
1. Введение
Обзор
Цель этой лабораторной работы — научиться разрабатывать комплексные приложения Agentic Retrieval-Augmented Generation (RAG) в Google Cloud. В этой работе вы создадите агента финансового анализа, который сможет отвечать на вопросы, комбинируя информацию из двух разных источников: неструктурированных документов ( ежеквартальные отчеты Alphabet для SEC — финансовая отчетность и операционные данные, которые каждая публичная компания в США предоставляет в Комиссию по ценным бумагам и биржам) и структурированных данных (исторические цены акций).
Вы будете использовать Vertex AI Search для создания мощной семантической поисковой системы для неструктурированных финансовых отчетов. Для структурированных данных вы создадите собственный инструмент на Python. Наконец, вы будете использовать Agent Development Kit (ADK) для создания интеллектуального агента, способного анализировать запрос пользователя, выбирать подходящий инструмент и синтезировать информацию в связный ответ.
Что вы будете делать
- Настройте хранилище данных Vertex AI Search для семантического поиска по закрытым документам.
- Создайте пользовательскую функцию на Python в качестве инструмента для агента.
- Используйте комплект разработки агентов (ADK) для создания многофункционального агента.
- Объедините методы поиска информации в неструктурированных и структурированных источниках данных для ответа на сложные вопросы.
- Протестируйте и взаимодействуйте с агентом, демонстрирующим способности к рассуждению.
Что вы узнаете
В этой лабораторной работе вы узнаете:
- Основные концепции генерации с расширенным извлечением информации (Retrieval-Augmented Generation, RAG) и агентной генерации с расширенным извлечением информации (Agentic RAG).
- Как реализовать семантический поиск по документам с помощью Vertex AI Search.
- Как предоставить агенту доступ к структурированным данным путем создания пользовательских инструментов.
- Как создать и организовать работу многофункционального агента с помощью комплекта разработки агентов (ADK).
- Как агенты используют рассуждения и планирование для ответа на сложные вопросы, опираясь на множество источников данных.
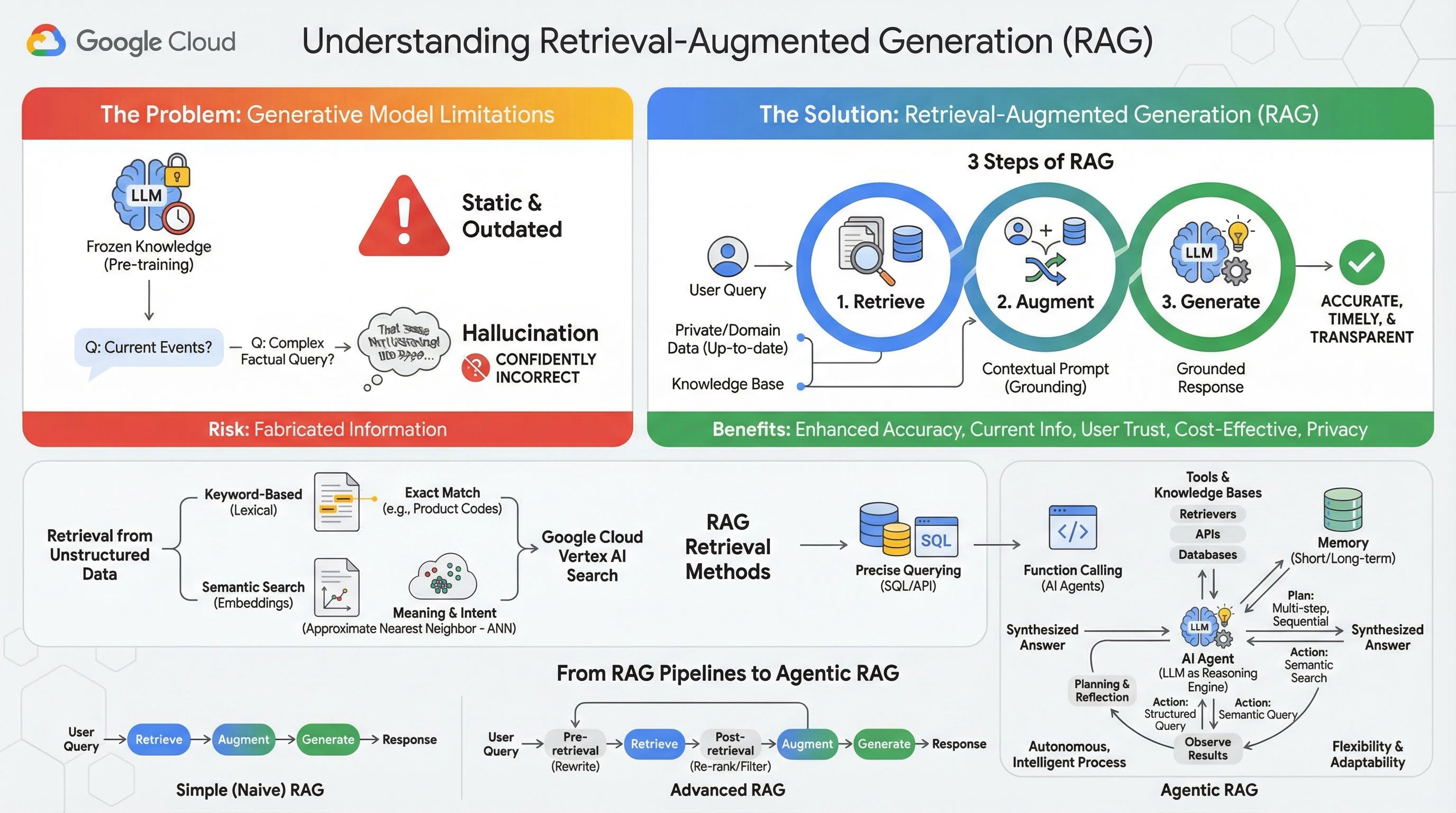
2. Понимание генерации с использованием методов, расширяющих возможности поиска информации.
