
1. Pengantar
Ringkasan
Tujuan lab ini adalah mempelajari cara mengembangkan aplikasi Agentic Retrieval-Augmented Generation (RAG) end-to-end di Google Cloud. Di lab ini, Anda akan membangun agen analisis keuangan yang dapat menjawab pertanyaan dengan menggabungkan informasi dari dua sumber yang berbeda: dokumen tidak terstruktur (laporan SEC kuartalan Alphabet - laporan keuangan dan detail operasional yang dikirimkan setiap perusahaan publik di Amerika Serikat kepada Securities and Exchange Commission), dan data terstruktur (harga saham historis).
Anda akan menggunakan Vertex AI Search untuk membangun mesin telusur semantik yang canggih untuk laporan keuangan yang tidak terstruktur. Untuk data terstruktur, Anda akan membuat alat Python kustom. Terakhir, Anda akan menggunakan Agent Development Kit (ADK) untuk membangun agen cerdas yang dapat melakukan penalaran tentang kueri pengguna, memutuskan alat mana yang akan digunakan, dan menyintesis informasi menjadi jawaban yang koheren.
Yang akan Anda lakukan
- Siapkan penyimpanan data Vertex AI Search untuk penelusuran semantik atas dokumen pribadi.
- Buat fungsi Python kustom sebagai alat untuk agen.
- Gunakan Agent Development Kit (ADK) untuk membangun agen multi-alat.
- Menggabungkan pengambilan dari sumber data tidak terstruktur dan terstruktur untuk menjawab pertanyaan kompleks.
- Uji dan berinteraksi dengan agen yang menunjukkan kemampuan penalaran.
Yang akan Anda pelajari
Di lab ini, Anda akan mempelajari:
- Konsep inti Retrieval-Augmented Generation (RAG) dan Agentic RAG.
- Cara menerapkan penelusuran semantik pada dokumen menggunakan Vertex AI Search.
- Cara mengekspos data terstruktur ke agen dengan membuat alat kustom.
- Cara membangun dan mengorkestrasi agen multi-alat dengan Agent Development Kit (ADK).
- Cara agen menggunakan penalaran dan perencanaan untuk menjawab pertanyaan kompleks menggunakan beberapa sumber data.
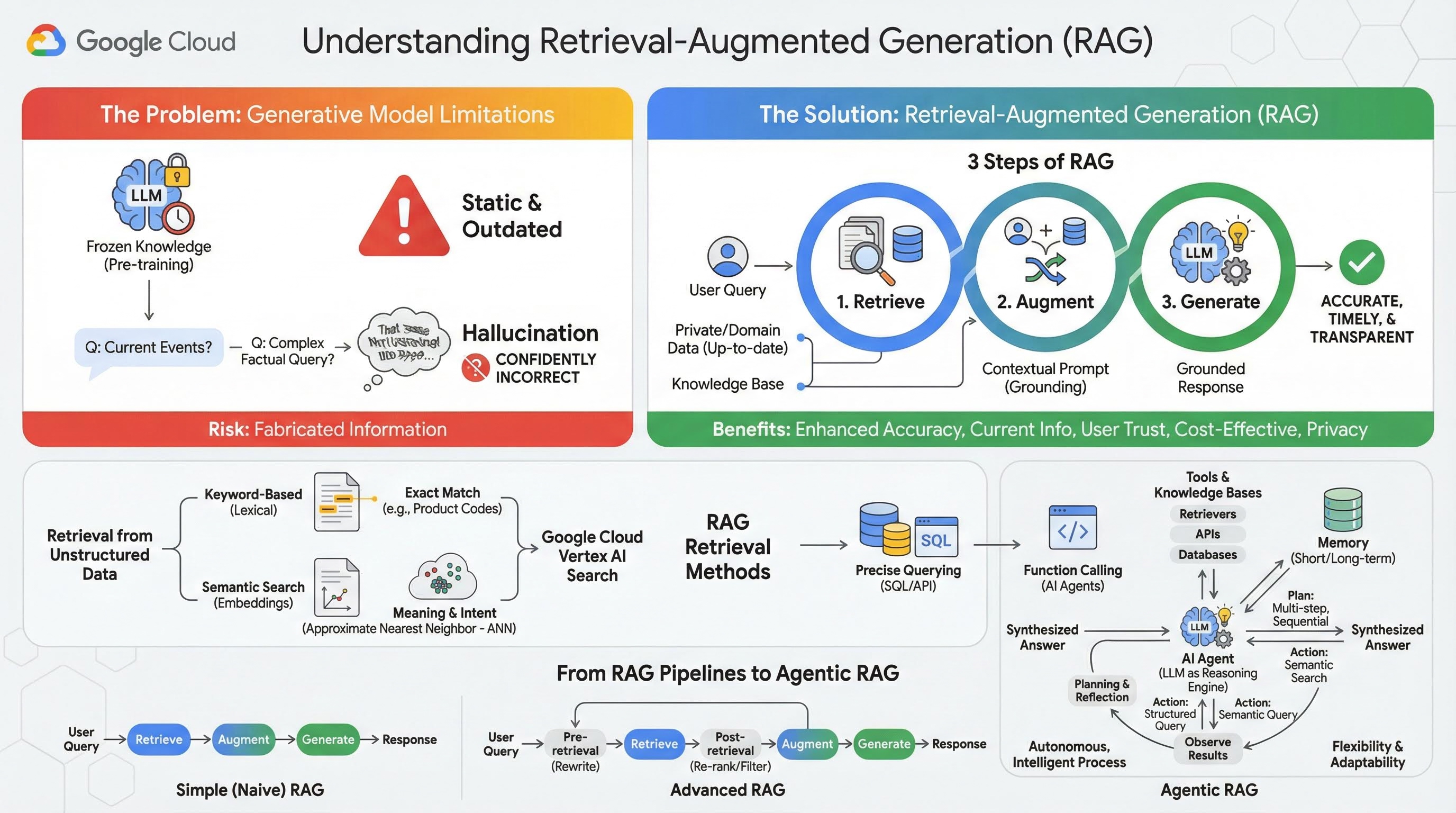
2. Memahami Retrieval-Augmented Generation
Model Generatif Besar (Model Bahasa Besar atau LLM, Model Bahasa-Visi, dll.) sangat canggih, tetapi memiliki keterbatasan bawaan. Pengetahuan mereka dibekukan pada saat prapelatihan, sehingga menjadi statis dan langsung kedaluwarsa. Bahkan setelah penyesuaian, pengetahuan model tidak menjadi lebih baru, karena hal ini bukan tujuan dari tahap pasca-pelatihan.
