
1. Giới thiệu
Tổng quan
Mục tiêu của lớp học lập trình này là tìm hiểu cách phát triển các ứng dụng Tạo sinh tăng cường truy xuất (RAG) dựa trên tác nhân từ đầu đến cuối trong Google Cloud. Trong phòng thí nghiệm này, bạn sẽ tạo một tác nhân phân tích tài chính có thể trả lời các câu hỏi bằng cách kết hợp thông tin từ hai nguồn khác nhau: tài liệu không có cấu trúc (Hồ sơ hằng quý của Alphabet gửi cho SEC – báo cáo tài chính và thông tin chi tiết về hoạt động mà mọi công ty đại chúng ở Hoa Kỳ gửi cho Uỷ ban Chứng khoán và Sàn giao dịch), và dữ liệu có cấu trúc (giá cổ phiếu trong quá khứ).
Bạn sẽ sử dụng Vertex AI Search để tạo một công cụ tìm kiếm ngữ nghĩa mạnh mẽ cho các báo cáo tài chính không có cấu trúc. Đối với dữ liệu có cấu trúc, bạn sẽ tạo một công cụ Python tuỳ chỉnh. Cuối cùng, bạn sẽ sử dụng Bộ công cụ phát triển tác nhân (ADK) để tạo một tác nhân thông minh có thể suy luận về cụm từ tìm kiếm của người dùng, quyết định sử dụng công cụ nào và tổng hợp thông tin thành một câu trả lời mạch lạc.
Bạn sẽ thực hiện
- Thiết lập một kho dữ liệu Vertex AI Search để tìm kiếm ngữ nghĩa trên các tài liệu riêng tư.
- Tạo một hàm Python tuỳ chỉnh làm công cụ cho một tác nhân.
- Sử dụng Bộ công cụ phát triển tác nhân (ADK) để tạo một tác nhân đa công cụ.
- Kết hợp việc truy xuất từ các nguồn dữ liệu không có cấu trúc và có cấu trúc để trả lời các câu hỏi phức tạp.
- Kiểm thử và tương tác với một tác nhân có khả năng suy luận.
Kiến thức bạn sẽ học được
Trong lớp học này, bạn sẽ tìm hiểu:
- Các khái niệm cốt lõi về tính năng Tạo sinh tăng cường truy xuất (RAG) và RAG dựa trên tác nhân.
- Cách triển khai tính năng tìm kiếm ngữ nghĩa trên tài liệu bằng Vertex AI Search.
- Cách hiển thị dữ liệu có cấu trúc cho một tác nhân bằng cách tạo các công cụ tuỳ chỉnh.
- Cách tạo và điều phối một tác nhân có nhiều công cụ bằng Bộ công cụ phát triển tác nhân (ADK).
- Cách các đặc vụ sử dụng khả năng suy luận và lập kế hoạch để trả lời các câu hỏi phức tạp bằng nhiều nguồn dữ liệu.
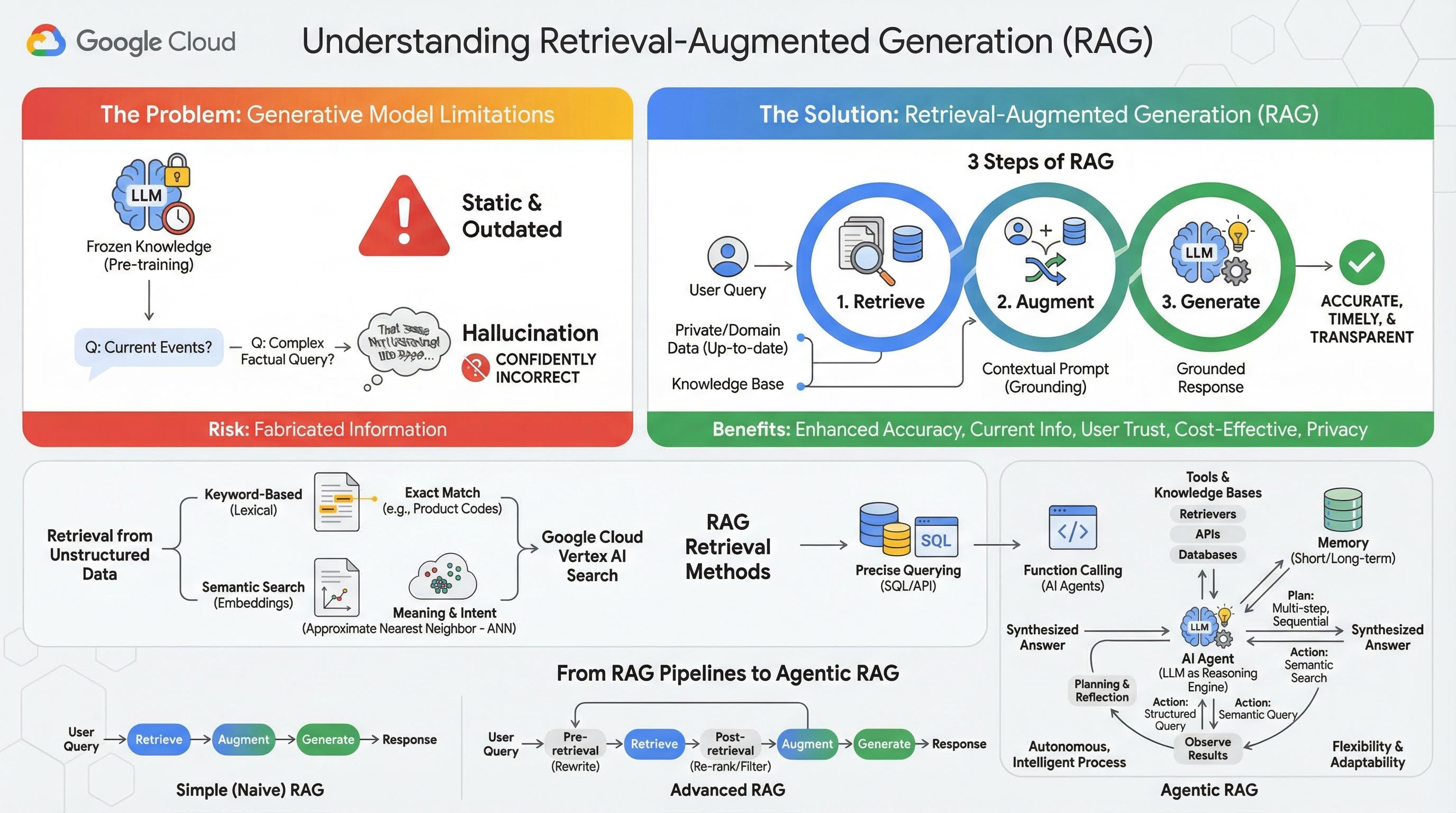
2. Tìm hiểu về tính năng tạo nội dung tăng cường khả năng truy xuất
Các Mô hình tạo sinh quy mô lớn (Mô hình ngôn ngữ lớn hoặc LLM, Mô hình ngôn ngữ thị giác, v.v.) có sức mạnh đáng kinh ngạc, nhưng chúng có những hạn chế vốn có. Kiến thức của các mô hình này bị giới hạn tại thời điểm huấn luyện trước, khiến kiến thức trở nên tĩnh và nhanh chóng lỗi thời. Ngay cả sau khi tinh chỉnh, kiến thức của mô hình cũng không trở nên mới hơn nhiều, vì đây không phải là mục tiêu của các giai đoạn huấn luyện sau.
