
1. Introduzione
Panoramica
La Retrieval Augmented Generation (RAG) migliora le risposte del modello linguistico di grandi dimensioni (LLM) basandole su conoscenze esterne. Tuttavia, la creazione di un sistema RAG pronto per la produzione richiede più di una semplice ricerca vettoriale. Devi ottimizzare la modalità di importazione dei dati, il ranking dei risultati pertinenti e l'elaborazione delle query degli utenti.
In questo lab completo, creerai un'applicazione RAG solida utilizzando Cloud SQL per PostgreSQL (esteso con pgvector) e Vertex AI. Vedrai tre tecniche avanzate:
- Strategie di suddivisione:osserverai come diversi metodi di suddivisione del testo (carattere, ricorsivo, token) influiscono sulla qualità del recupero.
- Ricalcolo del ranking:implementerai Vertex AI Reranker per perfezionare i risultati di ricerca e risolvere il problema della "perdita nel mezzo".
- Trasformazione delle query:utilizzerai Gemini per ottimizzare le query degli utenti tramite tecniche come HyDE (Hypothetical Document Embeddings) e Step-back Prompting.
In questo lab proverai a:
- Configura un'istanza Cloud SQL per PostgreSQL con
pgvector. - Crea una pipeline di importazione dei dati che suddivide il testo utilizzando più strategie e archivia gli incorporamenti in Cloud SQL.
- Esegui ricerche semantiche e confronta la qualità dei risultati ottenuti con diversi metodi di suddivisione.
- Integra un Reranker per riordinare i documenti recuperati in base alla pertinenza.
- Implementa trasformazioni delle query basate su LLM per migliorare il recupero di domande ambigue o complesse.
Obiettivi didattici
- Come utilizzare LangChain con Vertex AI e Cloud SQL.
- L'impatto dei separatori di testo Character, Recursive e Token.
- Come implementare la ricerca vettoriale in PostgreSQL.
- Come utilizzare ContextualCompressionRetriever per il ranking.
- Come implementare HyDE e Step-back Prompting.
2. Configurazione del progetto
Account Google
Se non hai ancora un Account Google personale, devi crearne uno.
Utilizza un account personale anziché un account di lavoro o della scuola.
Accedi alla console Google Cloud
Accedi a Google Cloud Console utilizzando un Account Google personale.
Abilita fatturazione
Riscatta i crediti Google Cloud (facoltativo)
Per partecipare a questo workshop, devi disporre di un account di fatturazione con del credito. Per iniziare, utilizza i crediti del banner nella parte superiore di questo codelab. Se hai già collegato un account di fatturazione, puoi saltare questo passaggio.
Configurare un account di fatturazione personale
Se hai configurato la fatturazione utilizzando i crediti Google Cloud, puoi saltare questo passaggio.
Per configurare un account di fatturazione personale, vai qui per abilitare la fatturazione nella console Cloud.
Alcune note:
- Il completamento di questo lab dovrebbe costare meno di 1 $in risorse cloud.
- Per evitare ulteriori addebiti, puoi seguire i passaggi alla fine di questo lab per eliminare le risorse.
- I nuovi utenti hanno diritto alla prova senza costi di 300$.
Creare un progetto (facoltativo)
Se non hai un progetto attuale che vuoi utilizzare per questo lab, creane uno nuovo qui.
3. Apri editor di Cloud Shell
- Fai clic su questo link per andare direttamente all'editor di Cloud Shell.
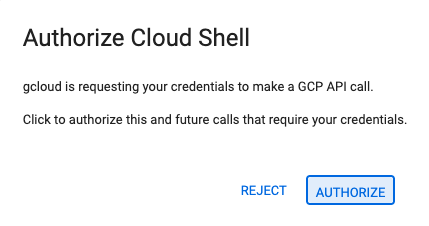
- Se ti viene richiesto di concedere l'autorizzazione in qualsiasi momento della giornata, fai clic su Autorizza per continuare.
