
1. מבוא
סקירה כללית
המטרה של שיעור ה-Lab הזה היא ללמוד איך לפתח אפליקציות Agentic Retrieval-Augmented Generation (יצירה משולבת-אחזור, RAG) מקצה לקצה ב-Google Cloud. בשיעור ה-Lab הזה תיצרו סוכן לניתוח פיננסי שיכול לענות על שאלות על ידי שילוב מידע משני מקורות שונים: מסמכים לא מובנים (דוחות רבעוניים של Alphabet לרשות ניירות הערך האמריקאית (SEC) – דוחות כספיים ופרטים תפעוליים שכל חברה ציבורית בארה"ב שולחת לרשות ניירות הערך) ונתונים מובנים (מחירים היסטוריים של מניות).
תשתמשו ב-חיפוש מבוסס-Vertex AI כדי ליצור מנוע חיפוש סמנטי מתקדם לדוחות כספיים לא מובנים. לנתונים המובְנים, תיצרו כלי Python בהתאמה אישית. בסוף, תשתמשו בערכה לפיתוח סוכנים (ADK) כדי ליצור סוכן חכם שיכול להסיק מסקנות לגבי שאילתה של משתמש, להחליט באיזה כלי להשתמש ולסכם את המידע לתשובה עקבית.
הפעולות שתבצעו:
- הגדרת מאגר נתונים של חיפוש מבוסס-Vertex AI לחיפוש סמנטי במסמכים פרטיים.
- יצירת פונקציית Python בהתאמה אישית ככלי לסוכן.
- אפשר להשתמש בערכה לפיתוח סוכנים (ADK) כדי ליצור סוכן עם כמה כלים.
- לשלב אחזור ממקורות נתונים לא מובְנים ומובְנים כדי לענות על שאלות מורכבות.
- בדיקה ואינטראקציה עם סוכן שמציג יכולות חשיבה רציונלית.
מה תלמדו
בשיעור ה-Lab הזה תלמדו:
- מושגי הליבה של Retrieval-Augmented Generation (יצירה משולבת-אחזור, RAG) ו-Agentic RAG.
- איך מטמיעים חיפוש סמנטי במסמכים באמצעות חיפוש מבוסס-Vertex AI.
- איך חושפים נתונים מובְנים לסוכן על ידי יצירת כלים בהתאמה אישית.
- איך ליצור סוכן מרובה-כלים ולתזמן אותו באמצעות הערכה לפיתוח סוכנים (ADK).
- איך סוכנים משתמשים בחשיבה רציונלית ובתכנון כדי לענות על שאלות מורכבות באמצעות מספר מקורות נתונים.
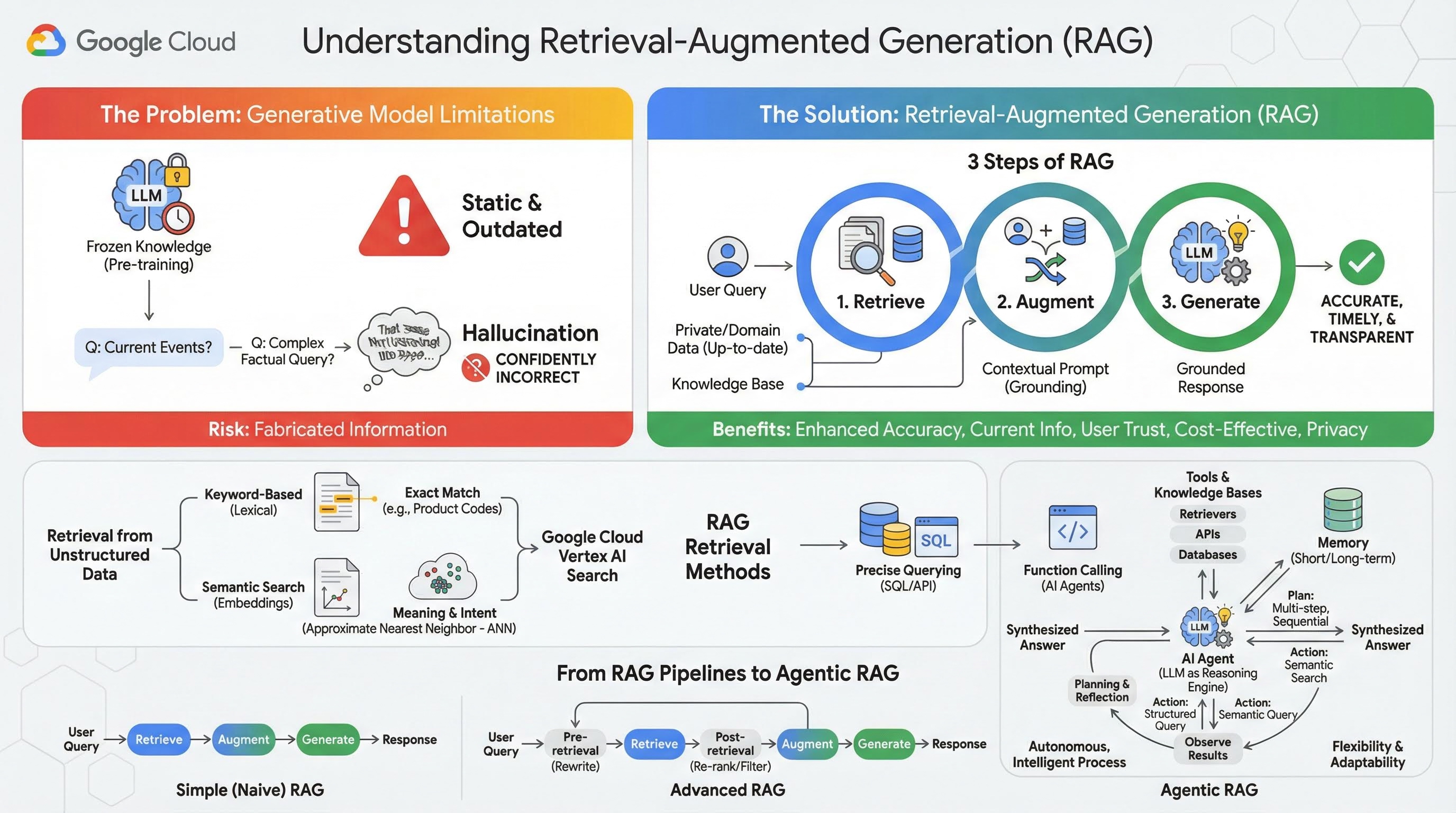
2. הסבר על Retrieval-Augmented Generation (יצירה משולבת-אחזור, RAG)
מודלים גנרטיביים גדולים (מודלים גדולים של שפה או LLM בקיצור, מודלים של שפה ויזואלית וכו') הם עוצמתיים מאוד, אבל יש להם מגבלות מובנות. הידע שלהם קפוא בזמן האימון המקדים, ולכן הוא סטטי ולא עדכני. גם אחרי התאמה עדינה, הידע של המודל לא מתעדכן באופן משמעותי, כי זה לא היעד של שלבי הפוסט-אימון.
