
1. Giriş
Genel Bakış
Bu laboratuvarın amacı, Google Cloud'da uçtan uca Agentic Retrieval-Augmented Generation (RAG) uygulamaları geliştirmeyi öğrenmektir. Bu laboratuvarda, iki farklı kaynaktan gelen bilgileri birleştirerek soruları yanıtlayabilen bir finansal analiz aracısı oluşturacaksınız: yapılandırılmamış dokümanlar (Alphabet'in üç aylık SEC başvuruları - ABD'deki her halka açık şirketin Menkul Kıymetler ve Borsa Komisyonu'na gönderdiği mali tablolar ve operasyonel ayrıntılar) ve yapılandırılmış veriler (geçmişteki hisse senedi fiyatları).
Yapılandırılmamış finansal raporlar için güçlü bir semantik arama motoru oluşturmak üzere Vertex AI Search'ü kullanacaksınız. Yapılandırılmış veriler için özel bir Python aracı oluşturacaksınız. Son olarak, kullanıcının sorgusu hakkında akıl yürütebilen, hangi aracın kullanılacağına karar verebilen ve bilgileri tutarlı bir yanıt halinde sentezleyebilen akıllı bir aracı oluşturmak için Agent Development Kit'i (ADK) kullanacaksınız.
Yapacaklarınız
- Özel belgelerde semantik arama için Vertex AI Search veri deposu oluşturma
- Bir temsilci için araç olarak özel bir Python işlevi oluşturun.
- Çok araçlı bir temsilci oluşturmak için Agent Development Kit'i (ADK) kullanın.
- Karmaşık soruları yanıtlamak için yapılandırılmamış ve yapılandırılmış veri kaynaklarından alınan bilgileri birleştirin.
- Muhakeme yetenekleri gösteren bir temsilciyle test yapın ve etkileşimde bulunun.
Neler öğreneceksiniz?
Bu laboratuvarda şunları öğreneceksiniz:
- Veriyle Artırılmış Üretim (RAG) ve Ajan Tabanlı RAG'nin temel kavramları.
- Vertex AI Search'ü kullanarak belgelerde semantik arama nasıl uygulanır?
- Özel araçlar oluşturarak yapılandırılmış verileri bir temsilciye nasıl sunacağınızı öğrenin.
- Agent Development Kit (ADK) ile çok araçlı bir ajanı nasıl oluşturup düzenleyeceğinizi öğrenin.
- Temsilcilerin, birden fazla veri kaynağı kullanarak karmaşık soruları yanıtlamak için akıl yürütme ve planlamayı nasıl kullandığı.
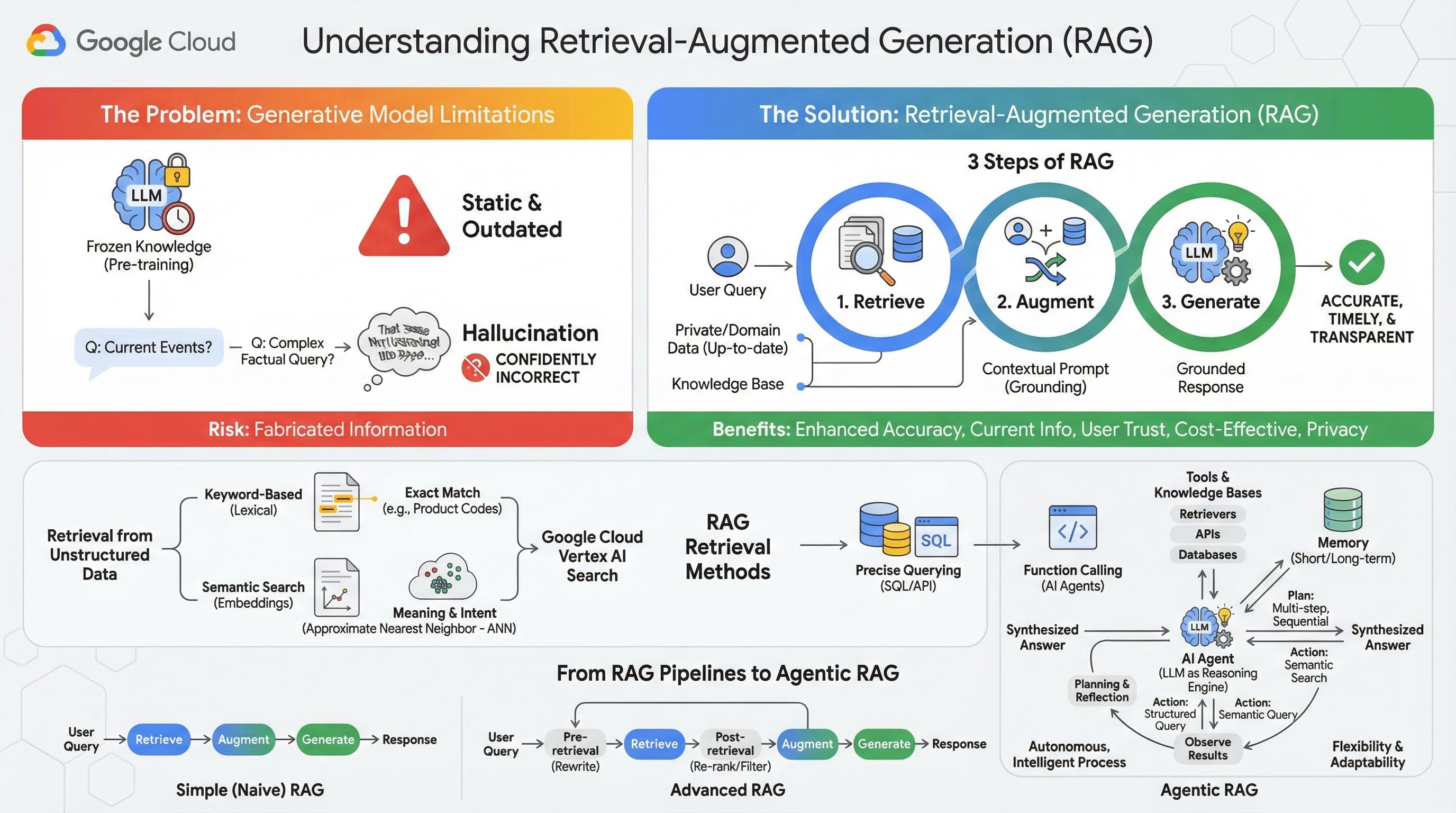
2. Veriyle Artırılmış Üretimi Anlama
Büyük üretken modeller (kısaca büyük dil modelleri veya LLM'ler, görsel-dil modelleri vb.) inanılmaz derecede güçlü olsa da doğasında sınırlamalar vardır. Bilgileri, ön eğitimleri sırasında sabitlenir. Bu nedenle, statiktir ve anında güncelliğini yitirir. İnce ayar yapıldıktan sonra bile modelin bilgileri çok daha güncel hale gelmez. Bunun nedeni, eğitim sonrası aşamaların amacının bu olmamasıdır.
