
1. はじめに
概要
検索拡張生成(RAG)は、大規模言語モデル(LLM)の回答を外部の知識に基づいてグラウンディングすることで、LLM の回答を強化します。ただし、本番環境対応の RAG システムを構築するには、単純なベクトル検索以上のものが必要です。 データの取り込み方法、関連性の高い結果のランキング方法、ユーザー クエリの処理方法を最適化する必要があります。
この包括的なラボでは、Cloud SQL for PostgreSQL(pgvector で拡張)と Vertex AI を使用して、堅牢な RAG アプリケーションを構築します。次の 3 つの高度な手法について説明します。
- チャンク化戦略: さまざまなテキスト分割方法(文字、再帰、トークン)が検索品質に与える影響を確認します。
- 再ランキング: Vertex AI Reranker を実装して検索結果を絞り込み、「中間で失われる」問題を解決します。
- クエリ変換: Gemini を使用して、HyDE (Hypothetical Document Embeddings)やステップバック プロンプト などの手法でユーザー クエリを最適化します。
演習内容
pgvectorを使用して Cloud SQL for PostgreSQL インスタンスを設定します。- 複数の戦略を使用してテキストをチャンク化し、エンベディングを Cloud SQL に保存するデータの取り込みパイプラインを構築します。
- セマンティック検索を実行し、さまざまなチャンク化方法の結果の品質を比較します。
- Reranker を統合して、関連性に基づいて取得したドキュメントの順序を変更します。
- LLM を活用したクエリ変換を実装して、曖昧な質問や複雑な質問に対する検索を改善します。
学習内容
- Vertex AI と Cloud SQL で LangChain を使用する方法。
- 文字、再帰、トークンテキスト分割ツールの影響。
- PostgreSQL で ベクトル検索 を実装する方法。
- 再ランキングに ContextualCompressionRetriever を使用する方法。
- HyDE と ステップバック プロンプト を実装する方法。
2. プロジェクトの設定
Google アカウント
個人の Google アカウントをまだお持ちでない場合は、Google アカウントを作成する必要があります。
仕事用または学校用アカウントではなく個人アカウントを使用 してください。
Google Cloud コンソールにログインする
個人の Google アカウントを使用して Google Cloud コンソール にログインします。
課金を有効にする
Google Cloud クレジットを利用する(省略可)
このワークショップを実行するには、クレジットが設定された請求先アカウントが必要です。この Codelab の上部にあるバナーのクレジットを使用して開始してください。請求先アカウントにすでに接続している場合は、この手順をスキップできます。
個人用の請求先アカウントを設定する
Google Cloud クレジットを使用して課金を設定した場合は、この手順をスキップできます。
個人用の請求先アカウントを設定するには、こちらに移動して課金を有効にします。
注意事項:
- このラボを完了するのにかかる費用は、Cloud リソースで 1 米ドル未満です。
- このラボの最後の手順に沿ってリソースを削除すると、追加料金が発生しなくなります。
- 新規ユーザーは 300 米ドル分の無料トライアルをご利用いただけます。
プロジェクトの作成(省略可)
このラボで使用する現在のプロジェクトがない場合は、こちらで新しいプロジェクトを作成してください。
3. Cloud Shell エディタを開く
- このリンクをクリックして、Cloud Shell エディタに直接移動します。
- 承認を求められたら、[承認] をクリックして続行します。
- 画面の下部にターミナルが表示されない場合は、次のようにして開きます。
- [表示] をクリックします。
- [Terminal]
- ターミナルで、次のコマンドを使用してプロジェクトを設定します。
gcloud config set project [PROJECT_ID]- 例:
gcloud config set project lab-project-id-example - プロジェクト ID がわからない場合は、次のコマンドでプロジェクト ID を一覧表示できます。
gcloud projects list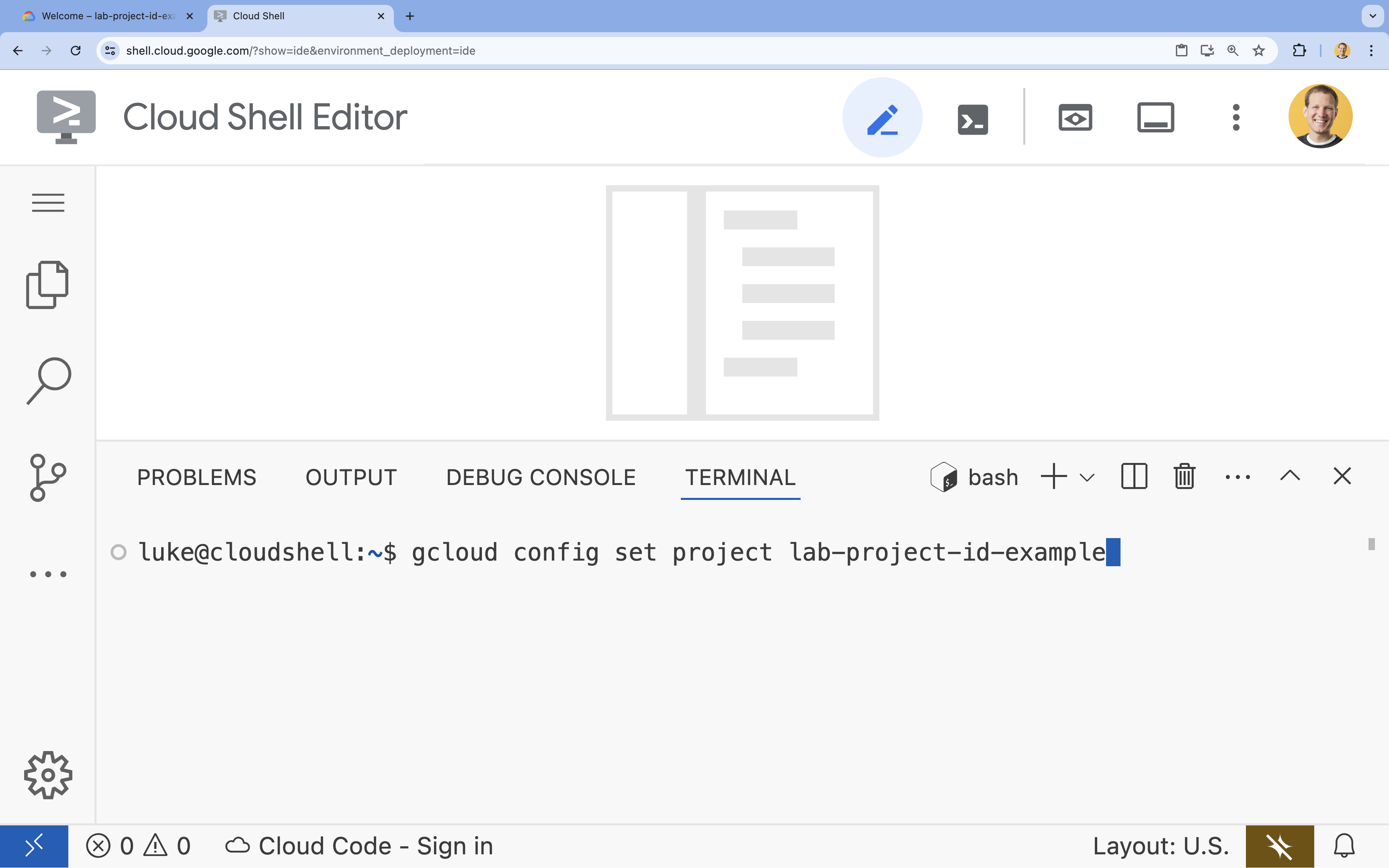
- 例:
- 次のようなメッセージが表示されます。
Updated property [core/project].
4. API の有効化
このソリューションを構築するには、Vertex AI、Cloud SQL、Reranking サービスに対して複数の Google Cloud API を有効にする必要があります。
- ターミナルで API を有効にします。
gcloud services enable \ aiplatform.googleapis.com \ sqladmin.googleapis.com \ cloudresourcemanager.googleapis.com \ serviceusage.googleapis.com \ discoveryengine.googleapis.com
API の概要
- Vertex AI API (
aiplatform.googleapis.com): 生成に Gemini を使用し、テキストのベクトル化に Vertex AI Embeddings を使用できるようにします。 - Cloud SQL Admin API (
sqladmin.googleapis.com): Cloud SQL インスタンスをプログラムで管理できます。 - Discovery Engine API (
discoveryengine.googleapis.com): Vertex AI Reranker の機能を強化します。 - Service Usage API (
serviceusage.googleapis.com): サービスの割り当てを確認して管理するために必要です。
5. 仮想環境を作成して依存関係をインストールする
Python プロジェクトを開始する前に、仮想環境を作成することをおすすめします。これにより、プロジェクトの依存関係が分離され、他のプロジェクトやシステムのグローバル Python パッケージとの競合を防ぐことができます。
rag-labsという名前のフォルダを作成し、そのフォルダに移動します。ターミナルで次のコードを実行します。mkdir rag-labs && cd rag-labs- 仮想環境を作成して有効にします。
uv venv --python 3.12 source .venv/bin/activate - 必要な依存関係を含む
