
1. はじめに
概要
このラボの目的は、Google Cloud でエンドツーエンドのエージェント検索拡張生成(RAG)アプリケーションを開発する方法を学ぶことです。このラボでは、2 つの異なるソース(非構造化ドキュメント(Alphabet の四半期ごとの SEC 提出書類 - 米国のすべての公開会社が証券取引委員会に提出する財務諸表と運用詳細)と構造化データ(過去の株価))の情報を組み合わせて質問に回答できる財務分析エージェントを構築します。
Vertex AI Search を使用して、非構造化財務レポート用の強力なセマンティック検索エンジンを構築します。構造化データについては、カスタムの Python ツールを作成します。最後に、Agent Development Kit(ADK)を使用して、ユーザーのクエリについて推論し、使用するツールを決定し、情報を一貫性のある回答に統合できるインテリジェント エージェントを構築します。
演習内容
- 非公開ドキュメントに対するセマンティック検索用に Vertex AI Search データストアを設定します。
- エージェントのツールとしてカスタム Python 関数を作成します。
- Agent Development Kit(ADK)を使用して、マルチツール エージェントを構築する。
- 非構造化データソースと構造化データソースからの検索を組み合わせて、複雑な質問に回答します。
- 推論機能を備えたエージェントをテストし、操作します。
学習内容
このラボでは、次のことを学びます。
- 検索拡張生成(RAG)とエージェント RAG の基本コンセプト。
- Vertex AI Search を使用してドキュメントに対するセマンティック検索を実装する方法。
- カスタムツールを作成して構造化データをエージェントに公開する方法。
- Agent Development Kit(ADK)を使用してマルチツール エージェントを構築し、オーケストレートする方法。
- エージェントが推論とプランニングを使用して、複数のデータソースから複雑な質問に回答する方法。
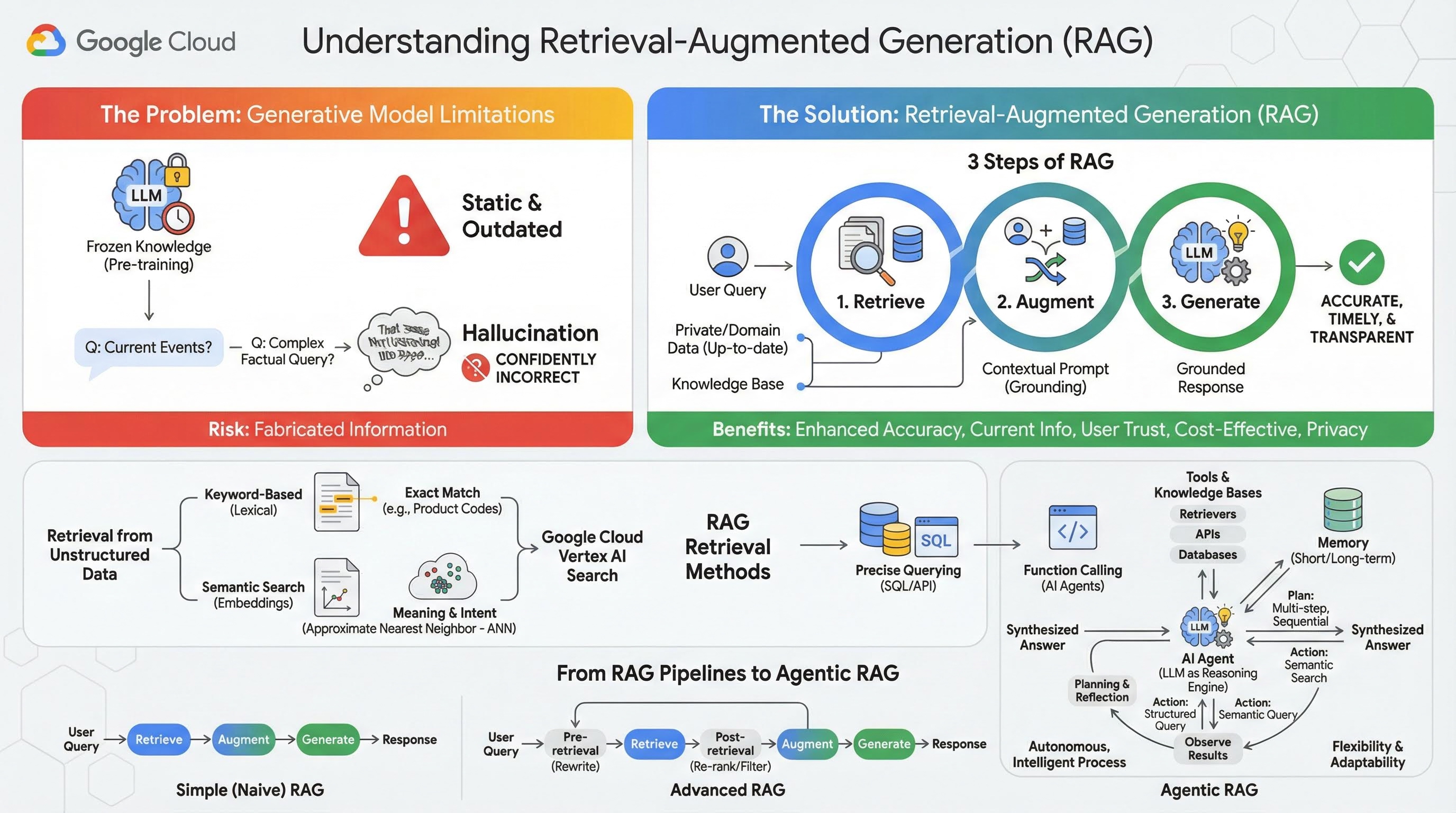
2. 検索拡張生成について
大規模生成モデル(大規模言語モデル(LLM)、ビジョン言語モデルなど)は非常に強力ですが、固有の制限があります。知識は事前トレーニングの時点で固定されるため、静的で、すぐに古くなります。ファインチューニングを行っても、モデルの知識はそれほど新しくなりません。これは、トレーニング後の段階の目標ではないためです。
大規模言語モデル、特に「思考」モデルのトレーニング方法では、モデル自体がその回答を裏付ける事実情報を持っていない場合でも、何らかの回答をすると「報酬」が与えられます。これは、モデルが「ハルシネーション」を起こした、つまり、もっともらしく聞こえるが事実と異なる情報を自信を持って生成した、と言われる場合です。
検索拡張生成は、まさにこれらの問題を解決するために設計された強力なアーキテクチャ パターンです。これは、大規模言語モデルを外部の信頼できるナレッジソースにリアルタイムで接続することで、大規模言語モデルの機能を強化するアーキテクチャ フレームワークです。RAG システムの LLM は、静的な事前トレーニング済みの知識のみに依存するのではなく、まずユーザーのクエリに関連する情報を取得し、その情報を使用して、より正確でタイムリーなコンテキスト認識型の回答を生成します。
このアプローチは、生成モデルの最も大きな弱点である、知識が特定の時点に固定されていることと、不正確な情報(「ハルシネーション」)を生成しやすいことを直接的に解決します。RAG は、LLM に「オープンブック試験」を効果的に提供します。ここで、「本」はプライベートでドメイン固有の最新のデータです。LLM に事実に基づくコンテキストを提供するこのプロセスは、「グラウンディング」と呼ばれます。
RAG の 3 つのステップ
標準的な検索拡張生成プロセスは、次の 3 つの簡単なステップに分けることができます。
- 取得: ユーザーがクエリを送信すると、システムはまず外部ナレッジベース(ドキュメント リポジトリ、データベース、ウェブサイトなど)を検索して、クエリに関連する情報を探します。
- 拡張: 取得した情報は、元のユーザークエリと組み合わされて拡張プロンプトになります。この手法は、プロンプトに事実に基づくコンテキストを追加するため、「プロンプト スタッフィング」と呼ばれることもあります。
- 生成: この拡張プロンプトが LLM に渡され、LLM が回答を生成します。モデルには関連性の高い事実データが提供されているため、出力は「グラウンディング」され、不正確または古いデータになる可能性ははるかに低くなります。
RAG を使用するメリット
RAG フレームワークの導入は、実用的で信頼性の高い AI アプリケーションの構築に大きな変革をもたらしました。主な特典は次のとおりです。