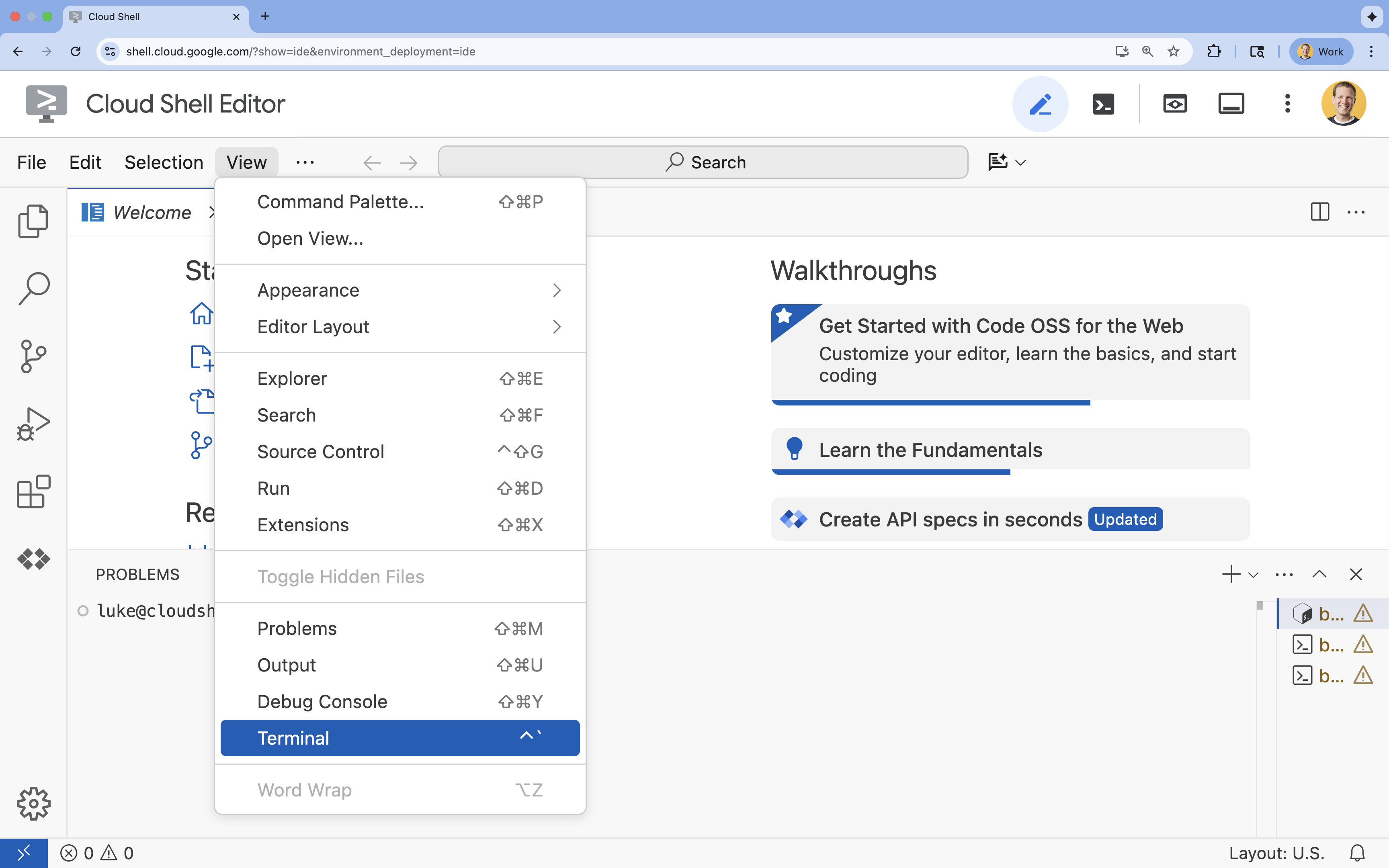
- Se il terminale non viene visualizzato nella parte inferiore dello schermo, aprilo:
- Fai clic su Visualizza.
- Fai clic su Terminale
 .
.
- Nel terminale, imposta il progetto con questo comando:
gcloud config set project [PROJECT_ID]- Esempio:
gcloud config set project lab-project-id-example - Se non ricordi l'ID progetto, puoi elencare tutti i tuoi ID progetto con:
gcloud projects list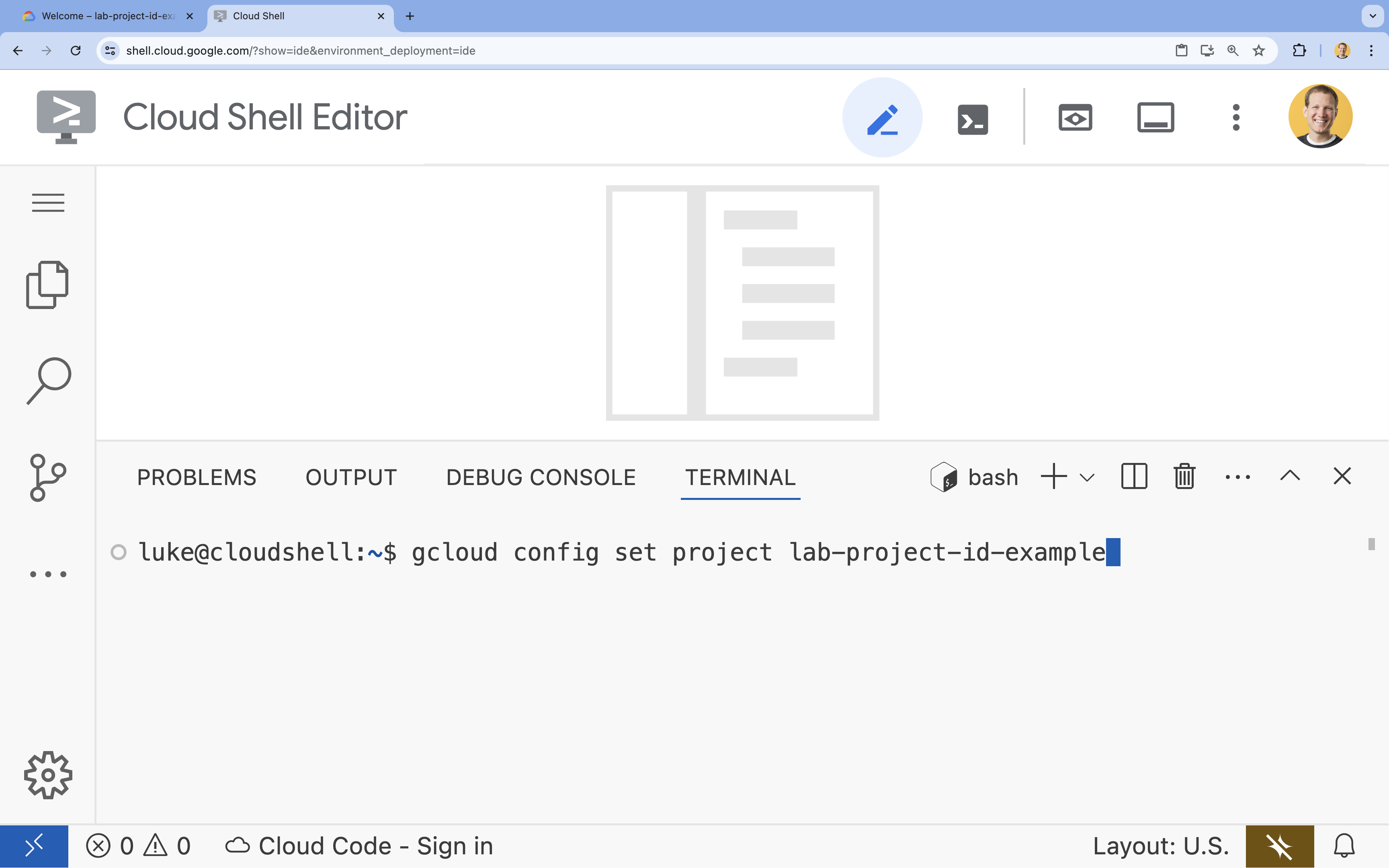
- Esempio:
- Dovresti visualizzare questo messaggio:
Updated property [core/project].
