environnement de développement, installer les bibliothèques nécessaires et créer les fichiers de données requis.
Créer un environnement virtuel et installer les dépendances
- Créez un répertoire pour votre agent et accédez-y. Exécutez le code suivant dans le terminal :
mkdir financial_agent cd financial_agent - Créez un environnement virtuel :
uv venv --python 3.12 - Activez l'environnement virtuel :
source .venv/bin/activate - Installez Agent Development Kit (ADK) et pandas.
uv pip install google-adk pandas
Créer les données sur le cours des actions
Comme l'atelier nécessite des données boursières historiques spécifiques pour démontrer la capacité de l'agent à utiliser des outils structurés, vous allez créer un fichier CSV contenant ces données.
- Dans le répertoire
financial_agent, créez le fichiergoog.csven exécutant la commande suivante dans le terminal :cat <<EOF > goog.csv Date,Open,High,Low,Close,Adj Close,Volume 2023-01-03,89.830002,91.550003,89.019997,89.699997,89.699997,20738500 2023-03-31,101.440002,103.889999,101.040001,103.730003,103.730003,36823200 2023-06-30,120.870003,122.029999,120.300003,120.970001,120.970001,23824700 2023-09-29,134.080002,134.550003,131.320007,131.850006,131.850006,21124200 2025-07-10,185.000000,188.000000,184.500000,186.500000,186.500000,25000000 EOF
Configurer les variables d'environnement
- Dans le répertoire
financial_agent, créez un fichier.envpour configurer les variables d'environnement de votre agent. Cela indique à l'ADK le projet, l'emplacement et le modèle à utiliser. Exécutez le code suivant dans le terminal :# Create the .env file using the captured variables cat << EOF > .env GOOGLE_GENAI_USE_VERTEXAI=TRUE GOOGLE_CLOUD_PROJECT="${GOOGLE_CLOUD_PROJECT}" GOOGLE_CLOUD_LOCATION="us-central1" EOF
Remarque : Plus loin dans l'atelier, si vous devez modifier le fichier .env, mais que vous ne le voyez pas dans le répertoire financial_agent, essayez d'activer la visibilité des fichiers cachés dans l'éditeur Cloud Shell à l'aide de l'élément de menu "Affichage / Afficher/Masquer les fichiers cachés".
8. Créer un datastore Vertex AI Search
Pour permettre à l'agent de répondre aux questions sur les rapports financiers d'Alphabet, vous allez créer un datastore Vertex AI Search contenant les documents publics déposés auprès de la SEC.
- Dans un nouvel onglet de navigateur, ouvrez la console Cloud (console.cloud.google.com), puis accédez à Applications d'IA à l'aide de la barre de recherche en haut de la page.
- Si vous y êtes invité, cochez la case des conditions d'utilisation, puis cliquez sur Continuer et activer l'API.
- Dans le menu de navigation de gauche, sélectionnez Datastores.
- Cliquez sur + Créer un datastore.
- Recherchez la carte Cloud Storage, puis cliquez sur Sélectionner.
- Pour la source de données, sélectionnez Documents non structurés.

- Pour la source d'importation (sélectionnez un dossier ou un fichier à importer), saisissez le chemin d'accès Google Cloud Storage
cloud-samples-data/gen-app-builder/search/alphabet-sec-filings. - Cliquez sur Continuer.
- Laissez l'emplacement défini sur mondial.
- Pour le nom du datastore, saisissez
alphabet-sec-filings - Développez la section Options de traitement des documents.

- Dans la liste déroulante Default document parser (Analyseur de documents par défaut), sélectionnez Layout Parser (Analyseur de mise en page).
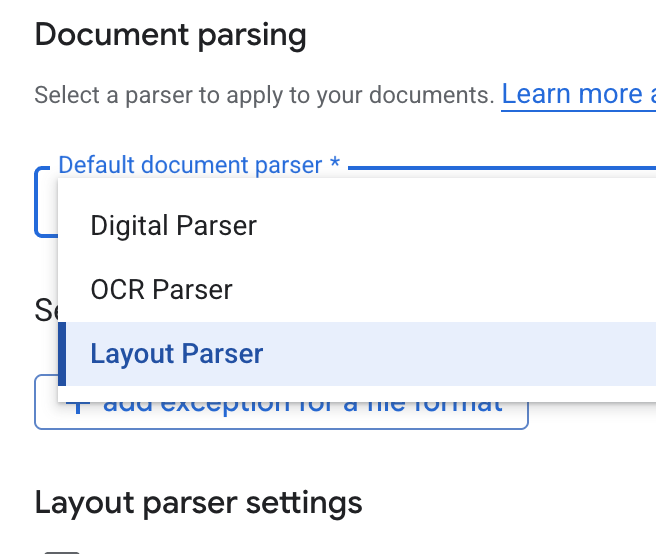
- Dans les options Paramètres de l'analyseur de mise en page, sélectionnez Activer l'annotation de tableaux et Activer l'annotation d'images.
