
1. บทนำ
ภาพรวม
เป้าหมายของ Lab นี้คือการเรียนรู้วิธีพัฒนาแอปพลิเคชัน Retrieval-Augmented Generation (RAG) แบบเป็น Agent ตั้งแต่ต้นจนจบใน Google Cloud ในแล็บนี้ คุณจะได้สร้างเอเจนต์วิเคราะห์ทางการเงินที่ตอบคำถามได้โดยการรวมข้อมูลจาก 2 แหล่งที่มา ได้แก่ เอกสารที่ไม่มีโครงสร้าง (การยื่นเอกสารต่อ SEC รายไตรมาสของ Alphabet - งบการเงินและรายละเอียดด้านการดำเนินงานที่บริษัทมหาชนทุกแห่งในสหรัฐอเมริกาต้องยื่นต่อสำนักงานคณะกรรมการกำกับหลักทรัพย์และตลาดหลักทรัพย์) และข้อมูลที่มีโครงสร้าง (ราคาหุ้นย้อนหลัง)
คุณจะใช้ Vertex AI Search เพื่อสร้างเครื่องมือค้นหาเชิงความหมายที่มีประสิทธิภาพสำหรับรายงานทางการเงินที่ไม่มีโครงสร้าง สำหรับ Structured Data คุณจะต้องสร้างเครื่องมือ Python ที่กำหนดเอง สุดท้าย คุณจะใช้ Agent Development Kit (ADK) เพื่อสร้างเอเจนต์อัจฉริยะที่สามารถให้เหตุผลเกี่ยวกับคำค้นหาของผู้ใช้ ตัดสินใจว่าจะใช้เครื่องมือใด และสังเคราะห์ข้อมูลเป็นคำตอบที่สอดคล้องกัน
สิ่งที่คุณต้องดำเนินการ
- ตั้งค่าพื้นที่เก็บข้อมูลสำหรับ Vertex AI Search เพื่อการค้นหาเชิงความหมายในเอกสารส่วนตัว
- สร้างฟังก์ชัน Python ที่กำหนดเองเป็นเครื่องมือสำหรับ Agent
- ใช้ Agent Development Kit (ADK) เพื่อสร้าง Agent แบบหลายเครื่องมือ
- รวมการดึงข้อมูลจากแหล่งข้อมูลที่ไม่มีโครงสร้างและ Structured Data เพื่อตอบคำถามที่ซับซ้อน
- ทดสอบและโต้ตอบกับเอเจนต์ที่มีความสามารถในการให้เหตุผล
สิ่งที่คุณจะได้เรียนรู้
ในแล็บนี้ คุณจะได้เรียนรู้สิ่งต่อไปนี้
- แนวคิดหลักของ Retrieval-Augmented Generation (RAG) และ Agentic RAG
- วิธีใช้การค้นหาเชิงความหมายในเอกสารโดยใช้ Vertex AI Search
- วิธีแสดง Structured Data ต่อ Agent โดยการสร้างเครื่องมือที่กำหนดเอง
- วิธีสร้างและจัดการเป็นกลุ่ม Agent แบบหลายเครื่องมือด้วย Agent Development Kit (ADK)
- วิธีที่เอเจนต์ใช้การให้เหตุผลและการวางแผนเพื่อตอบคำถามที่ซับซ้อนโดยใช้แหล่งข้อมูลหลายแหล่ง
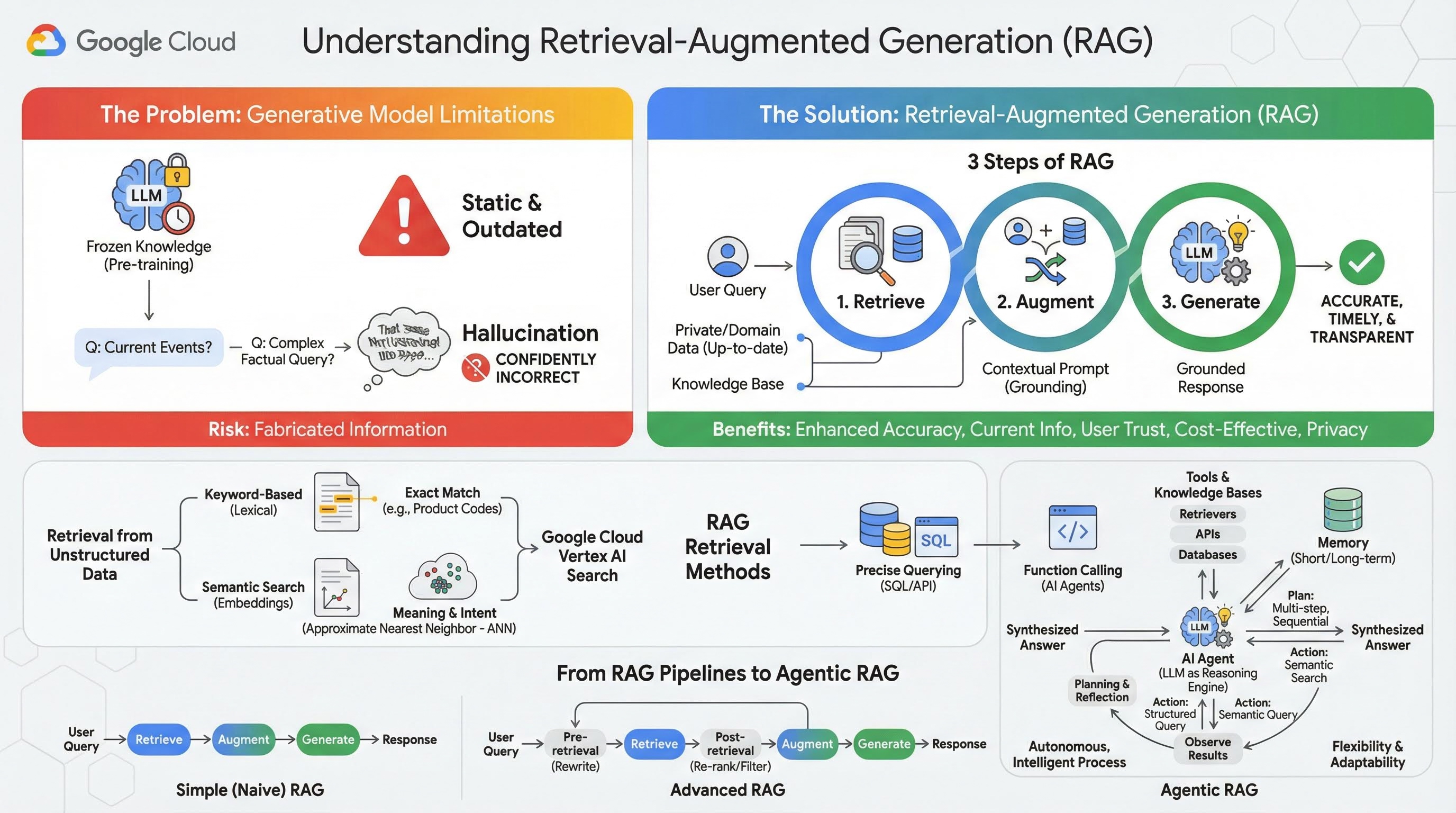
2. ทำความเข้าใจการสร้างที่เพิ่มประสิทธิภาพการดึงข้อมูล
โมเดล Generative ขนาดใหญ่ (โมเดลภาษาขนาดใหญ่หรือ LLM โดยย่อ โมเดล Vision-Language ฯลฯ) มีประสิทธิภาพอย่างยิ่ง แต่ก็มีข้อจำกัดโดยธรรมชาติ ความรู้ของโมเดลจะหยุดนิ่ง ณ เวลาที่การฝึกเบื้องต้น ซึ่งทำให้โมเดลไม่สามารถเปลี่ยนแปลงและล้าสมัยได้ในทันที แม้หลังจากปรับแต่งแล้ว ความรู้ของโมเดลก็ไม่ได้เป็นข้อมูลล่าสุดมากขึ้น เนื่องจากไม่ใช่เป้าหมายของขั้นตอนหลังการฝึก
วิธีการฝึกโมเดลภาษาขนาดใหญ่ โดยเฉพาะโมเดล "การคิด" จะ "ให้รางวัล" สำหรับการให้คำตอบบางอย่าง แม้ว่าตัวโมเดลเองจะไม่มีข้อมูลข้อเท็จจริงที่สนับสนุนคำตอบดังกล่าวก็ตาม ซึ่งเป็นกรณีที่ผู้คนกล่าวว่าโมเดล "หลอน" นั่นคือสร้างข้อมูลที่ฟังดูน่าเชื่อถือแต่ไม่ถูกต้องตามข้อเท็จจริงอย่างมั่นใจ
การสร้างข้อความโดยใช้การดึงข้อมูลเป็นรูปแบบสถาปัตยกรรมที่มีประสิทธิภาพซึ่งออกแบบมาเพื่อแก้ปัญหาเหล่านี้โดยเฉพาะ เป็นเฟรมเวิร์กสถาปัตยกรรมที่ช่วยเพิ่มความสามารถของโมเดลภาษาขนาดใหญ่ด้วยการเชื่อมต่อโมเดลกับแหล่งความรู้ภายนอกที่เชื่อถือได้แบบเรียลไทม์ LLM ในระบบ RAG จะไม่พึ่งพาความรู้แบบคงที่ที่ฝึกไว้ล่วงหน้าเพียงอย่างเดียว แต่จะดึงข้อมูลที่เกี่ยวข้องกับคำค้นหาของผู้ใช้ก่อน จากนั้นจึงใช้ข้อมูลดังกล่าวเพื่อสร้างคำตอบที่แม่นยำ ทันเวลา และคำนึงถึงบริบทมากขึ้น
แนวทางนี้ช่วยแก้จุดอ่อนที่สำคัญที่สุดของโมเดล Generative โดยตรง นั่นคือ ความรู้ของโมเดลจะคงที่ ณ จุดใดจุดหนึ่ง และมีแนวโน้มที่จะสร้างข้อมูลที่ไม่ถูกต้องหรือ "อาการหลอนของ AI" RAG ช่วยให้ LLM มี "ข้อสอบแบบเปิดหนังสือ" ได้อย่างมีประสิทธิภาพ โดย "หนังสือ" คือข้อมูลส่วนตัว ข้อมูลเฉพาะโดเมน และข้อมูลล่าสุดของคุณ กระบวนการให้บริบทที่เป็นข้อเท็จจริงแก่ LLM นี้เรียกว่า "การเชื่อมต่อแหล่งข้อมูล"
3 ขั้นตอนของ RAG
