
১. ভূমিকা
সংক্ষিপ্ত বিবরণ
রিট্রিভাল অগমেন্টেড জেনারেশন (RAG) লার্জ ল্যাঙ্গুয়েজ মডেল (LLM)-এর প্রতিক্রিয়াগুলোকে বাহ্যিক জ্ঞানের উপর ভিত্তি করে উন্নত করে। তবে, একটি প্রোডাকশন-রেডি RAG সিস্টেম তৈরি করতে শুধু একটি সাধারণ ভেক্টর সার্চের চেয়েও বেশি কিছু প্রয়োজন। ডেটা কীভাবে গ্রহণ করা হয়, প্রাসঙ্গিক ফলাফলগুলোকে কীভাবে র্যাঙ্ক করা হয় এবং ব্যবহারকারীর কোয়েরিগুলো কীভাবে প্রসেস করা হয়, তা আপনাকে অপ্টিমাইজ করতে হবে।
এই বিশদ ল্যাবে, আপনি Cloud SQL for PostgreSQL ( pgvector দ্বারা বর্ধিত) এবং Vertex AI ব্যবহার করে একটি শক্তিশালী RAG অ্যাপ্লিকেশন তৈরি করবেন। আপনি পর্যায়ক্রমে তিনটি উন্নত কৌশল শিখবেন:
- টেক্সট বিভাজনের কৌশল: আপনি লক্ষ্য করবেন কিভাবে টেক্সট বিভাজনের বিভিন্ন পদ্ধতি (ক্যারেক্টার, রিকার্সিভ, টোকেন) ডেটা পুনরুদ্ধারের গুণমানকে প্রভাবিত করে।
- পুনর্বিন্যাস: আপনি অনুসন্ধানের ফলাফল পরিমার্জন করতে এবং "মাঝখানে হারিয়ে যাওয়া" সমস্যার সমাধান করতে ভার্টেক্স এআই রির্যাঙ্কার প্রয়োগ করবেন।
- কোয়েরি রূপান্তর: আপনি HyDE (হাইপোথেটিক্যাল ডকুমেন্ট এমবেডিংস) এবং স্টেপ-ব্যাক প্রম্পটিং -এর মতো কৌশল ব্যবহার করে ব্যবহারকারীর কোয়েরি অপ্টিমাইজ করতে জেমিনি ব্যবহার করবেন।
আপনি যা করবেন
-
pgvectorব্যবহার করে একটি Cloud SQL for PostgreSQL ইনস্ট্যান্স সেট আপ করুন। - এমন একটি ডেটা ইনজেশন পাইপলাইন তৈরি করুন যা একাধিক কৌশল ব্যবহার করে টেক্সটকে খণ্ডে বিভক্ত করে এবং এমবেডিংগুলো ক্লাউড এসকিউএল-এ সংরক্ষণ করে।
- শব্দার্থিক অনুসন্ধান সম্পাদন করুন এবং বিভিন্ন চাংকিং পদ্ধতি থেকে প্রাপ্ত ফলাফলের গুণমান তুলনা করুন।
- প্রাসঙ্গিকতার ভিত্তিতে প্রাপ্ত ডকুমেন্টগুলোর ক্রম পরিবর্তন করতে একটি রির্যাঙ্কার যুক্ত করুন।
- অস্পষ্ট বা জটিল প্রশ্নের ফলাফল পুনরুদ্ধারের উন্নতি করতে এলএলএম-চালিত কোয়েরি রূপান্তর প্রয়োগ করুন।
আপনি যা শিখবেন
- Vertex AI এবং Cloud SQL-এর সাথে LangChain কীভাবে ব্যবহার করবেন।
- ক্যারেক্টার , রিকার্সিভ এবং টোকেন টেক্সট স্প্লিটারের প্রভাব।
- PostgreSQL-এ কীভাবে ভেক্টর সার্চ প্রয়োগ করবেন
- পুনর্বিন্যাসের জন্য কীভাবে ContextualCompressionRetriever ব্যবহার করবেন।
- HyDE এবং স্টেপ-ব্যাক প্রম্পটিং কীভাবে প্রয়োগ করবেন।
২. প্রজেক্ট সেটআপ
গুগল অ্যাকাউন্ট
