
1. Wprowadzenie
Przegląd
Celem tego modułu jest nauczenie się, jak tworzyć kompleksowe aplikacje generowania wspomaganego wyszukiwaniem (RAG) w Google Cloud. W tym laboratorium utworzysz agenta do analizy finansowej, który będzie odpowiadać na pytania, łącząc informacje z 2 różnych źródeł: nieustrukturyzowanych dokumentów (kwartalne raporty firmy Alphabet składane w Komisji Papierów Wartości i Giełd – sprawozdania finansowe i szczegóły operacyjne, które każda spółka publiczna w Stanach Zjednoczonych przekazuje do Komisji Papierów Wartości i Giełd) oraz danych strukturalnych (historyczne ceny akcji).
Do utworzenia zaawansowanej wyszukiwarki semantycznej dla nieustrukturyzowanych raportów finansowych użyjesz Vertex AI Search. W przypadku danych strukturalnych utworzysz niestandardowe narzędzie w języku Python. Na koniec użyjesz pakietu Agent Development Kit (ADK), aby utworzyć inteligentnego agenta, który potrafi analizować zapytania użytkowników, decydować, którego narzędzia użyć, i syntetyzować informacje w spójną odpowiedź.
Jakie zadania wykonasz
- Skonfiguruj magazyn danych Vertex AI Search do wyszukiwania semantycznego w dokumentach prywatnych.
- Utwórz niestandardową funkcję Pythona jako narzędzie dla agenta.
- Użyj pakietu Agent Development Kit (ADK), aby utworzyć agenta z wieloma narzędziami.
- Łącz wyszukiwanie w nieustrukturyzowanych i uporządkowanych źródłach danych, aby odpowiadać na złożone pytania.
- Testuj agenta, który wykazuje zdolność do rozumowania, i wchodź z nim w interakcje.
Czego się nauczysz
W tym module dowiesz się:
- Podstawowe koncepcje generowania wspomaganego wyszukiwaniem (RAG) i agentowego RAG.
- Jak wdrożyć wyszukiwanie semantyczne w dokumentach za pomocą Vertex AI Search.
- Jak udostępniać agentowi dane strukturalne, tworząc niestandardowe narzędzia.
- Jak utworzyć agenta z wieloma narzędziami i nim zarządzać za pomocą pakietu Agent Development Kit (ADK).
- Jak agenty wykorzystują rozumowanie i planowanie, aby odpowiadać na złożone pytania przy użyciu wielu źródeł danych.
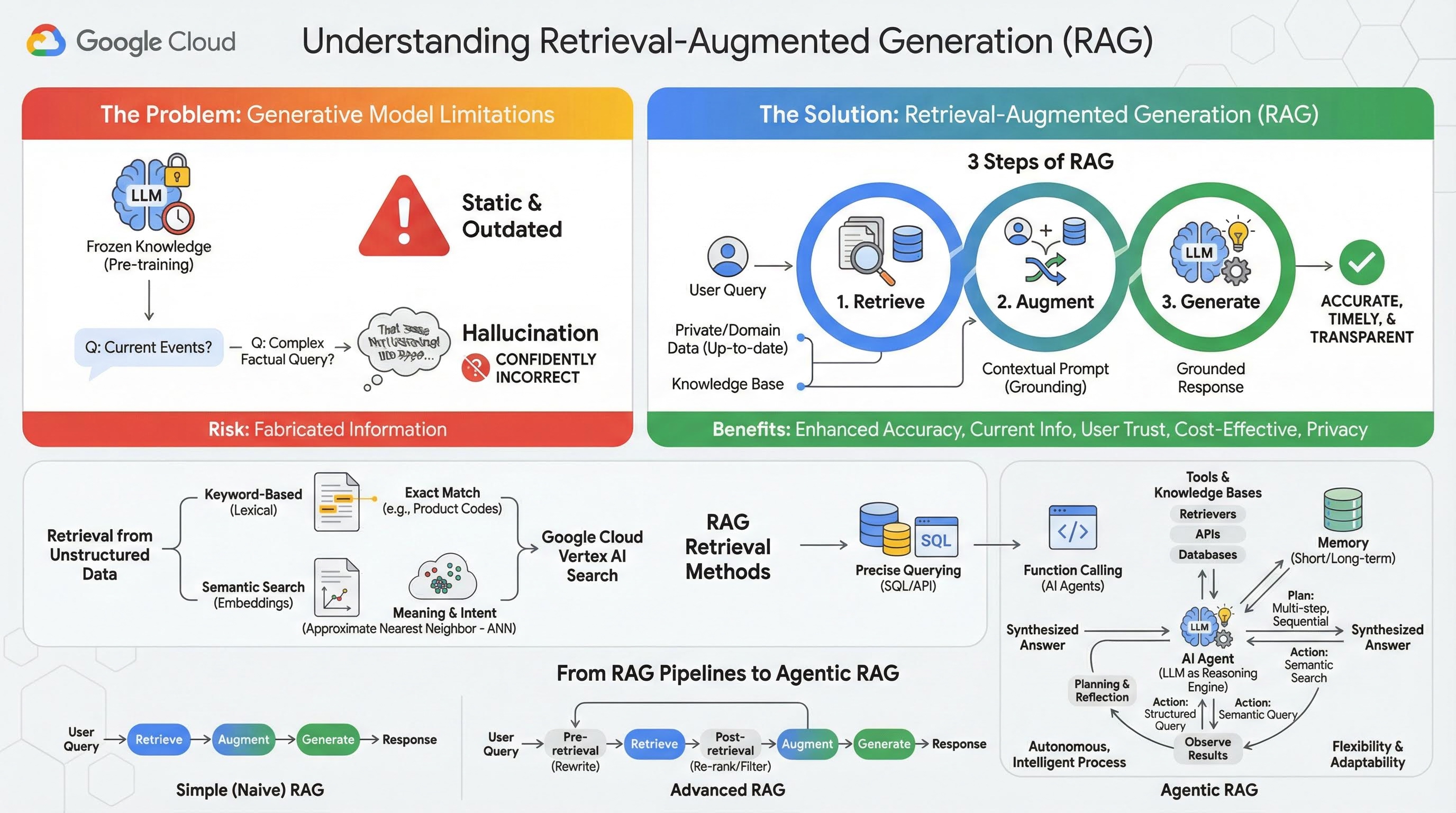
2. Informacje o generowaniu wspomaganym wyszukiwaniem
Duże modele generatywne (duże modele językowe, czyli LLM, modele wizualno-językowe itp.) są niezwykle zaawansowane, ale mają pewne ograniczenia. Ich wiedza jest zamrożona w momencie wstępnego trenowania, co sprawia, że jest statyczna i od razu nieaktualna. Nawet po dostrajaniu wiedza modelu nie staje się znacznie bardziej aktualna, ponieważ nie jest to celem etapów po trenowaniu.
Sposób trenowania dużych modeli językowych, zwłaszcza modeli „myślących”, sprawia, że są one „nagradzane” za udzielanie jakiejkolwiek odpowiedzi, nawet jeśli nie mają faktów, które by ją potwierdzały. Wtedy mówi się, że model „halucynuje” – generuje wiarygodnie brzmiące, ale nieprawdziwe informacje.
