
1. บทนำ
ภาพรวม
Retrieval Augmented Generation (RAG) ช่วยปรับปรุงคำตอบของโมเดลภาษาขนาดใหญ่ (LLM) โดยอิงตามความรู้ภายนอก อย่างไรก็ตาม การสร้างระบบ RAG ที่พร้อมใช้งานจริงต้องใช้มากกว่าการค้นหาเวกเตอร์แบบง่ายๆ คุณต้องเพิ่มประสิทธิภาพวิธีนำเข้าข้อมูล วิธีจัดอันดับผลลัพธ์ที่เกี่ยวข้อง และวิธีประมวลผลคำค้นหาของผู้ใช้
ในแล็บที่ครอบคลุมนี้ คุณจะได้สร้างแอปพลิเคชัน RAG ที่มีประสิทธิภาพโดยใช้ Cloud SQL สำหรับ PostgreSQL (ขยายด้วย pgvector) และ Vertex AI คุณจะได้เรียนรู้เทคนิคขั้นสูง 3 อย่างต่อไปนี้
- กลยุทธ์การแบ่งกลุ่ม: คุณจะเห็นว่าวิธีการแบ่งข้อความที่แตกต่างกัน (อักขระ แบบเรียกซ้ำ โทเค็น) ส่งผลต่อคุณภาพการดึงข้อมูลอย่างไร
- การจัดอันดับใหม่: คุณจะใช้ Vertex AI Reranker เพื่อปรับแต่งผลการค้นหาและแก้ปัญหา "หลงทางอยู่ตรงกลาง"
- การเปลี่ยนรูปแบบคำค้นหา: คุณจะใช้ Gemini เพื่อเพิ่มประสิทธิภาพคำค้นหาของผู้ใช้ผ่านเทคนิคต่างๆ เช่น HyDE (การฝังเอกสารสมมติ) และการแจ้งเตือนแบบย้อนกลับ
สิ่งที่คุณต้องดำเนินการ
- ตั้งค่าอินสแตนซ์ Cloud SQL สำหรับ PostgreSQL ด้วย
pgvector - สร้างไปป์ไลน์การนำเข้าข้อมูลที่แบ่งข้อความออกเป็นส่วนๆ โดยใช้กลยุทธ์หลายอย่าง และจัดเก็บการฝังใน Cloud SQL
- ทำการค้นหาเชิงความหมายและเปรียบเทียบคุณภาพของผลลัพธ์จากวิธีการแบ่งกลุ่มต่างๆ
- ผสานรวม Reranker เพื่อจัดลำดับเอกสารที่ดึงข้อมูลใหม่ตามความเกี่ยวข้อง
- ใช้การเปลี่ยนรูปแบบการค้นหาที่ทำงานด้วย LLM เพื่อปรับปรุงการดึงข้อมูลสำหรับคำถามที่ซับซ้อนหรือคลุมเครือ
สิ่งที่คุณจะได้เรียนรู้
- วิธีใช้ LangChain กับ Vertex AI และ Cloud SQL
- ผลกระทบของตัวแยกข้อความ Character, Recursive และ Token
- วิธีใช้ Vector Search ใน PostgreSQL
- วิธีใช้ ContextualCompressionRetriever สำหรับการจัดอันดับใหม่
- วิธีใช้ HyDE และการแจ้งแบบย้อนกลับ
2. การตั้งค่าโปรเจ็กต์
บัญชี Google
