
1. Introdução
Visão geral
O objetivo deste laboratório é aprender a desenvolver aplicativos de geração aumentada por recuperação (RAG) agentiva de ponta a ponta no Google Cloud. Neste laboratório, você vai criar um agente de análise financeira que pode responder a perguntas combinando informações de duas fontes diferentes: documentos não estruturados (arquivos trimestrais da Alphabet na SEC: demonstrações financeiras e detalhes operacionais que todas as empresas de capital aberto nos EUA enviam à Comissão de Valores Mobiliários) e dados estruturados (preços históricos das ações).
Você vai usar a Vertex AI para Pesquisa para criar um mecanismo de pesquisa semântica eficiente para os relatórios financeiros não estruturados. Para os dados estruturados, você vai criar uma ferramenta personalizada em Python. Por fim, você vai usar o Kit de Desenvolvimento de Agente (ADK) para criar um agente inteligente que pode raciocinar sobre a consulta de um usuário, decidir qual ferramenta usar e sintetizar as informações em uma resposta coerente.
Atividades deste laboratório
- Configure um repositório de dados da Vertex AI para Pesquisa para fazer pesquisas semânticas em documentos particulares.
- Crie uma função personalizada do Python como ferramenta para um agente.
- Use o Kit de Desenvolvimento de Agente (ADK) para criar um agente com várias ferramentas.
- Combine a recuperação de fontes de dados não estruturados e estruturados para responder a perguntas complexas.
- Teste e interaja com um agente que tenha recursos de raciocínio.
O que você vai aprender
Neste laboratório, você vai aprender a:
- Os principais conceitos da geração aumentada por recuperação (RAG) e da RAG agentiva.
- Como implementar a pesquisa semântica em documentos usando a Vertex AI para Pesquisa.
- Como expor dados estruturados a um agente criando ferramentas personalizadas.
- Como criar e orquestrar um agente com várias ferramentas usando o Kit de Desenvolvimento de Agente (ADK).
- Como os agentes usam raciocínio e planejamento para responder a perguntas complexas usando várias fontes de dados.
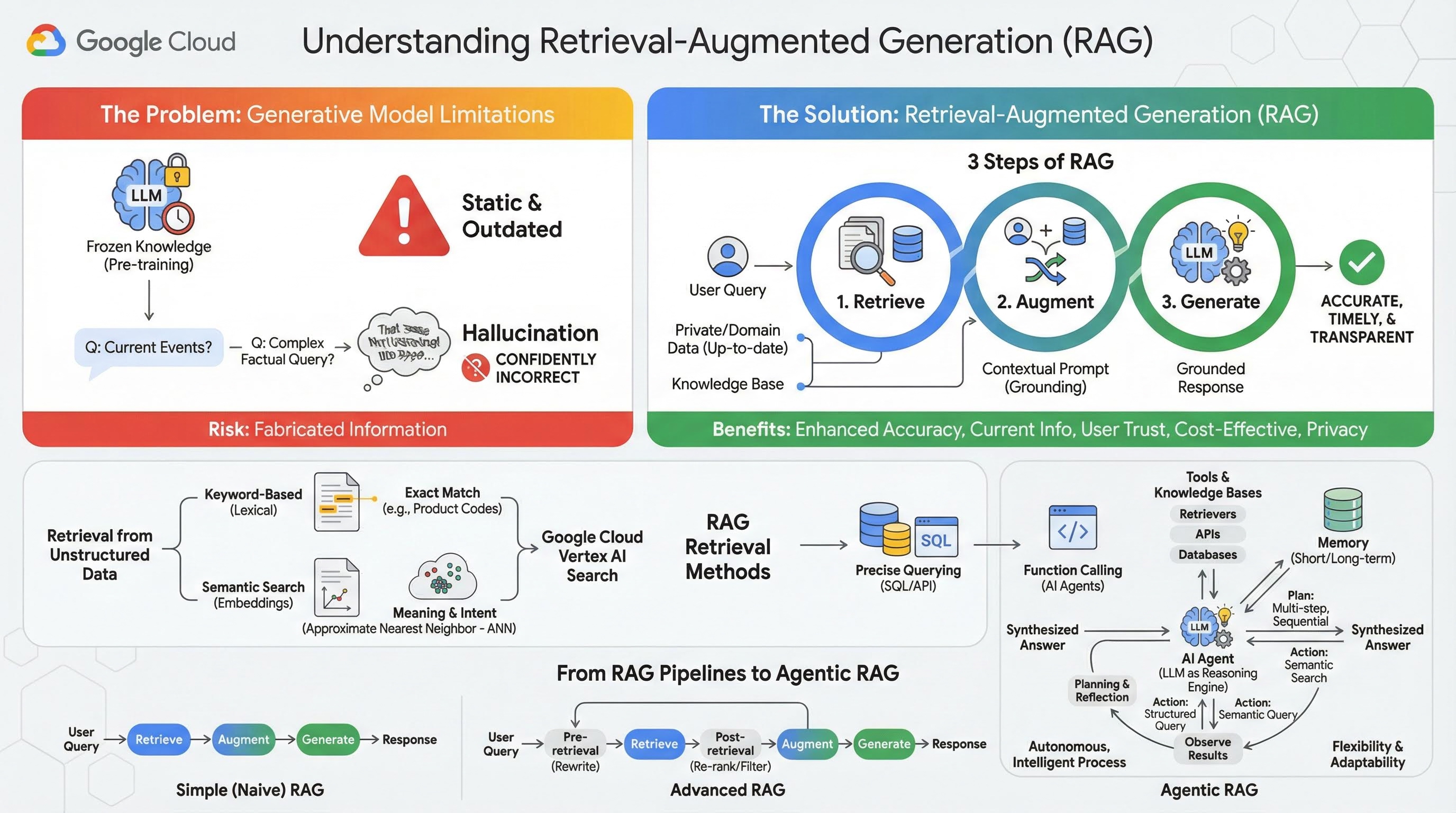
2. Entender a geração aumentada por recuperação
Os modelos generativos grandes (modelos de linguagem grandes ou LLMs, modelos de linguagem de visão etc.) são incrivelmente poderosos, mas têm limitações inerentes. O conhecimento deles é congelado no momento do pré-treinamento, o que o torna estático e instantaneamente desatualizado. Mesmo depois do ajuste refinado, o conhecimento do modelo não fica muito mais recente, já que esse não é o objetivo das etapas pós-treinamento.
A maneira como os modelos de linguagem grandes são treinados, especialmente os modelos de "pensamento", faz com que eles sejam "recompensados" por dar alguma resposta, mesmo que o modelo não tenha informações factuais que a apoiem. É quando dizem que um modelo "alucina", ou seja, gera com confiança informações que parecem plausíveis, mas são factualmente incorretas.