4. Abilita API
Per creare questa soluzione, devi abilitare diverse API Google Cloud per Vertex AI, Cloud SQL e il servizio di ranking.
- Nel terminale, abilita le API:
gcloud services enable \ aiplatform.googleapis.com \ sqladmin.googleapis.com \ cloudresourcemanager.googleapis.com \ serviceusage.googleapis.com \ discoveryengine.googleapis.com
Presentazione delle API
- API Vertex AI (
aiplatform.googleapis.com): consente l'utilizzo di Gemini per la generazione e di Vertex AI Embeddings per la vettorizzazione del testo. - API Cloud SQL Admin (
sqladmin.googleapis.com): consente di gestire le istanze Cloud SQL in modo programmatico. - API Discovery Engine (
discoveryengine.googleapis.com): supporta le funzionalità di Vertex AI Reranker. - API Service Usage (
serviceusage.googleapis.com): necessaria per controllare e gestire le quote di servizio.
5. Crea un ambiente virtuale e installa le dipendenze
Prima di iniziare qualsiasi progetto Python, è buona prassi creare un ambiente virtuale. In questo modo, le dipendenze del progetto vengono isolate, evitando conflitti con altri progetti o con i pacchetti Python globali del sistema.
- Crea una cartella denominata
rag-labse accedi. Esegui questo codice nel terminale:mkdir rag-labs && cd rag-labs - Crea e attiva un ambiente virtuale:
uv venv --python 3.12 source .venv/bin/activate - Crea un file
requirements.txtcon le dipendenze necessarie. Esegui questo codice nel terminale:cloudshell edit requirements.txt - Incolla le seguenti dipendenze ottimizzate in
requirements.txt. Queste versioni sono bloccate per evitare conflitti e velocizzare l'installazione.# Core LangChain & AI langchain-community==0.3.31 langchain-google-vertexai==2.1.2 langchain-google-community[vertexaisearch]==2.0.10 # Google Cloud google-cloud-storage==2.19.0 google-cloud-aiplatform[langchain]==1.130.0 # Database cloud-sql-python-connector[pg8000]==1.19.0 sqlalchemy==2.0.45 pgvector==0.4.2 # Utilities tiktoken==0.12.0 python-dotenv==1.2.1 requests==2.32.5 - Installa le dipendenze:
uv pip install -r requirements.txt
6. Configura Cloud SQL per PostgreSQL
In questa attività, eseguirai il provisioning di un'istanza Cloud SQL per PostgreSQL, creerai un database e lo preparerai per la ricerca vettoriale.
Definisci la configurazione di Cloud SQL
- Crea un file
.envper archiviare la configurazione. Esegui questo codice nel terminale:cloudshell edit .env - Incolla la seguente configurazione in
.env.# Project Config PROJECT_ID="[YOUR_PROJECT_ID]" REGION="us-central1" # Database Config SQL_INSTANCE_NAME="rag-pg-instance-1" SQL_DATABASE_NAME="rag_harry_potter_db" SQL_USER="rag_user" SQL_PASSWORD="StrongPassword123!" # RAG Config PGVECTOR_COLLECTION_NAME="rag_harry_potter" RANKING_LOCATION_ID="global" # Connection Name (Auto-generated in scripts usually, but useful to have) DB_INSTANCE_CONNECTION_NAME="${PROJECT_ID}:${REGION}:${SQL_INSTANCE_NAME}" - Sostituisci
[YOUR_PROJECT_ID]con l'ID del tuo progetto Google Cloud effettivo. (ad es.PROJECT_ID = "google-cloud-labs")
Se non ricordi l'ID progetto, esegui questo comando nel terminale. Verrà visualizzato un elenco di tutti i tuoi progetti e dei relativi ID.gcloud projects list - Carica le variabili nella sessione della shell:
source .env
Crea l'istanza e il database
- Crea un'istanza Cloud SQL per PostgreSQL. Questo comando crea una piccola istanza adatta a questo lab.
gcloud sql instances create ${SQL_INSTANCE_NAME} \ --database-version=POSTGRES_15 \ --tier=db-g1-small \ --region=${REGION} \ --project=${PROJECT_ID} - Quando l'istanza è pronta, crea il database:
gcloud sql databases create ${SQL_DATABASE_NAME} \ --instance=${SQL_INSTANCE_NAME} \ --project=${PROJECT_ID} - Crea l'utente del database:
gcloud sql users create ${SQL_USER} \ --instance=${SQL_INSTANCE_NAME} \ --password=${SQL_PASSWORD} \ --project=${PROJECT_ID}
Abilita l'estensione pgvector
L'estensione pgvector consente a PostgreSQL di archiviare e cercare incorporamenti vettoriali. Devi abilitarlo esplicitamente nel database.