หากยังไม่มีบัญชี Google ส่วนบุคคล คุณต้องสร้างบัญชี Google
ใช้บัญชีส่วนตัวแทนบัญชีของที่ทำงานหรือบัญชีโรงเรียน
ลงชื่อเข้าใช้คอนโซล Google Cloud
ลงชื่อเข้าใช้ คอนโซล Google Cloud โดยใช้บัญชี Google ส่วนบุคคล
เปิดใช้การเรียกเก็บเงิน
แลกรับเครดิต Google Cloud (ไม่บังคับ)
หากต้องการจัดเวิร์กช็อปนี้ คุณต้องมีบัญชีสำหรับการเรียกเก็บเงินที่มีเครดิตอยู่บ้าง ใช้เครดิตจากแบนเนอร์ที่ด้านบนของ Codelab นี้เพื่อเริ่มต้นใช้งาน หากเชื่อมต่อกับบัญชีสำหรับการเรียกเก็บเงินอยู่แล้ว ให้ข้ามขั้นตอนนี้
ตั้งค่าบัญชีสำหรับการเรียกเก็บเงินส่วนตัว
หากตั้งค่าการเรียกเก็บเงินโดยใช้เครดิต Google Cloud คุณจะข้ามขั้นตอนนี้ได้
หากต้องการตั้งค่าบัญชีสำหรับการเรียกเก็บเงินส่วนตัว ให้ไปที่นี่เพื่อเปิดใช้การเรียกเก็บเงินใน Cloud Console
ข้อควรทราบ
- การทำ Lab นี้ควรมีค่าใช้จ่ายน้อยกว่า $1 USD ในทรัพยากรระบบคลาวด์
- คุณสามารถทำตามขั้นตอนที่ส่วนท้ายของแล็บนี้เพื่อลบทรัพยากรเพื่อหลีกเลี่ยงการเรียกเก็บเงินเพิ่มเติม
- ผู้ใช้ใหม่มีสิทธิ์ใช้ช่วงทดลองใช้ฟรีมูลค่า$300 USD
สร้างโปรเจ็กต์ (ไม่บังคับ)
หากไม่มีโปรเจ็กต์ปัจจุบันที่ต้องการใช้สำหรับแล็บนี้ ให้สร้างโปรเจ็กต์ใหม่ที่นี่
3. เปิดเครื่องมือแก้ไข Cloud Shell
- คลิกลิงก์นี้เพื่อไปยัง Cloud Shell Editor โดยตรง
- หากระบบแจ้งให้ให้สิทธิ์ในขั้นตอนใดก็ตามในวันนี้ ให้คลิกให้สิทธิ์เพื่อดำเนินการต่อ
- หากเทอร์มินัลไม่ปรากฏที่ด้านล่างของหน้าจอ ให้เปิดโดยทำดังนี้
- คลิกดู
- คลิก Terminal
- ในเทอร์มินัล ให้ตั้งค่าโปรเจ็กต์ด้วยคำสั่งนี้
gcloud config set project [PROJECT_ID]- ตัวอย่าง
gcloud config set project lab-project-id-example - หากจำรหัสโปรเจ็กต์ไม่ได้ คุณสามารถแสดงรหัสโปรเจ็กต์ทั้งหมดได้โดยใช้คำสั่งต่อไปนี้
gcloud projects list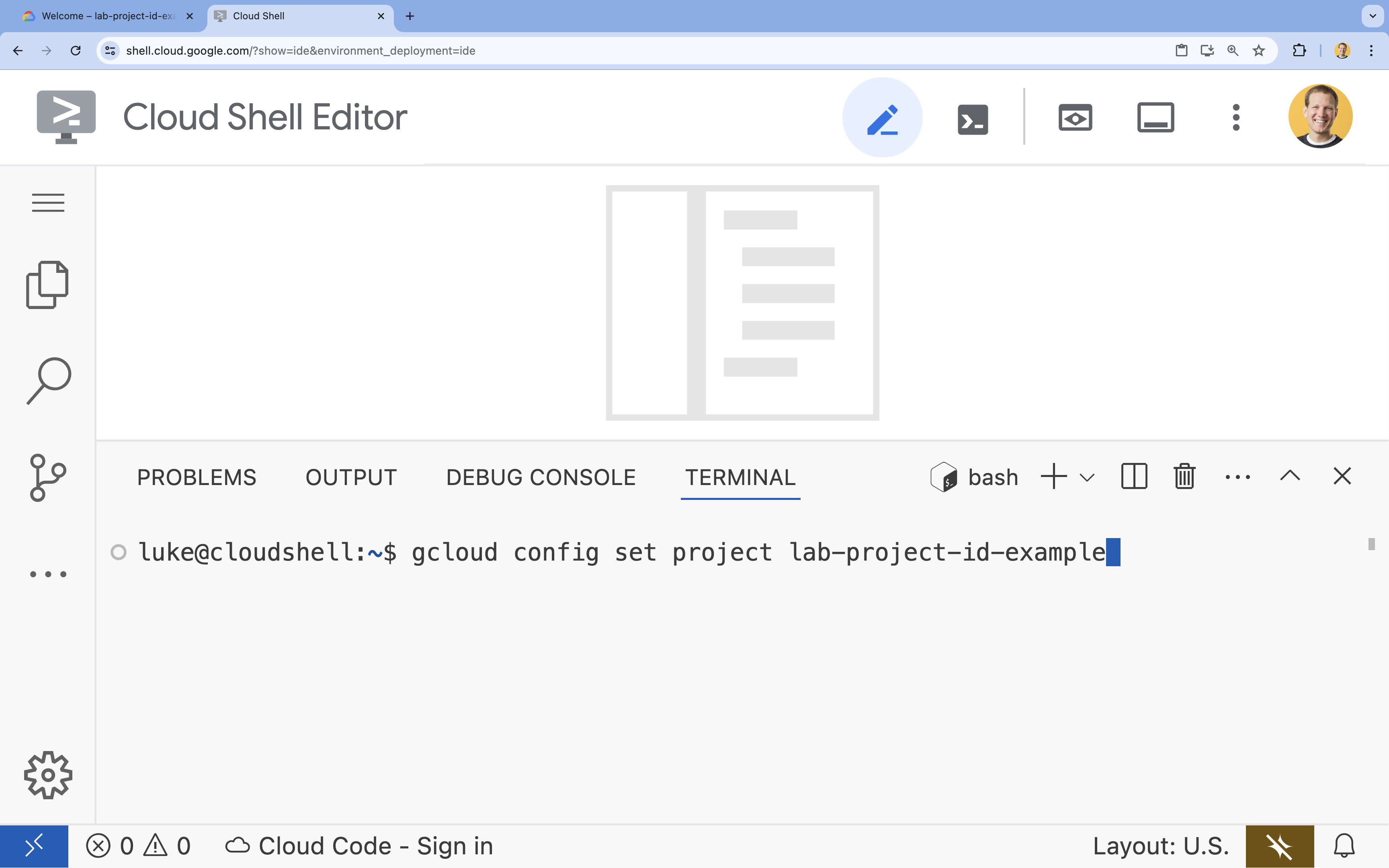
- ตัวอย่าง
- คุณควรเห็นข้อความต่อไปนี้
Updated property [core/project].