המודלים הגדולים של שפה (LLM), ובמיוחד מודלים שמתבססים על 'חשיבה', מאומנים כך שהם מקבלים 'תגמול' על מתן תשובה כלשהי, גם אם אין להם מידע עובדתי שתומך בתשובה כזו. במקרים כאלה אומרים שהמודל "מזייף" – כלומר, מייצר בביטחון מידע שנשמע הגיוני אבל לא נכון עובדתית.
Retrieval-Augmented Generation (יצירה עם שליפה משופרת) הוא דפוס ארכיטקטוני יעיל שנועד לפתור בדיוק את הבעיות האלה. זהו מסגרת ארכיטקטונית שמשפרת את היכולות של מודלים גדולים של שפה (LLM) על ידי חיבור שלהם למקורות ידע חיצוניים ומהימנים בזמן אמת. במקום להסתמך רק על הידע הסטטי שעליו הוא אומן מראש, מודל LLM במערכת RAG מאחזר קודם מידע רלוונטי שקשור לשאילתה של המשתמש, ואז משתמש במידע הזה כדי ליצור תשובה מדויקת יותר, עדכנית יותר ובהתאם להקשר.
הגישה הזו נותנת מענה ישיר לחולשות המשמעותיות ביותר של מודלים גנרטיביים: הידע שלהם קבוע בנקודת זמן מסוימת, והם נוטים ליצור מידע שגוי או "הזיות". במילים אחרות, RAG מאפשר ל-LLM לגשת לנתונים שלכם, שהם פרטיים, ספציפיים לדומיין ועדכניים. התהליך הזה של מתן הקשר עובדתי ל-LLM נקרא הארקה.
3 שלבים של RAG
אפשר לחלק את התהליך הרגיל של יצירה משופרת באמצעות אחזור לשלושה שלבים פשוטים:
- אחזור: כשמשתמש שולח שאילתה, המערכת מחפשת קודם בבסיס ידע חיצוני (כמו מאגר מסמכים, מסד נתונים או אתר) כדי למצוא מידע שרלוונטי לשאילתה.
- הגדלה: המידע שאוחזר משולב עם שאילתת המשתמש המקורית להרחבת ההנחיה. הטכניקה הזו נקראת לפעמים "הוספת פרטים להנחיה", כי היא מעשירה את ההנחיה בהקשר עובדתי.
- יצירה: ההנחיה המשופרת מוזנת ל-LLM, ואז המודל יוצר תשובה. מכיוון שהמודל קיבל נתונים רלוונטיים ועובדתיים, הפלט שלו מבוסס על עובדות והסיכוי שהוא יהיה לא מדויק או לא עדכני נמוך בהרבה.
היתרונות של RAG
ההשקה של מסגרת RAG שינתה את הדרך שבה אנחנו בונים אפליקציות AI מעשיות ואמינות. היתרונות העיקריים של התכונה:
- שיפור הדיוק והפחתת ההזיות: על ידי ביסוס התשובות על עובדות חיצוניות שניתנות לאימות, RAG מפחית באופן משמעותי את הסיכון שה-LLM ימציא מידע.
- גישה למידע עדכני: אפשר לחבר מערכות RAG למאגרי ידע שמתעדכנים כל הזמן, וכך הן יכולות לספק תשובות שמבוססות על המידע העדכני ביותר. זה משהו שמודל LLM שאומן באופן סטטי לא יכול לעשות.
- הגברת האמון של המשתמשים והשקיפות: מכיוון שהתשובה של מודל ה-LLM מבוססת על מסמכים שאוחזרו, המערכת יכולה לספק ציטוטים וקישורים למקורות שלה. כך המשתמשים יכולים לאמת את המידע בעצמם, ולבטוח באפליקציה.
- יעילות מבחינת עלות: כוונון עדין או אימון מחדש של מודל LLM עם נתונים חדשים הם תהליכים יקרים מבחינה חישובית וכלכלית. בעזרת RAG, כדי לעדכן את הידע של המודל צריך רק לעדכן את מקור הנתונים החיצוני, וזה הרבה יותר יעיל.
- התמחות בדומיין ופרטיות: RAG מאפשר לאנשים ולארגונים להפוך את הנתונים הפרטיים והקנייניים שלהם לזמינים ל-LLM בזמן השאילתה, בלי לכלול את המידע האישי הרגיש הזה בקבוצת הנתונים לאימון של המודל. כך אפשר להשתמש באפליקציות עוצמתיות שמתאימות לדומיין, תוך שמירה על פרטיות הנתונים והאבטחה שלהם.
שליפה
השלב 'אחזור' הוא הליבה של כל מערכת RAG. האיכות והרלוונטיות של המידע שאנחנו מאחזרים משפיעות ישירות על האיכות והרלוונטיות של התשובה הסופית שנוצרת. כדי שאפליקציית RAG תהיה יעילה, היא צריכה לאחזר מידע מסוגים שונים של מקורות נתונים באמצעות טכניקות שונות. שיטות השליפה העיקריות מתחלקות לשלוש קטגוריות: מבוססות מילות מפתח, סמנטיות ומובְנות.
אחזור מנתונים לא מובנים
בעבר, אחזור נתונים לא מובנים היה שם נוסף לחיפוש מסורתי. הוא עבר כמה שינויים, ואתם יכולים ליהנות משתי הגישות העיקריות.
חיפוש סמנטי הוא הטכניקה היעילה ביותר שאפשר להריץ בהיקף גדול ב-Google Cloud עם ביצועים מתקדמים ורמת שליטה גבוהה.
- חיפוש מבוסס מילות מפתח (לקסיקלי): זהו הגישה המסורתית לחיפוש, שקיימת עוד ממערכות אחזור המידע הראשונות של שנות ה-70. חיפוש לקסיקלי פועל על ידי התאמה של המילים המילוליות (או 'אסימונים') בשאילתה של משתמש לאותן מילים בדיוק במסמכים בתוך מאגר ידע. האפשרות הזו יעילה מאוד לשאילתות שבהן חשוב לדייק במונחים ספציפיים, כמו קודי מוצרים, סעיפים משפטיים או שמות ייחודיים.