Cara Model Bahasa Besar dilatih, terutama model "berpikir", model tersebut "diberi penghargaan" karena memberikan beberapa jawaban meskipun model itu sendiri tidak memiliki informasi faktual yang akan mendukung jawaban tersebut. Hal ini terjadi saat mereka mengatakan bahwa model "berhalusinasi" - menghasilkan informasi yang terdengar masuk akal, tetapi faktanya salah.
Retrieval-Augmented Generation adalah pola arsitektur canggih yang dirancang untuk mengatasi masalah ini. Framework ini adalah framework arsitektur yang meningkatkan kemampuan Model Bahasa Besar dengan menghubungkannya ke sumber pengetahuan eksternal dan tepercaya secara real-time. Daripada hanya mengandalkan pengetahuan statis yang telah dilatih sebelumnya, LLM dalam sistem RAG terlebih dahulu mengambil informasi yang relevan terkait kueri pengguna, lalu menggunakan informasi tersebut untuk menghasilkan respons yang lebih akurat, tepat waktu, dan sesuai konteks.
Pendekatan ini secara langsung mengatasi kelemahan paling signifikan dari model generatif: pengetahuan mereka tetap pada satu titik waktu, dan mereka cenderung menghasilkan informasi yang salah, atau "halusinasi". RAG secara efektif memberikan "ujian buku terbuka" kepada LLM, dengan "buku" berupa data pribadi, spesifik per domain, dan terbaru Anda. Proses penyediaan konteks faktual ke LLM ini dikenal sebagai "grounding".
3 langkah RAG
Proses Retrieval-Augmented Generation standar dapat dibagi menjadi tiga langkah sederhana:
- Pengambilan: Saat pengguna mengirimkan kueri, sistem akan terlebih dahulu menelusuri pusat informasi eksternal (seperti repositori dokumen, database, atau situs) untuk menemukan informasi yang relevan dengan kueri tersebut.
- Augmentasi: Informasi yang diambil kemudian digabungkan dengan kueri pengguna asli menjadi perintah yang diperluas. Teknik ini terkadang disebut "pengisian perintah", karena memperkaya perintah dengan konteks faktual.
- Buat: Perintah yang telah diaugmentasi ini dimasukkan ke LLM, yang kemudian menghasilkan respons. Karena model telah diberi data faktual yang relevan, outputnya "beralasan" dan cenderung tidak akurat atau sudah tidak berlaku.
Manfaat RAG
Pengenalan framework RAG telah mengubah cara membangun aplikasi AI yang praktis dan tepercaya. Manfaat utamanya meliputi:
- Peningkatan Akurasi dan Pengurangan Halusinasi: Dengan meng-grounding respons pada fakta eksternal yang dapat diverifikasi, RAG secara signifikan mengurangi risiko LLM membuat-buat informasi.
- Akses ke Informasi Terkini: Sistem RAG dapat terhubung ke pusat informasi yang terus diperbarui, sehingga memungkinkan sistem memberikan respons berdasarkan informasi terbaru, yang tidak mungkin dilakukan oleh LLM yang dilatih secara statis.
- Meningkatkan Kepercayaan dan Transparansi Pengguna: Karena respons LLM didasarkan pada dokumen yang diambil, sistem dapat memberikan kutipan dan link ke sumbernya. Hal ini memungkinkan pengguna memverifikasi informasi sendiri, sehingga membangun kepercayaan pada aplikasi.
- Efektivitas Biaya: Menyempurnakan atau melatih ulang LLM secara berkelanjutan dengan data baru memerlukan biaya komputasi dan finansial yang mahal. Dengan RAG, memperbarui pengetahuan model semudah memperbarui sumber data eksternal, yang jauh lebih efisien.
- Spesialisasi Domain dan Privasi: RAG memungkinkan orang dan organisasi menyediakan data eksklusif pribadi mereka untuk LLM pada waktu kueri tanpa perlu menyertakan data sensitif tersebut dalam set pelatihan model. Hal ini memungkinkan aplikasi khusus domain yang canggih sekaligus menjaga privasi dan keamanan data.
Retrieval (Pengambilan Informasi)
Langkah "Pengambilan" adalah inti dari sistem RAG apa pun. Kualitas dan relevansi informasi yang diambil secara langsung menentukan kualitas dan relevansi jawaban akhir yang dihasilkan. Aplikasi RAG yang efektif sering kali perlu mengambil informasi dari berbagai jenis sumber data menggunakan berbagai teknik. Metode pengambilan utama dibagi menjadi tiga kategori: berbasis kata kunci, semantik, dan terstruktur.
Pengambilan dari Data Tidak Terstruktur
Secara historis, pengambilan data tidak terstruktur adalah nama lain untuk Penelusuran tradisional. Data tersebut telah melalui beberapa transformasi, dan Anda dapat memanfaatkan kedua pendekatan utama tersebut.
Penelusuran semantik adalah teknik paling efisien yang dapat Anda jalankan dalam skala besar di Google Cloud dengan performa canggih dan tingkat kontrol yang tinggi.
- Penelusuran Berbasis Kata Kunci (Leksikal): Ini adalah pendekatan tradisional untuk penelusuran, yang sudah ada sejak sistem pengambilan informasi paling awal pada tahun 1970-an. Penelusuran leksikal berfungsi dengan mencocokkan kata-kata (atau "token") literal dalam kueri pengguna dengan kata-kata yang sama persis dalam dokumen di pusat informasi. Fitur ini sangat efektif untuk kueri yang memerlukan presisi pada istilah tertentu, seperti kode produk, klausul hukum, atau nama unik.
