
1. Wprowadzenie
Przegląd
Technologia Retrieval Augmented Generation (RAG) wzbogaca odpowiedzi dużych modeli językowych (LLM) o informacje z zewnętrznych źródeł wiedzy. Jednak zbudowanie gotowego do wdrożenia w środowisku produkcyjnym systemu RAG wymaga czegoś więcej niż tylko prostego wyszukiwania wektorowego. Musisz zoptymalizować sposób pozyskiwania danych, rankingowania trafnych wyników i przetwarzania zapytań użytkowników.
W tym obszernym module zbudujesz niezawodną aplikację RAG przy użyciu Cloud SQL for PostgreSQL (rozszerzonej o pgvector) i Vertex AI. Poznasz 3 zaawansowane techniki:
- Strategie dzielenia tekstu na części: zobaczysz, jak różne metody dzielenia tekstu (według znaku, rekurencyjna, według tokena) wpływają na jakość wyszukiwania.
- Ponowne rankingowanie: wdrożysz ponowne rankingowanie w Vertex AI, aby ulepszyć wyniki wyszukiwania i rozwiązać problem „zagubienia w środku”.
- Przekształcanie zapytań: będziesz używać Gemini do optymalizacji zapytań użytkowników za pomocą technik takich jak HyDE (Hypothetical Document Embeddings) i Step-back Prompting.
Jakie zadania wykonasz
- Skonfiguruj instancję Cloud SQL for PostgreSQL za pomocą
pgvector. - Utwórz potok pozyskiwania danych, który dzieli tekst na fragmenty za pomocą różnych strategii i przechowuje wektory dystrybucyjne w Cloud SQL.
- Przeprowadzaj wyszukiwania semantyczne i porównuj jakość wyników uzyskanych różnymi metodami dzielenia na części.
- Zintegruj Reranker, aby zmieniać kolejność pobranych dokumentów na podstawie trafności.
- Wdrażaj oparte na LLM przekształcenia zapytań, aby ulepszyć wyszukiwanie w przypadku niejednoznacznych lub złożonych pytań.
Czego się nauczysz
- Jak używać LangChain z Vertex AI i Cloud SQL.
- Wpływ dzielników tekstu Znak, Rekursywny i Token.
- Jak wdrożyć wyszukiwanie wektorowe w PostgreSQL.
- Jak używać klasy ContextualCompressionRetriever do ponownego rankingu.
- Jak wdrożyć HyDE i Step-back Prompting.
2. Konfigurowanie projektu
Konto Google
Jeśli nie masz jeszcze osobistego konta Google, musisz je utworzyć.
Używaj konta osobistego zamiast konta służbowego lub szkolnego.
Logowanie się w konsoli Google Cloud
Zaloguj się w konsoli Google Cloud, korzystając z osobistego konta Google.
Włącz płatności
Odbieranie środków w Google Cloud (opcjonalnie)
Aby przeprowadzić te warsztaty, musisz mieć konto rozliczeniowe z określonymi środkami. Aby rozpocząć, użyj środków z banera u góry tego modułu. Jeśli masz już połączenie z kontem rozliczeniowym, możesz pominąć ten krok.
Konfigurowanie osobistego konta rozliczeniowego
Jeśli skonfigurujesz płatności za pomocą środków w Google Cloud, możesz pominąć ten krok.
Aby skonfigurować osobiste konto rozliczeniowe, włącz płatności w konsoli Google Cloud.
Uwagi:
- Pod względem opłat za zasoby chmury ukończenie tego modułu powinno kosztować mniej niż 1 USD.
- Jeśli chcesz uniknąć dalszych opłat, wykonaj czynności opisane na końcu tego modułu, aby usunąć zasoby.
- Nowi użytkownicy mogą skorzystać z bezpłatnego okresu próbnego, w którym mają do dyspozycji środki w wysokości 300 USD.
Tworzenie projektu (opcjonalnie)
Jeśli nie masz bieżącego projektu, którego chcesz użyć w tym ćwiczeniu, utwórz nowy projekt.
3. Otwórz edytor Cloud Shell
- Kliknij ten link, aby przejść bezpośrednio do edytora Cloud Shell
- Jeśli w dowolnym momencie pojawi się prośba o autoryzację, kliknij Autoryzuj, aby kontynuować.
- Jeśli terminal nie pojawi się u dołu ekranu, otwórz go:
- Kliknij Wyświetl.
- Kliknij Terminal
 .
.
