
1. परिचय
खास जानकारी
इस लैब का मकसद, Google Cloud में एंड-टू-एंड एजेंटिक Retrieval-Augmented Generation (RAG) ऐप्लिकेशन डेवलप करने का तरीका सीखना है. इस लैब में, आपको फ़ाइनेंशियल एनालिसिस एजेंट बनाना होगा.यह एजेंट, दो अलग-अलग सोर्स से मिली जानकारी को मिलाकर सवालों के जवाब दे सकता है. ये सोर्स हैं: अनस्ट्रक्चर्ड दस्तावेज़ (Alphabet की तिमाही एसईसी फ़ाइलिंग - वित्तीय स्टेटमेंट और ऑपरेशनल जानकारी, जिसे अमेरिका में हर सार्वजनिक कंपनी, Securities and Exchange Commission को सबमिट करती है) और स्ट्रक्चर्ड डेटा (शेयर की पिछली कीमतें).
अनस्ट्रक्चर्ड फ़ाइनेंशियल रिपोर्ट के लिए, दमदार सिमैंटिक सर्च इंजन बनाने के लिए Vertex AI Search का इस्तेमाल किया जाएगा. स्ट्रक्चर्ड डेटा के लिए, आपको कस्टम Python टूल बनाना होगा. आखिर में, Agent Development Kit (ADK) का इस्तेमाल करके, एक ऐसा इंटेलिजेंट एजेंट बनाया जाएगा जो उपयोगकर्ता की क्वेरी को समझ सके, यह तय कर सके कि किस टूल का इस्तेमाल करना है, और जानकारी को एक साथ जोड़कर जवाब दे सके.
आपको क्या करना होगा
- निजी दस्तावेज़ों में सिमैंटिक सर्च करने के लिए, Vertex AI Search में डेटा स्टोर सेट अप करें.
- एजेंट के लिए, टूल के तौर पर कस्टम Python फ़ंक्शन बनाएं.
- एक से ज़्यादा टूल वाला एजेंट बनाने के लिए, Agent Development Kit (ADK) का इस्तेमाल करें.
- मुश्किल सवालों के जवाब देने के लिए, अनस्ट्रक्चर्ड और स्ट्रक्चर्ड डेटा सोर्स से जानकारी इकट्ठा करें.
- ऐसे एजेंट के साथ टेस्ट करें और उससे इंटरैक्ट करें जो तर्क देने की क्षमता रखता हो.
आपको क्या सीखने को मिलेगा
इस लैब में, आपको इनके बारे में जानकारी मिलेगी:
- Retrieval-Augmented Generation (RAG) और एजेंटिक RAG के मुख्य सिद्धांत.
- Vertex AI Search का इस्तेमाल करके, दस्तावेज़ों में सिमैंटिक सर्च की सुविधा लागू करने का तरीका.
- कस्टम टूल बनाकर, एजेंट को स्ट्रक्चर्ड डेटा दिखाने का तरीका.
- Agent Development Kit (ADK) की मदद से, मल्टी-टूल एजेंट बनाने और उसे व्यवस्थित करने का तरीका.
- एजेंट, कई डेटा सोर्स का इस्तेमाल करके मुश्किल सवालों के जवाब देने के लिए, रीज़निंग और प्लानिंग का इस्तेमाल कैसे करते हैं.
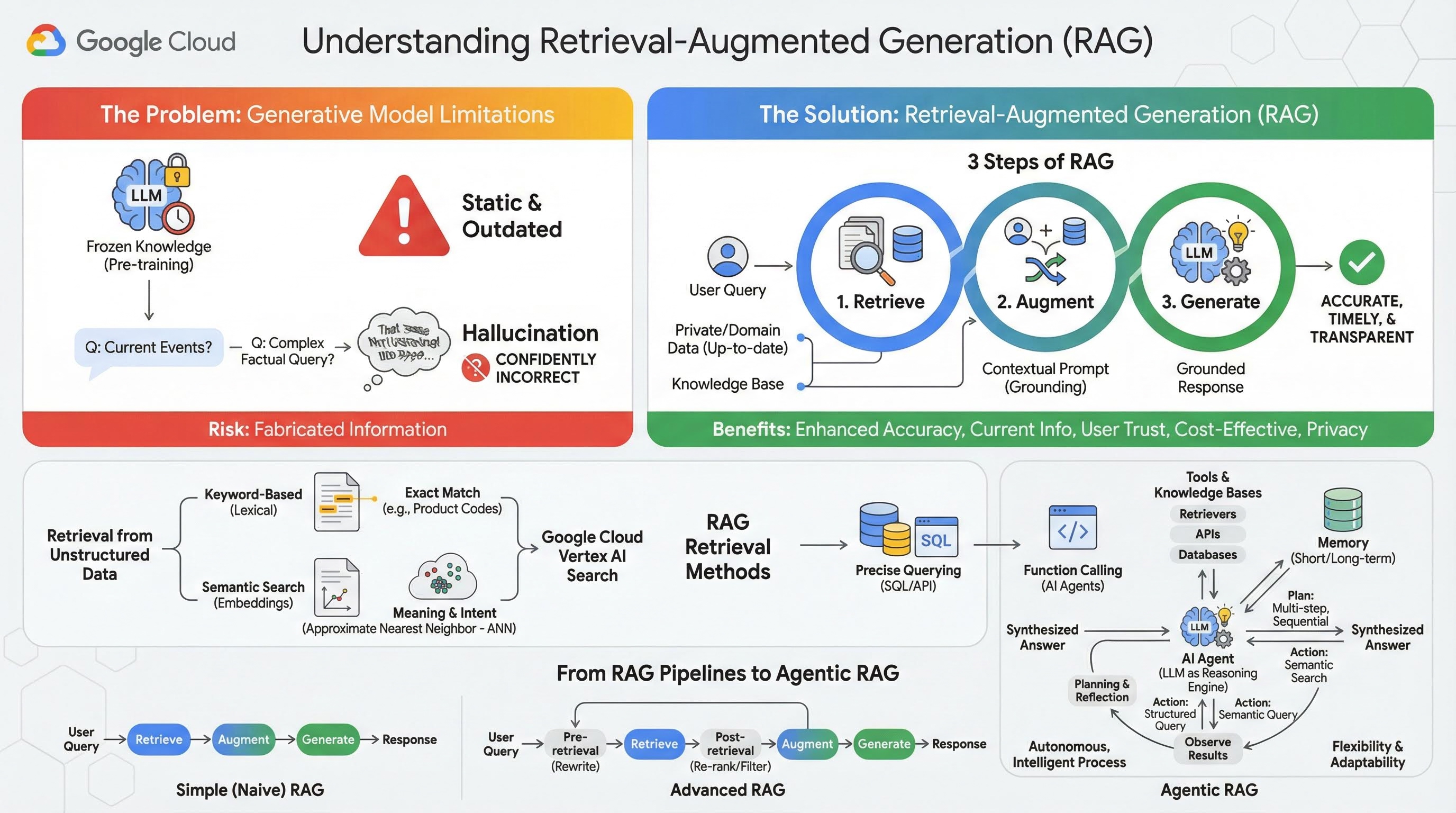
2. रीट्रिवल-ऑगमेंटेड जनरेशन के बारे में जानकारी
लार्ज जनरेटिव मॉडल (लार्ज लैंग्वेज मॉडल या एलएलएम, विज़न-लैंग्वेज मॉडल वगैरह) बहुत ज़्यादा असरदार होते हैं. हालांकि, इनकी कुछ सीमाएं होती हैं. इन मॉडल को प्री-ट्रेनिंग के दौरान जो डेटा दिया जाता है, वे उसी के आधार पर जवाब देते हैं. इसलिए, इनके जवाबों में नई जानकारी शामिल नहीं होती और वे तुरंत पुराने हो जाते हैं. फ़ाइन-ट्यूनिंग के बाद भी, मॉडल का ज्ञान ज़्यादा अपडेट नहीं होता. ऐसा इसलिए, क्योंकि ट्रेनिंग के बाद के चरणों का मकसद यह नहीं होता.