- חיפוש סמנטי: חיפוש סמנטי, או "חיפוש עם משמעות", הוא גישה מודרנית יותר שמטרתה להבין את הכוונה של המשתמש ואת המשמעות ההקשרית של השאילתה שלו, ולא רק את מילות המפתח המילוליות. חיפוש סמנטי מודרני מבוסס על הטמעה – טכניקה של למידת מכונה שממפה נתונים מורכבים עם הרבה ממדים למרחב וקטורי עם פחות ממדים של וקטורים מספריים. הווקטורים האלה מתוכננים כך שטקסטים עם משמעויות דומות ממוקמים קרוב זה לזה במרחב הווקטורי. חיפוש של "What are the best dog breeds for families?" [מהם הגזעים הטובים ביותר של כלבים למשפחות?] מומר לווקטור, ואז המערכת מחפשת וקטורים של מסמכים שהם ה "שכנים הקרובים" שלו במרחב הזה. כך הוא יכול למצוא מסמכים שמתייחסים ל'גולדן רטריבר' או ל'כלבים ידידותיים', גם אם הם לא מכילים את המילה המדויקת 'כלב'. החיפוש הרב-ממדי הזה מתבצע ביעילות באמצעות אלגוריתמים של חיפוש שכנים קרובים משוער (ANN). במקום להשוות את וקטור השאילתה לכל וקטור מסמך (מה שיהיה איטי מדי במערכי נתונים גדולים), אלגוריתמי ANN משתמשים במבני אינדקס חכמים כדי למצוא במהירות וקטורים שהם כנראה הכי קרובים.
אחזור מנתונים מובְנים
לא כל הידע הקריטי מאוחסן במסמכים לא מובנים. לרוב, המידע הכי מדויק ובעל הערך נמצא בפורמטים מובְנים כמו מסדי נתונים יחסיים, מסדי נתונים של NoSQL או סוגים מסוימים של ממשקי API, כמו API בארכיטקטורת REST לנתוני מזג אוויר או למחירי מניות.
השליפה מנתונים מובְנים היא בדרך כלל ישירה ומדויקת יותר מאשר חיפוש בטקסט לא מובנה. במקום לחפש דמיון סמנטי, אפשר לתת למודלים של שפה את היכולת ליצור ולהריץ שאילתה מדויקת, כמו שאילתת SQL במסד נתונים או קריאה ל-API של מזג האוויר למיקום ותאריך מסוימים.
התכונה הזו מיושמת באמצעות בקשה להפעלת פונקציה, אותה טכניקה שמפעילה סוכני AI. היא מאפשרת למודלים של שפה לקיים אינטראקציה עם קוד שניתן להפעלה ומערכות חיצוניות בצורה דטרמיניסטית ומובנית.
3. מצינורות RAG ל-Agentic RAG
הקונספט של RAG התפתח, וכך גם הארכיטקטורות להטמעה שלו. מה שהתחיל כפייפליין פשוט ולינארי התפתח למערכת דינמית וחכמה שמנוהלת על ידי סוכני AI.
- Simple (or Naive) RAG: זו הארכיטקטורה הבסיסית שדיברנו עליה עד עכשיו: תהליך ליניארי בן שלושה שלבים של אחזור, הרחבה ויצירה. הוא מגיב; הוא פועל לפי נתיב קבוע לכל שאילתה והוא יעיל מאוד למשימות פשוטות של שאלות ותשובות.
- RAG מתקדם: שיטה מתקדמת שבה מתווספים שלבים נוספים לפייפליין כדי לשפר את איכות ההקשר שאוחזר. השיפורים האלה יכולים להתרחש לפני או אחרי שלב האחזור.
- לפני שליפת המידע: אפשר להשתמש בטכניקות כמו שכתוב או הרחבה של השאילתה. יכול להיות שהמערכת תנתח את השאילתה הראשונית ותנסח אותה מחדש כדי שהיא תהיה יעילה יותר למערכת האחזור.
- אחרי השליפה: אחרי שליפה של קבוצה ראשונית של מסמכים, אפשר להחיל מודל לדירוג מחדש כדי לתת למסמכים ציון לפי הרלוונטיות שלהם, ולהציג את המסמכים הטובים ביותר בראש התוצאות. זה חשוב במיוחד בחיפוש היברידי. שלב נוסף אחרי אחזור המידע הוא סינון או דחיסה של ההקשר שאוחזר, כדי לוודא שרק המידע הבולט ביותר מועבר למודל ה-LLM.
- Agentic RAG: זוהי ארכיטקטורת RAG אג'נטית מתקדמת, שמייצגת שינוי מהותי מצינור קבוע לתהליך אוטונומי וחכם. במערכת Agentic RAG, כל תהליך העבודה מנוהל על ידי סוכני AI שיכולים להסיק מסקנות, לתכנן ולבחור באופן דינמי את הפעולות שלהם.
כדי להבין מה זה Agentic RAG, צריך קודם להבין מה זה סוכן AI. סוכן הוא יותר מסתם מודל שפה גדול (LLM). זו מערכת עם כמה רכיבים מרכזיים:
- מודל LLM כמנוע חשיבה רציונלית: הסוכן משתמש במודל LLM מתקדם כמו Gemini לא רק כדי ליצור טקסט, אלא כ "מוח" מרכזי לתכנון, לקבלת החלטות ולפירוק משימות מורכבות.
- ערכת כלים: לסוכן יש גישה לערכת כלים של פונקציות שהוא יכול להשתמש בהן כדי להשיג את המטרות שלו. הכלים האלה יכולים להיות כל דבר: מחשבון, API של חיפוש באינטרנט, פונקציה לשליחת אימייל, או, וזה הכי חשוב למעבדה הזו – כלי אחזור למאגרי הידע השונים שלנו.
- זיכרון: אפשר לתכנן סוכנים עם זיכרון לטווח קצר (כדי לזכור את ההקשר של השיחה הנוכחית) וזיכרון לטווח ארוך (כדי לשלוף מידע מאינטראקציות קודמות), וכך לאפשר חוויות מותאמות אישית ועקביות יותר.
- תכנון ורפלקציה: לסוכנים המתקדמים ביותר יש דפוסי חשיבה מתוחכמים. הם יכולים לקבל מטרה מורכבת וליצור תוכנית רב-שלבית כדי להשיג אותה. לאחר מכן הם יכולים לבצע את התוכנית הזו, ואפילו להסיק מסקנות מהתוצאות של הפעולות שלהם, לזהות שגיאות ולתקן את הגישה שלהם כדי לשפר את התוצאה הסופית.
השימוש ב-Agentic RAG משנה את כללי המשחק כי הוא מוסיף שכבה של אוטונומיה ואינטליגנציה שחסרה בצינורות סטטיים.
- גמישות ויכולת הסתגלות: סוכן לא מוגבל לנתיב אחזור יחיד. בהינתן שאילתת משתמש, הוא יכול להסיק מהו מקור המידע הטוב ביותר. יכול להיות שהוא יחליט קודם לשלוח שאילתה למסד הנתונים המובנה, ואז לבצע חיפוש סמנטי במסמכים לא מובנים, ואם הוא עדיין לא ימצא תשובה, הוא ישתמש בכלי של חיפוש Google כדי לחפש באינטרנט הציבורי, והכול במסגרת ההקשר של בקשת משתמש אחת.