- 精度が向上し、ハルシネーションが減少する: 検証可能な外部の事実に基づいて回答をグラウンディングすることで、RAG は LLM が情報を捏造するリスクを大幅に軽減します。
- 最新情報へのアクセス: RAG システムは常に更新されるナレッジベースに接続できるため、静的にトレーニングされた LLM では不可能な、最新の情報に基づく回答を提供できます。
- ユーザーの信頼性と透明性の向上: LLM の回答は取得されたドキュメントに基づいているため、システムは引用元とソースへのリンクを提供できます。これにより、ユーザーは自分で情報を確認して、アプリケーションに対する信頼を高めることができます。
- 費用対効果: 新しいデータで LLM を継続的にファインチューニングまたは再トレーニングするには、計算コストと費用がかかります。RAG を使用すると、モデルの知識の更新は外部データソースの更新と同じくらい簡単になり、効率が大幅に向上します。
- ドメインの専門性とプライバシー: RAG を使用すると、モデルのトレーニング セットにセンシティブ データを含めることなく、クエリ時に個人や組織がプライベートな専有データを LLM で利用できるようになります。これにより、データのプライバシーとセキュリティを維持しながら、強力なドメイン固有のアプリケーションを実現できます。
取得
「検索」ステップは、あらゆる RAG システムの中核です。取得された情報の品質と関連性は、生成された最終的な回答の品質と関連性を直接決定します。効果的な RAG アプリケーションでは、さまざまな手法を使用して、さまざまなタイプのデータソースから情報を取得する必要があります。主な検索方法は、キーワード ベース、セマンティック、構造化の 3 つのカテゴリに分類されます。
非構造化データからの検索
これまで、非構造化データ検索は従来の検索の別名でした。このモデルは複数の変換を経ており、両方の主要なアプローチのメリットを享受できます。
セマンティック検索は、最先端のパフォーマンスと高度な制御により、Google Cloud で大規模に実行できる最も効率的な手法です。
- キーワードベース(字句)検索: これは、1970 年代の初期の情報検索システムに遡る、従来の検索アプローチです。字句検索は、ユーザーのクエリ内の単語(トークン)をナレッジベース内のドキュメント内の単語と完全に一致させることで機能します。商品コード、法律条項、固有の名前などの特定の用語の精度が重要なクエリに非常に効果的です。
- セマンティック検索: セマンティック検索(意味検索)は、キーワードの文字どおりの意味だけでなく、ユーザーの意図とクエリの文脈上の意味を理解することを目指す、より新しいアプローチです。最新の意味検索は、エンベディングによって実現されています。エンベディングとは、複雑な高次元データを数値ベクトルの低次元ベクトル空間にマッピングする ML 手法です。これらのベクトルは、意味が類似するテキストがベクトル空間内で互いに近接するように設計されています。「家族に最適な犬種は?」という検索はベクトルに変換され、システムはその空間で「最近傍」となるドキュメント ベクトルを検索します。これにより、「ゴールデン レトリバー」や「友好的な犬」について言及しているドキュメントを、「犬」という単語が正確に含まれていなくても検索できます。この高次元検索は、近似最近傍(ANN)アルゴリズムによって効率化されます。ANN アルゴリズムは、クエリベクトルをすべてのドキュメント ベクトルと比較するのではなく(大規模なデータセットでは処理が遅すぎる)、巧妙なインデックス構造を使用して、最も近い可能性のあるベクトルをすばやく見つけます。
構造化データからの検索
重要な知識がすべて非構造化ドキュメントに保存されているわけではありません。多くの場合、最も正確で価値のある情報は、リレーショナル データベース、NoSQL データベース、天気データや株価の REST API などの API などの構造化された形式で存在します。
構造化データからの取得は、通常、非構造化テキストの検索よりも直接的で正確です。言語モデルは、意味的類似性を検索するのではなく、データベースに対する SQL クエリや、特定の場所と日付の天気予報 API に対する API 呼び出しなど、正確なクエリを作成して実行する機能を付与できます。
AI エージェントと同じ手法である関数呼び出しを介して実装され、言語モデルが実行可能コードや外部システムと決定論的な構造でやり取りできるようになります。
3. RAG パイプラインからエージェント RAG へ
RAG のコンセプト自体が進化してきたように、RAG を実装するためのアーキテクチャも進化してきました。単純な線形パイプラインとして始まったものが、AI エージェントによってオーケストレートされる動的でインテリジェントなシステムに進化しました。