Büyük dil modellerinin, özellikle "düşünme" modellerinin eğitilme şekli nedeniyle, modelin kendisinde bu yanıtı destekleyecek gerçek bilgiler olmasa bile bir yanıt vermesi "ödüllendirilir". Bu durumda, modelin "halüsinasyon gördüğü" yani mantıklı görünen ancak gerçekte yanlış olan bilgileri kendinden emin bir şekilde ürettiği söylenir.
Alma destekli üretim, tam olarak bu sorunları çözmek için tasarlanmış güçlü bir mimari kalıptır. Bu, Büyük Dil Modelleri'nin yeteneklerini, onları harici ve yetkili bilgi kaynaklarına gerçek zamanlı olarak bağlayarak geliştiren bir mimari çerçevedir. Bir RAG sistemindeki LLM, yalnızca statik ve önceden eğitilmiş bilgilerine güvenmek yerine önce kullanıcının sorgusuyla ilgili bilgileri alır, ardından bu bilgileri kullanarak daha doğru, zamanında ve bağlama duyarlı bir yanıt oluşturur.
Bu yaklaşım, üretken modellerin en önemli zayıf noktalarını doğrudan ele alır: Bilgileri belirli bir zaman noktasına sabitlenir ve yanlış bilgi üretmeye veya "halüsinasyon" görmeye yatkındırlar. RAG, LLM'ye etkili bir şekilde "açık kitap sınavı" sunar. Bu sınavda "kitap", özel, alana özgü ve güncel verilerinizdir. LLM'ye gerçek bağlam sağlama sürecine "temellendirme" denir.
RAG'nin 3 adımı
Standart almayla artırılmış üretim süreci üç basit adıma ayrılabilir:
- Alma: Bir kullanıcı sorgu gönderdiğinde sistem, sorguyla alakalı bilgileri bulmak için önce harici bir bilgi tabanında (ör. doküman deposu, veritabanı veya web sitesi) arama yapar.
- Artırma: Alınan bilgiler daha sonra orijinal kullanıcı sorgusuyla birleştirilerek genişletilmiş bir istem oluşturulur. Bu teknik, istemi gerçek bağlamla zenginleştirdiği için bazen "istem doldurma" olarak da adlandırılır.
- Oluşturma: Artırılmış bu istem, LLM'ye iletilir ve LLM yanıt oluşturur. Modele alakalı ve doğru veriler sağlandığı için çıkışı "temellendirilmiş" olup yanlış veya güncel olmama olasılığı çok daha düşüktür.
RAG'nin avantajları
RAG çerçevesinin kullanıma sunulması, pratik ve güvenilir yapay zeka uygulamaları geliştirme konusunda dönüştürücü bir etki yarattı. Bu çözümün temel avantajları şunlardır:
- Gelişmiş Doğruluk ve Azaltılmış Halüsinasyonlar: RAG, yanıtları doğrulanabilir harici olgulara dayandırarak LLM'nin bilgi uydurma riskini önemli ölçüde azaltır.
- Güncel bilgilere erişim: RAG sistemleri, sürekli güncellenen bilgi tabanlarına bağlanabilir. Bu sayede, statik olarak eğitilmiş bir LLM'nin yapamayacağı şekilde, en son bilgilere dayalı yanıtlar verebilir.
- Kullanıcı güveni ve şeffaflıkta artış: LLM'nin yanıtı, alınan belgelere dayandığından sistem, kaynaklarına alıntı ve bağlantı sağlayabilir. Bu sayede kullanıcılar, bilgileri kendileri doğrulayarak uygulamaya güven duyabilir.
- Maliyet etkinliği: Bir LLM'yi yeni verilerle sürekli olarak ince ayarlamak veya yeniden eğitmek, hesaplama açısından ve finansal olarak pahalıdır. RAG ile modelin bilgisini güncellemek, harici veri kaynağını güncellemek kadar basittir ve bu çok daha verimli bir yöntemdir.
- Alan Uzmanlığı ve Gizlilik: RAG, kişilerin ve kuruluşların özel ve tescilli verilerini, sorgu zamanında bir LLM'ye sunmasına olanak tanır. Bu sayede, hassas verilerin modelin eğitim setine dahil edilmesi gerekmez. Bu sayede, veri gizliliği ve güvenliği korunurken alana özgü güçlü uygulamalar kullanılabilir.
Alma
"Alma" adımı, tüm RAG sistemlerinin temelini oluşturur. Doğrudan alınan bilgilerin kalitesi ve alaka düzeyi, oluşturulan son yanıtın kalitesini ve alaka düzeyini doğrudan belirler. Etkili bir RAG uygulaması genellikle çeşitli teknikler kullanarak farklı türlerdeki veri kaynaklarından bilgi almalıdır. Birincil alma yöntemleri üç kategoriye ayrılır: anahtar kelime tabanlı, anlamsal ve yapılandırılmış.
Yapılandırılmamış Verilerden Alma
Geçmişte, yapılandırılmamış verileri alma işlemi geleneksel arama olarak da adlandırılıyordu. Bu yaklaşım, birden fazla dönüşüm geçirdi ve her iki ana yaklaşımdan da yararlanabilirsiniz.
Semantik arama, Google Cloud'da en son teknoloji performansıyla ve yüksek düzeyde kontrolle ölçekli olarak çalıştırabileceğiniz en verimli tekniktir.
- Anahtar Kelimeye Dayalı (Sözcüksel) Arama: Bu, 1970'lerin başlarındaki en eski bilgi getirme sistemlerine kadar uzanan, geleneksel arama yaklaşımıdır. Sözcüksel arama, kullanıcının sorgusundaki kelimeleri (veya "jetonları") bir bilgi tabanındaki dokümanlardaki kelimelerle tam olarak eşleştirerek çalışır. Ürün kodları, yasal maddeler veya benzersiz adlar gibi belirli terimlerde hassasiyetin kritik olduğu sorgular için oldukça etkilidir.
- Semantik Arama: Semantik arama veya "anlamlı arama", kullanıcının amacını ve sorgusunun bağlamsal anlamını (yalnızca kelimelerin anlamını değil) anlamayı amaçlayan daha modern bir yaklaşımdır. Modern semantik arama, karmaşık ve yüksek boyutlu verileri daha düşük boyutlu sayısal vektör uzayına eşleyen bir makine öğrenimi tekniği olan yerleştirme ile desteklenir. Bu vektörler, anlamları benzer olan metinlerin vektör uzayında birbirine yakın olacak şekilde tasarlanır. "Aileler için en iyi köpek cinsleri hangileridir?" araması vektöre dönüştürülür ve sistem, bu alanda "en yakın komşuları" olan belge vektörlerini arar. Bu sayede, "golden retriever" veya "dost canlısı köpekler" hakkında bilgi veren dokümanlar, "köpek" kelimesini içermese bile bulunabilir. Bu yüksek boyutlu arama, Yaklaşık En Yakın Komşu (ANN) algoritmaları sayesinde verimli bir şekilde gerçekleştirilir. ANN algoritmaları, sorgu vektörünü her bir doküman vektörüyle karşılaştırmak yerine (bu, büyük veri kümeleri için çok yavaş olurdu) muhtemelen en yakın olan vektörleri hızlı bir şekilde bulmak için akıllı indeksleme yapılarını kullanır.
