
1. 简介
概览
本实验的目标是学习如何在 Google Cloud 中开发端到端的智能体检索增强生成 (RAG) 应用。在本实验中,您将构建一个财务分析智能体,该智能体能够通过整合来自两个不同来源的信息来回答问题:非结构化文档(Alphabet 的季度 SEC 备案 - 美国每家上市公司向美国证券交易委员会提交的财务报表和运营详情)和结构化数据(历史股价)。
您将使用 Vertex AI Search 为非结构化财务报告构建强大的语义搜索引擎。对于结构化数据,您将创建一个自定义 Python 工具。最后,您将使用智能体开发套件 (ADK) 构建一个智能体,该智能体能够推理用户查询、决定使用哪个工具,并将信息合成到连贯的答案中。
您将执行的操作
- 设置 Vertex AI Search 数据存储区,以便对私有文档进行语义搜索。
- 创建自定义 Python 函数作为代理的工具。
- 使用智能体开发套件 (ADK) 构建多工具智能体。
- 结合从非结构化和结构化数据源检索到的信息来回答复杂问题。
- 测试并与具有推理能力的代理互动。
学习内容
在本实验中,您将学习:
- 检索增强生成 (RAG) 和智能体 RAG 的核心概念。
- 如何使用 Vertex AI Search 对文档实现语义搜索。
- 如何通过创建自定义工具向代理公开结构化数据。
- 如何使用智能体开发套件 (ADK) 构建和编排多工具智能体。
- 智能体如何使用推理和规划功能,通过多个数据源回答复杂问题。
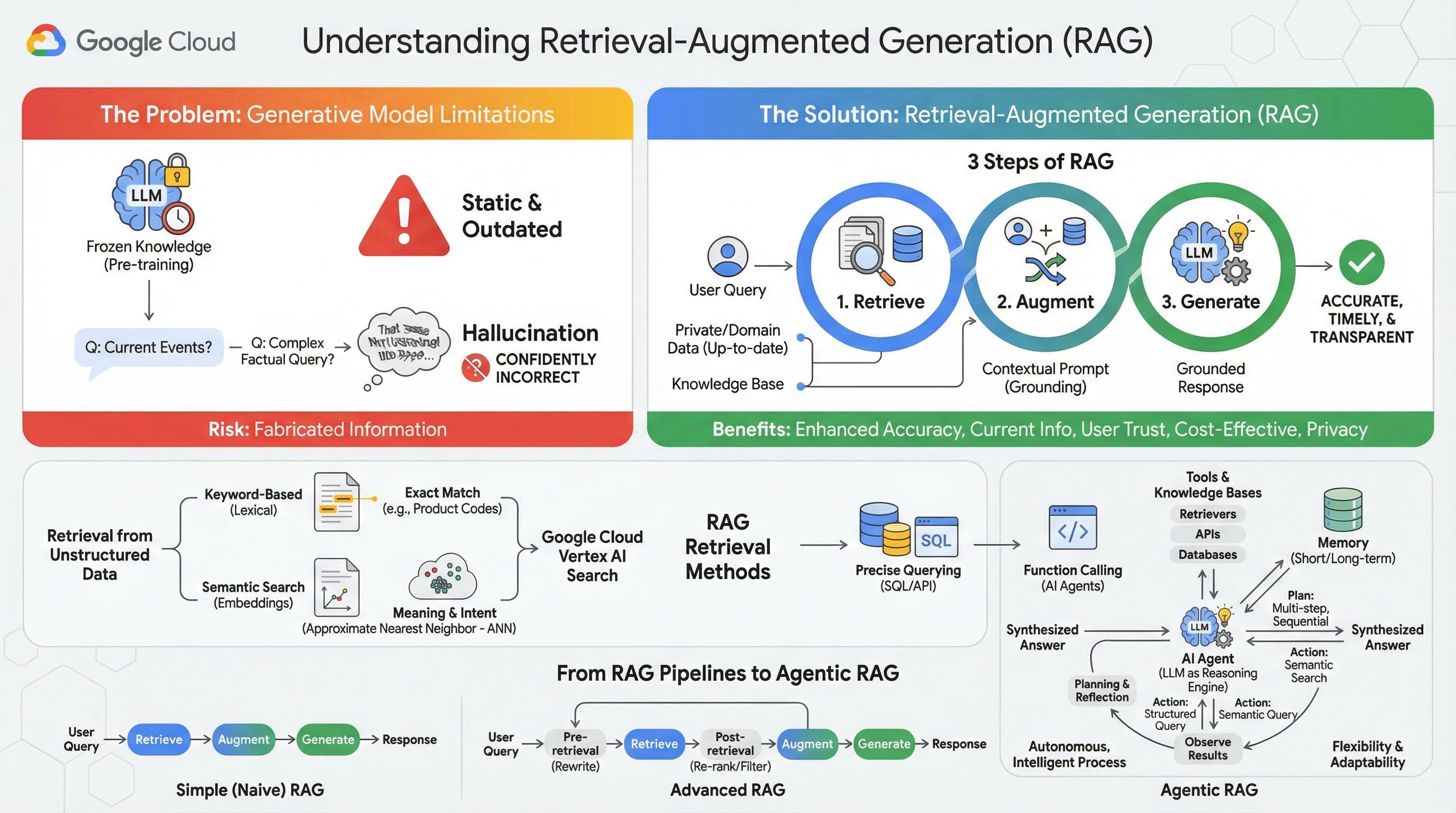
2. 了解检索增强生成
大型生成模型(简称大语言模型或 LLM、视觉语言模型等)功能非常强大,但存在固有的局限性。它们在预训练时获得的知识会被冻结,因此是静态的,并且会立即过时。即使经过微调,模型知识也不会变得新近很多,因为这不是训练后阶段的目标。
大语言模型(尤其是“思考”模型)的训练方式决定了,即使模型本身没有支持某个答案的事实信息,给出某种答案也会获得“奖励”。这就是他们所说的模型“产生幻觉”的情况,即自信地生成看似合理但实际上不正确的信息。
检索增强生成是一种强大的架构模式,旨在解决上述问题。它是一种架构框架,可通过将大语言模型与外部权威知识来源实时连接,增强大语言模型的功能。在 RAG 系统中,LLM 不仅依赖于其静态的预训练知识,还会先检索与用户查询相关的相关信息,然后使用这些信息生成更准确、更及时且更贴合上下文的回答。
这种方法直接解决了生成式模型最明显的缺点:它们的知识在某个时间点是固定的,并且容易生成不正确的信息,即“幻觉”。RAG 相当于给 LLM 开了一场“开卷考试”,其中“书本”是您的私有、特定于领域且最新的数据。为 LLM 提供事实背景信息的过程称为“接地”。
RAG 的 3 个步骤
标准检索增强生成流程可分为三个简单步骤:
- 检索:当用户提交查询时,系统首先搜索外部知识库(如文档库、数据库或网站),以查找与查询相关的信息。