Generowanie wspomagane wyszukiwaniem to zaawansowany wzorzec architektury zaprojektowany do rozwiązywania tych problemów. Jest to struktura architektoniczna, która zwiększa możliwości dużych modeli językowych, łącząc je w czasie rzeczywistym z zewnętrznymi, wiarygodnymi źródłami wiedzy. Zamiast polegać wyłącznie na statycznej, wstępnie wytrenowanej wiedzy, model LLM w systemie RAG najpierw pobiera istotne informacje związane z zapytaniem użytkownika, a następnie wykorzystuje je do wygenerowania dokładniejszej, aktualniejszej i uwzględniającej kontekst odpowiedzi.
To podejście bezpośrednio rozwiązuje największe słabości modeli generatywnych: ich wiedza jest stała w danym momencie, a one same są podatne na generowanie nieprawidłowych informacji, czyli „halucynacji”. RAG daje modelowi LLM „egzamin z książką”, w którym „książką” są Twoje prywatne, specyficzne dla domeny i aktualne dane. Proces dostarczania modelu LLM kontekstu opartego na faktach jest nazywany „uzasadnianiem”.
3 etapy RAG
Standardowy proces generowania wspomaganego wyszukiwaniem można podzielić na 3 proste kroki:
- Pobieranie: gdy użytkownik przesyła zapytanie, system najpierw przeszukuje zewnętrzną bazę wiedzy (np. repozytorium dokumentów, bazę danych lub witrynę), aby znaleźć informacje istotne dla zapytania.
- Wzbogacanie: pobrane informacje są następnie łączone z pierwotnym zapytaniem użytkownika w rozszerzony prompt. Ta technika jest czasami nazywana „wypełnianiem prompta”, ponieważ wzbogaca prompt o kontekst oparty na faktach.
- Generowanie: ten rozszerzony prompt jest przekazywany do LLM, który następnie generuje odpowiedź. Model otrzymał odpowiednie dane oparte na faktach, więc jego dane wyjściowe są „umocowane” i znacznie mniej prawdopodobne jest, że będą niedokładne lub nieaktualne.
Zalety RAG
Wprowadzenie platformy RAG zmieniło sposób tworzenia praktycznych i godnych zaufania aplikacji AI. Jego najważniejsze korzyści to:
- Większa dokładność i mniej halucynacji: dzięki oparciu odpowiedzi na weryfikowalnych faktach zewnętrznych RAG znacznie zmniejsza ryzyko zmyślania informacji przez LLM.
- Dostęp do aktualnych informacji: systemy RAG można połączyć z stale aktualizowanymi bazami wiedzy, co pozwala im udzielać odpowiedzi na podstawie najnowszych informacji. Jest to niemożliwe w przypadku statycznie trenowanego LLM.
- Większe zaufanie użytkowników i większa przejrzystość: ponieważ odpowiedź LLM jest oparta na pobranych dokumentach, system może podawać cytaty i linki do źródeł. Dzięki temu użytkownicy mogą samodzielnie sprawdzić informacje, co zwiększa ich zaufanie do aplikacji.
- Opłacalność: ciągłe dostrajanie lub ponowne trenowanie dużego modelu językowego z użyciem nowych danych jest kosztowne pod względem obliczeniowym i finansowym. W przypadku RAG aktualizacja wiedzy modelu jest tak prosta, jak aktualizacja zewnętrznego źródła danych, co jest znacznie bardziej wydajne.
- Specjalizacja w domenie i prywatność: RAG umożliwia osobom i organizacjom udostępnianie dużemu modelowi językowemu prywatnych danych zastrzeżonych w momencie zapytania bez konieczności uwzględniania tych danych wrażliwych w zbiorze treningowym modelu. Umożliwia to tworzenie zaawansowanych aplikacji w określonych domenach przy jednoczesnym zachowaniu prywatności danych i bezpieczeństwa.
Pobieranie
Krok „Pobieranie” jest kluczowy w każdym systemie RAG. Jakość i trafność pobranych informacji bezpośrednio wpływają na jakość i trafność ostatecznej wygenerowanej odpowiedzi. Skuteczna aplikacja RAG często musi pobierać informacje z różnych typów źródeł danych za pomocą różnych technik. Główne metody wyszukiwania dzielą się na 3 kategorie: oparte na słowach kluczowych, semantyczne i strukturalne.
Wyszukiwanie w danych nieuporządkowanych
W przeszłości pobieranie nieuporządkowanych danych było inną nazwą tradycyjnego wyszukiwania. Przeszła ona wiele przekształceń, a Ty możesz korzystać z obu głównych podejść.
Wyszukiwanie semantyczne to najskuteczniejsza technika, którą możesz stosować na dużą skalę w Google Cloud, uzyskując najwyższą wydajność i dużą kontrolę.
- Wyszukiwanie oparte na słowach kluczowych (leksykalne): to tradycyjne podejście do wyszukiwania, które sięga początków systemów wyszukiwania informacji z lat 70. XX wieku. Wyszukiwanie leksykalne polega na dopasowywaniu dosłownych słów (lub „tokenów”) w zapytaniu użytkownika do dokładnie tych samych słów w dokumentach w bazie wiedzy. Jest to bardzo skuteczne w przypadku zapytań, w których kluczowa jest precyzja w odniesieniu do konkretnych terminów, takich jak kody produktów, klauzule prawne czy unikalne nazwy.
- Wyszukiwanie semantyczne: wyszukiwanie semantyczne, czyli „wyszukiwanie ze znaczeniem”, to nowocześniejsze podejście, które ma na celu zrozumienie intencji użytkownika i kontekstowego znaczenia jego zapytania, a nie tylko dosłownych słów kluczowych. Nowoczesne wyszukiwanie semantyczne wykorzystuje wektory dystrybucyjne, czyli technikę uczenia maszynowego, która mapuje złożone dane wielowymiarowe na przestrzeń wektorową o mniejszej liczbie wymiarów. Te wektory są zaprojektowane tak, aby teksty o podobnym znaczeniu znajdowały się blisko siebie w przestrzeni wektorowej. Wyszukiwanie „Jakie rasy psów są najlepsze dla rodzin?” jest przekształcane w wektor, a następnie system wyszukuje wektory dokumentów, które są jego „najbliższymi sąsiadami” w tej przestrzeni. Dzięki temu może znajdować dokumenty, w których mowa jest o „golden retrieverach” lub „przyjaznych psach”, nawet jeśli nie zawierają one słowa „pies”. Wyszukiwanie w przestrzeni o dużej liczbie wymiarów jest możliwe dzięki algorytmom przybliżonego wyszukiwania najbliższych sąsiadów (ANN). Zamiast porównywać wektor zapytania z wektorem każdego dokumentu (co w przypadku dużych zbiorów danych byłoby zbyt wolne), algorytmy ANN używają inteligentnych struktur indeksowania, aby szybko znajdować wektory, które są prawdopodobnie najbliższe.
Wyszukiwanie w danych uporządkowanych
Nie wszystkie kluczowe informacje są przechowywane w nieustrukturyzowanych dokumentach. Najdokładniejsze i najcenniejsze informacje często znajdują się w formatach strukturalnych, takich jak relacyjne bazy danych, bazy danych NoSQL lub różnego rodzaju interfejsy API, np. interfejs REST API do danych pogodowych lub cen akcji.
Pobieranie danych z danych strukturalnych jest zwykle bardziej bezpośrednie i dokładne niż wyszukiwanie w tekście nieustrukturyzowanym. Zamiast wyszukiwać podobieństwa semantyczne, modele językowe mogą mieć możliwość formułowania i wykonywania precyzyjnych zapytań, np. zapytań SQL do bazy danych lub wywołań interfejsu API do interfejsu API pogodowego dla określonej lokalizacji i daty.