A geração aumentada por recuperação é um padrão arquitetônico avançado projetado para resolver exatamente esses problemas. É um framework arquitetônico que aprimora os recursos dos modelos de linguagem grandes ao conectá-los a fontes de conhecimento externas e confiáveis em tempo real. Em vez de depender apenas do conhecimento estático e pré-treinado, um LLM em um sistema de RAG primeiro recupera informações relevantes relacionadas à consulta de um usuário e depois usa essas informações para gerar uma resposta mais precisa, oportuna e contextualizada.
Essa abordagem aborda diretamente as fraquezas mais significativas dos modelos generativos: o conhecimento deles é fixado em um ponto no tempo, e eles são propensos a gerar informações incorretas, ou "alucinações". A RAG oferece ao LLM uma "prova com consulta", em que o "livro" são seus dados particulares, específicos do domínio e atualizados. Esse processo de fornecer contexto factual ao LLM é conhecido como embasamento.
Três etapas da RAG
O processo padrão de geração aumentada por recuperação pode ser dividido em três etapas simples:
- Recuperação: quando um usuário envia uma consulta, o sistema primeiro pesquisa uma base de conhecimento externa (como um repositório de documentos, um banco de dados ou um site) para encontrar informações relevantes para a consulta.
- Aumentar: as informações recuperadas são combinadas com a consulta original do usuário em um comando expandido. Essa técnica às vezes é chamada de "recheio de comandos", já que enriquece o comando com contexto factual.
- Gerar: esse comando aumentado é fornecido ao LLM, que gera uma resposta. Como o modelo recebeu dados relevantes e factuais, a saída dele é "embasada" e muito menos propensa a ser imprecisa ou desatualizada.
Benefícios da RAG
A introdução da estrutura RAG foi transformadora para a criação de aplicativos de IA práticos e confiáveis. Os principais benefícios incluem:
- Maior acurácia e menos alucinações: ao embasar as respostas em fatos externos verificáveis, a RAG reduz drasticamente o risco de o LLM inventar informações.
- Acesso a informações atuais: os sistemas de RAG podem ser conectados a bases de conhecimento constantemente atualizadas, permitindo que eles forneçam respostas com base nas informações mais recentes, algo impossível para um LLM treinado de forma estática.
- Aumento da confiança e da transparência para o usuário: como a resposta do LLM é baseada em documentos recuperados, o sistema pode fornecer citações e links para as fontes. Isso permite que os usuários verifiquem as informações por conta própria, aumentando a confiança no aplicativo.
- Custo-benefício: ajustar ou retreinar continuamente um LLM com novos dados é caro do ponto de vista computacional e financeiro. Com a RAG, atualizar o conhecimento do modelo é tão simples quanto atualizar a fonte de dados externa, o que é muito mais eficiente.
- Especialização de domínio e privacidade: a RAG permite que pessoas e organizações disponibilizem dados particulares e proprietários para um LLM no momento da consulta sem precisar incluir esses dados sensíveis no conjunto de treinamento do modelo. Isso permite aplicativos poderosos e específicos do domínio, mantendo a privacidade e a segurança dos dados.
Recuperação
A etapa de "recuperação" é o coração de qualquer sistema RAG. A qualidade e a relevância das informações recuperadas determinam diretamente a qualidade e a relevância da resposta final gerada. Um aplicativo de RAG eficaz geralmente precisa recuperar informações de diferentes tipos de fontes de dados usando várias técnicas. Os principais métodos de recuperação se enquadram em três categorias: com base em palavras-chave, semânticos e estruturados.
Recuperação de dados não estruturados
Historicamente, a recuperação de dados não estruturados é outro nome para a pesquisa tradicional. Ele passou por várias transformações, e você pode se beneficiar das duas abordagens principais.
A pesquisa semântica é a técnica mais eficiente que você pode executar em escala no Google Cloud com desempenho de ponta e alto grau de controle.
- Pesquisa baseada em palavras-chave (lexical): essa é a abordagem tradicional de pesquisa, que remonta aos primeiros sistemas de recuperação de informações da década de 1970. A pesquisa lexical funciona combinando as palavras literais (ou "tokens") na consulta de um usuário com as mesmas palavras nos documentos de uma base de conhecimento. Ele é muito eficaz para consultas em que a precisão em termos específicos, como códigos de produtos, cláusulas legais ou nomes exclusivos, é fundamental.
- Pesquisa semântica: a pesquisa semântica, ou "pesquisa com significado", é uma abordagem mais moderna que visa entender a intenção do usuário e o significado contextual da consulta, não apenas as palavras-chave literais. A pesquisa semântica moderna é alimentada por embeddings, uma técnica de machine learning que mapeia dados complexos e de alta dimensão em um espaço vetorial de baixa dimensão de vetores numéricos. Esses vetores são projetados para que textos com significados semelhantes fiquem próximos uns dos outros no espaço vetorial. Uma pesquisa por "Quais são as melhores raças de cachorro para famílias?" é convertida em um vetor, e o sistema procura vetores de documentos que sejam seus "vizinhos mais próximos" nesse espaço. Isso permite que ele encontre documentos que falam sobre "golden retrievers" ou "caninos amigáveis", mesmo que não contenham a palavra exata "cachorro". Essa pesquisa de alta dimensão é eficiente graças aos algoritmos de vizinho mais próximo aproximado (ANN). Em vez de comparar o vetor de consulta com cada vetor de documento (o que seria muito lento para grandes conjuntos de dados), os algoritmos de ANN usam estruturas de indexação inteligentes para encontrar rapidamente os vetores que provavelmente são os mais próximos.
Recuperação de dados estruturados
Nem todo o conhecimento crítico é armazenado em documentos não estruturados. Muitas vezes, as informações mais precisas e valiosas estão em formatos estruturados, como bancos de dados relacionais, bancos de dados NoSQL ou algum tipo de API, como uma API REST para dados meteorológicos ou preços de ações.
A recuperação de dados estruturados é normalmente mais direta e exata do que a pesquisa de texto não estruturado. Em vez de pesquisar a similaridade semântica, os modelos de linguagem podem formular e executar uma consulta precisa, como uma consulta SQL em um banco de dados ou uma chamada de API para uma API de clima em um determinado local e data.
Implementada com a chamada de função, a mesma técnica que alimenta os agentes de IA, ela permite que os modelos de linguagem interajam com código executável e sistemas externos de maneira estrutural determinista.