- Penelusuran Semantik: Penelusuran semantik, atau "penelusuran dengan makna", adalah pendekatan yang lebih modern yang bertujuan untuk memahami maksud pengguna dan makna kontekstual kueri mereka, bukan hanya kata kunci literal. Penelusuran semantik modern didukung oleh embedding - teknik machine learning yang memetakan data berdimensi tinggi yang kompleks ke ruang vektor berdimensi lebih rendah dari vektor numerik. Vektor ini dirancang sedemikian rupa sehingga teks dengan makna serupa terletak berdekatan satu sama lain dalam ruang vektor. Penelusuran "Apa saja ras terbaik untuk keluarga?" dikonversi menjadi vektor, lalu sistem menelusuri vektor dokumen yang merupakan "tetangga terdekat" dalam ruang tersebut. Dengan demikian, penelusuran dapat menemukan dokumen yang membahas "golden retriever" atau " ramah", meskipun tidak berisi kata "" yang sama persis. Penelusuran berdimensi tinggi ini menjadi efisien berkat algoritma Perkiraan Tetangga Terdekat (ANN). Alih-alih membandingkan vektor kueri dengan setiap vektor dokumen (yang akan terlalu lambat untuk set data besar), algoritma ANN menggunakan struktur pengindeksan cerdas untuk menemukan vektor yang mungkin paling dekat dengan cepat.
Pengambilan dari Data Terstruktur
Tidak semua pengetahuan penting disimpan dalam dokumen tidak terstruktur. Sering kali, informasi yang paling akurat dan berharga berada dalam format terstruktur seperti database relasional, database NoSQL, atau beberapa jenis API, seperti REST API untuk data cuaca atau harga saham.
Pengambilan dari data terstruktur biasanya lebih langsung dan tepat daripada menelusuri teks tidak terstruktur. Alih-alih menelusuri kemiripan semantik, model bahasa dapat diberi kemampuan untuk merumuskan dan mengeksekusi kueri yang tepat, seperti kueri SQL pada database atau panggilan API ke API cuaca untuk lokasi dan tanggal tertentu.
Diimplementasikan melalui panggilan fungsi, teknik yang sama yang mendukung Agen AI, teknik ini memungkinkan model bahasa berinteraksi dengan kode yang dapat dieksekusi dan sistem eksternal secara struktural yang deterministik.
3. Dari Pipeline RAG ke RAG Agentik
Sama seperti konsep RAG itu sendiri yang telah berkembang, begitu juga arsitektur untuk mengimplementasikannya. Yang awalnya merupakan pipeline linier sederhana telah berkembang menjadi sistem dinamis dan cerdas yang diatur oleh agen AI.
- RAG Sederhana (atau Naif): Ini adalah arsitektur dasar yang telah kita bahas sejauh ini: proses tiga langkah linear untuk mengambil, memperkaya, dan membuat. Agen ini reaktif; mengikuti jalur tetap untuk setiap kueri dan sangat efektif untuk tugas Tanya Jawab yang sederhana.
- RAG Tingkat Lanjut: Ini mewakili evolusi di mana langkah-langkah tambahan ditambahkan ke pipeline untuk meningkatkan kualitas konteks yang diambil. Peningkatan ini dapat terjadi sebelum atau setelah langkah pengambilan.
- Pra-pengambilan: Teknik seperti penulisan ulang atau perluasan kueri dapat digunakan. Sistem dapat menganalisis kueri awal dan menyusun ulang kueri tersebut agar lebih efektif untuk sistem pengambilan.
- Setelah pengambilan: Setelah mengambil kumpulan awal dokumen, model pemeringkatan ulang dapat diterapkan untuk memberi skor pada dokumen berdasarkan relevansinya dan mendorong dokumen terbaik ke bagian atas. Hal ini sangat penting dalam penelusuran campuran. Langkah pasca-pengambilan lainnya adalah memfilter atau memadatkan konteks yang diambil untuk memastikan hanya informasi yang paling penting yang diteruskan ke LLM.
- RAG Agentik: Ini adalah arsitektur RAG tercanggih, yang merepresentasikan perubahan paradigma dari pipeline tetap ke proses otonom dan cerdas. Dalam sistem RAG Agentik, seluruh alur kerja dikelola oleh satu atau beberapa Agen AI yang dapat melakukan penalaran, perencanaan, dan memilih tindakan mereka secara dinamis.
Untuk memahami RAG Agentik, Anda harus memahami terlebih dahulu apa yang membentuk agen AI. Agen bukan hanya sekadar LLM. Ini adalah sistem dengan beberapa komponen utama:
- LLM sebagai Mesin Penalaran: Agen ini menggunakan LLM canggih seperti Gemini, bukan hanya untuk menghasilkan teks, tetapi juga sebagai "otak" utamanya untuk merencanakan, mengambil keputusan, dan menguraikan tugas yang kompleks.
- Serangkaian Alat: Agen diberi akses ke toolkit fungsi yang dapat diputuskan untuk digunakan dalam mencapai tujuannya. Alat ini bisa berupa apa saja: kalkulator, API penelusuran web, fungsi untuk mengirim email, atau yang paling penting untuk lab ini - pengambil untuk berbagai basis pengetahuan kita.
- Memori: Agen dapat didesain dengan memori jangka pendek (untuk mengingat konteks percakapan saat ini) dan memori jangka panjang (untuk mengingat informasi dari interaksi sebelumnya), sehingga memungkinkan pengalaman yang lebih dipersonalisasi dan koheren.
- Perencanaan dan Refleksi: Agen yang paling canggih menunjukkan pola penalaran yang rumit. Agen ini dapat menerima tujuan yang kompleks dan membuat rencana multi-langkah untuk mencapainya. Kemudian, mereka dapat menjalankan rencana ini, dan bahkan merefleksikan hasil tindakan mereka, mengidentifikasi kesalahan, dan memperbaiki sendiri pendekatan mereka untuk meningkatkan hasil akhir.
RAG Agentik adalah terobosan karena memperkenalkan lapisan otonomi dan kecerdasan yang tidak dimiliki pipeline statis.
- Fleksibilitas dan Kemampuan Beradaptasi: Agen tidak terikat pada satu jalur pengambilan. Mengingat kueri pengguna, model ini dapat mempertimbangkan sumber informasi terbaik. Model ini dapat memutuskan untuk terlebih dahulu membuat kueri database terstruktur, lalu melakukan penelusuran semantik pada dokumen tidak terstruktur, dan jika masih tidak dapat menemukan jawaban, menggunakan alat Google Penelusuran untuk mencari di web publik, semuanya dalam konteks satu permintaan pengguna.