requirements.txtファイルを作成します。ターミナルで次のコードを実行します。cloudshell edit requirements.txt - 次の最適化された 依存関係を
requirements.txtに貼り付けます。これらのバージョンは、競合を回避してインストールを高速化するために固定されています。# Core LangChain & AI langchain-community==0.3.31 langchain-google-vertexai==2.1.2 langchain-google-community[vertexaisearch]==2.0.10 # Google Cloud google-cloud-storage==2.19.0 google-cloud-aiplatform[langchain]==1.130.0 # Database cloud-sql-python-connector[pg8000]==1.19.0 sqlalchemy==2.0.45 pgvector==0.4.2 # Utilities tiktoken==0.12.0 python-dotenv==1.2.1 requests==2.32.5 - 依存関係をインストールします。
uv pip install -r requirements.txt
6. Cloud SQL for PostgreSQL を設定する
このタスクでは、Cloud SQL for PostgreSQL インスタンスをプロビジョニングし、データベースを作成して、ベクトル検索の準備を行います。
Cloud SQL の構成を定義する
- 構成を保存する
.envファイルを作成します。ターミナルで次のコードを実行します。cloudshell edit .env - 次の構成を
.envに貼り付けます。# Project Config PROJECT_ID="[YOUR_PROJECT_ID]" REGION="us-central1" # Database Config SQL_INSTANCE_NAME="rag-pg-instance-1" SQL_DATABASE_NAME="rag_harry_potter_db" SQL_USER="rag_user" SQL_PASSWORD="StrongPassword123!" # RAG Config PGVECTOR_COLLECTION_NAME="rag_harry_potter" RANKING_LOCATION_ID="global" # Connection Name (Auto-generated in scripts usually, but useful to have) DB_INSTANCE_CONNECTION_NAME="${PROJECT_ID}:${REGION}:${SQL_INSTANCE_NAME}" [YOUR_PROJECT_ID]は、実際の Google Cloud プロジェクト ID に置き換えます。(例:PROJECT_ID = "google-cloud-labs"`PROJECT_ID = "google-cloud-labs"`)
プロジェクト ID がわからない場合は、ターミナルで次のコマンドを実行します。すべてのプロジェクトとその ID のリストが表示されます。gcloud projects list- 変数をシェル セッションに読み込みます。
source .env
インスタンスとデータベースを作成する
- Cloud SQL for PostgreSQL のインスタンスを作成します。このコマンドは、このラボに適した小規模なインスタンスを作成します。
gcloud sql instances create ${SQL_INSTANCE_NAME} \ --database-version=POSTGRES_15 \ --tier=db-g1-small \ --region=${REGION} \ --project=${PROJECT_ID} - インスタンスの準備ができたら、データベースを作成します。
gcloud sql databases create ${SQL_DATABASE_NAME} \ --instance=${SQL_INSTANCE_NAME} \ --project=${PROJECT_ID} - データベース ユーザーを作成します。
gcloud sql users create ${SQL_USER} \ --instance=${SQL_INSTANCE_NAME} \ --password=${SQL_PASSWORD} \ --project=${PROJECT_ID}
pgvector 拡張機能を有効にする
pgvector 拡張機能を使用すると、PostgreSQL でベクトル エンベディングを保存して検索できます。データベースで明示的に有効にする必要があります。
enable_pgvector.pyという名前のスクリプトを作成します。ターミナルで次のコードを実行します。cloudshell edit enable_pgvector.py- 次のコードを
enable_pgvector.pyに貼り付けます。このスクリプトはデータベースに接続し、CREATE EXTENSION IF NOT EXISTS vector;を実行します。import os import sqlalchemy from google.cloud.sql.connector import Connector, IPTypes import logging from dotenv import load_dotenv load_dotenv() logging.basicConfig(level=logging.INFO) # Config project_id = os.getenv("PROJECT_ID") region = os.getenv("REGION") instance_name = os.getenv("SQL_INSTANCE_NAME") db_user = os.getenv("SQL_USER") db_pass = os.getenv("SQL_PASSWORD") db_name = os.getenv("SQL_DATABASE_NAME") instance_connection_name = f"{project_id}:{region}:{instance_name}" def getconn(): with Connector() as connector: conn = connector.connect( instance_connection_name, "pg8000", user=db_user, password=db_pass, db=db_name, ip_type=IPTypes.PUBLIC, ) return conn def enable_pgvector(): pool = sqlalchemy.create_engine( "postgresql+pg8000://", creator=getconn, ) with