Zaimplementowana za pomocą wywoływania funkcji, czyli tej samej techniki, która obsługuje agenty AI, umożliwia modelom językowym interakcję z wykonywalnym kodem i systemami zewnętrznymi w deterministyczny sposób strukturalny.
3. Od potoków RAG do RAG z użyciem agentów
Podobnie jak sama koncepcja RAG, ewoluowały też architektury jej wdrażania. To, co zaczęło się jako prosty, liniowy potok, przekształciło się w dynamiczny, inteligentny system zarządzany przez agentów AI.
- Prosta (lub naiwna) architektura RAG: to podstawowa architektura, którą omówiliśmy do tej pory: liniowy, trzyetapowy proces pobierania, rozszerzania i generowania. Jest reaktywny – w przypadku każdego zapytania podąża stałą ścieżką i jest bardzo skuteczny w przypadku prostych zadań typu pytania i odpowiedzi.
- Zaawansowana technologia RAG: to rozwinięcie technologii RAG, w której do potoku dodano dodatkowe kroki, aby poprawić jakość pobranego kontekstu. Mogą one wystąpić przed etapem pobierania lub po nim.
- Przed pobraniem: można użyć technik takich jak ponowne zapisanie lub rozszerzenie zapytania. System może przeanalizować początkowe zapytanie i przeformułować je, aby było bardziej skuteczne dla systemu wyszukiwania.
- Po pobraniu: po pobraniu początkowego zestawu dokumentów można zastosować model ponownego rankingu, aby ocenić trafność dokumentów i przesunąć najlepsze z nich na początek listy. Jest to szczególnie ważne w przypadku wyszukiwania hybrydowego. Kolejnym krokiem po pobraniu jest filtrowanie lub kompresowanie pobranego kontekstu, aby mieć pewność, że do LLM przekazywane są tylko najważniejsze informacje.
- Agentic RAG: to najnowocześniejsza architektura RAG, która stanowi zmianę paradygmatu z stałego potoku na autonomiczny, inteligentny proces. W systemie RAG opartym na agentach cały przepływ pracy jest zarządzany przez co najmniej 1 agenta AI, który może wnioskować, planować i dynamicznie wybierać działania.
Aby zrozumieć Agentic RAG, musisz najpierw wiedzieć, czym jest agent AI. Agent to coś więcej niż tylko LLM. Jest to system składający się z kilku kluczowych komponentów:
- Model LLM jako silnik rozumowania: agent używa zaawansowanego modelu LLM, takiego jak Gemini, nie tylko do generowania tekstu, ale też jako centralnego „mózgu” do planowania, podejmowania decyzji i rozkładania złożonych zadań na mniejsze części.
- Zestaw narzędzi: agent ma dostęp do zestawu funkcji, których może używać do osiągania swoich celów. Mogą to być kalkulator, interfejs API wyszukiwarki internetowej, funkcja wysyłania e-maili lub, co najważniejsze w tym laboratorium, narzędzia do pobierania informacji z różnych baz wiedzy.
- Pamięć: agenci mogą być wyposażeni w pamięć krótkotrwałą (aby zapamiętywać kontekst bieżącej rozmowy) i długotrwałą (aby przypominać sobie informacje z wcześniejszych interakcji), co pozwala na bardziej spersonalizowane i spójne działanie.
- Planowanie i analiza: najbardziej zaawansowane modele wykazują złożone wzorce rozumowania. Może otrzymać złożony cel i utworzyć wieloetapowy plan jego osiągnięcia. Następnie może zrealizować ten plan, a nawet przeanalizować wyniki swoich działań, zidentyfikować błędy i samodzielnie skorygować podejście, aby poprawić ostateczny rezultat.
Agentic RAG to przełomowe rozwiązanie, ponieważ wprowadza warstwę autonomii i inteligencji, której brakuje statycznym potokom.
- Elastyczność i możliwość dostosowania: agent nie jest ograniczony do jednej ścieżki pobierania. Na podstawie zapytania użytkownika może określić najlepsze źródło informacji. Może najpierw wysłać zapytanie do bazy danych strukturalnych, a potem przeprowadzić wyszukiwanie semantyczne w dokumentach nieustrukturyzowanych. Jeśli nadal nie znajdzie odpowiedzi, użyje narzędzia wyszukiwarki Google, aby przeszukać publiczny internet – wszystko w ramach jednego żądania użytkownika.
- Złożone wnioskowanie wieloetapowe: ta architektura doskonale radzi sobie ze złożonymi zapytaniami, które wymagają wielu kolejnych kroków pobierania i przetwarzania.
Rozważmy zapytanie: „Znajdź 3 najlepsze filmy science fiction wyreżyserowane przez Christophera Nolana i do każdego z nich podaj krótkie streszczenie fabuły”. Prosty potok RAG nie zadziała.
Agent może jednak to wyjaśnić:
- Plan: najpierw muszę znaleźć filmy. Następnie muszę znaleźć fabułę każdego filmu.
- Działanie 1: użyj narzędzia do danych strukturalnych, aby wysłać zapytanie do bazy danych filmów o filmy science fiction Nolana: 3 najlepsze filmy posortowane według oceny malejąco.
- Obserwacja 1: narzędzie zwraca wyniki „Incepcja”, „Interstellar” i „Tenet”.
- Działanie 2: użyj narzędzia do nieustrukturyzowanych danych (wyszukiwanie semantyczne), aby znaleźć fabułę filmu „Incepcja”.
- Obserwacja 2: działka została pobrana.
- Czynność 3. Powtórz czynność dla filmu „Interstellar”.
- Działanie 4: powtórz dla filmu „Tenet”.
- Ostateczna synteza: połącz wszystkie uzyskane informacje w jedną spójną odpowiedź dla użytkownika.
4. Konfigurowanie projektu
Konto Google
Jeśli nie masz jeszcze osobistego konta Google, musisz je utworzyć.
Używaj konta osobistego zamiast konta służbowego lub szkolnego.
Logowanie się w konsoli Google Cloud
Zaloguj się w konsoli Google Cloud, korzystając z osobistego konta Google.
Włącz płatności
Użyj testowego konta rozliczeniowego (opcjonalnie)
Aby przeprowadzić te warsztaty, musisz mieć konto rozliczeniowe z określonymi środkami. Aby rozpocząć, użyj środków z banera u góry tego modułu. Jeśli masz już połączenie z kontem rozliczeniowym, możesz pominąć ten krok.
Konfigurowanie osobistego konta rozliczeniowego
Jeśli skonfigurujesz płatności za pomocą środków w Google Cloud, możesz pominąć ten krok.
Aby skonfigurować osobiste konto rozliczeniowe, włącz płatności w konsoli Google Cloud.
Uwagi:
- Pod względem opłat za zasoby chmury ukończenie tego modułu powinno kosztować mniej niż 1 USD.
- Jeśli chcesz uniknąć dalszych opłat, wykonaj czynności opisane na końcu tego modułu, aby usunąć zasoby.
- Nowi użytkownicy mogą skorzystać z bezpłatnego okresu próbnego, w którym mają do dyspozycji środki w wysokości 300 USD.
Tworzenie projektu (opcjonalnie)
Jeśli nie masz bieżącego projektu, którego chcesz użyć w tym ćwiczeniu, utwórz nowy projekt.
5. Otwórz edytor Cloud Shell
- Kliknij ten link, aby przejść bezpośrednio do edytora Cloud Shell
- Jeśli w dowolnym momencie pojawi się prośba o autoryzację, kliknij Autoryzuj, aby kontynuować.