- Penalaran Multi-Langkah yang Kompleks: Arsitektur ini unggul dalam menangani kueri kompleks yang memerlukan beberapa langkah pengambilan dan pemrosesan berurutan.
Pertimbangkan kueri: "Temukan 3 film fiksi ilmiah teratas yang disutradarai oleh Christopher Nolan, dan untuk setiap film, berikan ringkasan singkat alurnya." Pipeline RAG sederhana akan gagal.
Namun, agen dapat menguraikannya:
- Rencana: Pertama, saya perlu menemukan filmnya. Kemudian, untuk setiap film, saya perlu menemukan plotnya.
- Tindakan 1: Gunakan alat data terstruktur untuk membuat kueri database film guna menemukan film sci-fi Nolan: 3 film teratas, diurutkan berdasarkan rating secara menurun.
- Pengamatan 1: Alat menampilkan "Inception", "Interstellar", dan "Tenet".
- Tindakan 2: Gunakan alat data tidak terstruktur (penelusuran semantik) untuk menemukan plot "Inception".
- Pengamatan 2: Plot diambil.
- Tindakan 3: Ulangi untuk "Interstellar".
- Tindakan 4: Ulangi untuk "Tenet".
- Sintesis Akhir: Gabungkan semua informasi yang diambil menjadi satu jawaban yang koheren untuk pengguna.
4. Penyiapan project
Akun Google
Jika belum memiliki Akun Google pribadi, Anda harus membuat Akun Google.
Gunakan akun pribadi, bukan akun kantor atau sekolah.
Login ke Konsol Google Cloud
Login ke Konsol Google Cloud menggunakan Akun Google pribadi.
Aktifkan Penagihan
Gunakan Akun Penagihan Uji Coba (opsional)
Untuk menjalankan workshop ini, Anda memerlukan akun penagihan dengan sejumlah kredit. Gunakan kredit dari banner di bagian atas codelab ini untuk memulai. Jika sudah terhubung ke akun penagihan, Anda dapat melewati langkah ini.
Menyiapkan akun penagihan pribadi
Jika menyiapkan penagihan menggunakan kredit Google Cloud, Anda dapat melewati langkah ini.
Untuk menyiapkan akun penagihan pribadi, buka di sini untuk mengaktifkan penagihan di Cloud Console.
Beberapa Catatan:
- Menyelesaikan lab ini akan dikenai biaya kurang dari $1 USD untuk resource Cloud.
- Anda dapat mengikuti langkah-langkah di akhir lab ini untuk menghapus resource agar tidak dikenai biaya lebih lanjut.
- Pengguna baru memenuhi syarat untuk mengikuti Uji Coba Gratis senilai$300 USD.
Membuat project (opsional)
Jika Anda tidak memiliki project saat ini yang ingin digunakan untuk lab ini, buat project baru di sini.
5. Buka Cloud Shell Editor
- Klik link ini untuk langsung membuka Cloud Shell Editor
- Jika diminta untuk memberikan otorisasi kapan saja hari ini, klik Authorize untuk melanjutkan.
- Jika terminal tidak muncul di bagian bawah layar, buka terminal:
- Klik Lihat
- Klik Terminal
- Di terminal, tetapkan project Anda dengan perintah ini:
gcloud config set project [PROJECT_ID]- Contoh:
gcloud config set project lab-project-id-example - Jika tidak ingat project ID, Anda dapat mencantumkan semua project ID dengan:
gcloud projects list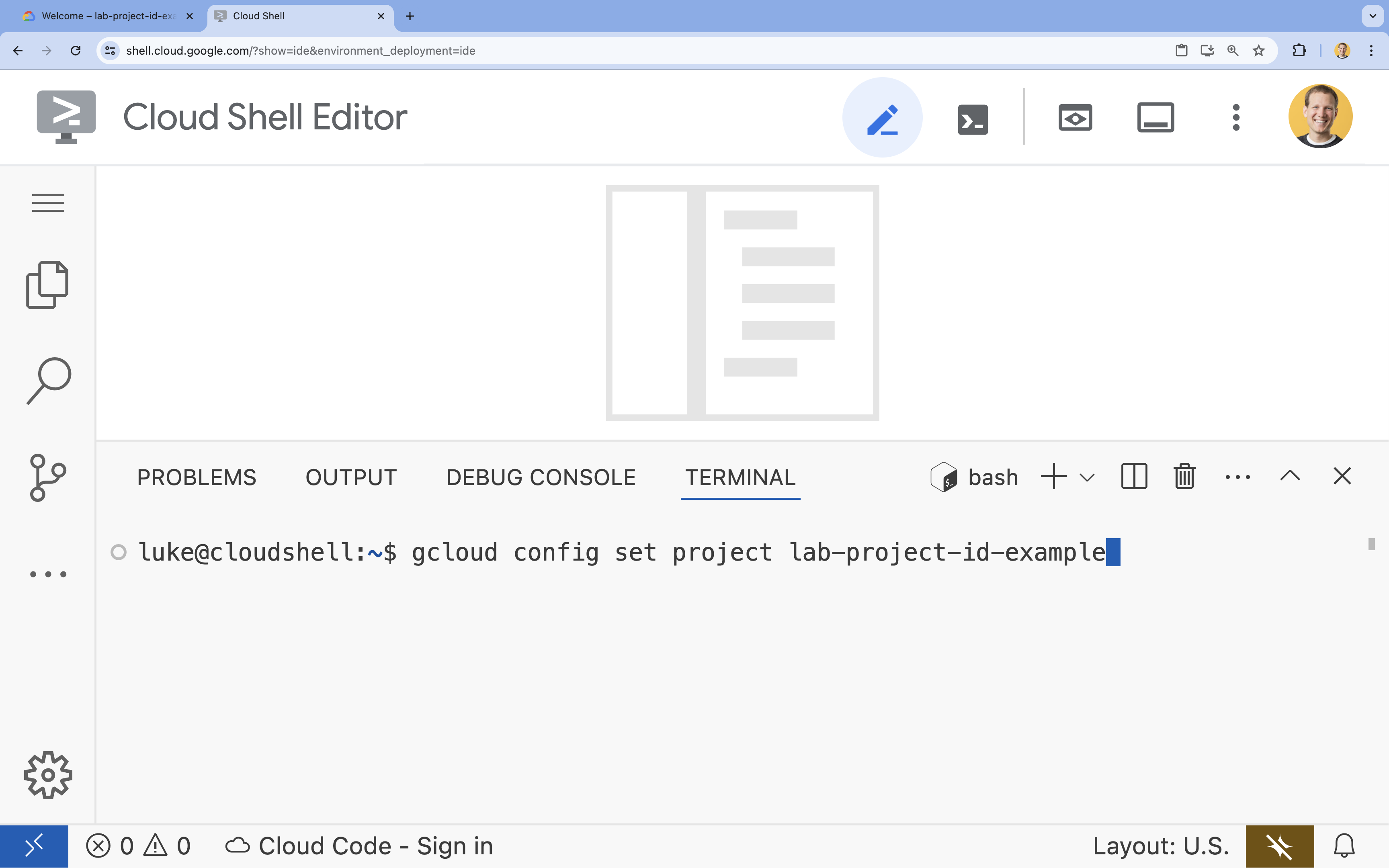
- Contoh:
- Anda akan melihat pesan ini:
Updated property [core/project].