Yapılandırılmış Verilerden Alma
Tüm önemli bilgiler yapılandırılmamış dokümanlarda saklanmaz. Genellikle en doğru ve değerli bilgiler, ilişkisel veritabanları, NoSQL veritabanları veya hava durumu verileri ya da hisse senedi fiyatı için REST API gibi bir API türü gibi yapılandırılmış biçimlerde bulunur.
Yapılandırılmış verilerden alma işlemi genellikle yapılandırılmamış metinlerde arama yapmaktan daha doğrudan ve kesindir. Anlamsal benzerlik aramak yerine, dil modellerine bir veritabanında SQL sorgusu veya belirli bir konum ve tarih için hava durumu API'sine API çağrısı gibi kesin bir sorgu oluşturma ve yürütme yeteneği verilebilir.
Yapay zeka ajanlarına güç veren teknik olan işlev çağrısı aracılığıyla uygulanan bu özellik, dil modellerinin yürütülebilir kod ve harici sistemlerle deterministik bir şekilde etkileşime girmesini sağlar.
3. RAG işlem hatlarından ajan tabanlı RAG'ye
RAG kavramı geliştikçe bu kavramı uygulamaya yönelik mimariler de gelişti. Basit ve doğrusal bir işlem hattı olarak başlayan bu sistem, yapay zeka aracıları tarafından yönetilen dinamik ve akıllı bir sisteme dönüştü.
- Basit (veya Naif) RAG: Bu, şimdiye kadar ele aldığımız temel mimaridir: bilgi getirme, artırma ve oluşturma işlemlerinden oluşan doğrusal ve üç adımlı bir süreçtir. Reaktiftir. Her sorgu için sabit bir yolu izler ve basit soru-cevap görevlerinde oldukça etkilidir.
- Gelişmiş RAG: Bu, alınan bağlamın kalitesini artırmak için işlem hattına ek adımların eklendiği bir gelişimi ifade eder. Bu geliştirmeler, alma adımından önce veya sonra gerçekleşebilir.
- Önceden alma: Sorguyu yeniden yazma veya genişletme gibi teknikler kullanılabilir. Sistem, ilk sorguyu analiz edip alma sistemi için daha etkili olacak şekilde yeniden ifade edebilir.
- Alma sonrası: İlk belge grubu alındıktan sonra, belgeleri alaka düzeyine göre puanlamak ve en iyilerini en üste taşımak için yeniden sıralama modeli uygulanabilir. Bu durum, özellikle karma arama için önemlidir. Alınan bağlamı filtrelemek veya sıkıştırmak da bir diğer alma sonrası adımdır. Bu adım, yalnızca en önemli bilgilerin LLM'ye iletilmesini sağlar.
- Ajan tabanlı RAG: Bu, RAG mimarisinin en ileri noktasıdır ve sabit bir ardışık düzenden otonom, akıllı bir sürece geçişi temsil eder. Agentic RAG sisteminde iş akışının tamamı, akıl yürütebilen, plan yapabilen ve eylemlerini dinamik olarak seçebilen bir veya daha fazla yapay zeka aracısı tarafından yönetilir.
Agentic RAG'i anlamak için öncelikle yapay zeka aracısının ne olduğunu anlamak gerekir. Bir aracı, yalnızca bir LLM değildir. Bu sistemin birkaç temel bileşeni vardır:
- Muhakeme motoru olarak büyük dil modeli: Temsilci, metin oluşturmanın yanı sıra planlama, karar verme ve karmaşık görevleri parçalama gibi işlemler için merkezi "beyni" olarak Gemini gibi güçlü bir büyük dil modelini kullanır.
- Araç Seti: Bir aracıya, hedeflerine ulaşmak için kullanmaya karar verebileceği bir işlev araç setine erişim verilir. Bu araçlar her şey olabilir: hesap makinesi, web arama API'si, e-posta gönderme işlevi veya bu laboratuvar için en önemlisi çeşitli bilgi tabanlarımız için alıcılar.
- Bellek: Aracıların hem kısa süreli bellekle (mevcut sohbetin bağlamını hatırlamak için) hem de uzun süreli bellekle (geçmiş etkileşimlerdeki bilgileri hatırlamak için) tasarlanması, daha kişiselleştirilmiş ve tutarlı deneyimler sunar.
- Planlama ve Yansıtma: En gelişmiş temsilciler, karmaşık akıl yürütme kalıpları sergiler. Karmaşık bir hedef alıp bu hedefe ulaşmak için çok adımlı bir plan oluşturabilirler. Ardından bu planı uygulayabilir, hatta yaptıkları işlemlerin sonuçları üzerinde düşünebilir, hataları belirleyebilir ve nihai sonucu iyileştirmek için yaklaşımlarını kendi kendilerine düzeltebilirler.
Agentic RAG, statik işlem hatlarında bulunmayan bir özerklik ve zeka katmanı sunduğu için çığır açan bir teknolojidir.
- Esneklik ve Uyarlanabilirlik: Bir aracı, tek bir alma yoluyla sınırlı değildir. Bir kullanıcı sorgusu verildiğinde en iyi bilgi kaynağı hakkında akıl yürütebilir. Önce yapılandırılmış veritabanına sorgu göndermeye, ardından yapılandırılmamış dokümanlarda anlamsal arama yapmaya ve yine de yanıt bulamazsa herkese açık web'de arama yapmak için Google Arama aracını kullanmaya karar verebilir. Tüm bunlar tek bir kullanıcı isteği bağlamında gerçekleşir.
- Karmaşık ve Çok Adımlı Akıl Yürütme: Bu mimari, birden fazla sıralı alma ve işleme adımı gerektiren karmaşık sorguları işlemekte üstündür.
Şu sorguyu ele alalım: "Christopher Nolan'ın yönettiği en iyi 3 bilim kurgu filmini bul ve her birinin kısa bir olay örgüsü özetini ver." Basit bir RAG ardışık düzeni başarısız olur.
Ancak bir temsilci bunu şu şekilde açıklayabilir:
- Plan: Öncelikle filmleri bulmam gerekiyor. Ardından, her filmin konusunu bulmam gerekiyor.
- 1. işlem: Yapılandırılmış veri aracını kullanarak Nolan'ın bilim kurgu filmleriyle ilgili bir film veritabanına sorgu gönderin: En iyi 3 film, puanı en yüksekten en düşüğe doğru sıralanmış.
- 1. gözlem: Araç,"Başlangıç", "Yıldızlararası" ve "Tenet" filmlerini döndürüyor.
- 2. işlem: "Başlangıç" filminin konusunu bulmak için yapılandırılmamış veri aracını (anlamsal arama) kullanın.
- 2. gözlem: Arsa bilgisi alınır.
- 3. işlem: "Yıldızlararası" için tekrarlayın.
- 4. işlem: "Tenet" için tekrarla.
- Son Sentez: Alınan tüm bilgileri kullanıcı için tek ve tutarlı bir yanıtta birleştir.
4. Proje ayarlama
Google Hesabı
Kişisel Google Hesabınız yoksa Google Hesabı oluşturmanız gerekir.
İş veya okul hesabı yerine kişisel hesap kullanın.