- Cliquez sur Continuer.
- Sélectionnez Tarification générale comme modèle de tarification (un modèle de paiement à l'usage basé sur la consommation), puis cliquez sur Créer.
- Votre datastore commence à importer les documents.
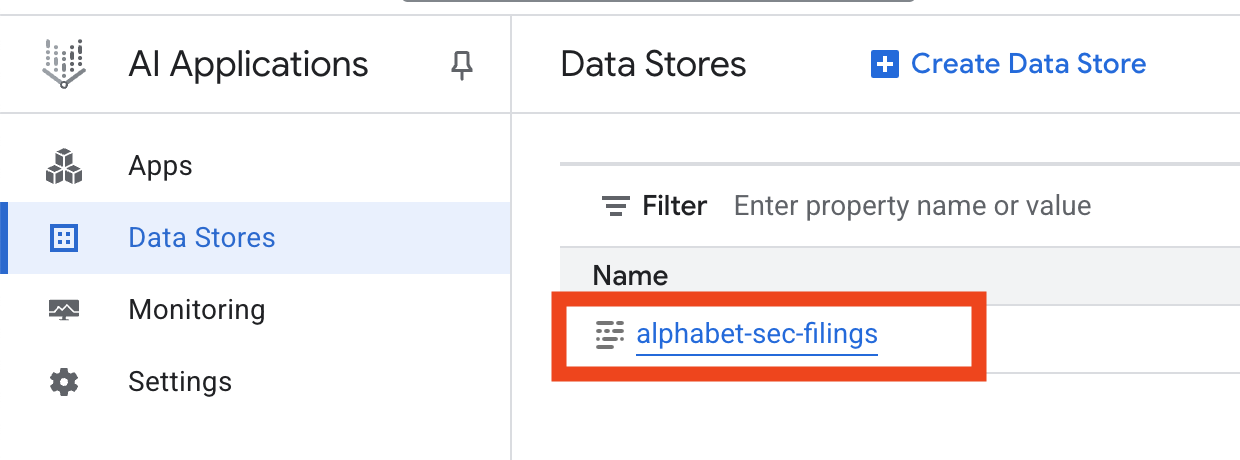
- Cliquez sur le nom du data store, puis copiez son ID dans le tableau "Data stores". Vous en aurez besoin à l'étape suivante.
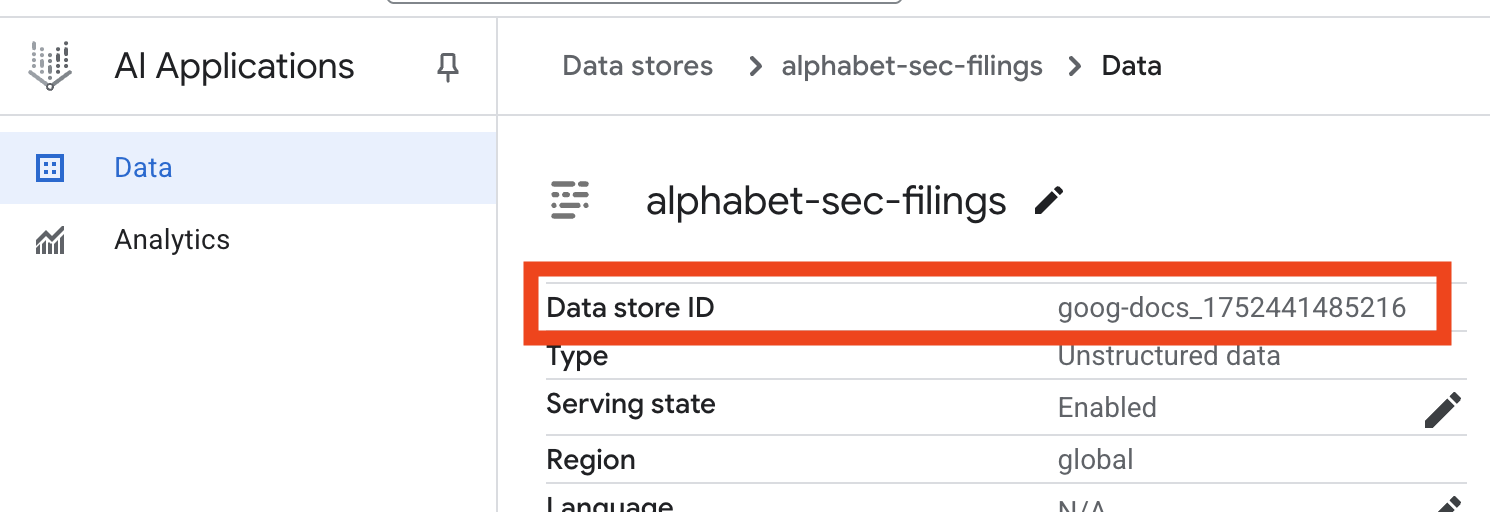
- Ouvrez le fichier
.envdans l'éditeur Cloud Shell et ajoutez l'ID du datastore sous la formeDATA_STORE_ID="YOUR_DATA_STORE_ID"(remplacezYOUR_DATA_STORE_IDpar l'ID réel de l'étape précédente). Remarque : L'importation, l'analyse et l'indexation des données dans le datastore prendront quelques minutes. Pour vérifier le processus, cliquez sur le nom du datastore pour ouvrir ses propriétés, puis ouvrez l'onglet Activité. Attendez que l'état devienne "Importation terminée".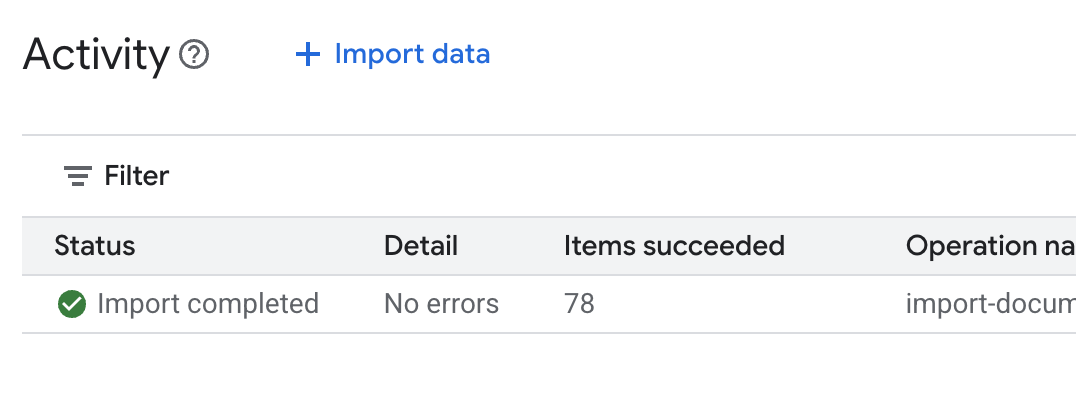
9. Créer un outil personnalisé pour les données structurées
Vous allez ensuite créer une fonction Python qui servira d'outil pour l'agent. Cet outil lira le fichier goog.csv pour récupérer l'historique des cours d'une action à une date donnée.
- Dans le répertoire
financial_agent, créez un fichier nomméagent.py. Exécutez la commande suivante dans le terminal :cloudshell edit agent.py - Ajoutez le code Python suivant à