6. Mengaktifkan API
Untuk menggunakan Agent Development Kit dan Vertex AI Search, Anda harus mengaktifkan API yang diperlukan di project Google Cloud Anda.
- Di terminal, aktifkan API:
gcloud services enable \ aiplatform.googleapis.com \ discoveryengine.googleapis.com
Memperkenalkan API
- Vertex AI API (
aiplatform.googleapis.com) memungkinkan agen berkomunikasi dengan model Gemini untuk penalaran dan pembuatan. - Discovery Engine API (
discoveryengine.googleapis.com) mendukung Vertex AI Search, sehingga Anda dapat membuat penyimpanan data dan melakukan penelusuran semantik pada dokumen tidak terstruktur.
7. Menyiapkan lingkungan
Sebelum mulai membuat kode Agen AI, Anda perlu menyiapkan lingkungan pengembangan, menginstal library yang diperlukan, dan membuat file data yang diperlukan.
Buat lingkungan virtual & instal dependensi
- Buat direktori untuk agen Anda dan buka direktori tersebut. Jalankan kode berikut di terminal:
mkdir financial_agent cd financial_agent - Buat lingkungan virtual:
uv venv --python 3.12 - Aktifkan lingkungan virtual:
source .venv/bin/activate - Instal Agent Development Kit (ADK) dan pandas.
uv pip install google-adk pandas
Buat data harga saham
Karena lab memerlukan data historis saham tertentu untuk mendemonstrasikan kemampuan agen dalam menggunakan alat terstruktur, Anda akan membuat file CSV yang berisi data ini.
- Di direktori
financial_agent, buat filegoog.csvdengan menjalankan perintah berikut di terminal:cat <<EOF > goog.csv Date,Open,High,Low,Close,Adj Close,Volume 2023-01-03,89.830002,91.550003,89.019997,89.699997,89.699997,20738500 2023-03-31,101.440002,103.889999,101.040001,103.730003,103.730003,36823200 2023-06-30,120.870003,122.029999,120.300003,120.970001,120.970001,23824700 2023-09-29,134.080002,134.550003,131.320007,131.850006,131.850006,21124200 2025-07-10,185.000000,188.000000,184.500000,186.500000,186.500000,25000000 EOF
Mengonfigurasi variabel lingkungan
- Di direktori
financial_agent, buat file.envuntuk mengonfigurasi variabel lingkungan agen Anda. Hal ini memberi tahu ADK project, lokasi, dan model yang akan digunakan. Jalankan kode berikut di terminal:# Create the .env file using the captured variables cat << EOF > .env GOOGLE_GENAI_USE_VERTEXAI=TRUE GOOGLE_CLOUD_PROJECT="${GOOGLE_CLOUD_PROJECT}" GOOGLE_CLOUD_LOCATION="us-central1" EOF
Catatan: Di bagian selanjutnya dalam lab ini, jika Anda perlu mengubah file .env, tetapi tidak melihatnya di direktori financial_agent, coba alihkan visibilitas file tersembunyi di Cloud Shell Editor menggunakan item menu "View / Toggle Hidden Files".
8. Membuat Penyimpanan Data Vertex AI Search
Untuk memungkinkan agen menjawab pertanyaan tentang laporan keuangan Alphabet, Anda akan membuat penyimpanan data Vertex AI Search yang berisi pengajuan SEC publik mereka.
- Di tab browser baru, buka Konsol Cloud (console.cloud.google.com), lalu buka AI Applications menggunakan kotak penelusuran di bagian atas.
- Jika diminta, centang kotak persyaratan dan ketentuan, lalu klik Continue and Activate the API.
- Dari menu navigasi di sebelah kiri, pilih Data Stores.
- Klik + Create Data Store.
- Temukan kartu Cloud Storage, lalu klik Select.
- Untuk sumber data, pilih Dokumen tidak terstruktur.

- Untuk sumber impor (Pilih folder atau file yang ingin Anda impor), masukkan jalur Google Cloud Storage
cloud-samples-data/gen-app-builder/search/alphabet-sec-filings. - Klik Lanjutkan.
- Biarkan lokasi ditetapkan ke global.
- Untuk nama penyimpanan data, masukkan
alphabet-sec-filings - Luaskan bagian Opsi pemrosesan dokumen.

- Di menu drop-down Default document parser, pilih Layout Parser.