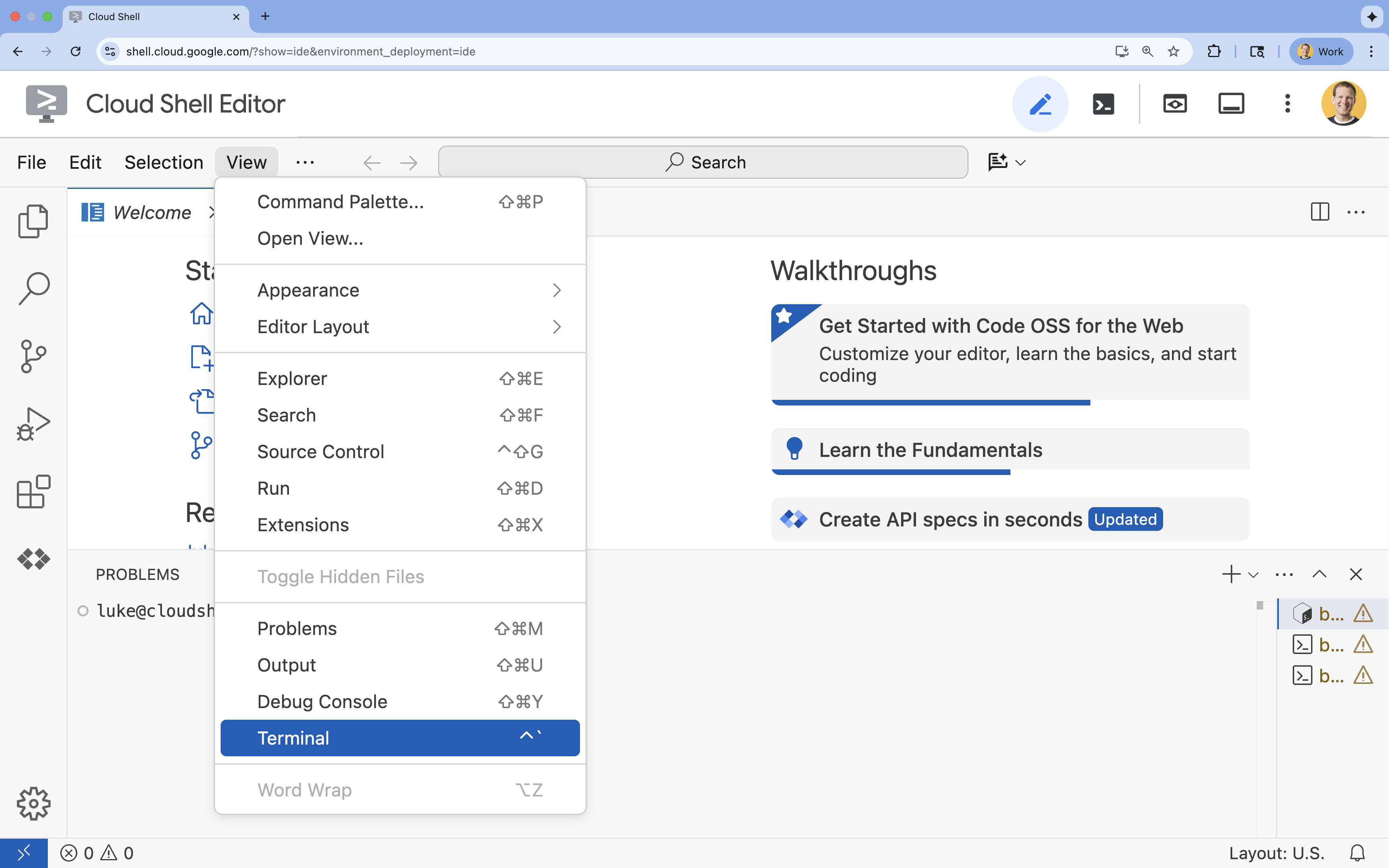
- Jeśli terminal nie pojawi się u dołu ekranu, otwórz go:
- Kliknij Wyświetl.
- Kliknij Terminal
 .
.
- W terminalu ustaw projekt za pomocą tego polecenia:
gcloud config set project [PROJECT_ID]- Przykład:
gcloud config set project lab-project-id-example - Jeśli nie pamiętasz identyfikatora projektu, możesz wyświetlić listę wszystkich identyfikatorów projektów za pomocą tego polecenia:
gcloud projects list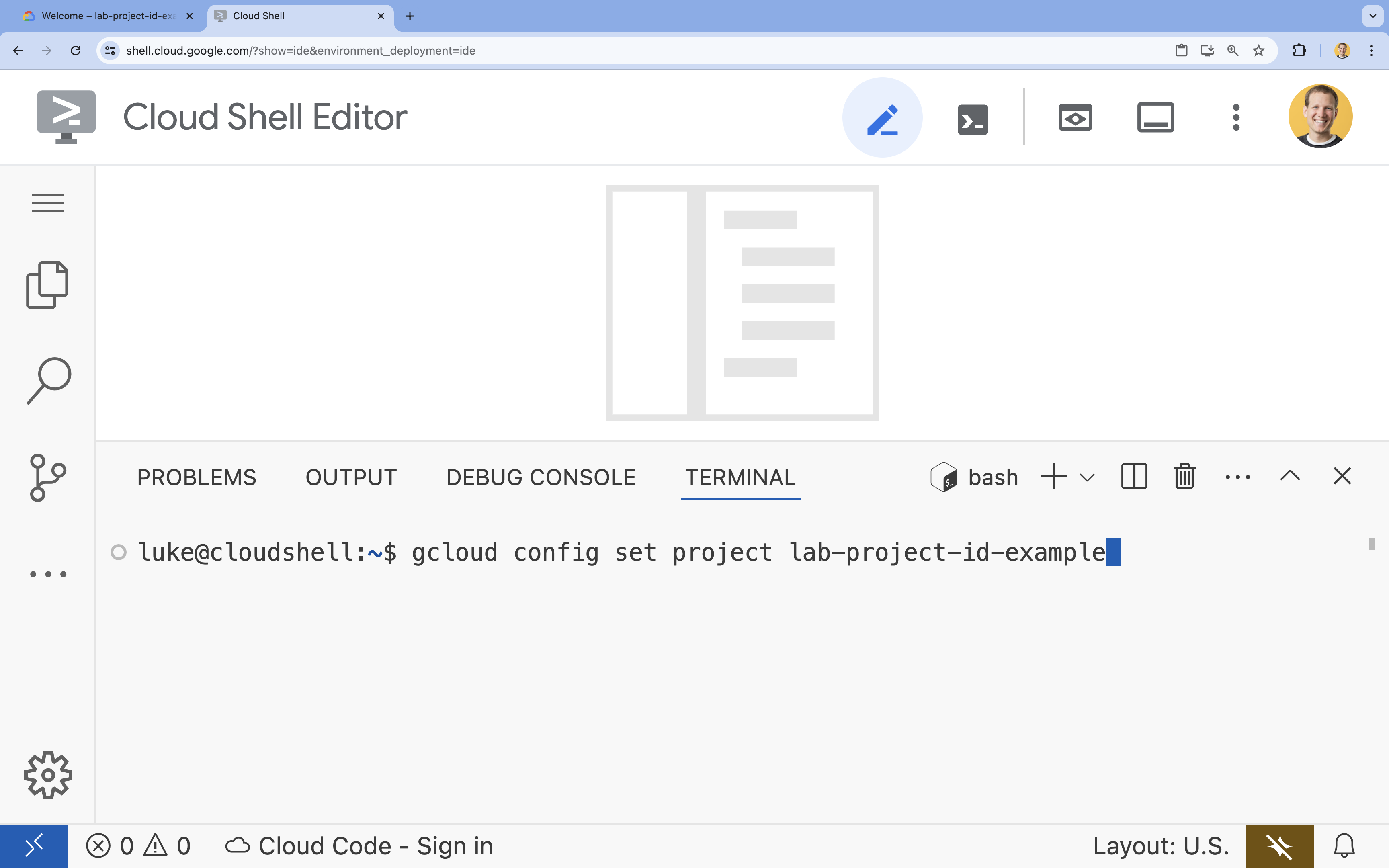
- Przykład:
- Powinien wyświetlić się ten komunikat:
Updated property [core/project].