- シンプルな(またはナイーブな)RAG: これは、これまで説明してきた基盤となるアーキテクチャです。検索、拡張、生成という 3 つのステップが直線的に行われます。リアクティブであり、すべてのクエリに対して固定パスをたどるため、簡単な Q&A タスクに非常に効果的です。
- 高度な RAG: これは、取得したコンテキストの品質を向上させるために、パイプラインに追加の手順が追加された進化を表します。これらの拡張機能は、取得ステップの前または後に行うことができます。
- 事前検索: クエリの書き換えや拡張などの手法を使用できます。システムは、最初のクエリを分析し、検索システムにとってより効果的な表現に言い換えることがあります。
- 取得後: 最初のドキュメント セットを取得した後、再ランク付けモデルを適用してドキュメントの関連性をスコアリングし、最も関連性の高いドキュメントを上位に表示できます。これは、ハイブリッド検索で特に重要です。取得後のもう 1 つのステップは、取得したコンテキストをフィルタリングまたは圧縮して、最も重要な情報のみが LLM に渡されるようにすることです。
- エージェント RAG: これは RAG アーキテクチャの最先端であり、固定パイプラインから自律的でインテリジェントなプロセスへのパラダイム シフトを表しています。エージェント型 RAG システムでは、ワークフロー全体が 1 つ以上の AI エージェントによって管理されます。AI エージェントは、推論、計画、アクションの動的な選択を行うことができます。
エージェント RAG を理解するには、まず AI エージェントの構成要素を理解する必要があります。エージェントは単なる LLM ではありません。このシステムは、次のようないくつかの主要コンポーネントで構成されています。
- 推論エンジンとしての LLM: エージェントは、Gemini などの強力な LLM をテキストの生成だけでなく、計画、意思決定、複雑なタスクの分解を行う中心的な「脳」として使用します。
- 一連のツール: エージェントには、目標達成のために使用する関数ツールキットへのアクセス権が付与されます。これらのツールは、電卓、ウェブ検索 API、メール送信関数など、さまざまなものがあります。このラボで最も重要なのは、さまざまなナレッジベース用のリトリーバーです。
- メモリ: エージェントは、短期記憶(現在の会話のコンテキストを記憶する)と長期記憶(過去のやり取りから情報を思い出す)の両方を備えて設計できます。これにより、よりパーソナライズされた一貫性のあるエクスペリエンスを実現できます。
- 計画とリフレクション: 最も高度なエージェントは、洗練された推論パターンを示します。複雑な目標を受け取り、それを達成するための複数のステップからなる計画を作成できます。その後、この計画を実行し、アクションの結果を反映して、エラーを特定し、アプローチを自己修正して最終的な結果を改善することもできます。
Agentic RAG は、静的パイプラインにはない自律性とインテリジェンスのレイヤを導入するため、画期的な技術です。
- 柔軟性と適応性: エージェントは単一の取得パスに縛られません。ユーザーのクエリに基づいて、最適な情報源を推論できます。たとえば、最初に構造化データベースをクエリし、次に非構造化ドキュメントでセマンティック検索を実行し、それでも回答が見つからない場合は、Google 検索ツールを使用して一般公開ウェブを検索するといった処理を、すべて 1 つのユーザー リクエストのコンテキスト内で実行する場合があります。
- 複雑なマルチステップ推論: このアーキテクチャは、複数の連続した取得と処理のステップを必要とする複雑なクエリの処理に優れています。
「クリストファー ノーラン監督の SF 映画の上位 3 作品を探し、それぞれの簡単なあらすじを教えて」というクエリを考えてみましょう。シンプルな RAG パイプラインは失敗します。
エージェントは、これを次のように分類できます。
- 計画: まず、映画を見つける必要があります。次に、各映画のプロットを見つける必要があります。
- アクション 1: 構造化データツールを使用して、ノーランの SF 映画(上位 3 本、評価の降順)の映画データベースをクエリします。
- 観察 1: ツールは「インセプション」、「インターステラー」、「テネット」を返します。
- アクション 2: 非構造化データツール(セマンティック検索)を使用して、「インセプション」のプロットを見つけます。
- 観察 2: プロットが取得されます。
- アクション 3: 「インターステラー」で繰り返します。
- アクション 4: 「Tenet」で繰り返します。
- 最終的な統合: 取得したすべての情報を統合して、ユーザーに一貫性のある回答を生成します。
4. プロジェクトの設定
Google アカウント