যদি আপনার আগে থেকে কোনো ব্যক্তিগত গুগল অ্যাকাউন্ট না থাকে, তাহলে আপনাকে অবশ্যই একটি গুগল অ্যাকাউন্ট তৈরি করতে হবে।
কর্মক্ষেত্র বা শিক্ষা প্রতিষ্ঠানের অ্যাকাউন্টের পরিবর্তে ব্যক্তিগত অ্যাকাউন্ট ব্যবহার করুন ।
গুগল ক্লাউড কনসোলে সাইন-ইন করুন
আপনার ব্যক্তিগত গুগল অ্যাকাউন্ট ব্যবহার করে গুগল ক্লাউড কনসোলে সাইন-ইন করুন।
বিলিং সক্ষম করুন
গুগল ক্লাউড ক্রেডিট রিডিম করুন (ঐচ্ছিক)
এই ওয়ার্কশপটি চালানোর জন্য আপনার কিছু ক্রেডিট সহ একটি বিলিং অ্যাকাউন্ট প্রয়োজন। শুরু করার জন্য এই কোডল্যাবের উপরের ব্যানার থেকে ক্রেডিট ব্যবহার করুন। আপনি যদি ইতিমধ্যেই একটি বিলিং অ্যাকাউন্টের সাথে সংযুক্ত থাকেন, তাহলে আপনি এই ধাপটি এড়িয়ে যেতে পারেন।
একটি ব্যক্তিগত বিলিং অ্যাকাউন্ট তৈরি করুন
আপনি যদি গুগল ক্লাউড ক্রেডিট ব্যবহার করে বিলিং সেট আপ করেন, তাহলে এই ধাপটি এড়িয়ে যেতে পারেন।
একটি ব্যক্তিগত বিলিং অ্যাকাউন্ট তৈরি করতে, ক্লাউড কনসোলে বিলিং চালু করার জন্য এখানে যান ।
কিছু নোট:
- এই ল্যাবটি সম্পন্ন করতে ক্লাউড রিসোর্সে ১ মার্কিন ডলারেরও কম খরচ হওয়া উচিত।
- পরবর্তী চার্জ এড়াতে, এই ল্যাবের শেষে দেওয়া ধাপগুলো অনুসরণ করে আপনি রিসোর্সগুলো মুছে ফেলতে পারেন।
- নতুন ব্যবহারকারীরা ৩০০ মার্কিন ডলারের ফ্রি ট্রায়ালের জন্য যোগ্য।
একটি প্রকল্প তৈরি করুন (ঐচ্ছিক)
এই ল্যাবের জন্য ব্যবহার করার মতো আপনার যদি কোনো চলমান প্রজেক্ট না থাকে, তাহলে এখানে একটি নতুন প্রজেক্ট তৈরি করুন ।
৩. ক্লাউড শেল এডিটর খুলুন
- সরাসরি ক্লাউড শেল এডিটর- এ যেতে এই লিঙ্কে ক্লিক করুন।
- আজ যেকোনো সময়ে অনুমোদনের জন্য অনুরোধ করা হলে, চালিয়ে যাওয়ার জন্য 'অনুমোদন করুন' (Authorize) বোতামে ক্লিক করুন।
- যদি স্ক্রিনের নিচে টার্মিনালটি দেখা না যায়, তাহলে এটি খুলুন:
- ভিউ ক্লিক করুন
- টার্মিনালে ক্লিক করুন
- টার্মিনালে এই কমান্ডটি দিয়ে আপনার প্রজেক্ট সেট করুন:
gcloud config set project [PROJECT_ID]- উদাহরণ:
gcloud config set project lab-project-id-example - আপনি যদি আপনার প্রজেক্ট আইডি মনে রাখতে না পারেন, তাহলে নিম্নলিখিত উপায়ে আপনার সমস্ত প্রজেক্ট আইডি তালিকাভুক্ত করতে পারেন:
gcloud projects list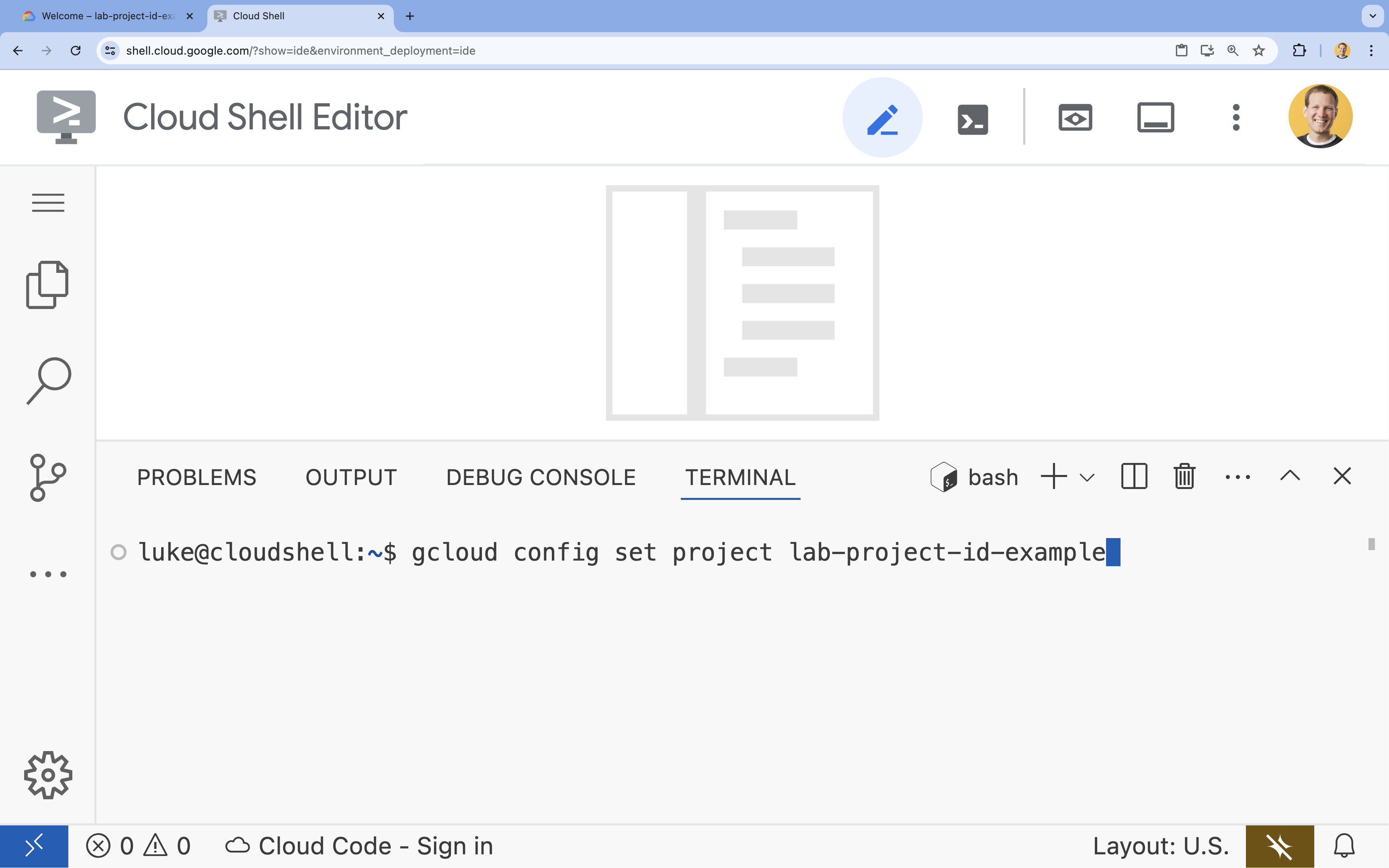
- উদাহরণ:
- আপনি এই বার্তাটি দেখতে পাবেন:
Updated property [core/project].