Большие генеративные модели (сокращенно большие языковые модели, или LLM, модели визуального и языкового анализа и т. д.) невероятно мощны, но имеют присущие им ограничения. Их знания остаются неизменными на момент предварительного обучения , что делает их статичными и мгновенно устаревающими. Даже после тонкой настройки знания модели не становятся намного более актуальными, поскольку это не является целью этапов постобучения.
В процессе обучения больших языковых моделей, особенно «мыслящих» моделей, их «вознаграждают» за предоставление какого-либо ответа, даже если сама модель не обладает фактической информацией, подтверждающей этот ответ. Именно тогда говорят, что модель «галлюцинирует» — уверенно генерирует правдоподобно звучащую, но фактически неверную информацию.
Генерация с расширением поиска (Retrieval-Augmented Generation, RAG) — это мощный архитектурный шаблон, разработанный именно для решения этих проблем. Это архитектурная структура, которая расширяет возможности больших языковых моделей, подключая их к внешним авторитетным источникам знаний в режиме реального времени. Вместо того чтобы полагаться исключительно на свои статические, предварительно обученные знания, большая языковая модель в системе RAG сначала извлекает релевантную информацию, связанную с запросом пользователя, а затем использует эту информацию для генерации более точного, своевременного и контекстно-зависимого ответа.
Этот подход напрямую устраняет наиболее существенные недостатки генеративных моделей: их знания фиксированы на определенный момент времени, и они склонны генерировать неверную информацию или «галлюцинации». RAG фактически предоставляет студентам магистратуры права «экзамен с открытой книгой», где «книгой» являются ваши личные, предметно-ориентированные и актуальные данные. Этот процесс предоставления фактического контекста для студентов магистратуры права известен как « обоснование ».
3 шага RAG
Стандартный процесс генерации с расширенными возможностями поиска можно разделить на три простых шага:
- Получение информации : Когда пользователь отправляет запрос, система сначала осуществляет поиск во внешней базе знаний (например, в хранилище документов, базе данных или на веб-сайте), чтобы найти информацию, относящуюся к запросу.
- Расширение : Полученная информация затем объединяется с исходным запросом пользователя в расширенный вариант ответа. Этот метод иногда называют «наполнением запроса», поскольку он обогащает запрос фактическим контекстом.
- Генерация : Этот дополненный запрос передается в LLM, которая затем генерирует ответ. Поскольку модели предоставлены соответствующие фактические данные, ее выходные данные являются «обоснованными» и гораздо менее вероятно, что они будут неточными или устаревшими.
Преимущества RAG
Внедрение фреймворка RAG кардинально изменило подход к созданию практичных и надежных приложений искусственного интеллекта. К его ключевым преимуществам относятся:
- Повышенная точность и снижение галлюцинаций : основывая ответы на проверяемых внешних фактах, метод RAG значительно снижает риск фальсификации информации со стороны обучающегося.
- Доступ к актуальной информации : системы RAG могут быть подключены к постоянно обновляемым базам знаний, что позволяет им предоставлять ответы на основе самой последней информации, чего невозможно достичь с помощью статически обученной модели LLM.
- Повышение доверия пользователей и прозрачности : поскольку ответ LLM основан на полученных документах, система может предоставлять ссылки на источники. Это позволяет пользователям самостоятельно проверять информацию, повышая доверие к приложению.
- Экономическая эффективность : Постоянная тонкая настройка или переобучение модели LLM с использованием новых данных обходится дорого как с вычислительной, так и с финансовой точки зрения. С помощью RAG обновление знаний модели осуществляется так же просто, как обновление внешнего источника данных, что значительно эффективнее.
- Специализация в предметной области и конфиденциальность : RAG позволяет людям и организациям предоставлять свои частные, конфиденциальные данные модели LLM во время выполнения запроса, не включая эти конфиденциальные данные в обучающий набор модели. Это позволяет создавать мощные приложения, ориентированные на конкретную предметную область, при сохранении конфиденциальности и безопасности данных.
Извлечение
Этап «Извлечение» — это сердце любой системы RAG. Качество и релевантность извлеченной информации напрямую определяют качество и релевантность конечного результата. Эффективное приложение RAG часто требует извлечения информации из различных типов источников данных с использованием различных методов. Основные методы извлечения делятся на три категории: по ключевым словам, семантический и структурированный.
Извлечение данных из неструктурированной базы данных
Исторически сложилось так, что поиск неструктурированных данных — это другое название традиционного поиска. Он претерпел множество трансформаций, и вы можете извлечь выгоду из обоих основных подходов.
Семантический поиск — это наиболее эффективная технология, которую можно масштабировать в Google Cloud, обеспечивая высочайшую производительность и высокий уровень контроля.
- Поиск по ключевым словам (лексический поиск) : это традиционный подход к поиску, восходящий к самым ранним системам поиска информации 1970-х годов. Лексический поиск работает путем сопоставления буквальных слов (или «токенов») в запросе пользователя с точно такими же словами в документах базы знаний. Он очень эффективен для запросов, где точность по конкретным терминам, таким как коды продуктов, юридические положения или уникальные названия, имеет решающее значение.