agent.py. Ce code importe les dépendances et définit la fonctionget_stock_price.from datetime import datetime import os import logging import google.cloud.logging from google.adk.tools import VertexAiSearchTool from google.adk.tools.agent_tool import AgentTool from google.adk.agents import LlmAgent import pandas as pd def get_stock_price(date: str) -> dict: """Gets the closing stock price for a given date. Args: date: The date to get the stock price for, in YYYY-MM-DD format. Returns: A dictionary containing the closing price, or an error message if the date is not found or the format is incorrect. """ try: # Load the CSV file df = pd.read_csv('goog.csv') # Convert the 'Date' column to datetime objects df['Date'] = pd.to_datetime(df['Date']) # Convert the input string to a datetime object query_date = datetime.strptime(date, '%Y-%m-%d') # Find the row for the given date row = df[df['Date'] == query_date] if not row.empty: # Get the closing price close_price = row['Close'].iloc[0] return {"status": "success", "date": date, "closing_price": close_price} else: return {"status": "error", "message": f"No data found for date: {date}"} except FileNotFoundError: return {"status": "error", "message": "Stock data file (goog.csv) not found."} except Exception as e: return {"status": "error", "message": f"An error occurred: {str(e)}"}
Notez le docstring détaillé de la fonction. Elle explique ce que fait la fonction, ses paramètres (Args) et ce qu'elle renvoie (Returns). L'ADK utilise cette docstring pour apprendre à l'agent comment et quand utiliser cet outil.