個人の Google アカウントをお持ちでない場合は、Google アカウントを作成する必要があります。
仕事用または学校用アカウントではなく、個人アカウントを使用します。
Google Cloud コンソールにログインする
個人の Google アカウントを使用して Google Cloud コンソールにログインします。
課金を有効にする
トライアルの請求先アカウントを使用する(省略可)
このワークショップを実施するには、クレジットが設定された請求先アカウントが必要です。この Codelab の上部にあるバナーのクレジットを使用して、開始します。請求先アカウントにすでに接続している場合は、この手順をスキップできます。
個人用の請求先アカウントを設定する
Google Cloud クレジットを使用して課金を設定した場合は、この手順をスキップできます。
個人用の請求先アカウントを設定するには、Cloud コンソールでこちらに移動して課金を有効にします。
注意事項:
- このラボを完了するのにかかる Cloud リソースの費用は 1 米ドル未満です。
- このラボの最後の手順に沿ってリソースを削除すると、それ以上の料金は発生しません。
- 新規ユーザーは、300 米ドル分の無料トライアルをご利用いただけます。
プロジェクトの作成(省略可)
このラボで使用する現在のプロジェクトがない場合は、こちらで新しいプロジェクトを作成します。
5. Cloud Shell エディタを開く
- このリンクをクリックすると、Cloud Shell エディタに直接移動します。
- 本日、承認を求めるメッセージがどこかの時点で表示された場合は、[承認] をクリックして続行します。
- ターミナルが画面の下部に表示されない場合は、ターミナルを開きます。
- [表示] をクリックします。
- [ターミナル] をクリックします。
- ターミナルで、次のコマンドを使用してプロジェクトを設定します。
gcloud config set project [PROJECT_ID]- 例:
gcloud config set project lab-project-id-example - プロジェクト ID が思い出せない場合は、次のコマンドでプロジェクト ID をすべて一覧表示できます。
gcloud projects list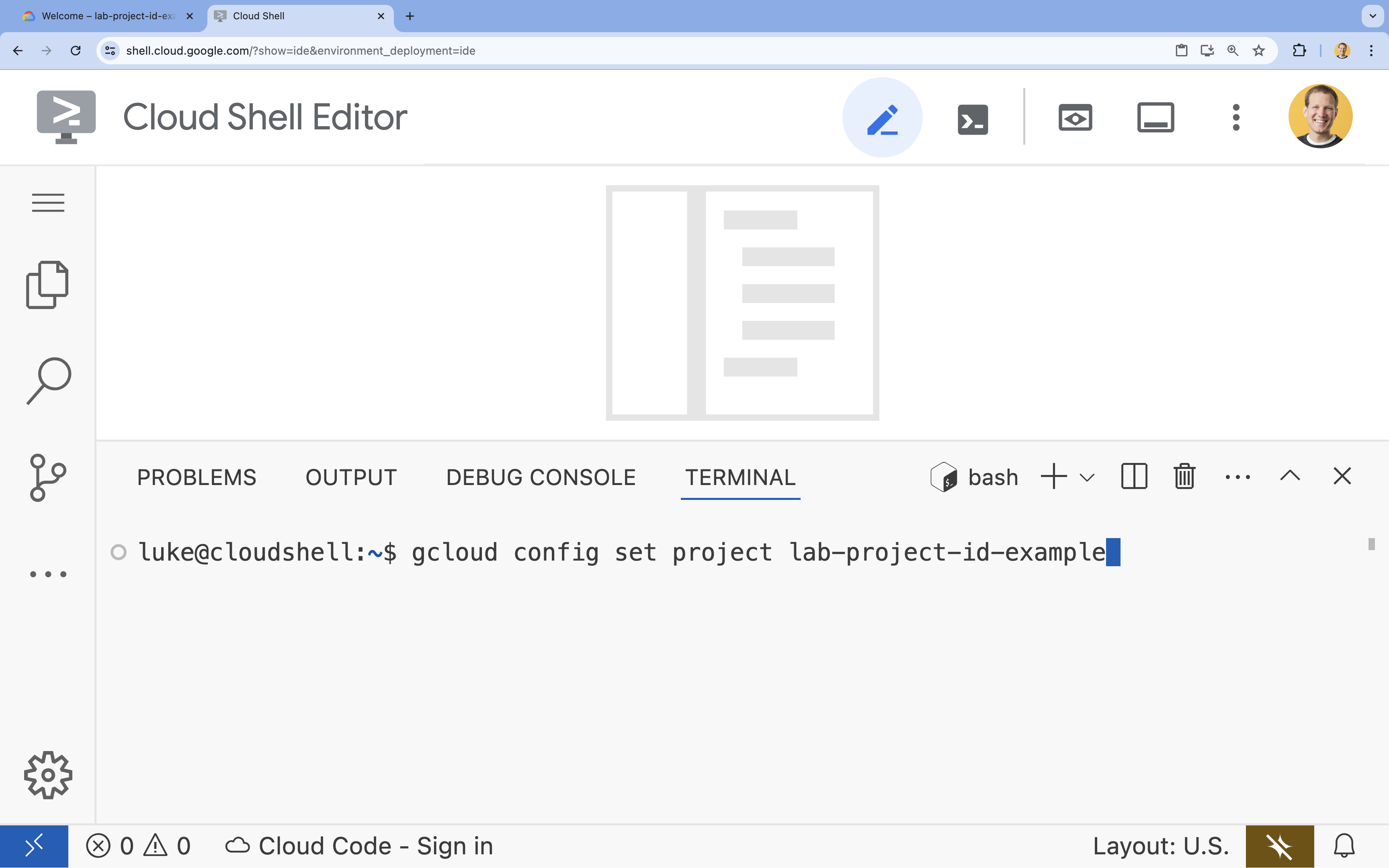
- 例:
- 次のようなメッセージが表示されます。
Updated property [core/project].
6. API を有効にする
Agent Development Kitと Vertex AI Search を使用するには、Google Cloud プロジェクトで必要な API を有効にする必要があります。
- ターミナルで API を有効にします。
gcloud services enable \ aiplatform.googleapis.com \ discoveryengine.googleapis.com
API の概要
- Vertex AI API(
aiplatform.googleapis.com)を使用すると、エージェントは Gemini モデルと通信して推論と生成を行うことができます。 - Discovery Engine API(
discoveryengine.googleapis.com)は Vertex AI Search を強化し、データストアの作成と非構造化ドキュメントに対するセマンティック検索の実行を可能にします。
7. 環境を設定する
AI エージェントのコーディングを開始する前に、開発環境を準備し、必要なライブラリをインストールして、必要なデータファイルを作成する必要があります。
仮想環境を作成して依存関係をインストールする
- エージェントのディレクトリを作成し、そのディレクトリに移動します。ターミナルで次のコードを実行します。
mkdir financial_agent cd financial_agent - 仮想環境を作成します。
uv venv --python 3.12 - 仮想環境をアクティブにします。
source .venv/bin/activate - Agent Development Kit(ADK)と pandas をインストールします。
uv pip install google-adk pandas
株価データを作成する
このラボでは、エージェントが構造化ツールを使用する能力を示すために、特定の過去の株価データが必要になります。このため、このデータを含む CSV ファイルを作成します。
