
1. Introduzione
Panoramica
L'obiettivo di questo lab è imparare a sviluppare applicazioni RAG (Retrieval-Augmented Generation) agentiche end-to-end in Google Cloud. In questo lab creerai un agente di analisi finanziaria in grado di rispondere alle domande combinando le informazioni di due fonti diverse: documenti non strutturati (documenti SEC trimestrali di Alphabet: bilanci e dettagli operativi che ogni società per azioni negli Stati Uniti invia alla Securities and Exchange Commission) e dati strutturati (prezzi storici delle azioni).
Utilizzerai Vertex AI Search per creare un potente motore di ricerca semantica per i report finanziari non strutturati. Per i dati strutturati, creerai uno strumento Python personalizzato. Infine, utilizzerai l'Agent Development Kit (ADK) per creare un agente intelligente in grado di ragionare sulla query di un utente, decidere quale strumento utilizzare e sintetizzare le informazioni in una risposta coerente.
In questo lab proverai a:
- Configura un datastore Vertex AI Search per la ricerca semantica nei documenti privati.
- Crea una funzione Python personalizzata come strumento per un agente.
- Utilizza l'Agent Development Kit (ADK) per creare un agente multi-strumento.
- Combina il recupero da origini dati strutturate e non strutturate per rispondere a domande complesse.
- Testa e interagisci con un agente che mostra capacità di ragionamento.
Obiettivi didattici
In questo lab imparerai a:
- I concetti fondamentali di Retrieval-Augmented Generation (RAG) e RAG agentico.
- Come implementare la ricerca semantica nei documenti utilizzando Vertex AI Search.
- Come esporre dati strutturati a un agente creando strumenti personalizzati.
- Come creare e orchestrare un agente multi-strumento con Agent Development Kit (ADK).
- In che modo gli agenti utilizzano il ragionamento e la pianificazione per rispondere a domande complesse utilizzando più origini dati.
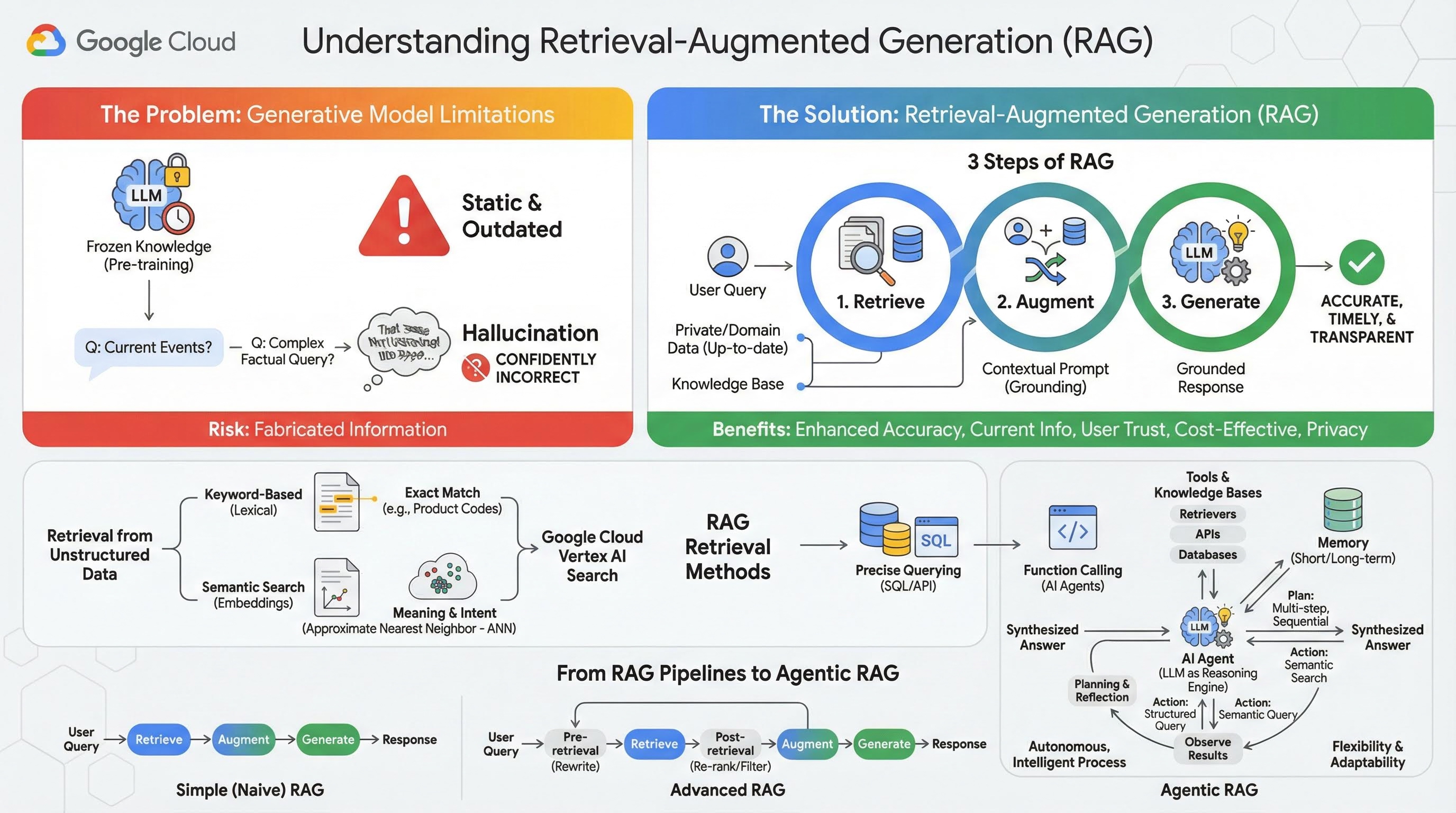
2. Informazioni sulla Retrieval-Augmented Generation
I modelli generativi di grandi dimensioni (modelli linguistici di grandi dimensioni o LLM, modelli di visione e linguaggio e così via) sono incredibilmente potenti, ma hanno limiti intrinseci. Le loro conoscenze sono congelate al momento del pre-addestramento, il che le rende statiche e immediatamente obsolete. Anche dopo il fine tuning, le conoscenze del modello non diventano molto più recenti, in quanto questo non è l'obiettivo delle fasi post-addestramento.