Google Cloud Console'da oturum açma
Kişisel bir Google Hesabı kullanarak Google Cloud Console'da oturum açın.
Faturalandırmayı Etkinleştir
Deneme faturalandırma hesabını kullanma (isteğe bağlı)
Bu atölyeyi düzenlemek için biraz kredisi olan bir faturalandırma hesabınızın olması gerekir. Başlamak için bu codelab'in üst kısmındaki banner'da yer alan kredileri kullanın. Zaten bir faturalandırma hesabına bağlıysanız bu adımı atlayabilirsiniz.
Kişisel faturalandırma hesabı oluşturma
Faturalandırmayı Google Cloud kredilerini kullanarak ayarladıysanız bu adımı atlayabilirsiniz.
Kişisel faturalandırma hesabı oluşturmak için Cloud Console'da faturalandırmayı etkinleştirmek üzere buraya gidin.
Bazı notlar:
- Bu laboratuvarı tamamlamak için 1 ABD dolarından daha az tutarda bulut kaynağı kullanmanız gerekir.
- Daha fazla ücret ödememek için bu laboratuvarın sonundaki adımları uygulayarak kaynakları silebilirsiniz.
- Yeni kullanıcılar 300 ABD doları değerinde ücretsiz deneme sürümünden yararlanabilir.
Proje oluşturma (isteğe bağlı)
Bu laboratuvarda kullanmak istediğiniz mevcut bir projeniz yoksa buradan yeni bir proje oluşturun.
5. Cloud Shell Düzenleyici'yi açma
- Doğrudan Cloud Shell Düzenleyici'ye gitmek için bu bağlantıyı tıklayın.
- Bugün herhangi bir noktada yetkilendirmeniz istenirse devam etmek için Yetkilendir'i tıklayın.
- Terminal ekranın alt kısmında görünmüyorsa açın:
- Görünüm'ü tıklayın.
- Terminal'i tıklayın.
- Terminalde şu komutla projenizi ayarlayın:
gcloud config set project [PROJECT_ID]- Örnek:
gcloud config set project lab-project-id-example - Proje kimliğinizi hatırlamıyorsanız tüm proje kimliklerinizi şu komutla listeleyebilirsiniz:
gcloud projects list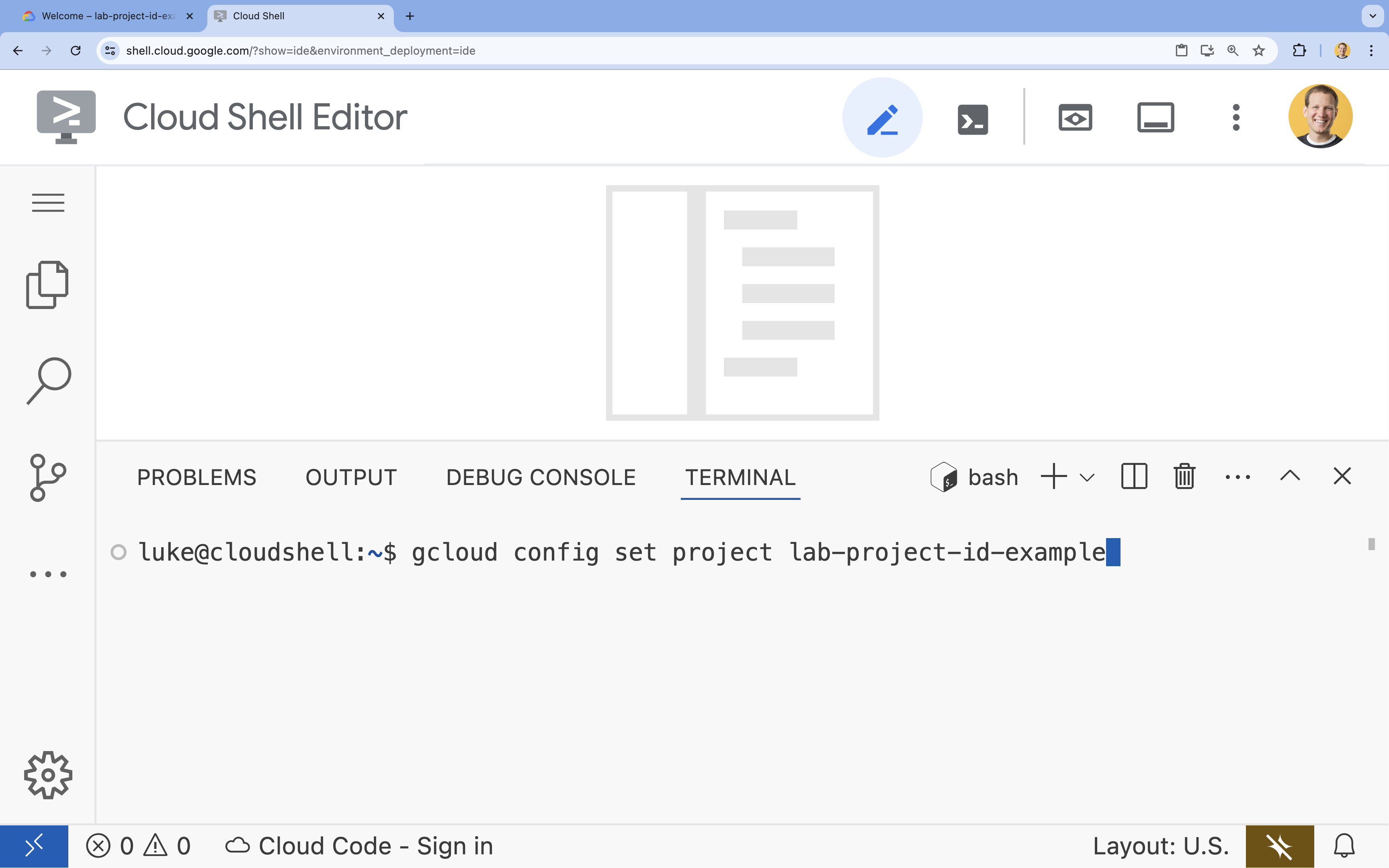
- Örnek:
- Şu mesajı görmeniz gerekir:
Updated property [core/project].
6. API'leri etkinleştir
Agent Development Kit ve Vertex AI Search'ü kullanmak için Google Cloud projenizde gerekli API'leri etkinleştirmeniz gerekir.
- Terminalde API'leri etkinleştirin:
gcloud services enable \ aiplatform.googleapis.com \ discoveryengine.googleapis.com
API'lerle tanışın
- Vertex AI API (
aiplatform.googleapis.com), temsilcinin akıl yürütme ve üretme için Gemini modelleriyle iletişim kurmasını sağlar. - Discovery Engine API (
discoveryengine.googleapis.com), Vertex AI Search'e güç vererek veri depoları oluşturmanıza ve yapılandırılmamış dokümanlarınızda anlamsal aramalar yapmanıza olanak tanır.
7. Ortamı ayarlama
Yapay zeka aracısını kodlamaya başlamadan önce geliştirme ortamınızı hazırlamanız, gerekli kitaplıkları yüklemeniz ve gerekli veri dosyalarını oluşturmanız gerekir.