กระบวนการสร้างข้อความโดยใช้การดึงข้อมูลมาตรฐานแบ่งออกเป็น 3 ขั้นตอนง่ายๆ ดังนี้
- ดึงข้อมูล: เมื่อผู้ใช้ส่งคำค้นหา ระบบจะค้นหาฐานความรู้ภายนอก (เช่น ที่เก็บเอกสาร ฐานข้อมูล หรือเว็บไซต์) ก่อนเพื่อค้นหาข้อมูลที่เกี่ยวข้องกับคำค้นหา
- เพิ่ม: จากนั้นระบบจะรวมข้อมูลที่ดึงมากับคำค้นหาเดิมของผู้ใช้เป็นพรอมต์แบบขยาย เทคนิคนี้บางครั้งเรียกว่า "การยัดเยียดพรอมต์" เนื่องจากเป็นการเพิ่มบริบทที่เป็นข้อเท็จจริงลงในพรอมต์
- สร้าง: ระบบจะป้อนพรอมต์ที่เพิ่มประสิทธิภาพนี้ไปยัง LLM ซึ่งจะสร้างคำตอบ เนื่องจากโมเดลได้รับการป้อนข้อมูลที่เกี่ยวข้องและเป็นข้อเท็จจริง ผลลัพธ์จึง "อิงตามข้อเท็จจริง" และมีโอกาสน้อยมากที่จะไม่ถูกต้องหรือล้าสมัย
สิทธิประโยชน์ของ RAG
การเปิดตัวกรอบงาน RAG ได้ปฏิรูปการสร้างแอปพลิเคชัน AI ที่ใช้งานได้จริงและเชื่อถือได้ ประโยชน์หลักๆ ของการใช้เครื่องมือนี้ ได้แก่
- ความแม่นยำที่เพิ่มขึ้นและอาการหลอนของ AI ที่ลดลง: การอ้างอิงคำตอบจากข้อเท็จจริงภายนอกที่ตรวจสอบได้ช่วยให้ RAG ลดความเสี่ยงที่ LLM จะสร้างข้อมูลขึ้นมาได้อย่างมาก
- การเข้าถึงข้อมูลล่าสุด: ระบบ RAG สามารถเชื่อมต่อกับฐานความรู้ที่อัปเดตอยู่เสมอ ทำให้สามารถให้คำตอบตามข้อมูลล่าสุด ซึ่งเป็นสิ่งที่ LLM ที่ได้รับการฝึกแบบคงที่ทำไม่ได้
- เพิ่มความน่าเชื่อถือและความโปร่งใสของผู้ใช้: เนื่องจากคำตอบของ LLM อิงตามเอกสารที่ดึงมา ระบบจึงสามารถระบุการอ้างอิงและลิงก์ไปยังแหล่งที่มาได้ ซึ่งจะช่วยให้ผู้ใช้ยืนยันข้อมูลด้วยตนเองได้ จึงสร้างความมั่นใจในแอปพลิเคชัน
- ความคุ้มค่า: การปรับแต่งหรือการฝึก LLM ใหม่ด้วยข้อมูลใหม่ๆ อย่างต่อเนื่องต้องใช้การคำนวณและมีค่าใช้จ่ายสูง เมื่อใช้ RAG การอัปเดตความรู้ของโมเดลจะง่ายเหมือนกับการอัปเดตแหล่งข้อมูลภายนอก ซึ่งมีประสิทธิภาพมากกว่ามาก
- ความเชี่ยวชาญเฉพาะโดเมนและความเป็นส่วนตัว: RAG ช่วยให้บุคคลและองค์กรสามารถทำให้ข้อมูลส่วนตัวที่เป็นกรรมสิทธิ์พร้อมใช้งานใน LLM ในเวลาค้นหาโดยไม่ต้องรวมข้อมูลที่ละเอียดอ่อนนั้นไว้ในชุดการฝึกของโมเดล ซึ่งช่วยให้แอปพลิเคชันที่ทรงพลังและเฉพาะโดเมนทำงานได้ในขณะที่ยังคงรักษาความเป็นส่วนตัวและความปลอดภัยของข้อมูล
การดึงข้อมูล
ขั้นตอน "การดึงข้อมูล" เป็นหัวใจสำคัญของระบบ RAG คุณภาพและความเกี่ยวข้องของข้อมูลที่ดึงมาจะเป็นตัวกำหนดคุณภาพและความเกี่ยวข้องของคำตอบสุดท้ายที่สร้างขึ้นโดยตรง แอปพลิเคชัน RAG ที่มีประสิทธิภาพมักต้องดึงข้อมูลจากแหล่งข้อมูลประเภทต่างๆ โดยใช้เทคนิคที่หลากหลาย วิธีการดึงข้อมูลหลักๆ แบ่งออกเป็น 3 หมวดหมู่ ได้แก่ ตามคีย์เวิร์ด ตามความหมาย และแบบมีโครงสร้าง
การดึงข้อมูลจากข้อมูลที่ไม่มีโครงสร้าง
ในอดีต การดึงข้อมูลที่ไม่มีโครงสร้างเป็นอีกชื่อหนึ่งของ Search แบบเดิม โดยผ่านการเปลี่ยนแปลงมาหลายครั้ง และคุณจะได้รับประโยชน์จากทั้ง 2 แนวทางหลัก
การค้นหาเชิงความหมายเป็นเทคนิคที่มีประสิทธิภาพมากที่สุดซึ่งคุณสามารถลดโหนดใน Google Cloud ได้ในวงกว้าง โดยมีประสิทธิภาพที่ล้ำสมัยและควบคุมได้ในระดับสูง
- การค้นหาตามคีย์เวิร์ด (คำศัพท์): นี่คือแนวทางการค้นหาแบบดั้งเดิมซึ่งมีมาตั้งแต่ระบบการดึงข้อมูลแรกสุดในช่วงทศวรรษ 1970 การค้นหาตามคำศัพท์จะทำงานโดยการจับคู่คำที่ตรงกัน (หรือ "โทเค็น") ในคำค้นหาของผู้ใช้กับคำที่ตรงกันในเอกสารภายในฐานความรู้ ซึ่งมีประสิทธิภาพสูงสำหรับคำค้นหาที่ต้องการความแม่นยำในคำที่เฉพาะเจาะจง เช่น รหัสผลิตภัณฑ์ ข้อกฎหมาย หรือชื่อที่ไม่ซ้ำกัน