लार्ज लैंग्वेज मॉडल को इस तरह से ट्रेन किया जाता है कि वे कुछ जवाब दे सकें. भले ही, मॉडल के पास ऐसे जवाब की पुष्टि करने वाली तथ्यपरक जानकारी न हो. खास तौर पर, "सोचने" वाले मॉडल को इस तरह से ट्रेन किया जाता है. इसे "गलत जानकारी" कहा जाता है. इसमें मॉडल, भरोसे के साथ ऐसी जानकारी जनरेट करता है जो भरोसेमंद लगती है, लेकिन तथ्यों के हिसाब से गलत होती है.
Retrieval-Augmented Generation, एक बेहतरीन आर्किटेक्चरल पैटर्न है. इसे इन समस्याओं को हल करने के लिए डिज़ाइन किया गया है. यह एक आर्किटेक्चरल फ़्रेमवर्क है. यह बड़े लैंग्वेज मॉडल की क्षमताओं को बेहतर बनाता है. इसके लिए, यह उन्हें रीयल-टाइम में बाहरी और भरोसेमंद जानकारी के सोर्स से कनेक्ट करता है. आरएजी सिस्टम में मौजूद एलएलएम, पहले से मौजूद जानकारी पर पूरी तरह से निर्भर नहीं रहता. इसके बजाय, यह उपयोगकर्ता की क्वेरी से जुड़ी काम की जानकारी को पहले खोजता है. इसके बाद, उस जानकारी का इस्तेमाल करके ज़्यादा सटीक, समय के हिसाब से सही, और कॉन्टेक्स्ट के हिसाब से जवाब जनरेट करता है.
यह तरीका, जनरेटिव मॉडल की सबसे बड़ी कमियों को सीधे तौर पर दूर करता है. जैसे, इनकी जानकारी किसी समय पर तय होती है. साथ ही, ये गलत जानकारी या "बनावटी तथ्यों वाली जानकारी" जनरेट कर सकते हैं. आरएजी, एलएलएम को "ओपन-बुक परीक्षा" देने जैसा है. इसमें "बुक" आपका निजी, डोमेन के हिसाब से, और अप-टू-डेट डेटा होता है. एलएलएम को तथ्यों के आधार पर जानकारी देने की इस प्रोसेस को "ग्राउंडिंग" कहा जाता है.
आरएजी के तीन चरण
स्टैंडर्ड आरएजी प्रोसेस को तीन आसान चरणों में बांटा जा सकता है:
- जानकारी पाना: जब कोई उपयोगकर्ता क्वेरी सबमिट करता है, तो सिस्टम सबसे पहले किसी बाहरी नॉलेज बेस (जैसे, दस्तावेज़ रिपॉज़िटरी, डेटाबेस या वेबसाइट) में क्वेरी से जुड़ी जानकारी खोजता है.
- बढ़ाना: इसके बाद, निकाली गई जानकारी को उपयोगकर्ता की ओरिजनल क्वेरी के साथ मिलाकर, एक बड़ा प्रॉम्प्ट बनाया जाता है. इस तकनीक को कभी-कभी "प्रॉम्प्ट स्टफ़िंग" कहा जाता है, क्योंकि यह प्रॉम्प्ट में तथ्यों के हिसाब से कॉन्टेक्स्ट जोड़ती है.
- जनरेट करना: इस बेहतर प्रॉम्प्ट को एलएलएम को भेजा जाता है. इसके बाद, एलएलएम जवाब जनरेट करता है. मॉडल को काम का और तथ्यों पर आधारित डेटा दिया गया है. इसलिए, इसका आउटपुट "ग्राउंडेड" होता है. साथ ही, इसमें गलत या पुरानी जानकारी होने की संभावना बहुत कम होती है.
आरएजी के फ़ायदे
RAG फ़्रेमवर्क के आने से, भरोसेमंद और काम के एआई ऐप्लिकेशन बनाने में मदद मिली है. इसके मुख्य फ़ायदे ये हैं:
- ज़्यादा सटीक जानकारी और गलत जानकारी देने की संभावना कम होना: भरोसेमंद और बाहरी तथ्यों के आधार पर जवाब देने की वजह से, RAG की मदद से एलएलएम के गलत जानकारी देने की संभावना काफ़ी कम हो जाती है.
- अप-टू-डेट जानकारी ऐक्सेस करना: RAG सिस्टम को लगातार अपडेट होने वाले नॉलेज बेस से कनेक्ट किया जा सकता है. इससे, उन्हें बिलकुल नई जानकारी के आधार पर जवाब देने की अनुमति मिलती है. यह काम, स्टैटिक तौर पर ट्रेन किए गए एलएलएम के लिए मुमकिन नहीं है.
- उपयोगकर्ताओं का भरोसा बढ़ाना और पारदर्शिता: एलएलएम का जवाब, खोजे गए दस्तावेज़ों पर आधारित होता है. इसलिए, सिस्टम अपने सोर्स के उद्धरण और लिंक दे सकता है. इससे उपयोगकर्ताओं को जानकारी की पुष्टि करने का मौका मिलता है. इससे ऐप्लिकेशन पर उनका भरोसा बढ़ता है.
- लागत: नए डेटा के साथ एलएलएम को लगातार बेहतर बनाना या फिर से ट्रेन करना, कंप्यूटेशनल और वित्तीय तौर पर महंगा होता है. RAG की मदद से, मॉडल की जानकारी को अपडेट करना उतना ही आसान है जितना बाहरी डेटा सोर्स को अपडेट करना. यह ज़्यादा असरदार है.
- डोमेन के हिसाब से जानकारी और निजता: RAG की मदद से, लोग और संगठन क्वेरी के समय अपने निजी और मालिकाना हक वाले डेटा को एलएलएम के लिए उपलब्ध करा सकते हैं. इसके लिए, उन्हें मॉडल के ट्रेनिंग सेट में उस संवेदनशील डेटा को शामिल करने की ज़रूरत नहीं होती. इससे, डोमेन के हिसाब से काम करने वाले बेहतरीन ऐप्लिकेशन बनाए जा सकते हैं. साथ ही, डेटा की निजता और सुरक्षा को बनाए रखा जा सकता है.
डेटा वापस पाना
"जानकारी वापस पाना" चरण, किसी भी RAG सिस्टम का मुख्य हिस्सा होता है. सीधे तौर पर खोजी गई जानकारी की क्वालिटी और उसके काम का होना, जनरेट किए गए जवाब की क्वालिटी और उसके काम का होना तय करता है. RAG ऐप्लिकेशन को अक्सर अलग-अलग तकनीकों का इस्तेमाल करके, अलग-अलग तरह के डेटा सोर्स से जानकारी पाने की ज़रूरत होती है. जानकारी पाने के मुख्य तरीकों को तीन कैटगरी में बांटा गया है: कीवर्ड पर आधारित, सिमैंटिक, और स्ट्रक्चर्ड.
अनस्ट्रक्चर्ड डेटा से जानकारी पाना
पहले, अनस्ट्रक्चर्ड डेटा को वापस पाने की सुविधा को पारंपरिक खोज कहा जाता था. इसमें कई बदलाव किए गए हैं. आपको दोनों मुख्य तरीकों से फ़ायदा मिल सकता है.
सिमैंटिक सर्च, सबसे असरदार तकनीक है. इसे Google Cloud पर बड़े पैमाने पर इस्तेमाल किया जा सकता है. साथ ही, इससे बेहतरीन परफ़ॉर्मेंस मिलती है और इस पर आपका पूरा कंट्रोल होता है.
- कीवर्ड के आधार पर (लेक्सिकल) खोज: यह खोज करने का पारंपरिक तरीका है. इसकी शुरुआत 1970 के दशक में हुई थी, जब जानकारी पाने के लिए सिस्टम बनाए गए थे. लेक्सिकल सर्च, उपयोगकर्ता की क्वेरी में मौजूद शब्दों (या "टोकन") को नॉलेज बेस में मौजूद दस्तावेज़ों में मौजूद शब्दों से मैच करके काम करती है. यह उन क्वेरी के लिए बहुत कारगर है जिनमें कुछ खास शब्दों के बारे में सटीक जानकारी देना ज़रूरी होता है. जैसे, प्रॉडक्ट कोड, कानूनी शर्तें या यूनीक नाम.