Cách các Mô hình ngôn ngữ lớn được huấn luyện, đặc biệt là các mô hình "tư duy", chúng được "thưởng" khi đưa ra một câu trả lời nào đó ngay cả khi bản thân mô hình không có thông tin thực tế để hỗ trợ câu trả lời đó. Đây là khi người ta nói rằng một mô hình "ảo tưởng" – tự tin tạo ra thông tin nghe có vẻ hợp lý nhưng thực chất lại không chính xác.
Tạo sinh tăng cường khả năng truy xuất là một mẫu kiến trúc mạnh mẽ được thiết kế để giải quyết chính xác những vấn đề này. Đây là một khung kiến trúc giúp nâng cao khả năng của Mô hình ngôn ngữ lớn bằng cách kết nối các mô hình này với các nguồn kiến thức bên ngoài, đáng tin cậy theo thời gian thực. Thay vì chỉ dựa vào kiến thức tĩnh, được huấn luyện trước, LLM trong hệ thống RAG trước tiên sẽ truy xuất thông tin liên quan đến cụm từ tìm kiếm của người dùng, sau đó sử dụng thông tin đó để tạo ra câu trả lời chính xác, kịp thời và phù hợp với bối cảnh hơn.
Phương pháp này trực tiếp giải quyết những điểm yếu quan trọng nhất của các mô hình tạo sinh: kiến thức của chúng được cố định tại một thời điểm và chúng có xu hướng tạo ra thông tin không chính xác hoặc "ảo giác". RAG mang lại cho LLM một "bài kiểm tra tham khảo tài liệu" hiệu quả, trong đó "tài liệu" là dữ liệu riêng tư, theo miền cụ thể và mới nhất của bạn. Quá trình cung cấp bối cảnh thực tế cho LLM này được gọi là "liên kết thực tế".
3 bước của RAG
Quy trình Tạo sinh tăng cường dựa trên thông tin truy xuất tiêu chuẩn có thể chia thành 3 bước đơn giản:
- Truy xuất: Khi người dùng gửi một câu hỏi, hệ thống sẽ tìm kiếm trong cơ sở kiến thức bên ngoài (chẳng hạn như kho lưu trữ tài liệu, cơ sở dữ liệu hoặc trang web) để tìm thông tin liên quan đến câu hỏi đó.
- Tăng cường: Sau đó, thông tin đã truy xuất sẽ được kết hợp với cụm từ tìm kiếm ban đầu của người dùng thành một câu lệnh mở rộng. Kỹ thuật này đôi khi được gọi là "nhồi câu lệnh", vì nó làm phong phú câu lệnh bằng ngữ cảnh thực tế.
- Tạo: Câu lệnh tăng cường này được cung cấp cho LLM, sau đó LLM sẽ tạo ra một câu trả lời. Vì mô hình này đã được cung cấp dữ liệu thực tế và phù hợp, nên đầu ra của mô hình sẽ "dựa trên thực tế" và ít có khả năng không chính xác hoặc lỗi thời hơn nhiều.
Lợi ích của RAG
Việc ra mắt khung RAG đã mang đến sự thay đổi lớn trong việc xây dựng các ứng dụng AI đáng tin cậy và thiết thực. Các lợi ích chính của tính năng này bao gồm:
- Tăng độ chính xác và giảm tình trạng ảo tưởng: Bằng cách dựa vào các thông tin thực tế bên ngoài có thể xác minh để đưa ra câu trả lời, RAG giúp giảm đáng kể nguy cơ LLM bịa đặt thông tin.
- Truy cập vào thông tin hiện tại: Các hệ thống RAG có thể kết nối với các cơ sở kiến thức được cập nhật liên tục, cho phép các hệ thống này đưa ra câu trả lời dựa trên thông tin mới nhất, điều mà LLM được huấn luyện tĩnh không thể làm được.
- Tăng độ tin cậy và tính minh bạch của người dùng: Vì câu trả lời của LLM dựa trên các tài liệu đã truy xuất, nên hệ thống có thể cung cấp thông tin trích dẫn và đường liên kết đến các nguồn của câu trả lời. Điều này cho phép người dùng tự xác minh thông tin, từ đó tạo dựng niềm tin vào ứng dụng.
- Tính hiệu quả về chi phí: Việc liên tục tinh chỉnh hoặc huấn luyện lại một LLM bằng dữ liệu mới sẽ tốn nhiều chi phí về điện toán và tài chính. Với RAG, việc cập nhật kiến thức của mô hình cũng đơn giản như việc cập nhật nguồn dữ liệu bên ngoài, hiệu quả hơn nhiều.
- Quyền riêng tư và chuyên môn hoá theo miền: RAG cho phép mọi người và các tổ chức cung cấp dữ liệu thuộc quyền sở hữu riêng, riêng tư của họ cho một LLM (mô hình ngôn ngữ lớn) tại thời điểm truy vấn mà không cần đưa dữ liệu nhạy cảm đó vào tập dữ liệu huấn luyện của mô hình. Điều này cho phép các ứng dụng mạnh mẽ, dành riêng cho từng miền hoạt động trong khi vẫn duy trì quyền riêng tư đối với dữ liệu và bảo mật.
Truy xuất
Bước "Truy xuất" là trọng tâm của mọi hệ thống RAG. Chất lượng và mức độ phù hợp của thông tin được truy xuất sẽ quyết định trực tiếp chất lượng và mức độ phù hợp của câu trả lời được tạo cuối cùng. Một ứng dụng RAG hiệu quả thường cần truy xuất thông tin từ nhiều loại nguồn dữ liệu bằng nhiều kỹ thuật. Các phương pháp truy xuất chính được chia thành 3 danh mục: dựa trên từ khoá, ngữ nghĩa và có cấu trúc.
Truy xuất từ dữ liệu không có cấu trúc
Trước đây, việc truy xuất dữ liệu không có cấu trúc là một tên gọi khác của hoạt động Tìm kiếm truyền thống. Mô hình này đã trải qua nhiều biến đổi và bạn có thể hưởng lợi từ cả hai phương pháp chính.
Tìm kiếm ngữ nghĩa là kỹ thuật hiệu quả nhất mà bạn có thể chạy trên quy mô lớn trong Google Cloud với hiệu suất hiện đại và mức độ kiểm soát cao.
- Tìm kiếm dựa trên từ khoá (từ vựng): Đây là phương pháp tìm kiếm truyền thống, có từ những hệ thống truy xuất thông tin sớm nhất vào những năm 1970. Tìm kiếm theo từ vựng hoạt động bằng cách so khớp các từ (hoặc "mã thông báo") theo nghĩa đen trong truy vấn của người dùng với chính xác các từ đó trong tài liệu thuộc cơ sở kiến thức. Điều này rất hiệu quả đối với những cụm từ tìm kiếm mà độ chính xác về các cụm từ cụ thể (chẳng hạn như mã sản phẩm, điều khoản pháp lý hoặc tên riêng) là yếu tố quan trọng.