- הסקת מסקנות מורכבת עם כמה שלבים: הארכיטקטורה הזו מצטיינת בטיפול בשאילתות מורכבות שדורשות כמה שלבים עוקבים של אחזור ועיבוד.
נניח שאתם רוצים להריץ את השאילתה: "Find the top 3 sci-fi movies directed by Christopher Nolan, and for each, provide a brief plot summary". פייפליין RAG פשוט ייכשל.
אבל נציג יכול לפרק את זה:
- תוכנית: קודם צריך למצוא את הסרטים. אחר כך, אני צריך למצוא את העלילה של כל סרט.
- פעולה 1: שימוש בכלי לנתונים מובְנים כדי לשלוח שאילתה למסד נתונים של סרטים ולחפש את 3 סרטי המדע הבדיוני המובילים של נולאן, לפי דירוג בסדר יורד.
- תצפית 1: הכלי מחזיר את התוצאות 'התחלה', 'בין כוכבים' ו'טנט'.
- פעולה 2: משתמשים בכלי לנתונים לא מובְנים (חיפוש סמנטי) כדי למצוא את העלילה של הסרט "התחלה".
- תצפית 2: התרשים מאוחזר.
- פעולה 3: חוזרים על הפעולה עבור הסרט "Interstellar".
- פעולה 4: חוזרים על הפעולה עבור הסרט Tenet.
- סיכום סופי: שילוב של כל המידע שנאסף לתשובה אחת עקבית למשתמש.
4. הגדרת הפרויקט
חשבון Google
אם אין לכם חשבון Google אישי, אתם צריכים ליצור חשבון Google.
משתמשים בחשבון לשימוש אישי במקום בחשבון לצורכי עבודה או בחשבון בית ספרי.
כניסה למסוף Google Cloud
נכנסים למסוף Google Cloud באמצעות חשבון Google אישי.
הפעלת חיוב
שימוש בחשבון לחיוב בתקופת ניסיון (אופציונלי)
כדי להשתתף בסדנה הזו, צריך חשבון לחיוב עם יתרה מסוימת. כדי להתחיל, משתמשים בקרדיטים שמופיעים בבאנר בחלק העליון של ה-codelab. אם כבר קישרתם חשבון לחיוב, אתם יכולים לדלג על השלב הזה.
הגדרה של חשבון לחיוב לשימוש אישי
אם הגדרתם חיוב באמצעות קרדיטים ל-Google Cloud, אתם יכולים לדלג על השלב הזה.
כדי להגדיר חשבון לחיוב לשימוש אישי, עוברים לכאן כדי להפעיל את החיוב ב-Cloud Console.
הערות:
- העלות של השלמת ה-Lab הזה במשאבי Cloud צריכה להיות פחות מ-1$.
- כדי למחוק משאבים ולמנוע חיובים נוספים, אפשר לבצע את השלבים בסוף ה-Lab הזה.
- משתמשים חדשים זכאים לתקופת ניסיון בחינם בשווי 300$.
יצירת פרויקט (אופציונלי)
אם אין לכם פרויקט שאתם רוצים להשתמש בו בסדנה הזו, אתם יכולים ליצור פרויקט חדש כאן.
5. פתיחת Cloud Shell Editor
- כדי לעבור ישירות אל Cloud Shell Editor, לוחצים על הקישור הזה.
- אם תתבקשו לאשר בשלב כלשהו היום, תצטרכו ללחוץ על אישור כדי להמשיך.
- אם הטרמינל לא מופיע בתחתית המסך, פותחים אותו:
- לוחצים על הצגה.
- לוחצים על Terminal (מסוף)
 .
.
- בטרמינל, מגדירים את הפרויקט באמצעות הפקודה הבאה:
gcloud config set project [PROJECT_ID]- דוגמה:
gcloud config set project lab-project-id-example - אם אתם לא זוכרים את מזהה הפרויקט, אתם יכולים להציג רשימה של כל מזהי הפרויקטים באמצעות הפקודה:
gcloud projects list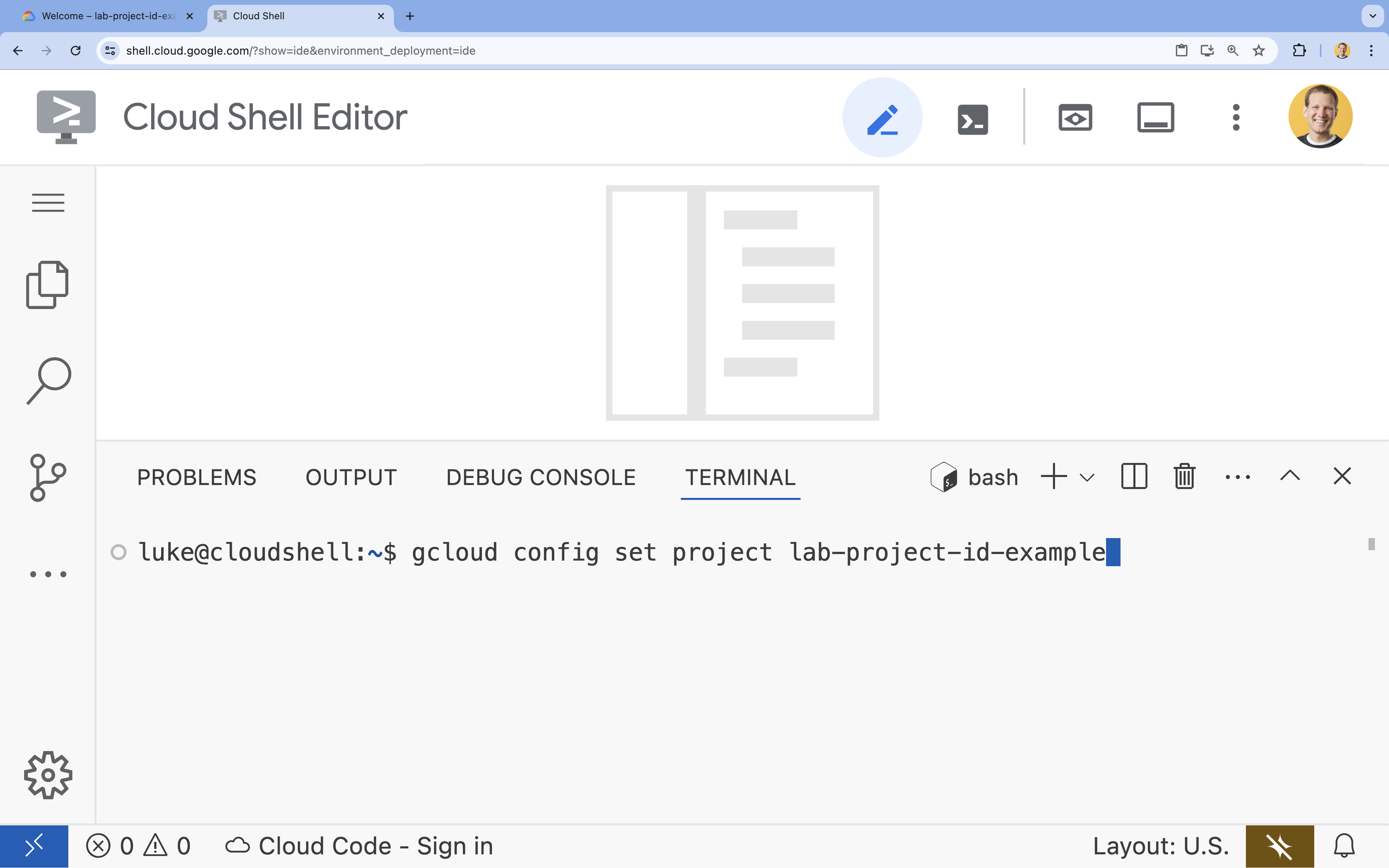
- דוגמה:
- תוצג ההודעה הבאה:
Updated property [core/project].