3. De pipelines de RAG para RAG com agentes
Assim como o conceito de RAG evoluiu, também evoluíram as arquiteturas para implementá-lo. O que começou como um pipeline simples e linear evoluiu para um sistema dinâmico e inteligente orquestrado por agentes de IA.
- RAG simples (ou ingênuo):é a arquitetura fundamental que discutimos até agora: um processo linear de três etapas de recuperação, aumento e geração. Ele é reativo, segue um caminho fixo para cada consulta e é altamente eficaz para tarefas simples de perguntas e respostas.
- RAG avançado:representa uma evolução em que etapas adicionais são incluídas no pipeline para melhorar a qualidade do contexto recuperado. Esses aprimoramentos podem ocorrer antes ou depois da etapa de recuperação.
- Pré-recuperação:podem ser usadas técnicas como reescrita ou expansão de consultas. O sistema pode analisar a consulta inicial e reformulá-la para ser mais eficaz para o sistema de recuperação.
- Pós-recuperação:depois de recuperar um conjunto inicial de documentos, um modelo de reclassificação pode ser aplicado para pontuar os documentos por relevância e colocar os melhores no topo. Isso é especialmente importante na pesquisa híbrida. Outra etapa pós-recuperação é filtrar ou compactar o contexto recuperado para garantir que apenas as informações mais importantes sejam transmitidas ao LLM.
- RAG agêntico:é a vanguarda da arquitetura RAG, representando uma mudança de paradigma de um pipeline fixo para um processo autônomo e inteligente. Em um sistema de RAG agêntico, todo o fluxo de trabalho é gerenciado por um ou mais agentes de IA que podem raciocinar, planejar e escolher ações de forma dinâmica.
Para entender a RAG com agentes, primeiro é preciso saber o que constitui um agente de IA. Um agente é mais do que apenas um LLM. É um sistema com vários componentes principais:
- Um LLM como um Reasoning Engine:o agente usa um LLM avançado como o Gemini não apenas para gerar texto, mas como o "cérebro" central para planejar, tomar decisões e decompor tarefas complexas.
- Um conjunto de ferramentas:um agente recebe acesso a um kit de ferramentas de funções que pode usar para alcançar os objetivos. Essas ferramentas podem ser qualquer coisa: uma calculadora, uma API de pesquisa na Web, uma função para enviar um e-mail ou, mais importante para este laboratório, recuperadores para nossas várias bases de conhecimento.
- Memória:os agentes podem ser projetados com memória de curto prazo (para lembrar o contexto da conversa atual) e de longo prazo (para recordar informações de interações anteriores), permitindo experiências mais personalizadas e coerentes.
- Planejamento e reflexão:os agentes mais avançados exibem padrões de raciocínio sofisticados. Eles podem receber uma meta complexa e criar um plano de várias etapas para alcançá-la. Em seguida, eles podem executar esse plano e até mesmo refletir sobre os resultados das ações, identificar erros e corrigir a abordagem para melhorar o resultado final.
A RAG com agente é revolucionária porque introduz uma camada de autonomia e inteligência que os pipelines estáticos não têm.
- Flexibilidade e adaptabilidade:um agente não fica preso a um único caminho de recuperação. Com base em uma consulta do usuário, ele pode determinar a melhor fonte de informações. Ele pode decidir primeiro consultar o banco de dados estruturado, depois realizar uma pesquisa semântica em documentos não estruturados e, se ainda não encontrar uma resposta, usar uma ferramenta da Pesquisa Google para procurar na Web pública, tudo no contexto de uma única solicitação do usuário.
- Raciocínio complexo e em várias etapas:essa arquitetura é excelente para processar consultas complexas que exigem várias etapas sequenciais de recuperação e processamento.
Considere a consulta: "Encontre os três melhores filmes de ficção científica dirigidos por Christopher Nolan e, para cada um, forneça um breve resumo do enredo". Um pipeline simples de RAG falharia.
No entanto, um agente pode detalhar isso:
- Planejar:primeiro, preciso encontrar os filmes. Depois, preciso encontrar o enredo de cada filme.
- Ação 1:use a ferramenta de dados estruturados para consultar um banco de dados de filmes sobre os filmes de ficção científica de Nolan: os três melhores filmes, em ordem decrescente de classificação.
- Observação 1:a ferramenta retorna "A Origem", "Interestelar" e "Tenet".
- Ação 2:use a ferramenta de dados não estruturados (pesquisa semântica) para encontrar o enredo de "A Origem".
- Observação 2:o gráfico é recuperado.
- Ação 3:repita para "Interestelar".
- Ação 4:repita para "Tenet".
- Síntese final:combine todas as informações recuperadas em uma única resposta coerente para o usuário.
4. Configurar o projeto
Conta do Google
Se você ainda não tiver uma Conta do Google pessoal, crie uma.
Use uma conta pessoal em vez de uma conta escolar ou de trabalho.
Fazer login no console do Google Cloud
Faça login no console do Google Cloud usando uma Conta do Google pessoal.
Ativar faturamento
Usar uma conta de faturamento de teste (opcional)
Para fazer este workshop, você precisa de uma conta de faturamento com algum crédito. Use os créditos do banner na parte de cima deste codelab para começar. Se você já estiver conectado a uma conta de faturamento, pule esta etapa.
Configurar uma conta de faturamento pessoal
Se você configurou o faturamento usando créditos do Google Cloud, pule esta etapa.
Para configurar uma conta de faturamento pessoal, acesse este link e ative o faturamento no console do Cloud.
Algumas observações:
- A conclusão deste laboratório custa menos de US $1 em recursos do Cloud.
- Siga as etapas no final deste laboratório para excluir recursos e evitar mais cobranças.
- Novos usuários podem aproveitar o teste sem custos financeiros de US$300.
Criar um projeto (opcional)
Se você não tiver um projeto atual que gostaria de usar neste laboratório, crie um novo projeto aqui.
5. Abrir editor do Cloud Shell
- Clique neste link para navegar diretamente até o editor do Cloud Shell.
- Se for preciso autorizar em algum momento, clique em Autorizar para continuar.
- Se o terminal não aparecer na parte de baixo da tela, abra-o:
- Clique em Visualizar.
- Clique em Terminal
 .
.