6. Włącz interfejsy API
Aby korzystać z pakietu Agent Development Kit i Vertex AI Search, musisz włączyć odpowiednie interfejsy API w projekcie Google Cloud.
- W terminalu włącz interfejsy API:
gcloud services enable \ aiplatform.googleapis.com \ discoveryengine.googleapis.com
Przedstawiamy interfejsy API
- Interfejs Vertex AI API (
aiplatform.googleapis.com) umożliwia agentowi komunikację z modelami Gemini w celu rozumowania i generowania treści. - Discovery Engine API (
discoveryengine.googleapis.com) obsługuje Vertex AI Search, umożliwiając tworzenie magazynów danych i przeprowadzanie wyszukiwań semantycznych w nieustrukturyzowanych dokumentach.
7. Konfigurowanie środowiska
Zanim zaczniesz kodować agenta AI, musisz przygotować środowisko programistyczne, zainstalować niezbędne biblioteki i utworzyć wymagane pliki danych.
Tworzenie środowiska wirtualnego i instalowanie zależności
- Utwórz katalog dla agenta i przejdź do niego. Uruchom w terminalu ten kod:
mkdir financial_agent cd financial_agent - Utwórz środowisko wirtualne:
uv venv --python 3.12 - Aktywuj środowisko wirtualne:
source .venv/bin/activate - Zainstaluj pakiet Agent Development Kit (ADK) i bibliotekę pandas.
uv pip install google-adk pandas
Tworzenie danych o cenach akcji
Laboratorium wymaga konkretnych historycznych danych giełdowych, aby zademonstrować zdolność agenta do korzystania z narzędzi strukturalnych, dlatego utworzysz plik CSV zawierający te dane.
- W katalogu
financial_agentutwórz plikgoog.csv, uruchamiając w terminalu to polecenie:cat <<EOF > goog.csv Date,Open,High,Low,Close,Adj Close,Volume 2023-01-03,89.830002,91.550003,89.019997,89.699997,89.699997,20738500 2023-03-31,101.440002,103.889999,101.040001,103.730003,103.730003,36823200 2023-06-30,120.870003,122.029999,120.300003,120.970001,120.970001,23824700 2023-09-29,134.080002,134.550003,131.320007,131.850006,131.850006,21124200 2025-07-10,185.000000,188.000000,184.500000,186.500000,186.500000,25000000 EOF
Konfigurowanie zmiennych środowiskowych
- W katalogu
financial_agentutwórz plik.env, aby skonfigurować zmienne środowiskowe agenta. Informuje to ADK, którego projektu, lokalizacji i modelu należy użyć. Uruchom w terminalu ten kod:# Create the .env file using the captured variables cat << EOF > .env GOOGLE_GENAI_USE_VERTEXAI=TRUE GOOGLE_CLOUD_PROJECT="${GOOGLE_CLOUD_PROJECT}" GOOGLE_CLOUD_LOCATION="us-central1" EOF
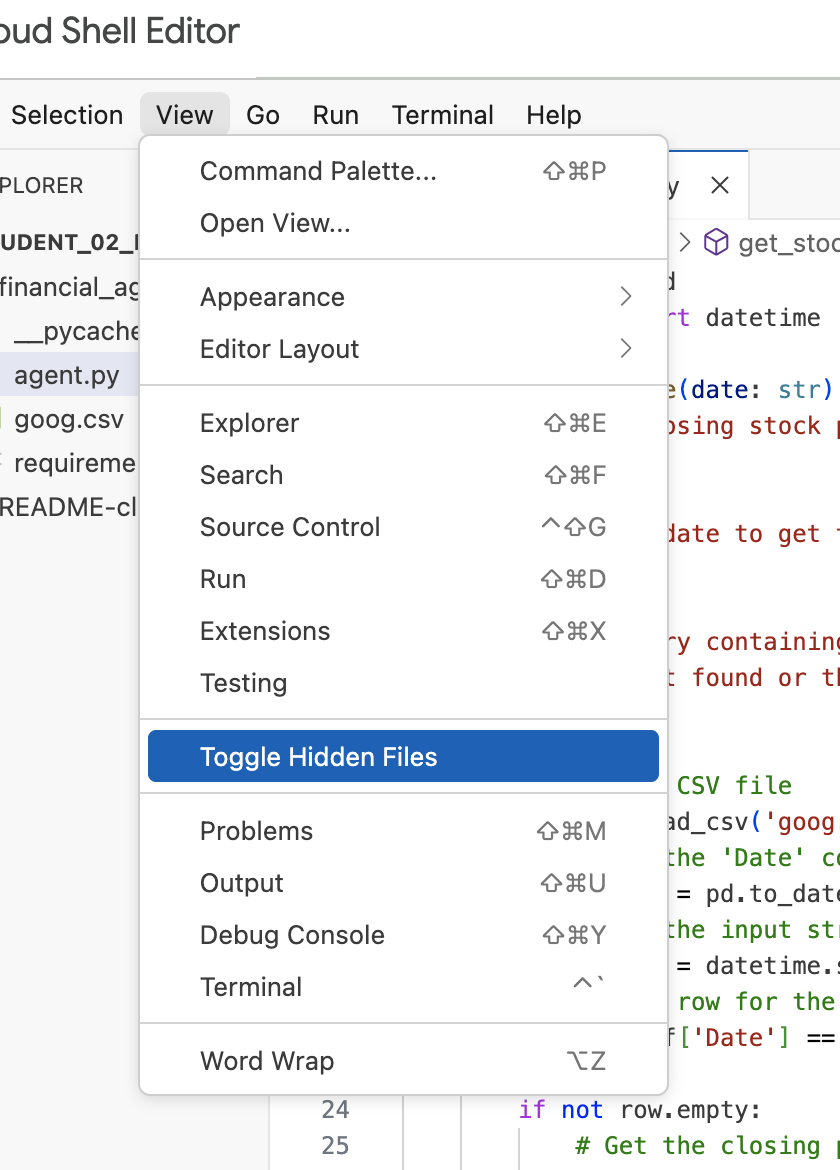
Uwaga: jeśli w dalszej części tego modułu będziesz musieć zmodyfikować plik .env, ale nie widzisz go w katalogu financial_agent, spróbuj przełączyć widoczność ukrytych plików w edytorze Cloud Shell za pomocą opcji menu „View / Toggle Hidden Files” (Widok / Przełącz ukryte pliki).
8. Tworzenie magazynu danych Vertex AI Search
Aby umożliwić agentowi odpowiadanie na pytania dotyczące raportów finansowych Alphabet, utworzysz magazyn danych Vertex AI Search zawierający publiczne dokumenty złożone w Komisji Papierów Wartościowych i Giełd.
- Na nowej karcie przeglądarki otwórz konsolę Cloud (console.cloud.google.com) i za pomocą paska wyszukiwania u góry przejdź do aplikacji AI.