৪. এপিআই সক্রিয় করুন
এই সলিউশনটি তৈরি করতে, আপনাকে Vertex AI, Cloud SQL, এবং Reranking সার্ভিসের জন্য বেশ কয়েকটি Google Cloud API সক্রিয় করতে হবে।
- টার্মিনালে, এপিআইগুলো সক্রিয় করুন:
gcloud services enable \ aiplatform.googleapis.com \ sqladmin.googleapis.com \ cloudresourcemanager.googleapis.com \ serviceusage.googleapis.com \ discoveryengine.googleapis.com
এপিআইগুলো চালু করা হচ্ছে
- ভার্টেক্স এআই এপিআই (
aiplatform.googleapis.com): জেনারেশনের জন্য জেমিনি এবং টেক্সট ভেক্টরাইজ করার জন্য ভার্টেক্স এআই এমবেডিংস ব্যবহারের সুযোগ দেয়। - ক্লাউড এসকিউএল অ্যাডমিন এপিআই (
sqladmin.googleapis.com): এর মাধ্যমে আপনি প্রোগ্রাম্যাটিকভাবে ক্লাউড এসকিউএল ইনস্ট্যান্সগুলো পরিচালনা করতে পারেন। - ডিসকভারি ইঞ্জিন এপিআই (
discoveryengine.googleapis.com): ভার্টেক্স এআই রির্যাঙ্কার সক্ষমতাগুলোকে শক্তি জোগায়। - সার্ভিস ইউসেজ এপিআই (
serviceusage.googleapis.com): সার্ভিস কোটা যাচাই ও পরিচালনা করার জন্য এটি প্রয়োজন।
৫. একটি ভার্চুয়াল এনভায়রনমেন্ট তৈরি করুন এবং ডিপেন্ডেন্সিগুলো ইনস্টল করুন
যেকোনো পাইথন প্রজেক্ট শুরু করার আগে একটি ভার্চুয়াল এনভায়রনমেন্ট তৈরি করে নেওয়া ভালো। এটি প্রজেক্টের ডিপেন্ডেন্সিগুলোকে আলাদা করে রাখে, ফলে অন্যান্য প্রজেক্ট বা সিস্টেমের গ্লোবাল পাইথন প্যাকেজগুলোর সাথে কোনো কনফ্লিক্ট বা সংঘাত হয় না।
-
rag-labsনামে একটি ফোল্ডার তৈরি করুন এবং তার ভেতরে প্রবেশ করুন। টার্মিনালে নিম্নলিখিত কোডটি চালান:mkdir rag-labs && cd rag-labs - একটি ভার্চুয়াল পরিবেশ তৈরি ও সক্রিয় করুন:
uv venv --python 3.12 source .venv/bin/activate - প্রয়োজনীয় ডিপেন্ডেন্সিগুলো দিয়ে একটি
requirements.txtফাইল তৈরি করুন। টার্মিনালে নিম্নলিখিত কোডটি চালান:cloudshell edit requirements.txt - নিম্নলিখিত অপ্টিমাইজ করা ডিপেন্ডেন্সিগুলো
requirements.txtফাইলে পেস্ট করুন। কনফ্লিক্ট এড়াতে এবং ইনস্টলেশন দ্রুত করতে এই ভার্সনগুলো পিন করা হয়েছে।# Core LangChain & AI langchain-community==0.3.31 langchain-google-vertexai==2.1.2 langchain-google-community[vertexaisearch]==2.0.10 # Google Cloud google-cloud-storage==2.19.0 google-cloud-aiplatform[langchain]==1.130.0 # Database cloud-sql-python-connector[pg8000]==1.19.0 sqlalchemy==2.0.45 pgvector==0.4.2 # Utilities tiktoken==0.12.0 python-dotenv==1.2.1 requests==2.32.5 - নির্ভরতাগুলি ইনস্টল করুন:
uv pip install -r requirements.txt
৬. PostgreSQL-এর জন্য ক্লাউড এসকিউএল সেট আপ করুন
এই টাস্কে, আপনাকে একটি Cloud SQL for PostgreSQL ইনস্ট্যান্স প্রোভিশন করতে হবে, একটি ডেটাবেস তৈরি করতে হবে এবং ভেক্টর সার্চের জন্য এটিকে প্রস্তুত করতে হবে।
ক্লাউড SQL কনফিগারেশন সংজ্ঞায়িত করুন
- আপনার কনফিগারেশন সংরক্ষণের জন্য একটি
.envফাইল তৈরি করুন। টার্মিনালে নিম্নলিখিত কোডটি চালান:cloudshell edit .env - নিম্নলিখিত কনফিগারেশনটি
.envফাইলে পেস্ট করুন।# Project Config PROJECT_ID="[YOUR_PROJECT_ID]" REGION="us-central1" # Database Config SQL_INSTANCE_NAME="rag-pg-instance-1" SQL_DATABASE_NAME="rag_harry_potter_db" SQL_USER="rag_user" SQL_PASSWORD="StrongPassword123!" # RAG Config PGVECTOR_COLLECTION_NAME="rag_harry_potter" RANKING_LOCATION_ID="global" # Connection Name (Auto-generated in scripts usually, but useful to have) DB_INSTANCE_CONNECTION_NAME="${PROJECT_ID}:${REGION}:${SQL_INSTANCE_NAME}" -
[YOUR_PROJECT_ID]এর জায়গায় আপনার আসল গুগল ক্লাউড প্রজেক্ট আইডি বসান। (যেমনPROJECT_ID = "google-cloud-labs")
আপনি যদি আপনার প্রজেক্ট আইডি মনে করতে না পারেন, তাহলে আপনার টার্মিনালে নিম্নলিখিত কমান্ডটি চালান। এটি আপনাকে আপনার সমস্ত প্রজেক্ট এবং তাদের আইডিগুলির একটি তালিকা দেখাবে।gcloud projects list - আপনার শেল সেশনে ভেরিয়েবলগুলো লোড করুন:
source .env
ইনস্ট্যান্স এবং ডাটাবেস তৈরি করুন
- একটি Cloud SQL for PostgreSQL ইনস্ট্যান্স তৈরি করুন। এই কমান্ডটি এই ল্যাবের জন্য উপযুক্ত একটি ছোট ইনস্ট্যান্স তৈরি করে।
gcloud sql instances create ${SQL_INSTANCE_NAME} \ --database-version=POSTGRES_15 \ --tier=db-g1-small \ --region=${REGION} \ --project=${PROJECT_ID} - ইনস্ট্যান্সটি প্রস্তুত হয়ে গেলে, ডাটাবেসটি তৈরি করুন:
gcloud sql databases create ${SQL_DATABASE_NAME} \ --instance=${SQL_INSTANCE_NAME} \ --project=${PROJECT_ID} - ডাটাবেস ব্যবহারকারী তৈরি করুন:
gcloud sql users create ${SQL_USER} \ --instance=${SQL_INSTANCE_NAME} \ --password=${SQL_PASSWORD} \ --project=${PROJECT_ID}
pgvector এক্সটেনশনটি সক্রিয় করুন
pgvector এক্সটেনশনটি PostgreSQL-কে ভেক্টর এমবেডিং সংরক্ষণ ও অনুসন্ধান করতে সক্ষম করে। আপনাকে অবশ্যই আপনার ডেটাবেসে এটি স্পষ্টভাবে সক্রিয় করতে হবে।
-
enable_pgvector.pyনামে একটি স্ক্রিপ্ট তৈরি করুন। টার্মিনালে নিম্নলিখিত কোডটি চালান:cloudshell edit enable_pgvector.py - নিম্নলিখিত কোডটি