- การค้นหาเชิงความหมาย: การค้นหาเชิงความหมายหรือ "การค้นหาที่มีความหมาย" เป็นแนวทางที่ทันสมัยกว่าซึ่งมีเป้าหมายเพื่อทำความเข้าใจความตั้งใจของผู้ใช้และความหมายตามบริบทของคำค้นหา ไม่ใช่แค่คีย์เวิร์ดตามตัวอักษร การค้นหาเชิงความหมายสมัยใหม่ขับเคลื่อนด้วยการฝัง ซึ่งเป็นเทคนิคแมชชีนเลิร์นนิงที่แมปข้อมูลที่ซับซ้อนและมีมิติสูงไปยังพื้นที่เวกเตอร์ที่มีมิติต่ำกว่าของเวกเตอร์ตัวเลข เวกเตอร์เหล่านี้ออกแบบมาเพื่อให้ข้อความที่มีความหมายคล้ายกันอยู่ใกล้กันในพื้นที่เวกเตอร์ ระบบจะแปลงการค้นหา "สุนัขพันธุ์ใดเหมาะกับครอบครัวมากที่สุด" เป็นเวกเตอร์ จากนั้นจะค้นหาเวกเตอร์เอกสารที่เป็น "เพื่อนบ้านที่ใกล้ที่สุด" ในพื้นที่นั้น ซึ่งช่วยให้สามารถค้นหาเอกสารที่พูดถึง "โกลเด้นรีทรีฟเวอร์" หรือ "สุนัขที่เป็นมิตร" ได้ แม้ว่าจะไม่มีคำว่า "สุนัข" ที่ตรงกันก็ตาม การค้นหาที่มีมิติสูงนี้มีประสิทธิภาพด้วยอัลกอริทึม Approximate Nearest Neighbor (ANN) แทนที่จะเปรียบเทียบเวกเตอร์การค้นหากับเวกเตอร์เอกสารทุกรายการ (ซึ่งจะช้าเกินไปสำหรับชุดข้อมูลขนาดใหญ่) อัลกอริทึม ANN จะใช้โครงสร้างการจัดทำดัชนีที่ชาญฉลาดเพื่อค้นหาเวกเตอร์ที่น่าจะใกล้เคียงที่สุดอย่างรวดเร็ว
การดึงข้อมูลจาก Structured Data
ความรู้ที่สำคัญบางอย่างไม่ได้จัดเก็บไว้ในเอกสารที่ไม่มีโครงสร้าง บ่อยครั้งที่ข้อมูลที่แม่นยำและมีคุณค่ามากที่สุดอยู่ในรูปแบบที่มีโครงสร้าง เช่น ฐานข้อมูลเชิงสัมพันธ์ ฐานข้อมูล NoSQL หรือ API บางประเภท เช่น REST API สำหรับข้อมูลสภาพอากาศหรือราคาหุ้น
โดยปกติแล้ว การดึงข้อมูลจาก Structured Data จะตรงไปตรงมาและแม่นยำกว่าการค้นหาข้อความที่ไม่มีโครงสร้าง โมเดลภาษาจะมีความสามารถในการสร้างและเรียกใช้คําค้นหาที่แม่นยํา เช่น คําค้นหา SQL ในฐานข้อมูลหรือการเรียก API ไปยัง API สภาพอากาศสําหรับสถานที่และวันที่ที่เฉพาะเจาะจง แทนที่จะค้นหาความคล้ายคลึงเชิงความหมาย
การเรียกใช้ฟังก์ชันเป็นเทคนิคเดียวกับที่ขับเคลื่อน AI Agent ซึ่งช่วยให้โมเดลภาษาโต้ตอบกับโค้ดที่เรียกใช้งานได้และระบบภายนอกในลักษณะโครงสร้างที่กำหนดได้
3. จากไปป์ไลน์ RAG ไปจนถึง Agentic RAG
สถาปัตยกรรมสำหรับการใช้งาน RAG ก็มีการพัฒนาเช่นเดียวกับแนวคิดของ RAG เอง สิ่งที่เริ่มต้นจากไปป์ไลน์เชิงเส้นแบบง่ายๆ ได้พัฒนามาเป็นระบบอัจฉริยะแบบไดนามิกที่จัดการโดยเอเจนต์ AI
- RAG แบบง่าย (หรือแบบพื้นฐาน): นี่คือสถาปัตยกรรมพื้นฐานที่เราได้กล่าวถึงไปแล้ว ซึ่งเป็นกระบวนการเชิงเส้นแบบ 3 ขั้นตอน ได้แก่ ดึงข้อมูล เสริม และสร้าง โดยจะตอบสนองตามเส้นทางที่กำหนดไว้สำหรับทุกคำค้นหา และมีประสิทธิภาพสูงสำหรับงานถามและตอบที่ตรงไปตรงมา
- RAG ขั้นสูง: แสดงถึงวิวัฒนาการที่มีการเพิ่มขั้นตอนเพิ่มเติมลงในไปป์ไลน์เพื่อปรับปรุงคุณภาพของบริบทที่ดึงมา การปรับปรุงเหล่านี้อาจเกิดขึ้นก่อนหรือหลังขั้นตอนการดึงข้อมูล
- ก่อนการดึงข้อมูล: สามารถใช้เทคนิคต่างๆ เช่น การเขียนคำค้นหาใหม่หรือการขยายคำค้นหา ระบบอาจวิเคราะห์คำค้นหาเริ่มต้นและเรียบเรียงใหม่เพื่อให้มีประสิทธิภาพมากขึ้นสำหรับระบบการดึงข้อมูล
- หลังการดึงข้อมูล: หลังจากดึงข้อมูลชุดเอกสารเริ่มต้นแล้ว คุณสามารถใช้โมเดลการจัดอันดับใหม่เพื่อให้คะแนนเอกสารตามความเกี่ยวข้องและดันเอกสารที่ดีที่สุดขึ้นไปด้านบน ซึ่งมีความสำคัญอย่างยิ่งในการค้นหาแบบไฮบริด ขั้นตอนหลังการดึงข้อมูลอีกอย่างคือการกรองหรือบีบอัดบริบทที่ดึงมาเพื่อให้มั่นใจว่าเฉพาะข้อมูลที่สำคัญที่สุดเท่านั้นที่จะส่งไปยัง LLM
- Agentic RAG: นี่คือสถาปัตยกรรม RAG ที่ล้ำสมัยที่สุด ซึ่งแสดงถึงการเปลี่ยนกระบวนทัศน์จากไปป์ไลน์แบบคงที่ไปเป็นกระบวนการอัจฉริยะแบบอัตโนมัติ ในระบบ Agentic RAG เวิร์กโฟลว์ทั้งหมดจะได้รับการจัดการโดยเอเจนต์ AI อย่างน้อย 1 ราย ซึ่งสามารถให้เหตุผล วางแผน และเลือกการดำเนินการแบบไดนามิกได้
หากต้องการทำความเข้าใจ RAG ที่เป็น Agent คุณต้องทำความเข้าใจก่อนว่าอะไรคือ AI Agent เอเจนต์เป็นมากกว่า LLM ซึ่งเป็นระบบที่มีองค์ประกอบหลักหลายอย่าง ได้แก่
- LLM เป็นเครื่องมือให้เหตุผล: เอเจนต์ใช้ LLM ที่มีประสิทธิภาพ เช่น Gemini ไม่ใช่แค่เพื่อสร้างข้อความ แต่ใช้เป็น "สมอง" ส่วนกลางในการวางแผน ตัดสินใจ และแบ่งงานที่ซับซ้อน
- ชุดเครื่องมือ: เอเจนต์จะได้รับสิทธิ์เข้าถึงชุดเครื่องมือฟังก์ชันที่สามารถตัดสินใจใช้เพื่อให้บรรลุเป้าหมายได้ เครื่องมือเหล่านี้อาจเป็นอะไรก็ได้ เช่น เครื่องคิดเลข, API การค้นหาเว็บ, ฟังก์ชันในการส่งอีเมล หรือที่สำคัญที่สุดสำหรับห้องทดลองนี้คือเครื่องมือดึงข้อมูลสำหรับฐานความรู้ต่างๆ ของเรา