- Jeśli pojawi się taka prośba, zaznacz pole wyboru warunków i kliknij Continue and Activate the API (Przejdź dalej i aktywuj API).
- W menu nawigacyjnym po lewej stronie wybierz Data Stores (Bazy danych).
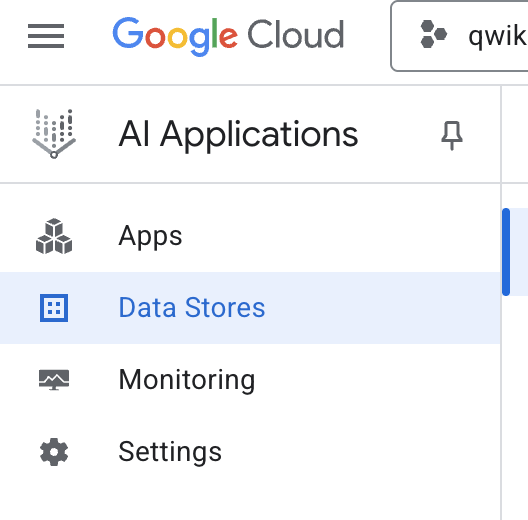
- Kliknij + Utwórz magazyn danych.
- Znajdź kartę Cloud Storage i kliknij Wybierz.
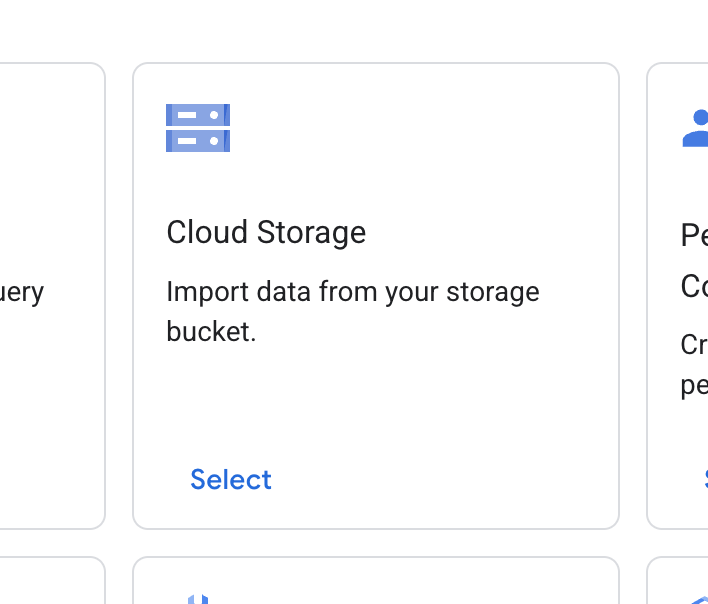
- Jako źródło danych wybierz Dokumenty bez struktury.

- Jako źródło importu (Wybierz folder lub plik, który chcesz zaimportować) wpisz ścieżkę do Google Cloud Storage
cloud-samples-data/gen-app-builder/search/alphabet-sec-filings. - Kliknij Dalej.
- Pozostaw ustawienie lokalizacji globalne.
- W polu nazwa magazynu danych wpisz
alphabet-sec-filings - Rozwiń sekcję Opcje przetwarzania dokumentów.

- Na liście Domyślny parser dokumentów wybierz Parser układu.
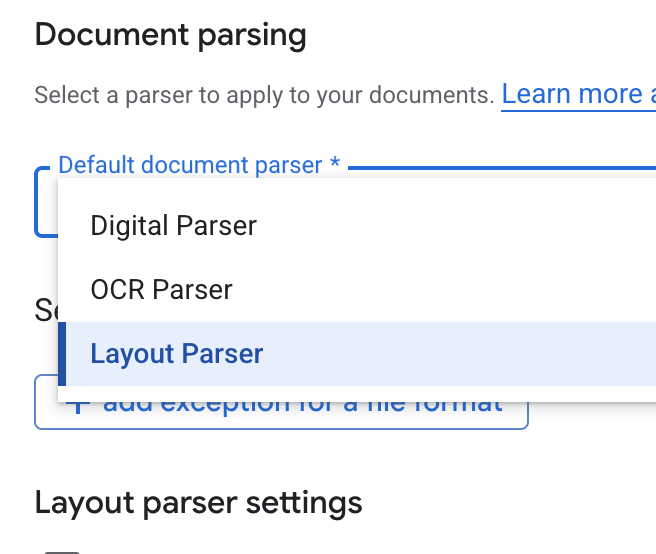
- W opcjach Ustawienia analizatora układu wybierz Włącz adnotacje do tabeli i Włącz adnotacje do obrazu.
- Kliknij Dalej.
- Wybierz model cenowy Ogólne ceny (model płatności według wykorzystania, oparty na zużyciu) i kliknij Utwórz.
- Magazyn danych rozpocznie importowanie dokumentów.
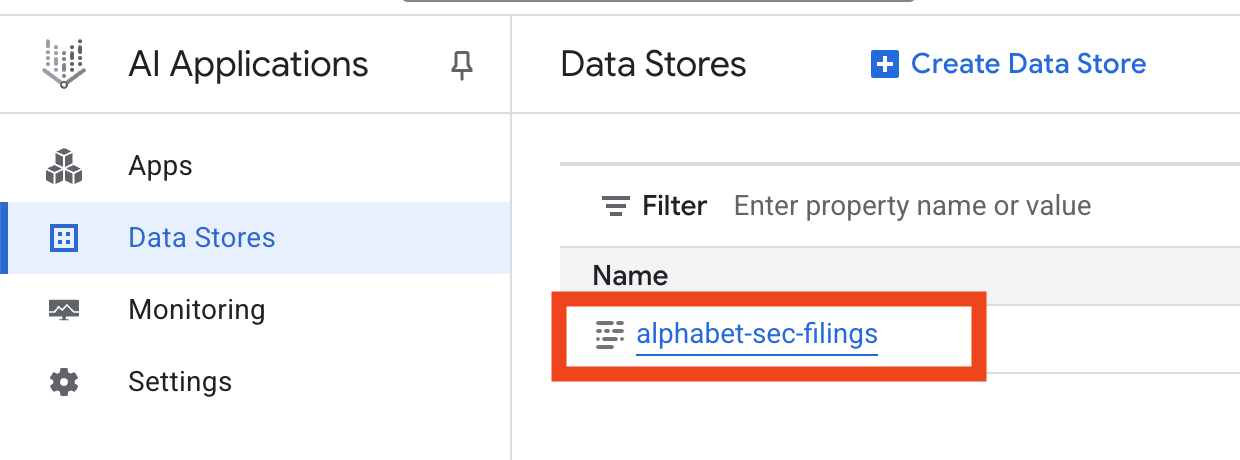
- Kliknij nazwę magazynu danych i skopiuj jego identyfikator z tabeli Magazyny danych. Będzie on potrzebny w następnym kroku.