- 增强:然后,将检索到的信息与原始用户查询合并为扩展提示。这种技术有时称为“提示填充”,因为它会使用事实背景信息来丰富提示。
- 生成:将增强的提示馈送到 LLM,然后由 LLM 生成回答。由于模型已获得相关的事实数据,因此其输出是“有依据的”,不太可能不准确或过时。
RAG 的优势
RAG 框架的推出为构建实用且值得信赖的 AI 应用带来了变革。其主要优势包括:
- 提高准确性并减少幻觉:通过以可验证的外部事实为依据来生成回答,RAG 可大幅降低 LLM 编造信息的风险。
- 访问最新信息:RAG 系统可以连接到不断更新的知识库,从而能够根据最新信息提供回答,这是静态训练的 LLM 无法做到的。
- 提高用户信任度和透明度:由于 LLM 的回答基于检索到的文档,因此系统可以提供来源的引用和链接。这样一来,用户可以自行验证信息,从而对应用建立信任。
- 经济高效:使用新数据持续微调或重新训练 LLM 在计算和财务方面成本高昂。借助 RAG,更新模型知识就像更新外部数据源一样简单,效率更高。
- 领域专业化和隐私保护:借助 RAG,个人和组织可以在查询时向大语言模型提供其私有专有数据,而无需将这些敏感数据纳入模型的训练集。这有助于开发强大的特定领域应用,同时确保数据隐私和安全。
检索
“检索”步骤是任何 RAG 系统的核心。检索到的信息的质量和相关性直接决定了最终生成的回答的质量和相关性。有效的 RAG 应用通常需要使用各种技术从不同类型的数据源中检索信息。主要检索方法分为三类:基于关键字的检索、语义检索和结构化检索。
从非结构化数据中检索
从历史上看,非结构化数据检索是传统搜索的另一种称法。它经历了多次转变,您可以同时受益于这两种主要方法。
语义搜索是您可以在 Google Cloud 中大规模运行的最有效技术,具有出色的性能和高度的控制能力。
- 基于关键字(词汇)的搜索:这是传统的搜索方法,可以追溯到 20 世纪 70 年代最早的信息检索系统。词汇搜索的工作原理是将用户查询中的字面字词(或“标记”)与知识库中文档中的完全相同的字词进行匹配。对于需要精确匹配特定字词(例如产品代码、法律条款或唯一名称)的查询,这种匹配方式非常有效。
- 语义搜索:语义搜索(或“有含义的搜索”)是一种更现代的方法,旨在理解用户的意图和查询的上下文含义,而不仅仅是字面意义上的关键字。现代语义搜索由嵌入提供支持,这是一种机器学习技术,可将复杂的高维数据映射到由数值向量组成的低维向量空间。这些向量的设计旨在使含义相似的文本在向量空间中彼此靠近。系统会将“哪些犬种最适合家庭饲养?”这一搜索查询转换为向量,然后在该空间中搜索与该向量最接近的文档向量。这样一来,即使文档中没有确切的“狗”字,它也能找到讨论“金毛寻回犬”或“友善犬类”的文档。近似最近邻 (ANN) 算法可高效执行这种高维度搜索。ANN 算法不会将查询向量与每个文档向量进行比较(对于大型数据集来说,这种做法太慢),而是使用巧妙的索引结构快速找到可能最接近的向量。
从结构化数据中检索