pool.connect() as db_conn: # Check if extension exists result = db_conn.execute(sqlalchemy.text("SELECT extname FROM pg_extension WHERE extname = 'vector';")).fetchone() if result: logging.info("pgvector extension is already enabled.") else: logging.info("Enabling pgvector extension...") db_conn.execute(sqlalchemy.text("CREATE EXTENSION IF NOT EXISTS vector;")) db_conn.commit() logging.info("pgvector extension enabled successfully.") if __name__ == "__main__": enable_pgvector() - スクリプトを実行します。
python enable_pgvector.py
7. パート 1: チャンク化戦略
RAG パイプラインの最初のステップは、ドキュメントを LLM が理解できる形式(チャンク )に変換することです。
LLM にはコンテキスト ウィンドウの制限(一度に処理できるテキストの量)があります。また、特定の質問に回答するために 50 ページのドキュメントを取得すると、情報が希薄になります。関連情報を分離するために、ドキュメントを小さな「チャンク」に分割します。
ただし、テキストを分割する方法は非常に重要です。
- 文字分割ツール: 文字数で厳密に分割します。高速ですが、リスクがあります。単語や文が途中で切断され、意味が失われる可能性があります。
- 再帰分割ツール: まず段落で分割し、次に文、次に単語で分割しようとします。意味単位を維持しようとします。
- トークン分割ツール: LLM 独自の語彙(トークン)に基づいて分割します。これにより、チャンクがコンテキスト ウィンドウに完全に収まりますが、生成に計算コストがかかる場合があります。
このセクションでは、3 つの戦略すべてを使用して同じデータを取り込み、比較します。
取り込みスクリプトを作成する
ハリー・ポッターのデータセットをダウンロードし、文字、再帰、トークンの戦略を使用して分割し、エンベディングを Cloud SQL の 3 つの別々のテーブルにアップロードするスクリプトを使用します。
- ファイル
ingest_data.pyを作成します。cloudshell edit ingest_data.py - 次の修正された コードを
ingest_data.pyに貼り付けます。このバージョンでは、データセットの JSON 構造が正しく解析されます。import os import json import logging import requests from typing import List, Dict, Any from dotenv import load_dotenv from google.cloud.sql.connector import Connector, IPTypes from langchain_google_vertexai import VertexAIEmbeddings from langchain_community.vectorstores import PGVector from langchain.text_splitter import CharacterTextSplitter, RecursiveCharacterTextSplitter, TokenTextSplitter from langchain.docstore.document import Document load_dotenv() logging.basicConfig(level=logging.INFO) # Configuration PROJECT_ID = os.getenv("PROJECT_ID") REGION = os.getenv("REGION") DB_USER = os.getenv("SQL_USER") DB_PASS = os.getenv("SQL_PASSWORD") DB_NAME = os.getenv("SQL_DATABASE_NAME") INSTANCE_CONNECTION_NAME = f"{PROJECT_ID}:{REGION}:{os.getenv('SQL_INSTANCE_NAME')}" BASE_COLLECTION_NAME = os.getenv("PGVECTOR_COLLECTION_NAME") BOOKS_JSON_URL = "https://storage.googleapis.com/github-repo/generative-ai/gemini/reasoning-engine/sample_data/harry_potter_books.json" CHUNK_SIZE = 500 CHUNK_OVERLAP = 50 MAX_DOCS_TO_PROCESS = 10 # Database Connector def getconn(): with Connector() as connector: return connector.connect( INSTANCE_CONNECTION_NAME, "pg8000", user=DB_USER, password=DB_PASS, db=DB_NAME, ip_type=IPTypes.PUBLIC, ) def download_data(): logging.info(f"Downloading data from {BOOKS_JSON_URL}...") response = requests.get(BOOKS_JSON_URL) return response.json() def prepare_chunks(json_data, strategy): documents = [] # Iterate through the downloaded data for entry in json_data[:MAX_DOCS_TO_PROCESS]: # --- JSON PARSING LOGIC --- # The data structure nests content inside 'kwargs' -> 'page_content' if "kwargs" in entry and "page_content" in entry["kwargs"]: content = entry["kwargs"]["page_content"] # Extract metadata if available, ensuring it's a dict metadata = entry["kwargs"].get("metadata", {}) if not