financial_agentディレクトリで、ターミナルで次のコマンドを実行してgoog.csvファイルを作成します。cat <<EOF > goog.csv Date,Open,High,Low,Close,Adj Close,Volume 2023-01-03,89.830002,91.550003,89.019997,89.699997,89.699997,20738500 2023-03-31,101.440002,103.889999,101.040001,103.730003,103.730003,36823200 2023-06-30,120.870003,122.029999,120.300003,120.970001,120.970001,23824700 2023-09-29,134.080002,134.550003,131.320007,131.850006,131.850006,21124200 2025-07-10,185.000000,188.000000,184.500000,186.500000,186.500000,25000000 EOF
環境変数を構成する
financial_agentディレクトリに.envファイルを作成して、エージェントの環境変数を構成します。これにより、使用するプロジェクト、ロケーション、モデルが ADK に指示されます。ターミナルで次のコードを実行します。# Create the .env file using the captured variables cat << EOF > .env GOOGLE_GENAI_USE_VERTEXAI=TRUE GOOGLE_CLOUD_PROJECT="${GOOGLE_CLOUD_PROJECT}" GOOGLE_CLOUD_LOCATION="us-central1" EOF
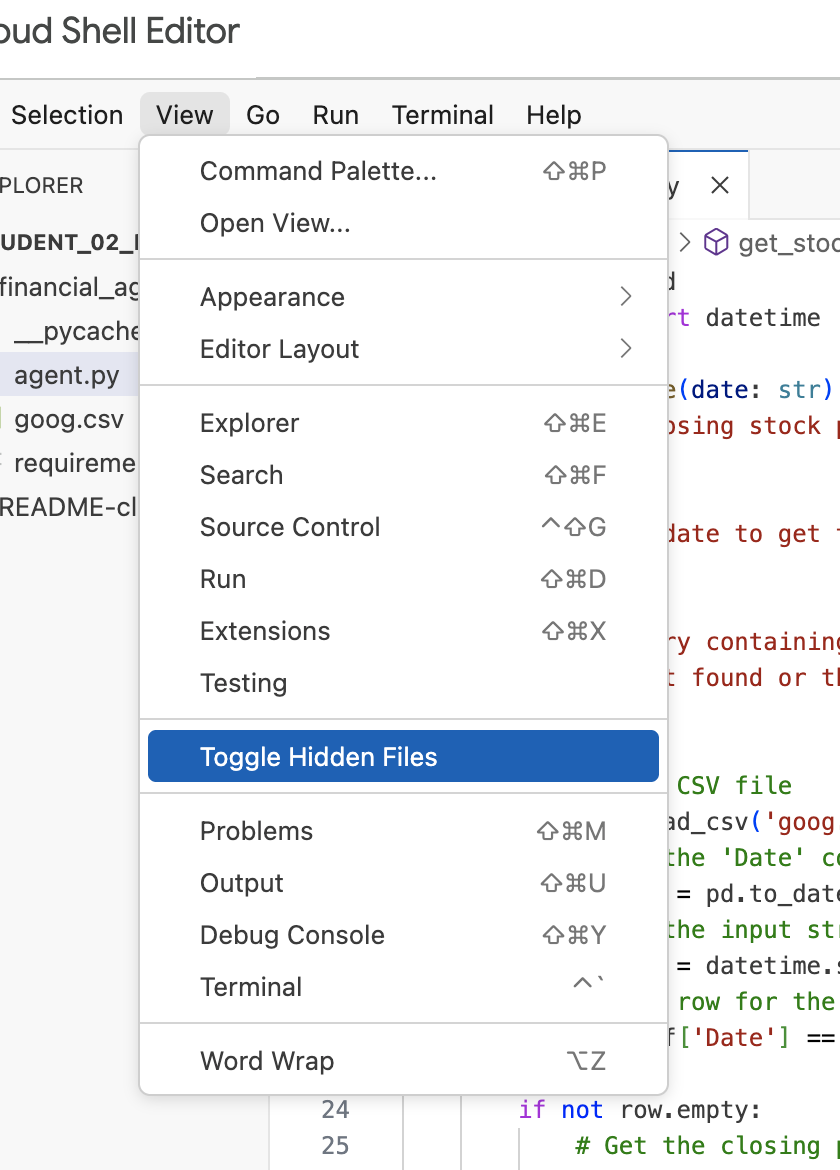
注: ラボの後半で .env ファイルを変更する必要があるのに、financial_agent ディレクトリに表示されない場合は、Cloud Shell エディタで [表示 / 隠しファイルを切り替える] メニュー項目を使用して、隠しファイルの表示を切り替えてみてください。
8. Vertex AI Search データストアを作成する
エージェントが Alphabet の財務報告に関する質問に回答できるようにするには、一般公開されている SEC 提出書類を含む Vertex AI Search データストアを作成します。
- 新しいブラウザタブで Cloud コンソール(console.cloud.google.com)を開き、上部の検索バーを使用して AI アプリケーションに移動します。
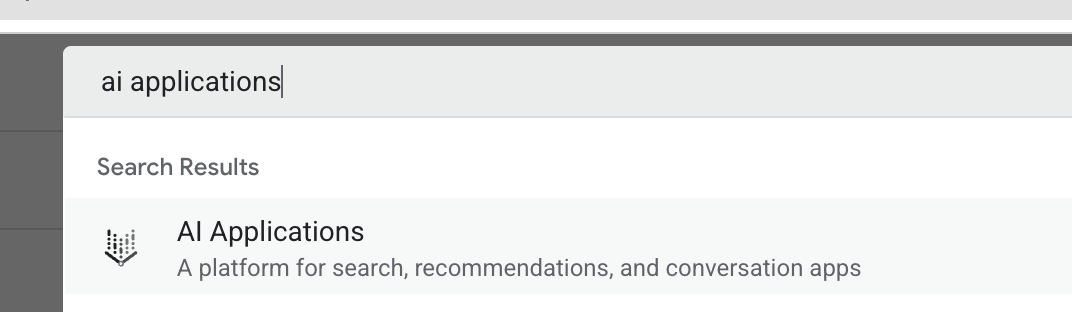
- プロンプトが表示されたら、利用規約のチェックボックスをオンにして、[続行して API を有効にする] をクリックします。
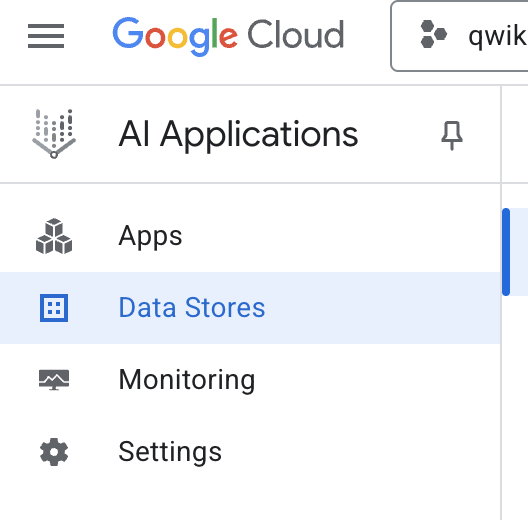
- 左側のナビゲーション メニューで、[データストア] を選択します。
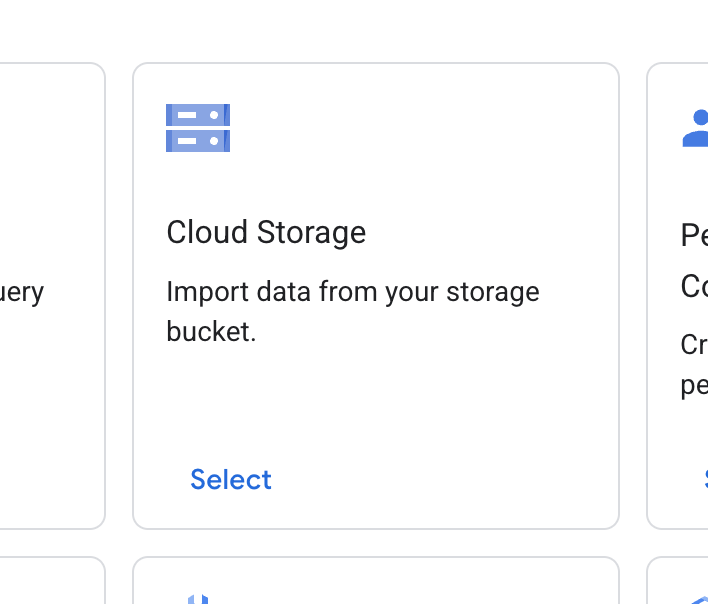
- [+ データストアを作成] をクリックします。
- [Cloud Storage] カードを見つけて、[選択] をクリックします。
- データソースとして [非構造化ドキュメント] を選択します。

- インポート元(インポートするフォルダまたはファイルを選択します)に、Google Cloud Storage パス
cloud-samples-data/gen-app-builder/search/alphabet-sec-filingsを入力します。 - [続行] をクリックします。
- ロケーションは [グローバル] のままにします。
- データストア名に、次のように入力します。
alphabet-sec-filings - [ドキュメント処理オプション] セクションを開きます。

- [デフォルトのドキュメント パーサー] プルダウン リストで、[レイアウト パーサー] を選択します。
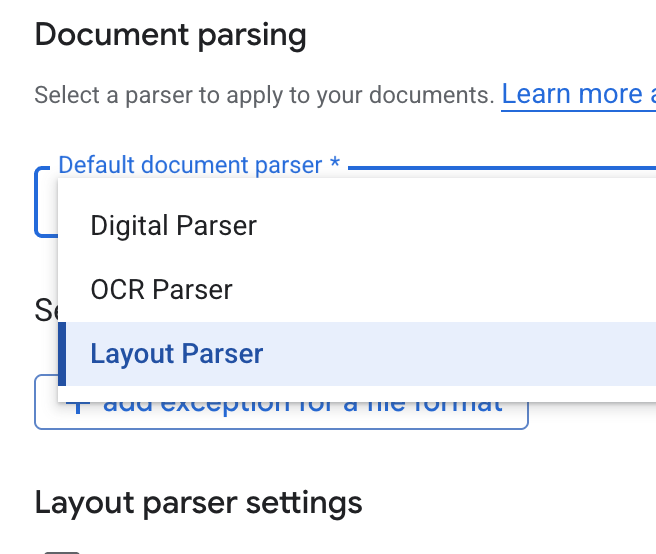
- [レイアウト パーサーの設定] オプションで、[表のアノテーションを有効にする] と [画像のアノテーションを有効にする] を選択します。
- [続行] をクリックします。
- 料金モデルとして [一般的な料金](従量課金制モデル)を選択し、[作成] をクリックします。
- データストアでドキュメントのインポートが開始されます。
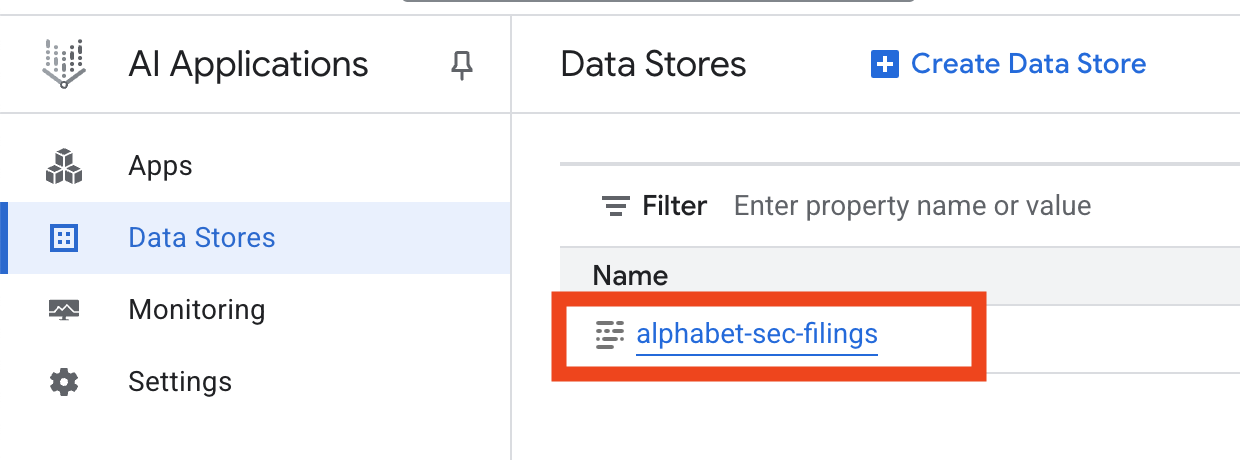
- データストア名をクリックし、[データストア] テーブルからその ID をコピーします。次のステップで必要になります。
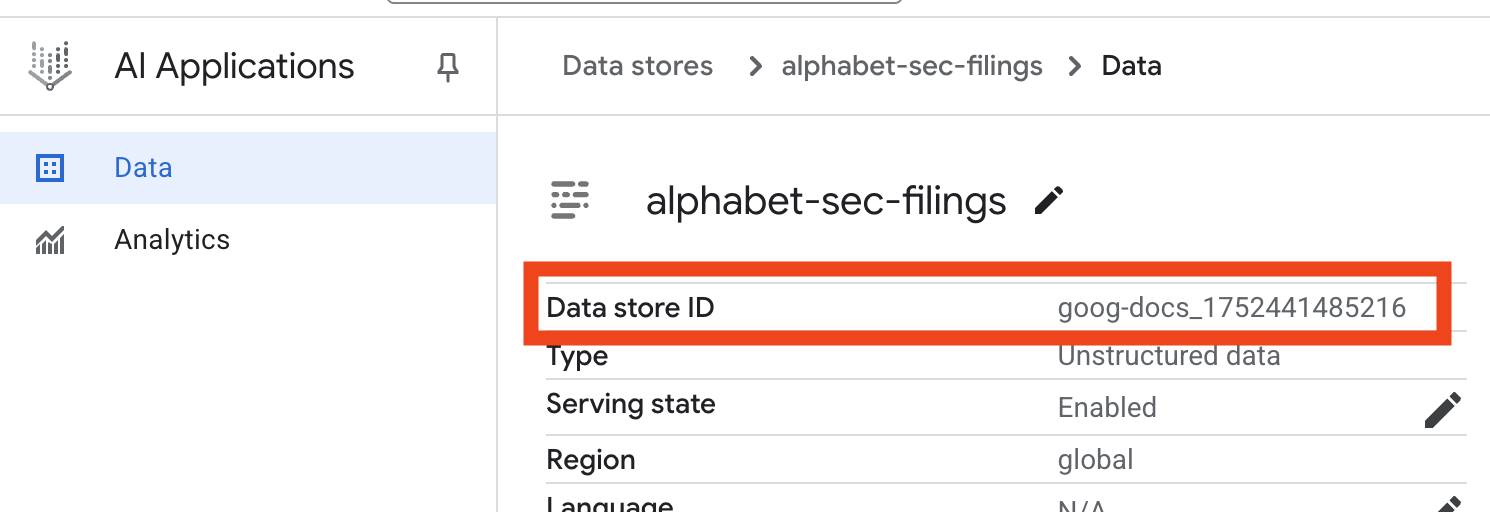
- Cloud Shell エディタで