- Семантический поиск : Семантический поиск, или «поиск со смыслом», — это более современный подход, цель которого — понять намерение пользователя и контекстное значение его запроса, а не только сами ключевые слова. Современный семантический поиск основан на эмбеддинге — методе машинного обучения, который отображает сложные многомерные данные в векторное пространство числовых векторов меньшей размерности. Эти векторы спроектированы таким образом, чтобы тексты со схожим смыслом располагались близко друг к другу в векторном пространстве. Поисковый запрос «Какие породы собак лучше всего подходят для семей?» преобразуется в вектор, и система затем ищет векторы документов, которые являются ее «ближайшими соседями» в этом пространстве. Это позволяет ей находить документы, в которых говорится о «золотистых ретриверах» или «дружелюбных собаках», даже если они не содержат точное слово «собака». Эффективность этого многомерного поиска обеспечивается алгоритмами приблизительного поиска ближайших соседей (ANN). Вместо сравнения вектора запроса с каждым отдельным вектором документа (что было бы слишком медленно для больших наборов данных), алгоритмы ИНС используют продуманные структуры индексации для быстрого поиска векторов, которые, вероятно, являются наиболее близкими.
Извлечение данных из структурированной базы данных
Не вся важная информация хранится в неструктурированных документах. Зачастую наиболее точная и ценная информация находится в структурированных форматах, таких как реляционные базы данных, базы данных NoSQL или какой-либо API, например, REST API для данных о погоде или ценах на акции.
Поиск в структурированных данных обычно более прямой и точный, чем поиск в неструктурированном тексте. Вместо поиска семантического сходства языковым моделям можно дать возможность формулировать и выполнять точный запрос, например, SQL-запрос к базе данных или вызов API к метеорологическому API для определенного местоположения и даты.
Реализованная посредством вызова функций , той же техники, которая используется в агентах искусственного интеллекта, она позволяет языковым моделям взаимодействовать с исполняемым кодом и внешними системами детерминированным структурным образом.
3. От трубопроводов RAG к агентному RAG
Подобно тому, как развивалась сама концепция RAG, эволюционировали и архитектуры для ее реализации. То, что начиналось как простой линейный конвейер, превратилось в динамичную, интеллектуальную систему, управляемую агентами искусственного интеллекта.
- Простая (или наивная) RAG: это базовая архитектура, которую мы обсуждали до сих пор: линейный трехэтапный процесс извлечения, дополнения и генерации. Она реактивна; для каждого запроса она следует фиксированному пути и очень эффективна для простых задач вопросов и ответов.
- Расширенный RAG: это этап развития, на котором в конвейер добавляются дополнительные шаги для повышения качества извлекаемого контекста. Эти улучшения могут происходить до или после этапа извлечения.
- Предварительный поиск: могут использоваться такие методы, как переформулирование или расширение запроса. Система может проанализировать исходный запрос и перефразировать его, чтобы сделать его более эффективным для системы поиска.
- После извлечения: После извлечения первоначального набора документов можно применить модель переранжирования, чтобы оценить релевантность документов и вывести лучшие из них на первое место. Это особенно важно в гибридном поиске. Еще один шаг после извлечения — фильтрация или сжатие полученного контекста, чтобы гарантировать, что в LLM будет передана только наиболее важная информация.
- Agentic RAG: Это передовая архитектура RAG, представляющая собой сдвиг парадигмы от фиксированного конвейера к автономному, интеллектуальному процессу. В системе Agentic RAG весь рабочий процесс управляется одним или несколькими агентами искусственного интеллекта , которые могут рассуждать, планировать и динамически выбирать свои действия.
Чтобы понять Agentic RAG, необходимо сначала понять, что представляет собой агент ИИ. Агент — это больше, чем просто LLM. Это система, состоящая из нескольких ключевых компонентов:
- LLM как механизм рассуждений: Агент использует мощный LLM, такой как Gemini, не только для генерации текста, но и в качестве своего центрального «мозга» для планирования, принятия решений и декомпозиции сложных задач.
- Набор инструментов: Агенту предоставляется доступ к набору функций, которые он может использовать для достижения своих целей. Эти инструменты могут быть любыми: калькулятором, API веб-поиска, функцией отправки электронного письма или, что наиболее важно для этой лабораторной работы, средствами поиска информации в наших различных базах знаний .
- Память: Агенты могут быть спроектированы с учетом как кратковременной памяти (для запоминания контекста текущего разговора), так и долговременной памяти (для воспроизведения информации из прошлых взаимодействий), что позволяет создавать более персонализированные и целостные взаимодействия.
- Планирование и анализ: Наиболее развитые агенты демонстрируют сложные модели мышления. Они могут получить сложную цель и разработать многоэтапный план для ее достижения. Затем они могут выполнить этот план и даже проанализировать результаты своих действий, выявить ошибки и скорректировать свой подход для улучшения конечного результата.
Agentic RAG меняет правила игры, поскольку вводит уровень автономности и интеллекта, которого не хватает статическим конвейерам.
- Гибкость и адаптивность: Агент не привязан к одному единственному пути поиска. Получив запрос пользователя, он может рассуждать о наилучшем источнике информации. Он может сначала запросить структурированную базу данных, затем выполнить семантический поиск в неструктурированных документах, и если все еще не может найти ответ, использовать инструмент поиска Google для поиска в общедоступной сети — и все это в контексте одного запроса пользователя.
- Сложные многоэтапные вычисления: Эта архитектура превосходно справляется с обработкой сложных запросов, требующих многократных последовательных этапов извлечения и обработки информации.
Рассмотрим запрос: «Найдите 3 лучших научно-фантастических фильма, снятых Кристофером Ноланом, и для каждого дайте краткое описание сюжета». Простой алгоритм RAG не сработает.
Однако агент может это объяснить:
- План: Сначала мне нужно найти фильмы. Затем для каждого фильма мне нужно найти его сюжет.
- Действие 1: Используйте инструмент структурированных данных, чтобы выполнить запрос к базе данных фильмов, содержащей научно-фантастические фильмы Нолана: 3 лучших фильма, отсортированные по рейтингу в порядке убывания.
- Наблюдение 1: Инструмент возвращает «Начало», «Интерстеллар» и «Тенет».
- Действие 2: Используйте инструмент для работы с неструктурированными данными (семантический поиск), чтобы найти сюжет фильма «Начало».