Sanal ortam oluşturma ve bağımlılıkları yükleme
- Temsilciniz için bir dizin oluşturun ve bu dizine gidin. Terminalde aşağıdaki kodu çalıştırın:
mkdir financial_agent cd financial_agent - Sanal ortam oluşturun:
uv venv --python 3.12 - Sanal ortamı etkinleştirin:
source .venv/bin/activate - Agent Development Kit (ADK) ve pandas'ı yükleyin.
uv pip install google-adk pandas
Borsa fiyatı verilerini oluşturma
Laboratuvar, temsilcinin yapılandırılmış araçları kullanma becerisini göstermek için belirli geçmiş stok verileri gerektirdiğinden bu verileri içeren bir CSV dosyası oluşturacaksınız.
financial_agentdizininde, terminalde aşağıdaki komutu çalıştırarakgoog.csvdosyasını oluşturun:cat <<EOF > goog.csv Date,Open,High,Low,Close,Adj Close,Volume 2023-01-03,89.830002,91.550003,89.019997,89.699997,89.699997,20738500 2023-03-31,101.440002,103.889999,101.040001,103.730003,103.730003,36823200 2023-06-30,120.870003,122.029999,120.300003,120.970001,120.970001,23824700 2023-09-29,134.080002,134.550003,131.320007,131.850006,131.850006,21124200 2025-07-10,185.000000,188.000000,184.500000,186.500000,186.500000,25000000 EOF
Ortam değişkenlerini yapılandırma
financial_agentdizininde, aracınızın ortam değişkenlerini yapılandırmak için bir.envdosyası oluşturun. Bu, ADK'ya hangi proje, konum ve modelin kullanılacağını bildirir. Terminalde aşağıdaki kodu çalıştırın:# Create the .env file using the captured variables cat << EOF > .env GOOGLE_GENAI_USE_VERTEXAI=TRUE GOOGLE_CLOUD_PROJECT="${GOOGLE_CLOUD_PROJECT}" GOOGLE_CLOUD_LOCATION="us-central1" EOF
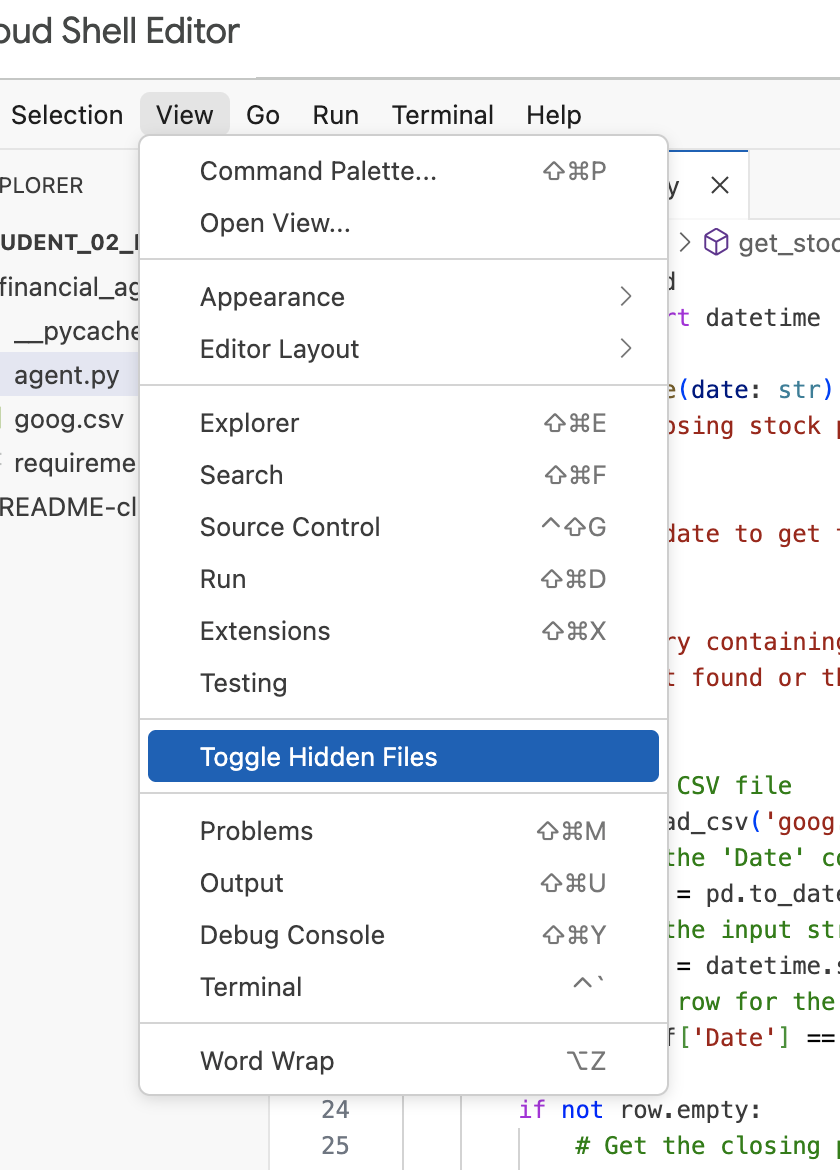
Not: Laboratuvarın ilerleyen aşamalarında .env dosyasını değiştirmeniz gerekirse ancak dosyayı financial_agent dizininde görmüyorsanız "View / Toggle Hidden Files " (Görünüm/Gizli Dosyaları Aç/Kapat) menü öğesini kullanarak Cloud Shell Düzenleyici'de gizli dosyaların görünürlüğünü açıp kapatmayı deneyin.
8. Vertex AI Arama veri deposu oluşturma
Temsilcinin Alphabet'in mali raporlarıyla ilgili soruları yanıtlamasını sağlamak için, kamuya açık SEC başvurularını içeren bir Vertex AI Search veri deposu oluşturacaksınız.
- Yeni bir tarayıcı sekmesinde Cloud Console'u (console.cloud.google.com) açın ve üstteki arama çubuğunu kullanarak AI Applications'a (Yapay Zeka Uygulamaları) gidin.
- İstenirse hükümler ve koşullar onay kutusunu işaretleyin ve Devam et ve API'yi etkinleştir'i tıklayın.
- Soldaki gezinme menüsünden Veri depoları'nı seçin.
- + Veri deposu oluştur'u tıklayın.
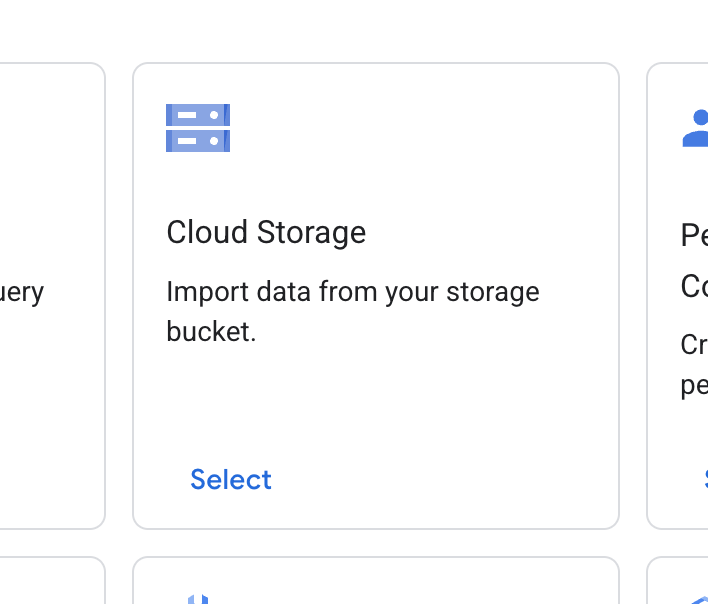
- Cloud Storage kartını bulup Seç'i tıklayın.