.envファイルを開き、データストア ID をDATA_STORE_ID="YOUR_DATA_STORE_ID"として追加します(YOUR_DATA_STORE_IDは前の手順の実際の ID に置き換えます)。注: データストアでのデータのインポート、解析、インデックス登録には数分かかります。プロセスを確認するには、データストア名をクリックしてプロパティを開き、[アクティビティ] タブを開きます。ステータスが [インポートが完了しました] になるまで待ちます。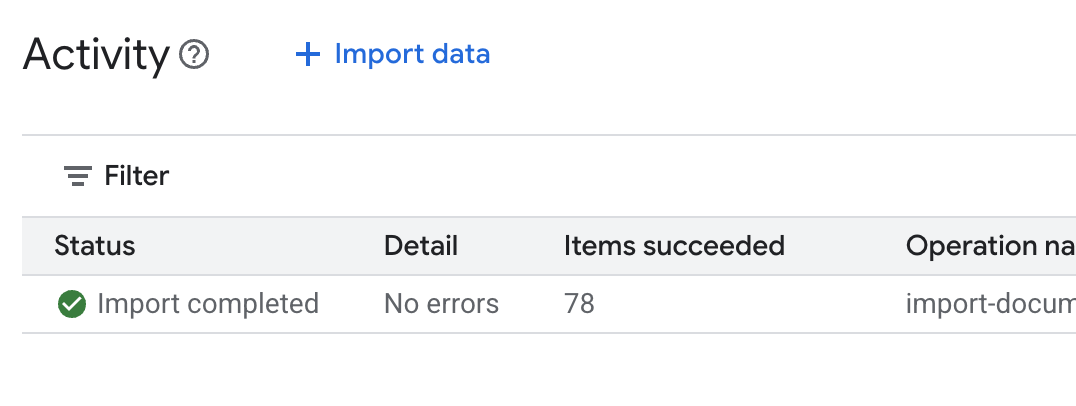
9. 構造化データ用のカスタムツールを作成する
次に、エージェントのツールとして機能する Python 関数を作成します。このツールは goog.csv ファイルを読み取り、特定の日付の過去の株価を取得します。
financial_agentディレクトリにagent.pyという名前の新しいファイルを作成します。ターミナルで次のコマンドを実行します。cloudshell edit agent.py- 次の Python コードを
agent.pyに追加します。このコードは、依存関係をインポートし、get_stock_price関数を定義します。from datetime import datetime import os import logging import google.cloud.logging from google.adk.tools import VertexAiSearchTool from google.adk.tools.agent_tool import AgentTool from google.adk.agents import LlmAgent import pandas as pd def get_stock_price(date: str) -> dict: """Gets the closing stock price for a given date. Args: date: The date to get the stock price for, in YYYY-MM-DD format. Returns: A dictionary containing the closing price, or an error message if the date is not found or the format is incorrect. """ try: # Load the CSV file df = pd.read_csv('goog.csv') # Convert the 'Date' column to datetime objects df['Date'] = pd.to_datetime(df['Date']) # Convert the input string to a datetime object query_date = datetime.strptime(date, '%Y-%m-%d') # Find the row for the given date row = df[df['Date'] == query_date] if not row.empty: # Get the closing price close_price = row['Close'].iloc[0] return {"status": "success", "date": date, "closing_price": close_price} else: return {"status": "error", "message": f"No data found for date: {date}"} except FileNotFoundError: return {"status": "error", "message": "Stock data file (goog.csv) not found."} except Exception as e: return {"status": "error", "message": f"An error occurred: {str(e)}"}
関数の詳細な docstring に注目してください。この docstring は、関数の機能、パラメータ(Args)、戻り値(Returns)を説明します。ADK はこの docstring を使用して、エージェントにこのツールの使用方法と使用タイミングを教えます。
10. RAG エージェントをビルドして実行する
次に、エージェントを組み立てます。非構造化データ用の Vertex AI Search ツールと、構造化データ用のカスタム get_stock_price ツールを組み合わせます。