- Crea uno script denominato
enable_pgvector.py. Esegui questo codice nel terminale:cloudshell edit enable_pgvector.py - Incolla il seguente codice in
enable_pgvector.py. Questo script si connette al tuo database ed esegueCREATE EXTENSION IF NOT EXISTS vector;.import os import sqlalchemy from google.cloud.sql.connector import Connector, IPTypes import logging from dotenv import load_dotenv load_dotenv() logging.basicConfig(level=logging.INFO) # Config project_id = os.getenv("PROJECT_ID") region = os.getenv("REGION") instance_name = os.getenv("SQL_INSTANCE_NAME") db_user = os.getenv("SQL_USER") db_pass = os.getenv("SQL_PASSWORD") db_name = os.getenv("SQL_DATABASE_NAME") instance_connection_name = f"{project_id}:{region}:{instance_name}" def getconn(): with Connector() as connector: conn = connector.connect( instance_connection_name, "pg8000", user=db_user, password=db_pass, db=db_name, ip_type=IPTypes.PUBLIC, ) return conn def enable_pgvector(): pool = sqlalchemy.create_engine( "postgresql+pg8000://", creator=getconn, ) with pool.connect() as db_conn: # Check if extension exists result = db_conn.execute(sqlalchemy.text("SELECT extname FROM pg_extension WHERE extname = 'vector';")).fetchone() if result: logging.info("pgvector extension is already enabled.") else: logging.info("Enabling pgvector extension...") db_conn.execute(sqlalchemy.text("CREATE EXTENSION IF NOT EXISTS vector;")) db_conn.commit() logging.info("pgvector extension enabled successfully.") if __name__ == "__main__": enable_pgvector() - Esegui lo script:
python enable_pgvector.py
7. Parte 1: strategie di chunking
Il primo passaggio di qualsiasi pipeline RAG consiste nel trasformare i documenti in un formato comprensibile per l'LLM: i chunk.
Gli LLM hanno un limite per la finestra contestuale (la quantità di testo che possono elaborare contemporaneamente). Inoltre, recuperare un documento di 50 pagine per rispondere a una domanda specifica diluisce le informazioni. Dividiamo i documenti in "blocchi" più piccoli per isolare le informazioni pertinenti.
Tuttavia, il modo in cui dividi il testo è molto importante:
- Separatore di caratteri:divide in base al numero di caratteri. Questo metodo è veloce ma rischioso, in quanto può tagliare a metà parole o frasi, distruggendo il significato semantico.
- Separatore ricorsivo:tenta di dividere prima per paragrafo, poi per frase e infine per parola. Cerca di mantenere unite le unità semantiche.
- Token Splitter: suddivide in base al vocabolario (token) del modello linguistico di grandi dimensioni. In questo modo, i chunk si adattano perfettamente alle finestre contestuali, ma la generazione può essere più costosa dal punto di vista computazionale.
In questa sezione, importerai gli stessi dati utilizzando tutte e tre le strategie per confrontarle.
Crea lo script di importazione
Utilizzerai uno script che scarica un set di dati di Harry Potter, lo suddivide utilizzando le strategie Character, Recursive e Token e carica gli incorporamenti in tre tabelle separate in Cloud SQL.