- Tìm kiếm ngữ nghĩa: Tìm kiếm ngữ nghĩa, hay "tìm kiếm theo ý nghĩa", là một phương pháp hiện đại hơn nhằm mục đích hiểu được ý định của người dùng và ý nghĩa theo ngữ cảnh của cụm từ tìm kiếm, chứ không chỉ là từ khoá theo nghĩa đen. Tính năng tìm kiếm ngữ nghĩa hiện đại được hỗ trợ bởi mô hình nhúng – một kỹ thuật học máy giúp ánh xạ dữ liệu phức tạp, đa chiều thành một không gian vectơ ít chiều hơn của các vectơ số. Các vectơ này được thiết kế sao cho những văn bản có ý nghĩa tương tự nằm gần nhau trong không gian vectơ. Câu hỏi tìm kiếm "What are the best dog breeds for families?" (Những giống chó nào phù hợp nhất với gia đình?) được chuyển đổi thành một vectơ, sau đó hệ thống sẽ tìm kiếm các vectơ tài liệu là "hàng xóm gần nhất" của vectơ đó trong không gian. Nhờ đó, Gemini có thể tìm thấy những tài liệu nói về "chó tha mồi vàng" hoặc "chó thân thiện", ngay cả khi những tài liệu đó không chứa chính xác từ "chó". Thuật toán Tìm kiếm lân cận gần đúng (ANN) giúp việc tìm kiếm nhiều chiều trở nên hiệu quả. Thay vì so sánh vectơ truy vấn với từng vectơ tài liệu (việc này sẽ quá chậm đối với các tập dữ liệu lớn), các thuật toán ANN sử dụng các cấu trúc lập chỉ mục thông minh để nhanh chóng tìm thấy những vectơ có khả năng gần nhất.
Truy xuất từ dữ liệu có cấu trúc
Không phải kiến thức quan trọng nào cũng được lưu trữ trong các tài liệu không có cấu trúc. Thông thường, thông tin chính xác và có giá trị nhất nằm ở các định dạng có cấu trúc như cơ sở dữ liệu quan hệ, cơ sở dữ liệu NoSQL hoặc một số loại API, chẳng hạn như API REST cho dữ liệu thời tiết hoặc giá cổ phiếu.
Việc truy xuất từ dữ liệu có cấu trúc thường trực tiếp và chính xác hơn so với việc tìm kiếm văn bản không có cấu trúc. Thay vì tìm kiếm sự tương đồng về ngữ nghĩa, các mô hình ngôn ngữ có thể được cung cấp khả năng xây dựng và thực thi một truy vấn chính xác, chẳng hạn như truy vấn SQL trên cơ sở dữ liệu hoặc lệnh gọi API đến API thời tiết cho một vị trí và ngày cụ thể.
Được triển khai thông qua chức năng gọi (cũng là kỹ thuật hỗ trợ các Đặc vụ AI), tính năng này cho phép các mô hình ngôn ngữ tương tác với mã thực thi và các hệ thống bên ngoài theo cách có cấu trúc và mang tính xác định.
3. Từ quy trình RAG đến RAG dựa trên tác nhân
Cũng như khái niệm về RAG đã phát triển, các cấu trúc để triển khai RAG cũng vậy. Từ một quy trình đơn giản và tuyến tính, hệ thống này đã phát triển thành một hệ thống thông minh và linh hoạt do các tác nhân AI điều phối.
- RAG đơn giản (hoặc sơ khai): Đây là cấu trúc cơ bản mà chúng ta đã thảo luận cho đến nay: một quy trình tuyến tính gồm 3 bước là truy xuất, tăng cường và tạo. Đây là một mô hình phản ứng; mô hình này tuân theo một đường dẫn cố định cho mọi truy vấn và có hiệu quả cao đối với các tác vụ hỏi và đáp đơn giản.
- RAG nâng cao: Đây là một bước tiến trong đó các bước bổ sung được thêm vào quy trình để cải thiện chất lượng của ngữ cảnh được truy xuất. Những điểm cải tiến này có thể xảy ra trước hoặc sau bước truy xuất.
- Truy xuất trước: Bạn có thể sử dụng các kỹ thuật như viết lại hoặc mở rộng truy vấn. Hệ thống có thể phân tích cụm từ tìm kiếm ban đầu và diễn đạt lại để cụm từ đó hiệu quả hơn đối với hệ thống truy xuất.
- Sau khi truy xuất: Sau khi truy xuất một nhóm tài liệu ban đầu, bạn có thể áp dụng mô hình xếp hạng lại để tính điểm mức độ liên quan của các tài liệu và đẩy những tài liệu tốt nhất lên đầu. Điều này đặc biệt quan trọng trong tìm kiếm kết hợp. Một bước khác sau khi truy xuất là lọc hoặc nén ngữ cảnh đã truy xuất để đảm bảo chỉ thông tin nổi bật nhất được truyền đến LLM.
- RAG dựa trên tác nhân: Đây là công nghệ tiên tiến của cấu trúc RAG, thể hiện sự thay đổi mô hình từ một quy trình cố định sang một quy trình tự động, thông minh. Trong hệ thống RAG dựa trên tác nhân, toàn bộ quy trình làm việc được quản lý bởi một hoặc nhiều Tác nhân AI có thể suy luận, lập kế hoạch và linh hoạt chọn hành động của mình.
Để hiểu về RAG dựa trên tác nhân, trước tiên, bạn phải hiểu rõ những yếu tố tạo nên một tác nhân AI. Một tác nhân không chỉ là một LLM. Đây là một hệ thống có một số thành phần chính:
- Mô hình ngôn ngữ lớn (LLM) dưới dạng Công cụ suy luận: Tác nhân này sử dụng một LLM mạnh mẽ như Gemini không chỉ để tạo văn bản mà còn là "bộ não" trung tâm để lập kế hoạch, đưa ra quyết định và phân tách các tác vụ phức tạp.
- Một bộ công cụ: Một tác nhân được cấp quyền truy cập vào một bộ công cụ gồm các chức năng mà tác nhân có thể quyết định sử dụng để đạt được mục tiêu của mình. Những công cụ này có thể là bất cứ thứ gì: máy tính, API tìm kiếm trên web, chức năng gửi email hoặc quan trọng nhất đối với phòng thí nghiệm này – các công cụ truy xuất cho nhiều cơ sở kiến thức của chúng tôi.
- Bộ nhớ: Các trợ lý ảo có thể được thiết kế với cả bộ nhớ ngắn hạn (để ghi nhớ bối cảnh của cuộc trò chuyện hiện tại) và bộ nhớ dài hạn (để nhớ lại thông tin từ các hoạt động tương tác trước đây), mang đến trải nghiệm phù hợp và nhất quán hơn.