Il modo in cui vengono addestrati i modelli linguistici di grandi dimensioni, in particolare i modelli "pensanti", fa sì che vengano "premiati" per aver dato una risposta anche se il modello stesso non dispone di informazioni oggettive che la supportino. È in questi casi che si dice che un modello "ha allucinazioni", ovvero genera con sicurezza informazioni che sembrano plausibili, ma che sono oggettivamente errate.
La Retrieval-Augmented Generation è un potente pattern architetturale progettato per risolvere questi problemi. Si tratta di un framework architetturale che migliora le capacità dei modelli linguistici di grandi dimensioni collegandoli a fonti di conoscenza esterne e autorevoli in tempo reale. Invece di fare affidamento esclusivamente sulle sue conoscenze statiche preaddestrate, un LLM in un sistema RAG recupera prima le informazioni pertinenti relative alla query di un utente e poi le utilizza per generare una risposta più accurata, tempestiva e consapevole del contesto.
Questo approccio affronta direttamente i punti deboli più significativi dei modelli generativi: le loro conoscenze sono fisse in un determinato momento e sono inclini a generare informazioni errate, o "allucinazioni". La RAG fornisce in modo efficace all'LLM un "esame a libro aperto", in cui il "libro" sono i tuoi dati privati, specifici del dominio e aggiornati. Questo processo di fornitura di un contesto oggettivo all'LLM è noto come "fondatezza".
3 passaggi di RAG
La procedura standard di Retrieval Augmented Generation può essere suddivisa in tre semplici passaggi:
- Recupero: quando un utente invia una query, il sistema cerca innanzitutto in una knowledge base esterna (come un repository di documenti, un database o un sito web) per trovare informazioni pertinenti alla query.
- Miglioramento: le informazioni recuperate vengono quindi combinate con la query dell'utente originale in un prompt espanso. Questa tecnica è talvolta chiamata "prompt stuffing", in quanto arricchisce il prompt con un contesto fattuale.
- Genera: questo prompt aumentato viene inviato all'LLM, che genera una risposta. Poiché al modello sono stati forniti dati pertinenti e reali, il suo output è "fondato" e ha molte meno probabilità di essere impreciso o obsoleto.
Vantaggi di RAG
L'introduzione del framework RAG ha rivoluzionato la creazione di applicazioni di AI pratiche e affidabili. I suoi principali vantaggi includono:
- Maggiore accuratezza e riduzione delle allucinazioni: basando le risposte su fatti esterni verificabili, la RAG riduce drasticamente il rischio che l'LLM inventi informazioni.
- Accesso a informazioni aggiornate: i sistemi RAG possono essere collegati a knowledge base costantemente aggiornate, consentendo loro di fornire risposte basate sulle informazioni più recenti, cosa impossibile per un LLM addestrato staticamente.
- Maggiore fiducia e trasparenza degli utenti: poiché la risposta del LLM si basa sui documenti recuperati, il sistema può fornire citazioni e link alle sue fonti. In questo modo, gli utenti possono verificare le informazioni in autonomia, aumentando la fiducia nell'applicazione.
- Convenienza: l'ottimizzazione o il riaddestramento continuo di un LLM con nuovi dati è costoso dal punto di vista computazionale e finanziario. Con la RAG, aggiornare le conoscenze del modello è semplice come aggiornare l'origine dati esterna, il che è molto più efficiente.
- Specializzazione e privacy del dominio: RAG consente a persone e organizzazioni di rendere disponibili i propri dati privati e proprietari a un LLM al momento della query senza dover includere questi dati sensibili nel set di addestramento del modello. Ciò consente di creare applicazioni potenti e specifiche per il dominio, mantenendo al contempo la privacy e la sicurezza dei dati.
Recupero
Il passaggio "Recupero" è il cuore di qualsiasi sistema RAG. La qualità e la pertinenza delle informazioni recuperate determinano direttamente la qualità e la pertinenza della risposta finale generata. Un'applicazione RAG efficace spesso deve recuperare informazioni da diversi tipi di origini dati utilizzando varie tecniche. I metodi di recupero principali rientrano in tre categorie: basati su parole chiave, semantici e strutturati.
Recupero da dati non strutturati
Storicamente, il recupero di dati non strutturati è un altro nome per la Ricerca tradizionale. Ha subito diverse trasformazioni e puoi trarre vantaggio da entrambi gli approcci principali.