6. הפעלת ממשקי ה-API
כדי להשתמש ב-ערכה לפיתוח סוכנים (ADK) וב-חיפוש מבוסס-Vertex AI, צריך להפעיל את ממשקי ה-API הנדרשים בפרויקט שלכם ב-Google Cloud.
- בטרמינל, מפעילים את ממשקי ה-API:
gcloud services enable \ aiplatform.googleapis.com \ discoveryengine.googleapis.com
מבוא לממשקי ה-API
- Vertex AI API (
aiplatform.googleapis.com) מאפשר לסוכן לתקשר עם מודלים של Gemini כדי להסיק מסקנות וליצור תוכן. - Discovery Engine API (
discoveryengine.googleapis.com) מפעיל את חיפוש מבוסס-Vertex AI, ומאפשר לכם ליצור מאגרי נתונים ולבצע חיפושים סמנטיים במסמכים לא מובְנים.
7. הגדרת הסביבה
לפני שמתחילים לכתוב את הקוד של נציג ה-AI, צריך להכין את סביבת הפיתוח, להתקין את הספריות הנדרשות וליצור את קובצי הנתונים הדרושים.
יצירת סביבה וירטואלית והתקנת יחסי תלות
- יוצרים ספרייה לסוכן ועוברים אליה. מריצים את הקוד הבא בטרמינל:
mkdir financial_agent cd financial_agent - יוצרים סביבה וירטואלית:
uv venv --python 3.12 - מפעילים את הסביבה הווירטואלית:
source .venv/bin/activate - מתקינים את הערכה לפיתוח סוכנים (ADK) ואת pandas.
uv pip install google-adk pandas
יצירת נתוני מחירי המניות
המעבדה דורשת נתוני מלאי היסטוריים ספציפיים כדי להדגים את היכולת של הסוכן להשתמש בכלים מובנים, ולכן תצטרכו ליצור קובץ CSV עם הנתונים האלה.
- בספרייה
financial_agent, יוצרים את הקובץgoog.csvעל ידי הרצת הפקודה הבאה בטרמינל:cat <<EOF > goog.csv Date,Open,High,Low,Close,Adj Close,Volume 2023-01-03,89.830002,91.550003,89.019997,89.699997,89.699997,20738500 2023-03-31,101.440002,103.889999,101.040001,103.730003,103.730003,36823200 2023-06-30,120.870003,122.029999,120.300003,120.970001,120.970001,23824700 2023-09-29,134.080002,134.550003,131.320007,131.850006,131.850006,21124200 2025-07-10,185.000000,188.000000,184.500000,186.500000,186.500000,25000000 EOF
הגדרת משתני סביבה
- בספרייה
financial_agent, יוצרים קובץ.envכדי להגדיר את משתני הסביבה של הסוכן. ההגדרה הזו מציינת ל-ADK באיזה פרויקט, מיקום ומודל להשתמש. מריצים את הקוד הבא בטרמינל:# Create the .env file using the captured variables cat << EOF > .env GOOGLE_GENAI_USE_VERTEXAI=TRUE GOOGLE_CLOUD_PROJECT="${GOOGLE_CLOUD_PROJECT}" GOOGLE_CLOUD_LOCATION="us-central1" EOF
הערה: בהמשך המעבדה, אם תצטרכו לשנות את הקובץ .env אבל הוא לא יופיע בספרייה financial_agent, נסו להפעיל או להשבית את האפשרות להצגת קבצים מוסתרים בכלי לעריכת Cloud Shell באמצעות פריט התפריט View / Toggle Hidden Files (תצוגה / הפעלה או השבתה של קבצים מוסתרים).
8. יצירת מאגר נתונים של חיפוש מבוסס-Vertex AI
כדי לאפשר לסוכן לענות על שאלות לגבי הדוחות הכספיים של Alphabet, תיצרו מאגר נתונים ב-חיפוש מבוסס-Vertex AI שמכיל את מסמכי הדיווח הציבוריים שלה לרשות ניירות הערך האמריקאית (SEC).
- בכרטיסייה חדשה בדפדפן, פותחים את Cloud Console (console.cloud.google.com) ועוברים אל AI Applications באמצעות סרגל החיפוש בחלק העליון.
- אם מוצגת בקשה לעשות זאת, מסמנים את התיבה של התנאים וההגבלות ולוחצים על המשך והפעלת ה-API.
- בתפריט הניווט שמימין, בוחרים באפשרות מאגרי נתונים.
- לוחצים על + יצירת מאגר נתונים.
- מאתרים את הכרטיס Cloud Storage ולוחצים על בחירה.
- במקור הנתונים, בוחרים באפשרות מסמכים לא מובְנים.

- במקור הייבוא (Select a folder or a file you want to import – בחירת תיקייה או קובץ לייבוא), מזינים את הנתיב של Google Cloud Storage
cloud-samples-data/gen-app-builder/search/alphabet-sec-filings. - לוחצים על המשך.
- משאירים את המיקום כglobal.
- בשדה שם מאגר הנתונים, מזינים
alphabet-sec-filings - מרחיבים את הקטע אפשרויות לעיבוד מסמכים.

- ברשימה הנפתחת Default document parser (מנתח מסמכים שמוגדר כברירת מחדל), בוחרים באפשרות Layout Parser (מנתח פריסות).