- सिमेंटिक सर्च: सिमेंटिक सर्च या "मतलब के साथ खोज" एक ज़्यादा आधुनिक तरीका है. इसका मकसद, उपयोगकर्ता के इंटेंट और उसकी क्वेरी के कॉन्टेक्स्ट के हिसाब से मतलब को समझना है. इसमें सिर्फ़ कीवर्ड के शाब्दिक मतलब को नहीं समझा जाता. आधुनिक सिमैंटिक सर्च, एंबेड करने की प्रोसेस की मदद से काम करती है. यह मशीन लर्निंग की एक ऐसी तकनीक है जो कॉम्प्लेक्स और ज़्यादा डाइमेंशन वाले डेटा को कम डाइमेंशन वाले वेक्टर स्पेस में मैप करती है. इन वेक्टर को इस तरह से डिज़ाइन किया गया है कि एक जैसे मतलब वाले टेक्स्ट, वेक्टर स्पेस में एक-दूसरे के नज़दीक मौजूद हों. "परिवारों के लिए कुत्ते की सबसे अच्छी नस्लें कौनसी हैं?" क्वेरी को एक वेक्टर में बदल दिया जाता है. इसके बाद, सिस्टम ऐसे दस्तावेज़ वेक्टर खोजता है जो उस स्पेस में "सबसे नज़दीकी पड़ोसी" होते हैं. इससे, ऐसे दस्तावेज़ों को ढूंढने में मदद मिलती है जिनमें "गोल्डन रिट्रीवर" या "दोस्ताना कुत्ते" के बारे में बताया गया हो. भले ही, उनमें "कुत्ता" शब्द शामिल न हो. ज़्यादा डाइमेंशन वाली इस खोज को, Approximate Nearest Neighbor (ANN) एल्गोरिदम की मदद से बेहतर बनाया जाता है. क्वेरी वेक्टर की तुलना हर दस्तावेज़ वेक्टर से करने के बजाय, एएनएन एल्गोरिदम बेहतर इंडेक्सिंग स्ट्रक्चर का इस्तेमाल करते हैं. इससे, मिलते-जुलते वेक्टर को तुरंत ढूंढा जा सकता है. क्वेरी वेक्टर की तुलना हर दस्तावेज़ वेक्टर से करने में, बड़े डेटासेट के लिए बहुत ज़्यादा समय लगता है.
स्ट्रक्चर्ड डेटा से जानकारी पाना
सभी ज़रूरी जानकारी, बिना किसी स्ट्रक्चर वाले दस्तावेज़ों में सेव नहीं होती है. अक्सर, सबसे सटीक और काम की जानकारी स्ट्रक्चर्ड फ़ॉर्मैट में होती है. जैसे, रिलेशनल डेटाबेस, NoSQL डेटाबेस या किसी तरह का एपीआई. जैसे, मौसम के डेटा या शेयर की कीमत के लिए REST API.
स्ट्रक्चर्ड डेटा से जानकारी पाना, आम तौर पर अनस्ट्रक्चर्ड टेक्स्ट को खोजने की तुलना में ज़्यादा सटीक और आसान होता है. सेमैंटिक समानता खोजने के बजाय, भाषा मॉडल को सटीक क्वेरी बनाने और उसे लागू करने की सुविधा दी जा सकती है. जैसे, किसी डेटाबेस पर एसक्यूएल क्वेरी या किसी खास जगह और तारीख के लिए मौसम के एपीआई को एपीआई कॉल.
इसे फ़ंक्शन-कॉलिंग के ज़रिए लागू किया जाता है. यह वही तकनीक है जो एआई एजेंट को काम करने की सुविधा देती है. इससे भाषा मॉडल, डिटरमिनिस्टिक स्ट्रक्चरल तरीके से एक्ज़ीक्यूटेबल कोड और बाहरी सिस्टम के साथ इंटरैक्ट कर पाते हैं.
3. आरएजी पाइपलाइन से लेकर एजेंटिक आरएजी तक
जैसे-जैसे RAG का कॉन्सेप्ट विकसित हुआ है वैसे-वैसे इसे लागू करने के लिए आर्किटेक्चर भी विकसित हुए हैं. पहले यह एक सामान्य और लीनियर पाइपलाइन थी. अब यह एक डाइनैमिक और इंटेलिजेंट सिस्टम बन गया है, जिसे एआई एजेंट मैनेज करते हैं.
- सिंपल (या नैव) आरएजी: यह बुनियादी आर्किटेक्चर है, जिसके बारे में हमने अब तक बात की है. यह तीन चरणों वाली एक लीनियर प्रोसेस है: जानकारी पाना, जानकारी बढ़ाना, और जनरेट करना. यह एक प्रतिक्रियात्मक मॉडल है. यह हर क्वेरी के लिए एक तय किए गए पाथ का पालन करता है. यह सीधे तौर पर पूछे गए सवालों के जवाब देने के लिए बहुत असरदार है.
- ऐडवांस आरएजी: यह एक ऐसा तरीका है जिसमें पाइपलाइन में अतिरिक्त चरण जोड़े जाते हैं, ताकि खोजे गए कॉन्टेक्स्ट की क्वालिटी को बेहतर बनाया जा सके. ये सुधार, डेटा वापस पाने से पहले या बाद में किए जा सकते हैं.
- प्री-रिट्रीवल: क्वेरी को फिर से लिखने या उसे बड़ा करने जैसी तकनीकों का इस्तेमाल किया जा सकता है. सिस्टम, शुरुआती क्वेरी का विश्लेषण कर सकता है और उसे फिर से लिख सकता है, ताकि जानकारी पाने के सिस्टम के लिए वह ज़्यादा असरदार हो.
- जानकारी वापस पाने के बाद: दस्तावेज़ों का शुरुआती सेट वापस पाने के बाद, री-रैंकिंग मॉडल लागू किया जा सकता है. इससे दस्तावेज़ों को काम के होने के आधार पर स्कोर किया जा सकता है और सबसे काम के दस्तावेज़ों को सबसे ऊपर रखा जा सकता है. यह हाइब्रिड सर्च के लिए खास तौर पर ज़रूरी है. जानकारी पाने के बाद, अगला चरण यह होता है कि मिले हुए कॉन्टेक्स्ट को फ़िल्टर किया जाए या कंप्रेस किया जाए. इससे यह पक्का किया जा सकता है कि एलएलएम को सिर्फ़ सबसे ज़रूरी जानकारी मिले.
- एजेंटिक आरएजी: यह आरएजी आर्किटेक्चर का सबसे नया वर्शन है. इसमें फ़िक्स्ड पाइपलाइन की जगह, अपने-आप काम करने वाली और स्मार्ट प्रोसेस का इस्तेमाल किया जाता है. एजेंटिक आरएजी सिस्टम में, पूरे वर्कफ़्लो को एक या उससे ज़्यादा एआई एजेंट मैनेज करते हैं. ये एजेंट, तर्क दे सकते हैं, प्लान बना सकते हैं, और अपनी कार्रवाइयां डाइनैमिक तरीके से चुन सकते हैं.
एजेंटिक आरएजी को समझने के लिए, यह जानना ज़रूरी है कि एआई एजेंट क्या होता है. एजेंट, सिर्फ़ एक एलएलएम नहीं होता. यह एक ऐसा सिस्टम है जिसमें कई मुख्य कॉम्पोनेंट होते हैं:
- एलएलएम को तर्क करने वाले इंजन के तौर पर इस्तेमाल करना: एजेंट, Gemini जैसे शक्तिशाली एलएलएम का इस्तेमाल सिर्फ़ टेक्स्ट जनरेट करने के लिए नहीं करता है. बल्कि, इसे अपने मुख्य "दिमाग" के तौर पर इस्तेमाल करता है. इससे उसे प्लान बनाने, फ़ैसले लेने, और मुश्किल टास्क को छोटे-छोटे हिस्सों में बाँटने में मदद मिलती है.
- टूल का सेट: एजेंट को फ़ंक्शन के टूलकिट का ऐक्सेस दिया जाता है. एजेंट अपने लक्ष्यों को पूरा करने के लिए, इन फ़ंक्शन का इस्तेमाल कर सकता है. ये टूल कुछ भी हो सकते हैं: कैलकुलेटर, वेब खोज एपीआई, ईमेल भेजने का फ़ंक्शन या इस लैब के लिए सबसे ज़रूरी - हमारी अलग-अलग नॉलेज बेस के लिए रिट्रीवर.