La ricerca semantica è la tecnica più efficiente che puoi eseguire su larga scala in Google Cloud con prestazioni all'avanguardia e un elevato grado di controllo.
- Ricerca basata su parole chiave (lessicale): si tratta dell'approccio tradizionale alla ricerca, risalente ai primi sistemi di recupero di informazioni degli anni '70. La ricerca lessicale funziona abbinando le parole letterali (o "token") nella query di un utente alle stesse parole esatte nei documenti all'interno di una knowledge base. È molto efficace per le query in cui la precisione su termini specifici, come codici prodotto, clausole legali o nomi univoci, è fondamentale.
- Ricerca semantica: la ricerca semantica, o "ricerca con significato", è un approccio più moderno che mira a comprendere l'intento dell'utente e il significato contestuale della sua query, non solo le parole chiave letterali. La ricerca semantica moderna è basata sull'embedding, una tecnica di machine learning che mappa dati complessi e ad alta dimensionalità in uno spazio vettoriale a bassa dimensionalità di vettori numerici. Questi vettori sono progettati in modo che i testi con significati simili si trovino vicini tra loro nello spazio vettoriale. Una ricerca di "Quali sono le migliori razze di cani per le famiglie?" viene convertita in un vettore e il sistema cerca quindi i vettori dei documenti che sono i suoi "vicini più prossimi" in quello spazio. In questo modo, può trovare documenti che parlano di "golden retriever" o "cani amichevoli", anche se non contengono la parola esatta "cane". Questa ricerca ad alta dimensionalità è resa efficiente dagli algoritmi Approximate Nearest Neighbor (ANN). Anziché confrontare il vettore della query con ogni singolo vettore del documento (operazione troppo lenta per set di dati di grandi dimensioni), gli algoritmi ANN utilizzano strutture di indicizzazione intelligenti per trovare rapidamente i vettori probabilmente più vicini.
Recupero dai dati strutturati
Non tutte le conoscenze critiche sono archiviate in documenti non strutturati. Spesso, le informazioni più precise e preziose si trovano in formati strutturati come database relazionali, database NoSQL o qualche tipo di API, ad esempio un'API REST per i dati meteo o il prezzo delle azioni.
Il recupero da dati strutturati è in genere più diretto ed esatto rispetto alla ricerca di testo non strutturato. Invece di cercare la somiglianza semantica, i modelli linguistici possono avere la capacità di formulare ed eseguire una query precisa, ad esempio una query SQL su un database o una chiamata API a un'API meteo per una determinata località e data.
Implementata tramite la chiamata di funzioni, la stessa tecnica che alimenta gli agenti AI, consente ai modelli linguistici di interagire con codice eseguibile e sistemi esterni in modo strutturale deterministico.
3. Dalle pipeline RAG alla RAG agentica
Così come si è evoluto il concetto di RAG, si sono evolute anche le architetture per la sua implementazione. Quella che era iniziata come una semplice pipeline lineare si è trasformata in un sistema dinamico e intelligente orchestrato da agenti AI.
- RAG semplice (o ingenuo):è l'architettura di base che abbiamo discusso finora: un processo lineare in tre fasi di recupero, aumento e generazione. È reattivo, segue un percorso fisso per ogni query ed è molto efficace per le attività di domande e risposte semplici.
- RAG avanzato:rappresenta un'evoluzione in cui vengono aggiunti passaggi aggiuntivi alla pipeline per migliorare la qualità del contesto recuperato. Questi miglioramenti possono verificarsi prima o dopo il passaggio di recupero.
- Pre-recupero:è possibile utilizzare tecniche come la riscrittura o l'espansione delle query. Il sistema potrebbe analizzare la query iniziale e riformularla per renderla più efficace per il sistema di recupero.
- Post-recupero:dopo aver recuperato un insieme iniziale di documenti, è possibile applicare un modello di riposizionamento per assegnare un punteggio ai documenti in base alla pertinenza e spostare quelli migliori in cima. Ciò è particolarmente importante nella ricerca ibrida. Un altro passaggio post-recupero consiste nel filtrare o comprimere il contesto recuperato per garantire che all'LLM vengano trasmesse solo le informazioni più importanti.
- RAG agentico:si tratta dell'architettura RAG all'avanguardia, che rappresenta un cambio di paradigma da una pipeline fissa a un processo autonomo e intelligente. In un sistema RAG agentico, l'intero flusso di lavoro è gestito da uno o più agenti AI che possono ragionare, pianificare e scegliere dinamicamente le proprie azioni.
Per comprendere la RAG agentica, è necessario prima capire cosa costituisce un agente AI. Un agente è molto più di un LLM. Si tratta di un sistema con diversi componenti chiave:
- Un LLM come motore di ragionamento:l'agente utilizza un LLM potente come Gemini non solo per generare testo, ma come "cervello" centrale per pianificare, prendere decisioni e scomporre attività complesse.
- Un insieme di strumenti:a un agente viene concesso l'accesso a un toolkit di funzioni che può decidere di utilizzare per raggiungere i suoi obiettivi. Questi strumenti possono essere qualsiasi cosa: una calcolatrice, un'API di ricerca web, una funzione per inviare un'email o, cosa più importante per questo lab, recuperatori per le nostre varie knowledge base.
- Memoria:gli agenti possono essere progettati con una memoria a breve termine (per ricordare il contesto della conversazione attuale) e una memoria a lungo termine (per richiamare informazioni dalle interazioni passate), consentendo esperienze più personalizzate e coerenti.