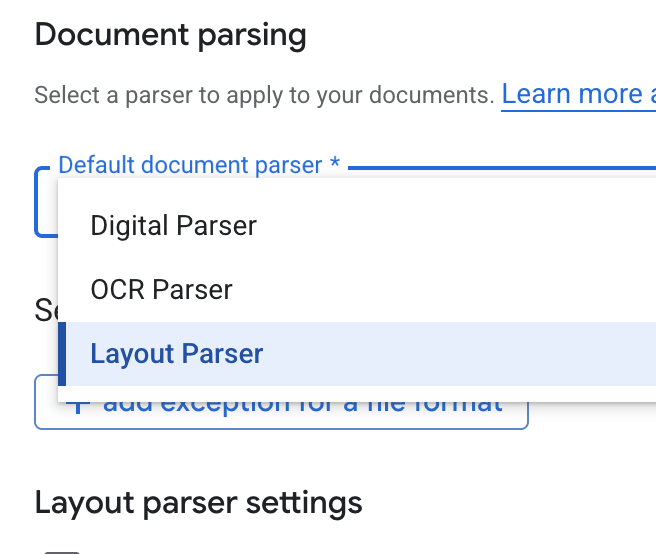
- Di opsi Setelan parser tata letak, pilih Aktifkan anotasi tabel dan Aktifkan anotasi gambar.
- Klik Lanjutkan.
- Pilih Harga umum sebagai model harga (model berbasis konsumsi, bayar sesuai penggunaan), lalu klik Buat.
- Penyimpanan data Anda akan mulai mengimpor dokumen.
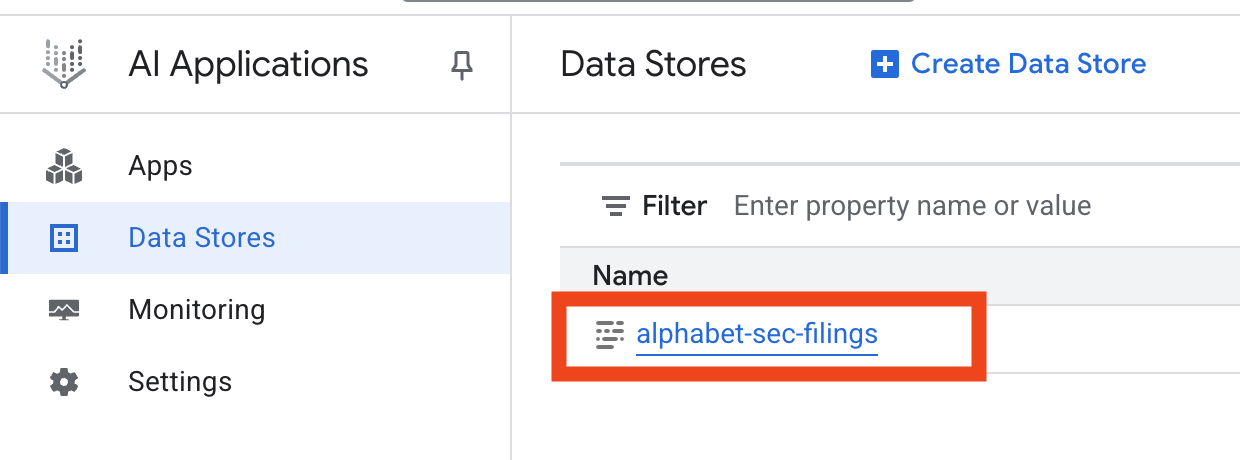
- Klik nama penyimpanan data, lalu salin ID-nya dari tabel Data Stores. Anda akan membutuhkannya pada langkah berikutnya.
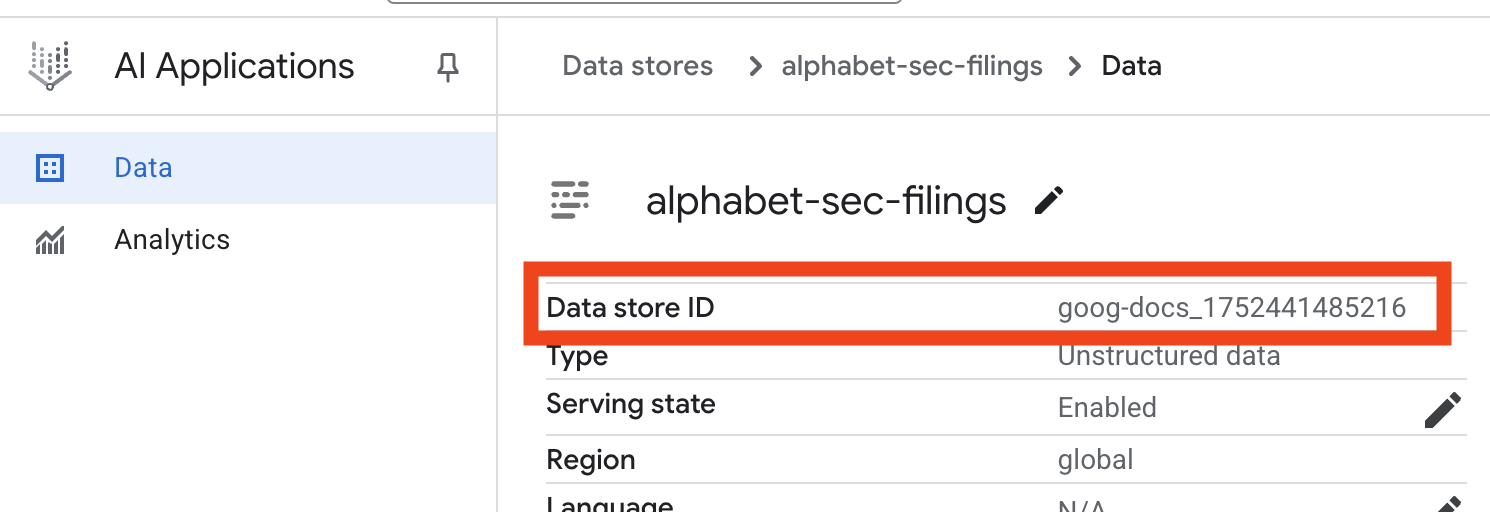
- Buka file
.envdi Cloud Shell Editor dan tambahkan ID penyimpanan data sebagaiDATA_STORE_ID="YOUR_DATA_STORE_ID"(gantiYOUR_DATA_STORE_IDdengan ID sebenarnya dari langkah sebelumnya.Catatan: Mengimpor, mengurai, & mengindeks data di penyimpanan data akan memerlukan waktu beberapa menit. Untuk memeriksa prosesnya, klik nama penyimpanan data untuk membuka propertinya, lalu buka tab Aktivitas. Tunggu hingga statusnya menjadi "Impor selesai".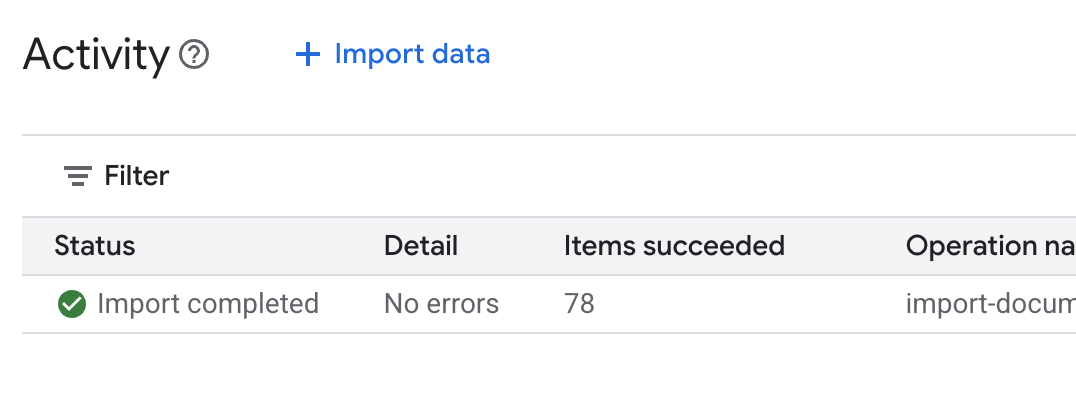
9. Membuat alat kustom untuk data terstruktur
Selanjutnya, Anda akan membuat fungsi Python yang akan bertindak sebagai alat untuk agen. Alat ini akan membaca file goog.csv untuk mengambil harga saham historis untuk tanggal tertentu.