- Veri kaynağı olarak Yapılandırılmamış dokümanlar'ı seçin.

- İçe aktarma kaynağı için (İçe aktarmak istediğiniz bir klasörü veya dosyayı seçin) Google Cloud Storage yolunu girin
cloud-samples-data/gen-app-builder/search/alphabet-sec-filings. - Devam'ı tıklayın.
- Konumu global olarak ayarlayın.
- Veri deposu adı için şunu girin:
alphabet-sec-filings - Belge işleme seçenekleri bölümünü genişletin.

- Varsayılan doküman ayrıştırıcı açılır listesinde Layout Parser'ı (Düzen Ayrıştırıcı) seçin.
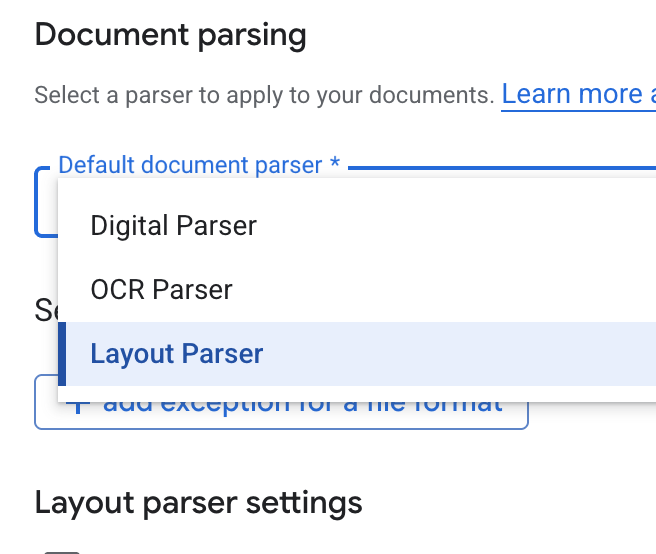
- Düzen ayrıştırıcı ayarları seçeneklerinde Tablo ek açıklamalarını etkinleştir ve Resim ek açıklamalarını etkinleştir'i seçin.
- Devam'ı tıklayın.
- Fiyatlandırma modeli olarak Genel fiyatlandırma'yı (kullandıkça öde, tüketime dayalı bir model) seçin ve Oluştur'u tıklayın.
- Veri deponuz belgeleri içe aktarmaya başlar.
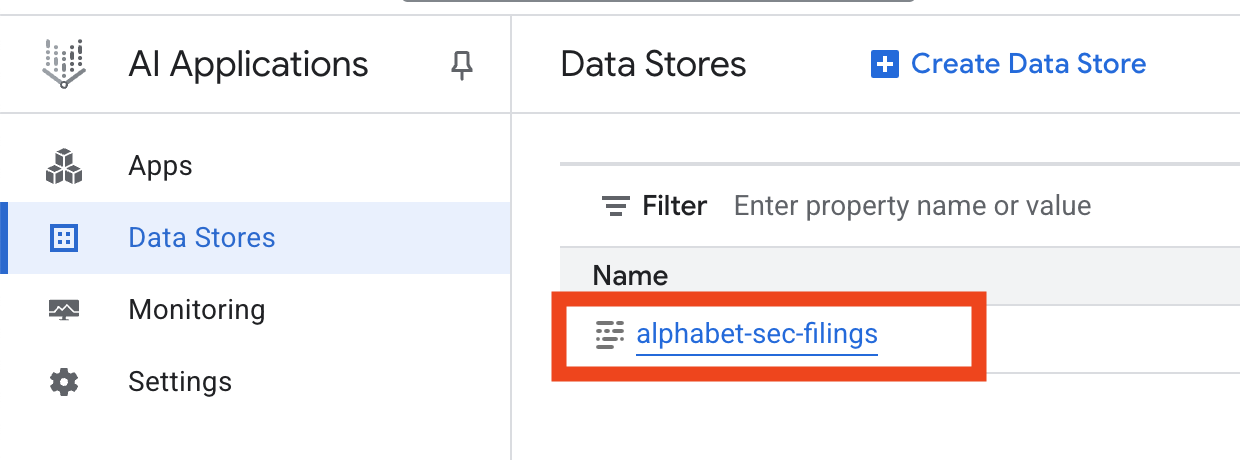
- Veri deposu adını tıklayın ve Veri Depoları tablosundan kimliğini kopyalayın. Bu bilgiye bir sonraki adımda ihtiyacınız olacak.