- No terminal, defina o projeto com este comando:
gcloud config set project [PROJECT_ID]- Exemplo:
gcloud config set project lab-project-id-example - Se você não se lembrar do ID do projeto, liste todos os IDs com:
gcloud projects list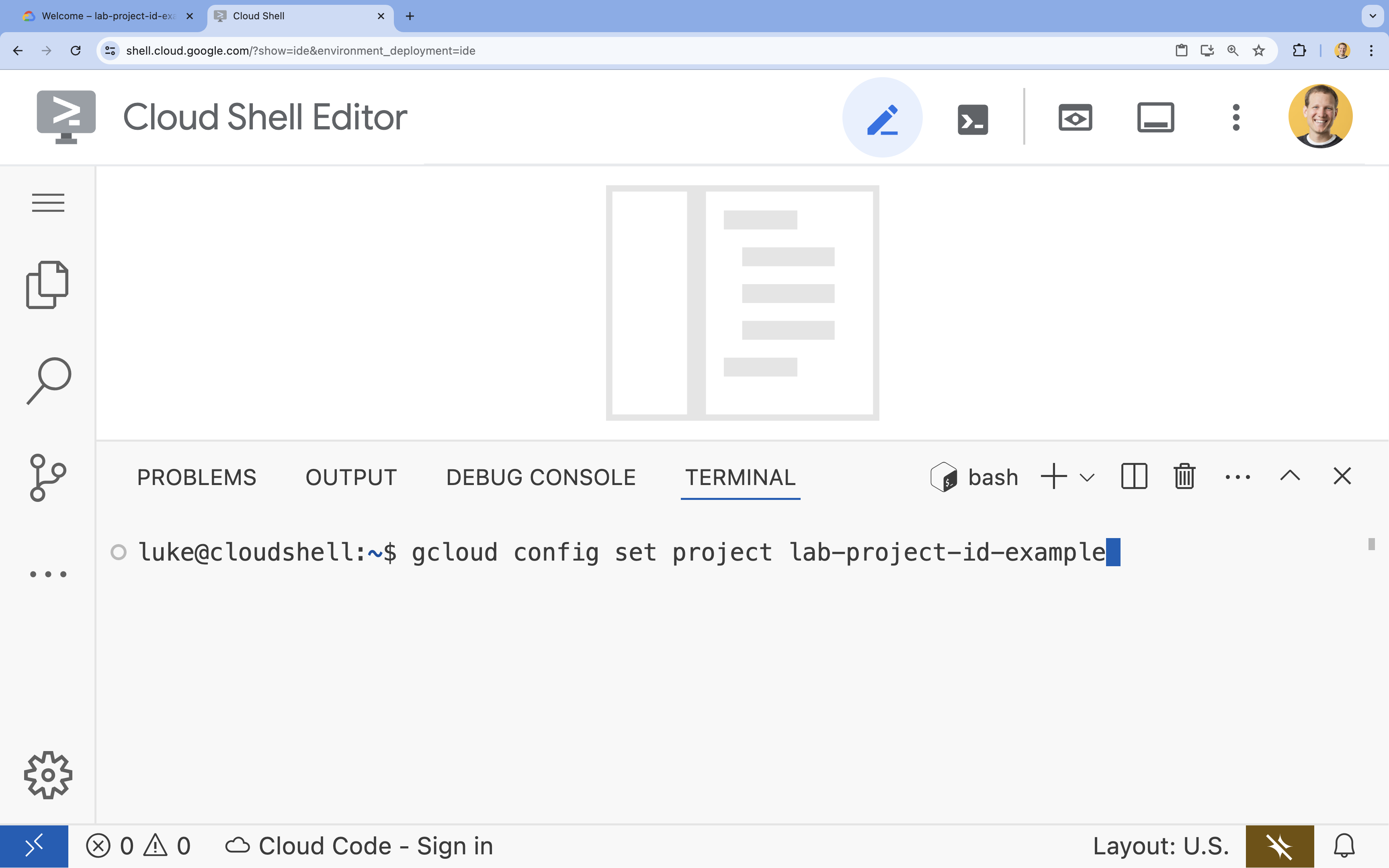
- Exemplo:
- Você vai receber esta mensagem:
Updated property [core/project].
6. Ativar APIs
Para usar o Kit de Desenvolvimento de Agente e a Vertex AI para Pesquisa, ative as APIs necessárias no seu projeto do Google Cloud.
- No terminal, ative as APIs:
gcloud services enable \ aiplatform.googleapis.com \ discoveryengine.googleapis.com
Apresentação das APIs
- A API Vertex AI (
aiplatform.googleapis.com) permite que o agente se comunique com os modelos do Gemini para raciocínio e geração. - A API Discovery Engine (
discoveryengine.googleapis.com) alimenta a Vertex AI para Pesquisa, permitindo que você crie repositórios de dados e faça pesquisas semânticas nos seus documentos não estruturados.
7. Configure o ambiente
Antes de começar a programar o agente de IA, prepare seu ambiente de desenvolvimento, instale as bibliotecas necessárias e crie os arquivos de dados obrigatórios.
Criar um ambiente virtual e instalar dependências
- Crie um diretório para seu agente e navegue até ele. Execute o seguinte código no terminal:
mkdir financial_agent cd financial_agent - Crie um ambiente virtual:
uv venv --python 3.12 - Ative o ambiente virtual:
source .venv/bin/activate - Instale o Kit de Desenvolvimento de Agente (ADK) e o pandas.
uv pip install google-adk pandas
Criar os dados de preços das ações
Como o laboratório exige dados históricos específicos de ações para demonstrar a capacidade do agente de usar ferramentas estruturadas, você vai criar um arquivo CSV com esses dados.