- Наблюдение 2: График получен.
- Действие 3: Повторите для фильма «Интерстеллар».
- Действие 4: Повторите для фильма «Тенет».
- Итоговый вывод: Объединить всю полученную информацию в единый, связный ответ для пользователя.
4. Настройка проекта
Аккаунт Google
Если у вас еще нет личного аккаунта Google, вам необходимо его создать .
Используйте личный аккаунт вместо рабочего или учебного.
Войдите в консоль Google Cloud.
Войдите в консоль Google Cloud, используя личную учетную запись Google.
Включить выставление счетов
Использовать пробный платёжный аккаунт (необязательно)
Для проведения этого мастер-класса вам потребуется платежный аккаунт с достаточным балансом. Используйте средства, указанные на баннере вверху этого руководства, чтобы начать. Если у вас уже есть платежный аккаунт, вы можете пропустить этот шаг.
Создайте личный платежный аккаунт.
Если вы настроили оплату с использованием кредитов Google Cloud, этот шаг можно пропустить.
Чтобы настроить личный платежный аккаунт, перейдите сюда, чтобы включить оплату в облачной консоли.
Несколько замечаний:
- Выполнение этой лабораторной работы должно обойтись менее чем в 1 доллар США в виде облачных ресурсов.
- В конце этой лабораторной работы вы можете выполнить действия по удалению ресурсов, чтобы избежать дальнейших списаний средств.
- Новые пользователи могут воспользоваться бесплатной пробной версией стоимостью 300 долларов США .
Создать проект (необязательно)
Если у вас нет текущего проекта, который вы хотели бы использовать для этой лабораторной работы, создайте новый проект здесь .
5. Откройте редактор Cloud Shell.
- Нажмите на эту ссылку, чтобы перейти непосредственно в редактор Cloud Shell.
- Если сегодня вам будет предложено авторизоваться, нажмите «Авторизовать» , чтобы продолжить.
- Если терминал не отображается внизу экрана, откройте его:
- Нажмите «Просмотреть».
- Нажмите «Терминал»
- В терминале настройте свой проект с помощью этой команды:
gcloud config set project [PROJECT_ID]- Пример:
gcloud config set project lab-project-id-example - Если вы не помните идентификатор своего проекта, вы можете перечислить все идентификаторы своих проектов с помощью следующей команды:
gcloud projects list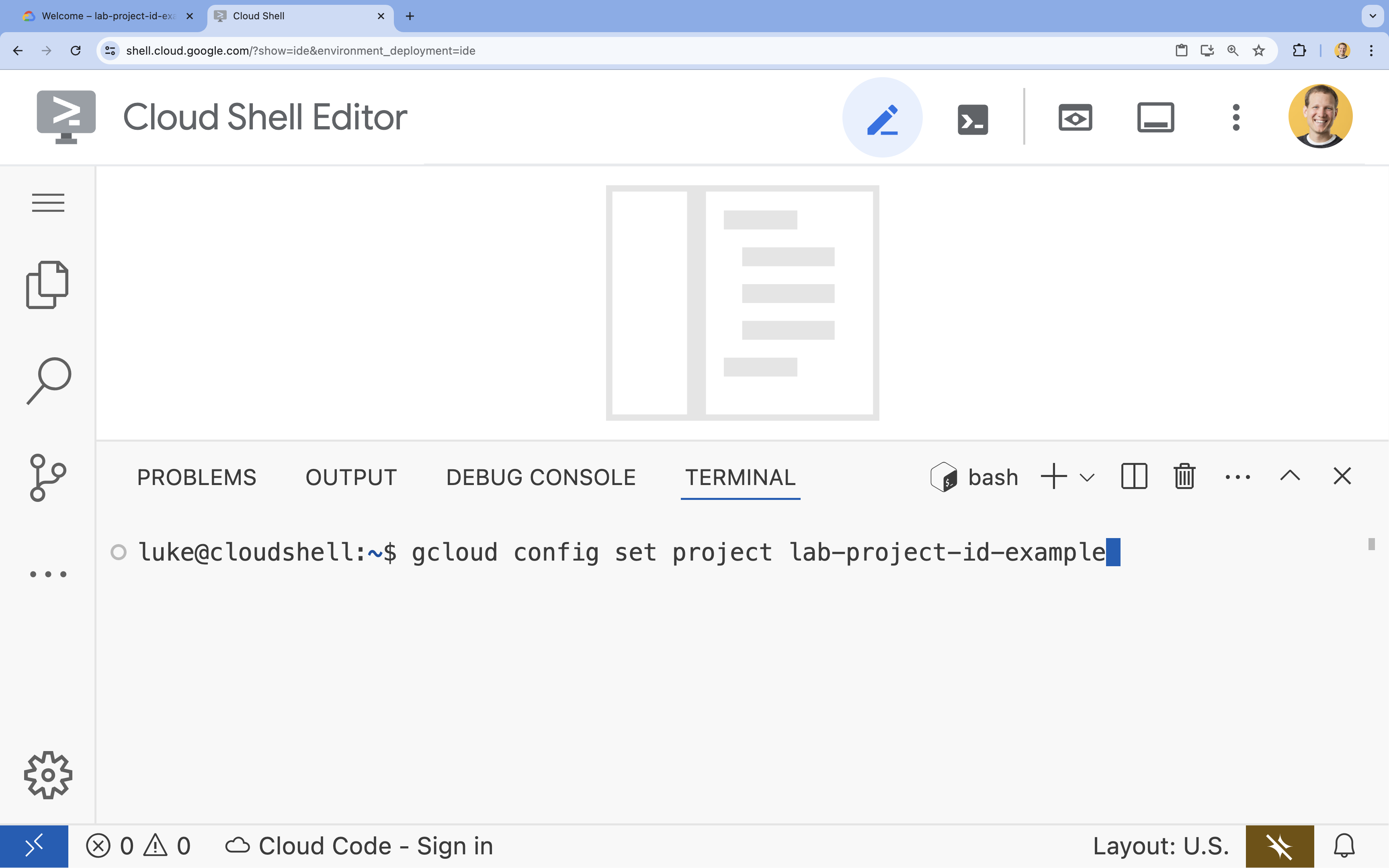
- Пример:
- Вы должны увидеть следующее сообщение:
Updated property [core/project].