并非所有关键知识都存储在非结构化文档中。通常,最精确、最有价值的信息以结构化格式存在,例如关系型数据库、NoSQL 数据库或某种 API(例如用于获取天气数据或股票价格的 REST API)。
从结构化数据中检索通常比搜索非结构化文本更直接、更准确。语言模型可以具备制定和执行精确查询的能力,例如对数据库执行 SQL 查询,或针对特定位置和日期向天气 API 发出 API 调用,而不是搜索语义相似性。
通过 function-calling(为 AI 智能体提供支持的同一技术)实现,它使语言模型能够以确定性的结构化方式与可执行代码和外部系统进行交互。
3. 从 RAG 流水线到智能体式 RAG
与 RAG 本身的概念一样,实现 RAG 的架构也在不断发展。最初的简单线性流水线已发展成为由 AI 代理编排的动态智能系统。
- 简单(或朴素)RAG:这是我们目前讨论的基础架构:一个线性三步流程,即检索、扩充和生成。它是反应式的,会针对每个查询遵循固定路径,并且在处理简单的问答任务时非常有效。
- 高级 RAG:这表示一种演变,其中向流水线添加了额外的步骤,以提高检索到的上下文的质量。这些增强功能可以在检索步骤之前或之后进行。
- 检索前:可以使用查询重写或扩展等技术。系统可能会分析初始查询,并对其进行重新措辞,以便更有效地用于检索系统。
- 检索后:在检索到一组初始文档后,可以应用重排序模型来评估文档的相关性,并将最相关的文档排在最前面。这在混合搜索中尤为重要。检索后的另一个步骤是过滤或压缩检索到的上下文,以确保仅将最突出的信息传递给 LLM。
- 智能体 RAG:这是 RAG 架构的最新发展,代表着从固定流水线到自主智能流程的范式转变。在智能体 RAG 系统中,整个工作流程由一个或多个 AI 智能体管理,这些智能体可以推理、规划并动态选择其行动。
若要了解 Agentic RAG,必须先了解什么是 AI 智能体。智能体不仅仅是 LLM。该系统包含几个关键组件:
- 将 LLM 用作推理引擎:代理不仅使用 Gemini 等强大的 LLM 来生成文本,还将其用作中央“大脑”,用于规划、做出决策和分解复杂任务。
- 一组工具:智能体可访问一组函数工具包,并可决定使用哪些函数来实现其目标。这些工具可以是任何东西:计算器、网络搜索 API、用于发送电子邮件的函数,或者对于本实验而言最重要的 - 用于各种知识库的检索器。
- 记忆:智能体可以设计为同时具备短期记忆(记住当前对话的上下文)和长期记忆(回忆过去互动中的信息),从而提供更加个性化且连贯的体验。
- 规划和反思:最先进的代理表现出复杂的推理模式。它们可以接收复杂的目标,并制定多步骤计划来实现该目标。然后,他们可以执行此方案,甚至可以反思其行动的结果、发现错误并自行纠正方法,以改进最终结果。
智能体 RAG 是一项颠覆性技术,因为它引入了静态流水线所不具备的自主性和智能性。