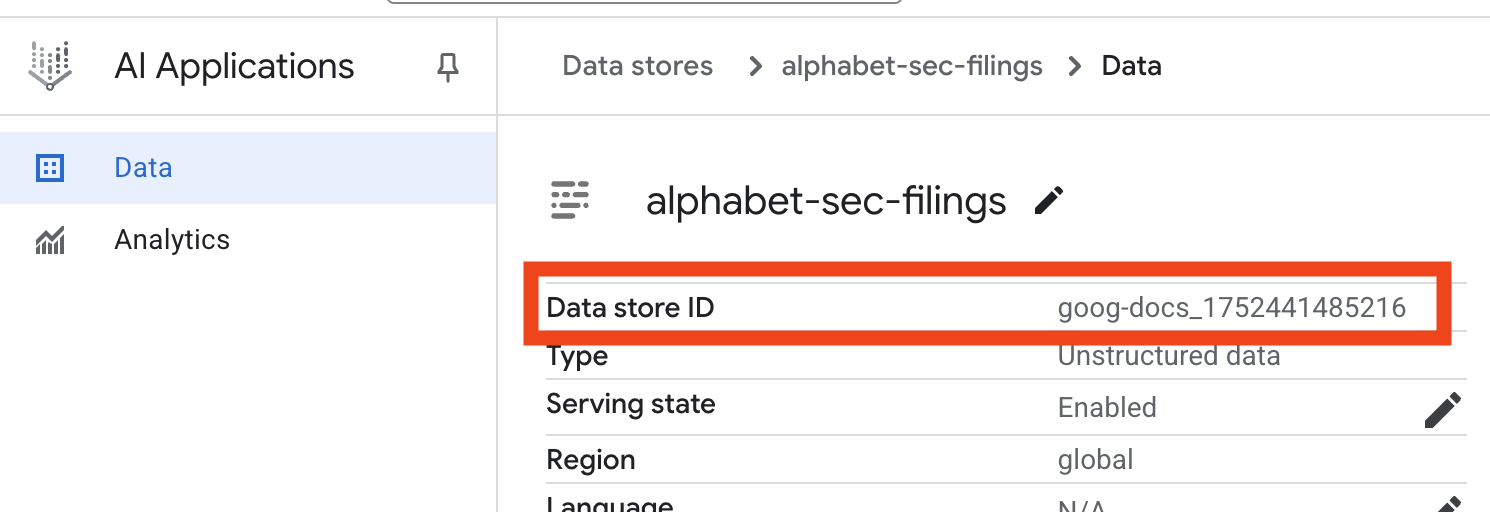
- Otwórz plik
.envw edytorze Cloud Shell i dołącz identyfikator magazynu danych jakoDATA_STORE_ID="YOUR_DATA_STORE_ID"(zastąpYOUR_DATA_STORE_IDrzeczywistym identyfikatorem z poprzedniego kroku).Uwaga: importowanie, analizowanie i indeksowanie danych w magazynie danych zajmie kilka minut. Aby sprawdzić ten proces, kliknij nazwę magazynu danych, aby otworzyć jego właściwości, a potem otwórz kartę Aktywność. Poczekaj, aż stan zmieni się na „Importowanie zakończone”.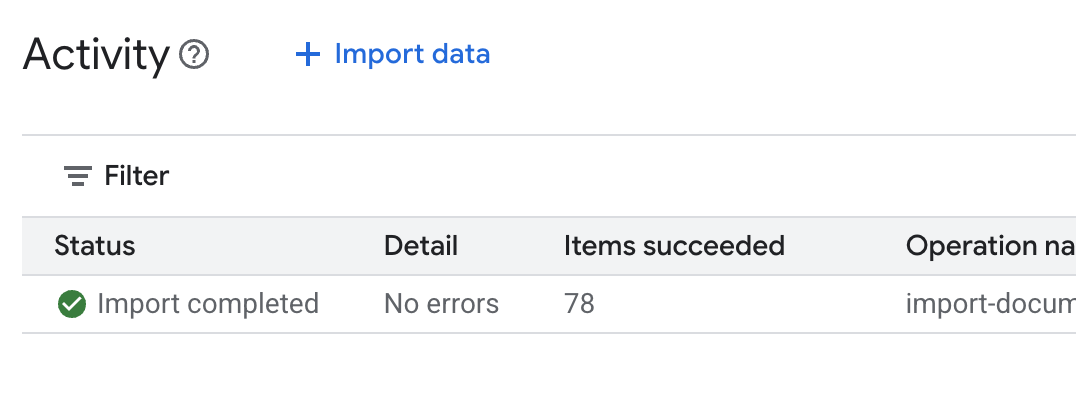
9. Tworzenie niestandardowego narzędzia do obsługi danych strukturalnych
Następnie utworzysz funkcję Pythona, która będzie działać jako narzędzie dla agenta. To narzędzie odczyta plik goog.csv, aby pobrać historyczne ceny akcji z określonej daty.
- W katalogu
financial_agentutwórz nowy plik o nazwieagent.py. Uruchom to polecenie w terminalu:cloudshell edit agent.py - Dodaj do pliku
agent.pyten kod w Pythonie. Ten kod importuje zależności i definiuje funkcjęget_stock_price.from datetime import datetime import os import logging import google.cloud.logging from google.adk.tools import VertexAiSearchTool from google.adk.tools.agent_tool import AgentTool from google.adk.agents import LlmAgent import pandas as pd def get_stock_price(date: str) -> dict: """Gets the closing stock price for a given date. Args: date: The date to get the stock price for, in YYYY-MM-DD format. Returns: A dictionary containing the closing price, or an error message if the date is not found or the format is incorrect. """ try: # Load the CSV file df = pd.read_csv('goog.csv') # Convert the 'Date' column to datetime objects df['Date'] = pd.to_datetime(df['Date']) # Convert the input string to a datetime object query_date = datetime.strptime(date, '%Y-%m-%d') # Find the row for the given date row = df[df['Date'] == query_date] if not row.empty: # Get the closing price close_price = row['Close'].iloc[0] return {"status": "success", "date": date, "closing_price": close_price} else: return {"status": "error", "message": f"No data found for date: {date}"} except FileNotFoundError: return {"status": "error", "message": "Stock data file (goog.csv) not found."} except Exception as e: return {"status": "error", "message": f"An error occurred: {str(e)}"}
Zwróć uwagę na szczegółowy ciąg dokumentujący funkcji. Wyjaśnia, co robi funkcja, jakie są jej parametry (Args) i co zwraca (Returns). ADK używa tego ciągu dokumentacyjnego, aby nauczyć agenta, jak i kiedy używać tego narzędzia.
10. Tworzenie i uruchamianie agenta RAG
Teraz nadszedł czas na złożenie agenta. Połączysz narzędzie Vertex AI Search do danych nieustrukturyzowanych z niestandardowym narzędziem get_stock_price do danych strukturalnych.
- Dołącz do pliku
agent.pyten kod: Ten kod importuje niezbędne klasy ADK, tworzy instancje narzędzi i definiuje agenta.logging.basicConfig(level=logging.INFO) cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() # 1. Create the Vertex AI Search tool full_datastore_id = f"projects/{os.environ['GOOGLE_CLOUD_PROJECT']}/locations/global/collections/default_collection/dataStores/{os.environ['DATA_STORE_ID']}" vertex_ai_search_tool = VertexAiSearchTool( data_store_id=full_datastore_id ) # 2. Define the Search+Q&A agent # Since we cannot combine tools with other tools in a single agent, # we create a separate Search+Q&A agent which will be used as a tool by the main root agent. doc_qa_agent = LlmAgent( name="search_and_qna_agent", model="gemini-2.5-flash", tools=[vertex_ai_search_tool], instruction="""You are a helpful assistant that answers questions based on information found in the document store. Use the search tool to find relevant information before answering. If the answer isn't in the documents, say that you couldn't find the information. """, description="Answers questions using a specific Vertex AI Search datastore.", ) # 3. Define the root agent with 2 tools. root_agent = LlmAgent( name="financial_agent", model="gemini-2.5-flash", tools=[ AgentTool(doc_qa_agent), get_stock_price, ], instruction="""You are an Financial Analytics Agent that answers question about Alphabet stock prices (using get_stock_price tool) and historical performance based on the data in Vertex AI Search datastore (using doc_qa_agent tool).""" ) - W terminalu w katalogu
financial_agenturuchom interfejs internetowy ADK, aby korzystać z agenta:adk web ~ - Kliknij link podany w danych wyjściowych terminala (zwykle
http://127.0.0.1:8000), aby otworzyć interfejs ADK Dev UI w przeglądarce.