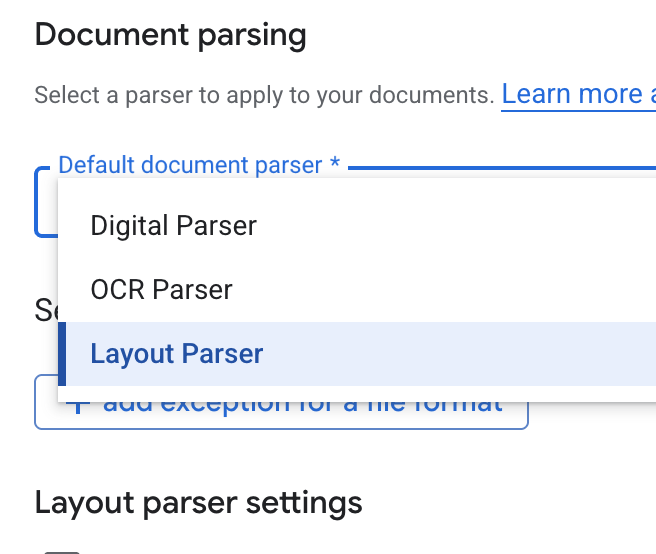
- באפשרויות של הגדרות מנתח הפריסות, בוחרים באפשרות הפעלת הערות בטבלה ובאפשרות הפעלת הערות בתמונה.
- לוחצים על המשך.
- בוחרים באפשרות General pricing (תמחור כללי) בתור מודל התמחור (מודל של תשלום לפי שימוש), ולוחצים על Create (יצירה).
- הייבוא של המסמכים למאגר הנתונים יתחיל.
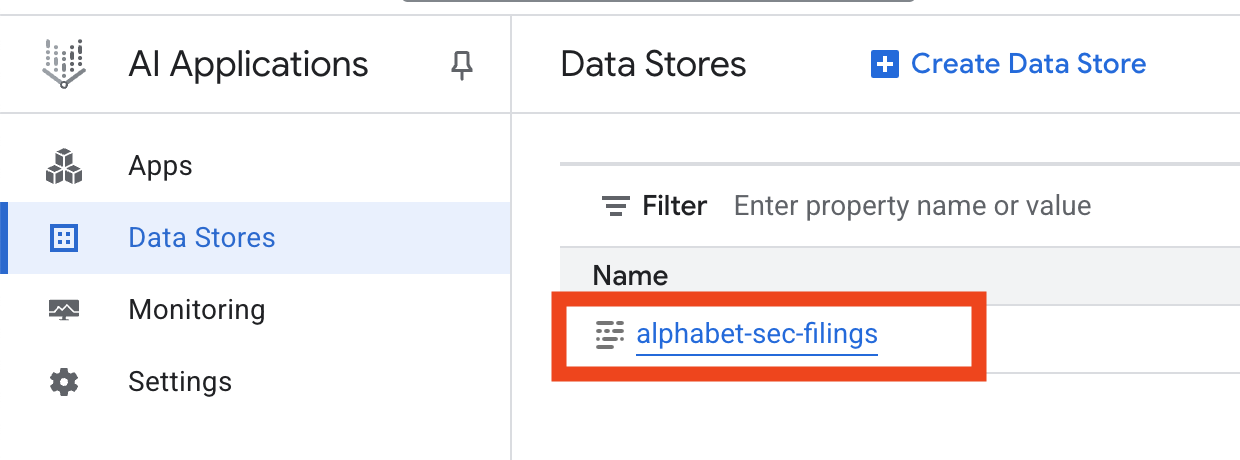
- לוחצים על השם של מאגר הנתונים ומעתיקים את המזהה שלו מהטבלה 'מאגרי נתונים'. תצטרכו אותו בשלב הבא.
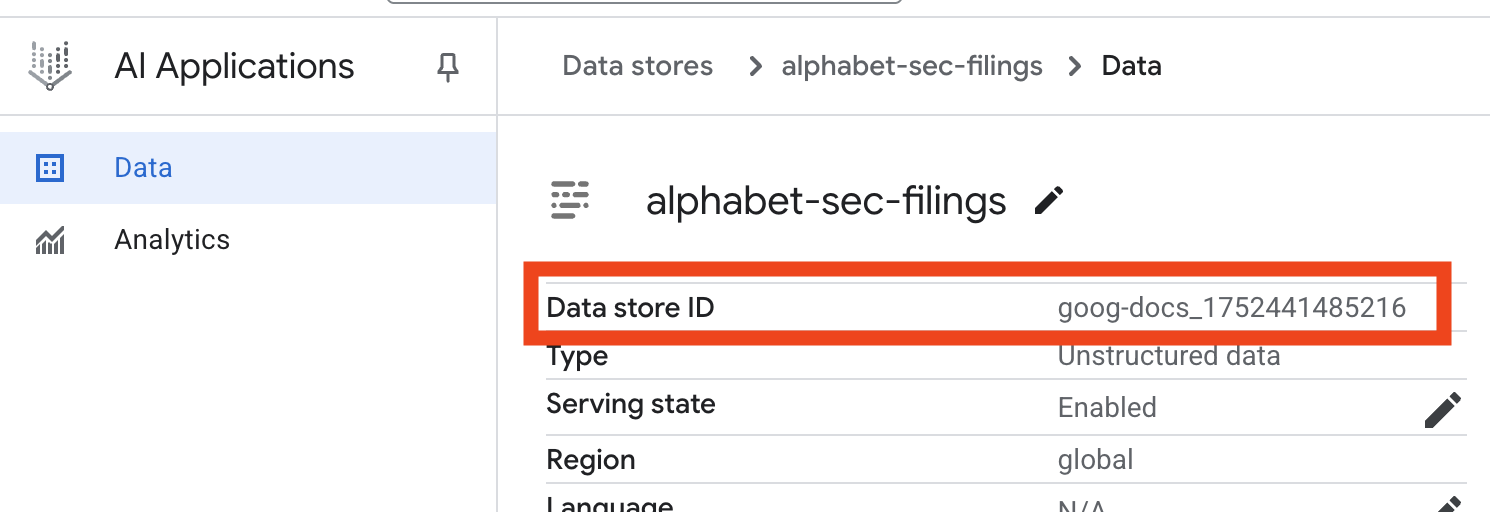
- פותחים את הקובץ
.envב-Cloud Shell Editor ומוסיפים את מזהה מאגר הנתונים בתורDATA_STORE_ID="YOUR_DATA_STORE_ID"(מחליפים אתYOUR_DATA_STORE_IDבמזהה בפועל מהשלב הקודם).הערה: ייבוא, ניתוח ואינדוקס של הנתונים במאגר הנתונים יימשכו כמה דקות. כדי לבדוק את התהליך, לוחצים על השם של מאגר הנתונים כדי לפתוח את המאפיינים שלו, ואז פותחים את הכרטיסייה פעילות. מחכים שהסטטוס יהפוך ל'הייבוא הושלם'.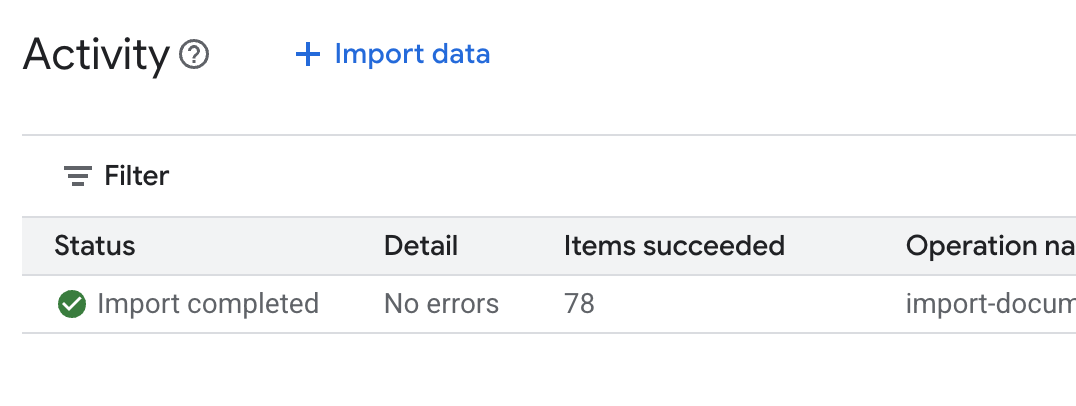
9. יצירת כלי בהתאמה אישית לנתונים מובְנים
בשלב הבא, תיצרו פונקציית Python שתשמש ככלי עבור הסוכן. הכלי הזה יקרא את הקובץ goog.csv כדי לאחזר את מחירי המניות ההיסטוריים לתאריך מסוים.