4. เปิดใช้ API
หากต้องการสร้างโซลูชันนี้ คุณต้องเปิดใช้ Cloud APIs ของ Google Cloud หลายรายการสำหรับ Vertex AI, Cloud SQL และบริการการจัดอันดับใหม่
- เปิดใช้ API ในเทอร์มินัลโดยทำดังนี้
gcloud services enable \ aiplatform.googleapis.com \ sqladmin.googleapis.com \ cloudresourcemanager.googleapis.com \ serviceusage.googleapis.com \ discoveryengine.googleapis.com
ขอแนะนำ API
- Vertex AI API (
aiplatform.googleapis.com): ช่วยให้ใช้ Gemini เพื่อสร้างข้อความและ Vertex AI Embeddings เพื่อแปลงข้อความเป็นเวกเตอร์ได้ - Cloud SQL Admin API (
sqladmin.googleapis.com): ช่วยให้คุณจัดการอินสแตนซ์ Cloud SQL ได้แบบเป็นโปรแกรม - Discovery Engine API (
discoveryengine.googleapis.com): ขับเคลื่อนความสามารถของ Vertex AI Reranker - Service Usage API (
serviceusage.googleapis.com): ต้องใช้เพื่อตรวจสอบและจัดการโควต้าบริการ
5. สร้างสภาพแวดล้อมเสมือนและติดตั้งการอ้างอิง
ก่อนเริ่มโปรเจ็กต์ Python ใดๆ คุณควรสร้างสภาพแวดล้อมเสมือน ซึ่งจะแยกการอ้างอิงของโปรเจ็กต์เพื่อป้องกันไม่ให้เกิดความขัดแย้งกับโปรเจ็กต์อื่นๆ หรือแพ็กเกจ Python ทั่วโลกของระบบ
- สร้างโฟลเดอร์ชื่อ
rag-labsแล้วเปลี่ยนเป็นโฟลเดอร์นั้น เรียกใช้โค้ดต่อไปนี้ในเทอร์มินัลmkdir rag-labs && cd rag-labs - สร้างและเปิดใช้งานสภาพแวดล้อมเสมือนโดยใช้คำสั่งต่อไปนี้
uv venv --python 3.12 source .venv/bin/activate - สร้างไฟล์
requirements.txtที่มีทรัพยากร Dependency ที่จำเป็น เรียกใช้โค้ดต่อไปนี้ในเทอร์มินัลcloudshell edit requirements.txt - วางทรัพยากร Dependency ที่เพิ่มประสิทธิภาพต่อไปนี้ลงใน
requirements.txtเราปักหมุดเวอร์ชันเหล่านี้ไว้เพื่อหลีกเลี่ยงความขัดแย้งและเร่งการติดตั้ง# Core LangChain & AI langchain-community==0.3.31 langchain-google-vertexai==2.1.2 langchain-google-community[vertexaisearch]==2.0.10 # Google Cloud google-cloud-storage==2.19.0 google-cloud-aiplatform[langchain]==1.130.0 # Database cloud-sql-python-connector[pg8000]==1.19.0 sqlalchemy==2.0.45 pgvector==0.4.2 # Utilities tiktoken==0.12.0 python-dotenv==1.2.1 requests==2.32.5 - ติดตั้งการอ้างอิง:
uv pip install -r requirements.txt
6. ตั้งค่า Cloud SQL สำหรับ PostgreSQL
ในงานนี้ คุณจะจัดสรรอินสแตนซ์ Cloud SQL สำหรับ PostgreSQL, สร้างฐานข้อมูล และเตรียมฐานข้อมูลสำหรับการค้นหาเวกเตอร์
กำหนดการกำหนดค่า Cloud SQL
- สร้างไฟล์
.envเพื่อจัดเก็บการกำหนดค่า เรียกใช้โค้ดต่อไปนี้ในเทอร์มินัลcloudshell edit .env - วางการกำหนดค่าต่อไปนี้ใน
.env# Project Config PROJECT_ID="[YOUR_PROJECT_ID]" REGION="us-central1" # Database Config SQL_INSTANCE_NAME="rag-pg-instance-1" SQL_DATABASE_NAME="rag_harry_potter_db" SQL_USER="rag_user" SQL_PASSWORD="StrongPassword123!" # RAG Config PGVECTOR_COLLECTION_NAME="rag_harry_potter" RANKING_LOCATION_ID="global" # Connection Name (Auto-generated in scripts usually, but useful to have) DB_INSTANCE_CONNECTION_NAME="${PROJECT_ID}:${REGION}:${SQL_INSTANCE_NAME}" - แทนที่
[YOUR_PROJECT_ID]ด้วยรหัสโปรเจ็กต์ Google Cloud จริง (เช่นPROJECT_ID = "google-cloud-labs")
หากจำรหัสโปรเจ็กต์ไม่ได้ ให้เรียกใช้คำสั่งต่อไปนี้ในเทอร์มินัล โดยจะแสดงรายการโปรเจ็กต์ทั้งหมดและรหัสของโปรเจ็กต์gcloud projects list - โหลดตัวแปรลงในเซสชันเชลล์
source .env
สร้างอินสแตนซ์และฐานข้อมูล
- สร้างอินสแตนซ์ Cloud SQL สำหรับ PostgreSQL คำสั่งนี้จะสร้างอินสแตนซ์ขนาดเล็กที่เหมาะกับห้องทดลองนี้
gcloud sql instances create ${SQL_INSTANCE_NAME} \ --database-version=POSTGRES_15 \ --tier=db-g1-small \ --region=${REGION} \ --project=${PROJECT_ID} - เมื่ออินสแตนซ์พร้อมแล้ว ให้สร้างฐานข้อมูลโดยทำดังนี้
gcloud sql databases create ${SQL_DATABASE_NAME} \ --instance=${SQL_INSTANCE_NAME} \ --project=${PROJECT_ID} - สร้างผู้ใช้ฐานข้อมูล
gcloud sql users create ${SQL_USER} \ --instance=${SQL_INSTANCE_NAME} \ --password=${SQL_PASSWORD} \ --project=${PROJECT_ID}
เปิดใช้ส่วนขยาย pgvector
ส่วนขยาย pgvector ช่วยให้ PostgreSQL จัดเก็บและค้นหาการฝังเวกเตอร์ได้ คุณต้องเปิดใช้ฟีเจอร์นี้อย่างชัดเจนในฐานข้อมูล
- สร้างสคริปต์ชื่อ
enable_pgvector.pyเรียกใช้โค้ดต่อไปนี้ในเทอร์มินัลcloudshell edit enable_pgvector.py - วางโค้ดต่อไปนี้ลงใน