- W terminalu ustaw projekt za pomocą tego polecenia:
gcloud config set project [PROJECT_ID]- Przykład:
gcloud config set project lab-project-id-example - Jeśli nie pamiętasz identyfikatora projektu, możesz wyświetlić listę wszystkich identyfikatorów projektów za pomocą tego polecenia:
gcloud projects list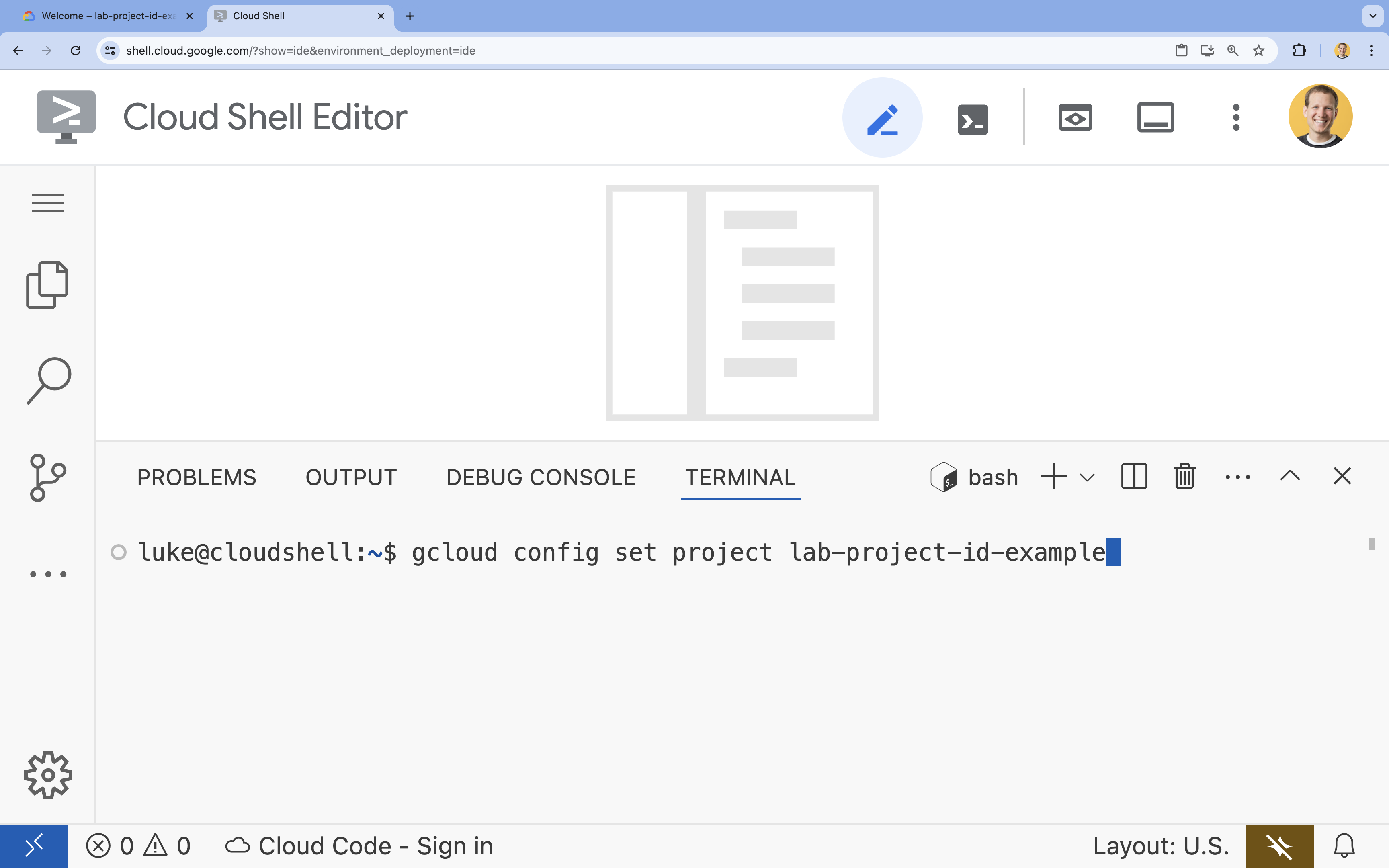
- Przykład:
- Powinien wyświetlić się ten komunikat:
Updated property [core/project].
4. Włącz interfejsy API
Aby zbudować to rozwiązanie, musisz włączyć kilka interfejsów Google Cloud API dla Vertex AI, Cloud SQL i usługi ponownego rankingu.
- W terminalu włącz interfejsy API:
gcloud services enable \ aiplatform.googleapis.com \ sqladmin.googleapis.com \ cloudresourcemanager.googleapis.com \ serviceusage.googleapis.com \ discoveryengine.googleapis.com
Przedstawiamy interfejsy API
- Vertex AI API (
aiplatform.googleapis.com): umożliwia korzystanie z Gemini do generowania treści i Vertex AI Embeddings do wektoryzacji tekstu. - Cloud SQL Admin API (
sqladmin.googleapis.com): umożliwia programowe zarządzanie instancjami Cloud SQL. - Discovery Engine API (
discoveryengine.googleapis.com): obsługuje funkcje Vertex AI Reranker. - Service Usage API (
serviceusage.googleapis.com): wymagany do sprawdzania limitów usług i zarządzania nimi.
5. Tworzenie środowiska wirtualnego i instalowanie zależności
Przed rozpoczęciem dowolnego projektu w Pythonie warto utworzyć środowisko wirtualne. Izoluje to zależności projektu, zapobiegając konfliktom z innymi projektami lub globalnymi pakietami Pythona w systemie.