agent.pyファイルに次のコードを追加します。このコードは、必要な ADK クラスをインポートし、ツールのインスタンスを作成して、エージェントを定義します。logging.basicConfig(level=logging.INFO) cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() # 1. Create the Vertex AI Search tool full_datastore_id = f"projects/{os.environ['GOOGLE_CLOUD_PROJECT']}/locations/global/collections/default_collection/dataStores/{os.environ['DATA_STORE_ID']}" vertex_ai_search_tool = VertexAiSearchTool( data_store_id=full_datastore_id ) # 2. Define the Search+Q&A agent # Since we cannot combine tools with other tools in a single agent, # we create a separate Search+Q&A agent which will be used as a tool by the main root agent. doc_qa_agent = LlmAgent( name="search_and_qna_agent", model="gemini-2.5-flash", tools=[vertex_ai_search_tool], instruction="""You are a helpful assistant that answers questions based on information found in the document store. Use the search tool to find relevant information before answering. If the answer isn't in the documents, say that you couldn't find the information. """, description="Answers questions using a specific Vertex AI Search datastore.", ) # 3. Define the root agent with 2 tools. root_agent = LlmAgent( name="financial_agent", model="gemini-2.5-flash", tools=[ AgentTool(doc_qa_agent), get_stock_price, ], instruction="""You are an Financial Analytics Agent that answers question about Alphabet stock prices (using get_stock_price tool) and historical performance based on the data in Vertex AI Search datastore (using doc_qa_agent tool).""" )- ターミナルの
financial_agentディレクトリ内で、ADK ウェブ インターフェースを起動してエージェントを操作します。adk web ~ - ターミナル出力に表示されたリンク(通常は
http://127.0.0.1:8000)をクリックして、ブラウザで ADK 開発 UI を開きます。
11. エージェントをテストする
エージェントの推論能力と、ツールを使用して複雑な質問に回答する能力をテストできるようになりました。
- ADK 開発 UI で、プルダウン メニューから
financial_agentが選択されていることを確認します。 - SEC 提出書類(非構造化データ)の情報が必要な質問をしてみます。チャットに次のクエリを入力します。
What were the total revenues for the quarter ending on March 31, 2023?search_and_qna_agentを呼び出す必要があります。これはVertexAiSearchToolを使用して財務書類から回答を見つけます。 - 次に、カスタムツール(構造化データ)の使用を必要とする質問をします。プロンプトの日付形式は、関数で必要な形式と完全に一致している必要はありません。LLM が自動的に形式を変換します。
What was the closing stock price for Alphabet on July 10, 2025?get_stock_priceツールを呼び出す必要があります。チャットでツールアイコンをクリックすると、関数呼び出しとその結果を確認できます。 - 最後に、エージェントが両方のツールを使用して結果を合成する必要がある複雑な質問をします。