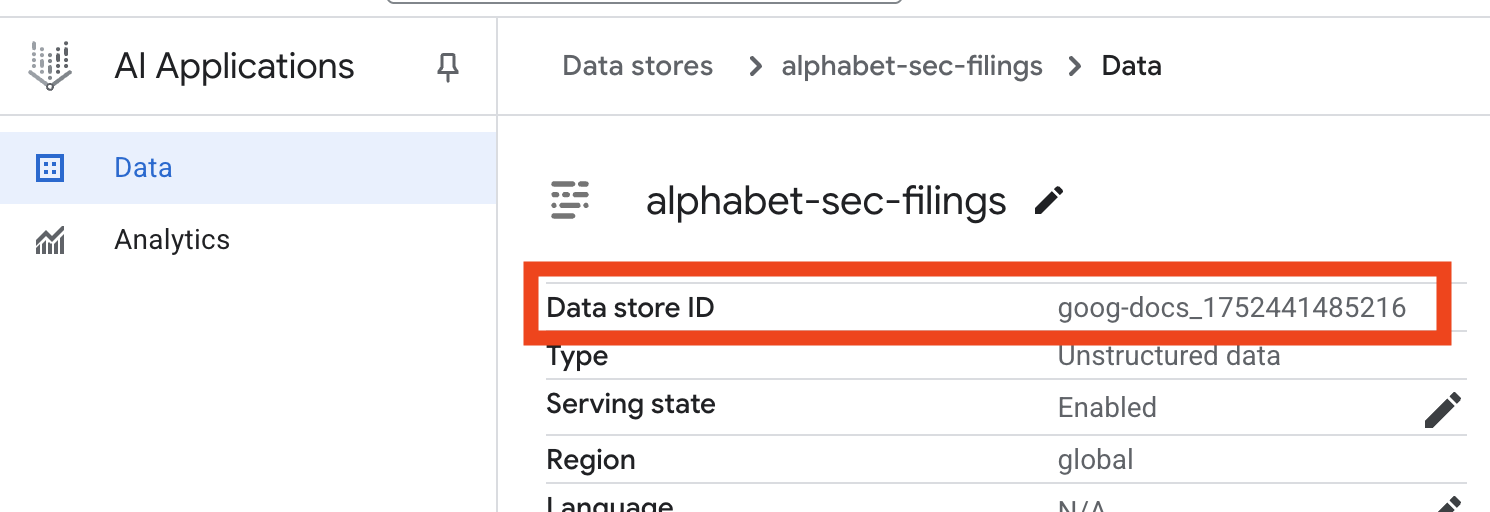
- Cloud Shell Editor'da
.envdosyasını açın ve veri deposu kimliğiniDATA_STORE_ID="YOUR_DATA_STORE_ID"olarak ekleyin (YOUR_DATA_STORE_IDyerine önceki adımdaki gerçek kimliği kullanın).Not: Veri deposundaki verilerin içe aktarılması, ayrıştırılması ve dizine eklenmesi birkaç dakika sürer. İşlemi kontrol etmek için veri deposu adını tıklayarak özelliklerini açın ve ardından Etkinlik sekmesini açın. Durumun "İçe aktarma tamamlandı" olmasını bekleyin.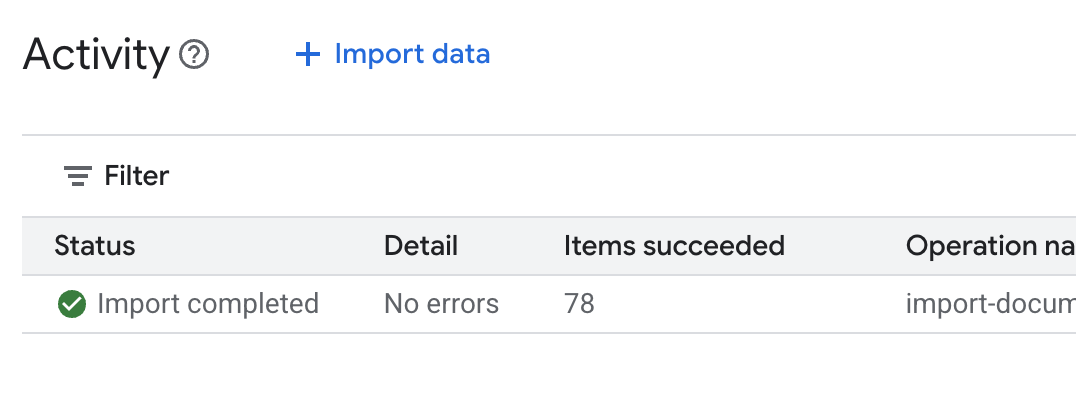
9. Yapılandırılmış veriler için özel bir araç oluşturma
Ardından, aracı için bir araç görevi görecek Python işlevi oluşturacaksınız. Bu araç, belirli bir tarihteki geçmiş borsa fiyatlarını almak için goog.csv dosyasını okur.
financial_agentdizininizdeagent.pyadlı yeni bir dosya oluşturun. Terminalde aşağıdaki komutu çalıştırın:cloudshell edit agent.py- Aşağıdaki Python kodunu
agent.pydosyasına ekleyin. Bu kod, bağımlılıkları içe aktarır veget_stock_priceişlevini tanımlar.from datetime import datetime import os import logging import google.cloud.logging from google.adk.tools import VertexAiSearchTool from google.adk.tools.agent_tool import AgentTool from google.adk.agents import LlmAgent import pandas as pd def get_stock_price(date: str) -> dict: """Gets the closing stock price for a given date. Args: date: The date to get the stock price for, in YYYY-MM-DD format. Returns: A dictionary containing the closing price, or an error message if the date is not found or the format is incorrect. """ try: # Load the CSV file df = pd.read_csv('goog.csv') # Convert the 'Date' column to datetime objects df['Date'] = pd.to_datetime(df['Date']) # Convert the input string to a datetime object query_date = datetime.strptime(date, '%Y-%m-%d') # Find the row for the given date row = df[df['Date'] == query_date] if not row.empty: # Get the closing price close_price = row['Close'].iloc[0] return {"status": "success", "date": date, "closing_price": close_price} else: return {"status": "error", "message": f"No data found for date: {date}"} except FileNotFoundError: return {"status": "error", "message": "Stock data file (goog.csv) not found."} except Exception as e: return {"status": "error", "message": f"An error occurred: {str(e)}"}
Fonksiyonun ayrıntılı docstring'ine dikkat edin. Bu doküman dizeleri, işlevin ne yaptığını, parametrelerini (Args) ve ne döndürdüğünü (Returns) açıklar. ADK, bu doküman dizelerini kullanarak aracıya bu aracı nasıl ve ne zaman kullanacağını öğretir.
10. RAG aracısını oluşturma ve çalıştırma
Şimdi aracıyı monte etme zamanı. Yapılandırılmamış veriler için Vertex AI Search aracını, yapılandırılmış veriler için özel get_stock_price aracınızla birlikte kullanacaksınız.
- Aşağıdaki kodu
agent.pydosyanıza ekleyin. Bu kod, gerekli ADK sınıflarını içe aktarır, araçların örneklerini oluşturur ve aracıyı tanımlar.logging.basicConfig(level=logging.INFO) cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() # 1. Create the Vertex AI Search tool full_datastore_id = f"projects/{os.environ['GOOGLE_CLOUD_PROJECT']}/locations/global/collections/default_collection/dataStores/{os.environ['DATA_STORE_ID']}" vertex_ai_search_tool = VertexAiSearchTool( data_store_id=full_datastore_id ) # 2. Define the Search+Q&A agent # Since we cannot combine tools with other tools in a single agent, # we create a separate Search+Q&A agent which will be used as a tool by the main root agent. doc_qa_agent = LlmAgent( name="search_and_qna_agent", model="gemini-2.5-flash", tools=[vertex_ai_search_tool], instruction="""You are a helpful assistant that answers questions based on information found in the document store. Use the search tool to find relevant information before answering. If the answer isn't in the documents, say that you couldn't find the information. """, description="Answers questions using a specific Vertex AI Search datastore.", ) # 3. Define the root agent with 2 tools. root_agent = LlmAgent( name="financial_agent", model="gemini-2.5-flash", tools=[ AgentTool(doc_qa_agent), get_stock_price, ], instruction="""You are an Financial Analytics Agent that answers question about Alphabet stock prices (using get_stock_price tool) and historical performance based on the data in Vertex AI Search datastore (using doc_qa_agent tool).""" ) - Terminalinizde,
financial_agentdizininde, temsilcinizle etkileşim kurmak için ADK web arayüzünü başlatın:adk web ~ - Tarayıcınızda ADK Dev kullanıcı arayüzünü açmak için terminal çıkışında sağlanan bağlantıyı (genellikle
http://127.0.0.1:8000) tıklayın.
11. Temsilciyi test etme
Artık temsilcinizin akıl yürütme ve karmaşık soruları yanıtlamak için araçlarını kullanma becerisini test edebilirsiniz.