10. Créer et exécuter l'agent RAG
Il est maintenant temps d'assembler l'agent. Vous combinerez l'outil Vertex AI Search pour les données non structurées avec votre outil get_stock_price personnalisé pour les données structurées.
- Ajoutez le code suivant à votre fichier
agent.py. Ce code importe les classes ADK nécessaires, crée des instances des outils et définit l'agent.logging.basicConfig(level=logging.INFO) cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() # 1. Create the Vertex AI Search tool full_datastore_id = f"projects/{os.environ['GOOGLE_CLOUD_PROJECT']}/locations/global/collections/default_collection/dataStores/{os.environ['DATA_STORE_ID']}" vertex_ai_search_tool = VertexAiSearchTool( data_store_id=full_datastore_id ) # 2. Define the Search+Q&A agent # Since we cannot combine tools with other tools in a single agent, # we create a separate Search+Q&A agent which will be used as a tool by the main root agent. doc_qa_agent = LlmAgent( name="search_and_qna_agent", model="gemini-2.5-flash", tools=[vertex_ai_search_tool], instruction="""You are a helpful assistant that answers questions based on information found in the document store. Use the search tool to find relevant information before answering. If the answer isn't in the documents, say that you couldn't find the information. """, description="Answers questions using a specific Vertex AI Search datastore.", ) # 3. Define the root agent with 2 tools. root_agent = LlmAgent( name="financial_agent", model="gemini-2.5-flash", tools=[ AgentTool(doc_qa_agent), get_stock_price, ], instruction="""You are an Financial Analytics Agent that answers question about Alphabet stock prices (using get_stock_price tool) and historical performance based on the data in Vertex AI Search datastore (using doc_qa_agent tool).""" ) - Dans votre terminal, à l'intérieur du répertoire
financial_agent, lancez l'interface Web ADK pour interagir avec votre agent :adk web ~ - Cliquez sur le lien fourni dans la sortie du terminal (généralement
http://127.0.0.1:8000) pour ouvrir l'UI de développement d'ADK dans votre navigateur.
11. Tester l'agent
Vous pouvez désormais tester la capacité de raisonnement de votre agent et son aptitude à utiliser ses outils pour répondre à des questions complexes.
- Dans l'UI de développement d'ADK, assurez-vous que votre
financial_agentest sélectionné dans le menu déroulant. - Essayez de poser une question qui nécessite des informations provenant des documents déposés auprès de la SEC (données non structurées). Saisissez la requête suivante dans le chat :
What were the total revenues for the quarter ending on March 31, 2023?search_and_qna_agent, qui utiliseVertexAiSearchToolpour trouver la réponse dans les documents financiers. - Ensuite, posez une question qui nécessite l'utilisation de votre outil personnalisé (données structurées). Notez que le format de date dans la requête ne doit pas nécessairement correspondre exactement au format requis par la fonction. Le LLM est suffisamment intelligent pour le reformater.
What was the closing stock price for Alphabet on July 10, 2025?get_stock_price. Vous pouvez cliquer sur l'icône d'outil dans le chat pour inspecter l'appel de fonction et son résultat. - Enfin, posez une question complexe qui nécessite que l'agent utilise les deux outils et synthétise les résultats.
According to the 10-Q filing for the period ending March 31, 2023, what were the company's net cash provided by operating activities, and what was the stock's closing price on that date?- Tout d'abord, il utilisera le
VertexAiSearchToolpour trouver les informations sur les flux de trésorerie dans les documents déposés auprès de la SEC. - Il reconnaîtra ensuite la nécessité d'obtenir le cours de l'action et appellera la fonction
get_stock_priceavec la date2023-03-31. - Enfin, il combinera les deux informations en une seule réponse complète.
- Tout d'abord, il utilisera le
- Lorsque vous avez terminé, vous pouvez fermer l'onglet du navigateur et appuyer sur
CTRL+Cdans le terminal pour arrêter le serveur ADK.
12. Choisir un service pour votre tâche
Vertex AI Search n'est pas le seul service de recherche vectorielle que vous pouvez utiliser. Vous pouvez également utiliser un service géré qui automatise l'ensemble du flux de génération augmentée par récupération : Vertex AI RAG Engine.