- Lập kế hoạch và phản ánh: Các tác nhân tiên tiến nhất thể hiện các mẫu suy luận tinh vi. Gemini có thể nhận được một mục tiêu phức tạp và tạo ra một kế hoạch gồm nhiều bước để đạt được mục tiêu đó. Sau đó, họ có thể thực hiện kế hoạch này, thậm chí suy nghĩ về kết quả của hành động, xác định lỗi và tự điều chỉnh phương pháp để cải thiện kết quả cuối cùng.
RAG dựa trên tác nhân là một bước đột phá vì nó giới thiệu một lớp tự chủ và thông minh mà các quy trình tĩnh không có.
- Tính linh hoạt và khả năng thích ứng: Một tác nhân không bị giới hạn trong một đường dẫn truy xuất duy nhất. Dựa trên câu hỏi của người dùng, mô hình này có thể suy luận về nguồn thông tin phù hợp nhất. Có thể trước tiên, mô hình sẽ quyết định truy vấn cơ sở dữ liệu có cấu trúc, sau đó thực hiện tìm kiếm ngữ nghĩa trên các tài liệu không có cấu trúc và nếu vẫn không tìm được câu trả lời, mô hình sẽ sử dụng một công cụ Google Tìm kiếm để tìm kiếm trên web công khai, tất cả đều nằm trong bối cảnh của một yêu cầu duy nhất của người dùng.
- Suy luận đa bước, phức tạp: Cấu trúc này có khả năng xử lý các truy vấn phức tạp đòi hỏi nhiều bước truy xuất và xử lý tuần tự.
Hãy xem xét câu hỏi: "Tìm 3 bộ phim khoa học viễn tưởng hàng đầu do Christopher Nolan đạo diễn và tóm tắt cốt truyện của từng bộ phim." Một quy trình RAG đơn giản sẽ không thành công.
Tuy nhiên, nhân viên hỗ trợ có thể giải thích rõ hơn:
- Kế hoạch: Trước tiên, tôi cần tìm phim. Sau đó, đối với mỗi bộ phim, tôi cần tìm cốt truyện.
- Hành động 1: Sử dụng công cụ dữ liệu có cấu trúc để truy vấn cơ sở dữ liệu phim về các bộ phim khoa học viễn tưởng của Nolan: 3 bộ phim hàng đầu, được sắp xếp theo thứ tự giảm dần theo điểm xếp hạng.
- Quan sát 1: Công cụ này trả về "Inception" (Kẻ đánh cắp giấc mơ), "Interstellar" (Hố đen tử thần) và "Tenet" (Tenet).
- Hành động 2: Sử dụng công cụ dữ liệu không có cấu trúc (tìm kiếm ngữ nghĩa) để tìm cốt truyện của bộ phim "Inception".
- Quan sát 2: Cốt truyện được truy xuất.
- Thao tác 3: Lặp lại cho "Interstellar".
- Hành động 4: Lặp lại cho "Tenet".
- Tổng hợp cuối cùng: Kết hợp tất cả thông tin đã truy xuất thành một câu trả lời duy nhất, mạch lạc cho người dùng.
4. Thiết lập dự án
Tài khoản Google
Nếu chưa có Tài khoản Google cá nhân, bạn phải tạo một Tài khoản Google.
Sử dụng tài khoản cá nhân thay vì tài khoản do nơi làm việc hoặc trường học cấp.
Đăng nhập vào Google Cloud Console
Đăng nhập vào Google Cloud Console bằng Tài khoản Google cá nhân.
Bật thanh toán
Sử dụng tài khoản thanh toán dùng thử (không bắt buộc)
Để tham gia hội thảo này, bạn cần có một tài khoản thanh toán có sẵn một số tín dụng. Hãy sử dụng tín dụng trong biểu ngữ ở đầu lớp học lập trình này để bắt đầu. Nếu đã kết nối với một tài khoản thanh toán, bạn có thể bỏ qua bước này.
Thiết lập tài khoản thanh toán cá nhân
Nếu thiết lập thông tin thanh toán bằng tín dụng Google Cloud, bạn có thể bỏ qua bước này.
Để thiết lập tài khoản thanh toán cá nhân, hãy truy cập vào đây để bật tính năng thanh toán trong Cloud Console.
Một số lưu ý:
- Việc hoàn thành bài thực hành này sẽ tốn ít hơn 1 USD cho các tài nguyên trên đám mây.
- Bạn có thể làm theo các bước ở cuối bài thực hành này để xoá tài nguyên nhằm tránh bị tính thêm phí.
- Người dùng mới đủ điều kiện dùng thử miễn phí trị giá 300 USD.
Tạo dự án (không bắt buộc)
Nếu bạn không có dự án hiện tại nào muốn sử dụng cho lớp học này, hãy tạo một dự án mới tại đây.
5. Mở Trình chỉnh sửa Cloud Shell
- Nhấp vào đường liên kết này để chuyển trực tiếp đến Cloud Shell Editor
- Nếu được nhắc uỷ quyền vào bất kỳ thời điểm nào trong ngày hôm nay, hãy nhấp vào Uỷ quyền để tiếp tục.
- Nếu thiết bị đầu cuối không xuất hiện ở cuối màn hình, hãy mở thiết bị đầu cuối:
- Nhấp vào Xem
- Nhấp vào Terminal (Thiết bị đầu cuối)
- Trong cửa sổ dòng lệnh, hãy thiết lập dự án bằng lệnh sau:
gcloud config set project [PROJECT_ID]- Ví dụ:
gcloud config set project lab-project-id-example - Nếu không nhớ mã dự án, bạn có thể liệt kê tất cả mã dự án bằng cách dùng lệnh:
gcloud projects list
- Ví dụ:
- Bạn sẽ thấy thông báo sau:
Updated property [core/project].
6. Bật API
Để sử dụng Agent Development Kit và Vertex AI Search, bạn cần bật các API cần thiết trong dự án Google Cloud của mình.
- Trong dòng lệnh, hãy bật các API:
gcloud services enable \ aiplatform.googleapis.com \ discoveryengine.googleapis.com
Giới thiệu về các API
- Vertex AI API (
aiplatform.googleapis.com) cho phép tác nhân giao tiếp với các mô hình Gemini để suy luận và tạo nội dung. - Discovery Engine API (
discoveryengine.googleapis.com) hỗ trợ Vertex AI Search, cho phép bạn tạo kho dữ liệu và thực hiện tìm kiếm ngữ nghĩa trên các tài liệu không có cấu trúc.
7. Thiết lập môi trường
Trước khi bắt đầu lập trình AI Agent, bạn cần chuẩn bị môi trường phát triển, cài đặt các thư viện cần thiết và tạo các tệp dữ liệu bắt buộc.