- หน่วยความจำ: สามารถออกแบบเอเจนต์ให้มีทั้งหน่วยความจำระยะสั้น (เพื่อจดจำบริบทของการสนทนาปัจจุบัน) และหน่วยความจำระยะยาว (เพื่อเรียกข้อมูลจากการโต้ตอบที่ผ่านมา) ซึ่งจะช่วยให้ได้รับประสบการณ์การใช้งานที่ปรับเปลี่ยนในแบบของคุณและสอดคล้องกันมากขึ้น
- การวางแผนและการไตร่ตรอง: เอเจนต์ที่ซับซ้อนที่สุดจะแสดงรูปแบบการให้เหตุผลที่ซับซ้อน โดยสามารถรับเป้าหมายที่ซับซ้อนและสร้างแผนแบบหลายขั้นตอนเพื่อให้บรรลุเป้าหมายนั้นได้ จากนั้นก็สามารถดำเนินการตามแผนนี้ และยังไตร่ตรองผลลัพธ์ของการดำเนินการ ระบุข้อผิดพลาด และแก้ไขแนวทางด้วยตนเองเพื่อปรับปรุงผลลัพธ์สุดท้ายได้ด้วย
RAG แบบเอเจนต์เป็นตัวเปลี่ยนเกมเนื่องจากมีการนำเลเยอร์ของความเป็นอิสระและสติปัญญาที่ไปป์ไลน์แบบคงที่ไม่มีมาใช้
- ความยืดหยุ่นและความสามารถในการปรับตัว: เอเจนต์ไม่ได้ล็อกเส้นทางการดึงข้อมูลเพียงเส้นทางเดียว เมื่อได้รับคำค้นหาจากผู้ใช้ โมเดลจะให้เหตุผลเกี่ยวกับแหล่งข้อมูลที่ดีที่สุดได้ โดยอาจตัดสินใจที่จะค้นหาฐานข้อมูลที่มีโครงสร้างก่อน จากนั้นจึงทำการค้นหาเชิงความหมายในเอกสารที่ไม่มีโครงสร้าง และหากยังหาคำตอบไม่ได้ ก็จะใช้เครื่องมือ Google Search เพื่อค้นหาในเว็บสาธารณะ ทั้งหมดนี้อยู่ภายในบริบทของคำขอเดียวจากผู้ใช้
- การให้เหตุผลที่ซับซ้อนและมีหลายขั้นตอน: สถาปัตยกรรมนี้มีความโดดเด่นในการจัดการคำค้นหาที่ซับซ้อนซึ่งต้องมีขั้นตอนการดึงข้อมูลและการประมวลผลหลายขั้นตอนตามลำดับ
พิจารณาคำค้นหา "ค้นหาภาพยนตร์ไซไฟ 3 อันดับแรกที่กำกับโดยคริสโตเฟอร์ โนแลน และสรุปเนื้อเรื่องสั้นๆ ของแต่ละเรื่อง" ไปป์ไลน์ RAG แบบง่ายจะไม่ทำงาน
แต่ตัวแทนจะสามารถให้ข้อมูลต่อไปนี้ได้
- แผน: ก่อนอื่นฉันต้องหาภาพยนตร์ จากนั้นสำหรับภาพยนตร์แต่ละเรื่อง ฉันต้องค้นหาเนื้อเรื่องของภาพยนตร์
- การดำเนินการที่ 1: ใช้เครื่องมือ Structured Data เพื่อค้นหาฐานข้อมูลภาพยนตร์สำหรับภาพยนตร์ไซไฟของโนแลน: ภาพยนตร์ 3 อันดับแรก เรียงตามคะแนนจากมากไปน้อย
- การสังเกตการณ์ที่ 1: เครื่องมือแสดงผลลัพธ์เป็น "Inception" "Interstellar" และ "Tenet"
- การดำเนินการที่ 2: ใช้เครื่องมือข้อมูลที่ไม่มีโครงสร้าง (การค้นหาเชิงความหมาย) เพื่อค้นหาเนื้อเรื่องของ "Inception"
- ข้อสังเกตที่ 2: ระบบดึงข้อมูลพล็อตเรื่อง
- การดำเนินการที่ 3: ทำซ้ำสำหรับ "Interstellar"
- ขั้นตอนที่ 4: ทำซ้ำสำหรับ "Tenet"
- การสังเคราะห์ขั้นสุดท้าย: รวมข้อมูลที่ดึงมาทั้งหมดเป็นคำตอบเดียวที่สอดคล้องกันสำหรับผู้ใช้
4. การตั้งค่าโปรเจ็กต์
บัญชี Google
หากยังไม่มีบัญชี Google ส่วนบุคคล คุณต้องสร้างบัญชี Google
ใช้บัญชีส่วนตัวแทนบัญชีของที่ทำงานหรือบัญชีโรงเรียน
ลงชื่อเข้าใช้คอนโซล Google Cloud
ลงชื่อเข้าใช้ คอนโซล Google Cloud โดยใช้บัญชี Google ส่วนบุคคล
เปิดใช้การเรียกเก็บเงิน
ใช้บัญชีสำหรับการเรียกเก็บเงินในช่วงทดลองใช้ (ไม่บังคับ)
หากต้องการจัดเวิร์กช็อปนี้ คุณต้องมีบัญชีสำหรับการเรียกเก็บเงินที่มีเครดิตอยู่บ้าง ใช้เครดิตจากแบนเนอร์ที่ด้านบนของ Codelab นี้เพื่อเริ่มต้นใช้งาน หากเชื่อมต่อกับบัญชีสำหรับการเรียกเก็บเงินอยู่แล้ว ให้ข้ามขั้นตอนนี้
ตั้งค่าบัญชีสำหรับการเรียกเก็บเงินส่วนตัว
หากตั้งค่าการเรียกเก็บเงินโดยใช้เครดิต Google Cloud คุณจะข้ามขั้นตอนนี้ได้
หากต้องการตั้งค่าบัญชีสำหรับการเรียกเก็บเงินส่วนตัว ให้ไปที่นี่เพื่อเปิดใช้การเรียกเก็บเงินใน Cloud Console
ข้อควรทราบ
- การทำ Lab นี้ควรมีค่าใช้จ่ายน้อยกว่า $1 USD ในทรัพยากรระบบคลาวด์
- คุณสามารถทำตามขั้นตอนที่ส่วนท้ายของแล็บนี้เพื่อลบทรัพยากรเพื่อหลีกเลี่ยงการเรียกเก็บเงินเพิ่มเติม
- ผู้ใช้ใหม่มีสิทธิ์ใช้ช่วงทดลองใช้ฟรีมูลค่า$300 USD
สร้างโปรเจ็กต์ (ไม่บังคับ)
หากไม่มีโปรเจ็กต์ปัจจุบันที่ต้องการใช้สำหรับแล็บนี้ ให้สร้างโปรเจ็กต์ใหม่ที่นี่
5. เปิดเครื่องมือแก้ไข Cloud Shell