6. Включите API.
Для использования Agent Development Kit и Vertex AI Search необходимо включить необходимые API в вашем проекте Google Cloud.
- В терминале включите API:
gcloud services enable \ aiplatform.googleapis.com \ discoveryengine.googleapis.com
Представляем API.
- API Vertex AI (
aiplatform.googleapis.com) позволяет агенту взаимодействовать с моделями Gemini для рассуждений и генерации. - API Discovery Engine (
discoveryengine.googleapis.com) лежит в основе Vertex AI Search, позволяя создавать хранилища данных и выполнять семантический поиск по неструктурированным документам.
7. Настройка среды
Прежде чем приступить к написанию кода для ИИ-агента, необходимо подготовить среду разработки, установить необходимые библиотеки и создать требуемые файлы данных.
Создайте виртуальное окружение и установите зависимости.
- Создайте директорию для вашего агента и перейдите в неё. Выполните следующий код в терминале :
mkdir financial_agent cd financial_agent - Создайте виртуальную среду:
uv venv --python 3.12 - Активируйте виртуальную среду:
source .venv/bin/activate - Установите Agent Development Kit (ADK) и pandas.
uv pip install google-adk pandas
Создайте данные о ценах акций.
Поскольку для демонстрации умения использовать структурированные инструменты в рамках лабораторной работы требуются конкретные исторические данные о фондовом рынке, вам необходимо создать CSV-файл, содержащий эти данные.
- В каталоге
financial_agentсоздайте файлgoog.csv, выполнив в терминале следующую команду:cat <<EOF > goog.csv Date,Open,High,Low,Close,Adj Close,Volume 2023-01-03,89.830002,91.550003,89.019997,89.699997,89.699997,20738500 2023-03-31,101.440002,103.889999,101.040001,103.730003,103.730003,36823200 2023-06-30,120.870003,122.029999,120.300003,120.970001,120.970001,23824700 2023-09-29,134.080002,134.550003,131.320007,131.850006,131.850006,21124200 2025-07-10,185.000000,188.000000,184.500000,186.500000,186.500000,25000000 EOF
Настройка переменных среды
- В каталоге
financial_agentсоздайте файл.envдля настройки переменных среды вашего агента. Это укажет ADK, какой проект, местоположение и модель использовать. Выполните следующий код в терминале :# Create the .env file using the captured variables cat << EOF > .env GOOGLE_GENAI_USE_VERTEXAI=TRUE GOOGLE_CLOUD_PROJECT="${GOOGLE_CLOUD_PROJECT}" GOOGLE_CLOUD_LOCATION="us-central1" EOF
Примечание: Позже в ходе лабораторной работы, если вам потребуется изменить файл .env , но вы не найдете его в каталоге financial_agent , попробуйте включить/выключить отображение скрытых файлов в редакторе Cloud Shell с помощью пункта меню «Просмотр / Отключение скрытых файлов».
8. Создайте хранилище данных для поиска Vertex AI.
Чтобы агент мог отвечать на вопросы о финансовых отчетах Alphabet, вам потребуется создать хранилище данных Vertex AI Search, содержащее их публичные документы, поданные в Комиссию по ценным бумагам и биржам США (SEC).
- В новой вкладке браузера откройте консоль Cloud Console (console.cloud.google.com) и, используя строку поиска вверху, перейдите в раздел «Приложения ИИ» .
- Если появится запрос, установите флажок «Условия использования» и нажмите «Продолжить» и «Активировать API» .
- В левом навигационном меню выберите «Хранилища данных» .
- Нажмите + Создать хранилище данных .
- Найдите карту «Облачное хранилище» и нажмите «Выбрать» .
- В качестве источника данных выберите «Неструктурированные документы» .

- В качестве источника импорта (выберите папку или файл для импорта) введите путь к Google Cloud Storage:
cloud-samples-data/gen-app-builder/search/alphabet-sec-filings. - Нажмите «Продолжить» .
- Оставьте параметр location установленным на «глобальный» .
- В поле " Имя хранилища данных" введите
alphabet-sec-filings - Разверните раздел « Параметры обработки документов» .

- В раскрывающемся списке «Парсер документа по умолчанию» выберите «Парсер макета» .
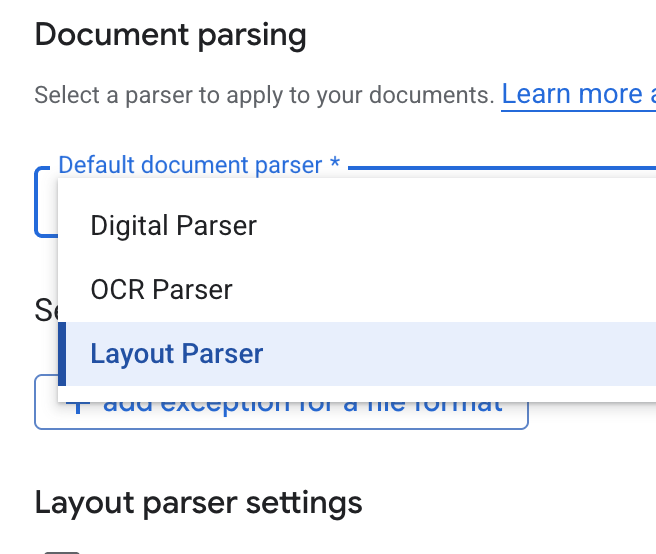
- В параметрах парсера макета выберите «Включить аннотации таблиц» и «Включить аннотации изображений» .