- Pianificazione e riflessione:gli agenti più avanzati mostrano sofisticati schemi di ragionamento. Possono ricevere un obiettivo complesso e creare un piano in più passaggi per raggiungerlo. Può quindi eseguire questo piano e persino riflettere sui risultati delle sue azioni, identificare gli errori e correggere autonomamente il suo approccio per migliorare il risultato finale.
L'Agentic RAG è una svolta perché introduce un livello di autonomia e intelligenza di cui le pipeline statiche sono prive.
- Flessibilità e adattabilità:un agente non è vincolato a un unico percorso di recupero. Data una query dell'utente, può ragionare sulla migliore fonte di informazioni. Potrebbe decidere di eseguire prima una query nel database strutturato, poi una ricerca semantica nei documenti non strutturati e, se ancora non riesce a trovare una risposta, utilizzare uno strumento di Ricerca Google per cercare sul web pubblico, il tutto nel contesto di una singola richiesta dell'utente.
- Ragionamento multi-step complesso: questa architettura eccelle nella gestione di query complesse che richiedono più passaggi di recupero ed elaborazione sequenziali.
Considera la query: "Trova i 3 migliori film di fantascienza diretti da Christopher Nolan e fornisci per ciascuno un breve riassunto della trama". Una semplice pipeline RAG non funzionerebbe.
Un agente, tuttavia, può fornire maggiori dettagli:
- Piano:prima di tutto, devo trovare i film. Poi, per ogni film, devo trovare la trama.
- Azione 1:utilizza lo strumento per i dati strutturati per eseguire una query in un database di film per trovare i film di fantascienza di Nolan: i primi 3 film, ordinati in base alla valutazione in ordine decrescente.
- Osservazione 1: lo strumento restituisce "Inception", "Interstellar" e "Tenet".
- Azione 2:utilizza lo strumento per i dati non strutturati (ricerca semantica) per trovare la trama di "Inception".
- Osservazione 2: il tracciato viene recuperato.
- Azione 3: ripeti l'operazione per "Interstellar".
- Azione 4: ripeti per "Tenet".
- Sintesi finale:combina tutte le informazioni recuperate in un'unica risposta coerente per l'utente.
4. Configurazione del progetto
Account Google
Se non hai ancora un Account Google personale, devi crearne uno.
Utilizza un account personale anziché un account di lavoro o della scuola.
Accedi alla console Google Cloud
Accedi a Google Cloud Console utilizzando un Account Google personale.
Abilita fatturazione
Utilizza l'account di fatturazione di prova (facoltativo)
Per partecipare a questo workshop, devi disporre di un account di fatturazione con del credito. Per iniziare, utilizza i crediti del banner nella parte superiore di questo codelab. Se hai già collegato un account di fatturazione, puoi saltare questo passaggio.
Configurare un account di fatturazione personale
Se hai configurato la fatturazione utilizzando i crediti Google Cloud, puoi saltare questo passaggio.
Per configurare un account di fatturazione personale, vai qui per abilitare la fatturazione nella console Cloud.
Alcune note:
- Il completamento di questo lab dovrebbe costare meno di 1 $in risorse cloud.
- Per evitare ulteriori addebiti, puoi seguire i passaggi alla fine di questo lab per eliminare le risorse.
- I nuovi utenti hanno diritto alla prova senza costi di 300$.
Creare un progetto (facoltativo)
Se non hai un progetto attuale che vuoi utilizzare per questo lab, creane uno nuovo qui.
5. Apri editor di Cloud Shell
- Fai clic su questo link per andare direttamente all'editor di Cloud Shell.
- Se ti viene richiesto di concedere l'autorizzazione in qualsiasi momento della giornata, fai clic su Autorizza per continuare.
- Se il terminale non viene visualizzato nella parte inferiore dello schermo, aprilo:
- Fai clic su Visualizza.
- Fai clic su Terminale
 .
.
- Nel terminale, imposta il progetto con questo comando:
gcloud config set project [PROJECT_ID]- Esempio:
gcloud config set project lab-project-id-example - Se non ricordi l'ID progetto, puoi elencare tutti i tuoi ID progetto con:
gcloud projects list
- Esempio:
- Dovresti visualizzare questo messaggio:
Updated property [core/project].
6. Abilita API
Per utilizzare l'Agent Development Kit e Vertex AI Search, devi abilitare le API necessarie nel tuo progetto Google Cloud.
- Nel terminale, abilita le API:
gcloud services enable \ aiplatform.googleapis.com \ discoveryengine.googleapis.com
Presentazione delle API
- L'API Vertex AI (
aiplatform.googleapis.com) consente all'agente di comunicare con i modelli Gemini per il ragionamento e la generazione. - L'API Discovery Engine (
discoveryengine.googleapis.com) potenzia Vertex AI Search, consentendoti di creare datastore ed eseguire ricerche semantiche nei tuoi documenti non strutturati.
7. Configurare l'ambiente
Prima di iniziare a programmare l'agente AI, devi preparare l'ambiente di sviluppo, installare le librerie necessarie e creare i file di dati richiesti.