11. Testowanie agenta
Możesz teraz sprawdzić, czy agent potrafi wnioskować i korzystać z narzędzi, aby odpowiadać na złożone pytania.
- W interfejsie ADK Dev UI upewnij się, że w menu wybrano
financial_agent. - Spróbuj zadać pytanie, które wymaga informacji z dokumentów SEC (danych nieustrukturyzowanych). Wpisz na czacie to zapytanie:
What were the total revenues for the quarter ending on March 31, 2023?search_and_qna_agent, która używa funkcjiVertexAiSearchTooldo znalezienia odpowiedzi w dokumentach finansowych. - Następnie zadaj pytanie, które wymaga użycia niestandardowego narzędzia (danych strukturalnych). Pamiętaj, że format daty w prompcie nie musi dokładnie odpowiadać formatowi wymaganemu przez funkcję. LLM jest wystarczająco inteligentny, aby go przekształcić.
What was the closing stock price for Alphabet on July 10, 2025?get_stock_price. Aby sprawdzić wywołanie funkcji i jego wynik, kliknij ikonę narzędzia na czacie. - Na koniec zadaj złożone pytanie, które wymaga od agenta użycia obu narzędzi i zestawienia wyników.
According to the 10-Q filing for the period ending March 31, 2023, what were the company's net cash provided by operating activities, and what was the stock's closing price on that date?- Najpierw użyje symbolu
VertexAiSearchTool, aby znaleźć informacje o przepływach pieniężnych w dokumentach złożonych w Komisji Papierów Wartościowych i Giełd. - Następnie rozpozna potrzebę uzyskania ceny akcji i wywoła funkcję
get_stock_pricez datą2023-03-31. - Na koniec połączy obie informacje w jedną, wyczerpującą odpowiedź.
- Najpierw użyje symbolu
- Gdy skończysz, możesz zamknąć kartę przeglądarki i nacisnąć
CTRL+Cw terminalu, aby zatrzymać serwer ADK.
12. Wybieranie usługi do wykonania zadania
Vertex AI Search to nie jedyna usługa wyszukiwania wektorowego, której możesz używać. Możesz też użyć usługi zarządzanej, która automatyzuje cały proces generowania wspomaganego wyszukiwaniem: Vertex AI RAG Engine.
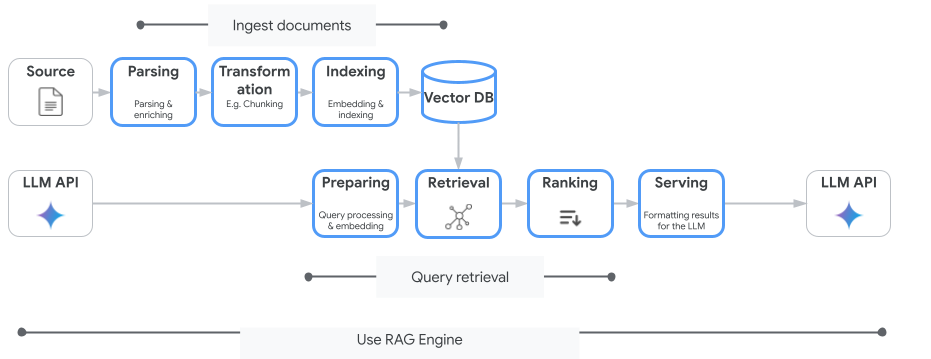
Obsługuje wszystko – od wczytywania dokumentów po ich pobieranie i ponowne rankingowanie. RAG Engine obsługuje wiele baz wektorowych, w tym Pinecone i Weaviate.
Możesz też samodzielnie hostować wiele specjalistycznych baz danych wektorowych lub korzystać z funkcji indeksowania wektorów w silnikach baz danych, takich jak pgvector w usłudze PostgreSQL (np. AlloyDB lub BigQuery Vector Search).
Kilka innych usług, które obsługują wyszukiwanie wektorowe:
Ogólne wskazówki dotyczące wyboru konkretnej usługi w Google Cloud są następujące:
- Jeśli masz już działającą i dobrze skalującą się infrastrukturę wyszukiwania wektorowego typu „zrób to sam”, wdróż ją w Google Kubernetes Engine, np. Weaviate lub DIY PostgreSQL.
- Jeśli dane znajdują się w BigQuery, AlloyDB, Firestore lub innej bazie danych, rozważ użycie funkcji wyszukiwania wektorowego , jeśli wyszukiwanie semantyczne można przeprowadzić na dużą skalę w ramach większego zapytania w tej bazie danych. Jeśli na przykład masz opisy produktów lub obrazy w tabeli BigQuery, dodanie kolumny z tekstem lub osadzaniem obrazu umożliwi korzystanie z wyszukiwania podobieństw na dużą skalę. Indeksy wektorowe z wyszukiwaniem ScaNN obsługują miliardy elementów w indeksie.
- Jeśli chcesz szybko rozpocząć pracę przy minimalnym wysiłku i na zarządzanej platformie, wybierz Vertex AI Search – w pełni zarządzaną wyszukiwarkę i interfejs API do pobierania danych, który idealnie nadaje się do złożonych zastosowań biznesowych wymagających wysokiej jakości, skalowalności i precyzyjnych kontroli dostępu. Ułatwia łączenie się z różnymi źródłami danych w przedsiębiorstwie i umożliwia wyszukiwanie w wielu źródłach.
- Jeśli szukasz rozwiązania, które łączy łatwość użycia z możliwością dostosowania, użyj silnika RAG Vertex AI. Umożliwia szybkie tworzenie prototypów i opracowywanie aplikacji bez utraty elastyczności.
- Zapoznaj się z architekturami referencyjnymi generowania wspomaganego wyszukiwaniem.
13. Podsumowanie
Gratulacje! Udało Ci się utworzyć i przetestować agenta AI z generowaniem wspomaganym wyszukiwaniem. Dowiedziałeś(-aś) się, jak:
- Tworzenie bazy wiedzy na podstawie nieustrukturyzowanych dokumentów za pomocą zaawansowanych funkcji wyszukiwania semantycznego w Vertex AI Search.
- Utwórz niestandardową funkcję Pythona, która będzie służyć jako narzędzie do pobierania uporządkowanych danych.
- Utwórz agenta z wieloma narzędziami opartego na Gemini za pomocą pakietu Agent Development Kit (ADK).
- Stworzenie agenta zdolnego do złożonego, wieloetapowego rozumowania, który będzie odpowiadać na zapytania wymagające syntezy informacji z wielu źródeł.
To laboratorium przedstawia podstawowe zasady agentowego RAG, czyli zaawansowanej architektury do tworzenia inteligentnych, dokładnych i uwzględniających kontekst aplikacji AI w Google Cloud.
Od prototypu do środowiska produkcyjnego
Ten moduł jest częścią ścieżki szkoleniowej Wdrożenie AI w Google Cloud.
- Poznaj pełny program nauczania, aby przejść od prototypu do produkcji.
- Podziel się swoimi postępami, używając hashtagu #ProductionReadyAI.