- Utwórz folder o nazwie
rag-labsi przejdź do niego. Uruchom w terminalu ten kod:mkdir rag-labs && cd rag-labs - Utwórz i aktywuj środowisko wirtualne:
uv venv --python 3.12 source .venv/bin/activate - Utwórz plik
requirements.txtz niezbędnymi zależnościami. Uruchom w terminalu ten kod:cloudshell edit requirements.txt - Wklej do pliku
requirements.txtte zoptymalizowane zależności. Te wersje są przypięte, aby uniknąć konfliktów i przyspieszyć instalację.# Core LangChain & AI langchain-community==0.3.31 langchain-google-vertexai==2.1.2 langchain-google-community[vertexaisearch]==2.0.10 # Google Cloud google-cloud-storage==2.19.0 google-cloud-aiplatform[langchain]==1.130.0 # Database cloud-sql-python-connector[pg8000]==1.19.0 sqlalchemy==2.0.45 pgvector==0.4.2 # Utilities tiktoken==0.12.0 python-dotenv==1.2.1 requests==2.32.5 - Zainstaluj zależności:
uv pip install -r requirements.txt
6. Konfigurowanie Cloud SQL for PostgreSQL
W tym zadaniu utworzysz instancję Cloud SQL for PostgreSQL, utworzysz bazę danych i przygotujesz ją do wyszukiwania wektorowego.
Definiowanie konfiguracji Cloud SQL
- Utwórz plik
.env, w którym zapiszesz konfigurację. Uruchom w terminalu ten kod:cloudshell edit .env - Wklej do pliku
.envtę konfigurację.# Project Config PROJECT_ID="[YOUR_PROJECT_ID]" REGION="us-central1" # Database Config SQL_INSTANCE_NAME="rag-pg-instance-1" SQL_DATABASE_NAME="rag_harry_potter_db" SQL_USER="rag_user" SQL_PASSWORD="StrongPassword123!" # RAG Config PGVECTOR_COLLECTION_NAME="rag_harry_potter" RANKING_LOCATION_ID="global" # Connection Name (Auto-generated in scripts usually, but useful to have) DB_INSTANCE_CONNECTION_NAME="${PROJECT_ID}:${REGION}:${SQL_INSTANCE_NAME}" - Zastąp
[YOUR_PROJECT_ID]identyfikatorem Twojego projektu Google Cloud. (np.PROJECT_ID = "google-cloud-labs")
Jeśli nie pamiętasz identyfikatora projektu, uruchom to polecenie w terminalu. Wyświetli się lista wszystkich Twoich projektów i ich identyfikatorów.gcloud projects list - Załaduj zmienne do sesji powłoki:
source .env
Tworzenie instancji i bazy danych
- Utwórz instancję Cloud SQL for PostgreSQL. To polecenie tworzy małą instancję odpowiednią do tego modułu.
gcloud sql instances create ${SQL_INSTANCE_NAME} \ --database-version=POSTGRES_15 \ --tier=db-g1-small \ --region=${REGION} \ --project=${PROJECT_ID} - Gdy instancja będzie gotowa, utwórz bazę danych:
gcloud sql databases create ${SQL_DATABASE_NAME} \ --instance=${SQL_INSTANCE_NAME} \ --project=${PROJECT_ID} - Utwórz użytkownika bazy danych:
gcloud sql users create ${SQL_USER} \ --instance=${SQL_INSTANCE_NAME} \ --password=${SQL_PASSWORD} \ --project=${PROJECT_ID}
Włącz rozszerzenie pgvector
Rozszerzenie pgvector umożliwia PostgreSQL przechowywanie i wyszukiwanie wektorów dystrybucyjnych. Musisz wyraźnie włączyć tę funkcję w bazie danych.
- Utwórz skrypt o nazwie
enable_pgvector.py. Uruchom w terminalu ten kod:cloudshell edit enable_pgvector.py - Wklej ten kod do pliku
enable_pgvector.py. Ten skrypt łączy się z bazą danych i uruchamiaCREATE EXTENSION IF NOT EXISTS vector;.import os import sqlalchemy from google.cloud.sql.connector import Connector, IPTypes import logging from dotenv import load_dotenv load_dotenv() logging.basicConfig(level=logging.INFO) # Config project_id = os.getenv("PROJECT_ID") region = os.getenv("REGION") instance_name = os.getenv("SQL_INSTANCE_NAME") db_user = os.getenv("SQL_USER") db_pass = os.getenv("SQL_PASSWORD") db_name = os.getenv("SQL_DATABASE_NAME") instance_connection_name = f"{project_id}:{region}:{instance_name}" def getconn(): with Connector() as connector: conn = connector.connect( instance_connection_name, "pg8000", user=db_user, password=db_pass, db=db_name, ip_type=IPTypes.PUBLIC, ) return conn def enable_pgvector(): pool = sqlalchemy.create_engine( "postgresql+pg8000://", creator=getconn, ) with pool.connect() as db_conn: # Check if extension exists result = db_conn.execute(sqlalchemy.text("SELECT extname FROM pg_extension WHERE extname = 'vector';")).fetchone() if result: logging.info("pgvector extension is already enabled.") else: logging.info("Enabling pgvector extension...") db_conn.execute(sqlalchemy.text("CREATE EXTENSION IF NOT EXISTS vector;")) db_conn.commit() logging.info("pgvector extension enabled successfully.") if __name__ == "__main__": enable_pgvector() - Uruchom skrypt:
python enable_pgvector.py
7. Część 1. Strategie podziału na fragmenty
Pierwszym krokiem w każdym potoku RAG jest przekształcenie dokumentów w format zrozumiały dla modelu LLM, czyli fragmenty.