Tạo môi trường ảo và cài đặt các phần phụ thuộc
- Tạo một thư mục cho tác nhân của bạn và chuyển đến thư mục đó. Chạy mã sau trong terminal:
mkdir financial_agent cd financial_agent - Tạo môi trường ảo:
uv venv --python 3.12 - Kích hoạt môi trường ảo:
source .venv/bin/activate - Cài đặt Bộ công cụ phát triển tác nhân (ADK) và pandas.
uv pip install google-adk pandas
Tạo dữ liệu giá cổ phiếu
Vì phòng thí nghiệm yêu cầu dữ liệu kho hàng cụ thể trong quá khứ để minh hoạ khả năng sử dụng các công cụ có cấu trúc của trợ lý, nên bạn sẽ tạo một tệp CSV chứa dữ liệu này.
- Trong thư mục
financial_agent, hãy tạo tệpgoog.csvbằng cách chạy lệnh sau trong thiết bị đầu cuối:cat <<EOF > goog.csv Date,Open,High,Low,Close,Adj Close,Volume 2023-01-03,89.830002,91.550003,89.019997,89.699997,89.699997,20738500 2023-03-31,101.440002,103.889999,101.040001,103.730003,103.730003,36823200 2023-06-30,120.870003,122.029999,120.300003,120.970001,120.970001,23824700 2023-09-29,134.080002,134.550003,131.320007,131.850006,131.850006,21124200 2025-07-10,185.000000,188.000000,184.500000,186.500000,186.500000,25000000 EOF
Định cấu hình các biến môi trường
- Trong thư mục
financial_agent, hãy tạo một tệp.envđể định cấu hình các biến môi trường của tác nhân. Thao tác này cho ADK biết dự án, vị trí và mô hình cần sử dụng. Chạy mã sau trong terminal:# Create the .env file using the captured variables cat << EOF > .env GOOGLE_GENAI_USE_VERTEXAI=TRUE GOOGLE_CLOUD_PROJECT="${GOOGLE_CLOUD_PROJECT}" GOOGLE_CLOUD_LOCATION="us-central1" EOF
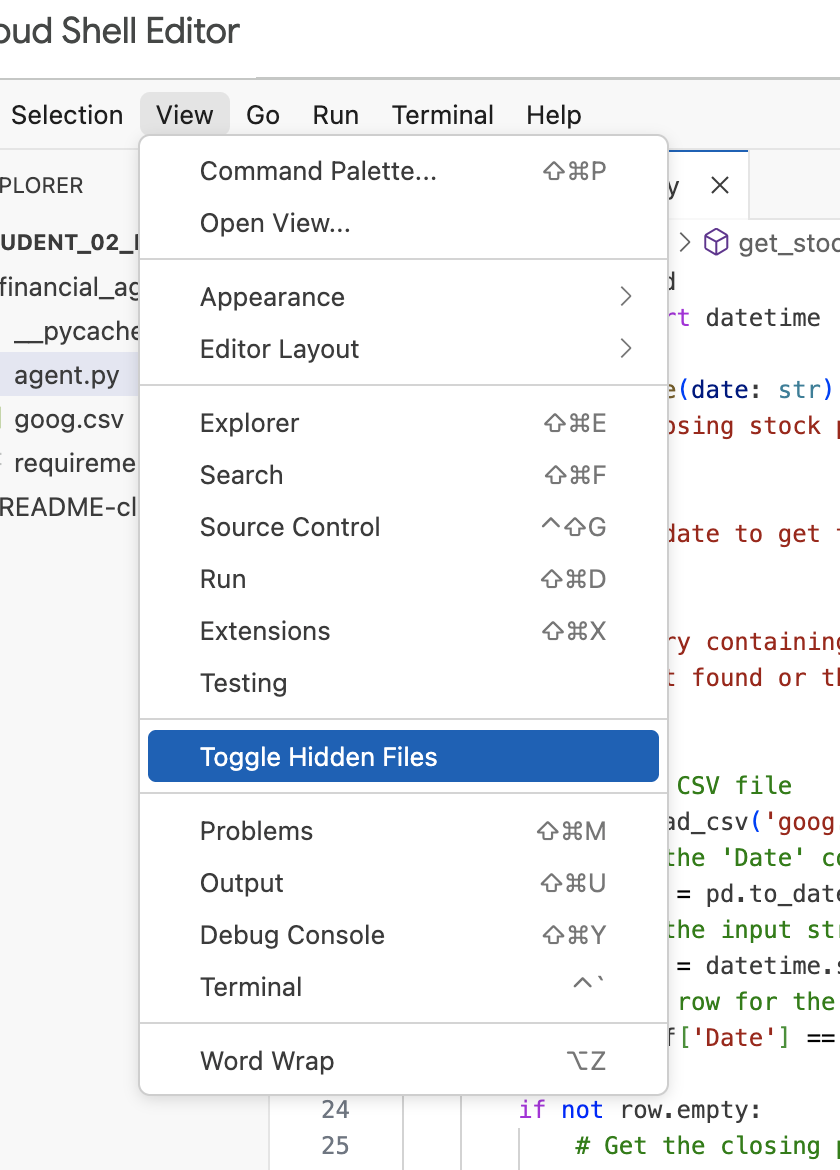
Lưu ý: Sau này trong phòng thí nghiệm, nếu bạn cần sửa đổi tệp .env nhưng không thấy tệp này trong thư mục financial_agent, hãy thử bật/tắt chế độ hiển thị tệp ẩn trong Cloud Shell Editor bằng cách sử dụng mục "View / Toggle Hidden Files" (Xem/Bật tắt tệp ẩn) trong trình đơn.
8. Tạo một Data Store của Vertex AI Search
Để cho phép tác nhân trả lời các câu hỏi về báo cáo tài chính của Alphabet, bạn sẽ tạo một kho dữ liệu Vertex AI Search chứa các hồ sơ công khai của họ tại Uỷ ban Chứng khoán và Sàn giao dịch Hoa Kỳ (SEC).
- Trong một thẻ trình duyệt mới, hãy mở Cloud Console (console.cloud.google.com), chuyển đến Ứng dụng AI bằng cách sử dụng thanh tìm kiếm ở trên cùng.
- Nếu được nhắc, hãy đánh dấu vào hộp điều khoản và điều kiện rồi nhấp vào Tiếp tục và kích hoạt API.
- Trong trình đơn điều hướng bên trái, hãy chọn Kho dữ liệu.
- Nhấp vào + Tạo kho dữ liệu.
- Tìm thẻ Cloud Storage rồi nhấp vào Chọn.
- Đối với nguồn dữ liệu, hãy chọn Tài liệu không có cấu trúc.

- Đối với nguồn nhập (Chọn một thư mục hoặc tệp bạn muốn nhập), hãy nhập đường dẫn Google Cloud Storage
cloud-samples-data/gen-app-builder/search/alphabet-sec-filings. - Nhấp vào Tiếp tục.
- Đặt vị trí thành global.
- Đối với tên kho dữ liệu, hãy nhập
alphabet-sec-filings - Mở rộng mục Lựa chọn xử lý tài liệu.

- Trong danh sách thả xuống Default document parser (Trình phân tích cú pháp tài liệu mặc định), hãy chọn Layout Parser (Trình phân tích cú pháp bố cục).