- Di direktori
financial_agent, buat file baru bernamaagent.py. Jalankan perintah berikut di terminal:cloudshell edit agent.py - Tambahkan kode Python berikut ke
agent.py. Kode ini mengimpor dependensi dan menentukan fungsiget_stock_price.from datetime import datetime import os import logging import google.cloud.logging from google.adk.tools import VertexAiSearchTool from google.adk.tools.agent_tool import AgentTool from google.adk.agents import LlmAgent import pandas as pd def get_stock_price(date: str) -> dict: """Gets the closing stock price for a given date. Args: date: The date to get the stock price for, in YYYY-MM-DD format. Returns: A dictionary containing the closing price, or an error message if the date is not found or the format is incorrect. """ try: # Load the CSV file df = pd.read_csv('goog.csv') # Convert the 'Date' column to datetime objects df['Date'] = pd.to_datetime(df['Date']) # Convert the input string to a datetime object query_date = datetime.strptime(date, '%Y-%m-%d') # Find the row for the given date row = df[df['Date'] == query_date] if not row.empty: # Get the closing price close_price = row['Close'].iloc[0] return {"status": "success", "date": date, "closing_price": close_price} else: return {"status": "error", "message": f"No data found for date: {date}"} except FileNotFoundError: return {"status": "error", "message": "Stock data file (goog.csv) not found."} except Exception as e: return {"status": "error", "message": f"An error occurred: {str(e)}"}
Perhatikan docstring fungsi yang mendetail. Docstring ini menjelaskan fungsi, parameternya (Args), dan nilai yang ditampilkan (Returns). ADK menggunakan docstring ini untuk mengajari agen cara dan waktu penggunaan alat ini.
10. Membangun dan menjalankan agen RAG
Sekarang saatnya merakit agen. Anda akan menggabungkan alat Vertex AI Search untuk data tidak terstruktur dengan alat get_stock_price kustom Anda untuk data terstruktur.
- Tambahkan kode berikut ke file
agent.pyAnda. Kode ini mengimpor class ADK yang diperlukan, membuat instance alat, dan menentukan agen.logging.basicConfig(level=logging.INFO) cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() # 1. Create the Vertex AI Search tool full_datastore_id = f"projects/{os.environ['GOOGLE_CLOUD_PROJECT']}/locations/global/collections/default_collection/dataStores/{os.environ['DATA_STORE_ID']}" vertex_ai_search_tool = VertexAiSearchTool( data_store_id=full_datastore_id ) # 2. Define the Search+Q&A agent # Since we cannot combine tools with other tools in a single agent, # we create a separate Search+Q&A agent which will be used as a tool by the main root agent. doc_qa_agent = LlmAgent( name="search_and_qna_agent", model="gemini-2.5-flash", tools=[vertex_ai_search_tool], instruction="""You are a helpful assistant that answers questions based on information found in the document store. Use the search tool to find relevant information before answering. If the answer isn't in the documents, say that you couldn't find the information. """, description="Answers questions using a specific Vertex AI Search datastore.", ) # 3. Define the root agent with 2 tools. root_agent = LlmAgent( name="financial_agent", model="gemini-2.5-flash", tools=[ AgentTool(doc_qa_agent), get_stock_price, ], instruction="""You are an Financial Analytics Agent that answers question about Alphabet stock prices (using get_stock_price tool) and historical performance based on the data in Vertex AI Search datastore (using doc_qa_agent tool).""" ) - Dari terminal Anda, di dalam direktori
financial_agent, luncurkan antarmuka web ADK untuk berinteraksi dengan agen Anda:adk web ~ - Klik link yang disediakan di output terminal (biasanya
http://127.0.0.1:8000) untuk membuka UI Dev ADK di browser Anda.
11. Menguji agen
Sekarang Anda dapat menguji kemampuan penalaran agen dan penggunaan alatnya untuk menjawab pertanyaan kompleks.
- Di UI Dev ADK, pastikan
financial_agentAnda dipilih dari menu dropdown. - Coba ajukan pertanyaan yang memerlukan informasi dari pengajuan SEC (data tidak terstruktur). Masukkan kueri berikut dalam percakapan:
What were the total revenues for the quarter ending on March 31, 2023?search_and_qna_agent, yang menggunakanVertexAiSearchTooluntuk menemukan jawaban dalam dokumen keuangan. - Selanjutnya, ajukan pertanyaan yang memerlukan penggunaan alat kustom Anda (data terstruktur). Perhatikan bahwa format tanggal dalam perintah tidak harus sama persis dengan format yang diperlukan oleh fungsi; LLM cukup pintar untuk memformat ulang.