LLM mają limit okna kontekstu (ilość tekstu, którą mogą przetworzyć jednocześnie). Poza tym pobieranie 50-stronicowego dokumentu w celu uzyskania odpowiedzi na konkretne pytanie rozwadnia informacje. Dzielimy dokumenty na mniejsze „fragmenty”, aby wyodrębnić istotne informacje.
Jednak sposób podziału tekstu ma ogromne znaczenie:
- Dzielenie według liczby znaków: dzieli ściśle według liczby znaków. Jest to szybkie, ale ryzykowne, ponieważ może przeciąć słowa lub zdania na pół, niszcząc ich znaczenie.
- Recursive Splitter:najpierw próbuje podzielić tekst na akapity, potem na zdania, a na końcu na słowa. Staramy się zachować spójność jednostek semantycznych.
- Dzielenie na tokeny: dzieli tekst na podstawie słownika modelu LLM (tokenów). Dzięki temu fragmenty idealnie pasują do okien kontekstowych, ale ich generowanie może być bardziej kosztowne pod względem obliczeniowym.
W tej sekcji prześlesz te same dane, korzystając z 3 strategii, aby je porównać.
Tworzenie skryptu pozyskiwania
Użyjesz skryptu, który pobiera zbiór danych o Harrym Potterze, dzieli go za pomocą strategii Character, Recursive i Token, a następnie przesyła wektory dystrybucyjne do 3 oddzielnych tabel w Cloud SQL.
- Utwórz plik
ingest_data.py:cloudshell edit ingest_data.py - Wklej do pliku
ingest_data.pyten stały kod: Ta wersja prawidłowo analizuje strukturę JSON zbioru danych.import os import json import logging import requests from typing import List, Dict, Any from dotenv import load_dotenv from google.cloud.sql.connector import Connector, IPTypes from langchain_google_vertexai import VertexAIEmbeddings from langchain_community.vectorstores import PGVector from langchain.text_splitter import CharacterTextSplitter, RecursiveCharacterTextSplitter, TokenTextSplitter from langchain.docstore.document import Document load_dotenv() logging.basicConfig(level=logging.INFO) # Configuration PROJECT_ID = os.getenv("PROJECT_ID") REGION = os.getenv("REGION") DB_USER = os.getenv("SQL_USER") DB_PASS = os.getenv("SQL_PASSWORD") DB_NAME = os.getenv("SQL_DATABASE_NAME") INSTANCE_CONNECTION_NAME = f"{PROJECT_ID}:{REGION}:{os.getenv('SQL_INSTANCE_NAME')}" BASE_COLLECTION_NAME = os.getenv("PGVECTOR_COLLECTION_NAME") BOOKS_JSON_URL = "https://storage.googleapis.com/github-repo/generative-ai/gemini/reasoning-engine/sample_data/harry_potter_books.json" CHUNK_SIZE = 500 CHUNK_OVERLAP = 50 MAX_DOCS_TO_PROCESS = 10 # Database Connector def getconn(): with Connector() as connector: return connector.connect( INSTANCE_CONNECTION_NAME, "pg8000", user=DB_USER, password=DB_PASS, db=DB_NAME, ip_type=IPTypes.PUBLIC, ) def download_data(): logging.info(f"Downloading data from {BOOKS_JSON_URL}...") response = requests.get(BOOKS_JSON_URL) return response.json() def prepare_chunks(json_data, strategy): documents = [] # Iterate through the downloaded data for entry in json_data[:MAX_DOCS_TO_PROCESS]: # --- JSON PARSING LOGIC --- # The data structure nests content inside 'kwargs' -> 'page_content' if "kwargs" in entry and "page_content" in entry["kwargs"]: content = entry["kwargs"]["page_content"] # Extract metadata if available, ensuring it's a dict metadata = entry["kwargs"].get("metadata", {}) if not isinstance(metadata, dict): metadata = {"source": "unknown"} # Add the strategy to metadata for tracking metadata["strategy"] = strategy else: continue if not content: continue # Choose the splitter based on the strategy if strategy == "character": splitter = CharacterTextSplitter(chunk_size=CHUNK_SIZE, chunk_overlap=CHUNK_OVERLAP, separator="\n") elif strategy == "token": splitter = TokenTextSplitter(chunk_size=CHUNK_SIZE, chunk_overlap=CHUNK_OVERLAP) else: # default to recursive splitter = RecursiveCharacterTextSplitter(chunk_size=CHUNK_SIZE, chunk_overlap=CHUNK_OVERLAP) # Split the content into chunks chunks = splitter.split_text(content) # Create Document objects for each chunk for chunk in chunks: documents.append(Document(page_content=chunk, metadata=metadata)) return documents def main(): logging.info("Initializing Embeddings...") embeddings = VertexAIEmbeddings(model_name="gemini-embedding-001", project=PROJECT_ID, location=REGION) data = download_data() strategies = ["character", "recursive", "token"] # Connection string for PGVector (uses the getconn helper) pg_conn_str = f"postgresql+pg8000://{DB_USER}:{DB_PASS}@placeholder/{DB_NAME}" for strategy in strategies: collection_name = f"{BASE_COLLECTION_NAME}_{strategy}" logging.info(f"--- Processing strategy: {strategy.upper()} ---") logging.info(f"Target Collection: {collection_name}") # Prepare documents with the specific strategy docs = prepare_chunks(data, strategy) if not docs: logging.warning(f"No documents generated for strategy {strategy}. Check data source.") continue logging.info(f"Generated {len(docs)} chunks. Uploading to Cloud SQL...") # Initialize the Vector Store store = PGVector( collection_name=collection_name, embedding_function=embeddings, connection_string=pg_conn_str, engine_args={"creator": getconn}, pre_delete_collection=True # Clears old data for this collection before adding new ) # Batch add documents store.add_documents(docs) logging.info(f"Successfully finished {strategy}.\n") if __name__ == "__main__": main() - Uruchom skrypt przesyłania. Spowoduje to wypełnienie bazy danych 3 różnymi tabelami (kolekcjami).