enable_pgvector.pyสคริปต์นี้เชื่อมต่อกับฐานข้อมูลและเรียกใช้CREATE EXTENSION IF NOT EXISTS vector;import os import sqlalchemy from google.cloud.sql.connector import Connector, IPTypes import logging from dotenv import load_dotenv load_dotenv() logging.basicConfig(level=logging.INFO) # Config project_id = os.getenv("PROJECT_ID") region = os.getenv("REGION") instance_name = os.getenv("SQL_INSTANCE_NAME") db_user = os.getenv("SQL_USER") db_pass = os.getenv("SQL_PASSWORD") db_name = os.getenv("SQL_DATABASE_NAME") instance_connection_name = f"{project_id}:{region}:{instance_name}" def getconn(): with Connector() as connector: conn = connector.connect( instance_connection_name, "pg8000", user=db_user, password=db_pass, db=db_name, ip_type=IPTypes.PUBLIC, ) return conn def enable_pgvector(): pool = sqlalchemy.create_engine( "postgresql+pg8000://", creator=getconn, ) with pool.connect() as db_conn: # Check if extension exists result = db_conn.execute(sqlalchemy.text("SELECT extname FROM pg_extension WHERE extname = 'vector';")).fetchone() if result: logging.info("pgvector extension is already enabled.") else: logging.info("Enabling pgvector extension...") db_conn.execute(sqlalchemy.text("CREATE EXTENSION IF NOT EXISTS vector;")) db_conn.commit() logging.info("pgvector extension enabled successfully.") if __name__ == "__main__": enable_pgvector() - เรียกใช้สคริปต์
python enable_pgvector.py
7. ส่วนที่ 1: กลยุทธ์การแบ่งเนื้อหา
ขั้นตอนแรกในไปป์ไลน์ RAG คือการแปลงเอกสารเป็นรูปแบบที่ LLM เข้าใจได้ ซึ่งก็คือก้อน
LLM มีขีดจำกัดหน้าต่างบริบท (ปริมาณข้อความที่ประมวลผลได้ในครั้งเดียว) นอกจากนี้ การดึงข้อมูลเอกสาร 50 หน้าเพื่อตอบคำถามที่เฉพาะเจาะจงจะทำให้ข้อมูลเจือจาง เราจะแบ่งเอกสารออกเป็น "ก้อน" เล็กๆ เพื่อแยกข้อมูลที่เกี่ยวข้อง
อย่างไรก็ตาม วิธีแยกข้อความมีความสำคัญอย่างยิ่ง
- ตัวแยกอักขระ: แยกตามจำนวนอักขระอย่างเคร่งครัด วิธีนี้รวดเร็วแต่มีความเสี่ยง เนื่องจากอาจตัดคำหรือประโยคออกครึ่งหนึ่ง ซึ่งทำลายความหมายเชิงความหมาย
- ตัวแยกแบบเรียกซ้ำ: พยายามแยกตามย่อหน้าก่อน จากนั้นแยกตามประโยค แล้วจึงแยกตามคำ โดยจะพยายามเก็บหน่วยความหมายไว้ด้วยกัน
- ตัวแยกโทเค็น: แยกตามคำศัพท์ของ LLM เอง (โทเค็น) วิธีนี้ช่วยให้มั่นใจได้ว่าก้อนข้อมูลจะพอดีกับหน้าต่างบริบท แต่การสร้างอาจมีค่าใช้จ่ายด้านการคำนวณสูงกว่า
ในส่วนนี้ คุณจะส่งผ่านข้อมูลเดียวกันโดยใช้กลยุทธ์ทั้ง 3 แบบเพื่อเปรียบเทียบ
สร้างสคริปต์การส่งผ่านข้อมูล
คุณจะใช้สคริปต์ที่ดาวน์โหลดชุดข้อมูลแฮร์รี่ พอตเตอร์ แบ่งชุดข้อมูลโดยใช้กลยุทธ์ Character, Recursive และ Token แล้วอัปโหลดการฝังไปยังตาราง 3 ตารางแยกกันใน Cloud SQL
- สร้างไฟล์
ingest_data.pyโดยทำดังนี้cloudshell edit ingest_data.py - วางโค้ดที่แก้ไขแล้วต่อไปนี้ลงใน
ingest_data.pyเวอร์ชันนี้จะแยกวิเคราะห์โครงสร้าง JSON ของชุดข้อมูลได้อย่างถูกต้องimport os import json import logging import requests from typing import List, Dict, Any from dotenv import load_dotenv from google.cloud.sql.connector import Connector, IPTypes from langchain_google_vertexai import VertexAIEmbeddings from langchain_community.vectorstores import PGVector from langchain.text_splitter import CharacterTextSplitter, RecursiveCharacterTextSplitter, TokenTextSplitter from langchain.docstore.document import Document load_dotenv() logging.basicConfig(level=logging.INFO) # Configuration PROJECT_ID = os.getenv("PROJECT_ID") REGION = os.getenv("REGION") DB_USER = os.getenv("SQL_USER") DB_PASS = os.getenv("SQL_PASSWORD") DB_NAME = os.getenv("SQL_DATABASE_NAME") INSTANCE_CONNECTION_NAME = f"{PROJECT_ID}:{REGION}:{os.getenv('SQL_INSTANCE_NAME')}" BASE_COLLECTION_NAME = os.getenv("PGVECTOR_COLLECTION_NAME") BOOKS_JSON_URL = "https://storage.googleapis.com/github-repo/generative-ai/gemini/reasoning-engine/sample_data/harry_potter_books.json" CHUNK_SIZE = 500 CHUNK_OVERLAP = 50 MAX_DOCS_TO_PROCESS = 10 # Database Connector def getconn(): with Connector() as connector: return connector.connect( INSTANCE_CONNECTION_NAME, "pg8000", user=DB_USER, password=DB_PASS, db=DB_NAME, ip_type=IPTypes.PUBLIC, ) def download_data(): logging.info(f"Downloading data from {BOOKS_JSON_URL}...") response = requests.get(BOOKS_JSON_URL) return response.json() def prepare_chunks(json_data, strategy): documents = [] # Iterate through the downloaded data for entry in json_data[:MAX_DOCS_TO_PROCESS]: # --- JSON PARSING LOGIC --- # The data structure nests content inside 'kwargs' -> 'page_content' if "kwargs" in entry and "page_content" in entry["kwargs"]: content = entry["kwargs"]["page_content"] # Extract metadata if available, ensuring it's a dict metadata = entry["kwargs"].get("metadata", {}) if not isinstance(metadata, dict): metadata = {"source": "unknown"} # Add the strategy to metadata for tracking metadata["strategy"] = strategy else: continue if not content: continue # Choose the splitter based on the strategy if strategy == "character": splitter = CharacterTextSplitter(chunk_size=CHUNK_SIZE, chunk_overlap=CHUNK_OVERLAP, separator="\n") elif strategy == "token": splitter = TokenTextSplitter(chunk_size=CHUNK_SIZE, chunk_overlap=CHUNK_OVERLAP) else: # default to recursive splitter = RecursiveCharacterTextSplitter(chunk_size=CHUNK_SIZE, chunk_overlap=CHUNK_OVERLAP) # Split