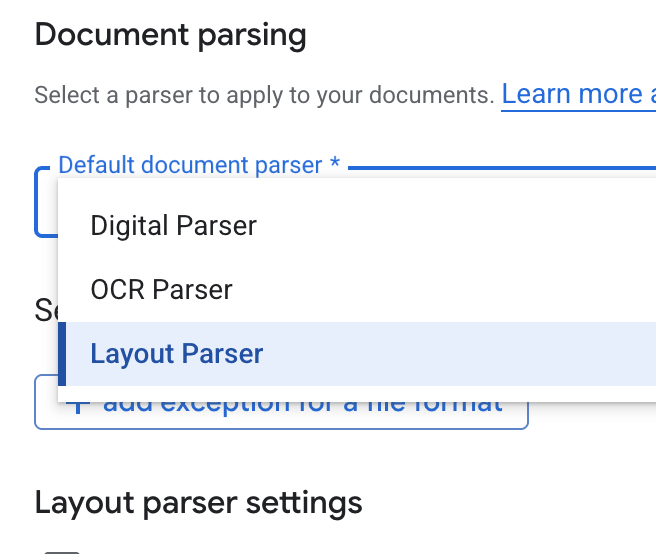
- Trong các lựa chọn Layout parser settings (Cài đặt trình phân tích bố cục), hãy chọn Enable table annotation (Bật chú thích bảng) và Enable image annotation (Bật chú thích hình ảnh).
- Nhấp vào Tiếp tục.
- Chọn Định giá chung làm mô hình định giá (mô hình trả tiền theo mức dùng, dựa trên mức tiêu thụ) rồi nhấp vào Tạo.
- Kho dữ liệu của bạn sẽ bắt đầu nhập các tài liệu.
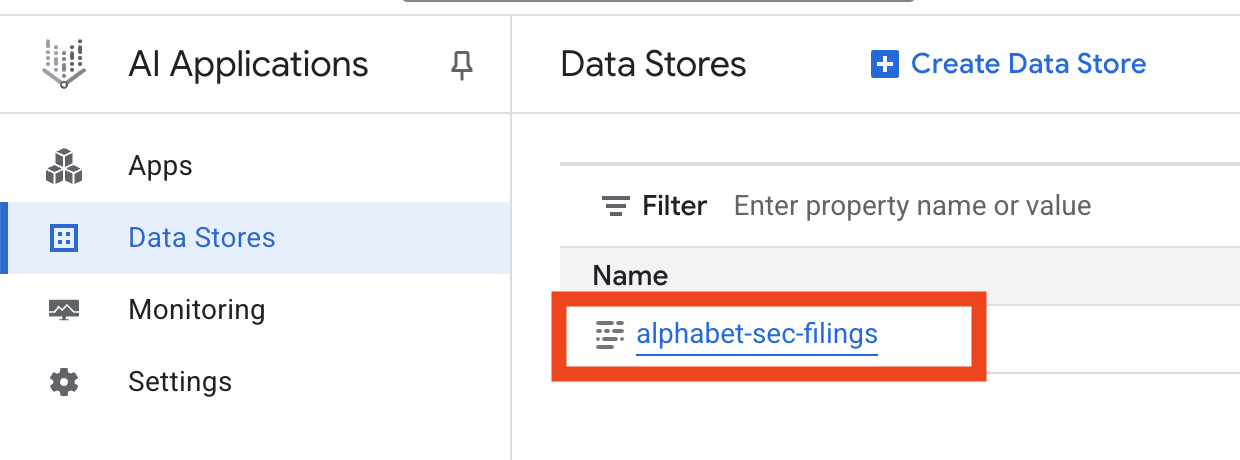
- Nhấp vào tên kho dữ liệu rồi sao chép mã nhận dạng của kho dữ liệu trong bảng Kho dữ liệu. Bạn sẽ cần khoá này trong bước tiếp theo.
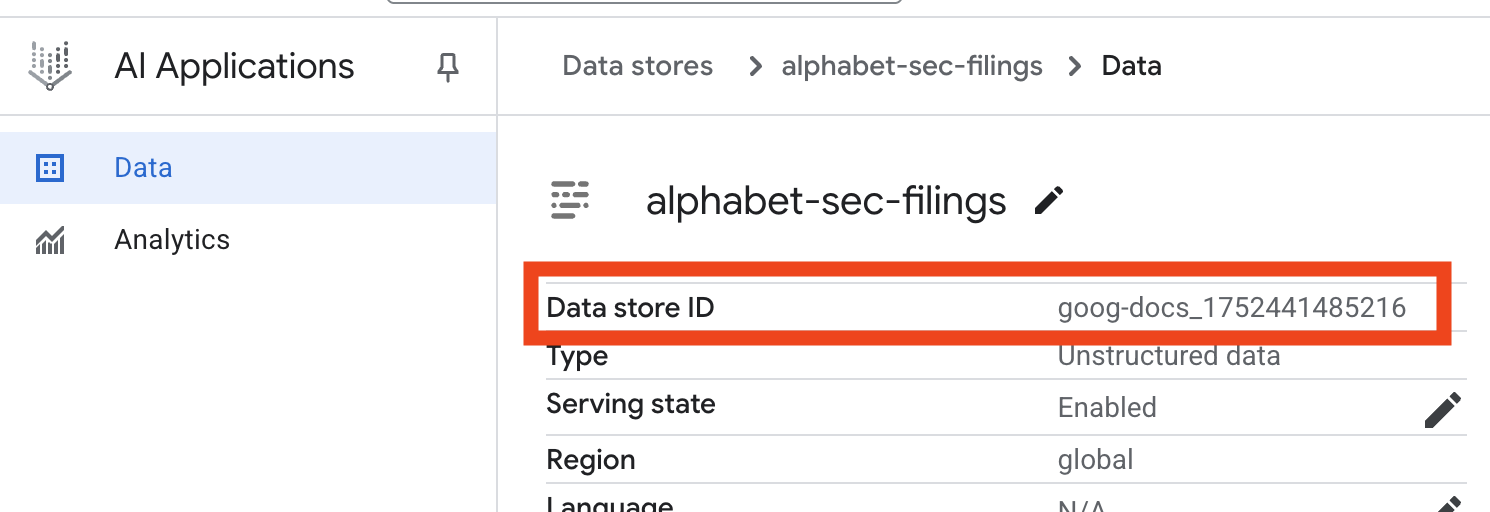
- Mở tệp
.envtrong Cloud Shell Editor và thêm mã nhận dạng kho dữ liệu dưới dạngDATA_STORE_ID="YOUR_DATA_STORE_ID"(thay thếYOUR_DATA_STORE_IDbằng mã nhận dạng thực tế ở bước trước.Lưu ý: Quá trình nhập, phân tích cú pháp và lập chỉ mục dữ liệu trong kho dữ liệu sẽ mất vài phút. Để kiểm tra quy trình, hãy nhấp vào tên kho dữ liệu để mở các thuộc tính của kho dữ liệu đó, sau đó mở thẻ Hoạt động. Chờ trạng thái chuyển thành "Đã nhập xong".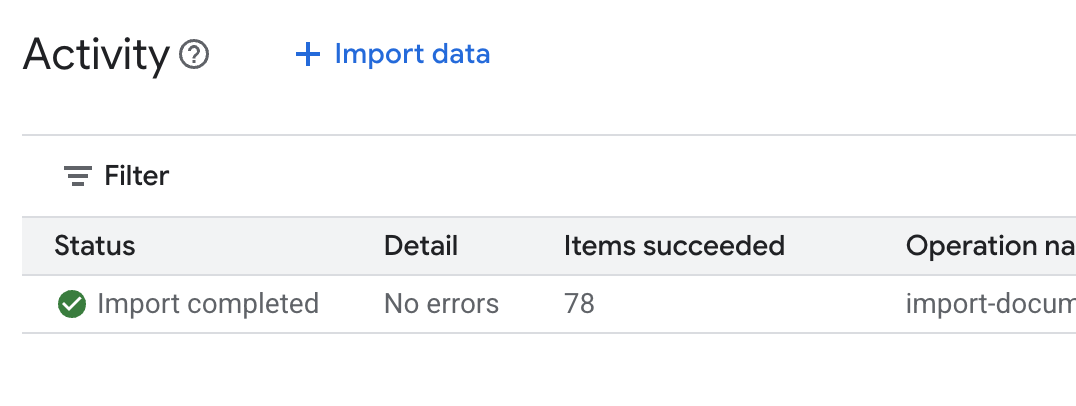
9. Tạo một công cụ tuỳ chỉnh cho dữ liệu có cấu trúc
Tiếp theo, bạn sẽ tạo một hàm Python đóng vai trò là công cụ cho tác nhân. Công cụ này sẽ đọc tệp goog.csv để truy xuất giá cổ phiếu trước đây cho một ngày nhất định.