- No diretório
financial_agent, crie o arquivogoog.csvexecutando o seguinte comando no terminal:cat <<EOF > goog.csv Date,Open,High,Low,Close,Adj Close,Volume 2023-01-03,89.830002,91.550003,89.019997,89.699997,89.699997,20738500 2023-03-31,101.440002,103.889999,101.040001,103.730003,103.730003,36823200 2023-06-30,120.870003,122.029999,120.300003,120.970001,120.970001,23824700 2023-09-29,134.080002,134.550003,131.320007,131.850006,131.850006,21124200 2025-07-10,185.000000,188.000000,184.500000,186.500000,186.500000,25000000 EOF
Configure as variáveis de ambiente
- No diretório
financial_agent, crie um arquivo.envpara configurar as variáveis de ambiente do agente. Isso informa ao ADK qual projeto, local e modelo usar. Execute o seguinte código no terminal:# Create the .env file using the captured variables cat << EOF > .env GOOGLE_GENAI_USE_VERTEXAI=TRUE GOOGLE_CLOUD_PROJECT="${GOOGLE_CLOUD_PROJECT}" GOOGLE_CLOUD_LOCATION="us-central1" EOF
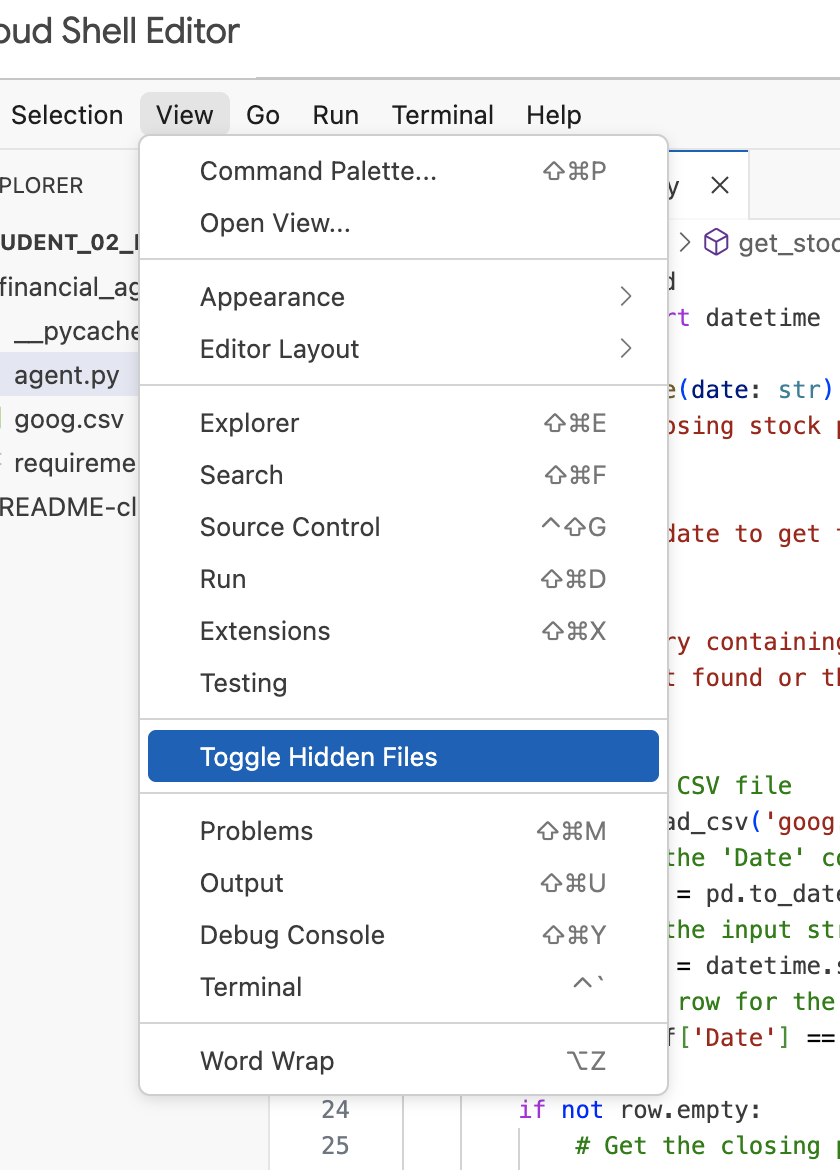
Observação:mais adiante no laboratório, se você precisar modificar o arquivo .env, mas não o encontrar no diretório financial_agent, tente ativar/desativar a visibilidade de arquivos ocultos no editor do Cloud Shell usando o item de menu "Visualizar / Ativar/desativar arquivos ocultos".
8. Criar um repositório de dados da Vertex AI para Pesquisa
Para permitir que o agente responda a perguntas sobre os relatórios financeiros da Alphabet, você vai criar um repositório de dados da Vertex AI para Pesquisa com os documentos públicos da SEC.
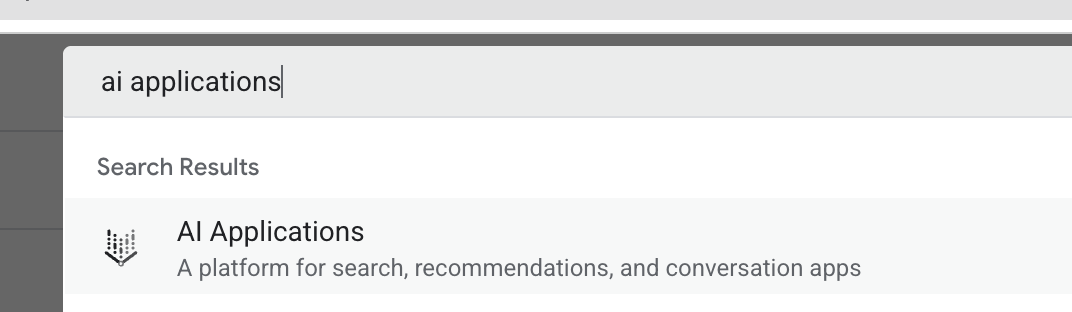
- Em uma nova guia do navegador, abra o console do Cloud (console.cloud.google.com) e acesse Aplicativos de IA usando a barra de pesquisa na parte de cima.
- Se solicitado, marque a caixa de seleção dos termos e condições e clique em Continuar e ativar a API.
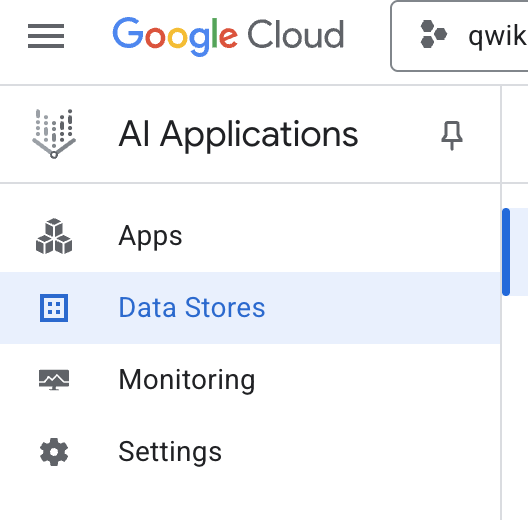
- No menu de navegação à esquerda, selecione Repositórios de dados.