the content into chunks chunks = splitter.split_text(content) # Create Document objects for each chunk for chunk in chunks: documents.append(Document(page_content=chunk, metadata=metadata)) return documents def main(): logging.info("Initializing Embeddings...") embeddings = VertexAIEmbeddings(model_name="gemini-embedding-001", project=PROJECT_ID, location=REGION) data = download_data() strategies = ["character", "recursive", "token"] # Connection string for PGVector (uses the getconn helper) pg_conn_str = f"postgresql+pg8000://{DB_USER}:{DB_PASS}@placeholder/{DB_NAME}" for strategy in strategies: collection_name = f"{BASE_COLLECTION_NAME}_{strategy}" logging.info(f"--- Processing strategy: {strategy.upper()} ---") logging.info(f"Target Collection: {collection_name}") # Prepare documents with the specific strategy docs = prepare_chunks(data, strategy) if not docs: logging.warning(f"No documents generated for strategy {strategy}. Check data source.") continue logging.info(f"Generated {len(docs)} chunks. Uploading to Cloud SQL...") # Initialize the Vector Store store = PGVector( collection_name=collection_name, embedding_function=embeddings, connection_string=pg_conn_str, engine_args={"creator": getconn}, pre_delete_collection=True # Clears old data for this collection before adding new ) # Batch add documents store.add_documents(docs) logging.info(f"Successfully finished {strategy}.\n") if __name__ == "__main__": main() - เรียกใช้สคริปต์การส่งผ่านข้อมูล ซึ่งจะสร้างตาราง (คอลเล็กชัน) ที่แตกต่างกัน 3 ตารางในฐานข้อมูล
python ingest_data.py
เปรียบเทียบผลลัพธ์ของการแบ่งกลุ่ม
เมื่อโหลดข้อมูลแล้ว ให้เรียกใช้การค้นหาในทั้ง 3 คอลเล็กชันเพื่อดูว่ากลยุทธ์การแบ่งข้อมูลส่งผลต่อผลลัพธ์อย่างไร
- สร้าง
query_chunking.py:cloudshell edit query_chunking.py - วางโค้ดต่อไปนี้ลงใน
query_chunking.pyimport os import logging from dotenv import load_dotenv from google.cloud.sql.connector import Connector, IPTypes from langchain_google_vertexai import VertexAIEmbeddings from langchain_community.vectorstores import PGVector load_dotenv() logging.basicConfig(level=logging.ERROR) # Only show errors to keep output clean # Config PROJECT_ID = os.getenv("PROJECT_ID") REGION = os.getenv("REGION") DB_USER = os.getenv("SQL_USER") DB_PASS = os.getenv("SQL_PASSWORD") DB_NAME = os.getenv("SQL_DATABASE_NAME") INSTANCE_CONNECTION_NAME = f"{PROJECT_ID}:{REGION}:{os.getenv('SQL_INSTANCE_NAME')}" BASE_COLLECTION_NAME = os.getenv("PGVECTOR_COLLECTION_NAME") def getconn(): with Connector() as connector: return connector.connect( INSTANCE_CONNECTION_NAME, "pg8000", user=DB_USER, password=DB_PASS, db=DB_NAME, ip_type=IPTypes.PUBLIC, ) def main(): embeddings = VertexAIEmbeddings(model_name="gemini-embedding-001", project=PROJECT_ID, location=REGION) pg_conn_str = f"postgresql+pg8000://{DB_USER}:{DB_PASS}@placeholder/{DB_NAME}" query = "Tell me about the Dursleys and their relationship with Harry Potter" print(f"\nQUERY: {query}\n" + "="*50) strategies = ["character", "recursive", "token"] for strategy in strategies: collection = f"{BASE_COLLECTION_NAME}_{strategy}" print(f"\nSTRATEGY: {strategy.upper()}") store = PGVector( collection_name=collection, embedding_function=embeddings, connection_string=pg_conn_str, engine_args={"creator": getconn} ) results = store.similarity_search_with_score(query, k=2) for i, (doc, score) in enumerate(results): print(f" Result {i+1} (Score: {score:.4f}): {doc.page_content[:150].replace(chr(10), ' ')}...") if __name__ == "__main__": main() - เรียกใช้สคริปต์การค้นหา
python query_chunking.py
ดูเอาต์พุต
โปรดสังเกตว่าการแยกอักขระอาจตัดประโยคกลางคัน ในขณะที่แบบเรียกซ้ำจะพยายามรักษารูปแบบย่อหน้า การแยกโทเค็นช่วยให้มั่นใจได้ว่าก้อนข้อมูลจะพอดีกับหน้าต่างบริบทของ LLM แต่ก็อาจละเลยโครงสร้างเชิงความหมาย
8. ส่วนที่ 2: การจัดอันดับใหม่
การค้นหาเวกเตอร์ (การดึงข้อมูล) รวดเร็วอย่างยิ่งเนื่องจากอาศัยการแสดงทางคณิตศาสตร์ที่บีบอัด (การฝัง) โดยจะครอบคลุมในวงกว้างเพื่อให้มั่นใจว่ามีการเรียกคืน (การค้นหารายการที่อาจเกี่ยวข้องทั้งหมด) แต่ก็มักจะมีความแม่นยำต่ำ (การจัดอันดับรายการเหล่านั้นอาจไม่สมบูรณ์)
บ่อยครั้งที่เอกสารที่เกี่ยวข้องจะ "หายไปกลาง" รายการผลการค้นหา LLM ที่สนใจผลการค้นหา 5 อันดับแรกอาจพลาดคำตอบสำคัญที่อยู่ในอันดับที่ 7
การจัดอันดับใหม่ช่วยแก้ปัญหานี้ได้ด้วยการเพิ่มขั้นตอนที่ 2
- ตัวดึงข้อมูล: ดึงชุดข้อมูลที่ใหญ่ขึ้น (เช่น 25 อันดับแรก) โดยใช้การค้นหาเวกเตอร์ที่รวดเร็ว
- Reranker: ใช้โมเดลเฉพาะ (เช่น Cross-Encoder) เพื่อตรวจสอบข้อความแบบเต็มของคู่คำค้นหาและเอกสาร ซึ่งจะช้ากว่า แต่แม่นยำกว่ามาก โดยจะให้คะแนนใหม่แก่ 25 อันดับแรกและแสดงผล 3 อันดับที่ดีที่สุด