python ingest_data.py
Porównywanie wyników dzielenia na części
Dane zostały już wczytane. Uruchommy teraz zapytanie dotyczące wszystkich 3 kolekcji, aby sprawdzić, jak strategia dzielenia na części wpływa na wyniki.
- Utwórz
query_chunking.py:cloudshell edit query_chunking.py - Wklej do pliku
query_chunking.pyten kod:import os import logging from dotenv import load_dotenv from google.cloud.sql.connector import Connector, IPTypes from langchain_google_vertexai import VertexAIEmbeddings from langchain_community.vectorstores import PGVector load_dotenv() logging.basicConfig(level=logging.ERROR) # Only show errors to keep output clean # Config PROJECT_ID = os.getenv("PROJECT_ID") REGION = os.getenv("REGION") DB_USER = os.getenv("SQL_USER") DB_PASS = os.getenv("SQL_PASSWORD") DB_NAME = os.getenv("SQL_DATABASE_NAME") INSTANCE_CONNECTION_NAME = f"{PROJECT_ID}:{REGION}:{os.getenv('SQL_INSTANCE_NAME')}" BASE_COLLECTION_NAME = os.getenv("PGVECTOR_COLLECTION_NAME") def getconn(): with Connector() as connector: return connector.connect( INSTANCE_CONNECTION_NAME, "pg8000", user=DB_USER, password=DB_PASS, db=DB_NAME, ip_type=IPTypes.PUBLIC, ) def main(): embeddings = VertexAIEmbeddings(model_name="gemini-embedding-001", project=PROJECT_ID, location=REGION) pg_conn_str = f"postgresql+pg8000://{DB_USER}:{DB_PASS}@placeholder/{DB_NAME}" query = "Tell me about the Dursleys and their relationship with Harry Potter" print(f"\nQUERY: {query}\n" + "="*50) strategies = ["character", "recursive", "token"] for strategy in strategies: collection = f"{BASE_COLLECTION_NAME}_{strategy}" print(f"\nSTRATEGY: {strategy.upper()}") store = PGVector( collection_name=collection, embedding_function=embeddings, connection_string=pg_conn_str, engine_args={"creator": getconn} ) results = store.similarity_search_with_score(query, k=2) for i, (doc, score) in enumerate(results): print(f" Result {i+1} (Score: {score:.4f}): {doc.page_content[:150].replace(chr(10), ' ')}...") if __name__ == "__main__": main() - Uruchom skrypt zapytania:
python query_chunking.py
Obserwuj dane wyjściowe.
Zwróć uwagę, że podział według znaku może przerywać zdania w trakcie myśli, a podział rekurencyjny stara się uwzględniać granice akapitów. Dzielenie na tokeny zapewnia, że fragmenty idealnie pasują do okien kontekstu LLM, ale może ignorować strukturę semantyczną.
8. Część 2. Ponowne ustalanie kolejności
Wyszukiwanie wektorowe (pobieranie) jest niezwykle szybkie, ponieważ opiera się na skompresowanych reprezentacjach matematycznych (wektorach dystrybucyjnych). Obejmuje szeroki zakres, aby zapewnić pełność (znalezienie wszystkich potencjalnie trafnych elementów), ale często ma niską precyzję (ranking tych elementów może być niedoskonały).
Często odpowiednie dokumenty „giną” w środku listy wyników. Duży model językowy, który zwraca uwagę na 5 najlepszych wyników, może pominąć kluczową odpowiedź znajdującą się na pozycji 7.
Ponowne rankingowanie rozwiązuje ten problem, dodając drugi etap.
- Wyszukiwarka: pobiera większy zbiór (np. 25 najlepszych wyników) za pomocą szybkiego wyszukiwania wektorowego.
- Ponowne sortowanie: używa specjalistycznego modelu (np. Cross-Encoder) do analizowania pełnego tekstu zapytań i par dokumentów. Jest wolniejsza, ale znacznie dokładniejsza. Ponownie ocenia 25 najlepszych wyników i zwraca 3 najlepsze.