- 灵活性和适应性:代理不会被锁定到单一的检索路径。给定用户查询,它可以推理出最佳信息来源。它可能会决定先查询结构化数据库,然后对非结构化文档执行语义搜索,如果仍然找不到答案,则使用 Google 搜索工具在公共网络上查找,所有这些操作都在单个用户请求的上下文中进行。
- 复杂的多步推理:此架构擅长处理需要多个连续检索和处理步骤的复杂查询。
以以下查询为例:“查找由克里斯托弗·诺兰执导的前 3 部科幻电影,并简要介绍每部电影的剧情。”简单的 RAG 流水线会失败。
不过,代理可以将其分解为:
- 计划:首先,我需要找到电影。然后,我需要找到每部电影的剧情。
- 操作 1:使用结构化数据工具查询电影数据库,查找诺兰的科幻电影:排名前 3 的电影,按评分降序排列。
- 观察 1:该工具返回了《盗梦空间》《星际穿越》和《信条》。
- 操作 2:使用非结构化数据工具(语义搜索)查找电影《盗梦空间》的剧情。
- 观察 2:系统检索到了剧情。
- 操作 3:针对“星际穿越”重复上述操作。
- 操作 4:针对“Tenet”重复上述操作。
- 最终合成:将所有检索到的信息整合到一起,形成连贯的回答,供用户参考。
4. 项目设置
Google 账号
如果您还没有个人 Google 账号,则必须先创建一个 Google 账号。
请改用个人账号,而不是工作账号或学校账号。
登录 Google Cloud 控制台
使用个人 Google 账号登录 Google Cloud 控制台。
启用结算功能
使用试用结算账号(可选)
如需参加此研讨会,您需要拥有一个有一定信用额度的结算账号。使用本 Codelab 顶部横幅中的积分开始学习。如果您已关联结算账号,则可以跳过此步骤。
设置个人结算账号
如果您使用 Google Cloud 抵用金设置了结算,则可以跳过此步骤。
如需设置个人结算账号,请点击此处在 Cloud 控制台中启用结算功能。
注意事项:
- 完成本实验的 Cloud 资源费用应不到 1 美元。
- 您可以按照本实验末尾的步骤删除资源,以避免产生更多费用。
- 新用户符合参与 $300 USD 免费试用计划的条件。
创建项目(可选)
如果您没有要用于此实验的当前项目,请在此处创建一个新项目。
5. 打开 Cloud Shell Editor
- 点击此链接可直接前往 Cloud Shell 编辑器
- 如果系统在今天任何时间提示您进行授权,请点击授权继续。
- 如果终端未显示在屏幕底部,请打开它:
- 点击查看
- 点击终端
- 在终端中,使用以下命令设置项目:
gcloud config set project [PROJECT_ID]- 示例:
gcloud config set project lab-project-id-example - 如果您不记得自己的项目 ID,可以使用以下命令列出所有项目 ID:
gcloud projects list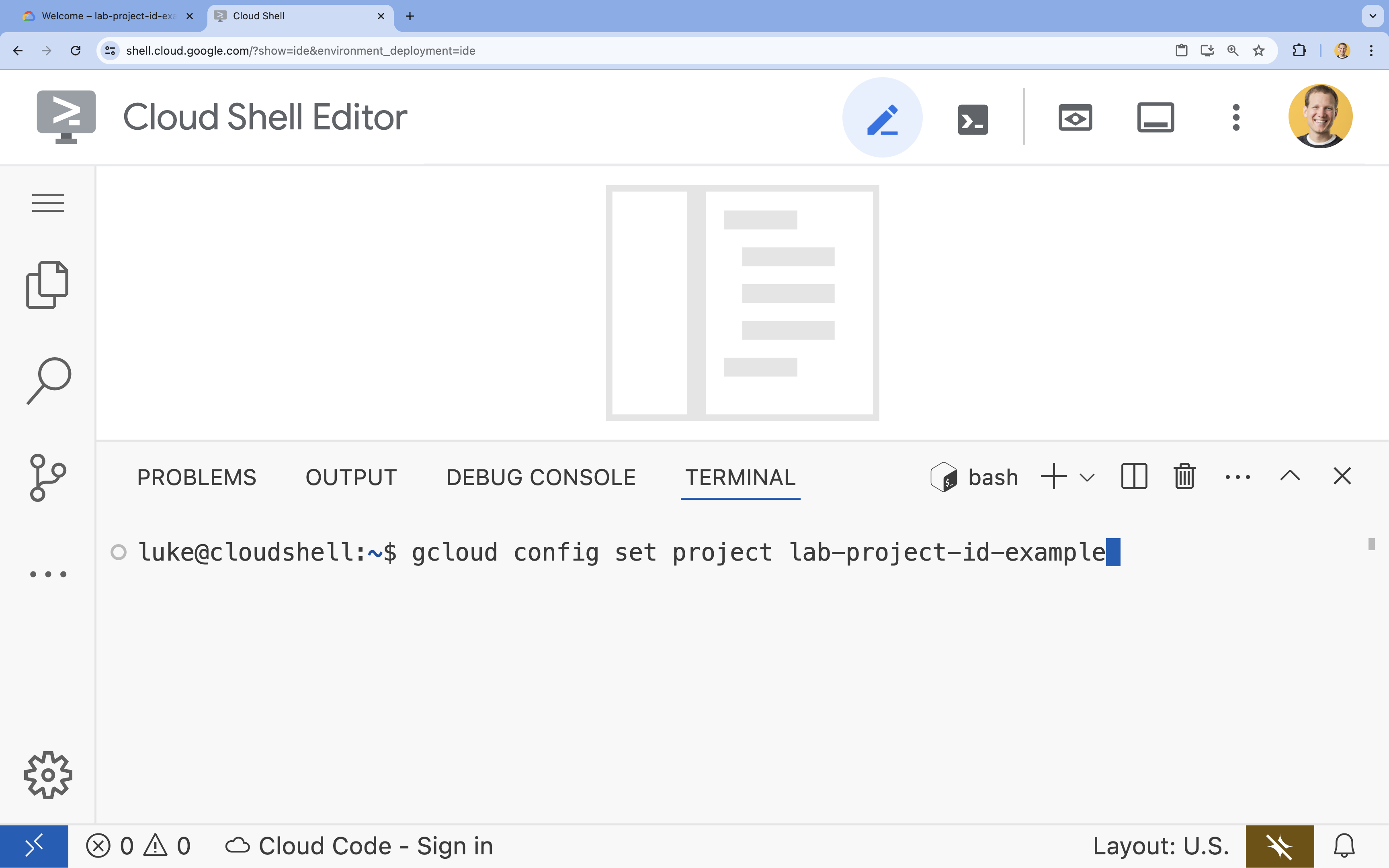
- 示例:
- 您应会看到以下消息:
Updated property [core/project].