- मेमोरी: एजेंट को शॉर्ट-टर्म मेमोरी (मौजूदा बातचीत के संदर्भ को याद रखने के लिए) और लॉन्ग-टर्म मेमोरी (पिछले इंटरैक्शन से जानकारी याद रखने के लिए) के साथ डिज़ाइन किया जा सकता है. इससे, आपको ज़्यादा मनमुताबिक़ और बेहतर अनुभव मिल पाते हैं.
- प्लानिंग और रिफ़्लेक्शन: सबसे अडवांस एजेंट, तर्क करने के बेहतर तरीके दिखाते हैं. इन्हें कोई मुश्किल लक्ष्य दिया जा सकता है. साथ ही, इसे हासिल करने के लिए कई चरणों वाला प्लान बनाया जा सकता है. इसके बाद, वे इस प्लान को लागू कर सकते हैं. साथ ही, अपनी कार्रवाइयों के नतीजों पर विचार कर सकते हैं, गड़बड़ियों की पहचान कर सकते हैं, और बेहतर नतीजे पाने के लिए अपने तरीके में सुधार कर सकते हैं.
एजेंटिक आरएजी, एआई के काम करने के तरीके में बड़ा बदलाव लाता है. ऐसा इसलिए, क्योंकि यह एआई को अपने हिसाब से काम करने और बेहतर तरीके से जानकारी इकट्ठा करने की सुविधा देता है. यह सुविधा, स्टैटिक पाइपलाइन में नहीं होती.
- लचीलापन और अडैप्टेबिलिटी: एजेंट को जानकारी पाने के लिए, सिर्फ़ एक तरीके का इस्तेमाल करने की ज़रूरत नहीं होती. उपयोगकर्ता की क्वेरी के आधार पर, यह जानकारी के सबसे अच्छे सोर्स के बारे में बता सकता है. यह पहले स्ट्रक्चर्ड डेटाबेस से क्वेरी कर सकता है. इसके बाद, बिना स्ट्रक्चर वाले दस्तावेज़ों पर सिमैंटिक सर्च कर सकता है. अगर इसे अब भी जवाब नहीं मिलता है, तो यह Google Search टूल का इस्तेमाल करके, सार्वजनिक वेब पर खोज कर सकता है. यह सब, उपयोगकर्ता के एक ही अनुरोध के संदर्भ में किया जाता है.
- मुश्किल और कई चरणों वाली रीज़निंग: यह आर्किटेक्चर, मुश्किल क्वेरी को हैंडल करने में बेहतर है. इसके लिए, कई चरणों में जानकारी को क्रम से प्रोसेस करना और उसे वापस पाना होता है.
इस क्वेरी पर विचार करें: "क्रिस्टोफ़र नोलन के निर्देशन में बनी टॉप 3 साइंस फ़िक्शन फ़िल्में खोजो. साथ ही, हर फ़िल्म की कहानी के बारे में कम शब्दों में जानकारी दो." ऐसे में, सामान्य RAG पाइपलाइन काम नहीं करेगी.
हालांकि, एजेंट इस बारे में ज़्यादा जानकारी दे सकता है:
- प्लान: सबसे पहले, मुझे फ़िल्में ढूंढनी हैं. इसके बाद, मुझे हर फ़िल्म की कहानी ढूंढनी है.
- पहली कार्रवाई: स्ट्रक्चर्ड डेटा टूल का इस्तेमाल करके, नोलन की साइंस फ़िक्शन फ़िल्मों के डेटाबेस से क्वेरी करें: सबसे ज़्यादा रेटिंग वाली तीन फ़िल्में, रेटिंग के हिसाब से घटते क्रम में.
- पहली जानकारी: टूल ने "इंसेप्शन", "इंटरस्टेलर", और "टेनेट" फ़िल्मों के नाम दिखाए.
- दूसरी कार्रवाई: "इंसेप्शन" की कहानी ढूंढने के लिए, अनस्ट्रक्चर्ड डेटा टूल (सिमैंटिक सर्च) का इस्तेमाल करें.
- दूसरी जानकारी: प्लॉट की जानकारी वापस मिल जाती है.
- तीसरी कार्रवाई: "इंटरस्टेलर" के लिए भी यही प्रोसेस दोहराएं.
- चौथी कार्रवाई: "टेनेट" के लिए भी यही प्रोसेस दोहराएं.
- जवाब तैयार करना: खोज के दौरान मिली सभी जानकारी को मिलाकर, उपयोगकर्ता के लिए एक जवाब तैयार करना.
4. प्रोजेक्ट सेटअप करना
Google खाता
अगर आपके पास पहले से कोई निजी Google खाता नहीं है, तो आपको Google खाता बनाना होगा.
ऑफ़िस या स्कूल वाले खाते के बजाय, निजी खाते का इस्तेमाल करें.
Google Cloud Console में साइन इन करना
किसी निजी Google खाते का इस्तेमाल करके, Google Cloud Console में साइन इन करें.
बिलिंग चालू करें
ट्रायल बिलिंग खाते का इस्तेमाल करें (ज़रूरी नहीं)
इस वर्कशॉप को चलाने के लिए, आपके पास कुछ क्रेडिट वाला बिलिंग खाता होना चाहिए. शुरू करने के लिए, इस कोडलैब के सबसे ऊपर मौजूद बैनर में दिए गए क्रेडिट का इस्तेमाल करें. अगर आपका खाता पहले से ही किसी बिलिंग खाते से कनेक्ट है, तो इस चरण को छोड़ा जा सकता है.
निजी बिलिंग खाता सेट अप करना
अगर आपने Google Cloud क्रेडिट का इस्तेमाल करके बिलिंग सेट अप की है, तो इस चरण को छोड़ें.
निजी बिलिंग खाता सेट अप करने के लिए, Cloud Console में बिलिंग की सुविधा चालू करने के लिए यहां जाएं.
ध्यान दें:
- इस लैब को पूरा करने में, Cloud संसाधनों पर 1 डॉलर से कम का खर्च आना चाहिए.
- ज़्यादा शुल्क से बचने के लिए, इस लैब के आखिर में दिए गए निर्देशों का पालन करके संसाधनों को मिटाया जा सकता है.
- नए उपयोगकर्ता, 300 डॉलर के मुफ़्त में आज़माने की सुविधा का फ़ायदा पा सकते हैं.
कोई प्रोजेक्ट बनाएं (ज़रूरी नहीं)
अगर आपके पास कोई ऐसा मौजूदा प्रोजेक्ट नहीं है जिसका इस्तेमाल आपको इस लैब के लिए करना है, तो यहां नया प्रोजेक्ट बनाएं.
5. Cloud Shell Editor खोलें
- सीधे Cloud Shell Editor पर जाने के लिए, इस लिंक पर क्लिक करें
- अगर आज किसी भी समय अनुमति देने के लिए कहा जाता है, तो जारी रखने के लिए अनुमति दें पर क्लिक करें.