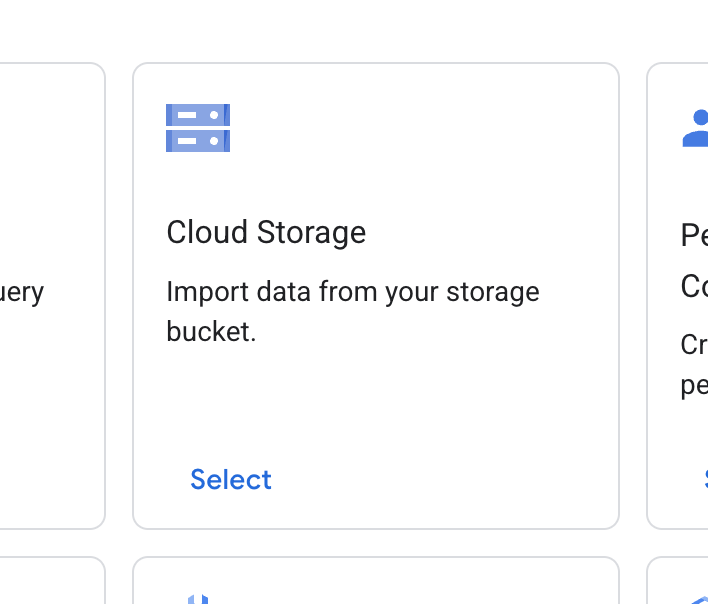
- Clique em + Criar repositório de dados.
- Encontre o card Cloud Storage e clique em Selecionar.
- Para a fonte de dados, selecione Documentos não estruturados.

- Para a origem da importação (Selecione uma pasta ou um arquivo para importar), insira o caminho do Google Cloud Storage
cloud-samples-data/gen-app-builder/search/alphabet-sec-filings. - Clique em Continuar.
- Mantenha o local definido como global.
- Em Nome do repositório de dados, insira
alphabet-sec-filings - Expanda a seção Opções de processamento do documento.

- Na lista suspensa Analisador de documentos padrão, selecione Analisador de layout.
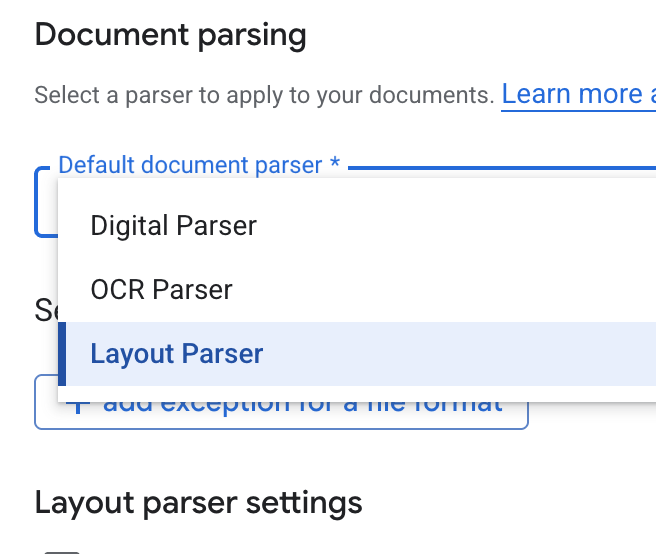
- Nas opções de Configurações do analisador de layout, selecione Ativar anotação de tabela e Ativar anotação de imagem.
- Clique em Continuar.
- Selecione Preços gerais como o modelo de preços (um modelo de pagamento por uso, baseado no consumo) e clique em Criar.
- Seu repositório de dados vai começar a importar os documentos.
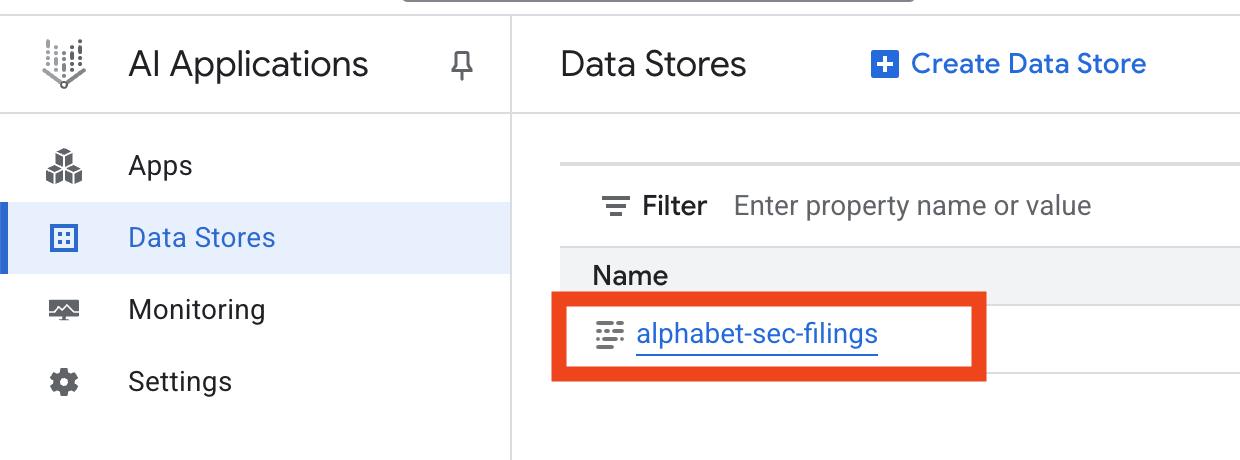
- Clique no nome do repositório de dados e copie o ID da tabela "Repositórios de dados". Você vai precisar dele na próxima etapa.