enable_pgvector.pyফাইলে পেস্ট করুন। এই স্ক্রিপ্টটি আপনার ডাটাবেসের সাথে সংযোগ স্থাপন করে এবংCREATE EXTENSION IF NOT EXISTS vector;চালায়।import os import sqlalchemy from google.cloud.sql.connector import Connector, IPTypes import logging from dotenv import load_dotenv load_dotenv() logging.basicConfig(level=logging.INFO) # Config project_id = os.getenv("PROJECT_ID") region = os.getenv("REGION") instance_name = os.getenv("SQL_INSTANCE_NAME") db_user = os.getenv("SQL_USER") db_pass = os.getenv("SQL_PASSWORD") db_name = os.getenv("SQL_DATABASE_NAME") instance_connection_name = f"{project_id}:{region}:{instance_name}" def getconn(): with Connector() as connector: conn = connector.connect( instance_connection_name, "pg8000", user=db_user, password=db_pass, db=db_name, ip_type=IPTypes.PUBLIC, ) return conn def enable_pgvector(): pool = sqlalchemy.create_engine( "postgresql+pg8000://", creator=getconn, ) with pool.connect() as db_conn: # Check if extension exists result = db_conn.execute(sqlalchemy.text("SELECT extname FROM pg_extension WHERE extname = 'vector';")).fetchone() if result: logging.info("pgvector extension is already enabled.") else: logging.info("Enabling pgvector extension...") db_conn.execute(sqlalchemy.text("CREATE EXTENSION IF NOT EXISTS vector;")) db_conn.commit() logging.info("pgvector extension enabled successfully.") if __name__ == "__main__": enable_pgvector() - স্ক্রিপ্টটি চালান:
python enable_pgvector.py
৭. পর্ব ১: খণ্ডীকরণের কৌশল
যেকোনো RAG পাইপলাইনের প্রথম ধাপ হলো ডকুমেন্টগুলোকে এমন একটি ফরম্যাটে রূপান্তর করা যা LLM বুঝতে পারে: অর্থাৎ খণ্ডে (chunks )।
এলএলএম-এর একটি কনটেক্সট উইন্ডো লিমিট থাকে (অর্থাৎ, এটি একবারে যে পরিমাণ টেক্সট প্রসেস করতে পারে)। তাছাড়া, একটি নির্দিষ্ট প্রশ্নের উত্তর খোঁজার জন্য ৫০ পৃষ্ঠার একটি ডকুমেন্ট ব্যবহার করলে তথ্যের মান কমে যায়। প্রাসঙ্গিক তথ্য আলাদা করার জন্য আমরা ডকুমেন্টগুলোকে ছোট ছোট ‘খন্ডে’ ভাগ করি।
তবে, আপনি কীভাবে লেখাটি ভাগ করছেন তা অত্যন্ত গুরুত্বপূর্ণ:
- ক্যারেক্টার স্প্লিটার: শুধুমাত্র অক্ষর সংখ্যা অনুযায়ী বিভক্ত করে। এটি দ্রুত হলেও ঝুঁকিপূর্ণ; এটি শব্দ বা বাক্যকে মাঝখান থেকে কেটে ফেলে অর্থগত তাৎপর্য নষ্ট করে দিতে পারে।
- রিকার্সিভ স্প্লিটার: প্রথমে অনুচ্ছেদ, তারপর বাক্য এবং সবশেষে শব্দ অনুসারে বিভক্ত করার চেষ্টা করে। এটি অর্থগত এককগুলোকে একত্রে রাখার চেষ্টা করে।
- টোকেন স্প্লিটার: এটি এলএলএম-এর নিজস্ব শব্দভান্ডার (টোকেন)-এর উপর ভিত্তি করে ডেটা বিভক্ত করে। এটি নিশ্চিত করে যে ডেটার খণ্ডগুলো কনটেক্সট উইন্ডোতে নিখুঁতভাবে ফিট হয়, কিন্তু এটি তৈরি করা কম্পিউটেশনালি আরও ব্যয়বহুল হতে পারে।
এই অংশে, আপনি তিনটি কৌশল ব্যবহার করে একই ডেটা গ্রহণ করবেন এবং সেগুলোর মধ্যে তুলনা করবেন।
ইনজেশন স্ক্রিপ্ট তৈরি করুন
আপনি এমন একটি স্ক্রিপ্ট ব্যবহার করবেন যা একটি হ্যারি পটার ডেটাসেট ডাউনলোড করে, সেটিকে ক্যারেক্টার , রিকার্সিভ এবং টোকেন স্ট্র্যাটেজি ব্যবহার করে বিভক্ত করে এবং এমবেডিংগুলো ক্লাউড এসকিউএল-এর তিনটি পৃথক টেবিলে আপলোড করে।
-
ingest_data.pyফাইলটি তৈরি করুন:cloudshell edit ingest_data.py - নিম্নলিখিত সংশোধিত কোডটি
ingest_data.pyফাইলে পেস্ট করুন। এই সংস্করণটি ডেটাসেটের JSON কাঠামো সঠিকভাবে পার্স করে।import os import json import logging import requests from typing import List, Dict, Any from dotenv import load_dotenv from google.cloud.sql.connector import Connector, IPTypes from langchain_google_vertexai import VertexAIEmbeddings from langchain_community.vectorstores import PGVector from langchain.text_splitter import CharacterTextSplitter, RecursiveCharacterTextSplitter, TokenTextSplitter from langchain.docstore.document import Document load_dotenv() logging.basicConfig(level=logging.INFO) # Configuration PROJECT_ID = os.getenv("PROJECT_ID") REGION = os.getenv("REGION") DB_USER = os.getenv("SQL_USER") DB_PASS = os.getenv("SQL_PASSWORD") DB_NAME = os.getenv("SQL_DATABASE_NAME") INSTANCE_CONNECTION_NAME = f"{PROJECT_ID}:{REGION}:{os.getenv('SQL_INSTANCE_NAME')}" BASE_COLLECTION_NAME = os.getenv("PGVECTOR_COLLECTION_NAME") BOOKS_JSON_URL = "https://storage.googleapis.com/github-repo/generative-ai/gemini/reasoning-engine/sample_data/harry_potter_books.json" CHUNK_SIZE = 500 CHUNK_OVERLAP = 50 MAX_DOCS_TO_PROCESS = 10 # Database Connector def getconn(): with Connector() as connector: return connector.connect( INSTANCE_CONNECTION_NAME, "pg8000", user=DB_USER, password=DB_PASS, db=DB_NAME, ip_type=IPTypes.PUBLIC, ) def download_data(): logging.info(f"Downloading data from {BOOKS_JSON_URL}...") response = requests.get(BOOKS_JSON_URL) return response.json() def prepare_chunks(json_data, strategy): documents = [] # Iterate through the downloaded data for entry in json_data[:MAX_DOCS_TO_PROCESS]: # --- JSON PARSING LOGIC --- # The data structure nests content inside 'kwargs' -> 'page_content' if "kwargs" in entry and "page_content" in entry["kwargs"]: content = entry["kwargs"]["page_content"] # Extract metadata if available, ensuring it's a dict metadata = entry["kwargs"].get("metadata", {}) if not isinstance(metadata, dict): metadata = {"source": "unknown"} # Add the strategy to metadata for tracking metadata["strategy"] = strategy else: continue if not content: continue # Choose the splitter based on the strategy if strategy == "character": splitter = CharacterTextSplitter(chunk_size=CHUNK_SIZE, chunk_overlap=CHUNK_OVERLAP, separator="\n") elif strategy == "token": splitter = TokenTextSplitter(chunk_size=CHUNK_SIZE, chunk_overlap=CHUNK_OVERLAP) else: # default to recursive splitter = RecursiveCharacterTextSplitter(chunk_size=CHUNK_SIZE, chunk_overlap=CHUNK_OVERLAP) # Split the content into chunks chunks = splitter.split_text(content) # Create Document objects for each chunk for chunk in chunks: documents.append(Document(page_content=chunk, metadata=metadata)) return documents def main(): logging.info("Initializing Embeddings...") embeddings = VertexAIEmbeddings(model_name="gemini-embedding-001", project=PROJECT_ID, location=REGION) data = download_data() strategies = ["character", "recursive", "token"] # Connection string for PGVector (uses the getconn helper) pg_conn_str = f"postgresql+pg8000://{DB_USER}:{DB_PASS}@placeholder/{DB_NAME}" for strategy in strategies: collection_name = f"{BASE_COLLECTION_NAME}_{strategy}" logging.info(f"--- Processing strategy: {strategy.upper()} ---") logging.info(f"Target Collection: {collection_name}") # Prepare documents with the specific strategy docs = prepare_chunks(data, strategy) if not docs: logging.warning(f"No documents generated for strategy {strategy}. Check data source.") continue logging.info(f"Generated {len(docs)} chunks. Uploading to Cloud SQL...") # Initialize the Vector Store store = PGVector( collection_name=collection_name, embedding_function=embeddings, connection_string=pg_conn_str, engine_args={"creator": getconn}, pre_delete_collection=True # Clears old data for this collection before adding new ) # Batch add documents store.add_documents(docs) logging.info(f"Successfully finished {strategy}.\n") if __name__ == "__main__": main() - ইনজেশন স্ক্রিপ্টটি চালান। এটি আপনার ডাটাবেসকে তিনটি ভিন্ন টেবিল (কালেকশন) দিয়ে পূর্ণ করবে।
python ingest_data.py
চাংকিং ফলাফল তুলনা করুন
এখন যেহেতু ডেটা লোড হয়ে গেছে, চলুন তিনটি কালেকশনের উপরেই একটি কোয়েরি চালিয়ে দেখি চাংকিং স্ট্র্যাটেজি ফলাফলের উপর কীভাবে প্রভাব ফেলে।
-
query_chunking.pyতৈরি করুন :cloudshell edit query_chunking.py - নিম্নলিখিত কোডটি
query_chunking.pyফাইলে পেস্ট করুন:import os import logging from dotenv import load_dotenv from google.cloud.sql.connector import Connector, IPTypes from langchain_google_vertexai import VertexAIEmbeddings from langchain_community.vectorstores import PGVector load_dotenv() logging.basicConfig(level=logging.ERROR) # Only show errors to keep output clean # Config PROJECT_ID = os.getenv("PROJECT_ID") REGION = os.getenv("REGION") DB_USER = os.getenv("SQL_USER") DB_PASS = os.getenv("SQL_PASSWORD") DB_NAME = os.getenv("SQL_DATABASE_NAME") INSTANCE_CONNECTION_NAME = f"{PROJECT_ID}:{REGION}:{os.getenv('SQL_INSTANCE_NAME')}" BASE_COLLECTION_NAME = os.getenv("PGVECTOR_COLLECTION_NAME") def getconn(): with Connector() as connector: return connector.connect( INSTANCE_CONNECTION_NAME, "pg8000", user=DB_USER, password=DB_PASS, db=DB_NAME, ip_type=IPTypes.PUBLIC, ) def main(): embeddings = VertexAIEmbeddings(model_name="gemini-embedding-001", project=PROJECT_ID, location=REGION) pg_conn_str = f"postgresql+pg8000://{DB_USER}:{DB_PASS}@placeholder/{DB_NAME}" query = "Tell me about the Dursleys and their relationship with Harry Potter" print(f"\nQUERY: {query}\n" + "="*50) strategies = ["character", "recursive", "token"] for strategy in strategies: collection = f"{BASE_COLLECTION_NAME}_{strategy}" print(f"\nSTRATEGY: {strategy.upper()}") store = PGVector( collection_name=collection, embedding_function=embeddings, connection_string=pg_conn_str, engine_args={"creator": getconn} ) results = store.similarity_search_with_score(query, k=2) for i, (doc, score) in enumerate(results): print(f" Result {i+1} (Score: {score:.4f}): {doc.page_content[:150].replace(chr(10), ' ')}...") if __name__ == "__main__": main() - কোয়েরি স্ক্রিপ্টটি চালান:
python query_chunking.py
আউটপুটটি পর্যবেক্ষণ করুন।
লক্ষ্য করুন, কীভাবে ক্যারেক্টার স্প্লিট মাঝপথে বাক্য কেটে দিতে পারে, যেখানে রিকার্সিভ পদ্ধতি অনুচ্ছেদের সীমানা মেনে চলার চেষ্টা করে। টোকেন স্প্লিটিং নিশ্চিত করে যে খণ্ডগুলো LLM কনটেক্সট উইন্ডোতে নিখুঁতভাবে খাপ খায়, কিন্তু এটি শব্দার্থিক কাঠামোকে উপেক্ষা করতে পারে।
৮. পর্ব ২: পুনর্বিন্যাস
ভেক্টর সার্চ (পুনরুদ্ধার) অত্যন্ত দ্রুত, কারণ এটি সংকুচিত গাণিতিক উপস্থাপনা (এম্বেডিং)-এর উপর নির্ভর করে। এটি রিকল (সমস্ত সম্ভাব্য প্রাসঙ্গিক আইটেম খুঁজে বের করা) নিশ্চিত করতে ব্যাপকভাবে অনুসন্ধান চালায়, কিন্তু প্রায়শই এটি কম প্রিসিশন (আইটেমগুলোর ক্রমবিন্যাস নিখুঁত নাও হতে পারে) সমস্যায় ভোগে।
প্রায়শই, প্রাসঙ্গিক নথিগুলো ফলাফলের তালিকার মাঝে হারিয়ে যায়। একজন এলএলএম শিক্ষার্থী শীর্ষ ৫টি ফলাফলের দিকে মনোযোগ দিলে ৭ নম্বর অবস্থানে থাকা গুরুত্বপূর্ণ উত্তরটি হয়তো তার চোখ এড়িয়ে যেতে পারে।
পুনর্বিন্যাস একটি দ্বিতীয় পর্যায় যোগ করার মাধ্যমে এর সমাধান করে।
- রিট্রিভার: দ্রুত ভেক্টর সার্চ ব্যবহার করে একটি বৃহত্তর সেট (যেমন, শীর্ষ ২৫টি) খুঁজে বের করে।