According to the 10-Q filing for the period ending March 31, 2023, what were the company's net cash provided by operating activities, and what was the stock's closing price on that date?- まず、
VertexAiSearchToolを使用して SEC 提出書類のキャッシュフロー情報を検索します。 - 次に、株価が必要であることを認識し、日付
2023-03-31を指定してget_stock_price関数を呼び出します。 - 最後に、両方の情報を組み合わせて、包括的な回答を生成します。
- まず、
- 完了したら、ブラウザタブを閉じ、ターミナルで
CTRL+Cを押して ADK サーバーを停止します。
12. タスクのサービスを選択する
Vertex AI Search は、使用できる唯一のベクトル検索サービスではありません。検索拡張生成のフロー全体を自動化するマネージド サービス(Vertex AI RAG Engine)を使用することもできます。
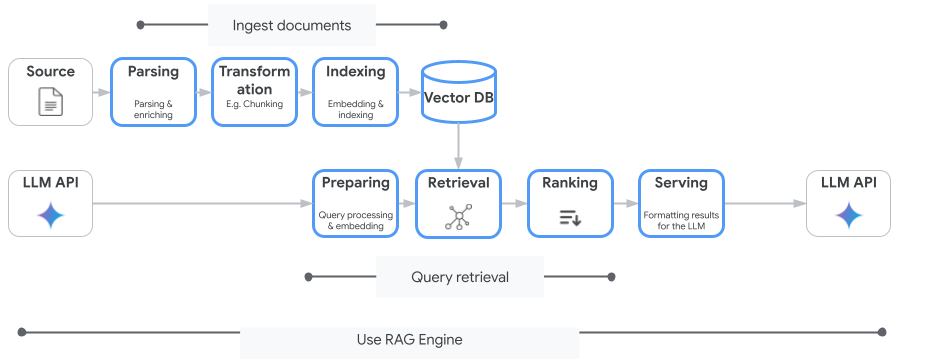
ドキュメントの取り込みから取得、再ランキングまで、すべてを処理します。RAG Engine は、Pinecone や Weaviate など、複数のベクトル ストアをサポートしています。
多くの専用ベクトル データベースをセルフホストすることも、PostgreSQL サービス(AlloyDB や BigQuery ベクトル検索など)の pgvector などのデータベース エンジンのベクトル インデックス機能を利用することもできます。
ベクトル検索をサポートするその他のサービスは次のとおりです。
Google Cloud で特定のサービスを選択する際の一般的なガイダンスは次のとおりです。
- すでに動作し、適切にスケーリングされたベクトル検索の DIY インフラストラクチャがある場合は、Weaviate や DIY PostgreSQL などの Google Kubernetes Engine にデプロイします。
- データが BigQuery、AlloyDB、Firestore などのデータベースにある場合は、そのデータベースの大きなクエリの一部としてセマンティック検索を大規模に実行できる場合に、ベクトル検索機能の使用を検討してください。たとえば、BigQuery テーブルに商品の説明や画像がある場合、テキスト エンベディング列や画像エンベディング列を追加すると、類似検索を大規模に使用できるようになります。ScaNN 検索を使用するベクトル インデックスは、インデックス内の数十億個のアイテムをサポートします。
- 最小限の労力でマネージド プラットフォームで迅速に開始する必要がある場合は、Vertex AI Search を選択します。これは、高い品質、スケーラビリティ、きめ細かいアクセス制御を必要とする複雑なエンタープライズ ユースケースに最適な、フルマネージドの検索エンジンとリトリーバー API です。さまざまなエンタープライズ データソースへの接続を簡素化し、複数のソースを検索できます。
- 使いやすさとカスタマイズのバランスを求めるデベロッパーにとって最適なソリューションをお探しの場合は、Vertex AI RAG Engine を使用してください。柔軟性を損なうことなく、迅速なプロトタイピングと開発を実現します。
- 検索拡張生成のリファレンス アーキテクチャを確認する。
13. まとめ
おめでとうございます!検索拡張生成を使用して AI エージェントを構築し、テストしました。具体的には、以下の方法について学習しました。
- Vertex AI Search の強力なセマンティック検索機能を使用して、非構造化ドキュメントのナレッジベースを作成します。
- 構造化データを取得するツールとして機能するカスタム Python 関数を開発します。
- Agent Development Kit(ADK)を使用して、Gemini を搭載したマルチツール エージェントを作成する。
- 複数のソースから情報を統合する必要があるクエリに回答するために、複雑なマルチステップの推論が可能なエージェントを構築します。
このラボでは、Google Cloud でインテリジェントで正確なコンテキスト認識 AI アプリケーションを構築するための強力なアーキテクチャであるエージェント型 RAG の基本原則について説明します。
プロトタイプから製品版へ
このラボは、Google Cloud でのプロダクション レディな AI の開発学習プログラムの一部です。
- カリキュラム全体を確認して、プロトタイプから本番環境への移行をスムーズに進めましょう。
- ハッシュタグ #ProductionReadyAI を使用して進捗状況を共有します。