Crea un ambiente virtuale e installa le dipendenze
- Crea una directory per l'agente e accedi alla directory. Esegui questo codice nel terminale:
mkdir financial_agent cd financial_agent - Crea un ambiente virtuale:
uv venv --python 3.12 - Attiva l'ambiente virtuale:
source .venv/bin/activate - Installa Agent Development Kit (ADK) e pandas.
uv pip install google-adk pandas
Creare i dati sul prezzo delle azioni
Poiché il lab richiede dati azionari storici specifici per dimostrare la capacità dell'agente di utilizzare strumenti strutturati, creerai un file CSV contenente questi dati.
- Nella directory
financial_agent, crea il filegoog.csveseguendo il seguente comando nel terminale:cat <<EOF > goog.csv Date,Open,High,Low,Close,Adj Close,Volume 2023-01-03,89.830002,91.550003,89.019997,89.699997,89.699997,20738500 2023-03-31,101.440002,103.889999,101.040001,103.730003,103.730003,36823200 2023-06-30,120.870003,122.029999,120.300003,120.970001,120.970001,23824700 2023-09-29,134.080002,134.550003,131.320007,131.850006,131.850006,21124200 2025-07-10,185.000000,188.000000,184.500000,186.500000,186.500000,25000000 EOF
Configura le variabili di ambiente
- Nella directory
financial_agent, crea un file.envper configurare le variabili di ambiente dell'agente. Indica all'ADK il progetto, la posizione e il modello da utilizzare. Esegui questo codice nel terminale:# Create the .env file using the captured variables cat << EOF > .env GOOGLE_GENAI_USE_VERTEXAI=TRUE GOOGLE_CLOUD_PROJECT="${GOOGLE_CLOUD_PROJECT}" GOOGLE_CLOUD_LOCATION="us-central1" EOF
Nota:più avanti nel lab, se devi modificare il file .env ma non lo vedi nella directory financial_agent, prova ad attivare/disattivare la visibilità dei file nascosti nell'editor di Cloud Shell utilizzando la voce di menu "Visualizza/Attiva/Disattiva file nascosti".
8. Crea un datastore Vertex AI Search
Per consentire all'agente di rispondere a domande sui report finanziari di Alphabet, creerai un datastore di Vertex AI Search contenente i documenti SEC pubblici.
- In una nuova scheda del browser, apri la console Cloud (console.cloud.google.com), vai ad AI Applications utilizzando la barra di ricerca in alto.
- Se richiesto, seleziona la casella di controllo dei termini e condizioni e fai clic su Continua e attiva l'API.
- Nel menu di navigazione a sinistra, seleziona Data Store.
- Fai clic su + Crea datastore.
- Trova la scheda Cloud Storage e fai clic su Seleziona.
- Per l'origine dati, seleziona Documenti non strutturati.

- Per l'origine dell'importazione (Seleziona una cartella o un file da importare), inserisci il percorso di Google Cloud Storage
cloud-samples-data/gen-app-builder/search/alphabet-sec-filings. - Fai clic su Continua.
- Mantieni la località impostata su globale.
- Per il nome del datastore, inserisci
alphabet-sec-filings - Espandi la sezione Opzioni di elaborazione documenti.

- Nell'elenco a discesa Parser documenti predefinito, seleziona Parser layout.
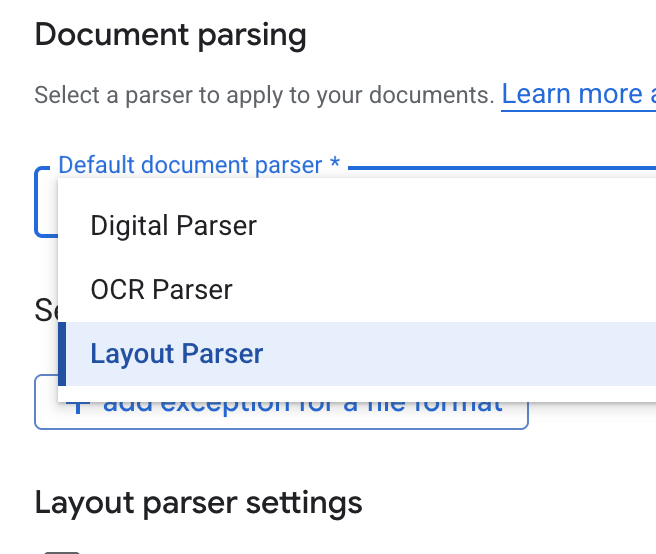
- Nelle opzioni Impostazioni parser layout, seleziona Attiva annotazione tabella e Attiva annotazione immagine.
- Fai clic su Continua.
- Seleziona Prezzi generali come modello di prezzo (un modello basato sul consumo e con pagamento a consumo) e fai clic su Crea.
- Il datastore inizierà a importare i documenti.