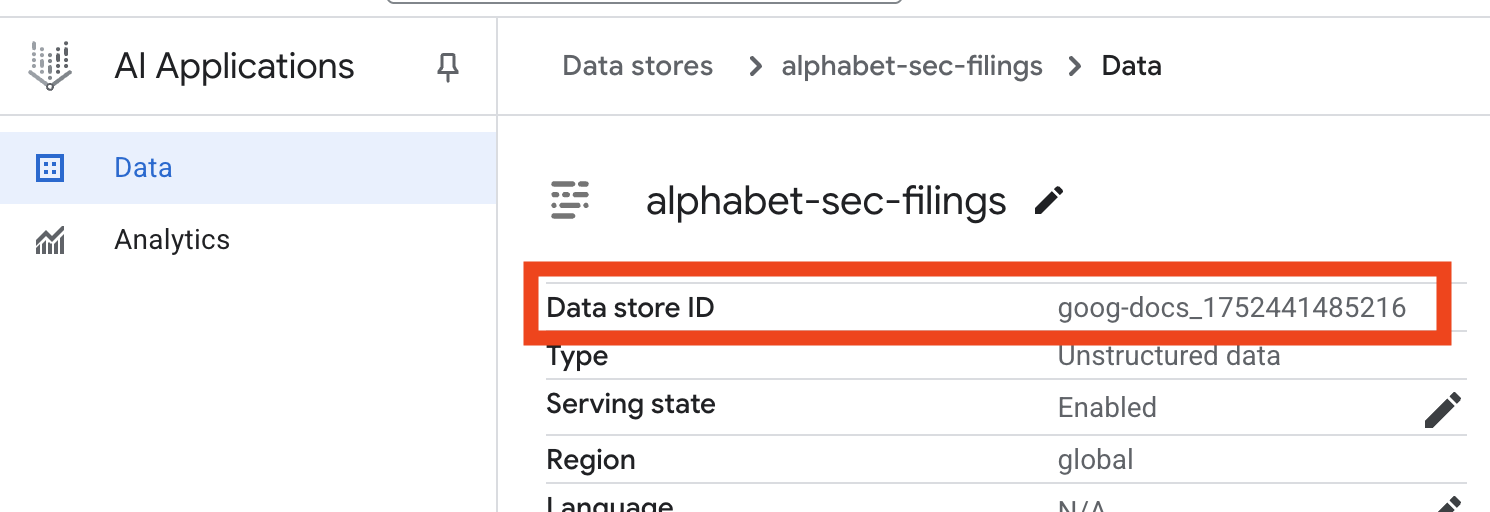
- Abra o arquivo
.envno editor do Cloud Shell e adicione o ID do repositório de dados comoDATA_STORE_ID="YOUR_DATA_STORE_ID". SubstituaYOUR_DATA_STORE_IDpelo ID real da etapa anterior. Observação:a importação, a análise e a indexação de dados no repositório de dados levam alguns minutos. Para verificar o processo, clique no nome do repositório de dados para abrir as propriedades e, em seguida, abra a guia Atividade. Aguarde até que o status seja "Importação concluída".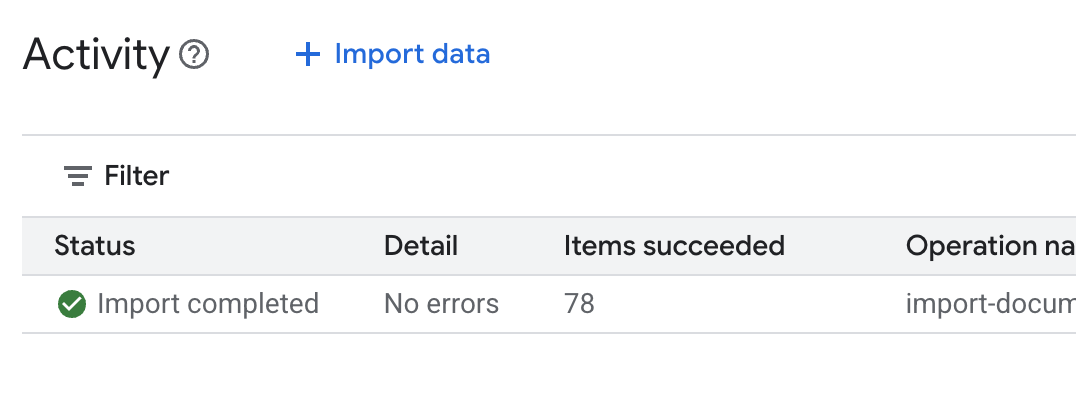
9. Criar uma ferramenta personalizada para dados estruturados
Em seguida, você vai criar uma função do Python que vai atuar como uma ferramenta para o agente. Essa ferramenta lê o arquivo goog.csv para recuperar os preços históricos das ações em uma determinada data.
- No diretório
financial_agent, crie um arquivo chamadoagent.py. Execute o seguinte comando no terminal:cloudshell edit agent.py - Adicione o seguinte código Python a
agent.py. Esse código importa dependências e define a funçãoget_stock_price.from datetime import datetime import os import logging import google.cloud.logging from google.adk.tools import VertexAiSearchTool from google.adk.tools.agent_tool import AgentTool from google.adk.agents import LlmAgent import pandas as pd def get_stock_price(date: str) -> dict: """Gets the closing stock price for a given date. Args: date: The date to get the stock price for, in YYYY-MM-DD format. Returns: A dictionary containing the closing price, or an error message if the date is not found or the format is incorrect. """ try: # Load the CSV file df = pd.read_csv('goog.csv') # Convert the 'Date' column to datetime objects df['Date'] = pd.to_datetime(df['Date']) # Convert the input string to a datetime object query_date = datetime.strptime(date, '%Y-%m-%d') # Find the row for the given date row = df[df['Date'] == query_date] if not row.empty: # Get the closing price close_price = row['Close'].iloc[0] return {"status": "success", "date": date, "closing_price": close_price} else: return {"status": "error", "message": f"No data found for date: {date}"} except FileNotFoundError: return {"status": "error", "message": "Stock data file (goog.csv) not found."} except Exception as e: return {"status": "error", "message": f"An error occurred: {str(e)}"}
Observe o docstring detalhado da função. Ela explica o que a função faz, os parâmetros (Args) e o que ela retorna (Returns). O ADK usa essa docstring para ensinar ao agente como e quando usar essa ferramenta.
10. Criar e executar o agente de RAG
Agora é hora de montar o agente. Você vai combinar a ferramenta da Vertex AI para Pesquisa de dados não estruturados com sua ferramenta get_stock_price personalizada para dados estruturados.
- Anexe o seguinte código ao arquivo
agent.py. Esse código importa as classes necessárias do ADK, cria instâncias das ferramentas e define o agente.logging.basicConfig(level=logging.INFO) cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() # 1. Create the Vertex AI Search tool full_datastore_id = f"projects/{os.environ['GOOGLE_CLOUD_PROJECT']}/locations/global/collections/default_collection/dataStores/{os.environ['DATA_STORE_ID']}" vertex_ai_search_tool = VertexAiSearchTool( data_store_id=full_datastore_id ) # 2. Define the Search+Q&A agent # Since we cannot combine tools with other tools in a single agent, # we create a separate Search+Q&A agent which will be used as a tool by the main root agent. doc_qa_agent = LlmAgent( name="search_and_qna_agent", model="gemini-2.5-flash", tools=[vertex_ai_search_tool], instruction="""You are a helpful assistant that answers questions based on information found in the document store. Use the search tool to find relevant information before answering. If the answer isn't in the documents, say that you couldn't find the information. """, description="Answers questions using a specific Vertex AI Search datastore.", ) # 3. Define the root agent with 2 tools. root_agent = LlmAgent( name="financial_agent", model="gemini-2.5-flash", tools=[ AgentTool(doc_qa_agent), get_stock_price, ], instruction="""You are an Financial Analytics Agent that answers question about Alphabet stock prices (using get_stock_price tool) and historical performance based on the data in Vertex AI Search datastore (using doc_qa_agent tool).""" ) - No terminal, dentro do diretório
financial_agent, inicie a interface da web do ADK para interagir com o agente:adk web ~ - Clique no link fornecido na saída do terminal (geralmente
http://127.0.0.1:8000) para abrir a interface de desenvolvimento do ADK no navegador.