ในงานนี้ คุณจะค้นหาrecursiveคอลเล็กชันที่สร้างขึ้นในส่วนที่ 1 แต่คราวนี้คุณจะใช้ Vertex AI Reranker เพื่อปรับแต่งผลลัพธ์
- สร้าง
query_reranking.py:cloudshell edit query_reranking.py - วางโค้ดต่อไปนี้ โปรดสังเกตว่านโยบายนี้มุ่งเน้นไปที่
_recursiveคอลเล็กชันและการใช้ContextualCompressionRetrieverอย่างชัดเจนimport os import logging from dotenv import load_dotenv from google.cloud.sql.connector import Connector, IPTypes from langchain_google_vertexai import VertexAIEmbeddings from langchain_community.vectorstores import PGVector # Reranking Imports from langchain.retrievers import ContextualCompressionRetriever from langchain_google_community.vertex_rank import VertexAIRank load_dotenv() logging.basicConfig(level=logging.ERROR) PROJECT_ID = os.getenv("PROJECT_ID") REGION = os.getenv("REGION") DB_USER = os.getenv("SQL_USER") DB_PASS = os.getenv("SQL_PASSWORD") DB_NAME = os.getenv("SQL_DATABASE_NAME") INSTANCE_CONNECTION_NAME = f"{PROJECT_ID}:{REGION}:{os.getenv('SQL_INSTANCE_NAME')}" # IMPORTANT: Target the recursive collection created in ingest_data.py COLLECTION_NAME = f"{os.getenv('PGVECTOR_COLLECTION_NAME')}_recursive" RANKING_LOCATION = os.getenv("RANKING_LOCATION_ID") def getconn(): with Connector() as connector: return connector.connect( INSTANCE_CONNECTION_NAME, "pg8000", user=DB_USER, password=DB_PASS, db=DB_NAME, ip_type=IPTypes.PUBLIC, ) def main(): embeddings = VertexAIEmbeddings(model_name="gemini-embedding-001", project=PROJECT_ID, location=REGION) pg_conn_str = f"postgresql+pg8000://{DB_USER}:{DB_PASS}@placeholder/{DB_NAME}" print(f"Connecting to collection: {COLLECTION_NAME}") store = PGVector( collection_name=COLLECTION_NAME, embedding_function=embeddings, connection_string=pg_conn_str, engine_args={"creator": getconn} ) query = "What are the Horcruxes?" print(f"QUERY: {query}\n") # 1. Base Retriever (Vector Search) - Fetch top 10 base_retriever = store.as_retriever(search_kwargs={"k": 10}) # 2. Reranker - Select top 3 from the 10 reranker = VertexAIRank( project_id=PROJECT_ID, location_id=RANKING_LOCATION, ranking_config="default_ranking_config", title_field="source", top_n=3 ) compression_retriever = ContextualCompressionRetriever( base_compressor=reranker, base_retriever=base_retriever ) # Execute try: reranked_docs = compression_retriever.invoke(query) if not reranked_docs: print("No documents returned. Check if the collection exists and is populated.") print(f"--- Top 3 Reranked Results ---") for i, doc in enumerate(reranked_docs): print(f"Result {i+1} (Score: {doc.metadata.get('relevance_score', 'N/A')}):") print(f" {doc.page_content[:200]}...\n") except Exception as e: print(f"Error during reranking: {e}") if __name__ == "__main__": main() - เรียกใช้การค้นหาการจัดอันดับใหม่
python query_reranking.py
สังเกต
คุณอาจสังเกตเห็นคะแนนความเกี่ยวข้องที่สูงขึ้นหรือการจัดลำดับที่แตกต่างกันเมื่อเทียบกับการค้นหาเวกเตอร์แบบดิบ ซึ่งจะช่วยให้ LLM ได้รับบริบทที่แม่นยำที่สุดเท่าที่จะเป็นไปได้
9. ส่วนที่ 3: การเปลี่ยนรูปแบบคำค้นหา
โดยส่วนใหญ่แล้ว จุดคอขวดที่ใหญ่ที่สุดใน RAG คือผู้ใช้ คำค้นหาของผู้ใช้มักจะคลุมเครือ ไม่สมบูรณ์ หรือใช้คำไม่ดี หากการฝังคำค้นหาไม่สอดคล้องกับการฝังเอกสารในเชิงคณิตศาสตร์ การดึงข้อมูลจะล้มเหลว
การเปลี่ยนรูปแบบคําค้นหาใช้ LLM เพื่อเขียนหรือขยายคําค้นหาก่อนที่จะเข้าถึงฐานข้อมูล คุณจะใช้เทคนิค 2 อย่างต่อไปนี้
- HyDE (Hypothetical Document Embeddings): ความคล้ายคลึงของเวกเตอร์ระหว่างคำถามกับคำตอบมักจะต่ำกว่าความคล้ายคลึงระหว่างคำตอบกับคำตอบสมมติ HyDE ขอให้ LLM สร้างคำตอบที่สมบูรณ์แบบ ฝังคำตอบนั้น และค้นหาเอกสารที่ดูเหมือนคำตอบที่สร้างขึ้น
- การแจ้งเตือนแบบย้อนกลับ: หากผู้ใช้ถามคำถามที่เฉพาะเจาะจงและมีรายละเอียด ระบบอาจพลาดบริบทที่กว้างขึ้น การแจ้งแบบย้อนกลับจะขอให้ LLM สร้างคำถามระดับสูงที่เป็นนามธรรม ("ประวัติของครอบครัวนี้เป็นอย่างไร") เพื่อดึงข้อมูลพื้นฐานควบคู่ไปกับรายละเอียดที่เฉพาะเจาะจง
- สร้าง
query_transformation.py:cloudshell edit query_transformation.py - วางโค้ดต่อไปนี้