- Crea il file
ingest_data.py:cloudshell edit ingest_data.py - Incolla il seguente codice corretto in
ingest_data.py. Questa versione analizza correttamente la struttura JSON del set di dati.import os import json import logging import requests from typing import List, Dict, Any from dotenv import load_dotenv from google.cloud.sql.connector import Connector, IPTypes from langchain_google_vertexai import VertexAIEmbeddings from langchain_community.vectorstores import PGVector from langchain.text_splitter import CharacterTextSplitter, RecursiveCharacterTextSplitter, TokenTextSplitter from langchain.docstore.document import Document load_dotenv() logging.basicConfig(level=logging.INFO) # Configuration PROJECT_ID = os.getenv("PROJECT_ID") REGION = os.getenv("REGION") DB_USER = os.getenv("SQL_USER") DB_PASS = os.getenv("SQL_PASSWORD") DB_NAME = os.getenv("SQL_DATABASE_NAME") INSTANCE_CONNECTION_NAME = f"{PROJECT_ID}:{REGION}:{os.getenv('SQL_INSTANCE_NAME')}" BASE_COLLECTION_NAME = os.getenv("PGVECTOR_COLLECTION_NAME") BOOKS_JSON_URL = "https://storage.googleapis.com/github-repo/generative-ai/gemini/reasoning-engine/sample_data/harry_potter_books.json" CHUNK_SIZE = 500 CHUNK_OVERLAP = 50 MAX_DOCS_TO_PROCESS = 10 # Database Connector def getconn(): with Connector() as connector: return connector.connect( INSTANCE_CONNECTION_NAME, "pg8000", user=DB_USER, password=DB_PASS, db=DB_NAME, ip_type=IPTypes.PUBLIC, ) def download_data(): logging.info(f"Downloading data from {BOOKS_JSON_URL}...") response = requests.get(BOOKS_JSON_URL) return response.json() def prepare_chunks(json_data, strategy): documents = [] # Iterate through the downloaded data for entry in json_data[:MAX_DOCS_TO_PROCESS]: # --- JSON PARSING LOGIC --- # The data structure nests content inside 'kwargs' -> 'page_content' if "kwargs" in entry and "page_content" in entry["kwargs"]: content = entry["kwargs"]["page_content"] # Extract metadata if available, ensuring it's a dict metadata = entry["kwargs"].get("metadata", {}) if not isinstance(metadata, dict): metadata = {"source": "unknown"} # Add the strategy to metadata for tracking metadata["strategy"] = strategy else: continue if not content: continue # Choose the splitter based on the strategy if strategy == "character": splitter = CharacterTextSplitter(chunk_size=CHUNK_SIZE, chunk_overlap=CHUNK_OVERLAP, separator="\n") elif strategy == "token": splitter = TokenTextSplitter(chunk_size=CHUNK_SIZE, chunk_overlap=CHUNK_OVERLAP) else: # default to recursive splitter = RecursiveCharacterTextSplitter(chunk_size=CHUNK_SIZE, chunk_overlap=CHUNK_OVERLAP) # Split the content into chunks chunks = splitter.split_text(content) # Create Document objects for each chunk for chunk in chunks: documents.append(Document(page_content=chunk, metadata=metadata)) return documents def main(): logging.info("Initializing Embeddings...") embeddings = VertexAIEmbeddings(model_name="gemini-embedding-001", project=PROJECT_ID, location=REGION) data = download_data() strategies = ["character", "recursive", "token"] # Connection string for PGVector (uses the getconn helper) pg_conn_str = f"postgresql+pg8000://{DB_USER}:{DB_PASS}@placeholder/{DB_NAME}" for strategy in strategies: collection_name = f"{BASE_COLLECTION_NAME}_{strategy}" logging.info(f"--- Processing strategy: {strategy.upper()} ---") logging.info(f"Target Collection: {collection_name}") # Prepare documents with the specific strategy docs = prepare_chunks(data, strategy) if not docs: logging.warning(f"No documents generated for strategy {strategy}. Check data source.") continue logging.info(f"Generated {len(docs)} chunks. Uploading to Cloud SQL...") # Initialize the Vector Store store = PGVector( collection_name=collection_name, embedding_function=embeddings, connection_string=pg_conn_str, engine_args={"creator": getconn}, pre_delete_collection=True # Clears old data for this collection before adding new ) # Batch add documents store.add_documents(docs) logging.info(f"Successfully finished {strategy}.\n") if __name__ == "__main__": main() - Esegui lo script di importazione. Il database verrà compilato con tre tabelle (raccolte) diverse.
python ingest_data.py
Confrontare i risultati del chunking
Ora che i dati sono caricati, eseguiamo una query su tutte e tre le raccolte per vedere in che modo la strategia di suddivisione influisce sui risultati.
- Crea
query_chunking.py:cloudshell edit query_chunking.py - Incolla il seguente codice in
query_chunking.py:import os import logging from dotenv import load_dotenv from google.cloud.sql.connector import Connector, IPTypes from langchain_google_vertexai import VertexAIEmbeddings from langchain_community.vectorstores import PGVector load_dotenv() logging.basicConfig(level=logging.ERROR) # Only show errors to keep output clean # Config PROJECT_ID = os.getenv("PROJECT_ID") REGION = os.getenv("REGION") DB_USER = os.getenv("SQL_USER") DB_PASS = os.getenv("SQL_PASSWORD") DB_NAME = os.getenv("SQL_DATABASE_NAME") INSTANCE_CONNECTION_NAME = f"{PROJECT_ID}:{REGION}:{os.getenv('SQL_INSTANCE_NAME')}" BASE_COLLECTION_NAME = os.getenv("PGVECTOR_COLLECTION_NAME") def getconn(): with Connector() as connector: return connector.connect( INSTANCE_CONNECTION_NAME, "pg8000", user=DB_USER, password=DB_PASS, db=DB_NAME, ip_type=IPTypes.PUBLIC, ) def main(): embeddings = VertexAIEmbeddings(model_name="gemini-embedding-001", project=PROJECT_ID, location=REGION) pg_conn_str = f"postgresql+pg8000://{DB_USER}:{DB_PASS}@placeholder/{DB_NAME}" query = "Tell me about the Dursleys and their relationship with Harry Potter" print(f"\nQUERY: {query}\n" + "="*50) strategies = ["character", "recursive", "token"] for strategy in strategies: collection = f"{BASE_COLLECTION_NAME}_{strategy}" print(f"\nSTRATEGY: {strategy.upper()}") store = PGVector( collection_name=collection, embedding_function=embeddings, connection_string=pg_conn_str, engine_args={"creator": getconn} ) results = store.similarity_search_with_score(query, k=2) for i, (doc, score) in enumerate(results): print(f" Result {i+1} (Score: {score:.4f}): {doc.page_content[:150].replace(chr(10), ' ')}...") if __name__ == "__main__": main() - Esegui lo script della query:
python query_chunking.py
Osserva l'output.