- คลิกลิงก์นี้เพื่อไปยัง Cloud Shell Editor โดยตรง
- หากระบบแจ้งให้ให้สิทธิ์ในขั้นตอนใดก็ตามในวันนี้ ให้คลิกให้สิทธิ์เพื่อดำเนินการต่อ
- หากเทอร์มินัลไม่ปรากฏที่ด้านล่างของหน้าจอ ให้เปิดโดยทำดังนี้
- คลิกดู
- คลิก Terminal
- ในเทอร์มินัล ให้ตั้งค่าโปรเจ็กต์ด้วยคำสั่งนี้
gcloud config set project [PROJECT_ID]- ตัวอย่าง
gcloud config set project lab-project-id-example - หากจำรหัสโปรเจ็กต์ไม่ได้ คุณสามารถแสดงรหัสโปรเจ็กต์ทั้งหมดได้โดยใช้คำสั่งต่อไปนี้
gcloud projects list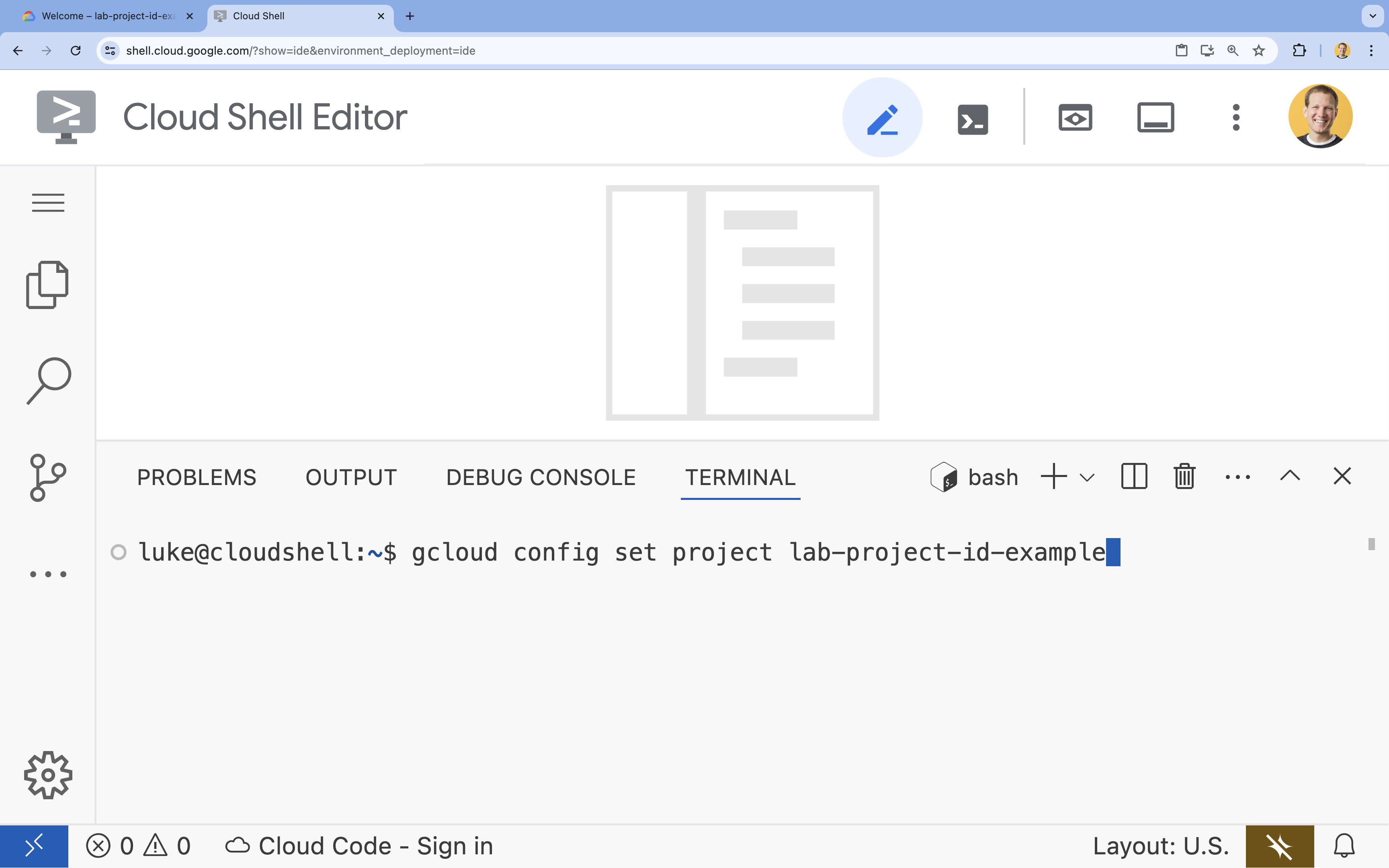
- ตัวอย่าง
- คุณควรเห็นข้อความต่อไปนี้
Updated property [core/project].
6. เปิดใช้ API
หากต้องการใช้ Agent Development Kit และ Vertex AI Search คุณต้องเปิดใช้ API ที่จำเป็นในโปรเจ็กต์ที่อยู่ในระบบคลาวด์ของ Google
- เปิดใช้ API ในเทอร์มินัลโดยทำดังนี้
gcloud services enable \ aiplatform.googleapis.com \ discoveryengine.googleapis.com
ขอแนะนำ API
- Vertex AI API (
aiplatform.googleapis.com) ช่วยให้เอเจนต์สื่อสารกับโมเดล Gemini เพื่อการให้เหตุผลและการสร้างได้ - Discovery Engine API (
discoveryengine.googleapis.com) ขับเคลื่อน Vertex AI Search ซึ่งช่วยให้คุณสร้างที่เก็บข้อมูลและทำการค้นหาเชิงความหมายในเอกสารที่ไม่มีโครงสร้างได้
7. ตั้งค่าสภาพแวดล้อม
ก่อนเริ่มเขียนโค้ด AI Agent คุณต้องเตรียมสภาพแวดล้อมในการพัฒนาซอฟต์แวร์ ติดตั้งไลบรารีที่จำเป็น และสร้างไฟล์ข้อมูลที่จำเป็น
สร้างสภาพแวดล้อมเสมือนและติดตั้งการอ้างอิง
- สร้างไดเรกทอรีสำหรับ Agent แล้วไปที่ไดเรกทอรีนั้น เรียกใช้โค้ดต่อไปนี้ในเทอร์มินัล
mkdir financial_agent cd financial_agent - สร้างสภาพแวดล้อมเสมือน
uv venv --python 3.12 - เปิดใช้งานสภาพแวดล้อมเสมือน
source .venv/bin/activate - ติดตั้ง Agent Development Kit (ADK) และ pandas
uv pip install google-adk pandas
สร้างข้อมูลราคาหุ้น
เนื่องจากห้องทดลองกำหนดให้ต้องมีข้อมูลสต็อกย้อนหลังที่เฉพาะเจาะจงเพื่อแสดงให้เห็นความสามารถของเอเจนต์ในการใช้เครื่องมือที่มีโครงสร้าง คุณจึงต้องสร้างไฟล์ CSV ที่มีข้อมูลนี้
- ในไดเรกทอรี
financial_agentให้สร้างไฟล์goog.csvโดยเรียกใช้คำสั่งต่อไปนี้ในเทอร์มินัลcat <<EOF > goog.csv Date,Open,High,Low,Close,Adj Close,Volume 2023-01-03,89.830002,91.550003,89.019997,89.699997,89.699997,20738500 2023-03-31,101.440002,103.889999,101.040001,103.730003,103.730003,36823200 2023-06-30,120.870003,122.029999,120.300003,120.970001,120.970001,23824700 2023-09-29,134.080002,134.550003,131.320007,131.850006,131.850006,21124200 2025-07-10,185.000000,188.000000,184.500000,186.500000,186.500000,25000000 EOF
กำหนดค่าตัวแปรสภาพแวดล้อม
- ในไดเรกทอรี
financial_agentให้สร้างไฟล์.envเพื่อกำหนดค่าตัวแปรสภาพแวดล้อมของเอเจนต์ ซึ่งจะบอก ADK ว่าควรใช้โปรเจ็กต์ สถานที่ และโมเดลใด เรียกใช้โค้ดต่อไปนี้ในเทอร์มินัล# Create the .env file using the captured variables cat << EOF > .env GOOGLE_GENAI_USE_VERTEXAI=TRUE GOOGLE_CLOUD_PROJECT="${GOOGLE_CLOUD_PROJECT}" GOOGLE_CLOUD_LOCATION="us-central1" EOF
หมายเหตุ: ในภายหลังของแล็บ หากคุณต้องการแก้ไขไฟล์ .env แต่ไม่เห็นไฟล์ดังกล่าวในไดเรกทอรี financial_agent ให้ลองสลับการแสดงไฟล์ที่ซ่อนไว้ใน Cloud Shell Editor โดยใช้รายการในเมนู "ดู / สลับไฟล์ที่ซ่อนไว้"
8. สร้างพื้นที่เก็บข้อมูลสำหรับ Vertex AI Search
หากต้องการให้เอเจนต์ตอบคำถามเกี่ยวกับรายงานทางการเงินของ Alphabet คุณจะต้องสร้างที่เก็บข้อมูล Vertex AI Search ที่มีเอกสารที่ยื่นต่อ SEC แบบสาธารณะ
- ในแท็บใหม่ของเบราว์เซอร์ ให้เปิด Cloud Console (console.cloud.google.com) แล้วไปที่แอปพลิเคชัน AI โดยใช้แถบค้นหาที่ด้านบน