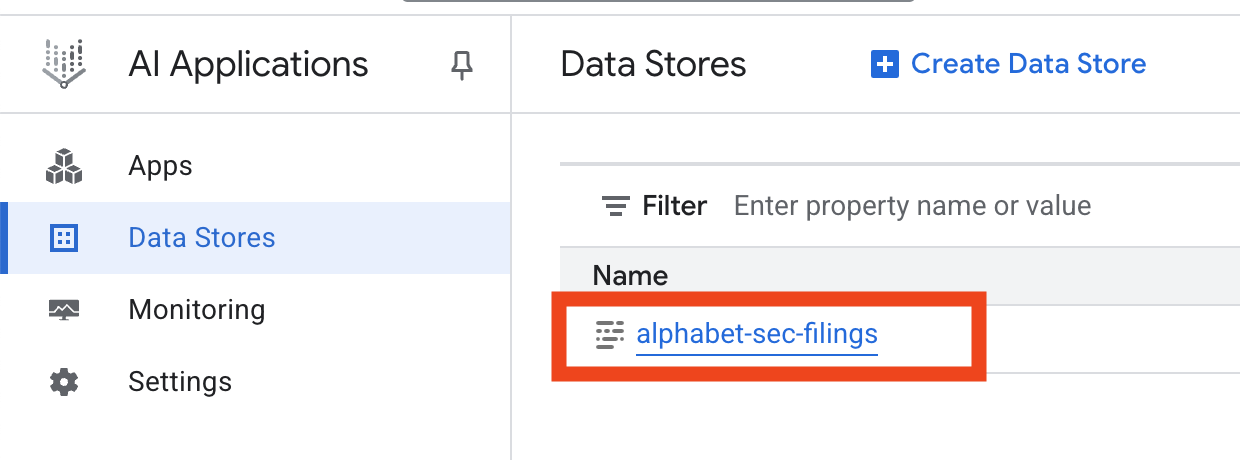
- Fai clic sul nome del datastore e copia il relativo ID dalla tabella Datastore. Ti servirà nel passaggio successivo.
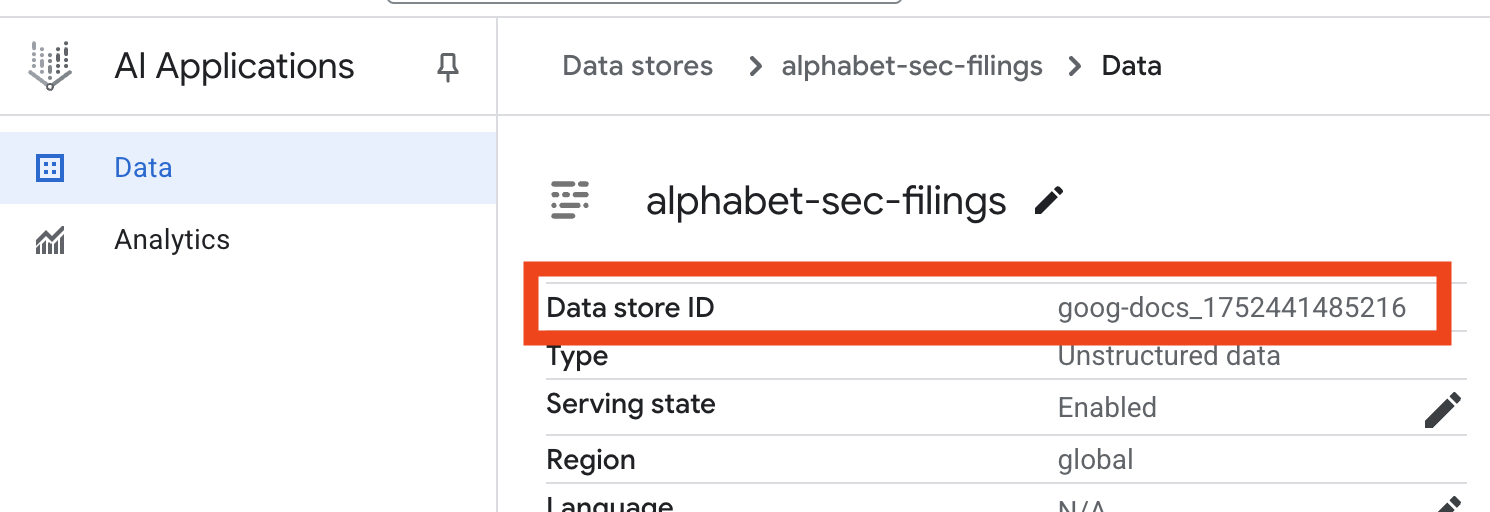
- Apri il file
.envin Cloud Shell Editor e aggiungi l'ID datastore comeDATA_STORE_ID="YOUR_DATA_STORE_ID"(sostituisciYOUR_DATA_STORE_IDcon l'ID effettivo del passaggio precedente.Nota: l'importazione, l'analisi e l'indicizzazione dei dati nel datastore richiedono alcuni minuti. Per controllare la procedura, fai clic sul nome del datastore per aprirne le proprietà, quindi apri la scheda Attività. Attendi che lo stato diventi "Importazione completata".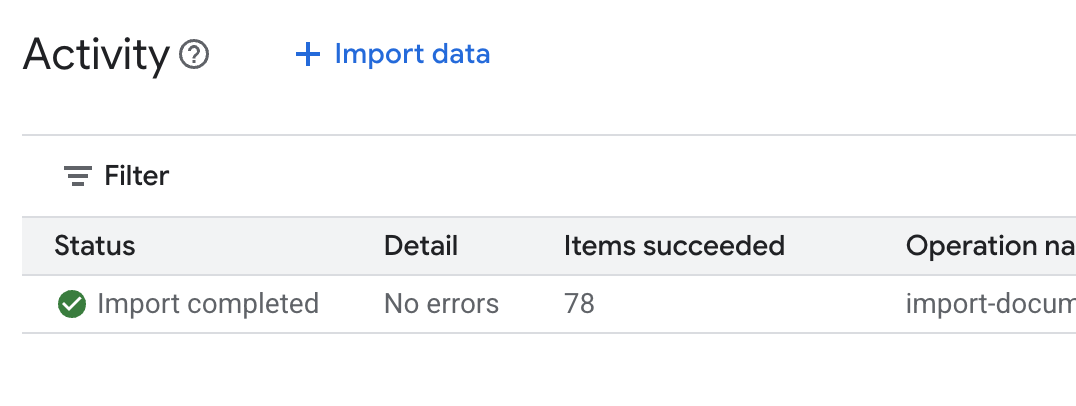
9. Creare uno strumento personalizzato per i dati strutturati
Successivamente, creerai una funzione Python che fungerà da strumento per l'agente. Questo strumento leggerà il file goog.csv per recuperare i prezzi storici delle azioni per una determinata data.