Nota come la suddivisione Carattere potrebbe interrompere le frasi a metà, mentre Ricorsiva cerca di rispettare i limiti dei paragrafi. La suddivisione dei token garantisce che i chunk si adattino perfettamente alle finestre contestuali degli LLM, ma potrebbe ignorare la struttura semantica.
8. Parte 2: riposizionamento
La ricerca vettoriale (recupero) è incredibilmente veloce perché si basa su rappresentazioni matematiche compresse (embedding). Viene utilizzato un criterio meno restrittivo per garantire il richiamo (trovare tutti gli elementi potenzialmente pertinenti), ma spesso la precisione è bassa (la classificazione di questi elementi potrebbe essere imperfetta).
Spesso, i documenti pertinenti vengono "persi nel mezzo" dell'elenco dei risultati. Un LLM che presta attenzione ai primi 5 risultati potrebbe non trovare la risposta cruciale che si trova alla posizione numero 7.
Il ranking secondario risolve questo problema aggiungendo una seconda fase.
- Recupero:recupera un insieme più ampio (ad es. i primi 25) utilizzando la ricerca vettoriale rapida.
- Reranker:utilizza un modello specializzato (come un Cross-Encoder) per esaminare il testo completo della query e delle coppie di documenti. È più lento, ma molto più preciso. Ricalcola il punteggio dei primi 25 e restituisce i 3 migliori in assoluto.
In questa attività, cercherai nella raccolta recursive creata nella parte 1, ma questa volta applicherai Vertex AI Reranker per perfezionare i risultati.
- Crea
query_reranking.py:cloudshell edit query_reranking.py - Incolla il seguente codice. Nota come prende di mira esplicitamente la
_recursiveraccolta e gli usiContextualCompressionRetriever.import os import logging from dotenv import load_dotenv from google.cloud.sql.connector import Connector, IPTypes from langchain_google_vertexai import VertexAIEmbeddings from langchain_community.vectorstores import PGVector # Reranking Imports from langchain.retrievers import ContextualCompressionRetriever from langchain_google_community.vertex_rank import VertexAIRank load_dotenv() logging.basicConfig(level=logging.ERROR) PROJECT_ID = os.getenv("PROJECT_ID") REGION = os.getenv("REGION") DB_USER = os.getenv("SQL_USER") DB_PASS = os.getenv("SQL_PASSWORD") DB_NAME = os.getenv("SQL_DATABASE_NAME") INSTANCE_CONNECTION_NAME = f"{PROJECT_ID}:{REGION}:{os.getenv('SQL_INSTANCE_NAME')}" # IMPORTANT: Target the recursive collection created in ingest_data.py COLLECTION_NAME = f"{os.getenv('PGVECTOR_COLLECTION_NAME')}_recursive" RANKING_LOCATION = os.getenv("RANKING_LOCATION_ID") def getconn(): with Connector() as connector: return connector.connect( INSTANCE_CONNECTION_NAME, "pg8000", user=DB_USER, password=DB_PASS, db=DB_NAME, ip_type=IPTypes.PUBLIC, ) def main(): embeddings = VertexAIEmbeddings(model_name="gemini-embedding-001", project=PROJECT_ID, location=REGION) pg_conn_str = f"postgresql+pg8000://{DB_USER}:{DB_PASS}@placeholder/{DB_NAME}" print(f"Connecting to collection: {COLLECTION_NAME}") store = PGVector( collection_name=COLLECTION_NAME, embedding_function=embeddings, connection_string=pg_conn_str, engine_args={"creator": getconn} ) query = "What are the Horcruxes?" print(f"QUERY: {query}\n") # 1. Base Retriever (Vector Search) - Fetch top 10 base_retriever = store.as_retriever(search_kwargs={"k": 10}) # 2. Reranker - Select top 3 from the 10 reranker = VertexAIRank( project_id=PROJECT_ID, location_id=RANKING_LOCATION, ranking_config="default_ranking_config", title_field="source", top_n=3 ) compression_retriever = ContextualCompressionRetriever( base_compressor=reranker, base_retriever=base_retriever ) # Execute try: reranked_docs = compression_retriever.invoke(query) if not reranked_docs: print("No documents returned. Check if the collection exists and is populated.") print(f"--- Top 3 Reranked Results ---") for i, doc in enumerate(reranked_docs): print(f"Result {i+1} (Score: {doc.metadata.get('relevance_score', 'N/A')}):") print(f" {doc.page_content[:200]}...\n") except Exception as e: print(f"Error during reranking: {e}") if __name__ == "__main__": main() - Esegui la query di riassegnazione del ranking:
python query_reranking.py
Osserva
Potresti notare punteggi di pertinenza più elevati o un ordinamento diverso rispetto a una ricerca vettoriale non elaborata. In questo modo, l'LLM riceve il contesto più preciso possibile.
9. Parte 3: trasformazione delle query
Spesso, il collo di bottiglia più grande nella RAG è l'utente. Le query degli utenti sono spesso ambigue, incomplete o formulate in modo errato. Se l'incorporamento della query non è allineato matematicamente all'incorporamento del documento, il recupero non va a buon fine.