- अगर टर्मिनल स्क्रीन पर सबसे नीचे नहीं दिखता है, तो इसे खोलें:
- देखें पर क्लिक करें
- टर्मिनल
 पर क्लिक करें
पर क्लिक करें
- टर्मिनल में, इस कमांड का इस्तेमाल करके अपना प्रोजेक्ट सेट करें:
gcloud config set project [PROJECT_ID]- उदाहरण:
gcloud config set project lab-project-id-example - अगर आपको अपना प्रोजेक्ट आईडी याद नहीं है, तो इन कमांड का इस्तेमाल करके अपने सभी प्रोजेक्ट आईडी की सूची देखी जा सकती है:
gcloud projects list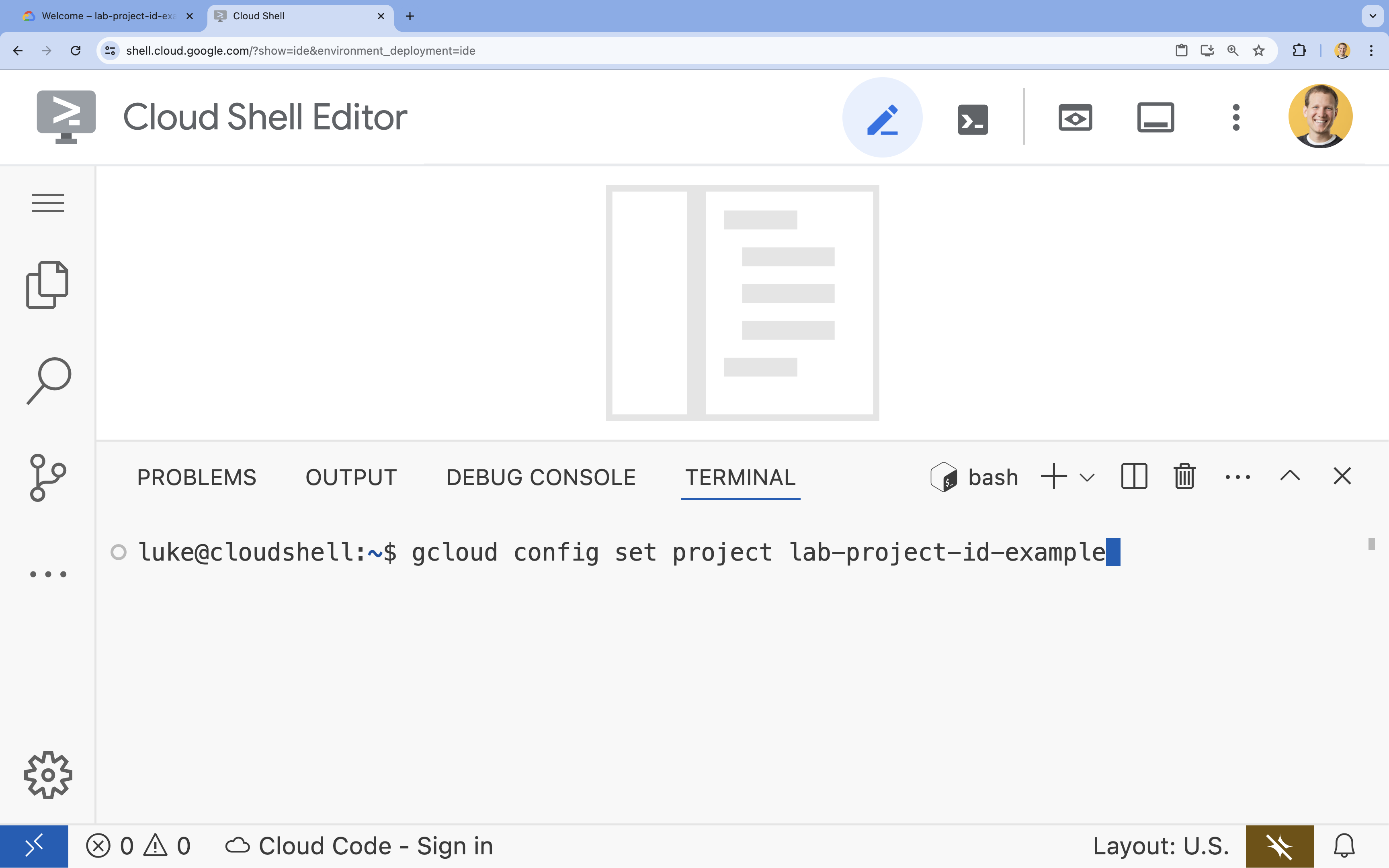
- उदाहरण:
- आपको यह मैसेज दिखेगा:
Updated property [core/project].
6. एपीआई चालू करें
Agent Development Kit और Vertex AI Search का इस्तेमाल करने के लिए, आपको अपने Google Cloud प्रोजेक्ट में ज़रूरी एपीआई चालू करने होंगे.
- टर्मिनल में, इन एपीआई को चालू करें:
gcloud services enable \ aiplatform.googleapis.com \ discoveryengine.googleapis.com
एपीआई के बारे में जानकारी
- Vertex AI API (
aiplatform.googleapis.com) की मदद से, एजेंट को Gemini मॉडल के साथ बातचीत करने की सुविधा मिलती है. इससे एजेंट को तर्क देने और जवाब जनरेट करने में मदद मिलती है. - Discovery Engine API (
discoveryengine.googleapis.com) की मदद से Vertex AI Search काम करता है. इससे आपको डेटा स्टोर बनाने और बिना स्ट्रक्चर वाले दस्तावेज़ों पर सिमैंटिक सर्च करने की सुविधा मिलती है.
7. एनवायरमेंट सेट अप करना
एआई एजेंट को कोड करना शुरू करने से पहले, आपको डेवलपमेंट एनवायरमेंट तैयार करना होगा. साथ ही, ज़रूरी लाइब्रेरी इंस्टॉल करनी होंगी और ज़रूरी डेटा फ़ाइलें बनानी होंगी.
वर्चुअल एनवायरमेंट बनाना और डिपेंडेंसी इंस्टॉल करना
- अपने एजेंट के लिए एक डायरेक्ट्री बनाएं और उसमें जाएं. टर्मिनल में यह कोड चलाएं:
mkdir financial_agent cd financial_agent - वर्चुअल एनवायरमेंट बनाएं:
uv venv --python 3.12 - वर्चुअल एनवायरमेंट चालू करें:
source .venv/bin/activate - Agent Development Kit (ADK) और pandas इंस्टॉल करें.
uv pip install google-adk pandas
शेयर की कीमत का डेटा बनाना
लैब को स्टॉक के पुराने डेटा की ज़रूरत होती है, ताकि यह दिखाया जा सके कि एजेंट, स्ट्रक्चर्ड टूल का इस्तेमाल कर सकता है या नहीं. इसलिए, आपको इस डेटा वाली एक CSV फ़ाइल बनानी होगी.
financial_agentडायरेक्ट्री में,goog.csvफ़ाइल बनाएं. इसके लिए, टर्मिनल में यह कमांड चलाएं:cat <<EOF > goog.csv Date,Open,High,Low,Close,Adj Close,Volume 2023-01-03,89.830002,91.550003,89.019997,89.699997,89.699997,20738500 2023-03-31,101.440002,103.889999,101.040001,103.730003,103.730003,36823200 2023-06-30,120.870003,122.029999,120.300003,120.970001,120.970001,23824700 2023-09-29,134.080002,134.550003,131.320007,131.850006,131.850006,21124200 2025-07-10,185.000000,188.000000,184.500000,186.500000,186.500000,25000000 EOF
एनवायरमेंट वैरिएबल कॉन्फ़िगर करना
financial_agentडायरेक्ट्री में, अपने एजेंट के एनवायरमेंट वैरिएबल को कॉन्फ़िगर करने के लिए,.envफ़ाइल बनाएं. इससे ADK को पता चलता है कि किस प्रोजेक्ट, जगह, और मॉडल का इस्तेमाल करना है. टर्मिनल में यह कोड चलाएं:# Create the .env file using the captured variables cat << EOF > .env GOOGLE_GENAI_USE_VERTEXAI=TRUE GOOGLE_CLOUD_PROJECT="${GOOGLE_CLOUD_PROJECT}" GOOGLE_CLOUD_LOCATION="us-central1" EOF
ध्यान दें: अगर आपको लैब में बाद में .env फ़ाइल में बदलाव करना है, लेकिन आपको वह financial_agent डायरेक्ट्री में नहीं दिख रही है, तो "देखें / छिपी हुई फ़ाइलें टॉगल करें" मेन्यू आइटम का इस्तेमाल करके, Cloud Shell Editor में छिपी हुई फ़ाइलों को दिखाने की सुविधा को टॉगल करें.
8. Vertex AI Search में डेटा स्टोर बनाना
एजेंट को Alphabet की फ़ाइनेंशियल रिपोर्ट के बारे में सवालों के जवाब देने की सुविधा चालू करने के लिए, आपको Vertex AI Search डेटा स्टोर बनाना होगा. इसमें Alphabet की सार्वजनिक एसईसी फ़ाइलिंग शामिल होंगी.
- नए ब्राउज़र टैब में, Cloud Console (console.cloud.google.com) खोलें. इसके बाद, सबसे ऊपर मौजूद खोज बार का इस्तेमाल करके, एआई ऐप्लिकेशन पर जाएं.