6. 启用 API
如需使用 智能体开发套件 和 Vertex AI Search,您需要在 Google Cloud 项目中启用必要的 API。
- 在终端中,启用以下 API:
gcloud services enable \ aiplatform.googleapis.com \ discoveryengine.googleapis.com
API 简介
- Vertex AI API (
aiplatform.googleapis.com) 使代理能够与 Gemini 模型通信,以进行推理和生成。 - Discovery Engine API (
discoveryengine.googleapis.com) 为 Vertex AI Search 提供支持,让您能够创建数据存储区并对非结构化文档执行语义搜索。
7. 设置环境
在开始为 AI 代理编写代码之前,您需要准备好开发环境,安装必要的库,并创建所需的数据文件。
创建虚拟环境并安装依赖项
- 为您的代理创建一个目录,然后导航到该目录。在终端中运行以下代码:
mkdir financial_agent cd financial_agent - 创建虚拟环境:
uv venv --python 3.12 - 激活此虚拟环境:
source .venv/bin/activate - 安装智能体开发套件 (ADK) 和 pandas。
uv pip install google-adk pandas
创建股价数据
由于实验需要特定的历史股票数据来展示智能体使用结构化工具的能力,因此您将创建一个包含这些数据的 CSV 文件。
- 在
financial_agent目录中,通过在终端中运行以下命令来创建goog.csv文件:cat <<EOF > goog.csv Date,Open,High,Low,Close,Adj Close,Volume 2023-01-03,89.830002,91.550003,89.019997,89.699997,89.699997,20738500 2023-03-31,101.440002,103.889999,101.040001,103.730003,103.730003,36823200 2023-06-30,120.870003,122.029999,120.300003,120.970001,120.970001,23824700 2023-09-29,134.080002,134.550003,131.320007,131.850006,131.850006,21124200 2025-07-10,185.000000,188.000000,184.500000,186.500000,186.500000,25000000 EOF
配置环境变量
- 在
financial_agent目录中,创建一个.env文件来配置代理的环境变量。这会告知 ADK 要使用哪个项目、位置和模型。在终端中运行以下代码:# Create the .env file using the captured variables cat << EOF > .env GOOGLE_GENAI_USE_VERTEXAI=TRUE GOOGLE_CLOUD_PROJECT="${GOOGLE_CLOUD_PROJECT}" GOOGLE_CLOUD_LOCATION="us-central1" EOF
注意:在本实验的后续步骤中,如果您需要修改 .env 文件,但未在 financial_agent 目录中看到该文件,请尝试使用“查看/显示/不显示隐藏文件”菜单项在 Cloud Shell 编辑器中切换隐藏文件的显示状态。
8. 创建 Vertex AI Search 数据存储区
为了让智能体能够回答有关 Alphabet 财务报告的问题,您将创建一个 Vertex AI Search 数据存储区,其中包含 Alphabet 的公开 SEC 备案文件。
- 在新浏览器标签页中打开 Cloud 控制台 (console.cloud.google.com),然后使用顶部的搜索栏前往 AI Applications。
- 如果系统提示,请选中条款及条件复选框,然后点击继续并激活 API。
- 从左侧导航菜单中选择数据存储区。
- 点击 + 创建数据存储区。
- 找到 Cloud Storage 卡片,然后点击选择。
- 对于数据源,请选择非结构化文档。

- 对于导入源(选择要导入的文件夹或文件),请输入 Google Cloud Storage 路径
cloud-samples-data/gen-app-builder/search/alphabet-sec-filings。 - 点击继续。