La trasformazione delle query utilizza un LLM per riscrivere o espandere la query prima che raggiunga il database. Implementerai due tecniche:
- HyDE (Hypothetical Document Embeddings): la somiglianza vettoriale tra una domanda e una risposta è spesso inferiore alla somiglianza tra una risposta e una risposta ipotetica. HyDE chiede all'LLM di generare una risposta perfetta, la incorpora e cerca documenti simili alla risposta generata.
- Prompt passo indietro: se un utente pone una domanda specifica e dettagliata, il sistema potrebbe perdere il contesto più ampio. Il prompt step-back chiede all'LLM di generare una domanda più astratta e di livello superiore ("Qual è la storia di questa famiglia?") per recuperare informazioni di base insieme ai dettagli specifici.
- Crea
query_transformation.py:cloudshell edit query_transformation.py - Incolla il seguente codice:
import os import logging from dotenv import load_dotenv from google.cloud.sql.connector import Connector, IPTypes from langchain_google_vertexai import VertexAIEmbeddings, VertexAI from langchain_community.vectorstores import PGVector from langchain_core.prompts import PromptTemplate load_dotenv() logging.basicConfig(level=logging.ERROR) PROJECT_ID = os.getenv("PROJECT_ID") REGION = os.getenv("REGION") DB_USER = os.getenv("SQL_USER") DB_PASS = os.getenv("SQL_PASSWORD") DB_NAME = os.getenv("SQL_DATABASE_NAME") INSTANCE_CONNECTION_NAME = f"{PROJECT_ID}:{REGION}:{os.getenv('SQL_INSTANCE_NAME')}" COLLECTION_NAME = f"{os.getenv('PGVECTOR_COLLECTION_NAME')}_recursive" def getconn(): with Connector() as connector: return connector.connect( INSTANCE_CONNECTION_NAME, "pg8000", user=DB_USER, password=DB_PASS, db=DB_NAME, ip_type=IPTypes.PUBLIC, ) def generate_hyde_doc(query, llm): prompt = PromptTemplate( input_variables=["question"], template="Write a concise, hypothetical answer to the question. Question: {question} Answer:" ) chain = prompt | llm return chain.invoke({"question": query}) def generate_step_back(query, llm): prompt = PromptTemplate( input_variables=["question"], template="Write a more general, abstract question that concepts in this question. Original: {question} Step-back:" ) chain = prompt | llm return chain.invoke({"question": query}) def main(): embeddings = VertexAIEmbeddings(model_name="gemini-embedding-001", project=PROJECT_ID, location=REGION) llm = VertexAI(model_name="gemini-2.5-flash", project=PROJECT_ID, location=REGION, temperature=0.5) pg_conn_str = f"postgresql+pg8000://{DB_USER}:{DB_PASS}@placeholder/{DB_NAME}" store = PGVector( collection_name=COLLECTION_NAME, embedding_function=embeddings, connection_string=pg_conn_str, engine_args={"creator": getconn} ) retriever = store.as_retriever(search_kwargs={"k": 2}) original_query = "Tell me about the Dursleys." print(f"ORIGINAL QUERY: {original_query}\n" + "-"*30) # 1. HyDE hyde_doc = generate_hyde_doc(original_query, llm) print(f"HyDE Generated Doc: {hyde_doc.strip()[:100]}...") hyde_results = retriever.invoke(hyde_doc) print(f"HyDE Retrieval: {hyde_results[0].page_content[:100]}...\n") # 2. Step-back step_back_q = generate_step_back(original_query, llm) print(f"Step-back Query: {step_back_q.strip()}") step_results = retriever.invoke(step_back_q) print(f"Step-back Retrieval: {step_results[0].page_content[:100]}...") if __name__ == "__main__": main() - Esegui lo script di trasformazione:
python query_transformation.py
Osserva l'output.
Nota come la query Step-back potrebbe recuperare un contesto più ampio sulla storia della famiglia Dursley, mentre HyDE si concentra sui dettagli specifici generati nella risposta ipotetica.
10. Parte 4: generazione end-to-end
Abbiamo suddiviso i dati, perfezionato la ricerca e ottimizzato la query dell'utente. Ora inseriamo finalmente la "G" in RAG: Generazione.
Fino a questo punto, abbiamo solo trovato informazioni. Per creare un vero assistente AI, dobbiamo inserire questi documenti di alta qualità e riordinati in un LLM (Gemini) per sintetizzare una risposta in linguaggio naturale.
In una pipeline di produzione, questo comporta un flusso specifico:
- Recupero:ottieni un ampio insieme di candidati (ad es. i primi 10) utilizzando la ricerca vettoriale rapida.
- Rerank:filtra fino a ottenere i risultati migliori (ad es. i primi 3) utilizzando Vertex AI Reranker.
- Costruzione del contesto:unisci i contenuti dei primi tre documenti in un'unica stringa.
- Prompting con grounding:inserisci questa stringa di contesto in un modello di prompt rigoroso che costringe l'LLM a utilizzare solo queste informazioni.
Crea lo script di generazione
Utilizzeremo gemini-2.5-flash per il passaggio di generazione. Questo modello è ideale per RAG perché ha una finestra contestuale lunga e una bassa latenza, il che gli consente di elaborare rapidamente più documenti recuperati.