- अगर आपसे कहा जाए, तो नियम और शर्तों वाले चेकबॉक्स को चुनें. इसके बाद, जारी रखें और एपीआई चालू करें पर क्लिक करें.
- बाईं ओर मौजूद नेविगेशन मेन्यू में जाकर, डेटा स्टोर चुनें.
- + डेटा स्टोर बनाएं पर क्लिक करें.
- Cloud Storage कार्ड ढूंढें और चुनें पर क्लिक करें.
- डेटा सोर्स के लिए, अनस्ट्रक्चर्ड दस्तावेज़ चुनें.

- इंपोर्ट सोर्स के लिए, Google Cloud Storage का पाथ डालें
cloud-samples-data/gen-app-builder/search/alphabet-sec-filings. इंपोर्ट सोर्स के लिए, वह फ़ोल्डर या फ़ाइल चुनें जिसे आपको इंपोर्ट करना है. - जारी रखें पर क्लिक करें.
- जगह की जानकारी को global पर सेट रखें.
- डेटा स्टोर के नाम के लिए, यह डालें
alphabet-sec-filings - दस्तावेज़ प्रोसेस करने के विकल्प सेक्शन को बड़ा करें.

- डिफ़ॉल्ट दस्तावेज़ पार्सर ड्रॉपडाउन सूची में, लेआउट पार्सर चुनें.
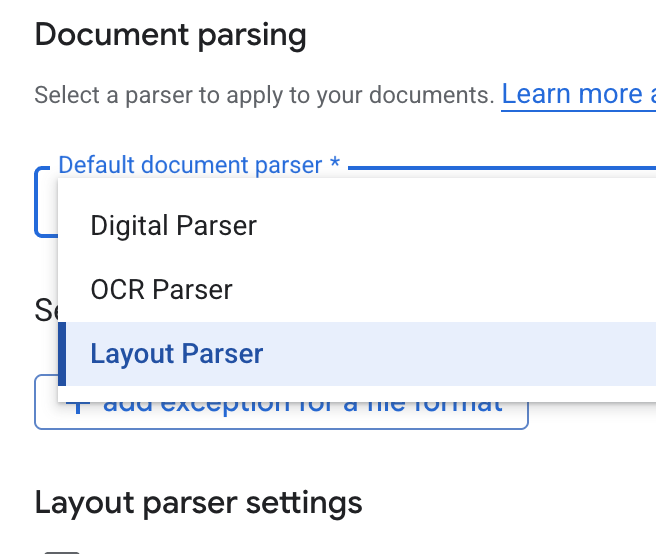
- लेआउट पार्सर की सेटिंग के विकल्पों में जाकर, टेबल एनोटेशन चालू करें और इमेज एनोटेशन चालू करें को चुनें.
- जारी रखें पर क्लिक करें.
- कीमत के मॉडल के तौर पर सामान्य कीमत (इस्तेमाल के हिसाब से पेमेंट करने वाला मॉडल) चुनें. इसके बाद, बनाएं पर क्लिक करें.
- आपका डेटा स्टोर, दस्तावेज़ इंपोर्ट करना शुरू कर देगा.
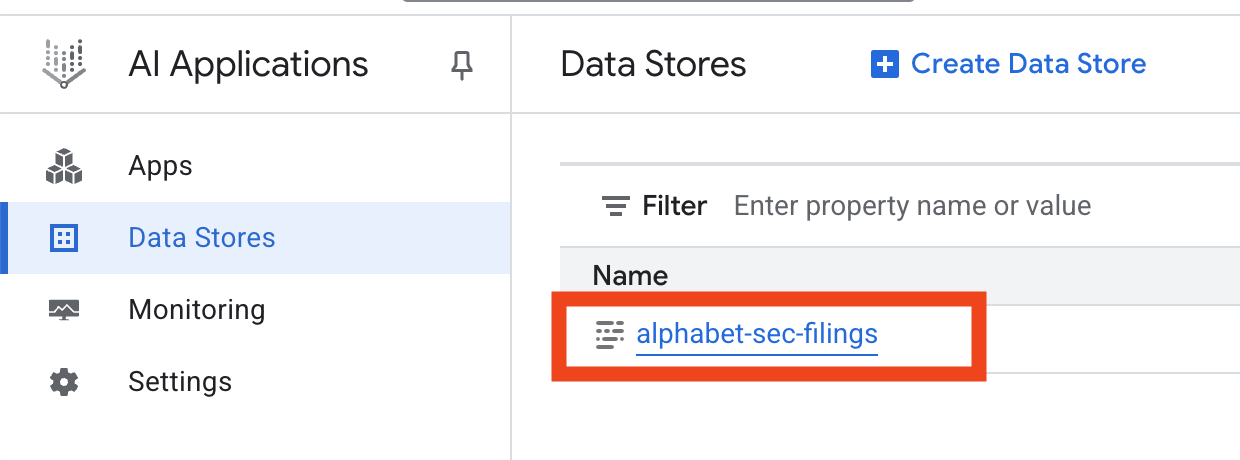
- डेटा स्टोर के नाम पर क्लिक करें. इसके बाद, डेटा स्टोर टेबल से उसका आईडी कॉपी करें. आपको इसकी ज़रूरत अगले चरण में पड़ेगी.
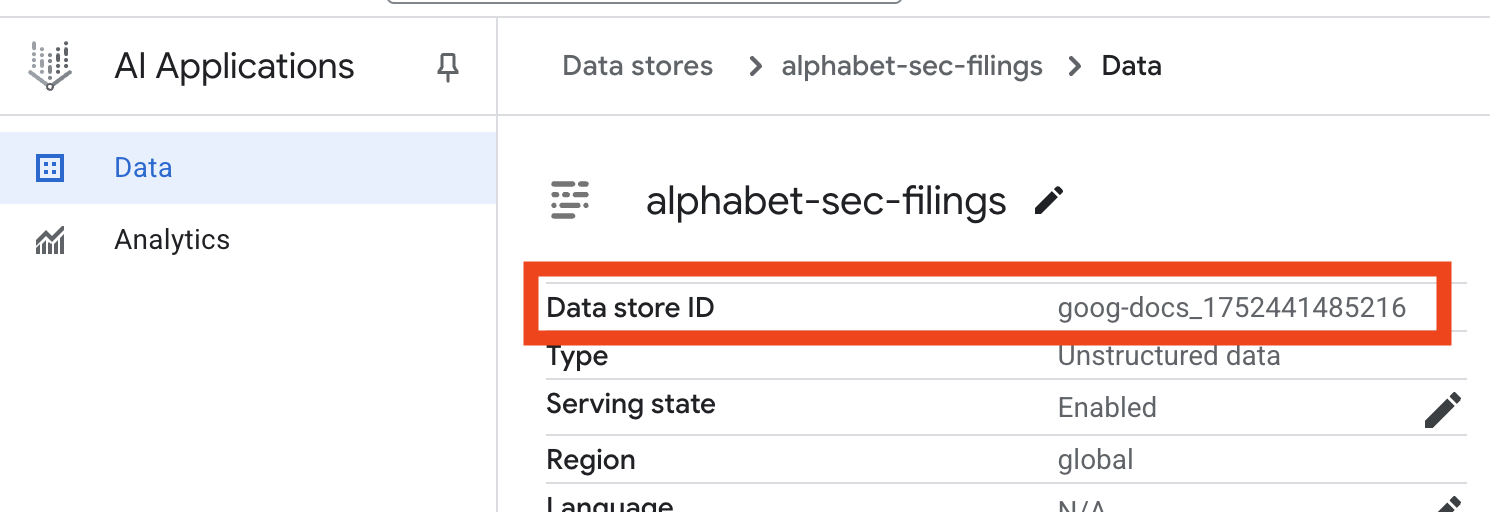
- Cloud Shell Editor में
.envफ़ाइल खोलें और डेटा स्टोर आईडी कोDATA_STORE_ID="YOUR_DATA_STORE_ID"के तौर पर जोड़ें (YOUR_DATA_STORE_IDको पिछले चरण के असली आईडी से बदलें.ध्यान दें: डेटास्टोर में डेटा इंपोर्ट करने, पार्स करने, और इंडेक्स करने में कुछ मिनट लगेंगे. प्रोसेस की जांच करने के लिए, डेटा स्टोर के नाम पर क्लिक करके उसकी प्रॉपर्टी खोलें. इसके बाद, गतिविधि टैब खोलें. स्टेटस को "इंपोर्ट पूरा हो गया" होने तक इंतज़ार करें.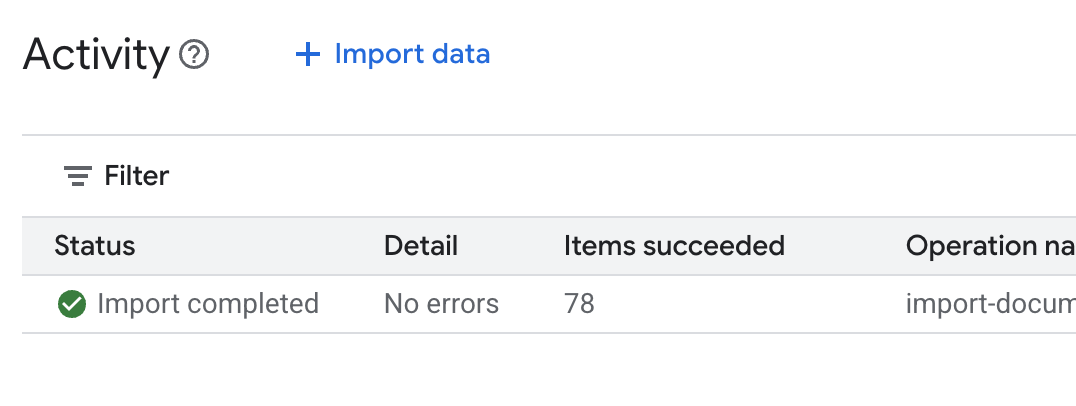
9. स्ट्रक्चर्ड डेटा के लिए कस्टम टूल बनाना
इसके बाद, आपको एक Python फ़ंक्शन बनाना होगा, जो एजेंट के लिए टूल के तौर पर काम करेगा. यह टूल, goog.csv फ़ाइल को पढ़ेगा, ताकि किसी तारीख के लिए स्टॉक की पुरानी कीमतें मिल सकें.