- Nella directory
financial_agent, crea un nuovo file denominatoagent.py. Esegui questo comando nel terminale:cloudshell edit agent.py - Aggiungi il seguente codice Python a
agent.py. Questo codice importa le dipendenze e definisce la funzioneget_stock_price.from datetime import datetime import os import logging import google.cloud.logging from google.adk.tools import VertexAiSearchTool from google.adk.tools.agent_tool import AgentTool from google.adk.agents import LlmAgent import pandas as pd def get_stock_price(date: str) -> dict: """Gets the closing stock price for a given date. Args: date: The date to get the stock price for, in YYYY-MM-DD format. Returns: A dictionary containing the closing price, or an error message if the date is not found or the format is incorrect. """ try: # Load the CSV file df = pd.read_csv('goog.csv') # Convert the 'Date' column to datetime objects df['Date'] = pd.to_datetime(df['Date']) # Convert the input string to a datetime object query_date = datetime.strptime(date, '%Y-%m-%d') # Find the row for the given date row = df[df['Date'] == query_date] if not row.empty: # Get the closing price close_price = row['Close'].iloc[0] return {"status": "success", "date": date, "closing_price": close_price} else: return {"status": "error", "message": f"No data found for date: {date}"} except FileNotFoundError: return {"status": "error", "message": "Stock data file (goog.csv) not found."} except Exception as e: return {"status": "error", "message": f"An error occurred: {str(e)}"}
Nota la docstring dettagliata della funzione. Spiega cosa fa la funzione, i suoi parametri (Args) e cosa restituisce (Returns). L'ADK utilizza questa docstring per insegnare all'agente come e quando utilizzare questo strumento.
10. Crea ed esegui l'agente RAG
Ora è il momento di assemblare l'agente. Combina lo strumento Vertex AI Search per i dati non strutturati con lo strumento get_stock_price personalizzato per i dati strutturati.
- Aggiungi il seguente codice al file
agent.py. Questo codice importa le classi ADK necessarie, crea istanze degli strumenti e definisce l'agente.logging.basicConfig(level=logging.INFO) cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() # 1. Create the Vertex AI Search tool full_datastore_id = f"projects/{os.environ['GOOGLE_CLOUD_PROJECT']}/locations/global/collections/default_collection/dataStores/{os.environ['DATA_STORE_ID']}" vertex_ai_search_tool = VertexAiSearchTool( data_store_id=full_datastore_id ) # 2. Define the Search+Q&A agent # Since we cannot combine tools with other tools in a single agent, # we create a separate Search+Q&A agent which will be used as a tool by the main root agent. doc_qa_agent = LlmAgent( name="search_and_qna_agent", model="gemini-2.5-flash", tools=[vertex_ai_search_tool], instruction="""You are a helpful assistant that answers questions based on information found in the document store. Use the search tool to find relevant information before answering. If the answer isn't in the documents, say that you couldn't find the information. """, description="Answers questions using a specific Vertex AI Search datastore.", ) # 3. Define the root agent with 2 tools. root_agent = LlmAgent( name="financial_agent", model="gemini-2.5-flash", tools=[ AgentTool(doc_qa_agent), get_stock_price, ], instruction="""You are an Financial Analytics Agent that answers question about Alphabet stock prices (using get_stock_price tool) and historical performance based on the data in Vertex AI Search datastore (using doc_qa_agent tool).""" ) - Dal terminale, all'interno della directory
financial_agent, avvia l'interfaccia web di ADK per interagire con l'agente:adk web ~ - Fai clic sul link fornito nell'output del terminale (di solito
http://127.0.0.1:8000) per aprire l'interfaccia utente di ADK Dev nel browser.
11. Testare l'agente
Ora puoi testare la capacità dell'agente di ragionare e utilizzare i suoi strumenti per rispondere a domande complesse.
- Nell'interfaccia utente di sviluppo dell'ADK, assicurati che
financial_agentsia selezionato dal menu a discesa. - Prova a porre una domanda che richieda informazioni dai documenti SEC (dati non strutturati). Inserisci la seguente query nella chat:
What were the total revenues for the quarter ending on March 31, 2023?search_and_qna_agent, che utilizzaVertexAiSearchToolper trovare la risposta nei documenti finanziari. - Dopodiché, poni una domanda che richieda l'utilizzo del tuo strumento personalizzato (dati strutturati). Tieni presente che il formato della data nel prompt non deve corrispondere esattamente al formato richiesto dalla funzione; l'LLM è abbastanza intelligente da riformattarlo.
What was the closing stock price for Alphabet on July 10, 2025?get_stock_price. Puoi fare clic sull'icona dello strumento nella chat per esaminare la chiamata di funzione e il relativo risultato. - Infine, poni una domanda complessa che richieda all'agente di utilizzare entrambi gli strumenti e sintetizzare i risultati.