- בספרייה
financial_agent, יוצרים קובץ חדש בשםagent.py. מריצים את הפקודה הבאה בטרמינל:cloudshell edit agent.py - מוסיפים את קוד Python הבא אל
agent.py. הקוד הזה מייבא יחסי תלות ומגדיר את הפונקציהget_stock_price.from datetime import datetime import os import logging import google.cloud.logging from google.adk.tools import VertexAiSearchTool from google.adk.tools.agent_tool import AgentTool from google.adk.agents import LlmAgent import pandas as pd def get_stock_price(date: str) -> dict: """Gets the closing stock price for a given date. Args: date: The date to get the stock price for, in YYYY-MM-DD format. Returns: A dictionary containing the closing price, or an error message if the date is not found or the format is incorrect. """ try: # Load the CSV file df = pd.read_csv('goog.csv') # Convert the 'Date' column to datetime objects df['Date'] = pd.to_datetime(df['Date']) # Convert the input string to a datetime object query_date = datetime.strptime(date, '%Y-%m-%d') # Find the row for the given date row = df[df['Date'] == query_date] if not row.empty: # Get the closing price close_price = row['Close'].iloc[0] return {"status": "success", "date": date, "closing_price": close_price} else: return {"status": "error", "message": f"No data found for date: {date}"} except FileNotFoundError: return {"status": "error", "message": "Stock data file (goog.csv) not found."} except Exception as e: return {"status": "error", "message": f"An error occurred: {str(e)}"}
שימו לב למחרוזת התיעוד המפורטת של הפונקציה. היא מסבירה מה הפונקציה עושה, מה הפרמטרים שלה (Args) ומה היא מחזירה (Returns). ה-ADK משתמש במחרוזת התיעוד הזו כדי ללמד את הסוכן איך ומתי להשתמש בכלי הזה.
10. פיתוח והרצה של סוכן RAG
עכשיו הגיע הזמן להרכיב את הסוכן. תשלבו את הכלי חיפוש מבוסס-Vertex AI לנתונים לא מובנים עם הכלי המותאם אישית get_stock_price לנתונים מובנים.
- מוסיפים את הקוד הבא לקובץ
agent.py. הקוד הזה מייבא את המחלקות הנדרשות של ADK, יוצר מופעים של הכלים ומגדיר את הסוכן.logging.basicConfig(level=logging.INFO) cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() # 1. Create the Vertex AI Search tool full_datastore_id = f"projects/{os.environ['GOOGLE_CLOUD_PROJECT']}/locations/global/collections/default_collection/dataStores/{os.environ['DATA_STORE_ID']}" vertex_ai_search_tool = VertexAiSearchTool( data_store_id=full_datastore_id ) # 2. Define the Search+Q&A agent # Since we cannot combine tools with other tools in a single agent, # we create a separate Search+Q&A agent which will be used as a tool by the main root agent. doc_qa_agent = LlmAgent( name="search_and_qna_agent", model="gemini-2.5-flash", tools=[vertex_ai_search_tool], instruction="""You are a helpful assistant that answers questions based on information found in the document store. Use the search tool to find relevant information before answering. If the answer isn't in the documents, say that you couldn't find the information. """, description="Answers questions using a specific Vertex AI Search datastore.", ) # 3. Define the root agent with 2 tools. root_agent = LlmAgent( name="financial_agent", model="gemini-2.5-flash", tools=[ AgentTool(doc_qa_agent), get_stock_price, ], instruction="""You are an Financial Analytics Agent that answers question about Alphabet stock prices (using get_stock_price tool) and historical performance based on the data in Vertex AI Search datastore (using doc_qa_agent tool).""" ) - במסוף, בתוך ספריית
financial_agent, מפעילים את ממשק האינטרנט של ADK כדי ליצור אינטראקציה עם הסוכן:adk web ~ - לוחצים על הקישור שמופיע בפלט של הטרמינל (בדרך כלל
http://127.0.0.1:8000) כדי לפתוח את ממשק המשתמש של ADK Dev בדפדפן.
11. בדיקת הנציג
עכשיו אפשר לבדוק את היכולת של הסוכן להסיק מסקנות ולהשתמש בכלים שלו כדי לענות על שאלות מורכבות.
- בממשק המשתמש של ADK Dev, מוודאים ש
financial_agentנבחר בתפריט הנפתח. - נסו לשאול שאלה שדורשת מידע מתוך מסמכי ה-SEC (נתונים לא מובְנים). מזינים את השאילתה הבאה בצ'אט:
What were the total revenues for the quarter ending on March 31, 2023?search_and_qna_agent, שמשתמש ב-VertexAiSearchToolכדי למצוא את התשובה במסמכים הפיננסיים. - בשלב הבא, שואלים שאלה שנדרש בה שימוש בכלי המותאם אישית (נתונים מובְנים). שימו לב: פורמט התאריך בהנחיה לא חייב להיות זהה בדיוק לפורמט שנדרש על ידי הפונקציה. מודל ה-LLM חכם מספיק כדי לשנות את הפורמט.