- Trong thư mục
financial_agent, hãy tạo một tệp mới có tên làagent.py. Chạy lệnh sau trong thiết bị đầu cuối:cloudshell edit agent.py - Thêm mã Python sau vào
agent.py. Mã này nhập các phần phụ thuộc và xác định hàmget_stock_price.from datetime import datetime import os import logging import google.cloud.logging from google.adk.tools import VertexAiSearchTool from google.adk.tools.agent_tool import AgentTool from google.adk.agents import LlmAgent import pandas as pd def get_stock_price(date: str) -> dict: """Gets the closing stock price for a given date. Args: date: The date to get the stock price for, in YYYY-MM-DD format. Returns: A dictionary containing the closing price, or an error message if the date is not found or the format is incorrect. """ try: # Load the CSV file df = pd.read_csv('goog.csv') # Convert the 'Date' column to datetime objects df['Date'] = pd.to_datetime(df['Date']) # Convert the input string to a datetime object query_date = datetime.strptime(date, '%Y-%m-%d') # Find the row for the given date row = df[df['Date'] == query_date] if not row.empty: # Get the closing price close_price = row['Close'].iloc[0] return {"status": "success", "date": date, "closing_price": close_price} else: return {"status": "error", "message": f"No data found for date: {date}"} except FileNotFoundError: return {"status": "error", "message": "Stock data file (goog.csv) not found."} except Exception as e: return {"status": "error", "message": f"An error occurred: {str(e)}"}
Hãy chú ý đến chuỗi tài liệu chi tiết của hàm. Nội dung này giải thích chức năng của hàm, các tham số (Args) và giá trị mà hàm trả về (Returns). ADK sử dụng chuỗi tài liệu này để hướng dẫn tác nhân cách thức và thời điểm sử dụng công cụ này.
10. Tạo và chạy tác nhân RAG
Giờ là lúc lắp ráp tác nhân. Bạn sẽ kết hợp công cụ Vertex AI Search cho dữ liệu không có cấu trúc với công cụ get_stock_price tuỳ chỉnh cho dữ liệu có cấu trúc.
- Thêm mã sau vào tệp
agent.py. Đoạn mã này nhập các lớp ADK cần thiết, tạo các thực thể của công cụ và xác định tác nhân.logging.basicConfig(level=logging.INFO) cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() # 1. Create the Vertex AI Search tool full_datastore_id = f"projects/{os.environ['GOOGLE_CLOUD_PROJECT']}/locations/global/collections/default_collection/dataStores/{os.environ['DATA_STORE_ID']}" vertex_ai_search_tool = VertexAiSearchTool( data_store_id=full_datastore_id ) # 2. Define the Search+Q&A agent # Since we cannot combine tools with other tools in a single agent, # we create a separate Search+Q&A agent which will be used as a tool by the main root agent. doc_qa_agent = LlmAgent( name="search_and_qna_agent", model="gemini-2.5-flash", tools=[vertex_ai_search_tool], instruction="""You are a helpful assistant that answers questions based on information found in the document store. Use the search tool to find relevant information before answering. If the answer isn't in the documents, say that you couldn't find the information. """, description="Answers questions using a specific Vertex AI Search datastore.", ) # 3. Define the root agent with 2 tools. root_agent = LlmAgent( name="financial_agent", model="gemini-2.5-flash", tools=[ AgentTool(doc_qa_agent), get_stock_price, ], instruction="""You are an Financial Analytics Agent that answers question about Alphabet stock prices (using get_stock_price tool) and historical performance based on the data in Vertex AI Search datastore (using doc_qa_agent tool).""" ) - Trong thư mục
financial_agenttrên thiết bị đầu cuối, hãy chạy giao diện web ADK để tương tác với tác nhân:adk web ~ - Nhấp vào đường liên kết có trong đầu ra của thiết bị đầu cuối (thường là
http://127.0.0.1:8000) để mở giao diện người dùng dành cho nhà phát triển ADK trong trình duyệt.
11. Kiểm thử nhân viên hỗ trợ
Giờ đây, bạn có thể kiểm tra khả năng suy luận và sử dụng các công cụ của trợ lý ảo để trả lời những câu hỏi phức tạp.
- Trong giao diện người dùng ADK Dev, hãy đảm bảo rằng bạn đã chọn
financial_agenttrong trình đơn thả xuống. - Hãy thử đặt câu hỏi yêu cầu thông tin từ các hồ sơ gửi cho SEC (dữ liệu không có cấu trúc). Nhập truy vấn sau vào cuộc trò chuyện:
What were the total revenues for the quarter ending on March 31, 2023?search_and_qna_agent, sử dụngVertexAiSearchToolđể tìm câu trả lời trong các tài liệu tài chính. - Tiếp theo, hãy đặt một câu hỏi yêu cầu sử dụng công cụ tuỳ chỉnh của bạn (dữ liệu có cấu trúc). Xin lưu ý rằng định dạng ngày trong câu lệnh không nhất thiết phải khớp chính xác với định dạng mà hàm yêu cầu; LLM (mô hình ngôn ngữ lớn) đủ thông minh để định dạng lại.
What was the closing stock price for Alphabet on July 10, 2025?get_stock_pricecủa bạn. Bạn có thể nhấp vào biểu tượng công cụ trong cuộc trò chuyện để kiểm tra lệnh gọi hàm và kết quả của lệnh gọi đó. - Cuối cùng, hãy đặt một câu hỏi phức tạp đòi hỏi tác nhân phải sử dụng cả hai công cụ và tổng hợp kết quả.