- রির্যাঙ্কার: কোয়েরি এবং ডকুমেন্ট জোড়ার সম্পূর্ণ টেক্সট পরীক্ষা করার জন্য একটি বিশেষায়িত মডেল (যেমন ক্রস-এনকোডার) ব্যবহার করে। এটি ধীরগতির হলেও অনেক বেশি নির্ভুল। এটি শীর্ষ ২৫টিকে পুনরায় স্কোর করে এবং সেরা ৩টি ফেরত দেয়।
এই টাস্কে, আপনি পার্ট ১-এ তৈরি করা recursive কালেকশনটি সার্চ করবেন, কিন্তু এবার ফলাফল পরিমার্জন করার জন্য ভার্টেক্স এআই রির্যাঙ্কার প্রয়োগ করবেন।
-
query_reranking.pyতৈরি করুন:cloudshell edit query_reranking.py - নিচের কোডটি পেস্ট করুন। লক্ষ্য করুন, এটি কীভাবে সুস্পষ্টভাবে
_recursiveকালেকশনকে টার্গেট করে এবংContextualCompressionRetrieverব্যবহার করে।import os import logging from dotenv import load_dotenv from google.cloud.sql.connector import Connector, IPTypes from langchain_google_vertexai import VertexAIEmbeddings from langchain_community.vectorstores import PGVector # Reranking Imports from langchain.retrievers import ContextualCompressionRetriever from langchain_google_community.vertex_rank import VertexAIRank load_dotenv() logging.basicConfig(level=logging.ERROR) PROJECT_ID = os.getenv("PROJECT_ID") REGION = os.getenv("REGION") DB_USER = os.getenv("SQL_USER") DB_PASS = os.getenv("SQL_PASSWORD") DB_NAME = os.getenv("SQL_DATABASE_NAME") INSTANCE_CONNECTION_NAME = f"{PROJECT_ID}:{REGION}:{os.getenv('SQL_INSTANCE_NAME')}" # IMPORTANT: Target the recursive collection created in ingest_data.py COLLECTION_NAME = f"{os.getenv('PGVECTOR_COLLECTION_NAME')}_recursive" RANKING_LOCATION = os.getenv("RANKING_LOCATION_ID") def getconn(): with Connector() as connector: return connector.connect( INSTANCE_CONNECTION_NAME, "pg8000", user=DB_USER, password=DB_PASS, db=DB_NAME, ip_type=IPTypes.PUBLIC, ) def main(): embeddings = VertexAIEmbeddings(model_name="gemini-embedding-001", project=PROJECT_ID, location=REGION) pg_conn_str = f"postgresql+pg8000://{DB_USER}:{DB_PASS}@placeholder/{DB_NAME}" print(f"Connecting to collection: {COLLECTION_NAME}") store = PGVector( collection_name=COLLECTION_NAME, embedding_function=embeddings, connection_string=pg_conn_str, engine_args={"creator": getconn} ) query = "What are the Horcruxes?" print(f"QUERY: {query}\n") # 1. Base Retriever (Vector Search) - Fetch top 10 base_retriever = store.as_retriever(search_kwargs={"k": 10}) # 2. Reranker - Select top 3 from the 10 reranker = VertexAIRank( project_id=PROJECT_ID, location_id=RANKING_LOCATION, ranking_config="default_ranking_config", title_field="source", top_n=3 ) compression_retriever = ContextualCompressionRetriever( base_compressor=reranker, base_retriever=base_retriever ) # Execute try: reranked_docs = compression_retriever.invoke(query) if not reranked_docs: print("No documents returned. Check if the collection exists and is populated.") print(f"--- Top 3 Reranked Results ---") for i, doc in enumerate(reranked_docs): print(f"Result {i+1} (Score: {doc.metadata.get('relevance_score', 'N/A')}):") print(f" {doc.page_content[:200]}...\n") except Exception as e: print(f"Error during reranking: {e}") if __name__ == "__main__": main() - রি-র্যাঙ্কিং কোয়েরিটি চালান:
python query_reranking.py
পর্যবেক্ষণ করুন
একটি সাধারণ ভেক্টর অনুসন্ধানের তুলনায় আপনি উচ্চতর প্রাসঙ্গিকতা স্কোর বা একটি ভিন্ন ক্রম লক্ষ্য করতে পারেন। এটি নিশ্চিত করে যে এলএলএম (LLM) সম্ভাব্য সবচেয়ে সুনির্দিষ্ট প্রেক্ষাপটটি পায়।
৯. পর্ব ৩: কোয়েরি রূপান্তর
প্রায়শই, RAG-এর সবচেয়ে বড় প্রতিবন্ধকতা হলো ব্যবহারকারী। ব্যবহারকারীর কোয়েরিগুলো প্রায়শই দ্ব্যর্থক, অসম্পূর্ণ বা দুর্বলভাবে গঠিত হয়। যদি কোয়েরি এমবেডিং গাণিতিকভাবে ডকুমেন্ট এমবেডিংয়ের সাথে সামঞ্জস্যপূর্ণ না হয়, তাহলে ডেটা পুনরুদ্ধার ব্যর্থ হয়।
কোয়েরি ট্রান্সফরমেশন ডাটাবেসে পৌঁছানোর আগেই কোয়েরিটিকে পুনর্লিখন বা সম্প্রসারণ করতে একটি LLM ব্যবহার করে। আপনি দুটি কৌশল প্রয়োগ করবেন:
- HyDE (হাইপোথেটিক্যাল ডকুমেন্ট এমবেডিংস): একটি প্রশ্ন ও তার উত্তরের মধ্যে ভেক্টর সাদৃশ্য প্রায়শই একটি উত্তর ও তার একটি কাল্পনিক উত্তরের সাদৃশ্যের চেয়ে কম হয়। HyDE, LLM-কে একটি নিখুঁত উত্তর কল্পনা করতে বলে, সেটিকে এমবেড করে এবং সেই কল্পনার মতো দেখতে ডকুমেন্টগুলো অনুসন্ধান করে।
- স্টেপ-ব্যাক প্রম্পটিং: যদি কোনো ব্যবহারকারী একটি নির্দিষ্ট বিস্তারিত প্রশ্ন জিজ্ঞাসা করেন, তাহলে সিস্টেমটি বৃহত্তর প্রেক্ষাপটটি ধরতে ব্যর্থ হতে পারে। স্টেপ-ব্যাক প্রম্পটিং এলএলএম-কে একটি উচ্চ-স্তরের, বিমূর্ত প্রশ্ন ("এই পরিবারের ইতিহাস কী?") তৈরি করতে বলে, যাতে নির্দিষ্ট বিবরণের পাশাপাশি মৌলিক তথ্যও সংগ্রহ করা যায়।
-
query_transformation.pyতৈরি করুন :cloudshell edit query_transformation.py - নিম্নলিখিত কোডটি পেস্ট করুন:
import os import logging from dotenv import load_dotenv from google.cloud.sql.connector import Connector, IPTypes from langchain_google_vertexai import VertexAIEmbeddings, VertexAI from langchain_community.vectorstores import PGVector from langchain_core.prompts import PromptTemplate load_dotenv() logging.basicConfig(level=logging.ERROR) PROJECT_ID = os.getenv("PROJECT_ID") REGION = os.getenv("REGION") DB_USER = os.getenv("SQL_USER") DB_PASS = os.getenv("SQL_PASSWORD") DB_NAME = os.getenv("SQL_DATABASE_NAME") INSTANCE_CONNECTION_NAME = f"{PROJECT_ID}:{REGION}:{os.getenv('SQL_INSTANCE_NAME')}" COLLECTION_NAME = f"{os.getenv('PGVECTOR_COLLECTION_NAME')}_recursive" def getconn(): with Connector() as connector: return connector.connect( INSTANCE_CONNECTION_NAME, "pg8000", user=DB_USER, password=DB_PASS, db=DB_NAME, ip_type=IPTypes.PUBLIC, ) def generate_hyde_doc(query, llm): prompt = PromptTemplate( input_variables=["question"], template="Write a concise, hypothetical answer to the question. Question: {question} Answer:" ) chain = prompt | llm return chain.invoke({"question": query}) def generate_step_back(query, llm): prompt = PromptTemplate( input_variables=["question"], template="Write a more general, abstract question that concepts in this question. Original: {question} Step-back:" ) chain = prompt | llm return chain.invoke({"question": query}) def main(): embeddings = VertexAIEmbeddings(model_name="gemini-embedding-001", project=PROJECT_ID, location=REGION) llm = VertexAI(model_name="gemini-2.5-flash", project=PROJECT_ID, location=REGION, temperature=0.5) pg_conn_str = f"postgresql+pg8000://{DB_USER}:{DB_PASS}@placeholder/{DB_NAME}" store = PGVector( collection_name=COLLECTION_NAME, embedding_function=embeddings, connection_string=pg_conn_str, engine_args={"creator": getconn} ) retriever = store.as_retriever(search_kwargs={"k": 2}) original_query = "Tell me about the Dursleys." print(f"ORIGINAL QUERY: {original_query}\n" + "-"*30) # 1. HyDE hyde_doc = generate_hyde_doc(original_query, llm) print(f"HyDE Generated Doc: {hyde_doc.strip()[:100]}...") hyde_results = retriever.invoke(hyde_doc) print(f"HyDE Retrieval: {hyde_results[0].page_content[:100]}...\n") # 2. Step-back step_back_q = generate_step_back(original_query, llm) print(f"Step-back Query: {step_back_q.strip()}") step_results = retriever.invoke(step_back_q) print(f"Step-back Retrieval: {step_results[0].page_content[:100]}...") if __name__ == "__main__": main() - রূপান্তর স্ক্রিপ্টটি চালান:
python query_transformation.py
আউটপুটটি পর্যবেক্ষণ করুন।
লক্ষ্য করুন, কীভাবে স্টেপ-ব্যাক কোয়েরি ডার্সলি পরিবারের ইতিহাস সম্পর্কে আরও ব্যাপক প্রেক্ষাপট তুলে ধরতে পারে, যেখানে হাইডিই (HyDE) অনুমানমূলক উত্তরে প্রাপ্ত নির্দিষ্ট বিবরণের উপর আলোকপাত করে।
১০. পর্ব ৪: এন্ড-টু-এন্ড জেনারেশন
আমরা আমাদের ডেটা ছেঁটেছি, সার্চকে পরিমার্জন করেছি এবং ব্যবহারকারীর কোয়েরিকে আরও উন্নত করেছি। এখন, আমরা অবশেষে RAG-এর 'G'-টি যুক্ত করেছি: জেনারেশন (Generation )।
এই পর্যন্ত আমরা কেবল তথ্যই খুঁজে বের করেছি। একটি সত্যিকারের এআই সহকারী তৈরি করতে, আমাদের সেই উচ্চ-মানের, পুনর্বিন্যস্ত নথিগুলোকে একটি এলএলএম (জেমিনি)-এ ইনপুট দিতে হবে, যা স্বাভাবিক ভাষায় একটি উত্তর সংশ্লেষণ করবে।
একটি উৎপাদন পাইপলাইনে, এর সাথে একটি নির্দিষ্ট প্রবাহ জড়িত থাকে:
- পুনরুদ্ধার: দ্রুত ভেক্টর সার্চ ব্যবহার করে প্রার্থীদের একটি বিস্তৃত সেট (যেমন, শীর্ষ ১০) সংগ্রহ করুন।
- পুনর্বিন্যাস: ভার্টেক্স এআই রির্যাঙ্কার ব্যবহার করে সেরাদের মধ্যে থেকে বাছাই করুন (যেমন, শীর্ষ ৩)।
- প্রসঙ্গ নির্মাণ: ওই শীর্ষ ৩টি ডকুমেন্টের বিষয়বস্তুকে একটি একক স্ট্রিং-এ সংযুক্ত করুন।
- গ্রাউন্ডেড প্রম্পটিং: সেই কনটেক্সট স্ট্রিংটিকে একটি কঠোর প্রম্পট টেমপ্লেটে সন্নিবেশ করুন যা এলএলএম-কে শুধুমাত্র সেই তথ্য ব্যবহার করতে বাধ্য করে।
জেনারেশন স্ক্রিপ্ট তৈরি করুন
আমরা জেনারেশন ধাপের জন্য gemini-2.5-flash ব্যবহার করব। এই মডেলটি RAG-এর জন্য আদর্শ, কারণ এর একটি দীর্ঘ কনটেক্সট উইন্ডো এবং কম ল্যাটেন্সি রয়েছে, যা এটিকে দ্রুত একাধিক পুনরুদ্ধার করা ডকুমেন্ট প্রসেস করতে সক্ষম করে।
-
end_to_end_rag.pyতৈরি করুন :
cloudshell edit end_to_end_rag.py
- নিচের কোডটি পেস্ট করুন।
templateভেরিয়েবলটির দিকে মনোযোগ দিন—এখানেই আমরা মডেলকে প্রদত্ত কনটেক্সটের সাথে বাইন্ড করার মাধ্যমে 'হ্যালুসিনেশন' (মনগড়া কথা বলা) এড়ানোর জন্য কঠোরভাবে নির্দেশ দিই।
import os
import logging
from dotenv import load_dotenv
from google.cloud.sql.connector import Connector, IPTypes
from langchain_google_vertexai import VertexAIEmbeddings, VertexAI
from langchain_community.vectorstores import PGVector
from langchain.retrievers import ContextualCompressionRetriever
from langchain_google_community.vertex_rank import VertexAIRank
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
load_dotenv()
logging.basicConfig(level=logging.ERROR)
PROJECT_ID = os.getenv("PROJECT_ID")
REGION = os.getenv("REGION")
# We use the recursive collection as it generally provides the best context boundaries
COLLECTION_NAME = f"{os.getenv('PGVECTOR_COLLECTION_NAME')}_recursive"
def getconn():
instance_conn = f"{PROJECT_ID}:{REGION}:{os.getenv('SQL_INSTANCE_NAME')}"
with Connector() as connector:
return connector.connect(
instance_conn, "pg8000",
user=os.getenv("SQL_USER"), password=os.getenv("SQL_PASSWORD"),
db=os.getenv("SQL_DATABASE_NAME"), ip_type=IPTypes.PUBLIC
)
def main():
print("--- Initializing Production RAG Pipeline ---")