What was the closing stock price for Alphabet on July 10, 2025?get_stock_priceAnda. Anda dapat mengklik ikon alat dalam chat untuk memeriksa panggilan fungsi dan hasilnya. - Terakhir, ajukan pertanyaan kompleks yang mengharuskan agen menggunakan kedua alat dan menyintesis hasilnya.
According to the 10-Q filing for the period ending March 31, 2023, what were the company's net cash provided by operating activities, and what was the stock's closing price on that date?- Pertama,
VertexAiSearchToolakan digunakan untuk menemukan informasi arus kas dalam pengajuan SEC. - Kemudian, aplikasi akan mengenali kebutuhan harga saham dan memanggil fungsi
get_stock_pricedengan tanggal2023-03-31. - Terakhir, model akan menggabungkan kedua informasi tersebut menjadi satu jawaban yang komprehensif.
- Pertama,
- Setelah selesai, Anda dapat menutup tab browser dan menekan
CTRL+Cdi terminal untuk menghentikan server ADK.
12. Memilih layanan untuk tugas Anda
Vertex AI Search bukan satu-satunya layanan penelusuran vektor yang dapat Anda gunakan. Anda juga dapat menggunakan layanan terkelola yang mengotomatiskan seluruh alur Retrieval-Augmented Generation: Vertex AI RAG Engine.
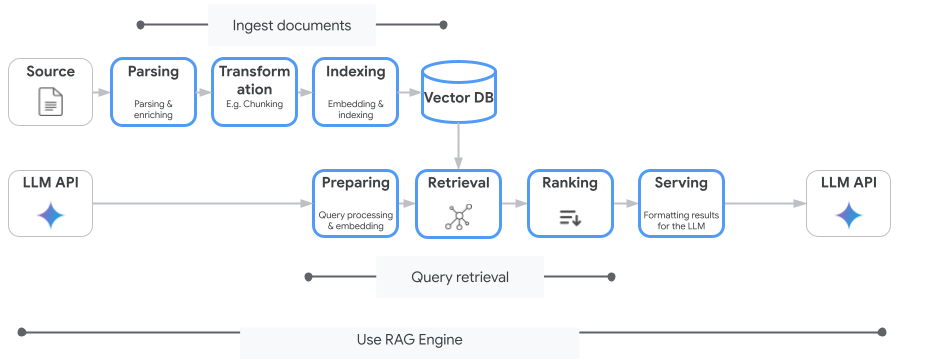
Sistem ini menangani semuanya mulai dari penyerapan dokumen hingga pengambilan dan pemeringkatan ulang. Mesin RAG mendukung beberapa penyimpanan vektor, termasuk Pinecone dan Weaviate.
Anda juga dapat menghosting sendiri banyak Database Vektor khusus atau memanfaatkan kemampuan indeks vektor di mesin database, seperti pgvector di layanan PostgreSQL (seperti AlloyDB atau BigQuery Vector Search.
Beberapa layanan lain yang mendukung Penelusuran Vektor adalah:
- Cloud SQL for PostgreSQL
- Cloud SQL untuk MySQL
- Cloud Spanner
- Memorystore for Redis
- Firestore
- Bigtable
Panduan umum tentang memilih layanan tertentu di Google Cloud adalah sebagai berikut:
- Jika Anda sudah memiliki infrastruktur Vector Search Do-It-Yourself yang berfungsi dan diskalakan dengan baik, deploy ke Google Kubernetes Engine, seperti Weaviate atau DIY PostgreSQL.
- Jika data Anda berada di BigQuery, AlloyDB, Firestore, atau database lainnya, pertimbangkan untuk menggunakan kemampuan Penelusuran Vektornya jika penelusuran semantik dapat dilakukan dalam skala besar sebagai bagian dari kueri yang lebih besar dalam database tersebut. Misalnya, jika Anda memiliki deskripsi dan/atau gambar produk dalam tabel BigQuery, menambahkan kolom sematan teks dan/atau gambar akan memungkinkan penggunaan penelusuran kemiripan dalam skala besar. Indeks Vektor dengan dukungan penelusuran ScaNN mendukung miliaran item dalam indeks.
- Jika Anda perlu memulai dengan cepat dan mudah di platform terkelola, pilih Vertex AI Search - API pengambilan dan mesin telusur terkelola sepenuhnya yang ideal untuk kasus penggunaan perusahaan yang kompleks yang memerlukan kualitas, skalabilitas, dan kontrol akses terperinci yang siap digunakan. Fitur ini menyederhanakan koneksi ke berbagai sumber data perusahaan dan memungkinkan penelusuran di beberapa sumber.
- Gunakan Vertex AI RAG Engine jika Anda mencari titik ideal bagi developer yang menginginkan keseimbangan antara kemudahan penggunaan dan penyesuaian. Hal ini memungkinkan pembuatan prototipe dan pengembangan yang cepat tanpa mengorbankan fleksibilitas.
- Pelajari Arsitektur Referensi untuk Retrieval-Augmented Generation.
13. Kesimpulan
Selamat! Anda telah berhasil membuat dan menguji Agen AI dengan Retrieval-Augmented Generation. Anda telah mempelajari cara:
- Buat pusat informasi untuk dokumen tidak terstruktur menggunakan kemampuan penelusuran semantik yang canggih dari Vertex AI Search.
- Kembangkan fungsi Python kustom untuk bertindak sebagai alat dalam mengambil data terstruktur.
- Gunakan Agent Development Kit (ADK) untuk membuat agen multi-alat yang didukung oleh Gemini.
- Bangun agen yang mampu melakukan penalaran multi-langkah yang kompleks untuk menjawab kueri yang memerlukan sintesis informasi dari berbagai sumber.
Lab ini menunjukkan prinsip-prinsip inti Agentic RAG, sebuah arsitektur canggih untuk membangun aplikasi AI yang cerdas, akurat, dan sadar konteks di Google Cloud.
Dari Prototipe hingga Produksi
Lab ini merupakan bagian dari Alur Pembelajaran AI Siap Produksi dengan Google Cloud.
- Jelajahi kurikulum lengkap untuk menjembatani kesenjangan dari prototipe hingga produksi.
- Bagikan progres Anda dengan hashtag #ProductionReadyAI.