import os import logging from dotenv import load_dotenv from google.cloud.sql.connector import Connector, IPTypes from langchain_google_vertexai import VertexAIEmbeddings, VertexAI from langchain_community.vectorstores import PGVector from langchain_core.prompts import PromptTemplate load_dotenv() logging.basicConfig(level=logging.ERROR) PROJECT_ID = os.getenv("PROJECT_ID") REGION = os.getenv("REGION") DB_USER = os.getenv("SQL_USER") DB_PASS = os.getenv("SQL_PASSWORD") DB_NAME = os.getenv("SQL_DATABASE_NAME") INSTANCE_CONNECTION_NAME = f"{PROJECT_ID}:{REGION}:{os.getenv('SQL_INSTANCE_NAME')}" COLLECTION_NAME = f"{os.getenv('PGVECTOR_COLLECTION_NAME')}_recursive" def getconn(): with Connector() as connector: return connector.connect( INSTANCE_CONNECTION_NAME, "pg8000", user=DB_USER, password=DB_PASS, db=DB_NAME, ip_type=IPTypes.PUBLIC, ) def generate_hyde_doc(query, llm): prompt = PromptTemplate( input_variables=["question"], template="Write a concise, hypothetical answer to the question. Question: {question} Answer:" ) chain = prompt | llm return chain.invoke({"question": query}) def generate_step_back(query, llm): prompt = PromptTemplate( input_variables=["question"], template="Write a more general, abstract question that concepts in this question. Original: {question} Step-back:" ) chain = prompt | llm return chain.invoke({"question": query}) def main(): embeddings = VertexAIEmbeddings(model_name="gemini-embedding-001", project=PROJECT_ID, location=REGION) llm = VertexAI(model_name="gemini-2.5-flash", project=PROJECT_ID, location=REGION, temperature=0.5) pg_conn_str = f"postgresql+pg8000://{DB_USER}:{DB_PASS}@placeholder/{DB_NAME}" store = PGVector( collection_name=COLLECTION_NAME, embedding_function=embeddings, connection_string=pg_conn_str, engine_args={"creator": getconn} ) retriever = store.as_retriever(search_kwargs={"k": 2}) original_query = "Tell me about the Dursleys." print(f"ORIGINAL QUERY: {original_query}\n" + "-"*30) # 1. HyDE hyde_doc = generate_hyde_doc(original_query, llm) print(f"HyDE Generated Doc: {hyde_doc.strip()[:100]}...") hyde_results = retriever.invoke(hyde_doc) print(f"HyDE Retrieval: {hyde_results[0].page_content[:100]}...\n") # 2. Step-back step_back_q = generate_step_back(original_query, llm) print(f"Step-back Query: {step_back_q.strip()}") step_results = retriever.invoke(step_back_q) print(f"Step-back Retrieval: {step_results[0].page_content[:100]}...") if __name__ == "__main__": main() - เรียกใช้สคริปต์การเปลี่ยนรูปแบบ
python query_transformation.py
ดูเอาต์พุต
โปรดสังเกตว่าคำค้นหาย้อนกลับอาจดึงบริบทที่กว้างขึ้นเกี่ยวกับประวัติครอบครัวเดอร์สลีย์ ขณะที่ HyDE จะมุ่งเน้นรายละเอียดเฉพาะที่สร้างขึ้นในคำตอบสมมติ
10. ส่วนที่ 4: การสร้างแบบครบวงจร
เราได้ตัดข้อมูล ปรับแต่งการค้นหา และขัดเกลาคำค้นหาของผู้ใช้ ตอนนี้เรามาใส่ "G" ใน RAG กัน นั่นก็คือ Generation
จนถึงตอนนี้ เราได้แต่ค้นหาข้อมูล หากต้องการสร้างผู้ช่วย AI อย่างแท้จริง เราต้องป้อนเอกสารคุณภาพสูงที่จัดอันดับใหม่เหล่านั้นลงใน LLM (Gemini) เพื่อสังเคราะห์คำตอบในภาษาธรรมชาติ
ในไปป์ไลน์การผลิต ขั้นตอนนี้เกี่ยวข้องกับโฟลว์ที่เฉพาะเจาะจงดังนี้
- ดึงข้อมูล: รับชุดผู้สมัครที่หลากหลาย (เช่น 10 อันดับแรก) โดยใช้การค้นหาเวกเตอร์ที่รวดเร็ว
- จัดอันดับใหม่: กรองให้เหลือเฉพาะรายการที่ดีที่สุด (เช่น 3 อันดับแรก) โดยใช้ Vertex AI Reranker
- การสร้างบริบท: เย็บเนื้อหาของเอกสาร 3 อันดับแรกเหล่านั้นเป็นสตริงเดียว
- การแจ้งแบบมีพื้นฐาน: แทรกสตริงบริบทนั้นลงในเทมเพลตพรอมต์ที่เข้มงวดซึ่งบังคับให้ LLM ใช้เฉพาะข้อมูลนั้น
สร้างสคริปต์การสร้าง
เราจะใช้ gemini-2.5-flash สำหรับขั้นตอนการสร้าง โมเดลนี้เหมาะสำหรับ RAG เนื่องจากมีหน้าต่างบริบทที่ยาวและมีเวลาในการตอบสนองต่ำ จึงประมวลผลเอกสารที่ดึงข้อมูลมาหลายฉบับได้อย่างรวดเร็ว
- สร้าง
end_to_end_rag.py:
cloudshell edit end_to_end_rag.py
- วางโค้ดต่อไปนี้ ให้ความสำคัญกับตัวแปร
templateซึ่งเป็นจุดที่เราสั่งให้โมเดลหลีกเลี่ยง "การหลอน" (การแต่งเรื่องขึ้นมา) อย่างเคร่งครัดด้วยการเชื่อมโยงตัวแปรกับบริบทที่ให้ไว้
import os
import logging
from dotenv import load_dotenv
from google.cloud.sql.connector import Connector, IPTypes
from langchain_google_vertexai import VertexAIEmbeddings, VertexAI
from langchain_community.vectorstores import PGVector
from langchain.retrievers import ContextualCompressionRetriever
from langchain_google_community.vertex_rank import VertexAIRank
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
load_dotenv()
logging.basicConfig(level=logging.ERROR)
PROJECT_ID = os.getenv("PROJECT_ID")
REGION = os.getenv("REGION")
# We use the recursive collection as it generally provides the best context boundaries
COLLECTION_NAME = f"{os.getenv('PGVECTOR_COLLECTION_NAME')}_recursive"
def getconn():
instance_conn = f"{PROJECT_ID}:{REGION}:{os.getenv('SQL_INSTANCE_NAME')}"
with Connector() as connector:
return connector.connect(
instance_conn, "pg8000",
user=os.getenv("SQL_USER"), password=os.getenv("SQL_PASSWORD"),
db=os.getenv("SQL_DATABASE_NAME"), ip_type=IPTypes.PUBLIC
)
def main():
print("--- Initializing Production RAG Pipeline ---")