- अपनी
financial_agentडायरेक्ट्री में,agent.pyनाम की एक नई फ़ाइल बनाएं. टर्मिनल में यह कमांड चलाएं:cloudshell edit agent.py agent.pyमें यह Python कोड जोड़ें. यह कोड, डिपेंडेंसी इंपोर्ट करता है औरget_stock_priceफ़ंक्शन को तय करता है.from datetime import datetime import os import logging import google.cloud.logging from google.adk.tools import VertexAiSearchTool from google.adk.tools.agent_tool import AgentTool from google.adk.agents import LlmAgent import pandas as pd def get_stock_price(date: str) -> dict: """Gets the closing stock price for a given date. Args: date: The date to get the stock price for, in YYYY-MM-DD format. Returns: A dictionary containing the closing price, or an error message if the date is not found or the format is incorrect. """ try: # Load the CSV file df = pd.read_csv('goog.csv') # Convert the 'Date' column to datetime objects df['Date'] = pd.to_datetime(df['Date']) # Convert the input string to a datetime object query_date = datetime.strptime(date, '%Y-%m-%d') # Find the row for the given date row = df[df['Date'] == query_date] if not row.empty: # Get the closing price close_price = row['Close'].iloc[0] return {"status": "success", "date": date, "closing_price": close_price} else: return {"status": "error", "message": f"No data found for date: {date}"} except FileNotFoundError: return {"status": "error", "message": "Stock data file (goog.csv) not found."} except Exception as e: return {"status": "error", "message": f"An error occurred: {str(e)}"}
फ़ंक्शन की पूरी डॉकस्ट्रिंग देखें. इसमें बताया गया है कि फ़ंक्शन क्या करता है, इसके पैरामीटर (Args) क्या हैं, और यह क्या दिखाता है (Returns). ADK इस डॉकस्ट्रिंग का इस्तेमाल करके, एजेंट को यह सिखाता है कि इस टूल का इस्तेमाल कब और कैसे करना है.
10. आरएजी एजेंट बनाना और उसे चलाना
अब एजेंट को असेंबल करने का समय है. अनस्ट्रक्चर्ड डेटा के लिए, Vertex AI Search टूल को स्ट्रक्चर्ड डेटा के लिए बनाए गए अपने कस्टम get_stock_price टूल के साथ जोड़ा जाएगा.
- अपनी
agent.pyफ़ाइल में यह कोड जोड़ें. यह कोड, ज़रूरी ADK क्लास इंपोर्ट करता है, टूल के इंस्टेंस बनाता है, और एजेंट को तय करता है.logging.basicConfig(level=logging.INFO) cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() # 1. Create the Vertex AI Search tool full_datastore_id = f"projects/{os.environ['GOOGLE_CLOUD_PROJECT']}/locations/global/collections/default_collection/dataStores/{os.environ['DATA_STORE_ID']}" vertex_ai_search_tool = VertexAiSearchTool( data_store_id=full_datastore_id ) # 2. Define the Search+Q&A agent # Since we cannot combine tools with other tools in a single agent, # we create a separate Search+Q&A agent which will be used as a tool by the main root agent. doc_qa_agent = LlmAgent( name="search_and_qna_agent", model="gemini-2.5-flash", tools=[vertex_ai_search_tool], instruction="""You are a helpful assistant that answers questions based on information found in the document store. Use the search tool to find relevant information before answering. If the answer isn't in the documents, say that you couldn't find the information. """, description="Answers questions using a specific Vertex AI Search datastore.", ) # 3. Define the root agent with 2 tools. root_agent = LlmAgent( name="financial_agent", model="gemini-2.5-flash", tools=[ AgentTool(doc_qa_agent), get_stock_price, ], instruction="""You are an Financial Analytics Agent that answers question about Alphabet stock prices (using get_stock_price tool) and historical performance based on the data in Vertex AI Search datastore (using doc_qa_agent tool).""" ) - अपने टर्मिनल में,
financial_agentडायरेक्ट्री में जाकर, ADK का वेब इंटरफ़ेस लॉन्च करें, ताकि अपने एजेंट के साथ इंटरैक्ट किया जा सके:adk web ~ - अपने ब्राउज़र में ADK Dev UI खोलने के लिए, टर्मिनल आउटपुट में दिए गए लिंक (आम तौर पर
http://127.0.0.1:8000) पर क्लिक करें.
11. एजेंट को टेस्ट करना
अब अपने एजेंट की, मुश्किल सवालों के जवाब देने के लिए तर्क करने और टूल इस्तेमाल करने की क्षमता की जांच की जा सकती है.
- ADK Dev UI में, पक्का करें कि ड्रॉपडाउन मेन्यू से
financial_agentचुना गया हो. - ऐसा सवाल पूछें जिसके लिए, एसईसी फ़ाइलिंग (अनस्ट्रक्चर्ड डेटा) से जानकारी की ज़रूरत हो. चैट में यह क्वेरी डालें:
What were the total revenues for the quarter ending on March 31, 2023?search_and_qna_agentको कॉल करना चाहिए. यहVertexAiSearchToolका इस्तेमाल करके, वित्तीय दस्तावेज़ों में जवाब ढूंढता है. - इसके बाद, ऐसा सवाल पूछें जिसके लिए आपके कस्टम टूल (स्ट्रक्चर्ड डेटा) का इस्तेमाल करना ज़रूरी हो. ध्यान दें कि प्रॉम्प्ट में तारीख का फ़ॉर्मैट, फ़ंक्शन के लिए ज़रूरी फ़ॉर्मैट से पूरी तरह मेल खाना ज़रूरी नहीं है. एलएलएम, इसे फिर से फ़ॉर्मैट करने में सक्षम है.
What was the closing stock price for Alphabet on July 10, 2025?get_stock_priceटूल पर कॉल करना चाहिए. फ़ंक्शन कॉल और उसके नतीजे की जांच करने के लिए, चैट में मौजूद टूल आइकॉन पर क्लिक करें. - आखिर में, कोई ऐसा मुश्किल सवाल पूछें जिसके लिए एजेंट को दोनों टूल का इस्तेमाल करना पड़े और नतीजों को एक साथ रखना पड़े.