isinstance(metadata, dict): metadata = {"source": "unknown"} # Add the strategy to metadata for tracking metadata["strategy"] = strategy else: continue if not content: continue # Choose the splitter based on the strategy if strategy == "character": splitter = CharacterTextSplitter(chunk_size=CHUNK_SIZE, chunk_overlap=CHUNK_OVERLAP, separator="\n") elif strategy == "token": splitter = TokenTextSplitter(chunk_size=CHUNK_SIZE, chunk_overlap=CHUNK_OVERLAP) else: # default to recursive splitter = RecursiveCharacterTextSplitter(chunk_size=CHUNK_SIZE, chunk_overlap=CHUNK_OVERLAP) # Split the content into chunks chunks = splitter.split_text(content) # Create Document objects for each chunk for chunk in chunks: documents.append(Document(page_content=chunk, metadata=metadata)) return documents def main(): logging.info("Initializing Embeddings...") embeddings = VertexAIEmbeddings(model_name="gemini-embedding-001", project=PROJECT_ID, location=REGION) data = download_data() strategies = ["character", "recursive", "token"] # Connection string for PGVector (uses the getconn helper) pg_conn_str = f"postgresql+pg8000://{DB_USER}:{DB_PASS}@placeholder/{DB_NAME}" for strategy in strategies: collection_name = f"{BASE_COLLECTION_NAME}_{strategy}" logging.info(f"--- Processing strategy: {strategy.upper()} ---") logging.info(f"Target Collection: {collection_name}") # Prepare documents with the specific strategy docs = prepare_chunks(data, strategy) if not docs: logging.warning(f"No documents generated for strategy {strategy}. Check data source.") continue logging.info(f"Generated {len(docs)} chunks. Uploading to Cloud SQL...") # Initialize the Vector Store store = PGVector( collection_name=collection_name, embedding_function=embeddings, connection_string=pg_conn_str, engine_args={"creator": getconn}, pre_delete_collection=True # Clears old data for this collection before adding new ) # Batch add documents store.add_documents(docs) logging.info(f"Successfully finished {strategy}.\n") if __name__ == "__main__": main() - 取り込みスクリプトを実行します。これにより、データベースに 3 つの異なるテーブル(コレクション)が入力されます。
python ingest_data.py
チャンク化の結果を比較する
データが読み込まれたので、3 つのコレクションすべてに対してクエリを実行して、チャンク化戦略が結果に与える影響を確認しましょう。
query_chunking.pyを作成します。cloudshell edit query_chunking.py- 次のコードを
query_chunking.pyに貼り付けます。import os import logging from dotenv import load_dotenv from google.cloud.sql.connector import Connector, IPTypes from langchain_google_vertexai import VertexAIEmbeddings from langchain_community.vectorstores import PGVector load_dotenv() logging.basicConfig(level=logging.ERROR) # Only show errors to keep output clean # Config PROJECT_ID = os.getenv("PROJECT_ID") REGION = os.getenv("REGION") DB_USER = os.getenv("SQL_USER") DB_PASS = os.getenv("SQL_PASSWORD") DB_NAME = os.getenv("SQL_DATABASE_NAME") INSTANCE_CONNECTION_NAME = f"{PROJECT_ID}:{REGION}:{os.getenv('SQL_INSTANCE_NAME')}" BASE_COLLECTION_NAME = os.getenv("PGVECTOR_COLLECTION_NAME") def getconn(): with Connector() as connector: return connector.connect( INSTANCE_CONNECTION_NAME, "pg8000", user=DB_USER, password=DB_PASS, db=DB_NAME, ip_type=IPTypes.PUBLIC, ) def