- Нажмите «Продолжить» .
- Выберите в качестве модели ценообразования «Общая ценовая политика» (оплата по мере использования, на основе потребления) и нажмите «Создать» .
- Ваше хранилище данных начнет импорт документов.
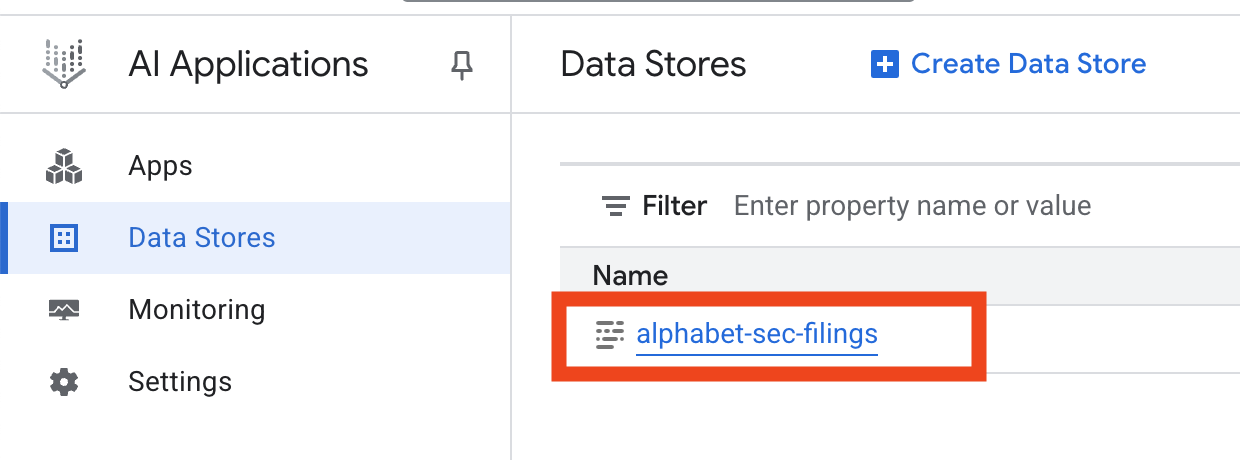
- Щелкните по названию хранилища данных и скопируйте его идентификатор из таблицы «Хранилища данных». Он понадобится вам на следующем шаге.
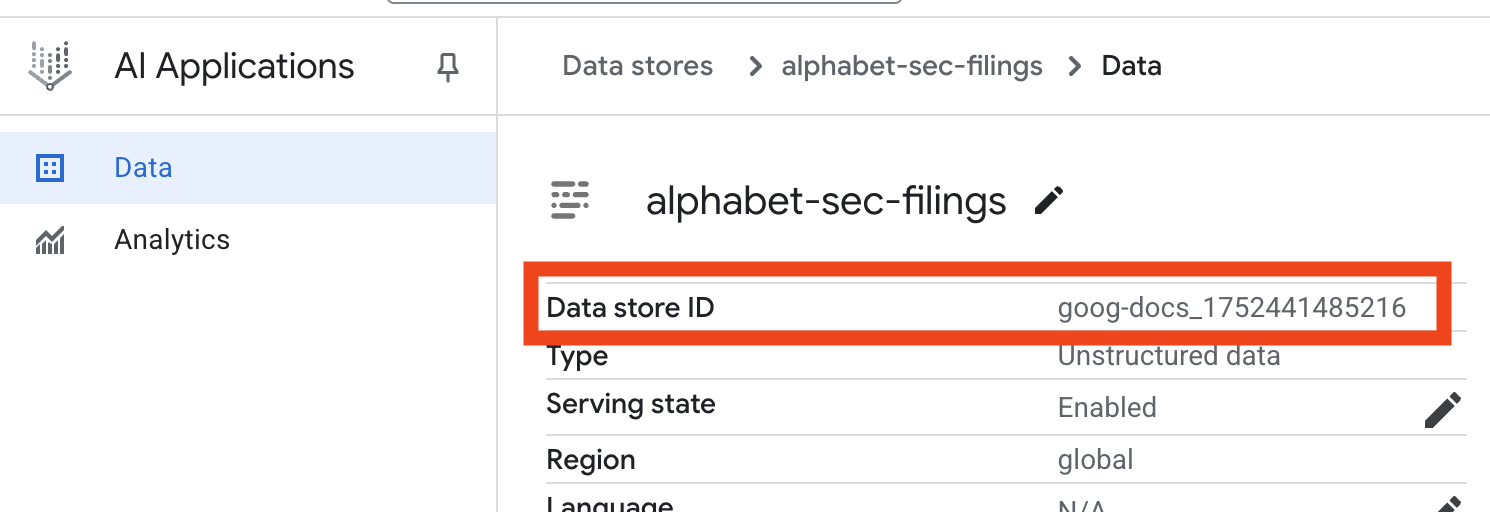
- Откройте файл
.envв редакторе Cloud Shell и добавьте идентификатор хранилища данных в форматеDATA_STORE_ID="YOUR_DATA_STORE_ID"(заменитеYOUR_DATA_STORE_IDна фактический идентификатор из предыдущего шага). Примечание: импорт, анализ и индексирование данных в хранилище данных займут несколько минут. Чтобы проверить процесс, щелкните имя хранилища данных, чтобы открыть его свойства, затем откройте вкладку «Действия» . Дождитесь, пока статус изменится на «Импорт завершен».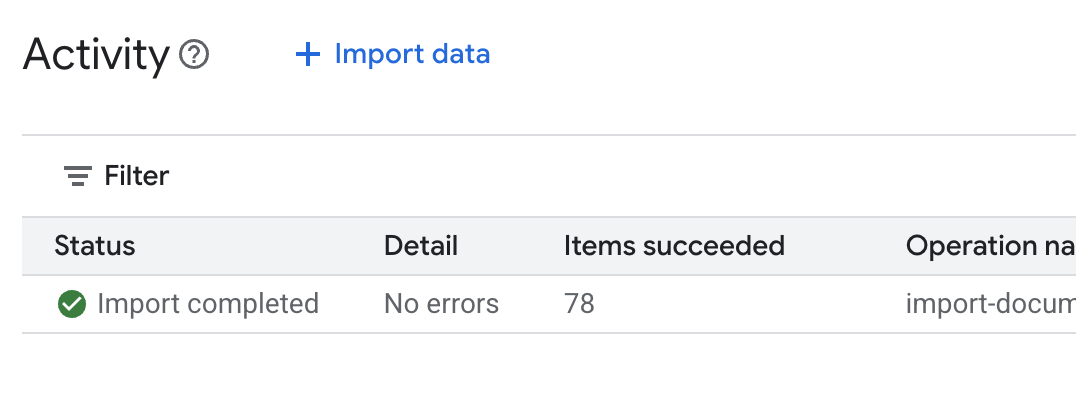
9. Создайте собственный инструмент для работы со структурированными данными.