According to the 10-Q filing for the period ending March 31, 2023, what were the company's net cash provided by operating activities, and what was the stock's closing price on that date?- Innanzitutto, utilizzerà
VertexAiSearchToolper trovare le informazioni sul flusso di cassa nei documenti depositati presso la SEC. - Poi, riconoscerà la necessità del prezzo delle azioni e chiamerà la funzione
get_stock_pricecon la data2023-03-31. - Infine, combinerà entrambe le informazioni in un'unica risposta completa.
- Innanzitutto, utilizzerà
- Al termine, puoi chiudere la scheda del browser e premere
CTRL+Cnel terminale per arrestare il server ADK.
12. Scegliere un servizio per l'attività
Vertex AI Search non è l'unico servizio di ricerca vettoriale che puoi utilizzare. Puoi anche utilizzare un servizio gestito che automatizza l'intero flusso di Retrieval-Augmented Generation: Vertex AI RAG Engine.
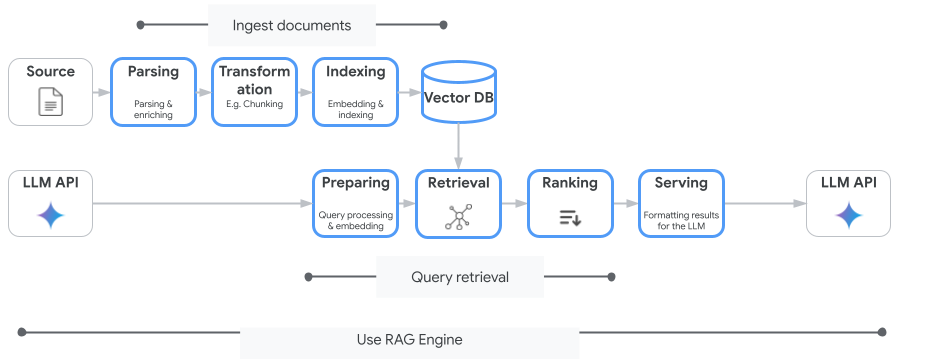
Gestisce tutto, dall'importazione dei documenti al recupero e al riposizionamento. RAG Engine supporta più vector store, tra cui Pinecone e Weaviate.
Puoi anche eseguire l'hosting autonomo di molti database vettoriali specializzati o sfruttare le funzionalità di indice vettoriale nei motori di database, come pgvector nel servizio PostgreSQL (ad esempio AlloyDB o BigQuery Vector Search).
Altri servizi che supportano la ricerca vettoriale sono:
Le indicazioni generali per la scelta di un servizio specifico su Google Cloud sono le seguenti:
- Se hai già un'infrastruttura di ricerca vettoriale fai da te funzionante e ben scalata, esegui il deployment su Google Kubernetes Engine, ad esempio Weaviate o DIY PostgreSQL.
- Se i dati si trovano in BigQuery, AlloyDB, Firestore o in qualsiasi altro database, valuta la possibilità di utilizzare le funzionalità di ricerca vettoriale se la ricerca semantica può essere eseguita su larga scala nell'ambito di una query più ampia nel database. Ad esempio, se hai descrizioni e/o immagini di prodotti in una tabella BigQuery, l'aggiunta di una colonna di incorporamento di testo e/o immagini consentirà di utilizzare la ricerca per similarità su larga scala. Gli indici vettoriali con il supporto della ricerca ScaNN possono contenere miliardi di elementi.
- Se hai bisogno di iniziare rapidamente con il minimo sforzo e su una piattaforma gestita, scegli Vertex AI Search, un motore di ricerca e un'API di recupero completamente gestiti, ideali per casi d'uso aziendali complessi che richiedono alta qualità, scalabilità e controlli dell'accesso granulari pronti all'uso. Semplifica la connessione a diverse origini dati aziendali e consente la ricerca in più origini.
- Utilizza Vertex AI RAG Engine se stai cercando un punto di incontro per gli sviluppatori che cercano un equilibrio tra facilità d'uso e personalizzazione. Consente la prototipazione e lo sviluppo rapidi senza sacrificare la flessibilità.
- Esplora le architetture di riferimento per la Retrieval-Augmented Generation.
13. Conclusione
Complimenti! Hai creato e testato correttamente un agente AI con Retrieval-Augmented Generation. Hai imparato a:
- Crea una knowledge base per documenti non strutturati utilizzando le potenti funzionalità di ricerca semantica di Vertex AI Search.
- Sviluppa una funzione Python personalizzata che funga da strumento per recuperare i dati strutturati.
- Utilizza Agent Development Kit (ADK) per creare un agente multi-strumento basato su Gemini.
- Crea un agente in grado di eseguire ragionamenti multi-step complessi per rispondere a query che richiedono la sintesi di informazioni provenienti da più fonti.
Questo lab mostra i principi fondamentali di RAG agentico, un'architettura potente per la creazione di applicazioni di AI intelligenti, accurate e sensibili al contesto su Google Cloud.
Dal prototipo alla produzione
Questo lab fa parte del percorso di apprendimento per l'AI pronta per la produzione con Google Cloud.
- Esplora il programma completo per colmare il divario tra prototipo e produzione.
- Condividi i tuoi progressi con l'hashtag #ProductionReadyAI.