- หากได้รับข้อความแจ้ง ให้เลือกช่องทำเครื่องหมายข้อกำหนดและเงื่อนไข แล้วคลิกดำเนินการต่อและเปิดใช้งาน API
- เลือกที่เก็บข้อมูลจากเมนูการนำทางด้านซ้ายมือ
- คลิก + สร้างพื้นที่เก็บข้อมูล
- ค้นหาการ์ด Cloud Storage แล้วคลิกเลือก
- สำหรับแหล่งข้อมูล ให้เลือกเอกสารที่ไม่มีโครงสร้าง

- สำหรับแหล่งที่มาของการนำเข้า (เลือกโฟลเดอร์หรือไฟล์ที่ต้องการนำเข้า) ให้ป้อนเส้นทาง Google Cloud Storage
cloud-samples-data/gen-app-builder/search/alphabet-sec-filings - คลิกต่อไป
- ตั้งค่าสถานที่ตั้งเป็นทั่วโลก
- สำหรับชื่อที่เก็บข้อมูล ให้ป้อน
alphabet-sec-filings - ขยายส่วนตัวเลือกการประมวลผลเอกสาร

- ในรายการแบบเลื่อนลงเครื่องมือแยกวิเคราะห์เอกสารเริ่มต้น ให้เลือกเครื่องมือแยกวิเคราะห์เลย์เอาต์
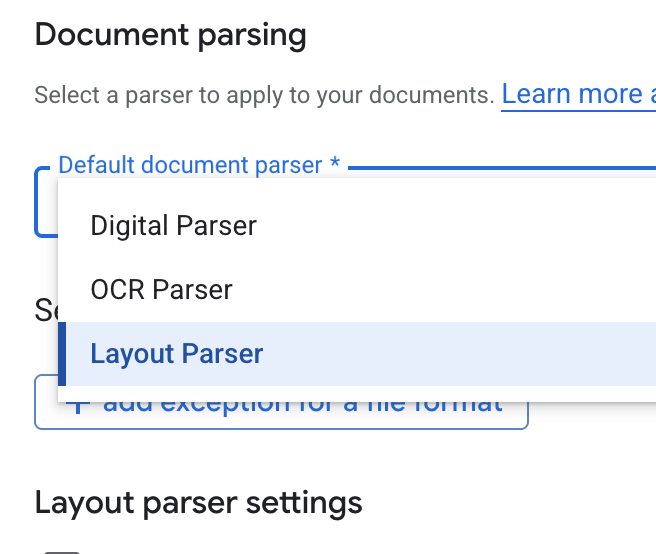
- ในตัวเลือกการตั้งค่าตัวแยกวิเคราะห์เลย์เอาต์ ให้เลือกเปิดใช้คำอธิบายประกอบตารางและเปิดใช้คำอธิบายประกอบรูปภาพ
- คลิกต่อไป
- เลือกการกำหนดราคาทั่วไปเป็นรูปแบบการกำหนดราคา (รูปแบบการจ่ายเมื่อใช้ตามการใช้งาน) แล้วคลิกสร้าง
- ที่เก็บข้อมูลจะเริ่มนำเข้าเอกสาร
- คลิกชื่อพื้นที่เก็บข้อมูล แล้วคัดลอกรหัสจากตารางพื้นที่เก็บข้อมูล เนื่องจากคุณจะต้องใช้ในขั้นตอนถัดไป
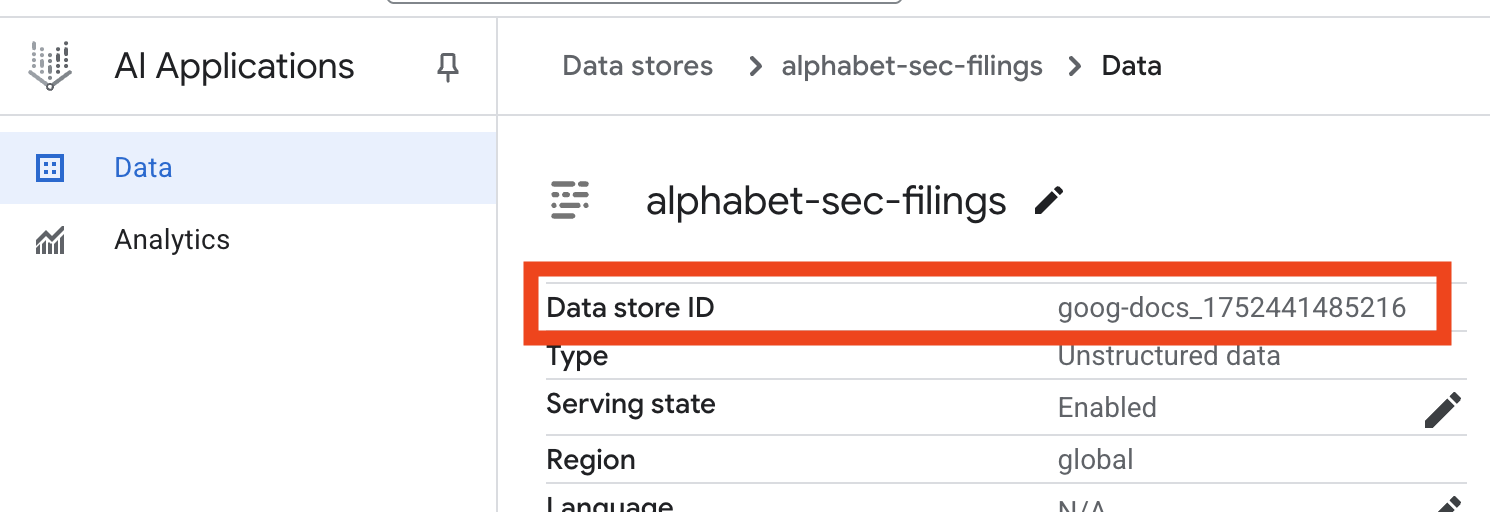
- เปิดไฟล์
.envใน Cloud Shell Editor แล้วต่อท้ายรหัสพื้นที่เก็บข้อมูลเป็นDATA_STORE_ID="YOUR_DATA_STORE_ID"(แทนที่YOUR_DATA_STORE_IDด้วยรหัสจริงจากขั้นตอนก่อนหน้าหมายเหตุ: การนำเข้า แยกวิเคราะห์ และจัดทำดัชนีข้อมูลในพื้นที่เก็บข้อมูลจะใช้เวลา 2-3 นาที หากต้องการตรวจสอบกระบวนการ ให้คลิกชื่อที่เก็บข้อมูลเพื่อเปิดพร็อพเพอร์ตี้ แล้วเปิดแท็บกิจกรรม รอให้สถานะเปลี่ยนเป็น "นำเข้าเสร็จสมบูรณ์"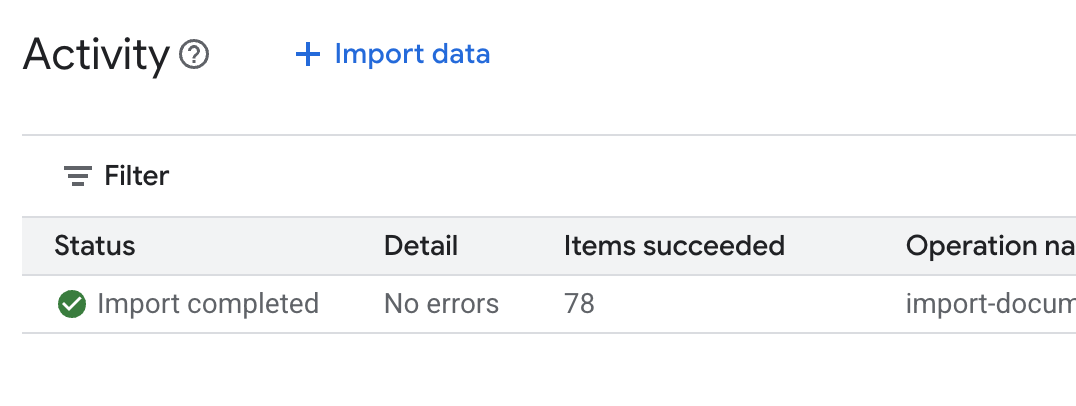
9. สร้างเครื่องมือที่กำหนดเองสำหรับ Structured Data
จากนั้นคุณจะสร้างฟังก์ชัน Python ที่จะทำหน้าที่เป็นเครื่องมือสำหรับเอเจนต์ เครื่องมือนี้จะอ่านไฟล์ goog.csv เพื่อดึงข้อมูลราคาหุ้นย้อนหลังของวันที่ที่ระบุ
- ในไดเรกทอรี
financial_agentให้สร้างไฟล์ใหม่ชื่อagent.pyเรียกใช้คำสั่งต่อไปนี้ในเทอร์มินัลcloudshell edit agent.py - เพิ่มโค้ด Python ต่อไปนี้ลงใน
agent.pyโค้ดนี้จะนำเข้าทรัพยากร Dependency และกำหนดฟังก์ชันget_stock_pricefrom datetime import datetime import os import logging import google.cloud.logging from google.adk.tools import VertexAiSearchTool from google.adk.tools.agent_tool import AgentTool from google.adk.agents import LlmAgent import pandas as pd def get_stock_price(date: str) -> dict: """Gets the closing stock price for a given date. Args: date: The date to get the stock price for, in YYYY-MM-DD format. Returns: A dictionary containing the closing price, or an error message if the date is not found or the format is incorrect. """ try: # Load the CSV file df = pd.read_csv('goog.csv') # Convert the 'Date' column to datetime objects df['Date'] = pd.to_datetime(df['Date']) # Convert the input string to a datetime object query_date = datetime.strptime(date, '%Y-%m-%d') # Find the row for the given date row = df[df['Date'] == query_date] if not row.empty: # Get the closing price close_price = row['Close'].iloc[0] return {"status": "success", "date": date, "closing_price": close_price} else: return {"status": "error", "message": f"No data found for date: {date}"} except FileNotFoundError: return {"status": "error", "message": "Stock data file (goog.csv) not found."} except Exception as e: return {"status": "error", "message": f"An error occurred: {str(e)}"}
โปรดสังเกตสตริงเอกสารโดยละเอียดของฟังก์ชัน โดยจะอธิบายสิ่งที่ฟังก์ชันทำ พารามิเตอร์ (Args) และสิ่งที่ฟังก์ชันส่งคืน (Returns) ADK ใช้ Docstring นี้เพื่อสอนเอเจนต์ถึงวิธีและเวลาที่ควรใช้เครื่องมือนี้