Далее вам нужно будет создать функцию на Python, которая будет служить инструментом для агента. Этот инструмент будет считывать файл goog.csv для получения исторических цен акций на заданную дату.
- В директории
financial_agentсоздайте новый файл с именемagent.py. Выполните следующую команду в терминале :cloudshell edit agent.py - Добавьте следующий код на Python в
agent.py. Этот код импортирует зависимости и определяет функциюget_stock_price.from datetime import datetime import os import logging import google.cloud.logging from google.adk.tools import VertexAiSearchTool from google.adk.tools.agent_tool import AgentTool from google.adk.agents import LlmAgent import pandas as pd def get_stock_price(date: str) -> dict: """Gets the closing stock price for a given date. Args: date: The date to get the stock price for, in YYYY-MM-DD format. Returns: A dictionary containing the closing price, or an error message if the date is not found or the format is incorrect. """ try: # Load the CSV file df = pd.read_csv('goog.csv') # Convert the 'Date' column to datetime objects df['Date'] = pd.to_datetime(df['Date']) # Convert the input string to a datetime object query_date = datetime.strptime(date, '%Y-%m-%d') # Find the row for the given date row = df[df['Date'] == query_date] if not row.empty: # Get the closing price close_price = row['Close'].iloc[0] return {"status": "success", "date": date, "closing_price": close_price} else: return {"status": "error", "message": f"No data found for date: {date}"} except FileNotFoundError: return {"status": "error", "message": "Stock data file (goog.csv) not found."} except Exception as e: return {"status": "error", "message": f"An error occurred: {str(e)}"}
Обратите внимание на подробную документацию функции. Она объясняет, что делает функция, её параметры ( Args ) и что она возвращает ( Returns ). ADK использует эту документацию, чтобы научить агента, как и когда использовать этот инструмент.
10. Соберите и запустите агент RAG.
Теперь пришло время собрать агента. Вам нужно будет объединить инструмент Vertex AI Search для неструктурированных данных с вашим собственным инструментом get_stock_price для структурированных данных.
- Добавьте следующий код в файл
agent.py. Этот код импортирует необходимые классы ADK, создает экземпляры инструментов и определяет агента.logging.basicConfig(level=logging.INFO) cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() # 1. Create the Vertex AI Search tool full_datastore_id = f"projects/{os.environ['GOOGLE_CLOUD_PROJECT']}/locations/global/collections/default_collection/dataStores/{os.environ['DATA_STORE_ID']}" vertex_ai_search_tool = VertexAiSearchTool( data_store_id=full_datastore_id ) # 2. Define the Search+Q&A agent # Since we cannot combine tools with other tools in a single agent, # we create a separate Search+Q&A agent which will be used as a tool by the main root agent. doc_qa_agent = LlmAgent( name="search_and_qna_agent", model="gemini-2.5-flash", tools=[vertex_ai_search_tool], instruction="""You are a helpful assistant that answers questions based on information found in the document store. Use the search tool to find relevant information before answering. If the answer isn't in the documents, say that you couldn't find the information. """, description="Answers questions using a specific Vertex AI Search datastore.", ) # 3. Define the root agent with 2 tools. root_agent = LlmAgent( name="financial_agent", model="gemini-2.5-flash", tools=[ AgentTool(doc_qa_agent), get_stock_price, ], instruction="""You are an Financial Analytics Agent that answers question about Alphabet stock prices (using get_stock_price tool) and historical performance based on the data in Vertex AI Search datastore (using doc_qa_agent tool).""" ) - В терминале, в директории
financial_agent, запустите веб-интерфейс ADK для взаимодействия с вашим агентом:adk web ~ - Чтобы открыть пользовательский интерфейс разработчика ADK в браузере, щелкните ссылку, указанную в выводе терминала (обычно
http://127.0.0.1:8000).
11. Проверьте агента.
Теперь вы можете проверить способность вашего агента рассуждать и использовать его инструменты для ответа на сложные вопросы.
- В пользовательском интерфейсе разработчика ADK убедитесь, что в выпадающем меню выбран ваш
financial_agent. - Попробуйте задать вопрос, требующий информации из документов SEC (неструктурированные данные). Введите следующий запрос в чат:
What were the total revenues for the quarter ending on March 31, 2023?search_and_qna_agent, которая используетVertexAiSearchToolдля поиска ответа в финансовых документах. - Далее задайте вопрос, требующий использования вашего пользовательского инструмента (структурированных данных). Обратите внимание, что формат даты в запросе не обязательно должен точно соответствовать формату, требуемому функцией; LLM достаточно интеллектуален, чтобы переформатировать его.