main(): embeddings = VertexAIEmbeddings(model_name="gemini-embedding-001", project=PROJECT_ID, location=REGION) pg_conn_str = f"postgresql+pg8000://{DB_USER}:{DB_PASS}@placeholder/{DB_NAME}" query = "Tell me about the Dursleys and their relationship with Harry Potter" print(f"\nQUERY: {query}\n" + "="*50) strategies = ["character", "recursive", "token"] for strategy in strategies: collection = f"{BASE_COLLECTION_NAME}_{strategy}" print(f"\nSTRATEGY: {strategy.upper()}") store = PGVector( collection_name=collection, embedding_function=embeddings, connection_string=pg_conn_str, engine_args={"creator": getconn} ) results = store.similarity_search_with_score(query, k=2) for i, (doc, score) in enumerate(results): print(f" Result {i+1} (Score: {score:.4f}): {doc.page_content[:150].replace(chr(10), ' ')}...") if __name__ == "__main__": main() - クエリ スクリプトを実行します。
python query_chunking.py
出力を確認します。
文字 分割では文が途中で切断されることがありますが、再帰 分割では段落の境界が尊重されます。トークン 分割では、チャンクが LLM コンテキスト ウィンドウに完全に収まりますが、セマンティック構造が無視される可能性があります。
8. パート 2: 再ランキング
ベクトル検索(検索)は、圧縮された数学的表現(エンベディング)に依存しているため、非常に高速です。再現率 (関連する可能性のあるすべてのアイテムを見つける)を確保するために広範囲に検索しますが、適合率 が低い(アイテムのランキングが不完全である)ことがよくあります。
関連するドキュメントが結果リストの「中間で失われる」ことがよくあります。上位 5 件の結果に注目している LLM は、7 位にある重要な回答を見逃す可能性があります。
再ランキング は、2 番目のステージを追加することでこの問題を解決します。
- Retriever: 高速ベクトル検索を使用して、より大きなセット(上位 25 件など)を取得します。
- Reranker: 特殊なモデル(Cross-Encoder など)を使用して、クエリとドキュメントのペアの全文を調べます。速度は遅くなりますが、精度は大幅に向上します。上位 25 件を再スコアリングし、最も優れた 3 件を返します。
このタスクでは、パート 1 で作成した recursive コレクションを検索しますが、今回はVertex AI Reranker を適用して結果を絞り込みます。
query_reranking.pyを作成します。cloudshell edit query_reranking.py- 次のコードを貼り付けます。
_recursiveコレクションを明示的にターゲットにし、ContextualCompressionRetrieverを使用している点に注意してください。import os import logging from dotenv import load_dotenv from google.cloud.sql.connector import Connector, IPTypes from langchain_google_vertexai import VertexAIEmbeddings from langchain_community.vectorstores import PGVector # Reranking Imports from langchain.retrievers import ContextualCompressionRetriever from langchain_google_community.vertex_rank import VertexAIRank load_dotenv() logging.basicConfig(level=logging.ERROR) PROJECT_ID = os.getenv("PROJECT_ID") REGION = os.getenv("REGION") DB_USER = os.getenv("SQL_USER") DB_PASS = os.getenv("SQL_PASSWORD") DB_NAME = os.getenv("SQL_DATABASE_NAME") INSTANCE_CONNECTION_NAME = f"{PROJECT_ID}:{REGION}:{os.getenv('SQL_INSTANCE_NAME')}" # IMPORTANT: Target the recursive collection created in ingest_data.py COLLECTION_NAME = f"{os.getenv('PGVECTOR_COLLECTION_NAME')}_recursive" RANKING_LOCATION = os.getenv("RANKING_LOCATION_ID") def getconn(): with Connector() as connector: return connector.connect( INSTANCE_CONNECTION_NAME, "pg8000", user=DB_USER, password=DB_PASS, db=DB_NAME, ip_type=IPTypes.PUBLIC, ) def main(): embeddings = VertexAIEmbeddings(model_name="gemini-embedding-001", project=PROJECT_ID, location=REGION) pg_conn_str = f"postgresql+pg8000://{DB_USER}:{DB_PASS}@placeholder/{DB_NAME}" print(f"Connecting to collection: {COLLECTION_NAME}") store = PGVector( collection_name=COLLECTION_NAME, embedding_function=embeddings, connection_string=pg_conn_str, engine_args={"creator": getconn} ) query = "What are the Horcruxes?" print(f"QUERY: {query}\n") # 1. Base Retriever (Vector Search) - Fetch top 10 base_retriever = store.as_retriever(search_kwargs={"k": 10}) # 2. Reranker - Select top 3 from the 10 reranker = VertexAIRank( project_id=PROJECT_ID, location_id=RANKING_LOCATION, ranking_config="default_ranking_config", title_field="source", top_n=3 ) compression_retriever = ContextualCompressionRetriever( base_compressor=reranker, base_retriever=base_retriever ) # Execute try: reranked_docs = compression_retriever.invoke(query) if not reranked_docs: print("No documents returned. Check if the collection exists and is populated.") print(f"--- Top 3 Reranked Results ---") for i, doc in enumerate(reranked_docs): print(f"Result {i+1} (Score: {doc.metadata.get('relevance_score', 'N/A')}):") print(f" {doc.page_content[:200]}...\n") except Exception as e: print(f"Error during reranking: {e}") if __name__ == "__main__": main() - 再ランキング クエリを実行します。
python query_reranking.py
観察
生のベクトル検索と比較して、関連性スコアが高くなったり、順序が異なったりすることがあります。これにより、LLM は可能な限り正確なコンテキストを受け取ることができます。
9. パート 3: クエリ変換
RAG の最大のボトルネックはユーザーであることがよくあります。ユーザー クエリは曖昧であったり、不完全であったり、表現が不適切であったりすることがよくあります。クエリ エンベディングがドキュメント エンベディングと数学的に一致しない場合、検索は失敗します。
クエリ変換 では、LLM を使用して、データベースにアクセスする前にクエリを書き換えるか、拡張します。 次の 2 つの手法を実装します。
- HyDE(Hypothetical Document Embeddings): 質問と回答のベクトル類似度は、回答と仮想回答の類似度よりも低いことがよくあります。 HyDE は、LLM に完璧な回答をハルシネーションさせ、それを埋め込み、そのハルシネーションに似たドキュメントを検索します。
- ステップバック プロンプト: ユーザーが具体的な詳細な質問をした場合、システムはより広範なコンテキストを見逃す可能性があります。ステップバック プロンプトでは、LLM に上位レベルの抽象的な質問(「この家族の歴史は何ですか?」)を生成させ、具体的な詳細とともに基礎情報を取得します。
query_transformation.pyを作成します。cloudshell edit query_transformation.py- 次のコードを貼り付けます。
import os import logging from dotenv import load_dotenv from google.cloud.sql.connector import Connector, IPTypes from langchain_google_vertexai import VertexAIEmbeddings, VertexAI from langchain_community.vectorstores import PGVector from langchain_core.prompts import PromptTemplate load_dotenv() logging.basicConfig(level=logging.ERROR) PROJECT_ID = os.getenv("PROJECT_ID") REGION = os.getenv("REGION") DB_USER = os.getenv("SQL_USER") DB_PASS = os.getenv("SQL_PASSWORD") DB_NAME = os.getenv("SQL_DATABASE_NAME") INSTANCE_CONNECTION_NAME = f"{PROJECT_ID}:{REGION}:{os.getenv('SQL_INSTANCE_NAME')}" COLLECTION_NAME = f"{os.getenv('PGVECTOR_COLLECTION_NAME')}_recursive" def getconn(): with Connector() as connector: return connector.connect( INSTANCE_CONNECTION_NAME, "pg8000", user=DB_USER, password=DB_PASS, db=DB_NAME, ip_type=IPTypes.PUBLIC, ) def generate_hyde_doc(query, llm): prompt = PromptTemplate( input_variables=["question"], template="Write a concise, hypothetical answer to the question. Question: {question} Answer:" ) chain = prompt | llm return chain.invoke({"question": query}) def generate_step_back(query, llm): prompt = PromptTemplate( input_variables=["question"], template="Write a more general, abstract question that concepts in this question. Original: {question} Step-back:" ) chain = prompt | llm return chain.invoke({"question": query}) def main(): embeddings = VertexAIEmbeddings(model_name="gemini-embedding-001", project=PROJECT_ID, location=REGION) llm = VertexAI(model_name="gemini-2.5-flash", project=PROJECT_ID, location=REGION, temperature=0.5) pg_conn_str = f"postgresql+pg8000://{DB_USER}:{DB_PASS}@placeholder/{DB_NAME}" store = PGVector( collection_name=COLLECTION_NAME, embedding_function=embeddings, connection_string=pg_conn_str, engine_args={"creator": getconn} ) retriever = store.as_retriever(search_kwargs={"k": 2}) original_query = "Tell me about the Dursleys." print(f"ORIGINAL QUERY: {original_query}\n" + "-"*30) # 1. HyDE hyde_doc = generate_hyde_doc(original_query, llm) print(f"HyDE Generated Doc: {hyde_doc.strip()[:100]}...") hyde_results = retriever.invoke(hyde_doc) print(f"HyDE Retrieval: {hyde_results[0].page_content[:100]}...\n") # 2. Step-back step_back_q = generate_step_back(original_query, llm) print(f"Step-back Query: {step_back_q.strip()}") step_results = retriever.invoke(step_back_q) print(f"Step-back Retrieval: {step_results[0].page_content[:100]}...") if __name__ == "__main__": main() - 変換スクリプトを実行します。
python query_transformation.py
出力を確認します。
ステップバック クエリでは、ダーズリー家の歴史に関する広範なコンテキストが取得されるのに対し、HyDE では、仮想回答で生成された具体的な詳細に焦点が当てられます。
10. パート 4: エンドツーエンドの生成
データを分割し、検索を絞り込み、ユーザーのクエリを洗練させました。これで、RAG の「G」である生成 を行います。
これまでは、情報を検索するだけでした。 真の AI アシスタントを構築するには、これらの高品質で再ランキングされたドキュメントを LLM(Gemini)にフィードして、自然言語の回答を合成する必要があります。
本番環境パイプラインでは、次の特定のフローが使用されます。
- 取得: 高速ベクトル検索を使用して、候補の広範なセット(上位 10 件など)を取得します。
- 再ランキング: Vertex AI Reranker を使用して、最も優れたもの(上位 3 件など)に絞り込みます。
- コンテキストの構築: 上位 3 件のドキュメントの内容を 1 つの文字列に結合します。
- グラウンディングされたプロンプト: そのコンテキスト文字列を厳密なプロンプト テンプレートに挿入して、LLM がその情報のみを使用するようにします。
生成スクリプトを作成する
生成ステップでは gemini-2.5-flash を使用します。このモデルは、コンテキスト ウィンドウが長く、レイテンシが低いため、RAG に最適です。これにより、取得した複数のドキュメントを迅速に処理できます。
end_to_end_rag.pyを作成します。
cloudshell edit end_to_end_rag.py
- 次のコードを貼り付けます。
template変数に注意してください。これは、提供されたコンテキストにバインドすることで、モデルが「幻覚」(でっち上げ)を回避するように厳密に指示する場所です。
import os
import logging
from dotenv import load_dotenv
from google.cloud.sql.connector import Connector, IPTypes
from langchain_google_vertexai import VertexAIEmbeddings, VertexAI
from langchain_community.vectorstores import PGVector
from langchain.retrievers import ContextualCompressionRetriever
from langchain_google_community.vertex_rank import VertexAIRank
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
load_dotenv()
logging.basicConfig(level=logging.ERROR)
PROJECT_ID = os.getenv("PROJECT_ID")
REGION = os.getenv("REGION")
# We use the recursive collection as it generally provides the best context boundaries
COLLECTION_NAME = f"{os.getenv('PGVECTOR_COLLECTION_NAME')}_recursive"
def getconn():
instance_conn = f"{PROJECT_ID}:{REGION}:{os.getenv('SQL_INSTANCE_NAME')}"
with Connector() as connector:
return connector.connect(
instance_conn, "pg8000",
user=os.getenv("SQL_USER"), password=os.getenv("SQL_PASSWORD"),
db=os.getenv("SQL_DATABASE_NAME"), ip_type=IPTypes.PUBLIC
)
def main():
print("--- Initializing Production RAG Pipeline ---")