W tym zadaniu przeszukasz recursive kolekcję utworzoną w części 1, ale tym razem zastosujesz Vertex AI Reranker, aby uściślić wyniki.
- Utwórz
query_reranking.py:cloudshell edit query_reranking.py - Wklej ten kod. Zwróć uwagę, że wyraźnie odnosi się do
_recursivezbierania i wykorzystywaniaContextualCompressionRetriever.import os import logging from dotenv import load_dotenv from google.cloud.sql.connector import Connector, IPTypes from langchain_google_vertexai import VertexAIEmbeddings from langchain_community.vectorstores import PGVector # Reranking Imports from langchain.retrievers import ContextualCompressionRetriever from langchain_google_community.vertex_rank import VertexAIRank load_dotenv() logging.basicConfig(level=logging.ERROR) PROJECT_ID = os.getenv("PROJECT_ID") REGION = os.getenv("REGION") DB_USER = os.getenv("SQL_USER") DB_PASS = os.getenv("SQL_PASSWORD") DB_NAME = os.getenv("SQL_DATABASE_NAME") INSTANCE_CONNECTION_NAME = f"{PROJECT_ID}:{REGION}:{os.getenv('SQL_INSTANCE_NAME')}" # IMPORTANT: Target the recursive collection created in ingest_data.py COLLECTION_NAME = f"{os.getenv('PGVECTOR_COLLECTION_NAME')}_recursive" RANKING_LOCATION = os.getenv("RANKING_LOCATION_ID") def getconn(): with Connector() as connector: return connector.connect( INSTANCE_CONNECTION_NAME, "pg8000", user=DB_USER, password=DB_PASS, db=DB_NAME, ip_type=IPTypes.PUBLIC, ) def main(): embeddings = VertexAIEmbeddings(model_name="gemini-embedding-001", project=PROJECT_ID, location=REGION) pg_conn_str = f"postgresql+pg8000://{DB_USER}:{DB_PASS}@placeholder/{DB_NAME}" print(f"Connecting to collection: {COLLECTION_NAME}") store = PGVector( collection_name=COLLECTION_NAME, embedding_function=embeddings, connection_string=pg_conn_str, engine_args={"creator": getconn} ) query = "What are the Horcruxes?" print(f"QUERY: {query}\n") # 1. Base Retriever (Vector Search) - Fetch top 10 base_retriever = store.as_retriever(search_kwargs={"k": 10}) # 2. Reranker - Select top 3 from the 10 reranker = VertexAIRank( project_id=PROJECT_ID, location_id=RANKING_LOCATION, ranking_config="default_ranking_config", title_field="source", top_n=3 ) compression_retriever = ContextualCompressionRetriever( base_compressor=reranker, base_retriever=base_retriever ) # Execute try: reranked_docs = compression_retriever.invoke(query) if not reranked_docs: print("No documents returned. Check if the collection exists and is populated.") print(f"--- Top 3 Reranked Results ---") for i, doc in enumerate(reranked_docs): print(f"Result {i+1} (Score: {doc.metadata.get('relevance_score', 'N/A')}):") print(f" {doc.page_content[:200]}...\n") except Exception as e: print(f"Error during reranking: {e}") if __name__ == "__main__": main() - Uruchom zapytanie ponownego rankingu:
python query_reranking.py
Obserwuj
Możesz zauważyć wyższe wyniki trafności lub inną kolejność w porównaniu z wyszukiwaniem surowych wektorów. Dzięki temu LLM otrzyma jak najdokładniejszy kontekst.
9. Część 3. Przekształcanie zapytań
Często największym wąskim gardłem w przypadku RAG jest użytkownik. Zapytania użytkowników są często niejednoznaczne, niekompletne lub źle sformułowane. Jeśli wektor zapytania nie jest matematycznie zgodny z wektorem dokumentu, pobieranie się nie powiedzie.
Przekształcanie zapytań wykorzystuje LLM do ponownego zapisywania lub rozszerzania zapytania zanim trafi ono do bazy danych. Zastosujesz 2 techniki:
- HyDE (Hypothetical Document Embeddings): podobieństwo wektorowe między pytaniem a odpowiedzią jest często mniejsze niż podobieństwo między odpowiedzią a hipotetyczną odpowiedzią. HyDE prosi LLM o wygenerowanie idealnej odpowiedzi, osadza ją i wyszukuje dokumenty, które wyglądają podobnie do wygenerowanej odpowiedzi.
- Wskazówki dotyczące kroków wstecz: jeśli użytkownik zada szczegółowe pytanie, system może pominąć szerszy kontekst. Technika step-back prompting polega na tym, że model LLM generuje pytanie na wyższym poziomie abstrakcji („Jaka jest historia tej rodziny?”), aby pobrać podstawowe informacje wraz ze szczegółami.