According to the 10-Q filing for the period ending March 31, 2023, what were the company's net cash provided by operating activities, and what was the stock's closing price on that date?- सबसे पहले, यह
VertexAiSearchToolका इस्तेमाल करके, एसईसी फ़ाइलिंग में कैश फ़्लो की जानकारी ढूंढेगा. - इसके बाद, यह शेयर की कीमत की ज़रूरत को समझेगा और तारीख
2023-03-31के साथget_stock_priceफ़ंक्शन को कॉल करेगा. - आखिर में, यह दोनों तरह की जानकारी को मिलाकर एक जवाब तैयार करेगा.
- सबसे पहले, यह
- काम पूरा हो जाने के बाद, ब्राउज़र टैब को बंद किया जा सकता है. साथ ही, ADK सर्वर को रोकने के लिए, टर्मिनल में
CTRL+Cदबाएं.
12. अपने टास्क के लिए कोई सेवा चुनना
Vertex AI Search, वेक्टर सर्च की ऐसी सेवा नहीं है जिसका इस्तेमाल सिर्फ़ आप कर सकते हैं. मैनेज की गई किसी ऐसी सेवा का भी इस्तेमाल किया जा सकता है जो जानकारी खोजने और जनरेट करने की पूरी प्रोसेस को अपने-आप पूरा करती है: Vertex AI RAG Engine.
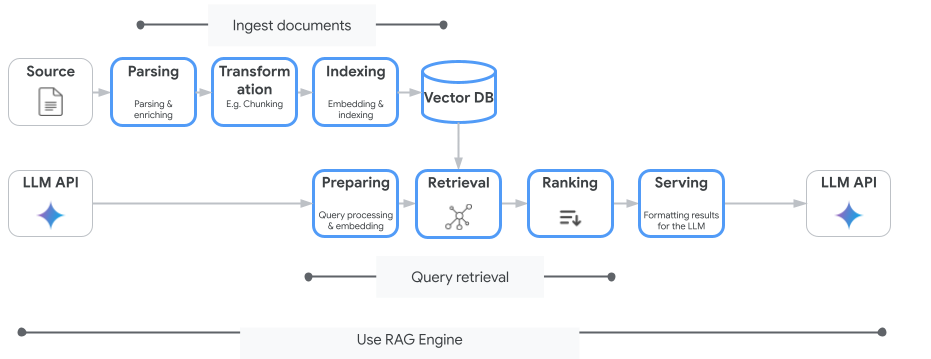
यह दस्तावेज़ों को शामिल करने से लेकर, उन्हें वापस पाने और फिर से रैंक करने तक की सभी प्रोसेस को मैनेज करता है. RAG इंजन, कई वेक्टर स्टोर के साथ काम करता है. जैसे, Pinecone और Weaviate.
आपके पास कई खास वेक्टर डेटाबेस को खुद होस्ट करने का विकल्प भी होता है. इसके अलावा, डेटाबेस इंजन में वेक्टर इंडेक्स की सुविधाओं का इस्तेमाल किया जा सकता है. जैसे, PostgreSQL सेवा में pgvector (जैसे, AlloyDB या BigQuery वेक्टर सर्च.
वेक्टर सर्च की सुविधा देने वाली कुछ अन्य सेवाएं ये हैं:
- PostgreSQL के लिए Cloud SQL
- Cloud SQL for MySQL
- Cloud Spanner
- Memorystore for Redis
- Firestore
- Bigtable
Google Cloud पर किसी सेवा को चुनने के बारे में सामान्य दिशा-निर्देश यहां दिए गए हैं:
- अगर आपके पास पहले से ही काम करने वाला और बड़े पैमाने पर इस्तेमाल किया जा सकने वाला, वेक्टर सर्च का खुद से बनाया गया इन्फ़्रास्ट्रक्चर है, तो उसे Google Kubernetes Engine पर डिप्लॉय करें. जैसे, Weaviate या DIY PostgreSQL.
- अगर आपका डेटा BigQuery, AlloyDB, Firestore या किसी अन्य डेटाबेस में है, तो वेक्टर सर्च की सुविधाओं का इस्तेमाल करें. अगर उस डेटाबेस में बड़ी क्वेरी के हिस्से के तौर पर, बड़े पैमाने पर सिमैंटिक सर्च की जा सकती है, तो ऐसा करें. उदाहरण के लिए, अगर आपके पास BigQuery टेबल में प्रॉडक्ट के ब्यौरे और/या इमेज हैं, तो टेक्स्ट और/या इमेज एम्बेड करने वाला कॉलम जोड़ने से, बड़े पैमाने पर मिलते-जुलते प्रॉडक्ट खोजने की सुविधा का इस्तेमाल किया जा सकेगा. ScANN सर्च की सुविधा वाले वेक्टर इंडेक्स, इंडेक्स में अरबों आइटम के साथ काम करते हैं.
- अगर आपको मैनेज किए जा रहे प्लैटफ़ॉर्म पर, कम समय में और कम मेहनत में काम शुरू करना है, तो Vertex AI Search को चुनें. यह पूरी तरह से मैनेज किया जाने वाला सर्च इंजन और रिट्रीवर एपीआई है. यह एंटरप्राइज़ के उन जटिल इस्तेमाल के मामलों के लिए सबसे सही है जिनमें बेहतर क्वालिटी, स्केलेबिलिटी, और ऐक्सेस कंट्रोल की ज़रूरत होती है. इससे, एंटरप्राइज़ के अलग-अलग डेटा सोर्स से कनेक्ट करना आसान हो जाता है. साथ ही, कई सोर्स में खोज करने की सुविधा मिलती है.
- अगर आपको डेवलपर के लिए ऐसा RAG इंजन चाहिए जिसे इस्तेमाल करना आसान हो और जिसमें ज़रूरत के हिसाब से बदलाव करने की सुविधा भी हो, तो Vertex AI RAG इंजन का इस्तेमाल करें. यह तेज़ी से प्रोटोटाइप बनाने और डेवलपमेंट करने में मदद करता है. साथ ही, इसमें फ़्लेक्सिबिलिटी भी मिलती है.
- रीट्रिवल-ऑगमेंटेड जनरेशन के लिए रेफ़रंस आर्किटेक्चर के बारे में जानें.
13. नतीजा
बधाई हो! आपने रीट्रिवल-ऑगमेंटेड जनरेशन की मदद से, एआई एजेंट को बना लिया है और उसकी जांच कर ली है. आपने इनके बारे में जाना:
- Vertex AI Search की बेहतर सिमैंटिक सर्च सुविधाओं का इस्तेमाल करके, अनस्ट्रक्चर्ड दस्तावेज़ों के लिए नॉलेज बेस बनाएं.
- स्ट्रक्चर्ड डेटा को वापस पाने के टूल के तौर पर काम करने के लिए, कस्टम Python फ़ंक्शन बनाएं.
- Gemini की मदद से, कई टूल वाला एजेंट बनाने के लिए, Agent Development Kit (ADK) का इस्तेमाल करें.
- एक ऐसा एजेंट बनाएं जो मुश्किल और कई चरणों वाली रीज़निंग कर सके. इससे उन सवालों के जवाब दिए जा सकेंगे जिनके लिए कई सोर्स से जानकारी इकट्ठा करनी पड़ती है.
इस लैब में, एजेंटिक RAG के मुख्य सिद्धांतों के बारे में बताया गया है. यह Google Cloud पर, ऐडवांस, सटीक, और कॉन्टेक्स्ट के हिसाब से काम करने वाले एआई ऐप्लिकेशन बनाने के लिए एक बेहतरीन आर्किटेक्चर है.
प्रोटोटाइप से प्रोडक्शन तक
यह लैब, Google Cloud की मदद से प्रोडक्शन-रेडी एआई बनाने के बारे में जानकारी देने वाले लर्निंग पाथ का हिस्सा है.
- प्रोटोटाइप से प्रोडक्शन तक के अंतर को कम करने के लिए, पूरा पाठ्यक्रम देखें.
- #ProductionReadyAI हैशटैग का इस्तेमाल करके, अपनी प्रोग्रेस शेयर करें.