10. สร้างและเรียกใช้ Agent RAG
ตอนนี้ได้เวลาประกอบเอเจนต์แล้ว คุณจะรวมเครื่องมือ Vertex AI Search สำหรับข้อมูลที่ไม่มีโครงสร้างเข้ากับเครื่องมือ get_stock_price ที่กำหนดเองสำหรับข้อมูลที่มีโครงสร้าง
- ต่อท้ายโค้ดต่อไปนี้ในไฟล์
agent.pyโค้ดนี้จะนำเข้าคลาส ADK ที่จำเป็น สร้างอินสแตนซ์ของเครื่องมือ และกำหนด Agentlogging.basicConfig(level=logging.INFO) cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() # 1. Create the Vertex AI Search tool full_datastore_id = f"projects/{os.environ['GOOGLE_CLOUD_PROJECT']}/locations/global/collections/default_collection/dataStores/{os.environ['DATA_STORE_ID']}" vertex_ai_search_tool = VertexAiSearchTool( data_store_id=full_datastore_id ) # 2. Define the Search+Q&A agent # Since we cannot combine tools with other tools in a single agent, # we create a separate Search+Q&A agent which will be used as a tool by the main root agent. doc_qa_agent = LlmAgent( name="search_and_qna_agent", model="gemini-2.5-flash", tools=[vertex_ai_search_tool], instruction="""You are a helpful assistant that answers questions based on information found in the document store. Use the search tool to find relevant information before answering. If the answer isn't in the documents, say that you couldn't find the information. """, description="Answers questions using a specific Vertex AI Search datastore.", ) # 3. Define the root agent with 2 tools. root_agent = LlmAgent( name="financial_agent", model="gemini-2.5-flash", tools=[ AgentTool(doc_qa_agent), get_stock_price, ], instruction="""You are an Financial Analytics Agent that answers question about Alphabet stock prices (using get_stock_price tool) and historical performance based on the data in Vertex AI Search datastore (using doc_qa_agent tool).""" ) - จากเทอร์มินัลภายในไดเรกทอรี
financial_agentให้เปิดใช้อินเทอร์เฟซเว็บ ADK เพื่อโต้ตอบกับ Agentadk web ~ - คลิกลิงก์ที่ระบุในเอาต์พุตของเทอร์มินัล (โดยปกติคือ
http://127.0.0.1:8000) เพื่อเปิด UI สำหรับนักพัฒนาซอฟต์แวร์ของ ADK ในเบราว์เซอร์
11. ทดสอบ Agent
ตอนนี้คุณสามารถทดสอบความสามารถของเอเจนต์ในการให้เหตุผลและใช้เครื่องมือเพื่อตอบคำถามที่ซับซ้อนได้แล้ว
- ใน UI ของ ADK Dev ให้ตรวจสอบว่าได้เลือก
financial_agentจากเมนูแบบเลื่อนลงแล้ว - ลองถามคำถามที่ต้องใช้ข้อมูลจากการยื่นเรื่องต่อ SEC (ข้อมูลที่ไม่มีโครงสร้าง) ป้อนคำค้นหาต่อไปนี้ในแชท
What were the total revenues for the quarter ending on March 31, 2023?search_and_qna_agentซึ่งใช้VertexAiSearchToolเพื่อค้นหาคำตอบในเอกสารทางการเงิน - จากนั้นถามคำถามที่ต้องใช้เครื่องมือที่กำหนดเอง (Structured Data) โปรดทราบว่ารูปแบบวันที่ในพรอมต์ไม่จำเป็นต้องตรงกับรูปแบบที่ฟังก์ชันกำหนดอย่างแน่นอน เนื่องจาก LLM มีความสามารถมากพอที่จะจัดรูปแบบใหม่ได้
What was the closing stock price for Alphabet on July 10, 2025?get_stock_priceของคุณ คุณสามารถคลิกไอคอนเครื่องมือในแชทเพื่อตรวจสอบการเรียกใช้ฟังก์ชันและผลลัพธ์ได้ - สุดท้าย ให้ถามคำถามที่ซับซ้อนซึ่งกำหนดให้เอเจนต์ต้องใช้เครื่องมือทั้ง 2 อย่างและสังเคราะห์ผลลัพธ์
According to the 10-Q filing for the period ending March 31, 2023, what were the company's net cash provided by operating activities, and what was the stock's closing price on that date?- ก่อนอื่นจะใช้
VertexAiSearchToolเพื่อค้นหาข้อมูลกระแสเงินสดในการยื่นเอกสารต่อ SEC - จากนั้นจะรับรู้ถึงความจำเป็นในการใช้ราคาหุ้นและเรียกใช้ฟังก์ชัน