- Crea
end_to_end_rag.py:
cloudshell edit end_to_end_rag.py
- Incolla il seguente codice. Presta attenzione alla variabile
template: è qui che chiediamo esplicitamente al modello di evitare "allucinazioni" (inventare cose) vincolandolo al contesto fornito.
import os
import logging
from dotenv import load_dotenv
from google.cloud.sql.connector import Connector, IPTypes
from langchain_google_vertexai import VertexAIEmbeddings, VertexAI
from langchain_community.vectorstores import PGVector
from langchain.retrievers import ContextualCompressionRetriever
from langchain_google_community.vertex_rank import VertexAIRank
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
load_dotenv()
logging.basicConfig(level=logging.ERROR)
PROJECT_ID = os.getenv("PROJECT_ID")
REGION = os.getenv("REGION")
# We use the recursive collection as it generally provides the best context boundaries
COLLECTION_NAME = f"{os.getenv('PGVECTOR_COLLECTION_NAME')}_recursive"
def getconn():
instance_conn = f"{PROJECT_ID}:{REGION}:{os.getenv('SQL_INSTANCE_NAME')}"
with Connector() as connector:
return connector.connect(
instance_conn, "pg8000",
user=os.getenv("SQL_USER"), password=os.getenv("SQL_PASSWORD"),
db=os.getenv("SQL_DATABASE_NAME"), ip_type=IPTypes.PUBLIC
)
def main():
print("--- Initializing Production RAG Pipeline ---")
# 1. Setup Embeddings (Gemini Embedding 001)
# We use this to vectorize the user's query to match our database.
embeddings = VertexAIEmbeddings(model_name="gemini-embedding-001", project=PROJECT_ID, location=REGION)
# 2. Connect to Vector Store
pg_conn_str = f"postgresql+pg8000://{os.getenv('SQL_USER')}:{os.getenv('SQL_PASSWORD')}@placeholder/{os.getenv('SQL_DATABASE_NAME')}"
store = PGVector(
collection_name=COLLECTION_NAME,
embedding_function=embeddings,
connection_string=pg_conn_str,
engine_args={"creator": getconn}
)
# 3. Setup The 'Filter Funnel' (Retriever + Reranker)
# Step A: Fast retrieval of top 10 similar documents
base_retriever = store.as_retriever(search_kwargs={"k": 10})
# Step B: Precise reranking to find the top 3 most relevant
reranker = VertexAIRank(
project_id=PROJECT_ID,
location_id="global",
ranking_config="default_ranking_config",
title_field="source",
top_n=3
)
# Combine A and B into a single retrieval object
compression_retriever = ContextualCompressionRetriever(
base_compressor=reranker,
base_retriever=base_retriever
)
# 4. Setup LLM (Gemini 2.5 Flash)
# We use a low temperature (0.1) to reduce creativity and increase factual adherence.
llm = VertexAI(model_name="gemini-2.5-flash", project=PROJECT_ID, location=REGION, temperature=0.1)
# --- Execution Loop ---
user_query = "Who is Harry Potter?"
print(f"\nUser Query: {user_query}")
print("Retrieving and Reranking documents...")
# Retrieve the most relevant documents
top_docs = compression_retriever.invoke(user_query)
if not top_docs:
print("No relevant documents found.")
return
# Build the Context String
# We stitch the documents together, labeling them as Source 1, Source 2, etc.
context_str = "\n\n".join([f"Source {i+1}: {d.page_content}" for i, d in enumerate(top_docs)])
print(f"Found {len(top_docs)} relevant context chunks.")
# 5. The Grounded Prompt
template = """You are a helpful assistant. Answer the question strictly based on the provided context.
If the answer is not in the context, say "I don't know."
Context:
{context}
Question:
{question}
Answer:
"""
prompt = PromptTemplate(template=template, input_variables=["context", "question"])
# Create the chain: Prompt -> LLM
chain = prompt | llm
print("Generating Answer via Gemini 2.5 Flash...")
final_answer = chain.invoke({"context": context_str, "question": user_query})
print(f"\nFINAL ANSWER:\n{final_answer}")
if __name__ == "__main__":
main()
- Esegui l'applicazione finale:
python end_to_end_rag.py
Comprendere l'output
Quando esegui questo script, osserva la differenza tra i blocchi recuperati non elaborati (che hai visto nei passaggi precedenti) e la risposta finale. L'LLM funge da sintetizzatore: legge i "blocchi" frammentati di testo forniti dal Reranker e li trasforma in una frase coerente e leggibile.
Concatenando questi componenti, si passa da una "ipotesi" stocastica a un flusso di lavoro deterministico e basato su dati concreti. Recupero lancia la rete, Riorganizzazione seleziona la preda migliore e Generatore cucina il pasto.
11. Conclusione
Complimenti! Hai creato una pipeline RAG avanzata che va ben oltre la ricerca vettoriale di base.
Riepilogo
- Hai configurato Cloud SQL con pgvector per l'archiviazione scalabile di vettori.
- Hai confrontato le strategie di suddivisione per capire in che modo la preparazione dei dati influisce sul recupero.
- Hai implementato il Riorganizzazione con Vertex AI per migliorare la precisione dei risultati.
- Hai utilizzato le trasformazioni delle query (HyDE, Step-back) per allineare l'intento dell'utente ai tuoi dati.
Scopri di più
- Architetture di riferimento RAG: esplora un elenco di guide alle architetture di riferimento correlate a RAG.
Dal prototipo alla produzione
Questo lab fa parte del percorso di apprendimento per l'AI pronta per la produzione con Google Cloud.
- Esplora il programma completo per colmare il divario tra prototipo e produzione.
- Condividi i tuoi progressi con l'hashtag #ProductionReadyAI.