# 1. Setup Embeddings (Gemini Embedding 001)
# We use this to vectorize the user's query to match our database.
embeddings = VertexAIEmbeddings(model_name="gemini-embedding-001", project=PROJECT_ID, location=REGION)
# 2. Connect to Vector Store
pg_conn_str = f"postgresql+pg8000://{os.getenv('SQL_USER')}:{os.getenv('SQL_PASSWORD')}@placeholder/{os.getenv('SQL_DATABASE_NAME')}"
store = PGVector(
collection_name=COLLECTION_NAME,
embedding_function=embeddings,
connection_string=pg_conn_str,
engine_args={"creator": getconn}
)
# 3. Setup The 'Filter Funnel' (Retriever + Reranker)
# Step A: Fast retrieval of top 10 similar documents
base_retriever = store.as_retriever(search_kwargs={"k": 10})
# Step B: Precise reranking to find the top 3 most relevant
reranker = VertexAIRank(
project_id=PROJECT_ID,
location_id="global",
ranking_config="default_ranking_config",
title_field="source",
top_n=3
)
# Combine A and B into a single retrieval object
compression_retriever = ContextualCompressionRetriever(
base_compressor=reranker,
base_retriever=base_retriever
)
# 4. Setup LLM (Gemini 2.5 Flash)
# We use a low temperature (0.1) to reduce creativity and increase factual adherence.
llm = VertexAI(model_name="gemini-2.5-flash", project=PROJECT_ID, location=REGION, temperature=0.1)
# --- Execution Loop ---
user_query = "Who is Harry Potter?"
print(f"\nUser Query: {user_query}")
print("Retrieving and Reranking documents...")
# Retrieve the most relevant documents
top_docs = compression_retriever.invoke(user_query)
if not top_docs:
print("No relevant documents found.")
return
# Build the Context String
# We stitch the documents together, labeling them as Source 1, Source 2, etc.
context_str = "\n\n".join([f"Source {i+1}: {d.page_content}" for i, d in enumerate(top_docs)])
print(f"Found {len(top_docs)} relevant context chunks.")
# 5. The Grounded Prompt
template = """You are a helpful assistant. Answer the question strictly based on the provided context.
If the answer is not in the context, say "I don't know."
Context:
{context}
Question:
{question}
Answer:
"""
prompt = PromptTemplate(template=template, input_variables=["context", "question"])
# Create the chain: Prompt -> LLM
chain = prompt | llm
print("Generating Answer via Gemini 2.5 Flash...")
final_answer = chain.invoke({"context": context_str, "question": user_query})
print(f"\nFINAL ANSWER:\n{final_answer}")
if __name__ == "__main__":
main()
- เรียกใช้แอปพลิเคชันสุดท้าย
python end_to_end_rag.py
ทำความเข้าใจเอาต์พุต
เมื่อเรียกใช้สคริปต์นี้ ให้สังเกตความแตกต่างระหว่างก้อนข้อมูลดิบที่ดึงมา (ซึ่งคุณเห็นในขั้นตอนก่อนหน้า) กับคำตอบสุดท้าย LLM ทำหน้าที่เป็นตัวสังเคราะห์ โดยจะอ่าน "ก้อน" ข้อความที่กระจัดกระจายซึ่ง Reranker จัดหาให้ แล้วเรียบเรียงให้เป็นประโยคที่สอดคล้องกันและมนุษย์อ่านได้
การเชื่อมโยงคอมโพเนนต์เหล่านี้จะช่วยให้คุณเปลี่ยนจาก "การคาดเดา" แบบสุ่มไปเป็นเวิร์กโฟลว์ที่กำหนดได้และมีพื้นฐาน Retriever จะทอดแห Reranker จะเลือกปลาที่ดีที่สุด และ Generator จะปรุงอาหาร
11. บทสรุป
ยินดีด้วย คุณได้สร้างไปป์ไลน์ RAG ขั้นสูงที่เหนือกว่าการค้นหาเวกเตอร์พื้นฐานเรียบร้อยแล้ว
สรุป
- คุณกำหนดค่า Cloud SQL ด้วย pgvector สำหรับพื้นที่เก็บข้อมูลเวกเตอร์ที่ปรับขนาดได้
- คุณเปรียบเทียบกลยุทธ์การแบ่งเพื่อทำความเข้าใจว่าการเตรียมข้อมูลส่งผลต่อการดึงข้อมูลอย่างไร
- คุณได้ติดตั้งใช้งานการจัดอันดับใหม่ด้วย Vertex AI เพื่อปรับปรุงความแม่นยำของผลลัพธ์
- คุณใช้การเปลี่ยนรูปแบบคําค้นหา (HyDE, Step-back) เพื่อให้ความตั้งใจของผู้ใช้สอดคล้องกับข้อมูล
ดูข้อมูลเพิ่มเติม
- สถาปัตยกรรมอ้างอิง RAG: ดูรายการคำแนะนำเกี่ยวกับสถาปัตยกรรมอ้างอิงที่เกี่ยวข้องกับ RAG
จากต้นแบบสู่เวอร์ชันที่ใช้งานจริง
แล็บนี้เป็นส่วนหนึ่งของเส้นทางการเรียนรู้ AI พร้อมใช้งานจริงด้วย Google Cloud
- สำรวจหลักสูตรทั้งหมดเพื่อเชื่อมช่องว่างจากต้นแบบไปสู่การผลิต
- แชร์ความคืบหน้าโดยใช้แฮชแท็ก #ProductionReadyAI