# 1. Setup Embeddings (Gemini Embedding 001)
# We use this to vectorize the user's query to match our database.
embeddings = VertexAIEmbeddings(model_name="gemini-embedding-001", project=PROJECT_ID, location=REGION)
# 2. Connect to Vector Store
pg_conn_str = f"postgresql+pg8000://{os.getenv('SQL_USER')}:{os.getenv('SQL_PASSWORD')}@placeholder/{os.getenv('SQL_DATABASE_NAME')}"
store = PGVector(
collection_name=COLLECTION_NAME,
embedding_function=embeddings,
connection_string=pg_conn_str,
engine_args={"creator": getconn}
)
# 3. Setup The 'Filter Funnel' (Retriever + Reranker)
# Step A: Fast retrieval of top 10 similar documents
base_retriever = store.as_retriever(search_kwargs={"k": 10})
# Step B: Precise reranking to find the top 3 most relevant
reranker = VertexAIRank(
project_id=PROJECT_ID,
location_id="global",
ranking_config="default_ranking_config",
title_field="source",
top_n=3
)
# Combine A and B into a single retrieval object
compression_retriever = ContextualCompressionRetriever(
base_compressor=reranker,
base_retriever=base_retriever
)
# 4. Setup LLM (Gemini 2.5 Flash)
# We use a low temperature (0.1) to reduce creativity and increase factual adherence.
llm = VertexAI(model_name="gemini-2.5-flash", project=PROJECT_ID, location=REGION, temperature=0.1)
# --- Execution Loop ---
user_query = "Who is Harry Potter?"
print(f"\nUser Query: {user_query}")
print("Retrieving and Reranking documents...")
# Retrieve the most relevant documents
top_docs = compression_retriever.invoke(user_query)
if not top_docs:
print("No relevant documents found.")
return
# Build the Context String
# We stitch the documents together, labeling them as Source 1, Source 2, etc.
context_str = "\n\n".join([f"Source {i+1}: {d.page_content}" for i, d in enumerate(top_docs)])
print(f"Found {len(top_docs)} relevant context chunks.")
# 5. The Grounded Prompt
template = """You are a helpful assistant. Answer the question strictly based on the provided context.
If the answer is not in the context, say "I don't know."
Context:
{context}
Question:
{question}
Answer:
"""
prompt = PromptTemplate(template=template, input_variables=["context", "question"])
# Create the chain: Prompt -> LLM
chain = prompt | llm
print("Generating Answer via Gemini 2.5 Flash...")
final_answer = chain.invoke({"context": context_str, "question": user_query})
print(f"\nFINAL ANSWER:\n{final_answer}")
if __name__ == "__main__":
main()
- 最終的なアプリケーションを実行します。
python end_to_end_rag.py
出力について
このスクリプトを実行すると、生の取得チャンク(前の手順で確認した)と最終的な回答の違いがわかります。LLM はシンセサイザーとして機能します。Reranker によって提供されたテキストの断片的な「チャンク」を読み取り、一貫性のある人間が読める文に変換します。
これらのコンポーネントを連結することで、確率的な「推測」から決定論的なグラウンディングされたワークフローに移行します。Retriever がネットをキャストし、Reranker が最適なキャッチを選択し、Generator が料理を作ります。
11. まとめ
おめでとうございます!基本的なベクトル検索をはるかに超える高度な RAG パイプラインを構築できました。
ハイライト
- スケーラブルなベクトル ストレージ用に pgvector を使用して Cloud SQL を構成しました。
- チャンク化戦略 を比較して、データ準備が検索に与える影響を理解しました。
- Vertex AI で 再ランキング を実装して、結果の精度を向上させました。
- クエリ変換 (HyDE、ステップバック)を使用して、ユーザーの意図をデータに合わせました。
詳細
- RAG リファレンス アーキテクチャ: RAG 関連のリファレンス アーキテクチャ ガイドの一覧を確認します。
プロトタイプから製品版へ
このラボは、Google Cloud でのプロダクション レディな AI の開発 学習プログラムの一部です。
- **カリキュラム全体を確認** して、プロトタイプから本番環境への移行に役立ててください。
- ハッシュタグ #ProductionReadyAI で進捗状況を共有 しましょう。