- Utwórz
query_transformation.py:cloudshell edit query_transformation.py - Wklej ten kod:
import os import logging from dotenv import load_dotenv from google.cloud.sql.connector import Connector, IPTypes from langchain_google_vertexai import VertexAIEmbeddings, VertexAI from langchain_community.vectorstores import PGVector from langchain_core.prompts import PromptTemplate load_dotenv() logging.basicConfig(level=logging.ERROR) PROJECT_ID = os.getenv("PROJECT_ID") REGION = os.getenv("REGION") DB_USER = os.getenv("SQL_USER") DB_PASS = os.getenv("SQL_PASSWORD") DB_NAME = os.getenv("SQL_DATABASE_NAME") INSTANCE_CONNECTION_NAME = f"{PROJECT_ID}:{REGION}:{os.getenv('SQL_INSTANCE_NAME')}" COLLECTION_NAME = f"{os.getenv('PGVECTOR_COLLECTION_NAME')}_recursive" def getconn(): with Connector() as connector: return connector.connect( INSTANCE_CONNECTION_NAME, "pg8000", user=DB_USER, password=DB_PASS, db=DB_NAME, ip_type=IPTypes.PUBLIC, ) def generate_hyde_doc(query, llm): prompt = PromptTemplate( input_variables=["question"], template="Write a concise, hypothetical answer to the question. Question: {question} Answer:" ) chain = prompt | llm return chain.invoke({"question": query}) def generate_step_back(query, llm): prompt = PromptTemplate( input_variables=["question"], template="Write a more general, abstract question that concepts in this question. Original: {question} Step-back:" ) chain = prompt | llm return chain.invoke({"question": query}) def main(): embeddings = VertexAIEmbeddings(model_name="gemini-embedding-001", project=PROJECT_ID, location=REGION) llm = VertexAI(model_name="gemini-2.5-flash", project=PROJECT_ID, location=REGION, temperature=0.5) pg_conn_str = f"postgresql+pg8000://{DB_USER}:{DB_PASS}@placeholder/{DB_NAME}" store = PGVector( collection_name=COLLECTION_NAME, embedding_function=embeddings, connection_string=pg_conn_str, engine_args={"creator": getconn} ) retriever = store.as_retriever(search_kwargs={"k": 2}) original_query = "Tell me about the Dursleys." print(f"ORIGINAL QUERY: {original_query}\n" + "-"*30) # 1. HyDE hyde_doc = generate_hyde_doc(original_query, llm) print(f"HyDE Generated Doc: {hyde_doc.strip()[:100]}...") hyde_results = retriever.invoke(hyde_doc) print(f"HyDE Retrieval: {hyde_results[0].page_content[:100]}...\n") # 2. Step-back step_back_q = generate_step_back(original_query, llm) print(f"Step-back Query: {step_back_q.strip()}") step_results = retriever.invoke(step_back_q) print(f"Step-back Retrieval: {step_results[0].page_content[:100]}...") if __name__ == "__main__": main() - Uruchom skrypt przekształcenia:
python query_transformation.py
Obserwuj dane wyjściowe.
Zwróć uwagę, że zapytanie Step-back może pobrać szerszy kontekst dotyczący historii rodziny Dursleyów, a zapytanie HyDE skupia się na konkretnych szczegółach wygenerowanych w hipotetycznej odpowiedzi.
10. Część 4. Generowanie kompleksowe
Podzieliliśmy dane, udoskonaliliśmy wyszukiwanie i dopracowaliśmy zapytanie użytkownika. Teraz wreszcie dodajemy do RAG literę „G”, czyli generowanie.
Do tej pory znajdowaliśmy tylko informacje. Aby stworzyć prawdziwego asystenta AI, musimy przekazać te wysokiej jakości, ponownie uszeregowane dokumenty do LLM (Gemini), aby wygenerować odpowiedź w języku naturalnym.
W potoku produkcyjnym obejmuje to określony przepływ:
- Pobieranie: pobierz szeroki zakres kandydatów (np. 10 najlepszych) za pomocą szybkiego wyszukiwania wektorowego.
- Ponowne rankingowanie: zawęź wyniki do najlepszych (np. 3 najlepszych) za pomocą narzędzia Vertex AI Reranker.
- Tworzenie kontekstu: połącz treść 3 najtrafniejszych dokumentów w jeden ciąg.
- Grounded Prompting: wstaw ten ciąg kontekstowy do szablonu ścisłego prompta, który zmusza LLM do używania tylko tych informacji.
Tworzenie skryptu generowania
W kroku generowania użyjemy gemini-2.5-flash. Ten model idealnie nadaje się do RAG, ponieważ ma długie okno kontekstu i niskie opóźnienie, co pozwala mu szybko przetwarzać wiele pobranych dokumentów.
- Utwórz
end_to_end_rag.py:
cloudshell edit end_to_end_rag.py
- Wklej ten kod. Zwróć uwagę na zmienną
template– w tym miejscu wyraźnie instruujemy model, aby unikał „halucynacji” (wymyślania rzeczy) poprzez powiązanie go z podanym kontekstem.