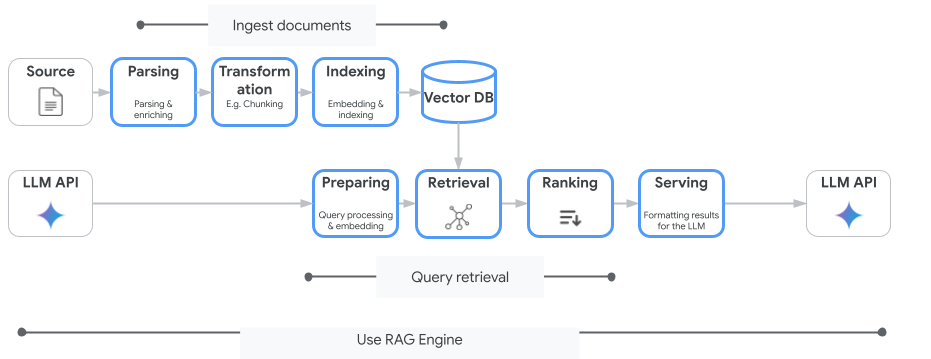
Il gère tout, de l'ingestion des documents à leur récupération et à leur reclassement. Le moteur RAG est compatible avec plusieurs magasins de vecteurs, y compris Pinecone et Weaviate.
Vous pouvez également auto-héberger de nombreuses bases de données vectorielles spécialisées ou exploiter les fonctionnalités d'index vectoriel dans les moteurs de base de données, comme pgvector dans le service PostgreSQL (par exemple, AlloyDB ou BigQuery Vector Search).
Voici quelques autres services compatibles avec la recherche vectorielle :
- Cloud SQL pour PostgreSQL
- Cloud SQL pour MySQL
- Cloud Spanner
- Memorystore pour Redis
- Firestore
- Bigtable
Voici les conseils généraux pour choisir un service particulier sur Google Cloud :
- Si vous disposez déjà d'une infrastructure de recherche vectorielle à faire soi-même fonctionnelle et bien dimensionnée, déployez-la sur Google Kubernetes Engine, comme Weaviate ou DIY PostgreSQL.
- Si vos données se trouvent dans BigQuery, AlloyDB, Firestore ou toute autre base de données, envisagez d'utiliser ses fonctionnalités de recherche vectorielle si la recherche sémantique peut être effectuée à grande échelle dans le cadre d'une requête plus vaste dans cette base de données. Par exemple, si vous disposez de descriptions et/ou d'images de produits dans une table BigQuery, l'ajout d'une colonne d'embeddings de texte et/ou d'image vous permettra d'utiliser la recherche par similarité à grande échelle. Les index vectoriels avec la recherche ScaNN prennent en charge des milliards d'éléments dans l'index.
- Si vous avez besoin de vous lancer rapidement avec un minimum d'efforts et sur une plate-forme gérée, choisissez Vertex AI Search. Il s'agit d'une API de moteur de recherche et de récupération entièrement gérée, idéale pour les cas d'utilisation complexes en entreprise qui nécessitent une qualité, une évolutivité et des contrôles d'accès précis prêts à l'emploi. Il simplifie la connexion à diverses sources de données d'entreprise et permet d'effectuer des recherches dans plusieurs sources.
- Utilisez le moteur RAG Vertex AI si vous recherchez un juste milieu entre facilité d'utilisation et personnalisation. Il permet de prototyper et de développer rapidement des applications sans sacrifier la flexibilité.
- Explorez les architectures de référence pour la génération augmentée par récupération.
13. Conclusion
Félicitations ! Vous avez réussi à créer et à tester un agent d'IA avec la génération augmentée par récupération. Vous avez appris à :
- Créez une base de connaissances pour les documents non structurés à l'aide des puissantes fonctionnalités de recherche sémantique de Vertex AI Search.
- Développez une fonction Python personnalisée qui servira d'outil pour récupérer des données structurées.
- Utilisez Agent Development Kit (ADK) pour créer un agent multi-outils optimisé par Gemini.
- Créez un agent capable d'effectuer un raisonnement complexe en plusieurs étapes pour répondre aux requêtes qui nécessitent de synthétiser des informations provenant de plusieurs sources.
Cet atelier présente les principes de base du RAG agentique, une architecture puissante permettant de créer des applications d'IA intelligentes, précises et contextuelles sur Google Cloud.
Du prototype à la production
Cet atelier fait partie du parcours de formation "L'IA prête pour la production avec Google Cloud".
- Découvrez le programme complet pour passer du prototype à la production.
- Partagez votre progression avec le hashtag #ProductionReadyAI.