# 1. Setup Embeddings (Gemini Embedding 001)
# We use this to vectorize the user's query to match our database.
embeddings = VertexAIEmbeddings(model_name="gemini-embedding-001", project=PROJECT_ID, location=REGION)
# 2. Connect to Vector Store
pg_conn_str = f"postgresql+pg8000://{os.getenv('SQL_USER')}:{os.getenv('SQL_PASSWORD')}@placeholder/{os.getenv('SQL_DATABASE_NAME')}"
store = PGVector(
collection_name=COLLECTION_NAME,
embedding_function=embeddings,
connection_string=pg_conn_str,
engine_args={"creator": getconn}
)
# 3. Setup The 'Filter Funnel' (Retriever + Reranker)
# Step A: Fast retrieval of top 10 similar documents
base_retriever = store.as_retriever(search_kwargs={"k": 10})
# Step B: Precise reranking to find the top 3 most relevant
reranker = VertexAIRank(
project_id=PROJECT_ID,
location_id="global",
ranking_config="default_ranking_config",
title_field="source",
top_n=3
)
# Combine A and B into a single retrieval object
compression_retriever = ContextualCompressionRetriever(
base_compressor=reranker,
base_retriever=base_retriever
)
# 4. Setup LLM (Gemini 2.5 Flash)
# We use a low temperature (0.1) to reduce creativity and increase factual adherence.
llm = VertexAI(model_name="gemini-2.5-flash", project=PROJECT_ID, location=REGION, temperature=0.1)
# --- Execution Loop ---
user_query = "Who is Harry Potter?"
print(f"\nUser Query: {user_query}")
print("Retrieving and Reranking documents...")
# Retrieve the most relevant documents
top_docs = compression_retriever.invoke(user_query)
if not top_docs:
print("No relevant documents found.")
return
# Build the Context String
# We stitch the documents together, labeling them as Source 1, Source 2, etc.
context_str = "\n\n".join([f"Source {i+1}: {d.page_content}" for i, d in enumerate(top_docs)])
print(f"Found {len(top_docs)} relevant context chunks.")
# 5. The Grounded Prompt
template = """You are a helpful assistant. Answer the question strictly based on the provided context.
If the answer is not in the context, say "I don't know."
Context:
{context}
Question:
{question}
Answer:
"""
prompt = PromptTemplate(template=template, input_variables=["context", "question"])
# Create the chain: Prompt -> LLM
chain = prompt | llm
print("Generating Answer via Gemini 2.5 Flash...")
final_answer = chain.invoke({"context": context_str, "question": user_query})
print(f"\nFINAL ANSWER:\n{final_answer}")
if __name__ == "__main__":
main()
- চূড়ান্ত অ্যাপ্লিকেশনটি চালান:
python end_to_end_rag.py
আউটপুট বোঝা
যখন আপনি এই স্ক্রিপ্টটি চালাবেন, তখন আগের ধাপগুলোতে দেখা মূল টেক্সট খণ্ডগুলো এবং চূড়ান্ত উত্তরের মধ্যে পার্থক্যটি লক্ষ্য করুন। এলএলএম (LLM) একটি সিন্থেসাইজার হিসেবে কাজ করে—এটি রির্যাঙ্কার (Reranker) দ্বারা সরবরাহ করা টেক্সটের খণ্ডিত 'খণ্ডগুলো' পড়ে এবং সেগুলোকে মসৃণ করে একটি সুসংহত, মানুষের পাঠযোগ্য বাক্যে পরিণত করে।
এই উপাদানগুলোকে শৃঙ্খলিত করার মাধ্যমে, আপনি একটি এলোমেলো 'অনুমান' থেকে একটি সুনির্দিষ্ট ও বাস্তবভিত্তিক কর্মপ্রবাহে অগ্রসর হন। রিট্রিভার জাল ফেলে, রির্যাঙ্কার সেরা শিকারটি বাছাই করে, এবং জেনারেটর খাবারটি রান্না করে।
১১. উপসংহার
অভিনন্দন! আপনি সফলভাবে একটি উন্নত RAG পাইপলাইন তৈরি করেছেন যা সাধারণ ভেক্টর অনুসন্ধানের চেয়ে অনেক উন্নত।
পুনরালোচনা
- আপনি পরিমাপযোগ্য ভেক্টর স্টোরেজের জন্য pgvector সহ ক্লাউড এসকিউএল কনফিগার করেছেন।
- ডেটা প্রস্তুতি কীভাবে ডেটা পুনরুদ্ধারকে প্রভাবিত করে তা বোঝার জন্য আপনি চাংকিং কৌশলগুলোর তুলনা করেছেন।
- আপনার ফলাফলের নির্ভুলতা উন্নত করার জন্য আপনি ভার্টেক্স এআই (Vertex AI) ব্যবহার করে রির্যাঙ্কিং (Reranking) প্রয়োগ করেছেন।
- ব্যবহারকারীর অভিপ্রায়ের সাথে আপনার ডেটার সামঞ্জস্য বিধান করতে আপনি কোয়েরি ট্রান্সফরমেশন (HyDE, Step-back) ব্যবহার করেছেন।
আরও জানুন
- RAG রেফারেন্স আর্কিটেকচার : RAG-সম্পর্কিত রেফারেন্স আর্কিটেকচার গাইডগুলির একটি তালিকা দেখুন।
প্রোটোটাইপ থেকে উৎপাদন পর্যন্ত
এই ল্যাবটি ‘প্রোডাকশন-রেডি এআই উইথ গুগল ক্লাউড’ লার্নিং পাথ- এর একটি অংশ।
- প্রোটোটাইপ থেকে উৎপাদনে উত্তরণের ব্যবধান পূরণ করতে সম্পূর্ণ পাঠ্যক্রমটি অন্বেষণ করুন ।
- #ProductionReadyAI হ্যাশট্যাগটি ব্যবহার করে আপনার কাজের অগ্রগতি শেয়ার করুন ।