import os
import logging
from dotenv import load_dotenv
from google.cloud.sql.connector import Connector, IPTypes
from langchain_google_vertexai import VertexAIEmbeddings, VertexAI
from langchain_community.vectorstores import PGVector
from langchain.retrievers import ContextualCompressionRetriever
from langchain_google_community.vertex_rank import VertexAIRank
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
load_dotenv()
logging.basicConfig(level=logging.ERROR)
PROJECT_ID = os.getenv("PROJECT_ID")
REGION = os.getenv("REGION")
# We use the recursive collection as it generally provides the best context boundaries
COLLECTION_NAME = f"{os.getenv('PGVECTOR_COLLECTION_NAME')}_recursive"
def getconn():
instance_conn = f"{PROJECT_ID}:{REGION}:{os.getenv('SQL_INSTANCE_NAME')}"
with Connector() as connector:
return connector.connect(
instance_conn, "pg8000",
user=os.getenv("SQL_USER"), password=os.getenv("SQL_PASSWORD"),
db=os.getenv("SQL_DATABASE_NAME"), ip_type=IPTypes.PUBLIC
)
def main():
print("--- Initializing Production RAG Pipeline ---")
# 1. Setup Embeddings (Gemini Embedding 001)
# We use this to vectorize the user's query to match our database.
embeddings = VertexAIEmbeddings(model_name="gemini-embedding-001", project=PROJECT_ID, location=REGION)
# 2. Connect to Vector Store
pg_conn_str = f"postgresql+pg8000://{os.getenv('SQL_USER')}:{os.getenv('SQL_PASSWORD')}@placeholder/{os.getenv('SQL_DATABASE_NAME')}"
store = PGVector(
collection_name=COLLECTION_NAME,
embedding_function=embeddings,
connection_string=pg_conn_str,
engine_args={"creator": getconn}
)
# 3. Setup The 'Filter Funnel' (Retriever + Reranker)
# Step A: Fast retrieval of top 10 similar documents
base_retriever = store.as_retriever(search_kwargs={"k": 10})
# Step B: Precise reranking to find the top 3 most relevant
reranker = VertexAIRank(
project_id=PROJECT_ID,
location_id="global",
ranking_config="default_ranking_config",
title_field="source",
top_n=3
)
# Combine A and B into a single retrieval object
compression_retriever = ContextualCompressionRetriever(
base_compressor=reranker,
base_retriever=base_retriever
)
# 4. Setup LLM (Gemini 2.5 Flash)
# We use a low temperature (0.1) to reduce creativity and increase factual adherence.
llm = VertexAI(model_name="gemini-2.5-flash", project=PROJECT_ID, location=REGION, temperature=0.1)
# --- Execution Loop ---
user_query = "Who is Harry Potter?"
print(f"\nUser Query: {user_query}")
print("Retrieving and Reranking documents...")
# Retrieve the most relevant documents
top_docs = compression_retriever.invoke(user_query)
if not top_docs:
print("No relevant documents found.")
return
# Build the Context String
# We stitch the documents together, labeling them as Source 1, Source 2, etc.
context_str = "\n\n".join([f"Source {i+1}: {d.page_content}" for i, d in enumerate(top_docs)])
print(f"Found {len(top_docs)} relevant context chunks.")
# 5. The Grounded Prompt
template = """You are a helpful assistant. Answer the question strictly based on the provided context.
If the answer is not in the context, say "I don't know."
Context:
{context}
Question:
{question}
Answer:
"""
prompt = PromptTemplate(template=template, input_variables=["context", "question"])
# Create the chain: Prompt -> LLM
chain = prompt | llm
print("Generating Answer via Gemini 2.5 Flash...")
final_answer = chain.invoke({"context": context_str, "question": user_query})
print(f"\nFINAL ANSWER:\n{final_answer}")
if __name__ == "__main__":
main()
- Uruchom aplikację końcową:
python end_to_end_rag.py
Interpretowanie danych wyjściowych
Po uruchomieniu tego skryptu zwróć uwagę na różnicę między pobranymi fragmentami (które były widoczne w poprzednich krokach) a ostateczną odpowiedzią. LLM działa jak syntezator – odczytuje podzielone na fragmenty „porcje” tekstu dostarczone przez Rerankera i przekształca je w spójne zdanie zrozumiałe dla człowieka.
Łącząc te komponenty, przechodzisz od stochastycznego „zgadywania” do deterministycznego, opartego na faktach przepływu pracy. Wyszukiwarka zarzuca sieć, Reranker wybiera najlepsze wyniki, a Generator przygotowuje odpowiedź.
11. Podsumowanie
Gratulacje! Udało Ci się utworzyć zaawansowany potok RAG, który wykracza daleko poza podstawowe wyszukiwanie wektorowe.
Podsumowanie
- Skonfigurowano Cloud SQL z pgvector na potrzeby skalowalnego przechowywania wektorów.
- Porównano strategie dzielenia na części, aby zrozumieć, jak przygotowanie danych wpływa na wyszukiwanie.
- Wdrożono ponowne rankingowanie za pomocą Vertex AI, aby zwiększyć precyzję wyników.
- Używasz przekształceń zapytań (HyDE, Step-back), aby dopasować intencje użytkowników do swoich danych.
Więcej informacji
- Architektury referencyjne RAG: zapoznaj się z listą przewodników po architekturach referencyjnych związanych z RAG.
Od prototypu do środowiska produkcyjnego
Ten moduł jest częścią ścieżki szkoleniowej Wdrożenie AI w Google Cloud.
- Poznaj pełny program nauczania, aby przejść od prototypu do produkcji.
- Podziel się swoimi postępami, używając hashtagu #ProductionReadyAI.