- 将位置保留设置为全球。
- 对于数据存储区名称,请输入
alphabet-sec-filings - 展开文档处理选项部分。

- 在默认文档解析器下拉列表中,选择 Layout Parser。
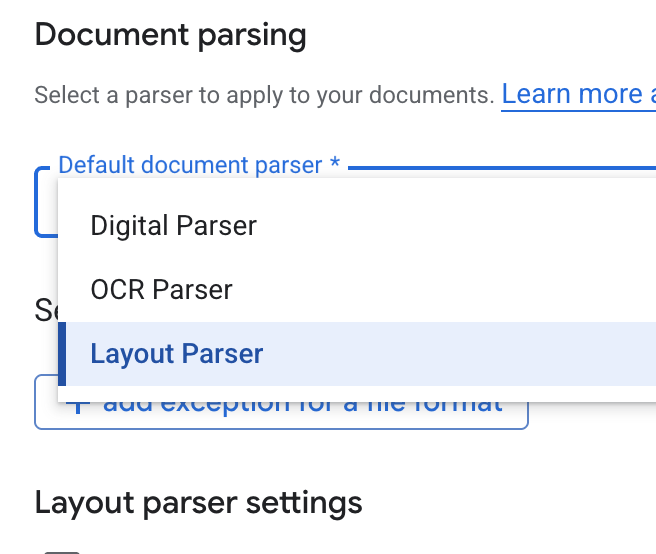
- 在布局解析器设置选项中,选择启用表格注释和启用图片注释。
- 点击继续。
- 选择一般价格作为价格模式(一种随用随付、基于用量的模式),然后点击创建。
- 您的数据存储区将开始导入文档。
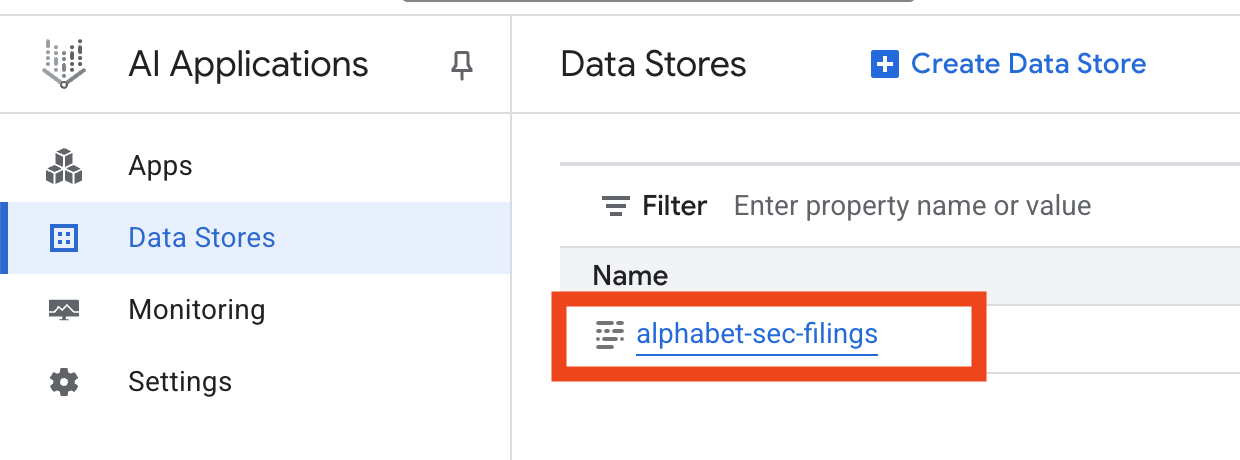
- 点击数据存储区名称,然后从“数据存储区”表格中复制其 ID。您将在下一步中用到此信息。
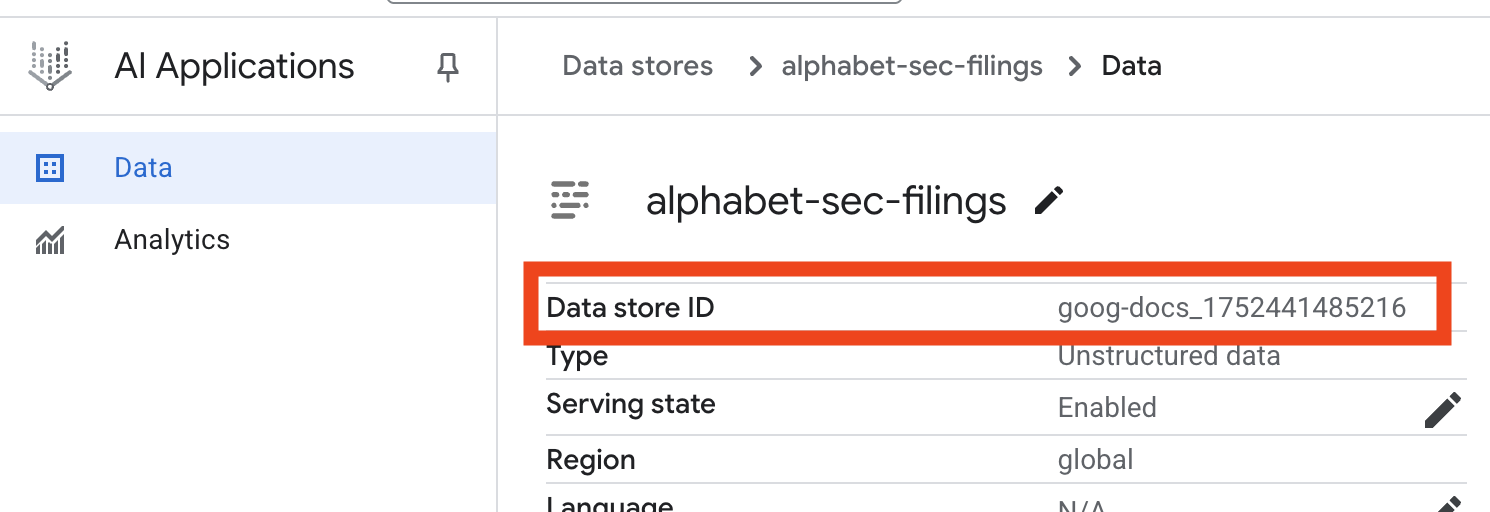
- 在 Cloud Shell 编辑器中打开
.env文件,并附加数据存储区 ID 作为DATA_STORE_ID="YOUR_DATA_STORE_ID"(将YOUR_DATA_STORE_ID替换为上一步中的实际 ID)。注意:导入、解析和索引数据存储区中的数据需要几分钟时间。如需查看该进程,请点击数据存储区名称以打开其属性,然后打开活动标签页。等待状态变为“导入完成”。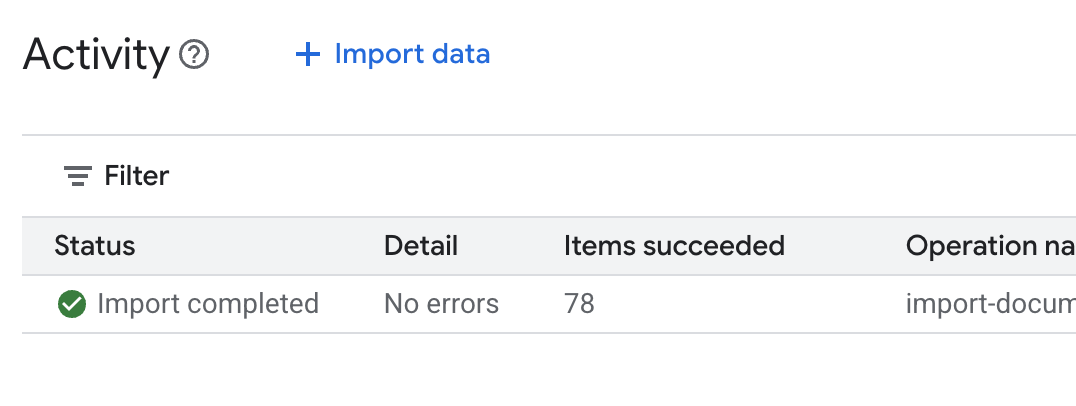
9. 为结构化数据创建自定义工具
接下来,您将创建一个 Python 函数,该函数将充当代理的工具。此工具将读取 goog.csv 文件,以检索指定日期的历史股价。
- 在
financial_agent目录中,新建一个名为agent.py的文件。在终端中运行以下命令:cloudshell edit agent.py - 将以下 Python 代码添加到
agent.py。此代码会导入依赖项并定义get_stock_price函数。from datetime import datetime import os import logging import google.cloud.logging from google.adk.tools import VertexAiSearchTool from google.adk.tools.agent_tool import AgentTool from google.adk.agents import LlmAgent import pandas as pd def get_stock_price(date: str) -> dict: """Gets the closing stock price for a given date. Args: date: The date to get the stock price for, in YYYY-MM-DD format. Returns: A dictionary containing the closing price, or an error message if the date is not found or the format is incorrect. """ try: # Load the CSV file df = pd.read_csv('goog.csv') # Convert the 'Date' column to datetime objects df['Date'] = pd.to_datetime(df['Date']) # Convert the input string to a datetime object query_date = datetime.strptime(date, '%Y-%m-%d') # Find the row for the given date row = df[df['Date'] == query_date] if not row.empty: # Get the closing price close_price = row['Close'].iloc[0] return {"status": "success", "date": date, "closing_price": close_price} else: return {"status": "error", "message": f"No data found for date: {date}"} except FileNotFoundError: return {"status": "error", "message": "Stock data file (goog.csv) not found."} except Exception as e: return {"status": "error", "message": f"An error occurred: {str(e)}"}