get_stock_priceพร้อมวันที่2023-03-31 - สุดท้ายนี้ โมเดลจะรวมข้อมูลทั้ง 2 ส่วนเข้าด้วยกันเป็นคำตอบเดียวที่ครอบคลุม
- ก่อนอื่นจะใช้
- เมื่อเสร็จแล้ว คุณสามารถปิดแท็บเบราว์เซอร์และกด
CTRL+Cในเทอร์มินัลเพื่อหยุดเซิร์ฟเวอร์ ADK
12. การเลือกบริการสำหรับงาน
Vertex AI Search ไม่ใช่บริการค้นหาแบบเวกเตอร์เพียงอย่างเดียวที่คุณใช้ได้ นอกจากนี้ คุณยังใช้บริการที่มีการจัดการซึ่งจะทำให้ขั้นตอนทั้งหมดของ Retrieval-Augmented Generation เป็นแบบอัตโนมัติได้ด้วย Vertex AI RAG Engine
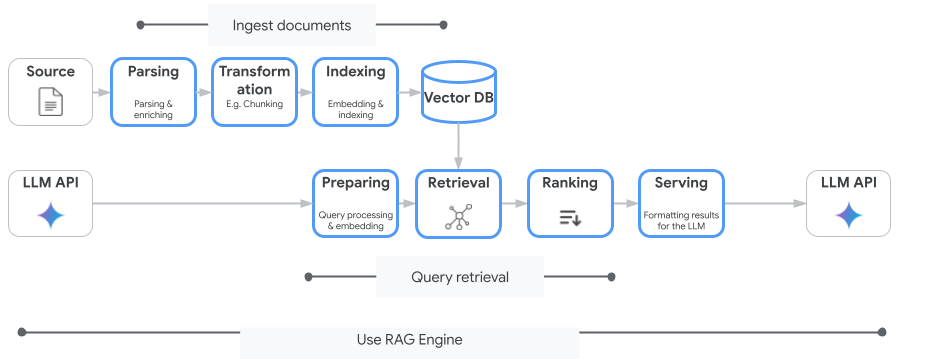
โดยจะจัดการทุกอย่างตั้งแต่การนำเข้าเอกสารไปจนถึงการดึงข้อมูลและการจัดอันดับใหม่ เครื่องมือ RAG รองรับ Vector Store หลายรายการ รวมถึง Pinecone และ Weaviate
นอกจากนี้ คุณยังโฮสต์ฐานข้อมูลเวกเตอร์เฉพาะทางหลายรายการด้วยตนเอง หรือใช้ประโยชน์จากความสามารถของดัชนีเวกเตอร์ในเครื่องมือฐานข้อมูล เช่น pgvector ในบริการ PostgreSQL (เช่น AlloyDB หรือ BigQuery Vector Search) ได้ด้วย
บริการอื่นๆ ที่รองรับการค้นหาเวกเตอร์มีดังนี้
- Cloud SQL สำหรับ PostgreSQL
- Cloud SQL สำหรับ MySQL
- Cloud Spanner
- Memorystore สำหรับ Redis
- Firestore
- Bigtable
คำแนะนำทั่วไปในการเลือกบริการใดบริการหนึ่งใน Google Cloud มีดังนี้
- หากคุณมีโครงสร้างพื้นฐาน Vector Search แบบทำเองที่ใช้งานได้และปรับขนาดได้ดี ให้ติดตั้งใช้งานใน Google Kubernetes Engine เช่น Weaviate หรือ PostgreSQL แบบทำเอง
- หากข้อมูลอยู่ใน BigQuery, AlloyDB, Firestore หรือฐานข้อมูลอื่นๆ ให้พิจารณาใช้ความสามารถในการค้นหาเวกเตอร์ของฐานข้อมูลนั้นๆ หากสามารถทำการค้นหาเชิงความหมายได้ในวงกว้างซึ่งเป็นส่วนหนึ่งของคําค้นหาที่ใหญ่ขึ้นในฐานข้อมูลนั้น ตัวอย่างเช่น หากคุณมีคำอธิบายและ/หรือรูปภาพผลิตภัณฑ์ในตาราง BigQuery การเพิ่มคอลัมน์การฝังข้อความและ/หรือรูปภาพจะช่วยให้ใช้การค้นหาความคล้ายคลึงกันได้ในวงกว้าง ดัชนีเวกเตอร์ที่รองรับการค้นหา ScANN จะรองรับรายการหลายพันล้านรายการในดัชนี
- หากต้องการเริ่มต้นใช้งานอย่างรวดเร็วโดยใช้ความพยายามน้อยที่สุดและบนแพลตฟอร์มที่มีการจัดการ ให้เลือก Vertex AI Search ซึ่งเป็นเครื่องมือค้นหาและ API สำหรับดึงข้อมูลที่จัดการครบวงจร เหมาะสำหรับกรณีการใช้งานที่ซับซ้อนระดับองค์กรซึ่งต้องมีคุณภาพ ความสามารถในการปรับขนาด และการควบคุมการเข้าถึงแบบละเอียดสูงตั้งแต่เริ่มต้น ซึ่งช่วยให้การเชื่อมต่อกับแหล่งข้อมูลขององค์กรที่หลากหลายเป็นเรื่องง่าย และช่วยให้ค้นหาในหลายแหล่งได้
- ใช้ Vertex AI RAG Engine หากคุณกำลังมองหาจุดที่เหมาะสมสำหรับนักพัฒนาซอฟต์แวร์ที่ต้องการความสมดุลระหว่างความง่ายในการใช้งานและการปรับแต่ง ซึ่งช่วยให้สร้างต้นแบบและพัฒนาได้อย่างรวดเร็วโดยไม่ลดทอนความยืดหยุ่น
- ดูสถาปัตยกรรมอ้างอิงสำหรับการสร้างที่เพิ่มประสิทธิภาพการดึงข้อมูล
13. บทสรุป
ยินดีด้วย คุณสร้างและทดสอบ AI Agent ด้วยการสร้างที่เพิ่มประสิทธิภาพการดึงข้อมูลเรียบร้อยแล้ว คุณได้เรียนรู้วิธีต่อไปนี้
- สร้างฐานความรู้สำหรับเอกสารที่ไม่มีโครงสร้างโดยใช้ความสามารถในการค้นหาเชิงความหมายที่มีประสิทธิภาพของ Vertex AI Search
- พัฒนาฟังก์ชัน Python ที่กำหนดเองเพื่อใช้เป็นเครื่องมือในการดึง Structured Data
- ใช้ Agent Development Kit (ADK) เพื่อสร้าง Agent แบบหลายเครื่องมือที่ขับเคลื่อนโดย Gemini
- สร้างเอเจนต์ที่สามารถใช้การให้เหตุผลหลายขั้นตอนที่ซับซ้อนเพื่อตอบคำค้นหาที่ต้องสังเคราะห์ข้อมูลจากหลายแหล่ง
Lab นี้แสดงหลักการสำคัญของ Agentic RAG ซึ่งเป็นสถาปัตยกรรมที่มีประสิทธิภาพสำหรับการสร้างแอปพลิเคชัน AI ที่ชาญฉลาด แม่นยำ และรับรู้บริบทใน Google Cloud
จากต้นแบบสู่เวอร์ชันที่ใช้งานจริง
แล็บนี้เป็นส่วนหนึ่งของเส้นทางการเรียนรู้ AI พร้อมใช้งานจริงด้วย Google Cloud
- สำรวจหลักสูตรทั้งหมดเพื่อเชื่อมช่องว่างจากต้นแบบไปสู่การผลิต
- แชร์ความคืบหน้าโดยใช้แฮชแท็ก #ProductionReadyAI