- ADK Dev UI'de açılır menüden
financial_agent'nizin seçildiğinden emin olun. - SEC dosyalarındaki (yapılandırılmamış veriler) bilgileri gerektiren bir soru sormayı deneyin. Sohbete aşağıdaki sorguyu girin:
What were the total revenues for the quarter ending on March 31, 2023?VertexAiSearchToolkullanansearch_and_qna_agentişlevini çağırmalıdır. - Ardından, özel aracınızın (yapılandırılmış veriler) kullanılmasını gerektiren bir soru sorun. İstemdeki tarih biçiminin, işlevin gerektirdiği biçimle tam olarak eşleşmesi gerekmez. LLM, biçimi yeniden düzenleyecek kadar akıllıdır.
What was the closing stock price for Alphabet on July 10, 2025?get_stock_pricearacınızı çağırmalıdır. İşlev çağrısını ve sonucunu incelemek için sohbetteki araç simgesini tıklayabilirsiniz. - Son olarak, aracının her iki aracı da kullanmasını ve sonuçları sentezlemesini gerektiren karmaşık bir soru sorun.
According to the 10-Q filing for the period ending March 31, 2023, what were the company's net cash provided by operating activities, and what was the stock's closing price on that date?- İlk olarak, SEC başvurularındaki nakit akışı bilgilerini bulmak için
VertexAiSearchToolkullanılır. - Ardından, hisse senedi fiyatına ihtiyaç olduğunu anlayacak ve
get_stock_priceişlevini tarihle birlikte2023-03-31çağıracaktır. - Son olarak, her iki bilgiyi tek ve kapsamlı bir yanıtta birleştirir.
- İlk olarak, SEC başvurularındaki nakit akışı bilgilerini bulmak için
- İşlemi tamamladığınızda tarayıcı sekmesini kapatabilir ve ADK sunucusunu durdurmak için terminalde
CTRL+Ctuşuna basabilirsiniz.
12. Göreviniz için hizmet seçme
Kullanabileceğiniz tek Vector Search hizmeti Vertex AI Search değildir. Ayrıca, almayla artırılmış üretimin tüm akışını otomatikleştiren yönetilen bir hizmet olan Vertex AI RAG Engine'i de kullanabilirsiniz.
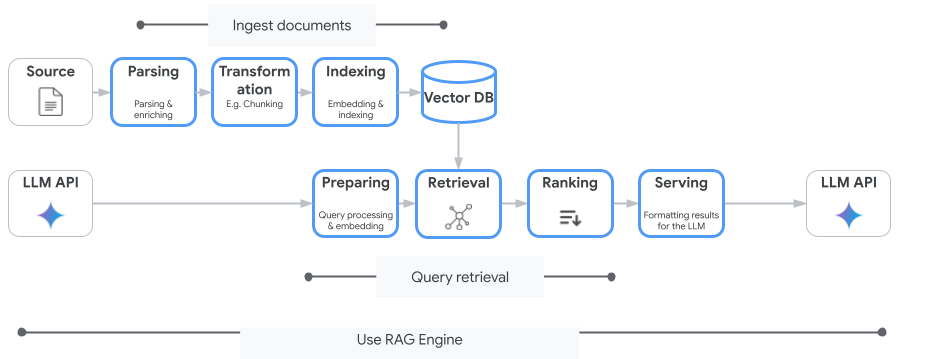
Doküman alımından alma ve yeniden sıralamaya kadar her şeyi yönetir. RAG Engine, Pinecone ve Weaviate dahil olmak üzere birden fazla vektör deposunu destekler.
Ayrıca, birçok özel vektör veritabanını kendiniz barındırabilir veya PostgreSQL hizmetindeki (ör. AlloyDB veya BigQuery Vector Search) pgvector gibi veritabanı motorlarındaki vektör dizini özelliklerinden yararlanabilirsiniz.
Vektör Arama'yı destekleyen diğer bazı hizmetler:
- PostgreSQL için Cloud SQL
- MySQL için Cloud SQL
- Cloud Spanner
- Redis için Memorystore
- Firestore
- Bigtable
Google Cloud'da belirli bir hizmeti seçmeyle ilgili genel rehberlik şu şekildedir:
- Çalışan ve iyi ölçeklendirilmiş bir Vector Search Kendin Yap altyapınız varsa bunu Google Kubernetes Engine'e (ör. Weaviate veya DIY PostgreSQL) dağıtın.
- Verileriniz BigQuery, AlloyDB, Firestore veya başka bir veritabanındaysa anlamsal arama, bu veritabanında daha büyük bir sorgunun parçası olarak büyük ölçekte gerçekleştirilebiliyorsa veritabanının Vector Search özelliklerini kullanmayı düşünebilirsiniz. Örneğin, bir BigQuery tablosunda ürün açıklamalarınız ve/veya resimleriniz varsa metin ve/veya resim yerleştirme sütunu eklemek benzerlik aramasının büyük ölçekte kullanılmasını sağlar. ScaNN arama desteği içeren Vector Index'ler, dizindeki milyarlarca öğeyi destekler.
- Yönetilen bir platformda minimum çabayla hızlı bir şekilde başlamanız gerekiyorsa Vertex AI Arama'yı seçin. Bu, yüksek kullanıma hazır kalite, ölçeklenebilirlik ve ayrıntılı erişim denetimleri gerektiren karmaşık kurumsal kullanım alanları için ideal olan, tümüyle yönetilen bir arama motoru ve alıcı API'sidir. Çeşitli kurumsal veri kaynaklarına bağlanmayı kolaylaştırır ve birden fazla kaynakta arama yapmayı sağlar.
- Kullanım kolaylığı ve özelleştirme arasında denge kurmak isteyen geliştiriciler için ideal bir çözüm arıyorsanız Vertex AI RAG Engine'i kullanın. Esneklikten ödün vermeden hızlı prototip oluşturma ve geliştirme olanağı sunar.
- Veriyle Artırılmış Üretim için Referans Mimarileri'ni inceleyin.
13. Sonuç
Tebrikler! Veriyle Artırılmış Üretim ile yapay zeka ajanı oluşturma ve test etme işlemlerini başarıyla tamamladınız. Öğrendikleriniz:
- Vertex AI Search'ün güçlü semantik arama özelliklerini kullanarak yapılandırılmamış belgeler için bilgi tabanı oluşturma
- Yapılandırılmış verileri almak için araç görevi görecek özel bir Python işlevi geliştirin.
- Gemini destekli çok araçlı bir ajan oluşturmak için Agent Development Kit'i (ADK) kullanın.
- Birden fazla kaynaktan bilgi sentezlemeyi gerektiren sorguları yanıtlamak için karmaşık ve çok adımlı akıl yürütme yapabilen bir ajan oluşturun.
Bu laboratuvarda, Google Cloud'da akıllı, doğru ve bağlama duyarlı yapay zeka uygulamaları oluşturmak için kullanılan güçlü bir mimari olan ajan tabanlı RAG'nin temel ilkeleri gösterilmektedir.
Prototipten Üretime
Bu laboratuvar, Google Cloud ile Üretime Hazır Yapay Zeka Öğrenme Rotası'nın bir parçasıdır.
- Prototip aşamasından üretim aşamasına geçiş yapmak için tüm müfredatı inceleyin.
- #ProductionReadyAI hashtag'ini kullanarak ilerlemenizi paylaşın.