请注意该函数的详细文档字符串。它说明了函数的功能、参数 (Args) 和返回值 (Returns)。ADK 使用此文档字符串来教导智能体如何以及何时使用此工具。
10. 构建并运行 RAG 智能体
现在,您可以组装代理了。您将把用于非结构化数据的 Vertex AI Search 工具与用于结构化数据的自定义 get_stock_price 工具相结合。
- 将以下代码附加到
agent.py文件。此代码会导入必要的 ADK 类,创建工具实例,并定义智能体。logging.basicConfig(level=logging.INFO) cloud_logging_client = google.cloud.logging.Client() cloud_logging_client.setup_logging() # 1. Create the Vertex AI Search tool full_datastore_id = f"projects/{os.environ['GOOGLE_CLOUD_PROJECT']}/locations/global/collections/default_collection/dataStores/{os.environ['DATA_STORE_ID']}" vertex_ai_search_tool = VertexAiSearchTool( data_store_id=full_datastore_id ) # 2. Define the Search+Q&A agent # Since we cannot combine tools with other tools in a single agent, # we create a separate Search+Q&A agent which will be used as a tool by the main root agent. doc_qa_agent = LlmAgent( name="search_and_qna_agent", model="gemini-2.5-flash", tools=[vertex_ai_search_tool], instruction="""You are a helpful assistant that answers questions based on information found in the document store. Use the search tool to find relevant information before answering. If the answer isn't in the documents, say that you couldn't find the information. """, description="Answers questions using a specific Vertex AI Search datastore.", ) # 3. Define the root agent with 2 tools. root_agent = LlmAgent( name="financial_agent", model="gemini-2.5-flash", tools=[ AgentTool(doc_qa_agent), get_stock_price, ], instruction="""You are an Financial Analytics Agent that answers question about Alphabet stock prices (using get_stock_price tool) and historical performance based on the data in Vertex AI Search datastore (using doc_qa_agent tool).""" ) - 在终端中,从
financial_agent目录内启动 ADK 网页界面,以便与智能体互动:adk web ~ - 点击终端输出中提供的链接(通常为
http://127.0.0.1:8000),以在浏览器中打开 ADK 开发者界面。
11. 测试代理
现在,您可以测试代理的推理能力,以及使用工具回答复杂问题的能力。
- 在 ADK 开发者界面中,确保从下拉菜单中选择
financial_agent。 - 尝试提出一个需要从 SEC 备案文件(非结构化数据)中获取信息的问题。在对话中输入以下查询:
What were the total revenues for the quarter ending on March 31, 2023?search_and_qna_agent,该函数使用VertexAiSearchTool在财务文件中查找答案。 - 接下来,提出一个需要使用自定义工具(结构化数据)回答的问题。请注意,提示中的日期格式不必与函数所需的格式完全一致;LLM 足够智能,可以重新设置格式。
What was the closing stock price for Alphabet on July 10, 2025?get_stock_price工具。您可以点击聊天中的工具图标,检查函数调用及其结果。 - 最后,提出一个复杂的问题,要求智能体同时使用这两种工具并综合分析结果。
According to the 10-Q filing for the period ending March 31, 2023, what were the company's net cash provided by operating activities, and what was the stock's closing price on that date?- 首先,它会使用
VertexAiSearchTool在 SEC 申报文件中查找现金流量信息。 - 然后,它会识别出需要股票价格,并使用日期
2023-03-31调用get_stock_price函数。 - 最后,它会将这两部分信息合并成一个全面的回答。
- 首先,它会使用
- 完成后,您可以关闭浏览器标签页,然后在终端中按
CTRL+C以停止 ADK 服务器。
12. 为任务选择服务
Vertex AI Search 并不是您可以使用的唯一向量搜索服务。您还可以使用可自动执行整个检索增强生成流程的托管式服务:Vertex AI RAG 引擎。
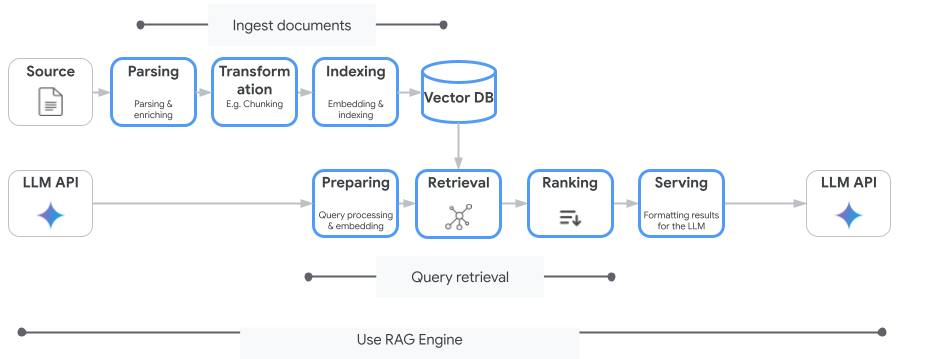
它可处理从文档提取到检索和重排序的所有事宜。RAG Engine 支持多个向量存储区,包括 Pinecone 和 Weaviate。
您还可以自行托管许多专用向量数据库,或利用数据库引擎中的向量索引功能,例如 PostgreSQL 服务(如 AlloyDB 或 BigQuery 向量搜索)中的 pgvector。
以下是一些支持向量搜索的其他服务:
有关在 Google Cloud 上选择特定服务的一般指导如下:
- 如果您已经拥有可正常运行且扩缩良好的 Vector Search 自建基础设施,请将其部署到 Google Kubernetes Engine,例如 Weaviate 或 DIY PostgreSQL。
- 如果您的数据位于 BigQuery、AlloyDB、Firestore 或任何其他数据库中,请考虑使用其向量搜索功能,前提是可以在该数据库中大规模执行语义搜索,作为更大查询的一部分。例如,如果您在 BigQuery 表中包含产品说明和/或图片,那么添加文本和/或图片嵌入列将有助于大规模使用相似度搜索功能。使用 ScaNN 搜索的向量索引支持索引中的数十亿个项。
- 如果您需要快速开始使用托管式平台,并尽可能减少工作量,请选择 Vertex AI Search。这是一款全托管式搜索引擎和检索器 API,非常适合复杂的企业用例,可提供出色的开箱即用质量、可伸缩性和精细的访问控制。它简化了与各种企业数据源的连接,并支持跨多个来源进行搜索。
- 如果您是希望在易用性和自定义程度之间取得平衡的开发者,不妨使用 Vertex AI RAG Engine。它支持快速原型设计和开发,同时不会牺牲灵活性。
- 探索检索增强生成的参考架构。
13. 总结
恭喜!您已成功构建并测试了具有检索增强生成功能的 AI 智能体。您学习了如何:
- 利用 Vertex AI Search 强大的语义搜索功能,为非结构化文档创建知识库。
- 开发一个自定义 Python 函数,用作检索结构化数据的工具。
- 使用智能体开发套件 (ADK) 创建由 Gemini 提供支持的多工具智能体。
- 构建能够进行复杂的多步推理的智能体,以回答需要综合来自多个来源的信息的查询。
本实验演示了智能体 RAG 的核心原则,这是一种强大的架构,可在 Google Cloud 上构建智能、准确且具有上下文感知能力的 AI 应用。
从原型设计到投入生产
本实验是“利用 Google Cloud 构建可用于生产用途的 AI”学习路线的组成部分。
- 探索完整课程,弥合从原型设计到生产的差距。
- 使用 #ProductionReadyAI 主题标签分享您的进度。