11. Testar o agente
Agora você pode testar a capacidade do seu agente de raciocinar e usar as ferramentas dele para responder a perguntas complexas.
- Na interface de desenvolvimento do ADK, verifique se o
financial_agentestá selecionado no menu suspenso. - Faça uma pergunta que exija informações dos registros da SEC (dados não estruturados). Insira a seguinte consulta no chat:
What were the total revenues for the quarter ending on March 31, 2023?search_and_qna_agent, que usaVertexAiSearchToolpara encontrar a resposta nos documentos financeiros. - Em seguida, faça uma pergunta que exija o uso da sua ferramenta personalizada (dados estruturados). O formato de data no comando não precisa corresponder exatamente ao formato exigido pela função. O LLM é inteligente o suficiente para reformular.
What was the closing stock price for Alphabet on July 10, 2025?get_stock_price. Clique no ícone de ferramenta no chat para inspecionar a chamada de função e o resultado dela. - Por fim, faça uma pergunta complexa que exija que o agente use as duas ferramentas e sintetize os resultados.
According to the 10-Q filing for the period ending March 31, 2023, what were the company's net cash provided by operating activities, and what was the stock's closing price on that date?- Primeiro, ele vai usar o
VertexAiSearchToolpara encontrar as informações de fluxo de caixa nos documentos da SEC. - Em seguida, ele vai reconhecer a necessidade do preço da ação e chamar a função
get_stock_pricecom a data2023-03-31. - Por fim, ele vai combinar as duas informações em uma resposta única e abrangente.
- Primeiro, ele vai usar o
- Quando terminar, feche a guia do navegador e pressione
CTRL+Cno terminal para interromper o servidor do ADK.
12. Escolher um serviço para sua tarefa
A Vertex AI para Pesquisa não é o único serviço de pesquisa vetorial que você pode usar. Você também pode usar um serviço gerenciado que automatiza todo o fluxo da geração aumentada por recuperação: o mecanismo RAG da Vertex AI.
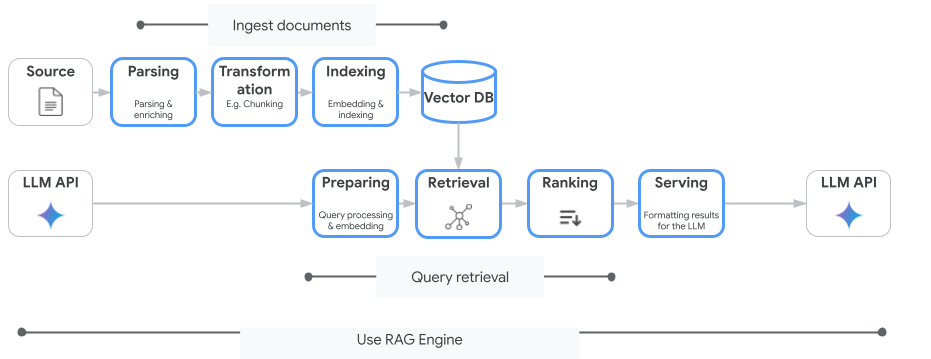
Ele processa tudo, desde a ingestão de documentos até a recuperação e a reclassificação. O mecanismo RAG é compatível com várias lojas de vetores, incluindo Pinecone e Weaviate.
Você também pode hospedar por conta própria muitos bancos de dados vetoriais especializados ou aproveitar os recursos de indexação vetorial em mecanismos de banco de dados, como o pgvector no serviço PostgreSQL (como a AlloyDB ou do BigQuery.
Outros serviços que oferecem suporte à pesquisa vetorial:
- Cloud SQL para PostgreSQL
- Cloud SQL para MySQL
- Cloud Spanner
- Memorystore para Redis
- Firestore
- Bigtable
A orientação geral para escolher um serviço específico no Google Cloud é a seguinte:
- Se você já tiver uma infraestrutura de pesquisa vetorial faça você mesmo funcionando e bem dimensionada, implante-a no Google Kubernetes Engine, como Weaviate ou DIY PostgreSQL.
- Se os dados estiverem no BigQuery, no AlloyDB, no Firestore ou em qualquer outro banco de dados, use os recursos de pesquisa vetorial se a pesquisa semântica puder ser realizada em grande escala como parte de uma consulta maior nesse banco de dados. Por exemplo, se você tiver descrições e/ou imagens de produtos em uma tabela do BigQuery, adicionar uma coluna de incorporação de texto e/ou imagem permitirá usar a pesquisa de similaridade em grande escala. Os índices de vetor com suporte à pesquisa ScANN podem ter bilhões de itens.
- Se você precisa começar rapidamente com o mínimo de esforço e em uma plataforma gerenciada, escolha a Vertex AI para Pesquisa, um mecanismo de pesquisa totalmente gerenciado e uma API de recuperação ideal para casos de uso empresariais complexos que exigem alta qualidade, escalonabilidade e controles de acesso refinados. Ela simplifica a conexão com diversas fontes de dados corporativas e permite pesquisar em várias fontes.
- Use o RAG Engine da Vertex AI se você estiver procurando um ponto ideal para desenvolvedores que buscam um equilíbrio entre facilidade de uso e personalização. Ele permite prototipagem e desenvolvimento rápidos sem sacrificar a flexibilidade.
- Conheça as arquiteturas de referência para geração aumentada por recuperação.
13. Conclusão
Parabéns! Você criou e testou um agente de IA com geração aumentada por recuperação. Você aprendeu a:
- Crie uma base de conhecimento para documentos não estruturados usando os recursos avançados de pesquisa semântica da Vertex AI para Pesquisa.
- Desenvolva uma função Python personalizada para atuar como uma ferramenta de recuperação de dados estruturados.
- Use o Kit de Desenvolvimento de Agente (ADK) para criar um agente com várias ferramentas com tecnologia do Gemini.
- Crie um agente capaz de raciocínio em várias etapas complexo para responder a consultas que exigem a síntese de informações de várias fontes.
Este laboratório demonstra os princípios básicos do RAG agêntico, uma arquitetura poderosa para criar aplicativos de IA inteligentes, precisos e com reconhecimento de contexto no Google Cloud.
Do protótipo à produção
Este laboratório faz parte do Programa de Aprendizado "IA pronta para produção com o Google Cloud".
- Confira o currículo completo para diminuir a distância entre o protótipo e a produção.
- Compartilhe seu progresso com a hashtag #ProductionReadyAI.