What was the closing stock price for Alphabet on July 10, 2025?get_stock_price. Вы можете щелкнуть значок инструмента в чате, чтобы просмотреть вызов функции и ее результат. - Наконец, задайте сложный вопрос, который потребует от агента использования обоих инструментов и синтеза результатов.
According to the 10-Q filing for the period ending March 31, 2023, what were the company's net cash provided by operating activities, and what was the stock's closing price on that date?- Во-первых, для поиска информации о движении денежных средств в документах, поданных в Комиссию по ценным бумагам и биржам США (SEC), будет использован инструмент
VertexAiSearchTool. - Затем система распознает необходимость в цене акций и вызовет функцию
get_stock_priceс датой2023-03-31. - В итоге, он объединит оба фрагмента информации в один исчерпывающий ответ.
- Во-первых, для поиска информации о движении денежных средств в документах, поданных в Комиссию по ценным бумагам и биржам США (SEC), будет использован инструмент
- Когда закончите, закройте вкладку браузера и нажмите
CTRL+Cв терминале, чтобы остановить сервер ADK.
12. Выбор услуги для выполнения вашей задачи
Vertex AI Search — не единственный сервис векторного поиска, который вы можете использовать. Вы также можете использовать управляемый сервис, который автоматизирует весь процесс генерации дополненной информации: Vertex AI RAG Engine .
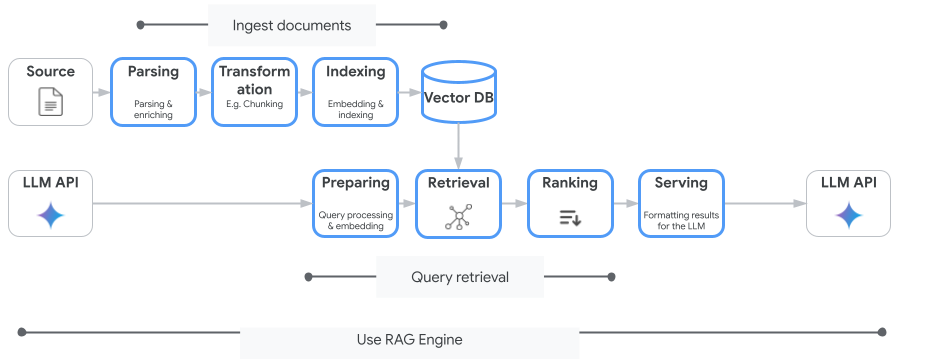
Он обрабатывает все этапы, от загрузки документов до их поиска и переранжирования. RAG Engine поддерживает несколько хранилищ векторной графики, включая Pinecone и Weaviate .
Вы также можете разместить множество специализированных векторных баз данных на собственном сервере или использовать возможности векторного индексирования в системах управления базами данных, таких как pgvector в сервисе PostgreSQL (например, AlloyDB или BigQuery Vector Search ).
К числу других сервисов, поддерживающих векторный поиск, относятся:
- Cloud SQL для PostgreSQL
- Cloud SQL для MySQL
- Облачный гальник
- Memorystore for Redis
- Магазин огней
- Большой стол
Общие рекомендации по выбору конкретной услуги в Google Cloud следующие:
- Если у вас уже есть работающая и хорошо масштабируемая самодельная инфраструктура для векторного поиска, разверните её в Google Kubernetes Engine , например, в Weaviate или DIY PostgreSQL .
- Если ваши данные хранятся в BigQuery, AlloyDB, Firestore или любой другой базе данных, рассмотрите возможность использования ее возможностей векторного поиска , если семантический поиск может быть выполнен в масштабе в рамках более крупного запроса в этой базе данных . Например, если у вас есть описания товаров и/или изображения в таблице BigQuery, добавление столбца для встраивания текста и/или изображений позволит использовать поиск по сходству в масштабе. Векторные индексы с поиском ScANN поддерживают миллиарды элементов в индексе.
- Если вам нужно быстро начать работу с минимальными усилиями и на управляемой платформе, выберите Vertex AI Search — полностью управляемую поисковую систему и API для извлечения данных, идеально подходящую для сложных корпоративных сценариев использования, требующих высокого качества «из коробки», масштабируемости и детального контроля доступа. Она упрощает подключение к различным корпоративным источникам данных и позволяет осуществлять поиск по нескольким источникам.
- Если вы ищете оптимальное решение для разработчиков, стремящихся к балансу между простотой использования и возможностью настройки, используйте Vertex AI RAG Engine. Он обеспечивает быстрое прототипирование и разработку без ущерба для гибкости.
- Изучите эталонные архитектуры для генерации с расширенными возможностями поиска .
13. Заключение
Поздравляем! Вы успешно создали и протестировали ИИ-агента с использованием генерации, дополненной функцией поиска информации. Вы научились:
- Создайте базу знаний для неструктурированных документов, используя мощные возможности семантического поиска Vertex AI Search.
- Разработайте пользовательскую функцию на Python, которая будет служить инструментом для извлечения структурированных данных.
- Используйте комплект разработки агентов (ADK) для создания многофункционального агента на базе Gemini.
- Создайте агента, способного к сложным многоэтапным рассуждениям для ответа на запросы, требующие синтеза информации из нескольких источников.
В этой лабораторной работе демонстрируются основные принципы Agentic RAG — мощной архитектуры для создания интеллектуальных, точных и контекстно-ориентированных приложений искусственного интеллекта в Google Cloud.
От прототипа к серийному производству
Данная лабораторная работа является частью учебного курса "Готовый к внедрению ИИ в производство с помощью Google Cloud" .
- Изучите полный учебный план , чтобы преодолеть разрыв между прототипом и серийным производством.
- Делитесь своими успехами, используя хэштег #ProductionReadyAI.