According to the 10-Q filing for the period ending March 31, 2023, what were the company's net cash provided by operating activities, and what was the stock's closing price on that date?- Trước tiên, khối mã này sẽ sử dụng
VertexAiSearchToolđể tìm thông tin về dòng tiền trong hồ sơ gửi lên SEC. - Sau đó, nó sẽ nhận ra nhu cầu về giá cổ phiếu và gọi hàm
get_stock_pricevới ngày2023-03-31. - Cuối cùng, Gemini sẽ kết hợp cả hai thông tin này thành một câu trả lời toàn diện.
- Trước tiên, khối mã này sẽ sử dụng
- Khi hoàn tất, bạn có thể đóng thẻ trình duyệt và nhấn
CTRL+Ctrong thiết bị đầu cuối để dừng máy chủ ADK.
12. Chọn dịch vụ cho việc cần làm
Vertex AI Search không phải là dịch vụ tìm kiếm vectơ duy nhất mà bạn có thể sử dụng. Bạn cũng có thể sử dụng một dịch vụ được quản lý để tự động hoá toàn bộ quy trình Tạo sinh tăng cường truy xuất: Công cụ RAG của Vertex AI.
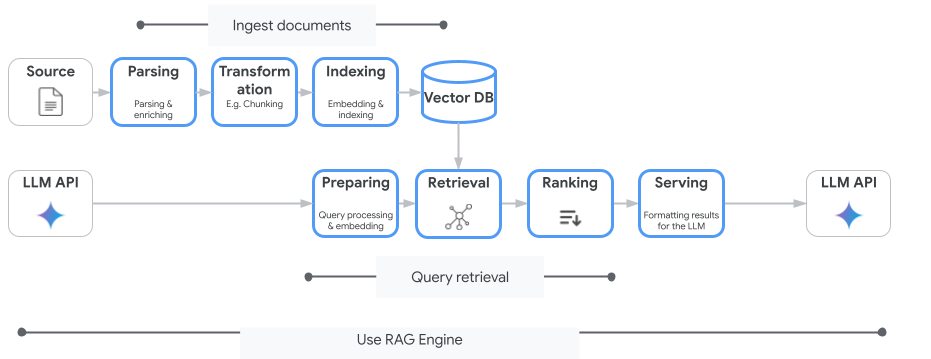
Nó xử lý mọi thứ, từ việc nhập tài liệu đến truy xuất và sắp xếp lại. Công cụ RAG hỗ trợ nhiều kho lưu trữ vectơ, bao gồm Pinecone và Weaviate.
Bạn cũng có thể tự lưu trữ nhiều Cơ sở dữ liệu vectơ chuyên biệt hoặc tận dụng các chức năng chỉ mục vectơ trong các công cụ cơ sở dữ liệu, chẳng hạn như pgvector trong dịch vụ PostgreSQL (chẳng hạn như AlloyDB hoặc BigQuery Vector Search.
Một số dịch vụ khác hỗ trợ tính năng Tìm kiếm vectơ là:
Hướng dẫn chung về cách chọn một dịch vụ cụ thể trên Google Cloud như sau:
- Nếu bạn đã có cơ sở hạ tầng Tìm kiếm vectơ tự xây dựng hoạt động và có quy mô phù hợp, hãy triển khai cơ sở hạ tầng đó vào Google Kubernetes Engine, chẳng hạn như Weaviate hoặc PostgreSQL tự xây dựng.
- Nếu dữ liệu của bạn nằm trong BigQuery, AlloyDB, Firestore hoặc bất kỳ cơ sở dữ liệu nào khác, hãy cân nhắc sử dụng các chức năng Tìm kiếm vectơ của cơ sở dữ liệu đó nếu bạn có thể thực hiện tìm kiếm ngữ nghĩa ở quy mô lớn trong một truy vấn lớn hơn trong cơ sở dữ liệu đó. Ví dụ: nếu bạn có nội dung mô tả và/hoặc hình ảnh sản phẩm trong một bảng BigQuery, thì việc thêm cột nhúng văn bản và/hoặc cột nhúng hình ảnh sẽ cho phép sử dụng tính năng tìm kiếm tương tự ở quy mô lớn. Chỉ mục vectơ có hỗ trợ tìm kiếm ScANN hàng tỷ mục trong chỉ mục.
- Nếu bạn cần bắt đầu nhanh chóng mà không tốn nhiều công sức và trên một nền tảng được quản lý, hãy chọn Vertex AI Search – một công cụ tìm kiếm và API truy xuất được quản lý hoàn toàn, lý tưởng cho các trường hợp sử dụng phức tạp của doanh nghiệp đòi hỏi chất lượng, khả năng mở rộng và quyền kiểm soát truy cập chi tiết cao. Công cụ này giúp đơn giản hoá việc kết nối với nhiều nguồn dữ liệu doanh nghiệp và cho phép tìm kiếm trên nhiều nguồn.
- Hãy sử dụng Vertex AI RAG Engine nếu bạn đang tìm kiếm một điểm cân bằng cho các nhà phát triển muốn có sự cân bằng giữa tính dễ sử dụng và khả năng tuỳ chỉnh. Nền tảng này hỗ trợ việc tạo mẫu và phát triển nhanh mà không làm giảm tính linh hoạt.
- Khám phá Kiến trúc tham chiếu để tạo nội dung tăng cường khả năng truy xuất.
13. Kết luận
Xin chúc mừng! Bạn đã tạo và thử nghiệm thành công một tác nhân AI bằng tính năng tạo nội dung tăng cường khả năng truy xuất. Bạn đã tìm hiểu cách:
- Tạo cơ sở kiến thức cho các tài liệu không có cấu trúc bằng cách sử dụng các chức năng tìm kiếm ngữ nghĩa mạnh mẽ của Vertex AI Search.
- Phát triển một hàm Python tuỳ chỉnh để đóng vai trò là công cụ truy xuất dữ liệu có cấu trúc.
- Sử dụng Bộ công cụ phát triển tác nhân (ADK) để tạo một tác nhân đa công cụ dựa trên Gemini.
- Xây dựng một tác nhân có khả năng suy luận phức tạp, đa bước để trả lời các câu hỏi cần tổng hợp thông tin từ nhiều nguồn.
Lớp học lập trình này minh hoạ các nguyên tắc cốt lõi của RAG dựa trên tác nhân, một cấu trúc mạnh mẽ để xây dựng các ứng dụng AI thông minh, chính xác và nhận biết ngữ cảnh trên Google Cloud.
Từ nguyên mẫu đến sản phẩm thực tế
Phòng thí nghiệm này thuộc Lộ trình học tập về AI sẵn sàng cho sản xuất trên Google Cloud.
- Khám phá toàn bộ chương trình học để thu hẹp khoảng cách từ nguyên mẫu đến phát hành công khai.
- Chia sẻ tiến trình của bạn bằng thẻ bắt đầu bằng #ProductionReadyAI.