What was the closing stock price for Alphabet on July 10, 2025?get_stock_price. אפשר ללחוץ על סמל הכלי בצ'אט כדי לבדוק את בקשה להפעלת פונקציה ואת התוצאה שלה. - לבסוף, שואלים שאלה מורכבת שמחייבת את הסוכן להשתמש בשני הכלים ולסנתז את התוצאות.
According to the 10-Q filing for the period ending March 31, 2023, what were the company's net cash provided by operating activities, and what was the stock's closing price on that date?- קודם כול, הוא ישתמש ב-
VertexAiSearchToolכדי למצוא את פרטי תזרים המזומנים במסמכי ה-SEC. - לאחר מכן, המערכת תזהה את הצורך במחיר המניה ותקרא לפונקציה
get_stock_priceעם התאריך2023-03-31. - לבסוף, הוא ישלב את שני חלקי המידע לתשובה מקיפה אחת.
- קודם כול, הוא ישתמש ב-
- כשמסיימים, אפשר לסגור את כרטיסיית הדפדפן וללחוץ על
CTRL+Cבמסוף כדי לעצור את שרת ה-ADK.
12. בחירת שירות למשימה
חיפוש מבוסס-Vertex AI הוא לא שירות החיפוש הווקטורי היחיד שבו אפשר להשתמש. אפשר גם להשתמש בשירות מנוהל שמבצע אוטומטית את כל התהליך של יצירה משופרת באמצעות אחזור: Vertex AI RAG Engine.
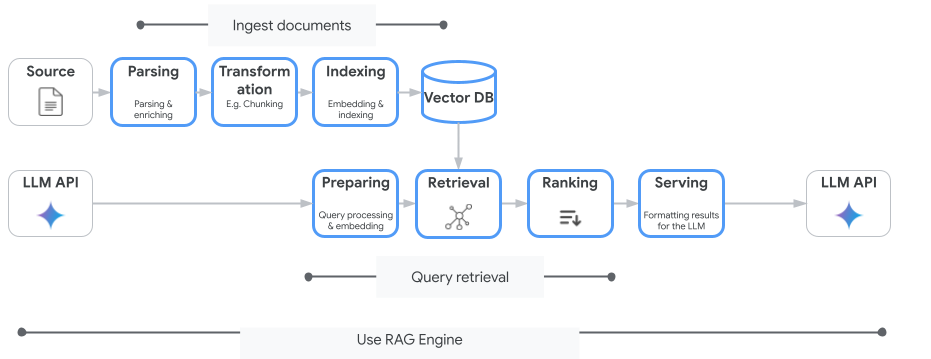
הוא מטפל בכל השלבים, החל מהוספת מסמכים ועד לאחזור ולדירוג מחדש. מנוע RAG תומך במספר מאגרי וקטורים, כולל Pinecone ו-Weaviate.
אפשר גם לארח בעצמכם הרבה מסדי נתונים וקטוריים ייעודיים, או להשתמש ביכולות של אינדקס וקטורי במנועי מסדי נתונים, כמו pgvector בשירות PostgreSQL (למשל AlloyDB או חיפוש וקטורי ב-BigQuery).
שירותים נוספים שתומכים בחיפוש וקטורי:
ההנחיות הכלליות לבחירת שירות מסוים ב-Google Cloud הן:
- אם כבר יש לכם תשתית של חיפוש וקטורים שפועלת וניתנת להרחבה, אתם יכולים לפרוס אותה ב-Google Kubernetes Engine, כמו Weaviate או DIY PostgreSQL.
- אם הנתונים שלכם נמצאים ב-BigQuery, ב-AlloyDB, ב-Firestore או בכל מסד נתונים אחר, כדאי להשתמש ביכולות החיפוש הווקטורי שלו אם אפשר לבצע חיפוש סמנטי בהיקף גדול כחלק משאילתה גדולה יותר במסד הנתונים הזה. לדוגמה, אם יש לכם תיאורי מוצרים או תמונות בטבלה ב-BigQuery, הוספה של עמודה עם הטמעה של טקסט או תמונה תאפשר לכם להשתמש בחיפוש דמיון בהיקף גדול. אינדקסים של וקטורים עם תמיכה בחיפוש ScANN יכולים להכיל מיליארדי פריטים באינדקס.
- אם אתם רוצים להתחיל במהירות עם מינימום מאמץ בפלטפורמה מנוהלת, כדאי לבחור ב-חיפוש מבוסס-Vertex AI – מנוע חיפוש מנוהל במלואו ו-API לאחזור מידע שמתאים לתרחישי שימוש מורכבים בארגונים שדורשים איכות גבוהה, מדרגיות ואמצעי בקרת גישה מפורטים. הוא מאפשר להתחבר בקלות למקורות נתונים מגוונים של ארגונים ולחפש בכמה מקורות.
- אם אתם מחפשים פתרון שמאפשר למפתחים לאזן בין קלות השימוש לבין התאמה אישית, כדאי להשתמש ב-Vertex AI RAG Engine. הוא מאפשר יצירת אב טיפוס ופיתוח מהירים בלי להתפשר על גמישות.
- דוגמאות לארכיטקטורות של Retrieval-Augmented Generation
13. סיכום
מעולה! יצרתם ובדקתם בהצלחה סוכן AI עם Retrieval-Augmented Generation (יצירה משולבת-אחזור, RAG). למדתם איך:
- יצירת מאגר ידע למסמכים לא מובנים באמצעות יכולות החיפוש הסמנטי המתקדמות של חיפוש מבוסס-Vertex AI.
- תפתח פונקציית Python מותאמת אישית שתשמש ככלי לאחזור נתונים מובְנים.
- איך משתמשים בערכה לפיתוח סוכנים (ADK) כדי ליצור סוכן מרובה כלים שמבוסס על Gemini.
- ליצור סוכן שיכול לבצע ניתוח מורכב עם כמה שלבים כדי לענות על שאילתות שדורשות סינתזה של מידע מכמה מקורות.
בשיעור ה-Lab הזה נדגים את עקרונות הליבה של Agentic RAG, ארכיטקטורה עוצמתית ליצירת אפליקציות AI חכמות, מדויקות ומודעות-הקשר ב-Google Cloud.
מאב טיפוס לייצור
שיעור ה-Lab הזה הוא חלק מתוכנית הלימודים Production-Ready AI with Google Cloud (בינה מלאכותית מוכנה לייצור עם Google Cloud).
- כאן אפשר לעיין בתוכנית הלימודים המלאה כדי לגשר על הפער בין אב-טיפוס לבין מוצר מוכן לייצור.
- שיתוף ההתקדמות עם ההאשטאג #ProductionReadyAI.